0x00 前言
- 双向链表
- hash 链表
- 队列:Priority sorted lists used for mutexes, drivers, etc
- rbtree:Red-Black trees are used for scheduling, virtual memory management, to track file descriptors and directory entries,etc
本文代码基于 v4.11.6 版本
offset_of 机制
// 说明:获得结构体 (TYPE) 的变量成员 (MEMBER) 在此结构体中的偏移量
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
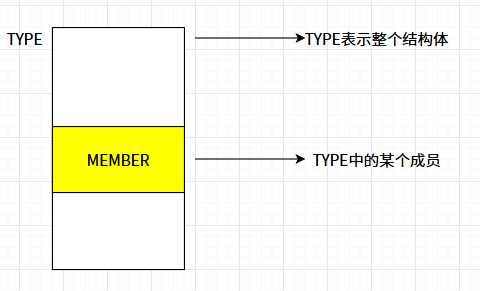
TYPE 是结构体,代表整体,而 MEMBER 是结构体成员,offsetof 的本质是已知整体和该整体中某一个部分,计算该部分在整体中的偏移,详细步骤如下:
((TYPE *)0 ):将零转型为TYPE类型指针,即TYPE类型的指针的地址是0((TYPE *)0)->MEMBER:访问结构中的数据成员&(( (TYPE *)0 )->MEMBER ):取出数据成员的地址,由于TYPE的地址是0,这里获取到的地址就是相对MEMBER在TYPE中的偏移(size_t)(&(((TYPE*)0)->MEMBER)):结果转换类型。对于32位系统而言,size_t是unsigned int类型;对于64位系统而言,size_t是unsigned long类型
container_of 机制
// 说明:根据结构体 (type) 变量中的域成员变量 (member) 的指针 (ptr) 来获取指向整个结构体变量的指针
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
同样的,已知成员 MEMBER 及 MEMBER 的指针地址,推算出结构体的开始地址,即已知整体和该整体中某一个部分,要根据该部分的地址,计算出整体的地址
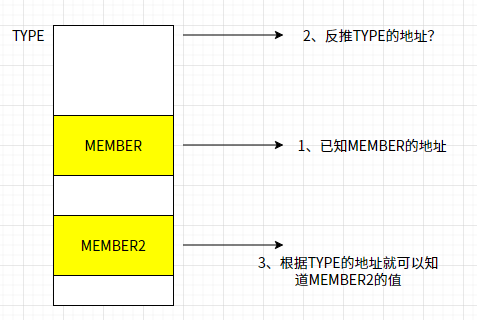
typeof(( (type *)0)->member ):取出member成员的变量类型const typeof(((type *)0)->member ) *__mptr = (ptr):定义变量__mptr指针,并将ptr赋值给__mptr。经过这一步,__mptr为member数据类型的常量指针,其指向ptr所指向的地址(char *)__mptr:将__mptr转换为字节型指针offsetof(type,member)):就是获取member成员在结构体type中的位置偏移(char *)__mptr - offsetof(type,member)):就是用来获取结构体type的指针的起始地址(为char *型指针)(type *)( (char *)__mptr - offsetof(type,member) ):就是将char *类型的结构体type的指针转换为type *类型的结构体type的指针
0x01 双向链表
内核实现的 double-linklist 和普通的 linklist 有差异,普通 linklist 实现缺点就是通用性不够好,而内核的 linklist 巧妙解决了这个问题,不是将用户数据保存在 linklist 节点中,而是将 linklist 节点保存在用户数据中。linux 的 linklist 节点只有 2 个指针成员 (prev 和 next),因此 linklist 的节点将独立于用户数据之外,便于实现 linklist 的共同操作
内核 linklist 中的最大问题是怎样通过链表的节点来取得用户数据?linux 的 linklist 节点 (node) 中没有包含用户的用户如 data1,data2 等,所以 Linux 中双向链表的使用思想也变成了将双向链表节点嵌套在其它的结构体(比如 linux 进程管理的 struct task_struct结构)中;在遍历链表的时候,根据双链表节点的指针获取 它所在结构体的指针(使用 container_of 宏),从而再获取数据或者该结构体的其他成员
struct list_head {
struct list_head *next, *prev;
};
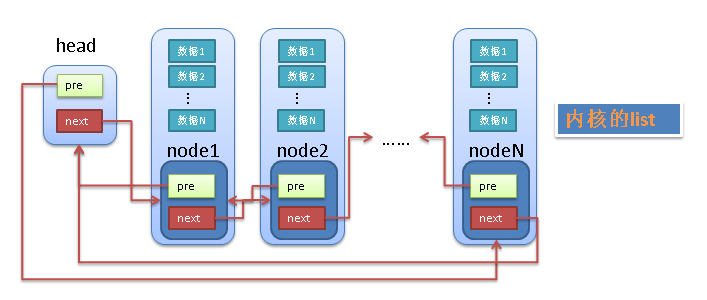
使用
1、结构定义
普通 linklist:
struct student{// 结构体 student 本身就是一个链表节点
struct student *prev;
struct student *next;
char name[64];
char id[64];
}
内核 linklist:
struct student{
struct list_head list_node;// 链表节点
char name[64];
char id[64];
};
2、遍历链表
参考 linklist.c
内核的相关应用
rt_prio_array:Linux CPU调度中用来表示实时调度实体所属的实时运行队列
0x02 hash 链表
hlist_head 和 hlist_node 用于内核 hash 表,分别表示列表头(数组中的一项)和列表头所在双向链表中的某项,结构定义及示意图如下:
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
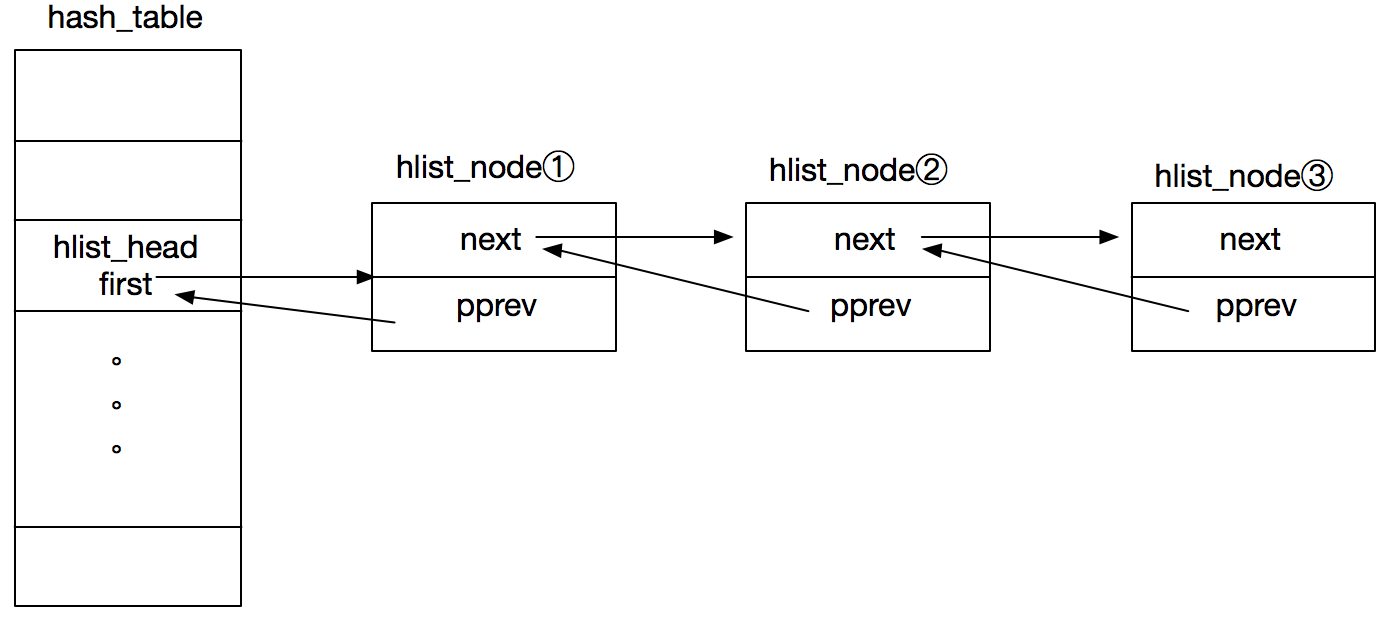
如上图 hash 表(数组)的元素类型为 struct hlist_head,以 hlist_head 为链表头的链表为冲突链,节点类型为 struct hlist_node。hash_table 的列表头仅存放一个 first 指针,指向的是对应冲突链表的头结点,不设计 tail 指针是为了减少内存空间(当数组的 size 很大时)。
此外,注意到 hlist_node.pprev 是一个指向指针的指针(保存前一个节点的 next 成员地址),目的是在删除链表头结点的时候,pprev 这个设计无需判断删除的节点是否为头结点(如果是普通双向 linklist 的设计,那么删除头结点之后,hlist_head 中的 first 指针需要指向新的头结点),参考 __hlist_del 的实现
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first; // 新节点的 next 指针指向原头结点
if (first)
first->pprev = &n->next;// 原头结点的 pprev 指向新节点的 next 字段
WRITE_ONCE(h->first, n);//first 指针指向新的节点(更换了头结点)
n->pprev = &h->first;// 此时 n 是链表的头结点, 将它的 pprev 指向 list_head 的 first 字段
}
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
WRITE_ONCE(*pprev, next); // pprev 指向的是前一个节点的 next 指针, 当该节点是头节点时指向 hlist_head 的 first, 两种情况下不论该节点是一般的节点还是头结点都可以通过这个操作删除掉所需删除的节点
if (next)
next->pprev = pprev;// 使删除节点的后一个节点的 pprev 指向删除节点的前一个节点的 next 字段,节点成功删除
}
和 list_head 一样,hlist_node 通常也是嵌套在其他结构中的,即 hlist_entry 函数用于根据 hlist_node 找到其外层结构体
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)
内核的应用
内核中用 hlist 来实现 hash table,如下:
[root@VM-X-X-tencentos kernel]# dmesg | grep "hash table entries"
[0.039306] PV qspinlock hash table entries: 256 (order: 0, 4096 bytes, linear)
[0.041316] Dentry cache hash table entries: 2097152 (order: 12, 16777216 bytes, linear)
[0.042294] Inode-cache hash table entries: 1048576 (order: 11, 8388608 bytes, linear)
[0.118822] Mount-cache hash table entries: 32768 (order: 6, 262144 bytes, linear)
[0.118822] Mountpoint-cache hash table entries: 32768 (order: 6, 262144 bytes, linear)
[0.129682] futex hash table entries: 2048 (order: 5, 131072 bytes, linear)
