0x00 前言
本文梳理下笔者在项目开发中使用过一些内存缓存的技巧
0x01 双缓冲:double buffering
有一个场景是,存在某一本地文件配置(修改少),程序初始化时把文件内容读取到本地内存里(假设为 map1),由于程序逻辑需要频繁且高性能的读取 map1(尽量不加锁),在这种背景下如何实现安全的修改文件自动同步到 map 里(且不加锁)?有两种思路:
- 分段锁
- 使用双缓冲(double buffering)技术,方法是在后台修改一个副本的
map,当修改完成后,将其原子性地替换为当前活动的map。这样在修改期间,程序可以继续高性能(原子)读取当前活动的 map,修改完成后,将当前活动的map指向已经完成新一轮加载读取的 map(ping-pong map)
参考代码如下,MapHolder 包含 2 个 map 和一个 atomic 变量 idx。LoadFile 方法读取文件内容并将其加载到一个新的 map 中,然后原子性地替换当前活动的 map。Get 方法根据当前活动的 map 来获取键值对;如此实现允许在不加锁的情况下实现对 map 的高性能访问。但注意该实现仅适用于读密集型场景,如果需要同时进行大量的写操作则不建议使用此方法
type MapHolder struct {
maps [2]*map[string]string
idx int32
}
func NewMapHolder() *MapHolder {
m1 := make(map[string]string)
m2 := make(map[string]string)
return &MapHolder{maps: [2]*map[string]string{&m1, &m2}}
}
func (h *MapHolder) LoadFile(filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close()
scanner := bufio.NewScanner(file)
newMap := make(map[string]string)
for scanner.Scan() {
parts := strings.Split(scanner.Text(), ":")
if len(parts) == 2 {
newMap[parts[0]] = parts[1]
}
}
// 原子性地替换活动 map
idx := atomic.LoadInt32(&h.idx)
atomic.StorePointer((*unsafe.Pointer)(unsafe.Pointer(&h.maps[idx^1])), unsafe.Pointer(&newMap))
atomic.StoreInt32(&h.idx, idx^1)
return scanner.Err()
}
func (h *MapHolder) Get(key string) (string, bool) {
idx := atomic.LoadInt32(&h.idx) // 原子获取当前活动的 index
m := h.maps[idx]
value, ok := (*m)[key]
return value, ok
}
func main() {
holder := NewMapHolder()
err := holder.LoadFile("file.txt")
if err != nil {
fmt.Println("Error loading file:", err)
return
}
go func() {
for {
time.Sleep(1 * time.Second)
err := holder.LoadFile("file.txt")
if err != nil {
fmt.Println("Error reloading file:", err)
}
}
}()
for {
time.Sleep(100 * time.Millisecond)
value, ok := holder.Get("a")
if ok {
fmt.Println("Value of a:", value)
} else {
fmt.Println("Key a not found")
}
}
}
0x02 go-cache 的使用
前面文章介绍了不少实用的内存 hashtable 结构实现,不过如果项目 ** 对性能要求不高 **,可以考虑使用 go-cache,该项目的特点就是足够简单,存取不需要序列化 / 反序列化,支持 Value 过期,对应 expired 的逻辑就是启动个 ticker 定时器,定时全量扫描 map 进行回收,如下:
func (j *janitor) Run(c *cache) {
ticker := time.NewTicker(j.Interval)
for {
select {
case <-ticker.C:
//
c.DeleteExpired()
case <-j.stop:
ticker.Stop()
return
}
}
}
// Delete all expired items from the cache.
