0x00 前言
本文从内核视角来跟踪下客户端与服务端的三次握手的流程,代码基于 v4.11.6 版本
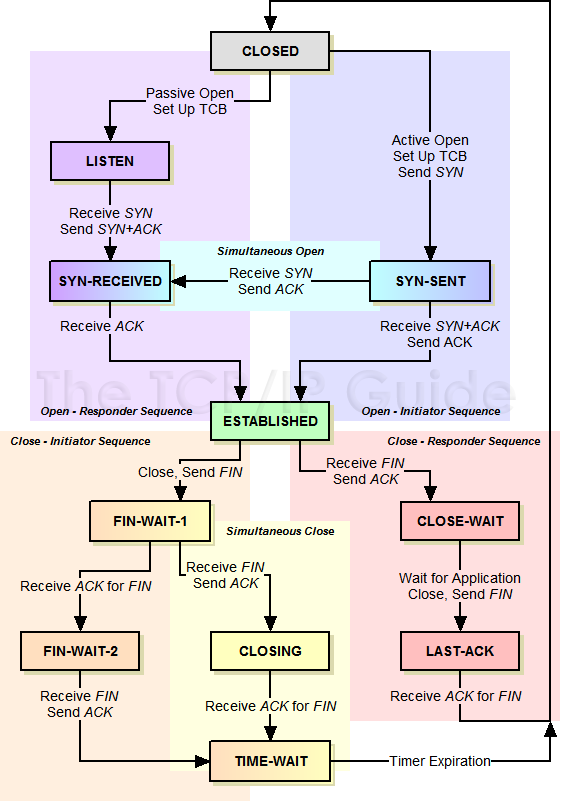
上图是经典的TCP切换状态机,不过内核v4.11.6 TCP三次握手的状态有些许改变,服务端新增了一个TCP_NEW_SYN_RECV状态
TCP状态切换:三次握手
- client:
TCP_SYN_SENT - server:
TCP_NEW_SYN_RECV - client:
TCP_ESTABLISHED - server:
TCP_SYN_RECV - server:
TCP_ESTABLISHED
TCP的状态信息,由struct sock的sk_state字段进行存储
服务端代码
int main(int argc, char const *argv[])
{
int fd = socket(AF_INET, SOCK_STREAM, 0);
bind(fd, ...);
listen(fd, 128);
accept(fd, ...);
//handler fd
}
客户端代码
int main(){
fd = socket(AF_INET,SOCK_STREAM, 0);
connect(fd, ...);
...
}
0x01 基础知识
socket/sock/inet_sock/inet_connection_sock
struct socket 是用于负责对(上层)给用户提供接口,并且和文件系统关联。而 struct sock 负责向下对接内核网络协议栈
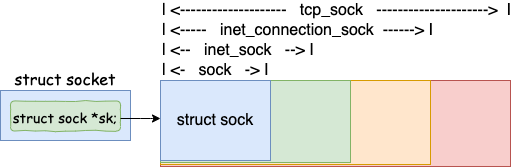
如上图sock -> inet_sock -> inet_connection_sock -> tcp_sock 四个结构体呈现从通用到专用的层次关系
1、sock基础层,内核网络栈的核心抽象,管理所有协议通用的基础设施,核心成员如下
- 等待队列:
struct socket_wq *sk_wq,用于同步阻塞模式以及epoll非阻塞模式下的等待唤醒机制 - 数据队列:
sk_receive_queue(接收队列)、sk_write_queue(发送队列) - 状态与内存:套接字状态(
sk_state)、缓冲区大小(sk_sndbuf/sk_rcvbuf)、内存计数器(sk_wmem_alloc) - 协议操作集:指向
struct proto(如tcp_prot),定义协议行为函数
2、inet_sock IP层扩展,继承sock,添加IPv4协议族专属字段,核心成员如下:
- 地址与端口:源/目的IP(
inet_saddr/inet_daddr)、源/目的端口(inet_sport/inet_dport) - IP选项:TTL(
uc_ttl)、服务类型(tos)、IP分片标志(hdrincl)等 - 多播支持:组播地址(
mc_addr)、设备索引(mc_index)
3、inet_connection_sock为面向连接协议扩展,继承inet_sock,为面向连接协议(如TCP)提供基础,核心成员如下:
- 连接管理:半连接队列(
request_sock_queue)、全连接队列(icsk_accept_queue) - 定时器:重传定时器(
icsk_retransmit_timer)、延迟ACK定时器(icsk_delack_timer) - 拥塞控制:算法操作集(
icsk_ca_ops)、私有数据(icsk_ca_priv)
4、tcp_sockTCP协议专属,继承inet_connection_sock,实现TCP协议完整状态机
- 序列号控制:发送序列(
snd_nxt)、接收序列(rcv_nxt)、未确认序列(snd_una) - 流量控制:拥塞窗口(
snd_cwnd)、接收窗口(rcv_wnd)、慢启动阈值(snd_ssthresh) - TCP的高级特性:乱序队列(
out_of_order_queue)、SACK选项、时间戳
内核通过单次内存分配与类型转换实现高效访问,创建TCP套接字时,一次性分配struct tcp_sock(包含所有父结构字段),当需要做层次间的类型转换时,直接通过指针强制转换访问父结构,由于父结构是子结构的首个成员,转换后可直接访问其字段(如tp->icsk->sk->sk_receive_queue)
struct tcp_sock *tp = alloc_tcp_sock();
struct inet_connection_sock *icsk = (struct inet_connection_sock *)tp;
struct sock *sk = (struct sock *)icsk; // 最终转为通用sock
inetsw_array
static struct inet_protosw inetsw_array[] =
{
{ //TCP 协议
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot, //重要
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{ //UDP 协议
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{ // ICMP 协议
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
},
//....
}
其中tcp_prot 的定义如下(sock 之下内核协议栈的动作)
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.get_port = inet_csk_get_port,
......
}
0x02 server:socket实现
当调用socket函数创建struct socket结构时,在用户层视角只看到返回了一个文件描述符 fd,内核做了哪些事情?
int socket(int domain, int type, int protocol);
socket调用的细节
创建 socket的过程如下,由于socket也是文件,所以需要关联到VFS即sockfs文件系统,参考前文
- 文件部分(VFS)
- 网络部分
- 建立进程
task_struct与打开文件描述符之间、VFS核心结构之间的关联关系
#------------------- 用户态 ---------------------------
socket
#------------------- 内核态 ---------------------------
__x64_sys_socket # 内核系统调用
__sys_socket
|-- sock_create
|-- __sock_create
#------------------- VFS ---------------------------
|-- sock_alloc
|-- new_inode_pseudo
|-- alloc_inode
|-- sock_alloc_inode
|-- kmem_cache_alloc
#------------------- 网络部分 ---------------------------
|-- inet_create # pf->create
|-- sk_alloc
|-- sk_prot_alloc
|-- kmem_cache_alloc
|-- inet_sk
|-- sock_init_data
|-- sk_init_common
|-- timer_setup
|-- sk->sk_prot->init(sk) # tcp_v4_init_sock
|-- tcp_init_sock
#------------------- 进程/VFS关系 ------------------------
|-- sock_map_fd # net/socket.c
|-- get_unused_fd_flags
|-- sock_alloc_file
|-- alloc_file_pseudo
|-- fd_install
|-- __fd_install
|-- fdt = rcu_dereference_sched(files->fdt)
|-- rcu_assign_pointer(fdt->fd[fd], file)
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/af_inet.c#L1014
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create,
.owner = THIS_MODULE,
};
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
//...
// 对AF_INET,这里的sock_create对应的是inet_create
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
goto out;
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
if (retval < 0)
goto out_release;
//...
}
socket主要完成:
- 调用
sock_create->__sock_create,新建一个struct socket及相关内容 - 调用
sock_map_fd,新建一个struct file并将file的private_data初始化为上一步创建的struct socket,这样对文件的操作可以调用socket结构体定义的方法,并关联fd和file
__socket_create函数主要工作如下:
- 调用
sock_alloc分配一个struct socket结构体和inode,并且标明inode是socket类型,这样对inode的操作最终可以调用socket的相关操作 - 根据输入参数,查找
net_families数组(该数组通过inet_init创建),获得域特定的socket创建函数 - 调用实际
create函数新建,如inet_create
//sock_alloc
struct socket *sock_alloc(void)
{
struct inode *inode;
struct socket *sock;
/*创建inode和socket*/
inode = new_inode_pseudo(sock_mnt->mnt_sb);
if (!inode)
return NULL;
/*返回创建的socket指针*/
sock = SOCKET_I(inode);
/*inode相关初始化*/
inode->i_ino = get_next_ino();
inode->i_mode = S_IFSOCK | S_IRWXUGO;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_op = &sockfs_inode_ops;
return sock;
}
EXPORT_SYMBOL(sock_alloc);
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
//...
sock = sock_alloc(); /*创建struct socket结构体*/
//...
sock->type = type; /*设置套接字类型*/
rcu_read_lock();
pf = rcu_dereference(net_families[family]); /*获取对应协议族的协议实例对象*/
err = -EAFNOSUPPORT;
if (!pf)
goto out_release;
//...
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
//...
}
EXPORT_SYMBOL(__sock_create);
对于__sock_create中的pf->create函数,其中pf由net_families[]数组获得,net_families[]数组里存放了各个协议族的信息,以family字段作为下标。net_families[]数组定义及初始化代码如下:
static DEFINE_SPINLOCK(net_family_lock);
static const struct net_proto_family __rcu *net_families[NPROTO] __read_mostly;
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create,
.owner = THIS_MODULE,
};
//net_families[]数组的初始化在inet_init函数
static int __init inet_init(void)
{
...
(void)sock_register(&inet_family_ops);
...
}
//注册
int sock_register(const struct net_proto_family *ops)
{
...
rcu_assign_pointer(net_families[ops->family], ops);
...
