0x00 前言
先列举几个概念:
- CRD(Custom Resource Definition):允许用户自定义 Kubernetes 资源,类比为一张MySQL的表
- CR (Custom Resourse): CRD 的一个具体实例,类比为MySQL表的一条数据(row)
- Controller:它会循环地处理上述工作队列,按照各自的逻辑把集群状态向预期状态推动。不同的 controller 处理的类型不同,比如 replicaset controller 关注的是副本数,会处理一些 Pod 相关的事件
- webhook: 本质上是一种 HTTP 回调,会注册到 apiserver 上。在 apiserver 特定事件发生时,会查询已注册的 webhook,并把相应的消息转发过去
- 工作队列: Controller 的核心组件,会监控集群内的资源变化,并把相关的对象,包括它的动作与 key,例如 Pod 的一个 Create 动作,作为一个事件存储于该队列中
- Operator:Operator 是一种封装(描述)、部署和管理 kubernetes 应用的方法,从实现上来说,可以将其理解为 CRD 配合可选的 webhook 与 controller 来实现用户业务逻辑,即 operator = CRD + Webhook + Controller
CR && CRD
本小节摘自CRD is just a table in Kubernetes,形象的介绍了CR(D)
Operator的应用场景
Operator 是由 kubernetes 自定义资源(CRD, Custom Resource Definition)和控制器(Controller)构成的云原生扩展服务。Operator 把部署应用的过程或业务运行过程中需要频繁操作的命令封装起来,运维人员只需要关注应用的配置和应用的期望运行状态即可,无需花费大量的精力在部署和容易出错的命令上面。如 Redis Operator,只需要关心 size 和 config 即可,而不用关心其部署过程:
apiVersion: Redis.io/v1beta1
kind: RedisCluster
metadata:
name: my-release
spec:
size: 3
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 1000m
memory: 1Gi
config:
maxclients: "10000"
或者一些自己开发的微服务应用:
apiVersion: custom.ops/v1
kind: MicroServiceDeploy
metadata:
name: ms-sample-v1s0
spec:
msName: "ms-sample" # 微服务名称
fullName: "ms-sample-v1s0" # 微服务实例名称
version: "1.0" # 微服务实例版本
