0x00 前言
前文介绍过内核的虚拟内存管理的基础知识,本文继续学习下Linux内核下的页表机制
虚拟内存是 CPU 和内核使用的一个障眼法,让进程误以为自己独占了全部的内存空间(对进程而言,它们各自看到的虚拟内存空间地址范围都是一样的)。如此内核为每个进程营造出一片独立的虚拟地址空间,使得进程与进程之间相互隔离,解决了多进程同时运行时产生的内存地址冲突问题。比如在 32 位系统中,进程以为自己独占了 3G 的内存空间,而在 64 位系统中,进程以为自己独占了 128T 的内存空间
当程序运行起来就变成了进程,在进程的视角里这些业务数据结构的引用(访问)全都都是虚拟内存地址,因为进程无论是在用户态还是在内核态能够看到的都是虚拟内存空间,物理内存空间被操作系统所屏蔽进程是看不到的,但当程序运行起来之后,程序中所需要的数据本质上还是保存在物理内存中的,即最终虚拟内存空间中每一个虚拟内存地址都是要映射到物理内存空间的中某一个特定物理内存地址上。进程虚拟内存空间中的每一个字节都有与其对应的虚拟内存地址,同样物理内存空间中每一个字节都有与其对应的物理内存地址(不然为什么叫虚拟内存)
- 在内存模型中,哪些是虚拟内存(概念),哪些是物理内存(概念)
0x01 基础知识
物理内存页 VS 虚拟内存页
1、物理内存页:内核管理物理内存的最小单位(通常为 4KB)
内核会将整个物理内存空间划分为一页页大小相同的的内存块(每个内存块大小为 4K),即物理内存页。一页大小的内存块在内核中用 struct page 来进行管理,struct page 中封装了每页内存块的状态信息,参考。内核会为每个物理内存页 page 进行统一编号(Page Frame Number,PFN),PFN 与 struct page 是一一对应的关系并且全局唯一
2、虚拟内存页:多级页表项(无单一结构体)
虚拟内存页没有独立的结构体,其映射关系通过页表层级结构描述,由硬件架构相关的页表项(Page Table Entry, 即PTE)管理
虚拟内存与物理内存的映射以及调度均是以页为单位进行的(通常单位大小都是4K)
物理内存地址/用户态虚拟内存地址/内核态虚拟内存地址
1、物理内存地址:内存硬件(RAM芯片)的实际电路单元位置,由地址总线直接寻址。使用场景举例:
- 内核态场景:DMA操作网卡、磁盘控制器等外设需直接读写物理内存,内核需提供物理内存地址
- 用户态:无法直接访问,用户进程无法操作物理地址,否则触发段错误(
SIGSEGV)
2、用户态虚拟内存地址:os为每个进程分配的私有虚拟内存地址空间(如32位系统为0~3GB),通过页表映射到物理内存。使用场景举例:
- 用户态场景:进程私有数据访问时,如代码段、堆、栈、全局变量等均通过用户虚拟内存地址访问(如
