0x00 前言
在 linux 内核网络协议栈中有多个网络钩子,数据包在进入到网卡再到流出网卡的过程会触发这些钩子上注册的回调函数执行相关过滤动作。如 netfilter 框架中的 5 个钩子,针对 ip 数据包进行过滤。除此之外在更低一层还有 xdp 和 tc 系统对数据包进行处理

XDP 与 TC 的位置
- XDP:Ingress
- TC:Egress

XDP VS DPDK
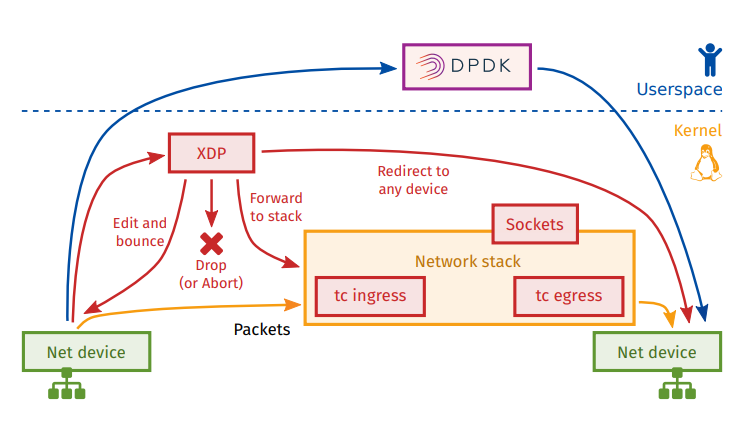
XDP VS IPTABLES
TC
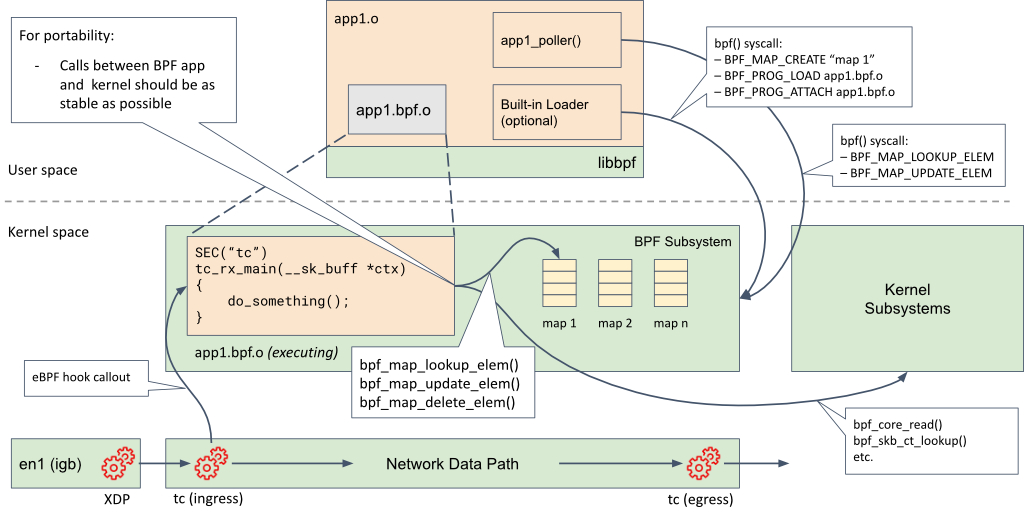
参考文档:
应用场景
- XDP:ACL(防火墙)
- LB:如 katran
0x01 XDP 基础
XDP(eXpress Data Path)机制运行于 Linux 内核网络栈的最底层,只存在于 RX 路径(Ingress)上,允许在网络设备驱动内部网络堆栈中数据来源最早的地方进行数据包处理,在特定模式下可以在操作系统分配内存(skb)之前就已经完成处理。XDP 暴露了一个可以加载 BPF 程序的 hook,hook 程序能够对传入的数据包进行任意修改和快速决策,避免了内核内部处理带来的额外开销
内核对XDP的支持
XDP 输入参数
XDP hook 的输入参数类型为 struct xdp_md(在内核头文件 bpf.h 中定义),是xdp_buff的BPF结构,对比sk_buff结构而言,sk_buff包含数据包的元数据,而xdp_buff创建更早,不依赖与其他内核层(因此XDP机制下可以更快的获取和处理数据包)
/* user accessible metadata for XDP packet hook
* new fields must be added to the end of this structure
*/
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
/* Below access go through struct xdp_rxq_info */
__u32 ingress_ifindex; /* rxq->dev->ifindex */
__u32 rx_queue_index; /* rxq->queue_index */
};
程序执行时,data 和 data_end 字段分别是数据包开始和结束的指针,它们是用来获取和解析传来的数据,第三个值是 data_meta 指针,初始阶段它是一个空闲的内存地址,供 XDP 程序与其他层交换数据包元数据时使用。最后两个字段分别是接收数据包的接口和对应的 RX 队列的索引。当访问这两个值时,BPF 代码会在内核内部重写,以访问实际持有这些值的内核结构 struct xdp_rxq_info
对struct xdp_md结构的 data 和 data_end 成员的详细理解:
1、data表示数据包在内核缓冲区中的起始地址,通常指向数据包的第一个字节(通常是链路层头部,如以太网帧头);data_end表示数据包在内核缓冲区中的结束地址,指向数据包最后一个字节的下一个位置
2、数据包访问规则:数据包内容范围为[data, data_end),即从data到data_end-1的连续内存空间,而且直接解引用指针(如*(__u32 *)ptr)可能导致非法内存访问,需显式边界检查,常用的访问模式如下(注意频繁的边界检查可能影响性能,建议将多次检查合并,如同时检查以太网和IP头部长度)
void *data_start = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
// 示例:解析以太网头部
struct ethhdr *eth = data_start;
if (data_start + sizeof(*eth) > data_end) {
