0x00 Etcd 最佳实践
此篇文章是本人在学习和使用 Etcd 中,遇到的问题和一些使用心得的总结,避免重复踩坑。
最近阅读的一篇文章 三年之久的 etcd 3 数据不一致 bug 分析,非常好,推荐看下。
此外,笔者将常用的 EtcdV3 接口进行了封装: 在此 etcd_tools
0x01 介绍
Etcd 是一个基于 Raft 协议实现的高可用的 KV 存储系统,具备如下几个优点:
- 简单:Golang 实现,可直接二进制部署
- 安全:支持 SSL 证书认证,数据传输加密
- 快速:在保证强一致性的同时,读写性能还算优秀
- 可靠:采用 Raft 算法实现分布式系统数据的高可用性和强一致性
0x02 CAP 定理基础
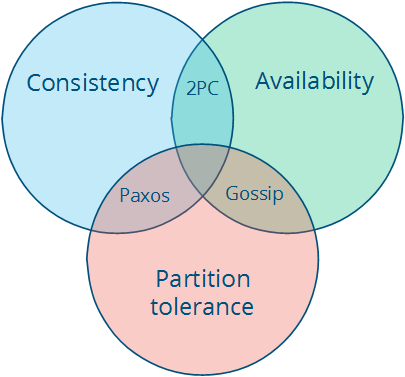
CAP 定理三要素
分布式系统的三个指标,即 CAP 定理的三要素:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容忍性(Partition Tolerance)
CAP 定理指的是,这三个要素中最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值。因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。而对于大多数 Web 应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向。
当然,牺牲一致性,并不是完全不管数据的一致性,否则数据是混乱的,那么系统可用性再高分布式再好也没有了价值。牺牲一致性,只是不再要求关系型数据库中的强一致性,而是只要系统能达到最终一致性即可,考虑到客户体验,这个最终一致的时间窗口,要尽可能的对用户透明,也就是需要保障 “用户感知到的一致性”。通常是通过数据的多份异步复制来实现系统的高可用和数据的最终一致性的,”用户感知到的一致性” 的时间窗口则取决于数据复制到一致状态的时间。
下面这个例子,可以解释为啥 C、A 和 P 这三者为什么不能同时满足:
假设有两台机器 A、B,两者之间互相同步保持数据的一致性。因为网络抖动是客观存在的事实,现在 B 由于网络原因不能与 A 通信(Network Partition),假设某个客户端向 A 写入数据,现在有两种选择:
- A 拒绝写入,这样能保证与 B 的一致性,但是牺牲了可用性
- A 允许写入,但是这样就不能保证与 B 的一致性了
Network Partition 是必然的,网络非常可能出现问题(断线、超时),因此 CAP 理论一般只能 AP 或 CP,而 CA 一般较难实现。
- CP: 要实现一致性,则需要一定的一致性算法,一般是基于多数派表决的,如 Paxos 和 Raft
- AP: 要实现可用性,则要有一定的策略决议到底用哪个数据,并且数据一般要进行冗余备份(replication),比如 Redis 集群中使用的 Gossip 协议
当然,在上面的例子中,A 可以先允许写入,等 B 的网络恢复以后再同步至 B(根据 CAP 原理这样不能保证强一致性了,但是可以考虑实现最终一致性)
最终一致性(Eventually Consistent)
对于一致性,可以分为从客户端和服务端两个不同的视角。从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。一致性是因为有并发读写才有的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景。
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
经典的 CAP 图
0x03 Etcd 原理
Etcd 官方提供了一个动态演示集群原理的项目
play.etcd.io
官方的 API 文档在这里:Etcd-API
0x04 物理节点
物理节点监控
物理节点的监控 + 进程监控
对于 N 个物理节点的 Etcd 集群,挂掉 $\frac{N-1}{2}$ 台,剩余节点组成的集群可以正常工作。
各个物理节点的 NTP 同步
Etcd 中,存在租约的概念,租约过期后,Key 就会被删除。假设三台机器组成了 Etcd 集群,那么如果其中某台机器的 NTP 误差较大的话,是存在风险的,可能会导致设置的 Lease 时间和预期不符。所以必要的 NTP 同步是需要的
0x05 客户端
版本差异
- Etcd 有 V2 和 V3 版本,数据是不互通的,所以勿用 V3 的 API 去操作 V2 版本 API 写入的数据,反之亦然
- 在 V2 版本中,每一个 key 都进行一次 Etcd 的
Set操作,这个操作是加锁的,所以,在读写的情况下会耗时很多在锁上面。V3 版本中,是先聚合,再每128个操作进行一次事务性执行。V3 较 V2 性能提升明显。
更安全的客户端
在很多环境中启动 Etcd 都是通过配置 TLS 方式进行的(比如 Kubernetes), 所以在连接 Etcd 的时候需要使用 TLS 方式连接:
tlsInfo := transport.TLSInfo{
