0x00 前言
不要把路由表和 iptables 混淆,路由表决定如何传输数据包,而 iptables 决定是否传输数据包,他俩的职责不一样;最近印象较深的一句话
0x01 iptables/router/ip rule 区别
ip route(即route -n),iproute2提供的命令ip rule:策略路由(最重要),定义了数据包路由查询的规则iptables
[root@VM-16-10-tencentos ~]# ip rule
0: from all lookup local
9500: not from all dport 53 lookup main suppress_prefixlength 0
9510: not from all iif lo lookup 1970566510
9520: from 0.0.0.0 iif lo uidrange 0-4294967294 lookup 1970566510
9530: from 198.18.0.1 iif lo uidrange 0-4294967294 lookup 1970566510
32766: from all lookup main
32767: from all lookup default
[root@VM-16-10-tencentos ~]# ip route
default via 172.16.16.1 dev eth0
172.16.16.0/20 dev eth0 proto kernel scope link src 172.16.16.10 metric 100
198.18.0.0/16 dev utun proto kernel scope link src 198.18.0.1
本小节梳理 ip rule,ip route,iptables 三者之间的关系:
1、策略路由 (使用 ip rule 命令操作路由策略数据库)
1、ip rule 命令参数
ip rule [list | add | del] SELECTOR ACTION (add 添加;del 删除; llist 列表)
SELECTOR := [from PREFIX 数据包源地址] [ to PREFIX 数据包目的地址] [ tos TOS 服务类型][ dev STRING 物理接口] [ pref NUMBER ] [fwmark MARK iptables 标签]
ACTION := [table TABLE_ID 指定所使用的路由表] [ nat ADDRESS 网络地址转换][ prohibit 丢弃该表 | reject 拒绝该包 | unreachable 丢弃该包]
[flowid CLASSID]
TABLE_ID := [local | main | default | new | NUMBER]
2、作用
基于策略的路由比传统路由在功能上更强大(使用更灵活),它不仅能够像传统路由一样,根据目的地址来转发数据,而且也能够根据报文大小、应用,协议或 ip 源地址来选择路由转发路径
3、规则
在 Linux 系统启动时,内核会为路由策略数据库配置三条缺省的规则(参考前面笔者网关的配置):
0:匹配任何条件,查询路由表local(ID 255),路由表local是一个特殊的路由表,包含对于本地和广播地址的高优先级控制路由。rule 0非常特殊,不能被删除或者覆盖32766: 匹配任何条件,查询路由表main(ID 254),路由表main(ID 254)是一个通常的表,包含所有的无策略路由。系统管理员可以删除或者使用另外的规则覆盖这条规则32767:匹配任何条件,查询路由表default(ID 253),路由表default(ID 253)是一个空表,它是为一些后续处理保留的。对于前面的缺省策略没有匹配到的数据包,系统使用这个策略进行处理。这个规则也可以删除
在默认情况下进行路由时,首先会根据规则 0 在本地路由表里寻找路由,如果目的地址是本网络,或是广播地址的话,在这里就可以找到合适的路由;如果路由失败,就会匹配下一个不空的规则,在这里只有 32766 规则,在这里将会在主路由表里寻找路由;如果失败,就会匹配 32767 规则,即寻找默认路由表。如果失败,路由将匹配失败(包会被丢弃)。由此可知,策略性路由是往前兼容的。
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
左边的数字(0, 32764 等)表示规则的优先级:数值越小的规则,优先级越高
除了优先级之外,每个规则还有一个选择器(selector)和对应的执行策略(action)。选择器会判断该规则是否适用于当前的数据包,如果适用,就执行对应的策略。最常见的执行策略就是查询一个特定的路由表。如果该路由表包含了当前数据包的路由,那么就执行该路由;否则就会跳过当前路由表,继续匹配下一个路由规则
PS:路由表和策略区别:
规则指向路由表,多个规则可以引用一个路由表,而且某些路由表可以没有策略指向它。如果系统管理员删除了指向某个路由表的所有规则,这个表就没有用了,但是仍然存在,直到里面的所有路由都被删除,它才会消失。
