0x01 Golang 的 io 包介绍
在 golang 中,标准库中的 package 设计的基本原则是职责内聚。通常开发者可以使用自定义 Wrapper 的方式来封装标准库 package 中的 interface 接口,亦或在此基础上扩展,添加自定义的功能。N但是有一点,返回值必须封装的方法保持一致
0x02 神奇的 io.Copy
io.Copy 的好处
io.Copy() 相较于 ioutil.ReadAll() 之类,最大的不同是它采用了一个定长的缓冲区做中转,复制过程中,内存的消耗量是较为固定的。如果你的代理的网络状况不佳,就会发现 io.Copy() 比 ioutil.ReadAll() 的好处了。
io.Copy 与 Tcp 的开发结合
做过服务端开发的同学一定都写过代理 Proxy,代理的本质,是转发两个相同方向路径上的 stream(数据流)。例如,一个 A-->B-->C 的代理模式,B 作为代理,需要完成下面两件事情:
- 读取从
A--->B的数据,转发到B--->C - 读取从
C--->B的数据,转发到B--->A
在 golang 中,只需要 io.Copy() 就能轻而易举的完成上面的事情,其 实现代码 如下所示:
func copyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) {
// If the reader has a WriteTo method, use it to do the copy.
// Avoids an allocation and a copy.
if wt, ok := src.(WriterTo); ok {
return wt.WriteTo(dst)
}
// Similarly, if the writer has a ReadFrom method, use it to do the copy.
if rt, ok := dst.(ReaderFrom); ok {
return rt.ReadFrom(src)
}
if buf == nil {
size := 32 * 1024
if l, ok := src.(*LimitedReader); ok && int64(size) > l.N {
if l.N < 1 {
size = 1
} else {
size = int(l.N)
}
}
buf = make([]byte, size)
}
for {
nr, er := src.Read(buf)
if nr > 0 {
nw, ew := dst.Write(buf[0:nr])
if nw > 0 {
written += int64(nw)
}
if ew != nil {
err = ew
break
}
if nr != nw {
err = ErrShortWrite
break
}
}
if er != nil {
if er != EOF {
err = er
}
break
}
}
return written, err
}
io.Copy 与 Http 的开发结合
在 Web 开发中,如果我们要实现下载一个文件(并保存在本地),有哪些高效的方式呢?
第一种方式:http.Get()+ioutil.WriteFile(),将下载内容直接写到文件中
func DownloadFile() error {
url :="http://xxx/somebigfile"
resp ,err := http.Get(url)
if err != nil {
fmt.Fprint(os.Stderr ,"get url error" , err)
}
defer resp.Body.Close()
data ,err := ioutil.ReadAll(resp.Body)
if err != nil {
panic(err)
}
return ioutil.WriteFile("/tmp/xxx_file", data, 0755)
}
But,第一种方式的问题在于,如果是大文件,会出现内存不足的问题,因为它是需要先把请求内容全部读取到内存中,然后再写入到文件中的。优化的方案就是使用 io.Copy(),它是将源复制到目标,并且是按默认的缓冲区 32k 循环操作的,不会将内容一次性全写入内存中
第二种方式:使用 io.Copy()
func DownloadFile() {
url :="http://xxx/somebigfile"
resp ,err := http.Get(url)
if err != nil {
fmt.Fprint(os.Stderr ,"get url error" , err)
}
defer resp.Body.Close()
out, err := os.Create("/tmp/xxx_file")
// 很重要:初始化一个 io.Writer
wt :=bufio.NewWriter(out)
defer out.Close()
n, err :=io.Copy(wt, resp.Body)
if err != nil {
panic(err)
}
wt.Flush()
}
同理,复制大文件也可以用 io.copy() 这个,防止产生内存溢出。
使用 io.Copy 实现 SSH 代理
利用 io.Copy() 实现 SSH 代理的代码如下,只需要 2 个 io.Copy() 就简单的将两条连接无缝衔接起来了,非常直观。
type Endpoint struct {
Host string
Port int
}
func (endpoint *Endpoint) String() string {
return fmt.Sprintf("%s:%d", endpoint.Host, endpoint.Port)
}
type SSHtunnel struct {
Local *Endpoint
Server *Endpoint
Remote *Endpoint
Config *ssh.ClientConfig
}
func (tunnel *SSHtunnel) Start() error {
listener, err := net.Listen("tcp", tunnel.Local.String())
if err != nil {
return err
}
defer listener.Close()
for {
conn, err := listener.Accept()
if err != nil {
return err
}
go tunnel.forward(conn)
}
}
func (tunnel *SSHtunnel) forward(localConn net.Conn) {
serverConn, err := ssh.Dial("tcp", tunnel.Server.String(), tunnel.Config)
if err != nil {
