0x00 前言
上文 介绍了 ebpf 的内核态 / 用户态的通信示例,本文关注这几个问题:
- 为什么要使用 maps
- maps 使用的一般场景
- maps 的基本结构及实现原理
- maps 的常用操作及场景(用户态 –> 内核态)
- 项目中的应用
BPF Map 是内核空间和用户空间之间用于数据交换、信息传递的桥梁,是 eBPF 程序中使用的主要数据结构。BPF Map 本质上是以键 / 值方式存储在内核中的数据结构,在内核空间的程序创建 BPF Map 并返回对应的文件描述符,在用户空间运行的程序就可以通过这个文件描述符来访问并操作 BPF Map,从而实现 kernel 内核空间与 user 用户空间的数据交换
建议阅读:
0x01 BPF maps 基础
先回顾下 ebpf 的架构,思考下内核态与用户态如何通信?
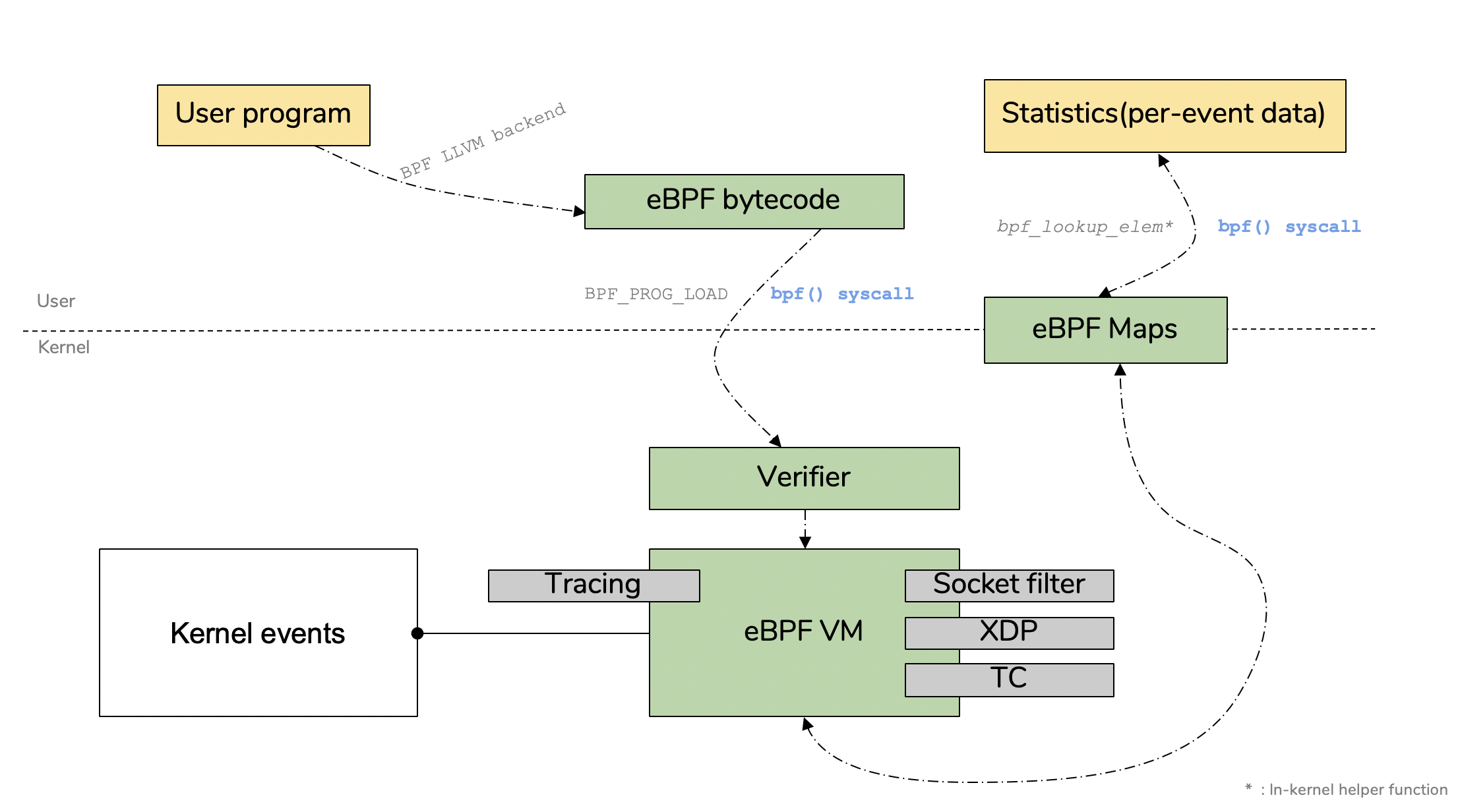
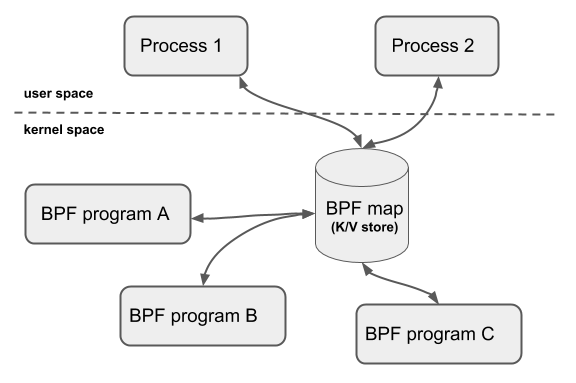
map 驻留在内存中,可以通过用户空间的文件描述符 fd 访问,可以在任意 BPF 程序以及用户空间应用之间共享。共享 map 的 BPF 程序不需要是相同的程序类型,单个 BPF 程序最多可以访问 64 个 map。map 有 per-CPU 以及 non-per-CPU 的通用 map,另外还有提供给特定辅助函数的非通用 map
通用 map 如下,它们都使用相同的一组 BPF 辅助函数来执行 CRUD 操作:
BPF_MAP_TYPE_HASHBPF_MAP_TYPE_ARRAYBPF_MAP_TYPE_PERCPU_HASHBPF_MAP_TYPE_PERCPU_ARRAYBPF_MAP_TYPE_LRU_HASHBPF_MAP_TYPE_LRU_PERCPU_HASHBPF_MAP_TYPE_LPM_TRIE
非通用 map 如下:
BPF_MAP_TYPE_PROG_ARRAYBPF_MAP_TYPE_PERF_EVENT_ARRAYBPF_MAP_TYPE_CGROUP_ARRAYBPF_MAP_TYPE_STACK_TRACEBPF_MAP_TYPE_ARRAY_OF_MAPSBPF_MAP_TYPE_HASH_OF_MAPS
例如 BPF_MAP_TYPE_PROG_ARRAY 用于存储其他 BPF 程序,BPF_MAP_TYPE_ARRAY_OF_MAPS 用于存储其他 map 的指针,非通用 map 都是为了与 bpf help 一起完成特定功能
这里还有更多的分类,可 参考
PERCPU 类型的 MAPS
这里特别提一下,内核从 4.10 版本开始,提供了 PERCPU 类型的 MAP。顾名思义,这些 PERCPU 类型的 MAPS 由多个副本组成,主机上的每个逻辑 CPU 都有一个副本。例如,在 CPU#0 上下文中运行的程序将看到与在 CPU#2 上运行的程序不同的映射内容。由于此模式多个 CPU 永远不会读取或写入另一个 CPU 正在访问的内存,因此不会出现竞争条件,因此程序无需在自旋锁或原子指令等机制上浪费周期来同步访问,因此可以提高访问速度。PERCPU 类型 MAPS 常用场景如下:
- 保存数据,不计入 eBPF 程序的堆栈限制(通用功能)
- 临时缓冲区:由于 eBPF 程序在整个执行过程中(包括 tail calls)始终在同一逻辑 CPU 上执行,所以此类 MAPS 可用于在 tail calls 之间传输信息
当通过用户空间访问每个 CPU 的映射时,所有副本始终同时访问。实际上,通过系统调用读取和写入这些映射的值就像数组一样,其大小等于主机的逻辑 CPU 数量。缺点是程序无法跨 CPU 边界共享信息。因此,这类映射通常更适合数据从 eBPF 程序流向用户空间的用例(如计数器)或相关事件始终发生在同一个逻辑 CPU 上的用例(例如由于 RSS 而导致的同一流的传入网络数据包)
0x02 BPF Map 数据结构
定义
每个 BPF Map 由四个值定义:类型、元素的最大个数、值大小 (Byte) 和键大小 (Byte),在实际场景中常用的是基于 SEC("maps") 这个语法糖来做到声明即创建:
struct {
__uint(type, BPF_MAP_TYPE_HASH); // 类型
__uint(max_entries, 8192); // 元素的最大个数
__type(key, pid_t); // 键大小 (以字节为单位)
__type(value, u64); // 值大小 (以字节为单位)
} rb SEC(".maps"); // SEC(".maps") 声明并创建了一个名为 rb 的 BPFMap
第二种定义方式:
struct bpf_map_def SEC("maps") my_bpf_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 100,
.map_flags = BPF_F_NO_PREALLOC,
};
关键点就是 SEC("maps"),即 ELF convention,它的工作原理如下描述:
- 声明 ELF Section 属性
SEC("maps") - 内核代码
bpf_load.c扫描目标文件中所有 Section 信息,它会扫描目标文件里定义的 Section,其中就有用来创建 BPF Map 的SEC("maps")
所有类型的 定义,需要注意类型对应的内核版本 or patch(开发)
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH, // 一种哈希表
BPF_MAP_TYPE_ARRAY, // 一种为快速查找速度而优化的数组类型 map 键值对,通常用于计数器
BPF_MAP_TYPE_PROG_ARRAY, // 与 eBPF 程序相对应的一种文件描述符数组; 用于实现跳转表和处理特定(网络)包协议的子程序
BPF_MAP_TYPE_PERF_EVENT_ARRAY, // 存储指向 perf_event 数据结构的指针,用于读取和存储 perf 事件计数器
BPF_MAP_TYPE_PERCPU_HASH, // 一种基于每个 CPU 的哈希表
BPF_MAP_TYPE_PERCPU_ARRAY, // 一种基于每个 cpu 的数组,用于实现展现延迟的直方图
BPF_MAP_TYPE_STACK_TRACE, // 存储堆栈跟踪信息
BPF_MAP_TYPE_CGROUP_ARRAY, // 存储指向控制组的指针
BPF_MAP_TYPE_LRU_HASH, // 一种只保留最近使用项的哈希表
BPF_MAP_TYPE_LRU_PERCPU_HASH, // 一种基于每个 CPU 的哈希表,只保留最近使用项
BPF_MAP_TYPE_LPM_TRIE, // 一个匹配最长前缀的字典树数据结构,适用于将 IP 地址匹配到一个范围
BPF_MAP_TYPE_ARRAY_OF_MAPS, // 一种 map-in-map 数据结构
BPF_MAP_TYPE_HASH_OF_MAPS, // 一种 map-in-map 数据结构
BPF_MAP_TYPE_DEVMAP,
BPF_MAP_TYPE_SOCKMAP,
BPF_MAP_TYPE_CPUMAP,
BPF_MAP_TYPE_XSKMAP,
BPF_MAP_TYPE_SOCKHASH,
BPF_MAP_TYPE_CGROUP_STORAGE,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE,
BPF_MAP_TYPE_QUEUE,
BPF_MAP_TYPE_STACK,
BPF_MAP_TYPE_SK_STORAGE,
BPF_MAP_TYPE_DEVMAP_HASH,
BPF_MAP_TYPE_STRUCT_OPS,
BPF_MAP_TYPE_RINGBUF, // 一种高性能字节形缓冲区
BPF_MAP_TYPE_INODE_STORAGE,
};
Hash Maps
内核代码在 kernel/bpf/hashtab.c
BPF_MAP_TYPE_HASH
BPF_MAP_TYPE_PERCPU_HASH