func (c *cache) DeleteExpired() {
var evictedItems []keyAndValue
now := time.Now().UnixNano()
c.mu.Lock()
// 锁表:先扫描哪些需要被删除的 kv 并收集
for k, v := range c.items {
// "Inlining" of expired
if v.Expiration > 0 && now > v.Expiration {
ov, evicted := c.delete(k)
if evicted {
evictedItems = append(evictedItems, keyAndValue{k, ov})
}
}
}
// 全部处理完再解锁
c.mu.Unlock()
for _, v := range evictedItems {
c.onEvicted(v.key, v.value)
}
}
使用 go-cache 要注意下面几点:
- 加锁力度过粗,项目需要衡量好并发后再使用;高 QPS 的接口尽量不要去直接
Set数据, 如果必须Set考虑采用异步操作 - 定时清理逻辑中,如果耗时过长,又整个 cache 加锁,可能会导致其他的 goroutine 阻塞等待在 lock 上无法写入,参考 一次错误使用 go-cache 导致出现的线上问题 此文的坑
- 关于
map[string]interface{}存储的 value,有可能会改变;如果存的是 slice/map 或者指针等,当取出使用的时候,修改值,会导致缓存中的原始值变化;此外,如果是非线程安全的 value,还 ** 必须考虑读写加锁以实现并发操作安全 **,看下面的例子 - 尽量存放那些相对不怎么变化的数据, 适用于所有的 local cache(包括 map,
sync.map) - 监控 go-cache 里面 key 的数量, 如果过多时, 需要及时调整参数
- go-cache 的过期检查时间要设置相对较小, 也不能过小
// 一个修改了 value 指针的例子
func main() {
c := cache.New(5*time.Minute, 10*time.Minute)
var tmap = make(map[int]int)
c.Set("foo", tmap, cache.DefaultExpiration)
foo, found := c.Get("foo")
if found {
fmt.Println(foo)
}
foom, _ := foo.(map[int]int)
// 如果是并发操作,还需要考虑并发安全
foom[1] = 1
foo, found = c.Get("foo")
if found {
fmt.Println(foo)
}
}
0x03 一个典型的缓存使用:bk-iam
本小节,分析下 bk-iam 项目给出的典型的缓存应用,包含下面 4 种用法:
gocache.Cachememory.Cacheredis.Cachecleaner.CacheCleaner
memory.Cache
gopkg.Cache
基于 go-cache 实现,增加了若干特性
redis.Cache:提供缓存 + 外部数据接口
redis.Cache 是一个封装了 go-redis/cache 的共享缓存实现:
结构如下:
// RetrieveFunc ...
type RetrieveFunc func(key gopkgcache.Key) (interface{}, error)
// Cache is a cache implements
type Cache struct {
name string
keyPrefix string
codec *cache.Cache
cli *redis.Client
defaultExpiration time.Duration
G singleflight.Group
}
// NewCache create a cache instance
func NewCache(name string, expiration time.Duration) *Cache {
cli := GetDefaultRedisClient()
// key format = iam:{version}:{cache_name}:{real_key}
keyPrefix := fmt.Sprintf("iam:%s:%s", CacheVersion, name)
// 初始化的时候没有传入 localcache 实现
codec := cache.New(&cache.Options{
Redis: cli,
})
return &Cache{
name: name,
keyPrefix: keyPrefix,
codec: codec,
cli: cli,
defaultExpiration: expiration,
}
}
注意结构中的 codec 成员,是来自于 "github.com/go-redis/cache/v8" 实现的 cache.Cache 结构,具体分析参考此文 go-redis/cache 库分析与使用。在 Cache.Get、Cache.Set 等方法中,都是优先调用 c.codec 提供的方法处理(代码如下)
另外还有一个细节是,codec 初始化时,并未传入 localcache 实现,所以从 实现 看,codec 就仅仅退化为 redis 缓存了
// Set execute `set`
func (c *Cache) Set(key gopkgcache.Key, value interface{}, duration time.Duration) error {
if duration == time.Duration(0) {
duration = c.defaultExpiration
}
k := c.genKey(key.Key())
return c.codec.Set(&cache.Item{
Key: k,
Value: value,
TTL: duration,
})
}
// Get execute `get`
func (c *Cache) Get(key gopkgcache.Key, value interface{}) error {
k := c.genKey(key.Key())
return c.codec.Get(context.TODO(), k, value)
}
// Delete execute `del`
func (c *Cache) Delete(key gopkgcache.Key) (err error) {
k := c.genKey(key.Key())
ctx := context.TODO()
_, err = c.cli.Del(ctx, k).Result()
return err
}
该结构提供的所有方法可以参考 代码
此外,结构还提供了 GetInto 方法,并且用 singleflight 进行了封装,意义在于当缓存失效时,从远端(如数据库 / 接口等)获取数据并设置缓存,不过这里为啥 c.Set 逻辑不一齐放置在 singleflight 里面?
