0x00 前言
笔者初学 golang 之时,阅读过 Handling 1 Million Requests per Minute with Go 这篇关于协程池实现的文章。这篇文章给出的优化思路及代码实现非常之典型,可以作为一个通用的并发模型参考。本篇文章,简单回顾下其实现。
原文中要解决的问题就是下面这段代码:
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
go payload.UploadToS3() // <----- DON'T DO THIS
}
这种暴力启动 goroutine 的方式,在实际项目中应该避免,因为你不知道 content.Payloads 的并发数量,大量的 goroutine 简直就是并发灾难。
0x01 整体架构
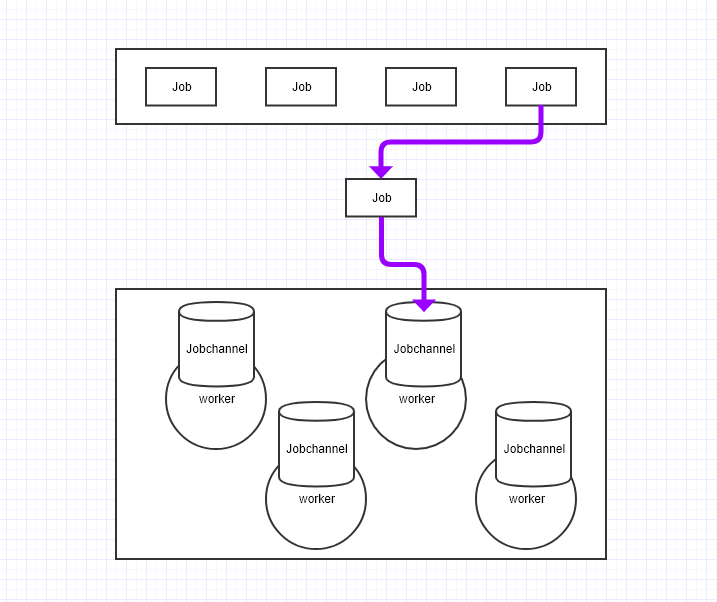
项目整体是一个生产(job) - 消费者(worker)模型,采用 channel 来控制 worker 的并发,即预先生成一定数量的 worker,每个 worker 内置一个 jobChannel,当 worker 空闲或处理任务完成时,就将 jobChannel 注册给 WorkerPool,告诉 WorkerPool,自己已经空闲,可以继续处理任务。在本模型中,worker 的数量(即 goroutine 数量)是固定的,避免了 goroutine 过多导致的资源竞争及消耗。抽象的系统模型如下图所示:
0x02 代码分析
核心结构
可执行作业单元 Job:
// Job represents the job to be run
type Job struct {
Payload Payload
}
生产者:需要一个存放 Job 的数据结构,这里使用 chan Job 来代替:
// A buffered channel that we can send work requests on.
var JobQueue chan Job
Worker 消费者:
// Worker represents the worker that executes the job
type Worker struct {
WorkerPool chan chan Job // 用于 Worker 的并发控制
JobChannel chan Job // 用来存储 Job
quit chan bool
}
工作 Worker 池调度器,和 Worker 结构对应:
type Dispatcher struct {
// A pool of workers channels that are registered with the dispatcher
WorkerPool chan chan Job
}
生产者
生产者的逻辑如下,创建一个带有负载的 Job 结构体实例,并将其发送到 JobQueue channel 中以供 Workers 获取:
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
// let's create a job with the payload
work := Job{Payload: payload}
// Push the work onto the queue.
