0x00 前言
Redis 是 Linux C 项目中单线程开发模型的典范,其内置了多种高性能的数据结构,如 sds 动态字符串、skiplist 跳表,zset,hashset 等。今天这篇文章是想分享下项目中使用 Redis 的一些技巧,结合 go-redis 这个客户端库。
0x01 Pipeline 加速
在大批量的操作 Redis(写入 / 读取)时,采用 pipeline 是个非常好的优化思路,可以提高在单个 Redis 连接操作的数据吞吐量,从而提升整体性能。
通过 pipeline 方式将 client 端命令(打包后)一起发出,Redis 服务端会处理完多条命令后,将结果一起打包返回 client,从而节省大量的网络延迟开销。这里需要注意两点:
- 服务端的模式(主从 Sentinel、集群 Cluster、Proxy)是否支持
pipeline操作? - 项目中使用的 Redis 客户端库,是否支持 pipeline 操作?
- 一次
pipeline.Exec()操作打包多少条 Redis 命令?
这里有趣的问题是第 3 个,从下面这个问题中,大概可以找到答案: How many commands could redis-py pipeline have?
Not sure that there is a maximum, but I don’t think that you want to reach it in case there is. In most cases, limiting the size of the pipeline to 100-1000 operations gives the best results. But, you can do a little benchmark >research that includes typical requests that you send. Pipelining requests is generally good, but keep in mind that the responses >are kept in Redis memory until all pipeline requests are served, and your client waits for the long reply of all requests. You should try to find the sweet spot of concurrent connections, pipelined requests and your Redis memory.
Pipeline 的要点(重要)
- Pipeline 无法保证原子性:Pipeline 模式只是将客户端发送命令的方式改为发送批量命令,而服务端在处理批量命令的数据流时,仍然是解析出多个单命令并按顺序执行,各个命令相互独立,即服务端仍有可能在该过程中执行其他客户端的命令。如需保证原子性,需要使用事务或 Lua 脚本(如lua脚本,打包为一个整体,相当于是在redis服务端执行lua脚本,操作要么成功OR失败,执行是原子性且是整体执行的)
- 服务端架构无关:Pipeline 的本质为客户端与服务端的交互模式,与服务端的架构无关,因此集群架构代理模式、集群架构直连模式以及读写分离架构实例均支持 Pipeline。在集群架构中使用 Pipeline 时,一定要确保 Pipeline 内部的命令符合集群架构的可执行条件
Pipeline 的坑
注意当 pipeClient.Exec 方法返回 err 时,还需要处理返回值(当 err==redis.Nil 时),看下面批量 HGet,其他批量操作也是同理,测试代码见 pipeline.go
// PipelineGetHashField 使用 pipeline 命令获取多个 hash key 的单个字段
// keyList,需要获取的 hash key 列表
// field 需要获取的字段值
func PipelineGetHashField(keyList []string,filed string) []string {
pipeClient :=client.Pipeline()
for _, key := range keyList {
pipeClient.HGet(key, filed)
}
res, err := pipeClient.Exec()
if err != nil {
if err != redis.Nil {
logrus.WithField("key_list", keyList).Errorf("get from redis error:%s", err.Error())
}
// 注意这里如果某一次获取时出错(常见的 redis.Nil),返回的 err 即不为空
// 如果需要处理 redis.Nil 为默认值,此处不能直接 return
}
valList := make([]string, 0, len(keyList))
for index, cmdRes := range res {
var val string
// 此处断言类型为在 for 循环内执行的命令返回的类型, 上面 HGet 返回的即为 * redis.StringCmd 类型
// 处理方式和直接调用同样处理即可
cmd, ok := cmdRes.(*redis.StringCmd)
if ok {
val,err = cmd.Result()
if err != nil {
logrus.WithField("key",keyList[index]).Errorf("get key error:%s",err.Error())
}
}
valList = append(valList, val)
}
return valList
}
关于上面代码示例中 res,也可以通过保存每一步 pipeline 的结果来实现一些额外的功能,看下面的例子:
1、批量获取 kv 数据,不过 pipeline.Exec 的结果中不会包含 key 的数据,所以建议在 value 中包含 key 的数据(写入 kv 时就设计好),这样就可直接在 value 中拿到 key 的信息(比如 hostid)
func pipeline_1(){
for _, hk := range xxxxxx {
redis_pipe.Get(hk)
}
cmders, err := redis_pipe.Exec()
if err != nil {
//WARN:当 pipeline 里面的 key 不存在时(过期或删除),此时 pipeline 会报错: redis: nil
}
for _, cmder := range cmders {
if cmder == nil {
continue
}
cmd, ok := cmder.(*redis.StringCmd)
if !ok {
continue
}
strmap, err := cmd.Result()
if err != nil {
continue
}
if len(strmap) == 0 {
continue
}
//check data valid
// .....
