0x00 前言
延迟队列(Delay Queue)任务相关的业务场景如下:
场景一: 在订单系统中,一个用户某个时刻下单之后通常有 30 分钟的时间进行支付,如果 30 分钟之内没有支付成功,那么这个订单需要关闭;此外在未过期之前的 N 分钟需要通知用户进行支付
场景二: 用户某个时刻通过手机远程遥控家里的智能设备,设置在指定的时间(后)进行工作。这时就可以将用户指令发送到延时队列,当指令设定的时间到了再将指令推送到智能设备(运行)
关于延迟队列的文章,推荐阅读如下几篇:
美图开源了一款基于 Golang 实现的延迟队列 lmstfy:Let Me Schedule Tasks For You:基于 Redis 实现的简单任务队列(Task Queue)服务。主要提供以下特性:
- 任务具备延时、自动重试、优先级以及过期等功能
- 通过 HTTP restful
API提供服务 - 具备横向扩展能力
- 丰富的业务和性能指标(Redis
metrics)
0x01 设计目标
从业务的可用性出发,延迟队列建议具备如下的特性:
- 消息传输可靠:消息进入到延迟队列后,保证至少被消费一次,有消费失败的重试逻辑
- 高可用 + 可扩展性:支持多实例部署。挂掉一个实例后,还有后备实例继续提供服务
- 实时性:允许存在一定的时间误差
- 支持消息删除:业务使用方,可以随时删除指定消息
- 支持存储落地
对任务队列的设计要求
- 任务支持延时 / 优先级任务和自动重试
- 高可用,服务去单点以及保证数据不丢失
- 可扩展,主要是容量和性能需要可扩展
为什么不使用 kafka?
也考虑过类似基于 kafka/rocketmq 等消息队列作为存储的方案,最后从存储设计模型和团队技术栈等原因决定选择基于 redis 作为存储来实现任务队列的功能。举个例子,假设以 Kafka 这种消息队列存储来实现延时功能,每个队列的时间都需要创建一个单独的 topic(如: Q1-1s, Q1-2s..)。这种设计在延时时间比较固定的场景下问题不太大,但如果是延时时间变化比较大会导致 topic 数目过多,会把磁盘从顺序读写会变成随机读写从导致性能衰减,同时也会带来其他类似重启或者恢复时间过长的问题。
使用 Redis 实现延时队列
延迟队列主要使用了 Redis 的数据结构:Sorted Set
Sorted Set 是一个有序的 Set,Set 内元素的排序基于其加入集合时指定的 Score。通过 ZRANGEBYSCORE ,可以得到基于 Score 在指定区间内的元素(排序)。基于 Sorted Set 的延时队列模型如下:
- SortSet 的 key 作为业务维度的属性(队列)名字,比如一种命名方式为 <业务: 命名空间: 队列名>
- SortSet 中的元素做为任务消息,Score 视为本任务延迟的时间(戳)
举例来说,假设我们有个延迟队列的 SortSet,名为 def:dely-queue-1,简单描述下生产消费过程,假设当前时间为 Sun Sep 27 06:37:32 UTC 2020,时间戳为 1601188690:
1、生产者通过 ZADD 将任务 1(当前时间戳 +100s)发送到延时队列中,意为 100s 之后需要执行任务 1, 将任务 2(当前时间戳 +120s)发送到延时队列中,意为 120s 之后需要执行任务 2:
127.0.0.1:6379> ZADD def:delay-queue-1 1601188790 "doing job-1"
(integer) 1
127.0.0.1:6379> ZADD def:delay-queue-1 1601188810 "doing job-2"
(integer) 1
2、消费者通过 ZRANGEBYSCORE 获取任务。以当前时间戳为 Score 的比较基准,如果时间戳未到(上一步写入的时间戳),将得不到消息;当时间已到或已超时情况下,都可以取到延时任务:
未达到延迟队列的时间戳:
127.0.0.1:6379> ZRANGEBYSCORE def:delay-queue-1 -inf 1601188780 Withscores
(empty list or set)
已超时情况下,获取到任务:
127.0.0.1:6379> ZRANGEBYSCORE def:delay-queue-1 -inf 1601188820 Withscores
1) "doing job-1"
2) "1601188790"
3) "doing job-2"
4) "1601188810"
