0x00 前言
本文分析下tunny协程池的实现。先说结论:tunny的并发控制核心是固定数量的工作goroutine,监听唯一的任务管道,即全局reqChan,每个工作goroutine都需要经历等待获取任务->获取任务->获取任务参数->执行任务->异步返回任务结果->再次等待获取任务这一完整的过程,从而Pool通过此实现了控制并发。
由于工作协程goroutine的数量是固定的,所以tunny的并发数也是固定的
tunny是一个很经典的多并发goroutine的实现模型,源码很值得阅读
0x01 tunny 协程池使用
要点;
- 全局池,初始化处理方法
- 在逻辑较重的地方,使用
pool.Process(input)处理并返回 - 如果项目针对多个方法都需要使用协程池,那么有两个方法
- 每个方法都开启独立的协程池
- 仅开启
1个协程池,根据传入参数做switch
import (
"io/ioutil"
"net/http"
"runtime"
"github.com/Jeffail/tunny"
)
func main() {
numCPUs := runtime.NumCPU()
pool := tunny.NewFunc(numCPUs, func(payload interface{}) interface{} {
var result []byte
// TODO: Something CPU heavy with payload
return result
})
defer pool.Close()
http.HandleFunc("/work", func(w http.ResponseWriter, r *http.Request) {
input, err := ioutil.ReadAll(r.Body)
if err != nil {
http.Error(w, "Internal error", http.StatusInternalServerError)
}
defer r.Body.Close()
// Funnel this work into our pool. This call is synchronous and will
// block until the job is completed.
result := pool.Process(input)
w.Write(result.([]byte))
})
http.ListenAndServe(":8080", nil)
}
数据结构
1、Pool
注意reqChan这个成员,初始化长度为1:reqChan: make(chan workRequest),各个空闲的worker把自己的workRequest.jobChan,workRequest.retChan发送给Pool,Pool会把待处理的payload放入workRequest.jobChan,并且等待从workRequest.retChan获取执行结果,代码在此
// Pool is a struct that manages a collection of workers, each with their own
// goroutine. The Pool can initialize, expand, compress and close the workers,
// as well as processing jobs with the workers synchronously.
type Pool struct {
queuedJobs int64
ctor func() Worker
workers []*workerWrapper //存储worker的地方,len()表示有多少个worker
reqChan chan workRequest //有点像令牌
workerMut sync.Mutex
}
2、Worker
工作的抽象,需要实现下面几个方法,tunny提供了closureWorker和callbackWorker两个minimal的Worker实现:
- closureWorker:参数
payload为参数,调用w.processor(payload)处理;对应初始化方法为NewFunc - callbackWorker:参数
payload为func类型,调用f, ok := payload.(func());f()处理;对应初始化方法为NewCallback
type Worker interface {
// Process will synchronously perform a job and return the result.
Process(interface{}) interface{}
// BlockUntilReady is called before each job is processed and must block the
// calling goroutine until the Worker is ready to process the next job.
BlockUntilReady()
// Interrupt is called when a job is cancelled. The worker is responsible
// for unblocking the Process implementation.
Interrupt()
// Terminate is called when a Worker is removed from the processing pool
// and is responsible for cleaning up any held resources.
Terminate()
}
3、workerWrapper
// workerWrapper takes a Worker implementation and wraps it within a goroutine
// and channel arrangement. The workerWrapper is responsible for managing the
// lifetime of both the Worker and the goroutine.
type workerWrapper struct {
worker Worker
interruptChan chan struct{}
// reqChan is NOT owned by this type, it is used to send requests for work.
reqChan chan<- workRequest
// closeChan can be closed in order to cleanly shutdown this worker.
closeChan chan struct{}
// closedChan is closed by the run() goroutine when it exits.