malloc()返回的地址),此外,在访问未初始化的malloc内存时,内核会按需分配物理页,即首次访问虚拟内存地址时触发缺页异常,内核分配物理页并更新页表 - 内核态场景:如系统调用
read()实现数据拷贝时,需将数据从内核缓冲区拷贝到用户虚拟地址,参考copy_to_user()函数
3、内核态虚拟内存地址,内核专属的虚拟地址空间,所有进程共享同一内核空间映射,以32位系统举例,内核虚拟内存地址范围为3~4GB
- 内核态分为直接映射区(
0~896MB)和动态映射区(896MB以上),其中对于直接映射区,内核代码、数据结构等通过线性映射(__va()快速转换物理地址)访问物理内存;而动态映射区通常用于高端内存管理和设备寄存器访问,高端内存管理指通过kmap()或vmalloc()临时映射ZONE_HIGHMEM的物理页(如大文件I/O缓冲区),设备寄存器访问指使用ioremap()将硬件物理地址映射到内核虚拟地址 - 用户态:对于内核态虚拟内存地址禁止访问,用户进程访问内核虚拟地址会触发权限错误(
SIGSEGV)
虚拟内存页的类型

如上图:
- 未分配页面(灰):进程的虚拟内存空间size远超物理内存空间,进程对虚拟内存的使用也是需要向内核申请的(如
mmap)。进程虚拟内存空间中的虚拟内存页在未被进程申请之前的状态就是未分配页面 - 已分配未映射页面(紫):在进程中可以通过glibc的
malloc或者直接通过系统调用mmap向内核申请虚拟内存,申请到的虚拟内存页此时就变为了已分配的页面。但此时的虚拟内存页只是虚拟内存,还未与物理内存建立映射 - 正常页面(绿):当进程开始读写这些已分配未映射的虚拟内存页时,在 CPU 中用于地址翻译的硬件 MMU 会产生一个缺页中断,随后内核会为其分配相应的物理内存页面,并将虚拟内存页与物理内存页映射起来。此时进程就可以正常读写这些虚拟内存页
FROM 虚拟内存 TO 物理内存:映射关系的管理
虚拟内存跟物理内存要如何对应?让虚拟地址能够索引到物理内存单元,但是虚拟地址和物理地址显然不能一一对应,因此需要在虚拟地址空间与物理地址空间之间加一个类似的转换函数p=f(v),该函数传入一个虚拟内存地址,它就能返回一个物理地址。此外,对于没法计算的地址或者没有权限的地址,还能返回一个禁止访问。这个函数对应的硬件就是 CPU 中的 MMU(内存管理单元),可以简单理解,为了高效对虚拟地址和物理地址转换,MMU 使用一个地址转换表
这个地址转换表就是页表,页表本质也是一个物理内存页(当然要存储在内存中),只不过这个物理内存页比较特殊,里面存放的是 PTE(Page Table Entry),用于保存虚拟内存与物理内存的映射关系。既然它是一个普通的物理内存页,那么也会参与内核的调度,既会被内核 swap in 以及 swap out,也会被缓存在 CPU 高速缓存中加速访问
