0x00 前言
现网中可能会遇到如下场景,批量提交一批任务(如 MYSQL 语句),或是从 kafka 等队列中批量消费一批数据;Go 的现有库没有诸如灵活定义作业运行、批量提交任务减少小任务提交等特性,当然可以借助于线程池来解决,不过 goZero 给出了一套更为轻量化的实现:executors
本文分析下 executors 组件实现,在 goZero 中,executors 充当任务池,做多任务缓冲,使用做批量处理的任务。如 clickhouse 大批量 insert,sql batch insert 等等。同时也可以在 go-queue 也可以看到 executors (在 queue 里面使用的是 ChunkExecutor ,限定任务提交字节大小)
使用场景
- 批量提交(运行)任务
- 缓冲一部分任务,惰性(超过某个设定的条件,比如超过数量 OR 超时)提交
- 延迟任务提交
实现原理
以 PeriodicalExecutor 为例:
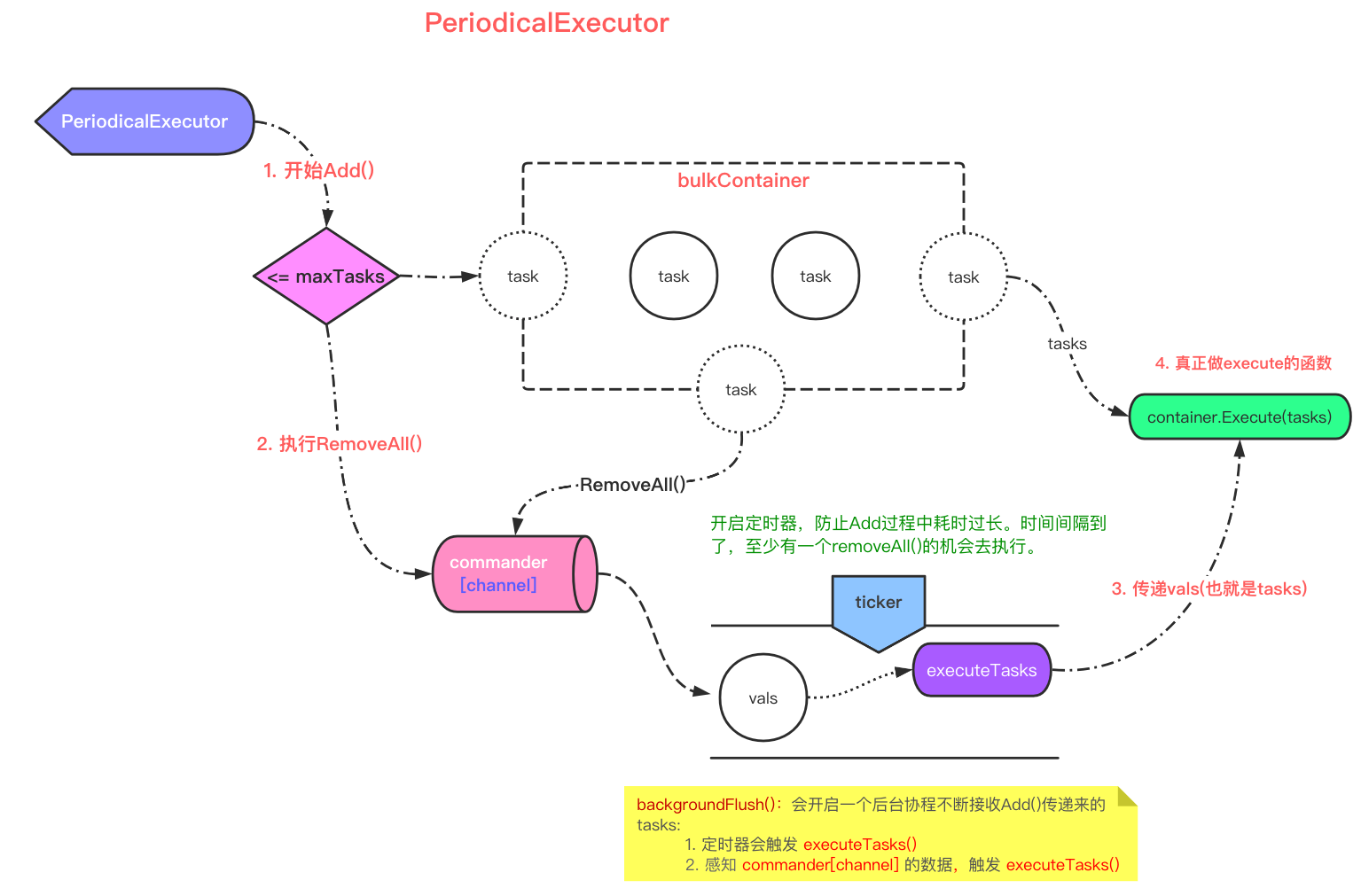
0x01 接口设计
executors 包实现了这几个 executor :大部分都是 executor 配合 container 的组合设计
bulkexecutor:达到maxTasks(最大任务数)提交chunkexecutor达到maxChunkSize(最大字节数)提交periodicalexecutor:最基础的executor实现delayexecutor:延迟执行传入的fn()lessexecutor:特殊功能
0x02 源码分析
依赖关系
bulkexecutor:periodicalexecutor+bulkContainerchunkexecutor:periodicalexecutor+chunkContainer
这里以 bulkexecutor 为例,本质上就是:
periodicalexecutor:提供任务执行的逻辑框架bulkContainer:提供任务缓冲区(特殊)
不过 periodicalexecutor 的实现可能初看有点绕,继续分析
基础定义
1、TaskContainer(是一个 interface):实例化为 bulkContainer、chunkContainer,可以理解为一个任务缓冲队列,AddTask 用来提示添加任务后是否超过了队列的最大值
type TaskContainer interface {
// AddTask adds the task into the container.
