0x00 前言
限流是当服务负载(或 Qps)超过一定量级(Load)时,主动丢弃一部分请求,是保护服务路径核心系统不被拖垮的常用方案。是服务端常用的一种过载保护的手段。有几个知识点:
- little’s Law:利特尔法则,估算系统的最大吞吐量
- 系统最大吞吐量的计算
- EWMA:指数加权移动平均法
0x01 传统限流方法 VS BBR 限流
little法则:预估系统最大吞吐量
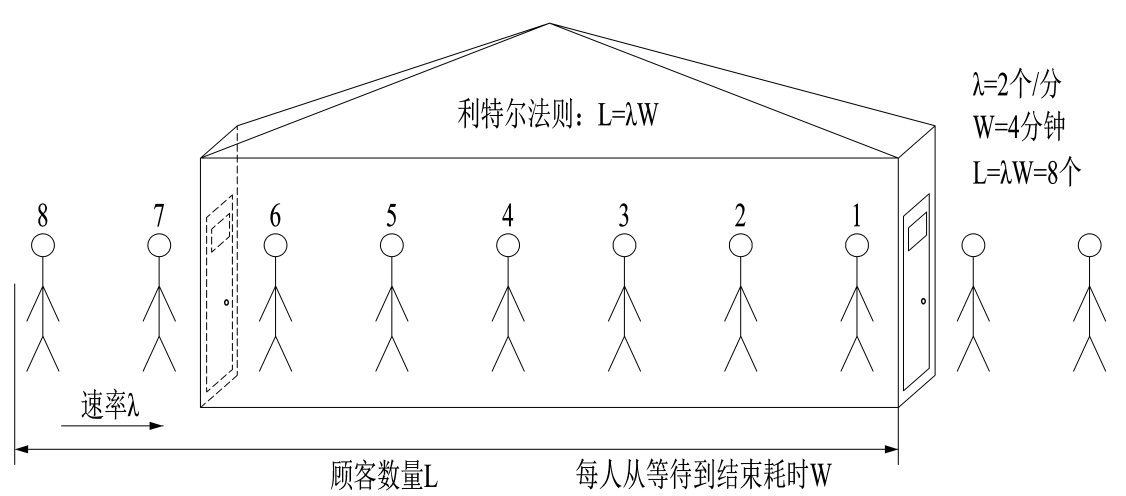 如上图,定义一个小店的吞吐量,平均每分钟进店
如上图,定义一个小店的吞吐量,平均每分钟进店 2 个客人(λ),每位客人从等待到完成交易需要 4 分钟(W),那我们店里能承载的客人数量就是 2 * 4 = 8 个人;同理,可将 λ 看做 QPS, W 是每个请求需要花费的时间,那系统的吞吐量就是 L = λ * W。
系统的最大吞吐量(重要)
下面这段文字解释了maxFlight的计算逻辑:什么时候系统的吞吐量就是最大的吞吐量?
