0x00 前言
本文分析下协程池库 ants 的实现,仓库 在此,此库基于 fasthttp 的协程池实现。
0x01 ants 协程池使用
ants 提供了两种执行模式:
1、ants.NewPool(pool_size)
通过这种方式创建的 Pool,需要调用 pool.Submit(task) 提交任务,任务是一个无参数无返回值的函数,适合不关注结果的并发任务场景
2、ants.NewPoolWithFunc(pool_size, func(interface{}))
这种方式创建的 Pool 需要指定任务处理函数,需调用 p.Invoke(arg) 提交任务,arg 是传递给 func(interface{}) 的参数,此 Pool 适合关注结果的并发任务执行场景
现网中,大部分使用 2 的方式,因为需要关注任务执行的结果
Options 选项
// src/github.com/panjf2000/ants/options.go
type Options struct {
ExpiryDuration time.Duration
PreAlloc bool
MaxBlockingTasks int
Nonblocking bool
PanicHandler func(interface{})
Logger Logger
}
ExpiryDuration:过期时间。表示 goroutine 空闲多长时间之后会被池回收PreAlloc:预分配。调用NewPool()/NewPoolWithFunc()之后预分配 worker(管理一个工作 goroutine 的结构体)切片。而且使用预分配与否会直接影响池中管理 worker 的结构MaxBlockingTasks:最大阻塞任务数量。即池中 goroutine 数量已到池容量,且所有 goroutine 都处理繁忙状态,这时到来的任务会在阻塞列表等待。这个选项设置的是列表的最大长度。阻塞的任务数量达到这个值后,后续任务提交直接返回失败Nonblocking:池是否阻塞,默认阻塞。提交任务时,如果 goroutine池中 goroutine 已到上限且全部繁忙,阻塞的池会将任务添加的阻塞列表等待(当然受限于阻塞列表长度)非阻塞的池直接返回失败PanicHandler:panic 处理。遇到 panic 会调用这里设置的处理函数
1、最大等待队列长度:设置池容量之后,如果所有的 goroutine 都在处理任务。这时提交的任务默认会进入等待队列,超过这个长度,提交任务直接返回错误:
func wrapper(i int, wg *sync.WaitGroup) func() {
return func() {
fmt.Printf("hello from task:%d\n", i)
time.Sleep(1 * time.Second)
wg.Done()
}
}
func main() {
p, _ := ants.NewPool(4, ants.WithMaxBlockingTasks(2))
defer p.Release()
var wg sync.WaitGroup
wg.Add(8)
for i := 1; i <= 8; i++ {
go func(i int) {
//提交任务必须并行进行。如果是串行提交,第 5 个任务提交时由于池中没有空闲的 goroutine 处理该任务,Submit() 方法会被阻塞,后续任务就都不能提交了
err := p.Submit(wrapper(i, &wg))
if err != nil {
fmt.Printf("task:%d err:%v\n", i, err)
wg.Done()
}
}(i)
}
wg.Wait()
}
2、非阻塞:默认是阻塞的,非阻塞的 ants 池中,在所有 goroutine 都在处理任务时,提交新任务会直接返回错误:
func main() {
p, _ := ants.NewPool(2, ants.WithNonblocking(true))
defer p.Release()
var wg sync.WaitGroup
wg.Add(3)
for i := 1; i <= 3; i++ {
err := p.Submit(wrapper(i, &wg))
if err != nil {
fmt.Printf("task:%d err:%v\n", i, err)
wg.Done()
}
}
wg.Wait()
}
3、panic 处理器:ants 中如果 goroutine 在执行任务时发生 panic,会终止当前任务的执行,将发生错误的堆栈输出到 os.Stderr。注意,该 goroutine 还是会被放回池中,下次可以取出执行新的任务
func wrapper(i int, wg *sync.WaitGroup) func() {
return func() {
fmt.Printf("hello from task:%d\n", i)
if i%2 == 0 {