}
}
2、通过一个 map,保存每次 pipeline.Get 的结果,借此来保存 kv 的映射关系,参考代码如下:
func pipeline_2(){
var (
err error
pipeline = h.rds.Pipeline()
allowsCacheMap = make(map[string]bool)
pipelineResult = make(map[string]*redis.StringCmd)
)
for key, _ := range keyMap {
key = fmt.Sprintf("%s#%s", subject, key)
pipelineResult[key] = pipeline.Get(ctx, key)
}
_, err = pipeline.Exec(ctx)
if err != nil {
h.apiLogger.Error("pipeline exec found error", zap.Any("errmsg", err))
}
for key, r := range pipelineResult {
var (
array []string
)
v, err := r.Result()
if err != nil {
//no data
continue
}
array = strings.Split(key, "#")
if len(array) < 2 {
continue
}
if v == "1" {
//use key
allowsCacheMap[array[1]] = true
} else {
allowsCacheMap[array[1]] = false
}
}
}
0x02 Pool 连接池使用
连接池的好处,在于避免每次 Redis 操作时,新建 TCP 连接的开销,在要求高性能的场景推荐开启。个人建议,使用的 Redis 客户端库,包含的连接池至少满足下面的特性:
- 连接健康检查
- 自动关闭空连接
下面这张表格总结了常见的 Golang 的 Redis 客户端库的连接池特性,笔者在项目中使用的连接池是基于 go-redis 的。
| 连接池功能 | go-redis | radix.V2 | redigo |
|---|---|---|---|
| 实现数据结构 | slice | channel | linklist |
| 连接健康检查 | No | Yes | Yes |
| 自动关闭空闲连接 | Yes | No | Yes |
| 连接的 Max 生存时间 | Yes | No | Yes |
关于 go-redis 连接池的实现可见此文 Go-Redis 连接池(Pool)源码分析
连接池的大小的合理性
在 go-redis 中,在高并发的场景下,如果连接池的 size 设置过小,可能会导致 connection pool timeout 的 报错。一般通过如下策略优化:
- 优化耗时过久的操作
- 调大连接池的大小
- 合理设置
PoolTimeout、IdleTimeout、ReadTimeout、MinIdleConns以及WriteTimeout等 参数 的值
如:
Cluster = redis.NewClient(&redis.ClusterOptions{
Addrs: addresses,
PoolSize: 512,
PoolTimeout: 2 * time.Minute,
IdleTimeout: 10 * time.Minute,
ReadTimeout: 2 * time.Minute,
WriteTimeout: 1 * time.Minute,
})
健康度检查
使用 go-redis 初始化的时候,建议开启如下配置:
func InitRedisClient(config *config.Config) error {
redisCfg := config.RedisConfig
if redisCfg.PoolSize == 0 {
redisCfg.PoolSize = 5
}
redisClient = redis.NewClient(&redis.Options{
