0x00 前言
项目中使用 Kafka 作为消息队列,本篇文章就个人使用 Kafka 的一些经验做一些总结。大概从下面几个方面:
- Kafka 的基础知识总结
- Kakfa 的生产者分区选择
- Kafka 的消费者组机制
- Kafka 的 offset 机制?
- Kafka 的消费延迟问题如何监控和优化?
- 关于 Kafka 应用的场景
0x01 Kafka 的基本概念
Kafka 的基础知识可以参见 这篇文章。 Kafka 中,Topic 是逻辑上的概念,而 Partition 是物理上的概念,简而言之:
- topic:理解为一个消息的集合(或者表),topic 存储在 broker 中,一个 topic 可以有多个 partition 分区,一个 topic 可以有多个 Producer 来 push 消息,一个 topic 可以有多个消费者向其 pull 消息,一个 topic 可以存在一个或多个 broker 中。写入不同的 topic 即写入不同的表
- partition:是 topic 的子集(topic 下的物理分组),每个 partition 是一个有序的队列(大文件)。不同 partition 分配在不同的 broker 上进行水平扩展从而增加 kafka 并行处理能力,同 topic 下的不同分区信息是不同的,同一分区信息是有序的;每一个分区都有一个或者多个副本,其中会选举一个 leader,fowller 从 leader 拉取数据更新自己的 log(每个分区逻辑上对应一个 log 文件夹),消费者向 leader 中 pull 信息;partition 中每一条消息都有一个有序的 offset
Offset 机制
Partition 中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号(Offset),该编号可以唯一的定位当前分区的每一条消息,一般有两种 Offset:
1、生产者 offset
生产者的 offset 更新由 Kafka 完成,根据客户端设置的分区写入策略写入给定的 partition 中