}
TCP协议对应的family字段是AF_INET,pf->create对应的函数即为inet_create,此外,在 sk_alloc 函数中,struct inet_protosw *answer 结构的 tcp_prot 赋值给了 struct sock *sk 的 sk_prot 成员(后续看到sock结构关联的sk_prot调用即参考tcp_prot结构的函数搜索即可)。核心逻辑如下:
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
//socket 状态设置
sock->state = SS_UNCONNECTED;
/* Look for the requested type/protocol pair. */
//查找全局数组inetsw(在inet_init函数中初始化)中对应的协议操作集合,最重要的是struct proto和struct proto_ops,分别用于处理四层和socket相关的内容
lookup_protocol:
err = -ESOCKTNOSUPPORT;
rcu_read_lock();
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) {
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}
//调用sk_alloc(),分配一个struct sock,并将proto类型的指针指向第二步获得的内容
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
if (!sk)
goto out;
err = 0;
if (INET_PROTOSW_REUSE & answer_flags)
sk->sk_reuse = SK_CAN_REUSE;
//初始化inet_sock,调用sock_init_data,形成socket和sock一一对应的关系,相互有指针指向对方
inet = inet_sk(sk);
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
inet->uc_ttl = -1;
inet->mc_loop = 1;
inet->mc_ttl = 1;
inet->mc_all = 1;
inet->mc_index = 0;
inet->mc_list = NULL;
inet->rcv_tos = 0;
//...
//最后调用proto中注册的init函数,err = sk->sk_prot->init(sk),如果对应于TCP,其函数指针指向tcp_v4_init_sock
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk);
if (err) {
sk_common_release(sk);
goto out;
}
}
//...
}
socket函数最后的逻辑是调用sock_map_fd函数负责分配文件,并与struct socket进行绑定,主要做两件事:
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
//分配文件描述符
int fd = get_unused_fd_flags(flags);
if (unlikely(fd < 0)) {
sock_release(sock);
return fd;
}
//调用sock_alloc_file,分配一个struct file,并将私有数据指针指向socket结构
newfile = sock_alloc_file(sock, flags, NULL);
if (likely(!IS_ERR(newfile))) {
//关联文件描述符fd和file
fd_install(fd, newfile);
return fd;
}
put_unused_fd(fd);
return PTR_ERR(newfile);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/net/socket.c#L395
struct file *sock_alloc_file(struct socket *sock, int flags, const char *dname)
{
// ......
path.dentry = d_alloc_pseudo(sock_mnt->mnt_sb, &name);
if (unlikely(!path.dentry))
return ERR_PTR(-ENOMEM);
path.mnt = mntget(sock_mnt);
d_instantiate(path.dentry, SOCK_INODE(sock));
file = alloc_file(&path, FMODE_READ | FMODE_WRITE,
&socket_file_ops);
if (IS_ERR(file)) {
/* drop dentry, keep inode */
ihold(d_inode(path.dentry));
path_put(&path);
return file;
}
sock->file = file;
file->f_flags = O_RDWR | (flags & O_NONBLOCK);
file->private_data = sock; //file的private成员设置为 struct socket
return file;
}
注意到上面sock_alloc_file函数的最后,会把file->private_data设置为struct socket*变量,由于socket也是文件,所以基于VFS的这套框架,各个成员有如下关系:
这里多说一句,内核在accept函数中也会创建struct socket结构,这两个具体的执行流程是不同的
最后,小结下创建socket结构时,内核会:
- 创建接收队列
sk_receive_queue,用于接收软中断softirq时存储对应的数据包 - 等待队列
sk_wq,当连接完成后,如果当前没有数据到来,那么当前进程会阻塞,并且状态从运行态切换至阻塞(主动让出CPU),并且当前进程关联的socket存储在该队列中,等到有数据到来的时候,内核再通过该队列中获取对应的进程将其唤醒 - 软中断处理函数
sk_data_ready,会直接将软中断的回调函数注册好,当数据到来的时候,调用该方法来处理 - 协议族函数
proto_ops,内核会将一系列内核协议栈相关的处理函数提前注册好,比如针对AF_INET注册的是inet_create - 初始化
struct sock结构内部的相关队列信息
0x03 server:listen实现
listen系统调用的功能如下:
- 将 socket 设置为监听 socket,作为服务端被动等待客户端连接
- backlog 限制全连接队列的大小及半连接个数
/* backlog:全连接队列和半连接队列限制大小
* return:正确返回 0,否则返回 -1
*/
int listen(int sockfd, int backlog);
listen实现:2.6内核
listen实现:4.11内核
####
listen系统调用的主要作用就是申请和初始化接收队列,包括全连接队列(链表)和半连接队列(hash表),如图
//https://elixir.bootlin.com/linux/v4.11.6/source/net/socket.c#L1437
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
......
//根据 fd 查找 socket 内核对象
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
//获取内核参数 net.core.somaxconn
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
// 配置检查,校准backlog 配置默认最大值
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
//调用协议栈注册的 listen 函数:inet_listen
err = sock->ops->listen(sock, backlog);
//...
}
......
}
sock->ops->listen 调用的是 inet_listen函数:
int inet_listen(struct socket *sock, int backlog) {
struct sock *sk = sock->sk;
unsigned char old_state;
int err, tcp_fastopen;
lock_sock(sk);
err = -EINVAL;
// 只有 tcp 才允许 listen,作为服务端的 socket,不能主动连接其它服务
if (sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM)
goto out;
// 状态检查:只有处于 TCP_CLOSE 或者 TCP_LISTEN 状态的 socket 才能调用 listen
old_state = sk->sk_state;
if (!((1 << old_state) & (TCPF_CLOSE | TCPF_LISTEN)))
goto out;
//设置全连接队列长度
sk->sk_max_ack_backlog = backlog;
// listen 可以重复调用,重复调用 listen 可修改 backlog
// 还不是 listen 状态(尚未 listen 过)
if (old_state != TCP_LISTEN) {
......
// 开始监听:listen 核心逻辑(下)
err = inet_csk_listen_start(sk, backlog);
}
......
}
继续贴下inet_csk_listen_start的实现:
int inet_csk_listen_start(struct sock *sk, int backlog) {
// 参考基础知识:根据sock结构拿到inet_connection_sock结构的指针
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
reqsk_queue_alloc(&icsk->icsk_accept_queue);
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
// 经过验证后,设置 socket 的状态为 TCP_LISTEN
inet_sk_state_store(sk, TCP_LISTEN);
// 疑惑:重新验证端口,虽然在这之前 bind 绑定了端口,但是 bind 和 listen 这是两个独立的操作
// 这两个操作之间时间段,整个系统,可能执行了一些影响端口的操作
// 所以 listen 要重新验证一下端口是否已经成功绑定了
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
// 关联注册的函数:inet_hash,用于初始化全连接表等
err = sk->sk_prot->hash(sk);
......
}
......
}
int inet_hash(struct sock *sk) {
int err = 0;
if (sk->sk_state != TCP_CLOSE) {
local_bh_disable();
// hash 保存 sk 值
err = __inet_hash(sk, NULL);
local_bh_enable();
}
return err;
}
listen中hashtable的逻辑
在开始之前,先梳理下这里用到的若干关键数据结构:
TODO
inet_csk_listen_start,其中icsk->icsk_accept_queue 定义在 inet_connection_sock(类型为request_sock_queue),是内核用来接收客户端请求的主要数据结构,其中包含了重要的全连接队列request_sock结构成员rskq_accept_head和rskq_accept_tail,这里注意对于全连接队列来说,在它上面不需要进行复杂的查找工作,accept 的时候只是先进先出处理就好了,因此全连接队列通过 rskq_accept_head 和 rskq_accept_tail 以链表的形式来管理,而半连接队列由于需要快速的查找,所以使用hash表来实现
//https://elixir.bootlin.com/linux/v4.11.6/source/include/net/request_sock.h#L161
struct request_sock_queue {
spinlock_t rskq_lock;
u8 rskq_defer_accept;
atomic_t qlen;
atomic_t young;
//全连接队列
struct request_sock *rskq_accept_head;
struct request_sock *rskq_accept_tail;
//...
};
int inet_csk_listen_start(struct sock *sk, int backlog)
{
//将 struct sock 对象强制转换成了 inet_connection_sock
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
reqsk_queue_alloc(&icsk->icsk_accept_queue);
sk->sk_max_ack_backlog = backlog;
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
/* There is race window here: we announce ourselves listening,
* but this transition is still not validated by get_port().
* It is OK, because this socket enters to hash table only
* after validation is complete.
*/
sk_state_store(sk, TCP_LISTEN);
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
err = sk->sk_prot->hash(sk);
if (likely(!err))
return 0;
}
sk->sk_state = TCP_CLOSE;
return err;
}
EXPORT_SYMBOL_GPL(inet_csk_listen_start);
在4.11.6内核的reqsk_queue_alloc并未发现半连接hash表初始化的代码,事实上该版本的实现已经不同于2.6了,主要区别是:
- 全局整合:移除独立哈希表,半连接请求(
struct request_sock)直接插入全局连接哈希表ehash,与其他状态的 socket 共用同一hash表 - 无预分配:
reqsk_queue_alloc仅初始化锁和全连接队列头,半连接队列无独立内存预分配
ehash的初始化
全局 ehash(Established Hash)是 Linux 内核中用于管理所有非 LISTEN 状态的 TCP 连接的核心哈希表(包括 SYN_RECV、ESTABLISHED、TIME_WAIT 等),其初始化发生在内核启动阶段,位于tcp_init
void __init tcp_init(void)
{
//...
tcp_hashinfo.ehash =
alloc_large_system_hash("TCP established",
sizeof(struct inet_ehash_bucket),
thash_entries,
17, /* one slot per 128 KB of memory */
0,
NULL,
&tcp_hashinfo.ehash_mask,
0,
thash_entries ? 0 : 512 * 1024);
for (i = 0; i <= tcp_hashinfo.ehash_mask; i++)
INIT_HLIST_NULLS_HEAD(&tcp_hashinfo.ehash[i].chain, i);
if (inet_ehash_locks_alloc(&tcp_hashinfo))
panic("TCP: failed to alloc ehash_locks");
//...
