0x00 前言
Go Concurrency Patterns: Pipelines and cancellation 一文介绍了 Golang 的最经典的并发及控制模型:Pipeline(流水线模型),基于 Channel 的生产者消费者模型。本文即整理及总结。
文中给出了几个典型 goroutine 的并发及控制场景:
- Squaring numbers:计算平方数
- Fan-out-fan-in:扇入扇出
- Stopping short
- Explicit cancellation
- Digesting a tree
- Parallel digestion
- Bounded parallelism
关于 goroutine 的并发及控制场景,要解决两个问题:
- goroutine 的生成及 goroutine 间的通信效率
- goroutine 的回收及退出(原文给出的 goroutine 通知退出方式个人感觉并不是很优雅)
0x01 什么是 Pipeline
Pipeline(流水线)是由多个阶段组成的,相邻的两个阶段由 channel 进行连接;每个阶段是由一组在同一个函数中启动的 goroutine 组成。在每个阶段,这些 goroutine 会执行下面三个操作:
- 通过 Inbound Channels 从上游接收数据
- 对接收到的数据执行一些操作,通常会生成新的数据
- 将新生成的数据通过 Outbound Channels 发送给下游
除了第一个和最后一个阶段,每个阶段都可以有任意个 Inbound 和 Outbound Channel,有点 Map-Reduce 的味道。本质上还是生产者 - 消费者的模型。
0x02 case1:计算平方数
| 阶段 | 功能 | 方法 |
|---|---|---|
阶段 1 |
传入输入 | gen |
阶段 2 |
计算平方 | sq |
阶段 3 |
main 打印结果 |
代码如下:
阶段 1:创建输入参数为可变长 int 整数的 gen 函数,它通过 goroutine 发送所有输入参数,并在发送完成后关闭相应 channel
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
阶段 2:sq 函数,负责从 Inbound channel 中接收数据并作平方处理再发送到 Outbound channel 中。在输入 channel 关闭并把所有数据都成功发送至 Outbound Channel,关闭输出 channel
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
阶段 3:主函数 main 中创建 pipeline 并执行了最后阶段的任务,即从 Outbound Channel 接收数据并打印出来
func main() {
// Set up the pipeline
c := gen(2, 3)
out := sq(c)
// Consume the output
fmt.Println(<-out)
fmt.Println(<-out)
/*
// Set up the pipeline and consume the output.
for n := range sq(sq(gen(2, 3))) {
fmt.Println(n)
}
*/
}
由于sq的入站和出站channel类型一样,所以可以多次组合使用它:
func main() {
for n := range sq(sq(gen(2, 3))) {
fmt.Println(n)
}
}
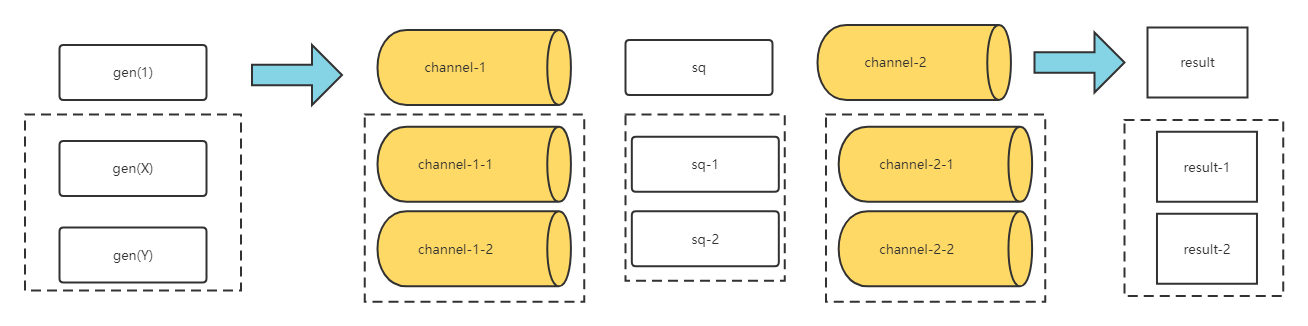
0x03 Fan-out-fan-in:扇出,扇入
- 扇出:多个方法可以从同一个channel读取数据,直到该channel被关闭。扇出提供了一种分发任务,从而并行化使用CPU和I/O的方式(不过注意一点:这里多个goroutine同时访问一个channel时,由runtime来调度哪个goroutine来获取数据,不需要开发者实现)
- 扇入:将多个输入channel复用到单个channel上,在所有输入channel关闭时,关闭这个channel。通过这种方式,一个函数可以从多个输入读取数据,并执行相应的操作直到所有的数据源都被关闭
继续上面的例子,运行两个sq,每个sq都从同一个输入channel读取数据。引入merge方法扇入结果,如下(通过merge接收多个channel的数据,写入一个结果channel):
func merge(cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// 为每个入channel启动一个名为output的goroutine
// output从每个channel中读取值并传入out,直到入channel被关闭,然后调用wg.Done
output := func(c <-chan int) {
for n := range c {
out <- n
}
//for range可感知channel的退出!