return XDP_DROP; // 越界检查失败
}
//解析IPv4头部
SEC("xdp")
int xdp_parser(struct xdp_md *ctx) {
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
// 1. 检查以太网头部
struct ethhdr *eth = data;
if (data + sizeof(*eth) > data_end) {
return XDP_DROP;
}
// 2. 检查是否为IPv4
if (eth->h_proto != htons(ETH_P_IP)) {
return XDP_PASS;
}
// 3. 解析IPv4头部
struct iphdr *ip = data + sizeof(*eth);
if ((void *)ip + sizeof(*ip) > data_end) {
return XDP_DROP;
}
// 4. 提取源IP地址
__be32 src_ip = ip->saddr;
// ... 其他处理逻辑
return XDP_PASS;
}
3、地址类型而言,data和data_end都是内核虚拟地址,直接映射到网络设备接收数据包的缓冲区,这些地址可能通过DMA映射到物理内存,但对eBPF程序透明
4、对多缓冲区支持方面,若XDP程序启用BPF_F_XDP_HAS_FRAGS标志(支持分片),单个数据包可能跨多个物理页。此时data和data_end仅指向第一个分片的起始和结束地址,需通过其他方式访问后续分片(TODO)
XDP 输出参数
在处理完一个数据包后,XDP 程序(hook 函数)会返回一个动作(Action)作为输出,它代表了程序退出后对数据包应该做什么样的最终裁决。定义了以下 5 种动作类型(前面 4 个动作不需要参数,最后一个动作需要额外指定一个 NIC 网络设备名称,作为转发这个数据包的目的地)
enum xdp_action {
XDP_ABORTED = 0, // Drop packet while raising an exception
XDP_DROP, // Drop packet silently
XDP_PASS, // Allow further processing by the kernel stack
XDP_TX, // Transmit from the interface it came from
XDP_REDIRECT, // Transmit packet from another interface
};
XDP 数据包的路径
1、网络数据包传输路径

2、启用 XDP 后,网络包传输路径(三种模式)
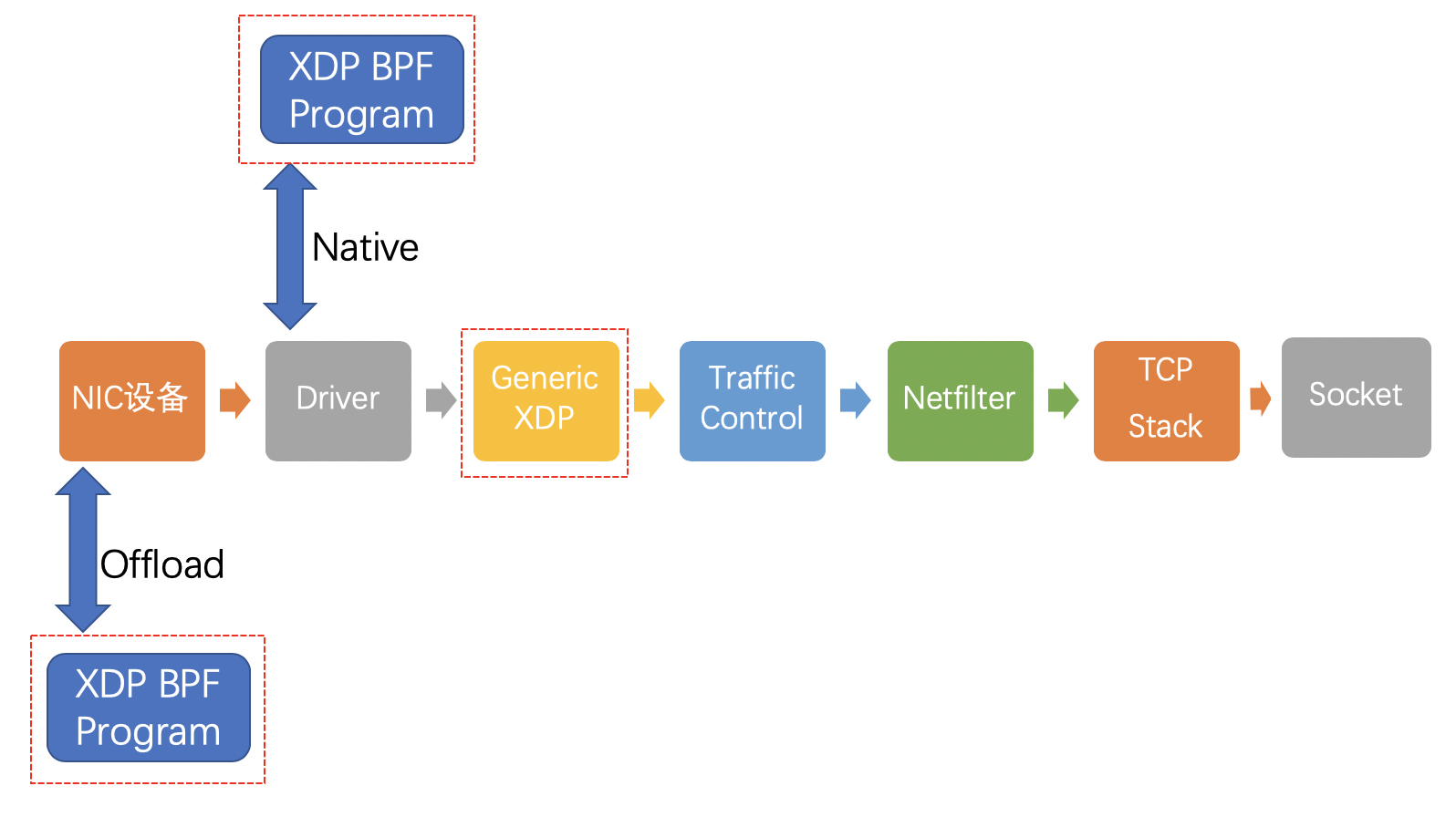
offload模式:XDP 程序直接 hook 到可编程网卡硬件设备上,处理性能最强;由于处于数据链路的最前端,过滤效率也是最高的。如果需要使用这种模式,需要在加载程序时明确声明(目前支持较少)native模式:XDP 程序 hook 到网络设备的驱动上,是 XDP 最原始的模式,因为还是先于操作系统进行数据处理,它的执行性能还是很高的,当然需要网络驱动支持,目前已知的有i40e、nfp、mlx系列和ixgbe系列。通俗点描述就是,XDP程序直接运行在网卡驱动程序中,项目通过bpf()系统调用加载eBPF程序到内核,并通过BPF_PROG_TYPE_XDP类型实现(通常是在真实生产环境中的典型部署方式)generic模式:这是 os 内核提供的通用 XDP 兼容模式,可以在没有硬件或驱动程序支持的主机上执行 XDP 程序。在这种模式下,XDP 的执行是由操作系统本身来完成的,以模拟native模式执行。缺点是由于是仿真执行,需要分配额外的套接字缓冲区(SKB),导致处理性能下降,跟native模式在10倍左右的差距