CertFile: "etcd-v3.3.12-linux-amd64/etcd.pem",
KeyFile: "etcd-v3.3.12-linux-amd64/etcd-key.pem",
TrustedCAFile: "etcd-v3.3.12-linux-amd64/ca.pem",
}
tlsConfig, err := tlsInfo.ClientConfig()
if err != nil {
log.Fatal(err)
}
config := clientv3.Config{
Endpoints: []string{"127.0.0.1:2379"},
TLS: tlsConfig,
}
client, e := clientv3.New(config)
if e != nil {
log.Fatal(e.Error())
}
defer client.Close()
当然也可以使用 User+Password 的方式来创建,看这里的 clientv3.Client 结构
type Client struct {
Cluster
KV
Lease
Watcher
Auth
Maintenance
// Username is a user name for authentication.
Username string
// Password is a password for authentication.
Password string
// contains filtered or unexported fields
}
此外,由于 EtcdV3 的客户端是 gRPC 实现的,所以也提供了 gRPC 拦截器的初始化:
cli, err := clientv3.New(clientv3.Config{
Endpoints: endpoints,
DialOptions: []grpc.DialOption{
grpc.WithUnaryInterceptor(grpcprom.UnaryClientInterceptor),
grpc.WithStreamInterceptor(grpcprom.StreamClientInterceptor),
},
})
0x06 MVCC
MVCC(Multiversion concurrency control 多版本并发控制),Etcd 在内存中维护了一个 BTREE(B 树) 纯内存索引,它是有序的。(回想起 MYSQL 的索引也是 BTREE 实现的,极大的提升查找效率)
在这个 BTREE 中,整个 KV 存储大概就是这样:
type treeIndex struct {
sync.RWMutex
tree *btree.BTree
}
当存储大量的 Key-Value 时,因为用户的 Value 一般比较大,全部放在内存 BTREE 里内存耗费过大,所以 Etcd 将用户 Value 保存在磁盘中。
Etcd 在事件模型(Watch 机制)上与 ZooKeeper 完全不同,每次数据变化都会通知,并且通知里携带有变化后的数据内容,其基础就是自带 MVCC 的 Bboltdb 存储引擎。
MVCC 要点
- 每个
tx事务有唯一事务 ID,在 Etcd 中叫做 main ID,全局递增不重复 - 一个
tx可以包含多个修改操作(put 和 delete),每一个操作叫做一个 revision(修订),共享同一个 main ID - 一个
tx内连续的多个修改操作会被从 0 递增编号,这个编号叫做 sub ID - 每个 Revision 由(main ID,sub ID)唯一标识
关于 Version/Revision/ModRevison 的概念与区别
从 MVCC 引出 Version/Revision/ModRevison 这三个重要概念:
Revision表示改动序号(ID),每次 KV 的变化,leader 节点都会修改Revision值,因此,这个值在 cluster 内是全局唯一的,而且是递增的ModRevison记录了某个 key 最近修改时的 Revision,即它是与 key 关联的Version表示 KV 的版本号,初始值为1,每次修改 KV 对应的Version都会加1,也就是说它是作用在 KV 之内的
使用参数 --write-out 可以格式化(json/fields …)输出详细的信息,包括 Revision、ModRevison、Version,此外,还包括 LeaseID
如:
Etcdctl get /a/b --prefix --write-out=fields #
"Key" : "/a/b/key1-Iag4se1uz1"
"CreateRevision" : 3758
"ModRevision" : 3758
"Version" : 1
"Value" : "127.0.0.1:11111"
"Lease" : 6547788213836736818
"Key" : "/a/b/key2-IYg3We7uzQ"
"CreateRevision" : 3754
"ModRevision" : 3754
"Version" : 1
"Value" : "127.0.0.1:11112"