2、路由表 (使用 ip route 命令操作静态路由表)
路由表,指的是路由器或者其他互联网网络设备上存储的表,该表中存有到达特定网络终端的路径,在某些情况下,还有一些与这些路径相关的度量。路由器的主要工作就是为经过路由器的每个数据包寻找一条最佳的传输路径,并将该数据有效地传送到目的站点。由此可见,选择最佳路径的策略即路由算法是路由器的关键所在。为了完成这项工作,在路由器中保存着各种传输路径的相关数据——路由表(Routing Table),供路由选择时使用,表中包含的信息决定了数据转发的策略。打个比方,路由表就像平时使用的地图一样,标识着各种路线,路由表中保存着子网的标志信息、网上路由器的个数和下一个路由器的名字等内容。路由表根据其建立的方法,可以分为动态路由表和静态路由表
1、路由表分类
linux 系统中,可以自定义从 1-252 个路由表,其中,linux 系统维护了 4 个路由表(路由表序号和表名的对应关系在 /etc/iproute2/rt_tables):
0#表: 系统保留表253#表: default table 没特别指定的默认路由都放在该表254#表: main table 没指明路由表的所有路由放在该表255#表: local table 保存本地接口地址,广播地址、NAT 地址 由系统维护,用户不得更改
Linux 从 2.2 版本左右的内核开始,便包含了多个路由表;还有一套规则,这套规则会告诉内核如何为每个数据包选择正确的路由表。当执行 ip route 时,你看到的是一个特定的路由表 main,除了 main 之外还有其他的路由表存在
[root@VM-16-10-tencentos ~]# cat /etc/iproute2/rt_tables
#
# reserved values
#
255 local
254 main
253 default
0 unspec
#
# local
#
#1 inr.ruhep
2、常用命令
路由表的查看有如下命令:
ip route list table table_number
ip route list table table_name
路由表添加完毕即时生效,下面为实例:
ip route add default via 192.168.1.1 table 1 #在一号表中添加默认路由为 192.168.1.1
ip route add 192.168.0.0/24 via 192.168.1.2 table 1 #在一号表中添加一条到 192.168.0.0 网段的路由为 192.168.1.2
一个例子:使用 ip route , ip rule , iptables 配置策略路由
需求:公司内网要求 192.168.0.100 以内的使用 10.0.0.1 网关上网(电信),其他 IP 使用 20.0.0.1 (网通)上网
实现如下:
1、首先要在网关服务器上添加一个默认路由,当然这个指向是绝大多数的 IP 的出口网关
ip route add default gw 20.0.0.1
2、通过 ip route 添加一个路由表
ip route add table 3 via 10.0.0.1 dev eth0 #(eth0 是 10.0.0.1 所在的网卡, 3 是路由表的编号)
3、添加 ip rule 规则
将标记 fwmark 与指定的路由相关联
ip rule add fwmark 3 table 3 #(fwmark 3 是标记,table 3 是路由表 3 上边,意思就是凡是标记了 3 的数据使用 table3 路由表)
4、使用 iptables 给相应的数据打上标记
利用 iptables 把数据包打上 fwmark(tproxy 也是这样操作的),在 PREROUTING 链的 mangle 表修改标记,让打了这种标记的包走路由表 3 出去:
iptables -A PREROUTING -t mangle -i eth0 -m iprange --src-range 192.168.0.1-192.168.0.100 -j MARK --set-mark 3
上面规则会匹配 eth0 接口上源 IP 地址在 192.168.0.1 到 192.168.0.100 之间的所有传入数据包,如果一个数据包匹配了这个规则,它会被标记为 3。这个规则的作用是为了对符合条件的数据包进行标记,以便在后续的处理中进行特殊的路由、过滤或者 QoS 策略等操作。
回顾前文 iptables 的使用,由于 mangle 的处理是优先于 nat 和 fiter 表的,所以相依数据包到达之后先打上标记,之后在通过 ip rule 规则,对应的数据包使用相应的路由表进行路由,最后读取路由表信息,将数据包送出网关
这里可以看出 Netfilter 处理网络包的先后顺序:接收网络包,先 DNAT,然后查路由策略,查路由策略指定的路由表做路由,然后 SNAT,再发出网络包
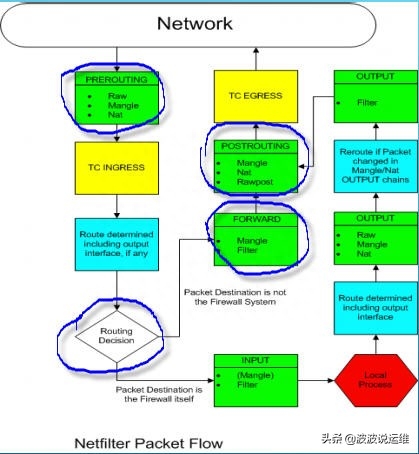
