0x00 前言
健康检查(HealthCheck)机制用于检测后端服务节点是否正常工作,通常应用于负载均衡下的业务,如果后端节点的状态探测异常,将会把该实例下线,保证服务的可用性。
服务的健康检测一般是指的是检测服务是否正常运行:
- 是否存在,因为程序逻辑错误或者 OOM 等进程不存在
- 存在是否可以正常的响应请求,尽管进程存在但可能因为请求量过大或者程序逻辑错误,导致服务 HANG 住,无法正常对外请求
健康检查的要素有如下几点:
- 后端服务信息(如
ip:port)、协议及发送健康检查的数据 - 健康检查所使用的协议以及发送的数据(比如 HTTP 协议的话检查所访问的 url path, HTTP method, 认证信息等,TCP 协议的话可能是发送特定的数据表示请求做健康检查等)
- 判断服务健康的依据:
- 基本的连通性
- 响应的内容,比如表示服务健康的 HTTP 响应状态码是哪些,响应的 body 内容需要包含什么内容等
- 不健康的策略:检查不通过几次算服务不健康(对于 Connection Refused 错误一般建议直接标记为不健康而不是等几次失败再标记为不健康);以及健康恢复的策略:从不健康到健康需要通过几次检查才算恢复健康
- 健康检查的间隔,健康检查太频繁可能会影响被检查的服务,间隔太长可能会失去健康检查的意义无法及时探查到不健康的状态