wg.Done()
}
//对每个chan int都单独启动goroutine,将chan中的数据取出来放在out里面
wg.Add(len(cs))
for _, c := range cs {
go output()
}
// 当所有的output 的goroutine都执行完成时,启动一个新的goroutine来关闭out
// 必须在调用wg.Add后执行这个操作。
//回收操作
go func() {
wg.Wait()
//特别处理close(out)的时机
close(out)
}()
return out
}
func main() {
in := gen(2, 3)
// Distribute the sq work across two goroutines that both read from in.
c1 := sq(in)
c2 := sq(in)
// Consume the merged output from c1 and c2.
for n := range merge(c1, c2) {
fmt.Println(n) // 4 then 9, or 9 then 4
}
}
上面这个例子给出了很典型的经验汇总:
sync.WaitGroup管理goroutine正常退出- 向一个已经关闭的channel传入值会导致程序崩溃,所以在关闭channel前一定要保证所有的传值操作都已完成
- 利用channel做结果传输的通道
上面的模式,很好的总结了这样的channel异步模型:
- 输入模块:创建数据channel,当所有的输入操作完成(放入channel)时,关闭入数据channel
- 计算模块:创建结果channel,持续从数据channel接收数据,直到数据channel被关闭;同时将计算结果写入结果channel
- 结果模块:获取结果,等待上游关闭channel
- 此模式允许每个接收阶段被写成range循环,并确保所有goroutine在所有的值成功发送到下游后退出(下游模块必须被动退出)
0x04 Stopping short
引入问题,如何使得下游模块不阻塞?(在上面的示例pipeline中,如果一个阶段无法使用所有的channel值,那么尝试发送这些值的goroutine将会无限期地阻塞)
现实中,可能会遇到接收端只需要部分数据(并不需要读完所有的),如下面的例子,由于没有接收out的第2个值,所以2个output中的一个将会阻塞
// 接收output中第一个值
out := merge(c1, c2)
fmt.Println(<-out) //只读出一个
一种可能的解法是为channel设置buffer,但是并不完美,如下例:
c := make(chan int, 2)
c <- 1 // 执行成功
c <- 2 // 执行成功
c <- 3 // 阻塞住,直到另外一个goroutine做 <-c这样的操作并且获取1
修改上面的merge代码如下:
func merge(cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int, 2)
// ... 其余部分不变 ...
}
依然有问题,如果向gen多传值,或者下游读取较少值,代码中又将会出现阻塞的goroutine。相反,需要为下游阶段提供一种方法,向发送方指示让它们停止接受输入。
0x05 Explicit cancellation(显示取消)
在main方法决定退出,并且不再从out中接收值时,必须告诉上游阶段的goroutine丢弃将要发送的值。再改造代码,增加done这个通知的channel:
func main() {
in := gen(2, 3)
c1 := sq(in)
c2 := sq(in)
done := make(chan struct{}, 2)
out := merge(done, c1, c2)
fmt.Println(<-out) // 4 或者 9
done <- struct{}{}
done <- struct{}{} //c1 and c2
}
更进一步,在所有模块中都加入done的逻辑,并且利用close(done)来替代done <- struct{}{}的功能(该关闭操作时间是向发送者的广播信号):
func main() {
// 创建一个整个pipeline共享的channel
// 在pipeline退出时,关闭这个channel
// 同时作为信号让启动的所有goroutine退出
done := make(chan struct{})
defer close(done)
in := gen(done, 2, 3)
c1 := sq(done, in)
c2 := sq(done, in)
out := merge(done, c1, c2)
fmt.Println(<-out) // 4或者9
// done 会通过defer被关闭
}
merge与sq方法改造如下,多增加了case分支:
func merge(done <-chan struct{}, cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// 为每个cs中的channel启动一个output goroutine
// output从c复制值到out,直到c被关闭,或者从done中收到一个值
// 然后调用wg.Done
output := func(c <-chan int) {
defer wg.Done()
for n := range c {
select {
case out <- n:
case <-done:
return
}
}
}
// ...其余代码不变
}
func sq(done <-chan struct{}, in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n:= range in {
select {
case out <- n* n:
case <-done:
return
}
}
}()
return out
}
到此,pipeline的模型优化为如下(新增1条):
- 通过确保对所有发送的值有足够的缓冲区或者通过在接收器放弃channel时显式地发送信号通知发送方,pipeline可以主动解除发送方的阻塞
0x05 Digesting a tree
本节引入一个应用的pipeline例子,计算多个文件的md5
# md5 *.go
MD5 (bounded.go) = e3635300581854a5dd4ae6f748b38775
MD5 (parallel.go) = 9efb4ffcca07e6994ef003a18925502a
MD5 (serial.go) = 26a2162e7cb28f4ed9f67e92616dbb24
示例代码,传入单个目录作为参数,并打印该目录下每个常规文件的摘要值,按路径名排序:
代码1:串行方法
func main() {
// 计算目录下每个文件的MD5值
// 按路径名排序输出结果
m, err := MD5All(os.Args[1])
if err != nil {
fmt.Println(err)
return
}
var paths []string
for path := range m {
paths = append(paths, path)
}
sort.Strings(paths)
for _, path := range paths {
fmt.Printf("%x %s\n", m[path], path)
}
}
func MD5All(root string) (map[string][md5.Size]byte, error) {