fmt.Printf("Server dial error: %s\n", err)
return
}
remoteConn, err := serverConn.Dial("tcp", tunnel.Remote.String())
if err != nil {
fmt.Printf("Remote dial error: %s\n", err)
return
}
copyConn := func(writer, reader net.Conn) {
defer writer.Close()
defer reader.Close()
_, err := io.Copy(writer, reader)
if err != nil {
fmt.Printf("io.Copy error: %s", err)
}
}
go copyConn(localConn, remoteConn)
go copyConn(remoteConn, localConn)
}
func main() {
localEndpoint := &Endpoint{
Host: "localhost",
Port: 9000,
}
serverEndpoint := &Endpoint{
Host: "some-real-ssh-listening-port",
Port: 22,
}
remoteEndpoint := &Endpoint{
Host: "www.baidu.com",
Port: 80,
}
sshConfig := &ssh.ClientConfig{
User: "root",
Auth: []ssh.AuthMethod{
ssh.Password("real-password"),
},
HostKeyCallback: func(hostname string, remote net.Addr, key ssh.PublicKey) error {
// Always accept key.
return nil
},
}
tunnel := &SSHtunnel{
Config: sshConfig,
Local: localEndpoint,
Server: serverEndpoint,
Remote: remoteEndpoint,
}
tunnel.Start()
}
0x03 golang io.Pipe 的妙用
另外一个有趣的方法是 io.Pipe,其实现 在此,有点像 Linux 的 Pipe。其官方描述如下,简言之,就是提供了一个单工的数据传输管道。
读端只可以读,写端只可以写。
Pipe creates a synchronous in-memory pipe. It can be used to connect code expecting an io.Reader with code expecting an io.Writer. Reads and Writes on the pipe are matched one to one except when multiple Reads are needed to consume a single Write. That is, each Write to the 》》PipeWriter blocks until it has satisfied one or more Reads from the PipeReader that fully consume the written data. The data is copied directly from the Write to the corresponding Read (or Reads); there is no internal buffering. It is safe to call Read and Write in parallel with each other or with Close. Parallel calls to Read and parallel calls to Write are also safe: the individual calls will be gated sequentially.
func Pipe() (*PipeReader, *PipeWriter) {
p := &pipe{
wrCh: make(chan []byte),
rdCh: make(chan int),
done: make(chan struct{}),
}
return &PipeReader{p}, &PipeWriter{p}
}
官方给的例子比较易懂,通过 io.Pipe() 生成一对 (PipeReader,PipeWriter) 在单独的协程中,向 PipeWriter 写入数据,在主协程中,通过 io.Copy() 将 PipeReader 的数据复制到标准输出 os.Stdout 上:
func main() {
r, w := io.Pipe()
go func() {
fmt.Fprint(w, "some io.Reader stream to be read\n")
w.Close()
}()
if _, err := io.Copy(os.Stdout, r); err != nil {
log.Fatal(err)
}
}
一个经典的例子
再通过下面这个非常经典的例子加深下对 io.Pipe() 的印象:
func read(r io.Reader) {
buf := make([]byte, 1024)
pos := 0
lastPrint := time.Now()
for {
n, err := r.Read(buf[pos:])
if n > 0 {
pos += n
}
if pos >= len(buf) || time.Since(lastPrint) > 100*time.Millisecond && pos > 0 {
fmt.Printf("read: %s\n", buf[:pos])
lastPrint = time.Now()
pos = 0
}
if err != nil {
if err != io.EOF {
fmt.Println(err)
}
break
}
}
if pos > 0 {
fmt.Printf("read: %s\n", buf[:pos])
}
}
func main() {
pr, pw := io.Pipe()
go func() {
io.Copy(pw, &trickle{})
pw.Close()
}()
read(pr)
}
type trickle struct{counter int}
// 作为 io.Copy 的 src 端,必须实现 Read() 方法
func (t *trickle) Read(p []byte) (n int, err error) {
if t.counter > 25 {
return 0, io.EOF // Terminate after a few reads.