"Lease" : 6547788213836736811
"More" : false
"Count" : 15
Revision 和 CreateVsion 的区别
0x07 数据压缩
定期压缩(compac)、碎片整理(defrag)
对于 Etcd 这种多版本的 kv 存储系统而言,每一次成功修改数据的原子操作,都会被记录到新的版本中,每一个历史版本的数据都会被完整保存下来。由于 Etcd 本身是磁盘存储,随着数据量的增大,不可避免的会出现两个问题:一是数据体积增大、二是磁盘碎片增多;随着修改次数的增多,存储的数据量会越来越大,这对 Etcd 集群的性能和稳定性都会带来很大的影响。
因此,在大量使用的 Etcd 的实际生产场景中,需要考虑优化 Etcd 集群的配置,定期做 compact 和 defrag,且对每个节点的 defrag 时间需要错开,不能同时进行。Etcd 提供了如下参数来帮助实现自动压缩和碎片整理:
--auto-compaction-retention #
--max-request-bytes #
--quota-backend-bytes #
此参数 Etcd-db 数据大小,默认是 2G, 当数据达到 2G 的时候就不允许写入,必须对历史数据进行压缩才能继续写入。在启动的时候就应该提前确定大小,官方推荐是 8G
0x08 租约机制
Lease 机制(Heartbeat)
EtcdV3 中提供了自动续期的函数 Lease.KeepAlive,可以实现自动定时的续约某个租约(绑定到某个 KEY)。关于 Lease 的 TTL 时间设置大小,是有个双刃剑的问题:
- 如果
LeaseID过长,某台应用服务故障(服务不可用),导致 Lease 突然中断且 Etcd 不能及时感知到服务下线,那么来自客户端的请求很有可能继续发送到故障的服务,从而导致调用失败; - 如果
LeaseID过短,网络的突然抖动,导致 Key 在 Lease 未成功续期而被 Etcd 移除,这就导致应用服务是正常的,但是在 Etcd 中,该(应用服务)因为 Lease 的 TTL 过期导致节点(KEY)已经不存在了。 - KeepAlive 和 Put 一样,如果在执行之前 Lease 就已经过期了,那么需要重新分配 Lease。Etcd 并没有提供 API 来实现原子的 Put with Lease。
解决的方法,我这里提供两点思路:
- 使用定时器 timer 代替 Lease 的 Keepalive 功能,定时 PUT-KEY-with-Lease,续期时间建议设置为 LeaseTTL 的
1/3 - 监听 Lease 的 channel,如果发现 channel 被动关闭了,重新申请 Lease 然后再执行 KeepAlive 方法进行续期(当然了,也要先判断 Key 是不是丢失了)
总结一下:
Etcd 的 lease 可以用来做心跳,监控模块存活状态。Lease 的存活时间决定了发现服务异常的及时性,太长会较晚才能发现服务异常,较短容易受网络波动的影响。另外一种解决的思路是结合心跳和探测。把 Lease 设置为一个较小的值,在发现心跳消失的时候,做网络探测,确实不通了,再判定为不可用。需要注意的是,上报心跳的进程要对 lease not found 这种情况做处理,重新生成一个 lease 进行上报。
以下上 GODOC 中对 KeepAlive 方法的说明:
// KeepAlive attempts to keep the given lease alive forever. If the keepalive responses posted
// to the channel are not consumed promptly the channel may become full. When full, the lease
// client will continue sending keep alive requests to the Etcd server, but will drop responses
// until there is capacity on the channel to send more responses.
//
// If client keep alive loop halts with an unexpected error (e.g. "Etcdserver: no leader") or
// canceled by the caller (e.g. context.Canceled), KeepAlive returns a ErrKeepAliveHalted error
// containing the error reason.
//
// The returned "LeaseKeepAliveResponse" channel closes if underlying keep
// alive stream is interrupted in some way the client cannot handle itself;
// given context "ctx" is canceled or timed out.