panic(fmt.Sprintf("panic from task:%d", i))
}
wg.Done()
}
}
func panicHandler(err interface{}) {
fmt.Fprintln(os.Stderr, err)
}
func main() {
//p, _ := ants.NewPool(2)
p, _ := ants.NewPool(2, ants.WithPanicHandler(panicHandler))
defer p.Release()
var wg sync.WaitGroup
wg.Add(3)
for i := 1; i <= 2; i++ {
p.Submit(wrapper(i, &wg))
}
time.Sleep(1 * time.Second)
p.Submit(wrapper(3, &wg))
p.Submit(wrapper(5, &wg))
wg.Wait()
}
0x02 整体分析
ants 的运行流程图如下,比较直观,按照如下几个核心模块进行分析:
- Pool:协程池的核心结构,一个 Pool 一般生成固定个 Worker
- Worker:ants 中为每个任务都是由 worker 对象来处理的,每个 worker 对象会对应创建一个 goroutine 来处理任务,一个 worker 对应于一个 goroutine
- Task:用户指定的运行方法,即单个任务
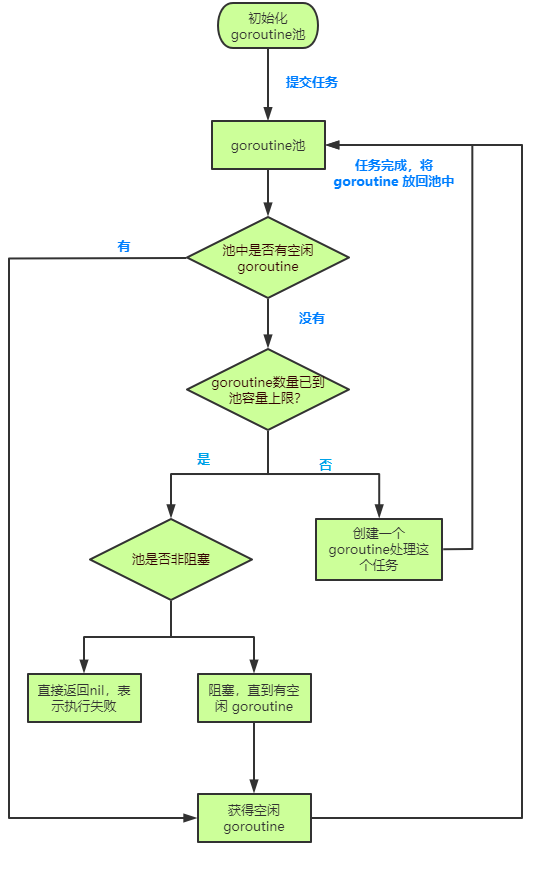
任务运行模式
每一个 worker 对应一个 goroutine,然后这个 goroutine 会不断监听并执行 taskChan 里面的 task,类似生产者消费者模式,如下图:
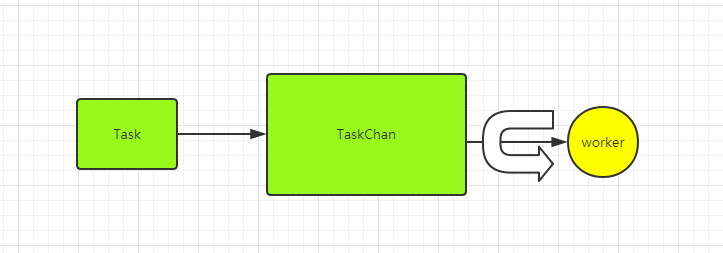
Pool && 任务 && worker 模型
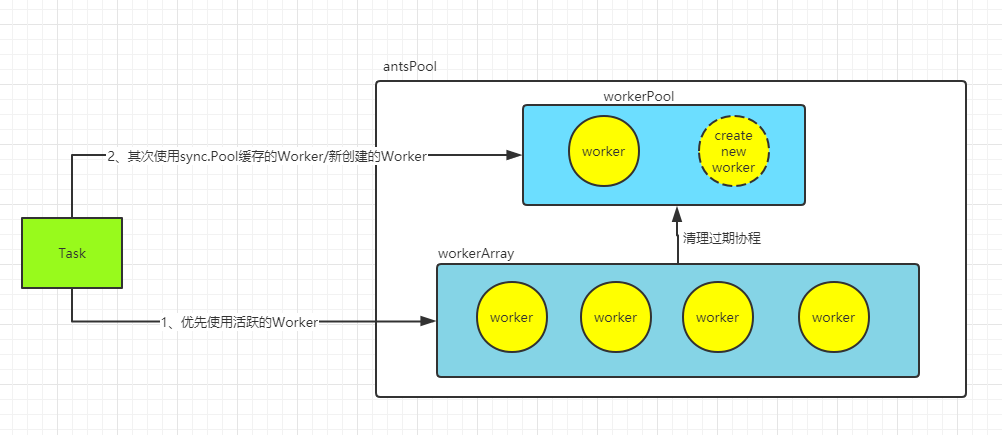
- 协程池通过
workerArray管理各个 worker。workerArray按照 worker 的入队时间有序存放 worker(方便过期清理时查找过期协程 - 协程池会定时清理过期 worker,定期从
workerArray中查找过期的 worker,将其放入workerPool sync.Pool中缓存下来,等待 GC 或者被复用
0x03 Pool 分析
Pool 结构定义
Pool 的结构体 定义 如下:
// Pool accepts the tasks from client, it limits the total of goroutines to a given number by recycling goroutines.
type Pool struct {
// capacity of the pool, a negative value means that the capacity of pool is limitless, an infinite pool is used to
// avoid potential issue of endless blocking caused by nested usage of a pool: submitting a task to pool
// which submits a new task to the same pool.
capacity int32 //ants 最多能创建的 goroutine 数量(协程池数量)
// running is the number of the currently running goroutines.
running int32 // 已经创建的 worker goroutine 的数量
// lock for protecting the worker queue.
lock sync.Locker //ants 自己实现了一个自旋锁。用于同步并发操作(用于保护 workerArray)
// workers is a slice that store the available workers.
workers workerArray // 存放一组 worker 对象,即一组 goroutine,workerArray 只是一个 interface,存放 goWorker 对象的容器(见下文分析)
// state is used to notice the pool to closed itself.
state int32 // 记录池子当前的状态,是否已关闭(CLOSED)
// cond for waiting to get a idle worker.
cond *sync.Cond // 条件变量,处理任务等待和唤醒
// workerCache speeds up the obtainment of a usable worker in function:retrieveWorker.