}
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
// 向 p 写入数据(看起来有些奇怪)
p[0] = byte('a' + t.counter%26)
t.counter++
return 1, nil
}
上面这段代码大体执行流程如下:
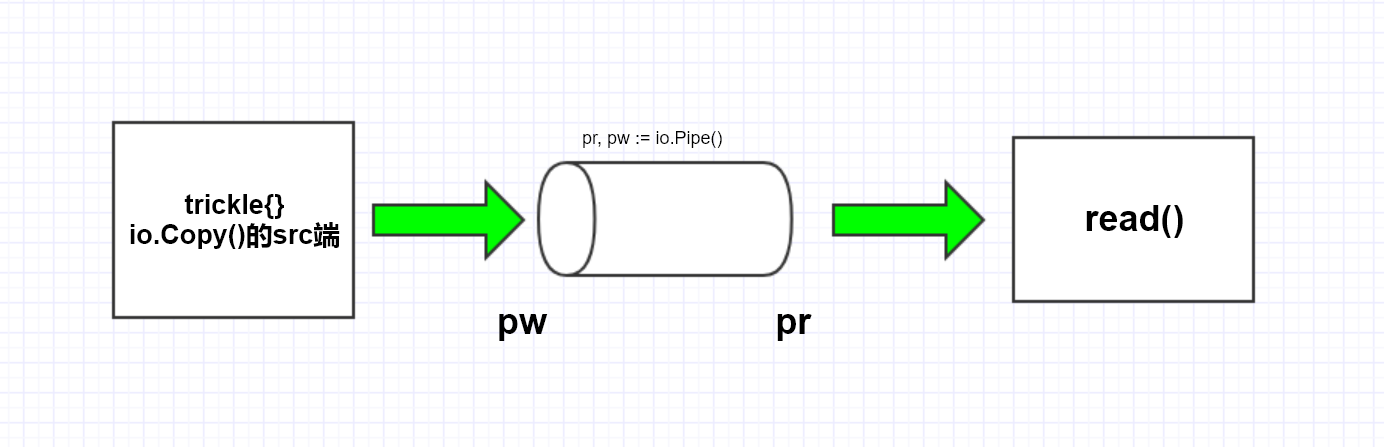
io.Pipe 分析
我们看看 write 方法的实现:
func (p *pipe) write(b []byte) (n int, err error) {
// pipe uses nil to mean not available
if b == nil {
b = zero[:]
}
// One writer at a time.
p.wl.Lock()
defer p.wl.Unlock()
p.l.Lock()
defer p.l.Unlock()
if p.werr != nil {
err = ErrClosedPipe
return
}
p.data = b // 注意:这里是引用赋值,只是复制了地址而已
p.rwait.Signal() // 通知 p.rwait.Wait, 释放 p.rwait.Wait 等待, 可以开始读数据了. 让读操作把 data 都读完, 读完之后即可等待准备下一次写操作
for {
if p.data == nil {
break // 有数据来了, break 等待循环, 进行写操作
}
if p.rerr != nil {
err = p.rerr
break
}
if p.werr != nil {
err = ErrClosedPipe
break
}
p.wwait.Wait() // 写的等待, 等待 p.wwait.Signal
}
n = len(b) - len(p.data)
p.data = nil // in case of rerr or werr // 将 data 置为 nil, 等待下一次的写操作
return
}
使用 io.Pipe() 的场景
在 io.Pipe 的实现中,每次 Read 需要等待 Write 写完,是串行的。即 io.Pipe 描述了这样一种场景,即产生了一条数据,紧接着就要处理掉这条数据的场景。此外,从其实现来看,在 Write 流程中,将参数 b 这个 slice 放到 p.data 中,这是一次引用赋值。然后在 Read 流程中,把 p.data copy 出去,本质上相当于 copy 了 write 的原始数据,并没有用占用临时 slice 存储,减少了内存使用量。
0x04 使用 io.copyN 传输文件
下载 / 上传文件
CopyN 方法借用了 io.LimitReader 的能力,而 LimitReader(r Reader, n int64) Reader 返回一个内容长度受限的 Reader,当从这个 Reader 中读取了 n 个字节一会就会遇到 EOF。其实现如下:
func CopyN(dst Writer, src Reader, n int64) (written int64, err error) {
written, err = Copy(dst, LimitReader(src, n))
if written == n {
return n, nil
}
if written < n && err == nil {
// src stopped early; must have been EOF.