注意:ZRANGEBYSCORE 的指令是:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count],其中 min 和 max 可以是 -inf 和 +inf ,它提供了可以在不知道 SortSet 的最低和最高 Score 值的情况下获取到我们需要的排序结果。
另外,还有两个细节需要考虑:
1、使用 ZRANGEBYSCORE 获取到任务后,任务并没有从集合中删除。这样需要使用 ZREM 指令,删除这条任务,以达到队列模拟 Pop 的效果
2、此外,由于多消费者组合使用 ZRANGEBYSCORE 和 ZREM 的过程并非原子的,当有多个消费者时会存在竞争,可能使得一条消息被消费多次。在现网项目中,需要保证多消费者操作的原子性,解决方法是使用 Lua 原子脚本封装:
local message = redis.call('ZRANGEBYSCORE', KEYS[1], '-inf', ARGV[1], 'WITHSCORES', 'LIMIT', 0, 1);
if #message > 0 then
redis.call('ZREM', KEYS[1], message[1]);
return message;
else
return {};
end
0x02 设计模块
从通用的设计来看,延迟队列也需要数据平面、管理平面及对外接口三个维度:
- 数据平面:负责存储任务
- 管理平面:负责任务的调度,延迟队列的消费等
- 对外接口:主要负责
API及用户交互
基于上面的模块,先整理下 lmstfy 对应的实现
- 管理平面:代码主要位于 位置,主要基于
gin框架的 CGI 后端,实现了系统(Admin API)/ 限速器(token-throttler API)/ 生产者(pusher API)等的 CGI 接口 - 数据平面:代码主要位于 位置,提供了任务队列(基于
go-redis)的操作接入,包含生产(Producer)/ 消费(Consumer)等 所有接口
0x03 lmstfy 的后台架构
延迟队列的一般结构为:

lmstfy 的设计也是类似,整个系统被划分为如下几块:

我们先看下整体的数据(队列中的数据)流程:
 ,从调用流程,大概有下面几个过程:
,从调用流程,大概有下面几个过程:
- 用户通过
publish接口注册延迟任务,任务存储在queue中 - 在消费端,(延迟)到期的任务被取出执行,成功的任务被删除,失败的任务继续放回
queue中尝试下次执行
加入了任务处理模块的架构如下图所示:

lmstfy 是 HTTP 协议的无状态服务(类似 CGI),可以通过 L4 或 L7 的 LB 方式来接入,实际部署的时候前端挂一个 Nginx 做负载均衡是比较适合的。整体的架构图如下:
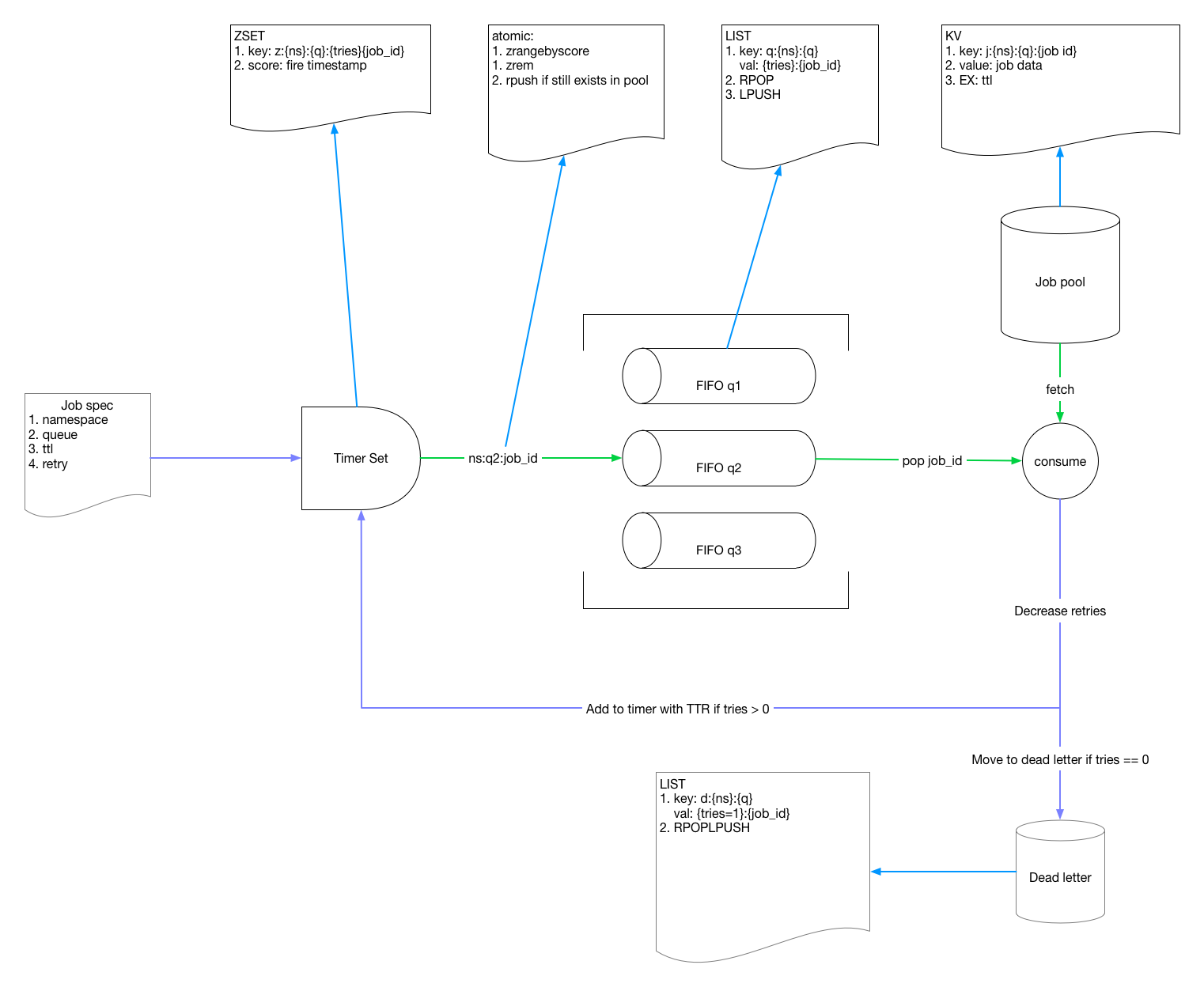
其内部主要由几个模块组成:

Pump Thread: 每秒轮询 Redis 将(延迟)到期的任务迁移到就绪队列(Ready Queue)Metric Collector, 定时收集队列相关统计数据到实例再通过 prometheus exporter 暴露给监控系统Token Manager,用来管理 namespace 和 token 的模块,namespace 是用来做业务隔离的单位Producer/Consumer,用来处理用户的任务和消费请求Redis storage:使用 Redis 存储任务数据Default Pool除了用来存储业务数据,namespace/token 这类元数据也会默认存储到 Default 这个 Redis 池子里面
基础概念
- namespace - 用来隔离业务,每个业务是独立的 namespace
- queue - 队列名称,用区分同一业务不同消息类型
- job - 业务定义的业务,主要包含以下几个属性:
- id: 任务 ID,全局唯一
- delay: 任务延时下发时间, 单位是秒
- tries: 任务最大重试次数,tries = N 表示任务会最多下发 N 次
- ttl(time to live): 任务最长有效期,超过之后任务自动消失
- ttr(time to run): 任务预期执行时间,超过 ttr 则认为任务消费失败,触发任务自动重试
数据存储
lmstfy 的 redis 存储由四部分组成:
- timer(sorted set) - 用来实现延迟任务的排序,再由后台线程定期将到期的任务写入到 Ready Queue 里面
- ready queue (list) - 无延时或者已到期任务的队列