[0.298401] VFS: Dquot-cache hash table entries: 512 (order 0, 4096 bytes)
[0.306529] IP idents hash table entries: 262144 (order: 9, 2097152 bytes, linear)
[0.309459] tcp_listen_portaddr_hash hash table entries: 8192 (order: 5, 131072 bytes, linear)
[0.309480] Table-perturb hash table entries: 65536 (order: 6, 262144 bytes, linear)
[0.309509] TCP established hash table entries: 1048576 (order: 11, 8388608 bytes, vmalloc hugepage)
[0.310554] TCP bind hash table entries: 65536 (order: 9, 2097152 bytes, linear)
[0.311066] MPTCP token hash table entries: 16384 (order: 6, 393216 bytes, linear)
[0.311098] UDP hash table entries: 8192 (order: 6, 262144 bytes, linear)
[0.311134] UDP-Lite hash table entries: 8192 (order: 6, 262144 bytes, linear)
进程管理:upid hash table
回想下,在 linux 进程管理 struct pid/upid结构 中就使用了 hash linklist
struct upid {
/* Try to keep pid_chain in the same cacheline as nr for find_vpid */
int nr;
struct pid_namespace *ns;
struct hlist_node pid_chain; //hash list 中的 node
};
struct pid
{
atomic_t count;
unsigned int level;
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX]; // 数组头节点
struct rcu_head rcu;
struct upid numbers[1]; //柔性数组,可扩展为多个
};
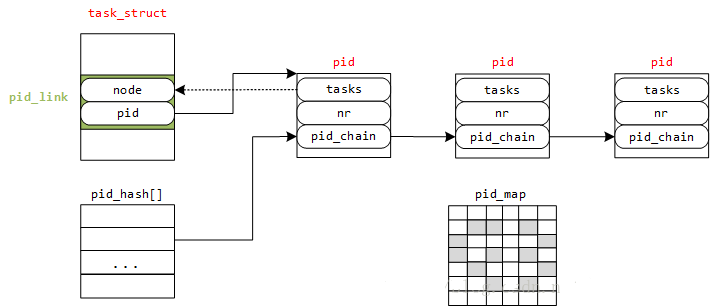
如上图展示了当pid.upid长度为1时的内存布局,upid.pid_chain作为hash list中的node节点

上图展示了,struct pid结构体中的struct hlist_head tasks[PIDTYPE_MAX]成员,这是一个hash list 头节点,其冲突链上的每个struct hlist_node节点,对应着struct task_struct结构体中的struct pid_link pids[PIDTYPE_MAX]成员,而pid_link定义为如下:
struct pid_link
{
struct hlist_node node;
struct pid *pid;
};
常用操作函数/宏
1、hlist_for_each_entry_rcu:用于在 RCU 读锁的保护下,无锁地遍历该哈希桶中的单向链表
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/rculist.h#L584
#define hlist_for_each_entry_rcu(pos, head, member) \
for (pos = hlist_entry_safe (rcu_dereference_raw(hlist_first_rcu(head)),\
typeof(*(pos)), member); \
pos; \
pos = hlist_entry_safe(rcu_dereference_raw(hlist_next_rcu(\
&(pos)->member)), typeof(*(pos)), member))
hlist_for_each_entry_rcu宏的三个入参含义如下:
pos:当前位置指针,指向包含hlist_node的结构体的指针,用于在遍历过程中指向当前链表元素,注意点:
- 必须是有效的指针变量
- 类型应该与链表元素的实际类型匹配
- 在宏展开后会被自动初始化和更新
head:链表头指针,类型为struct hlist_head *,作用是指向要遍历的哈希链表的头节点
member:节点成员名称,即结构体成员的名称(标识符),用来指定hlist_node在包含结构体中的字段名(链表节点在包含结构体中的字段名称)
列举几个例子:
find_pid_ns,用于遍历全局upid hashtable,第一个参数pnr表示 upid hashtable中每个hash链表桶元素(类型为struct upid *);第二个参数&pid_hash[pid_hashfn(nr, ns)],直接定位到upid hashtable的bucket 头指针,类型为struct hlist_head *;第三个参数为pid_chain,对应于upid结构体的node成员pid_chain,类型为struct hlist_node
static struct hlist_head *pid_hash; //全局hashtable
struct upid {
/* Try to keep pid_chain in the same cacheline as nr for find_vpid */
int nr;
struct pid_namespace *ns;
struct hlist_node pid_chain;
};
struct pid *find_pid_ns(int nr, struct pid_namespace *ns)
{
struct upid *pnr;
//
hlist_for_each_entry_rcu(pnr,
&pid_hash[pid_hashfn(nr, ns)], pid_chain)
if (pnr->nr == nr && pnr->ns == ns)
return container_of(pnr, struct pid,
numbers[ns->level]);
return NULL;
}
再看一个宏定义宏的例子:
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/pid.h#L178
#define do_each_pid_task(pid, type, task) \
do { \
if ((pid) != NULL) \
hlist_for_each_entry_rcu((task), \
&(pid)->tasks[type], pids[type].node) {
调用do_each_pid_task的代码:
static bool has_stopped_jobs(struct pid *pgrp)
{
struct task_struct *p;
do_each_pid_task(pgrp, PIDTYPE_PGID, p) {
if (p->signal->flags & SIGNAL_STOP_STOPPED)
return true;
} while_each_pid_task(pgrp, PIDTYPE_PGID, p);
return false;
}
struct pid {
// ...
struct hlist_head tasks[PIDTYPE_MAX]; // 每个pid有自己的任务链表
// ...
};
struct task_struct {
// ...
struct pid_link pids[PIDTYPE_MAX]; // 链接到对应pid的tasks链表
// ...
};
struct pid_link {
struct hlist_node node; // ← 这就是member参数指向的节点
struct pid *pid;
};
在do_each_pid_task调用hlist_for_each_entry_rcu宏,第一个参数为task(p),是struct task_struct *类型;第二个参数为&(pid)->tasks[type],调用展开为&(pgrp)->tasks[PIDTYPE_PGID],即struct pid中的hashtable头;第三个参数为pids[type].node,展开为pids[PIDTYPE_PGID].node,对应task_struct中的成员pids[PIDTYPE_MAX].node,其类型正为struct hlist_node,简化为如下:
struct task_struct *task; // pos: 遍历时的当前任务
struct hlist_head *head = &pid->tasks[type]; // head: PID的任务链表头
// member: pids[type].node
hlist_for_each_entry_rcu(task, head, pids[type].node) {
// 处理每个task
......
