0x00 前言
本文介绍一种高性能的 hashtable,使用场景是结合最小堆统计单位时间窗口的 key 值计数并排序,该 hashtable 的特点是:
- hashtable 的整体大小是固定的,不扩容(避免问题),存储地址连续的(需要提前预估好存储上限)
- 无指针,以 index 作为链接下一个节点
- 存储分为 bucket 区和冲突链,冲突链上以 hop(非链表,还是以位置代替指针指向) 的形式进行查找及回收
- 避免频繁内存申请和释放导致的内存碎片
现网中的使用场景,针对一段时间内,海量的访问 IP(请求),如何高效的查找到其中的 TOP-N?此问题的一种高效解法就是 hashtable 加最大堆排序。
0x01 Hashtable 简介
hashtable 的结构如下图所示:
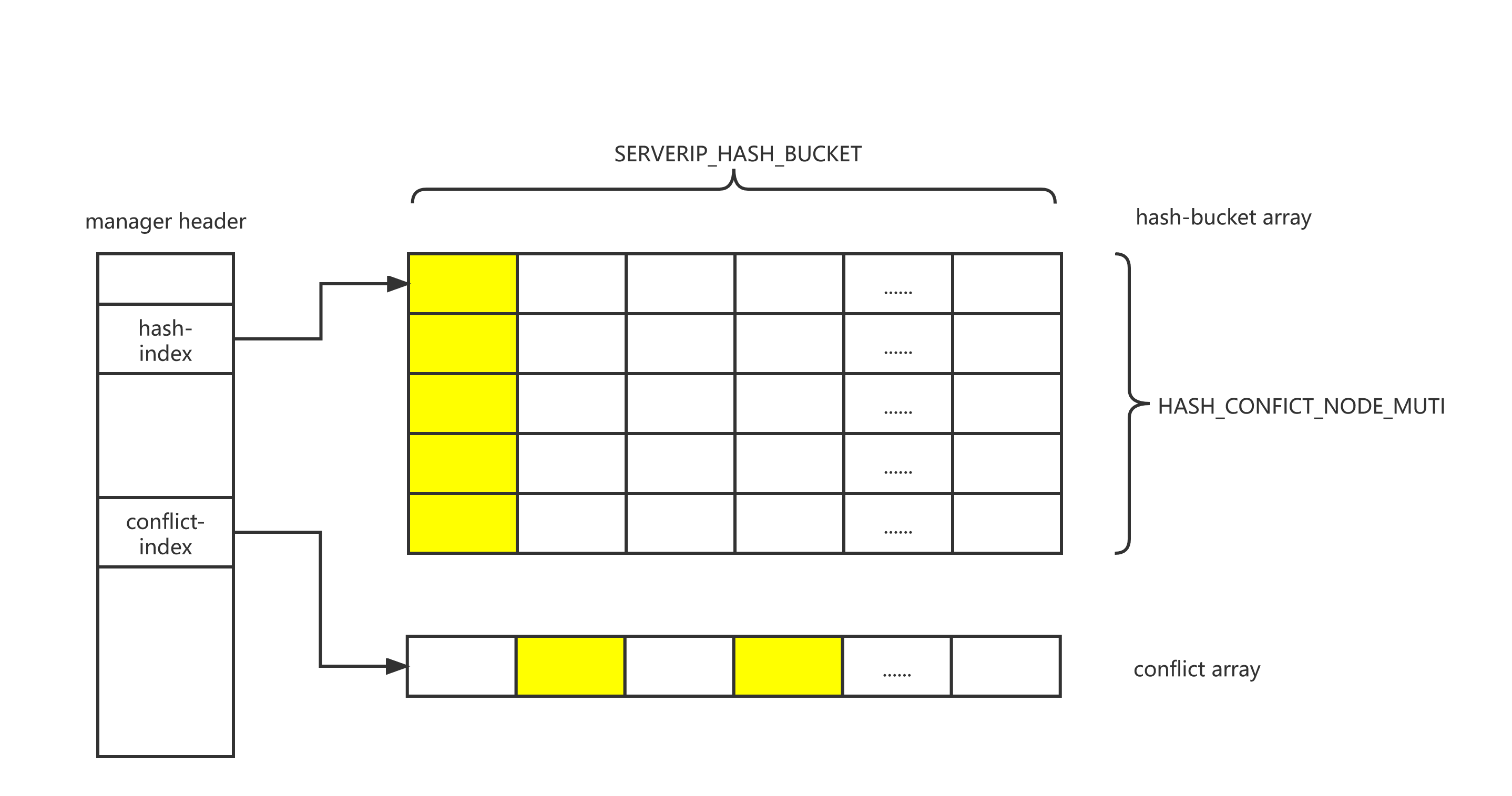
0x01 结构定义
hash 节点
enum HASH_TABLE_ENUM_CONSTANT{
//IP 哈希桶数
SERVERIP_HASH_BUCKET = 65536,//2^16
SERVERIP_HASH_BUCKET_SHIFT = 16,
};
冲突链
enum HASH_TABLE_TYPE{
HASH_CONFICT_NODE_MUTI=4,
HASH_CONFICT_NODE_MUTI_SHIFT=2,
};
管理节点
// 通用的 hashtable 头结点定义
struct _comm_hash_table{
void *pMemStart; // 内存首地址
void *pHashArray;
void *pConflictArray;
int32_t iCurBucketIndex;
int32_t iNodeCount;
int32_t iConflictCount;
void *pCurNode;
int32_t iCurIndexType;
int32_t iType;
uint32_t uUsed;
uint32_t uReserved;
}__rte_cache_aligned;
hash-item 节点
_server_ip 是每个 hashtable 的 item 节点,
//hashtable 的实例化节点 1
struct _server_ip{
uint32_t uServerip; //key:ip 地址
uint32_t uServeripCount; //value:统计数量
uint32_t uNextIndex; // 指向下一个节点
uint32_t uReserved; // 对齐用
};
0x02 操作
创建
hashtable 创建方法如下:
int32_t CreateCommHashTable(CommHashTable **t_pCommHashTable, uint32_t t_uTotalTableSize, uint32_t t_uTableSize,uint32_t t_uConflictTableSize)
{
//....
//total buffersize
uint32_t uTotalMemSize = sizeof(CommHashTable)+t_uTotalTableSize;
int8_t *pMem = (uint8_t *)calloc(uTotalMemSize, 1);
(*t_pCommHashTable)=(CommHashTable *)pMem;
memset(pAllocBuffer, 0, uTotalMemSize);
(*t_pCommHashTable)->pHashArray = (int8_t *)pMem + sizeof(CommHashTable);
(*t_pCommHashTable)->pConflictArray = (int8_t *)pMem + sizeof(CommHashTable)+t_uTableSize;
return RET_RIGHT;
}
插入
插入分两种情况:
- 插入主链
- 若主链已满,则插入到扩展链,同时建立该元素(在扩展链)与主链上最后一个元素的连接(index)
int32_t InsertServerIpHashTable(CommHashTable *t_pHashTable, uint32_t t_uServerip)
{
if (!t_pHashTable)
return RET_ERROR;
ServerIp *pHead = ((ServerIp *)t_pHashTable->pHashArray) + GetServerIpNodePos(t_uServerip);
if (pHead == NULL){
return RET_ERROR;
}
int32_t i = 1;
for (i = 1; i < HASH_CONFICT_NODE_MUTI; i++)
{