RedisAlive: 0, // 健康度标识
DB: redisCfg.Db,
Addr: redisCfg.Addr,
Password: redisCfg.Password,
PoolSize: redisCfg.PoolSize, // 连接池大小
MinIdleConns: redisCfg.MinIdleConns,
IdleTimeout: time.Duration(redisCfg.IdleTimeout) * time.Second,
})
_, err := redisClient.Ping(context.TODO()).Result()
if err != nil {
return err
}
// 是否支持特殊指令
enableSpecialCommand = redisCfg.EnableSpecialCommand
go StartRedisMonitor()
return nil
}
// 异步监控
func (c *Client) StartRedisMonitor() {
ticker := time.NewTicker(pingInterval)
for range ticker.C {
if _, err := lim.store.Ping(context.TODO().Result()); err == nil {
atomic.StoreUint32(&c.redisAlive, 1)
} else {
// 健康度检查失败
atomic.StoreUint32(&c.redisAlive, 0)
}
}
}
0x03 Redis 常用操作
Set 集合
Set 作为 CS 中最基础的数据结构,使用非常广泛,Redis 的 Set 在高性能查找中扮演着极为重要的角色。举例来说,SInter(Store) 和 SUnion(Store) 及 SDiff(STORE) 这几个操作,取(多个)集合的交集、并集及差集并直接存储。在实际项目中,如计算多个子集合间的交集、并集和差集,非常方便。
sinter key [key ...]返回一个集合的全部成员,该集合是所有给定集合的交集sunion key [key ...]返回一个集合的全部成员,该集合是所有给定集合的并集sdiff key [key ...]返回所有给定 key 与第一个 key 的差集sinterstore destination key [key ...]将 交集 数据存储到某个对象中sunionstore destination key [key ...]将 并集 数据存储到某个对象中sdiffstore destination key [key ...]将 差集 数据存储到某个对象中
举例看下:
1、计算 Set5 和 Set1~4 之间并集的交集
127.0.0.1:6379> sadd set1 a b c d e f g
(integer) 7
127.0.0.1:6379>
127.0.0.1:6379> sadd set2 a b c d e f g h i j k l m n
(integer) 14
127.0.0.1:6379> sadd set3 a c d e f g h i j
(integer) 9
127.0.0.1:6379> sadd set4 a b c e f g h i j m n
(integer) 11
127.0.0.1:6379>
127.0.0.1:6379> sadd set5 b c d g h j q z
(integer) 8
127.0.0.1:6379>
127.0.0.1:6379> SUNIONSTORE tempset set1 set2 set3 set4
(integer) 26
127.0.0.1:6379>
127.0.0.1:6379> SINTER tempset set5
1) "h"
2) "g"
3) "j"
4) "d"
5) "c"
6) "b"
2、复制一个 Set
127.0.0.1:6379> SADD set1 a b c
(integer) 3
127.0.0.1:6379> SUNIONSTORE set2 set1 temp