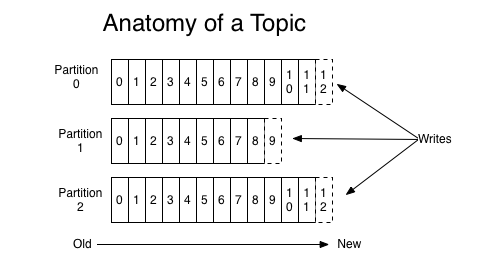
2、消费者 offset
在 consumer group 机制中,每个 consumer 实例都会为它消费的 partition 维护属于自己的位置信息来记录当前消费了多少条信息。consumer group 使用 Kafka 的内部 topic __consumer_offsets 保存 offset 信息。由于一个 partition 只能固定的交给一个 consumer group 中的一个 consumer 消费,因此 Kafka 保存 offset 时并不直接为每个 consumer 保存,而是以 <group.id-topic-partition -> offset> 的格式保存。
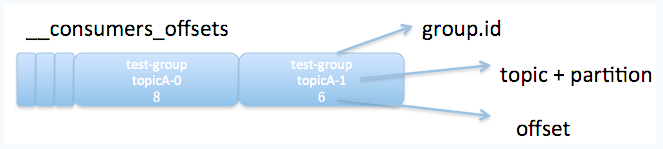
消费者 offset 的意义,个人理解有两点:
- 开发者可以主动告知 Kafka,已经成功消费了哪些 offset 上的数据(消费完了 commit)
- Kafka 反馈开发者,当前 partition 的消费位移到哪了(在此 offset 之前的数据开发者可能不需要)
正是由于消费者 offset 机制的存在,会导致重复消费及数据丢失这两种异常的 case,后文再讨论如何优化这些问题。
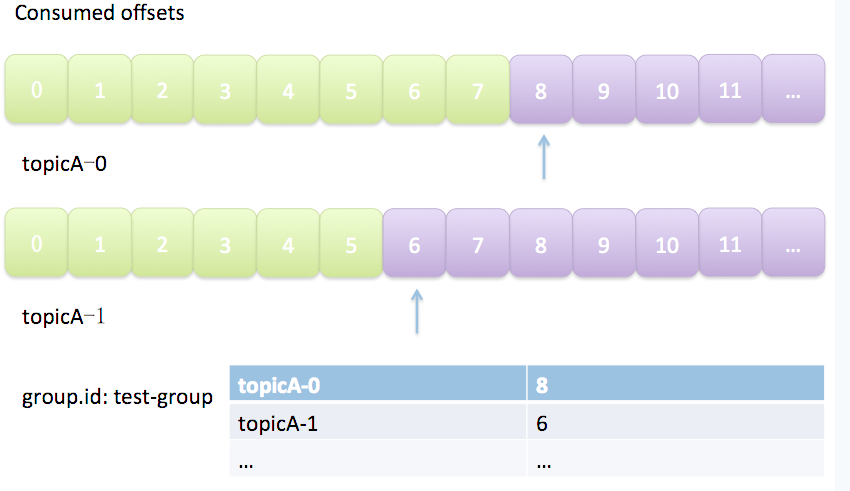
kafka 的生产消费模型
0x02 Kafka 生产者 Producer
Kakfa 的生产者流程如下:
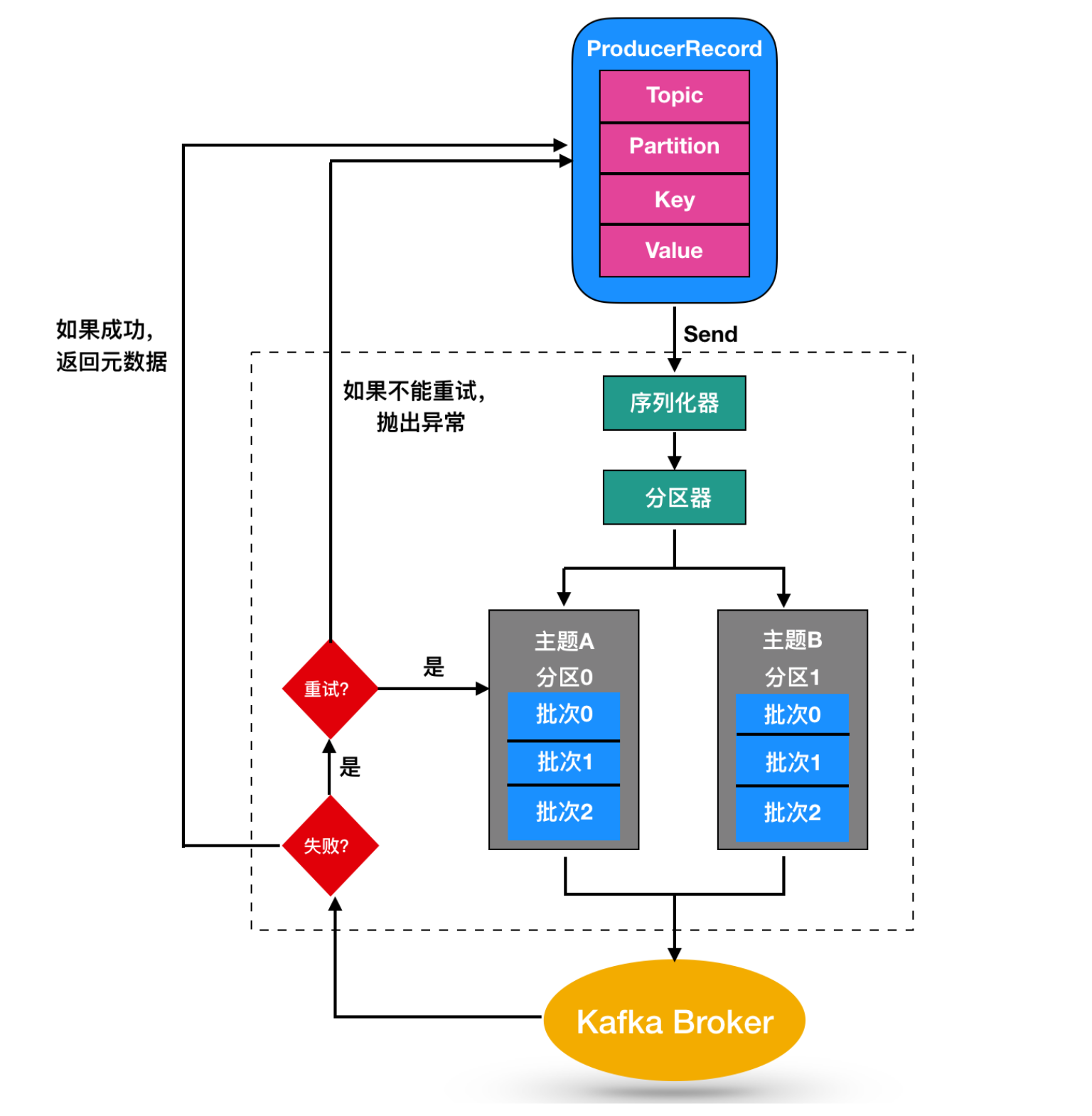
Producer 采用 push 的方式将消息发到 broker 上进行存储,然后由 consumer 采用 pull 模式订阅并消费消息。
存储结构的要素
- Msg: 消息,每个 msg 在 topic 下的不同 partiton 仅有一份,在 partition 中有一个唯一的 offset 用于定位