当前主流内核版本的 Linux 系统在加载 XDP BPF 程序时,会自动在 native 和 generic 这两种模式选择,完成加载后,可以使用 ip 命令行工具来查看选择的模式
0x02 XDP:内核态代码
SSH 端口访问限制
int xdp_firewall(struct xdp_md *ctx)
{
// Cast the numerical addresses to pointers for packet data access
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
// Define a pointer to the Ethernet header at the start of the packet data
struct ethhdr *eth = data;
// Ensure the packet includes a full Ethernet header; if not, we let it continue up the stack
if (data + sizeof(struct ethhdr) > data_end)
{
return XDP_PASS;
}
// Check if the packet's protocol indicates it's an IP packet
if (eth->h_proto != __constant_htons(ETH_P_IP))
{
// If not IP, continue with regular packet processing
return XDP_PASS;
}
// Access the IP header positioned right after the Ethernet header
struct iphdr *ip = data + sizeof(struct ethhdr);
// Ensure the packet includes the full IP header; if not, pass it up the stack
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) > data_end)
{
return XDP_PASS;
}
// Confirm the packet uses TCP by checking the protocol field in the IP header
if (ip->protocol != IPPROTO_TCP)
{
return XDP_PASS;
}
// Locate the TCP header that follows the IP header
struct tcphdr *tcp = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
// Validate that the packet is long enough to include the full TCP header
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) + sizeof(struct tcphdr) > data_end)
{
return XDP_PASS;
}
// Check if the destination port of the packet is the one we're monitoring
if (tcp->dest != __constant_htons(22)) {
return XDP_PASS;
}
// Construct the key for the lookup by using the source IP address from the IP header