BPF_MAP_TYPE_LRU_HASH
BPF_MAP_TYPE_LRU_PERCPU_HASH
BPF_MAP_TYPE_HASH_OF_MAPS
汇总下,Hash map 的特点如下:
- key 的长度没有限制
- 给定 key 查找 value 时,内部通过哈希实现,而非数组索引,此机制 key/value 是可删除的;作为对比,Array 类型的 map 中,key/value 是不可删除的(但用空值覆盖掉 value ,可实现删除效果)。原因其实也很简单:哈希表是链表,可以删除链表中的元素;array 是内存空间连续的数组,即使某个
index处的 value 不用了,这段内存区域会被保留,不可能将其释放
PERCPU VS NONE-PERCPU
NONE-PERCPU 是 global 的,只有一个实例;PERCPU 是 cpu-local 的,每个 CPU 上都有一个 map 实例;多核并发访问时,global map 需要加锁;per-cpu map 无需加锁,每个核上的程序访问 local-cpu 上的 map
Array Maps
以 BPF_MAP_TYPE_ARRAY 为例,key 就是数组中的索引(index),因此 key 一定是整形,也无需对 key 进行哈希
BPF_MAP_TYPE_ARRAYBPF_MAP_TYPE_PERCPU_ARRAYBPF_MAP_TYPE_PROG_ARRAYBPF_MAP_TYPE_PERF_EVENT_ARRAYBPF_MAP_TYPE_ARRAY_OF_MAPSBPF_MAP_TYPE_CGROUP_ARRAY
CGroup Maps
BPF_MAP_TYPE_CGROUP_ARRAYBPF_MAP_TYPE_CGROUP_STORAGE
Tracing Maps
BPF_MAP_TYPE_STACK_TRACEBPF_MAP_TYPE_STACKBPF_MAP_TYPE_RINGBUF
Socket Maps
BPF_MAP_TYPE_SOCKMAPBPF_MAP_TYPE_REUSEPORT_SOCKARRAYBPF_MAP_TYPE_SK_STORAGE
pin map:持久化
此机制用于将ebpf map 保存到本地文件系统中进行持久化,当使用libbpf 库时,会自动保存到 /sys/fs/bpf/<map_name> 路径下。定义 pin map 的方法是在普通 map 的基础上加一个 pinning 字段,代码可参考
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, u32);
__type(value, struct event_t);
__uint(max_entries, 1024 * 16);
__uint(pinning, LIBBPF_PIN_BY_NAME); // <- pin
} event_map SEC(".maps");
0x03 BPF Map 操作(重点)
BPF Map 创建后,对其 CRUD 操作主要方法:
bpf_map_lookup_elem(map, key):通过 key 查询 BPF Map,得到对应 valuebpf_map_update_elem(map, key, value, options):通过 key-value 更新 BPF Map,如果这个 key 不存在,也可以作为新的元素插入到 BPF Map 中bpf_map_delete_elem(map, key):删除 BPF Map 中的某个 key
bpf_map_lookup_elem/bpf_lookup_elem
bpf_lookup_elem 用于在 fd 指向的映射中根据 key 查找对应元素,如果找到一个元素那么会返回 0 并把元素的值保存在 value 中,value 必须是指向 value_size 字节的缓冲区;如果没找到, 会返回 -1, 并把 errno 设置为 ENOENT
int bpf_lookup_elem(int fd, const void* key, void* value)
{
union bpf_attr attr = {
.map_fd = fd,
.key = ptr_to_u64(key),
.value = ptr_to_u64(value),
};
return bpf(BPF_MAP_LOOKUP_ELEM, &attr, sizeof(attr));
}
bpf_map_update_elem
bpf_map_update_elem用于在fd引用的映射中用给定的key/value去创建或者更新一个元素(由flags参数决定),出错返回-1, 典型的errno如下:
E2BIG:映射中的元素数量已经到达了创建时max_entries指定的上限EEXIST:flag设置BPF_NOEXIST,但是key已有对应元素ENOENT:flag设置BPF_EXIST,但是key没有对应元素
int bpf_update_elem(int fd, const void* key, const void* value, uint64_t flags)
{
union bpf_attr attr = {
.map_fd = fd,
.key = ptr_to_u64(key),
.value = ptr_to_u64(value),
.flags = flags,
};
return bpf(BPF_MAP_UPDATE_ELEM, &attr, sizeof(attr));
}
flags 参数如下:
| 选型 | 含义 |
|---|---|
BPF_ANY |
创建一个新元素或者更新一个已有的 |
BPF_NOEXIST |
只在元素不存在的情况下创建一个新的元素 |
BPF_EXIST |
更新一个已经存在的元素 |
bpf_delete_elem
bpf_delete_elem用于在fd指向的映射汇总删除键为key的元素
int bpf_delete_elem(int fd, const void* key)
{
union bpf_attr attr = {
.map_fd = fd,
.key = ptr_to_u64(key),
};
return bpf(BPF_MAP_DELETE_ELEM, &attr, sizeof(attr));
}
bpf_get_next_key
用于在fd引用的映射中根据key查找对应元素, 并设置next_key指向下一个元素的key,该方法可用于迭代map中所有的元素。详细描述下
- 如果存在
key,那么会返回0并设置指针next_pointer指向下一个元素的key - 如果
key没找到,会返回0并设置next_pointer指向映射中第一个元素的键 - 如果
key就是最后一个元素,会返回-1, 并设置errno为ENOENT
int bpf_get_next_key(int fd, const void* key, void* next_key)
{
union bpf_attr attr = {
.map_fd = fd,
.key = ptr_to_u64(key),
.next_key = ptr_to_u64(next_key),
};
return bpf(BPF_MAP_GET_NEXT_KEY, &attr, sizeof(attr));
}
小结
1、内核态helper函数
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)
long bpf_map_update_elem(struct bpf_map *map, const void *key,const void *value, u64 flags)
long bpf_map_delete_elem(struct bpf_map *map, const void *key)
2、用户态libbpf(user space)
// https://elixir.bootlin.com/linux/v4.19.261/source/tools/lib/bpf/bpf.c#L299
int bpf_map_lookup_elem(int fd, const void *key, void *value)
