0x00 前言
本文分析下 Prometheus 以及常用的 Metrics,Metrics 是一种采样数据的总称,是一种对于度量计算单位的抽象。Prometheus 是一个数据监控的解决方案,能随时掌握系统运行的状态,快速定位问题和排除故障。并提供了从指标暴露,到指标抓取、存储和可视化,以及最后的监控告警等一系列组件。
prometheus 的整体架构如下:
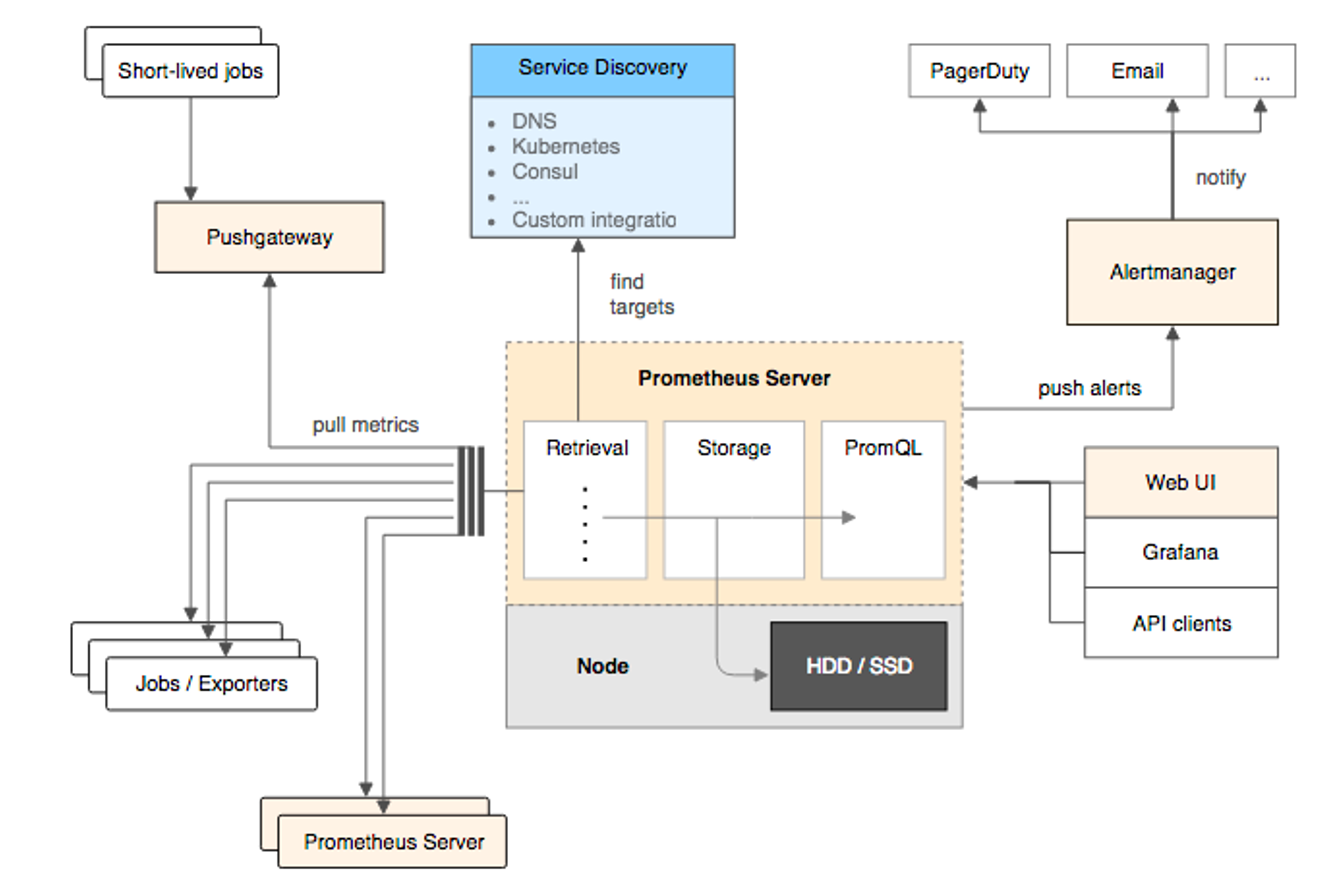
Prometheus 的基本原理是通过 HTTP 协议周期性抓取被监控组件的状态,任意组件只要提供对应的 HTTP 接口就可以接入监控。不需要任何 SDK 或者其他的集成过程,非常适合做虚拟化环境监控系统,比如 Docker、Kubernetes 等;输出被监控组件信息的 HTTP 接口通常称为 Exporter
- 支持多维数据模型:由度量名和键值对组成的时间序列数据
- 内置时间序列数据库 TSDB
- 支持 PromQL 查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义
- 支持 HTTP 的 Pull 方式采集时间序列数据
- 支持 PushGateway 采集瞬时任务的数据
- 支持服务发现和静态配置两种方式发现目标
- 支持接入 Grafana
0x01 Prometheus 介绍
为何要使用 Prometheus?
传统监控依赖实时指标,通过采集的日志流处理写入时序数据库,一般流程较长,任何一环出问题会导致监控不可用;其次存储成本和查询速度也需要考虑,假设每次的请求耗时都需要保存,那么这个记录量级可能非常大,影响查询时性能。Prometheus 直接采集服务暴露的指标,简化中间流程,通过提供 client 在采集端做了预聚合,虽然这样损失了精确度,但大大减少数据量以及提升查询速度
指标暴露
对应于监控系统的两种方式,针对服务端而言:
- 被动方式(PUSH):适用于短时间执行的脚本任务或者不好直接 Pull 指标的服务(进程),Prometheus 提供了 PushGateWay 网关给此类任务将服务指标主动推 Push 到网关,Prometheus 再从网关里 Pull 指标
- 主动方式(PULL):使用 Prometheus 提供的官方的 SDK,利用 SDK 可以自定义并导出自己的业务指标(或者使用 Exporter)
一般来说,主动模式对 Server 端压力较大,被动模式对 Server 端压力相对会小。一般考虑如下选择:
- PULL 方式拉取:Server 与 Node 之间网络直连(或者自己实现一个代理,让 Prometheus 从代理进行 PULL)
- Promethues Server 无法直接和 Node 节点通讯的情况下,可以通过 PUSH 搭配 PushGateWay 的方式
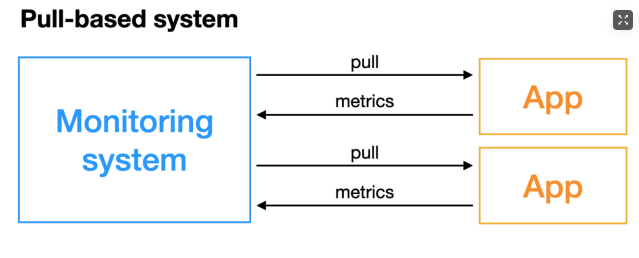
PULL 模型:监控服务主动拉取被监控服务的指标,被监控服务一般通过主动暴露 metrics 端口或者通过 Exporter 的方式暴露指标,监控服务依赖服务发现模块发现被监控服务,从而去定期的抓取指标
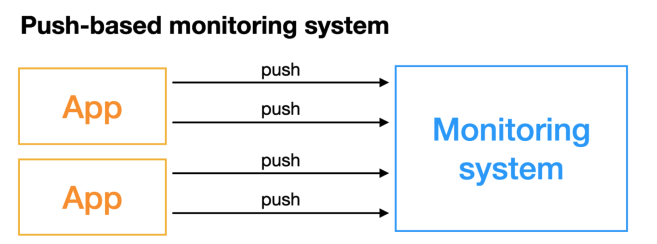
PUSH 模型:被监控服务主动将指标推送到监控服务,可能需要对指标做协议适配,必须得符合监控服务要求的指标格式
指标存储和查询
- 指标抓取后会存储在 Prometheus 内置的时序数据库
- PromQL 查询语言给我们做指标的查询
- 可以在 Prometheus 的 WebUI 上通过 PromQL,可视化查询我们的指标,也可以很方便的接入第三方的可视化工具 grafana 进行查询
工作原理
Prometheus 的从被监控服务的注册到指标抓取到指标查询的流程如下:
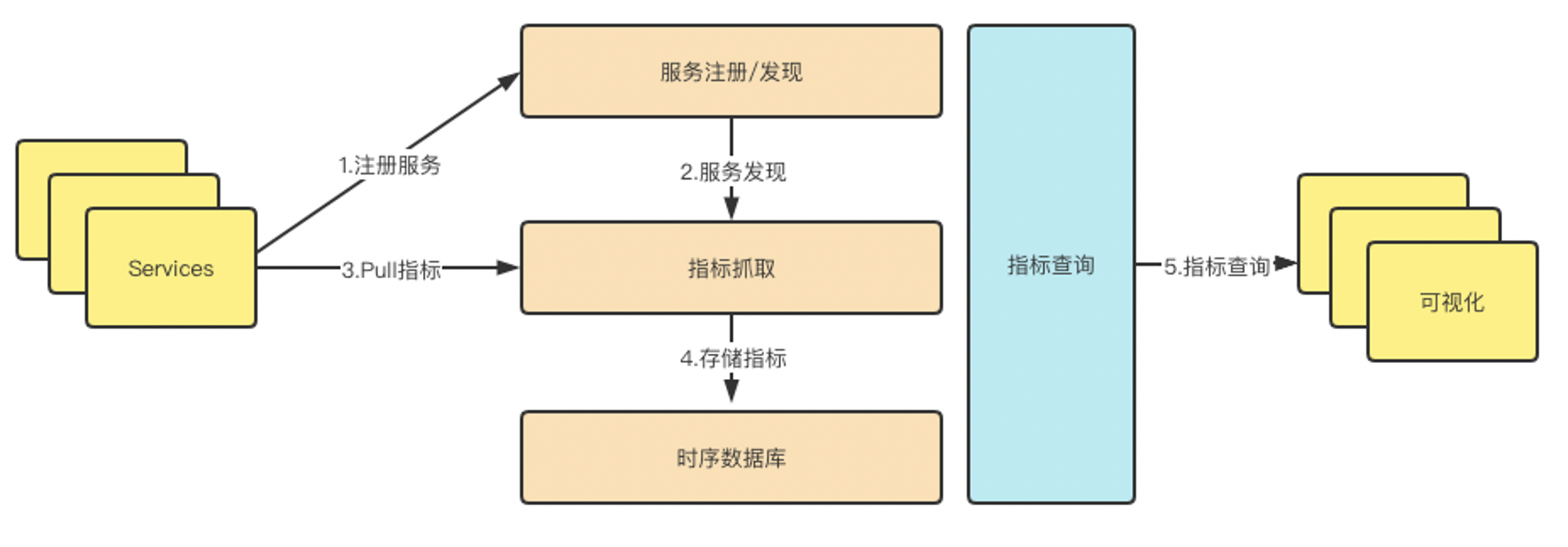
1、 (被监控)服务注册
被监控服务在 Prometheus 中是一个 Job 存在,被监控服务的所有实例在 Prometheus 中是一个 target 的存在,所以被监控服务的注册就是在 Prometheus 中注册一个 Job 和其所有的 target。注册有如下两种类型:
- 静态注册:配置文件配置采集指标的 IP + 端口,配合 Prometheus 提供的
reloadAPI 以及--web.enable-lifecycle参数实现热更新 - 动态注册:配置文件配置 endpoint 地址,类似于服务发现(支持 Consul/DNS / 文件 / K8S 等多种服务发现机制)