// GetInto will retrieve the data from cache and unmarshal into the obj
func (c *Cache) GetInto(key gopkgcache.Key, obj interface{}, retrieveFunc RetrieveFunc) (err error) {
// 1. get from cache, hit, return
err = c.Get(key, obj)
if err == nil {
return nil
}
// 2. if missing
// 2.1 check the guard
// 2.2 do retrieve
data, err, _ := c.G.Do(key.Key(), func() (interface{}, error) {
return retrieveFunc(key)
})
// 2.3 do retrieve fail, make guard and return
if err != nil {
// if retrieve fail, should wait for few seconds for the missing-retrieve
// c.makeGuard(key)
return
}
// 3. set to cache
errNotImportant := c.Set(key, data, 0)
if errNotImportant != nil {
log.Errorf("set to redis fail, key=%s, err=%s", key.Key(), errNotImportant)
}
// 注意, 这里基础类型无法通过 *obj = value 来赋值
// 所以利用从缓存再次反序列化给对应指针赋值 (相当于底层 msgpack.unmarshal 帮做了转换再次反序列化给对应指针赋值
return c.copyTo(data, obj)
}
cleaner.CacheCleaner
cleaner.CacheCleaner 提供了一种异步的,提供清理 cache-key 的方法
- 通过
buffer提供异步删除的 key 通道 - 开发者需要使用
CacheDeleter接口实现Execute方法,实现删除 key 的方法
// CacheDeleter ...
type CacheDeleter interface {
Execute(key cache.Key) error
}
// CacheCleaner ...
type CacheCleaner struct {
name string
ctx context.Context
buffer chan cache.Key // 待删除 key 的异步队列
deleter CacheDeleter // 删除 key 的方法
}
操作方式也比较直观,经典的模型,调用开发者实现 Execute 执行删除逻辑,如下:
// Run ...
func (r *CacheCleaner) Run() {
log.Infof("running a cache cleaner: %s", r.name)
var err error
for {
select {
case <-r.ctx.Done():
return
case d := <-r.buffer:
err = r.deleter.Execute(d)
if err != nil {
log.Errorf("delete cache key=%s fail: %s", d.Key(), err)
}
}
}
}
// Delete ...
func (r *CacheCleaner) Delete(key cache.Key) {
r.buffer <- key
}
// BatchDelete ...
func (r *CacheCleaner) BatchDelete(keys []cache.Key) {
// TODO: support batch delete in pipeline or tx?
