0x00 前言
本篇文章,了解下 Kratos Warden 框架中的超时传递机制。
在微服务中,超时和熔断、重试、Backoff 策略都是有关联的。在实际项目中,每一个 RPC 调用都应该有超时退出的能力,这是比较合理的 API 设计。在 Context Deadlines and How to Set Them 中总结了超时的要点:
- Return an error. This is the simplest, but unless you know there is error handling upstream, this can actually deliver the worst user experience.
- Return a fallback value. We can return a default value, a cached value, or fall back to a simpler computed value. Depending on the circumstances, this can offer a better user experience.
- Retry. In the best case, a retry will succeed and deliver the intended response to the caller, albeit with the added timeout delay. However, there are other complexities to consider for retries to be effective. For a full discussion on this topic, see Circuit Breaker vs Retries Part 1and Circuit Breaker vs Retries Part 2.
0x01 回顾 Context
Context 接口如下:
// A Context carries a deadline, cancelation signal, and request-scoped values
// across API boundaries. Its methods are safe for simultaneous use by multiple
// goroutines.
type Context interface {
// Done returns a channel that is closed when this Context is canceled
// or times out.
Done() <-chan struct{}
// Err indicates why this context was canceled, after the Done channel
// is closed.
Err() error
// Deadline returns the time when this Context will be canceled, if any.
Deadline() (deadline time.Time, ok bool)
// Value returns the value associated with key or nil if none.
Value(key interface{}) interface{}
}
包含了四个方法:
Done(),返回一个 channel,当 Timeout 或者调用cancel方法时,将会close掉Err(),返回一个错误,该Context为什么被取消掉Deadline(),返回截止时间deadline和设置标记okValue(),返回(存储的)值,interface{}类型
进一步说:
Done()会返回一个 channel,当该 context 被取消的时候,该 channel 会被关闭,同时对应的使用该Context的 goroutine 也应该结束并返回Context中的方法是协程安全的,这也就代表了在父 goroutine 中创建的Context,可以传递给任意数量的子 goroutine 并让他们同时访问Deadline()会返回一个超时时间,goroutine 获得了超时时间后,可以对某些 io 操作设定超时时间(超时后立即返回)Value机制可以让 goroutine 共享一些数据,当然获取数据也是协程安全的
Context 提供了 4 个接口:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithDeadline(parent Context, deadline time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