int bpf_map_update_elem(int fd, const void *key, const void *value, __u64 flags)
int bpf_map_delete_elem(int fd, const void *key)
0x04 典型用法介绍
本小节主要参考 BPF 进阶笔记(二):BPF Map 类型详解:使用场景、程序示例 一文
BPF_MAP_TYPE_HASH 的用法
BPF_MAP_TYPE_HASH 是最基础的 hashmap,初始化时需要指定支持的最大条目数(max_entries), 满了之后继续插入数据时,会报 E2BIG 错误;与 BPF_MAP_TYPE_LRU_HASH 类型不同,后者如果 map 满了,再插入时它会自动将最久未被使用(least recently used)的 entry 从 map 中移除,比较适用于 connection 连接表等存储场景
典型的应用场景:
1、将内核态得到的数据,传递给用户态程序。这是非常典型在内核态和用户态传递数据场景;例如,BPF 程序过滤网络设备设备上的包,统计流量信息,并将其写到 map。 用户态程序从 map 读取统计,做后续处理
2、存放全局配置信息,供 BPF 程序使用。例如,对于防火墙功能的 BPF 程序,将过滤规则放到 map 里。用户态控制程序通过 bpftool 之类的工具更新 map 里的配置信息,BPF 程序动态加载
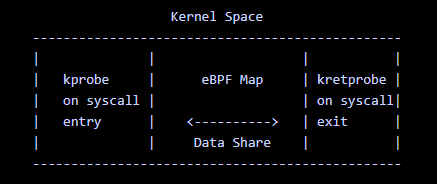
3、在内核态 syscall enter/exit 之间共享数据,如下图
示例 1:内核源码的 bpf 示例 sockex2_kern.c,将内核态数据传递到用户态
struct pair {
long packets;
long bytes;
};
struct {
__uint(type, BPF_MAP_TYPE_HASH); // BPF map 类型
__uint(max_entries, 1024); // 最大 entry 数量
__type(key, __be32); // 目的 IP 地址
__type(value, struct pair); // 包数和字节数
} hash_map SEC(".maps");
SEC("socket2")
int bpf_prog2(struct __sk_buff *skb)
{
// 解包:https://elixir.bootlin.com/linux/v4.15/source/samples/bpf/sockex2_kern.c#L99
flow_dissector(skb, &flow);
key = flow.dst; // 目的 IP 地址
value = bpf_map_lookup_elem(&hash_map, &key);
if (value) { // 如果已经存在,则更新相应计数
__sync_fetch_and_add(&value->packets, 1);
__sync_fetch_and_add(&value->bytes, skb->len);
} else { // 否则,新建一个 entry
struct pair val = {1, skb->len};
bpf_map_update_elem(&hash_map, &key, &val, BPF_ANY);
}
return 0;
}
内核态代码的作用是,用 BPF 程序过滤网络设备上的包,统计包数和字节数, 并以目的 IP 地址为 key 将统计信息写到 BPF_MAP_TYPE_HASH,用户态如何读取呢?参考 sockex2_user.c
#include <stdio.h>
#include <assert.h>
#include <linux/bpf.h>
#include "libbpf.h"
#include "bpf_load.h"
#include "sock_example.h"
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/resource.h>
struct pair {
__u64 packets;
__u64 bytes;
};
int main(int ac, char **argv)
{
struct rlimit r = {RLIM_INFINITY, RLIM_INFINITY};
char filename[256];
FILE *f;
int i, sock;
snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
setrlimit(RLIMIT_MEMLOCK, &r);
if (load_bpf_file(filename)) {
printf("%s", bpf_log_buf);
return 1;
}
sock = open_raw_sock("lo");
assert(setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, prog_fd,
sizeof(prog_fd[0])) == 0);
f = popen("ping -c5 localhost", "r");
(void) f;
for (i = 0; i < 5; i++) {
int key = 0, next_key;
struct pair value;
while (bpf_map_get_next_key(map_fd[0], &key, &next_key) == 0) {
bpf_map_lookup_elem(map_fd[0], &next_key, &value);
printf("ip %s bytes %lld packets %lld\n",
inet_ntoa((struct in_addr){htonl(next_key)}),
value.bytes, value.packets);
key = next_key;
}
sleep(1);
}
return 0;
}
示例 2:key为char[64]结构
typedef __u64 u64;
typedef char stringkey[64];
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 128);
//__type(key, stringkey);
stringkey* key; //这两种方式都可以
__type(value, u64);
} execve_counter SEC(".maps");
SEC("tracepoint/syscalls/sys_enter_execve")
int bpf_prog(void *ctx) {
stringkey key = "execve_counter";
u64 *v = NULL;
v = bpf_map_lookup_elem(&execve_counter, &key);
if (v != NULL) {
*v += 1;
}
return 0;
}
示例 3:key 和 value 均为自定义结构体
// define the struct for the key of bpf map
struct pair {
__u32 src_ip;
__u32 dest_ip;
};
struct stats {
__u64 tx_cnt; // the sending request count
__u64 rx_cnt; // the received request count
__u64 tx_bytes; // the sending request bytes
__u64 rx_bytes; // the sending received bytes
};
struct bpf_map_def SEC("maps") tracker_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(struct pair), //注意:key为struct pair结构,需要对齐!