//
// TODO(v4.0): post errors to last keep alive message before closing
// (see https://github.com/Etcd-io/Etcd/pull/7866)
0x09 Watcher(监听器)
Etcd 提供了 watcher,来监控集群 kv 的变化。这个在开发 gRPC 服务发现的 ClientConn 实时更新接口时,必不可少。但是 Watch 返回的 WatchChan 有可能在运行过程中失败而关闭,此时 WatchResponse.Canceled 会被置为 true,WatchResponse.Err() 也会返回具体的错误信息。所以在 range WatchChan 的时候,每一次循环都要检查 WatchResponse.Canceled,在关闭的时候重新发起 Watch 或报错。
0x0A Etcd WatchPrefix 的最佳方式
最近读了一些开源实现,发现对 Etcd WatchPrefix 的一些细节上的考虑,一个考虑完备的实现如下:
- 如何优雅的(自动化)监听某个 Prefix
- 如何优雅的关闭 Watch,见 issue:clientv3: how watch know the remote etcd is closed?
- Etcd 的 Watch 实现
etcdV3 的 Watch
一般在应用中,使用 clientv3.Watch() 的方法如下,WithPrefix 表示需要以前缀方式 watch,WithPrevKV 表示在删除时附带删除的值:
- 调用
clientv3.Watch()获取一个 Event channel - 使用
for range遍历上面的 channel,拿到 Event 事件,执行对应的逻辑 - 注意
clientv3.Watch()的第一个参数为context,通过此参数来关闭 Watch 的运行(context是一个管理协程树生命周期的解决方案,父协程能通过context来控制其子协程什么时候退出)
// 使用 WithCancel 构造一个带控制的 context
ctx, cancel := context.WithCancel(context.Background())
//defer cancel()
rch := r.EtcdCliV3Client.Watch(ctx, r.EtcdKeyPrefix, clientv3.WithPrefix(), clientv3.WithPrevKV())
for n := range rch {
//rch is a remote channel
for _, ev := range n.Events {
switch ev.Type {
case mvccpb.PUT:
//do something with event ADD
case mvccpb.DELETE:
//do something with event DEL
fmt.Println("find DETELE:", ev.PrevKv.Key, ev.PrevKv.Value)
}
}
}
简单看下 Watch() 的 实现代码 可知,其内部启动了单独的 goroutine 来完成对指定 Prefix 的 Watcher,所以使用 context 即可完美的控制其启动停止。
封装 watcher 结构
基于 Etcd Watcher 的特性,可以封装如下的结构:
// Watch A watch only tells the latest revision
type Watch struct {
revision int64 // 保存最新的 revision 号
cancel context.CancelFunc // 控制 watcher 退出
eventChan chan *clientv3.Event // 返回给上层的数据 channel
eventChanSize int
lock *sync.RWMutex
logger *zap.Logger
incipientKVs []*mvccpb.KeyValue // 保存了目前 prefix 下的所有值
}
WatchPrefix 的实现
如下面代码所示,WatchPrefix 方法的步骤如下:
- 使用
client.Get()配合clientv3.WithPrefix()获取到当前 Prefix 关联最新的revision及 Prefix 对应的所有值 - 构造
context传入子 goroutineclient.Client.Watch,这样上层便具备的对 watcher 的控制能力 - goroutine 中
client.Client.Watch的处理逻辑,见for {...}中的注释 - 返回控制 channel 及事件 channel 给上层,上层通过控制 channel 控制
WatchPrefix的启动停止,通过事件 channel 获取WatchPrefix监听得到的事件(增 / 删)
func (client *Client) WatchPrefix(ctx context.Context, prefix string) (*Watch, error) {
// 初始化请求 WithPrefix
resp, err := client.Get(ctx, prefix, clientv3.WithPrefix())
if err != nil {
return nil, err
}
// 初始化 Watch 结构
var w = &Watch{
eventChanSize:64,
revision: resp.Header.Revision,
eventChan: make(chan *clientv3.Event, 64),
incipientKVs: resp.Kvs,
}
go func() {
ctx, cancel := context.WithCancel(context.Background())
// 注意:给外部的 cancel 方法,用于取消下面的 watch
w.cancel = cancel
// 注意,client.Watch 是一个子协程
rch := client.Client.Watch(ctx, prefix, clientv3.WithPrefix(), clientv3.WithCreatedNotify(), clientv3.WithRev(w.revision))
for {
for n := range rch {
// 一般情况下,协程的逻辑会阻塞在此
if n.CompactRevision > w.revision {
w.revision = n.CompactRevision
}
// 是否需要更新当前的最新的 revision
if n.Header.GetRevision()> w.revision {