func WithValue(parent Context, key, val interface{}) Context
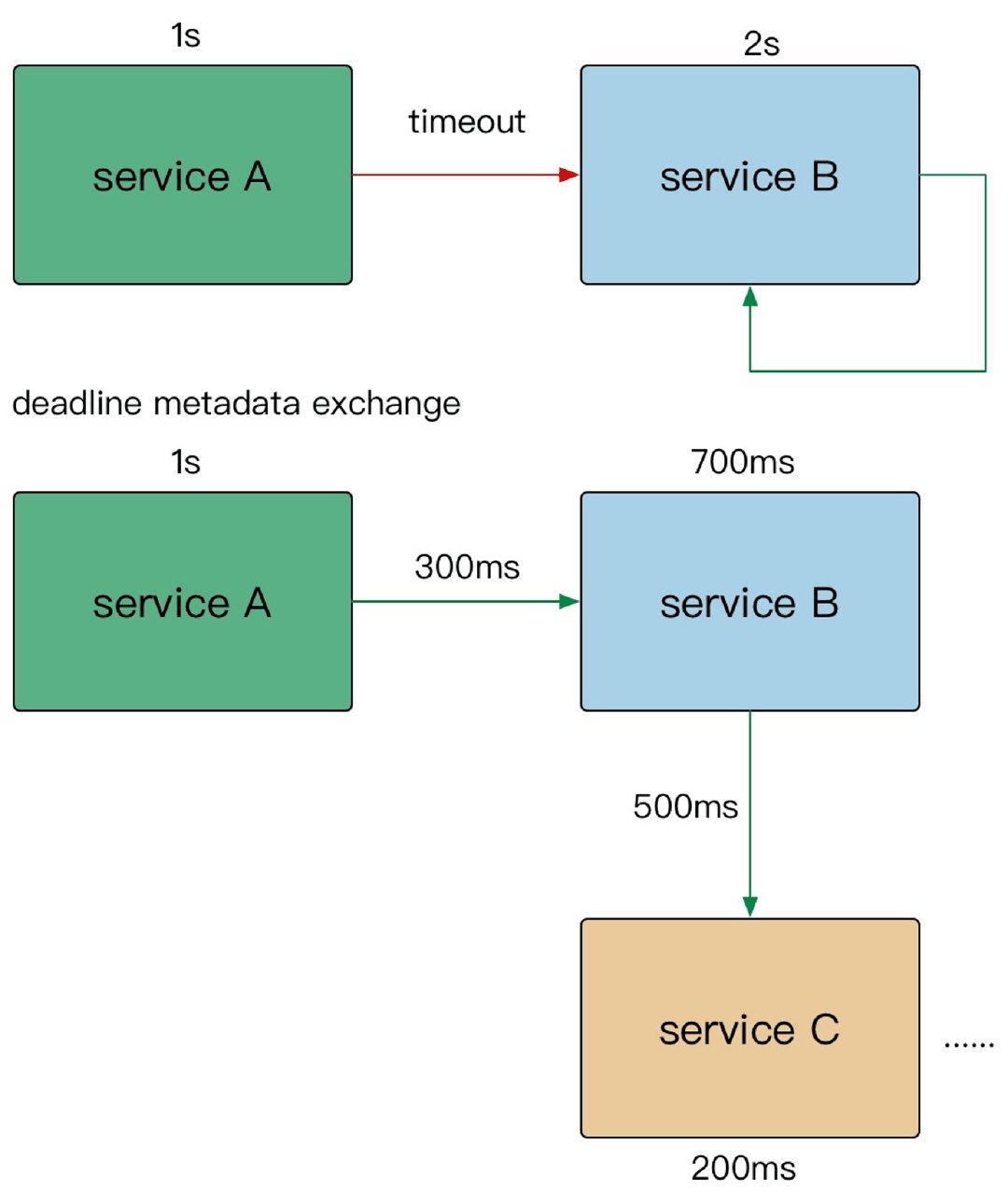
其中,有一个超时的生成方法 func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) 正是我们本文(超时传递)需要用到的。而超时传递分为进程内传递及跨进程传递两种场景。
0x01 进程内传递
进程内超时传递自然使用 context.WithTimeout 来实现了。
0x02 跨进程传递
在这篇博客 gRPC 系列——grpc 超时传递原理,介绍了跨进程(语言)的超时传递的场景。先给出结论:gRPC 框架确实是通过 HTTP2 HEADERS Frame 中的 grpc-timeout 字段来实现跨进程传递超时时间,Go 和 Java 服务(基于 gRPC)之间,超时也会随着调用链传递 。
问题描述
简单描述下问题,出问题的业务方的服务调用路径如下,业务反馈 DoXORM 服务(基于 Xorm 改造,加入 ctx 支持)偶现错误 context deadline exceeded,很明显错误是由于 context.WithTimeout() 超时导致的。
ServiceA -> ServiceB -> ServiceC -> DoXORM
DoXORM 大致逻辑如下(业务方的 gRPC handler 中对传入的 ctx 未做 context.WithTimeout() 处理),猜测原因是使用 db.Find(ctx,...) 时使用了带 timeout 的 ctx(参数),如果这个 ctx 的 timeout 时间很短,有可能会在执行查询操作前就抛出 context deadline execcded 错误:
func (s Svc) BizHandler(ctx context.Context, r *projectv1.BizHandlerRequest) (*projectv1.BizHandlerResponse, error) {
var bean dao.Bean
// 查询某个记录
if err := db.W().Find(ctx, &bean); err != nil {
return nil, err
}
//...
}
分析
从 database/sql 提供的底层接口出发(xorm 底层),最终执行查询的方法可能是 ctxDriverQuery、ctxDriverStmtQuery,代码中明显看到针对 ctx.Done() 的处理过程:
func ctxDriverQuery(ctx context.Context, queryerCtx driver.QueryerContext, queryer driver.Queryer, query string, nvdargs []driver.NamedValue) (driver.Rows, error) {
//...
select {
default:
// 若 ctx 超时或用户主动 cancel(),则抛出错误
// 如果只因为 ctx 超时,此时错误就是 `context deadline execcded`
case <-ctx.Done():
return nil, ctx.Err()
}
// 否则继续执行查询
return queryer.Query(query, dargs)
}
如上可知,如果 db.W().Find(ctx, &bean) 中使用的 ctx 是设置了 timeout 的 ctx,那么是有可能在经过 xorm 的一些冗长的前置处理后,调用标准包的 ctxDriver 方法时产生了 context deadline execcded 错误。
溯源:谁构造的带 timeout 的 context?
根据上面的调用路径,查询 xorm 报错的是 ServiceC,找到 ServiceB 看了下调用 ServiceC gRPC Handler 代码。ServiceB 中 ctx 来自 ServiceA,ServiceB 中拿到 ctx 后,也并未设置 timeout。看来设置 timeout 的只可能是整个调用链发起方(即 ServiceA)。从代码看 ServiceA 发起 RPC 调用时,确实传入了带 timeout 的 ctx。
注意:这里的 ServiceA,充当的是客户端行为,那么 gRPC 超时如何做到跨进程传递?