}
抽象:对hashtable的读/写操作的并发安全讨论
本小节讨论下hlist_for_each_entry_rcu的并发安全性,前文已经介绍了,该宏实内核中 RCU(Read-Copy-Update)机制下用于遍历哈希链表的宏。它的设计目标是允许在无需获取重量级锁的情况下,安全地进行并发读操作
- 内部并发安全实现?
- 外部调用方是否需要加锁?
#define hlist_for_each_entry_rcu(pos, head, member) \ for (pos = hlist_entry_safe (rcu_dereference_raw(hlist_first_rcu(head)),\ typeof(*(pos)), member); \ pos; \ pos = hlist_entry_safe(rcu_dereference_raw(hlist_next_rcu(\ &(pos)->member)), typeof(*(pos)), member))
1、内部并发机制,宏本质上是一个 for 循环,通过以下步骤实现安全遍历:
hlist_first_rcu(head):获取哈希桶(bucket)的第一个节点rcu_dereference_raw(...):内部并发安全机制的核心,它确保从内存中读取指针时,编译器不会进行错误的优化,并配合内存屏障保证读取到的是最新的、初始化的数据hlist_entry_safe(...):安全转换宏,如果指针不为NULL,它利用container_of原理将链表节点指针转换为包含该节点的结构体指针pos。如果为NULL,则返回NULL,从而终止循环hlist_next_rcu(...):在循环迭代时,获取当前节点的下一个节点
其核心设计保证了,当读者在遍历这个hash表时,即使写者正在删除或插入节点,读者也始终能看到一个有效的链表状态(要么是旧数据,要么是新数据),而不会因为指针悬空而崩溃。在其他内核实现中,也可以看到rcu_dereference_raw的大量使用场景
2、外部调用方是否需要加锁?这里需要取决于外部调用方是读者还是写者,分类讨论如下:
2.1、对读者而言(遍历链表):不需要加传统的锁(如 Spinlock/Mutex),这是 RCU 的最大优势。但必须包含在 RCU 读端临界区内(如下代码)。在这个范围内,RCU 保证被你引用的节点在循环结束前不会被物理释放
也可以这样理解,在读情况下,既没有整体加锁,也没有对单个 item 加锁,它是完全无锁的(Lockless)
rcu_read_lock(); // 禁用抢占,标记进入读端临界区
hlist_for_each_entry_rcu(pos, head, member) {
// 安全地引用 pos,但不能在其中睡眠(除非是可睡眠 RCU)
}
rcu_read_unlock(); // 退出临界区
2.2、对写者而言(修改链表):必须加锁,因为RCU 只解决一写多读的并发问题,并不解决多写之间的冲突。如果多个线程可能同时修改这个hash表(插入/删除),你必须使用 spinlock 或其他同步机制来保护写操作,以防止链表结构被破坏
3、注意事项
- 禁止在遍历时修改:在
hlist_for_each_entry_rcu内部,绝对不能执行删除当前节点的操作。如果需要删除,应使用_safe版本的宏(尽管在 RCU 语义下,删除通常由写者配合synchronize_rcu()完成) - (很重要!)数据可见性:RCU 保证的是指针引用的安全性,但不保证当前读到的是绝对最新的数据。如果对数据实时性要求极其苛刻,RCU 可能不合适
- 读者用
rcu_read_lock()即可,无需互斥锁;写方依然需要传统的加锁机制来保证原子性
rcu_read_lock(在调用hlist_for_each_entry_rcu宏之前通常要加 rcu_read_lock())到底完成了什么功能呢?实际上rcu_read_lock是一个非常轻量级的实现:
- 非抢占内核:它甚至可能是一个空操作(或者仅仅是禁止编译器优化)
- 可抢占内核:它只是禁止了当前 CPU 的内核抢占,或者增加一个计数器
本质区别是,它不会阻塞任何写者,也不会导致读者进入睡眠等待。它的作用仅仅是告诉内核我现在正在读这块内存,在 rcu_read_unlock() 之前,请不要物理释放(kfree)那些被移除的节点
小结下,hlist_for_each_entry_rcu 模式的特点:
- 读端:完全没有锁的概念(不争用任何原子变量),它只是在安全地顺着指针爬行
- 写端:通常需要对对应的哈希桶加锁(
spin_lock),以防止多个写者同时破坏链表结构
RCU VS lock?为什么不需要锁也能保证并发安全
RCU 特别适合读多写少的场景(如路由表、进程描述符列表),因为它的读性能几乎等同于单线程程序的性能。传统的锁(无论是全局锁还是细粒度锁)都是通过互斥来保证安全的。而 RCU 走的是另一种实现机制,即保证内存访问的顺序性和有效性,具体表现在:
- 指针的原子性:在大多数架构上,对一个对齐的指针进行读取是原子性的。
hlist_for_each_entry_rcu实际上是沿着next指针不断向后读取 - 写端的配合:写者在修改链表时,会遵循先初始化新节点,再修改指针的顺序
- 内存屏障:宏内部的
rcu_dereference_raw包含了编译器屏障和内存屏障,确保 CPU 不会乱序执行,保证读者看到的指针指向的是一个已经初始化完毕的合法内存地址
hlist_for_each_entry_rcu对应的写场景
以4.11.6 内核为例,与读端的 hlist_for_each_entry_rcu 宏相对应的写端(修改场景)函数,包含了增加、删除、替换等,共同点事负责以原子可见性的方式更新指针,并确保在不同 CPU 架构上通过内存屏障维持正确的执行顺序
hlist_add_head_rcu:将新节点插入到哈希桶(bucket)的头部
hlist_add_before_rcu:将新节点插入到指定节点之前
hlist_add_after_rcu:将新节点插入到指定节点之后
hlist_del_rcu:从链表中移除一个节点(但不释放内存)
hlist_replace_rcu:用一个新节点替换掉旧节点
以hlist_add_head_rcu为例,介绍一下写入场景的运行过程。如在alloc_pid函数中,通过hlist_add_head_rcu向pid_hash这个hash表中添加节点
static inline void hlist_add_head_rcu(struct hlist_node *n, struct hlist_head *h){
struct hlist_node *first = h->first;
n->next = first;
n->pprev = &h->first;
// 非常重要
rcu_assign_pointer(hlist_first_rcu(h), n);
if (first)
first->pprev = &n->next;
}
在 hlist_add_head_rcu 的源码没有锁(spinlock/mutex都无),内核的核心思想是将同步的责任从工具函数转移到调用者,参考下面的alloc_pid函数实现。像 hlist_add_head_rcu 这样的函数只负责按 RCU 的原则正确地修改指针,而谁有权修改则由外部调用者决定。此外,在内核开发中,如果在没有持有锁的情况下调用 hlist_add_head_rcu,通常会触发内核的 RCU Lockdep 警告(开启内核调试选项)
此外,在上面代码中,rcu_assign_pointer 的用法很精妙,这行代码不仅仅是赋值操作(h->first = n),其背后包含了内存屏障(Memory Barrier),即内部的屏障保护了时序。细节如下:
- 保证执行顺序:它确保在执行
h->first = n之前,前面那两行n->next = first; n->pprev = &h->first;已经完全写入内存了 - 防止读者看到半成品:如果没有这个屏障,在弱内存模型架构上,读者可能会先看到
h->first指向了新节点n,但此时n->next还没初始化好(垃圾值)。这会导致读者在遍历时直接崩溃 rcu_assign_pointer解决了读写冲突问题,使得读者不需要锁也能安全通过
static struct hlist_head *pid_hash;
// lock define
static __cacheline_aligned_in_smp DEFINE_SPINLOCK(pidmap_lock);
//https://elixir.bootlin.com/linux/v4.11.6/source/kernel/pid.c#L338
struct pid *alloc_pid(struct pid_namespace *ns)
{
......
get_pid_ns(ns);
atomic_set(&pid->count, 1);
for (type = 0; type < PIDTYPE_MAX; ++type)
INIT_HLIST_HEAD(&pid->tasks[type]);
upid = pid->numbers + ns->level;
/* 1. 写者必须显式加锁,保证同一时间只有一个写者在修改链表 */
spin_lock_irq(&pidmap_lock);
if (!(ns->nr_hashed & PIDNS_HASH_ADDING))
goto out_unlock;
for ( ; upid >= pid->numbers; --upid) {
/* 2. 调用 RCU 写端函数,此时由于有 spinlock,不会有第二个写者来干扰指针修改 */
hlist_add_head_rcu(&upid->pid_chain,
&pid_hash[pid_hashfn(upid->nr, upid->ns)]);
upid->ns->nr_hashed++;
}
/* 3. 解锁 */
spin_unlock_irq(&pidmap_lock);
return pid;
......