w.revision = n.Header.GetRevision()
}
if err := n.Err(); err != nil {
xlog.Error(ecode.MsgWatchRequestErr, xlog.FieldErrKind(ecode.ErrKindRegisterErr), xlog.FieldErr(err), xlog.FieldAddr(prefix))
continue
}
for _, ev := range n.Events {
select {
// 将事件 event 通过 eventChan 通知上层
case w.eventChan <- ev:
default:
xlog.Error("watch etcd with prefix", xlog.Any("err", "block event chan, drop event message"))
}
}
}
// 当 watch() 被上层取消时,逻辑会走到此
ctx, cancel := context.WithCancel(context.Background())
w.cancel = cancel
if w.revision > 0 {
// 如果 revision 非 0,那么使用 WithRev 从 revision 的位置开始监听好了
rch = client.Watch(ctx, prefix, clientv3.WithPrefix(), clientv3.WithCreatedNotify(), clientv3.WithRev(w.revision))
} else {
rch = client.Watch(ctx, prefix, clientv3.WithPrefix(), clientv3.WithCreatedNotify())
}
}
}()
// 返回 w(控制 channel 和数据 channel 给上层应用)
return w, nil
}
至此,一个优雅的 WatchPrefix 就实现完成。
0x0B Etcd 集群的健康检查
在现网中,通常使用如下命令来检查整个集群的运行及健康状况:
- endpoint status
- endpoint health
- cluster-health
#需要证书验证时需要加入如下选项
#--cacert=/k8s/kubernetes/ssl/ca.pem --cert=/k8s/kubernetes/ssl/server.pem --key=/k8s/kubernetes/ssl/server-key.pem
[user00@TENCENT64site ~/apps/bin]$ export ETCDCTL_API=3;./etcdctl --write-out=table --endpoints="XXX,XXX,XXX" endpoint health
XXXX:2379 is healthy: successfully committed proposal: took = 26.014239ms
XXXX:2379 is healthy: successfully committed proposal: took = 27.405666ms
XXXX:2379 is healthy: successfully committed proposal: took = 29.05686ms
[user00@TENCENT64site ~/apps//bin]$
[user00@TENCENT64site ~/apps/bin]$ export ETCDCTL_API=3;./etcdctl --write-out=table --endpoints="XXX,XXX,XXX" endpoint status
+-------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+-------------------+------------------+---------+---------+-----------+-----------+------------+
| X.X.X.X:2379 | 4edc33d36d6a5602 | 3.3.12 | 733 kB | true | 16 | 13551 |
| X.X.X.X:2379 | b63c9d64ba39c269 | 3.3.12 | 733 kB | false | 16 | 13551 |
| X.X.X.X:2379 | 3a346af4a0185ade | 3.3.12 | 733 kB | false | 16 | 13551 |
+-------------------+------------------+---------+---------+-----------+-----------+------------+
[user00@TENCENT64site ~/apps/bin]$ export ETCDCTL_API=3;./etcdctl member list --endpoints="XXX,XXX,XXX" cluster-health --write-out=table
+------------------+---------+-----------+--------------------------+------------------------------------------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS |
+------------------+---------+-----------+--------------------------+------------------------------------------------+
| 3a346af4a0185ade | started | etcd03 | http://X.X.X.X:2380 | http://127.0.0.1:2379,http://X.X.X.X:2379 |
| 4edc33d36d6a5602 | started | etcd01 | http://X.X.X.X:2380 | http://127.0.0.1:2379,http://X.X.X.X:2379 |
| b63c9d64ba39c269 | started | etcd02 | http://X.X.X.X:2380 | http://127.0.0.1:2379,http://X.X.X.X:2379 |
+------------------+---------+-----------+--------------------------+------------------------------------------------+
0x0C 参考文档
转载请注明出处,本文采用 CC4.0 协议授权