}
0x04 client:connect实现(发起三次握手)
客户端通过 connect 发起连接请求(发送SYN包),connect系统调用及设计到的接口实例化的代码如下:
/* sockfd: socket 函数返回的套接字描述符
* servaddr: 要连接的目标服务地址(IP/PORT)
* addrlen: 地址长度
* return: 正确返回 0,否则返回 -1
*/
int connect(int sockfd, const struct sockaddr *servaddr, socklen_t addrlen);
/* include/linux/net.h */
struct socket {
socket_state state;
short type;
......
struct sock *sk;
const struct proto_ops *ops;
};
/* include/net/sock.h */
struct proto {
......
int (*connect)(struct sock *sk, struct sockaddr *uaddr, int addr_len);
......
};
/* net/ipv4/tcp_ipv4.c */
struct proto tcp_prot = {
......
.connect = tcp_v4_connect,
......
};
/* net/ipv4/af_inet.c */
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
......
.connect = inet_stream_connect,
......
};
/* af_inet.c */
static struct inet_protosw inetsw_array[] = {
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot, //tcp_prot实例化
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK,
},
......
};
0x05 server:接收客户端的SYN包
在服务器端,所有的 TCP 报文都经过网卡及软中断,进入到 tcp_v4_rcv函数,在该函数中根据网络包(skb)TCP 头信息中的目的 IP 信息查到当前在 listen 的 socket(关联__inet_lookup_skb函数),然后继续进入 tcp_v4_do_rcv 处理握手过程,服务端收到客户端发送的 SYN 包后,将状态修改为 TCP_NEW_SYN_RECV,为了节省资源,并没有为 struct sock 分配空间,而是创建轻量级的连接请求数据结构 struct request_sock
这里涉及到几个关键点:
- 状态机切换
- 父子sock
tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_established的核心过程tcp_v4_rcv的参数struct sk_buff *skb是在哪里获取的,代表什么意义?- 半连接队列及操作实现
inet_reqsk_alloc(const struct request_sock_ops * ops, struct sock * sk_listener, bool attach_listener)
tcp_conn_request(struct request_sock_ops * rsk_ops, const struct tcp_request_sock_ops * af_ops, struct sock * sk, struct sk_buff * skb)
tcp_rcv_state_process(struct sock * sk, struct sk_buff * skb)
tcp_v4_do_rcv(struct sock * sk, struct sk_buff * skb)
tcp_v4_rcv(struct sk_buff * skb)
主要过程
1、协议校验与安全防御(tcp_v4_rcv->tcp_v4_do_rcv)
2、连接对象创建与初始化(tcp_rcv_state_process->tcp_v4_conn_request)
在 tcp_rcv_state_process 的 TCP_LISTEN 分支中,主要两个步骤:
- 拒绝非法报文
- 创建连接请求对象,调用
icsk->icsk_af_ops->conn_request(实际为tcp_v4_conn_request函数),此函数中struct request_sock *req = inet_reqsk_alloc(&tcp_request_sock_ops, sk, false)代码用来分配request_sock结构,存储连接元数据(即源/目的 IP、端口、序列号),然后对序列号初始化,生成服务端初始序列号(ISN)并预测客户端序列号(用于后续 ACK 验证)
3、半连接队列管理与定时器设置(tcp_v4_conn_request)
4、SYN+ACK 报文构造与发送(tcp_v4_conn_request)
tcp_v4_rcv的核心流程(ALL sk_state)
先梳理下TCP报文在内核流转的主要代码以及不同状态的处理,函数调用链为tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process
int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
......
th = (const struct tcphdr *)skb->data;
......
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
memmove(&TCP_SKB_CB(skb)->header.h4, IPCB(skb),
sizeof(struct inet_skb_parm));
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin +
skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th);
TCP_SKB_CB(skb)->tcp_tw_isn = 0;
TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph);
TCP_SKB_CB(skb)->sacked = 0;
lookup:
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, &refcounted);
if (!sk)
goto no_tcp_socket;
// 处理TIME_WAIT
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
// 处理TCP_NEW_SYN_RECV
if (sk->sk_state == TCP_NEW_SYN_RECV) {
// 半连接状态下的处理
.....
}
if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
.......
}
tcp_v4_do_rcv函数:
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
// TCP_ESTABLISHED
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
......
tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len);
return 0;
}
if (tcp_checksum_complete(skb))
goto csum_err;
// TCP_LISTEN
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_cookie_check(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
sock_rps_save_rxhash(nsk, skb);
sk_mark_napi_id(nsk, skb);
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}
if (tcp_rcv_state_process(sk, skb)) {
rsk = sk;
goto reset;
}
......
}
tcp_rcv_state_process函数:
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
case TCP_CLOSE:
goto discard;
// 这里的case对应的是服务端三次握手的逻辑
case TCP_LISTEN:
if (th->ack)
return 1;
if (th->rst)
goto discard;
if (th->syn) {
if (th->fin)
goto discard;
local_bh_disable();
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
local_bh_enable();
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
goto discard;
//客户端第二次握手处理
case TCP_SYN_SENT:
tp->rx_opt.saw_tstamp = 0;
//客户端响应 SYN+ACK 的主要逻辑
queued = tcp_rcv_synsent_state_process(sk, skb, th);
if (queued >= 0)
return queued;
/* Do step6 onward by hand. */
tcp_urg(sk, skb, th);
__kfree_skb(skb);
tcp_data_snd_check(sk);
return 0;
}
tp->rx_opt.saw_tstamp = 0;
req = tp->fastopen_rsk;
if (req) {
WARN_ON_ONCE(sk->sk_state != TCP_SYN_RECV &&
sk->sk_state != TCP_FIN_WAIT1);
if (!tcp_check_req(sk, skb, req, true))
goto discard;
}
if (!th->ack && !th->rst && !th->syn)
goto discard;
if (!tcp_validate_incoming(sk, skb, th, 0))
return 0;
/* step 5: check the ACK field */
acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH |
FLAG_UPDATE_TS_RECENT) > 0;
switch (sk->sk_state) {
case TCP_SYN_RECV:
if (!acceptable)
return 1;
if (!tp->srtt_us)
tcp_synack_rtt_meas(sk, req);
if (req) {
inet_csk(sk)->icsk_retransmits = 0;
reqsk_fastopen_remove(sk, req, false);
} else {
/* Make sure socket is routed, for correct metrics. */
icsk->icsk_af_ops->rebuild_header(sk);
tcp_init_congestion_control(sk);
tcp_mtup_init(sk);
tp->copied_seq = tp->rcv_nxt;
tcp_init_buffer_space(sk);
}
smp_mb();
tcp_set_state(sk, TCP_ESTABLISHED);
sk->sk_state_change(sk);
if (sk->sk_socket)
sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT);
tp->snd_una = TCP_SKB_CB(skb)->ack_seq;
tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale;
tcp_init_wl(tp, TCP_SKB_CB(skb)->seq);
if (tp->rx_opt.tstamp_ok)
tp->advmss -= TCPOLEN_TSTAMP_ALIGNED;
if (req) {
tcp_rearm_rto(sk);
} else
tcp_init_metrics(sk);
if (!inet_csk(sk)->icsk_ca_ops->cong_control)
tcp_update_pacing_rate(sk);
tp->lsndtime = tcp_time_stamp;
tcp_initialize_rcv_mss(sk);
tcp_fast_path_on(tp);
break;
case TCP_FIN_WAIT1: {
int tmo;
if (req) {
if (!acceptable)
return 1;
reqsk_fastopen_remove(sk, req, false);
tcp_rearm_rto(sk);
}
if (tp->snd_una != tp->write_seq)
break;
tcp_set_state(sk, TCP_FIN_WAIT2);
sk->sk_shutdown |= SEND_SHUTDOWN;
sk_dst_confirm(sk);
if (!sock_flag(sk, SOCK_DEAD)) {
/* Wake up lingering close() */
sk->sk_state_change(sk);
break;
}
if (tp->linger2 < 0 ||
(TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq &&
after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt))) {
tcp_done(sk);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
return 1;
}
tmo = tcp_fin_time(sk);
if (tmo > TCP_TIMEWAIT_LEN) {
inet_csk_reset_keepalive_timer(sk, tmo - TCP_TIMEWAIT_LEN);
} else if (th->fin || sock_owned_by_user(sk)) {
inet_csk_reset_keepalive_timer(sk, tmo);
} else {
tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
goto discard;
}
break;
}
case TCP_CLOSING:
if (tp->snd_una == tp->write_seq) {
tcp_time_wait(sk, TCP_TIME_WAIT, 0);
goto discard;
}
break;
case TCP_LAST_ACK:
if (tp->snd_una == tp->write_seq) {
tcp_update_metrics(sk);
tcp_done(sk);
goto discard;
}
break;
}
/* step 6: check the URG bit */
tcp_urg(sk, skb, th);
/* step 7: process the segment text */
switch (sk->sk_state) {
case TCP_CLOSE_WAIT:
case TCP_CLOSING:
case TCP_LAST_ACK:
if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt))
break;
case TCP_FIN_WAIT1:
case TCP_FIN_WAIT2:
if (sk->sk_shutdown & RCV_SHUTDOWN) {
if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq &&
after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
tcp_reset(sk);
return 1;
}
}
/* Fall through */
case TCP_ESTABLISHED:
tcp_data_queue(sk, skb);
queued = 1;
break;
}
/* tcp_data could move socket to TIME-WAIT */
if (sk->sk_state != TCP_CLOSE) {
tcp_data_snd_check(sk);
tcp_ack_snd_check(sk);
}
if (!queued) {
discard:
tcp_drop(sk, skb);
}
return 0;
}
状态机切换流程
tcp_v4_rcv是TCP协议的核心处理函数,处理从 IP 层传入的 TCP 数据包,它的入口在IP层的结束位置ip_local_deliver_finish函数
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
......
// tcp_v4_rcv函数,将skb传入TCP层处理
ret = ipprot->handler(skb);
......
}
从IP进入到TCP层时tcp_v4_rcv被调用,主要涉及的核心代码如下,其中包含了这些重要函数:
int tcp_v4_rcv(struct sk_buff *skb) {
struct sock *sk;
......