通过声明 Prometheus 配置文件中的 scrape_configs 选项,指定 Prometheus 在运行时要拉取指标的目标,目标实例需要实现一个可以被 Prometheus 进行轮询的 endpoint,而要实现如此接口,可以用来给 Prometheus 提供监控样本数据的独立程序一般被称作为 Exporter,比如用来拉取操作系统指标的 Node Exporter,它会从 os 收集硬件指标,提供 Prometheus 来拉取。配置示例如下:
# A scrape configuration containing exactly one endpoint to scrape.
scrape_configs:
# nodeexporter
- job_name: 'nodeexporter'
scrape_interval: 5s
static_configs:
- targets: ['nodeexporter:9100']
- job_name: 'cadvisor'
scrape_interval: 5s
static_configs:
- targets: ['cadvisor:8080']
# 配置服务地址
- job_name: 'test-application-metrics'
scrape_interval: 2s
static_configs:
- targets: ['localhost:12345']
如,静态注册,启动指令 prometheus --config.file=/usr/local/etc/prometheus.yml --web.enable-lifecycle:
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
动态注册,使用 consul,consul 地址 localhost:8500,服务名是 node_exporter,在该服务下有一个 Exporter 实例 localhost:9600
- job_name: "node_export_consul"
metrics_path: /node_metrics
scheme: http
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
2、指标抓取和存储
Prometheus 对指标的抓取采取主动 PULL 方式,即周期性的请求被监控服务暴露的 metrics 接口或者是 PushGateway,从而获取到 Metrics 指标,默认时间是 15s 抓取一次;抓取到的指标会被以时间序列的形式保存在内存中,并且定时刷到磁盘上(默认 2h)
0x02 基础:Metrics
在 Prometheus 内部,所有采样样本都是以时间序列的形式保存在时序数据库中,本小节详细介绍下 4 种指标类型已经使用场景。
数据模型
Prometheus 采集的所有指标都是以时间序列的形式进行存储,每一个时间序列有三部分组成:
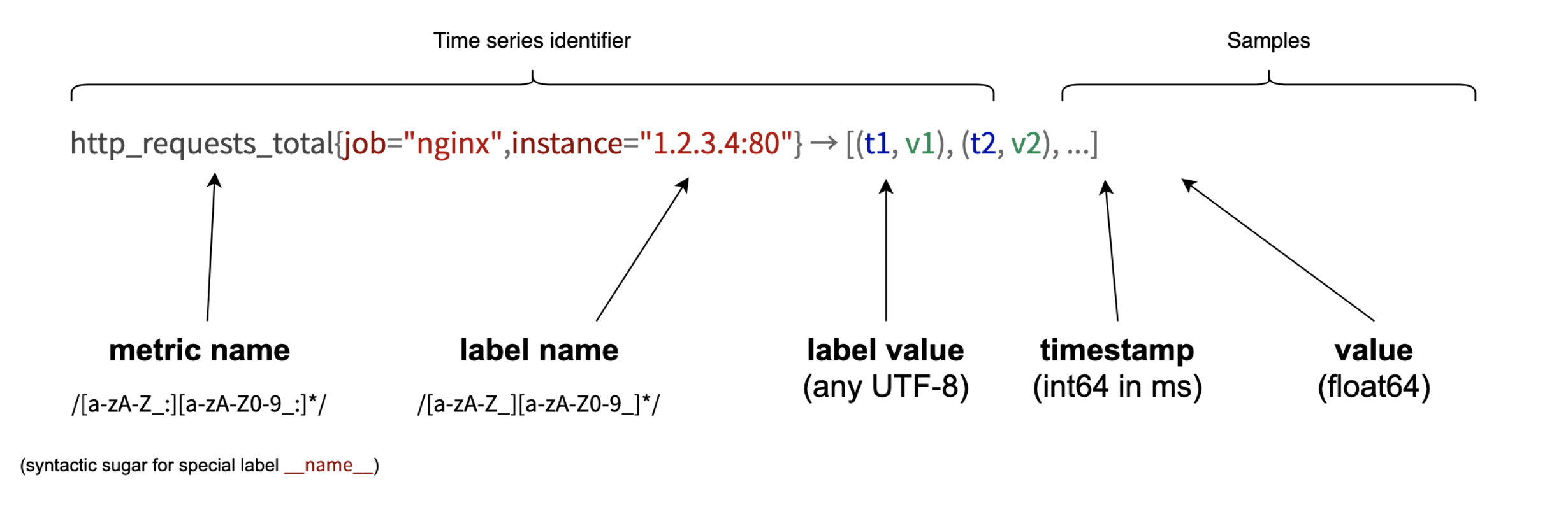
- 指标名和指标标签集合:metric_name{<label1=v1>,<label2=v2>….}
- 指标名:表示这个指标是监控哪一方面的状态,如
http_request_total表示 HTTP 请求数量 - 指标标签,描述这个指标有哪些维度,比如
http_request_total指标,有请求状态码code = 200/400/500,请求方式:method = GET/POST等标签
- 指标名:表示这个指标是监控哪一方面的状态,如
- 时间戳:描述当前时间序列的时间(ms)
- 样本值:当前监控指标的具体数值,比如
http_request_total的值就代表请求数是多少
标签 label 是使同一个时间序列有了不同维度的识别。例如 http_requests_total{method="GET"} 表示所有 HTTP 请求中的 GET 请求。当 method="post" 时,则为新的一个 metric,表示 POST 请求
指标的格式
格式如下:
# HELP // HELP:这里描述的指标的信息,表示这个是一个什么指标,统计什么的
# TYPE // TYPE:这个指标是什么类型的
<metric name>{<label name>=<label value>, ...} value // 指标的具体格式,< 指标名 >{标签集合} 指标值
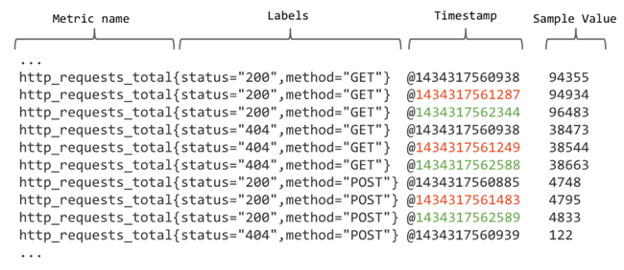
时间序列是时间和标签所发构成的多维度内数据,样本为实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。下图为样本的示例:
指标类型
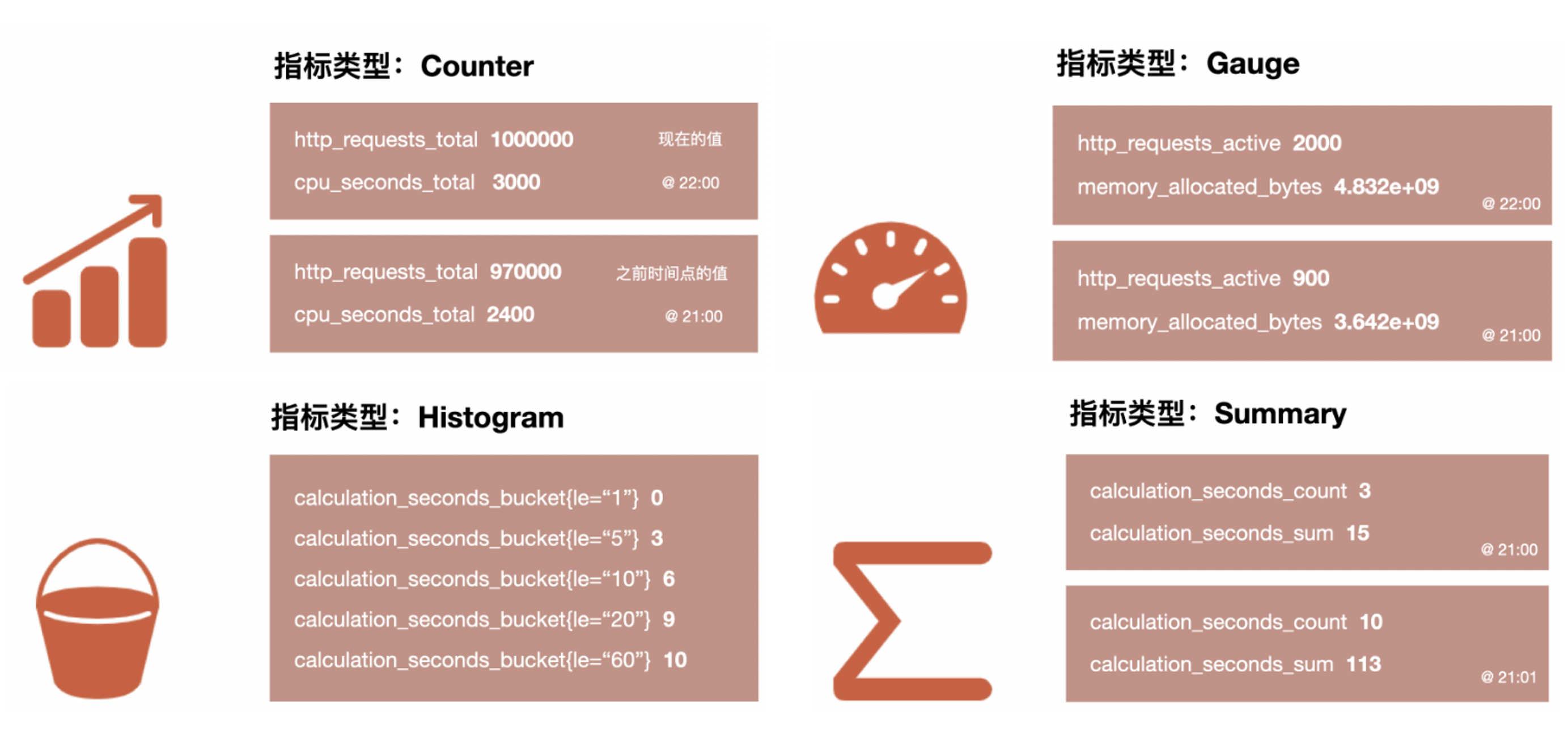