-
首先我们可以通过统计过去一段时间的数据,获取到平均每秒的请求量 QPS,以及请求的耗时时间,为了避免出现前面
900ms一个请求都没有最后100ms请求特别多的情况,使用滑动窗口算法来进行统计 -
一般的方法是从系统启动开始,就把这些值给保存下来,然后计算一个吞吐的最大值,用这个来表示我们的最大吞吐量就可以了。但是这样存在一个问题是,我们很多系统其实都不是独占一台机器的,一个物理机上面往往有很多服务,并且一般还存在一些超卖,所以可能第一个小时最大处理能力是
100,但是这台节点上其他服务实例同时都在抢占资源的时候,这个处理能力最多就只能到80了 -
所以,需要一个数据来做启发阈值,只要这个指标达到了阈值那我们就进入流控当中。常见的选择一般是 CPU、Memory、System Load,Kratos这里采用的是CPU(
80%),即 CPU 负载超过80%的时候,获取过去5s的最大吞吐数据(假设滑动窗口的单位是100ms,那么需要统计5s/100ms=50个窗口的值),然后再统计当前系统中的请求数量,只要当前系统中的请求数大于最大吞吐那么我们就丢弃这个请求。
传统限流方式
之前文章中介绍过,传统的限流算法,如漏桶、令牌桶等,他们的缺点是单一限流和无差别限流。此外,系统需要先做压测,拿到一个初始的限流参考值,超过这个值才启动限流机制。
自适应限流保护
而 BBR 限流的思路 和传统方式有很大区别:
TCP BBR 拥塞控制算法 的思想给了我们一个很大的启发。我们应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。最终我们追求的目标是 在系统不被拖垮的情况下,提高系统的吞吐率,而不是 load 一定要到低于某个阈值。如果我们还是按照固有的思维,超过特定的 load 就禁止流量进入,系统 load 恢复就放开流量,这样做的结果是无论我们怎么调参数,调比例,都是按照果来调节因,都无法取得良好的效果。
简言之,自适应限流就是根据当前负载情况,来嗅探 load 的值,尽可能提高系统的吞吐量。
0x02 自适应限流算法原理
本篇引用自 alibaba/Sentinel 项目的文档:
Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合 应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数 等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
背景
在开始之前,我们先了解一下系统保护的目的:
- 保证系统不被拖垮
- 在系统稳定的前提下,保持系统的吞吐量
长期以来,系统保护的思路是根据硬指标,即系统的负载(load1)来做系统过载保护。当系统负载高于某个阈值,就禁止或者减少流量的进入;当 load 开始好转,则恢复流量的进入。这个思路给我们带来了不可避免的两个问题:
- load 是一个 “结果”,如果根据 load 的情况来调节流量的通过率,那么就始终有延迟性。也就意味着通过率的任何调整,都会过一段时间才能看到效果。当前通过率是使 load 恶化的一个动作,那么也至少要过 1 秒之后才能观测到;同理,如果当前通过率调整是让 load 好转的一个动作,也需要 1 秒之后才能继续调整,这样就浪费了系统的处理能力。所以我们看到的曲线,总是会有抖动。
- 恢复慢。想象一下这样的一个场景(真实),出现了这样一个问题,下游应用不可靠,导致应用 RT 很高,从而 load 到了一个很高的点。过了一段时间之后下游应用恢复了,应用 RT 也相应减少。这个时候,其实应该大幅度增大流量的通过率;但是由于这个时候 load 仍然很高,通过率的恢复仍然不高。
TCP BBR 的思想给了我们一个很大的启发。我们应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。最终我们追求的目标是 在系统不被拖垮的情况下,提高系统的吞吐率,而不是 load 一定要到低于某个阈值 。如果我们还是按照固有的思维,超过特定的 load 就禁止流量进入,系统 load 恢复就放开流量,这样做的结果是无论我们怎么调参数,调比例,都是按照果来调节因,都无法取得良好的效果。
Sentinel 在系统自适应保护的做法是, 用 load1 作为启动自适应保护的因子,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