(integer) 3
127.0.0.1:6379> smembers set1
1) "b"
2) "a"
3) "c"
127.0.0.1:6379> smembers set2
1) "a"
2) "b"
3) "c"
127.0.0.1:6379> smembers temp //temp 并不存在的 key
(empty list or set)
Hash
Hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,特别适合用于存储对象,参考如下操作:
127.0.0.1:6379> HMSET runoobkey name "redis tutorial" description "redis basic commands for caching" likes 20 visitors 23000
OK
127.0.0.1:6379> HGETALL runoobkey
1) "name"
2) "redis tutorial"
3) "description"
4) "redis basic commands for caching"
5) "likes"
6) "20"
7) "visitors"
8) "23000"
127.0.0.1:6379> HGETALL runoobkey
1) "name"
2) "redis tutorial"
3) "description"
4) "redis basic commands for caching"
5) "likes"
6) "20"
7) "visitors"
8) "23000"
127.0.0.1:6379> HEXISTS name
(error) ERR wrong number of arguments for 'hexists' command
127.0.0.1:6379> HEXISTS runoobkey name
(integer) 1
127.0.0.1:6379> HGET runoobkey name
"redis tutorial"
127.0.0.1:6379> HGET runoobkey name
"redis tutorial"
ZSET:有序不重复集合
ZSET 即有序集合,通常用来实现延时队列或者排行榜(如销量 / 积分排行、成绩排行等等)。ZSET 通常包含 3 个 关键字操作:
key(与 redis 通常操作的 key value 中的 key 一致)score(用于排序的分数,该分数是有序集合的关键,可以是双精度或者是整数)member(指传入的 obj,与 key value 中的 value 一致)
几个细节:
ZADD,如果操作的key中已经有了相同的member,则更新该member的score值,并会重排序ZRANGE/ZREVRANGE,按照score排序并返回,注意需要传入score的[start,end]区间ZSET每个元素都会关联一个float64类型的分数,Redis 是通过分数来为集合中的成员进行从小到大的排序ZSET的成员member是唯一的, 但分数score却允许重复ZSET是通过哈希表实现的,所以添加 / 删除 / 查找的复杂度都是O(1)- 从使用意义来看,
ZSET中只有score值非常重要,value值没有特别的意义,只需要保证它是唯一的就可以 ZREMRANGEBYSCORE key startScore endScore会删除[startScore,endScore]区间的数据(包含左右区间)- 一个 key 表示一个有序集合
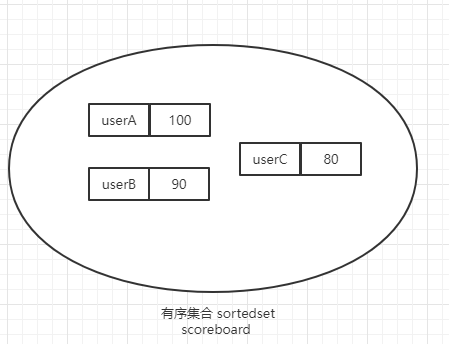
127.0.0.1:6379> zadd key1 1 a 2 b 3 c
(integer) 3
127.0.0.1:6379> zrange key1 0 -1
1) "a"
2) "b"
3) "c"
127.0.0.1:6379> zrevrange key1 0 -1
1) "c"
2) "b"
3) "a"
127.0.0.1:6379> ZREMRANGEBYSCORE key1 1 3