- 超时,健康检查的请求也需要设置超时
0x01 Kubernetes的健康检查
Kubernetes 服务的主动健康检查机制是通过健康探针来实现的。Kubernetes 提供了两种探针:
就绪探针 (Readiness Probe)
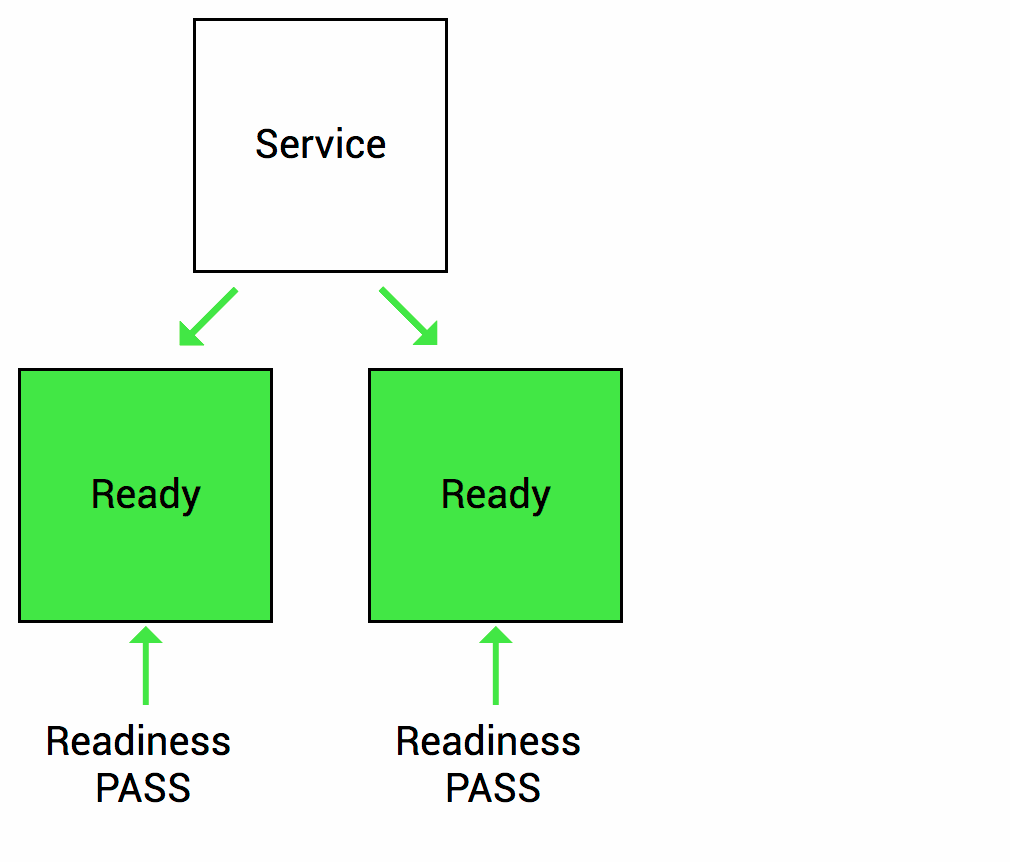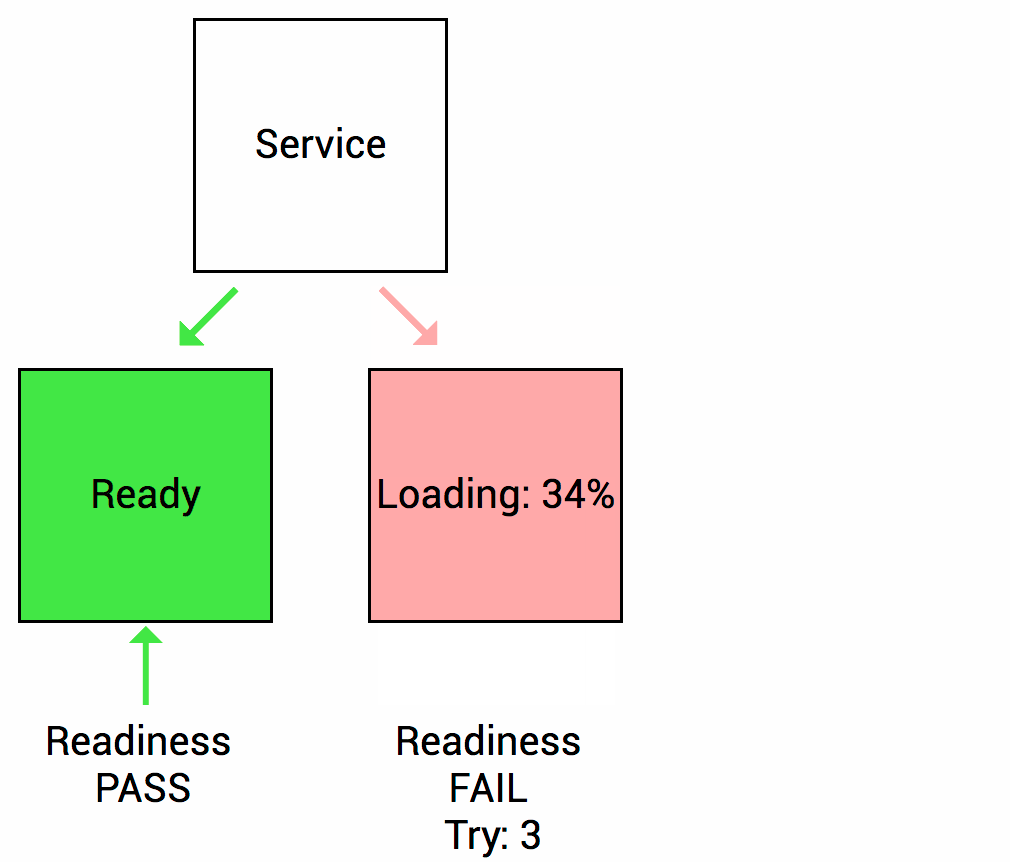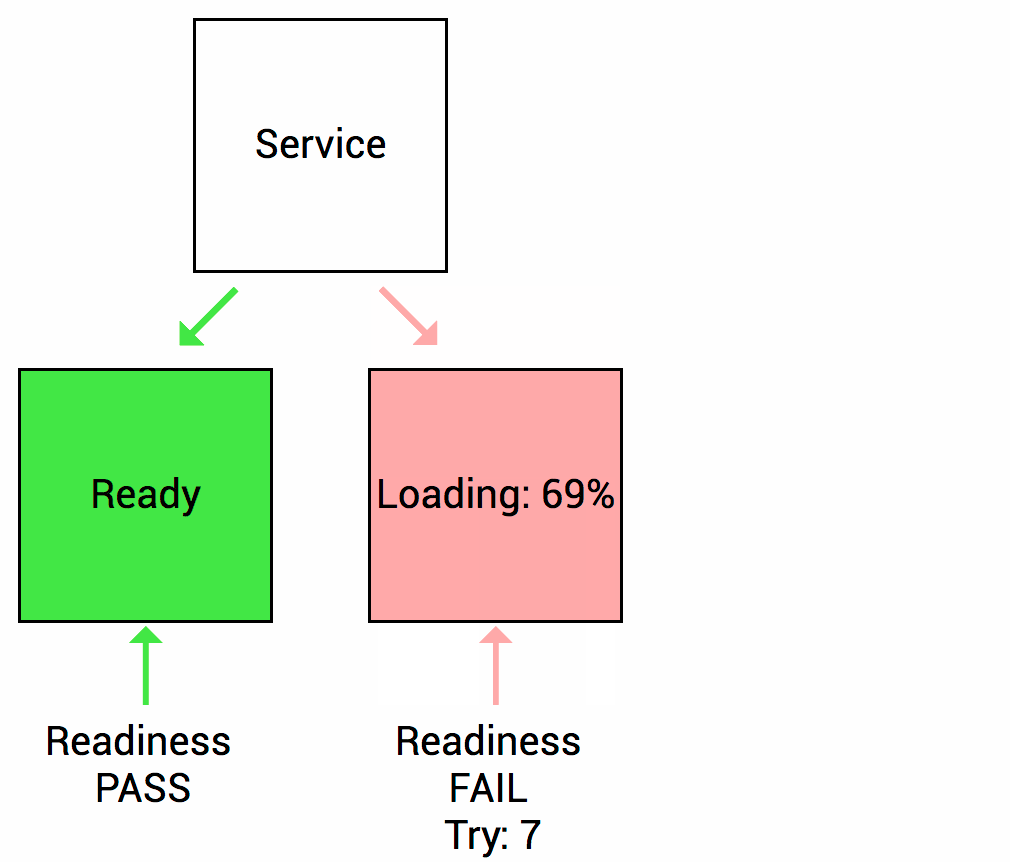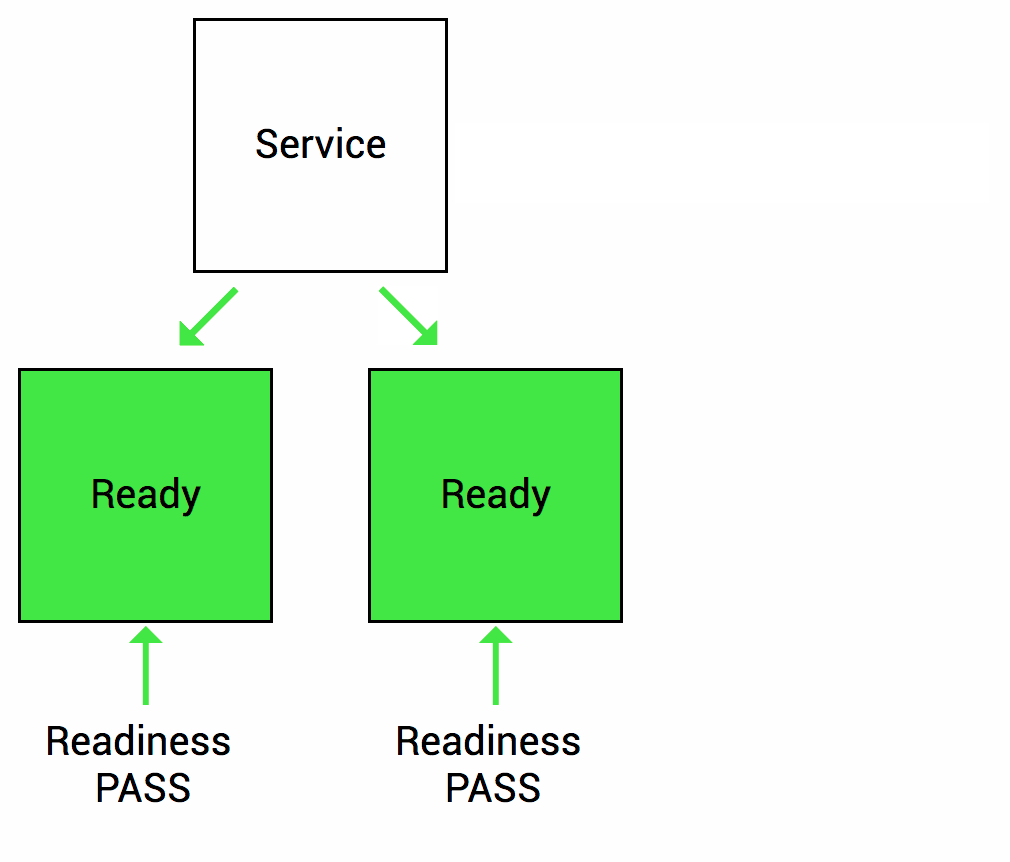
在 Pod 启动时,Kubelet 使用 Readiness probe(就绪探针)来确定容器是否已经就绪可以接受流量。只有当 Pod 中的容器都处于就绪状态时 Kubelet 才会认定该 Pod 处于就绪状态。该信号的作用是控制哪些 Pod 应该作为 Service 的后端。如果 Pod 处于非就绪状态,那么它们将会被从 Service 的 Load balancer 中移除
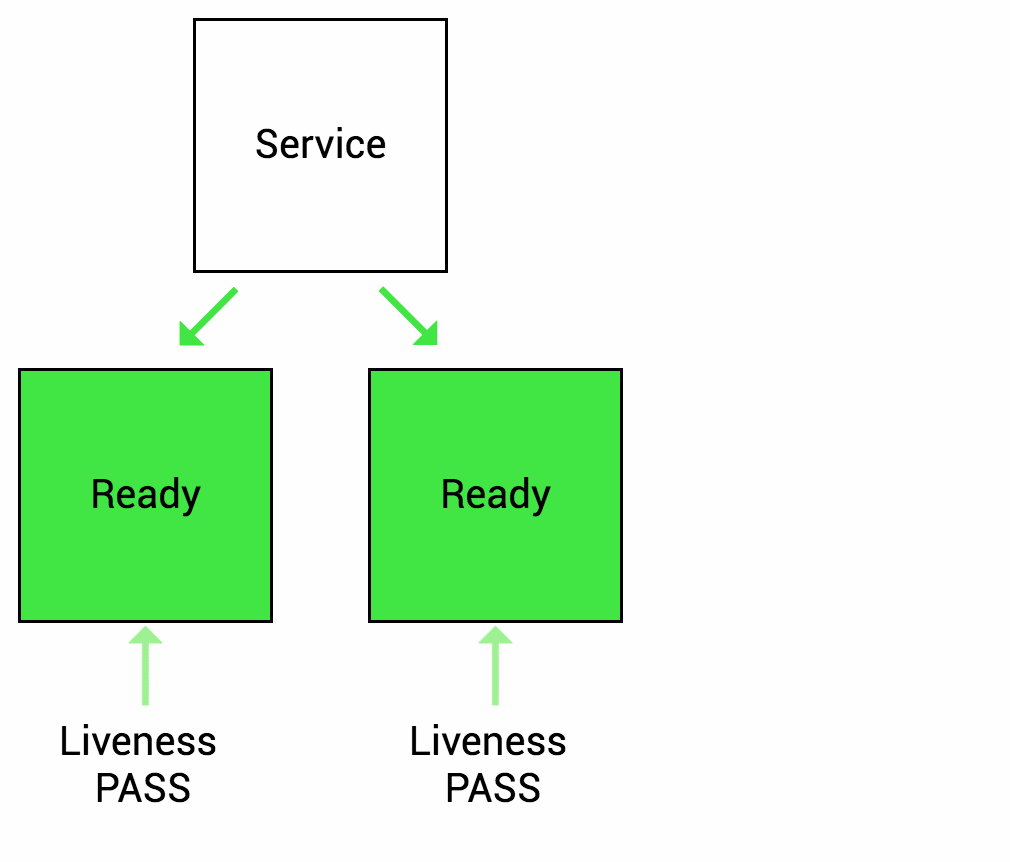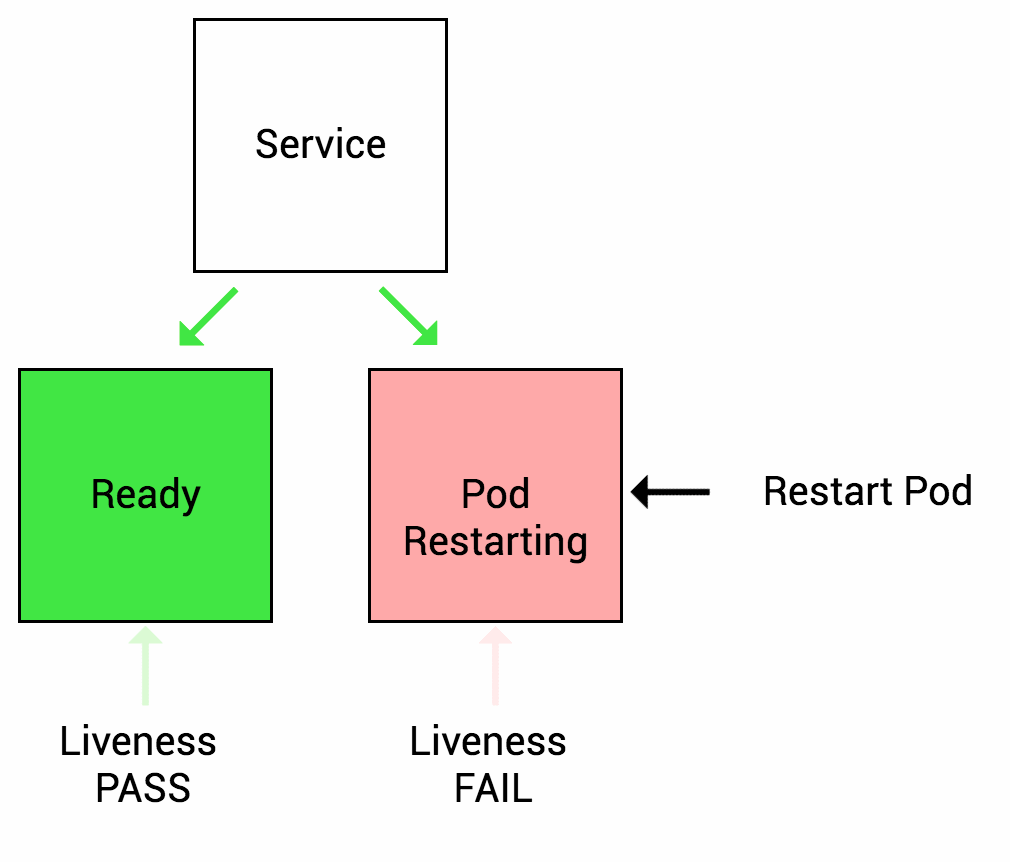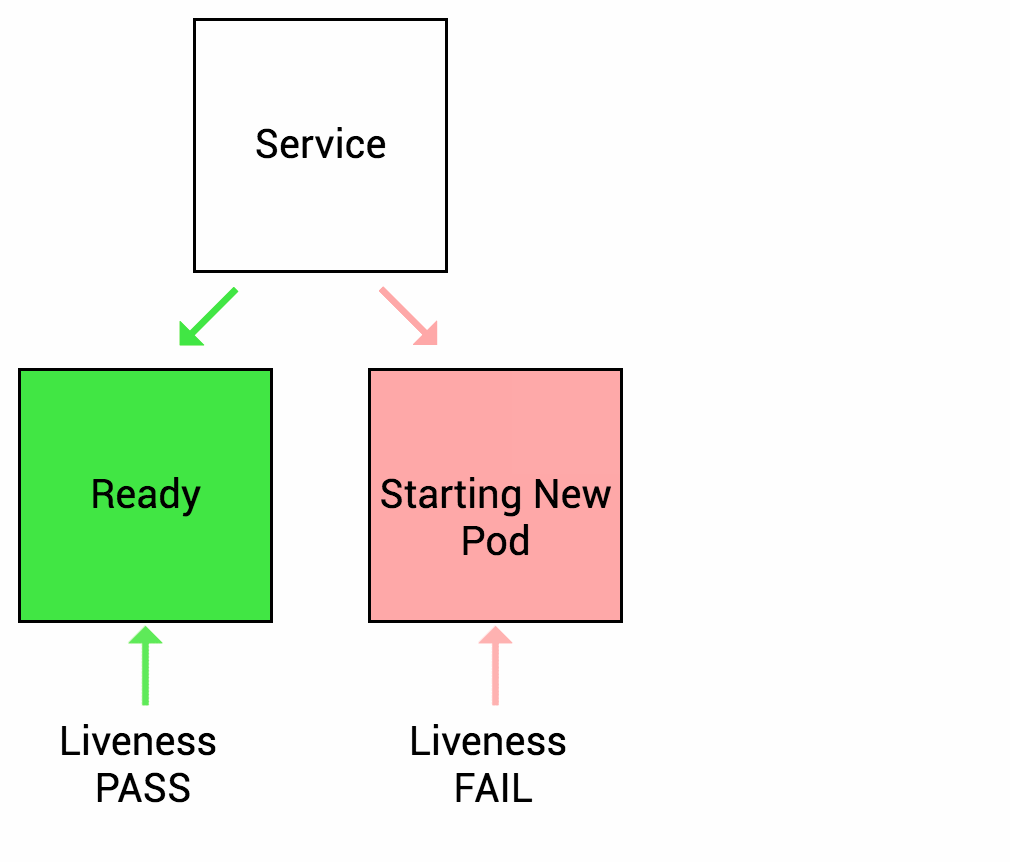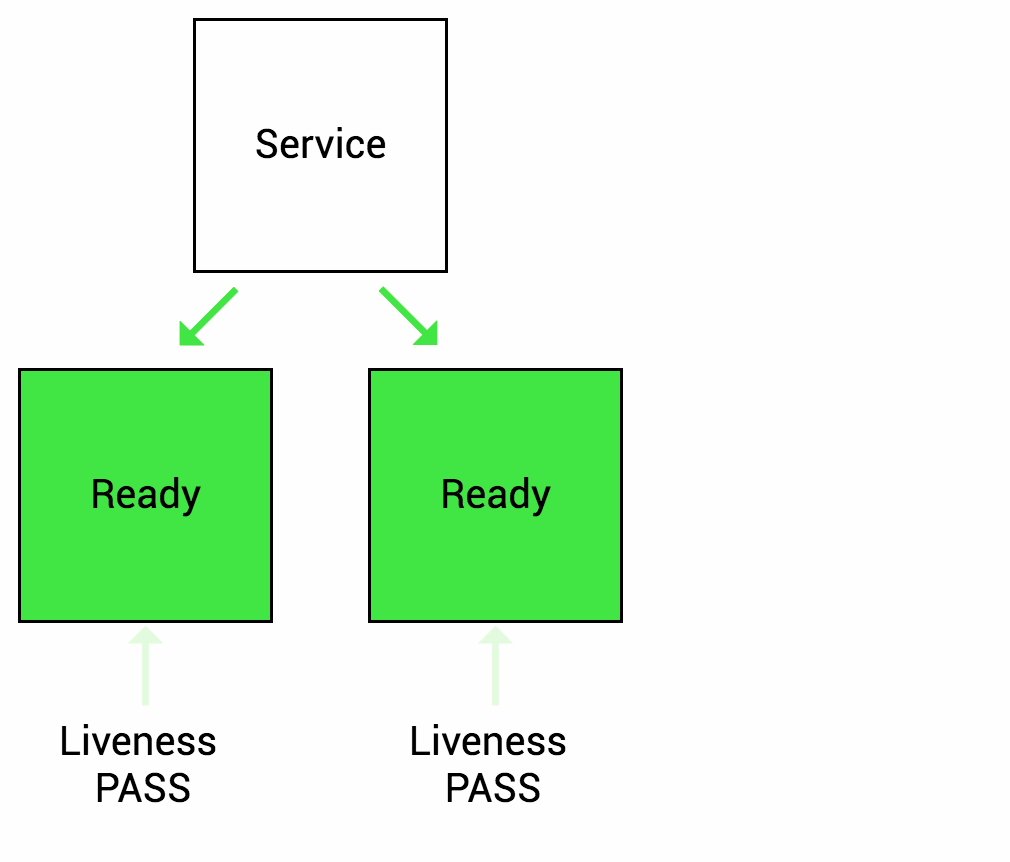