- Offset:一个逻辑意义上的偏移,用于区分每一条消息,producer 可认为 partition 是一个大的串行文件,msg 存储时被分配了唯一的 offset
- Replica: 副本,partition 的数据冗余备份,用于实现分布式的数据可靠性,但引入了不同副本间的数据一致性问题,带来了一定的复杂度
- Leader/Follower: replica 的角色,leader replica 用来提供该 partition 的读写服务。Follower 不停的从 leader 侧同步写入的消息。它们之间的消息状态采用一致性策略来解决
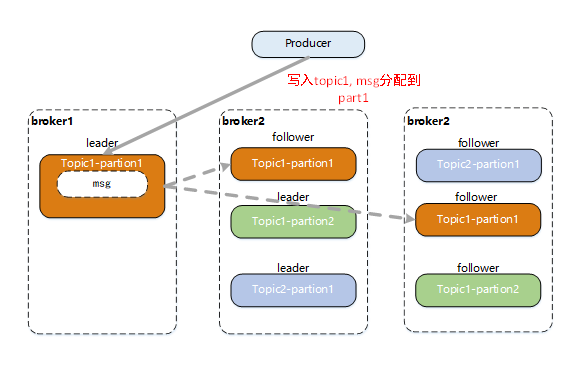
当 Producer 发送一条消息(某个 topic 下的)到 broker 中, 会根据分配 partition 规则选择被存储到哪一个 partition(基于 partition 分区的选择),消息会均匀的分布到不同的 partition 里,这样就实现了水平扩展。另外,partition 本身作为文件,可以有多个分布于不同 broker 上的副本 replica(leader/follower),这样就实现了 Msg 的多副本。
0x03 Kafka 消费者(组)
消费者组
消费者组(Consumer Group)是由一个或多个消费者实例组成的 Group,具有可扩展性和可容错性的一种机制。消费者组内的 consumer 共享一个消费者组 Id(Group Id),组内的 consumer 共同对一个 topic 进行订阅和消费,同一个 group 中的 consumer 只能消费一个 partition 的消息,多余的 consumer 会空闲。
- 一个消费者群组消费一个主题中的消息,这种消费模式又称为点对点的消费方式,点对点的消费方式又被称为消息队列
- 一个主题中的消息被多个消费者群组共同消费,这种消费模式又称为发布 - 订阅模式
分区 Rebalance
0x04 Kafka 的生产者分区选择
本小节解决的问题是:生产者发送数据到哪个分区?如何体现生产者的扩展性?