.value_size = sizeof(struct stats),
.max_entries = 2048,
};
struct stats *stats, newstats = {0, 0, 0, 0};
stats = bpf_map_lookup_elem(&tracker_map, pair);
if (stats)
{
stats->rx_cnt++;
stats->rx_bytes += bytes;
} else {
newstats.rx_cnt = 1;
newstats.rx_bytes = bytes;
bpf_map_update_elem(&tracker_map, pair, &newstats, BPF_NOEXIST);
}
BPF_MAP_TYPE_PERCPU_HASH 的用法
参考 samples/bpf/map_perf_test_kern.c
BPF_MAP_TYPE_LRU_HASH 的用法
BPF_MAP_TYPE_LRU_HASH 相对于 BPF_MAP_TYPE_HASH 的优点是,BPF_MAP_TYPE_HASH 有大小限制,超过最大数量后无法再插入了。而 BPF_MAP_TYPE_LRU_HASH 可以规避这个问题,如果 map 容量满了,再插入时它会自动应用 LRU 策略将的最久未被使用(least recently used)的 entry 从 map 中移除
使用场景如下:
- 连接跟踪(conntrack)表、NAT 表等固定大小哈希表,满了之后最老的
entry会被移除
参考代码 samples/bpf/map_perf_test_kern.c
BPF_MAP_TYPE_HASH_OF_MAPS
复合结构(map-in-map)第一个 map 内的元素是指向另一个 map 的指针。与 BPF_MAP_TYPE_ARRAY_OF_MAPS 等类型类似,但外层 map 使用的是哈希而不是数组。可以将整个(内层)map 在运行时实现原子替换
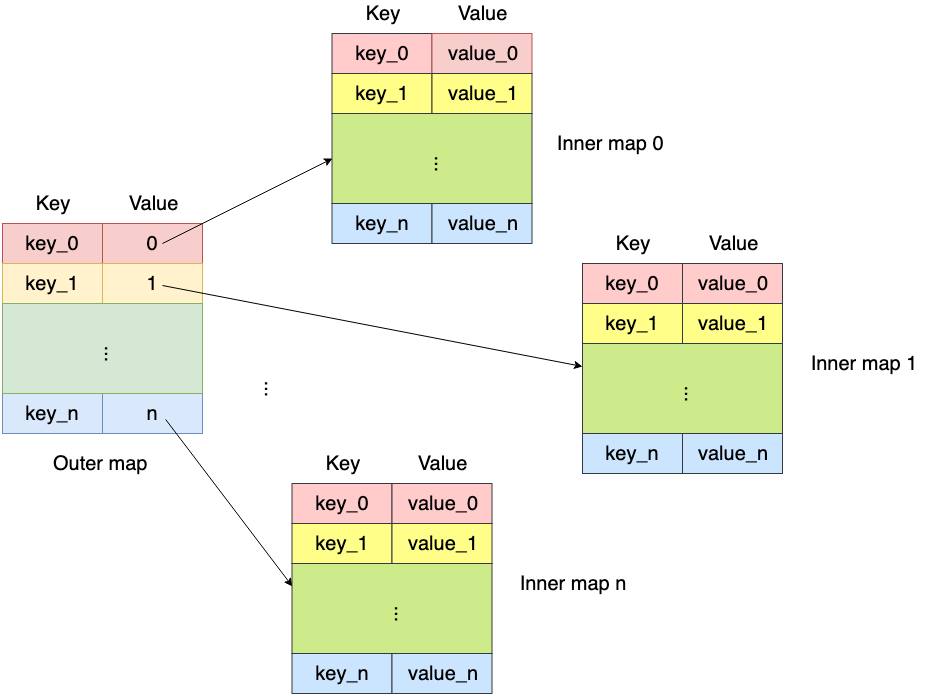
使用场景:
- map-in-map
- Array of array
- Hash of array
- Hash of hash
参考代码 samples/bpf/test_map_in_map_kern.c
Array Maps:BPF_MAP_TYPE_ARRAY
参考代码 samples/bpf/sockex1_kern.c,功能是根据协议类型(proto as key)统计流量,内核态代码如下:
// samples/bpf/sockex1_kern.c
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 256);
__type(key, u32); // L4 协议类型(长度是 uint8),例如 IPPROTO_TCP,范围是 0~255
__type(value, long); // 累计包长(skb->len)
} my_map SEC(".maps");
SEC("socket1")
int bpf_prog1(struct __sk_buff *skb)
{
int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol)); // L4 协议类型
if (skb->pkt_type != PACKET_OUTGOING)
return 0;
// 注意:在用户态程序和这段 BPF 程序里都没有往 my_map 里插入数据;
// * 如果这是 hash map 类型,那下面的 lookup 一定失败,因为没插入过任何数据;
// * 但这里是 array 类型,而且 index 表示的 L4 协议类型,在 IP 头里占一个字节,因此范围在 255 以内;
// 又 map 的长度声明为 256,所以这里的 lookup 一定能定位到 array 的某个位置,即查找一定成功
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
__sync_fetch_and_add(value, skb->len);
return 0;
}
BPF_MAP_TYPE_PROG_ARRAY
BPF_MAP_TYPE_PROG_ARRAY,程序数组,尾调用 bpf_tail_call() 时会用到。示例代码:根据协议类型尾调用到下一层 parser,代码 samples/bpf/sockex3.c
使用场景:
- 尾调用(tail call)
结构:
- key:任意整形(因为要作为 array index),具体表示什么由使用者设计(例如表示协议类型 proto)
- value:BPF 程序的文件描述符(fd)
BPF_MAP_TYPE_PERF_EVENT_ARRAY
BPF_MAP_TYPE_PERF_EVENT_ARRAY 常用于保存 tracing 结果。示例代码:保存 perf event,代码 samples/bpf/trace_output_kern.c
struct bpf_map_def SEC("maps") my_map = {
.type = BPF_MAP_TYPE_PERF_EVENT_ARRAY,
.max_entries = 2,
.key_size = sizeof(int),
.value_size = sizeof(u32),
};
SEC("kprobe/sys_write")
int bpf_prog1(struct pt_regs *ctx)
{
struct S {
u64 pid;
u64 cookie;
} data;
data.pid = bpf_get_current_pid_tgid();
data.cookie = 0x12345678;
bpf_perf_event_output(ctx, &my_map, 0, &data, sizeof(data));
return 0;
}
HASH MAP:复合结构
BPF_MAP_TYPE_HASH_OF_MAPS、BPF_MAP_TYPE_ARRAY_OF_MAPS 等
使用场景:
- map-in-map,values 是指向内层 map 的 fd。只支持两层 map。 two levels of map,也就是一层 map 嵌套另一层 map
BPF_MAP_TYPE_PROG_ARRAY类型的 BPF 程序不支持 map-in-map 功能 ,因为这会使 tail call 的 verification 更加困难
参考代码:
BPF_MAP_TYPE_CGROUP_ARRAY
在用户空间存放 cgroup fds,用来检查给定的 skb 是否与 cgroup_array[index] 指向的 cgroup 关联,使用场景如下:
- cgroup 级别的包过滤(拒绝 / 放行)
- cgroup 级别的进程过滤(权限控制等)
1、Pin & update pinned cgroup array,参考代码 samples/bpf/test_cgrp2_array_pin.c,将 cgroupv2 array pin 到 BPFFS,更新 pinned cgroupv2 array
// samples/bpf/test_cgrp2_array_pin.c
if (create_array) {
array_fd = bpf_create_map(BPF_MAP_TYPE_CGROUP_ARRAY, sizeof(uint32_t), sizeof(uint32_t), 1, 0);
} else {
array_fd = bpf_obj_get(pinned_file);
}
bpf_map_update_elem(array_fd, &array_key, &cg2_fd, 0);
if (create_array) {
ret = bpf_obj_pin(array_fd, pinned_file);
}
2、CGroup 级别的包过滤,代码 samples/bpf/test_cgrp2_tc_kern.c,核心是调用 bpf_skb_under_cgroup() 判断 skb 是否在给定 cgroup 中
// samples/bpf/test_cgrp2_tc_kern.c
struct bpf_elf_map SEC("maps") test_cgrp2_array_pin = {
.type = BPF_MAP_TYPE_CGROUP_ARRAY,
.size_key = sizeof(uint32_t),
.size_value = sizeof(uint32_t),
.pinning = PIN_GLOBAL_NS,
.max_elem = 1,
};
SEC("filter")
int handle_egress(struct __sk_buff *skb)
{
...
if (bpf_skb_under_cgroup(skb, &test_cgrp2_array_pin, 0) != 1) {
bpf_trace_printk(pass_msg, sizeof(pass_msg));
return TC_ACT_OK;
}
...
}
3、判断进程是否在给定 cgroup 中:samples/bpf/test_current_task_under_cgroup_kern.c,代码通过调用 bpf_current_task_under_cgroup() 判断当前进程是否在给定 cgroup 中:
struct bpf_map_def SEC("maps") cgroup_map = {
.type = BPF_MAP_TYPE_CGROUP_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(u32),
.max_entries = 1,
};
/* Writes the last PID that called sync to a map at index 0 */
SEC("kprobe/sys_sync")
int bpf_prog1(struct pt_regs *ctx)
{
...
if (!bpf_current_task_under_cgroup(&cgroup_map, 0))
return 0;
...