workerCache sync.Pool // 使用 sync.Pool 对象池管理和创建 worker 对象,提升性能
// blockingNum is the number of the goroutines already been blocked on pool.Submit, protected by pool.lock
blockingNum int // 当前阻塞等待的任务数量(阻塞协程数量,指提交任务的协程)
options *Options // 协程池的配置,包括过期时间、是否支持预分配、最大阻塞数量、panic 处理、日志等
}
// workerArray,一个 workerArray 代表一个 worker 池(协程池)
type workerArray interface {
len() int
isEmpty() bool
insert(worker *goWorker) error
detach() *goWorker
retrieveExpiry(duration time.Duration) []*goWorker
reset()
}
capacity:池容量,最多能创建的 goroutine 数量。如果为负数,表示容量无限制running:已经创建的 worker goroutine 的数量workers:存放一组 worker 对象,workerArray 只是一个接口state:记录池子当前的状态,是否已关闭(CLOSED)lock:锁。ants 自己实现了一个自旋锁。用于同步并发操作cond:条件变量。处理任务等待和唤醒workerCache:使用sync.Pool对象池管理和创建 worker 对象,提升性能blockingNum:阻塞等待的任务数量
注意 workerArray 类型是一个抽象类型 interface{},ants 提供了基于 stackType 和 loopQueueType 的两种 实现。workerArray 中的核心结构是 goWorker。通常对于协程池,一个 Pool 会生成固定的若干个 goWorker,对任务分配指定的 goWorker 来实现流水线任务运行,从而达到复用 worker 的目的。
// goWorker is the actual executor who runs the tasks,
// it starts a goroutine that accepts tasks and
// performs function calls.
type goWorker struct {
// pool who owns this worker. // 用于记录当前 worker 属于哪一个协程池
pool *Pool
// task is a job should be done. // 接受任务的 chan,多核环境 chan 大小为 1,单核环境 chan 大小为 0(借鉴 fastHttp 的实现)
task chan func()
// recycleTime will be updated when putting a worker back into queue. // worker 进入队列的时间
recycleTime time.Time
}
创建 Pool 的方式
NewPool 方法如下,注意 p.workerCache 及 p.workers 的初始化,此外在 NewPool 中还创建了子协程 purgePeriodically() 用于定时回收割超时的 worker,如下:
- 加载用户自定义配置
- 指定
workerCache这个sync.Pool类型创建 worker 的方法 - 进行
workerArray的初始化;在 ants 中有两种实现workerArray的方式,使用预分配的情况下采用loopQueue循环队列实现,不使用预分配采用workerStack栈实现 - 开启一个子协程,定时清理
workerArray中的 worker
// NewPool generates an instance of ants pool.
func NewPool(size int, options ...Option) (*Pool, error) {
opts := loadOptions(options...)
if size <= 0 {
size = -1
}
// 设置回收协程定时器触发时间
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime
}
if opts.Logger == nil {
opts.Logger = defaultLogger
}
// 创建 Pool 对象
p := &Pool{
capacity: int32(size),
lock: internal.NewSpinLock(),
options: opts,
}
// 指定 sync.Pool 创建 worker 的方法
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
// 根据预分配标志,使用不同的 workerArray 的实现方式
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
// 预先分配固定 Size 的池子
p.workers = newWorkerArray(loopQueueType, size)
} else {
// 初始化不创建,运行时再创建
p.workers = newWorkerArray(stackType, 0)
}
p.cond = sync.NewCond(p.lock)
// Start a goroutine to clean up expired workers periodically.
// 开启一个协程周期清理过期的 worker
go p.purgePeriodically()
return p, nil
}
此外,在创建 Pool 时,根据 options.PreAlloc 设置,分两种方式(上面代码):
- 预先分配,size 需要指定,使用 Queue 结构进行创建
- 运行时创建,初始化 size 为
0,使用 Stack 结构进行创建
原因见下文分析。
定期回收超时的 goWorker(协程池清理)
在 NewPool 方法中会启动一个 goroutine 定期清理过期的 goWorker。过期的定义是:每个 goWorker.recycleTime 加上 Pool.options.ExpiryDuration 小于 time.Now() 时即认为该协程已过期。具体流程如下:
- 在每个清理周期,调用
p.workers.retrieveExpiry方法,取出过期的goWorker(goroutine)- 向每个
goWorker的taskchannel 发送一个nil,通知 goWorker 退出(因为goWorker启动的 goroutine 阻塞在 channeltask上,其接收值为nil的任务后会return退出) goWorkergoroutine 正常退出
- 向每个
- 若所有
goWorker都被清理,可能这时还有 goroutine 阻塞在pool.retrieveWorker方法中的p.cond.Wait()上,所以这里需要调用p.cond.Broadcast()唤醒这些 goroutine,执行后续的逻辑(创建新的 goWorker 等等)
func (p *Pool) purgePeriodically() {
heartbeat := time.NewTicker(p.options.ExpiryDuration)
defer heartbeat.Stop()
for range heartbeat.C {
if p.IsClosed() {
// 如果 Pool 被主动关闭,直接退出 goroutine
// 如果协程池已经被关闭,就退出清理的定时任务
break
}
// 从 workers 中获取过期的 worker
p.lock.Lock()
expiredWorkers := p.workers.retrieveExpiry(p.options.ExpiryDuration)
p.lock.Unlock()
// 执行清理过期的 worker
for i := range expiredWorkers {
// 向 worker 的 taskChan 发送终止信号;当 worker 接收到 nil 的任务时,会进入 workerCache 等待 GC
expiredWorkers[i].task <- nil
// 清空 worker 的引用,方便 GC
expiredWorkers[i] = nil
}
// 唤醒获取 worker 的协程
if p.Running() == 0 {
// 唤醒阻塞在 p.cond.Wait() 上的 goroutine
p.cond.Broadcast()
}
}
}
注意上面的 retrieveExpiry 方法,实现 1、实现 2,该方法通过 binarySearch 获取到从 wq.head 到 wq.index 之间的所有 []*goWorker 返回,同时置 nil(注意下面 loopQueue 实现对 Queue 环结构的特殊处理);
func (wq *loopQueue) retrieveExpiry(duration time.Duration) []*goWorker {
expiryTime := time.Now().Add(-duration)
index := wq.binarySearch(expiryTime)
if index == -1 {
return nil
}
wq.expiry = wq.expiry[:0]
if wq.head <= index {
wq.expiry = append(wq.expiry, wq.items[wq.head:index+1]...)
for i := wq.head; i < index+1; i++ {
wq.items[i] = nil
}
} else {
wq.expiry = append(wq.expiry, wq.items[0:index+1]...)
wq.expiry = append(wq.expiry, wq.items[wq.head:]...)
for i := 0; i < index+1; i++ {
wq.items[i] = nil
}
for i := wq.head; i < wq.size; i++ {
wq.items[i] = nil
}
}
head := (index + 1) % wq.size
wq.head = head
if len(wq.expiry) > 0 {
wq.isFull = false
}
// 返回所有过期的 worker 列表
return wq.expiry
}
如何触发某个 goroutine 主动退出呢?
