0x00 前言
hashtable 是一种非常高效的数据结构,它通过散列函数将 key 映射成数组下标以达到 O(1) 算法复杂度的高效数据结构,通常对于不同的 key 哈希函数算出的结果出现哈希碰撞,解决方式通常有:开放地址法、再哈希法、链地址法。多阶(级)Hashtable 是一种极其精妙的实现,常用于海量数据(如 UIN、即时通讯关系链等)的存储,此外,结合 Linux 共享内存机制,可以方便的实现在游戏后台中保存用户状态(进程崩溃恢复)。多阶(级)hash 有几个特点:
- 容量固定:开发者需要预估好自己系统的存储规模
- 利用率极高:按照公司同事的测试,
50阶多级 hash 的利用率至少可以达到95%了 - 可根据开发场景灵活设计,可选择内存或者是共享内存来存储
- 根据 KeyValue 是否变长,又引申出几种变体;
- 固定 Size,多阶 hash 每个节点包含了 value
- 不固定 Size,单独开辟一大块数据区域,按照 KeyValue 分离的方式存储,多阶 hash 的 Key 节点包含指向数据区域的 Value 的指针
0x01 多阶 Hash 简介
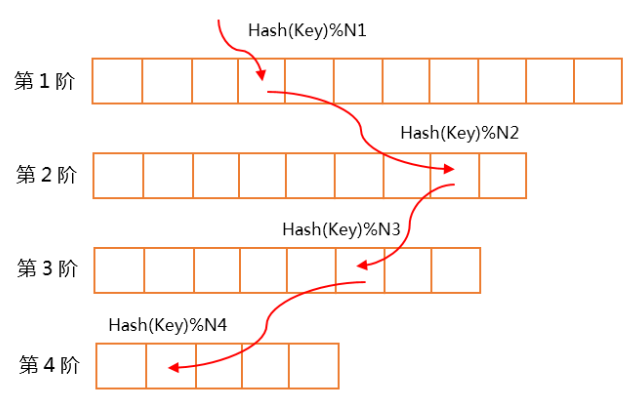
多阶 hash 实际上是一个(相对平滑)锯齿状数组。从第一层级开始执行插入时,将某一层冲突的 key,交由下一层进行填充,直到最终层。如下所示:
多阶 Hash 的特点是:
- 每一行是一阶,每一行的元素个数都是素数个(连续素数,需要取模均匀)
- 数组的每个节点用于存储数据的内容,其中,节点存储
int类型的 key/hash_code 的索引以及数据,通常适合定长数据的场景 - 也可以选择索引与数据分离存储,适合不定长数据的场景
- 可以使用内存,也可以使用共享内存机制实现(不使用指针,使用一大块固定 size 的共享内存)
- 使用率高,实测
20阶的结构使用率可以达到95% - 查找和插入的复杂度都是
O(n),其中n是阶数
插入与冲突解决
多阶 hash 的插入方式为:依次从第 1 阶开始往后查找是否已存在当前阶中,如果找到则直接覆盖更新(或者返回失败,依赖业务逻辑)数据,如果查找完所有的阶都没有找到记录,则找出从第 1 阶到最后一阶可以分配给该 key 并且没有被使用的位置插入该记录。通常情况下会上面的阶数先被填满,然后再逐步填下面的阶数
查找
- 先将 key 在第
1阶内取模,看是否是这个元素,如果这个位置为空,直接返回不存在;如果是这个 key,则返回这个位置,查找结束 - 如果这个位置有元素,但是已存在的 Key 与带查找的 key 不同,则说明 hash 冲突,再到第二阶去找
- 循环往复,直到查找完最后一阶,任未查找到,退出
即先从第一阶开始依次往后查找,如果找到就返回,没找到就到下一阶继续查找,直到查找完所有的哈希桶返回查找失败。
0x02 素数集中原理算法
对于多阶 Hash 而言,每一阶究竟应该选择多少个元素?答案是素数集中原理(6N-1/6N+1 素数选择)。例如,假设每阶最多 1000 个元素,一共 10 阶,则算法选择十个比 1000 小的最大素数,从大到小排列,以此作为各阶的元素个数。通过素数集中的算法得到的 10 个素数分别是:997、991、983、977、971、967、953、947、941 和 937。从结果可见,虽然是锯齿数组,各层之间的数量差别并不是很多。
0x03 源码分析:结构
本小节给出 mem_hash 项目实现的分析,很经典的例子,此实现如下特点:
- 内存结构即最终磁盘组织结构,不需要额外转存,设计巧妙
- 共享内存:配合内存映射 mmap(操作内存即是操作文件),当然也可以基于 shm 机制实现
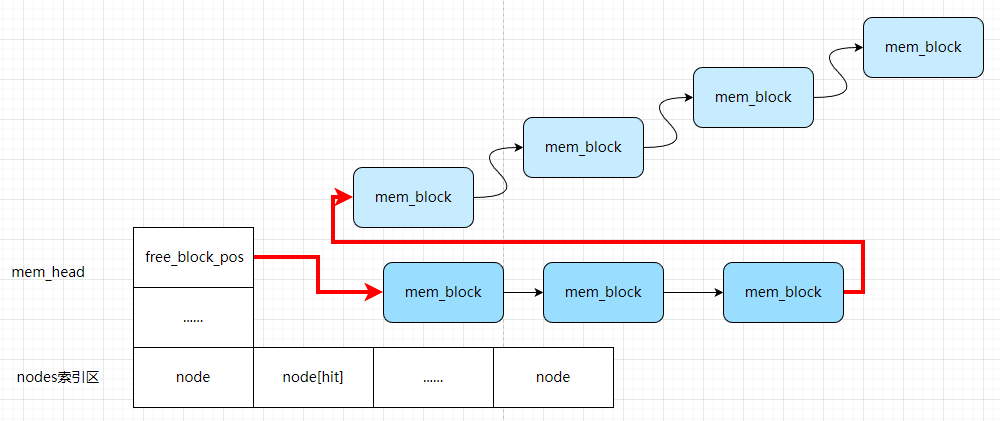
- 顺序存储结构,且支持索引与数据分离,通过
free_block_pos索引巧妙的将数据区空闲分块链接起来
基础结构
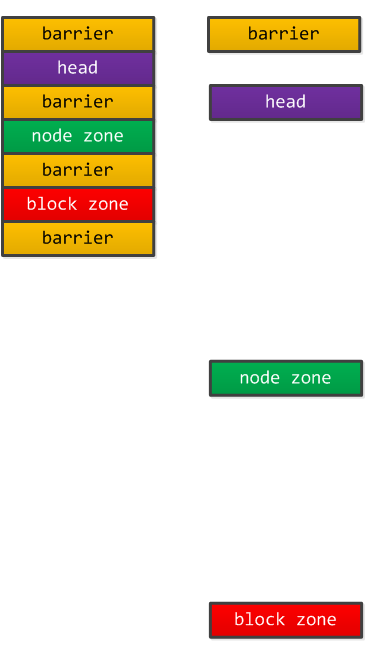
整个存储由 header + nodes + blocks 三部分构成,其中 nodes 由所有的 mem_node 节点组成,blocks 由所有的 mem_block 元素构成;核心这是一个顺序结构,初始化的代码 TotalSizeInit 对应上图:
void MemHash::TotalSizeInit()
{
//---|barrier|head|barrier|node zone|barrier|block zone|barrier|---
total_size = sizeof(struct mem_barrier) * 1 +