Prometheus 底层存储上其实并没有对指标做类型的区分,都是以时间序列的形式存储,但是为了方便用户的使用和理解不同监控指标之间的差异,Prometheus 定义计数器 counter / 仪表盘 gauge / 直方图 histogram 以及摘要 summary 这四种 Metrics 类型。
Gauge/Counter 是数值指标,代表数据的变化情况,Histogram/Summary 是统计类型的指标,表示数据的分布情况
下面分别介绍指标类型,部分配图来源于 一文带你了解 Prometheus。
Gauge
Gauge 理解为(待监控的)瞬时状态,如当前时刻 CPU 的使用率、内存的使用量、硬盘的容量以及 GC 次数等等。因为此类型的特点是随着时间的推移不断,值(相对而言)没有规则的变化。在 Kratos 框架中,针对 RPC 每次请求的延迟(latency)就是一个 Gauge,一段时间内的 Gauge 就组合成了一个 RollingGauges;此外,Gauge 可增可减,与 Counter 不一样,在 Prometheus 上通过 Gauge,可以不用经过内置函数直观的反映数据的变化情况
 下图表示堆可分配的空间大小:
下图表示堆可分配的空间大小:
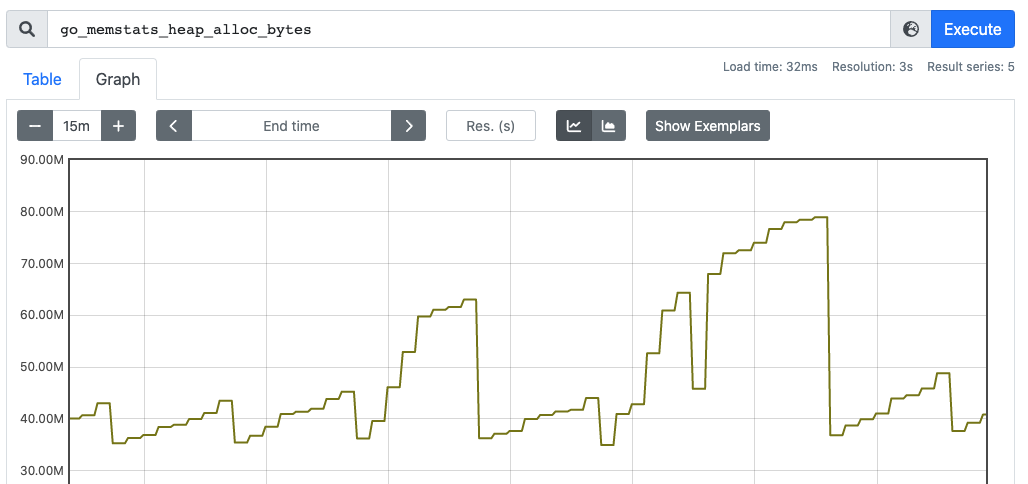
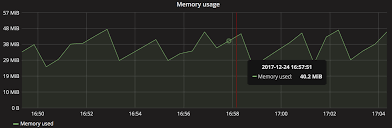
以时间为横坐标、数值为纵坐标,如下面的内存的使用图,就是典型的采集使用 Gauge 形式的 Metrics:
Gauge 的定义如下,对比 Counter 的定义,增加了 Dec 和 Sub 这样的减少数值的接口,同时提供了 Set 和 SetToCurrentTime 这样的直接设置数值的接口,可以用来监控 goroutine 的数量、CPU 使用率、内存使用率(量)等可增可减的指标:
type Gauge interface {
Metric
Collector
// Set sets the Gauge to an arbitrary value.
Set(float64)
// Inc increments the Gauge by 1. Use Add to increment it by arbitrary
// values.
Inc()
// Dec decrements the Gauge by 1. Use Sub to decrement it by arbitrary
// values.
Dec()
// Add adds the given value to the Gauge. (The value can be negative,
// resulting in a decrease of the Gauge.)
Add(float64)
// Sub subtracts the given value from the Gauge. (The value can be
// negative, resulting in an increase of the Gauge.)
Sub(float64)
// SetToCurrentTime sets the Gauge to the current Unix time in seconds.
SetToCurrentTime()
}
Counter:计数器(只增)
Counter 就是计数器,从数据量 0 开始累计计算,只能增加,或者保持不变(增加 0),典型对应的场景是:持续增加的访问量采样数据。Counter 一般从 0 开始,一直不断的累加,但有可能保持不变(在图中以一条水平线表示)。通过 Counter 指标可以统计 HTTP 请求数量,请求错误数,接口调用次数等单调递增的数据,同时可结合 increase 和 rate 等函数统计变化速率
以时间为横坐标、数值为纵坐标,可以画出用 Counters 形式的 Metrics:
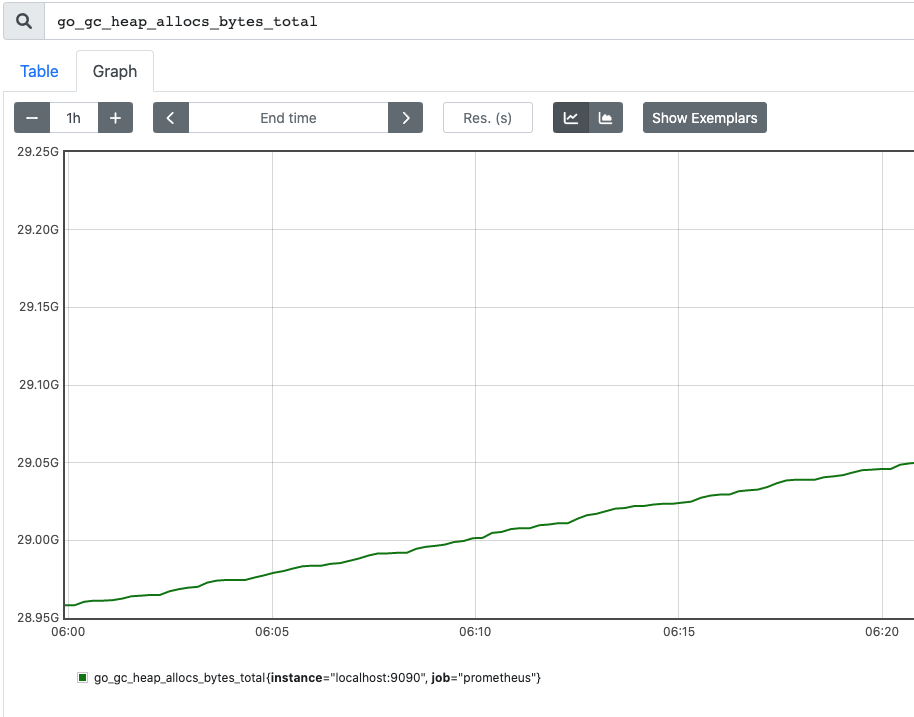
同样的,在 Kratos 中,每个连接上 RPC 请求的总次数和错误次数,就是一个 Counters。
一定要注意的是:不要使用计数器来监控可能减少的值。例如,不要使用计数器来处理当前正在运行的进程数,而应该用 Gauge。Counter 主要有两个方法:
type Counter interface {
Metric
Collector
// Inc increments the counter by 1. Use Add to increment it by arbitrary non-negative values
// 将 counter 值加 1
Inc()
// Add adds the given value to the counter. It panics if the value is < 0.