生产者在生产数据的时候,可以为每条消息指定 Key,这样消息被发送到 broker 时,会根据分区规则选择被存储到哪一个分区中,如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。
Kafka 的 Partition 发送规则是:
- 如果不指定 Message 的 Key,则一般采用顺序轮询各个 Partition 的方式;当然也可以使用自定义策略
- 如果指定了 Message 的 Key,则会根据消息的 hash 值和 topic 的分区数取模来获取 Partition 如果应用有消息顺序性(Message 有先后之分)的需要,则可以通过指定 Message 的 Key 和自定义分区类来将符合某种规则的消息发送到同一个分区。同一个分区消息是有序的,同一个分区只有一个消费者就可以保证消息的顺序性消费。
比如,在实现 OpenSSH 终端会话(Session)审计时,生产者端为每条消息都按照 SessionId 指定 key 值,这样可以保证每个会话的数据一定被顺序性消费的。
msg := &sarama.ProducerMessage{
Topic: topic_name,
Value: sarama.ByteEncoder(sendmsg),
//Key: nil, // 如不指定 key, 则按照轮询方式写入每个 partition
Key: sarama.StringEncoder(sessionid), // 指定 sessionid,将相同会话写入一个 partition
}
0x05 Kafka 的消费者组的意义
- 消费者组机制提供了 Kafka 消费端的高可用,实际项目中强烈推荐以此方式来部署消费端。
- 消费者组实现了一种发布 - 订阅模式的概念
0x06 消费 Lag 计算及意义
为什么要(如何)计算 Kafka 的消费延迟?这个问题是我在腾讯 T9 升 T10 的评审们提问过的。使用消息队列,在消费端一定要处理好这个问题。当生产者大批量写入数据时,Kafka Consumer 消费会存在延迟情况,我们需要查看消息堆积情况,就是所谓的消息 Lag。原因可能是因为消费端性能,亦或是消费端的消费速度本来就比较慢。
此时监控消费 Lag 的指标,非常有意义,是否需要对消费端进行扩容等等。那么如何计算消费 Lag 呢?
计算 Lag
在计算 Lag 之前先普及几个基本概念:
- LEO(LOG-END-OFFSET): 这里主要是指堆 Consumer 可见的 Offset. 即 HW(High Watermark)
- CURRENT-OFFSET: Consumer 消费到的具体位移 从此二者意义可知 \(Lag=LEO-CURRENT-OFFSET\),计算出来的值即为消费延迟的差值。
这里首先要记得,消费 Lag 是针对于某个消费者组 Id 的 Lag,通过官方方包里提供的 kafka-consumer-groups.sh 工具即可获取此值:
/data/home/user00/application/kafka_2.12-2.2.0/bin/kafka-consumer-groups.sh --describe --bootstrap-server 1.2.3.4:19092 --group group_name
比如,项目中的一个消费者组的 Lag 数据如下:

TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
topidc1 0 1057030 1057030 0 kafka-python-1.4.7-2d802e7f-157d-4768-8a1d-3b7727724c71 /1.1.1.1 kafka-python-1.4.7
