0x00 前言
本文分析下 golang 标准库 bytes.Buffer 的实现(本文基于 go1.17 版本的实现分析)
笔者在给 ssh 网关增加终端解析功能中大量使用了 bytes.Buffer 这个结构,bytes.Buffer 是 Golang 标准库 []byte 缓冲区(流式缓冲区),具有读写方法和可变大小的字节存储功能。缓冲区的零值是一个待使用的空缓冲区。可以持续向 Buffer 尾部写入数据,从 Buffer 头部读取数据。当 Buffer 内部空间不足以满足写入数据的大小时,会自动扩容。
定义如下:
type Buffer struct {
buf []byte // contents are the bytes buf[off : len(buf)]
off int // read at &buf[off], write at &buf[len(buf)]
lastRead readOp // last read operation, so that Unread* can work correctly.
}
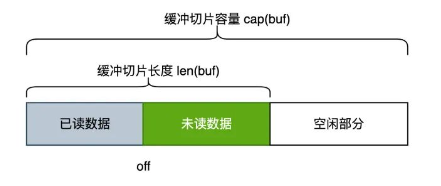
buf:底层的缓冲字节切片,用于保存数据。len(buf)表示字节切片长度,cap(buf)表示切片容量off:已读计数,在该位置之前的数据都是被读取过的,off表示下次读取时的开始位置。因此未读数据部分为buf[off:len(buf)]lastRead:保存上次的读操作类型,用于后续的回退操作
从结构看,很像先前文章 数据结构与算法回顾(四):环形内存缓冲区 ringbuffer 介绍的环形缓冲区 此外,由于底层存储是字节切片,理解golang的slice底层机制就很重要
使用
func main(){
var buffer bytes.Buffer
n, err := buffer.WriteString("this is a test for bytes buffer")
fmt.Println(n, err) // 31 nil
fmt.Println(buffer.Len(), buffer.Cap()) // 31 64
s := make([]byte, 1000)
n, err = buffer.Read(s)
fmt.Println(n, err) // 31 nil
fmt.Println(string(s)) // this is a test for bytes buffer
fmt.Println(buffer.Len(), buffer.Cap()) // 0 64
}
0x01 bytes.Buffer 提供的核心方法
// 将 Buffer 读取(拷贝)到 p
// @满足 interface io.Reader
func (b *Buffer) Read(p []byte) (n int, err error)
// 将 p 写入(拷贝)Buffer
// @满足 interface io.Writer
func (b *Buffer) Write(p []byte) (n int, err error)
// 死循环读取 r 的内容,写入(拷贝)Buffer 中,直到读取失败
// @满足 interface io.ReaderFrom
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error)
// 将 Buffer 的内容全部写入(拷贝)w 中
// @满足 interface io.WriterTo
func (b *Buffer) WriteTo(w io.Writer) (n int64, err error)
// 读取一个字节
// @满足 interface io.ByteReader
func (b *Buffer) ReadByte() (byte, error)
// 撤销一个字节的读操作
// 撤销是有前提的,比如前一个操作不能是写相关的操作,也不能是撤销的操作
// @满足 interface io.ByteScanner
func (b *Buffer) UnreadByte() error
// 和 UTF8 Unicode 相关的读取
// @满足 interface RuneReader
func (b *Buffer) ReadRune() (r rune, size int, err error)
// 撤销一个 rune 的读操作
// @满足 interface RuneScanner
func (b *Buffer) UnreadRune() error
// 写入一个字节
// @满足 interface io.ByteWriter
func (b *Buffer) WriteByte(c byte) error
// 见 func Write
// @满足 interface StringWriter
func (b *Buffer) WriteString(s string) (n int, err error)
// 整个待读取的内容,类似于 peek 预览
// @并不会真正消费
// @不发生拷贝
func (b *Buffer) Bytes() []byte
// 预览待读取内容的前 n 个字节
// @并不会真正消费
// @不发生拷贝
func (b *Buffer) Next(n int) []byte
// 见 func Bytes
func (b *Buffer) String() string
// 待读取内容的大小
func (b *Buffer) Len() int
// 总容量大小
func (b *Buffer) Cap() int
// 读取直到 delim 字符的内容
// @消费
// @发生拷贝
func (b *Buffer) ReadBytes(delim byte) (line []byte, err error)
// 见 ReadBytes
func (b *Buffer) ReadString(delim byte) (line string, err error)
// 丢弃待读取内容的前 n 个字节
func (b *Buffer) Truncate(n int)
// 清空所有数据
func (b *Buffer) Reset()
// 确保有 n 大小的剩余空间可供写入
func (b *Buffer) Grow(n int)
// 将 r 写入
func (b *Buffer) WriteRune(r rune) (n int, err error)
// 创建 Buffer 对象时就写入 buf
func NewBuffer(buf []byte) *Buffer
func NewBufferString(s string) *Buffer
0x02 核心方法分析
readOp 常量描述了对缓冲区执行的最后一个操作:
// The readOp constants describe the last action performed on
// the buffer, so that UnreadRune and UnreadByte can check for
// invalid usage. opReadRuneX constants are chosen such that
// converted to int they correspond to the rune size that was read.
