0x00 前言
下图形象的说明了filebeat的功能,主要包括两点:
- 支持从不同数据源收集数据并转换成事件
- 发送事件到指定的输出(支持多种输出)
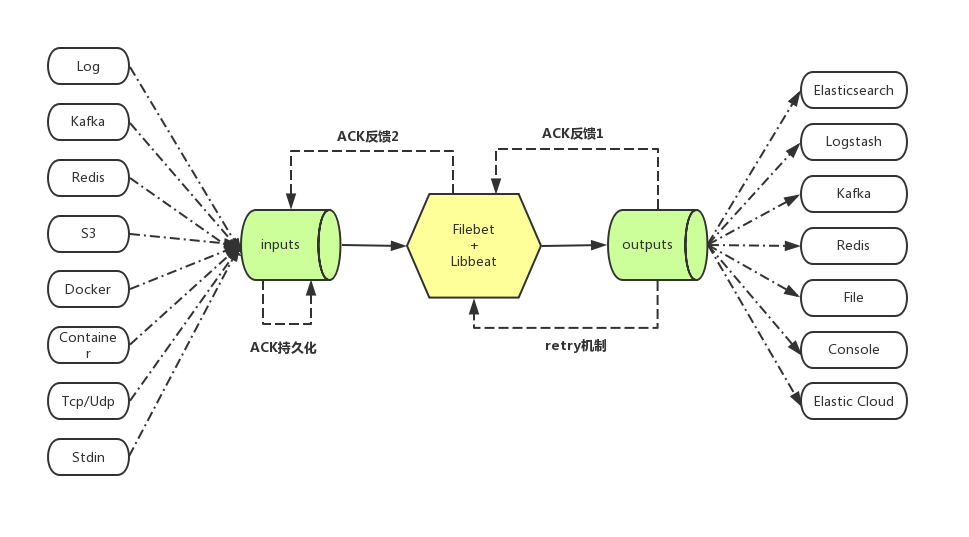
- 支持从多种不同的input(上游)中接受需要收集的数据(如log input从日志文件中收集数据)
- 对收集来的数据进行加工(如多行合并,增加业务自定义字段,json encode等)
- 将加工好的数据发送到output(下游)
- Filebeat实现了ACK反馈确认机制:成功发送到output后,会将当前进度反馈给input
- Filebeat在发送output失败后,会启动retry机制,配合ACK反馈确认机制,保证了每次消息至少发送一次的语义
- Filebeat在发送output时,由于网络等原因发生阻塞,则在input端会减慢收集,自适应匹配output的状态
本文版本基于v9.0.1进行
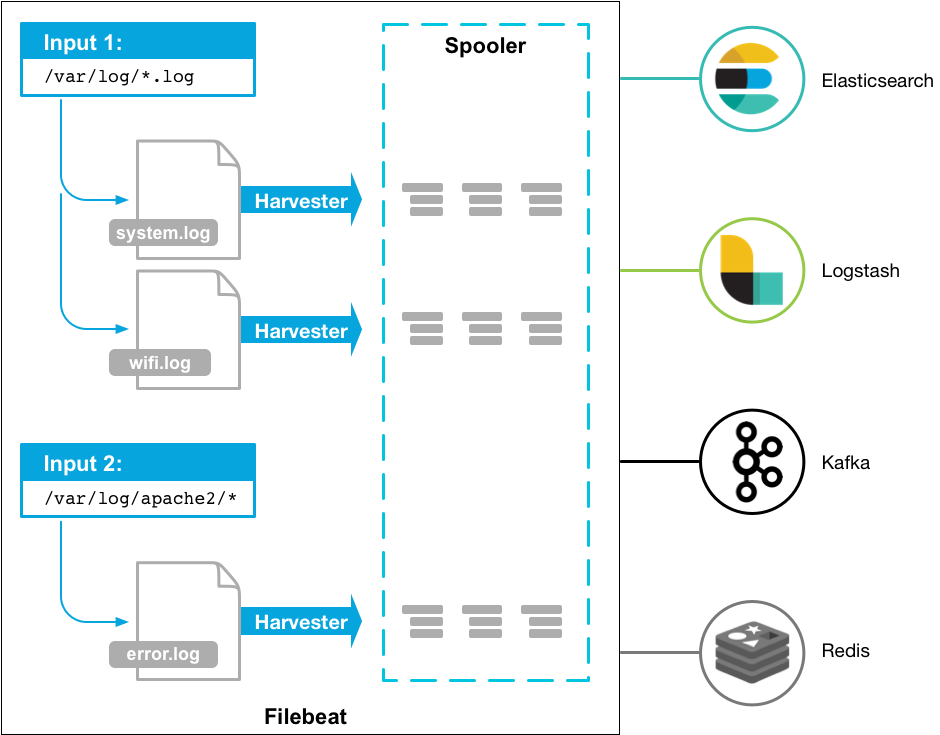
基础组件介绍
下面是官方的架构图,两个重要组件Input、Harvester:
0x01 源码分析:libbeat
TODO
基础数据结构
核心方法实现
0x02 源码分析:filebeat
从源码视角,filebeat的架构如下:
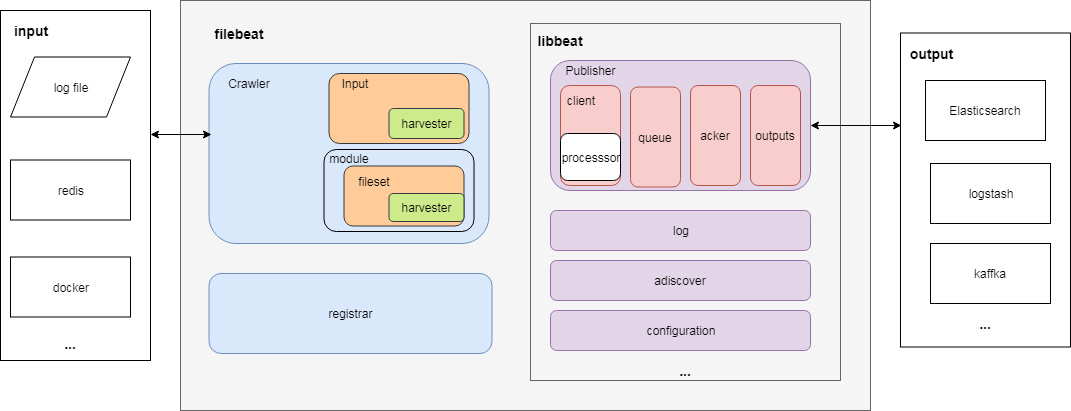
filebeat主要模块
Crawler: 负责管理和启动各个Input,管理所有Input收集数据并发送事件到libbeat的PublisherInput: 负责管理和解析输入源的信息,以及为每个文件启动HarvesterHarvester: 负责读取一个文件的数据,对应一个输入源,是收集数据的实际工作者(配置中一个具体的Input可以包含多个输入源Harvester)module:简化了一些常见程序日志(比如nginx日志)收集、解析、可视化(kibana dashboard)配置项fileset:module下具体的一种Input定义(比如nginx包括access和error log),包含- 输入配置
- es ingest node pipeline定义
- 事件字段定义
- 示例kibana dashboard
Registrar:接收libbeat反馈回来的ACK, 作相应的持久化,管理记录每个文件处理状态,包括偏移量、文件名等信息。当 Filebeat 启动时,会从Registrar恢复文件处理状态
libbeat主要模块
Pipeline(publisher):负责管理缓存、Harvester 的信息写入以及 Output 的消费等,是 Filebeat 最核心的组件
client: 提供Publish接口让filebeat将事件发送到Publisher。在发送到队列之前,内部会先调用processors(包括input 内部的processors和全局processors)进行处理processor:事件处理器,可对事件按照配置中的条件进行各种处理(比如删除事件、保留指定字段,过滤添加字段,多行合并等)queue:事件队列,有memqueue(基于内存)和spool(基于磁盘文件)两种实现outputs:事件的输出端,比如ES、Logstash、kafka等acker:事件确认回调,在事件发送成功后进行回调