// Returns true if the container needs to be flushed after the addition.
// 把 task 加入 container
AddTask(task any) bool
// Execute handles the collected tasks by the container when flushing.
// 实际上是去执行传入的 execute func()
Execute(tasks any)
// RemoveAll removes the contained tasks, and return them.
// 达到临界值,移除 container 中全部的 task,通过 channel 传递到 execute func() 执行
RemoveAll() any
}
type bulkContainer struct {
tasks []any // 用来缓冲任务
execute Execute
maxTasks int
}
func (bc *bulkContainer) AddTask(task any) bool {
bc.tasks = append(bc.tasks, task)
// 添加任务后,如果数量超过阈值,则返回 true
return len(bc.tasks) >= bc.maxTasks
}
// 调用 bc.execute 处理真正的任务
func (bc *bulkContainer) Execute(tasks any) {
vals := tasks.([]any)
bc.execute(vals)
}
// 将当前 bc.tasks 缓冲区的所有任务全部取出
func (bc *bulkContainer) RemoveAll() any {
tasks := bc.tasks
bc.tasks = nil
return tasks
}
type chunkContainer struct {
tasks []any
execute Execute
size int
maxChunkSize int
}
func (bc *chunkContainer) AddTask(task any) bool {
ck := task.(chunk)
bc.tasks = append(bc.tasks, ck.val)
bc.size += ck.size
return bc.size >= bc.maxChunkSize
}
func (bc *chunkContainer) Execute(tasks any) {
vals := tasks.([]any)
bc.execute(vals)
}
func (bc *chunkContainer) RemoveAll() any {
tasks := bc.tasks
bc.tasks = nil
bc.size = 0
return tasks
}
type chunk struct {
val any
size int
}
TaskContainer 被设计为 interface,开发者可以实现自己的 executor(上面 3 个接口)
核心:PeriodicalExecutor 的实现
PeriodicalExecutor定义 如下:
// A PeriodicalExecutor is an executor that periodically execute tasks.
type PeriodicalExecutor struct {
commander chan any // 异步执行
interval time.Duration
container TaskContainer
waitGroup sync.WaitGroup
// avoid race condition on waitGroup when calling wg.Add/Done/Wait(...)
wgBarrier syncx.Barrier
confirmChan chan lang.PlaceholderType
inflight int32
guarded bool
newTicker func(duration time.Duration) timex.Ticker
lock sync.Mutex
}
// 初始化
func NewPeriodicalExecutor(interval time.Duration, container TaskContainer) *PeriodicalExecutor {
executor := &PeriodicalExecutor{
commander: make(chan interface{}, 1),
interval: interval,
container: container,
confirmChan: make(chan lang.PlaceholderType),
newTicker: func(d time.Duration) timex.Ticker {
return timex.NewTicker(interval)
},
}
//...
return executor
}
PeriodicalExecutor 结构的重要成员定义如下:
commander:异步传递tasks的 channel(从container加入的 tasks)container:暂存Add()增加的 taskconfirmChan:阻塞Add(),在开始本次的executeTasks()会放开阻塞ticker:定时器,防止Add()阻塞时(未达批量处理上限),会有一个定时执行的机会,及时释放暂存的 task
PeriodicalExecutor.Add 方法
在 PeriodicalExecutor 初始化后,在业务逻辑的第一步就是通过 Add 方法把 task 加入 executor:
AddFlushSyncWait
addAndCheck() 中 AddTask() 就是在控制最大 tasks 数,如果超过就执行 RemoveAll() ,将暂存 container 的 tasks pop,传递给 pe.commander ,后面有 goroutine 循环读取,然后去执行 tasks
// Add adds tasks into pe.