}
这里小结写场景的标准流程,在 RCU 机制中,写端必须遵循修改 –> 等待 –> 释放的范式:
//假设一个哈希表节点 my_node
// 1. 写者必须持有锁来防止多个写者冲突
spin_lock(&my_lock);
//2. 调用写端 API 将节点从链表中断开
// 此时读者依然可以通过旧指针访问该节点,所以不能立即 kfree
hlist_del_rcu(&my_node->list_member);
spin_unlock(&my_lock);
// 3. 等待所有读者完成(宽限期)
synchronize_rcu();
// 4. 只有到了这里,物理释放才是安全的
kfree(my_node);
- 加锁(写者互斥):RCU 不保护写者之间的竞争,所以必须先获取锁(如
spin_lock) - 移除/修改节点:调用
hlist_del_rcu或hlist_add_head_rcu,此时,旧节点可能仍被某些读者持有 - 进入宽限期(Grace Period):
- 同步方式:调用
synchronize_rcu()。这会阻塞写者,直到所有正在读取该节点的 CPU 都退出读临界区 - 异步方式:调用
call_rcu()或kfree_rcu(),注册一个回调函数,等安全时再释放内存
- 同步方式:调用
- 物理释放:在宽限期结束后,执行
kfree()释放旧节点的内存
0x03 rbtree
rbtree
经典数据结构,性能稳定,插入/删除/查找的时间复杂度接近O(logN),而且中序遍历的结果是从小到大有序,内核中有如下应用:
- linux高精度定时器的实现(
hrtimer):以rbtree的形式组织,树的最左边的节点就是最快到期的事件节点 - Ext3文件系统,通过rbtree组织目录项
- linux内存中内存的管理:分配和回收。用rbtree组织已经分配的内存块,当应用程序调用free释放内存的时候,可以根据内存地址在rbtree中快速找到目标内存块
- linux内核进程调度算法通过rbtree组织管理,便于快速插入、删除、查找进程的
task_struct
此外,这里再补充关于rbtree的几个细节:
- rbtree的键值可以重复么?
- rbtree必须有键值么?
- rbtree的精髓在于其动态的高度调整,即在增、删、改的过程中,为了避免rbtree退化成单链表,rbtree的特性会动态地调整树的高度,让树高不超过
2lg(n+1)
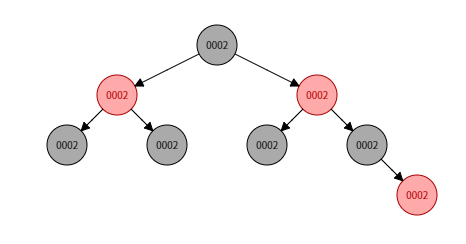
参考上面这棵树的创建过程,对于键值相同的节点是有时间顺序的,插入晚的默认为大值,放在后面,也就是说rbtree自动实现了按时间轴存储键值的功能。即使到期时间相等(键值Key相等),也可以根据其插入红黑树的时间顺序来取出最小到期事件去执行
基本概念
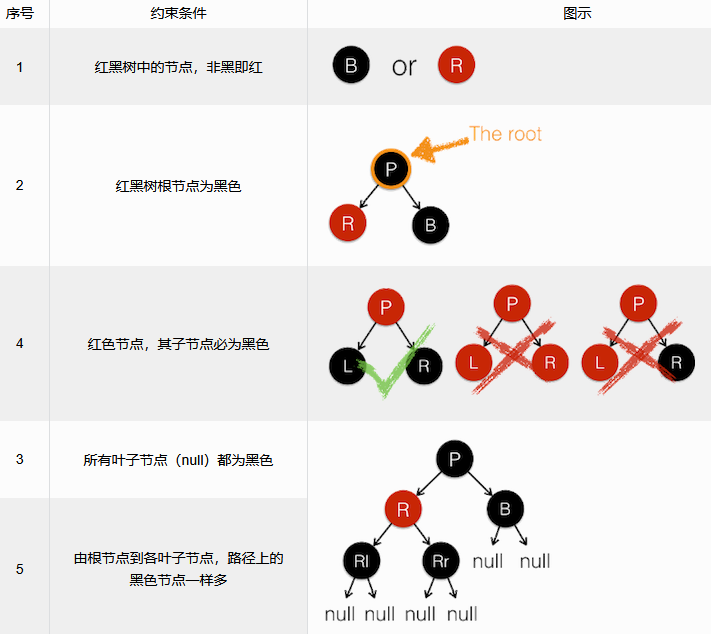
结构体定义
与其他的内核数据结构相同,为了通用性,rb_node只保留了红黑树节点自身的必须属性,即左孩子、右孩子、节点颜色
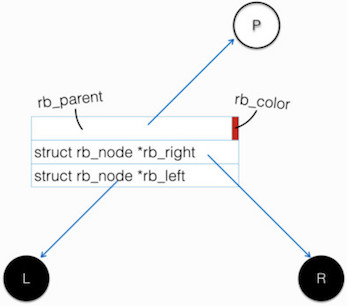
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
/* The alignment might seem pointless, but allegedly CRIS needs it */
此结构体特点:
- 按
sizeof(long)字节对齐,long在32位系统下是4字节,64位为8字节,因为结构体中的首个字段地址就是整个结构体的地址,所以__rb_parent_color至少是4字节对齐的(即地址必须是4的倍数),那么分配给__rb_parent_color字段地址值的最后两个bits始终是0,可以用来存储额外的信息 __rb_parent_color保存了父节点的地址与本节点的颜色这两个信息
内核提供的相关的基础定义如下:
#define rb_parent(r) ((struct rb_node*)((r)->__rb_parent_color & ~3))
/* 'empty' nodes are nodes that are known not be inserted in an rbtree */
#define RB_EMPTY_NODE(node) \
((node)->__rb_parent_color == (unsigned long)(node))
#define RB_CLEAR_NODE(node) \
((node)->__rb_parent_color = (unsigned long)(node))
/* 其他一些辅助宏 */
#define RB_RED 0
#define RB_BLACK 1
#define RB_ROOT (struct rb_root){NULL,}
#define rb_entry(ptr, type, member) contaier_of(ptr,type, member)
#define RB_EMPTY_ROOT(root) (READ_ONCE((root)->rb_node) == NULL)
/* 设置parent的相关内联函数 */
static inline void rb_set_parent(struct rb_node *rb, struct rb_node *p)
{
rb->__rb_parent_color |= (unsigned long)p; /* 不影响rb节点的颜色属性 */
}
static inline void rb_set_parent_color(struct rb_node *rb, struct rb_node *p, int color)
{
rb->__rb_parent_color = (unsigned long)p | color; /* 指定rb节点的颜色属性 */
}
/* 初始化新节点的内联函数 */
static inline void rb_link_node(struct rb_node *node, struct rb_node *parent, struct rb_node **rb_link)
{
/**
* 设置其双亲节点的首地址(根节点的双亲节点为NULL),且颜色属性为黑色
*/
node->__rb_parent_color = (unsigned long)parent;
node->rb_left = node->rb_right = NULL;
/**
* 指向新节点
*/
*rb_link = node;
}
与普通的红黑树实现不同,内核的红黑树实现 TODO
rbtree:内核的若干细节(lockless lookup)
rbtree:内核的若干细节(augment)
核心代码解析:插入
核心代码解析:删除
TODO
查找
1、find_vma:遍历红黑树,寻找第一个tmp->vm_end < addr的红黑树节点
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L2097
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
{
struct rb_node *rb_node;
struct vm_area_struct *vma;
/* Check the cache first. */
vma = vmacache_find(mm, addr);
if (likely(vma))
return vma;
rb_node = mm->mm_rb.rb_node;
while (rb_node) {
struct vm_area_struct *tmp;
tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (tmp->vm_end > addr) {
vma = tmp;
if (tmp->vm_start <= addr){
//命中条件,跳出查找过程
break;
}
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
vmacache_update(addr, vma);
return vma;
}
rbtree的应用
1、CFS 非实时任务调度
在Linux CFS调度算法(2.6.24 版本之后)中,所有非实时可运行进程都以虚拟运行时间(vruntime)为键值(注意,vruntime是红黑树的key非value)用一棵红黑树进行维护,以完成更公平高效地调度所有任务。CFS 算法弃用 active/expired 数组和动态计算优先级,不再跟踪任务的睡眠时间和区别是否交互任务,而是在调度中采用基于时间计算键值的红黑树来选取下一个任务,根据所有任务占用 CPU 时间的状态来确定调度任务优先级,优点如下:
- 高效的查找、插入和删除操作:红黑树是一种自平衡二叉搜索树,能够在
O(logN)时间内完成查找、插入和删除操作,适合调度器频繁调整任务的需求 - 自平衡特性:红黑树通过颜色标记和旋转操作保持平衡,避免树结构退化为链表,确保操作效率稳定
- 支持快速获取最小节点:CFS每次调度需要选择
vruntime最小的任务,红黑树的最左节点即为最小节点,可以在O(logN)时间内快速定位 - 动态任务管理:CFS需要频繁插入新任务和删除已完成任务,红黑树的高效动态操作能力满足了这一需求
- 内存效率:红黑树每个节点只需额外存储一个颜色标记,内存开销较小,适合内核这种对内存敏感的环境
0x0 vm_area_struct:rb_subtree_gap实现分析