// InvokeServiceB 发起对 SerivceB 的 RPC 调用
func InvokeServiceB() {
//...
ctx,_ := context.WithTimeout(ctx, 3*time.Second) // 设置了 3 秒超时
response, err := grpcClient.ServicebBiz(ctx, request) // 调用 ServiceB 的 RPC 时,使用的是上方定义的带 timeout 的 ctx
//...
}
0x03 gRPC 超时如何做到跨进程传递
先给结论: 不仅是 Go gRPC 服务之间超时可以传递(如果你拿到上游的 ctx 继续往下透传的话)。Go 和 Java 服务之间,超时也会随着调用链传递
- gRPC 的超时传递并非依靠 metadata 实现
- gRPC 框架确实是通过 HTTP2 HEADERS Frame 中的 grpc-timeout 字段来实现跨进程传递超时时间
客户端调用路径
对于每一个在 protobuf 中定义的 RPC 方法,底层都会通过 ClientConn.Invoke() 向服务端发起调用(注意 SayHiOK 中的 ctx context.Context 是加了 timeout 属性的),调用路径如下:
func (c *demoServiceClient) SayHiOK(ctx context.Context, in *HiRequest, opts ...grpc.CallOption) (*HiResponse, error) {
out := new(HiResponse)
// 调用 grpc.ClientConn.Invoke() 函数,grpc.ClientConn.Invoke() 内部最终会调用 invoke() 函数
err := c.cc.Invoke(ctx, "/proto.DemoService/SayHi", in, out, opts...)
if err != nil {
return nil, err
}
return out, nil
}
//====> 接上,ClientConn.Invoke() 方法
func invoke(ctx context.Context, method string, req, reply interface{}, cc *ClientConn, opts ...CallOption) error {
// 构造 clientStream
cs, err := newClientStream(ctx, unaryStreamDesc, cc, method, opts...)
if err != nil {
return err
}
// 发送 RPC 请求
if err := cs.SendMsg(req); err != nil {
return err
}
return cs.RecvMsg(reply)
}
// ====> 接上,newClientStream 方法
func newClientStream(ctx context.Context, desc *StreamDesc, cc *ClientConn, method string, opts ...CallOption) (_ClientStream, err error) {
...
// 等待 resolver 解析出可用地址
if err := cc.waitForResolvedAddrs(ctx); err != nil {
return nil, err
}
...
// 构造 *clientStream
cs := &clientStream{
callHdr: callHdr,
ctx: ctx,
...
}
// 构造新的 *csAttempt,newAttemptLocked 内部会获取 grpc.ClientTransport 并赋值给 *csAttemp.t
if err := cs.newAttemptLocked(sh, trInfo); err != nil {
cs.finish(err)
return nil, err
}
...
return cs, nil
}
通过 csAttempt.newStream() 创建了客户端的 transport 和 stream 等信息:
//======> clientStream 初始化
type csAttempt struct {
cs *clientStream
t transport.ClientTransport // 客户端 Transport
s *transport.Stream // 真正处理 RPC 的 Stream
//...
}
func (a *csAttempt) newStream() error {
//...
// 通过 Transport.NewStream 构造 RPC Stream
s, err := a.t.NewStream(cs.ctx, cs.callHdr)
cs.attempt.s = s
//...
return nil
}
//=====> NewStream
// gRPC 内部 internal/transport.http2Client 实现了 csAttempt 结构中定义的 transport.ClientTransport 接口
// http2Client.NewStream 方法如下
func (t *http2Client) NewStream(ctx context.Context, callHdr *CallHdr) (_ *Stream, err error) {
ctx = peer.NewContext(ctx, t.getPeer())
headerFields, err := t.createHeaderFields(ctx, callHdr)
...
hdr := &headerFrame{
hf: headerFields,
endStream: false,
...