系统规则
系统保护规则是从应用级别的入口流量进行控制,从单台机器的 load、CPU 使用率、平均 RT、入口 QPS 和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的, 而不是资源维度的,并且仅对入口流量生效 。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
系统规则支持以下的模式:
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的
maxQps * minRt估算得出。设定参考值一般是CPU cores * 2.5。 - CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
原理
先用经典图来镇楼:

我们把系统处理请求的过程想象为一个水管,到来的请求是往这个水管灌水,当系统处理顺畅的时候, 请求不需要排队,直接从水管中穿过,这个请求的 RT 是最短的 ;反之, 当请求堆积的时候,那么处理请求的时间则会变为:排队时间 + 最短处理时间 。
- 推论一: 如果我们能够保证水管里的水量,能够让水顺畅的流动,则不会增加排队的请求;也就是说,这个时候的系统负载不会进一步恶化。 我们用 $T$ 来表示(水管内部的水量),用 $RT$ 来表示请求的处理时间,用 $P$ 来表示进来的请求数,那么一个请求从进入水管道到从水管出来,这个水管会存在 $P*RT$ 个请求。换一句话来说,当 $T \approx QPS * Avg(RT)$ 的时候,我们可以认为系统的处理能力和允许进入的请求个数达到了平衡,系统的负载不会进一步恶化。
接下来的问题是,水管的水位是可以达到了一个平衡点,但是这个平衡点只能保证水管的水位不再继续增高,但是还面临一个问题,就是在达到平衡点之前,这个水管里已经堆积了多少水。如果之前水管的水已经在一个量级了,那么这个时候系统允许通过的水量可能只能缓慢通过,$RT$ 会大,之前堆积在水管里的水会滞留;反之,如果之前的水管水位偏低,那么又会浪费了系统的处理能力。
- 推论二: 当保持入口的流量是水管出来的流量的最大的值的时候,可以最大利用水管的处理能力。
然而,和 TCP BBR 的不一样的地方在于,还需要用一个系统负载的值(load1)来激发这套机制启动。
注:这种系统自适应算法对于低 load 的请求,它的效果是一个 "兜底" 的角色。对于不是应用本身造成的 load 高的情况(如其它进程导致的不稳定的情况),效果不明显。
0x02 Kraots 的限流算法
kratos 借鉴了 Sentinel 项目的自适应限流系统,通过综合分析服务的 cpu 使用率、请求成功的 qps 和请求成功的 rt(请求成功的响应耗时) 来做自适应限流保护。从官方文档上看,限流算法要实现的核心目标有如下两点:
- 自动 嗅探负载和 qps,减少人工配置 && 干预
- 削顶, 保证超载时系统不被拖垮,并能以高水位 qps 继续运行
BBR 限流规则依靠下面 4 个指标共同确定:
| 指标名称 | 指标含义 |
|---|---|
| cpu | 最近 1s 的 CPU 使用率均值,使用滑动窗口平均计算,采样周期是 250ms |
| inflight | 当前处理中正在处理的请求数量 |
| pass | 请求处理成功的量 |
| rt | 请求成功的响应耗时 |
滑动窗口
在自适应限流保护中,采集到的指标的时效性非常强,系统只需要采集最近一小段时间内的 qps、rt 即可,对于较老的数据,会自动丢弃。为了实现这个效果,kratos 使用了滑动窗口来保存采样数据。

如上图,展示了一个具有两个桶(bucket)的滑动窗口(rolling window)。整个滑动窗口用来保存最近 1s 的采样数据,每个小的桶用来保存 500ms 的采样数据。 当时间流动之后,过期的桶会自动被新桶的数据覆盖掉,在图中,在 1000-1500ms 时,bucket 1 的数据因为过期而被丢弃,之后 bucket 3 的数据填到了窗口的头部。
使用EWMA计算CPU使用率,避免毛刺现象
针对单服务的CPU指标采集,采用如下公式,避免毛刺:
\[cpu = cpu^{t-1} * \beta + cpu^{t} * (1 - \beta)\]限流公式(核心!)