存活探针 (Liveness Probe)
在 Pod 运行中,Kubelet 使用 Liveness probe(存活探针)来确定何时重启容器。例如,当应用程序处于运行状态但无法做进一步操作,Liveness 探针将捕获到 Deadlock,重启处于该状态下的容器,使应用程序在存在 bug 的情况下依然能够继续运行下去
就绪探针的意义
很常见的一个场景,某个服务刚启动,需要做一系列的初始化工作(比如初始化 Mysql/Redis/Kafka 等),需要一些时间,而这段时间里,不希望 Kubernetes 把流量导入到这些还未初始化完成的 Pod 上。所以就绪探针非常适合这种场景,只有 Pod 就绪后 Kubernetes 才会把请求打过来,如果非就绪状态,这些 Pod 会从 Service 的 Load balancer 中短暂移除
就绪探针常用 HTTP-CGI 接口来实现:
在服务端,一般以一个单独的 goroutine 启动 CgiServer,实现 /ready 的逻辑,在逻辑中加入对初始化的检查,如检查 Mysql 是否建立连接成功、Redis 数据查询是否可用等等。
readinessProbe:
httpGet:
path: /ready
port: 8001
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 1
periodSeconds: 30
优雅关闭
这里我们先简单介绍下 Kubernetes 如何支持服务的优雅退出,优雅关闭是指在 Pod 准备关闭时,可能还需要做一些处理,比如保存数据等。这期间服务不会接受新的请求。Kubernetes 提供了 terminationGracePeriodSeconds 的配置选项:在给 Pod 发出关闭指令时,Kubernetes 将会给应用发送 SIGTERM 信号,程序只需要捕获 SIGTERM 信号并做相应处理即可。配置为 Kubernetes 会等待 terminationGracePeriodSeconds 秒后关闭。
terminationGracePeriodSeconds: 60
0x02 Kubernetes 中的优雅退出
本小节,详细介绍下 Kubernetes 中的 Pod 优雅退出的步骤。
Kubernetes 终止一个完全健康的容器有很多原因,常见的有:
- 滚动更新更新部署时,Kubernetes 会在启动新 Pod 时慢慢终止旧 Pod。
- 节点驱逐,Kubernetes 将终止该节点上的所有 Pod,如果节点资源不足,Kubernetes 将终止 Pod 以释放这些资源