if (pHead[i].uServerip == t_uServerip){
pHead[i].uServeripCount++;
return RET_RIGHT;
}
else{
//free node
if (pHead[i].uServerip == 0){
pHead[i].uServerip = t_uServerip;
pHead[i].uServeripCount = 1;
pHead[0].uServerip++;
t_pHashTable->iNodeCount++;
return RET_RIGHT;
}
}
}
uint32_t uNextIndex = pHead[HASH_CONFICT_NODE_MUTI - 1].uNextIndex;
if (uNextIndex && uNextIndex <= SERVERIP_HASH_BUCKET){
ServerIp *pConflictArray = (ServerIp *)(t_pHashTable->pConflictArray);
uint32_t uFind = uNextIndex;
while (uNextIndex && uNextIndex <= SERVERIP_HASH_BUCKET)
{
if (pConflictArray[uNextIndex - 1].uServerip == t_uServerip){
pConflictArray[uNextIndex - 1].uServeripCount++;
return RET_RIGHT;
}
uFind = uNextIndex;
uNextIndex = pConflictArray[uNextIndex - 1].uNextIndex;
}
for (i = 0; i < SERVERIP_HASH_BUCKET; i++)
{
if (pConflictArray[i].uServerip == 0){
pConflictArray[i].uServerip = t_uServerip;
pConflictArray[i].uNextIndex = 0;
pConflictArray[i].uServeripCount = 1;
pConflictArray[uFind - 1].uNextIndex = i + 1;
pHead[0].uServerip++;
t_pHashTable->iNodeCount++;
t_pHashTable->iConflictCount++;
return RET_RIGHT;
}
}
return RET_ERROR;
}
else{
ServerIp *pConflictArray = (ServerIp *)(t_pHashTable->pConflictArray);
for (i = 0; i < SERVERIP_HASH_BUCKET; i++)
{
if (pConflictArray[i].uServerip == 0){
pConflictArray[i].uServerip = t_uServerip;
pConflictArray[i].uNextIndex = 0;
pConflictArray[i].uServeripCount = 1;
pHead[HASH_CONFICT_NODE_MUTI - 1].uNextIndex = i + 1;
pHead[0].uServerip++;
t_pHashTable->iNodeCount++;
t_pHashTable->iConflictCount++;
return RET_RIGHT;
}
}
return RET_ERROR;
}
}
查找
uint32_t SearchServerIpHashTable(CommHashTable *t_pHashTable, uint32_t t_uServerip)
{
if (!t_pHashTable)
return RET_ERROR;
ServerIp *pHead = ((ServerIp *)t_pHashTable->pHashArray) + GetServerIpNodePos(t_uServerip);
if (NULL == pHead){
return RET_ERROR;
}
if (pHead[0].uServerip == 0)
return RET_ERROR;
int32_t i = 1;
for (i = 1; i < HASH_CONFICT_NODE_MUTI; i++)
{
if (pHead[i].uServerip == t_uServerip){
return RET_RIGHT;
}
}
if (pHead[HASH_CONFICT_NODE_MUTI - 1].uNextIndex){
ServerIp *pConflictArray = (ServerIp *)(t_pHashTable->pConflictArray);