特别注意上图中的,蓝色部分,路由寻址
小结
内核是如何知道哪个数据包应该使用哪个路由表的呢?系统中有一套规则会告诉内核如何为每个数据包选择正确的路由表,这套规则就是路由策略数据库,即 ip rule
0x02 wireguard 中的路由
本节主要内容来源 彻底理解 WireGuard 的路由策略
问题起因
在网关主机上运行 wireguard,所有的流量都通过 WireGuard 路由出去,但却无法通过 ip route 的输出中看出路由走向;下面的路由全部是走 eth0 出入的,并未看到 wireguard 的虚拟网卡配置:
default via 192.168.100.254 dev eth0 proto dhcp src 192.168.100.63 metric 100
192.168.100.0/24 dev eth0 proto kernel scope link src 192.168.100.63
192.168.100.254 dev eth0 proto dhcp scope link src 192.168.100.63 metric 100
猜想可能是配置在其他的路由表中,再看看系统的策略路由配置
WireGuard 全局路由策略
通常在网关上,wireguard 的配置(注意 AllowedIPs = 0.0.0.0/0)如下:
# /etc/wireguard/wg0.conf
[Interface]
PrivateKey = xxxx
Address = 10.0.0.2/32
# PostUp = iptables -A FORWARD -i wg0 -j ACCEPT; iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
# PostDown = iptables -D FORWARD -i wg0 -j ACCEPT; iptables -t nat -D POSTROUTING -o eth0 -j MASQUERADE
# ListenPort = 51820
[Peer]
PublicKey = xxxx
Endpoint = 192.168.100.251:51820
AllowedIPs = 0.0.0.0/0 #一般会设置为将本机的所有流量通过 WireGuard 对端路由
理论上这样就可以让所有的流量都通过 wg0 进行处理完成并发送到对端路由了,But,如果是旧版本的 wg-quick ,执行了 wg-quick up wg0 之后,大概率会出现异常情况。原因是 WireGuard 自身的流量也通过虚拟网络接口进行路由了,这肯定是不行的
新版本 wg-quick 的解决
新版的 wg-quick 通过策略路由巧妙地解决了这个问题。首先,使用 wg-quick 启动 wg0 网卡:
$ wg-quick up wg0
[#] ip link add wg0 type wireguard
[#] wg setconf wg0 /dev/fd/63
[#] ip -4 address add 10.0.0.2/32 dev wg0
[#] ip link set mtu 1420 up dev wg0
[#] wg set wg0 fwmark 51820
[#] ip -4 route add 0.0.0.0/0 dev wg0 table 51820
[#] ip -4 rule add not fwmark 51820 table 51820
[#] ip -4 rule add table main suppress_prefixlength 0
[#] sysctl -q net.ipv4.conf.all.src_valid_mark=1
[#] iptables-restore -n
wg-quick 创建的路由表和 fwmark 使用的是同一个数字:51820(0xca6c 是 51820 的十六进制)
再检查下策略路由的配置(注意,核心的策略就在这里):
$ ip rule
0: from all lookup local
32764: from all lookup main suppress_prefixlength 0 #核心规则 1
32765: not from all fwmark 0xca6c lookup 51820 #核心规则 2
32766: from all lookup main
32767: from all lookup default
顺带也贴一下 main 路由表(主路由中没有任何一条去往 wg0 的路由):
$ ip route
default via 192.168.100.254 dev eth0 proto dhcp src 192.168.100.63 metric 100
192.168.100.0/24 dev eth0 proto kernel scope link src 192.168.100.63
192.168.100.254 dev eth0 proto dhcp scope link src 192.168.100.63 metric 100