}
...
for {
success, err := t.controlBuf.executeAndPut(func(it interface{}) bool {
if !checkForStreamQuota(it) {
return false
}
if !checkForHeaderListSize(it) {
return false
}
return true
}, hdr)
...
return s, nil
}
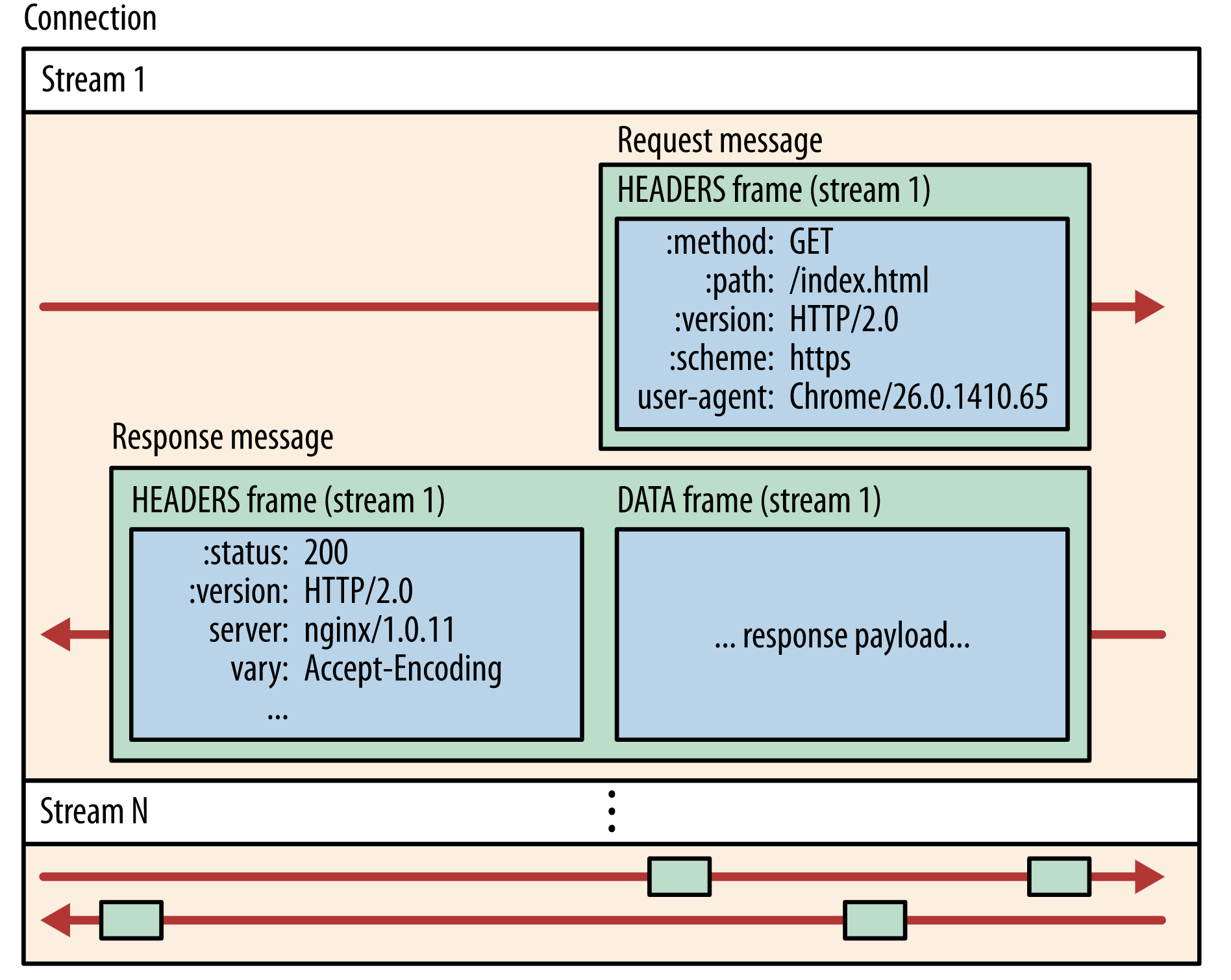
根据上面代码的流程,最终客户端走到了 createHeaderFields 逻辑中, 可以看到客户端发起请求时,如果设置了带 timeout 的 context 上下文,则会导致底层 HTTP2 HEADERS Frame 中追加 grpc-timeout 字段
func (t *http2Client) createHeaderFields(ctx context.Context, callHdr *CallHdr) ([]hpack.HeaderField, error) {
...
// 如果透传过来的 ctx 被设置了 timeout/deadline,则在 HTTP2 headers frame 中添加 grpc-timeout 字段,
// grpc-timeout 字段值被转化成 XhYmZs 字符串形式的超时时间
if dl, ok := ctx.Deadline(); ok {
timeout := time.Until(dl)
headerFields = append(headerFields, hpack.HeaderField{Name: "grpc-timeout", Value: encodeTimeout(timeout)})
}
...
return headerFields, nil
}
服务端解析 timeout 的流程
接下来揭开超时传递的面纱。服务端通过 Serve() 方法启动 grpc Server,监听来自客户端连接:
func (s *Server) Serve(lis net.Listener) error {
...
for {
// 接收客户端的连接
rawConn, err := lis.Accept()
...
s.serveWG.Add(1)
go func() {
// 对每一个客户端的连接单独开一个协程来处理
s.handleRawConn(rawConn)
s.serveWG.Done()
}()
}
}
//=====>handleRawConn 方法
func (s *Server) handleRawConn(rawConn net.Conn) {
...