// 将指定值加到 counter 值上,如果指定值 < 0 会 panic.
Add(float64)
}
用户可以调用 Inc 接口进行上报数据,也可调用 Add 接口增加任意的值(必须为非负数)。Prometheus 将数据拆分为不同监控指标名和不同的维度,上报的值需要绑定到具体的监控指标,代码如下:
httpReqs := prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "How many HTTP requests processed, partitioned by status code and HTTP method.",
},
[]string{"code", "method"},
)
prometheus.MustRegister(httpReqs)
// 以打标签的方式上报
httpReqs.WithLabelValues("404", "POST").Add(10)
指定的 metric_name 是 http_requests_total,分成两个维度(code / method),在 (404, POST) 维度上上报了一个数据值为 10
Histograms
尽管能够通过 gauge 监控可增可减的值,并可以在查询时求出其一段时间内的平均值,但是对于一些典型的场景是请求时延、响应数据量大小等,平均值可能并不能很好地反映问题(此类场景,对于开发者更关注的或许是 P90/P95/P99 等)。Histogram 可以解决这个问题,它并不是记录一个值的变化情况,而是将被观测到的值划分进某一个区间中,称为桶(Bucket)。
Histograms 意为直方图,Histogram 会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(Bucket)中。可以观察到指标在各个不同的区间范围的分布情况,可以观察到请求耗时在各个桶的分布。如下图:
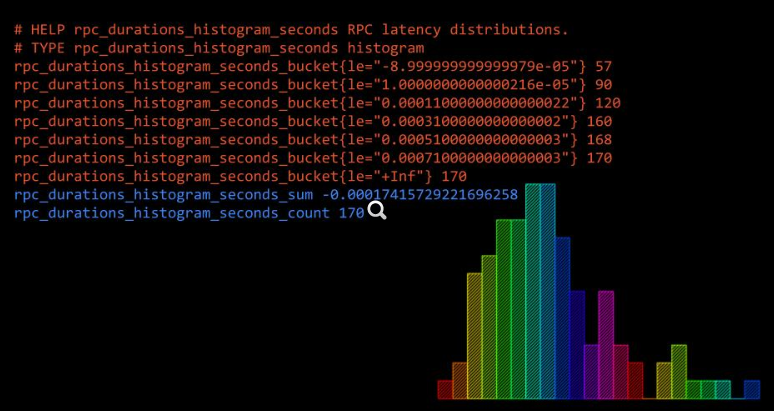
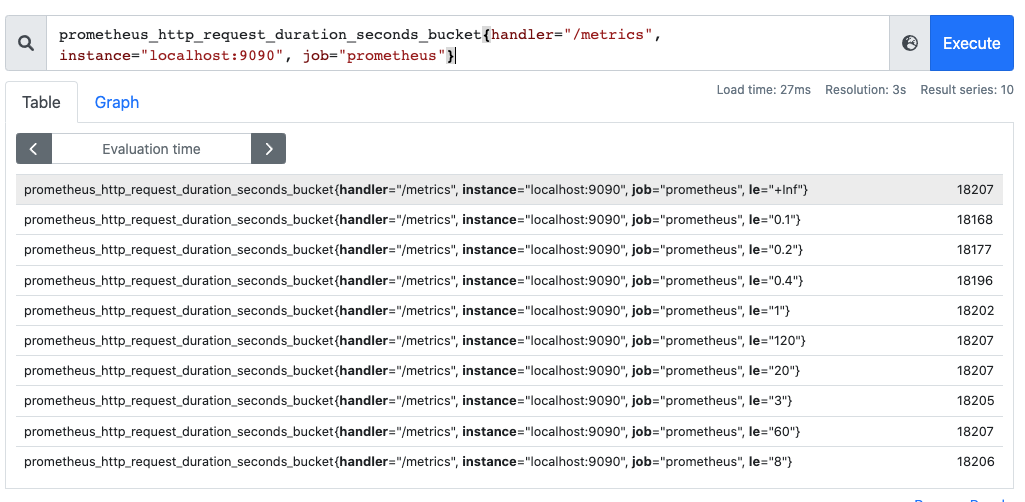
有一点要注意的是,Histogram 是累计直方图,即每一个桶的是只有上区间,例如下图表示小于 0.1ms(le="0.1")的请求数量是 18173 个,小于 0.2ms(le="0.2")的请求是 18182 个,在 le="0.2" 这个桶中是包含了 le="0.1" 这个桶的数据,如果要拿到 0.1ms~0.2ms 的请求数量,可以通过两个桶相减

此外,在直方图中,还可以通过 histogram_quantile 函数求出百分位数,比如 P50/P90/P99 等数据
Histogram 的定义如下,可以看到 Histogram 只有一个 Observe 方法:
type Histogram interface {
Metric
Collector
// Observe adds a single observation to the histogram.
Observe(float64)
}
Histogram 和 Counter/Gauge 的上报模型不同,在 Counter 中,一个 Counter 对应了一个时间序列,当创建一个 Counter 然后上报数据,它影响的时间序列是确定的。而 Histogram 则会帮我们创建多个时间序列,当调用 Observe 方法时,被观测到的值会被放进预先划分好的桶中,每一个桶中并不记录被观测的值,而是对其进行计数。代码示例如下:
temps := prometheus.NewHistogram(prometheus.HistogramOpts{
Name: "pond_temperature_celsius",
Help: "The temperature of the frog pond.", // Sorry, we can't measure how badly it smells.
Buckets: prometheus.LinearBuckets(20, 5, 5), // 5 buckets, each 5 centigrade wide.
})
// Simulate some observations.
for i := 0; i < 1000; i++ {
temps.Observe(30 + math.Floor(120*math.Sin(float64(i)*0.1))/10)
}
// Just for demonstration, let's check the state of the histogram by
// (ab)using its Write method (which is usually only used by Prometheus
// internally).
metric := &dto.Metric{}
temps.Write(metric)
fmt.Println(proto.MarshalTextString(metric))
桶的指定可以直接指定,如 ` Buckets: []float64{0,2.5,5,7.5,10}`,但是 务必注意,只有设定了合适的桶大小(分布),Histogram 的指标才更有意义,如果桶的设定不合理,那么结果就不一定靠谱。那假设开发者对一个数据没有什么先验知识,那么是否有更准确的方式计算出这个数据呢?Prometheus 给出的方案就是用 Summary。
Summary
Summary 也是用来做统计分析的,和 Histogram 区别在于,Summary 直接存储的就是百分位数,如下所示:可以直观的观察到样本的中位数,如 P90 和 P99:
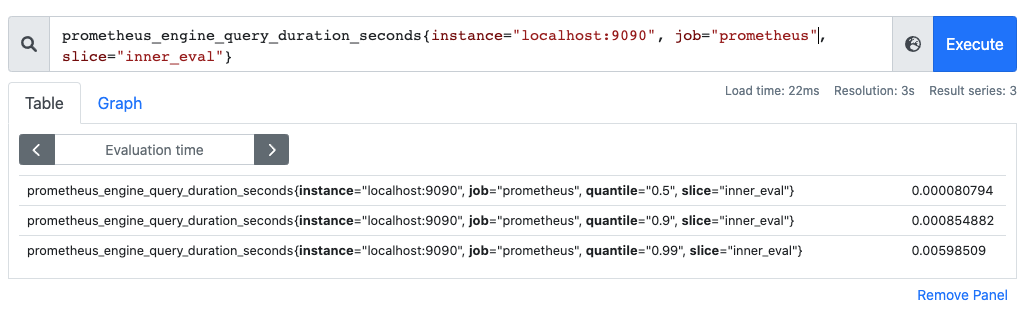
再次强调下,Summary 的百分位数是客户端计算好直接让 Prometheus 抓取的,不需要 Prometheus 计算,直方图是通过内置函数 histogram_quantile 在 Prometheus 服务端计算出来的
type Summary interface {
Metric
Collector
// Observe adds a single observation to the summary.