// 从连接表(ehash、lhash等)获取sk最新结构
// __inet_lookup_skb的实现
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, &refcounted);
//server响应SYN packet时,sk_state为TCP_LISTEN状态
if (sk->sk_state == TCP_LISTEN) {
// sk_state
ret = tcp_v4_do_rcv(sk, skb);
}
......
}
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) {
......
//服务器收到客户端的第一步握手 SYN 或者第三步 ACK 都会走到这里
if (sk->sk_state == TCP_LISTEN) {
//SYN Cookie 检查
struct sock *nsk = tcp_v4_cookie_check(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
// 创建新 socket 处理连接
sock_rps_save_rxhash(nsk, skb);
sk_mark_napi_id(nsk, skb);
// 服务端收到客户端的ACK(三次握手最后步骤)
// 处理子 socket(视为完整新连接)
// 这里的逻辑见下文
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
} else{
sock_rps_save_rxhash(sk, skb);
}
// 注意:本小节的流程
// 处理 SYN 包,这里传入的sk仍然是旧sk
if (tcp_rcv_state_process(sk, skb)) {
rsk = sk;
goto reset;
}
reset:
tcp_v4_send_reset(rsk, skb);
...
}
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) {
...
switch (sk->sk_state) {
...
case TCP_LISTEN: // 这里sk的sk_state仍然是TCP_LISTEN状态
...
if (th->syn) {
...
// 实际上对应的是tcp_v4_conn_request,然后调用tcp_conn_request
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
...
}
...
}
...
}
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/tcp_ipv4.c#L1266
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
......
return tcp_conn_request(&tcp_request_sock_ops,
&tcp_request_sock_ipv4_ops, sk, skb);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/tcp_input.c#L6277
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb) {
...
req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie);
...
if (fastopen_sk) {
...
} else {
...
if (!want_cookie)
// 加入半连接队列并启动定时器
inet_csk_reqsk_queue_hash_add(sk, req, TCP_TIMEOUT_INIT);
// 服务端给客户端发送 SYN + ACK 包
// https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/tcp_input.c#L6414
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE);
...
}
}
struct request_sock *inet_reqsk_alloc(const struct request_sock_ops *ops,
struct sock *sk_listener,
bool attach_listener) {
struct request_sock *req = reqsk_alloc(ops, sk_listener,
attach_listener);
if (req) {
struct inet_request_sock *ireq = inet_rsk(req);
...
// 设置 TCP_NEW_SYN_RECV 状态(本文内核版本)
ireq->ireq_state = TCP_NEW_SYN_RECV;
...
}
return req;
}
af_ops->send_synack对应的是 TODO
状态迁移的可观测
额外补充,新版本内核(如6.16)提供了一个观测点tracepoint:sock:inet_sock_set_state,可以用来获取TCP状态的变迁
void inet_sk_set_state(struct sock *sk, int state)
{
//sk->sk_state:旧状态
//state:新状态
trace_inet_sock_set_state(sk, sk->sk_state, state);
sk->sk_state = state;
}
0x06 client:响应SYN-ACK包
客户端发送完SYN包,等待接收服务端的SYN+ACK,当该报文到来时,同样会进入到 tcp_rcv_state_process 函数中,默认阻塞(inet_wait_for_connect)的进程被唤醒处理 SYN+ACK(注意客户端当前socket 的状态是 TCP_SYN_SENT)。在正常三次握手的情况下,客户端将当前 TCP 状态改变为 TCP_ESTABLISHED,并给服务端返回的 SYN 包,发送对应的 ACK
主要逻辑
tcp_rcv_synsent_state_process函数 是客户端响应 SYN+ACK 的主要逻辑
状态机切换
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) {
...
if (tcp_rcv_state_process(sk, skb)) {
...
}
...
}
// 除了 ESTABLISHED、TCP_NEW_SYN_RECV 和 TIME_WAIT,其他状态下的 TCP 处理都会走到这个函数
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) {
...
switch (sk->sk_state) {
...
case TCP_SYN_SENT: //客户端处理SYN+ACK包
...
queued = tcp_rcv_synsent_state_process(sk, skb, th);
...
}
...
}
//核心逻辑
static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th) {
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
...
if (th->ack) {
...
// tcp_ack
// https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/tcp_input.c#L3538
// tcp_ack->tcp_clean_rtx_queue
// 见下面
tcp_ack(sk, skb, FLAG_SLOWPATH);
// 将 TCP 状态改变为 TCP_ESTABLISHED,连接建立完成
tcp_finish_connect(sk, skb);
...
if (sk->sk_write_pending ||
icsk->icsk_accept_queue.rskq_defer_accept ||
icsk->icsk_ack.pingpong) {
//延迟确认
...
} else {
// 向服务发送 ack
tcp_send_ack(sk);
}
}
}
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/tcp_input.c#L5547
void tcp_finish_connect(struct sock *sk, struct sk_buff *skb) {
...
// 修改socket状态,客户端设置状态为TCP_ESTABLISHED
tcp_set_state(sk, TCP_ESTABLISHED);
//初始化拥塞控制
tcp_init_congestion_control(sk);
//开启TCP保活计时器
if (sock_flag(sk, SOCK_KEEPOPEN))
inet_csk_reset_keepalive_timer(sk, keepalive_time_when(tp));
...
}
tcp_send_ack主要用于向服务端发回ACK报文
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/tcp_output.c#L3462
void tcp_send_ack(struct sock *sk)
{
struct sk_buff *buff;
/* If we have been reset, we may not send again. */
if (sk->sk_state == TCP_CLOSE)
return;
//申请和构造 ACK 包
buff = alloc_skb(MAX_TCP_HEADER,
sk_gfp_mask(sk, GFP_ATOMIC | __GFP_NOWARN));
if (unlikely(!buff)) {
// 异常处理
inet_csk_schedule_ack(sk);
inet_csk(sk)->icsk_ack.ato = TCP_ATO_MIN;
inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK,
TCP_DELACK_MAX, TCP_RTO_MAX);
return;
}
// 发送ACK
tcp_transmit_skb(sk, buff, 0, (__force gfp_t)0);
}
小结下当客户端处理SYN+ACK时,清除了 connect 时设置的重传定时器,把当前 socket 状态设置为 ESTABLISHED,开启保活计时器后发出第三次握手的 ACK 确认报文
tcp_ack的主要过程
static int tcp_ack(struct sock *sk, const struct sk_buff *skb, int flag)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
struct tcp_sacktag_state sack_state;
u32 ack_seq = TCP_SKB_CB(skb)->seq;
u32 ack = TCP_SKB_CB(skb)->ack_seq;
// 删除定时器
tcp_rearm_rto(sk);
//删除发送队列
tcp_clean_rtx_queue(sk, prior_fackets, prior_snd_una, &acked,
&sack_state);
}
0x07 server:响应ACK包
服务端收到客户端第三次握手的 ACK 包,服务端将 TCP 状态从 TCP_NEW_SYN_RECV 更新为 TCP_SYN_RECV,然后才为连接结构struct sock分配空间,关于TCP_NEW_SYN_RECV的改动请参考inet: add TCP_NEW_SYN_RECV state
即第二次握手(服务端收到SYN报文)TCP 状态是 TCP_NEW_SYN_RECV,第三次握手后,TCP 状态才是 TCP_SYN_RECV
状态机切换
1、tcp_v4_rcv->tcp_check_req->tcp_v4_syn_recv_sock->inet_csk_complete_hashdance:tcp_check_req 是处理 TCP 第三次握手(ACK 包)的核心函数,负责验证 ACK 合法性、创建child socket 并迁移连接状态,TCP状态由TCP_NEW_SYN_RECV切换为TCP_SYN_RECV。涉及到的核心函数流转如下
__inet_lookup_skbtcp_check_req
int tcp_v4_rcv(struct sk_buff *skb) {
......
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, &refcounted);
if (sk->sk_state == TCP_NEW_SYN_RECV) { //服务器状态为TCP_NEW_SYN_RECV
// 获取半连接结构request_sock
struct request_sock *req = inet_reqsk(sk);
struct sock *nsk; //NULL
sk = req->rsk_listener;
......
// 第一步:tcp_check_req
nsk = tcp_check_req(sk, skb, req, false);
if (!nsk) {
// nsk == NULL,quit
reqsk_put(req); // 释放半连接对象
goto discard_and_relse;
}
if (nsk == sk) {
// 释放半连接对象,但监听 socket 引用不变
reqsk_put(req);
} else if (tcp_child_process(sk, nsk, skb)) { // nsk!=sk,说明成功创建子 socket
// tcp_child_process失败
// 向客户端发送RST
tcp_v4_send_reset(nsk, skb);
// 释放资源
goto discard_and_relse;
} else {
// tcp_child_process成功、
// 释放监听 socket 的引用计数
sock_put(sk);
return 0;
}
}
......