m := make(map[string][md5.Size]byte)
err := filepath.Walk(root, func(path string, info os.FileInfo, err error) error {
if err != nil {
return err
}
if !info.Mode().IsRegular() {
return nil
}
data, err := ioutil.ReadFile(path)
if err != nil {
return err
}
m[path] = md5.Sum(data)
return nil
})
if err != nil {
return nil, err
}
return m, nil
}
下一小节对上面的串行解法做优化
0x06 Parallel digestion
并行解法如下,将MD5All方法拆成有两个阶段的pipeline:
- 第一个阶段:
sumFiles中,遍历目录,为每个文件启动一个goroutine来计算文件的MD5值,并将结果发送到一个类型为result的channel中 - 第二个阶段:
type result struct {
path string
sum [md5.Size]byte
err error
}
// `sumFiles`:遍历目录,为每个文件启动一个goroutine来计算文件的MD5值,并将结果发送到一个类型为result的channel中
//`sumFiles`返回两个channel:一个用于`results`,另外一个用于`filepath.Walk`返回的错误信息
// `Walk`方法启动一个新的goroutine来处理每个常规文件,然后检查`done`。如果`done`被关闭,`Walk`方法马上停止
func sumFiles(done <-chan struct{}, root string) (<-chan result, <-chan error) {
c := make(chan result)
errc := make(chan error, 1)
go func() {
var wg sync.WaitGroup
err := filepath.Walk(root, func(path string, info os.FileInfo, err error) error {
if err != nil {
return nil
}
if !info.Mode().IsRegular() {
return nil
}
wg.Add(1)
//为每个文件都启动一个goroutine
go func() {
data, err := ioutil.ReadFile(path)
select {
case c <- result{path, md5.Sum(data), err}:
case <-done:
}
wg.Done()
}()
select <-done{
case <-done:
return errors.New("walk canceled")
default:
return nil
}
})
go func(){
wg.Wait()
close(c)
}()
errc <- err
}()
return c, errc
}
结果模块:MD5All从channel c中接收结果,在发生错误时提前返回,通过defer关闭donechannel:
func MD5All(root string) (map[string][md5.Size]byte, error) {
done := make(chan struct{})
defer close(done)
c, errc := sumFiles(done, root)
m := make(map[string][md5.Size]byte)
for r := range c {
if r.err != nil {
return nil, r.err
}
m[r.path] = r.sum
}
if err := <-errc; err != nil {
return nil, err
}
return m, nil
}
0x07 Bounded parallelism(有界并行)
在上一节的例子中,MD5All为每个文件都启动了一个goroutine。在处理有很多且大文件的文件夹时,这可能分配超过机器上可用上限的内存。可以通过限制并行读取文件的数量来限制占用的内存,通过创建固定数量的goroutine来读取文件。
pipeline的3阶段:
- 遍历目录
- 读取文件并计算摘要
- 收集摘要
//阶段1:获取目录中的常规文件的路径
func walkFiles(done <-chan struct{}, root string) (<-chan string, <-chan error) {
paths := make(chan string)
errc := make(chan error, 1)
go func() {
defer close(paths)
errc <- filepath.Walk(root, func(path string, info os.FileInfo, err error) error {
if err != nil {
return err
}
if !info.Mode().IsRegular() {
return nil
}
select {
case paths <- path:
case <-done:
return errors.New("walk canceled")
}
return nil
})
}()
return paths, errc
}
中间阶段启动固定数量的goroutine,从paths中接收文件名并在channel:c上发送结果;和之前的例子不同,digester不关闭其输出channel,因为多个goroutine在共享channel上发送。在所有digester完成后,MD5All会关闭该channel:
func digester(done <-chan struct{}, paths <-chan string, c chan<- results) {
for path := range paths {
data, err := ioutil.ReadFile(path)
select {
case c <- result{path, md5.Sum(data), err}:
case <-done:
return
}
}
}
可以让每个digester创建和返回自己的输出channel,但是这就需要额外的goroutine来扇出结果:
{
c := make(chan result)
var wg sync.WaitGroup
const numDigesters = 20
wg.Add(numDigesters)
for i := 0; i < numDigesters; i++ {
go func() {
digester(done, paths, c)
wg.Done()
}()
}
go func() {
wg.Wait()
close(c)
}()
}
最后阶段从c接收所有结果,然后检查errc中的错误(此检查不能发生地更早,因为在这之前,walkFiles可能阻塞向下游发送值)
{
m := make(map[string][md5.Size]byte)
for r := range c {
if r.err != nil {
return nil, r.err
}
m[r.path] = r.sum
}
if err := <-errc; err != nil {
return nil, err
}
return m, nil
}