在 Kratos 的限流算法中,判断是否丢弃当前请求的算法如下:
( $cpu > 800\(OR\)(Now - PrevDrop) < 1s$ ) AND $(\frac{MaxPass * MinRt * windows}{1000} < InFlight$
cpu > 800:表示 CPU 负载大于80%进入限流(Now - PrevDrop) < 1s:表示只要触发过限流(1次),那么在1s内都会去做限流的判定,这是为了避免反复出现限流恢复导致请求时间和系统负载产生大量毛刺(MaxPass * MinRt * windows / 1000) < InFlight:判断最大负载是否小于当前实际的负载(即过载了)InFlight:表示当前系统中有多少请求(MaxPass * MinRt * windows / 1000):表示过去一段时间的最大负载MaxPass:表示最近5s内,单个采样窗口中最大的请求数MinRt:表示最近5s内,单个采样窗口中最小的响应时间windows:表示一秒内采样窗口的数量,默认配置中是5s50个采样,那么windows的值为10
所以,上面这个指标可以解读为:
- CPU超过容忍值,且实时并发量超过系统吞吐量,进入过载逻辑
- CPU未超过容忍值,但是有丢弃记录,且当前时间与上一次丢弃请求的时间差小于
1s,且实时并发量超过系统吞吐量,进入过载逻辑
第一种情况较易理解,第二种情况是在CPU未过负载,为了避免限流/恢复机制导致的CPU毛刺而采用了优化策略,其目的是使CPU的负载达到一个相对稳定的水平
压测报告
场景 1,请求以每秒增加 1 个的速度不停上升,压测效果如下:

左测是没有限流的压测效果,右侧是带限流的压测效果。 可以看到,没有限流的场景里,系统在 700qps 时开始抖动,在 1k qps 时被拖垮,几乎没有新的请求能被放行,然而在使用限流之后,系统请求能够稳定在 600 qps 左右,rt 没有暴增,服务也没有被打垮,可见,限流有效的保护了服务。
接下来的篇幅从代码实现层面来进一步深入理解 BBR 限流算法。
0x03 Limiter 公共接口封装
Limter 公共接口 limiter.go 定义如下:
核心 Allow 方法,返回 error 不为 nil 表示需要限流,回调函数 func(info DoneInfo),传入的参数为 Doneifno,有点类似于 gPRC 的 balancer.picker 实现,在 RPC 返回成功时调用的回调方法。
const (
// Success opertion type: success
Success Op = iota
// Ignore opertion type: ignore
Ignore
// Drop opertion type: drop
Drop
)
// DoneInfo done info.
type DoneInfo struct {
Err error
Op Op
}
// Limiter limit interface.
type Limiter interface {
//func(info DoneInfo) 调用参数为 Doneinfo,返回值无
Allow(ctx context.Context, opts ...AllowOption) (func(info DoneInfo), error)
}
0x03 BBR 实现
我们先从引用的包开始:
"github.com/go-kratos/kratos/pkg/container/group"
"github.com/go-kratos/kratos/pkg/ecode"
limit "github.com/go-kratos/kratos/pkg/ratelimit"
"github.com/go-kratos/kratos/pkg/stat/metric"
cpustat "github.com/go-kratos/kratos/pkg/stat/sys/cpu"
)
var (
cpu int64
decay = 0.95
initTime = time.Now()
defaultConf = &Config{
Window: time.Second * 10,
WinBucket: 100,
CPUThreshold: 800,
}
)
type cpuGetter func() int64
CPU 使用率计算
在包初始化函数 init 中,启动了一个新的子协程来计算 CPU 的利用率数据,注意这里使用了 指数加权平均算法 来修正偏差,值得借鉴:
此外,计算出的 CPU 使用率是一个 Gauge,使用 atomic 包存储在全局变量 cpu int64 中。
func init() {
go cpuproc()
}
// cpu = cpuᵗ⁻¹ * decay + cpuᵗ * (1 - decay)
func cpuproc() {
ticker := time.NewTicker(time.Millisecond * 250)
defer func() {
ticker.Stop()
if err := recover(); err != nil {
log.Error("rate.limit.cpuproc() err(%+v)", err)
// 在 recover 中重启 CPU 监控
go cpuproc()
}
}()
// EMA algorithm: https://blog.csdn.net/m0_38106113/article/details/81542863
for range ticker.C {
stat := &cpustat.Stat{}
cpustat.ReadStat(stat)
// 获取前一个周期的 cpu 数据
prevCpu := atomic.LoadInt64(&cpu)
//decay = 0.95
curCpu := int64(float64(prevCpu)*decay + float64(stat.Usage)*(1.0-decay))
// 保存新的校准后的 CPU 数据
atomic.StoreInt64(&cpu, curCpu)
}
}
BBR 核心结构
BBR 的核心结构定义如下:
// BBR implements bbr-like limiter.