0x0 参考
- Filebeat 收集日志的那些事儿
- 【Elastic Stack系列】第四章:源码分析(一) Filebeat篇
- Configure the output
- filebeat源码解析
- 监控日志系列—- Filebeat原理
- elastic:使用 Linux 安全计算模式 (seccomp)
- 监控日志系列—- Filebeat
FEATURED TAGS
Latex
gRPC
负载均衡
OpenSSH
Authentication
Consul
Etcd
Kubernetes
性能优化
Python
分布式锁
WebConsole
后台开发
Golang
OpenSource
Nginx
Vault
网络安全
Perl
分布式理论
Raft
正则表达式
Redis
分布式
限流
go-redis
微服务
反向代理
ReverseProxy
Cache
缓存
连接池
OpenTracing
GOMAXPROCS
GoMicro
微服务框架
日志
zap
Pool
Kratos
Hystrix
熔断
并发
Pipeline
证书
Prometheus
Metrics
PromQL
Breaker
定时器
Timer
Timeout
Kafka
Xorm
MySQL
Fasthttp
bytebufferpool
任务队列
队列
异步队列
GOIM
Pprof
errgroup
consistent-hash
Zinx
网络框架
设计模式
HTTP
Gateway
Queue
Docker
网关
Statefulset
NFS
Machinery
Teleport
Zero Trust
Oxy
存储
Confd
热更新
OAuth
SAML
OpenID
Openssl
AES
微服务网关
IM
KMS
安全
数据结构
hashtable
Sort
Asynq
基数树
Radix
Crontab
热重启
系统编程
sarama
Go-Zero
RDP
VNC
协程池
UDP
hashmap
网络编程
自适应技术
环形队列
Ring Buffer
Circular Buffer
InnoDB
timewheel
GroupCache
Jaeger
GOSSIP
CAP
Bash
websocket
事务
GC
TLS
singleflight
闭包
Helm
network
iptables
MITM
HTTPS
Tap
Tun
路由
wireguard
gvisor
Git
NAT
协议栈
Envoy
FRP
DPI
gopacket
Cgroup
Namespace
DNS
eBPF
GoZero
Gost
Clash
Tracee
gopsutil
Linux
HIDS
ELKEID
XDP
TC
Systemd
DDoS
DPDK
netlink
Kernel
BCC
rootkit
bpftrace
AI
TCP
eino
Memory