0x00 前言
本文代码基于 v4.11.6 版本
0x01 报文发送过程
本小节使用以太网的物理网卡,以一个UDP包的发送过程作为示例,了解下具体的发包过程
socket层
1、socket():创建一个UDP socket结构体,并初始化相应的UDP操作函数
2、sendto(sock, ...):应用层的程序(Application)调用该函数开始发送数据包,该函数会进而调用inet_sendmsg
3、inet_sendmsg:该函数主要是检查当前socket有无绑定源端口,如果没有的话,调用inet_autobind分配一个,然后调用UDP层的函数
4、inet_autobind:该函数会调用socket上绑定的get_port函数获取一个可用端口,由于该socket是UDP的socket,所以get_port函数会调到UDP内核实现里面的相应函数
+-------------+
| Application |
+-------------+
|
|
↓
+------------------------------------------+
| socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP) |
+------------------------------------------+
|
|
↓
+-------------------+
| sendto(sock, ...) |
+-------------------+
|
|
↓
+--------------+
| inet_sendmsg |
+--------------+
|
|
↓
+---------------+
| inet_autobind |
+---------------+
|
|
↓
+-----------+
| UDP layer |
+-----------+
UDP层
|
|
↓
+-------------+
| udp_sendmsg |
+-------------+
|
|
↓
+----------------------+
| ip_route_output_flow |
+----------------------+
|
|
↓
+-------------+
| ip_make_skb |
+-------------+
|
|
↓
+------------------------+
| udp_send_skb(skb, fl4) |
+------------------------+
|
|
↓
+----------+
| IP layer |
+----------+
IP层
|
|
↓
+-------------+
| ip_send_skb |
+-------------+
|
|
↓
+-------------------+ +-------------------+ +---------------+
| __ip_local_out_sk |------>| NF_INET_LOCAL_OUT |------>| dst_output_sk |
+-------------------+ +-------------------+ +---------------+
|
|
↓
+------------------+ +----------------------+ +-----------+
| ip_finish_output |<-------| NF_INET_POST_ROUTING |<------| ip_output |
+------------------+ +----------------------+ +-----------+
|
|
↓
+-------------------+ +------------------+ +----------------------+
| ip_finish_output2 |----->| dst_neigh_output |------>| neigh_resolve_output |
+-------------------+ +------------------+ +----------------------+
|
|
↓
+----------------+
| dev_queue_xmit |
+----------------+
netdevice子系统
|
|
↓
+----------------+
+----------------| dev_queue_xmit |
| +----------------+
| |
| |
| ↓
| +-----------------+
| | Traffic Control |
| +-----------------+
| loopback |
| or +--------------------------------------------------------------+
| IP tunnels ↓ |
| ↓ |
| +---------------------+ Failed +----------------------+ +---------------+
+----------->| dev_hard_start_xmit |---------->| raise NET_TX_SOFTIRQ |- - - - >| net_tx_action |
+---------------------+ +----------------------+ +---------------+
|
+----------------------------------+
| |
↓ ↓
+----------------+ +------------------------+
| ndo_start_xmit | | packet taps(AF_PACKET) |
+----------------+ +------------------------+
Device Driver
0x02 内核数据发送:详细分析
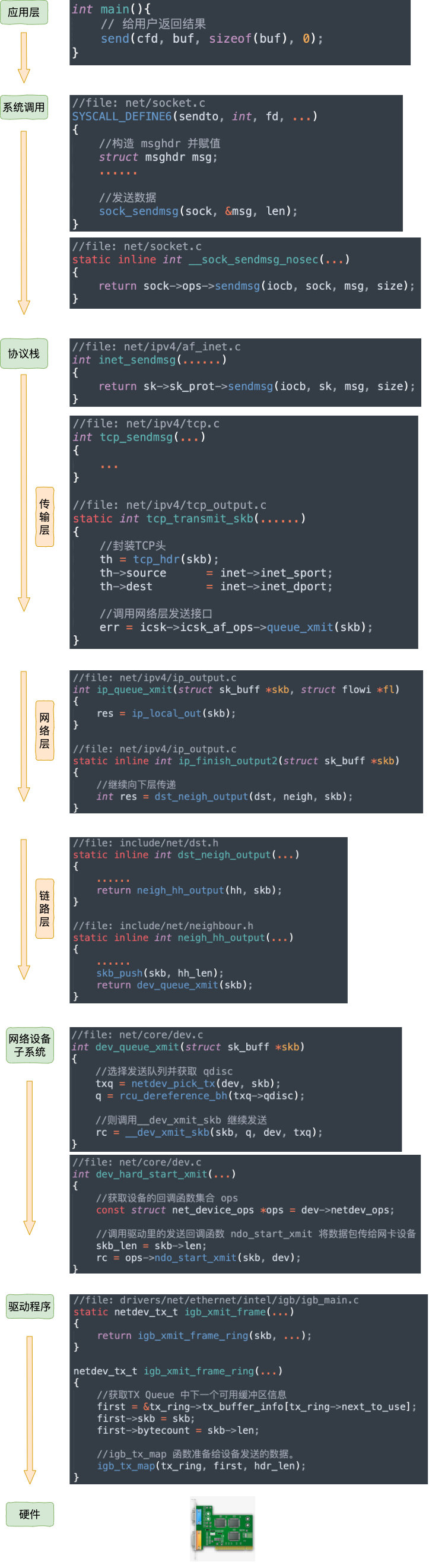
0x0 基础知识
MTU && MSS
- MTU:Maximum Transmission Unit
- MSS:Max Segment Size
0x 基础数据结构
msghdr 相关
struct msghdr {
void *msg_name; /* ptr to socket address structure */
int msg_namelen; /* size of socket address structure */
struct iov_iter msg_iter; /* data */
void *msg_control; /* ancillary data */
__kernel_size_t msg_controllen; /* ancillary data buffer length */
unsigned int msg_flags; /* flags on received message */
struct kiocb *msg_iocb; /* ptr to iocb for async requests */
};
struct iov_iter {
int type;
size_t iov_offset;
size_t count;
union {
const struct iovec *iov; //
......