由于 workerArray 结构是按照 worker 的 插入时间排序(每个最新的 worker 始终插入在最后一个位置),在获取过期 worker 时仅需要通过二分查找就可以找出过期的 worker 列表。找到过期的 worker 列表后,会向每个过期的 worker 发送终止信号 nil,并清空过期 worker 的引用,以方便 worker 被 GC。
这里抛出个疑问,为什么要对 worker 设置过期机制呢?
向 Pool 中提交 Task
任务提交流程首先从协程池中获取空闲的 worker,然后向 worker 的 taskChan 中提交任务,等待 worker 消费任务。Pool 提供了 Submit 方法,提供外部发起任务调度的接口,此方法调用 pool.retrieveWorker 方法获取一个空闲的 goWorker(如果能成功获取),然后将任务 task 发送到 goWorker 的 channel w.task:
func (p *Pool) Submit(task func()) error {
// 判断 pool 是否关闭
if p.IsClosed() {
return ErrPoolClosed
}
var w *goWorker
//retrieveWorker 方法获取空闲的 worker
if w = p.retrieveWorker(); w == nil {
return ErrPoolOverload
}
// 将待执行的任务 send 到 goWorker 的 任务 channel 中
w.task <- task
return nil
}
retrieveWorker 方法:Pool 获取可用的 goWoker
通过 retrieveWorker 方法获取当前池中可用的(空闲的) goWorker,该方法实现了开头流程图的逻辑。空闲 worker 的获取采用优先级策略,其优先级如下:
- 优先从
workerArray中获取可用的 worker(有空闲 worker 直接用) - 如果当前运行的协程未达到协程池的容量,从
workerCache中获取并启动一个 worker(即spawnWorker实现,直接从sync.Pool的缓存中复用一个) - 若协程池设置了非阻塞,直接返回一个空 worker
- 若协程池阻塞(默认配置),则阻塞等待可用的 worker(全部阻塞在
p.cond.Wait()上)
func (p *Pool) retrieveWorker() (w *goWorker) {
//spawnWorker 方法
spawnWorker := func() {
// 实例化 worker
w = p.workerCache.Get().(*goWorker)
// 启动 worker
w.run()
}
p.lock.Lock()
//1. 从 workers 中取出一个 goWorker( 优先从 workerArray 中获取 worker)
//p.workers 是 loopQueue 或者 workerStack 对象,它们都实现了 detach() 方法
w = p.workers.detach()
if w != nil {
//SUCC,有空闲 goroutine,直接返回
p.lock.Unlock()
} else if capacity := p.Cap(); capacity == -1 || capacity> p.Running() {
// 池容量还没用完(即容量大于正在工作的 goWorker 数量),则调用 spawnWorker() 新建一个 goWorker,执行其 run() 方法,直接返回
// 2. 可扩容,从 workerCache 中获取
p.lock.Unlock()
spawnWorker()
} else {
if p.options.Nonblocking {
// 3. 若设置了非阻塞选项,直接返回 nil
p.lock.Unlock()
return
}
RETRY:
if p.options.MaxBlockingTasks != 0 && p.blockingNum >= p.options.MaxBlockingTasks {
// 如果设置了最大阻塞队列长度限制,并且当前阻塞等待的任务数量已经达到这个上限,直接返回 nil
p.lock.Unlock()
return
}
// 未超过最大阻塞队列长度限制,阻塞等待数量 +1,调用 p.cond.Wait() 阻塞等待(此操作会被 p.cond.Signal()/p.cond.Broadcast() 这两个方法唤醒)
p.blockingNum++
// 调用 p.cond.Wait() 等待
// 注意!这里会阻塞,通过 p.cond.Signal() 方法会唤醒这里的逻辑
p.cond.Wait()
// 异步:被唤醒后, 阻塞的任务数减 1
p.blockingNum--
var nw int
if nw = p.Running(); nw == 0 {
// 判断当前 goWorker 的数量(goroutine 数量)是否等于 0,若为 0,很有可能 Pool 刚刚执行了 Release() ,及 Pool 被主动关闭了
p.lock.Unlock()
if !p.IsClosed() {
//Pool 未被关闭,说明可以创建新的 goWorker,调用 spawnWorker() 创建一个新的 goWorker 并执行其 run() 方法
spawnWorker()
}
// 如果 Pool 被关闭了,p.IsClosed 为 true,那么直接返回
return
}
// 如果当前 goWorker 数量不为 0,则调用 p.workers.detach() 方法尝试取出一个空闲的 goWorker
if w = p.workers.detach(); w == nil {
// 若取出失败(有可能发生),因为可能同时有多个 goroutine 在等待,唤醒的时候只有部分 goroutine 能获取到 goWorkerr
if nw < capacity {