Observe(float64)
}
在创建一个 Summary 时,并不是像创建 Histogram 那样划分桶,而是直接划分所要计算的分位数区间,如下:
temps := prometheus.NewSummary(prometheus.SummaryOpts{
Name: "pond_temperature_celsius",
Help: "The temperature of the frog pond.",
Objectives: map[float64]float64{0.5: 0.05, 0.9: 0.01, 0.99: 0.001},
})
// Simulate some observations.
for i := 0; i < 1000; i++ {
temps.Observe(30 + math.Floor(120*math.Sin(float64(i)*0.1))/10)
}
// Just for demonstration, let's check the state of the summary by
// (ab)using its Write method (which is usually only used by Prometheus
// internally).
metric := &dto.Metric{}
temps.Write(metric)
fmt.Println(proto.MarshalTextString(metric))
通过 Summary ,能够更加准确地获知 50% 的观测值,90% 的观测值以及 99% 的观测值,避免了 Histogram 经验值的问题。但缺点是 Summary 的数据计算是由客户端进行的,会造成一定的性能损耗。
Histograms 的应用意义
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数、延迟在 10~20ms 之间的请求数等等。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,可以快速了解监控样本的分布情况。
小结
Counter(计数器):表示一个单调递增的值,如请求总数、错误总数等。它只能增加,不能减少(除非系统重启)Gauge(仪表盘):表示一个可以任意增减的值,如当前内存使用量、CPU 利用率等Histogram(直方图):表示一组数据的分布情况,如请求延迟的分布。它包含多个 bucket(桶),每个 bucket 对应一个值范围,以及落入该范围的样本数量Summary(摘要):与直方图类似,也表示一组数据的分布情况,但它提供了更精确的分位数(如中位数、95% 分位数等)计算
当 Prometheus 采集这些指标时,会获取这些指标在当前时间点的瞬时值
0x03 指标操作 / 开发
指标导出
- 使用 exporter
- 利用 官方库 实现,笔者较常用
代码示例,见 仓库
快速接入示例
下面是一个最简的 Prometheus 指标暴露代码,定义了 Counter 和 Histogram 两种指标,并通过 /metrics 接口对外暴露:
package main
import (
"net/http"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
requestCounter = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "myapp_requests_total",
Help: "Total number of requests",
},
[]string{"method", "endpoint"},
)
requestDuration = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "myapp_request_duration_seconds",
Help: "Request duration in seconds",
Buckets: prometheus.DefBuckets,
},
[]string{"method", "endpoint"},
)
)
func init() {
prometheus.MustRegister(requestCounter)
prometheus.MustRegister(requestDuration)
}
func main() {
http.HandleFunc("/api/hello", func(w http.ResponseWriter, r *http.Request) {