closedChan chan struct{}
}
4、workRequest
workRequest可以视为一个请求处理单元
0x02 分析
tunny的核心原理如下图,涵盖了tunny从资源池中获取goroutine并进行处理的逻辑:
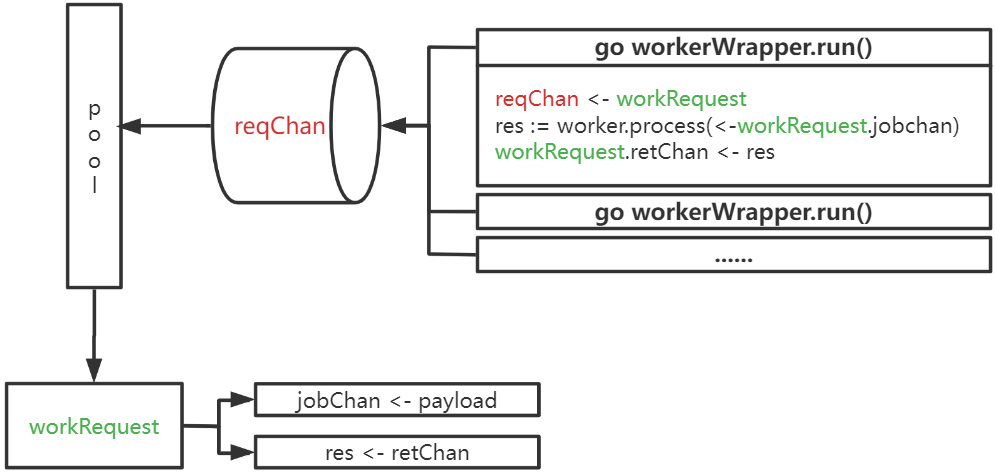
先梳理下tunny的要点,后续再详细分析:
- tunny将goroutine处理单元封装为
workWrapper并且固定数量,由此可以对goroutine的数目进行限制 workerWrapper.run()作为一个goroutine,内部负责具体事务的处理;当一个worker空闲时,会将一个workRequest(可看作是请求处理单元)放入reqChan,并阻塞等待使用方的调用,核心代码在此workRequest包含两个channel,其中jobChan用于传入调用方的输入,retChan用于给调用方返回执行结果- 调用方会从pool的
reqChan中获取一个workRequest请求处理单元,并在workRequest.jobChan中传参,这样workerWrapper.run()中就会继续进行work.process执行;处理结束之后将结果通过workRequest.retChan返回给调用方,然后继续通过reqChan <- workRequest阻塞等待下一个调用方的处理 workerWrapper.run()中的work是一个需要用户实现的接口,必须实现Process(interface{}) interface{},即业务逻辑方法!
0x03 Pool创建
tunny提供了三种创建Pool的方法:
// New creates a new Pool of workers that starts with n workers. You must
// provide a constructor function that creates new Worker types and when you
// change the size of the pool the constructor will be called to create each new
// Worker.
func New(n int, ctor func() Worker) *Pool {
p := &Pool{
ctor: ctor,
reqChan: make(chan workRequest),
}
p.SetSize(n)
return p
}
// NewFunc creates a new Pool of workers where each worker will process using
// the provided func.
func NewFunc(n int, f func(interface{}) interface{}) *Pool {
return New(n, func() Worker {
return &closureWorker{
processor: f,
}
})
}
// NewCallback creates a new Pool of workers where workers cast the job payload
// into a func() and runs it, or returns ErrNotFunc if the cast failed.
func NewCallback(n int) *Pool {
return New(n, func() Worker {
return &callbackWorker{}
})
}
0x03 生产者
tunny的调用入口,是从下面三个方法开始的(开发者不需要关注worker是如何运行的,本质上worker的运行是在PrcessX内部完成的,开发者仅需要关注ProcessX的返回就好了),tunny提供了3种方法:ProcessX,用来插入任务列表
p.Process():会一直阻塞直到任务完成,即使当前没有空闲 worker 也会阻塞p.ProcessTimed():带超时的Process(),支持传入一个超时时间,如果超过这个时间还没有空闲 worker,或者任务还没有处理完成,就会终止,并返回错误p.ProcessCtx():当前 context 状态变为Done之后,任务也会停止执行。context 会由于超时、取消等原因切换为Done状态。
通常,在协程池中超时有 2 种情况:
- 等不到空闲的 worker:所有 worker 一直处理繁忙状态,正在处理的任务比较耗时,无法短时间内完成
- 任务本身比较耗时,必须加一个超时时间方式任务执行被长期阻塞
// Process will use the Pool to process a payload and synchronously return the
// result. Process can be called safely by any goroutines, but will panic if the
// Pool has been stopped.
