0x00 背景
本地后台程序容器化,服务上云,Saas 化尝试,现阶段没有比 Kubernetes 更好的选择了。从七月到现在,三个月时间,通过对项目代码改造、后台服务的迁移和现网运行排障,算是对 Kubernetes 的服务部署和微服务化有了比较全面的认知。这篇博客就以 gRPC 服务在 Kubernetes 上的 LoadBalancer 改造来开个头。
0x01 Kubernetes 从入门到放弃
网上有很多关于 Kubernetes 的高质量文章,以及阿里的公开课,可以帮助读者构建 Kubernetes 的生态认知。Kubernetes 的几个核心概念中,只要理解了分层的概念,穿透各个组件都是围绕此来设计和实现的。下层为上层提供服务,上层不要知道下层的具体实现细节,只需使用下层提供的服务。而层与层之间联系的桥梁就是接口 (Interface)
0x02 开发需要掌握的 Kubernetes
作为一名开发者,需要理清楚下面的知识概念:
POD–>Deployment–>Service—>Ingress服务应用如何对照入座,在 K8S 中部署的应用无法脱离这几种应用形态Statefulset和Damonset的应用场景JOB/crontabJOB的应用场景PV和PVC的实践CONFIG-MAP与Secret如何与应用搭配(或者说更安全、更灵活的搭配)- 如何实现
CONFIG-MAP的热更新 POD之间如何共享数据,POD生产的日志如何持久化- 容器的健康检查(