type readOp int8
// Don't use iota for these, as the values need to correspond with the
// names and comments, which is easier to see when being explicit.
const (
opRead readOp = -1 // Any other read operation.
opInvalid readOp = 0 // Non-read operation.
opReadRune1 readOp = 1 // Read rune of size 1.
opReadRune2 readOp = 2 // Read rune of size 2.
opReadRune3 readOp = 3 // Read rune of size 3.
opReadRune4 readOp = 4 // Read rune of size 4.
)
Reset()方法
func (b *Buffer) Reset() {
b.buf = b.buf[:0]
b.off = 0
b.lastRead = opInvalid
}
0x03 bytes.Buffer 的内存伸缩策略
0x04 bytes.Buffer 的坑
笔者在工作中遇到过两个问题
1、bytes.Buffer 结构不是并发安全(not thread safe)
解决方法有两种:
a)增加互斥锁,封装操作
缺点是,对性能有较大损耗
// Buffer is a goroutine safe bytes.Buffer
type Buffer struct {
buffer bytes.Buffer
mutex sync.Mutex
}
// Write appends the contents of p to the buffer, growing the buffer as needed. It returns
// the number of bytes written.
func (s *Buffer) Write(p []byte) (n int, err error) {
s.mutex.Lock()
defer s.mutex.Unlock()
return s.buffer.Write(p)
}
// String returns the contents of the unread portion of the buffer
// as a string. If the Buffer is a nil pointer, it returns "<nil>".
func (s *Buffer) String() string {
s.mutex.Lock()
defer s.mutex.Unlock()
return s.buffer.String()
}
b)使用io.Pipe()来完成异步功能(当然这里仅仅是解决并发安全)
参考Is the Go bytes.Buffer thread-safe?的回答:
Use io.Pipe() function call which provide pair of connected objects (*PipeReader, *PipeWriter) for synchronous read/write. This could be done in parallel, and it’s a thread-safe.
示例代码如下:
fileBytes := //convert image file to []byte here
pipeReader, pipeWriter := io.Pipe()
// create a new thread to handle Write
go func() {
defer pipeWriter.Close()
pipeWriter.Write(fileBytes)
}()
// in main thread
sendToCloud(pipeReader)
2、bytes.Buffer 的内存疯涨问题
这个解决办法也比较简单,对bytes.Buffer进行封装,在Write*相关方法前先检测当前的buffer长度,如果超过限制则不再进行写入即可,如下:
var (
MAX_BUFFER_LENGTH = 2048
)
type BufferV2 struct {
sync.Mutex
session_id string
Buf bytes.Buffer
}
// WriteData...
func (p *BufferV2) Write(data []byte) (int, error) {
p.Lock()
defer p.Unlock()
if p.Buf.Len() >= MAX_BUFFER_LENGTH {
//超过2kb的数据,不再写入
return 0, nil
}
return p.Buf.Write(data)
}
0x05 总结
- 从
bytes.Buffer读取数据后,被成功读取的数据仍保留在原缓冲区,只是无法被使用,因为缓冲区的可见数据从偏移off开始,即buf[off:len(buf)]