0x00 前言
本篇介绍下 InnoDB 引擎的索引使用及优化。重点关注几个问题:
- 索引的原理
- 如何建索引
- 如何使用索引
- 如何调优?
索引的本质
索引就像一本书的目录。而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点。这样就帮助用户有效地提高了查找速度。所以,使用索引可以有效地提高数据库系统的整体性能。
索引分类
- 从用户使用的角度:单列索引(主键索引 / 唯一索引 / 普通索引) 与组合索引,用户的设置与
SELECT会受此影响 - 从磁盘存储结构:聚簇索引和非聚簇索引
- 从索引的数据结构:
B+树索引 / Hash 索引 / 倒排索引
聚簇索引 VS 非聚簇索引
1、聚簇索引
一张表只有一个聚簇索引,数据库会以聚簇索引来构造一个 B+ 树 (即聚簇索引一定也是 B+ 树索引),叶子节点即表的行数据。默认的聚簇索引为主键索引。表内行数据按照聚簇索引的顺序在磁盘存放。建议 InnoDB 表使用默认自增 id 做主键(相较于 uuid 这类字符串做主键,由于主键使用了聚簇索引,如果主键是自增 id,那么对应的数据一定也是相邻地存放在磁盘上的,写入性能比较高。如果是 uuid 的形式,频繁的插入会使 InnoDB 频繁地移动磁盘块,写入性能相对较低)
主键的生成规则:
- 没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引
- 若无此类索引,InnoDB 会隐式定义一个主键来作为聚簇索引
此外,直接 SELECT * 就是按照聚簇索引的顺序展示数据。
2、非聚簇索引(辅助索引)
创建的索引,如复合索引、前缀索引、唯一索引,都是属于非聚簇索引,底层有两种数据结构:B+ 树和 Hash 表。B+ 树则是在叶子节点存放对应行数据的聚簇索引和该树对应的索引值。
小结
innodb 存储引擎的 B+ 树,innodb 按索引是否是主键可以分为聚簇索引(主键索引)和辅助索引(也叫非聚簇索引);按照索引单列还是多列可以分为单列索引和复合索引(也叫联合索引、多列索引)
0x01 索引查询的基础
简单例子
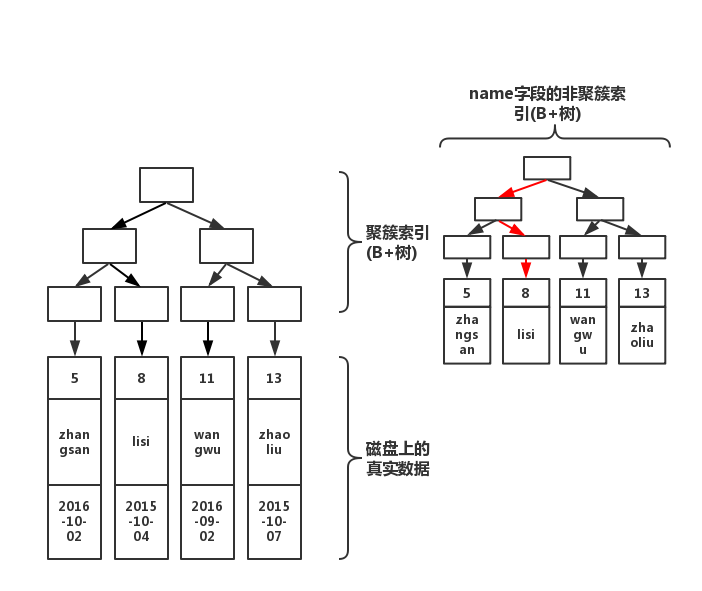
以 此文 的例子:
| pId | name | birthday |
|---|---|---|
| 5 | zhangsan | 2016-10-02 |
| 8 | lisi | 2015-10-04 |
| 11 | wangwu | 2016-09-02 |
| 13 | zhaoliu | 2015-10-07 |
存储结构如下图所示(上半部分是由主键形成的 B+ 树,下半部分就是磁盘上存储的数据):
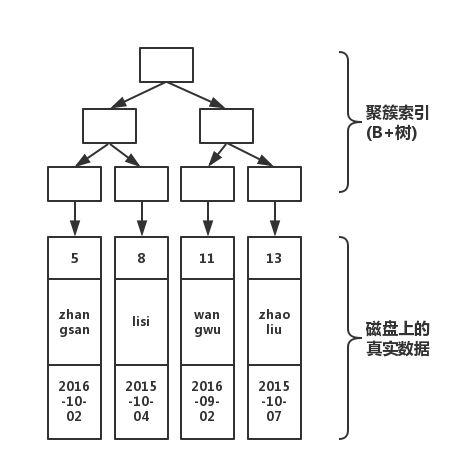
查询:聚簇索引
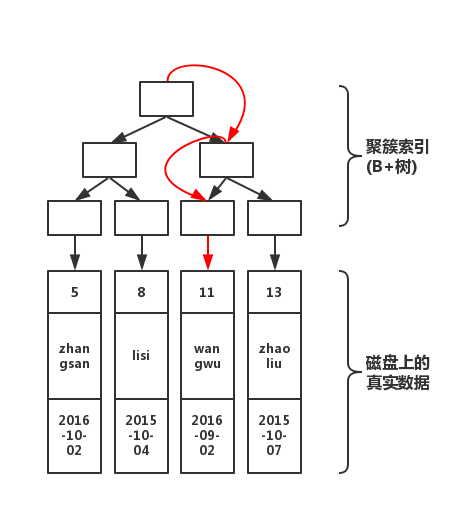
select * from table where pId='11'
对应的查询过程为,从根开始,经过 3 次查找即完成。若不使用索引,那就要在磁盘上,进行逐行扫描,直到找到数据位置。显然,使用索引速度会快。但是在插入数据的时候,需要维护这颗 B+ 树的结构,因此写入性能会下降。
查询:非聚簇索引
将 name 列建立 index,innodb 根据索引字段 name 生成一颗新的 B+ 树(增加了表空间)。非聚簇索引的叶子节点并非真实数据,它的叶子节点依然是索引节点,存放的是该索引字段的值以及对应的主键索引(聚簇索引)。
create index index_name on table(name);
存储结构变成下面这样:
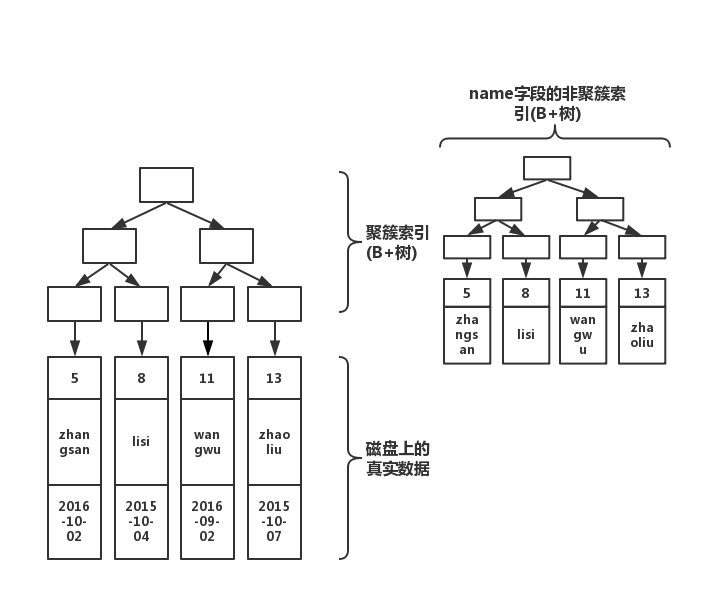
如果使用 name 字段做查询,查询过程变成先从非聚簇索引树开始查找,然后找到聚簇索引后。根据聚簇索引,在聚簇索引的 B+ 树上,找到完整的数据:
select * from table where name='lisi'
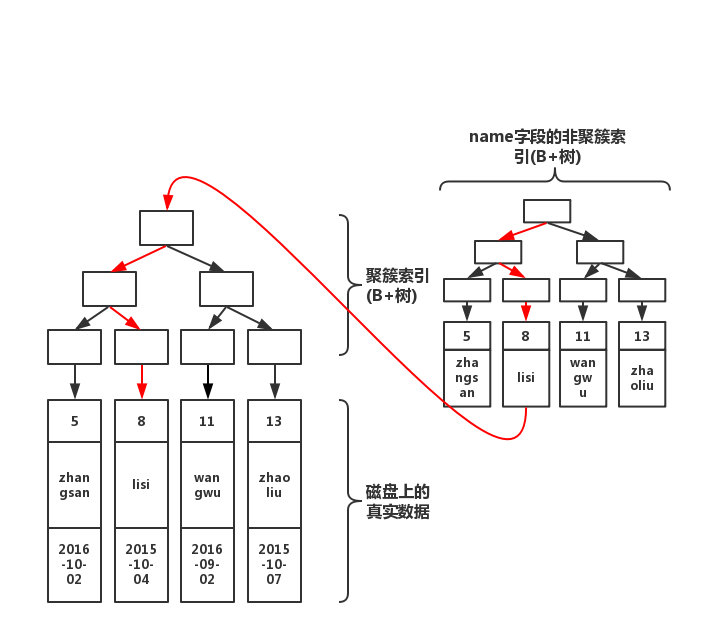
查询:非聚簇索引的特殊情况
如果在非聚簇索引树上找到了想要的值,就不会去聚簇索引树上查询(常见的优化场景就是尽量用 SELECT col 代替 SELECT *)。如下面的查询:
select name from table where name='lisi'
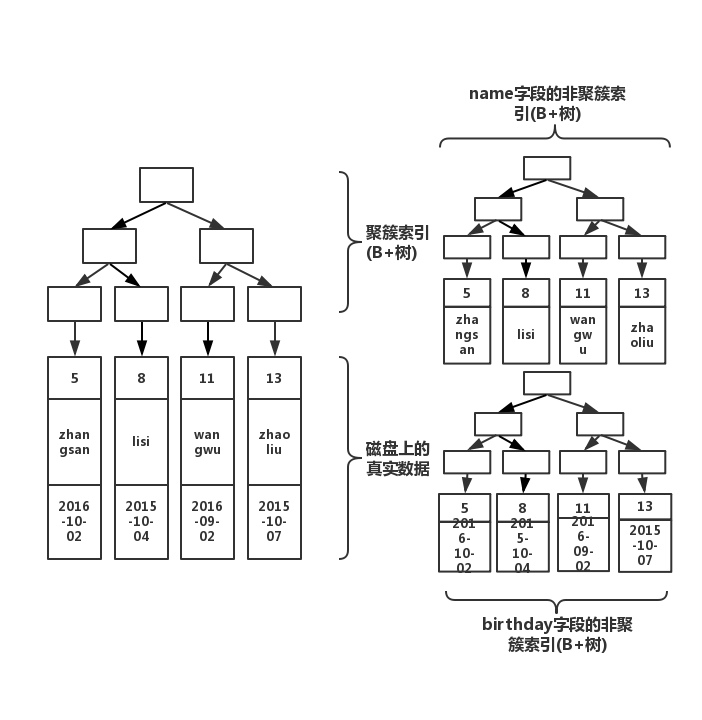
索引:按需添加
多增加一个索引,就会多生成一颗非聚簇索引树。在做插入操作的时候,需要同时维护这几颗树的变化,因此,如果索引太多,插入性能就会下降。因此,索引并非越多越好,如下面增加多一个索引之后的视图:
create index index_birthday on table(birthday);
0x02 联合索引
最左匹配原则(重点)
最左匹配原则指的 SQL 中用到了联合索引中的最左边的索引(相对顺序),那么这条 SQL 语句就可以利用这个联合索引去进行匹配,当遇到范围查询(>/</between/like)就会停止匹配。
举例来说,(a,b) 字段为联合索引,WHERE 后条件有如下几种 case:
a = 1或a = 1 AND b = 2、b = 2 AND a =1:可以匹配索引b = 2:不能匹配
又如:(a,b,c,d) 字段的联合索引,当 WHERE 为 a = 1 AND b = 2 AND c > 3 AND d = 4 时,则只有 a/b/c 字段能用到索引,而 d 就匹配不到(原因是遇到了范围查询 c>3 停止)
最左匹配的原理
对 (a,b) 字段建立联合索引,本质上还是一棵 B+ 树,如下所示。a 按顺序排列(1/1/2/2/3/3),b 在 a 确定的情况下按顺序排列(全局无序,局部有序)。所以必须基于 a 来查找 b 字段,否则 b 就是无序的,就无法使用索引了。
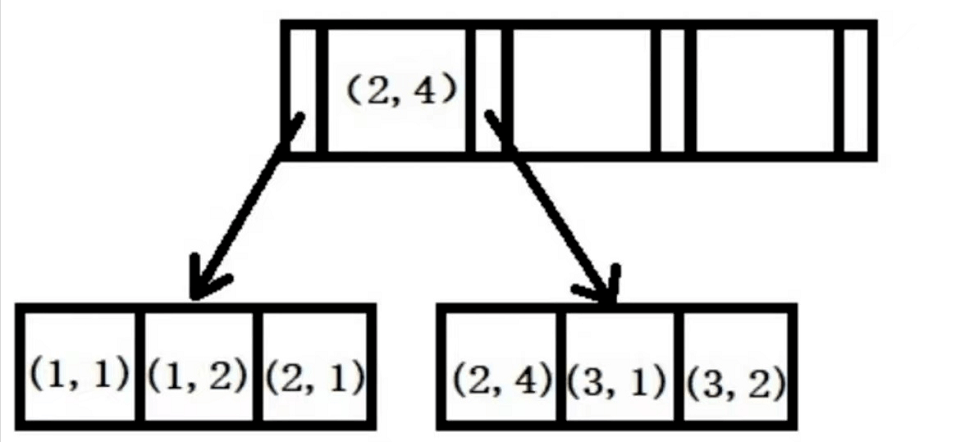
注意,上文描述的匹配不到,不代表不会触发索引,看下面的例子(联合索引字段为 (a,b,c)):
查询示例
create table t_test(
id bigint(20) primary key,
a int not null default 0,
b int not null default 0,
c int not null default 0,
`name` varchar(16) not null default '',
index (a,b,c)
)engine=InnoDB;
mysql> EXPLAIN SELECT b FROM t_test WHERE a=2;
+----+-------------+--------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | t_test | NULL | ref | a | a | 4 | const | 1 | 100.00 | Using index |
+----+-------------+--------+------------+------+---------------+------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT b FROM t_test WHERE b=2;
+----+-------------+--------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | t_test | NULL | index | a | a | 12 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