uint32_t uNextIndex = pHead[HASH_CONFICT_NODE_MUTI - 1].uNextIndex;
while (uNextIndex && uNextIndex <= SERVERIP_HASH_BUCKET)
{
if (pConflictArray[uNextIndex - 1].uServerip == t_uServerip){
return RET_RIGHT;
}
uNextIndex = pConflictArray[uNextIndex - 1].uNextIndex;
}
}
return RET_ERROR;
}
删除
删除与插入的情况差不多,删除某个节点时,记得要重建当前删除结点的前后节点(后节点若存在)的关系
int32_t DeleteServerIpHashTable(CommHashTable *t_pHashTable, uint32_t t_uServerip)
{
if (!t_pHashTable)
return RET_ERROR;
ServerIp *pHead = ((ServerIp *)t_pHashTable->pHashArray) + GetServerIpNodePos(t_uServerip);
if (pHead[0].uServerip == 0)
return RET_RIGHT;
int32_t i = 1;
for (i = 1; i < HASH_CONFICT_NODE_MUTI; i++)
{
if (pHead[i].uServerip == t_uServerip){
pHead[i].uServerip = 0;
pHead[0].uServerip--;
t_pHashTable->iNodeCount--;
return RET_RIGHT;
}
}
if (pHead[HASH_CONFICT_NODE_MUTI - 1].uNextIndex){
ServerIp *pConflictArray = (ServerIp *)(t_pHashTable->pConflictArray);
uint32_t uNextIndex = pHead[HASH_CONFICT_NODE_MUTI - 1].uNextIndex;
uint32_t uFind = uNextIndex;
while (uNextIndex && uNextIndex <= SERVERIP_HASH_BUCKET)
{
if (pConflictArray[uNextIndex - 1].uServerip == t_uServerip)
break;
uFind = uNextIndex;
uNextIndex = pConflictArray[uNextIndex - 1].uNextIndex;
}
if (uNextIndex && uNextIndex <= SERVERIP_HASH_BUCKET){
if (uNextIndex == pHead[HASH_CONFICT_NODE_MUTI - 1].uNextIndex){
pHead[HASH_CONFICT_NODE_MUTI - 1].uNextIndex = pConflictArray[uNextIndex - 1].uNextIndex;
}
else{
pConflictArray[uFind - 1].uNextIndex = pConflictArray[uNextIndex - 1].uNextIndex;
}
pConflictArray[uNextIndex - 1].uNextIndex = 0;
pConflictArray[uNextIndex - 1].uServerip = 0;
pHead[0].uServerip--;
t_pHashTable->iNodeCount--;
t_pHashTable->iConflictCount--;
}
}
return RET_RIGHT;
}
0x02 建堆及排序
在 hashtable 一轮操作完成后(定时器间隔),可以对 hashtable 中的数据进行排序及汇总,这里采用最小堆实现次数排序:
1、建堆
void BuildHeapOfHashTable(CommHashTable *t_pCommHashTable,uint32_t *t_pHeapArray,uint32_t *t_pKeyArray,int32_t t_uLen)
{
// 遍历 hashtable, 首先建立一个长度为 N 的小根堆
int32_t i = 0;
ServerIp *pTempTcpSessionNode =NULL;
pTempTcpSessionNode = (ServerIp *)GetHashTableFirstNode(t_pCommHashTable);