type BBR struct {
cpu cpuGetter
// 请求数,和响应时间的采样数据,使用滑动窗口进行统计
//passStat:请求处理成功的量(滑动窗口计数器)
passStat metric.RollingCounter
//rtStat:请求成功的响应耗时(滑动窗口计数器)
rtStat metric.RollingCounter
// 当前系统中的并发请求数
inFlight int64
// 每秒钟内的采样数量,默认是10
winBucketPerSec int64
// 单个 bucket 的时间(滑动窗口)
bucketDuration time.Duration
// 窗口数量
winSize int
conf *Config
prevDrop atomic.Value
// 表示最近 5s 内,单个采样窗口中最大的请求数的缓存数据
maxPASSCache atomic.Value
// 表示最近 5s 内,单个采样窗口中最小的响应时间的缓存数据
minRtCache atomic.Value
}
结构体中有两个基于滑动窗口的统计结构(计数器),passStat 及 rtStat,用来统计每次经过 Allow() 方法时的状态结果。
核心:Allow 方法:判断请求是否允许通过
先看看 Allow 方法的实现,在每次的服务端请求中都会调用此方法,注意下面节点:
passStat及rtStat的数据上报的逻辑rt– 请求成功的响应耗时的计算方法
rt 的计算方法比较巧妙:
- 初始化全局变量
initTime = time.Now() - 请求开始前计算
stime := time.Since(initTime) Allow返回一个函数对象func(info limit.DoneInfo),在函数对象中计算rt := int64((time.Since(initTime) - stime) / time.Millisecond)这样就成功的避免每次需要保存前一个周期计时点了,不过引入的成本就是需要取两次当前最新的时间戳。
值得细品的是返回的这个函数对象,通过对这个函数对象的延迟调用,可以实现一些在 “某某事情(接口调用、请求执行)完成后再执行的” 功能,在 golang 中可以算是通用的解决方式了。比如,在 Warden 的服务端实现中,默认加载了 bbr.Limiter 作为服务端过载保护的手段,实现的 Limiter 拦截器代码:
// Limit is a server interceptor that detects and rejects overloaded traffic.
func (b *RateLimiter) Limit() grpc.UnaryServerInterceptor {
return func(ctx context.Context, req interface{}, args *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
uri := args.FullMethod
limiter := b.group.Get(uri)
done, err := limiter.Allow(ctx)
if err != nil {
_metricServerBBR.Inc(uri)
return
}
defer func() {
done(limit.DoneInfo{Op: limit.Success})
b.printStats(uri, limiter)
}()
resp, err = handler(ctx, req)
return
}
}
注意上面代码中的 done, err := limiter.Allow(ctx),就是调用了 bbr.Limiter 实现的 Allow() 方法,然后在 defer func() {......} 中巧妙的调用了 done 方法。注意 defer 的调用位置在 resp, err = handler(ctx, req) 之后,这代表,在真正的 RPC 方法执行完之后才调用 defer 中的逻辑:done(limit.DoneInfo{Op: limit.Success}),这里就调用了函数对象里面的实现逻辑:
- 计算
rt的值 - 向
rtStat滑动窗口计数器中累加rt及次数 - 当前正在处理请求数
inFlight减1 - 根据
do.Op取值,若为limit.Success,则向滑动窗口计数器passStat累加计数 - 返回
代码片段如下:
func(do limit.DoneInfo) {
// 获取执行过程的耗时
rt := int64((time.Since(initTime) - stime) / time.Millisecond)
// 向 RollingCounter 中添加 rt(这是把 RollingCounter 当做累加器使用)
l.rtStat.Add(rt)
atomic.AddInt64(&l.inFlight, -1)
switch do.Op {
case limit.Success:
l.passStat.Add(1)
return
default:
return
}
}
完整的 Allow 实现代码如下,注意是在 shouldDrop 方法是基于 bbr 的限流算法来判断是否应该丢弃请求,常用于中间件方式:
// Allow checks all inbound traffic.
