0x00 背景
在微服务项目的构建中,存在这样一种场景,当对项目组件进行微服务化拆分后,一个客户端发起的请求将会经过多个微服务模块处理之后再返回,假如在请求的链路上某个服务出现访问故障时,(如何)排查故障将会比较困难。一种排查方式是,需要将请求经过的服务,挨个分析日志,查看是否是请求故障的原因,这种方式无疑是十分低效的。为了解决这种场景,调用链(OpenTracing)技术应运而生。
在微服务架构中,调用链是漫长而复杂的,要了解其中的每个环节及其性能,最佳方案就是全链路跟踪。追踪的做法是在每个请求开始时生成一个唯一的 RequestID, 并将其传递到整个调用链,用 RequestID 来跟踪整个请求并获得各个调用环节的性能指标。关于 RequestID,要解决下面两个问题:
- 如何在应用程序内部传递 RequestID,进程内跟踪(in-process)
- 当需要调用另一个微服务接口时,如何通过网络传递 RequestID,跨进程跟踪(cross-process)
0x01 Distributed Tracing 介绍
什么是 Tracing?简单理解是追踪一次请求(操作)的路径上所有的调用情况,包含调用方法,子方法,接口耗时及相关日志等。软件工程中有三个基础概念:Logging、Metrics 和 Tracing。

- Logging:用于记录离散的事件,包含程序执行到某一点或某一阶段的详细信息。
- Metrics:可聚合的数据,且通常是固定类型的时序数据,包括 Counter、Gauge、Histogram 等。
- Tracing:记录单个请求的处理流程,其中包括服务调用和处理时长等信息。
这三者的交集,构成了不同维度的计算机应用:
- Logging & Metrics:可聚合的事件。例如分析某对象存储的 Nginx 日志,统计某段时间内 GET、PUT、DELETE 操作的总数。
- Metrics & Tracing:单个请求中的可计量数据。例如 SQL 执行总时长、gRPC 调用总次数。
- Tracing & Logging:请求阶段的标签数据。例如在 Tracing 的信息中标记详细的错误原因。
这几种交织的 case 都具有典型的应用,如下:
- Logging:ELK
- Metrics:Prometheus
- Tracing:Jaeger、Zipkin
0x02 OpenTracing 的概念与原理
OpenTracing 的三大组件:
- 数据采集:在代码逻辑中埋点,设置请求中要上报的阶段,以及设置当前记录的阶段(RPC 方法)隶属于哪个上级阶段
- 数据持久化(存储):将上报的数据落地,如 Jaeger 就支持 Cassandra 或者 Elasticsearch
- 数据展示:展示前端根据 Trace ID 查询与之关联的请求阶段
如下面一个经典的 OpenTracing 图,它是一个请求的流程例子,请求从客户端发出,到达负载均衡,再依次进行认证、计费,最后取到目标资源。

最终,基于 OpenTracing 的设计,呈现给用户的是下图:横坐标是时间,圆角矩形是请求的执行的各个阶段,当然,存储的数据需要有一定层次或上下文关系。

在上图中可以看到以下内容:
- 执行时间的上下文
- 服务间的层次关系
- 服务间串行或并行调用链
0x03 数据模型基础
原始文档在此 The OpenTracing Semantic Specification
Tracing 的流程和基于时间维度的示例如下:


Trace: 调用链Span:某个处理阶段(我通常理解为 RPC 方法,但是通常一个 RPC 方法会包含一个或多个 Span),翻译为阶段、或者跨度
进一步的,每个 Span 包含如下状态:
- 操作名称:RPC 方法
- 起始时间
- 结束时间
- 一组 KV 值,作为阶段的标签(Span Tags),关联 Span 的 KV 值
- 阶段日志(Span Logs)
- 阶段上下文(SpanContext),其中包含 Trace ID 和 Span ID(Trace ID 是全局 ID,Span ID 是该 Span 的 ID)
- 引用关系(References):有 ChildOf 和 FollowsFrom 两种引用关系。ChildOf 用于表示父子关系,即在某个阶段中发生了另一个阶段,是最常见的阶段关系,典型的场景如调用 RPC 接口、执行 SQL、写数据。FollowsFrom 表示跟随关系,意为在某个阶段之后发生了另一个阶段,用来描述顺序执行关系。
0x04 OpenTracing 架构
OpenTracing 建立了一套跟踪库的通用接口,这样你的程序只需要调用这些接口而不被具体的跟踪库绑定,将来可以切换到不同的跟踪库而无需更改代码。常用的 Zipkin 和 Jaeger 都支持 OpenTracing,Kratos 框架也基于 OpenTracing 实现了自己的 Trace 语义
追踪系统的架构
追踪系统中通常有四个组件,以 Zipkin 为例:
- recorder(记录器):记录跟踪数据
- Reporter(collecting agent):通过报告器(收集代理),从记录器收集数据并将数据发送到 UI 程序
- Tracer:生成跟踪数据
- UI:负责在 UI or WEB 中显示跟踪数据
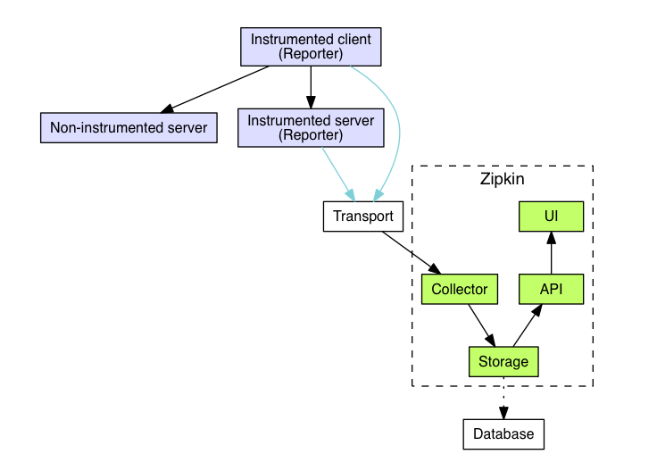
0x04 非侵入式的 OpenTracing
上面讨论的方式,是通过修改应用程序代码增加分布式 OpenTracing 的功能。那么当今微服务的领域,也有非侵入式的技术,比如 Service Mesh,它通过 Sidecar 的方式为 Pod 增加一层代理,通过这层网络代理来实现一些服务治理的功能。Istio 则是目前最成熟的 Service Mash 工具,支持启用分布式追踪服务。Istio 会修改微服务之间发送的网络请求,在请求中注入 Trace 和 Span 标记,再将采集到的数据发送到支持 OpenTracing 的分布式追踪服务中,从而拿到请求在微服务中的调用链。
0x05 最佳实践
下面的博客,会基于 gRPC 实现 OpenTracing 的功能:
- 中间件:Jaeger 或 Zipkin
- 数据持久化(存储): ELK
- 数据展示:ELK
这里可以先预想下如何来(查询)追踪日志:
- Request ID:对于每一个 RPC 请求,都会有一个贯穿整个请求流程的 RequestID,当然可以采用 gRPC 提供的 Interceptor 实现。在客户端或服务端设置?
- Trace ID:这是最核心的一点。 在 Trace 的起始处,将 TraceID 设置为 RequestID,这么一来就打通了日志系统和分布式追踪系统,可以使用同一个 ID 查询请求的事件流和日志流
0x06 总结
本文梳理了 Opentracing 的基础概念。一般而言全链路跟踪分成三个跟踪级别:
- 跨进程跟踪
- 数据库跟踪
- 进程内部的跟踪
下文会结合 Kratos 中 Opentracing 实现来分析这三块内容。
0x07 参考
转载请注明出处,本文采用 CC4.0 协议授权