理解 ip rule 的输出,需要搞懂下面几个问题:
suppress_prefixlength的作用0xca6c/51820又是啥not from all对数据包的影响是什么
核心规则 1
先看看核心规则 1,规则 32764 数值较小,会被优先匹配:
32764: from all lookup main suppress_prefixlength 0
上面这条规则没有使用选择器,内核会为每一个数据包去查询 main 路由表;本机的 main 路由表如下:
$ ip route
default via 192.168.100.254 dev eth0 proto dhcp src 192.168.100.63 metric 100
192.168.100.0/24 dev eth0 proto kernel scope link src 192.168.100.63
192.168.100.254 dev eth0 proto dhcp scope link src 192.168.100.63 metric 100
但是由于有参数 suppress_prefixlength 0 的限制,在所有的数据包通过 main 路由表之前,需要按照下面的规则检查,先看下 suppress_prefixlength 的作用:
suppress_prefixlength NUMBER
reject routing decisions that have a prefix length of NUMBER or less.
上面的 prefix 是前缀,表示路由表中匹配的地址范围的掩码。如果路由表中包含 10.2.3.4 的路由,前缀长度就是 32;如果是 10.0.0.0/8,前缀长度就是 8;suppress_prefixlength 0 的意思是 ** 拒绝前缀长度小于或等于 0 的路由策略 **,那么什么样的地址范围前缀长度才会 <=0?只有一种可能:0.0.0.0/0,也就是默认路由。以本机为例,默认路由如下:
default via 192.168.100.254 dev eth0 proto dhcp src 192.168.100.63 metric 100
如果数据包匹配到了默认路由,就拒绝转发;如果是其他路由,就正常转发。
所以,这条规则的作用是,管理员手动添加到 main 路由表中的路由都会正常转发,而默认路由会被忽略,继续匹配下一条规则;目的也很简单,不影响 main 主路由表
核心规则 2
下一条规则就是 32765:
32765: not from all fwmark 0xca6c lookup 51820
上面规则,换成容易理解的如下:
32765: from all not fwmark 0xca6c lookup 51820
从前面 wg-quick up wg0 的输出日志看,本条规则的选择器是没有添加 from 前缀(地址或者地址范围)的:
ip -4 rule add not fwmark 51820 table 51820
上面这条规则选择器没有 from 前缀,所以 ip rule 会打印出 from all,所以这条规则的结果显示 32765: not from all fwmark 0xca6c lookup 51820;再看 wg-quick 创建的 51820 这个路由表对应的路由是啥:
$ ip route show table 51820
default dev wg0 scope link #只包含唯一一条路由
所以规则 2 的效果是:匹配到该规则的所有数据包都通过 WireGuard 对端进行路由,除了带标记的 not fwmark 0xca6c,而 0xca6c 只是一个 iptables 标记,wg-quick 会让 wg 标记它发出的所有数据包(wg set wg0 fwmark 51820),由于这些数据包走到 wg0 虚拟网卡经由 wireguard 处理后已经封装了其他数据包,如果这些数据包也通过 WireGuard 进行路由,就会形成一个无限路由环路(这是必须要避免出现的情况!);所以 not from all fwmark 0xca6c lookup 51820 的含义是满足条件 from all fwmark 0xca6c(WireGuard 发出的都带 fwmark 0xca6c)请忽略本条规则,继续往下走。否则,请使用 51820 路由表,通过 wg0 隧道进入到 wireguard 应用程序内部处理(最终这些包会被打上 0xca6c 标记,然后再走物理网卡 eth0 发送到物理网络)
最后,对于 wg0 接口发包自带的 0xca6c 的数据包,继续走下一条规则,也就是匹配默认的 main 路由表:
32766: from all lookup main
此时已经没有抑制器了,所有的数据包都可以自由使用 main 路由表,因此 WireGuard 对端的 Endpoint 地址会通过 eth0 接口发送出去
设置 wg0 的 fwmark
下面这段代码对应的操作是什么?