topidc1 1 1118889 1118889 0 kafka-python-1.4.7.dev-fe05daa9-a6f3-47c5-8801-2a28b6a4b7a5 /2.2.2.2 kafka-python-1.4.7.dev
计算 LAG 的方法 1 – Broker
Broker 消费方式 offset 获取的实现思路为:
- 根据 Topic 获取消费该 Topic 的 Group 信息
- 通过 Consumer-API 读取 Broker 上指定 Group 和 Topic 的消费情况,可以获取到
clientId,CURRENT-OFFSET,patition,host等数据 - 通过 Consumer-API 获取 LogEndOffset(可见 offset)
- 将上面 2 处信息合并,计算 Lag
计算 LAG 的方法 2 –Zookeeper
Zookeeper 消费方式 offset 获取的 实现思路为:
- 根据 topic 获取消费该 topic 的 group
- 读取 Zookeeper 上指定 group 和 topic 的消费情况,可以获取到
clientId,CURRENT-OFFSET,patition等 - 通过 Consumer-API 获取 LogEndOffset(可见 offset)
- 将上面 2 处信息合并,计算 Lag
下面给出一段计算 Lag 的 Python 脚本:
#coding=utf-8
from kafka import SimpleClient, KafkaConsumer
from kafka.common import OffsetRequestPayload, TopicPartition
def get_topic_offset(brokers, topic):
"""
获取一个 topic 的 offset 值的和
"""
client = SimpleClient(brokers)
partitions = client.topic_partitions[topic]
offset_requests = [OffsetRequestPayload(topic, p, -1, 1) for p in partitions.keys()]
offsets_responses = client.send_offset_request(offset_requests)
return sum([r.offsets[0] for r in offsets_responses])
def get_group_offset(brokers, group_id, topic):
"""
获取一个 topic 特定 group 已经消费的 offset 值的和
"""
consumer = KafkaConsumer(bootstrap_servers=brokers,group_id=group_id)
pts = [TopicPartition(topic=topic, partition=i) for i in consumer.partitions_for_topic(topic)]
result = consumer._coordinator.fetch_committed_offsets(pts)
return sum([r.offset for r in result.values()])
if __name__ == '__main__':
topic_offset = get_topic_offset("kafka-cluster-addrlist", "topic_name")
group_offset = get_group_offset("kafka-cluster-addrlist", "group_name", "topic_name")
lag = topic_offset - group_offset
print topic_offset,group_offset,lag
0x07 重复消费