sizeof(struct mem_head) * 1 +
sizeof(struct mem_barrier) * 1 +
sizeof(struct mem_node) * max_node +
sizeof(struct mem_barrier) * 1 +
sizeof(struct mem_block) * max_block +
sizeof(struct mem_barrier) * 1;
return ;
}
几个基础结构定义:
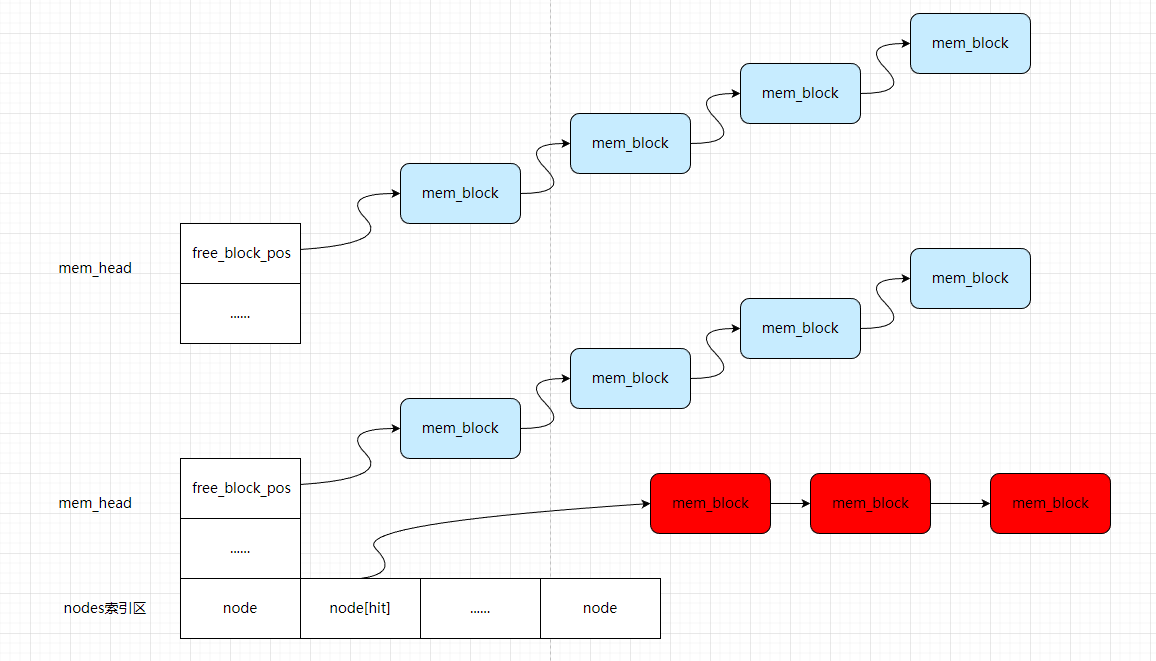
mem_head:头部固定信息mem_node:索引节点,max_node是所有阶数的素数总和,代表分配多少 size,参考BucketInit方法实现mem_block:数据节点,每个节点包含了真正的存储单元data[BLOCK_DATA_SIZE]
// 头部固定信息
struct mem_head {
uint32_t crc32_head_info;
struct head_info head_info_;
int32_t free_block_pos; // 指向 mem_block 当前可用的块的位置(初始化为 0)
uint32_t node_used;
uint32_t block_used;
};
//NODE 节点
struct mem_node {
uint64_t key; //hash 值
time_t tval;
uint32_t size; // 本索引占用了多少块 mem_block
uint32_t crc32; // 数据校验和
int32_t pos; // 此字段标识该 key 对应的 data 在 mem_block 区域的第一个块的地址
};
//BLOCK 节点
struct mem_block {
uint32_t flag; // 标识此块是否正在被使用
int32_t pos; // 初始化指向下一个 mem_block 的位置,用来标识下一块的位置(同一个 key)
char data[BLOCK_DATA_SIZE];
};
nodes 即是多阶 hash,而 blocks 本来就是预先申请的大块存储,如下图:


0x04 源码分析:主要操作
初始化
InitNewMemHash:新建共享内存InitOldMemHash:已存在 mmap 文件
int MemHash::Init(const char* name,
time_t data_store_time,
int mlock_open_flag,
int msync_freq,
int msync_flag,
uint32_t bucket_time,
uint32_t bucket_len,
uint32_t max_block)
{
// 打开日志文件
log_fd = open("run.log", O_CREAT | O_RDWR | O_APPEND, 0666);
if (log_fd == -1) {
printf("MemHash::Init open log error[%d]. %s\n",
errno, strerror(errno));
exit(-1);
}
// 超时设置
if (data_store_time <= 0)
this->data_store_time = 0;
else
this->data_store_time = data_store_time;
//mmap 相关设置
this->mlock_open_flag = mlock_open_flag;
if (msync_freq> 0)
this->msync_freq = msync_freq;
else
this->msync_freq = 0;
if (msync_flag != MS_ASYNC || msync_flag != MS_SYNC)
this->msync_flag = MS_ASYNC;
else
this->msync_flag = msync_flag;
int fd = open(name, O_RDWR, 0666);
if (fd == -1)
InitNewMemHash(name, bucket_time, bucket_len, max_block);
else
InitOldMemHash(fd, bucket_time, bucket_len, max_block);
return 0;
}
插入
int MemHash::Set(uint64_t key, const char* data, int len)
{
// 防止 key 为 0 的情况
if (key == 0)