discard_it:
/* Discard frame. */
kfree_skb(skb);
return 0;
discard_and_relse:
sk_drops_add(sk, skb);
if (refcounted)
sock_put(sk);
goto discard_it;
}
tcp_check_req函数主要用于负责验证 ACK 合法性、创建子 socket 并迁移连接状态,注意tcp_check_req函数有三种返回值(NULL、sk、child),需要结合tcp_v4_rcv中调用nsk = tcp_check_req(sk, skb, req, false)之后的处理来看
nsk = tcp_check_req(sk, skb, req, false); // 处理第三次握手 ACK,创建子 socket
if (!nsk) { ... } // case 1: nsk 为 NULL
if (nsk == sk) { ... } // case 2: nsk 等于原监听 socket
else if { tcp_child_process(sk, nsk, skb) } // case 3: nsk 为新创建的子 socket(成功),
else { ... } //case 4 :创建子socket成功 && 加全连接队列成功
1、case1,当nsk == NULL时,说明无法创建子 socket,可能原因为packet非法或者全连接队列已满sk_acceptq_is_full(sk)==true,如果为全连接队列满导致,则参考tcp_check_req中标签listen_overflow的处理。默认内核的行为如下:
reqsk_put(req); // 释放半连接对象(request_sock)
goto discard_and_relse; // 丢弃数据包,释放资源
可增大 net.core.somaxconn 和 listen() 的 backlog 参数,避免队列溢出
2、case2,当nsk == sk时(nsk 等于原监听 socket sk),触发原因为收到重复或无效 ACK,比如收到重复 ACK报文,半连接队列中无匹配的 request_sock,但 ACK 序列号合法,可能是重传导致;另一种情况是开启了SYN Cookie 验证通过,未创建半连接对象,需重新生成 request_sock,默认内核的行为如下:
reqsk_put(req); // 释放当前临时 req(非必需对象)
// 继续用监听 socket 处理后续数据包
3、case3,当 nsk != sk且tcp_child_process返回非0表示成功创建子 Socket,但tcp_child_process失败,内核默认行为:
tcp_v4_send_reset(nsk, skb); // 向客户端发送 RST
goto discard_and_relse; // 释放资源
4、case4,nsk != sk且tcp_child_process调用成功,此时内核会将子 socket 状态从 TCP_SYN_RECV 转为 TCP_ESTABLISHED(连接已经先前就移入了全连接队列),随后唤醒因 accept() 阻塞进程
/*
参数
sk:监听 Socket(TCP_LISTEN 状态)
skb:收到的 ACK 数据包
req:半连接队列中对应的 request_sock(存储 SYN 包信息)
fastopen:是否启用 TCP Fast Open
*/
struct sock *tcp_check_req(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
bool fastopen, bool *req_stolen)
{
struct sock *child;
......
/* Check for pure retransmitted SYN. */
// 检查是否为重传的SYN包
if (TCP_SKB_CB(skb)->seq == tcp_rsk(req)->rcv_isn &&
flg == TCP_FLAG_SYN &&
!paws_reject) {
if (!tcp_oow_rate_limited(sock_net(sk), skb,
LINUX_MIB_TCPACKSKIPPEDSYNRECV,
&tcp_rsk(req)->last_oow_ack_time) &&
!inet_rtx_syn_ack(sk, req)) {
unsigned long expires = jiffies;
expires += min(TCP_TIMEOUT_INIT << req->num_timeout,
TCP_RTO_MAX);
if (!fastopen)
mod_timer_pending(&req->rsk_timer, expires);
else
req->rsk_timer.expires = expires;
}
return NULL;
}
// 这里syn_recv_sock对应的是 tcp_v4_syn_recv_sock
/* OK, ACK is valid, create big socket and
* feed this segment to it. It will repeat all
* the tests. THIS SEGMENT MUST MOVE SOCKET TO
* ESTABLISHED STATE. If it will be dropped after
* socket is created, wait for troubles.
*/
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL,
req, &own_req);
if (!child)
goto listen_overflow;
......
// 完成连接的最终状态迁移与资源移交
// 核心作用是将新创建的子 socket 加入全连接队列(AcceptQueue)
return inet_csk_complete_hashdance(sk, child, req, own_req);
listen_overflow:
if (!sysctl_tcp_abort_on_overflow) {
// 注意:对应net.ipv4.tcp_abort_on_overflow配置
// 如果为0(默认配置),则返回NULL,服务端静默丢弃 ACK,客户端重传 ACK 直至超时
// 如果为1,则服务端发送 RST 复位连接,客户端收到 ECONNREFUSED
inet_rsk(req)->acked = 1;
return NULL;
}
embryonic_reset:
if (!(flg & TCP_FLAG_RST)) {
req->rsk_ops->send_reset(sk, skb);
} else if (fastopen) { /* received a valid RST pkt */
reqsk_fastopen_remove(sk, req, true);
tcp_reset(sk);
}
.......
return NULL;
}
tcp_v4_syn_recv_sock函数是处理第三次握手ACK包的核心函数,负责创建子套接字并完成连接状态迁移,其核心流程为:
- 创建子套接字
newsk:调用tcp_create_openreq_child(sk, req, skb)克隆监听套接字,基于监听套接字sk和半连接对象req创建子套接字newsk - 初始化子套接字成员,从半连接对象
req中提取客户端和服务端 IP/端口,初始化子套接字newsk,初始化顺序为inet_csk_clone_lock->sk_clone_lock->sk_prot_alloc - 关联路由与传输层初始化
struct tcp_sock *newtp = tcp_sk(newsk)
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/tcp_ipv4.c#L1286
// sk:监听套接字(TCP_LISTEN)
// skb:收到的 ACK 数据包
// req:半连接对象(存储 SYN 包信息)
// dst:路由缓存
struct sock *tcp_v4_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst,
struct request_sock *req_unhash,
bool *own_req) {
......
if (sk_acceptq_is_full(sk))
//全连接队列满了
goto exit_overflow;
//创建 sock && 初始化
newsk = tcp_create_openreq_child(sk, req, skb);
if (!newsk)
goto exit_nonewsk;
......
sk_daddr_set(newsk, ireq->ir_rmt_addr);
sk_rcv_saddr_set(newsk, ireq->ir_loc_addr);
newinet->inet_saddr = ireq->ir_loc_addr;
......
return newsk;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/tcp_minisocks.c#L432
struct sock *tcp_create_openreq_child(const struct sock *sk,
struct request_sock *req,
struct sk_buff *skb) {
struct sock *newsk = inet_csk_clone_lock(sk, req, GFP_ATOMIC);
......
}
//
struct sock *inet_csk_clone_lock(const struct sock *sk,
const struct request_sock *req,
const gfp_t priority) {
// 根据原始sk 复制一个新的struct sock结构出来
struct sock *newsk = sk_clone_lock(sk, priority);
if (newsk) {
struct inet_connection_sock *newicsk = inet_csk(newsk);
//为新连接分配 sock 空间,tcp 改变为 TCP_SYN_RECV
newsk->sk_state = TCP_SYN_RECV;
newicsk->icsk_bind_hash = NULL;
inet_sk(newsk)->inet_dport = inet_rsk(req)->ir_rmt_port; //目的端口
inet_sk(newsk)->inet_num = inet_rsk(req)->ir_num;
inet_sk(newsk)->inet_sport = htons(inet_rsk(req)->ir_num); //源端口
......
}
return newsk;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/net/core/sock.c#L1483
struct sock *sk_clone_lock(const struct sock *sk, const gfp_t priority)
{
struct sock *newsk;
bool is_charged = true;
newsk = sk_prot_alloc(sk->sk_prot, priority, sk->sk_family);
if (newsk != NULL) {
sock_copy(newsk, sk);
......
// newsk 初始化
// 初始化sock接收队列
skb_queue_head_init(&newsk->sk_receive_queue);
// 初始化sock等待队列
skb_queue_head_init(&newsk->sk_write_queue);
sk_set_socket(newsk, NULL);
newsk->sk_wq = NULL;
}
return newsk;
}
在跟踪完syn_rcv_sock之后,正常情况下会运行到inet_csk_complete_hashdance(sk, child, req, own_req),此函数负责将新建立的连接从半连接队列转移到全连接队列(accept 队列)
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/inet_connection_sock.c#L947
/*
struct sock *sk // 监听套接字(父套接字)
struct sock *child // 新创建的子套接字(代表新连接)
struct request_sock *req // 半连接队列中的请求块
bool own_req // 资源所有权标志
*/
struct sock *inet_csk_complete_hashdance(struct sock *sk, struct sock *child,
struct request_sock *req, bool own_req)
{
if (own_req) {
// 从半连接队列移除请求req
inet_csk_reqsk_queue_drop(sk, req);
// 更新半连接队列计数
reqsk_queue_removed(&inet_csk(sk)->icsk_accept_queue, req);
// 加入全连接队列(重要)
if (inet_csk_reqsk_queue_add(sk, req, child))
return child; //返回child socket
}
/*
own_req的核心作用:
若为 true,表示当前路径成功创建了 child且需处理队列转移;
若为 false,说明其他路径已处理该请求,需释放 child避免重复操作
*/
bh_unlock_sock(child);
sock_put(child);
return NULL;
}
继续分析下inet_csk_reqsk_queue_add的实现,根据上文可以了解到,当前版本的全连接队列通过链表管理(rskq_accept_head和 rskq_accept_tail)
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/inet_connection_sock.c#L922
struct sock *inet_csk_reqsk_queue_add(struct sock *sk,
struct request_sock *req,
struct sock *child)
{
struct request_sock_queue *queue = &inet_csk(sk)->icsk_accept_queue;
// 加自旋锁保护队列
spin_lock(&queue->rskq_lock);
if (unlikely(sk->sk_state != TCP_LISTEN)) {
inet_child_forget(sk, req, child);
child = NULL;
} else {
// 关联子套接字到请求块
req->sk = child;
req->dl_next = NULL;
// 链表插入操作
if (queue->rskq_accept_head == NULL) // 队列为空时
queue->rskq_accept_head = req; // 设为头节点
else // 队列非空
queue->rskq_accept_tail->dl_next = req; // 尾插法
queue->rskq_accept_tail = req; // 更新尾指针
sk_acceptq_added(sk); // 增加全连接队列计数(sk->sk_ack_backlog++)
}
spin_unlock(&queue->rskq_lock); // 解锁
return child;
}
2、tcp_v4_rcv->tcp_check_req->tcp_child_process:TCP_SYN_RECV切换为TCP_ESTABLISHED,在这个阶段,内核将 TCP 状态更新为 TCP_SYN_RECV,处理完逻辑后,随后将状态更新为 TCP_ESTABLISHED,这一阶段的核心函数是tcp_child_process
int tcp_v4_rcv(struct sk_buff *skb) {
...
if (sk->sk_state == TCP_NEW_SYN_RECV) {
...
if (!tcp_filter(sk, skb)) {
...
// 修改 TCP 状态为:TCP_SYN_RECV
nsk = tcp_check_req(sk, skb, req, false, &req_stolen);
}
......
if (nsk == sk) {
......
} else if (tcp_child_process(sk, nsk, skb)) {
// 处理新连接的核心逻辑
......