}
BPF_MAP_TYPE_STACK_TRACE
内核程序能通过 bpf_get_stackid() helper 存储 stack 信息, 将 stack 信息关联到一个 id,而这个 id 是对当前栈的指令指针地址(instruction pointer address)进行 32-bit hash 得到的
使用场景:
- 存储 profiling 信息
- 在内核中获取 stack id,用它作为 key 更新另一个 map。例如通过对指定的 stack traces 进行 profiling,统计它们的出现次数,或者将 stack trace 信息与当前 pid 关联起来
- 参考代码 samples/bpf/offwaketime_kern.c,打印调用栈
BPF_MAP_TYPE_RINGBUF(重要)
BPF perf buffer(perfbuf)是目前这一过程的事实标准,但它存在一些问题,例如 浪费内存(因为其 per-CPU 设计)、事件顺序无法保证等。作为改进,内核 5.8 引入另一个新的 BPF 数据结构 ring buffer,相比 perf buffer,它内存效率更高、保证事件顺序,性能也不输前者;在使用上,既提供了与 perf buffer 类似的 API ,以方便用户迁移;又提供了一套新的 reserve/commit API(先预留再提交),以实现更高性能
ringbuf 是一个 多生产者单消费者(multi-producer, single-consumer,MPSC) 队列,可安全地在多个 CPU 之间共享和操作。perfbuf 支持的一些功能它都支持,包括:
- 可变长数据(variable-length data records)
- 通过 memory-mapped region 来高效地从 userspace 读数据,避免内存复制或系统调用
- 支持 epoll notifications 和 busy-loop 两种获取数据方式
- 压测结果表明,从 BPF 程序发送数据给用户空间时, 应该首选 BPF ring buffer
使用场景如下:
- 更高效、保证事件顺序地往用户空间发送数据
- 常规场景:对于所有实际场景(尤其是那些基于
bcc/libbpf的默认配置在使用 perfbuf 的场景), ringbuf 的性能都优于 perfbuf 性能 - 高吞吐场景:每秒百万级事件(millions of events per second)以上的场景
这里列举一个使用 ringbuff 的经典例子,当一个进程执行新的可执行文件(例如通过 execve 系统调用)时,内核会发出 sched_process_exec 跟踪事件(hook 点),以便跟踪和记录进程执行的相关信息
1、结构定义
/* SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) */
/* Copyright (c) 2020 Andrii Nakryiko */
#ifndef __COMMON_H
#define __COMMON_H
struct trace_entry {
short unsigned int type;
unsigned char flags;
unsigned char preempt_count;
int pid;
};
/* sched_process_exec tracepoint context */
struct trace_event_raw_sched_process_exec {
struct trace_entry ent;
unsigned int __data_loc_filename;
int pid;
int old_pid;
char __data[0];
};
#define TASK_COMM_LEN 16
#define MAX_FILENAME_LEN 512
/* definition of a sample sent to user-space from BPF program */
struct event {
int pid;
char comm[TASK_COMM_LEN];
char filename[MAX_FILENAME_LEN];
};
#endif /* __COMMON_H */
2、内核态代码
// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause
/* Copyright (c) 2020 Andrii Nakryiko */
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include "common.h"
char LICENSE[] SEC("license") = "Dual BSD/GPL";
/* BPF ringbuf map */
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF); // 定义一个 rb 结构
__uint(max_entries, 256 * 1024 /* 256 KB */);
} rb SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_ARRAY); //
__uint(max_entries, 1);
__type(key, int);
__type(value, struct event);
} heap SEC(".maps");
SEC("tp/sched/sched_process_exec")
int handle_exec(struct trace_event_raw_sched_process_exec *ctx)
{
unsigned fname_off = ctx->__data_loc_filename & 0xFFFF;
struct event *e;
int zero = 0;
// 什么作用?
e = bpf_map_lookup_elem(&heap, &zero);
if (!e) /* can't happen */
return 0;
e->pid = bpf_get_current_pid_tgid()>> 32;
bpf_get_current_comm(&e->comm, sizeof(e->comm));
bpf_probe_read_str(&e->filename, sizeof(e->filename), (void *)ctx + fname_off);
// 写入 ringbuff
bpf_ringbuf_output(&rb, e, sizeof(*e), 0);
return 0;
}
3、用户态代码
// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause)
// Copyright (c) 2020 Andrii Nakryiko
#include <errno.h>
#include <signal.h>
#include <stdio.h>
#include <time.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "common.h"
#include "ringbuf-output.skel.h"
int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
/* Ignore debug-level libbpf logs */
if (level> LIBBPF_INFO)
return 0;
return vfprintf(stderr, format, args);
}
void bump_memlock_rlimit(void)
{
struct rlimit rlim_new = {
.rlim_cur = RLIM_INFINITY,
.rlim_max = RLIM_INFINITY,
};
if (setrlimit(RLIMIT_MEMLOCK, &rlim_new)) {
fprintf(stderr, "Failed to increase RLIMIT_MEMLOCK limit!\n");
exit(1);
}
}
static volatile bool exiting = false;
static void sig_handler(int sig)
{
exiting = true;
}
int handle_event(void *ctx, void *data, size_t data_sz)
{
const struct event *e = data;
struct tm *tm;
char ts[32];
time_t t;
time(&t);
tm = localtime(&t);
strftime(ts, sizeof(ts), "%H:%M:%S", tm);
printf("%-8s %-5s %-7d %-16s %s\n", ts, "EXEC", e->pid, e->comm, e->filename);
return 0;
}
int main(int argc, char **argv)
{
struct ring_buffer *rb = NULL;
struct ringbuf_output_bpf *skel;
int err;
/* Set up libbpf logging callback */
libbpf_set_print(libbpf_print_fn);
/* Bump RLIMIT_MEMLOCK to create BPF maps */
bump_memlock_rlimit();
/* Clean handling of Ctrl-C */
signal(SIGINT, sig_handler);
signal(SIGTERM, sig_handler);
/* Load and verify BPF application */
skel = ringbuf_output_bpf__open_and_load();
if (!skel) {
fprintf(stderr, "Failed to open and load BPF skeleton\n");
return 1;
}
/* Attach tracepoint */
err = ringbuf_output_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
/* Set up ring buffer polling */
rb = ring_buffer__new(bpf_map__fd(skel->maps.rb), handle_event, NULL, NULL);
if (!rb) {
err = -1;
fprintf(stderr, "Failed to create ring buffer\n");
goto cleanup;
}
/* Process events */
printf("%-8s %-5s %-7s %-16s %s\n",
"TIME", "EVENT", "PID", "COMM", "FILENAME");
while (!exiting) {
err = ring_buffer__poll(rb, 100 /* timeout, ms */);
/* Ctrl-C will cause -EINTR */
if (err == -EINTR) {
err = 0;
break;
}
if (err < 0) {
printf("Error polling ring buffer: %d\n", err);
break;
}
}
cleanup:
ring_buffer__free(rb);
ringbuf_output_bpf__destroy(skel);
return err < 0 ? -err : 0;
}
BPF_MAP_TYPE_PERF_EVENT_ARRAY
使用场景:
- Perf events:BPF 程序将数据存储在
mmap()共享内存中,用户空间程序可以访问。
参考代码 samples/bpf/trace_output,trace write() 系统调用
- 非固定大小数据(不适合 map)
- 无需与其他 BPF 程序共享数据
BPF_MAP_TYPE_SOCKMAP
主要用于 socket redirection:将 sockets 信息插入到 map,后面执行到 bpf_sockmap_redirect() 时,用 map 里的信息触发重定向(socket redirection)
BPF_MAP_TYPE_SK_STORAGE
使用场景:
- per-socket 存储空间
示例,代码 samples/bpf/tcp_dumpstats_kern.c,在内核定期 dump socket 详情
struct {
__u32 type;
__u32 map_flags;
int *key;
__u64 *value;
} bpf_next_dump SEC(".maps") = {
.type = BPF_MAP_TYPE_SK_STORAGE,
.map_flags = BPF_F_NO_PREALLOC,
};
SEC("sockops")
int _sockops(struct bpf_sock_ops *ctx)
{
struct bpf_tcp_sock *tcp_sk;
struct bpf_sock *sk;
__u64 *next_dump;
switch (ctx->op) {
case BPF_SOCK_OPS_TCP_CONNECT_CB:
bpf_sock_ops_cb_flags_set(ctx, BPF_SOCK_OPS_RTT_CB_FLAG);
return 1;
case BPF_SOCK_OPS_RTT_CB:
break;
default:
return 1;
}
sk = ctx->sk;
next_dump = bpf_sk_storage_get(&bpf_next_dump, sk, 0, BPF_SK_STORAGE_GET_F_CREATE);
now = bpf_ktime_get_ns();
if (now < *next_dump)
return 1;
tcp_sk = bpf_tcp_sock(sk);
*next_dump = now + INTERVAL;
bpf_printk("dsack_dups=%u delivered=%u\n", tcp_sk->dsack_dups, tcp_sk->delivered);
bpf_printk("delivered_ce=%u icsk_retransmits=%u\n", tcp_sk->delivered_ce, tcp_sk->icsk_retransmits);
return 1;
}
开源项目的经典示例
本小节分享几个经典的 MAPS 应用示例
1、bcc 的 opensnoop 工具
2、bcc 的 ksnoop 工具
ksnoop工具 用来
3、libbpf-bootstrap 的 execsnoop 工具
execsnoop 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果,所以它需要对两个地方进行 hook:
tracepoint/syscalls/sys_enter_execvetracepoint/syscalls/sys_exit_execve
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include "execsnoop.h"
static const struct event empty_event = { }; // 给 MAP bpf_map_update_elem 函数,做初始化填入空结构体使用
// define hash map and perf event map
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, pid_t);
__type(value, struct event);
} execs SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
}
events SEC(".maps");
// tracepoint for sys_enter_execve.