return -100;
const char *start_data = data;
// 该数据要使用的 BLOCK 节点的个数
uint32_t nbu = GetNodeBlockUsed(len);
// 该数据要使用的最后一个 BLOCK 节点的偏移量
uint32_t lbu = GetLastBlockUsed(len);
if (nbu> MAX_BLOCK_NUM) {
LOG("[Set][%lu][failed] blocks > MAX_BLOCK_NUM[%u]",
key, MAX_BLOCK_NUM);
return -1;
}
// 无可用空间了
if (nbu> max_block - head_->block_used) {
LOG("[Set][%lu][failed] blocks > free blocks num [%u]",
key, max_block - head_->block_used);
return -2;
}
struct mem_node *tmp_node = NULL;
uint32_t base_pos = 0;
// 调用 Del 调用
DelForInner(key);
time_t cur_time = time(0);
for (uint32_t i = 0; i < bucket_time; i++) {
if (i> 0) base_pos += bucket[i-1];
tmp_node = node_ + base_pos + (key % bucket[i]);
// 数据超时
if (tmp_node->key != 0 && data_store_time != 0) {
time_t interval = cur_time - tmp_node->tval;
if (interval> data_store_time) {
DelForInner(tmp_node->key);
}
}
// 查找空闲的 NODE 节点
if (tmp_node->key == 0) {
head_->node_used++;
int32_t pre_free_pos = head_->free_block_pos;
struct mem_block *tmp_block = GetBlock(pre_free_pos);
// 处理前 n-1 个 BLOCK 节点
for (uint32_t j = 0; j < nbu - 1; j++) {
head_->block_used++;
SET_BLOCK_USED_FLAG(tmp_block->flag);
memcpy(tmp_block->data, data, BLOCK_DATA_SIZE);
data += BLOCK_DATA_SIZE;
tmp_block = GetBlock(tmp_block->pos);
}
// 处理最后一个 BLOCK 节点
head_->block_used++;
SET_BLOCK_USED_FLAG(tmp_block->flag);
memcpy(tmp_block->data, data, lbu);
head_->free_block_pos = tmp_block->pos;
tmp_block->pos = -1;
tmp_node->pos = pre_free_pos;
tmp_node->crc32 = Crc32Compute(start_data, len);
tmp_node->tval = time(0);
tmp_node->size = len;
tmp_node->key = key;
data_change++;
if ((msync_freq != 0) && (data_change > msync_freq)) {
data_change = 0;
MemSync(msync_flag);
}
return 0;
}
}
LOG("[Set][%lu][failed] no empty node", key);
return -3;
}
删除
int MemHash::Del(uint64_t key)
{
struct mem_node *tmp_node = GetNode(key);
if (tmp_node == NULL) {
LOG("[Del][%lu][failed] not find the key.", key);
return -1;
}
// 该节点使用的 BLOCK 节点的个数
uint32_t nbu = GetNodeBlockUsed(tmp_node->size);
