0x00 开篇
ccache 是笔者在项目中经常使用的一款 Local-Cache 的高性能组件,作为常用的性能优化手段,选择此库是因为它有如下的特点:
- Value 是
interface{}类型,支持结构化存储 - 支持 LRU 算法的 Key 淘汰机制,LRU链记录访问时间顺序,通常使用
list.List实现 - 支持多级 Cache,如 LayeredCache 和 SecondaryCache
- 采用分段锁及其他一些优化策略来降低锁冲突(Competition)
在项目,用此库来缓存那些不经常改动且有大量读请求的数据场景。本文代码分析基于V2版本
0x01 CCache 的使用
使用方法见 文档,需要注意的一点是,当使用 Get() 方法获取值时,需要使用 Expired() 方法来判断设置的 key 是否到期,到期后需要调用 cache.Delete() 方法进行删除,开发者可以视场景使用或丢弃过期的 value 值
0x02 CCache 的优化
分段锁
第一次接触 Golang 的这个概念,是在 goim 的代码中:
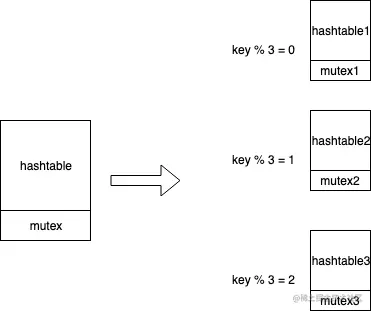
注意看 Server 的 buckets 成员,就是一个典型的分段锁的实现(只在每个 Bucket 中绑定一个读写锁 sync.RWMutex),用来保护并发读写的安全性。在 CCache 中也是 类似做法,将一个 HashTable 根据 key 拆分成多个 HashTable,每个 HashTable 对应一个锁,锁粒度更细,冲突的概率也就相应的降低了。
goim 中的分段锁定义如下:
// Server is comet server.
type Server struct {
c *conf.Config
round *Round // accept round store
buckets []*Bucket // subkey bucket
bucketIdx uint32
serverID string
rpcClient logic.LogicClient
}
// Bucket is a channel holder.
type Bucket struct {
c *conf.Bucket
cLock sync.RWMutex // protect the channels for chs
chs map[string]*Channel // map sub key to a channel
// room
rooms map[string]*Room // bucket room channels
routines []chan *grpc.BroadcastRoomReq
routinesNum uint64
ipCnts map[string]int32
}
在 CCache 中,通过 FNV 算法,根据 Key 来获取到具体存储到哪个 Bucket 中:
func (c *Cache) bucket(key string) *bucket {
h := fnv.New32a()
h.Write([]byte(key))
return c.buckets[h.Sum32()&c.bucketMask]
}
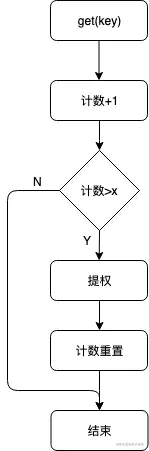
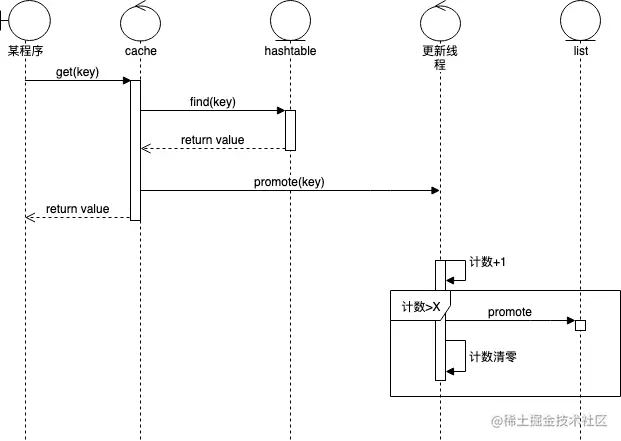
累计访问多次才做LRU提权(提高LRU操作的效率)
具体做法是:每当触发Set或Get方法时,当前被操作的Item的指针会异步被发送至worker工作协程处理(c.promotables <- item);处理时,会判断累计访问多次才做LRU提权操作(c.list.MoveToFront(item.element))
shouldPromote方法对提权计数加1,并且判断是否需要提权
代码如下:
func (c *Cache) set(key string, value interface{}, duration time.Duration, track bool) *Item {
item, existing := c.bucket(key).set(key, value, duration, track)
if existing != nil {
c.deletables <- existing
}
//TODO:需要增加防止阻塞
c.promotables <- item
return item
}
//检查是否需要提权
func (c *Cache) doPromote(item *Item) bool {
//already deleted
if item.promotions == -2 {
return false
}
if item.element != nil { //not a new item
if item.shouldPromote(c.getsPerPromote) {
//当计数达到阈值时,才将其移动到list的队首,同时将计数重置为0