func (pe *PeriodicalExecutor) Add(task any) {
// 每次添加任务都会检查
if vals, ok := pe.addAndCheck(task); ok {
pe.commander <- vals
// 会阻塞在此,等待 container 缓存区被解除阻塞
<-pe.confirmChan
}
}
func (pe *PeriodicalExecutor) addAndCheck(task interface{}) (interface{}, bool) {
pe.lock.Lock()
defer func() {
// 一开始为 false
var start bool
if !pe.guarded {
// backgroundFlush() 会将 guarded 重新置反
pe.guarded = true
start = true
}
pe.lock.Unlock()
// 在第一条 task 加入的时候就会执行 if 中的 backgroundFlush()。后台协程刷 task
if start {
pe.backgroundFlush()
}
}()
// 控制 maxTask,>=maxTask 将 container 中 tasks pop, return
if pe.container.AddTask(task) {
return pe.container.RemoveAll(), true
}
return nil, false
}
和通常的实现不一样,在 addAndCheck 实现通过 defer 开启 pe.backgroundFlush() 逻辑(受 start 开关影响),而且 backgroundFlush 这个 goroutine 只会存在 1 个
backgroundFlush 开启一个后台协程,对 container 中的 task,不断刷新,实现如下:
func (pe *PeriodicalExecutor) backgroundFlush() {
go func() {
// flush before quit goroutine to avoid missing tasks
// 注意,不加此逻辑,会有 bug,参考 issue(下面参考链接)
defer pe.Flush()
ticker := pe.newTicker(pe.interval)
defer ticker.Stop()
var commanded bool
last := timex.Now()
// 异步接受 pe.commander 的任务并处理
for {
select {
case vals := <-pe.commander:
// 从 channel 拿到 []tasks
commanded = true
//
atomic.AddInt32(&pe.inflight, -1)
// 实质:wg.Add(1),这里的 enterExecution 也是异步的
pe.enterExecution()
// 放开 Add() 的阻塞,而且此时暂存区也为空。才开始新的 task 加入
pe.confirmChan <- lang.Placeholder
// 真正的执行 task 逻辑
pe.executeTasks(vals)
// 更新本次执行结束时间
last = timex.Now()
case <-ticker.Chan():
if commanded {
// 由于 select 选择的随机性,如果同时满足两个条件同时执行完上面的,此处置反,并跳过本段执行
// https://draveness.me/golang/docs/part2-foundation/ch05-keyword/golang-select/
commanded = false
} else if pe.Flush() {
// 定时刷新逻辑
// 刷新完成,定时器清零。暂存区空了,开始下一次定时刷新
last = timex.Now()
} else if pe.shallQuit(last) {
// 特别注意这里,如果检查满足退出条件,则 backgroundFlush 就自行退出
return
}
}
}
}()
}
// executeTasks 异步执行 tasks,并发控制由 waitgroup 处理
func (pe *PeriodicalExecutor) executeTasks(tasks any) bool {
defer pe.doneExecution()
ok := pe.hasTasks(tasks)
if ok {
threading.RunSafe(func() {
pe.container.Execute(tasks)
})
}
return ok
}
PeriodicalExecutor.backgroundFlush 的实现有点意思,它的这个 backgroundFlush 任务执行监听 goroutine 不是常驻的,而是过一段时间,会自行检查当前是否存在任务执行的 goroutine(atomic.LoadInt32(&pe.inflight) == 0),如果不存在就退出,如 pe.shallQuit 实现,下面的代码:
func (pe *PeriodicalExecutor) shallQuit(last time.Duration) (stop bool) {
if timex.Since(last) <= pe.interval*idleRound {
return
}
// checking pe.inflight and setting pe.guarded should be locked together
pe.lock.Lock()
if atomic.LoadInt32(&pe.inflight) == 0 {
// 如果超过了空闲时间且当前不存在活动 groutine,就退出
// 既没到 maxTask,Flush() err,并且 last->now 时间过长,会再次触发 Flush()
// 只有这置反,才会开启一个新的 backgroundFlush() 后台协程
pe.guarded = false
stop = true
}
pe.lock.Unlock()
return
}
小结下任务执行的过程:
- commander 接收到
RemoveAll()传递来的 tasks,然后做执行,并放开Add()的阻塞,得以继续Add() - ticker 定时器到时间了,如果第一步没有执行,则自动执行
Flush(),也会去做 task 的执行
PeriodicalExecutor.Flush 方法
// Flush forces pe to execute tasks.