wg set wg0 fwmark 51820
小结
wg-quick 对路由处理的巧妙之处在于,不会扰乱主路由表,而是通过规则匹配新创建的路由表;而断开连接(程序退出)时只需删除这两条路由规则,默认路由就会被重新激活。这种设置方式比较值得借鉴
0x03 clash.Meta tun 模式中的路由
clash.Meta 用作透明代理的路由设置和 wireguard 类似,如下
[root@VM-16-10-tencentos ~]# ip route
default via 172.16.16.1 dev eth0
172.16.16.0/20 dev eth0 proto kernel scope link src 172.16.16.10 metric 100
198.18.0.0/16 dev utun proto kernel scope link src 198.18.0.1
[root@VM-16-10-tencentos ~]# ip rule
0: from all lookup local
9500: not from all dport 53 lookup main suppress_prefixlength 0
9510: not from all iif lo lookup 1970566510
9520: from 0.0.0.0 iif lo uidrange 0-4294967294 lookup 1970566510
9530: from 198.18.0.1 iif lo uidrange 0-4294967294 lookup 1970566510
32766: from all lookup main
32767: from all lookup default
1970566510 的路由表信息:
[root@VM-16-10-tencentos ~]# ip route show table 1970566510
default dev utun proto static
9500: 所有不是目的端口为53的数据包都会被发送到主路由表中进行处理,suppress_prefixlength 0表示在进行路由查找时不会缩短前缀长度(参考 wireguard)9510: 所有从lo接口进入的数据包都会被发送到标识符为1970566510的路由表中进行处理9520: 所有从0.0.0.0地址进入lo接口的数据包都会被发送到标识符为1970566510的路由表中进行处理。uidrange 0-4294967294表示匹配所有UID范围内的数据包9530: 所有从198.18.0.1地址进入lo接口的数据包都会被发送到标识符为1970566510的路由表中进行处理
上面的 uidrange 的意义如下:uidrange 是 iptables 中用来匹配用户 ID(UID)范围的一个匹配条件。它可以用于过滤特定用户或用户组的网络流量。UID 为 0 是 root 用户;uidrange 可以用于匹配指定 UID 范围内的用户发起的网络流量。例如,uidrange 1000-2000 可以匹配 UID 在 1000 到 2000 范围内的用户发起的网络流量。可以将这个匹配条件与其他条件结合使用,例如源 IP 地址、目的端口等,以实现更精细的流量过滤和控制
不过,clash premium 的 ip rule 设置为 uidrange 0-4294967294,表示所有用户的流量都会被代理到 Clash
0x04 基于 uid(用户 ID)的路由策略技巧
此技巧借鉴于 Clash 配置,通常使用 TUN 技术的引流,有两种方式 Fake-IP/Real-IP:
Fake-IP:假设网关的 TUN 网卡配置为10.19.0.1/15,通过 DNS 透明劫持、DHCP 等机制等,将 DNS 域名www.qq.com解析到10.19.0.1/15子网中的 IP,以此方式将所有访问www.qq.com的流量导入至 TUN 网卡Real-IP:不干扰 DNS 解析结果,流量经过网关时,www.qq.com的 IP 为其真实解析 IP,不过需要配置引流路由将该 IP 的流量导入到 TUN 网卡
从经验而言,Fake-IP 模式配置简单,而 Real-IP 模式使用真实 IP 地址则需要比较复杂的配置过程,但是其工作状态最接近真实网络环境,兼容性好,此外有些应用只能使用真实 IP 进行连接,则必须使用 RealIP 模式