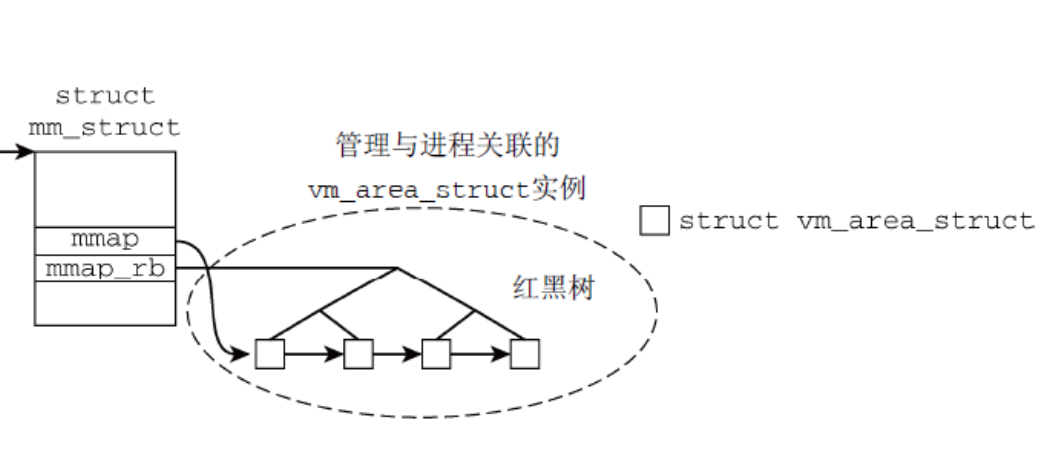
在文中遇到过 rb_subtree_gap这个字段的用法,它并非用于标准的红黑树算法,而是为了实现增幅红黑树(Augmented Red-Black Tree),专门解决在VMA寻址中,在区间中寻找足够大的空隙(gap)这一效率问题。rb_subtree_gap 表示以当前节点为根的子树中,最大的连续空闲空间(Gap)的大小
rb_subtree_gap 通常不直接放在基础的 rb_node 结构中,而是通过宏定义和扩展结构体实现的。在内核内存管理中,它被包含在 struct vm_area_struct 相关的红黑树逻辑中,利用 rb_augment_callbacks 来维护。
背景:为什么要引入 rb_subtree_gap?
在进程的虚拟地址空间中,多个 vma 分布在 0~TASK_SIZE 之间(虚拟内存地址),当需要分配mmap一块新的内存时,内核需要找到一个足够大的gap来分配
- 没有
rb_subtree_gap字段时:内核必须按地址顺序遍历所有的 vma,计算vma->next->start - vma->end,时间复杂度是O(n) - 设计
rb_subtree_gap字段:红黑树变成了一个空间索引。通过检查rb_subtree_gap,可以瞬间判断某个子树里是否存在足够大的空间,复杂度为O(logN)
计算规则(以x86_64架构的64位内核为例)如下,对于红黑树中的任意节点 N,其 rb_subtree_gap 的值取自以下三者的最大值:
- 当前节点的间隙:
N->start - N->prev->end(即当前节点与前一个节点之间的距离) - 左子树的最大间隙:
N->left->rb_subtree_gap - 右子树的最大间隙:
N->right->rb_subtree_gap
所以,查找过程就演变为如下(关联函数get_unmapped_area-->arch_get_unmapped_area_topdown[unmapped_area_topdown]/unmapped_area_topdown[unmapped_area]),内核会利用该字段进行二分查找
- 检查右子树:如果右子树的
rb_subtree_gap大于所需空间,优先往右找(高地址) - 检查当前节点:如果当前节点的 gap 足够,直接返回
- 检查左子树:如果右边和中间都不行,再看左子树
- 剪枝:如果某个子树的
rb_subtree_gap小于所需空间,直接跳过整个子树
为什么这里要强调是x86_64架构的64位内核呢?因为在该架构下mmap区域VMA的分配策略是优先从高地址向低地址方向搜索。Linux 支持两种内存布局模式:
- 底向上 (Bottom-up):地址从低向高增长(通常用于
32位系统) - 顶向下 (Top-down):地址从堆栈下方(高地址)开始向低地址增长,通常应用于现代系统(为了让堆和栈有更大的自由增长空间,中间的 mmap 区域通常从高地址往低地址分配),本质还是优化了堆区与匿名映射区的虚拟内存地址争用问题
unmapped_area_topdown的实现
分析下rb_subtree_gap的利用机制,以arch_get_unmapped_area_topdown、unmapped_area_topdown为例
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/mm.h#L2169
static inline unsigned long
vm_unmapped_area(struct vm_unmapped_area_info *info)
{
if (info->flags & VM_UNMAPPED_AREA_TOPDOWN)
return unmapped_area_topdown(info);
else
return unmapped_area(info);
}
unsigned long
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L2002
arch_get_unmapped_area_topdown(struct file *filp, const unsigned long addr0,
const unsigned long len, const unsigned long pgoff,
const unsigned long flags)
{
struct vm_area_struct *vma;
struct mm_struct *mm = current->mm;
unsigned long addr = addr0;
struct vm_unmapped_area_info info;
/* requested length too big for entire address space */
if (len > TASK_SIZE - mmap_min_addr)
return -ENOMEM;
if (flags & MAP_FIXED)
return addr;
/* requesting a specific address */
if (addr) {
addr = PAGE_ALIGN(addr);
vma = find_vma(mm, addr);
if (TASK_SIZE - len >= addr && addr >= mmap_min_addr &&
(!vma || addr + len <= vma->vm_start))
return addr;
}
info.flags = VM_UNMAPPED_AREA_TOPDOWN;
info.length = len;
info.low_limit = max(PAGE_SIZE, mmap_min_addr);
info.high_limit = mm->mmap_base;
info.align_mask = 0;
//
addr = vm_unmapped_area(&info);
/*
* A failed mmap() very likely causes application failure,
* so fall back to the bottom-up function here. This scenario
* can happen with large stack limits and large mmap()
* allocations.
*/
if (offset_in_page(addr)) {
VM_BUG_ON(addr != -ENOMEM);
info.flags = 0;
info.low_limit = TASK_UNMAPPED_BASE;
info.high_limit = TASK_SIZE;
addr = vm_unmapped_area(&info);
}
return addr;
}
在vm_unmapped_area函数中会调用unmapped_area_topdown,利用 rb_subtree_gap 将原本需要 O(n) 遍历的线性空间搜索,转化为 O(logN) 的红黑树深度优先搜索(带有剪枝),这个函数的大致流程如下:
- 如果最高处的gap有足够空间,那就优先分配,不涉及rbtree寻找
- 从rbtree树的根节点开始,搜索的起始物理节点是红黑树的root节点
unmapped_area_topdown的搜索逻辑具有强烈的方向性偏好,它第一时间就试图往右(子树)切入- 初始状态:vma = 根节点
- 循环的第一步通常是检查
vma->vm_rb.rb_right,如果右子树够大,它会立刻抛弃根节点,直接进入右子树,由于红黑树是按地址排序的,右子树意味着更高地址。对于 topdown 算法来说,根节点往往只是一个路口,它会尽可能快地顺着右子树爬到整棵树的最右侧(最高地址处),然后从那里开始真正地扫描gap
- 搜索的三个阶段(动态视角)
- 从根节点开始,只要右子树有足够的
rb_subtree_gap,就拼命往右子树切入。直到碰到一个节点,它的右子树不够大或者不存在 - 检查阶段:检查当前这个最靠右的节点的间隙
- 回溯阶段:如果当前间隙不够,需要向父节点回溯逻辑,往左边和上边找
- 从根节点开始,只要右子树有足够的
//unmapped_area_topdown:精髓在于优先寻找尽可能高的地址,同时利用 rb_subtree_gap 进行剪枝
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L1855
unsigned long unmapped_area_topdown(struct vm_unmapped_area_info *info)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
unsigned long length, low_limit, high_limit, gap_start, gap_end;
/* Adjust search length to account for worst case alignment overhead */
length = info->length + info->align_mask;
if (length < info->length)
return -ENOMEM;
/*
* Adjust search limits by the desired length.
* See implementation comment at top of unmapped_area().