Healthy Check),就绪探针与保活探针的使用 POD之间的互相访问和服务发现方式Kubernetes上的负载均衡如何做Kubernetes中的认证与授权、RBACRBAC的应用,如何使用ServiceAccount+Token+ 证书来调用ApiServer的相关操作(当然了,必须对 SA 授权)- 如何通过
Kubernetes的API来获取POD列表的实时变化(实现gRPC+Kubernetes的自定义负载均衡的算法) - 如何理解
Kubernetes的资源限制,如何应用HPA(Horizontal Pod Autoscaler)
0x03 进阶话题
Kubernetes路由的实现原理,IPVSIstio,感觉这个开源的作品在未来若干年会成为主流的管理应用Kube-CRD开发,满足各种现网的特殊需求,原生提供的Crontroller可能无法满足,需要定制化适合业务的Controller
0x04 Service 的本质
理解 Service 从下面几点出发:
- 发现后端
Pod服务 - 为一组具有相同功能的容器应用提供一个统一的入口地址
- 将请求进行负载分发到后端的各个
Container应用上的控制器
0x05 Service 的常用类型
ClusterIPService:通过为Kubernetes的Service分配一个集群内部可访问的固定虚拟 IP(Cluster IP),实现集群内的访问Headless Service:该服务不会分配Cluster IP,也不通过Kube-proxy做反向代理和负载均衡。而是通过DNS提供稳定的网络 ID 来访问,DNS会将Headless Service的后端直接解析为Pod IP列表
-