__u32 key = ip->saddr;
// Attempt to find this key in the 'allowed_ips' map
__u32 *value = allowed_ips.lookup(&key);
if (value) {
// If a matching key is found, the packet is from an allowed IP and can proceed
bpf_trace_printk("Authorized TCP packet to ssh !\\n");
return XDP_PASS;
}
// If no matching key is found, the packet is not from an allowed IP and will be dropped
bpf_trace_printk("Unauthorized TCP packet to ssh !\\n");
// drop packet
return XDP_DROP;
}
DROP-TCP
通过 xdp 拦截所有系统的 packet,如果是 TCP 报文则全部丢弃
/*
check whether the packet is of TCP protocol
*/
static bool is_TCP(void *data_begin, void *data_end){
struct ethhdr *eth = data_begin;
// Check packet's size
// the pointer arithmetic is based on the size of data type, current_address plus int(1) means:
// new_address= current_address + size_of(data type)
// 重要!注意(eth + 1)前面加了一个显示类型转换,如果不做这个操作,编译时会有如下warning
// warning: comparison of distinct pointer types ('struct ethhdr *' and 'void *')
//代码里其他类似这样的显示类型转换都是出于规避编译warning的考虑
if ((void *)(eth + 1) > data_end) //
return false;
/*
括号里运算式 eth+1 是个非常有趣的表达式,它的本质是指针运算,指针变量 + 1 就是指针向右移动 n 个字节,这个 n 为该指针变量指向的对象类型的字节长度,这里就是 struct ethhdr 的字节长度,为 14 个字节,可以在这个内核头文件里找到相关定义:
struct ethhdr {
// ETH_ALEN 为 6 个字节
unsigned char h_dest[ETH_ALEN]; // destination eth addr
unsigned char h_source[ETH_ALEN]; // source ether addr
// __be16 为 16 bit,也就是 2 个字节
__be16 h_proto; // packet type ID field
}
// 所以整个 struct 就是 14 个字节长度
*/
// Check if Ethernet frame has IP packet
if (eth->h_proto == bpf_htons(ETH_P_IP))
{
struct iphdr *iph = (struct iphdr *)(eth + 1); // or (struct iphdr *)( ((void*)eth) + ETH_HLEN );
if ((void *)(iph + 1) > data_end)
return false;