start := time.Now()
defer func() {
requestCounter.WithLabelValues(r.Method, "/api/hello").Inc()
requestDuration.WithLabelValues(r.Method, "/api/hello").Observe(time.Since(start).Seconds())
}()
w.Write([]byte("hello"))
})
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":8080", nil)
}
运行后通过 curl http://localhost:8080/metrics 即可查看暴露的指标数据
0x04 PromQL 介绍
PromQL 的查询表达式有 4 种类型:
- 字符串:只作为某些内置函数的参数出现
- 标量:单一的数字值,可以是函数参数,也可以是函数的返回结果
- 瞬时向量:某一时刻的时序数据
- 区间向量:某一时间区间内的时序数据集合(范围向量,Range Vector)
瞬时查询
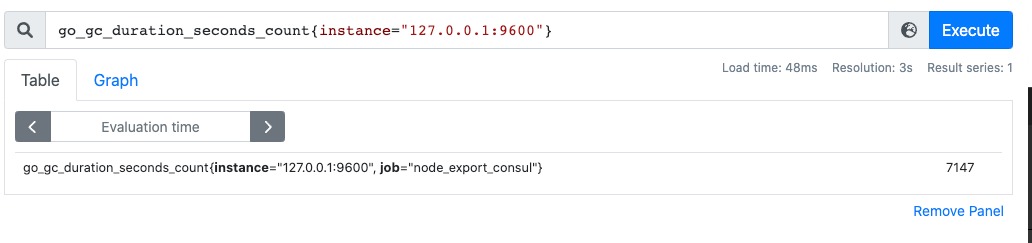
直接通过指标名即可进行查询,查询结果是当前指标最新的时间序列,比如查询 GC 累积消耗的时间:
1. go_gc_duration_seconds_count #
2. go_gc_duration_seconds_count{instance="127.0.0.1:9600"} #按照 label 过滤
3. go_gc_duration_seconds_count{instance=~"localhost.*"} #支持对 label 正则过滤
范围过滤
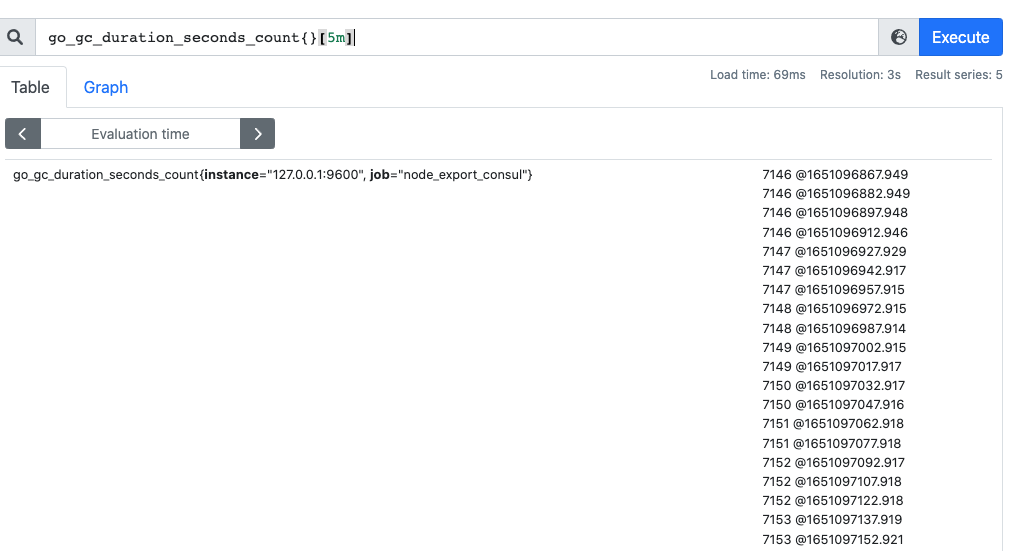
范围查询的结果集就是区间向量,可以通过 [] 指定时间来做范围查询。如下面查询 5 分钟内的 GC 累积消耗时间(注意:这里范围查询第一个点并不一定精确到刚刚好 5 分钟前的那个时序样本点,这里是以 5 分钟作为一个区间,寻找这个区间的第一个点到最后一个样本点)
时间单位支持 d / 天,h / 小时,m / 分,ms / 毫秒,s / 秒,w / 周,y / 年,同样支持类似 SQL 中的 offset 查询,如查询一天前当前 5 分钟前的时序数据集
go_gc_duration_seconds_count{}[5m]
go_gc_duration_seconds_count{}[5m] offset 1d #查询一天前此刻 5 分钟前的时序数据集
注意:需要用内置的函数将 Range Vector 换为一个瞬时向量后才能被绘制。例如每 1 分钟的 HTTP 请求量(查看一分钟范围内的变化量),那么以用 increase 函数:
increase(http_requests_total [1m])
Prometheus 内置函数
列举几个比较重要的:
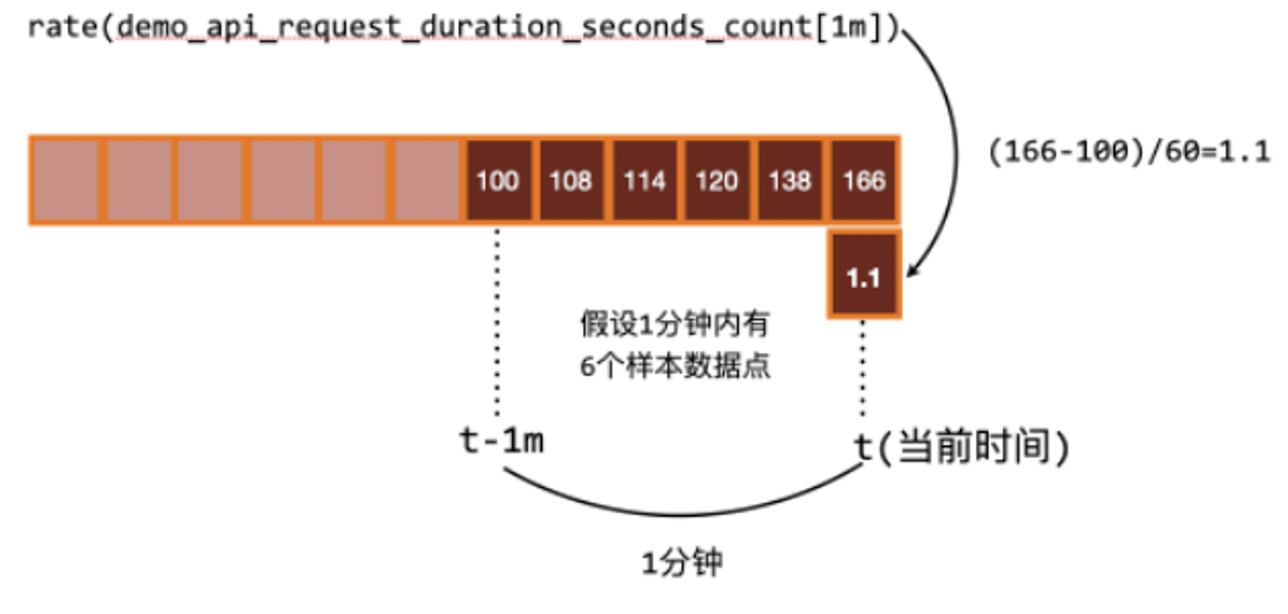
1、rate 函数:用来求指标的平均变化速率
该函数通常用来求某个时间区间内的请求速率,也就是我们常说的 QPS,注意 rate 函数只是算出来了某个时间区间内的平均速率,没办法反映突发变化
$rate 结果 =\frac{时间区间前后两个点的差}{时间范围}$
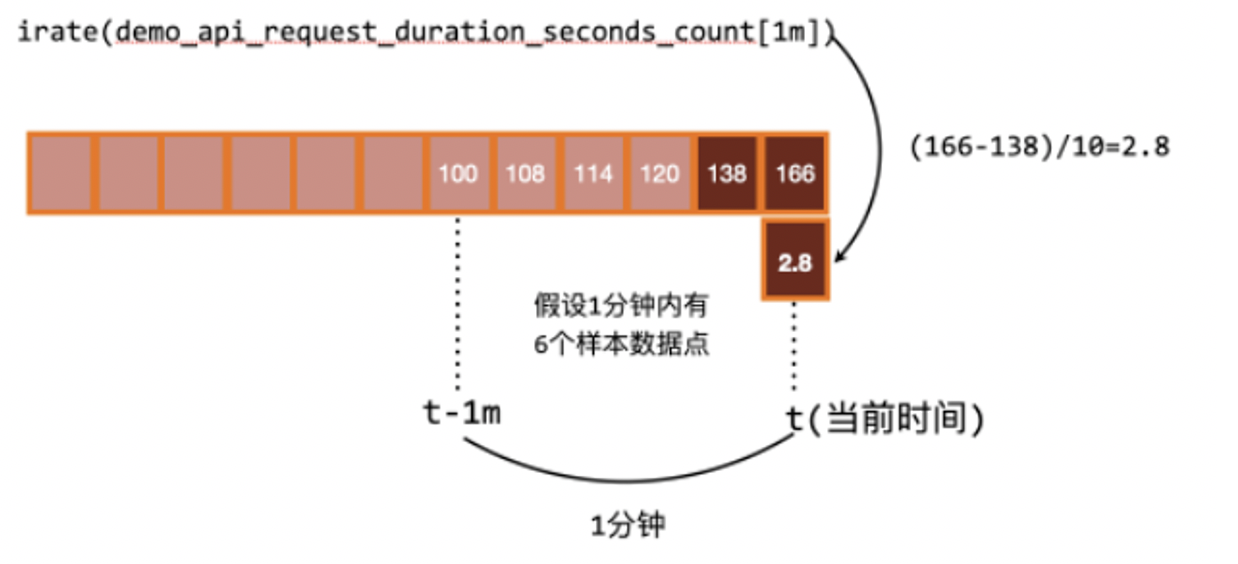
2、irate 函数:计算瞬时变化率
$irate 结果 =\frac{时间区间内最后两个样本点的差}{最后两个样本点的时间差}$
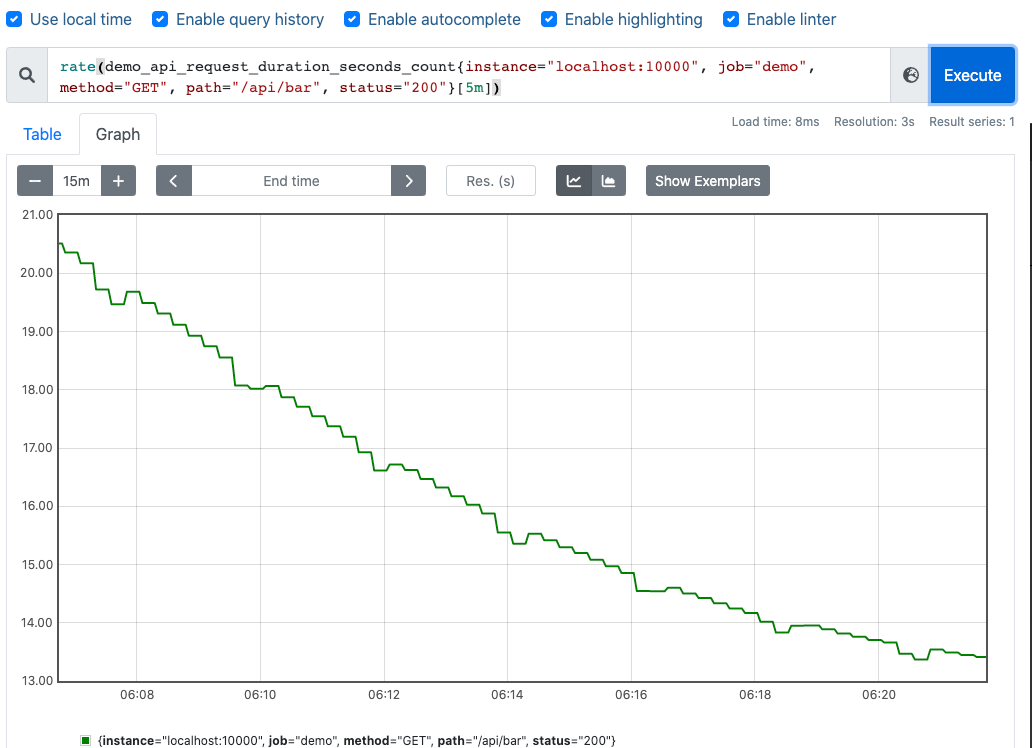
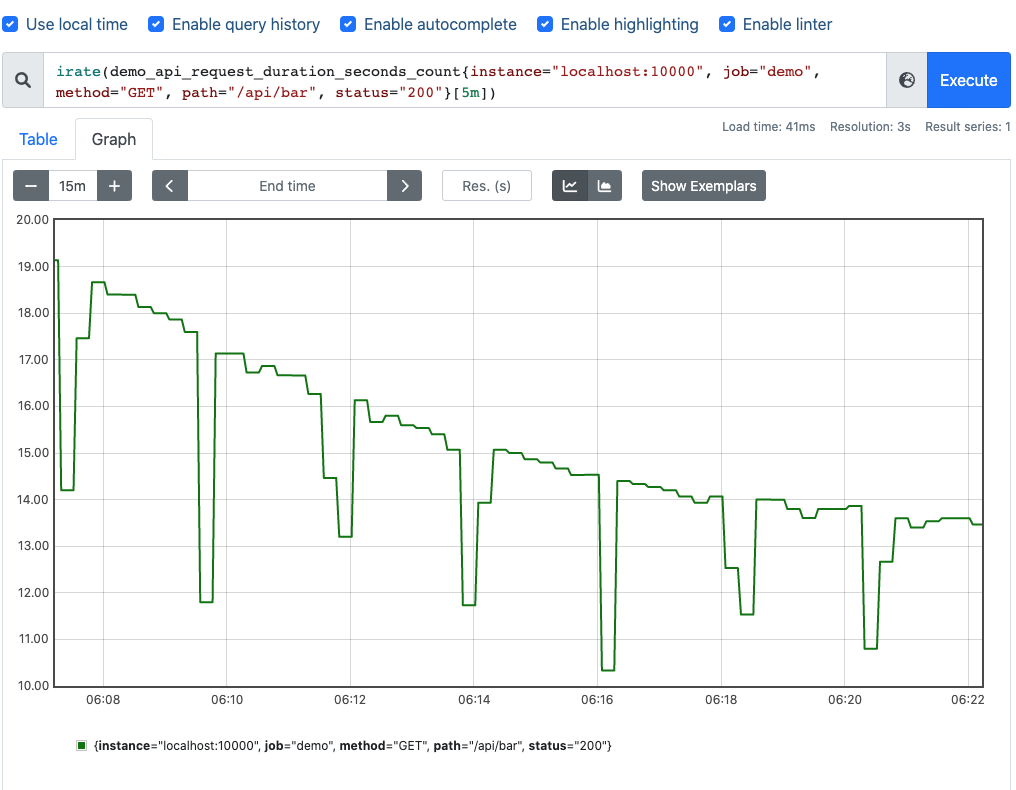
rate 和 irate 方法的比较,从结果看 irate 函数的图像峰值变化大,rate 函数变化较为平缓
3、聚合运算符:Sum/by/without
这里使用 demo_api_request_duration_seconds_count 例子,有如下 label:
instancejobmethodpathstatus
rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m])
采样数据如下:
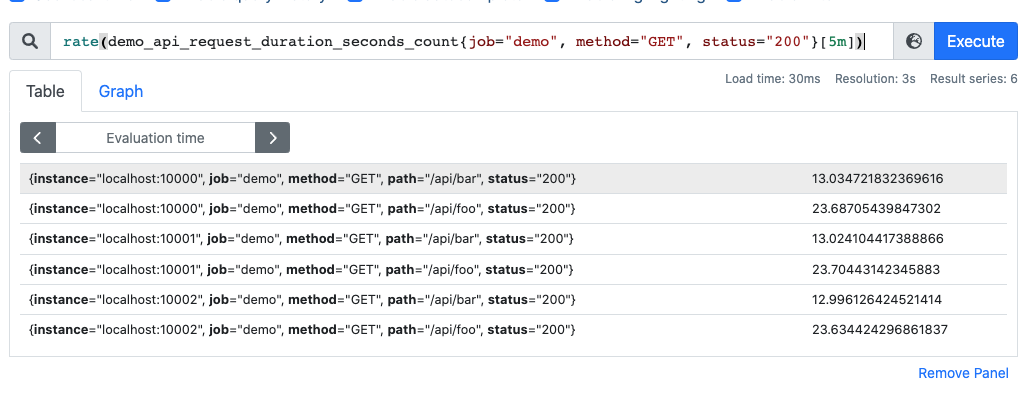
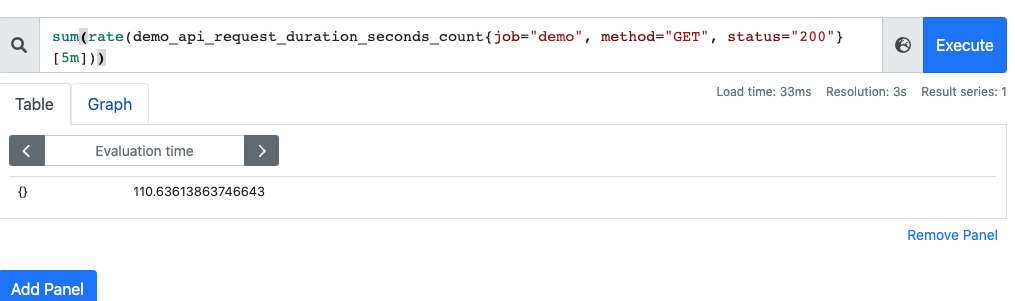
通过 sum 运算符可以将所有的 QPS 聚合,即可得到整个服务该接口的 QPS(sum 就是将指标值做相加)