// 从 Pool 中取出失败,检查容量是否还有额度,直接创建新的 goWorke
p.lock.Unlock()
spawnWorker()
return
}
// 如果没有取到 goWorker,那么就返回到 p.cond.Wait() 继续阻塞等待好了
// TODO
goto RETRY
}
p.lock.Unlock()
}
return
}
再详细描述下该方法的细节,首先调用 p.workers.detach() 获取 goWorker(p.workers 是 loopQueueORworkerStack),如果返回了一个 goWorker 对象,说明有空闲 goroutine,直接返回。否则,goroutine 池容量还有余额(即说明容量大于正在工作的 goWorker 数量),则调用 spawnWorker() 方法新建一个 goWorker,执行其 run() 方法,参考上面 spawnWorker 的实现。
若 goroutine 池容量已用完。如果设置了非阻塞选项,则直接返回(如果使用 Invoke 调用方法会报错 too many goroutines blocked on submit or Nonblocking is set)。如果设置了最大阻塞队列长度上限,且当前阻塞等待的任务数量已经达到这个上限,直接返回。否则,阻塞 goroutine 等待数量加 1,调用 p.cond.Wait() 等待
然后 goWorker.run() 执行完成一个任务后,调用池的 revertWorker() 方法放回 goWorker,在此方法中最后会调用 p.cond.Signal() 唤醒之前 retrieveWorker() 方法中 cond.Wait() 的等待,retrieveWorker() 方法继续执行阻塞等待数量减 1,这里判断当前 goWorker 的数量(也即 goroutine 数量)。如果数量为 0,很有可能 goroutine 池刚刚执行了 Release() 关闭,所以此时需要先判断池是否处于关闭状态,如果是则直接返回。否则,调用 spawnWorker() 创建一个新的 goWorker 并执行其 run() 方法,这就将本次的 goroutine 调度和用户调用之间绑定了
如果当前 goWorker 数量不为 0(说明池正在正常的工作状态),则调用 p.workers.detach() 取出一个空闲的 goWorker 返回。这个操作有可能失败,因为可能同时有多个 goroutine 在等待,唤醒的时候只有部分 goroutine 能获取到 goWorker。如果失败了,其容量还未用完,直接创建新的 goWorker,反之重新执行阻塞等待逻辑(为何获取不到goWorker?)
func (p *Pool) revertWorker(worker *goWorker) bool {
if capacity := p.Cap(); (capacity> 0 && p.Running() > capacity) || p.IsClosed() {
return false
}
worker.recycleTime = time.Now()
p.lock.Lock()
if p.IsClosed() {
p.lock.Unlock()
return false
}
// 放回池
err := p.workers.insert(worker)
if err != nil {
p.lock.Unlock()
return false
}
//唤醒同时解锁
p.cond.Signal()
p.lock.Unlock()
return true
}
最后,理解这里的实现,需要搞清楚 p.cond.Wait() 内部会将当前 goroutine 挂起,然后解开它持有的锁,即会调用 p.lock.Unlock()。这也是为什么 revertWorker() 中 p.lock.Lock() 加锁能成功的原因。然后 p.cond.Signal() 或 p.cond.Broadcast() 会唤醒因为 p.cond.Wait() 而挂起的 goroutine,但是需要 Signal()/Broadcast() 所在 goroutine 调用解锁方法。而调用 p.cond.Wait() 的 goroutine 被唤醒之后,内部会重新执行加锁操作(即调用 p.lock.Lock()),所以 p.cond.Wait() 之后的逻辑还是在有锁的状态下执行的
动态修改 Pool 容量
ants 提供了 Tune 方法用以动态调整非 PreAlloc 模式下的容量,通过 atomic 原子写入 pool.capacity 即可。
- 下次执行
pool.revertWorker方法时就会以新的容量pool.capacity判断是否能放回 - 下次执行
pool.retrieveWorker方法时会以新容量判断是否能创建新 goWorker
func (p *Pool) Tune(size int) {
if capacity := p.Cap(); capacity == -1 || size <= 0 || size == capacity || p.options.PreAlloc {
return
}
atomic.StoreInt32(&p.capacity, int32(size))
}
为何 PreAlloc 模式下无法动态调整?
销毁 / Restart Pool
pool.Release 用来关闭协程池,注意方法中的 p.cond.Broadcast(),此为了唤醒有任务阻塞在 p.cond.Wait() 上。
func (p *Pool) Release() {
// 设置 pool 的关闭状态
atomic.StoreInt32(&p.state, CLOSED)
p.lock.Lock()
// 关闭 workerArray 中的每个 goroutine
p.workers.reset()
p.lock.Unlock()
// 注意!为了防止有 goroutine 阻塞在 p.cond.Wait() 上,执行一次 p.cond.Broadcast() 唤醒这些阻塞的任务!