// Check if IP packet contains a TCP segment
if (iph->protocol == IPPROTO_TCP)
return true;
}
return false;
}
SEC("xdp")
int xdp_drop_tcp(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
if (is_TCP(data, data_end))
return XDP_DROP;
return XDP_PASS;
}
//tc hook
SEC("tc")
int tc_drop_tcp(struct __sk_buff *skb)
{
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
if (is_TCP(data, data_end))
return TC_ACT_SHOT;
return TC_ACT_OK;
}
char _license[] SEC("license") = "GPL";
上面代码有几处细节,这里列举下(仅分析 xdp 的部分),在 is_TCP 函数中,eth 是 struct ethhdr 指针类型,eth+1 是指针运算,指针变量 +1 就是指针向右移动 n 个字节(n为该指针变量指向的对象类型的字节长度,即struct ethhdr的字节长度,为14个字节),是必须的数据包边界检查,该表达式有两层意思:
- 如果
data_end-data_begin的结果小于sizeof(struct ethhdr),那么说明这不是一个以太网的数据包,可以直接转发 - 如果
data_end-data_begin的结果大于等于sizeof(struct ethhdr),那么说明程序可以安全的操作这sizeof(struct ethhdr)个字节的数据(试想下ebpf verifier的安全要求)
因此,整体的if逻辑是判断括号内运算结果会不会内存越界,这对于BPF verifier是必要的,如果没有,BPF verifier会阻止这个程序加载到内核中,原因是后面的代码struct iphdr *iph = (struct iphdr *)(eth + 1),即通过右移data变量获取到IP头,因此需要判断这个右移结果是否有效,如果无效,就直接return出去了,防止内存越界(类似的右移判断逻辑在BPF程序里出现时,一定要做好边界判断逻辑,属于BPF开发基本操作)
static bool is_TCP(void *data_begin, void *data_end){
//...
if ((void *)(eth + 1) > data_end){
return false;
}
//...
}
// ethhdr total size = 14 bytes
struct ethhdr {
// ETH_ALEN 为 6 个字节
unsigned char h_dest[ETH_ALEN]; /* destination eth addr */
unsigned char h_source[ETH_ALEN]; /* source ether addr */
// __be16 为 16 bit,也就是 2 个字节
__be16 h_proto; /* packet type ID field */
}
如果不使用指针运算,还是作显式的长度判断,那么代码如下:
static bool is_TCP(void *data_begin, void *data_end){
//...
u64 h_offset;
// 显式声明并赋值ethhdr长度
h_offset = sizeof(*eth);
// 根据左右变量类型,运算符号加号重载成相关运算机制
if (data + h_offset > data_end)
return false;
//...