优雅退出,是 Kubernetes 在完全清理掉一个 Pod 之前,会发送信号通知 Pod 中的进程,并且预留了一个等待期,在等待期之后,Kubernetes 会完全强制删除该 Pod。在这段时间,我们的服务可以实现优雅退出,举例来说:不再接受新连接,有序释放掉已存在的连接等,同时可能需要保存相关的数据,关闭网络连接,完成剩下的收尾工作。
facebook 开源的库 grace,可以实现 httpserver 的优雅退出。
一般而言,Kubernetes 清除一个 Pod 需要走完下面 5 步:
-
Pod 被设置为 终止 状态,并从所有服务的端点列表中删除,此时,Pod 停止获得新的流量。在 Pod 中运行的容器不会受到影响
-
preStop Hook被执行:preStop Hook是一个特殊命令或 http 请求,发送到 pod 中的容器
如果应用程序在接收SIGTERM时没有正常关闭,可以使用此 Hook 来触发正常关闭。 接收SIGTERM时大多数程序都会正常关闭,但是如果使用的是第三方代码或管理系统则无法控制,所以preStop Hook是在不修改应用程序的情况下触发正常关闭的好方法 -
SIGTERM信号被发送到 Pod 此时,Kubernetes 将向 Pod 中的容器发送SIGTERM信号,这个信号让容器知道它们很快就会被关闭。这里很重要,在我们的代码应该监听此事件并在此时开始执行收尾工作、清理资源及优雅退出 -