p.cond.Broadcast()
}
// workerStack.reset
func (wq *workerStack) reset() {
for i := 0; i <wq.len(); i++ {
// 对每个 worker,发送 nil 到 task 通道从而结束 goroutine
wq.items[i].task <- nil
wq.items[i] = nil
}
//free wq.items,好习惯
wq.items = wq.items[:0]
}
注意到在关闭过程中,只是清理了 p.workers 以及更新了相关字段,并未对 pool 的管理结构做回收,所以可以很方便的实现 restart:
func (p *Pool) Reboot() {
// 打开 pool 的状态
if atomic.CompareAndSwapInt32(&p.state, CLOSED, OPENED) {
// 由于 p.purgePeriodically() 在 p.Release() 之后检测到池关闭就直接退出了,需要重新开启 purgePeriodically 方法
go p.purgePeriodically()
}
}
将 goWorker 放回 Pool
revertWorker 方法用于将任务处理完成的 goWorker 放回 Pool,该方法返回 true 表示 goWorker 成功放回 Pool,返回 false 表示放回失败,此 goroutine 会退出。注意这里设置了 goWorker 的 recycleTime 字段,用于在 p.workers.retrieveExpiry 方法中判断 goroutine 是否过期。
func (p *Pool) revertWorker(worker *goWorker) bool {
if capacity := p.Cap(); (capacity> 0 && p.Running() > capacity) || p.IsClosed() {
// 不满足放回条件,返回 false
return false
}
worker.recycleTime = time.Now() // 重置空闲计时器,用于判定过期
p.lock.Lock()
if p.IsClosed() {
// 如果 Pool 被关闭,那么退出
p.lock.Unlock()
return false
}
// 调用 workerArray 的 insert 方法,放回 pool
err := p.workers.insert(worker)
if err != nil {
p.lock.Unlock()
return false
}
// 放回成功,通过 p.cond.Signal() 唤醒一个可能阻塞的 goroutine
p.cond.Signal()
p.lock.Unlock()
return true
}
0x04 Worker 实现
ants 中为每个任务都是由 worker 对象来处理的,每个 worker 对象会对应创建一个 goroutine 来处理任务,Worker 对应的结构是 goWorker,其中 recycleTime 标识了空闲开始时间,该字段只在非 PreAlloc 模式(运行时创建模式)下才起效;
当无法从 workerArray 和 workerCache 中获取 worker 时,协程池会创建一个新的 worker,并调用 worker.run() 启动 worker。worker 启动之后,会开启一个 goroutine 监听并执行 taskChan 中任务。直到 worker 接收到终止信号 nil 或协程池已满无法放回协程池时,worker 会退出 taskChan 的监听,进入清理回收环节
// goWorker is the actual executor who runs the tasks,
// it starts a goroutine that accepts tasks and
// performs function calls.
type goWorker struct {
// pool who owns this worker.
pool *Pool // 指向属主池
// task is a job should be done.
task chan func() // 非常重要!任务通道,通过这个通道将类型为 func () 的函数作为任务发送给 goWorker 执行
// recycleTime will be updated when putting a worker back into queue.
recycleTime time.Time // 此字段记录 goroutine 放回池中的时间(即什么时候开始空闲),注意:此字段只在非 PreAlloc 模式下才起效
}
goWorker 的核心是 run 方法,该方法启动一个子 goroutine,然后不停地从 task 通道中接收任务,然后执行任务 f(),任务执行完成之后调用 Pool.revertWorker 方法将该 goWorker 对象放回 Pool 中,以便下次取出处理新的任务;
PS:这里其实可以修改为 goroutine 一直不停的监听在 w.task 上,不必放回池中?
// run starts a goroutine to repeat the process
// that performs the function calls.
func (w *goWorker) run() {
// 任务 + 1
w.pool.incRunning() // 正在运行的协程数 + 1
go func() {
// 异常处理!
defer func() {
// 任务执行失败,goroutine 结束,运行数量减 1
w.pool.decRunning() // 正在运行的协程数 - 1
//goWorker 对象可以重复利用,利用 sync.Pool 回收,将 goWorker 对象放回 sync.Pool 池中
w.pool.workerCache.Put(w) // 将 worker 放入 workerCache 中等待 GC
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
// 自定义 panic_handler
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from a panic: %v\n", p)
var buf [4096]byte
n := runtime.Stack(buf[:], false)
w.pool.options.Logger.Printf("worker exits from panic: %s\n", string(buf[:n]))
}
}
// Call Signal() here in case there are goroutines waiting for available workers.
// 这里有意思,调用 w.pool.cond.Signal() 通知现在有空闲的 goWorker 了
// 因为实际运行的 goWorker 数量由于 panic 少了一个,而池中可能有其他任务在等待处理
w.pool.cond.Signal() // 唤醒获取 worker 的协程
}()
//CORE!
// 不断消费 taskChan 中的任务
for f := range w.task {
//for loop here......
if f == nil { // 接收到终止信号 nil 时,退出循环进入清理环节
// 外部主动通知本协程关闭
return
}
f() // 执行任务
// 调用池的 revertWorker() 方法放回 Pool,返回 false,goroutine 退出;返回 true,说明此 goroutine 被正确的放回了 pool,阻塞在 range 上,等待下一次 task 被塞入任务!