struct mem_block *tmp_block = GetBlock(tmp_node->pos);
tmp_node->key = 0;
head_->node_used--;
// 处理前 n-1 个 BLOCK 节点
for (uint32_t i = 0; i < nbu - 1; i++) {
CLR_BLOCK_USED_FLAG(tmp_block->flag);
tmp_block = GetBlock(tmp_block->pos);
}
// 处理最后一个 BLOCK 节点
CLR_BLOCK_USED_FLAG(tmp_block->flag);
// 增加 BLOCK 空闲队列
tmp_block->pos = head_->free_block_pos;
head_->free_block_pos = tmp_node->pos;
head_->block_used -= nbu;
// 处理 NODE 节点
tmp_node->crc32 = 0;
tmp_node->tval = 0;
tmp_node->size = 0;
tmp_node->pos = -1;
data_change++;
if ((msync_freq != 0) && (data_change > msync_freq)) {
data_change = 0;
MemSync(msync_flag);
}
return 0;
}
查找
int MemHash::Get(uint64_t key, char* data, int max_len, int& data_len)
{
// 防止 key 为 0 的情况
if (key == 0)
return -100;
struct mem_node *tmp_node = GetNode(key);
if (tmp_node == NULL) {
LOG("[Get][%lu][failed] not find the key.", key);
return -1;
}
if (tmp_node->size > (uint32_t)max_len) {
LOG("[Get][%lu][failed] node.size > buffer len.", key);
return -2;
}
// 数据超时
if (data_store_time != 0) {
time_t interval = time(0) - tmp_node->tval;
if (interval> data_store_time) {
DelForInner(key);
LOG("[Get][%lu][failed] interval[%lu] > data_store_time[%lu]",
interval, data_store_time, key);
return -3;
}
}
// 该节点使用的 BLOCK 节点的个数
uint32_t nbu = GetNodeBlockUsed(tmp_node->size);
// 该节点使用的最后一个 BLOCK 节点的偏移量
uint32_t lbu = GetLastBlockUsed(tmp_node->size);
struct mem_block *tmp_block = GetBlock(tmp_node->pos);
char *tmp_buf = data;
// 处理前 n-1 个 BLOCK 节点
for (uint32_t j = 0; j < nbu - 1; j++) {
memcpy(tmp_buf, tmp_block->data, BLOCK_DATA_SIZE);
tmp_buf += BLOCK_DATA_SIZE;
tmp_block = GetBlock(tmp_block->pos);
}
// 处理最后一个 BLOCK 节点
memcpy(tmp_buf, tmp_block->data, lbu);
data_len = tmp_node->size;
return 0;
}
Append 方法
int MemHash::Append(uint64_t key, const char* data, int len)
{
// 防止 key 为 0 的情况
if (key == 0)
return -100;
const char *start_data = data;
struct mem_node *tmp_node = GetNode(key);
if (tmp_node == NULL) {
LOG("[Append][%lu] node not exist call [Set]", key);