ref:这种类型表示 mysql 会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。index:这种类型表示 mysql 会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个联合索引的一部分,mysql 都可能会采用 index 类型的方式扫描。缺点是效率不高,mysql 会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。
关于 EXPLAIN 的应用及字段意义,下面再详述。
联合索引的意义(建议使用)
- 减少开销:建立
1个联合索引(a,b,c),相当于(a)、(a,b)、(a,b,c)这3个索引。由于新建索引会增加写操作的开销和磁盘空间的开销,对于大量数据的表,推荐使用联合索引 - 避免回表:如对联合索引
(a,b,c),如果查询的字段落在索引中,如SELECT a,b,c FROM t_test WHERE a=1 AND b=2,那么 MySQL 可以直接通过遍历索引取得数据,而无需回表,减少了很多的随机 IO 操作
此外,联合索引相对于单索引,可以提升查询效率。索引列越多,通过索引筛选出的数据越少。比如要查询需要回表的 SELECT * 操作,联合索引筛选出需要回表的数据可能更小。
总结:开发者需要了解的索引应用
这里先汇总下,MYSQL 索引的应用:
聚簇索引(pk 为主键)
- 主键等值查询:
SELECT * FROM t WHERE pk=100 - 按主键范围查询:
SELECT * FROM t WHERE pk>10 AND pk<10000,key 为 PRIMARY,type 为 range。通过10和10000这两个pk叶子节点的父节点 key 定位在这个范围的 page,然后直接顺序读这些 page 即可 - 按主键排序:
SELECT * FROM t ORDER BY pk LIMIT 10,key 为 PRIMARY,type 为 index,并没有 Using filesort。因为 pk 上的数据是有序的,就在索引树上遍历顺序取10行记录即可
辅助索引的应用
和聚簇索引一样,同样可以按索引列等值查询、排序、按索引列范围查询,但是辅助索引上可能没有查询语句 SELECT 的列,这就引出了 innodb 非聚簇索引独有的耗时操作回表,和重要的 SQL 优化手段 覆盖索引。
1、覆盖索引与回表问题
覆盖索引是指从辅助索引就可以得到查询结果,不需要回聚簇索引中查询,注意,在辅助索引既可能是等值查询,也可能是范围查询,也可能是全索引扫描(因为辅助索引也有自己的一颗 B+ 树),只要不回表。反之,回表就是对二级索引中一次查询得到每个主键,都需要回聚簇索引中查询每行数据。如 SELECT * 往往会造成回表,一般的 SQL 规范都会要求尽量避免。覆盖索引可以减少 I/O 数量,提升查询性能
COUNT 是一种特殊的覆盖索引(虽然它往往是一种扫描遍历),由于 COUNT 没有 SELECT 具体列,只是统计个数。例如 SELECT COUNT(*) FROM table,如果 table 有一个辅助索引,辅助索引的体积远小于聚簇索引,就不会走聚簇索引。
2、回表太多还不如顺序扫描
3、联合索引的应用
3.1、最左前缀原则
联合索引最重要的概念是 最左前缀原则,即最左前缀原则指的是 WHERE 查询从索引的最左列开始匹配索引,并且不跳过索引中的列。
- 不是从最左前缀开始匹配的,索引全部失效
- 从最左前缀开始匹配,中间出现跳跃或者范围查询导致了索引失效,只有从左开始匹配的索引生效(即部分生效,右边的列索引失效。需要理解优化器对范围查询的工作方式)
-- 假设有复合索引 `(a, b, c)`,主键 `(pk1, pk2)`
-- 符合最左前缀原则,索引生效
SELECT b FROM test WHERE a=xxx;