if ok := w.pool.revertWorker(w); !ok { // 将 worker 放回到 workerArray 中
// 如果放回操作失败,则会调用 return,这会让 goroutine 运行结束,防止 goroutine 泄漏
return
}
}
}()
}
从上面 Worker 运行的代码可知,每个由 Pool 创建的 goroutine 都会经过如下运行处理的逻辑:
- 为了保证 goroutine 运行的稳定性,调用
defer进行异常处理(捕获任务执行过程中抛出的 panic),在异常处理中勿忘记更新 pool 的状态- 更新 pool 状态
- 回收
goWorker以复用 - 在
defer逻辑中,发送w.pool.cond.Signal通知现在有空闲的 goWorker 了(因为实际运行的 goWorker 数量由于panic少了一个,而池中可能有其他任务在等待处理)
- 工作 goroutine 会一直阻塞在
for f := range w.task上,等到w.task这个 channel 有事件发生:- 有任务被成功的 recv,然后进行任务处理逻辑
- 接收到
nil,表示有外界需要主动关闭此 goroutine 的行为,那么 goroutine 就退出
- 正常运行的 goroutine 会向 Pool 申请放回,表示 自己已经处理完当前任务,可以等待下一次调度
- 若返回 Pool 失败,则本 goroutine 退出
- 放回成功的 goroutine,继续阻塞在
range上,等待下一次任务调度(或者因为超时被回收了)
每个 goWorker 只会启动一次 goroutine,正常情况下,此 goroutine 一直在运行(后续重复利用这个 goroutine),goroutine 每次只执行一个任务就会被放回池中。这也是协程池高性能的关键所在。同时这里要考虑到,放回操作失败时需要确保 goroutine 正常退出(避免 goroutine 泄漏)。
0x05 workerArray 实现
前面描述过,workerArray 是一个抽象的接口,实现了 goroutine 池的核心逻辑 ,ants 提供了 workerStack 和 loopQueue 两种实现:
workerArray 定义
type workerArray interface {
len() int
isEmpty() bool
insert(worker *goWorker) error // 任务执行结束后,将相应的 worker (goroutine)放回 workerArray 中
detach() *goWorker // 从 workerArray 中取出一个 worker(goroutine)
retrieveExpiry(duration time.Duration) []*goWorker // 取出所有的过期 worker
reset()
}
下面看下 workerArray 具体的实现。
loopQueue 实现
LoopQueue 是基于循环队列的 实现,
type loopQueue struct {
items []*goWorker
expiry []*goWorker
head int
tail int
size int
isFull bool
}
TODO:待补充
workerStack 实现
workerStack 实现,结构包含 items 和 expiry 两个成员,workerArray 也是采用运行时创建的逻辑来创建 goroutine:
type workerStack struct {
items []*goWorker // 当前可用(空闲的) worker
expiry []*goWorker // 过期的 worker
size int
}
// 非预先创建,采用运行时创建的逻辑,insert 始终是插入到末尾位置
func (wq *workerStack) insert(worker *goWorker) error {
wq.items = append(wq.items, worker)
return nil
}
detach 方法实现了当有任务带处理时,从 workerArray 中取出一个空闲的 goroutine(goWorker),根据 stack 后进先出的特点,这里始终返回最后一个位置的节点 wq.items[l-1]:
func (wq *workerStack) detach() *goWorker {
l := wq.len()
if l == 0 {
return nil
}
w := wq.items[l-1]
wq.items[l-1] = nil // avoid memory leaks
wq.items = wq.items[:l-1]
return w
}
当 goroutine 完成任务之后,Pool 池会将相应的 worker 放回 workerStack,调用 workerStack.insert() 直接将 goroutine 放回 items 中。
此外,通过 retrieveExpiry 方法,获取到当前过期的 worker 列表,由于 ants 库是按运行时创建,所以这里加入过期的逻辑来回收掉那些多余的 goroutine,该方法会被 Pool.purgePeriodically 方法中调用与处理:
retrieveExpiry 的回收过程包含如下几个部分:
- 查找过期的 goroutines 位置
- 回收到这部分 goroutine
- 未过期的 goroutine 转移到
wq.items首部
// 二分查找的是最近过期的 worker,即将过期的 worker 的前一个位置,在此位置之前的 worker 已经全部过期了
func (wq *workerStack) binarySearch(l, r int, expiryTime time.Time) int {
var mid int
for l <= r {
mid = (l + r) / 2
//expiryTime < recycleTime
if expiryTime.Before(wq.items[mid].recycleTime) {
r = mid - 1
} else {
l = mid + 1
}
}
return r
}
func (wq *workerStack) retrieveExpiry(duration time.Duration) []*goWorker {
n := wq.len()
if n == 0 {
return nil
}
// 获取超时的底限刻度
expiryTime := time.Now().Add(-duration)
// 采用二分法查找 index
index := wq.binarySearch(0, n-1, expiryTime)
//reset wq.expiry
wq.expiry = wq.expiry[:0]
if index != -1 {
wq.expiry = append(wq.expiry, wq.items[:index+1]...) // 在 0:index+1 区间的 goroutine 都需要被回收
// 将 wq.items[index+1:] 部分的 goroutine 重新放回 wq.items(这些元素都是未过期的)
m := copy(wq.items, wq.items[index+1:])
for i := m; i < n; i++ {
//reset origin zone
wq.items[i] = nil
}
// 重新生成 wq.items
wq.items = wq.items[:m]
}
return wq.expiry
}
思考一下,这里为何采用二分法进行搜索呢?二分法查找需要数组有序,而在 workerStack 中,由于过期时间是按照 goroutine 执行任务后的空闲时间计算的,而 workerStack.insert 方法的插入顺序正好满足这个特性,wq.item 中各个元素的过期时间是从早到晚有序的。
0x06 Options 选项
ants 提供了一些选项用于定制 goroutine Pool:
type Options struct {
ExpiryDuration time.Duration // 过期时间,表示 goroutine 空闲多长时间之后会被 ants 池回收
PreAlloc bool // 是否预分配
MaxBlockingTasks int // 最大阻塞任务数量,即池中 goroutine 数量已到池容量,且所有 goroutine 都处于繁忙状态,这时到来的任务会在阻塞列表等待。阻塞的任务数量达到这个值后,后续任务提交直接返回失败
Nonblocking bool // 阻塞开关,提交任务时,如果 ants 池中 goroutine 已到上限且全部繁忙,阻塞的池会将任务添加的阻塞列表等待(受限于阻塞列表长度)。非阻塞下直接返回失败
PanicHandler func(interface{}) //panic 钩子方法,遇到 panic 会调用这里设置的处理函数
Logger Logger
}
0x07 一些细节
pool.retrieveWorker 方法的 Lock 问题
retrieveWorker 方法关于 lock 的代码如下:
// retrieveWorker returns an available worker to run the tasks.