*/
gap_end = info->high_limit;
if (gap_end < length)
return -ENOMEM;
high_limit = gap_end - length;
if (info->low_limit > high_limit)
return -ENOMEM;
low_limit = info->low_limit + length;
/* Check highest gap, which does not precede any rbtree node */
// 第一阶段:优先检查"最高处"的空隙
// 在红黑树之外,从进程已有的最后一个 VMA 结束地址到 high_limit 之间,往往存在一个巨大的未映射区域
// 既然是顶向下查找,这里是逻辑上的第一首选。如果这里够大,直接收工
// 就不需要走rbtree寻找了
// gap_start<= gap_start成立,说明high_limit在较高位置,gap_start在较低位置,长度可分配
gap_start = mm->highest_vm_end;
if (gap_start <= high_limit)
goto found_highest;
/* Check if rbtree root looks promising */
if (RB_EMPTY_ROOT(&mm->mm_rb))
return -ENOMEM;
//第二阶段:根节点整体判断
//如果最高处没位置,就需要进行rbtree查找
//利用 rb_subtree_gap 秒杀所有不可能的情况。如果根节点记录的最大空隙都塞不下 length,直接报内存不足
vma = rb_entry(mm->mm_rb.rb_node, struct vm_area_struct, vm_rb);
if (vma->rb_subtree_gap < length)
return -ENOMEM;
//第三阶段:带剪枝的高地址优先深度搜索(中序遍历,顺序是:右 -> 中 -> 左)
while (true) {
/* Visit right subtree if it looks promising */
gap_start = vma->vm_prev ? vma->vm_prev->vm_end : 0;
//1. 尝试右子树(更高地址)
if (gap_start <= high_limit && vma->vm_rb.rb_right) {
struct vm_area_struct *right =
rb_entry(vma->vm_rb.rb_right,
struct vm_area_struct, vm_rb);
if (right->rb_subtree_gap >= length) {
//右子树代表了更高地址的 VMA。如果右子树里有足够大的 gap,立刻进入右子树
vma = right;
continue;
}
}
//2. 右子树不满足,检查当前 Gap
//检查当前节点 vma 和它前一个节点 vma_prev 之间的缝隙。如果够大,由于是从右往左找的,这个位置就是目前能找到的最高合法位置
check_current:
/* Check if current node has a suitable gap */
gap_end = vma->vm_start;
if (gap_end < low_limit)
return -ENOMEM;
if (gap_start <= high_limit && gap_end - gap_start >= length)
goto found;
//3. 都不满足,尝试左子树(更低地址)
//只有右边和中间都行不通时,才被迫向左走,寻找低地址区域
/* Visit left subtree if it looks promising */
if (vma->vm_rb.rb_left) {
struct vm_area_struct *left =
rb_entry(vma->vm_rb.rb_left,
struct vm_area_struct, vm_rb);
if (left->rb_subtree_gap >= length) {
vma = left;
continue;
}
}
/* Go back up the rbtree to find next candidate node */
// 4. 复杂的回溯逻辑(见上面分析)
// 当一棵子树找完了(或者被剪枝了),必须回到父节点:
// 如果是从右子树回来的:意味着比父节点地址高的区域都找过了,没合适的。那么下一步就该检查父节点自身的 gap,不行再看左子树
// 如果是从左子树回来的:意味着这棵子树及其父节点全部找遍了,继续向上回溯
while (true) {
struct rb_node *prev = &vma->vm_rb;
if (!rb_parent(prev))
return -ENOMEM;
vma = rb_entry(rb_parent(prev),
struct vm_area_struct, vm_rb);
if (prev == vma->vm_rb.rb_right) { // 如果是从右边回来的
gap_start = vma->vm_prev ?
vma->vm_prev->vm_end : 0;
goto check_current; // 那么接下来该查当前节点和左边了
}
}
}
// 结果对齐:从 Gap 转换到 Address
// 由于是顶向下,需要返回这个 Gap 里的最高地址
found:
/* We found a suitable gap. Clip it with the original high_limit. */
if (gap_end > info->high_limit)
gap_end = info->high_limit;
found_highest:
/* Compute highest gap address at the desired alignment */
gap_end -= info->length;
//细节:先减去长度,再进行向下对齐。这保证了分配出的 [return_addr, return_addr + length) 一定落在 Gap 内部且满足对齐要求
gap_end -= (gap_end - info->align_offset) & info->align_mask;
VM_BUG_ON(gap_end < info->low_limit);
VM_BUG_ON(gap_end < gap_start);
return gap_end;
}
rb_subtree_gap的更新机制
TODO
0x0 等待队列
等待(waiter) - 唤醒(waker)模型是 Linux 中的一种基础机制。当进程要获取某些资源(例如从网卡读取数据)的时候,但资源并没有准备好(例如网卡还没接收到数据),这时候内核必须切换到其他进程运行,直到资源准备好再唤醒进程。waitqueue 机制就是内核用于管理等待资源的进程,当某个进程获取的资源没有准备好的时候,可以通过调用 add_wait_queue() 函数把进程添加到 waitqueue 中,然后切换到其他进程继续执行。当资源准备好,由资源提供方通过调用 wake_up() 函数来唤醒等待的进程
等待队列结构
和linklist类似,waitqueue 本质上是一个链表,waitqueue包含了wait_queue_head_t(头)以及__wait_queue(节点)两个基础结构
struct __wait_queue_head {
spinlock_t lock; //lock 字段用于保护等待队列在多核环境下数据被破坏
struct list_head task_list; //task_list 字段用于保存等待资源的进程列表
};
struct __wait_queue {
unsigned int flags; // 重要:可以设置为 WQ_FLAG_EXCLUSIVE,表示等待的进程应该独占资源(解决惊群现象)
void *private; //一般用于保存等待进程的进程描述符 task_struct,也可以设置为NULL(epoll下的acceptfd)
wait_queue_func_t func; //唤醒函数,一般设置为 default_wake_function() 函数,当然也可以设置为自定义的唤醒函数
struct list_head task_list; //用于链接其他等待资源的进程
};
等待同一事件的任务(由private 指向)通过双向链表串接(对应__wait_queue 节点),形成一个等待队列,在等待的事件发生后,waitqueue上的任务被唤醒,并执行func 回调函数
重点指出flags、private及func成员,在后面的文章中会有不同的用途
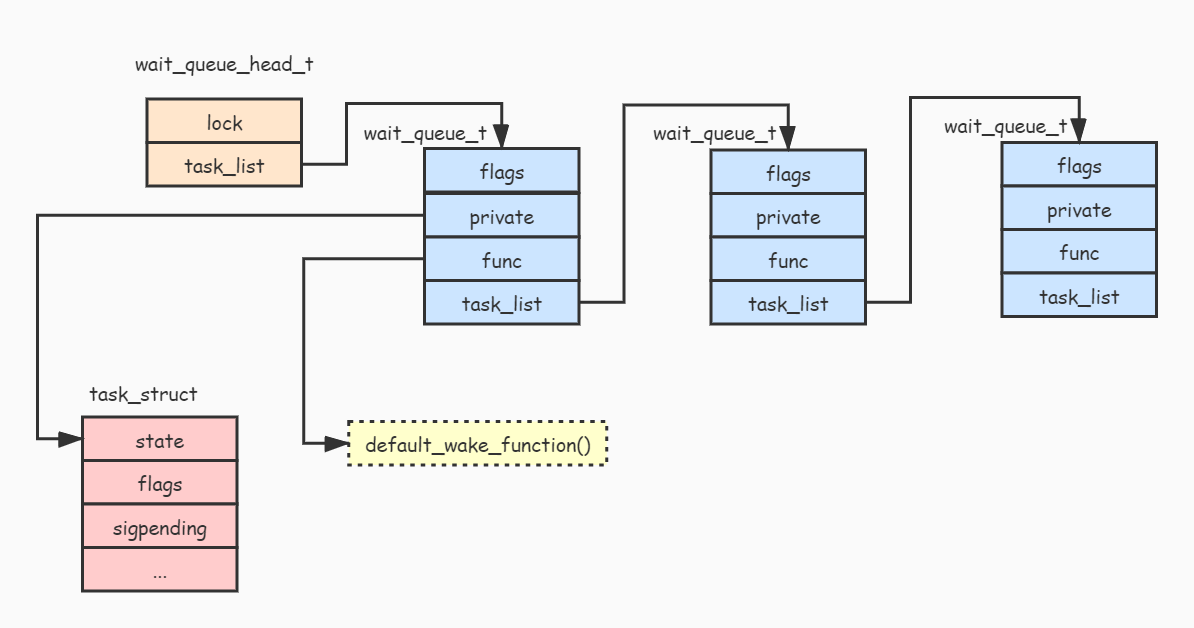
等待队列操作
1、waitqueue 初始化:通过调用 init_waitqueue_head() 函数来初始化 wait_queue_head_t 结构,首先调用 spin_lock_init() 来初始化自旋锁 lock,然后调用 INIT_LIST_HEAD() 来初始化进程链表
void init_waitqueue_head(wait_queue_head_t *q)
{
spin_lock_init(&q->lock);
INIT_LIST_HEAD(&q->task_list);
}
2、向waitqueue添加等待进程,要向 waitqueue 添加等待进程,首先要声明一个 wait_queue_t 结构的变量即等待队列成员,通过init_waitqueue_entry实现。初始化完 wait_queue_t 结构变量后,可以通过调用 add_wait_queue() 函数把等待进程添加到等待队列,其中add_wait_queue() 函数的实现逻辑为首先通过调用 spin_lock_irqsave() 上锁,然后调用 list_add() 函数把节点添加到等待队列链表即可
// init_waitqueue_entry 初始化为系统默认的等待唤醒函数
static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p)
{
q->flags = 0;
q->private = p;
q->func = default_wake_function;
}
//可以通过调用 init_waitqueue_func_entry() 函数来初始化为自定义的唤醒函数