由于数据存储在 Kafka 中,我们可以根据某个 Offset 来实现固定 Offset 区间的消费:这里注意,consumer_start_offset 一定要大于等于 consumer.beginning_offsets(consumer.assignment()) 计算出来的分区的起始 offset
#coding=utf-8
import os
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
consumer = KafkaConsumer('topic_name', bootstrap_servers='1.1.1.1:19092,2.2.2.2:19092,3.3.3.3:19092')
#指定消费者开始的 offset 和结束的 offset
partition_id = 0
consumer_start_offset = 0
consumer_end_offset = 200000
print consumer.partitions_for_topic("topic_name") #获取 test 主题的分区信息
print consumer.topics() #获取主题列表
print consumer.subscription() #获取当前消费者订阅的主题
print consumer.assignment() #获取当前消费者 topic、分区信息
print "************************"
print consumer.beginning_offsets(consumer.assignment()) #获取当前消费者可消费的偏移量
#consumer.seek(TopicPartition(topic=u'test', partition=0), 5) #重置偏移量,从第 5 个偏移量消费
consumer.seek(TopicPartition(topic=u'topic_name', partition=partition_id), consumer_start_offset) #重置偏移量,从第 5 个偏移量消费
count = 0
for message in consumer:
if message.offset> consumer_end_offset:
break
count+=1
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition, message.offset, message.key, message.value))
print count
0x08 Python-kafka 库的基础用法
生产者
Kafka 的生产者代码如下:其中调用了 send 方法向 Kafka 写入数据,该方法的 原型如下:
send(topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None)
from kafka import KafkaProducer
from kafka.errors import KafkaError
import json
class KafkaProducer():
def __init__(self, kafka_serverlist, kafkatopic):
self.kafkatopic = kafkatopic
self.serverslist = kafka_serverlist
self.producer = KafkaProducer(bootstrap_servers = kafka_serverlist)
def sendjsondata(self, params, key):
try:
parmas_message = json.dumps(params)
producer = self.producer