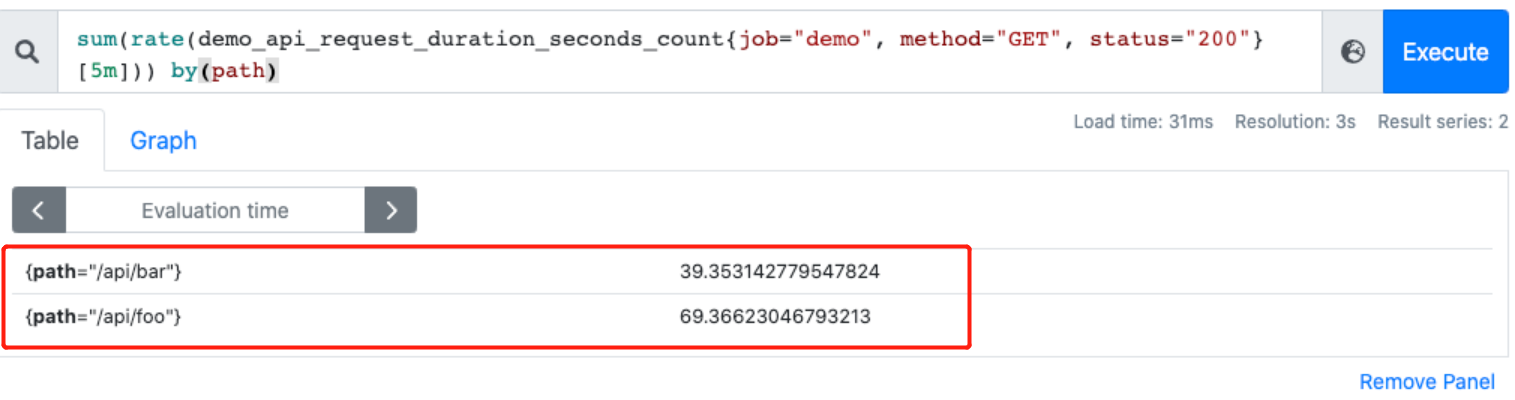
此外,可以配合 by 和 without 函数在 sum 的时候,基于某些标签分组(类似 group by)
如,可以根据请求接口标签分组,拿到的就是具体某个接口的 QPS:
sum(rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m])) by(path)
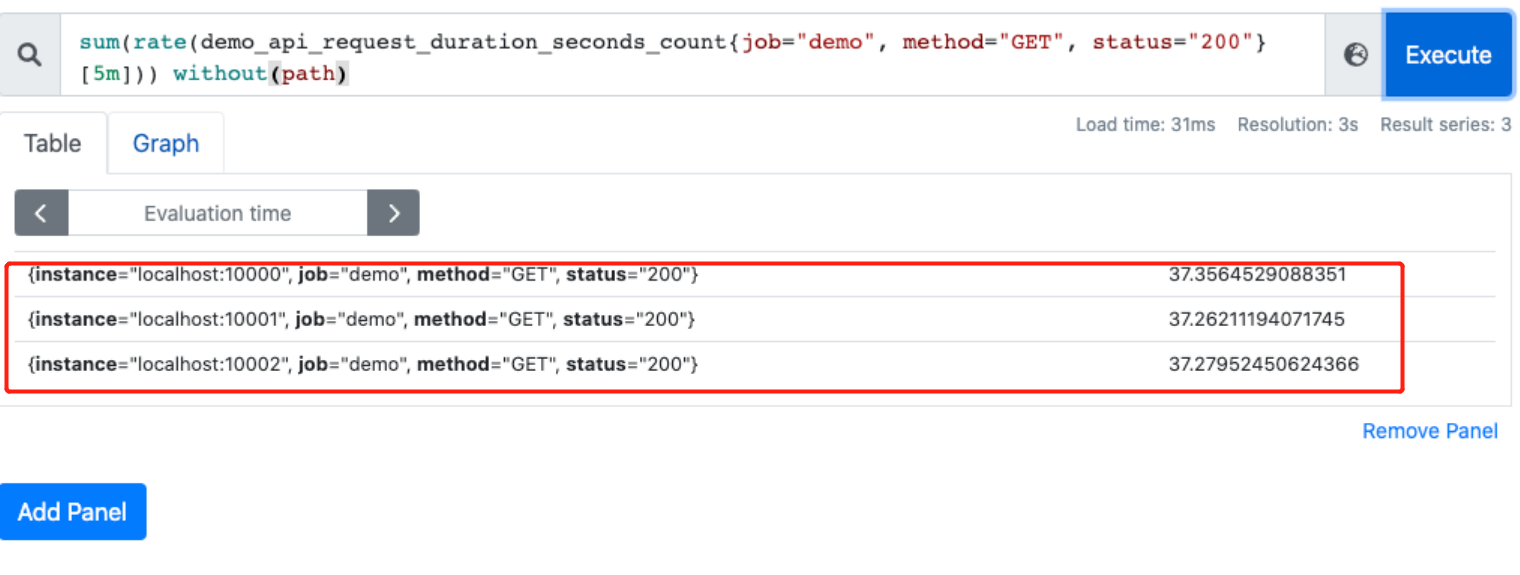
通过 without 排除某些 label,如不根据接口路径分组:
sum(rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m])) without(path)
 再列举例子:
再列举例子:
http_requests_total {code=200, method=GET}
http_requests_total {code=200, method=GET}
http_requests_total {code=404, method=POST}
http_requests_total {code=404, method=POST}
sum(increase(http_requests_total [1m])) #查看每分钟的请求总量,将数据聚合起来
sum by (code) (increase(http_requests_total [1m])) #按照 code 筛选
#上面等价于
sum (increase(http_requests_total [1m])) by (code)
#上面等价于
sum without (method) (increase(http_requests_total [1m]))
4、数据统计函数:histogram_quantile
通过 histogram_quantile 函数做数据统计,用来统计百分位数:第一个参数是百分位,第二个 histogram 指标,这样计算出来的就是中位数,即 P50,如下例子:
histogram_quantile(0.5,go_gc_pauses_seconds_total_bucket)
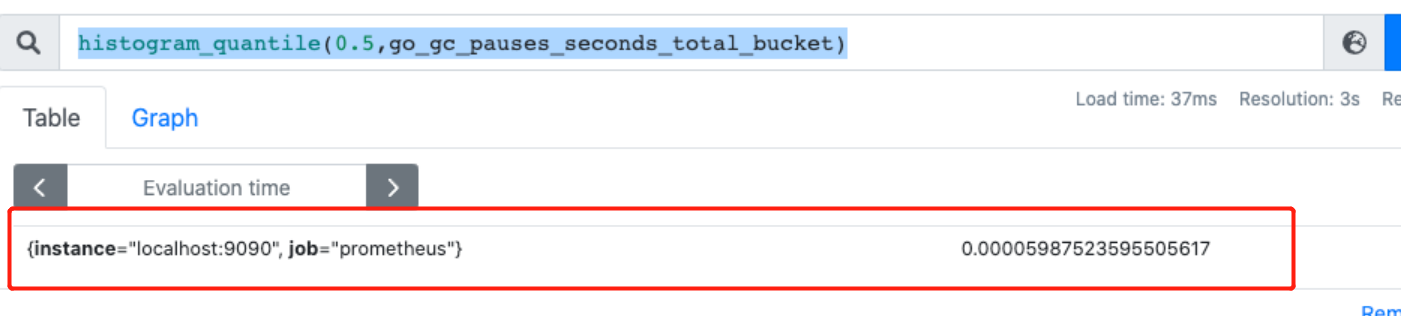
关于 promql 的一些细节
Histogram/Summary 时间序列要如何进行查询呢?事实上,Prometheus 会根据一定的规则来给这些时间序列命名。假设监控指标 mymetric,设置了 1/2/3 bucket ,且采集到了如下数据:
| buckets | observe | write | values |
|---|---|---|---|
| 1 | 2 | 2 | 0.2, 0.6 |
| 2 | 3 | 5 | 1.3, 1.5, 1.5 |
| 3 | 4 | 9 | 2.4, 2.6, 2.8, 2.9 |
那么,可以得到这样的结果(注意 bucket 的结果向下包含):
mymetric_bucket {le="1"} = 2
mymetric_bucket {le="2"} = 5
mymetric_bucket {le="3"} = 9
mymetric_bucket {le="+Inf"} = 9
mymetric_count = 9
mymetric_sum = 15.8
Histogram 并没有存储数据采样点的值,只保留了总和和每一个区间的 counter。可以在 PromQL 中用 histogram_quantile() 函数来计算其值的分位数。
0x05 Grafana 可视化
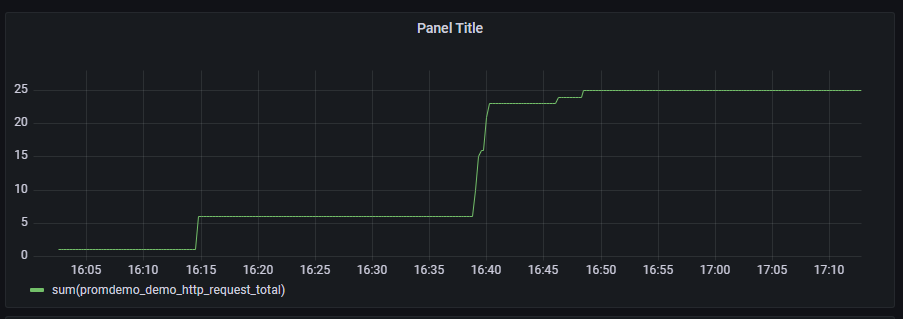
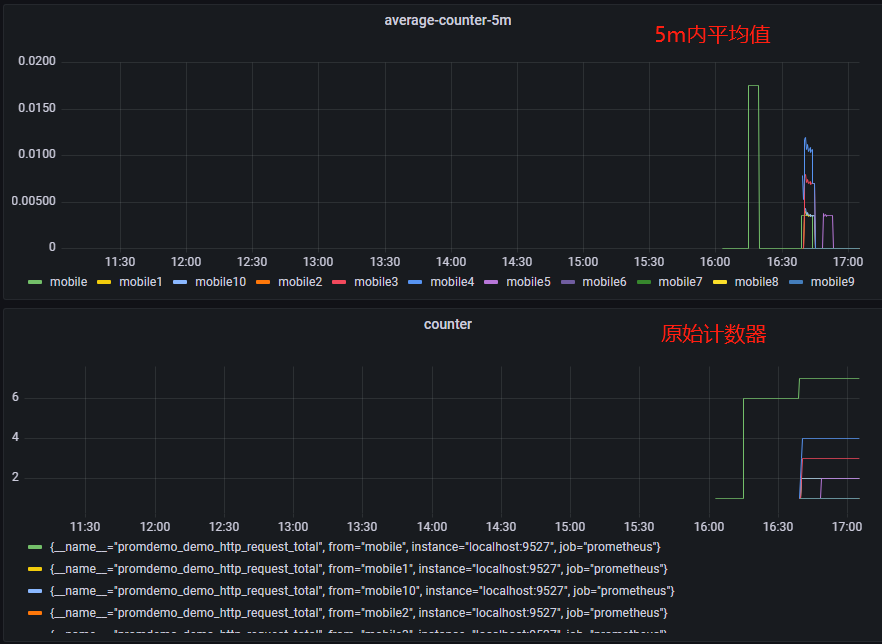
Grafana 里面的面板也是通过 PromQL 来进行数据查询的,本小节介绍下 grafana 的使用例子。下面的代码,定义了一个 CounterVec,label 为请求的参数,按照下面 3 种配置 panel:
- 不考虑 label 的请求总数:表达式为
sum(promdemo_demo_http_request_total) - 基于 label 的原始 counter
5m内的平均值(按标签):表达式为sum(rate(promdemo_demo_http_request_total[5m])) by(from),[5m]代表5分钟之内的平均值,by(from)表示通过该指标中的from标签分组