static inline void init_waitqueue_func_entry(wait_queue_t *q, wait_queue_func_t func)
{
q->flags = 0;
q->private = NULL;
q->func = func;
}
void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait)
{
unsigned long flags;
wait->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
__add_wait_queue(q, wait);
spin_unlock_irqrestore(&q->lock, flags);
}
static inline void __add_wait_queue(wait_queue_head_t *head, wait_queue_t *new)
{
list_add(&new->task_list, &head->task_list);
}
3、休眠等待进程,当把进程添加到等待队列后,就可以休眠当前进程,让出CPU给其他进程运行。通常按照下面的代码可以完成休眠当前进程->让出当前CPU的操作:
set_current_state(TASK_INTERRUPTIBLE); //把当前进程运行状态设置为可中断休眠状态`TASK_INTERRUPTIBLE`
schedule(); //调用 schedule() 函数可以使当前进程让出CPU,切换到其他进程执行
关联的函数有如下:
wait_event(wq_head, condition)
wait_event_timeout(wq_head, condition, timeout)
wait_event_interruptible(wq_head, condition)
wait_event_interruptible_timeout(wq_head, condition, timeout)
4、唤醒等待队列,当资源准备好后,就可以唤醒等待队列中的进程,可以通过 wake_up()->__wake_up_common() 函数来唤醒等待队列中的进程。唤醒等待队列就是遍历等待队列的等待进程(即list_for_each_entry_safe方法),然后调用唤醒函数来唤醒它们
关联的函数有如下:
wake_up(&wq_head)
wake_up_interruptible(&wq_head)
wake_up_nr(&wq_head, nr)
wake_up_interruptible_nr(&wq_head, nr)
wake_up_interruptible_all(&wq_head)
static void __wake_up_common(wait_queue_head_t *q,
unsigned int mode, int nr_exclusive, int sync, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, sync, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
一些细节
1、wait_event的实现细节
Linux 内核的 ___wait_event 宏通过循环检查条件(condition)+ 主动让出 CPU(cmd) + 唤醒后重新检查条件的机制实现了等待队列的核心逻辑
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/wait.h#L266
#define ___wait_event(wq, condition, state, exclusive, ret, cmd) \
({ \
__label__ __out; \
wait_queue_t __wait; \
long __ret = ret; /* explicit shadow */ \
\
init_wait_entry(&__wait, exclusive ? WQ_FLAG_EXCLUSIVE : 0); \
for (;;) { \
long __int = prepare_to_wait_event(&wq, &__wait, state);\
\
// 被唤醒后再次检查condition是否满足
if (condition) \
break; \
\
if (___wait_is_interruptible(state) && __int) { \
__ret = __int; \
goto __out; \
} \
\
//内置schedule实现,让出CPU
cmd; \
} \
finish_wait(&wq, &__wait); \
__out: __ret; \
})
// finish_wait ...
void finish_wait(wait_queue_head_t *q, wait_queue_t *wait)
{
unsigned long flags;
__set_current_state(TASK_RUNNING);
if (!list_empty_careful(&wait->task_list)) {
spin_lock_irqsave(&q->lock, flags);
list_del_init(&wait->task_list);
spin_unlock_irqrestore(&q->lock, flags);
}
}
1、在for主循环里,condition 是一个true/false的标志位,通常由 waker 设置(需要保证并发安全),当 waiter 检测到其值为 true时,表明事件发生,通过break跳出循环
2、跳出循环后,调用 finish_wait()将状态重置为运行态TASK_RUNNING,并从 waitqueue 移除,等待的过程彻底结束
3、如果没有收到信号,condition 条件也没满足,那么任务应该已经在 waitqueue 上面了,接下来调用cmd执行任务切换,cmd是由上一层的宏或者函数传入的参数,通常为schedule/schedule_timeout,底层的调用链为__schedule() --> deactivate_task() --> dequeue_task() ,最后dequeue_task() 将作为 waiter 的任务从所在CPU的 runqueue 移除,正式让出 CPU 的控制权,当前进程由运行态切换为睡眠态
4、当发生上下文切换时,内核保存了进程的寄存器状态、栈指针、程序计数器(PC)等,恢复时直接从 schedule() 的下一条指令开始,当进程再次被调度时,确实从 schedule()后的代码继续执行
5、当从 schedule/schedule_timeout 函数返回时,意味着事件到了或者信号来了或者超时了,即被唤醒了,继续回到for循环的开头,再次判断condition是否为true,这里引出一个问题,内核为何要执行先唤醒后重新检查条件这个策略呢?
TODO
2、关于wait_event*函数中condition的理解,condition是谁负责更新的?
3、内核的典型用法一:一个队列等待多个事件
如果一个 page 正在经历 I/O 换出,为了避免同时访问造成的数据不一致,需要上锁,之后试图使用这个 page 的任务将调用 wait_on_page_locked() 排队。当 I/O 操作完成,page 解锁,等待任务被唤醒
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/pagemap.h#L497
static inline void wait_on_page_locked(struct page *page)
{
if (PageLocked(page))
wait_on_page_bit(compound_head(page), PG_locked);
}
直觉上应该每个 page 有一个 waitqueue,但这样开销太大了,内核的做法是将 page 按照一定的 hash 规则分组(一共 256 个分组),等待同一组内的 page 的任务都将被挂接在同一个 waitqueue 上。当分组内的某一个 page 解锁时,通过 hash 比对,查找 waitqueue 中等待该 page 的所有任务并唤醒
#define PAGE_WAIT_TABLE_SIZE (1 << 8)
wait_queue_head_t page_wait_table[PAGE_WAIT_TABLE_SIZE];
wait_queue_head_t *page_waitqueue(struct page *page)
{
return &page_wait_table[hash_ptr(page, PAGE_WAIT_TABLE_BITS)];
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L912
void add_page_wait_queue(struct page *page, wait_queue_t *waiter)
{
wait_queue_head_t *q = page_waitqueue(page);
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
__add_wait_queue(q, waiter);
SetPageWaiters(page);
spin_unlock_irqrestore(&q->lock, flags);
}
EXPORT_SYMBOL_GPL(add_page_wait_queue);
4、内核的典型用法二:一个任务等待多个队列
I/O 多路复用场景下,一个任务可以同时等待多个事件,这里的同时等待就利用了等待队列的机制来实现。以epoll机制为例,通过accept获取的fd关联的eppoll_entry 结构体就包含了等待队列的相关数据结构,如下
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/eventpoll.c#L230
struct eppoll_entry {
/* List header used to link this structure to the "struct epitem" */
struct list_head llink;
/* The "base" pointer is set to the container "struct epitem" */
struct epitem *base;
/*
* Wait queue item that will be linked to the target file wait
* queue head.