c.list.MoveToFront(item.element)
item.promotions = 0
}
return false
}
c.size += item.size
item.element = c.list.PushFront(item)
return true
}
//检查提权
//value中新增一个访问计数,每次get/set操作时,计数加1
func (i *Item) shouldPromote(getsPerPromote int32) bool {
i.promotions += 1
return i.promotions == getsPerPromote
}
上述设计的好处是,可以显著降低对LRU list的写操作的频率,降低锁冲突的概率;不过缺点是该策略会使list的顺序不完全等同于访问时间序。考虑到多读的场景,该策略对命中率的损失应该是可以容忍的
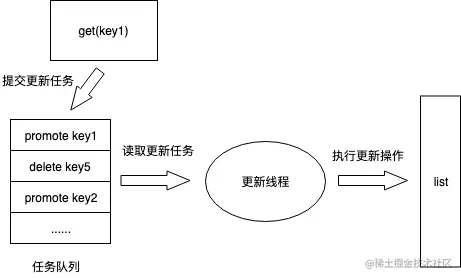
独立goroutine更新LRU链,避免加锁(提权/删除)
ccache在Get和Set操作时,需要更新记录访问时间序的list,Delete操作需要删除掉list的相应节点。ccache通过单独goroutine对list做更新,在调用Get/Set/Delete方法时,提交更新任务到队列(前两者共用同一个channel)中,工作goroutine不停从队列中取任务做更新
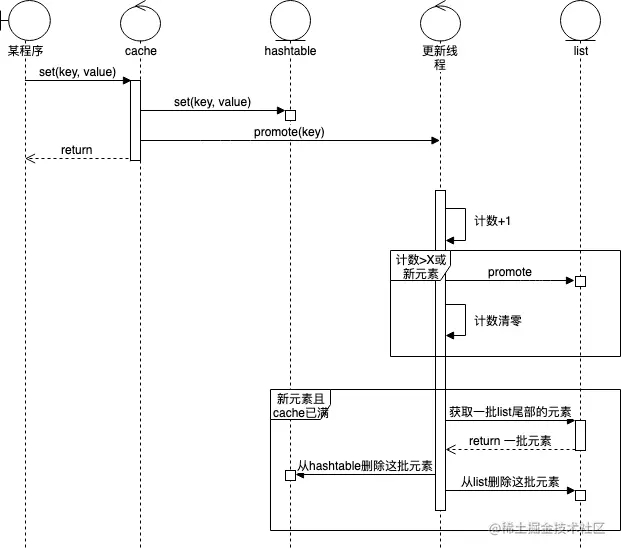
上述设计好处是,list不存在多线程访问,不需加锁(原生的list.List非线程安全),操作完对应的分段hashtable直接返回,异步更新list,操作相对更快。
缺点是worker更新线程可能成为瓶颈,当操作QPS并发较高时,需要考虑有损处理(比如限制channel的大小,增加select超时机制等)
0x02 核心代码分析
item:底层数据存储
item结构代表了KV存储结构:
type Item struct {
key string
group string
promotions int32
refCount int32 //?何用
expires int64 //原子性的操作:过期时间
size int64
value interface{} //value存储
element *list.Element
}
对外提供了如下方法,功能比较直观了:
func (i *Item) Value() interface{} {
return i.value
}
func (i *Item) Release() {
atomic.AddInt32(&i.refCount, -1)
}
func (i *Item) Expired() bool {
expires := atomic.LoadInt64(&i.expires)
return expires < time.Now().UnixNano()
}
func (i *Item) TTL() time.Duration {
expires := atomic.LoadInt64(&i.expires)
return time.Nanosecond * time.Duration(expires-time.Now().UnixNano())
}
func (i *Item) Expires() time.Time {
expires := atomic.LoadInt64(&i.expires)
return time.Unix(0, expires)
}
func (i *Item) Extend(duration time.Duration) {
atomic.StoreInt64(&i.expires, time.Now().Add(duration).UnixNano())
}
func (i *Item) String() string {
return fmt.Sprintf("Item(%v)", i.value)
}
bucket:map的载体
bucket结构,本质上就是一个带读写锁的map,数据的读/写/删除操作最终会落地在此,bucket的操作基本上是对map操作的二次封装:
type bucket struct {
sync.RWMutex
lookup map[string]*Item //存储
}
cache:管理结构
type Cache struct {
*Configuration
list *list.List
size int64
buckets []*bucket //分段锁
bucketMask uint32
deletables chan *Item
promotables chan *Item
control chan interface{}
}
在创建Cache结构时,会异步启动goroutine,执行work方法:
func (c *Cache) worker() {
defer close(c.control)
dropped := 0
for {