// 构造 HTTP2 Transport
st := s.newHTTP2Transport(conn, authInfo)
go func() {
// 处理 HTTP2 Stream
s.serveStreams(st)
s.removeConn(st)
}()
}
// =====> serveStreams 方法
func (s *Server) serveStreams(st transport.ServerTransport) {
defer st.Close()
var wg sync.WaitGroup
// http2Server 实现了 transport.ServerTransport 接口,此处会调用 http2Server.HandleSteams 方法
// st.HandleStreams 方法签名中第一个参数 handle func(stream *transport.Stream) {} 为函数类型,
// handle 随后会在 operateHeaders 中被调用
st.HandleStreams(func(stream *transport.Stream) {
wg.Add(1)
go func() {
defer wg.Done()
// 解析出 gPRC Service, gRPC method, gRPC request message,执行注册到 gRPC.Server 中的 RPC 方法
s.handleStream(st, stream, s.traceInfo(st, stream))
}()
}, ...)
wg.Wait()
}
// =====> HandleStreams 方法
// http2Server.HandleStreams 会调用传入的 handle 处理 HTTP2 Stream
func (t *http2Server) HandleStreams(handle func(*Stream), traceCtx func(context.Context, string) context.Context) {
defer close(t.readerDone)
for {
t.controlBuf.throttle()
frame, err := t.framer.fr.ReadFrame()
...
switch frame := frame.(type) {
// 如果是 Headers 帧,则调用 operateHeaders 方法处理 Headers
case *http2.MetaHeadersFrame:
if t.operateHeaders(frame, handle, traceCtx) {
t.Close()
break
}
// 如果是 Data 帧,则调用 handleData 方法处理
case *http2.DataFrame:
t.handleData(frame)
...
}
}
}
服务端真正处理超时的逻辑实现位于 operateHeaders() 方法中,该方法用于解析 Headers 帧,仔细看下面 state.data.timeoutSet 处的逻辑:
// =====> operateHeaders 方法:解析 Headers 帧
func (t *http2Server) operateHeaders(frame *http2.MetaHeadersFrame, handle func(*Stream), traceCtx func(context.Context, string) context.Context) (fatal bool) {
// 从 HTTP2 Headers 帧中获取 StreamID
streamID := frame.Header().StreamID
state := &decodeState{
serverSide: true,
}
// 从 HTTP2 Headers 帧中解析出 Header。如果其中包含 grpc-timeout HEADER,
// 则解析出其值并赋值给 state.data.timeout,并将 state.data.timeoutSet 设成 true
if err := state.decodeHeader(frame); err != nil {
if se, ok := status.FromError(err); ok {
...
}
buf := newRecvBuffer()
// 构造 HTTP2 Stream
s := &Stream{
id: streamID,
st: t,
buf: buf,
fc: &inFlow{limit: uint32(t.initialWindowSize)},
recvCompress: state.data.encoding,
method: state.data.method,
contentSubtype: state.data.contentSubtype,
}
...
// 如果 state.data.timeoutSet 为 true,则构造一个新的带 timeout 的 ctx 覆盖原 s.ctx
// s.ctx 最终会透传到用户实现的 gRPC Handler 中,参与业务逻辑处理
// 见 server.go 中 processUnaryRPC 内:
// ctx := NewContextWithServerTransportStream(stream.Context(), stream)
// reply, appErr := md.Handler(srv.server, ctx, df, s.opts.unaryInt)
// 此处不再赘述
if state.data.timeoutSet {
s.ctx, s.cancel = context.WithTimeout(t.ctx, state.data.timeout)
} else {
s.ctx, s.cancel = context.WithCancel(t.ctx)
}
...
t.controlBuf.put(®isterStream{
streamID: s.id,
wq: s.wq,
})
// 调用 serveStreams 定义好的 handle,执行 gRPC 调用
handle(s)
return false
}
在 decodeHeader() 方法中, 会遍历 frame 中所有 Fields,并调用 processHeaderField 对 HTTP2 HEADERS 帧中的特定的 Field 进行处理。包含了从 grpc-timeout 中解析出上游传递过来的 timeout 这部分逻辑,即对 state.data.timeoutSet 的设置:
func (d *decodeState) decodeHeader(frame *http2.MetaHeadersFrame) error {
...