path: "v1" # 微服务实例的大版本,该字符串将出现在微服务实例的域名中
image: "just a image url" # 微服务实例的镜像地址
replicas: 3 # 微服务实例的 replica 数量
autoscaling: true # 该微服务是否开启自动扩缩容功能
needAuth: true # 访问该微服务实例时,是否需要租户 base 认证
config: "password=12345678" # 该微服务实例的运行时配置项
creationTimestamp: "1535546718115" # 该微服务实例的创建时间戳
resourceRequirements: # 该微服务实例要求的机器资源
limits: # 该微服务实例会使用到的最大资源配置
cpu: "2"
memory: 4Gi
requests: # 该微服务实例至少要用到的资源配置
cpu: "2"
memory: 4Gi
idle: false # 是否进入空载状态
CRD的使用场景
-
提供、管理外部数据存储,因为Customer Resource就是一种存在Etcd中的数据结构,可以将外部数据存储到Etcd中而不使用单独的数据库,用Kubernetes的声明式API去管理其生命周期
-
对Kubernetes的基础资源进行更高层次的抽象,例如:一些自定义控制器,既可以管理自定义的资源状态,也可以改变Kubernetes原有资源,如Ingress-controller
operator工作模式
工作流程如下:
- 用户创建一个自定义资源 (CRD)
- apiserver 根据自己注册的一个 pass 列表,把该 CRD 的请求转发给 webhook
- webhook 一般会完成该 CRD 的缺省值设定和参数检验。webhook 处理完之后,相应的 CR 会被写入数据库(ETCD),返回给用户
- 与此同时,controller 会在后台监测该自定义资源,按照业务逻辑,处理与该自定义资源相关联的特殊操作
- 上述处理一般会引起集群内的状态变化,controller 会监测这些关联的变化,把这些变化记录到 CRD 的状态中
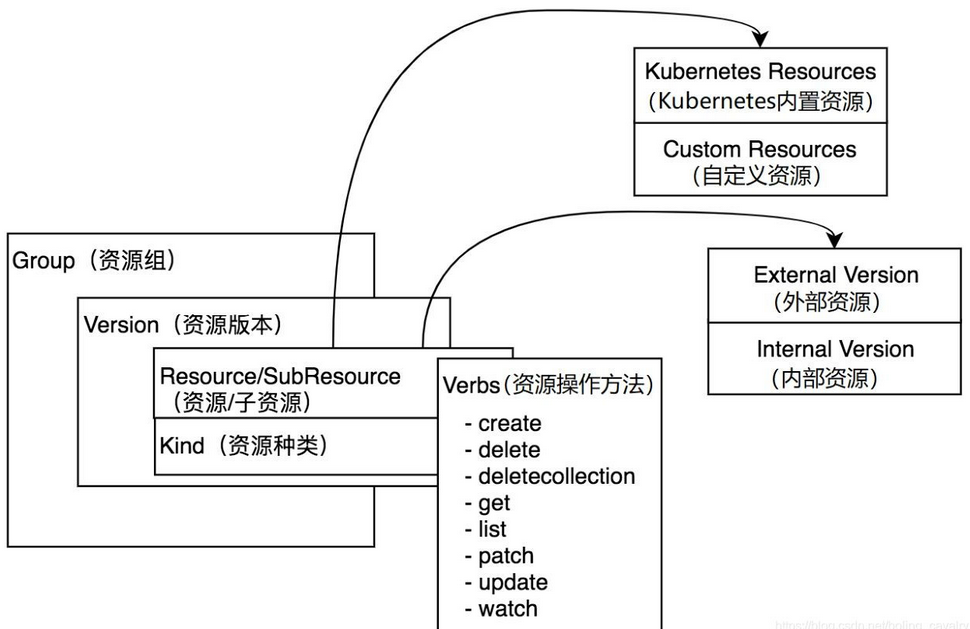
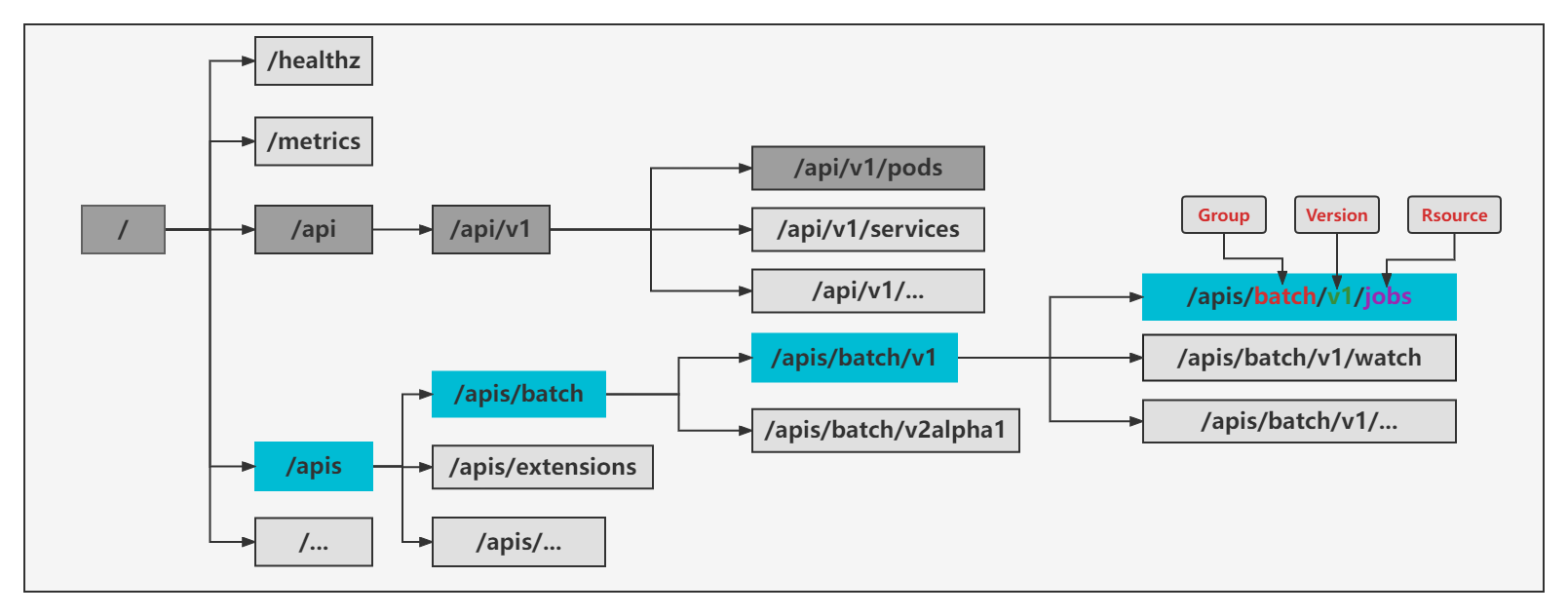
GVR 与 GVK
GVK(GroupVersionKind) 和 GVR(GroupVersionResource),区别是 GVK 是一个 Object 概念,而 GVR 代表一个 Http Path, GV对应apiVersion
1、GVR
GVR是由Group、Version、Resource定义一个唯一且固定的HTTP路径,group为相关kind的集合即kube-batch(如Job或者Pod等),Version对应为API Group,例如,v1alpha1、v1beta1、v1。Resource 通常是小写复数形式的单词(如jobs或者pods),用来识别一组HTTP endpoints用来对外某对象类型的CRUD(如GET /api/v1/namespaces/{namespace}/pods)