func (p *Pool) retrieveWorker() (w *goWorker) {
//...
p.lock.Lock()
w = p.workers.detach()
if w != nil { // first try to fetch the worker from the queue
p.lock.Unlock()
} else if capacity := p.Cap(); capacity == -1 || capacity> p.Running() {
// if the worker queue is empty and we don't run out of the pool capacity,
// then just spawn a new worker goroutine.
p.lock.Unlock()
spawnWorker()
} else { // otherwise, we'll have to keep them blocked and wait for at least one worker to be put back into pool.
if p.options.Nonblocking {
p.lock.Unlock()
return
}
retry:
if p.options.MaxBlockingTasks != 0 && p.blockingNum >= p.options.MaxBlockingTasks {
p.lock.Unlock()
return
}
p.blockingNum++
p.cond.Wait() // block and wait for an available worker
p.blockingNum--
var nw int
if nw = p.Running(); nw == 0 { // awakened by the scavenger
p.lock.Unlock()
if !p.IsClosed() {
spawnWorker()
}
return
}
if w = p.workers.detach(); w == nil {
if nw < capacity {
p.lock.Unlock()
spawnWorker()
return
}
goto retry
}
p.lock.Unlock()
}
return
}
注意 p.lock.Lock() 这里加的锁,会在 p.cond.Wait() 方法中被释放。这样,goroutine 不会阻塞在 p.lock.Lock() 上。在 NewPool 方法中初始化 sync.Cond 对象的代码中,是传了 p.lock 进去的:
p.cond = sync.NewCond(p.lock)
通过分析 p.cond.Wait() 内部实现的机制可知,此方法会将当前 goroutine 挂起,然后解开它持有的锁(此锁必须由初始化传入),即会调用 p.lock.Unlock() 解锁。这也是为何上述代码中多个 goroutine 可以通过 p.lock.Lock() 加锁逻辑继续执行的的原因。
下一个问题,为何在 p.cond.Wait() 之后还需要对 p.lock 做解锁操作呢?按道理这里是无锁了,此原因是因为异步由其他 goroutine 调用 p.cond.Signal() 或 p.cond.Broadcast() 方法唤醒了阻塞在 p.cond.Wait() 的 goroutine 时,内部会重新对 p.lock 执行加锁操作(即调用 p.lock.Lock())。即说明 p.cond.Wait() 之后的逻辑还是在有锁的状态下执行的。
从 sync.Cond 的实现方法不难理清上述的逻辑:
func (c *Cond) Wait() {
c.checker.check()
t := runtime_notifyListAdd(&c.notify)
// 先解锁
c.L.Unlock()
// 等待唤醒
runtime_notifyListWait(&c.notify, t)
// 加锁
c.L.Lock()
}
// Signal wakes one goroutine waiting on c, if there is any.
//
// It is allowed but not required for the caller to hold c.L
// during the call.
func (c *Cond) Signal() {
c.checker.check()
runtime_notifyListNotifyOne(&c.notify)
}
// Broadcast wakes all goroutines waiting on c.
//
// It is allowed but not required for the caller to hold c.L
// during the call.
func (c *Cond) Broadcast() {
c.checker.check()
runtime_notifyListNotifyAll(&c.notify)
}
PreAlloc 对数据结构选型的影响
slice 指针的回收
在 workerStack 的 detach 方法中,由于切片的底层结构是数组,只要有引用数组的指针,数组中的元素就不会释放。这里取出切片最后一个元素后,将对应数组元素的指针设置为 nil,主动释放这个引用。这也是防止内存泄漏的好办法。
func (wq *workerStack) detach() *goWorker {
l := wq.len()
if l == 0 {
return nil
}
w := wq.items[l-1]
wq.items[l-1] = nil // avoid memory leaks
wq.items = wq.items[:l-1]
return w
}
0x08 ants 使用的坑
1、默认启动的 goroutine 池是阻塞的,如 p, _ := ants.NewPoolWithFunc(1024, func(interface{})),这里的风险在于当整个 goroutine 池中没有可用的 goroutine 时(池容量已用完),会导致 goroutine 泄漏,如下图:
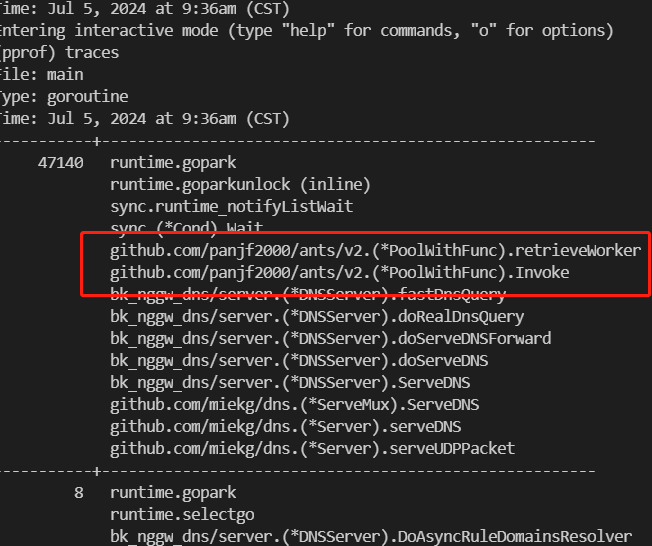
如何解决?
- 设置了非阻塞选项,则直接返回(代码实现相应的补偿逻辑)
- 设置了最大阻塞队列长度上限,且当前阻塞等待的任务数量已经达到这个上限,直接返回
- 定位并解决池阻塞的根本原因