select {
case item, ok := <-c.promotables:
if ok == false {
goto drain
}
if c.doPromote(item) && c.size > c.maxSize { //doPromote 完成LRU的更新
dropped += c.gc()
}
case item := <-c.deletables:
c.doDelete(item)
case control := <-c.control:
switch msg := control.(type) {
case getDropped:
msg.res <- dropped
dropped = 0
case setMaxSize:
c.maxSize = msg.size
if c.size > c.maxSize {
dropped += c.gc()
}
case clear:
for _, bucket := range c.buckets {
bucket.clear()
}
c.size = 0
c.list = list.New()
msg.done <- struct{}{}
}
}
}
drain:
for {
select {
case item := <-c.deletables:
c.doDelete(item)
default:
close(c.deletables)
return
}
}
}
关注下这段代码中的几个方法:
doPromote方法:LRU的提权实现,即一个元素在累计被访问多次后才做提权(提权指将元素移动到lru链的头部)doDelete方法:异步删除lru list的节点gc方法:垃圾回收操作
gc 方法 实现了 LRU 删除的逻辑,就是自双链表 c.list 的尾部遍历,按照配置 itemsToPrune 的个数为上限,进行删除(为空时退出):
func (c *Cache) gc() int {
dropped := 0
element := c.list.Back()
for i := 0; i < c.itemsToPrune; i++ {
if element == nil {
return dropped
}
// 取 prev
prev := element.Prev()
item := element.Value.(*Item)
if c.tracking == false || atomic.LoadInt32(&item.refCount) == 0 {
// 删除 bucket 中的 key
c.bucket(item.key).delete(item.key)
c.size -= item.size
// 从 list 中 remove
c.list.Remove(element)
if c.onDelete != nil {
c.onDelete(item)
}
dropped += 1
item.promotions = -2
}
// 继续遍历
element = prev
}
return dropped
}
0x03 Set/Get/Del实现
1、Set操作
底层调用的set方法,值得注意的是当key已经存在时,先通过newItem方法生成新的Item,然后删除旧的Item,同时更新对应的LRU链:
func (c *Cache) set(key string, value interface{}, duration time.Duration, track bool) *Item {
//存储在bucket层
item, existing := c.bucket(key).set(key, value, duration, track)
if existing != nil {
//如果存在,更新新的value,同时删除旧的
c.deletables <- existing
}
c.promotables <- item //异步计算更新LRU
return item
}
func (b *bucket) set(key string, value interface{}, duration time.Duration, track bool) (*Item, *Item) {
expires := time.Now().Add(duration).UnixNano()
item := newItem(key, value, expires, track)
b.Lock()
existing := b.lookup[key]
b.lookup[key] = item
b.Unlock()
return item, existing
}
2、Get操作
获取key对应的value,如果value过期了,则不需要进行LRU提权处理,用户侧需要调用TTL方法判断Item是否过期,一般的方式是过期时调用ccache.Delete方法删除key:
// Get an item from the cache. Returns nil if the item wasn't found.