(integer) 3
127.0.0.1:6379> zadd scoreboard 100 userA 90 userB 80 userC
(integer) 3
【WARNING】慎用的操作
在项目实践中,也遇到了一些性能问题,如下:
- 慢操作:
SMEMBERS命令是从一个 SET 结构获取集合,但这个集合数据量已经很大,当这个命令被频繁的调用,会极大的占用网络 IO,当网络被占满时,其余的操作也会受到影响;尽量使用 Redis 提供的操作来操作集合运算,如SISMEMBER等 - 危险操作,如
KEYS *等,不要在现网中使用
0x04 Redis 的应用场景
本小节梳理下,项目中使用 Redis 的场景
消息队列
主要是利用 Redis 的 List 数据结构,实现 Broker 机制,又细分为三种模式:
1、List:使用生产者:LPUSH;消费者:RBPOP 或 RPOP 模拟队列
2、Stream
3、PUB/SUB(订阅)
基于 go-redis 的 pub/sub测试代码 在此。基于 Redis 来实现消息的发布与订阅,优点是比较轻量级(适合数据量不大且容忍数据丢失的场景),缺点是消息不能堆积,一旦消费者节点没有消费消息,消息将会丢失。订阅的模型如下:
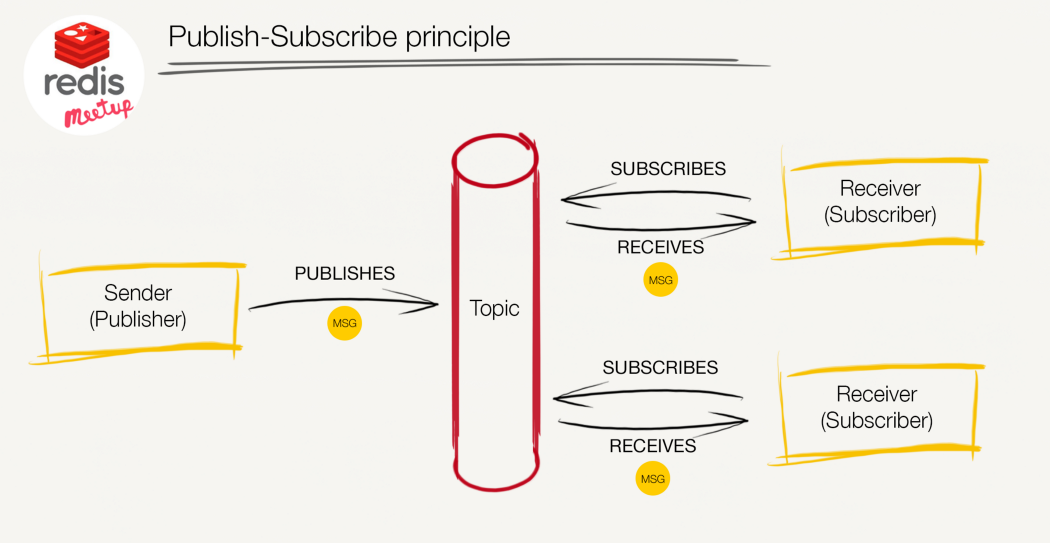
在项目中,一个可实践的场景是借助 Redis 的订阅 / 发布机制和 WebSocket 长连接结合,实现轻量级的订阅发布和消息实时推送功能。
延迟队列
1、实现一思路
- 使用
ZSET配合定时轮询的方式实现延时队列机制,任务集合记为taskGroupKey - 生成任务以 当前时间戳 与 延时时间 相加后得到任务真正的触发时间,记为
time1,任务的 uuid 即为taskid,当前时间戳记为curTime - 使用
ZADD taskGroupKey time1 taskid将任务写入ZSET - 主逻辑不断以轮询方式
ZRANGE taskGroupKey curTime MAXTIME withscores获取[curTime,MAXTIME)之间的任务,记为已经到期的延时任务(集) - 处理延时任务,处理完成后删除即可
- 保存当前时间戳
curTime,作为下一次轮询时的ZRANGE指令的范围起点
滑动窗口(rolling window)
场景 1:通过 Redis 构建滑动窗口并实现计数器限流
比如,系统要限定用户的某个行为在指定的时间里只能允许发生 N 次,采用滑动窗口的方式实现。利用 ZSET 可实现滑动窗口的机制。如下图所示,使用 ZSET 记录所有用户的访问历史数据,每个 key 表示不同的用户,用 score 标记时间范围的刻度,value 这里无意义,仅用于唯一性考虑。该流程大致流程如下:
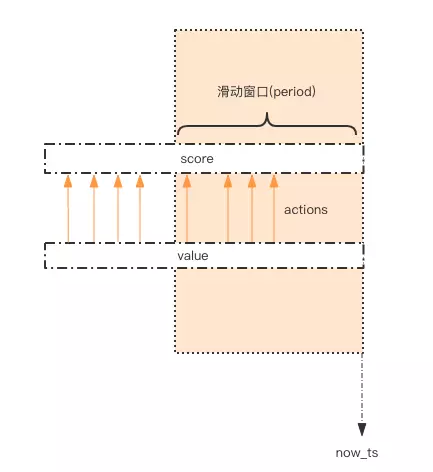
- 当用户 A 访问时,向
ZSET中添加ZADD usernameA curTime uuid,其中score值$curtime为当前时间戳,value值uuid为保证唯一性的字符串(或者改用毫秒时间戳减少size) - 针对用户
usernameA,限流只需要计算指定的时间区间的总数ZCOUNT usernameA startTime endTime,将此值与限流值limiter比较即可;通过score值圈出时间窗口,实现了滑动窗口的效果 - 对于
score窗口之外的数据,会有占用内存过大的风险,有两个方法优化:- 异步清理
score过期的数据(滑动窗口外的数据) - 若某个时间段检查用户并并未触发限流(滑动窗口内的行为是空记录),那么可以直接删掉 ZSET 的此
key以减少内存占用
- 异步清理
- 该方案的 Redis 操作都是针对同一个
key的,使用pipeline可以显著提升存取效率 - 该方案的缺点是要记录时间窗口内所有的行为记录,如果这个并发量很大,会消耗大量的内存
通常分布式场景使用 lua 脚本实现,如下:
--KEYS[1]: 限流对应的 key
--ARGV[1]: 一分钟之前的时间戳(假设按照 1 分钟为滑动窗口的区间)