func (pe *PeriodicalExecutor) Flush() bool {
pe.enterExecution()
return pe.executeTasks(func() any {
pe.lock.Lock()
defer pe.lock.Unlock()
return pe.container.RemoveAll()
}())
}
func (pe *PeriodicalExecutor) executeTasks(tasks any) bool {
defer pe.doneExecution()
ok := pe.hasTasks(tasks)
if ok {
threading.RunSafe(func() {
pe.container.Execute(tasks)
})
}
return ok
}
PeriodicalExecutor.Sync 方法
// Sync lets caller run fn thread-safe with pe, especially for the underlying container.
func (pe *PeriodicalExecutor) Sync(fn func()) {
pe.lock.Lock()
defer pe.lock.Unlock()
fn()
}
PeriodicalExecutor.Wait 相关方法
pe.waitGroup 相关,用于并发控制的,通常在用户侧代码最后需要加上 PeriodicalExecutor.Wait 方法,等待全部的 goroutine task 完成
// Wait waits the execution to be done.
func (pe *PeriodicalExecutor) Wait() {
pe.Flush()
pe.wgBarrier.Guard(func() {
pe.waitGroup.Wait()
})
}
func (pe *PeriodicalExecutor) doneExecution() {
pe.waitGroup.Done()
}
func (pe *PeriodicalExecutor) enterExecution() {
pe.wgBarrier.Guard(func() {
pe.waitGroup.Add(1)
})
}
PeriodicalExecutor 实现小结
PeriodicalExecutor 实现的几个细节
- 使用大量的 lock 来实现并发安全
pe.confirmChan的作用是什么?在backgroundFlush实现中,先wg.Add(1),再放开confirmChan的阻塞 如果 executor func 执行阻塞,Add task 还在进行,因为没有阻塞,可能很快执行到Executor.Wait(),这是就会出现wg.Wait()在wg.Add()前执行,这会导致 panic
BulkExecutor 实现
如前文描述,BulkExecutor 依赖于 PeriodicalExecutor 及 bulkContainer
// A BulkExecutor is an executor that can execute tasks on either requirement meets:
// 1. up to given size of tasks
// 2. flush interval time elapsed
type BulkExecutor struct {
executor *PeriodicalExecutor
container *bulkContainer
}
func NewBulkExecutor(execute Execute, opts ...BulkOption) *BulkExecutor {
// 选项模式:在 go-zero 中多处出现。在多配置下,比较好的设计思路
// https://halls-of-valhalla.org/beta/articles/functional-options-pattern-in-go,54/
options := newBulkOptions()
for _, opt := range opts {
opt(&options)
}
// 1. task container: [execute 真正做执行的函数] [maxTasks 执行临界点]
container := &bulkContainer{
execute: execute,
maxTasks: options.cachedTasks,
}
// 2. 可以看出 bulkexecutor 底层依赖 periodicalexecutor
executor := &BulkExecutor{
executor: NewPeriodicalExecutor(options.flushInterval, container),
container: container,
}
return executor
}
0x03 应用举例
这里引用原文的一个例子,定时同步任务,每天固定时间去执行从 mysql 到 clickhouse 的数据同步,这里采用 BulkExecutor 实现,先定义基础结构:
type DailyTask struct {
ckGroup *clickhousex.Cluster
insertExecutor *executors.BulkExecutor
mysqlConn sqlx.SqlConn
}
再次,初始化 bulkExecutor:
func (dts *DailyTask) Init() {
// insertIntoCk() 是真正 insert 执行函数【需要开发者自己编写具体业务逻辑】
dts.insertExecutor = executors.NewBulkExecutor(
dts.insertIntoCk,
executors.WithBulkInterval(time.Second*3), // 3s 会自动刷一次 container 中 task 去执行
executors.WithBulkTasks(10240), // container 最大 task 数。一般设为 2 的幂次
)
}
主体业务逻辑编写:
func (dts *DailyTask) insertNewData(ch chan interface{}, sqlFromDb *model.Task) error {
for item := range ch {
if r, vok := item.(*model.Task); !vok {
continue
}
err := dts.insertExecutor.Add(r)
if err != nil {
r.Tag = sqlFromDb.Tag
r.TagId = sqlFromDb.Id
r.InsertId = genInsertId()
r.ToRedis = toRedis == constant.INCACHED
r.UpdateWay = sqlFromDb.UpdateWay
// 1. Add Task
err := dts.insertExecutor.Add(r)
if err != nil {
logx.Error(err)
}
}
}
// 添加数据结束后,有其他 goroutine 关闭 ch
// 2. Flush Task container
dts.insertExecutor.Flush()
// 3. Wait All Task Finish
dts.insertExecutor.Wait()
}
从业务实现代码看,大致需要 3 步:
- 调用
Add():加入 task(这里Add()的时候就会同时触发 executors 的执行逻辑了) - 调用
Flush():刷新 container 中的 task - 调用
Wait():等待全部的 task 执行完成