// This can return an expired item. Use item.Expired() to see if the item
// is expired and item.TTL() to see how long until the item expires (which
// will be negative for an already expired item).
func (c *Cache) Get(key string) *Item {
item := c.bucket(key).get(key)
if item == nil {
return nil
}
if !item.Expired() {
select {
case c.promotables <- item:
default:
}
}
return item
}
3、Del操作
删除bucket操作是同步的,删除LRU链是异步的:
// Remove the item from the cache, return true if the item was present, false otherwise.
func (c *Cache) Delete(key string) bool {
item := c.bucket(key).delete(key)
if item != nil {
c.deletables <- item //删除LRU链
return true
}
return false
}
//在worker线程中删除
func (c *Cache) doDelete(item *Item) {
if item.element == nil {
item.promotions = -2
} else {
c.size -= item.size
if c.onDelete != nil {
c.onDelete(item)
}
c.list.Remove(item.element)
}
}
0x04 LRU 的实现
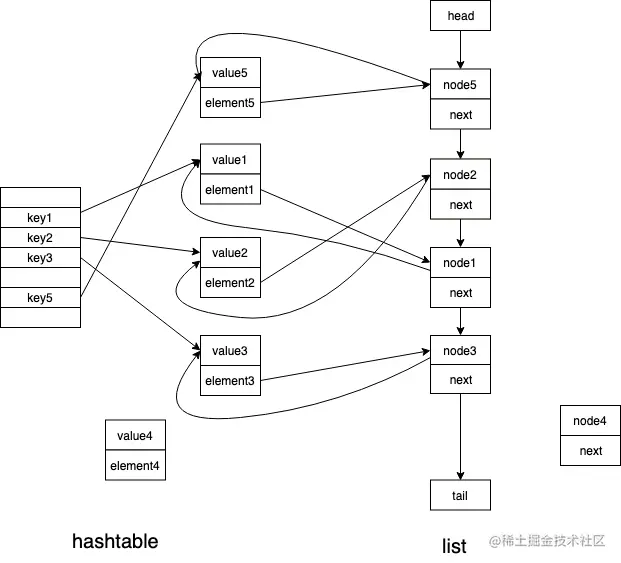
前面已经大致介绍了LRU的操作,LRU机制,当缓存满后,先淘汰最久未访问的内容。在Golang中通常采用hashtable和list数据结构来实现,hashtable支持通过key快速检索到对应的value,list用来记录元素的访问时间序,支持淘汰最久未访问的内容,实现是插入/读取时,将被访问的节点移动到LRU链的最前面(一般被优先淘汰的是list尾部,提权一般放在list头部)
需要考虑的点
由于Golang原生的hashtable和list都不是线程安全的,按照上述LRU策略,无论Set还是Get操作都需要加锁,操作LRU的list也需要加锁,于是ccache的实现就突显了少加锁/不加锁的核心优化点
代码实现
1、主结构
type Cache struct {
//...
list *list.List //LRU链
deletables chan *Item
promotables chan *Item //异步提权
//...
}
2、LRU更新
LRU的操作集中在worker方法中,加上一小节的代码注释。调用了doPromote方法进行LRU提权操作:
func (c *Cache) doPromote(item *Item) bool {
//already deleted
if item.promotions == -2 {
return false
}
if item.element != nil { //not a new item
if item.shouldPromote(c.getsPerPromote) {
//已存在的节点,移动至链表最前
c.list.MoveToFront(item.element)
item.promotions = 0
}
return false
}
//新节点,插入到头部
c.size += item.size
item.element = c.list.PushFront(item)
return true
}
3、LRU淘汰元素
LRU淘汰元素的方法在gc中,itemsToPrune为淘汰元素的个数:
func (c *Cache) gc() int {
dropped := 0
//从LRU链尾部开始淘汰
element := c.list.Back()
itemsToPrune := int64(c.itemsToPrune)
if min := c.size - c.maxSize; min > itemsToPrune {
itemsToPrune = min //计算本次gc中被淘汰的元素个数
}
for i := int64(0); i < itemsToPrune; i++ {
if element == nil {
return dropped
}
prev := element.Prev()
item := element.Value.(*Item)
//淘汰元素,删除bucket且删除LRU链
if c.tracking == false || atomic.LoadInt32(&item.refCount) == 0 {
c.bucket(item.key).delete(item.key)
c.size -= item.size
c.list.Remove(element)
if c.onDelete != nil {
c.onDelete(item)
}
dropped += 1
item.promotions = -2 //打标记
}
element = prev
}
return dropped
}