};
union {
unsigned long nr_segs;
struct {
int idx;
int start_idx;
};
};
};
struct iovec
{
void __user *iov_base; /* BSD uses caddr_t (1003.1g requires void *) */
__kernel_size_t iov_len; /* Must be size_t (1003.1g) */
};
sk_buff
sk_buff_head
https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/skbuff.h#L281
struct sk_buff_head {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen;
spinlock_t lock;
};
sock结构中发送的成员
tcp 数据发送的过程,首先是从应用层再流入内核,内核会将应用层传入的数据copy到 sk_buff 链表中进行发送,关联struct sock结构的sk_write_queue与sk_send_head是最重要的两个成员:
sk_write_queue:发送队列的双向链表头sk_send_head:指向发送队列中下一个要发送的数据包
struct sock {
......
struct sk_buff *sk_send_head; //指针
struct sk_buff_head sk_write_queue; //对象
......
}
这两个成员的关系如下图所示
0x0 内核数据发送
本小节基于TCP三次握手完成,通过accept获取到客户端的连接fd,基于这个fd发送数据的场景进行分析
1、accept 获取fd完成的布局
2、send* 系统调用
不管是send、sendto、sendmsg等系统调用,最终都会调用sock_sendmsg,主要完成:
- 通过fd在内核中定位到对应的 socket/sock 结构对象,在这个对象里记录着各种协议栈的函数地址(在生成fd的时候就已经初始化好了)
- 构造一个
struct msghdr对象,把用户传入的数据,比如 buffer地址、数据长度等等都设置进去 - 调用
sock_sendmsg,即协议栈对应的函数inet_sendmsg,其中inet_sendmsg函数地址是通过 socket 内核对象里的ops成员找到的
以sendto系统调用为例:
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len,
unsigned int, flags, struct sockaddr __user *, addr,
int, addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
int err;
struct msghdr msg;
struct iovec iov;
......
// 根据fd定位socket/sock结构
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
// 设置msghdr对象
msg.msg_name = NULL;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
err = move_addr_to_kernel(addr, addr_len, &address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
err = sock_sendmsg(sock, &msg);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
继续sock_sendmsg -> sock_sendmsg_nosec:
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg)
{
// sendmsg对应 inet_sendmsg
// 该函数是 AF_INET 协议族提供的通用发送函数
int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg));
BUG_ON(ret == -EIOCBQUEUED);
return ret;
}
对于inet_sendmsg而言:
int inet_sendmsg(......)
{
......
// 对于 TCP socket, sendmsg 指向 tcp_sendmsg
// 对于 UDP socket, sendmsg 指向 udp_sendmsg
return sk->sk_prot->sendmsg(iocb, sk, msg, size);
}
tcp_sendmsg 函数分析
内核协议栈 inet_sendmsg 会关联对应 socket 上的具体协议发送函数,对于 TCP 协议而言就是 tcp_sendmsg(通过 socket 内核对象定位到),注意到tcp_sendmsg的参数sk,说明其用于处理某个具体的socket/sock的数据发送功能,tcp_sendmsg的核心功能如下:
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
struct sockcm_cookie sockc;
int flags, err, copied = 0;
int mss_now = 0, size_goal, copied_syn = 0;
bool process_backlog = false;
bool sg;
long timeo;
/* 加锁,避免与软中断的冲突 */
lock_sock(sk);
flags = msg->msg_flags;
// 若开启了TCP Fast Open,会在发送SYN时携带上数据
if (unlikely(flags & MSG_FASTOPEN || inet_sk(sk)->defer_connect)) {
err = tcp_sendmsg_fastopen(sk, msg, &copied_syn, size);
if (err == -EINPROGRESS && copied_syn > 0)
goto out;
else if (err)
goto out_err;
}
// 获取发送的超时时间,如果是非阻塞则为0
timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
tcp_rate_check_app_limited(sk); /* is sending application-limited? */
/* Wait for a connection to finish. One exception is TCP Fast Open
* (passive side) where data is allowed to be sent before a connection
* is fully established.