JobQueue <- work
}
w.WriteHeader(http.StatusOK)
}
Worker 消费者
正如上文 Worker 结构定义,为了创建一个 2 层的 channel 系统,我们决定使用一个通用模式,一个用来插入作业,一个用来控制作业队列上同时运行的工作协程。 初始化 Worker 的结构:
func NewWorker(workerPool chan chan Job) Worker {
return Worker{
WorkerPool: workerPool, // 指明 worker 属于哪个 WorkerPool 管理
JobChannel: make(chan Job),
quit: make(chan bool)}
}
启动 Worker:
// Start method starts the run loop for the worker, listening for a quit channel in
// case we need to stop it
func (w Worker) Start() {
go func() {
for {
// register the current worker into the worker queue
// 将当前 worker 的 JobChannel 注册到 WorkerPool 中,告诉 WorkerPool 自己可以处理 Job
// 工作者的 JOB 队列再放回工作者池
w.WorkerPool <- w.JobChannel
select {
// 拿到 job 并执行
case job := <-w.JobChannel:
// we have received a work request.
// 执行真正的 JOB
if err := job.Payload.UploadToS3(); err != nil {
log.Errorf("Error uploading to S3: %s", err.Error())
}
case <-w.quit:
// we have received a signal to stop
return
}
}
}()
}
Worker 退出:
// Stop signals the worker to stop listening for work requests.
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}
Worker 池(调度器)
我们创建了一个 Dispatcher,为 worker 池,worker 个数为 maxWorkers,调用 Run()来创建 works pool 并开始侦听即将出现在 JobQueue 中的作业
dispatcher := NewDispatcher(MaxWorker)
dispatcher.Run()
// 新建 NewDispatcher
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool}
}
Dispatcher 的核心方法为 Run,该方法完成如下工作:
- 初始化及启动
Worker - 分发
JobQueue中的Job给各个Worker
func (d *Dispatcher) Run() {
// starting n number of workers
for i := 0; i < d.maxWorkers; i++ {
worker := NewWorker(d.pool)
worker.Start()
}
// 在子 goroutine 中分发 Job
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
// a job request has been received
go func(job Job) {
// try to obtain a worker job channel that is available.
// this will block until a worker is idle
jobChannel := <-d.WorkerPool
// dispatch the job to the worker job channel
jobChannel <- job
}(job)
}
}
}
注意,上面这段代码中 jobChannel 有两层作用:
- 用来实现
Worker的并发控制 - 作为
Job传输通道
0x03 依然存在的问题
但是这个模型依然是有问题的,原因出在这里 case job:= <-JobQueue,从 JobQueue 中取任务,如何控制这里的频率?(生产者生产过快,这里还是会导致生成大量的 goroutine,阻塞在 jobChannel := <- d.WorkerPool 上),那么,在实际应用中,我们必须事先明确 Job 生产的速率。
func (d *Dispatcher) dispatch() {
for{
select{
case job:= <-JobQueue:
// a job request has been received
go func(job Job){
//try to obtain a worker job channel that is available.
//this will block until a worker is idle
jobChannel := <- d.WorkerPool
//dispatch the job to the worker job channel
jobChannel <- job
}(job)
}
}
}
0x04 控制生产者速率
上一小节说到,此模型还有一个不足之处,如果有大量的任务(Job)同时涌入,会发生什么样的结果。大量的 goroutine 会阻塞等待可用的 Worker,即
jobChannel := <- d.WorkerPool
本模型中的生产者调度也是在不断的创建协程等待空闲的 Worker,如何控制生产者速率的,最直接想到的方式就是令牌,使用一个带缓冲的 Channel 作为令牌桶,控制并发执行的任务数:
- 有
Job生成时,向TokenBucket放置一个令牌,如TokenBucket <- struct{}{},这样当TokenBucket满了之后,Job便排队等待放入 - 获取
Job的Worker完成工作之后,释放令牌,如<- TokenBucket
// 用于控制并发的 goroutine(生产者)
const (
MAX_GOROUTINE_NUM = 2000
)
var TokenBucket = make(chan struct{}, MAX_GOROUTINE_NUM)
func Limiter(job Job) {
select {
case TokenBucket <- struct{}{}:
// 任务放入任务队列 channal
JobQueue <- work
return
case <-time.After(time.Millisecond * 200):
return
}
}