func (p *Pool) Process(payload interface{}) interface{} {
atomic.AddInt64(&p.queuedJobs, 1)
//1. 获取一个执行令牌
request, open := <-p.reqChan
if !open {
panic(ErrPoolNotRunning)
}
//2. 将运行参数通过channel传递给执行goroutine
request.jobChan <- payload
//3. 阻塞等待获取结果
payload, open = <-request.retChan
if !open {
panic(ErrWorkerClosed)
}
//4. 返回调用方结果
atomic.AddInt64(&p.queuedJobs, -1)
return payload
}
// ProcessTimed will use the Pool to process a payload and synchronously return
// the result. If the timeout occurs before the job has finished the worker will
// be interrupted and ErrJobTimedOut will be returned. ProcessTimed can be
// called safely by any goroutines.
func (p *Pool) ProcessTimed(
payload interface{},
timeout time.Duration,
) (interface{}, error) {
atomic.AddInt64(&p.queuedJobs, 1)
defer atomic.AddInt64(&p.queuedJobs, -1)
tout := time.NewTimer(timeout)
var request workRequest
var open bool
select {
case request, open = <-p.reqChan:
if !open {
return nil, ErrPoolNotRunning
}
case <-tout.C:
return nil, ErrJobTimedOut
}
select {
case request.jobChan <- payload:
case <-tout.C:
request.interruptFunc()
return nil, ErrJobTimedOut
}
select {
case payload, open = <-request.retChan:
if !open {
return nil, ErrWorkerClosed
}
case <-tout.C:
request.interruptFunc()
return nil, ErrJobTimedOut
}
tout.Stop()
return payload, nil
}
// ProcessCtx will use the Pool to process a payload and synchronously return
// the result. If the context cancels before the job has finished the worker will
// be interrupted and ErrJobTimedOut will be returned. ProcessCtx can be
// called safely by any goroutines.
func (p *Pool) ProcessCtx(ctx context.Context, payload interface{}) (interface{}, error) {
atomic.AddInt64(&p.queuedJobs, 1)
defer atomic.AddInt64(&p.queuedJobs, -1)
var request workRequest
var open bool
select {
case request, open = <-p.reqChan:
if !open {
return nil, ErrPoolNotRunning
}
case <-ctx.Done():
return nil, ctx.Err()
}
select {
case request.jobChan <- payload:
case <-ctx.Done():
request.interruptFunc()
return nil, ctx.Err()
}
select {
case payload, open = <-request.retChan:
if !open {
return nil, ErrWorkerClosed
}
case <-ctx.Done():
request.interruptFunc()
return nil, ctx.Err()
}
return payload, nil
}
Process分析
以Process方法为例,生产者的几个步骤:
- 首先阻塞在逻辑
request, open := <-p.reqChan上,当前空闲的worker会把自己的jobChan、retChan放入到p.reqChan中,这样解除阻塞 - 生产者把用户数据
payload放到Worker的jobChan中 - 阻塞在
payload, open = <-request.retChan上,等待Worker执行完成并获取结果,获取结果后解除阻塞 Process运行完成
func (p *Pool) Process(payload interface{}) interface{} {
atomic.AddInt64(&p.queuedJobs, 1)
request, open := <-p.reqChan
if !open {
panic(ErrPoolNotRunning)
}
request.jobChan <- payload
//等待worker处理payload
payload, open = <-request.retChan
if !open {
panic(ErrWorkerClosed)
}
atomic.AddInt64(&p.queuedJobs, -1)
return payload
}
0x04 任务传输
如上所述,tunny的实现思路也是把Worker自身的channel暴露给Pool
- 任务数据channel(Pool把要处理的数据或者func传递给Worker)
- 结果channel,Worker把结果异步传输给Pool
0x05 消费者:任务执行
worker的代码实现如下,worker的实现比较简单,就是两步:
- 当空闲时,就把自己的
jobChan,retChan告知Pool(当前可以处理任务) - 处理完成后,结果发送到
retChan,继续处理下一个任务
func (w *workerWrapper) run() {
jobChan, retChan := make(chan interface{}), make(chan interface{})
defer func() {
w.worker.Terminate()
close(retChan)
close(w.closedChan)
}()
for {
// NOTE: Blocking here will prevent the worker from closing down.