}
......
}
......
}
重点看一下tcp_child_process的实现,该函数的主要作用是将新创建的子 socket 从协议栈移交至应用层,主要工作为:
- 处理子 socket 的状态迁移,当内核收到第三次 ACK 包后,
tcp_child_process通过调用tcp_rcv_state_process驱动子 socket 状态机,将其状态从TCP_SYN_RECV更新为TCP_ESTABLISHED,即完成连接的协议栈层就绪,标志连接可传输数据 - 触发父进程唤醒(通知
accept()),若子 socket 状态从SYN_RECV成功迁移至ESTABLISHED,函数会调用监听 socket(parent)的sk_data_ready()回调函数(默认为sock_def_readable),唤醒阻塞在accept上的进程
// parent:listen socket
// child:accept socket
int tcp_child_process(struct sock *parent, struct sock *child,
struct sk_buff *skb) {
...
if (!sock_owned_by_user(child)) {
// 处理状态迁移
// TCP_SYN_RECV->TCP_ESTABLISHED
ret = tcp_rcv_state_process(child, skb);
/* Wakeup parent, send SIGIO */
if (state == TCP_SYN_RECV && child->sk_state != state)
// 非常重要:当新连接到达时,唤醒socket(listenfd)的等待队列!
// sk_data_ready() 通过 wake_up_interruptible() 唤醒监听队列上的进程
// 若listen socket 配置了异步 I/O(O_ASYNC),会额外发送 SIGIO 信号通知应用层
//目的:避免频繁唤醒,仅在连接真正就绪(状态变更)时通知应用层
parent->sk_data_ready(parent);
}
...
}
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) {
......
switch (sk->sk_state) {
case TCP_SYN_RECV:
......
// 当前服务端的socket状态是TCP_SYN_RECV,更新为TCP_ESTABLISHED
tcp_set_state(sk, TCP_ESTABLISHED);
......
}
}
在tcp_child_process函数中这段代码parent->sk_data_ready(parent)的作用是什么?为什么需要使用parent来调用?
-
通知对象是listen socket,即
parent(状态为TCP_LISTEN),其任务是接收新连接,而新创建的子socket(child)用于实际数据传输,所以需要唤醒listen socket上的关联的sock等待队列。当子socket状态从TCP_SYN_RECV迁移到TCP_ESTABLISHED后,需要通知listen socket 有新连接就绪,唤醒阻塞在accept()进程关联在listen socket的等待队列(sk->sk_wq) -
子socket,即
child关联的sock等待队列,在同步阻塞模式下,可以用于唤醒等待数据传输的进程
重要:__inet_lookup_listener的实现逻辑
TODO
重要:sock对象的创建
这里来说明下此握手阶段的sock对象创建与系统调用socket()的sock对象创建的不同之处
在服务端收到客户端第一个SYN包时,tcp_v4_rcv->tcp_child_process->tcp_child_process->tcp_child_process 的过程,通过icsk->icsk_af_ops->conn_request(sk, skb)创建半连接队列hashtable表项(最终调用的函数为inet_reqsk_alloc),这个半连接表项对应的结构为inet_reqsk_alloc,并非一个完整的struct sock对象
当服务端收到客户端第三次ACK时且正常完成握手后,才会把这个inet_reqsk_alloc结构升级为正常的struct sock,关联调用链为tcp_v4_syn_recv_sock->tcp_create_openreq_child->inet_csk_clone_lock->sk_clone_lock
半连接结构inet_reqsk_alloc + 监听listen sock = 新连接的sock结构
再贴一下sk_clone_lock的实现代码,在克隆场景sk_clone_lock中,子 sock 通过复制父对象状态继承字段值,无需再次初始化(子 sock 需继承父对象的上下文如回调函数、队列状态,确保协议栈行为一致)。此外,这里格外关注sk_wq等待队列与sk_data_ready sock就绪回调函数两个字段
struct sock *sk_clone_lock(const struct sock *sk, const gfp_t priority)
{
struct sock *newsk;
bool is_charged = true;
// sk_prot_alloc(prot, ...):分配子 sock 内存
// prot 是父 sock->sk_prot,决定了分配的内存大小
// 如 TCP 对应 tcp_prot,TCPv6 对应 tcpv6_prot
newsk = sk_prot_alloc(sk->sk_prot, priority, sk->sk_family);
if (newsk != NULL) {
struct sk_filter *filter;
// 重点:复制父 sock 字段到子对象newsk
// 包括 sk_data_ready、sk_wq 在内的核心字段
sock_copy(newsk, sk);
sk_set_socket(newsk, NULL);
newsk->sk_wq = NULL;
}
out:
return newsk;
}
sk_data_ready成员:由父对象的sock_copy()复制,直接继承父对象的回调函数,通常为sock_def_readablesk_wq:同样由父对象的sock_copy()复制,初始为空队列,后续由用户进程通过epoll_ctl()或select()等动态添加等待项
这里着重点出sk_wq与sk_data_ready的意义是,用户态编程时,当某个fd(关联sock数据就绪时)可读可写时,内核会通过这二者配合的机制唤醒上层进程进行数据处理
0x08 server:accept操作
服务端accept系统调用的功能就是从已经建立好的全连接队列(链表)中取出一个返回给用户进程。当 accept 之后,通常服务端进程会创建一个新的 socket 出来,专门用于和对应的客户端通信,然后把它放到当前进程的打开文件列表中,这里内核数据结构关系如下(注意到file.file_operations是指向socket_file_ops)
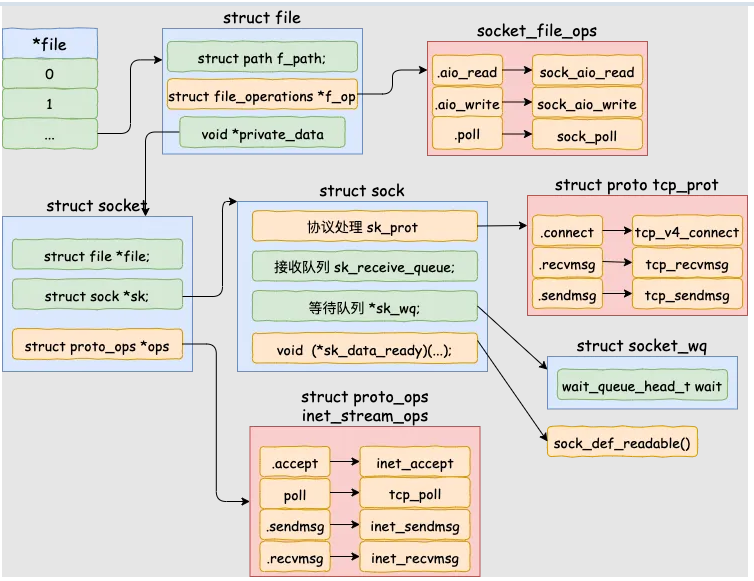
先回想一下struct socket的结构,其中包含了非常重要的sock成员,也是 socket 的核心内核对象,其中发送队列、接收队列、等待队列等核心数据结构都位于此
struct socket {
//...
struct file *file;
struct sock *sk;
//...
}
accept系统调用核心代码如下,主要分为四步即新建socket并初始化、初始化socket的VFS结构、接收连接(fd),最后添加新fd到当前进程的打开文件列表中
// https://elixir.bootlin.com/linux/v4.11.6/source/net/socket.c#L1470
// 返回一个新fd,用于后续客户端连接
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
//根据 fd 查找到监听的 socket
//这里的fd关联的是listen(socket)API 使用的那个fd
sock = sockfd_lookup_light(fd, &err, &fput_needed);
//申请并初始化新的 socket
// 注意sock_alloc函数的返回值为 struct socket * 类型
newsock = sock_alloc();
newsock->type = sock->type;
newsock->ops = sock->ops;
//申请新的 file 对象,并设置到新 socket 上
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
......
//接收连接
err = sock->ops->accept(sock, newsock, sock->file->f_flags);
//添加新文件fd到当前进程的打开文件列表fdtable中
//newfd为与客户端连接使用的fd
fd_install(newfd, newfile);
}
1、初始化 struct socket 对象,accept中首先是调用 sock_alloc 申请一个newsock(类型为 struct socket),然后接着把 listen 状态的 socket 对象上的协议操作函数集合 ops 赋值给新的 socket(对于所有的 AF_INET 协议族下的 socket 来说,它们的 ops 方法都是一样的)。其中 inet_stream_ops 的定义如下:
const struct proto_ops inet_stream_ops = {
......
.accept = inet_accept, //新连接接收
.listen = inet_listen,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
}
2、调用sock_alloc_file函数:为新 socket 对象申请 file(初始化struct socket的file成员),sock_alloc_file 又会调用 alloc_file对struct file结构进行初始化,注意在 alloc_file 方法中,把 socket_file_ops 函数集合设置到 file->f_op了,最后注意到在accept里创建的新 socket 里的 file->f_op->poll 函数指向的是 sock_poll TODO
struct file *sock_alloc_file(struct socket *sock, int flags,
const char *dname)
{
struct file *file;
// 调用alloc_file
file = alloc_file(&path, FMODE_READ | FMODE_WRITE,
&socket_file_ops);
......
// 将alloc的file对象挂到sock的file成员上
sock->file = file;
//......
}
//alloc_file
struct file *alloc_file(struct path *path, fmode_t mode,
const struct file_operations *fop)
{
struct file *file;
//注意在 alloc_file 方法中,把 socket_file_ops 函数集合一并赋到了新 file->f_op 中了
file->f_op = fop;
// file 对象的成员 socket 指针,指向 socket 对象
......
}
// file_operations的实例化:socket_file_ops
static const struct file_operations socket_file_ops = {
...
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
.poll = sock_poll, //核心:记住这个poll成员及对应的方法`sock_poll`
.release = sock_close,
...