if (pTempTcpSessionNode != NULL){
t_pHeapArray[i] = pTempTcpSessionNode->uServeripCount;
t_pKeyArray[i] = pTempTcpSessionNode->uServerip;
//printf("####i=%d,key=%d,count=%d\n",i, t_pKeyArray[i],t_pHeapArray[i]);
i++;
//printf("%p\n", pTempTcpSessionNode);
//DeleteServerIpHashTable(&pCommHashTable, uHash);
//ClearTcpSessionNode(pTempTcpSessionNode);
while (1)
{
if (i>= t_uLen){
break;
}
pTempTcpSessionNode = (ServerIp *)GetHashTableNextNode(t_pCommHashTable);
if (!pTempTcpSessionNode){
break;
}
t_pHeapArray[i] = pTempTcpSessionNode->uServeripCount;
t_pKeyArray[i] = pTempTcpSessionNode->uServerip;
//printf("####key=%d,count=%d\n", t_pKeyArray[i],t_pHeapArray[i]);
i++;
}
}
// 将 m_Data[0, Len-1] 建成小根堆,这里只维护一个小根堆,不排序
for (i = t_uLen / 2 - 1; i>= 0; i--)
{
HashtableHeapAdjust(t_pHeapArray, t_pKeyArray, i, t_uLen);
}
while (1)
{
pTempTcpSessionNode = (ServerIp *)GetHashTableNextNode(t_pCommHashTable);
if (!pTempTcpSessionNode){
break;
}
uint32_t uKey = pTempTcpSessionNode->uServerip;
uint32_t uCount = pTempTcpSessionNode->uServeripCount;
if (uCount> t_pHeapArray[0])
{
// 如果新的元素比最小堆顶的元素大的话, 淘汰堆顶的元素, 调整堆
// 交换并调整堆
t_pHeapArray[0] = uCount;
t_pKeyArray[0] = uKey;
HashtableHeapAdjust(t_pHeapArray,t_pKeyArray,0,t_uLen);
}
}
return;
}
2、堆排序
// 调整小根堆,堆顶为 Top K 最小
void HashtableHeapAdjust(uint32_t *t_pHeapArray, uint32_t *t_pKeyArray,int32_t t_iStart, int32_t t_iLen){
int32_t nMinChild = 0;
while ((2 * t_iStart + 1) < t_iLen)
{
nMinChild = 2 * t_iStart + 1;
if ((2 * t_iStart + 2) < t_iLen)
{
// 比较左子树和右子树, 记录最小值的 Index
if (t_pHeapArray[2 * t_iStart + 2] < t_pHeapArray[2 * t_iStart + 1])
{
nMinChild = 2 * t_iStart + 2;
}
}
//change data
if (t_pHeapArray[t_iStart] > t_pHeapArray[nMinChild])
{
// 交换 t_iStart 与 nMaxChild 的数据
uint32_t uTemp = t_pHeapArray[t_iStart];
t_pHeapArray[t_iStart] = t_pHeapArray[nMinChild];
t_pHeapArray[nMinChild] = uTemp;
// 交换 key
uint32_t uKeyTemp = t_pKeyArray[t_iStart];
t_pKeyArray[t_iStart] = t_pKeyArray[nMinChild];
t_pKeyArray[nMinChild] = uKeyTemp;
// 堆被破坏, 需要重新调整
t_iStart = nMinChild;
}
else
{
// 比较左右孩子均大则堆未破坏, 不再需要调整
break;
}
}
}
0x03 参考
转载请注明出处,本文采用 CC4.0 协议授权