// Once overload is detected, it raises ecode.LimitExceed error.
func (l *BBR) Allow(ctx context.Context, opts ...limit.AllowOption) (func(info limit.DoneInfo), error) {
allowOpts := limit.DefaultAllowOpts()
for _, opt := range opts {
opt.Apply(&allowOpts)
}
if l.shouldDrop() {
return nil, ecode.LimitExceed
}
atomic.AddInt64(&l.inFlight, 1)
stime := time.Since(initTime)
return func(do limit.DoneInfo) {
rt := int64((time.Since(initTime) - stime) / time.Millisecond)
l.rtStat.Add(rt)
atomic.AddInt64(&l.inFlight, -1)
switch do.Op {
case limit.Success:
l.passStat.Add(1)
return
default:
return
}
}, nil
}
小结下,Allow方法的逻辑如下:
- 首先调用
shouldDrop方法判断这个请求是否应该丢弃 - 如果成功放行,那么当前系统中的请求数就
+1 - 然后返回一个 function 用于请求结束之后,function的逻辑如下:
- 统计请求的响应时间
- 如果请求成功了,给成功的请求数
+1 - 并且当前系统中的请求数量
Inflight-1
MaxPass 计算
MaxPass 表示最近 5s 内,单个采样窗口(window)中最大的请求数。换言之,就是找出当前时间戳的滑动窗口的所有桶中,最大的请求计数器的值(单个桶):
func (l *BBR) maxPASS() int64 {
rawMaxPass := atomic.LoadInt64(&l.rawMaxPASS)
if rawMaxPass > 0 && l.passStat.Timespan() < 1 {
// 当前的时间跨度未超过一个单位
return rawMaxPass
}
// 通过 Reduce 方法来获取最大的 Pass 值
rawMaxPass = int64(l.passStat.Reduce(func(iterator metric.Iterator) float64 {
var result = 1.0
for i := 1; iterator.Next() && i < l.conf.WinBucket; i++ {
bucket := iterator.Bucket()
count := 0.0
for _, p := range bucket.Points {
// 叠加 bucket.Points,注意 Points 的类型是 Points []float64
count += p
}
result = math.Max(result, count)
}
return result
}))
if rawMaxPass == 0 {
rawMaxPass = 1
}
// 存储在 rawMaxPASS 中并返回
atomic.StoreInt64(&l.rawMaxPASS, rawMaxPass)
return rawMaxPass
}
MinRt 计算
MinRt 表示最近 5s 内,单个采样窗口中最小的响应时间。windows 表示一秒内采样窗口的数量,默认配置中是 5s 50 个采样,那么 windows 的值为 10。
func (l *BBR) minRT() int64 {
rawMinRT := atomic.LoadInt64(&l.rawMinRt)
if rawMinRT > 0 && l.rtStat.Timespan() < 1 {
return rawMinRT
}
rawMinRT = int64(math.Ceil(l.rtStat.Reduce(func(iterator metric.Iterator) float64 {
var result = math.MaxFloat64
for i := 1; iterator.Next() && i < l.conf.WinBucket; i++ {
bucket := iterator.Bucket()
if len(bucket.Points) == 0 {
continue
}
total := 0.0
for _, p := range bucket.Points {
total += p
}
avg := total / float64(bucket.Count)
result = math.Min(result, avg)
}
return result
})))
if rawMinRT <= 0 {
rawMinRT = 1
}
atomic.StoreInt64(&l.rawMinRt, rawMinRT)
return rawMinRT
}
maxFlight
maxFlight代表什么?其实就是使用little法则计算出来的系统最大吞吐量(系统的最大负载),即计算过去一段时间系统的最大负载是多少
另外注意,这个值是动态变化的(依赖的maxPASS和minRT都是动态的),计算是通过滑动窗口的统计值得出。
func (l *BBR) maxFlight() int64 {
return int64(math.Floor(float64(l.maxPASS()*l.minRT()*l.winBucketPerSec)/1000.0 + 0.5))
}
shouldDrop 方法(核心)
shouldDrop判断请求是否应该被丢弃, 代码实现了前文的公式:
\(cpu > 800\) AND \((Now - PrevDrop) < 1s\) AND \((\frac{MaxPass * MinRt * windows}{ 1000} < InFlight\)