for _, key := range keys {
r.buffer <- key
}
}
具体例子可以参考 systemCacheDeleter,比如可以支持异步删除多个其他类型的缓存:
func (d systemCacheDeleter) Execute(key cache.Key) (err error) {
err = multierr.Combine(
SystemCache.Delete(key),
LocalSystemClientsCache.Delete(key),
)
return
}
0x03 go-zero 的本地 Cache 实现
go-zero 的 Local Cache 也是一个不错的选择,它提供了 LRU 的功能(借助于 timewheel),使用参考。缓存实质是一个存储有限热点数据的介质,面临如下问题:
- 有限容量,选择何种淘汰策略
- 热点数据统计
- 并发 goroutine 存 / 取
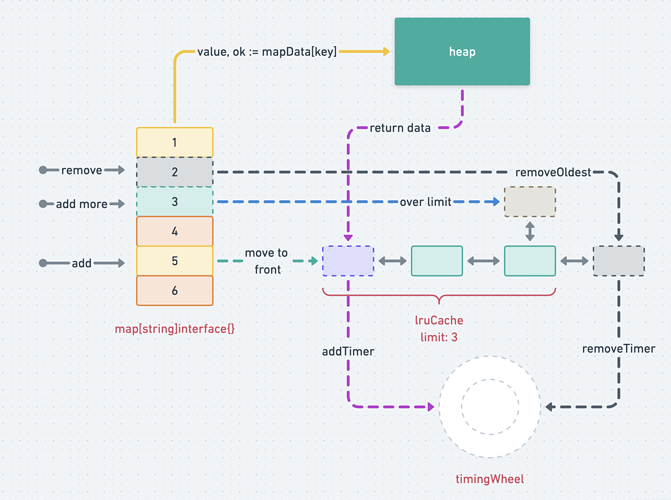
有限容量:过期及删除策略
有限就意味着满了要淘汰,这个就涉及到淘汰策略。淘汰如何触发呢?这里有几种常用方法:
- 方法 1:主动删除,异步开一个定时器,不断循环所有 key,超过预设过期时间,执行回调函数(如删除 map 中过期的 key)
- 方法 2:惰性删除,访问时判断该 key 是否被删除。缺点是:如果未访问的话,会加重空间浪费
本实现采用方法 1,主动删除中遇到最大的问题是不断循环,空消耗 CPU 资源(并且加锁会加剧并发竞争),优化为采取时间轮 timingwheel 记录额外过期通知,等过期 channel 中有通知时,然后触发删除回调。
热数据统计
对于缓存来说,开发者需要知道这个缓存在使用额外空间和代码的情况下是否有价值,以及想知道需不需要进一步优化过期时间或者缓存大小,所有这些就依赖统计能力,相关代码如下:
func (c *Cache) Get(key string) (interface{}, bool) {
value, ok := c.doGet(key)
if ok {
// 命中 hit+1
c.stats.IncrementHit()
} else {
// 未命中 miss+1
c.stats.IncrementMiss()
}
return value, ok
}
并发存取安全
当多个协程并发存取的时候,对于缓存来说,涉及的问题以下几个:
- 写 - 写冲突
- LRU 中元素的移动过程冲突
- 并发执行写入缓存时,造成流量冲击或者无效流量
写冲突最简单的方法就是加锁(应加尽加),如下
// Set(key, value)
func (c *Cache) Set(key string, value interface{}) {
// 加锁,然后将 <key, value> 作为键值对写入 cache 中的 map
c.lock.Lock()
_, ok := c.data[key]
c.data[key] = value
// lru add key
c.lruCache.add(key)
c.lock.Unlock()
//...
}
// 在操作 LRU 的地方时:Get(),也需要加锁
func (c *Cache) doGet(key string) (interface{}, bool) {
c.lock.Lock()
defer c.lock.Unlock()
// 当 key 存在时,则调整 LRU item 中的位置,这个过程也是加锁的
value, ok := c.data[key]
if ok {
c.lruCache.add(key)
}
return value, ok
}
而并发执行写入逻辑,这个逻辑主要是开发者自己传入的。而这个过程通过使用 sharedCalls 即 singleflight 机制来减少多次执行方法:
func (c *Cache) Take(key string, fetch func() (interface{}, error)) (interface{}, error) {
// 1. 先获取 doGet() 中的值
if val, ok := c.doGet(key); ok {
c.stats.IncrementHit()
return val, nil
}
var fresh bool
// 2. 多协程中通过 sharedCalls 去获取,一个协程获取多个协程共享结果
val, err := c.barrier.Do(key, func() (interface{}, error) {
// double check,防止多次读取
if val, ok := c.doGet(key); ok {
return val, nil
}
...
// 重点是执行了传入的缓存设置函数
val, err := fetch()
...
c.Set(key, val)
})
if err != nil {
return nil, err
}
...
return val, nil
}