}
基于xdp实现syn cookies
参考xdp-syn-cookie,核心流程process_ether->process_ip->process_tcp,syn-cookie的原理可以参考Linux内核协议栈的实现,这里略有不同。先简单看下cookies生成/校验算法:
static __attribute__((always_inline)) u32
cookie_counter() {
return bpf_ktime_get_ns() >> (10 + 10 + 10 + 3); /* 8.6 sec */
}
static __attribute__((always_inline)) u32
hash_crc32(u32 data, u32 seed) {
return hash_32(seed | data, 32); /* TODO: use better hash */
}
static __attribute__((always_inline)) u32
cookie_make(struct FourTuple tuple, u32 seqnum, u32 count) {
return seqnum + cookie_hash_count(cookie_hash_base(tuple, seqnum), count);
}
static __attribute__((always_inline)) int
cookie_check(struct FourTuple tuple, u32 seqnum, u32 cookie, u32 count) {
u32 hb = cookie_hash_base(tuple, seqnum);
cookie -= seqnum;
if (cookie == cookie_hash_count(hb, count)) {
return 1;
}
return cookie == cookie_hash_count(hb, count - 1);
}
static __attribute__((always_inline)) u32
cookie_hash_count(u32 seed, u32 count) {
return hash_crc32(count, seed);
}
static __attribute__((always_inline)) u32
cookie_hash_base(struct FourTuple t, u32 seqnum) {
/* TODO: randomize periodically from external source */
u32 cookie_seed = 42;
u32 res = hash_crc32(((u64)t.daddr << 32) | t.saddr, cookie_seed);
return hash_crc32(((u64)t.dport << 48) | ((u64)seqnum << 16) | (u64)t.sport, res);
}
从上面的代码可以看出:
cookie_make:计算cookie,因子为四元组、syn->seq以及cookie_countercookie_check:校验cookie,校验传入的参数cookie是否等于因子计算出的结果
思考下cookie_counter这个函数的作用是什么,以及为何cookie_check函数实现中,cookie == cookie_hash_count(xxxxx)要判断两次?
1、process_tcp的实现
static __attribute__((always_inline)) int
process_tcp(struct Packet* packet) {
struct tcphdr* tcp = packet->tcp;
LOG("TCP(sport=%d dport=%d flags=0x%x)",
bpf_ntohs(tcp->source), bpf_ntohs(tcp->dest),
bpf_ntohs(tcp->flags) & 0xff);
//只处理SYN、ACK这两个被置位的数据包,如
// SYN
// ACK
// PSH ACK等
switch (bpf_ntohs(tcp->flags) & (TH_SYN | TH_ACK)) {
case TH_SYN:
return process_tcp_syn(packet);
case TH_ACK:
return process_tcp_ack(packet);
default:
return XDP_PASS;
}
}
2、process_tcp_syn的实现,该方法利用原始的TCP SYN packet,原地伪造SYN-ACK response并通过XDP_TX模式将SYN-ACK包回复给客户端。此外,这里需要留意几点
- 伪造的序列号为SYN-ACK包中的