--ARGV[2]: 此时此刻的时间戳(score 值)
--ARGV[3]: 允许通过的最大数量
--ARGV[4]:member 名称(随机生成)
redis.call('zremrangeByScore', KEYS[1], 0, ARGV[1])
local res = redis.call('zcard', KEYS[1])
if (res == nil) or (res < tonumber(ARGV[3])) then
redis.call('zadd', KEYS[1], ARGV[2], ARGV[4])
return 0
else return 1 end
场景 2:通过 EXPIRE 实现滑动窗口计数器限流
和上面使用 ZSET 不同,这里用 EXPIRE 来模拟窗口(注意:仅能使用秒为单位),从某个时间点开始每次请求过来请求数 +=1,同时判断当前时间窗口内请求数是否超过限制,超过限制则拒绝该请求,然后下个时间窗口开始时计数器清零等待请求,lua 代码如下:
-- KYES[1]: 限流器 key
-- ARGV[1]:qos, 单位时间内最多请求次数
-- ARGV[2]: 单位限流窗口时间
-- 请求最大次数, 等于 p.quota
local limit = tonumber(ARGV[1])
-- 窗口即一个单位限流周期, 这里用过期模拟窗口效果, 等于 p.permit
local window = tonumber(ARGV[2])
-- 请求次数 + 1, 获取请求总数
local current = redis.call("INCRBY",KYES[1],1)
-- 如果是第一次请求, 则设置过期时间并返回 成功
if current == 1 then
redis.call("EXPIRE",KYES[1],window)
return 1
-- 如果当前请求数量小于 limit 则返回 成功
elseif current < limit then
return 1
-- 如果当前请求数量 ==limit 则返回 最后一次请求
elseif current == limit then
return 2
-- 请求数量 > limit 则返回 失败
else
return 0
end
场景 3:利用滑动窗口实现 DNS 域名解析合并
使用时间戳作为 score,DNS 解析的域名 A 记录(IP)作为 member,如下图:

每次将新解析出来的 DNS 域名的 A 记录增加(更新)到 ZSET,其中将时间戳更新为当前的 IP(如果已经存在相同的 IP,那么时间戳会更新),参考如下操作:
1.1.1.1:6380> zadd www.baidu.com 12345 1.1.1.1
(integer) 1
1.1.1.1:6380> zadd www.baidu.com 12346 1.1.1.2
(integer) 1
1.1.1.1:6380> zadd www.baidu.com 12348 1.1.1.1
(integer) 0
1.1.1.1:6380> ZRANGEBYSCORE www.baidu.com -inf +inf WITHSCORES
1) "1.1.1.2"
2) "12346"
3) "1.1.1.1"
4) "12348"
1.1.1.1:6380> zadd www.baidu.com 12349 1.1.1.3
(integer) 1
1.1.1.1:6380>
1.1.1.1:6380> ZRANGEBYSCORE www.baidu.com -inf +inf WITHSCORES
1) "1.1.1.2"
2) "12346"
3) "1.1.1.1"
4) "12348"
5) "1.1.1.3"
6) "12349"
0x05 参考
- Using pipelining to speedup Redis queries
- 聊聊 GO-REDIS 的一些高级用法
- Redis 设计与实现:订阅与发布
- 把 Redis 当作队列来用,真的合适吗?
转载请注明出处,本文采用 CC4.0 协议授权