SEC("tracepoint/syscalls/sys_enter_execve")
int tracepoint__syscalls__sys_enter_execve(struct trace_event_raw_sys_enter *ctx)
{
struct event *event;
const char **args = (const char **)(ctx->args[1]); // 获取 execve 系统调用的第二个入参,即 char *const __argv[]
const char *argp;
// get the PID
u64 id = bpf_get_current_pid_tgid();
pid_t pid = (pid_t) id; // 获取进程 pid
// update the exec metadata to execs map
//BPF_NOEXIST 只在元素不存在的情况下创建一个新的元素
if (bpf_map_update_elem(&execs, &pid, &empty_event, BPF_NOEXIST)) {
return 0;
}
// 前一步保证了肯定能查询到数据,获取 key(pid)对应的 value 指针
// bpf_map_lookup_elem 返回值就是 value 的指针类型
event = bpf_map_lookup_elem(&execs, &pid);
if (!event) {
return 0;
}
// update event metadata
event->pid = pid;
event->args_count = 0;
event->args_size = 0;
// query the first parameter
unsigned int ret = bpf_probe_read_user_str(event->args, ARGSIZE,
(const char *)ctx->args[0]); //ctx->args[0] 为 execve 的第一个参数,即 const char *__path
if (ret <= ARGSIZE) {
event->args_size += ret;
} else {
/* write an empty string */
event->args[0] = '\0';
event->args_size++;
}
// 读取剩余的参数
// query the extra parameters
event->args_count++;
#pragma unroll
for (int i = 1; i < TOTAL_MAX_ARGS; i++) {
bpf_probe_read_user(&argp, sizeof(argp), &args[i]);
if (!argp)
return 0;
if (event->args_size > LAST_ARG)
return 0;
ret = bpf_probe_read_user_str(&event->args[event->args_size],ARGSIZE, argp);
if (ret> ARGSIZE)
return 0;
event->args_count++;
event->args_size += ret;
}
/* try to read one more argument to check if there is one */
bpf_probe_read_user(&argp, sizeof(argp), &args[TOTAL_MAX_ARGS]);
if (!argp)
return 0;
/* pointer to max_args+1 isn't null, assume we have more arguments */
event->args_count++;
return 0;
}
// tracepoint for sys_exit_execve.
SEC("tracepoint/syscalls/sys_exit_execve")
int tracepoint__syscalls__sys_exit_execve(struct trace_event_raw_sys_exit *ctx)
{
u64 id;
pid_t pid;
int ret;
struct event *event;
// get the exec metadata from execs map
id = bpf_get_current_pid_tgid();
pid = (pid_t) id;
event = bpf_map_lookup_elem(&execs, &pid);
if (!event)
return 0;
// update event retval
// 从 MAP 取出 pid 对应的 value,并且更新调用返回值
ret = ctx->ret;
event->retval = ret;
bpf_get_current_comm(&event->comm, sizeof(event->comm));
// submit to perf event
// 提交给 ringbuffer
size_t len = EVENT_SIZE(event);
if (len <= sizeof(*event))
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, event,len);
// 移除 pid key(因为 pid 已经执行完成了)
// cleanup exec from hash map
bpf_map_delete_elem(&execs, &pid);
return 0;
}
trace_event_raw_sys_enter 这个结构体的定义在 vmlinux.h 头文件中:
struct trace_entry {
short unsigned int type;
unsigned char flags;
unsigned char preempt_count;
int pid;
};
struct trace_event_raw_sys_enter {
struct trace_entry ent;
long int id;
long unsigned int args[6];
char __data[0]; // 柔性数据,不占空间
};
0x05 关于 MAPS 的应用细节(重要)
BPF_MAP_TYPE_PERCPU_HASH VS BPF_MAP_TYPE_HASH
思考下,PERCPU 这种 MAP 类型出现和使用场景是什么?下面是类型对应的内核版本 支持:
BPF_MAP_TYPE_ARRAYwas introduced in kernel version 3.19BPF_MAP_TYPE_PERCPU_ARRAYwas introduced in version 4.6- Both
BPF_MAP_TYPE_LRU_HASHandBPF_MAP_TYPE_LRU_PERCPU_HASHwere introduced in version 4.10
随着多 CPU 架构的成熟发展,BPF Map 也引入了 per-cpu 类型,如 BPF_MAP_TYPE_PERCPU_HASH、BPF_MAP_TYPE_PERCPU_ARRAY 等,使用这种类型的 BPF Map 时,每个 CPU 都会存储并看到它自己的 Map 数据,从属于不同 CPU 之间的数据是互相隔离的,这样做的好处是,在进行查找和聚合操作时更加高效,性能更好,尤其是做收集时间序列型数据的 eBPF 程序,如流量数据或指标等场景下效果会更好
1、BPF_MAP_TYPE_PERCPU_ARRAY的使用场景
当选择 map 类型时,如果多个事件关联并发生在同一个 CPU 上,则使用每个 CPU 的数组来跟踪时间戳比使用 hashmap 要简单得多,效率也更高。但是必须确保内核不会在两个 BPF 程序调用之间将进程从一个 CPU 迁移到另一个 CPU
BPF_MAP_TYPE_PERCPU_ARRAY是eBPF(Extended Berkeley Packet Filter)中的一种特殊类型的映射(map)。它用于在eBPF程序中创建一个数组,每个CPU都有自己的副本,可以在不同的CPU上并发地进行读写操作。BPF_MAP_TYPE_PERCPU_ARRAY是一种用于多核系统的映射类型,它提供了一种在不同CPU上进行并发读写的机制,避免了竞争条件和锁的使用。
struct bpf_map_def SEC("maps/heap") heap = {
.type = BPF_MAP_TYPE_PERCPU_ARRAY,
.key_size = sizeof(int),
.value_size = sizeof(u32),
.max_entries = 1,
};
struct data_t {
u32 pid;
};
struct bpf_map_def SEC("maps/perf_map") perf_map = {
.type = BPF_MAP_TYPE_PERF_EVENT_ARRAY,
.key_size = sizeof(int),
.value_size = sizeof(u32),
.max_entries = 1024,
};
SEC("kprobe/vfs_mkdir")
int kprobe_vfs_mkdir(void *ctx)
{
bpf_printk("mkdir_perf_event (vfs hook point)%u\n", bpf_get_current_pid_tgid());
int zero = 0;
struct data_t *data = bpf_map_lookup_elem(&heap, &zero);
if (!data) {
return 0;
}
data->pid = bpf_get_current_pid_tgid();
bpf_perf_event_output(ctx, &perf_map, BPF_F_CURRENT_CPU, data, sizeof(*data));
return 0;
}