seq序列号:tcp->seq = bpf_htonl(cookie) - ip以及tcp的checksum都需要重新计算,且源、目的要置反
static __attribute__((always_inline)) int
process_tcp_syn(struct Packet* packet) {
struct xdp_md* ctx = packet->ctx;
struct ethhdr* ether = packet->ether;
struct iphdr* ip = packet->ip;
struct tcphdr* tcp = packet->tcp;
/* Required to verify checksum calculation */
const void* data_end = (void*)ctx->data_end;
/* Validate IP header length */
const u32 ip_len = ip->ihl * 4;
if ((void*)ip + ip_len > data_end) {
return XDP_DROP; /* malformed packet */
}
if (ip_len > MAX_CSUM_BYTES) {
return XDP_ABORTED; /* implementation limitation */
}
/* Validate TCP length */
const u32 tcp_len = tcp->doff * 4;
if ((void*)tcp + tcp_len > data_end) {
return XDP_DROP; /* malformed packet */
}
if (tcp_len > MAX_CSUM_BYTES) {
return XDP_ABORTED; /* implementation limitation */
}
/* Create SYN-ACK with cookie */
struct FourTuple tuple = {ip->saddr, ip->daddr, tcp->source, tcp->dest};
const u32 cookie = cookie_make(tuple, bpf_ntohl(tcp->seq), cookie_counter());
tcp->ack_seq = bpf_htonl(bpf_ntohl(tcp->seq) + 1);
tcp->seq = bpf_htonl(cookie);
tcp->ack = 1;
/* Reverse TCP ports */
const u16 temp_port = tcp->source;
tcp->source = tcp->dest;
tcp->dest = temp_port;
/* Reverse IP direction */
const u32 temp_ip = ip->saddr;
ip->saddr = ip->daddr;
ip->daddr = temp_ip;
/* Reverse Ethernet direction */
struct ethhdr temp_ether = *ether;
memcpy(ether->h_dest, temp_ether.h_source, ETH_ALEN);
memcpy(ether->h_source, temp_ether.h_dest, ETH_ALEN);
/* Clear IP options */
memset(ip + 1, ip_len - sizeof(struct iphdr), 0);
/* Update IP checksum */
ip->check = 0;
ip->check = carry(sum16(ip, ip_len, data_end));
/* Update TCP checksum */
u32 tcp_csum = 0;
tcp_csum += sum16_32(ip->saddr);
tcp_csum += sum16_32(ip->daddr);
tcp_csum += 0x0600;
tcp_csum += tcp_len << 8;
tcp->check = 0;
tcp_csum += sum16(tcp, tcp_len, data_end);
tcp->check = carry(tcp_csum);
/* Send packet back */
return XDP_TX;
}
3、process_tcp_ack的实现,这里主要是通过syn-cookie校验cookie_check算法,验证ACK包中的ack序列号是否符合预期
static __attribute__((always_inline)) int
process_tcp_ack(struct Packet* packet) {