// 遍历 Headers 帧,解析 Field
for _, hf := range frame.Fields {
d.processHeaderField(hf)
}
}
func (d *decodeState) processHeaderField(f hpack.HeaderField) {
switch f.Name {
...
// 解析出 grpc-timeout
case "grpc-timeout":
d.data.timeoutSet = true
var err error
if d.data.timeout, err = decodeTimeout(f.Value); err != nil {
d.data.grpcErr = status.Errorf(codes.Internal, "transport: malformed time-out: %v", err)
}
...
// 解析出 grpc 带 protobuf package path、Service name、RPC method name 的完整路径
// 形如 /package.service/method
case ":path":
d.data.method = f.Value
}
}
至此可以看到,gRPC 框架确实是通过 HTTP2 HEADERS Frame 中的 grpc-timeout 字段来实现跨进程传递了超时时间。
小结
- gRPC 客户端发起 RPC 调用时传入了带 timeout 的
ctx - gRPC 框架底层通过 HTTP2 协议发送 RPC 请求时,将 timeout 值写入到
grpc-timeoutHEADERS Frame 中 - 服务端接收 RPC 请求时,gRPC 框架底层解析 HTTP2 HEADERS 帧,读取
grpc-timeout值,并覆盖透传到实际处理 RPC 请求的业务 gPRC Handle 中 - 如果此时服务端又发起对其他 gRPC 服务的调用,且使用的是透传的
ctx,这个 timeout 会减去在本进程中耗时(核心逻辑在客户端的createHeaderFields方法),从而导致这个 timeout 传递到下一个 gRPC 服务端时变短,这样即实现了所谓的 超时传递
简言之,gRPC client 中的 context 设置了超时的话, 会经过 grpc-timeout 这个 HEADERS 传递到 server,server 取出超时信息设置到 context 中。核心的超时逻辑,单独提取下:
1、客户端
func (t *http2Client) createHeaderFields(ctx context.Context, callHdr *CallHdr) ([]hpack.HeaderField, error) {
//...
if dl, ok := ctx.Deadline(); ok {
// Send out timeout regardless its value. The server can detect timeout context by itself.
// TODO(mmukhi): Perhaps this field should be updated when actually writing out to the wire.
timeout := time.Until(dl)
headerFields = append(headerFields, hpack.HeaderField{Name: "grpc-timeout", Value: encodeTimeout(timeout)})
}
//...
}
2、服务端
func (d *decodeState) processHeaderField(f hpack.HeaderField) {
//...
case "grpc-timeout":
d.data.timeoutSet = true
var err error
if d.data.timeout, err = decodeTimeout(f.Value); err != nil {
d.data.grpcErr = status.Errorf(codes.Internal, "transport: malformed time-out: %v", err)
}
//...
}