1、Fake-IP,假设网段为 198.18.0.0/16 可以添加路由将该网段的流量发向 Clash Tun:
route add -net 198.18.0.0/16 dev utun
2、 Real-IP模式的复杂性主要有两点:
- 如何使得 Clash Outbound 还能正确的连接互联网
- 如何使得 DIRECT 出口的流v量不要经过 Tun NIC 回到 Clash 造成回环(这个非常重要)
在实践中,分为网关模式和普通单机模式来看:
- 网关模式:当 Clash 作为网关工作,如果运行 Clash 的主机本身并不需要通过 Tun 代理,仅仅是转发其他设备的流量,该模式下的配置就会较为简单(一些不需要走TUN代理的流量,比如网关的外发流量、SSH流量、一些内置agent流量等,可以通过设置路由优先级解决,最低优先级的默认路由是指向TUN代理网卡)
- 单机模式:运行 Clash 的 Linux 的主机本身也需要代理,这时候不能使用添加 Default 路由到 Tun NIC 的方式应用 Clash Tun 模式,否则 Clash 将无法连接远程代理服务器(即主机到代理的流量不能在走到TUN网卡,这样就回环了)
3、如何解决单机模式下Clash Tun模式的使用问题?(Linux)
解决思路是将 Clash 运行在一个单独的用户下,用以给操作系统一个区分网络流量是否是 Clash 发出的特征。使用 iptables 在 mangle 表中,将流量打上 fwmark,再由 IP rule 决定将这些有 mark的流量使用策略路由 (policy route)将流量转发给 Tun NIC,这个包含了两个步骤:
- 在 mangle 表 OUTPUT 链中使用 uid-owner 排除 Clash 发出的流量(不过Clash)
- 在 mangle 表 PREROUTING 中,将其他设备发来的流量打上
fwmark(根据策略路由决定要不要发给Clash)
实际操作流程如下,假设 clash 运行在 alice 用户下,该用户的 UID 为 129,fwmark 也用 129,clash 策略路由的路由表 id 也为 129(用户 uid,fwmark ,路由表 id 是三个不相关的值)
第一步:创建NIC,配置 Tun NIC,配置 iptables 和 ip rule(假设 Tun NIC 为 clash0,owner 也为 alice,并且已经 bring up)
第二步:配置 iptables,首先在 mangle 表中创建 CLASH 链,主要用于排除一些局域网地址(使用 ipset可参考下面被注释的 chnroute 项,排除一些国内地址)
iptables -t mangle -N CLASH # 创建 Clash Chain
# 排除一些局域网地址
iptables -t mangle -A CLASH -d 0.0.0.0/8 -j RETURN
iptables -t mangle -A CLASH -d 10.0.0.0/8 -j RETURN
iptables -t mangle -A CLASH -d 127.0.0.0/8 -j RETURN
iptables -t mangle -A CLASH -d 169.254.0.0/16 -j RETURN
iptables -t mangle -A CLASH -d 172.16.0.0/12 -j RETURN
iptables -t mangle -A CLASH -d 192.168.0.0/16 -j RETURN
iptables -t mangle -A CLASH -d 224.0.0.0/4 -j RETURN
iptables -t mangle -A CLASH -d 240.0.0.0/4 -j RETURN #上面这些规则都是直接放行,不打mark
# iptables -t mangle -A CLASH -m set --match-set chnroute dst -j RETURN
iptables -t mangle -A CLASH -j MARK --set-xmark 129 #打mark
简单解释下上面这段操作的意义(该组操作主要作用在mangle表是对流量进行标记和过滤),mangle表本来就是拆解报文,作出修改,封装报文场景下使用的:
iptables -t mangle -N CLASH:创建了一个新的 chain,名字叫做 CLASH。Mangle chains 的主要功能就是修改包的内容,比如 TTL 值,TCP options 等iptables -t mangle -A CLASH -d 0.0.0.0/8 -j RETURN:向 CLASH chain 中添加了一条规则,-j RETURN表示一旦匹配成功就停止继续往下检查,不再执行剩余的规则,这样做的目的是为了跳过不需要处理的流量iptables -t mangle -A CLASH -j MARK --set-xmark 129:此步骤设置了一个 mark,然后把这个 mark (129)写入到了每一个经过 CLASH chain 的包的xmark位(这里隐含了前面的iptables规则都没有命中)
这里多提一下,0.0.0.0/8这个cidr的意义:
0.0.0.0/8通常作为默认路由使用。当某台设备收到一个不知道应该发送给哪个网络接口的数据包时,就会将其转发到0.0.0.0/8网络,然后再由相应的网络接口处理0.0.0.0/8也是保留的IP地址块之一,不能分配给任何网络设备,即不能在这个范围内建立自己的网络0.0.0.0/8出现在防火墙规则中,作为通配符,匹配任意来源或目标地址
然后在 PREROUTING 链中,给所有转发(forward)流量打上 fwmark。PREROUTING 链的流量来自于其他设备(如果有必要,可以限制高目标端口以防止 BT 流量被转发到 Clash),如下:
# 限制高目标端口的流量
# iptables -t mangle -A PREROUTING -p udp -m udp --dport 4096:65535 -j RETURN
# iptables -t mangle -A PREROUTING -p tcp -m tcp --dport 8192:65535 -j RETURN
iptables -t mangle -A PREROUTING -j CLASH #走到CLASH链去,最后会被打上mark
最后在 OUTPUT 链中,将本机外出流量打上 fwmark:
iptables -t mangle -A OUTPUT -m owner --uid-owner 129 -j RETURN
# 如果本机有某些不想被代理的应用(如BT),可以将其运行在特定用户下,加以屏蔽
# iptables -t mangle -A OUTPUT -m owner --uid-owner xxx -j RETURN
iptables -t mangle -A OUTPUT -j CLASH
下面添加策略路由,使得被打上 fwmark 的流量交由特定路由表(129)处理,并转发到 Clash 监听的 Tun NIC 上:
ip route add default dev clash0 table 129 #设置路由表
ip rule add fwmark 129 lookup 129 #设置fwmark策略
PS:可以用 ip route验证下策略路由是否生效:
ip route get 1.1.1.1 mark 129
#应该有如下的返回(0x81 是 129 的 16进制)
1.2.3.4 dev clash0 table 129 src 192.168.31.194 mark 0x81 uid 1000
cache
第三步:排除 rp_filter 的故障(rp_filter 机制是 Linux 的安全功能,rp_filter 会在计算路由决策的时候,计算包的反向路由,也就是将包中的源地址和目的地址对调再查找路由表,由本机或者其他设备流向 clash0 的 IP Packet一般不会有问题,但是当 rp_filter 检查 clash0 流出的包时,由于这些包不会带有 fwmark,检查反向路由时不会走刚才定义的策略路由,导致 rp_filter 检查失败,包被丢弃),
解决方法是临时关闭 clash0 NIC 的 rp_filter功能,操作如下:
sysctl -w net.ipv4.conf.clash0.rp_filter=0
sysctl -w net.ipv4.conf.all.rp_filter=0
#将 all.rp_filter设置为 0 是必须的
#将 all.rp_filter 设置为 0 并不会将所有其他网卡的 rp_filter一并关闭。此时其他网卡的 rp_filter由它们各自的rp_filter控制