2、GVK
GVK与GVR不同为Resource改为Kind,类型(kind)也从属于某个API组(group)的某个版本(version)。根据GVK,k8s就能找到一个yaml所对应的资源类型
Declarative State
Declarative State(声明式状态管理)大多数 API 对象区分 specification 定义的资源的期望状态(desired state)和对象的当前状态(current status)
spec:
deploymentName: example-foo
replicas: 1
specification(简称 spec)是对资源的期望状态的完整描述,spec 通常会持久化存储,一般存到 etcd 中,也就是describe资源展示的status
Status: Running
IP: 10.X.0.34
IPs:
IP: 10.X.0.34
Controlled By: ReplicaSet/example-foo-5897b717b4
Containers:
nginx:
...
Conditions:
...
Volumes:
...
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
...
Events: <none>
Status 表述了观察到的或者说实际的资源的状态,由控制面(control plane)或者核心组件比如 Controller manager,又或者自定义的 Controller 来管理
0x01 CRD介绍
0x02 Controller介绍
Controller工作原理
Controller可以有一个或多个informer来跟踪某一个resource。Informer跟 apiserver保持通讯获取资源的最新状态并更新到本地的cache中,一旦跟踪的资源有变化,informer就会调用callback。把关心的变更的Object放到workqueue里面。然后woker执行真正的业务逻辑,计算和比较workerqueue里items的当前状态和期望状态的差别,然后通过client-go向 apiserver发送请求,直到驱动这个集群向用户要求的状态演化
0x03 Operator实践:client-go
如何自定义客户端实现呢?通常有两种方式,一是基于client-go实践动态客户端,二是使用脚手架(本质上对client-go进行封装)完成
以官方代码workqueue的实现为例:
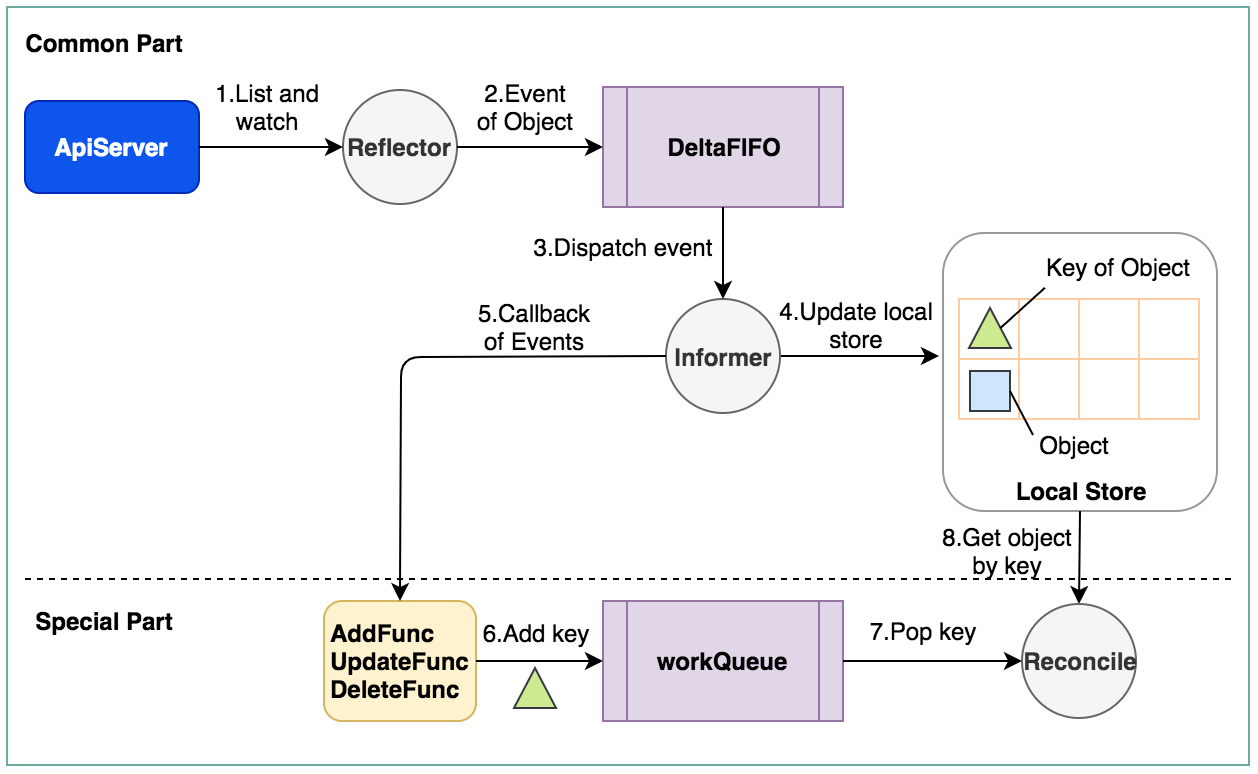
图中包含了两部分:Common part(client-go的基本流程)、Special Part(controller逻辑实现),主要逻辑如下:
1、Reflector通过ListAndWatch方法去监听指定的Object
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(3).Infof("Starting reflector %v (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.Until(func() {
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}
2、Reflector会将所监听到的event,包括对object的Add,Update,Delete的操作push到DeltaFIFO这个queue中
3、Informer首先会解析event中的action和object
4、Informer将解析的object更新到local store,也就是本地cache中的数据更新
5、然后Informer会执行Controller在初始化Infromer时注册的ResourceEventHandler()
6、ResourceEventHandler中注册的callback会将对应变化的object的key存入其初始化的一个workQueue
7、最终controller会循环进行reconcile,就是从workQueue不停地pop key,然后去local store中取到对应的object,然后进行处理,最终多数情况会再通过client去更新这个object
0x04 Operator实践:sample-controller
自定义controller可以先通过参考官方提供的sample-controller来完成控制器开发。Client-Go 是负责与 Kubernetes APIServer 服务进行交互的客户端库,利用 Client-Go 与Kubernetes APIServer 进行的交互访问,来对 Kubernetes 中的各类资源对象进行管理操作,包括内置的资源对象及CRD
sample-controller的原理大致如下:
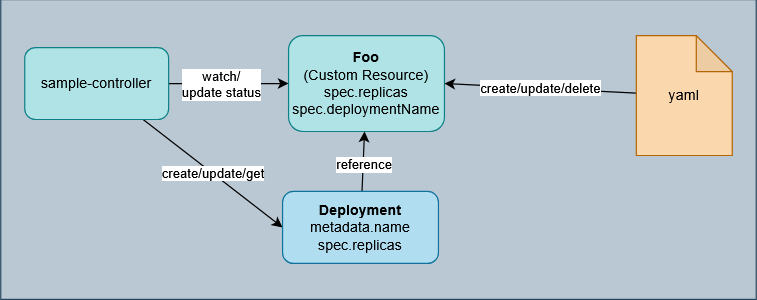
阅读:
0x05 Operator实践:kubebuilder
虽然 sample-controller 提供了学习自定义 Controller 的实现示例,但通常更希望关注业务逻辑的编写而不是这些示例代码。所以可以使用脚手架(也叫做类型化客户端 typed client)来实现,Kubebuilder 和 Operator SDK,二者都基于kubernetes-sigs/controller-runtime实现。Kubebuilder既是一个工具,也是一组库,可以更简单以及高效地构建 Operator。本小节简单介绍一下kubebuilder的原理及使用
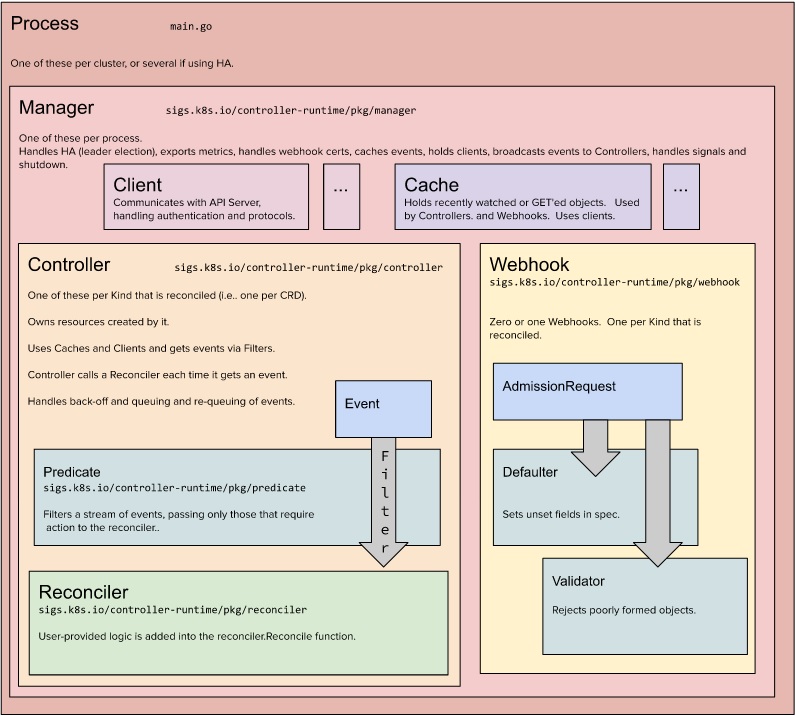
