0x00 前言
goworker 是一个基于 Go 后台队列任务执行的高性能框架,下面是它的官方描述:
goworker is a Go-based background worker that runs 10 to 100,000* times faster than Ruby-based workers
goworker 兼容 Resque,所以可以使用 Rails/PHP 和 Resque 推送你的作业,然后利用 goworker 在后台执行。例如 发送 push,发送邮件, 通用统计 等等的任务。整个项目小巧而精悍,源码十分值得一读。
此外,goworker 是基于 resque 的用 golang 语言封装的库,Resque 是使用 Redis 创建后台任务,存储进队列,并随后执行。它是 rails 下最常用的后台任务管理工具之一。
分析此项目,准备从如下两个方面着手:
- 封装 Redis 的
LIST实现的 Queue 模型 - Worker 的并发模型
- golang
select机制典型的应用
0x01 简单使用
1、测试代码见此
func myFunc(queue string, args ...interface{}) error {
fmt.Printf("From %s, %v\n", queue, args)
return nil
}
func init() {
settings := goworker.WorkerSettings{
URI: "redis://localhost:6379/",
Connections: 100,
Queues: []string{"myqueue", "delimited", "queues"},
UseNumber: true,
ExitOnComplete: false,
Concurrency: 2,
Namespace: "resque:",
Interval: 5.0,
}
goworker.SetSettings(settings)
goworker.Register("Hello", myFunc) //注册Hello对应的处理方法为myFunc
}
func main() {
if err := goworker.Work(); err != nil {
fmt.Println("Error:", err)
}
}
2、使用 RPUSH 指令向 Redis 写入数据:RPUSH resque:queue:myqueue '{"class":"Hello","args":["hi","there"]}'
127.0.0.1:6379> RPUSH resque:queue:myqueue '{"class":"Hello","args":["hi","there"]}'
(integer) 1
3、查看任务被成功运行
[root@VM_120_245_centos ~/goworker]# ./main
From myqueue, [hi there]
0x02 整体框架
goworker 的整体框架大致如下图所示:
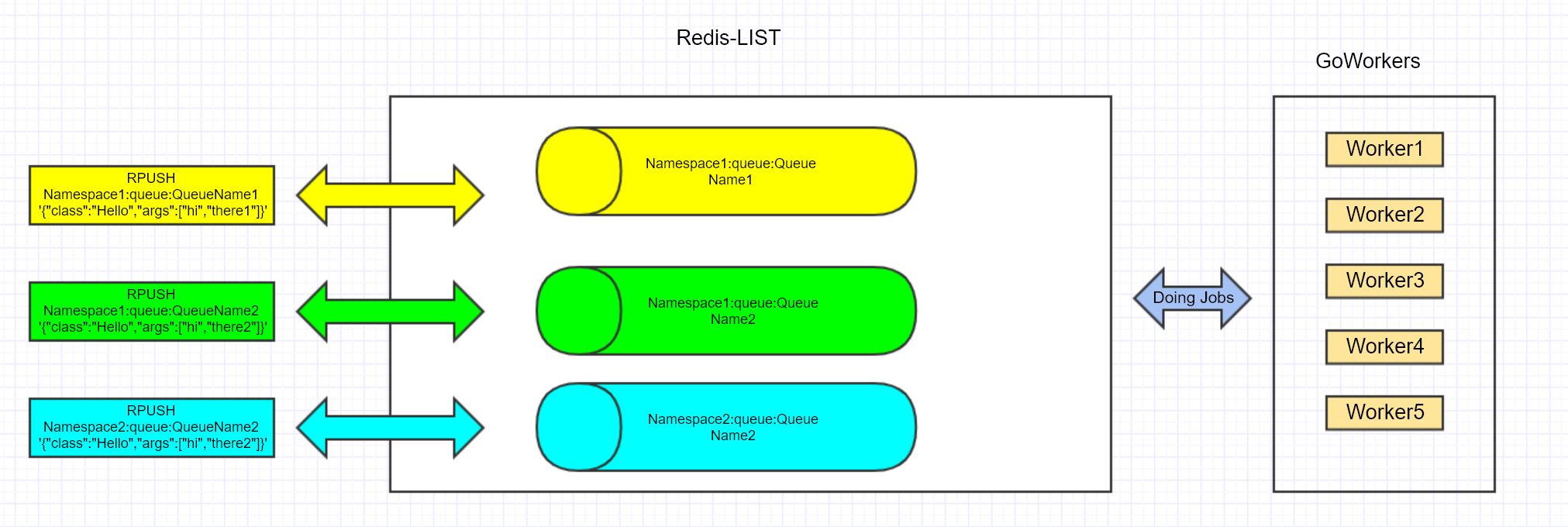
配置参数说明
type WorkerSettings struct {
QueuesString string
Queues queuesFlag
IntervalFloat float64
Interval intervalFlag
Concurrency int
Connections int
URI string
Namespace string
ExitOnComplete bool
IsStrict bool
UseNumber bool
SkipTLSVerify bool
TLSCertPath string
}
0x03 基于 Redis 封装的 Queue 分析
Redis 库及连接池
goworker 的 redis初始化代码在此,使用在此 ,它使用了 vitess.io/vitess/go/pools 构建生成了一个 Redis 连接(资源)池。它提供了两个重要的接口 GetConn 和 PutConn代码:
GetConn:从 pool 中取出一个可用连接PutConn:向 pool 中归还连接
// GetConn returns a connection from the goworker Redis
// connection pool. When using the pool, check in
// connections as quickly as possible, because holding a
// connection will cause concurrent worker functions to lock
// while they wait for an available connection. Expect this
// API to change drastically.