struct iphdr* ip = packet->ip;
struct tcphdr* tcp = packet->tcp;
const struct FourTuple tuple = {
ip->saddr, ip->daddr, tcp->source, tcp->dest};
if (cookie_check(
tuple,
bpf_ntohl(tcp->seq) - 1,
bpf_ntohl(tcp->ack_seq) - 1,
cookie_counter())) {
/* TODO: remember legitimate client */
LOG("cookie matches for client %x", ip->saddr);
} else {
LOG("cookie mismatch");
return XDP_DROP;
}
return XDP_PASS;
}
不过,这段代码的流程上是不够完善的(从原代码的TODO也可以看出),一个完整的syn-cookies流程图如下:
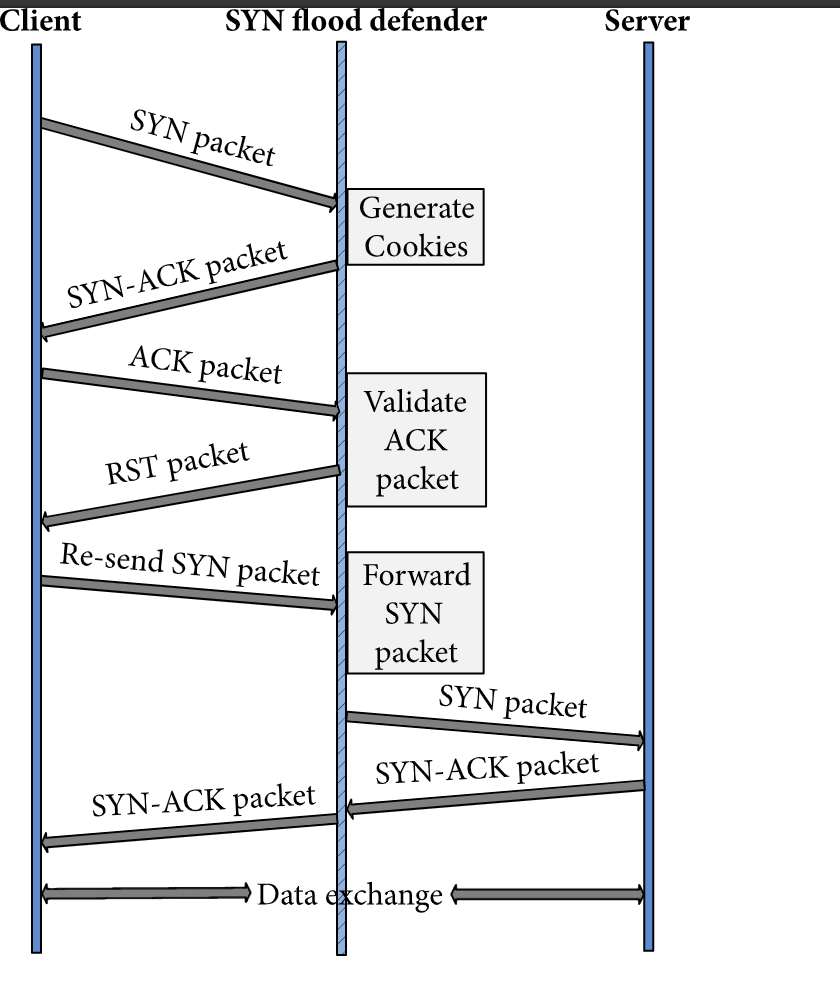
改进版本的syncookie代码隐藏了一处细节,在cookie_check方法中校验ACK包通过后,其XDP的action为XDP_PASS,即把此ACK包转发给协议栈处理,由于没有前置的SYN packet,协议栈收到这个ACK之后会直接向原客户端发送RST packet,根据RFC的解释,这样会触发原客户端的TCP 重连,下一次重连时,由于客户端的源IP已在XDP的MAPS中放行,所以客户端可以成功通过syncookie算法,验证流程可参考下面方式
#模拟ACK发送的命令
#服务端查询RST packet
tcpdump -i eth1 'tcp[tcpflags] & (tcp-rst) != 0'
#客户端发送ACK packet
hping3 -A -p 8000 X.X.X.X
0x03 TC 基础
0x04 TC VS XDP
小结下,tc(Traffic Control)和 xdp(eXpress Data Path)是 Linux 网络中两种不同的数据包处理机制,他们的区别如下:
- 位置不同: tc 位于 Linux 网络协议栈的较高层,主要用于在网络设备的出入口处对数据包进行分类、调度和限速等操作。而 xdp 位于网络设备驱动程序的接收路径上,用于快速处理数据包并决定是否将其传递给协议栈
- 执行时机不同: tc 在数据包进入或离开网络设备时执行,通常在内核空间中进行。而 xdp 在数据包进入网络设备驱动程序的接收路径时执行,可以在内核空间中或用户空间中执行
- 处理能力不同: tc 提供了更复杂的流量控制和分类策略,可以实现各种 QoS(Quality of Service)功能。它可以对数据包进行过滤、限速、排队等操作。而 xdp 主要用于快速的数据包过滤和处理,以降低延迟和提高性能
- XDP 程序对应的类型是
BPF_PROG_TYPE_XDP,它在网络驱动程序刚刚收到数据包时触发执行,由于无需通过复杂的内核网络协议栈,所以 XDP 程序可以用来实现高性能的网络处理方案,常用于 DDos 防御、防护墙、4 层负载均衡等 - TC 程序 对应的类型是
BPF_PROG_TYPE_SCHED_CLS和BPF_PROG_TYPE_SCHED_ACT,分别用于流量控制的分类器和执行器。Linux 流量控制通过网卡队列、排队规则、分类器、过滤器以及执行器实现了网络流量的整形调度和带宽控制
0x05 XDP项目参考
- Utilities and example programs for use with XDP
- A high performance ACL basied on XDP
- A firewall that utilizes the Linux kernel’s XDP hook
0x06 参考
- 每秒 1 百万的包传输,几乎不耗 CPU 的那种
- eBPF 技术实践:高性能 ACL
- eBPF Talk: 解密 XDP generic 模式
- 你的第一个 XDP BPF 程序
- Deep Dive into Facebook’s BPF edge firewall
- 你的第一个 TC BPF 程序
- eBPF 中常见的事件类型
- A toy tool that leverages the super powers of XDP to bring in-kernel IP filtering
- Cilium 原理解析:网络数据包在内核中的流转过程
- eBPF 在 Golang 中的应用介绍
- eBPF Talk: XDP 解析所有 TCP options
- eBPF Talk: XDP 系列文章
- eBPF Firewall
- eBPF 开发者教程: 简单的 XDP 负载均衡器