producer.send(self.kafkatopic, key=key, parmas_message.encode('utf-8'))
producer.flush()
except KafkaError as e:
print e
消费者
from kafka import KafkaConsumer
class Kafka_consumer():
'''
使用 Kafka—python 的消费模块
'''
def __init__(self, kafkahost, kafkaport, kafkatopic, groupid):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.consumer = KafkaConsumer(self.kafkatopic, group_id = self.groupid,
bootstrap_servers = '{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort ))
def consume_data(self):
try:
#其中返回的 message 为一个生成器
#其中元素的 type 为 <class 'kafka.consumer.fetcher.ConsumerRecord'>
for message in self.consumer:
# print json.loads(message.value)
yield message
except KeyboardInterrupt, e:
print e
测试
(TO BE CONTINUED)
def main():
'''
测试 consumer 和 producer
:return:
'''
## 测试生产模块
#producer = Kafka_producer("127.0.0.1", 9092, "ranktest")
#for id in range(10):
# params = '{abetst}:{null}---'+str(i)
# producer.sendjsondata(params)
## 测试消费模块
#消费模块的返回格式为 ConsumerRecord(topic=u'ranktest', partition=0, offset=202, timestamp=None,
#\timestamp_type=None, key=None, value='"{abetst}:{null}---0"', checksum=-1868164195,
#\serialized_key_size=-1, serialized_value_size=21)
consumer = Kafka_consumer('127.0.0.1', 9092, "ranktest", 'test-python-ranktest')
message = consumer.consume_data()
for i in message:
print i.value
0x09 Kafka 的应用场景
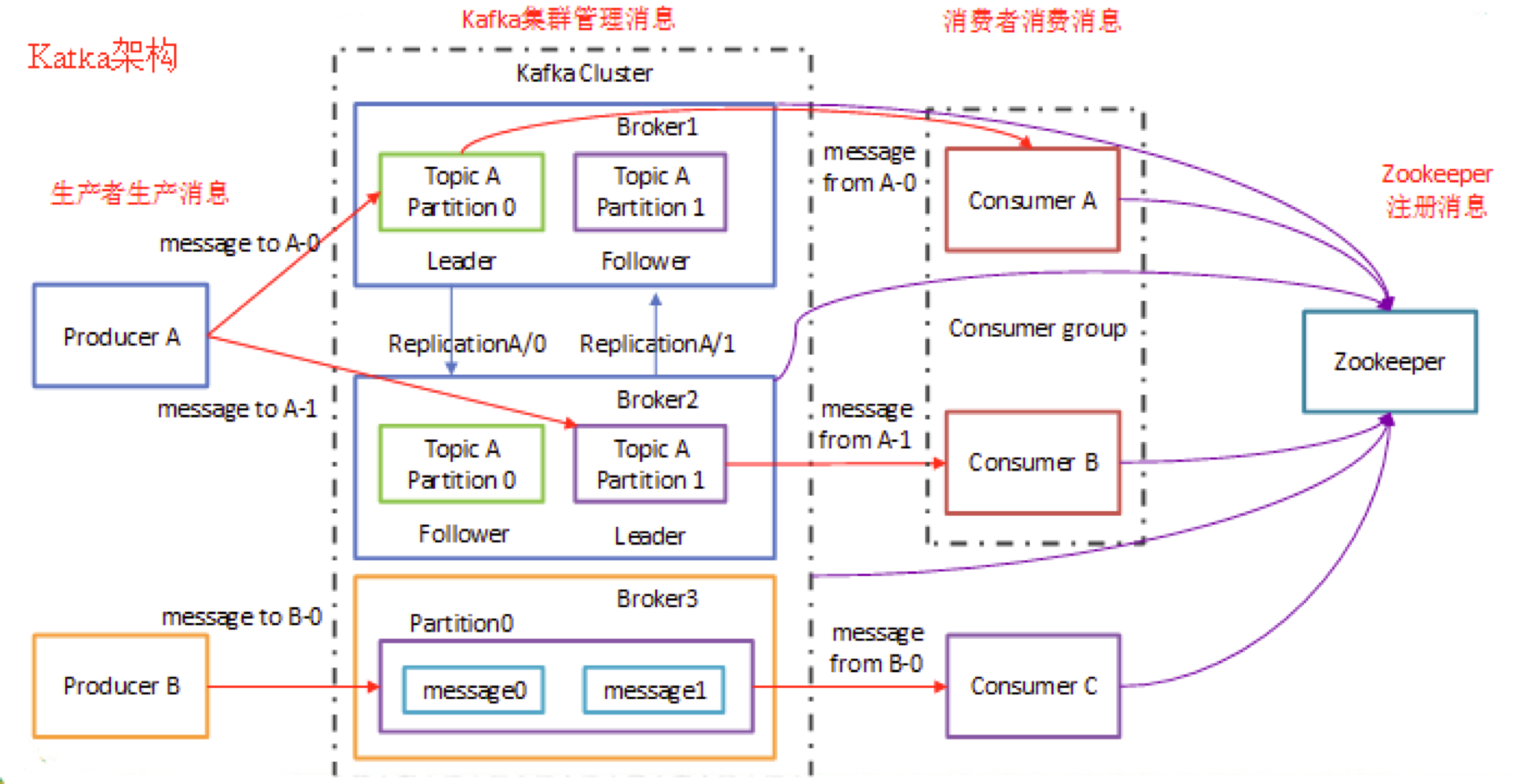
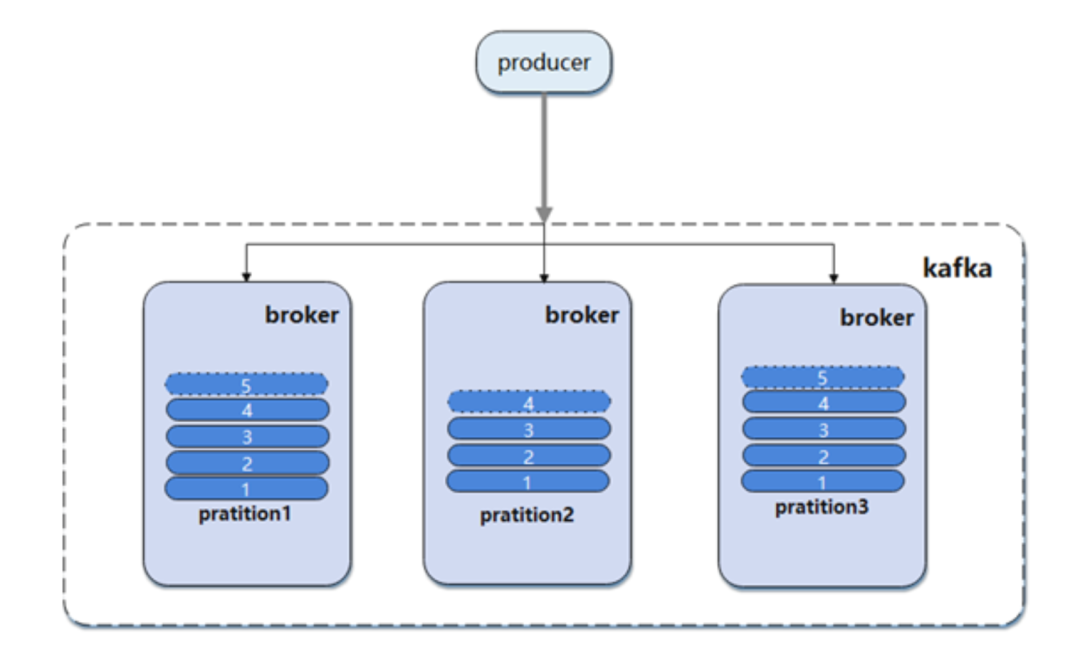
项目使用的 Kafka 整体模型如下图所示,N 个生产者,针对每个 Topic 默认开启 2 个消费者组来消费:

0x0A 参考
- Understanding Kafka Topics and Partitions
- KafkaConsumer
- 通过 python 操作 kafka
- Kafka offset 管理
- Aug 2019 - Kafka Consumer Lag programmatically
- 简单理解 Kafka 的消息可靠性策略
转载请注明出处,本文采用 CC4.0 协议授权