func GetConn() (*RedisConn, error) {
resource, err := pool.Get(ctx)
if err != nil {
return nil, err
}
return resource.(*RedisConn), nil
}
// PutConn puts a connection back into the connection pool.
// Run this as soon as you finish using a connection that
// you got from GetConn. Expect this API to change
// drastically.
func PutConn(conn *RedisConn) {
pool.Put(conn)
}
Queue 中数据的封装
从本文开篇的应用测试来看,数据部分 Payload 定义为一个 JSON,里面包含了 CLASS 属性,
type Payload struct {
Class string `json:"class"`
Args []interface{} `json:"args"`
}
而 Job 就是定义为,一个 Payload 在哪个 Queue 中将会被处理:
type Job struct {
Queue string
Payload Payload
}
回调函数的定义:
type workerFunc func(string, ...interface{}) error
Poller 的 getJob 方法,将 Redis 中 LPOP 出来的数据,封装为一个 Job 结构:
func (p *poller) getJob(conn *RedisConn) (*Job, error) {
for _, queue := range p.queues(p.isStrict) {
logger.Debugf("Checking %s", queue)
// 根据 queue 的名字从这个 LIST 上获取数据
reply, err := conn.Do("LPOP", fmt.Sprintf("%squeue:%s", workerSettings.Namespace, queue))
if err != nil {
return nil, err
}
if reply != nil {
logger.Debugf("Found job on %s", queue)
job := &Job{Queue: queue}
decoder := json.NewDecoder(bytes.NewReader(reply.([]byte)))
if workerSettings.UseNumber {
decoder.UseNumber()
}
if err := decoder.Decode(&job.Payload); err != nil {
return nil, err
}
return job, nil
}
}
return nil, nil
}
Queue 的统计结构 process
每个 Queue,都附带了一个基于 Redis 的统计接口 process,统计 Queue 的相关属性及每次消费结果的统计信息。
type process struct {
Hostname string
Pid int
ID string
Queues []string //
}
整个队列运行的状态都保存在 Redis 中,退出后会被清除,这里需要加入一些持久化的机制。
Queue 的轮询机制 Poller
goworker 中是通过轮询方式,依次对每个 Redis-LIST 进行 LPOP 操作来消费数据的,此流程的 代码在此,其核心逻辑在 for select{...} 结构中:
- 使用
job, err := p.getJob(conn)从 Redis 中获取数据 - 使用
jobs <- job将数据封装的Job分发给worker协程处理 - 退出时的清理工作
PS:这里有个 小细节 需要注意下,当从 channel 中获取到 job,收到 case <-quit 事件退出前,把 job 重新封装为 Payload,通过 LPUSH 操作写回 Redis 中;另外,这里的 channel Job 是无缓冲型的,也就是说当 channel 中的 Job 未被取出来之前,第二个 jobs <- job 操作会阻塞,也就是 Poller 协程会阻塞在 jobs <- job 上。
func (p *poller) poll(interval time.Duration, quit <-chan bool) (<-chan *Job, error) {
jobs := make(chan *Job)
conn, err := GetConn()
if err != nil {
logger.Criticalf("Error on getting connection in poller %s: %v", p, err)
close(jobs)
return nil, err
} else {
p.open(conn)
p.start(conn)
PutConn(conn)
}
go func() {
defer func() {
close(jobs)
conn, err := GetConn()
if err != nil {
logger.Criticalf("Error on getting connection in poller %s: %v", p, err)
return
} else {
p.finish(conn)
p.close(conn)
PutConn(conn)
}
}()
for {