Kubernetes 优雅等待期 此时,Kubernetes 等待指定的时间称为优雅终止等待期。 默认情况为
30秒(可以视程序的逻辑处理适当延长)。 值得注意的是,这与preStop Hook和SIGTERM信号并行发生。 Kubernetes 不会等待preStop Hook完成。如果应用程序完成关闭并在terminationGracePeriod完成之前退出,Kubernetes 会立即进入下一步 -
SIGKILL信号被发送到 Pod,并删除 Pod 如果容器在优雅等待期结束后仍在运行,则会发送SIGKILL信号并强制删除。 此时,所有 Kubernetes 对象也会被清除,至此,Kubernetes 清理 Pod 的整个流程结束
0x03 Kubernetes 中的 gRPC 服务
健康检查的方式
- 端口检测,判断服务端口是否存活
- API,发出 API 请求,查看是否正常回应(超时返回错误)
- 执行命令,写自定义命令判断服务是否正常运行
gRPC 的健康检查协议
gRPC 中提供了健康检查的协议,文档在此。所以,RPC 服务需要实现 Check 和 Watch 这2个方法。此外,官方文档还建议使用的 package 及 service 命令方式如下:
The suggested format of service name is package_names.ServiceName, such as grpc.health.v1.Health.
健康检查的协议如下:
syntax = "proto3";
package grpc.health.v1;
message HealthCheckRequest {
string service = 1;
}
message HealthCheckResponse {
enum ServingStatus {
UNKNOWN = 0;
SERVING = 1;
NOT_SERVING = 2;
}
ServingStatus status = 1;
}
service Health {
rpc Check(HealthCheckRequest) returns (HealthCheckResponse);
rpc Watch(HealthCheckRequest) returns (stream HealthCheckResponse);
}
在后端逻辑的实现中,我们需要在 gRPC-Server 端实现这个健康检查的协议:
import (
//......
"google.golang.org/grpc/health/grpc_health_v1"
//......