*/
// 只有ESTABLISHED 和 CLOSE_WAIT才允许发送数据
if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) &&
!tcp_passive_fastopen(sk)) {
// 否则,只能等待连接建立
err = sk_stream_wait_connect(sk, &timeo);
if (err != 0)
goto do_error;
}
if (unlikely(tp->repair)) {
if (tp->repair_queue == TCP_RECV_QUEUE) {
copied = tcp_send_rcvq(sk, msg, size);
goto out_nopush;
}
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out_err;
}
sockc.tsflags = sk->sk_tsflags;
if (msg->msg_controllen) {
err = sock_cmsg_send(sk, msg, &sockc);
if (unlikely(err)) {
err = -EINVAL;
goto out_err;
}
}
/* This should be in poll */
sk_clear_bit(SOCKWQ_ASYNC_NOSPACE, sk);
/* Ok commence sending. */
copied = 0;
restart:
// 获取当前有效的 mss
// size_goal:数据段的最大长度
mss_now = tcp_send_mss(sk, &size_goal, flags);
/*
* mtu: max transmission unit
* mss: max segment size. (mtu - (ip header size) - (tcp header size))
* GSO: Generic Segmentation Offload
* size_goal 表示数据报到达网络设备时,数据段的最大长度,该长度用来分割数据,
* TCP 发送段时,每个 SKB 的大小不能超过 size_goal
* 不支持 GSO 情况下, size_goal 就等于 MSS,如果支持 GSO,
* 那么 size_goal 是 mss 的整数倍,数据报发送到网络设备后再由网络设备根据 MSS 进行分割
*/
err = -EPIPE;
if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN))
goto do_error;
sg = !!(sk->sk_route_caps & NETIF_F_SG);
// msg_data_left:msghdr的count字段
while (msg_data_left(msg)) {
int copy = 0;
// max:size_goal
int max = size_goal;
// tcp_write_queue_tail:获取socket/sock(sk)对象对于的发送队列即sk_write_queue
skb = tcp_write_queue_tail(sk);
if (tcp_send_head(sk)) {
if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
/*
当 size_goal - skb->len>0,判断 skb 是否已满,大于零说明 skb(sk_buff) 还有剩余空间
即还可以继续向 skb 追加填充数据,组成一个 mss 的数据包,发往 ip 层
*/
copy = max - skb->len;
}
if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) {
/*
1、copy<=0 说明当前 skb 空间不足,那么要重新创建一个 sk_buff 来装载当前数据
2、被设置了 eor 标记不能合并
*/
bool first_skb;
new_segment:
/* Allocate new segment. If the interface is SG,
* allocate skb fitting to single page.
*/
/* 如果发送队列的总大小(sk_wmem_queued)>= 发送缓存上限(sk_sndbuf)
* 或者发送缓冲区中尚未发送的数据量,超过了用户的设置值,那么进入等待状态。*/
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf;
if (process_backlog && sk_flush_backlog(sk)) {
process_backlog = false;
goto restart;
}
first_skb = skb_queue_empty(&sk->sk_write_queue);
/*
正常情况:
重新分配一个 sk_buff 结构
*/
skb = sk_stream_alloc_skb(sk,
select_size(sk, sg, first_skb),
sk->sk_allocation,
first_skb);
if (!skb)
goto wait_for_memory;
process_backlog = true;
/*
* Check whether we can use HW checksum.
*/
if (sk_check_csum_caps(sk))
skb->ip_summed = CHECKSUM_PARTIAL;
//skb_entail:将 skb 添加进发送队列sk_write_queue(双链表)尾部
skb_entail(sk, skb);
//由于申请了一个新的sk_buff,初始化skb 数据缓冲区大小是 size_goal
copy = size_goal;
max = size_goal;
/* All packets are restored as if they have
* already been sent. skb_mstamp isn't set to
* avoid wrong rtt estimation.