select {
case <-quit:
return
default:
conn, err := GetConn()
if err != nil {
logger.Criticalf("Error on getting connection in poller %s: %v", p, err)
return
}
// 从 Redis 中获取数据
job, err := p.getJob(conn)
if err != nil {
logger.Criticalf("Error on %v getting job from %v: %v", p, p.Queues, err)
PutConn(conn)
return
}
if job != nil {
conn.Send("INCR", fmt.Sprintf("%sstat:processed:%v", workerSettings.Namespace, p))
conn.Flush()
PutConn(conn)
select {
// 向 Jobs channel 中分发数据
case jobs <- job:
case <-quit:
buf, err := json.Marshal(job.Payload)
if err != nil {
logger.Criticalf("Error requeueing %v: %v", job, err)
return
}
conn, err := GetConn()
if err != nil {
logger.Criticalf("Error on getting connection in poller %s: %v", p, err)
return
}
conn.Send("LPUSH", fmt.Sprintf("%squeue:%s", workerSettings.Namespace, job.Queue), buf)
conn.Flush()
PutConn(conn)
return
}
} else {
// 这里,job 数据格式有错误时,Sleep 下
PutConn(conn)
if workerSettings.ExitOnComplete {
return
}
logger.Debugf("Sleeping for %v", interval)
logger.Debugf("Waiting for %v", p.Queues)
timeout := time.After(interval)
select {
case <-quit:
return
case <-timeout:
}
}
}
}
}()
return jobs, nil
}
0x04 Worker 分析
Worker 入口
官网给的 worker 例子如下,worker 的入口方法为 goworker.SetSettings(settings) --> goworker.Register("Hello", helloWorker) --> goworker.Work(),其中 helloWorker 是注册的队列数据处理方法。
func init() {
settings := goworker.WorkerSettings{
URI: "redis://localhost:6379/",
Connections: 100,
Queues: []string{"myqueue0", "myqueue1", "myqueue2"},
UseNumber: true,
ExitOnComplete: false,
Concurrency: 2,
Namespace: "resque:",
Interval: 5.0,
}
goworker.SetSettings(settings)
goworker.Register("Hello", helloWorker)
}
func helloWorker(queue string, args ...interface{}) error {
fmt.Printf("Hello, world! --> From %s, %v\n", queue, args)
return nil
}
func main() {
//worker 入口
if err := goworker.Work(); err != nil {
fmt.Println("Error:", err)
}
}
goworker.Worker 方法 如下,它的逻辑也很清晰:
Init()方法初始化 Redis 连接池及完成其他一些初始化工作newPoller创建Pooler,并创建一个子协程来完成轮询 Redis 的工作,返回一个jobs <-chan *Job,通过此 channel 与 worker 进行交互。Poller向此 channel 中发送Job,然后分发给worker执行- 根据配置中的
workerSettings.Concurrency,创建worker子协程,并且 与配置中workerSettings.Queues的队列(s)进行工作绑定 monitor.Wait()阻塞等待流程结束,Worker 退出。这里也包含了对退出 signal 的处理
goworker 中的协程并发模型是 1:N 的,即一个生产者 Poller,多个消费者 Worker,看下面的代码,jobs 这个 channel 被多个 worker 共享,由于 channel 本身是协程安全的,这种也是非常常见的 golang 并发模式:
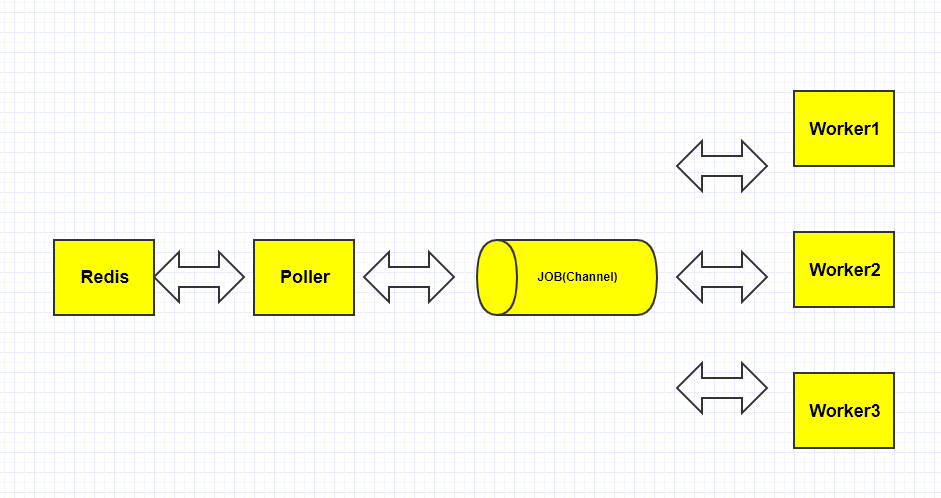
jobs, err := poller.poll(time.Duration(workerSettings.Interval), quit)
...