func (l *BBR) shouldDrop() bool {
if l.cpu() < l.conf.CPUThreshold {
prevDrop, _ := l.prevDrop.Load().(time.Duration)
if prevDrop == 0 {
return false
}
if time.Since(initTime)-prevDrop <= time.Second {
//if atomic.LoadInt32(&l.prevDropHit) == 0 {
// atomic.StoreInt32(&l.prevDropHit, 1)
//}
inFlight := atomic.LoadInt64(&l.inFlight)
return inFlight > 1 && inFlight > l.maxFlight()
}
l.prevDrop.Store(time.Duration(0))
return false
}
inFlight := atomic.LoadInt64(&l.inFlight)
drop := inFlight > 1 && inFlight > l.maxFlight()
if drop {
prevDrop, _ := l.prevDrop.Load().(time.Duration)
if prevDrop != 0 {
return drop
}
l.prevDrop.Store(time.Since(initTime))
}
return drop
}
shouldDrop方法的主要逻辑如下:
- 首先检查 CPU 的使用率(通过EWMA算法计算出)是否达到了阈值
80% - 如果未超过CPU
80%阈值,则判断一下上次触发限流到现在是否在1s以内- 如果在
1s内,判断当前并发请求量inFlight是否超过系统的最大吞吐量maxFlight(),如果超过了就需要丢弃 - 如果不在
1s内或者是请求数量已经降下来了,那么把prevDrop清零然后返回false,放行请求
- 如果在
- 如果超过CPU
80%阈值,则判断一下当前并发请求量inFlight是否超过系统的最大吞吐量maxFlight()- 如果超过了,则设置丢弃时间
prevDrop,返回true需要丢弃请求 - 如果没超过直接返回
false,放行请求
- 如果超过了,则设置丢弃时间
这里再次注意,maxFlight()的值是通过滑动窗口最近50个窗口的单个采样窗口中最小的响应时间及最大请求数估算得出。
Limiter 组 && 初始化
在 limiter 中,也有分组的概念,比如针对后端某个 CGI 或 RPC 方法,应用不通的限速策略及规则,这里直接就使用了 container/group 来进行封装:
封装 group.Group 的指针成员,作为 bbr.Group:
// Group represents a class of BBRLimiter and forms a namespace in which
// units of BBRLimiter.
type Group struct {
group *group.Group
}
初始化 bbr.Group:
// NewGroup new a limiter group container, if conf nil use default conf.
func NewGroup(conf *Config) *Group {
if conf == nil {
// 使用默认 group 配置
conf = defaultConf
}
// 创建 group
group := group.NewGroup(func() interface{} {
return newLimiter(conf)
})
return &Group{
group: group,
}
}
通过 key 获取对应的 limter 配置(不存在则创建),获取到 limter 对象之后,直接调用 limiter.Allow() 就可以进行限速判定了:
// Get get a limiter by a specified key, if limiter not exists then make a new one.
func (g *Group) Get(key string) limit.Limiter {
limiter := g.group.Get(key)
return limiter.(limit.Limiter)
}
通过 newLimiter 方法创建一个 bbr.Limiter 并返回,注意看初始化的参数,
func newLimiter(conf *Config) limit.Limiter {
if conf == nil {
conf = defaultConf
}
size := conf.WinBucket
bucketDuration := conf.Window / time.Duration(conf.WinBucket)
//
passStat := metric.NewRollingCounter(metric.RollingCounterOpts{Size: size, BucketDuration: bucketDuration})
rtStat := metric.NewRollingCounter(metric.RollingCounterOpts{Size: size, BucketDuration: bucketDuration})
// 定义了 cpu 为 func,直接返回全局变量 cpu 的值(atomic 方式)
cpu := func() int64 {
return atomic.LoadInt64(&cpu)
}
limiter := &BBR{
cpu: cpu,
conf: conf,
passStat: passStat,
rtStat: rtStat,
winBucketPerSec: int64(time.Second) / (int64(conf.Window) / int64(conf.WinBucket)),
}
return limiter
}