func (ht *serverHandlerTransport) HandleStreams(startStream func(*Stream), traceCtx func(context.Context, string) context.Context) {
//...
if ht.timeoutSet {
ctx, cancel = context.WithTimeout(ctx, ht.timeout)
} else {
ctx, cancel = context.WithCancel(ctx)
}
//...
}
0x03 Warden 框架的超时传递实现
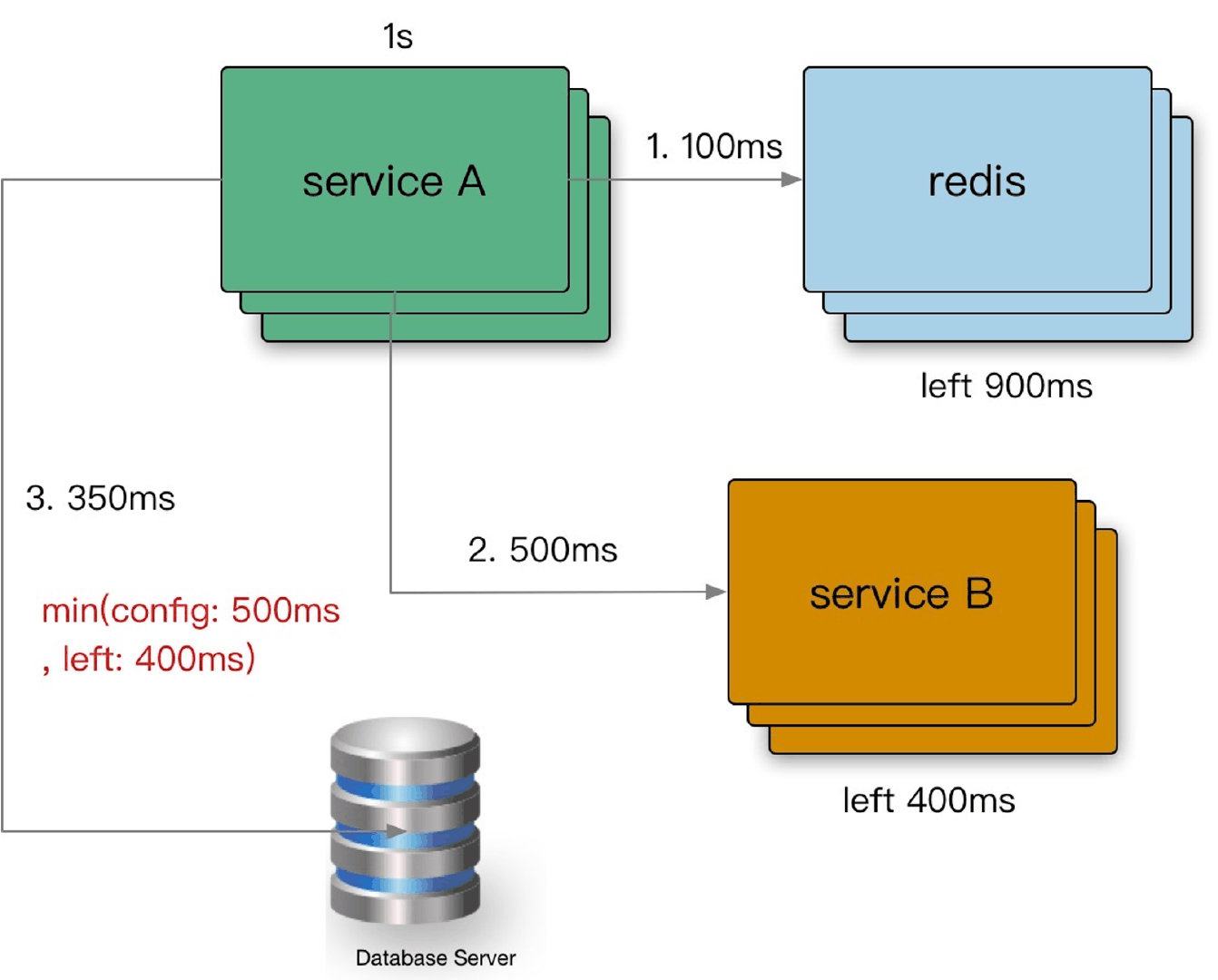
通过 Shrink(c context.Context) 方法来完成进程内的超时判定及传递:
// Shrink will decrease the duration by comparing with context's timeout duration
// and return new timeout\context\CancelFunc.
// 非常棒的实现!RPC 超时传递
func (d Duration) Shrink(c context.Context) (Duration, context.Context, context.CancelFunc) {
//Deadline 方法是获取设置的截止时间的意思,第一个返回是截止时间,到了这个时间点,Context 会自动发起取消请求;第二个返回值 ok==false 时表示没有设置截止时间,如果需要取消的话,需要调用取消函数进行取消。
if deadline, ok := c.Deadline(); ok {
// 该 ctx 设置了截止时间
if ctimeout := xtime.Until(deadline); ctimeout < xtime.Duration(d) {
// deliver small timeout
return Duration(ctimeout), c, func() {}
}
}
// 未设置截止时间时,设置为当前时间
// 更新 ctx 的超时时间并 fork(子孙)
ctx, cancel := context.WithTimeout(c, xtime.Duration(d))
return d, ctx, cancel
}
0x04 Warden 超时传递的应用
本小节,我们看下 Warden 框架中,对超时的应用逻辑是怎样做的,分为服务端和客户端两类。
客户端超时
在 Warden 的 client.go 中,关于超时设置的代码如下:
func (c *Client) handle() grpc.UnaryClientInterceptor {
return func(ctx context.Context, method string, req, reply interface{}, cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) (err error) {
......
// 熔断统计结果必须要在 rpc 调用最后
defer onBreaker(brk, &err)
var timeOpt *TimeoutCallOption
for _, opt := range opts {
var tok bool
timeOpt, tok = opt.(*TimeoutCallOption)
if tok {
break
}
}
if timeOpt != nil && timeOpt.Timeout > 0 {
// 如果定义了超时配置,那么久使用定义的逻辑
ctx, cancel = context.WithTimeout(nmd.WithContext(ctx), timeOpt.Timeout)
} else {
// 否则,使用 shrink 继承 CONTEXT 中的超时配置
_, ctx, cancel = conf.Timeout.Shrink(ctx)
}
defer cancel()
nmd.Range(ctx,
func(key string, value interface{}) {
if valstr, ok := value.(string); ok {
gmd[key] = []string{valstr}
}
},
nmd.IsOutgoingKey)
......