w.worker.BlockUntilReady()
select {
case w.reqChan <- workRequest{
jobChan: jobChan,
retChan: retChan,
interruptFunc: w.interrupt,
}:
select {
case payload := <-jobChan:
result := w.worker.Process(payload)
select {
case retChan <- result:
case <-w.interruptChan:
w.interruptChan = make(chan struct{})
}
case <-w.interruptChan:
w.interruptChan = make(chan struct{})
}
case <-w.closeChan:
return
}
}
}
0x06 动态调整大小
tunny支持使用SetSize方法动态改变Worker大小,tunny对Worker的存储依然使用slice完成,动态调整的思路是:
- 扩容:如果当前协程池大小
lWorkers小于目标sizen,则扩容p.workers = append(p.workers, newWorkerWrapper(p.reqChan, p.ctor())) - 缩容:反之,则停止待缩容的Worker:
p.workers[i].stop()
这里缩容的部分有个小插曲,主要是slice不需要使用时,需要使其slice[i]=nil触发gc回收,否则会有内存泄漏的风险。关于内存泄漏的问题,可以参考此文
// SetSize changes the total number of workers in the Pool. This can be called
// by any goroutine at any time unless the Pool has been stopped, in which case
// a panic will occur.
func (p *Pool) SetSize(n int) {
p.workerMut.Lock()
defer p.workerMut.Unlock()
//当前pool大小
lWorkers := len(p.workers)
if lWorkers == n {
return
}
// Add extra workers if N > len(workers)
for i := lWorkers; i < n; i++ {
p.workers = append(p.workers, newWorkerWrapper(p.reqChan, p.ctor()))
}
// Asynchronously stop all workers > N
for i := n; i < lWorkers; i++ {
p.workers[i].stop()
}
// Synchronously wait for all workers > N to stop
for i := n; i < lWorkers; i++ {
p.workers[i].join()
p.workers[i] = nil
}
// Remove stopped workers from slice
p.workers = p.workers[:n]
}
这里关于缩容的操作,依次调用了stop和join两个方法(类似Linux的线程pthread思路实现很直观,值得借鉴):
stop:向Worker发送退出信号,调用workerWrapper.stop()会关闭closeChan通道,会触发workerWrapper.run()中的for循环跳出,进而执行defer中的close(retChan)和close(closedChan),代码join:阻塞等待每个Worker成功退出
这里需要关闭retChan channel是为了防止ProcessX方法在等待retChan数据,closedChanchannel关闭后,workerWrapper.join()方法就返回了,这里的动态扩缩容都是实时生效的
{
// Asynchronously stop all workers > N
for i := n; i < lWorkers; i++ {
p.workers[i].stop()
}
// Synchronously wait for all workers > N to stop
for i := n; i < lWorkers; i++ {
p.workers[i].join()
p.workers[i] = nil
}
// Remove stopped workers from slice
p.workers = p.workers[:n]
}
func (w *workerWrapper) stop() {
close(w.closeChan)
}
func (w *workerWrapper) join() {
<-w.closedChan
}
0x07 一些细节
0x08 总结
tunny的思路与ants有较大的区别:
- tunny仅支持同步的方式执行任务(适用于需要同步等待结果的场景),虽然任务在另一个 goroutine 执行,但是提交任务的 goroutine 必须等待结果返回或超时,不能做其他事情
- tunny 为了支持超时和取消,设计了多个channel用于和执行任务的 goroutine 通信。一次任务执行的过程涉及多次通信,性能会有损失
- 而ants完全是异步的任务执行流程,相比tunny性能是稍高一些的。但是也因为它的异步特性,导致没有任务超时、取消这些机制。而且如果需要收集结果,必须要自己编写额外的代码