SELECT pk2, b FROM test WHERE a=xxx AND b=xxx;
SELECT pk1, pk2, a, b FROM test WHERE a=xxx AND b=xxx AND c=xxx;
-- 违反最左前缀原则,索引失效
SELECT * FROM test WHERE b=xxx;
SELECT * FROM test WHERE b=xxx AND c=xxx;
-- 跳跃中间列,只有最左列索引生效
SELECT * FROM test WHERE a=xxx AND c=xxx;
-- 索引 a, b 生效,c 失效
SELECT * FROM test WHERE a=xxx AND b>xxx AND c=xxx;
3.2、使用复合索引优化 ORDEY BY
-- 假设有复合索引 `(a, b, c)`,主键 `(pk1, pk2)`
-- 符合最左前缀原则,索引生效
SELECT * FROM t WHERE a=xxx ORDER BY b
SELECT * FROM t WHERE a=xxx AND b=xxx ORDER BY c
-- 违反最左前缀原则,索引失效
SELECT * FROM t WHERE a=xxx ORDER BY c
3.3、复合索引 + 最左前缀 + 覆盖索引
以上的例子索引虽然生效但是需要回表,但是覆盖索引就可以不用回表了,这种方式 ORDEY BY 的排序方式是有序索引顺序扫描,EXPLAIN 的 type 为 index,Extra 显示 Using index
此外,需要理解的重要一点是,联合索引的意义,比如 (a,b) 是联合索引,那么在辅助索引树中就意味着,在 a 相等的情况下,那么 b 也是相对有序的,看下面的例子:
-- 复合索引 (a, b),主键 pk
-- 如果不覆盖索引,优化器可能不走索引,type 为 ALL,Using filesort
SELECT * FROM t ORDER BY a ASC;
SELECT * FROM t ORDER BY a DESC;
-- 以下为覆盖索引,没有回表的问题,ORDER BY 会走索引
-- 单列排序,Using index
SELECT pk FROM t ORDER BY a ASC;
SELECT pk, a FROM t ORDER BY a ASC;
SELECT pk, a, b FROM t ORDER BY a ASC;
-- 多列排序,Using index
SELECT pk, a, b FROM t ORDER BY a, b ASC;
SELECT pk, a, b FROM t ORDER BY a DESC, b DESC;
-- 不合最左前缀,Using index, Using filesort
SELECT pk, a, b FROM t ORDER BY b DESC, a DESC;
-- 排序升降序不同,Using index, Using filesort
SELECT pk, a, b FROM t ORDER BY a ASC, b DESC;
那么,最佳实践就是:
- 减少额外排序,通过索引返回有序结果
WHERE的列和ORDER BY的使用相同的索引ORDER BY的顺序符合最左前缀ORDER BY的顺序要么都升序,要么都降序,保持一致(MySQL8.0 可以创建不同升降序的索引,如ALTER TABLE t ADD INDEX idx_a_b_c (a, b DESC, c))- Using filesort 的调参优化方式:调大
sort_buffer_size和max_length_for_sort_data参数
0x03 索引的要点及使用建议
工作中,对 MySQL 索引的应用一般分为正面场景和反面场景:
- 正面场景启发开发者何时去使用?
- 反面场景提醒开发者何时去优化?