return Set(key, data, len);
}
// 数据超时
time_t cur_time = time(0);
if (data_store_time != 0) {
time_t interval = cur_time - tmp_node->tval;
if (interval> data_store_time) {
DelForInner(key);
return Set(key, data, len);
}
}
//append 之后总共使用的 BLOCK 个数
uint32_t total_nbu = GetNodeBlockUsed((tmp_node->size + len));
if (total_nbu> MAX_BLOCK_NUM) {
LOG("[Append][%lu][failed] blocks > MAX_BLOCK_NUM[%u]",
key, MAX_BLOCK_NUM);
return -1;
}
// 该节点现在使用的 BLOCK 个数
uint32_t nbu = GetNodeBlockUsed(tmp_node->size);
// 该节点最后一个 BLOCK 偏移量
uint32_t lbu = GetLastBlockUsed(tmp_node->size);
// 寻找最后一个 BLOCK 节点
struct mem_block *tmp_block = GetBlock(tmp_node->pos);
for (uint32_t i = 0; i < nbu - 1; i++) {
tmp_block = GetBlock(tmp_block->pos);
}
struct mem_block *last_block = tmp_block;
// 新增数据在最后一个 BLOCK 节点可以容纳下
if ((uint32_t)len <= BLOCK_DATA_SIZE - lbu) {
memcpy(last_block->data + lbu, data, len);
tmp_node->size += len;
tmp_node->crc32 = Crc32Append(tmp_node->crc32,
last_block->data + lbu,
len);
data_change++;
if ((msync_freq != 0) && (data_change > msync_freq)) {
data_change = 0;
MemSync(msync_flag);
}
return 0;
} else {
// 新增数据在最后一个 BLOCK 节点容纳不下了
// 需要新增 BLOCK 的数据量
uint32_t left = len - (BLOCK_DATA_SIZE - lbu);
// 剩下的数据需要的 BLOCK 节点数目
uint32_t left_nbu = GetNodeBlockUsed(left);
// 剩下的数据的最后一个 BLOCK 节点的偏移量
uint32_t left_lbu = GetLastBlockUsed(left);
if (left_nbu> max_block - head_->block_used) {
LOG("[Append][%lu][failed] blocks > free blocks num [%u]",
key, max_block - head_->block_used);
return -2;
}
// 填充最后一个 BLOCK 节点
memcpy(last_block->data + lbu, data, BLOCK_DATA_SIZE - lbu);
data += BLOCK_DATA_SIZE - lbu;
// 处理剩余数据量的前 n-1 个 BLOCK 节点
int32_t pre_free_pos = head_->free_block_pos;
tmp_block = GetBlock(pre_free_pos);
for (uint32_t j = 0; j < left_nbu - 1; j++) {
head_->block_used++;
SET_BLOCK_USED_FLAG(tmp_block->flag);
memcpy(tmp_block->data, data, BLOCK_DATA_SIZE);
data += BLOCK_DATA_SIZE;
tmp_block = GetBlock(tmp_block->pos);
}
// 处理剩余数据量的最后一个 BLOCK 节点
head_->block_used++;
SET_BLOCK_USED_FLAG(tmp_block->flag);