)
// HealthImpl 健康检查实现
type HealthService struct{}
// Check 实现健康检查接口,在实际中需要更加复杂的健康检查策略,比如根据服务器 CPU、内存负载等
func (h *HealthService) Check(ctx context.Context, req *grpc_health_v1.HealthCheckRequest) (*grpc_health_v1.HealthCheckResponse, error) {
...
return &grpc_health_v1.HealthCheckResponse{
Status: grpc_health_v1.HealthCheckResponse_SERVING,
}, nil
}
func main(){
//...
server := grpc.NewServer(...)
grpc_health_v1.RegisterHealthServer(server, &HealthService{})
//...
}
客户端健康检查代码如下:
import (
healthpb "google.golang.org/grpc/health/grpc_health_v1"
)
// 调用健康检查
healthClient := healthpb.NewHealthClient(conn)
ir := &healthpb.HealthCheckRequest{
Service: "grpc.health.v1.Health", //常填写服务名字
}
// 调用Check检查服务是否正常
deadline, cancelFunc := context.WithDeadline(context.Background(), time.Now().Add(5*time.Second))
healthCheckResponse, err := healthClient.Check(deadline, ir)
if err != nil {
return
}
fmt.Println(healthCheckResponse)
cancelFunc()
0x04 consul的健康检查支持
比如在grpclb2consul项目中,使用consul接口注册服务,可以选择以gRPC健康检查的方式,如下:
registerfunc := func() error {
//健康检查
healthcheck := &consulapi.AgentServiceCheck{
Interval: DefaultCheckInterval, // 健康检查间隔 // 健康检查间隔
GRPC: fmt.Sprintf("%s:%d/%s", c.GeneNodeData.Ip, c.GeneNodeData.Port, c.GeneNodeData.ServiceName), // grpc 支持,执行健康检查的地址,service 会传到 Health.Check 函数中
DeregisterCriticalServiceAfter: DefaultDeregisterCriticalServiceAfter, // 注销时间,相当于过期时间
}
crs := &consulapi.AgentServiceRegistration{
ID: c.GeneNodeData.UniqID, //uniq-id
Name: c.GeneNodeData.ServiceName,
Address: c.GeneNodeData.Ip, // 服务 IP
Port: c.GeneNodeData.Port, // 服务端口
Tags: tags, // tags,可以为空([]string{})
Meta: c.GeneNodeData.Metadata,
Check: healthcheck}
err := c.ConsulAgent.Agent().ServiceRegister(crs) //单例模式
if err != nil {
c.Logger.Error("Register with consul error", zap.String("errmsg", err.Error()))
return fmt.Errorf("Register with consul error: %s\n", err.Error())
}
return nil
}
服务注册后,consul Agent会使用上述AgentServiceCheck参数来进行健康检查(使用的是gRPC标准健康检查协议),同时服务端要实现健康检查的接口:
func (h *HealthyCheck) Check(ctx context.Context, in *pb.HealthCheckRequest) (*pb.HealthCheckResponse, error) {
//more check method/logic could be add
fmt.Println("call health check", in.Service)
return &pb.HealthCheckResponse{Status: pb.HealthCheckResponse_SERVING}, nil
//return &pb.HealthCheckResponse{Status: pb.HealthCheckResponse_NOT_SERVING }, nil
}
如果Check方法持续返回pb.HealthCheckResponse_NOT_SERVING时,consul Agent会启动DeregisterCriticalServiceAfter机制,在DefaultDeregisterCriticalServiceAfter之后会把服务标记为下线,达到了健康检查的效果
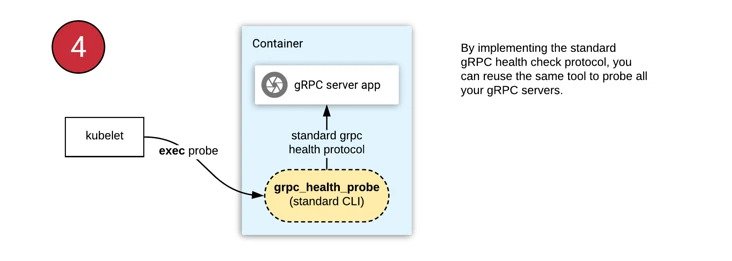
0x05 官方提供的探针
grpc-health-probe,这里提供了的gRPC的客户端健康检查工具,可以直接编译拿来使用(打包到镜像中):
spec:
containers:
- name: server
image: "[YOUR-DOCKER-IMAGE]"
ports:
- containerPort: 5000
readinessProbe:
exec:
command: ["/bin/grpc_health_probe", "-addr=:5000"]
initialDelaySeconds: 5
livenessProbe:
exec:
command: ["/bin/grpc_health_probe", "-addr=:5000"]
initialDelaySeconds: 10