这里先给出一些使用经验:
何时加索引
- 规划表中需要使用到查询的字段并尽量建立联合索引(可能使用到单条件查询的放在前面)
- 需要快速找到符合
WHERE查询条件的结果,包括全值匹配、范围查询、LIMIT查询等 - 如果有多个索引,通常走选择度最高的索引,选择度越高,遍历行数越少
- 关联查询
JOIN时的外键 - 找
MIN()或者MAX()时 ORDER BY和GROUP BY子句,本质就是排序的时候- 覆盖索引不需要回表检索数据行,只需查索引树,尽量不要使用
SELECT *,回表的开销可能会超过全表扫描排序 - 尽量使用复合索引,如
(col_1, col_2, col_3)的复合索引相当于有(col_1)、(col_1, col_2)、(col_1, col_2, col_3)三个索引可以选择,而对于单列索引(col_1)、(col_2)、(col_3)MySQL 只能选择其中一个最优的来走,所以只要复合索引顺序恰当,是比单列索引性能更高的 - 合理用好索引,应该可解决大部分 SQL 问题。当然索引也非越多越好,过多的索引会影响写操作性能
如何避免索引失效
1、不一定要走索引的情况
MySQL 评估走索引比全表扫描更慢,则不走索引。现在的评估机制比较复杂,会评估很多因素,比如表大小、表行数、IO 块大小等。一般来说,行数很少的表,或者需要的结果占了全表的大部分,走索引不如走全表扫描快
2、索引列匹配不上(即索引失效,不当的查询条件引发索引失效,非常重要!常见于以下几种情况)
-
发生了自动转换,如索引列
key_col是int型,而查询WHERE key_col='1',或者索引列key_col是varchar型,而查询WHERE key_col=1;在此情况下,MySQL 的优化器会自动进行类型转换,造成索引失效 -
左边出现通配符
%,如查询方式WHERE key_col LIKE '%XXX',会导致key_col列索引失效 -
索引列上进行运算操作,如
substring(),x+1等,同样会导致索引失效 -
关联查询
JOIN时的外键类型定义不同。比如VARCHAR(10)和CHAR(10)被视为相同类型,但VARCHAR(10)和CHAR(15)就不是相同类型;见下文的例子 -
值比较时不是相同的字符编码,比如
key_col是utf8编码,查询WHERE是latin1,不走索引 -
若建表时使用的
default charset utf8mb4,但是指定了字段的字符集为utf8,联表JOIN查询中 A 表和 B 表的字段字符集不一致也会导致索引失效
3、排序时 ORDER BY
- 不符合最左前缀
- 升降序不统一
4、OR 连接的条件,只要有一列没有索引,则全部索引列都不生效
# AND 连接,都有索引就走索引
SELECT * FROM test WHERE key_col_1=val_1 AND key_col_2=val_2;
# OR 连接,一列没索引就都不走索引
SELECT * FROM test WHERE key_col_1=val_1 OR not_key_col_2=val_2;
举个例子,下面SQL如何优化?
SELECT count(id) as var_a FROM xxxxx_table
where DATE_FORMAT(statistic_time, '%Y-%m') = DATE_FORMAT(CURDATE(), '%Y-%m') AND status != "termination" AND operator_center IN (26046,44158,44159,44160,44161,44162,44163,53604)
根据本小节描述的规范,优化后的查询语句如下:
# 创建索引
CREATE INDEX idx_operator_center_statistic_time_status
ON xxxxx_table(operator_center, statistic_time, status);
SELECT COUNT(id) AS var_a
FROM xxxxx_table
WHERE operator_center IN (26046,44158,44159,44160,44161,44162,44163,53604)
AND statistic_time >= DATE_FORMAT(NOW(), '%Y-%m-01')
AND statistic_time < DATE_FORMAT(NOW() + INTERVAL 1 MONTH, '%Y-%m-01')
AND status != 'termination';
优化思路如下:
- 将
operator_center放在索引最左侧,因为IN条件能有效利用索引的范围扫描,接着是statistic_time,避免全表扫描并通过范围查询快速定位本月数据,最后一列索引失效 - 查询条件优化:将
DATE_FORMAT(statistic_time, '%Y-%m') = DATE_FORMAT(CURDATE(), '%Y-%m')替换为明确的日期范围查询,避免对字段使用函数导致索引失效 - 使用
statistic_time >= 本月第一天和 statistic_time < 下个月第一天的方式,既保证准确包含本月所有数据,又允许索引有效使用
业务中常用索引技巧
通常在项目中,遇到的常见问题都是索引相关的问题,这里列举几个典型的:
1、最最关键:使用合适的索引,避免全表扫描
通过慢查询分析,大多数问题都是忘了加索引或者索引使用不当,如索引字段上加函数导致索引失效等 (如 WHERE UNIX_TIMESTAMP(update_time)>123456789 就是典型的不当且常用法)
+----------+------------+---------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------+