err = EOF
}
return
}
CopyN 提供了一定的保护措施,可以传输指定 size 的文件后自行退出。就是提供了一个保护的功能,其它和普通的 Reader 无区别。那么使用 CopyN 传输文件:
1、上传文件:使用 os.Open 打开需要传输的文件,然后使用 os.Lstat 获取 FileInfo,然后开始传输 io.CopyN(net.Conn, os.File,os.FileInfo.Size())
2、下载文件:使用 os.Create 创建写入文件,然后实现 io.CopyN(os.File, net.Conn,os.FileInfo.Size())
3、下载文件,还可以使用 ReadAtLeast 与 LimitReader 进行配合
func main() {
// 建立连接
conn, err := net.Dial("tcp", "127.0.0.1:80")
if err != nil {
return
}
defer conn.Close()
// 发送请求, http 1.0 协议
fmt.Fprintf(conn, "GET / HTTP/1.0\r\n\r\n")
// 读取 response
var sb strings.Builder
buf := make([]byte, 256)
rr := io.LimitReader(conn, 102400)
for {
n, err := io.ReadAtLeast(rr, buf, 256)
if err != nil {
if err != io.EOF && err != io.ErrUnexpectedEOF {
fmt.Println("read error:", err)
}
break
}
sb.Write(buf[:n])
}
fmt.Println("response:", sb.String())
fmt.Println("total response size:", sb.Len())
}
0x05 一些 IO 优化的 tips
关于 io.Copy 的优化
在前面讨论过,io.Copy 此方法,从 src 拷贝数据到 dst,中间会借助字节 slice 作为 buffer。可以使用 io.CopyBuffer 替代 io.Copy,并使用 sync.Pool 缓存 buffer, 以减少临时对象的申请和释放。见 issue:io: consider reusing buffers for io.Copy to reduce GC pressure
io.CopyBuffer(dst Writer, src Reader, buf []byte)
// 提供 buf 的引用参数传入
func copyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) {
// If the reader has a WriteTo method, use it to do the copy.
// Avoids an allocation and a copy.
if wt, ok := src.(WriterTo); ok {
return wt.WriteTo(dst)
}
// Similarly, if the writer has a ReadFrom method, use it to do the copy.
if rt, ok := dst.(ReaderFrom); ok {
return rt.ReadFrom(src)
}
// 当 buf 为空时,和 copy 行为一致
if buf == nil {
size := 32 * 1024
// 如果源Reader 为LimitedReader, 此时比较 可读数据数 和 默认缓冲区,取较小那个
if l, ok := src.(*LimitedReader); ok && int64(size) > l.N {
if l.N < 1 {
size = 1
} else {
size = int(l.N)
}
}
buf = make([]byte, size)
}
//在连接关闭之前,一直都在 for 循环。而连接关闭时,读取到的就是 io.EOF
for {
nr, er := src.Read(buf)
if nr > 0 {
nw, ew := dst.Write(buf[0:nr])
if nw > 0 {
written += int64(nw)
}
if ew != nil {
err = ew
break
}
if nr != nw {
err = ErrShortWrite
break
}
}
if er != nil {
if er != EOF {
err = er
}
break
}
}
return written, err
}
上述优化可以在 frp 项目中找到,这里使用了 io.CopyBuffer 来把两个连接之间的流量转发:
// Join two io.ReadWriteCloser and do some operations.
func Join(c1 io.ReadWriteCloser, c2 io.ReadWriteCloser) (inCount int64, outCount int64) {
var wait sync.WaitGroup
pipe := func(to io.ReadWriteCloser, from io.ReadWriteCloser, count *int64) {
defer to.Close()
defer from.Close()
defer wait.Done()
buf := pool.GetBuf(16 * 1024)
defer pool.PutBuf(buf)
*count, _ = io.CopyBuffer(to, from, buf)
}
wait.Add(2)
go pipe(c1, c2, &inCount)
go pipe(c2, c1, &outCount)
wait.Wait()
return
}
此外,golang 的 httputil.reverseproxy 实现,也加入了此 机制:
net/http/httputil: add hook for managing io.Copy buffers per request
Adds ReverseProxy.BufferPool for users with sensitive allocation
requirements. Permits avoiding 32 KB of io.Copy garbage per request.
0x06 参考
转载请注明出处,本文采用 CC4.0 协议授权