NodePort:除了使用Cluster IP之外,还通过将Service的port映射到集群内每个节点的相同一个端口,实现通过nodeIP:nodePort从集群外访问服务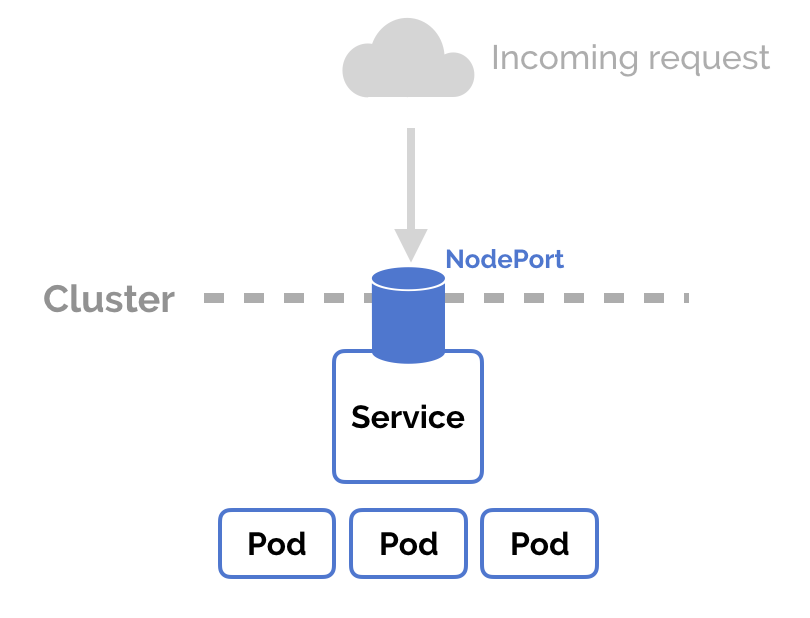
-
LoadBalancer:和NodePort类似,不过除了使用一个Cluster IP和NodePort之外,还会向所使用的公有云申请一个负载均衡器(负载均衡器后端映射到各节点的NodePort),实现从集群外通过 LB 访问服务,一般需要依赖公有云的实现(比如TKE上一般为公网IP或是一个公网域名)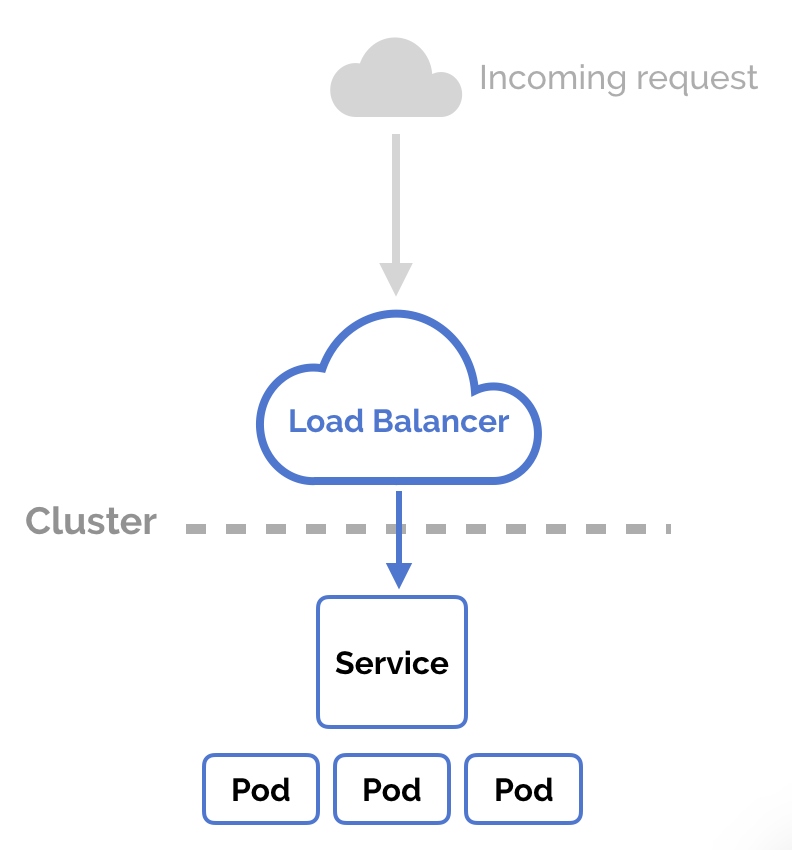
Ingress: 类似于反向代理,可以配置按特定条件将流量分发到不同的Service上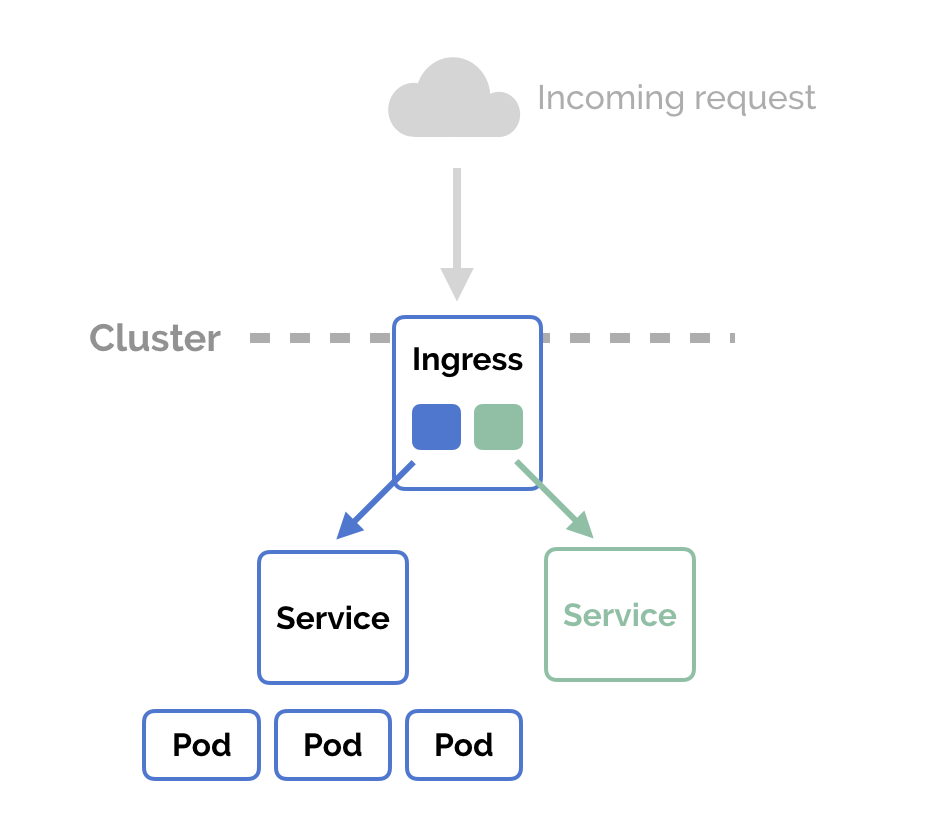
0x06 Loadbalancer In Kubernetes
引用一下 GKE 的图:
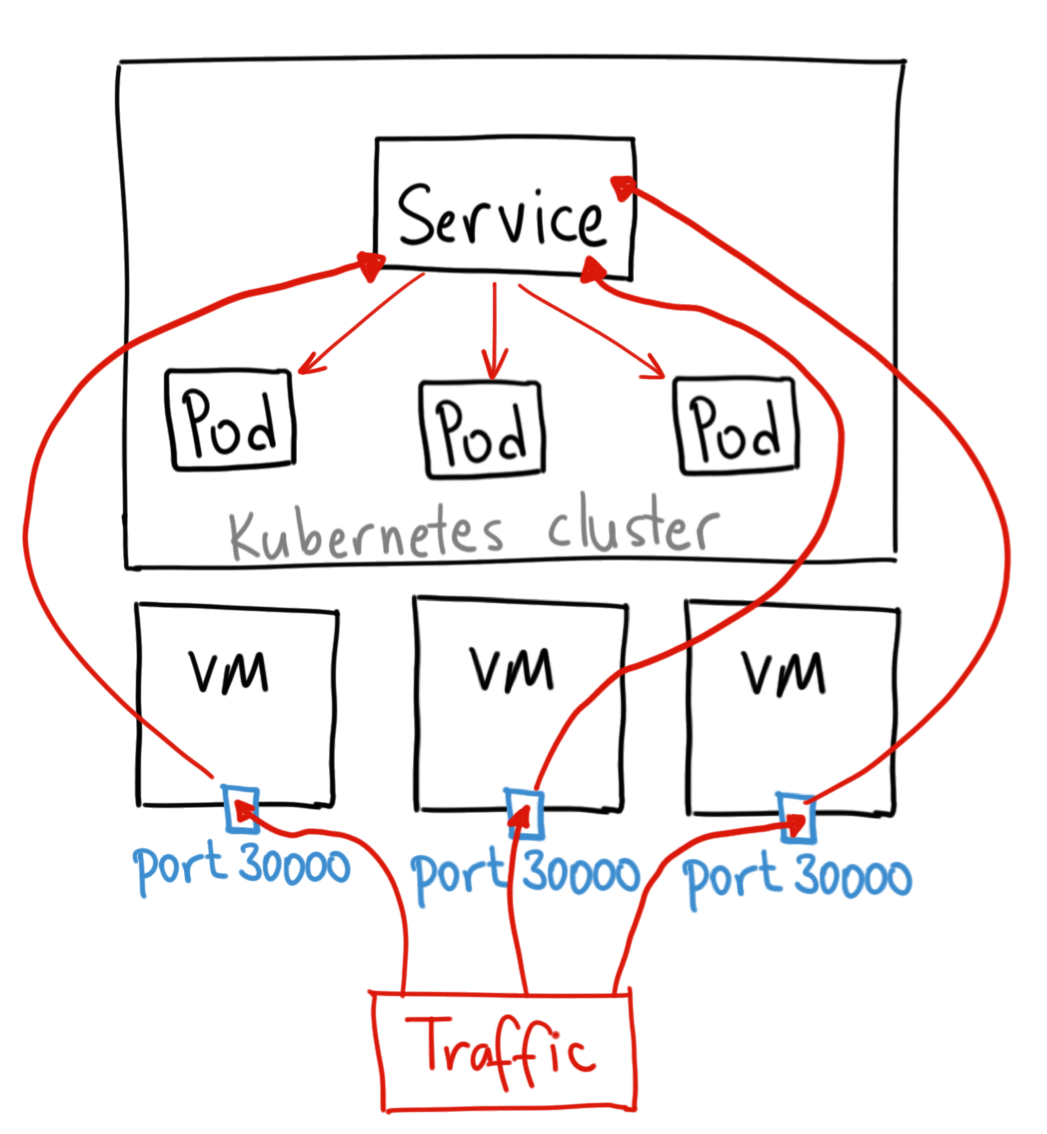
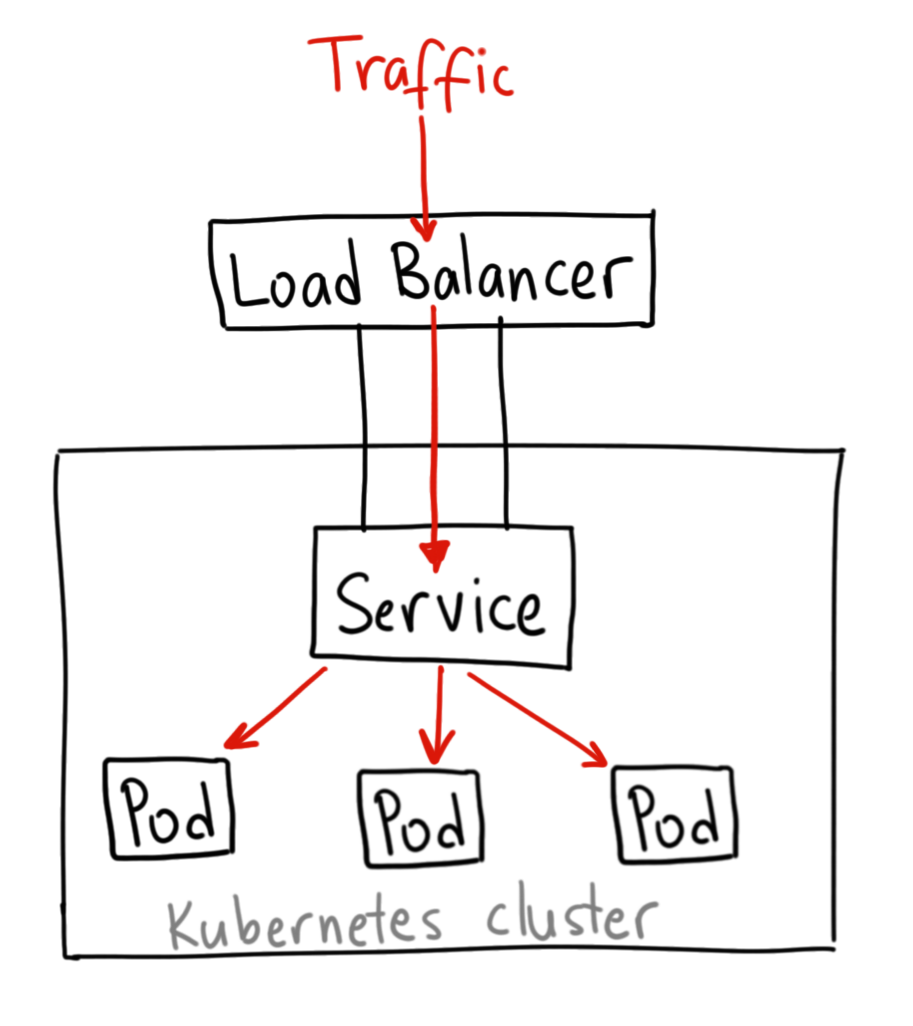
一般应用中都使用 Load Balancer 的方式,这个实现起来,也并不复杂,后续会新开一篇文章来讲解下如何实现。
0x07 Kubernetes+gRPC 的负载均衡的问题
使用 Kubernetes 默认的 Service 做负载均衡的情况下,gRPC 的 RPC 通信是基于 HTTP/2 标准实现的,HTTP/2 的一大特性就是不需要像 HTTP/1.1 一样,每次发出请求都要新建立一个连接,而会复用原有的连接。所以这将导致 Kube-proxy 只有在连接建立时才会做负载均衡,而在这之后的每一次 RPC 请求都会利用原本的连接,那么实际上后续的每一次的 RPC 请求都跑到了同一个地方。看下面的这篇文章
gRPC Load Balancing on Kubernetes without Tears
既然在 HTTP/2 中存在了这样一个特性,那么 gRPC 如何与 Kubernetes 进行整合呢?从 Kubernetes Service 的几个类型中来寻找解决 LB 问题的方案
0x08 再看 Headless Service
如前所说,Kubernetes 提供了一个基础的 Pod 控制方式给用户,参加官方文档 Headless Services
Headless Service 需要将 spec.clusterIP 设置成 None,因为没有 ClusterIP,Kube-proxy 并不处理此类服务,因为没有 Load balancing 或 proxy 代理设置,在访问服务的时候回返回后端的全部的 Pods IP 地址,主要用于开发者自己根据 pods 进行负载均衡器的开发(设置了 selector)
0x09 测试 Headless Service
这里用到 gRPC Service 的 yaml 文件如下(注意 clusterIP 字段必须设置为 None):
apiVersion: v1
kind: Service
metadata:
name: serv-ca
namespace: nspace
spec:
selector:
name: test
clusterIP: None # This is important!