};
3、接收连接的核心逻辑:sock->ops->accept(sock, newsock, sock->file->f_flags),对应的方法是 inet_accept,此函数执行时会从握手队列(全连接队列)里直接获取创建好的 sock 并关联与该 struct sock的关系
这里先回想下在三次握手最后阶段(服务端处理ACK包),服务端通过调用tcp_v4_syn_recv_sock->inet_csk_complete_hashdance->inet_csk_reqsk_queue_add将新连接加入到全连接队列中,那么对于accept,内核就需要把连接从全连接队列中取出来,并通知(应用层)来取
int inet_accept(struct socket *sock, struct socket *newsock, int flags, bool kern)
{
......
struct sock *sk1 = sock->sk;
//这里对应的是 inet_csk_accept
//https://elixir.bootlin.com/linux/v4.11.6/source/net/ipv4/inet_connection_sock.c#L427
struct sock *sk2 = sk1->sk_prot->accept(sk1, flags, &err, kern);
// 重要:struct sock与struct socket结构建立关联
sock_graft(sk2, newsock);
newsock->state = SS_CONNECTED;
//....
}
inet_accept 会调用 struct sock 的 sk1->sk_prot->accept,也即 tcp_prot 的 accept 函数即inet_csk_accept 函数,见下一小节
void sock_init_data(struct socket *sock, struct sock *sk)
{
sk->sk_wq = NULL;
//将sock 对象的 sk_data_ready 函数指针设置为 sock_def_readable
sk->sk_data_ready = sock_def_readable;
}
4、添加新文件到当前进程的打开文件列表中,当 file、socket、sock 等关键内核对象创建完毕以后,剩下要做的一件事情就是把它挂到当前进程的打开文件列表即完成
这里介绍下sockfd_lookup_light的实现,在accept系统调用中,参数fd指向的是listen的socket,该socket包含的VFS结构指向已经基本完整,所以从该函数的作用就是从进程->进程打开的fd->struct file->file.private_data拿到struct socket结构对象
static struct socket *sockfd_lookup_light(int fd, int *err, int *fput_needed){
struct fd f = fdget(fd);
struct socket *sock;
*err = -EBADF;
if (f.file) {
// call sock_from_file
sock = sock_from_file(f.file, err);
if (likely(sock)) {
*fput_needed = f.flags;
return sock;
}
fdput(f);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/net/socket.c#L489
static struct socket *sockfd_lookup_light(int fd, int *err, int *fput_needed)
{
struct fd f = fdget(fd);
struct socket *sock;
*err = -EBADF;
if (f.file) {
// 实际socket *是存储在file->private_data成员上
sock = sock_from_file(f.file, err);
if (likely(sock)) {
*fput_needed = f.flags;
return sock;
}
fdput(f);
}
return NULL;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/net/socket.c#L448
struct socket *sock_from_file(struct file *file, int *err){
if (file->f_op == &socket_file_ops)
return file->private_data; /* set in sock_map_fd */
//.....
}
accept 的核心逻辑:inet_csk_accept
inet_csk_accept主要实现了tcp协议accept操作,其主要功能是从已经完成三次握手的全连接队列(对于成员是struct inet_connection_sock的icsk_accept_queue成员)中取控制块,如果没有已经完成的连接,则需要根据(socket)阻塞标记来来区分对待,若非阻塞则直接返回,若阻塞则需要在一定时间范围内阻塞等待。这里有两个关键的子流程:
inet_csk_wait_for_connect:reqsk_queue_remove:
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern){
struct inet_connection_sock *icsk = inet_csk(sk);
// 获取全连接队列
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
......
/* 不是listen状态 */
if (sk->sk_state != TCP_LISTEN)
goto out_err;
/* 还没有已完成的连接 */
if (reqsk_queue_empty(queue)) {
/* 获取等待时间,非阻塞为0 */
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* If this is a non blocking socket don't sleep */
error = -EAGAIN;
/* 非阻塞立即返回错误 */
if (!timeo)
goto out_err;
/* 阻塞模式下等待连接到来 */
/*
如果请求队列中没有已完成握手的连接,
并且套接字已经设置了阻塞标记,
则需要加入调度队列等待连接的到来
*/
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
/* 从已完成连接队列中移除 */
req = reqsk_queue_remove(queue, sk);
/* 设置新控制块指针,如果没有错误newsk会被返回给调用方 */
newsk = req->sk;
/* TCP协议 && fastopen */
if (sk->sk_protocol == IPPROTO_TCP &&
tcp_rsk(req)->tfo_listener) {
spin_lock_bh(&queue->fastopenq.lock);
if (tcp_rsk(req)->tfo_listener) {
req->sk = NULL;
req = NULL;
}
spin_unlock_bh(&queue->fastopenq.lock);
}
out:
release_sock(sk);
/* 释放请求控制块 */
if (req)
reqsk_put(req);
/* 返回找到的连接控制块 */
return newsk;
}
inet_csk_wait_for_connect函数实现了当请求队列中没有已完成三次握手的连接,并且套接字已经设置了阻塞标记,则需要加入等待队列等待连接的到来,这又是一个很典型的内核等待队列的应用,核心代码如下:
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
int err;
//熟悉的循环
for (;;) {
/* 加入等待队列 */
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
release_sock(sk);
/* 如果全连接队列为空,说明还是等待的条件不满足,进行CPU切换调度,主动让出CPU */
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo); //进程第一调度定律
sched_annotate_sleep();
lock_sock(sk);
err = 0;
/* 走到这里说明进程已经被唤醒,重新拿到CPU的执行权,需要检查全连接队列不为空(等待的条件),如果满足即可退出等待队列*/
/* 这里唤醒方会把当前阻塞在等待队列上的task_struct移除,然后再唤醒 */
/* 所以解释了为何在for()循环开始要重新把进程加入到等待队列中 */
if (!reqsk_queue_empty(&icsk->icsk_accept_queue))
break;
err = -EINVAL;
/* 连接状态非LISTEN */
if (sk->sk_state != TCP_LISTEN)
break;
/* 信号打断 */
err = sock_intr_errno(timeo);
if (signal_pending(current))
break;
err = -EAGAIN;
/* 调度超时也需要退出等待 */
if (!timeo)
break;
}
/* 结束等待 */
/* sk_sleep(sk) 的作用是获取sk的等待队列头 */
finish_wait(sk_sleep(sk), &wait);
return err;
}
reqsk_queue_remove函数作用是将完成三次握手的控制块从请求队列移除:
static inline struct request_sock *reqsk_queue_remove(struct request_sock_queue *queue,
struct sock *parent)
{
struct request_sock *req;
/* 需要加锁 */
spin_lock_bh(&queue->rskq_lock);
/* 找到队列头 */
req = queue->rskq_accept_head;
if (req) {
/* 减少已连接计数 */
sk_acceptq_removed(parent);
/* 头部指向下一节点 */
queue->rskq_accept_head = req->dl_next;
/* 队列为空 */
if (queue->rskq_accept_head == NULL)
queue->rskq_accept_tail = NULL;
}
spin_unlock_bh(&queue->rskq_lock);
return req;
}
struct sock创建的区别(TODO)
void sock_init_data(struct socket *sock, struct sock *sk)
{
if (sock) {
sk->sk_type = sock->type;
sk->sk_wq = sock->wq;
sock->sk = sk;
sk->sk_uid = SOCK_INODE(sock)->i_uid;
} else {
sk->sk_wq = NULL;
sk->sk_uid = make_kuid(sock_net(sk)->user_ns, 0);
}
}
0x09 数据传输
回到tcp_v4_rcv->tcp_v4_do_rcv的处理过程中,数据接收的核心逻辑位于tcp_rcv_established函数
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
struct dst_entry *dst = sk->sk_rx_dst;
sock_rps_save_rxhash(sk, skb);
sk_mark_napi_id(sk, skb);
if (dst) {
if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif ||
!dst->ops->check(dst, 0)) {
dst_release(dst);
sk->sk_rx_dst = NULL;
}
}
tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len);
return 0;
}
......