*/
wait_queue_t wait;
/* The wait queue head that linked the "wait" wait queue item */
wait_queue_head_t *whead;
};
而通过epoll_ctl() 增加监听fd及事件的过程,也包含了加入 waitqueue 的动作(注册socket就绪时的wait_queue_t结构,包含了就绪回调函数)等,主要内核函数调用链为epoll_ctl(EPOLL_CTL_ADD) --> ep_insert() --> ep_ptable_queue_proc() --> add_wait_queue(),调用它的任务会被挂在多个 waitqueue 上面,当其中一个 waitqueue 上的事件到来时(比如文件有可读的内容,或者腾出了可写的空闲区域),创建 waitqueue 节点时填入的回调函数 ep_poll_callback() 会将这个 entry 移入 ready list(或者 ovflist),等待任务唤醒后处理
0x0 IDR(整数基数树)
0x0 内核常用的并发机制(小结)
原子操作(Atomic Operations)
这是最底层的同步方式,利用 CPU 的原子指令(如 x86 的 LOCK 前缀指令)保证对单个变量的修改不可分割。特点是开销极低,不会阻塞,不会休眠,适用场景通常是简单的计数器(如 refcount 引用计数)
//在 get_task_struct 中增加进程引用计数:
atomic_inc(&t->usage); // 确保多 CPU 同时增加计数时不会冲突
rcu_read_lock/rcu_read_unlock
rcu_read_lock()/rcu_read_unlock() 并非针对单个 CPU 的锁定操作,它们甚至不产生任何传统的锁开销(比如内存屏障或原子指令),更像是一种声明机制。即rcu_read_lock 不是针对单个 CPU 的锁,而是一个极其轻量级的标记。它保证了在读操作期间,所引用的内存对象不会被其他 CPU 释放掉
//https://elixir.bootlin.com/linux/v4.11.6/source/kernel/pid.c#L475
struct task_struct *get_pid_task(struct pid *pid, enum pid_type type)
{
struct task_struct *result;
//这个操作保证了:在它增加 task_struct 的引用计数之前,没有任何一个 CPU 能够彻底销毁这个进程对象
rcu_read_lock();
result = pid_task(pid, type);
if (result)
get_task_struct(result);
rcu_read_unlock();
return result;
}
1、在非抢占式内核中,这两个函数的实现极其简单,它们只是禁止内核抢占
rcu_read_lock():告诉内核,我正在读 RCU 保护的数据,请不要在我完成之前把我切走(禁止抢占)rcu_read_unlock():告诉内核,我读完了,你可以随意调度我了
2、在现代抢占式内核中的变化,rcu_read_lock 甚至不再禁止抢占。它改为增加一个按任务(Per-task)的嵌套计数器
- 即使读进程被抢占切换走了,内核也会记录下:这个任务还在 RCU 读临界区内
- 此时,写者必须继续等待,直到这个被切走的项目重新运行并执行完
rcu_read_unlock
3、为什么它不是针对单个 CPU呢?虽然 RCU 的执行状态确实是按 CPU 维护的(每个 CPU 都有自己的 RCU 状态机),但它的作用是全局的:
- 无锁并行:在 CPU 0 执行
rcu_read_lock期间,CPU 1 可以完全自由地修改数据(通过rcu_assign_pointer) - 等待宽限期(Grace Period):如果 CPU 1 修改了数据并想删除旧内存,它必须等待所有 CPU 都经历过至少一次上下文切换或进入空闲状态(这被称为宽限期)
- 全局可见性:这意味着 RCU 保护的是一种全局的内存一致性逻辑,而不是像自旋锁那样阻止其他 CPU 访问特定资源
spin_lock
自旋锁是内核中最常用的锁,如果锁被占用,调用者会在原地打转(消耗 CPU)直到获得锁,特点如下:
- 不可休眠:持有自旋锁的代码严禁睡眠
- 上下文:可以用在中断处理程序中
- 开销:获得锁的过程快,但长时间持有会浪费 CPU
典型场景如保护进程状态切换(调度队列):
spin_lock(&rq->lock); // 获取运行队列锁
// ... 修改任务状态 ...
spin_unlock(&rq->lock);
信号量 (Semaphore)
信号量是一种允许睡眠的锁。如果无法获取锁,进程会进入睡眠状态,让出 CPU 给其他任务。特点如下:
- 允许休眠:只能在进程上下文中使用
- 多持有者:可以允许多个线程同时进入(如果计数值 > 1)
典型场景如,使用信号量保护较慢的 I/O 操作:
down(&sem); // 如果锁被占用,进程进入 TASK_UNINTERRUPTIBLE 状态
// ... 执行复杂的磁盘或设备操作 ...
up(&sem); // 释放并唤醒等待者
互斥锁 (Mutex)
Mutex 类似于二值信号量(只能由一个持有者),在内核中经过了高度优化。特点如下:
- 比信号量快:支持乐观自旋,如果发现锁持有者正在其他 CPU 上运行,它会先自旋一会儿而不是立即睡眠
- 严格的所有权:谁加锁谁必须负责解锁
典型场景如,保护文件系统挂载点或 VFS 层的关键数据:
mutex_lock(&inode->i_mutex);
// ... 操作文件 inode ...
mutex_unlock(&inode->i_mutex);
读写锁(Reader-Writer Locks)
读写锁分为读写自旋锁(rwlock_t)和读写信号量(rwsem)。它允许多个读者同时进入,但写者排他。优点是提高了并发性。如果数据场景是读多写少,这比单一锁高效得多
典型场景如,mmap_sem(内存管理中最著名的读写信号量):
down_read(&mm->mmap_sem); // 多个线程可以同时查找虚拟内存区域 (VMA)
// ... 查找地址空间 ...
up_read(&mm->mmap_sem);
PerCPU 变量 (Per-CPU Variables)
PerCPU变量是是一种避重就轻的策略。与其争夺一个全局锁,不如给每个 CPU 分配一份独立的数据。这个在ebpf内核态开发很常用,特点是:
- 完全无锁,因为每个 CPU 只访问自己的那份数据,不存在竞争
典型场景如,内核统计信息(如收发包统计、CPU 利用率):
unsigned int *count = this_cpu_ptr(&net_stats);
(*count)++; // 极高性能,无需任何同步指令
小结
- 在中断中吗?必须用 spinlock 或 atomic
- 临界区包含 I/O 或睡眠吗?必须用 mutex 或 semaphore
- 主要是读操作吗?优先考虑 RCU,其次是 rwsem
- 只是个计数器吗?优先使用 atomic
| 机制 | 类型 | 是否可休眠 | 是否可用在中断 | 核心优势 |
|---|---|---|---|---|
| atomic | 原子指令 | 否 | 是 | 性能最高,用于简单计数 |
| spinlock | 忙等 | 否 | 是 | 响应快,中断安全 |
| mutex | 睡眠 | 是 | 否 | 效率比信号量高,适合进程间同步 |
| semaphore | 睡眠 | 是 | 否 | 历史悠久,支持多个持有者 |
| RCU | 订阅/回收 | 否 (读) | 是 | 读操作几乎零开销 |
| rwsem | 读写睡眠 | 是 | 否 | 提高大并发读的效率 |
0x0 加锁粒度
| 模式 | 锁的粒度 | 性能影响 | 并发性 |
|---|---|---|---|
| 全局 spinlock | 整个 Hash 表 | 极高(所有读者、写者互斥) | 差,容易造成 CPU 瓶颈 |
| 细粒度 Lock (Per-bucket) | 单个哈希桶 | 中等(不同桶之间可并行) | 一般,高频读时依然有锁竞争开销 |
RCU机制hlist_..._rcu |
无锁 | 极低(仅相当于普通的内存指针跳转) | 极佳,读写完全并行,读者之间零干扰 |
0x0 小结
1、链表 VS hashtable,内核更偏爱后者
对比内核中二者实现,哈希链表的结构struct hlist_head和 struct hlist_node。它与普通的 struct list_head双链表有一个关键区别:
struct list_head有prev和next两个指针,构成一个完美的双向链表struct hlist_head只有一个指向第一个节点的first指针struct hlist_node有next和pprev(指向指向上一个节点的指针的指针)
hashtable这样设计主要是为了节省内存,哈希表的表头是一个数组,每个桶都是一个链表头。如果使用普通的 list_head,每个链表头都会有两个指针(prev/next),但在表头数组中,prev指针对于桶头来说是浪费的,因为桶头之间并不需要相互链接。hlist的这种设计将表头的开销减少了一半,对于拥有大量桶的哈希表来说,节省的内存非常可观
内核中双链表更多用于需要严格顺序或集合管理的场景,例如调度器中的就绪队列、等待某个事件发生的进程队列或者需要按顺序处理的软中断或工作队列等
0x0 参考
- Linux 内核中的数据结构
- 内核基础设施——hlist_head/hlist_node 结构解析
- 《Linux 内核设计与实现》读书笔记(六)- 内核数据结构
- linux kernel 中 HList 和 Hashtable
- Linux 内核中双向链表的经典实现
- rbtree
- linux源码解读(十五):红黑树在内核的应用——CFS调度器
- linux源码解读(十四):红黑树在内核的应用——红黑树原理和api解析
- 数据结构可视化
- Linux 中的等待队列机制
- 等待队列原理与实现
- 如何阅读内核源码
- 红黑树 IN Linux (一)
- 红黑树 IN Linux (二)
- 红黑树 IN Linux (三)