ports:
- name: tcp
port: 8088
targetPort: 8088
下面尝试执行 nslookup 命令来获取服务 serv-ca 对应的所有 Pod 的列表:
[root@docker-79b475496-4nbl8 /]# nslookup -q=srv bf-serv-ca
Server: 1.2.3.4
Address: 1.2.3.4#53
serv-ca.nspace.svc.cluster.local service = 0 25 8088 172-16-0-20.serv-ca.nspace.svc.cluster.local.
serv-ca.nspace.svc.cluster.local service = 0 25 8088 172-16-0-21.serv-ca.nspace.svc.cluster.local.
serv-ca.nspace.svc.cluster.local service = 0 25 8088 172-16-1-17.serv-ca.nspace.svc.cluster.local.
serv-ca.nspace.svc.cluster.local service = 0 25 8088 172-16-1-18.serv-ca.nspace.svc.cluster.local.
可以发现这个 serv-ca 的服务有 4 个 pod,给出了分别对应的 IP 以及对应端口是 8088。于是通过将服务地址配置为服务端地址后,就可以很简单地实现负载均衡了,Here We Go!!
0x0A gRPC+Headless Service 应用
接上篇,如何将 gRPC、CoreDNS(集群中的默认 DNS 插件)和 Headless Service 这三者融合起来,实现长连接 + 负载均衡呢?
答案就是 gRPC-DnsResolver,默认的 DNS 查询时间是 30s
经过改造后的方案效果,见下图,以 Pod 视角来看,成功与 4 个后端 Pod 建立了长连接,大功告成。
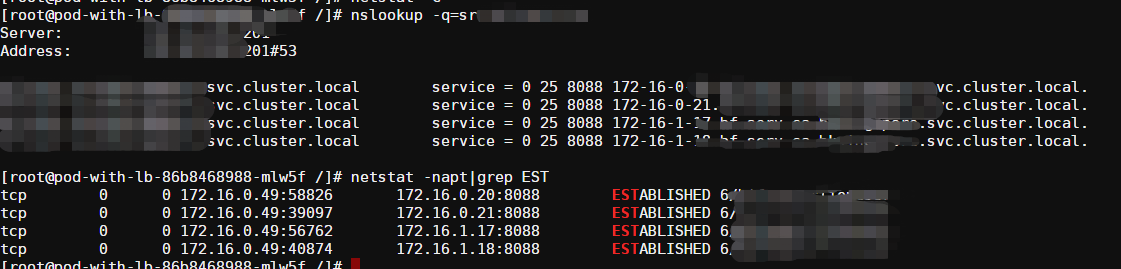
相关的gRPC客户端连接代码如下:
func ClientConnect(){
//...
// addr 是 headless service 的 service name:port
addr := "myserviceName:12345"
// 使用 scheme dns:/// ,这样就会使用dns解析到 server 端的 pod ip
conn, err := grpc.Dial(
"dns:///"+addr,
grpc.WithDefaultServiceConfig(`{"loadBalancingPolicy":"round_robin"}`), //grpc.WithBalancerName(roundrobin.Name) 是旧版本写法,已废弃
grpc.WithInsecure(),
grpc.WithBlock(),
)
//...
}
0x0B gRPC+DNS解析方案的不足
但是,在实践中使用该方式可能会存在问题,当发生了Pod扩缩容、上下线的时候;在工程中,Pod 扩容是十分常见的场景,在扩容的时候希望客户端可以及时对新启动的 Pod 快速感知到请求并接收处理。但是对于DNS服务发现,存在下面的问题:
- 当缩容后,由于 grpc 有连接探活机制,会自动丢弃(剔除)无效连接
- 当扩容后,由于没有感知机制,会导致后续的 Pod 无法被请求到
上述问题出现的原因是:由于DNS有缓存,gRPC-DNSresolver 解析会缓存解析结果,解析后每 30min 才会刷新一次,当 Pod 被销毁时,gRPC 会剔除不健康的 Pod-ip,但是新增的 Pod-ip 必须要在重新链接之后才能解析到
转载请注明出处,本文采用 CC4.0 协议授权