- deadletter (list) - 消费失败 (重试次数到达上限) 的任务,可以手动重新放回队列
- job pool(string) - 存储消息内容的池子
sorted set 的 封装代码 如下:
注意 Score 和 Member 对应值的包装:
func (t *Timer) Add(namespace, queue, jobID string, delaySecond uint32, tries uint16) error {
metrics.timerAddJobs.WithLabelValues(t.redis.Name).Inc()
timestamp := time.Now().Unix() + int64(delaySecond)
// struct-pack the data in the format `Hc0Hc0HHc0`:
// {namespace len}{namespace}{queue len}{queue}{tries}{jobID len}{jobID}
// length are 2-byte uint16 in little-endian
namespaceLen := len(namespace)
queueLen := len(queue)
jobIDLen := len(jobID)
buf := make([]byte, 2+namespaceLen+2+queueLen+2+2+jobIDLen)
binary.LittleEndian.PutUint16(buf[0:], uint16(namespaceLen))
copy(buf[2:], namespace)
binary.LittleEndian.PutUint16(buf[2+namespaceLen:], uint16(queueLen))
copy(buf[2+namespaceLen+2:], queue)
binary.LittleEndian.PutUint16(buf[2+namespaceLen+2+queueLen:], uint16(tries))
binary.LittleEndian.PutUint16(buf[2+namespaceLen+2+queueLen+2:], uint16(jobIDLen))
copy(buf[2+namespaceLen+2+queueLen+2+2:], jobID)
return t.redis.Conn.ZAdd(t.Name(), redis.Z{Score: float64(timestamp), Member: buf}).Err()
}
0x04 lmstfy 简单使用
本小节主要看下 lmstfy 对用户提供的 API 接口,详细 API 说明见项目 README
1、创建 namespace 和 token, 注意这里使用管理端口 7778
$ ./scripts/token-cli -c -n test_ns -p default -D "test ns apply by @hulk" 127.0.0.1:7778
{
"token": "01DT9323JACNBQ9JESV80G0000"
}
2、写入内容为 value 的任务,延迟(delay)为 1s
$ curl -XPUT -d "value" -i "http://127.0.0.1:7777/api/test_ns/q1?tries=3&delay=1&token=01DT931XGSPKNB7E2XFKPY3ZPB"
{"job_id":"01DT9323JACNBQ9JESV80G0000","msg":"published"}
3、消费任务
$ curl -i "http://127.0.0.1:7777/api/test_ns/q1?ttr=30&timeout=3&&token=01DT931XGSPKNB7E2XFKPY3ZPB"
{"data":"value","elapsed_ms":272612,"job_id":"01DT9323JACNBQ9JESV80G0000","msg":"new job","namespace":"test_ns","queue":"q1","ttl":86127}
4、ACK 任务 id,表示消费成功不再重新下发改任务
curl -i -XDELETE "http://127.0.0.1:7777/api/test_ns/q1/job/01DT9323JACNBQ9JESV80G0000?token=01DT931XGSPKNB7E2XFKPY3ZPB"
客户端接口
Golang 客户端接口 在此