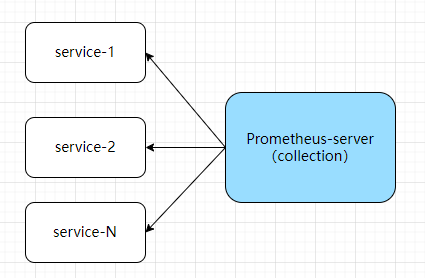
部署的架构如下:
var (
MetricHttpRequestTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Namespace: "promdemo",
Subsystem: "demo",
Name: "http_request_total",
Help: "http request total",
},
[]string{"from"},
)
)
func init() {
prometheus.MustRegister(MetricHttpRequestTotal)
}
func main() {
go func() {
muxProm := http.NewServeMux()
muxProm.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":9527", muxProm)
}()
http.HandleFunc("/", func(w http.ResponseWriter, req *http.Request) {
values := req.URL.Query()
from := values.Get("from")
MetricHttpRequestTotal.WithLabelValues(from).Inc()
w.Write([]byte("Hello,from" + from))
})
http.ListenAndServe(":28080", nil)
}
上面三种查询 panel 对应的图如下,注意到,虽然指标都是同一个,但是可以灵活的通过 PromQL 来实现我们想要观测的维度:
0x06 总结
本文介绍了 Prometheus/Merics 的基础概念。Prometheus 中存储的数据都为时间序列(time series),它是一串随着时间移动而产生的属于某个 metric name 和一系列标签(键值对)的数据。时间序列是由 metric name 和一系列的标签 label(键值对)唯一标识的,不同的标签代表了不同的时间序列。最后,再罗列几个问题:
1、Prometheus 每次采集的数据到底是什么,是否为瞬时值?采集周期对 Prometheus 的影响?
Prometheus 每次采集数据时,会收集目标(应用程序等)暴露的指标在当前时间点的值,通常被认为是瞬时值,因为它们表示在某个特定时间点的度量值。例如,对于 Counter 类型的指标,每次采集时,Prometheus 会获取当前的计数值。然后,Prometheus 会将这些瞬时值存储在其时间序列数据库中,以便后续进行查询、聚合和分析。此外,Prometheus 是基于拉取(pull)模式的监控系统,它会定期从目标处获取指标数据。因此,采集到的数据会受到采集周期(scrape interval)的影响,较长的采集周期可能导致数据粒度较低,从而影响数据的准确性和监控的实时性
2、每调用一次 /metrics,数据是否会重置?
答案是不会重置数据。Prometheus 的 /metrics 接口是用来暴露和收集指标数据的,当 Prometheus 服务器调用 /metrics 接口时,它会获取当前的指标数据,但这并不会导致数据重置。这些数据会持续更新,并在 Prometheus 服务器中进行聚合和存储。因此,多次调用 /metrics 接口只会获取不同时间点的指标数据,但并不会导致数据重置
3、采集周期的影响,采集周期的选择
假设采集周期设置为 5 分钟,那么在这 5 分钟内发生的任何事件或性能波动都可能被忽略,因为 Prometheus 只会每 5 分钟收集一次数据。这可能会导致对系统性能问题或故障的检测和响应变慢;为了获得更精确的数据,可以缩短采集周期。但请注意,缩短采集周期会增加 Prometheus 的负载和存储需求,因为需要处理和存储更多的数据点
4、Prometheus的metrics,比如GaugeVec等,都是协程并发安全的
0x07 参考
- 一文带你了解 Prometheus
- 一文搞懂 Prometheus 的直方图
- 如何区分 prometheus 中 Histogram 和 Summary 类型的 metrics?
- Metrics 设计:teleport
- Lock-free Observations for Prometheus Histograms
- golang API
- HISTOGRAMS AND SUMMARIES
- prometheus 的内置函数
转载请注明出处,本文采用 CC4.0 协议授权