*/
if (tp->repair)
TCP_SKB_CB(skb)->sacked |= TCPCB_REPAIRED;
}
/* Try to append data to the end of skb. */
// 重试复制数据,先再次校验长度
if (copy > msg_data_left(msg))
copy = msg_data_left(msg);
/* Where to copy to? */
// 检查skb 的线性存储区底部是否还有空间?
if (skb_availroom(skb) > 0) {
/* We have some space in skb head. Superb! */
copy = min_t(int, copy, skb_availroom(skb));
// 将数据拷贝到连续的数据区域
err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy);
if (err)
goto do_fault;
} else {
// skb线性存储区无可用空间
bool merge = true;
int i = skb_shinfo(skb)->nr_frags;
struct page_frag *pfrag = sk_page_frag(sk);
if (!sk_page_frag_refill(sk, pfrag))
goto wait_for_memory;
if (!skb_can_coalesce(skb, i, pfrag->page,
pfrag->offset)) {
if (i >= sysctl_max_skb_frags || !sg) {
tcp_mark_push(tp, skb);
goto new_segment;
}
merge = false;
}
copy = min_t(int, copy, pfrag->size - pfrag->offset);
if (!sk_wmem_schedule(sk, copy))
goto wait_for_memory;
/* 如果 skb 的线性存储区底部已经没有空间了,
* 将数据拷贝到 skb 的 struct skb_shared_info 结构指向的不需要连续的页面区域 */
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
pfrag->page,
pfrag->offset,
copy);
if (err)
goto do_error;
/* Update the skb. */
if (merge) {
skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy);
} else {
skb_fill_page_desc(skb, i, pfrag->page,
pfrag->offset, copy);
page_ref_inc(pfrag->page);
}
pfrag->offset += copy;
}
//如果复制的数据长度为零(或者第一次拷贝),那么取消 PSH 标志
if (!copied)
TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH;
//更新发送队列的最后一个序号 write_seq
tp->write_seq += copy;
//更新 skb 的结束序号
TCP_SKB_CB(skb)->end_seq += copy;
// 初始化 gso 分段数 gso_segs
tcp_skb_pcount_set(skb, 0);
copied += copy;
if (!msg_data_left(msg)) {
if (unlikely(flags & MSG_EOR))
TCP_SKB_CB(skb)->eor = 1;
//用户层数据已经拷贝完毕,进行发送
goto out;
}
/* 如果当前 skb 还可以填充数据,或者发送的是带外数据,或者使用 tcp repair 选项,
* 那么继续拷贝数据,先不发送*/
if (skb->len < max || (flags & MSG_OOB) || unlikely(tp->repair))
continue;
// 重要!检查是否必须立即发送
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
// 积累的数据包数量太多了,需要发送出去
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
// 如果是第一个网络包,那么只发送当前段
tcp_push_one(sk, mss_now);
// 不走下面的流程
continue;
wait_for_sndbuf:
//若发送队列中段数据总长度已经达到了发送缓冲区的长度上限,那么设置 SOCK_NOSPACE
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
wait_for_memory:
// 在进入睡眠等待前,如果已有数据从用户空间复制过来,那么通过 tcp_push 先发送出去
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
// 进入睡眠,等待内存空闲信号唤醒
err = sk_stream_wait_memory(sk, &timeo);
if (err != 0)
goto do_error;
//睡眠后 MSS 和 TSO 段长可能会发生变化,需要重新计算
mss_now = tcp_send_mss(sk, &size_goal, flags);
}
out:
/* 在连接状态下,在发送过程中,如果有正常的退出,或者由于错误退出(参考上面跳转到out的代码)
* 但是已经有复制数据了,都会进入发送环节。 */
if (copied) {
// 如果已经有数据复制到发送队列了,就尝试立即发送
tcp_tx_timestamp(sk, sockc.tsflags, tcp_write_queue_tail(sk));
// 是否能立即发送数据要看是否启用了 Nagle 算法
tcp_push(sk, flags, mss_now, tp->nonagle, size_goal);
}
out_nopush:
release_sock(sk);
return copied + copied_syn;
do_fault:
if (!skb->len) {
tcp_unlink_write_queue(skb, sk);
/* It is the one place in all of TCP, except connection
* reset, where we can be unlinking the send_head.
*/
tcp_check_send_head(sk, skb);
sk_wmem_free_skb(sk, skb);
}
do_error:
if (copied + copied_syn)
goto out;
out_err:
err = sk_stream_error(sk, flags, err);
/* make sure we wake any epoll edge trigger waiter */
if (unlikely(skb_queue_len(&sk->sk_write_queue) == 0 &&
err == -EAGAIN)) {
sk->sk_write_space(sk);
tcp_chrono_stop(sk, TCP_CHRONO_SNDBUF_LIMITED);
}
release_sock(sk);
return err;
}
这里再强调一下sk_write_queue与sk_send_head的配合机制