向比较BPF_MAP_TYPE_PERF_EVENT_ARRAY的代码,在本例中存在一处不一样的代码,struct data_t *data = bpf_map_lookup_elem(&heap, &zero);。 bpf_map_lookup_elem主要在堆上申请空间,bpf_map_lookup_elem的作用是查找heap映射中键为zero的元素。因为heap是一个BPF_MAP_TYPE_PERCPU_ARRAY类型的映射,所以每个CPU都有一个与键zero关联的元素。这个元素的类型是data_t,它是一个结构体,包含一个u32类型的成员pid。如果成功返回了,那么就说明成功申请了这段内存。接下来,就可以将当前进程的PID作为性能事件的数据发送到perf_map映射中。这样,用户空间程序可以通过读取perf_map映射来获取性能事件数据,并通过读取heap映射来获取每个CPU上的数据。 这段代码的含义同样也很简单,在vfs_mkdir系统调用的钩子函数中,将当前进程的PID作为性能事件的数据发送到perf_map映射中。同时,使用heap映射来存储每个CPU的数据,以便在不同CPU上进行并发读写操作。用户空间程序可以通过读取perf_map映射来获取性能事件数据,并通过读取heap映射来获取每个CPU上的数据
BPF_MAP_TYPE_LPM_TRIE 类型的应用
BPF_MAP_TYPE_LPM_TRIE类型的map,是 eBPF 中专门用于最长前缀匹配(Longest Prefix Matching)的数据结构,常用于基于前缀匹配算法的网络层的数据包IP处理。LPM_TRIE 基于前缀树(Trie)实现,允许快速匹配键值的最长公共前缀。例如,在 IPv4 地址匹配中,192.168.1.0/24、192.168.0.0/16的 CIDR 块会被组织成树状结构,按bit逐层比较以确定最长匹配项
BPF_MAP_TYPE_LPM_TRIE类型的key由两部分组成:
prefixlen:前缀长度(以bit为单位,如/24)data:实际数据(按网络字节序存储的大端格式,例如 IPv4 地址192.168.1.0对应的二进制)
struct ipv4_lpm_key {
__u32 prefixlen;
__u32 data;
};
struct {
__uint(type, BPF_MAP_TYPE_LPM_TRIE);
__type(key, struct ipv4_lpm_key);
__type(value, __u32);
__uint(map_flags, BPF_F_NO_PREALLOC); //必须设置BPF_F_NO_PREALLOC标志,避免内存浪费
__uint(max_entries, 255);
} ipv4_lpm_map SEC(".maps");
//插入数据
int add_prefix_entry(int lpm_fd, __u32 addr, __u32 prefixlen, struct value *value)
{
struct ipv4_lpm_key ipv4_key = {
.prefixlen = prefixlen,
.data = addr
};
return bpf_map_update_elem(lpm_fd, &ipv4_key, value, BPF_ANY);
}
//查找数据
void *lookup(__u32 ipaddr)
{
struct ipv4_lpm_key key = {
.prefixlen = 32,
.data = ipaddr
};
return bpf_map_lookup_elem(&ipv4_lpm_map, &key);
}
BPF_MAP_TYPE_LPM_TRIE类型的MAP常用于:
- XDP中基于CIDR的IP匹配,比如ACL功能
- XDP中基于路由的下一跳优先级选择,将路由表(如
10.0.0.0/8指向网关 A,172.16.0.0/12指向网关 B)存储为 LPM_TRIE 的键值,程序在数据包到达时查询MAP来获取匹配最长前缀,以决定转发路由
ebpf MAP性能比较
关于常用的ebpf MAP的性能指标,这里给出此文的结论:
- 常用的 map 的查询性能:
array > percpu array > hash > percpu hash > lru hash > lpm,原文给出 lpm 类型 map 的查询最大影响约20%整体性能、lru hash 类型 map 查询影响约10%。特别注意,array 的查询性能比 percpu array 更好,hash 的查询性能也比 percpu hash 更好,这是由于 array 和 hash 的 lookup helper 层面在内核有更多的优化。对于数据面读多写少情况下,使用 array 比 percpu array 更优(hash、percpu hash 同理),而对于需要数据面写数据的情况使用 percpu 更优,比如统计计数 - 尽可能在一个 map 中查询到更多的数据,减少 map 查询次数
- 尽可能使用 array map,在控制面实现更复杂的逻辑,如分配一个 index,将一些 hash map 查询转换为 array map 查询
0x05 MAP 开发实践
本小节汇总于 BPF 数据传递的桥梁:BPF MAP 一文,推荐阅读
MAP 创建
实战
借助 BPF Map 来实现在内核空间收集网络包信息,主要包括源地址和目标地址,并在用户空间展示这些信息。代码主要分两个部分:
- 一个是运行在内核空间的程序,主要功能为创建出定制版 BPF Map,收集目标信息并存储至 BPF Map 中
- 另一个是运行在用户空间的程序,主要功能为读取上面内核空间创建出的 BPF Map 里的数据,并进行格式化展示( BPF Map 在两者之间进行数据传递)
1、通用结构定义(pair 为 MAPS 的 key,stats 为 MAPS 的 value)
// define the struct for the key of bpf map
struct pair {
__u32 src_ip;
__u32 dest_ip;
};
// define the struct for the value of bpf map
struct stats {
__u64 tx_cnt; // the sending request count
__u64 rx_cnt; // the received request count
__u64 tx_bytes; // the sending request bytes
__u64 rx_bytes; // the sending received bytes
};
2、内核态代码
// 通过 SEC("maps") 声明并创建了一个名为 tracker_map 的 BPF Map
//key 和 value 都是自定义的 struct
struct bpf_map_def SEC("maps") tracker_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(struct pair),
.value_size = sizeof(struct stats),
.max_entries = 2048,
};
/*
对网络包进行分析和过滤,把源地址和目的地址联合起来作为 BPF Map 的 key,把当前网络包的大小以 byte 单位记录下来,并联合网络包计数器作为 BPF Map 的 value。对于连续的网络包,如果生成的 key 已经存在,就把 value 累加,否则就新增一对 key-value 存入 BPF Map 中。其中通过 bpf_map_lookup_elem() 函数来查找元素,bpf_map_update_elem() 函数来新增元素
*/
static __always_inline bool parse_and_track(bool is_rx, void *data_begin, void *data_end, struct pair *pair)
{
struct ethhdr *eth = data_begin;
if ((void *)(eth + 1) > data_end)
return false;
if (eth->h_proto == bpf_htons(ETH_P_IP))
{
struct iphdr *iph = (struct iphdr *)(eth + 1);
if ((void *)(iph + 1) > data_end)
return false;
pair->src_ip = is_rx ? iph->daddr : iph->saddr;
pair->dest_ip = is_rx ? iph->saddr : iph->daddr;
// update the map for track
struct stats *stats, newstats = {0, 0, 0, 0};
long long bytes = data_end - data_begin;
stats = bpf_map_lookup_elem(&tracker_map, pair);
if (stats)
{
if (is_rx)
{
stats->rx_cnt++;
stats->rx_bytes += bytes;
}
else
{
stats->tx_cnt++;
stats->tx_bytes += bytes;
}
}
else
{
if (is_rx)
{
newstats.rx_cnt = 1;
newstats.rx_bytes = bytes;
}
else
{
newstats.tx_cnt = 1;
newstats.tx_bytes = bytes;
}
// 注意 BPF_NOEXIST 这个选项的意义
bpf_map_update_elem(&tracker_map, pair, &newstats, BPF_NOEXIST);
}
return true;
}
return false;
}
SEC("xdp_ip_tracker")
int _xdp_ip_tracker(struct xdp_md *ctx)
{
// the struct to store the ip address as the keys of bpf map
struct pair pair;
bpf_printk("starting xdp ip tracker...\n");
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
// pass if the network packet is not ipv4
if (!parse_and_track(true, data, data_end, &pair))
return XDP_PASS;
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";
3、用户态代码
static int ifindex = 6; // target network interface to attach, you can find it via `ip a`