for id := 0; id < workerSettings.Concurrency; id++ {
worker.work(jobs, &monitor)
}
// Work starts the goworker process. Check for errors in
// the return value. Work will take over the Go executable
// and will run until a QUIT, INT, or TERM signal is
// received, or until the queues are empty if the
// -exit-on-complete flag is set.
func Work() error {
err := Init()
if err != nil {
return err
}
defer Close()
quit := signals()
// 创建 poller
poller, err := newPoller(workerSettings.Queues, workerSettings.IsStrict)
if err != nil {
return err
}
jobs, err := poller.poll(time.Duration(workerSettings.Interval), quit)
if err != nil {
return err
}
var monitor sync.WaitGroup
// 创建 worker
for id := 0; id < workerSettings.Concurrency; id++ {
// workerSettings.Queues 传入的参数标示为该 worker 与哪些 queue 绑定
worker, err := newWorker(strconv.Itoa(id), workerSettings.Queues)
if err != nil {
return err
}
// 启动 worker 协程,注意 jobs <-chan *Job:是用来做任务分发的 channel
worker.work(jobs, &monitor)
}
monitor.Wait()
return nil
}
Pooler 逻辑
Worker 逻辑
worker 的结构,worker 中包含了一个 process,
type worker struct {
process
}
worker.work() 方法,核心逻辑在 for job := range jobs { ...} 里面,当 channel 中有可读事件时,使用 w.run(job, workerFunc) 处理数据:
func (w *worker) work(jobs <-chan *Job, monitor *sync.WaitGroup) {
conn, err := GetConn()
if err != nil {
logger.Criticalf("Error on getting connection in worker %v: %v", w, err)
return
} else {
w.open(conn)
PutConn(conn)
}
monitor.Add(1)
// 创建新的 goroutine
go func() {
defer func() {
// 完成时收尾工作
defer monitor.Done()
conn, err := GetConn()
if err != nil {
logger.Criticalf("Error on getting connection in worker %v: %v", w, err)
return
} else {
w.close(conn)
PutConn(conn)
}
}()
// 注意:jobs 是一个只读的 channel
for job := range jobs {
if workerFunc, ok := workers[job.Payload.Class]; ok {
w.run(job, workerFunc)
logger.Debugf("done: (Job:%s | %s | %v)", job.Queue, job.Payload.Class, job.Payload.Args)
} else {
errorLog := fmt.Sprintf("No worker for %s in queue %s with args %v", job.Payload.Class, job.Queue, job.Payload.Args)
logger.Critical(errorLog)
conn, err := GetConn()
if err != nil {
logger.Criticalf("Error on getting connection in worker %v: %v", w, err)
return
} else {
w.finish(conn, job, errors.New(errorLog))
PutConn(conn)
}
}
}
}()
}
上面代码中 worker.run() 方法如下,最后调用初始化传入的回调方法 workerFunc 执行真正对数据的处理逻辑:
func (w *worker) run(job *Job, workerFunc workerFunc) {
var err error
defer func() {
conn, errCon := GetConn()
if errCon != nil {
logger.Criticalf("Error on getting connection in worker on finish %v: %v", w, errCon)
return
} else {
w.finish(conn, job, err)
PutConn(conn)
}
}()
defer func() {
if r := recover(); r != nil {
err = errors.New(fmt.Sprint(r))
}
}()
conn, err := GetConn()
if err != nil {
logger.Criticalf("Error on getting connection in worker on start %v: %v", w, err)
return
} else {
//start 方法,向 Redis 中写入数据及 process 上报统计数据等
w.start(conn, job)
PutConn(conn)
}
// 执行处理数据的回调方法
err = workerFunc(job.Queue, job.Payload.Args...)
}
Worker 定义
在 goworker 中,workers 是一个全局的 map,其中保存了 name-->callback 即名字到回调方法的映射关系。在应用中使用 goworker.Register("Hello", helloWorker) 来完成相关方法的注册。该名字对应于 Payload 结构中的 CLASS 属性,这样一个完整的处理流程就成功关联了:由写入队列的数据决定该数据被哪个回调方法进行处理,在实际应用中是相当灵活的。
var (
workers map[string]workerFunc
)
func init() {
workers = make(map[string]workerFunc)
}
0x05 参考
- goworker Home Page
- golang 基于 resque 的作业队列 – goworker
- Handling 1 Million Requests per Minute with Golang
转载请注明出处,本文采用 CC4.0 协议授权