}
服务端超时
服务端关于超时处理的代码在拦截器 server.handle() 中:
func (s *Server) handle() grpc.UnaryServerInterceptor {
return func(ctx context.Context, req interface{}, args *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
var (
cancel func()
addr string
)
s.mutex.RLock()
conf := s.conf
s.mutex.RUnlock()
// get derived timeout from grpc context,
// compare with the warden configured,
// and use the minimum one
timeout := time.Duration(conf.Timeout)
if dl, ok := ctx.Deadline(); ok {
ctimeout := time.Until(dl)
if ctimeout-time.Millisecond*20 > 0 {
ctimeout = ctimeout - time.Millisecond*20
}
if timeout > ctimeout {
timeout = ctimeout
}
}
ctx, cancel = context.WithTimeout(ctx, timeout)
defer cancel()
// get grpc metadata(trace & remote_ip & color)
var t trace.Trace
cmd := nmd.MD{}
if gmd, ok := metadata.FromIncomingContext(ctx); ok {
t, _ = trace.Extract(trace.GRPCFormat, gmd)
for key, vals := range gmd {
if nmd.IsIncomingKey(key) {
cmd[key] = vals[0]
}
}
}
if t == nil {
t = trace.New(args.FullMethod)
} else {
t.SetTitle(args.FullMethod)
}
if pr, ok := peer.FromContext(ctx); ok {
addr = pr.Addr.String()
t.SetTag(trace.String(trace.TagAddress, addr))
}
defer t.Finish(&err)
// use common meta data context instead of grpc context
ctx = nmd.NewContext(ctx, cmd)
ctx = trace.NewContext(ctx, t)
resp, err = handler(ctx, req)
return resp, status.FromError(err).Err()
}
}
0x05 思考
这里有个疑问,为何仅仅在 gRPC 的 client 端才嵌入超时传递的 Shrink 逻辑呢?而 Warden 的服务端却不需要 Shrink 逻辑?
0x06 Database 中超时传递的实现
基于上面 gRPC 的经验,理解 Database 中的超时传递实现也就不难了。
Kratos的封装
看下Query方法的封装:
- 从context中获取真正的超时时间:
Shrink方法,生成新的子contextc,注意到这个context是带超时控制的! - 将
c传入stmt.QueryContext方法 - 等待执行结果或者超时错误返回
// Shrink will decrease the duration by comparing with context's timeout duration
// and return new timeout\context\CancelFunc.
func (d Duration) Shrink(c context.Context) (Duration, context.Context, context.CancelFunc) {
if deadline, ok := c.Deadline(); ok {
if ctimeout := xtime.Until(deadline); ctimeout < xtime.Duration(d) {
// deliver small timeout
return Duration(ctimeout), c, func() {}
}
}
ctx, cancel := context.WithTimeout(c, xtime.Duration(d))
return d, ctx, cancel
}
// Query executes a prepared query statement with the given arguments and
// returns the query results as a *Rows.
func (s *Stmt) Query(c context.Context, args ...interface{}) (rows *Rows, err error) {
//.......
stmt, ok := s.stmt.Load().(*sql.Stmt)
if !ok {
err = ErrStmtNil
return
}
//从context中获取真正的超时时间
_, c, cancel := s.db.conf.QueryTimeout.Shrink(c)
rs, err := stmt.QueryContext(c, args...)
s.db.onBreaker(&err)
_metricReqDur.Observe(int64(time.Since(now)/time.Millisecond), s.db.addr, s.db.addr, "stmt:query")
if err != nil {
err = errors.Wrapf(err, "query:%s, args:%+v", s.query, args)
cancel()
return
}
rows = &Rows{Rows: rs, cancel: cancel}
return
}
超时在何处触发?
通过跟踪stmt.QueryContext方法,一步步跟踪下去,最终到达ctxDriverQuery方法,这里看到了熟悉的代码(看select的逻辑):
func ctxDriverQuery(ctx context.Context, queryerCtx driver.QueryerContext, queryer driver.Queryer, query string, nvdargs []driver.NamedValue) (driver.Rows, error) {
if queryerCtx != nil {
return queryerCtx.QueryContext(ctx, query, nvdargs)
}
dargs, err := namedValueToValue(nvdargs)
if err != nil {
return nil, err
}
//如果ctx超时或者被cancel,则触发ctx.Done()
select {
default:
case <-ctx.Done():
return nil, ctx.Err()
}
return queryer.Query(query, dargs)
}
0x07 总结
本文梳理了Kratos框架的超时传递实现机制。