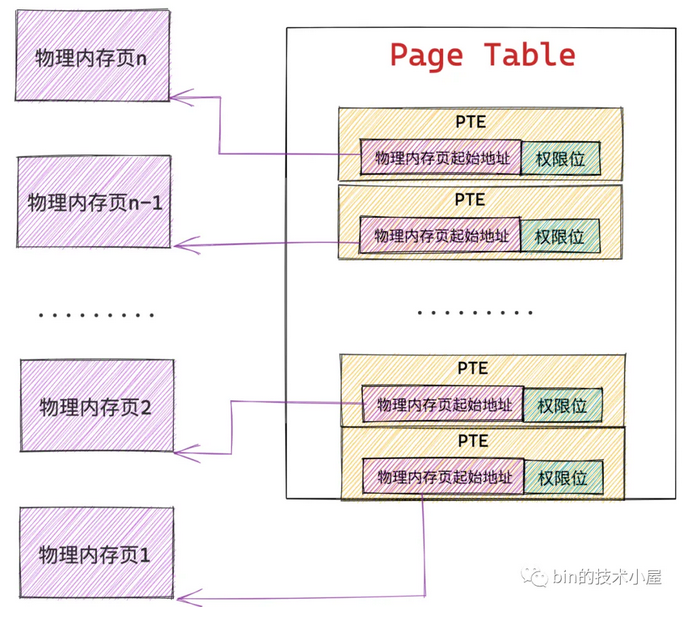
PTE(Page Table Entry)
内核会在页表中划分出来一个个大小相等的小内存块,即页表项 PTE(Page Table Entry),PTE 保存了进程虚拟内存空间中的虚拟页与物理内存页的映射关系,以及控制物理内存访问的相关权限位,通常在 32 位系统中页表中的 PTE 占用 4byte ,64 位系统中页表的 PTE 占用 8byte,因为内存映射的粒度是按照页为单位进行的,所以进程虚拟内存空间中的每个虚拟页在页表中都会有一个 PTE 与之对应,而虚拟页背后映射的物理内存页的起始地址就保存在 PTE 中
虚拟内存地址
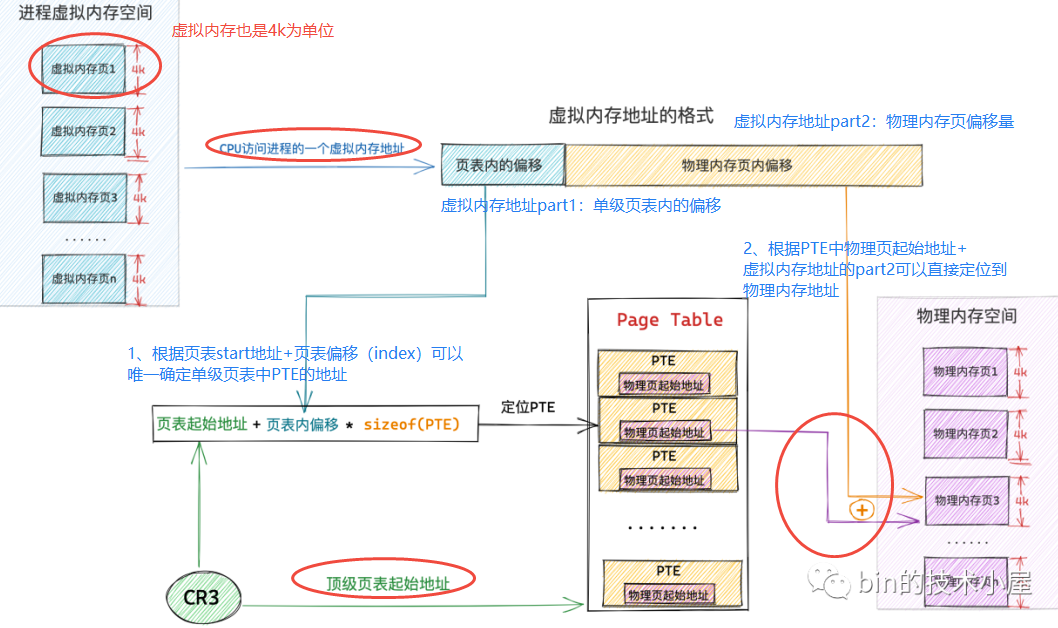
虚拟内存地址(比如64位内核,内核空间虚拟地址ffffffff8101bd40、用户空间虚拟地址0x7fffa9b07c14)的意义是什么?进程虚拟内存空间中的每一个字节都有一个虚拟内存地址来表示,格式为页表内偏移 + 物理内存页内偏移,进程虚拟内存空间中的每一个虚拟页在页表中都会有一个 PTE 与之对应,专门用来存储该虚拟页背后映射的物理内存页的起始地址
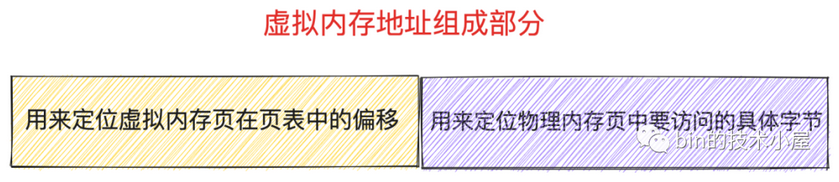
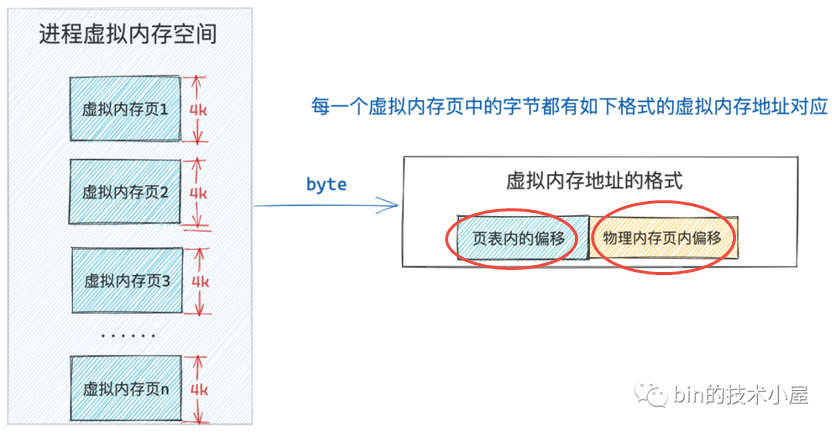
虚拟内存地址格式中的页表内偏移就是专门用来定位虚拟内存页在页表中的 PTE 的,因为页表本质其实还是一个物理内存页,而一个物理内存页里边的内存肯定都是连续的,每个 PTE 的尺寸又是相同的,所以可以把页表看做一个数组,PTE 看做数组里的元素,在数组中定位元素直接通过数组索引 index 即可,这个索引 index 就称为页表内偏移
这样一来,CPU要访问某个虚拟内存地址,内核会先从这个虚拟内存地址中提取出页表内偏移,然后根据页表起始地址 + 页表内偏移 * sizeof(PTE) 就能获取到该虚拟内存地址所在虚拟页在页表中对应的 PTE 了
TODO:虚拟内存地址的可表示上限
PDE
页表的分类
而 CPU 无论是在用户态还是在内核态,访问的均是虚拟内存地址,不管是用户空间的虚拟内存地址还是内核空间的虚拟内存地址最终都是要与物理内存进行映射的,即虚拟内存与物理内存的映射关系是通过页表来管理的
- 进程用户态页表:主要负责管理进程用户态虚拟内存空间到物理内存的映射关系
- 内核态页表:主要负责管理内核态虚拟内存空间到物理内存的映射关系,主要供内核使用
//内核态虚拟内存空间的定义:struct mm_struct 结构