上面引述workQueue的例子已经实现了一个controller的逻辑,除此以外,kubebuilder还实现了以下的额外工作:
- kubebuilder引入了manager这个概念,一个manager可以管理多个controller,而这些controller会共享manager的client;如果manager挂掉或者停止了,所有的controller也会随之停止
- kubebuilder使用一个
map[GroupVersionKind]informer来管理这些controller,所以每个controller还是拥有其独立的workQueue,deltaFIFO,并且kubebuilder也已经帮开发者实现了这部分代码 - 开发者仅需要关注实现
Reconcile中的逻辑
核心:Reconcile的理解
理解 Reconcile是理解 Kubernetes Operator/Controller 工作模式的关键,什么是 Reconcile?可以把 Reconcile函数想象成一个调停人或闭环控制系统。它的任务非常简单:
- 观察现状 (Observe):查看 Kubernetes 集群中某个资源(比如用户自定义的 CronTab对象)的当前实际状态 (Actual State)
- 对比期望 (Compare):读取该资源定义中描述的期望状态 (Desired State),如
spec.replicas: 3 - 执行操作 (Act):采取一切必要的操作,努力让实际状态无限接近期望状态。如果实际状态已经是期望状态,它就什么也不做
上述这个观察-对比-操作的循环会为每一个被监控的资源对象持续不断地运行,这就是所谓的调和循环(Reconciliation Loop),下面列举两个例子
1、普通任务:一个简单的 Deployment 控制器,假设有一个自定义资源 MyApp,其 Spec中定义了 replicas和 image,那么Reconcile的工作流程(一次循环)如下:
# 期望状态 (Defined by user)
apiVersion: "app.example.com/v1"
kind: MyApp
metadata:
name: my-app-instance
spec:
replicas: 2
image: nginx:1.20
step 1:获取现状
- 收到一个事件,告知
my-app-instance这个 MyApp对象发生了变化(创建、更新、删除) - Reconcile 函数被调用,其参数是这个对象的
Namespace和Name - 函数首先通过 APIServer 获取这个
MyApp对象的最新信息,从而知道用户的期望状态(spec.replicas: 2与image: nginx:1.20) - 然后,函数去检查当前状态:是否存在一个名为
my-app-instance的 Deployment?这个 Deployment 的副本数和镜像版本是否正确?