memcpy(tmp_block->data, data, left_lbu);
tmp_node->crc32 = Crc32Append(tmp_node->crc32,
start_data,
len);
head_->free_block_pos = tmp_block->pos;
tmp_block->pos = -1;
last_block->pos = pre_free_pos;
tmp_node->size += len;
data_change++;
if ((msync_freq != 0) && (data_change > msync_freq)) {
data_change = 0;
MemSync(msync_flag);
}
return 0;
}
}
细节
上面的代码思路基本上很清晰了,不过有两个地方需要特别做下解释:
1、问题 1:插入新元素时,如何查找可用 mem_block?回想在 mem_head 中 free_block_pos 成员,该成员标记了 mem_block 区域空闲块的首地址。如此这样将空闲 block 组织成链表结构(链表的指针是索引位置),在每个空闲 block 中记录下一个空闲的 block 地址,将空闲 block 逻辑上串联,在 header 中记录空闲链表头部地址;需要空闲 block 时,从空闲链表头部开始获取即可,然后对于每个占用的 mem_block,对其 flag 进行置位标识该 block 已被使用,同时更新mem_node 索引的 pos 字段
2、问题 2:删除元素后如何回收 block?查找待删除的最后一个 block,将其 next 设置为 header 中空闲链表头部地址,同时将 header 中空闲链表头部地址更新为删除的第一个 mem_block 地址
小结
1、如何解决 hash 冲突
多阶 hash,可以 hash bucket_time 次,如果都冲突了,操作失败
2、文件结构检查机制
- 检查
barrier - 检查
head,通过crc32检查head_info重要区域(该文件结构的bucket_time、bucket_len、max_block) - 检查
node_zone,通过对非0key 的node节点与其对应的block节点进行crc32完整性检查,判断数据的完整性
3、内存映射机制:采用 mmap 对文件映射到内存中,使用 mlock 进行锁定
4、内存落地机制
- 落地依赖于操作系统 msync 机制
- 可以调用
Memsync进行同步或异步的落地(建议采用异步落地机制) - 初始化时,可设定多少次数据写入时,程序自动调用
Memsync进行异步的落地(设为0时,取消自动调用Memsync)
5、数据过期机制:node 节点记录数据最新修改时间(设置为 0 时,取消数据过期机制)。在初始化时可自定义数据过期时间,当请求到达时根据当前时间判断数据是否过期
0x05 一些小技巧
减少 hash 算法的冲突率
针对于不同的字符串,可能 hash 出同一个值,如何减小这种冲突率?比如 time33 算法,100W 数量级的冲突率约为 0.00015,从测试结果来看,murmur_hash 是相对较好的 选择,该算法支持设置初始值可以生成多个不同的 hash 值,采用类似 Cuckoo hashing 的思路:
1、对一个字符串 str1, 使用 murmur_hash 同时 hash 出 3 个值(足够了),记为 h1、h2 和 h3
h1 = murmur_hash(str, 0);
h2 = murmur_hash(str, 1);
h3 = murmur_hash(str, 2);
2、h1 用来作多阶 hashtable 中 key 的定位,计算 hash 要保存的位置。而 h2 和 h3 仅用于辅助比较。对于一个 key, 需要满足 3 个 hash 值都一致时才认为是需要找的 key。如此做法,可以将冲突率降至约 2.24e-12,基本上满足优化需求了
0x06 总结
本文讨论了多阶 hash 的实现思路,这里总结下:
优点
- 查找和插入时间稳定高效,正比于阶数虽然不是最高效的,解决了链地址法冲突太多退化成链表操作效率不稳定
- 实现简单,使用多维数组实现
- 便于扩容,只要在加一阶数组就可以完成扩容
缺点
- 容量有限,虽然可以很简便的扩容,但是数量总是有上限的
- 扩展性一般,在每一阶都填满的情况下会出现 key 无法存储,相比于链地址法碰撞的情况可以增加到链表末尾相比扩展性更差
- 由于数组是定长的,所以定义元素的时候需要以最大的 value 来定义元素大小(如果不采用索引与数据分离的方式来实现的话)