static __u32 xdp_flags = 0;
// unlink the xdp program and exit
static void int_exit(int sig)
{
printf("stopping\n");
set_link_xdp_fd(ifindex, -1, xdp_flags);
exit(0);
}
// An XDP program which track packets with IP address
// Usage: ./xdp_ip_tracker
int main(int argc, char **argv)
{
char *filename = "xdp_ip_tracker_kern.o";
// change limits
/*
1. rlimit,全称是 resource limit,顾名思义,它是控制应用进程能使用资源的限额
2. 常量 RLIM_INFINITY 是无限的意思,因此第一行代码定义了一个没有上限的资源配额。
3. 第二行代码使用了函数 setrlimit(),传入的第一个参数是一个资源规格名称——RLIMIT_MEMLOCK,即内存;第二个参数是刚才定义的无限资源配额,这行代码作用就是为内存资源配置了无限配额,即没有内存上限
4. 为什么要把内存限制放开呢?因为操作系统在不同的 CPU 架构,对于应用进程能使用的内存限制是不统一的,而不同的 BPF 程序需要使用到的内存资源也是可变的,比如 BPF Map 申请了很大的 max_entries,那么这个 BPF 程序一定会使用不少的内存。因此为了成功运行 BPF 程序,就把对应内存的限制放开成无限了
*/
struct rlimit r = {RLIM_INFINITY, RLIM_INFINITY};
if (setrlimit(RLIMIT_MEMLOCK, &r))
{
perror("setrlimit(RLIMIT_MEMLOCK, RLIM_INFINITY)");
return 1;
}
// load the kernel bpf object file
// 通过 load_bpf_file() 函数(本质就是用 BPF_PROG_LOAD 命令进行系统调用)加载对应内核空间的 BPF 程序编译出来的. o 文件
if (load_bpf_file(filename))
{
printf("error - bpf_log_buf: %s", bpf_log_buf);
return 1;
}
// confirm the bpf prog fd is available
if (!prog_fd[0])
{
printf("load_bpf_file: %s\n", strerror(errno));
return 1;
}
// add signal handlers
signal(SIGINT, int_exit);
signal(SIGTERM, int_exit);
// link the xdp program to the network interface
/* 加载完 BPF 程序之后,使用 set_link_xdp_fd() 函数 attach 到目标 hook 上,本例
是 XDP network hook。它接受的两个主要的参数是:
- ifindex,这个是目标网卡的序号(可以通过 ip a 查看),这里填写的是 6,它是对应了一个 docker 容器的 veth 虚拟网络设备
- prog_fd[0],这个是 BPF 程序加载到内存后生成的文件描述符 fd
*/
if (set_link_xdp_fd(ifindex, prog_fd[0], xdp_flags) < 0)
{
printf("link set xdp fd failed\n");
return 1;
}
int result;
struct pair next_key, lookup_key = {0, 0};
struct stats value = {};
while (1)
{
sleep(2);
// 循环遍历 MAP
// retrieve the bpf map of statistics
/*
通过 bpf_map_get_next_key(map_fd[0], &lookup_key, &next_key) 函数
*/
while (bpf_map_get_next_key(map_fd[0], &lookup_key, &next_key) != -1)
{
//printf("The local ip of next key in the map is:'%d'\n", next_key.src_ip);
//printf("The remote ip of next key in the map is:'%d'\n", next_key.dest_ip);
struct in_addr local = {next_key.src_ip};
struct in_addr remote = {next_key.dest_ip};
printf("The local ip of next key in the map is:'%s'\n", inet_ntoa(local));
printf("The remote ip of next key in the map is:'%s'\n", inet_ntoa(remote));
// get the value via the key
// TODO: change to assert
// assert(bpf_map_lookup_elem(map_fd[0], &next_key, &value) == 0)
result = bpf_map_lookup_elem(map_fd[0], &next_key, &value);
if (result == 0)
{
// print the value
printf("rx_cnt value read from the map:'%llu'\n", value.rx_cnt);
printf("rx_bytes value read from the map:'%llu'\n", value.rx_bytes);
}
else
{
printf("Failed to read value from the map: %d (%s)\n", result, strerror(errno));
}
lookup_key = next_key;
printf("\n\n");
}
printf("start a new loop...\n");
// reset the lookup key for a fresh start
lookup_key.src_ip = 0;
lookup_key.dest_ip = 0;
}
printf("end\n");
// unlink the xdp program
set_link_xdp_fd(ifindex, -1, xdp_flags);
return 0;
}
用户态代码中,有两个重要的变量 prog_fd/map_fd,它们都是定义在 bpf_load.c 的全局变量,其中 prog_fd 是一个数组,在加载内核空间 BPF 程序时,一旦 fd 生成后,就添加到这个数组中去;map_fd 也是一个数组,在运行 load_maps() 函数时,一旦完成创建 BPF Map 系统调用生成 fd 后,同样会添加到该数组中。因此用户态程序可以直接使用这两个变量,作为对于 BPF 程序和 BPF Map 的引用
可以通过 bpf_map_get_next_key(map_fd[0], &lookup_key, &next_key) 函数来遍历 BPF_MAP_TYPE_HASH,参数:
map_fd[0]:目标 BPF Maplookup_key:需要查找的 BPF Map 目标 key(要主动传入)next_key:目标 key 相邻的下一个 key(被动赋值)
如果需要从头开始遍历 BPF Map,可以通过传入一个一定不存在的 key 作为 lookup_key,然后 next_key 会被自动赋值为 BPF Map 中第一个 key,这样通过 next_key 可以获取对应的 value,直到 bpf_map_get_next_key() 返回为 -1,即 next_key 没有可以被赋值的了,至此遍历完成
感兴趣的知识点,遍历 BPF_MAP_TYPE_HASH 中不停调用 bpf_map_get_next_key、bpf_map_lookup_elem 生效的过程中,锁的情况是如何实现的(rcu_read_lock/rcu_read_unlock)?相关内核代码:
0x06 perf_event/ringbuf(环形缓冲区队列)
本小节描述下 perf_event 和 ringbuf 原理介绍和使用
BPF_MAP_TYPE_PERF_EVENT_ARRAY VS BPF_MAP_TYPE_RINGBUF
0x07 MAP 的实现原理
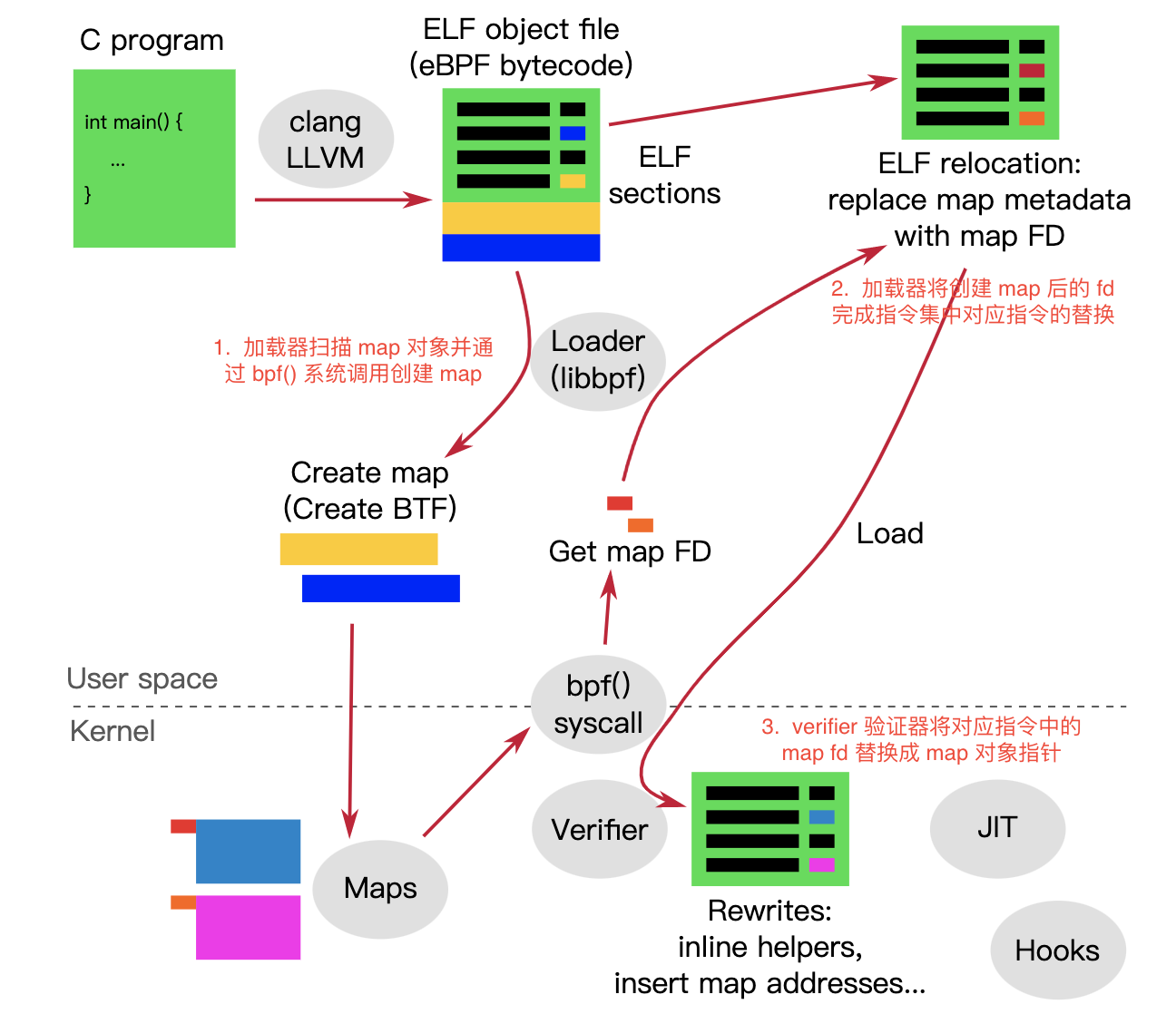
0x08 总结
总体来看,BPF_MAP_TYPE_HASH、BPF_MAP_TYPE_ARRAY、BPF_MAP_TYPE_RINGBUF 这个类型基本可以覆盖到大部分内核与用户空间传递数据的需求场景,且能满足高性能的要求
0x09 参考
- 深入了解 ebpf map
- Head First eBPF
- BPF 数据传递的桥梁——BPF MAP(一)
- BPF 进阶笔记(二):BPF Map 类型详解:使用场景、程序示例
- 【BPF 入门系列 - 6】BPF 环形缓冲区
- eBPF Map—内核空间与用户空间数据传递的桥梁
- perf_event 和 ringbuf 原理介绍和使用
- eBPF Map 操作
- BPF 进阶笔记(三):BPF Map 内核实现
- BPF_MAP_TYPE_ARRAY and BPF_MAP_TYPE_PERCPU_ARRAY
- BPF_MAP_TYPE_HASH, with PERCPU and LRU Variants
- map_lru_hash_update.svg
- perf_event 和 ringbuf 原理介绍和使用
- Tips and Tricks for Writing Linux BPF Applications with libbpf
- eBPF 入门开发实践教程十:在 eBPF 中使用 hardirqs 或 softirqs 捕获中断事件
- libbpfgo 使用示例:在内核态和用户态使用 ebpf map
- 边缘网络 eBPF 超能力:eBPF map 原理与性能解析
{kind=link}