| 1 | 0.00024700 | select * from mytable where id=100 |
| 2 | 0.27912900 | select * from mytable where id+1=101 |
+----------+------------+---------------------------------------+
2、在拉取全表数据场景时的优化,不要使用 SELECT xx FROM xx LIMIT 5000,1000 这种形式批量拉取,其实这个 SQL 每次都是全表扫描;建议添加自增 id 做索引,将 SQL 改为 SELECT xx FROM xx WHERE id>5000 and id<6000
+----------+------------+-----------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-----------------------------------------------------+
| 1 | 0.00415400 | select * from mytable where id>=90000 and id<=91000 |
| 2 | 0.10078100 | select * from mytable limit 90000,1000 |
+----------+------------+-----------------------------------------------------+
3、只 SELECT 出需要的字段,避免 SELECT *
+----------+------------+-----------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-----------------------------------------------------+
| 1 | 0.02948800 | select count(1) from ( select id from mytable ) a |
| 2 | 1.34369100 | select count(1) from ( select * from mytable ) a |
+----------+------------+-----------------------------------------------------+
4、尽量早做过滤,使 JOIN 或者 UNION 等后续操作的数据量尽量小
5、把能在逻辑层算的提到逻辑层来处理,不要在 MYSQL 字段计算,如一些数据排序、时间函数计算等
0x04 索引的应用及优化
对于工作中使用索引优化查询问题,对前一节内容再进行下扩充:
1、选择创建单列索引还是联合索引?如果查询语句中的 WHERE、ORDER BY、GROUP BY 涉及多个字段,一般需要创建多列索引
如下,选择对 (nick_name,job) 建立联合索引:
select * from t_user where nick_name = 'panday' and job = 'engineer';
2、联合索引的顺序如何选择?一般情况下,把选择性高的字段放在前面
select * from t_user where age = '20' and lan = 'zh' order by nick_name;
建索引的话,首字段应该是 age,因为 age 定位到的数据更少,选择性更高。但是务必注意一点,满足了某个查询场景就可能导致另外一个查询场景更慢
3、避免使用范围查询,如果要使用,那么也尽量放在查询的最后一个位置(参考 0x02 小节的例子);很多情况下,范围查询都可能导致无法使用索引
4、尽量避免查询不需要的数据
select * from t_user where job like 'engine%';
select job from t_user where job like 'engine%';
同样的查询,不同的返回值,第二个就可以使用覆盖索引,第一个只能全表遍历(需要回表才能拿到其他字段)
5、查询的数据类型要正确
select * from t_user where create_date >= now();
select * from t_user where create_date >= '2020-05-01 00:00:00';
第一条语句就可以使用 create_date 的索引,第二个就无法使用
0x05 索引失效的原因
为何会导致索引失效?
0x06 EXPLAIN 的使用
参考下图,来源于 Mysql 执行计划 explain 图解
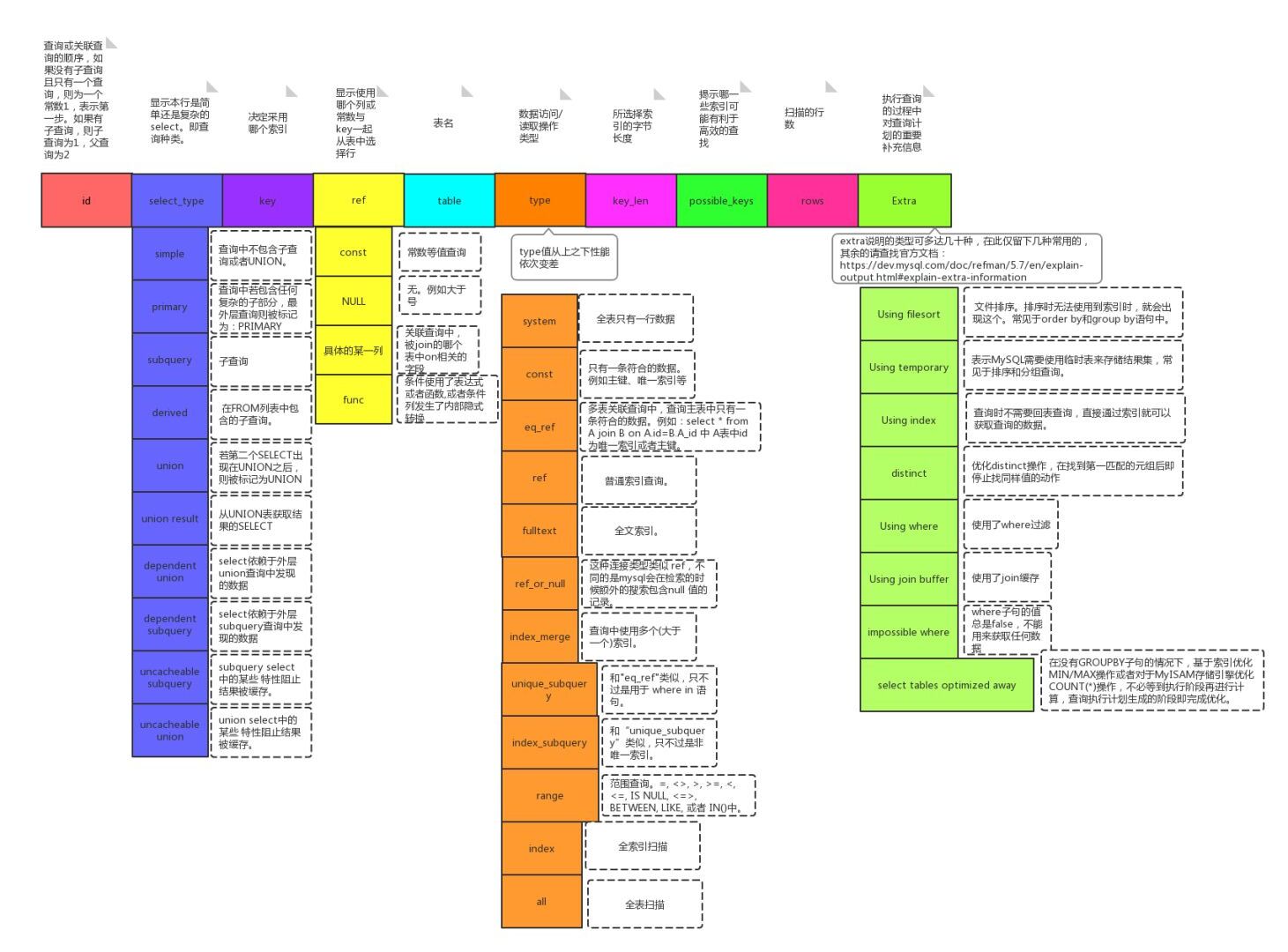
开发者至少要了解的 explain
使用 Explain 分析 SQL 语句执行计划
mysql> explain select * from t_online_group_records where UNIX_TIMESTAMP(gre_updatetime) > 123456789;
+----+-------------+------------------------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------------------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t_online_group_records | ALL | NULL | NULL | NULL | NULL | 47 | Using where |
+----+-------------+------------------------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
开发者需要重点关注下 type,rows 和 Extra 这 3 个字段:
- type:使用类别,有无使用到索引。如结果值从好到坏: > range(使用到索引) > index > ALL(全表扫描),一般查询应达到 range 级别
- rows:SQL 执行检查的记录数
- Extra:SQL 执行的附加信息,如 “Using index” 表示查询只用到索引列,不需要回表等(见下文)
explain 分析执行计划
通过 explain 可以分析出一些可能导致慢查询的原因,给优化指出方向。explain 结果由多行组成。一条 SQL 语句可以看成有多个子步骤。参数不同的 SQL 语句在优化器看来当然不是同一个 SQL 语句,因为参数不同执行计划可能千差万别,它会通过 cost 选择最优的执行计划(cost 算法较为复杂,这里不讨论,可通过 JSON 结果查看)。每行代表一个子步骤,类比用面向对象的观点来说,每一行就是一个对象,那么它有一些属性字段,属性值用来描述这个对象的特征,先列举下每个子步骤有哪些属性,如下表:
| 字段名 | JSON 字段 | 字段含义 |
|---|---|---|
| id | SELECT_id | SELECT 查询的序列号 |
| SELECT_type | None | SELECT 的类型 |
| table | table_name | 输出结果集的表 |
| type | access_type | 表示表的连接类型 |
| possible_keys | possible_key | 可供使用的索引 |
| key | key | 表示实际使用的索引 |
| key_len | key_length | 索引字段的长度 |
| ref | ref | 和索引比较的列 |
| rows | rows | 估计要扫描的行数 |
| filtered | filtered | 按条件过滤的行百分比 |
| Extra | None | 附加信息 |
接下来,对各个字段的含义做一下解析。
id
用来标识各条 SELECT 子步骤的标识 id,要点如下:
- 不同
id的行能看出执行顺序,数值越大优先级越大,越先执行。但有一种反例,type字段为DEPENDENT SUBQUERY的相关子查询,是依赖外表的,所以是后执行的 - 相同
id的行是什么执行顺序?- 首先需要知道外表、内表的概念。外表是驱动表,内表是被驱动表,代表优化器决定关联的顺序,它和 SQL 语句谁在里谁在外无关。在里面的子句在逻辑上需要先被预估得出结果没错,但是优化器预估之后既可能拿外面的做驱动表,也可能拿里面的做驱动表。
- 相同
id,关联顺序从上往下,表示优化器决定上面的适合做驱动表了。上面的是外表,在下面的是内表,这才有了从上往下的口诀。
id字段为NULL。表示这一行是其他子步骤的union,此时 table 字段会显示为<unionm, n="">的形式,表示id为M和N的两行UNION的临时表</unionm,>
partition
该行匹配的分区。对没有分区的表,该值为 NULL
【重要】type
type 表示这张表(table)是如何跟该查询 join 的(官方文档解释了任何查询都是广义 “关联”),这里的 join 可以理解为查询的方式、走索引的方式。
| type | 含义 | 备注 |
|---|---|---|
| NULL | MySQL 不访问任何表,索引,直接返回结果 | |
| system | 表只有一行记录(相当于系统表) | 这是 const 类型的特例 |
| const | 对这张表的查询至多只有一行结果 | 行结果在查询的一开始就被读取,并且接下来优化器会把它当做常量。const table 非常快,因为它只会被读取一次 |
| eq_ref | 关联查询中,该表走索引时只有一行被关联 | 说明关联索引全部为主键或唯一索引。这是最优的 join 方式。eq_ref 在使用 = 比较运算符时出现 |
| ref | 关联查询中,该表走索引时有多行被关联 | 说明关联索引不是唯一索引,查找 + 扫描。在关联行数比较少时,这也是一种性能优秀的关联方式。ref 可以在使用 = 或 <=> 比较运算符时出现 |
| full_text | 查询使用了全文索引 | |
| ref_or_null | 比 ref 多了查询 NULL 值的操作 |
索引字段的长度 |
| index_merge | 使用了索引合并优化 | 此时 explain 的 key 字段系显示了使用的索引,key_len 字段显示了使用的最长索引长度 |
| unique_subquery | 某些 IN() 中存在唯一索引子查询,替换这种形式的子查询: IN(SELECT primary_key FROM t WHERE some_expr) |
替换子查询的一种优化 |
| index_subquery | 某些 IN() 中存在非唯一索引子查询,替换这种形式的子查询: IN(SELECT non_primary_key FROM t WHERE some_expr) |
替换子查询的一种优化 |
| range | 使用索引进行范围查询 | WHERE 之后出现 between/</>/in 等操作 |
| index | 遍历了索引树 | 有两种情况 type 为 index:第一,覆盖索引,通常比 ALL 快,ALL 是遍历数据,index 是遍历索引树,此时 Extra 字段会显示 Using index;第二:没用覆盖索引,以索引顺序遍历(也就是从小到大遍历)索引树和数据,此时 Extra 字段不显示 Using index |
| ALL | 对于之前的表的行组合,将全表扫描以找到匹配的行 | 如果依赖的表的 type 不是 const,这种查询方式性能较差。除非使用了 LIMIT,或者在 Extra 列中显示 Using distinct/not exists |
关于 type 的要点汇总:
- ALL, index, range, index_merge, ref_or_null, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
- index 与 ALL 区别为 index 类型只遍历索引树
举例来说:
-- const
SELECT * FROM tb1_name WHERE primary_key=1;
-- eq_ref
SELECT * FROM ref_table, other_table WHERE ref_table.key_column=other_table.column
SELECT * FROM ref_table, other_table WHERE ref_table.key_col_1=other_table.col AND ref_table.key_col_2=1;
-- ref_or_null
SELECT * FROM ref_table WHERE key_col=expr OR key_column IS NULL;
-- range
SELECT * FROM tbl_name WHERE key_column = 10;
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30);
possible_keys
possible_keys 表示 MySQL 可能选择的索引,基于查询列和使用的比较操作符判断,在优化过程早期得出,可能对后续优化过程没用,显示的顺序也跟实际使用的优先顺序无关;如果 possible_keys 为 NULL,说明没有可用索引,应该考虑加索引
key
- key 字段表示 MySQL 实际走的索引,优化器决定走哪一个索引能最小化查询成本
- key 字段使用的索引可能没出现在 possible_keys 中,这种情况出现在覆盖索引时;如果需要强制使用 / 使用 / 忽略 possible_keys 中的索引,使用
FORCE INDEX/USE INDEX/IGNORE INDEX命令
key_len
key_len 表示 MySQL 决定使用的索引字节数;这个数字是表定义中的数据类型决定的,而不是表中数据的实际字节数;通过 key_len 可以知道复合索引使用的是那几列的复合索引;如果 key 字段为 NULL,key_len 字段也为 NULL
ref
ref 表示走索引时与 key 字段中索引比较的列名或者常量;如果 ref 值为 func,表示 ref 的是某函数调用的结果,可以在 EXPLAIN 之后使用 SHOW WARNINGS 来查看使用的是哪一个函数。
【重要】rows
rows 表示 MySQL 为了查到最终结果估计要扫描的行数;把 explain 结果各行的 rows 值想成可以粗略估计整个查询会检查的行数。由于缓冲区、软硬件缓存,MySQL 可能不必真的读它估计的行
filtered
filter 表示过滤之后的行数占 rows 的百分比,该值越小越好
【重要】Extra
Extra 为 explain 得到的附加信息,常见的信息有:
- Using index:表示覆盖索引得到结果,避免回表;注意和虽然 Using index 但 type 为 index 的情况区分开,那是遍历索引,遍历索引可能覆盖索引,但覆盖索引当然不一定需要遍历索引
- Using index condition:通过访问索引并首先测试它们来确定是否读取完整来读取表表行。这样,索引信息用于延迟读取全表行(下推)
- Using index for group by:只需要索引就能处理
group by或distinct语句 - Using where:表示 MySQL 在存储引擎查询出结果集后再进行过滤。一般情况除非查询指定要扫描所有行,都会有 Using where,但有时候因为索引下推,走索引时存储引擎层就会过滤行,因此不是所有带
WHERE子句的查询都会显示 Using where - Using temporary:表示在对查询结果排序时会使用一个临时表
- Using filesort:表示 MySQL 会对结果使用外部排序,而不是按索引次序从表里读取行。两种方式都可以在内存或磁盘上完成。
EXPLAIN不能看出使用哪一种文件排序,也不会告诉你排序在内存还是磁盘上完成。 - Range checked for each record(index map: N):表示没有好用的索引,新的索引将在连接的每一行上重新估算
0x07 索引的设计原则
总结一下,在业务中一开始创建索引时的时候建议遵循的原则,通常能更高效的使用索引:
- 对查询频次较高,且数据量比较大的表建立索引
- 索引不是多多益善。对于增删改等 DML 操作比较频繁的表来说,要考虑到空间的浪费和维护、选择索引的开销,最好的索引设计就是用尽量少尽量小的索引覆盖尽量多的查询
- 对
SELECT...WHERE型查询、JOIN关联查询首先想到的就是加索引。如果WHERE子句中的组合比较多,那么有些经验挑选原则:常用列、基数(cardinality)大的列、选择度高的列的组合。如果表的字段太多,应该把一些不常用的字段分离到另一张表,这样在只需要常用字段的查询中可以节省 IO 开销 - 使用主键。主键的快速查询得益于其自带的唯一且
NOT NULL的索引。建议大表应该有一个自增的主键来唯一标识一行,建议使用bigint - 使用唯一索引,区分度越高,使用索引的效率越高
- 使用短索引或索引前缀优化。索引也是使用硬盘上的
B+树来存储的。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升 MySQL 访问索引的 I/O 效率 - 利用最左前缀原则,N 个列组合而成的复合索引,那么相当于是创建了 N 个索引,如果查询时
WHERE子句中使用了组成该索引的前几个字段,那么这条查询 SQL 可以利用复合索引来提升查询效率(这里前面已经反复提及多次)
0x08 总结
本文总结了 MYSQL 的索引的要点及优化技巧。