}
tcp_rcv_established
tcp_rcv_established的逻辑比较复杂,其核心逻辑是通过快速路径(Fast Path) 和 慢速路径(Slow Path)的分流机制优化数据处理效率,首先了解下:
tcp_queue_rcv:负责将数据包加入接收队列tcp_data_queue:TODO
在tcp_rcv_established中可以看到数据成功接收时唤醒逻辑,大致为数据入队后立即调用 sk_data_ready 回调函数:
eaten = tcp_queue_rcv(.......); // 数据入队
sk->sk_data_ready(sk, 0); // 触发唤醒
这里的sk->sk_data_ready(......)在同步阻塞模式以及epoll IO多路复用模式下的机制是不同的,见文末分析
fast path VS slow path
TODO
void tcp_rcv_established(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th, unsigned int len)
{
struct tcp_sock *tp = tcp_sk(sk);
if (unlikely(!sk->sk_rx_dst))
inet_csk(sk)->icsk_af_ops->sk_rx_dst_set(sk, skb);
tp->rx_opt.saw_tstamp = 0;
if ((tcp_flag_word(th) & TCP_HP_BITS) == tp->pred_flags &&
TCP_SKB_CB(skb)->seq == tp->rcv_nxt &&
!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt)) {
int tcp_header_len = tp->tcp_header_len;
/* Check timestamp */
if (tcp_header_len == sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) {
/* No? Slow path! */
if (!tcp_parse_aligned_timestamp(tp, th))
goto slow_path;
if ((s32)(tp->rx_opt.rcv_tsval - tp->rx_opt.ts_recent) < 0)
goto slow_path;
}
if (len <= tcp_header_len) {
/* Bulk data transfer: sender */
if (len == tcp_header_len) {
if (tcp_header_len ==
(sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) &&
tp->rcv_nxt == tp->rcv_wup)
tcp_store_ts_recent(tp);
tcp_ack(sk, skb, 0);
__kfree_skb(skb);
tcp_data_snd_check(sk);
return;
} else { /* Header too small */
TCP_INC_STATS(sock_net(sk), TCP_MIB_INERRS);
goto discard;
}
} else {
int eaten = 0;
bool fragstolen = false;
if (tp->ucopy.task == current &&
tp->copied_seq == tp->rcv_nxt &&
len - tcp_header_len <= tp->ucopy.len &&
sock_owned_by_user(sk)) {
__set_current_state(TASK_RUNNING);
if (!tcp_copy_to_iovec(sk, skb, tcp_header_len)) {
if (tcp_header_len ==
(sizeof(struct tcphdr) +
TCPOLEN_TSTAMP_ALIGNED) &&
tp->rcv_nxt == tp->rcv_wup)
tcp_store_ts_recent(tp);
tcp_rcv_rtt_measure_ts(sk, skb);
__skb_pull(skb, tcp_header_len);
tcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq);
NET_INC_STATS(sock_net(sk),
LINUX_MIB_TCPHPHITSTOUSER);
eaten = 1;
}
}
if (!eaten) {
if (tcp_checksum_complete(skb))
goto csum_error;
if ((int)skb->truesize > sk->sk_forward_alloc)
goto step5;
if (tcp_header_len ==
(sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) &&
tp->rcv_nxt == tp->rcv_wup)
tcp_store_ts_recent(tp);
tcp_rcv_rtt_measure_ts(sk, skb);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPHPHITS);
/* Bulk data transfer: receiver */
eaten = tcp_queue_rcv(sk, skb, tcp_header_len,
&fragstolen);
}
tcp_event_data_recv(sk, skb);
if (TCP_SKB_CB(skb)->ack_seq != tp->snd_una) {
/* Well, only one small jumplet in fast path... */
tcp_ack(sk, skb, FLAG_DATA);
tcp_data_snd_check(sk);
if (!inet_csk_ack_scheduled(sk))
goto no_ack;
}
__tcp_ack_snd_check(sk, 0);
no_ack:
if (eaten)
kfree_skb_partial(skb, fragstolen);
sk->sk_data_ready(sk);
return;
}
}
slow_path:
if (len < (th->doff << 2) || tcp_checksum_complete(skb))
goto csum_error;
if (!th->ack && !th->rst && !th->syn)
goto discard;
if (!tcp_validate_incoming(sk, skb, th, 1))
return;
step5:
if (tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT) < 0)
goto discard;
tcp_rcv_rtt_measure_ts(sk, skb);
/* Process urgent data. */
tcp_urg(sk, skb, th);
/* step 7: process the segment text */
tcp_data_queue(sk, skb);
tcp_data_snd_check(sk);
tcp_ack_snd_check(sk);
return;
csum_error:
TCP_INC_STATS(sock_net(sk), TCP_MIB_CSUMERRORS);
TCP_INC_STATS(sock_net(sk), TCP_MIB_INERRS);
discard:
tcp_drop(sk, skb);
}
tcp_queue_rcv函数
tcp_queue_rcv函数的主要作用是:
- 数据包合并优化:尝试将新收到的 skb 与接收队列尾部的 skb 合并(通过
tcp_try_coalesce),减少内存碎片和复制开销 - 队列尾部插入,若无法合并(
eaten = 0),则调用__skb_queue_tail()将 skb 加入sk->sk_receive_queue即sock的接收队列的尾部 - 更新接收序号:调用
tcp_rcv_nxt_update()更新下一个期望接收的 TCP 序列号
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb, int hdrlen,
bool *fragstolen)
{
int eaten;
struct sk_buff *tail = skb_peek_tail(&sk->sk_receive_queue);
__skb_pull(skb, hdrlen);
eaten = (tail &&
tcp_try_coalesce(sk, tail, skb, fragstolen)) ? 1 : 0;
tcp_rcv_nxt_update(tcp_sk(sk), TCP_SKB_CB(skb)->end_seq);
if (!eaten) {
__skb_queue_tail(&sk->sk_receive_queue, skb);
skb_set_owner_r(skb, sk);
}
return eaten;
}
0x0A 总结
socket VS accept
在分析三次握手源码时产生的疑问:socket系统调用创建struct socket结构,与accept系统调用创建的struct socket结构,作用上有哪些不同?
1、监听套接字(socket)的核心功能是管理连接,而非数据传输。当用户调用 socket() 创建套接字时(如监听套接字),内核会通过sock_init_data初始化 struct sock的核心队列,包括:
- 接收队列(
sk_receive_queue):用于存储接收到的数据包(sk_buff),但监听套接字本身不使用此队列传输数据 - 发送队列(
sk_write_queue):缓存待发送数据,监听套接字通常不主动发送数据 - 等待队列(
sk_sleep):管理因 I/O 事件(如accept()阻塞)而休眠的进程
同时设置回调函数(如 sk_data_ready = sock_def_readable),用于数据到达(主要是有新连接到达时)时唤醒进程
2、通过 accept() 创建的新套接字关联的 struct sock 是三次握手期间内核已经创建的(非 accept() 新建),其队列作用完全不同,主要过程描述如下:
- 新建连接的
struct sock在握手完成时创建,并加入监听套接字的icsk_accept_queue即全连接队列,accept()函数仅将其取出,并与新struct socket结构绑定 - 此接收队列(
sk_receive_queue)的核心作用是存储客户端发送的数据包,用户调用recv()时从此队列读取数据 - 发送队列(
sk_write_queue)的作用是缓存待发送给客户端的数据,由协议栈逐步发送 - 等待队列(
sk_sleep)会管理因recv()或send()阻塞的进程(如缓冲区空/满时)
因此在accept()系统调用新建的struct socket并关联的struct sock结构对应的队列是作为数据传输的载体,这些队列是实际数据收发的核心通道,与监听套接字的预留队列有本质区别
唤醒机制:同步阻塞 VS epoll
在前文描述了sock结构体时,介绍了两个关键成员:sk_wq(套接字等待队列)和sk_data_ready(数据就绪回调函数),这二者共同完成了内核管理I/O事件的核心机制,下面梳理下在同步阻塞I/O和epoll多路复用场景的区别
struct socket_wq sk_wq:即socket/sock的等待队列头,用于管理因等待I/O事件(如数据到达)而阻塞的进程或回调项;这个成员在同步阻塞模式中存储用户进程的等待项wait_queue_t结构;在epoll模式中存储epoll注册的回调项(epoll模式中又分为listenfd与acceptfd两种)sk_data_ready:函数指针,默认指向sock_def_readable的内核实现,当数据到达套接字接收队列(sk_receive_queue)时、或者TCP三次握手完成时被调用,用于触发事件通知,其核心行为是检查sk_wq并唤醒其中的等待项
1、同步阻塞场景下的等待与唤醒机制:进程直接挂起
举例来说,当用户进程调用recv()且无数据可读时,内核会将当前被阻塞的进程加入sock的sk_wq队列,然后内核通过DEFINE_WAIT创建等待项,其.private成员会指向当前进程,.func成员会被设置为autoremove_wake_function(即唤醒后移除),接着调用add_wait_queue将该等待项插入sk_wq,完成后内核会将该进程状态设为TASK_INTERRUPTIBLE并让出CPU(发生第一次上下文切换)
当数据到达时的唤醒流程是,软中断处理数据包 -> 放入sk_receive_queue -> 调用sk_data_ready(sk),即调用sock_def_readable,默认的sock_def_readable的步骤是先检查(遍历)sk_wq的等待项队列,调用等待项的.func(autoremove_wake_function)-> 直接唤醒进程并移出队列(又发生了一次上下文切换)
所以从上述步骤可以了解,这种模式由于要进行两次进程上下文切换(挂起+唤醒),每次耗时3–5μs,单进程仅能处理一个连接,性能较差
// 默认回调函数 sock_def_readable 的实现
// 事件触发:协议栈调用 sk_data_ready(sk)
static void sock_def_readable(struct sock *sk) {
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq); // 获取 sk_wq 队列
if (wq_has_sleeper(wq)) { // 队列检查:检查 sk_wq 中是否有阻塞进程
// 唤醒操作:唤醒队列中的进程(POLLIN 表示可读事件)
// 遍历 sk_wq 中的等待项,执行其回调函数(如 autoremove_wake_function)唤醒进程
// 唤醒策略:传入参数 nr_exclusive=1,表示仅唤醒一个进程(避免惊群效应)
wake_up_interruptible_sync_poll(&wq->wait, POLLIN | POLLPRI);
}
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN); // 发送异步信号(如 SIGIO)
rcu_read_unlock();
}
2、epoll I/O多路复用场景下的等待唤醒机制:事件驱动与回调转发
epoll通过改造sk_wq和sk_data_ready的协作实现高效多路复用,步骤拆解如下
- epoll注册改造
sk_wq:epoll_ctl(EPOLL_CTL_ADD)为每个socket添加特殊等待项,即.private = NULL(不关联进程)以及.func = ep_poll_callback(epoll自定义回调),此等待项通过eppoll_entry结构关联到epoll的红黑树节点epitem - 数据到达触发epoll回调:当数据就绪时,内核仍然会调用
sk_data_ready,随后步骤调用sock_def_readable-> 遍历sk_wq-> 执行ep_poll_callback
而ep_poll_callback的核心步骤为:
- 将就绪的
epitem加入epoll就绪队列rdllist - 检查
eventpoll自身的等待队列,唤醒因epoll_wait阻塞的用户进程 - 用户进程被唤醒后,批量处理就绪事件:
epoll_wait从rdllist获取所有就绪事件,仅需一次系统调用即可处理海量连接 - 在高并发场景下,epoll_wait机制会持续占用CPU达到处理高并发请求的场景,性能非常高
小结下,从内核的这种解耦与分层设计来看,保证了sk_data_ready的统一性,无论何种模式,数据到达时均调用同一回调,但根据sk_wq的内容动态适配行为,对同步阻塞模式是唤醒进程->进程主动读数据,对epoll模式是触发回调 -> 事件入队 -> 用户进程批量处理,sk_wq与sk_data_ready的关系本质是事件发布-订阅模型,同步阻塞模式下是进程直接订阅,导致高开销,而epoll通过回调中转和事件批量交付,实现高性能IO多路复用
- 订阅者:
sk_wq管理订阅该事件的实体(进程或epoll实例),作为事件订阅中心,隔离内核协议栈与上层模型 - 发布者:
sk_data_ready在数据到达时发布事件