step 2:对比与决策,可能有如下场景
- 场景A:当Deployment 不存在时,决策是需要创建这个 Deployment
- 场景B:当Deployment 存在时,但镜像被用户从
nginx:1.20更新为了nginx:1.25,决策是需要更新这个 Deployment 的镜像版本 - 场景C:Deployment 存在,且配置完全正确,决策是无需任何操作,直接返回
- 场景D:用户删除了
MyApp对象,决策是需要清理并删除对应的 Deployment
step3:执行操作,根据上述决策,函数会调用 Kubernetes API 来执行相应的操作(创建、更新或删除 Deployment),这个循环通常很快,操作几乎是同步的(在 Reconcile函数结束前,创建Deployment的API调用已经完成)
2、耗时任务,一个数据库备份任务,假设有一个自定义资源 DatabaseBackup,其 Spec中定义了 databaseName和 backupPath
apiVersion: "backup.example.com/v1"
kind: DatabaseBackup
metadata:
name: my-db-backup
spec:
databaseName: "production-db"
backupPath: "s3://my-bucket/backup.sql"
status:
phase: "Pending" # || InProgress || Completed || Failed
startTime: "2023-10-27T01:23:45Z"
completionTime: "2023-10-27T01:53:45Z"
与上面的任务不同,对于耗时类任务,绝对不能在 Reconcile函数内部同步地等待其完成,这会阻塞整个控制器,导致无法处理其他资源。正确的 Reconcile 函数设计需要借助于状态机模式完成,Reconcile函数在这里的角色不再是执行者,而是协调者和状态管理器。它需要维护一个状态机(status.phase),核心步骤如下:
step 1:获取现状
- 函数被调用,获取 DatabaseBackup对象
- 同时检查其 Status字段,了解当前任务进展到了哪一步
step2:对比与决策(状态机驱动),也是分为多个场景
2.1 场景A:status.phase是 Pending(新任务),决策为执行下面三步:
- 更新状态:将
status.phase设置为InProgress,并记录startTime - 发起异步任务,而不是等待。例如,向一个消息队列发送一个任务,或者启动一个 Kubernetes Job 来真正执行备份命令
- 立即返回:
Reconcile函数到此结束(不阻塞)。备份任务在后台由另一个程序(Job Pod)异步执行
2.2 场景B:status.phase是 InProgress(任务进行中),决策:
- 检查后台任务状态:函数去检查那个异步任务(如检查刚启动的 Job 的状态)是否完成
- 如果任务还在运行:什么也不做,直接返回。等待下一次触发(可能是定时器,也可能是Job状态变化事件)再来检查
- 如果任务成功完成:更新
status.phase为Completed,记录completionTime - 如果任务失败:更新
status.phase为Failed,并记录错误信息
2.3 场景C:status.phase是 Completed或 Failed(终态),决策为任务已结束,无需任何操作。直接返回
在这种场景下Reconcile函数的运行特点是:
- 非阻塞:
Reconcile函数本身执行得非常快,只是协调状态和发起检查,不执行实际耗时操作 - 异步驱动:实际工作由其他组件(Job Pod)完成
- 事件驱动与定时驱动结合:调和循环既会被资源对象(DatabaseBackup)的更新事件触发,也会被后台任务(Job)的状态变化事件触发。控制器还会设置一个定时重新调和(Requeue)的机制,即使没有事件,也会定期(例如每
30s)检查一次进行中的任务状态,防止事件丢失
kubebuilder 核心代码解读
1、Manager通过map[GroupVersionKind]informer启动所有controller:
func (ip *specificInformersMap) Start(stop <-chan struct{}) {
...
for _, informer := range ip.informersByGVK {
go informer.Informer.Run(stop)
}
...
<-stop
}
2、controller实现了前面提到的workqueue的大部分关于Controller的核心逻辑实现,也包含了处理event的逻辑
0x06 总结
0x07 参考
- Kubernetes 自定义控制器 Demo 例子
- Kubernetes CRD 开发实践
- 如何从零开始编写一个 Kubernetes CRD
- CRD 就像 Kubernetes 中的一张表
- KUBERNETES CRD&CONTROLLER入门实践
- Repository for sample controller. Complements sample-apiserver
- KubeFlow -> CRD开发实践
- Kubernetes Operator 开发教程
- Operator基础-开始Operator开发
- CRD is just a table in Kubernetes
- K8s 的核心是 API 而非容器(一):从理论到 CRD 实践(2022)
- Kubernetes Operator 快速入门教程
- 开发Redis CRD
- 从零开始写一个 kubebuilder
- 从零开始入门 K8s:Kubernetes API 编程利器 Operator 和 Operator Framework
- 使用kubebuilder开发operator详解
- kubebuilder 的运行逻辑
- 深入解析 Kubebuilder:让编写 CRD 变得更简单
- kubebuilder-2:原理
- 基于 sample-controller 实现自定义 CRD 控制器(Operator)的一般步骤
- Building your own kubernetes CRDs