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
一些核心概念
- 页表本质上是一个物理内存页(无论是几级页表体系),只不过页表中存放的是 PTE,保存虚拟内存与物理内存的映射关系。既然它是一个普通的物理内存页,那么也会参与内核的调度,既会被内核 swap in 以及 swap out,也会被缓存在 CPU 高速缓存中加速访问
- 在
32位系统中,一个 PTE 占用4byte,可以映射4K的物理内存,一张页表本身占用4K的物理内存,可以映射4M的物理内存;在64位系统中,一个 PTE 占用8byte,不过要视页表的级别来计算其可以映射物理内存的size - 定位虚拟内存页在进程页表中对应的 PTE 是通过数组的访问方式进行的,虚拟内存地址中包含了其对应的 PTE 在页表中的偏移(页表数组中的 index),所以这就要求每一级页表(内的PTE)都必须是连续的,比如单级页表中
1024张页表必须是连续的物理内存(4M) - 进程对系统内存的访问具有明显的局部性,在任意时刻只需要为进程分配很少的内存就能保证进程的正常运行
0x01 寻址过程(基础)
以单级页表为例,CPU访问虚拟内存地址的过程
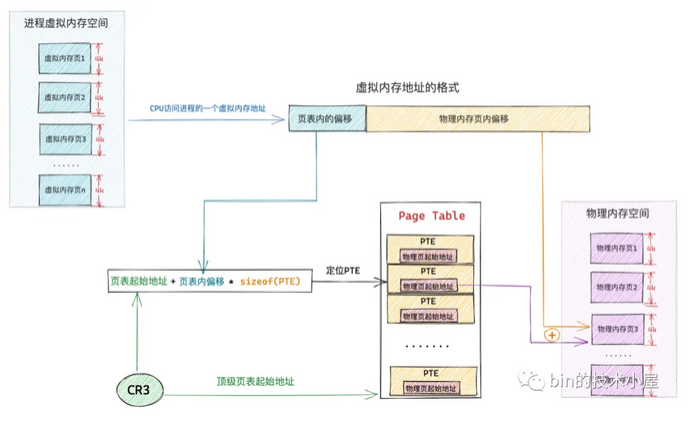
1、无论是几级页表,它们通过虚拟内存寻址的本质就是定位虚拟内存页对应在页表中的 PTE,然后通过 PTE 找到其映射的具体物理内存页
2、页表的本质是一个物理内存页(4K),其中包含了 1024 个 PTE,每个 PTE 可以映射一个具体的物理内存页,PTE 中保存了物理内存页的起始地址,进程地址空间中的一个虚拟内存页对应页表中的一个 PTE。因为在内核中是按照页为单位进行内存映射的
3、在单级页表体系下,1024 张一级页表背后是通过连续的 4M 物理内存保存的,通过单级页表的起始物理内存地址配合虚拟内存页对应 PTE 在单级页表(1024 张一级页表)中的 index,可以直接定位到 PTE(单级页表起始物理内存地址指的是 1024 张一级页表中,第一张页表的起始物理内存地址)
4、cr3 寄存器保存了顶级页表(本例指单级页表)的起始物理内存地址,顶级页表随着进程的创建而创建,保存在进程结构 mm_struct->pgd,当进程被 CPU 调度的时候,会伴随着进程上下文切换,其中就会将 mm_struct->pgd 转换为物理内存地址并加载到 cr3 寄存器
5、无论在几级页表体系下,进程虚拟内存空间中的虚拟内存地址格式在设计上总共分为两大部分,一部分是用来定位虚拟内存页在页表中对应的 PTE 偏移,另一部分是用来定位物理内存页中要访问的具体字节
6、通过单级页表的起始物理内存地址(保存在 cr3 寄存器)以及虚拟内存页在单级页表中对应 PTE 的偏移(保存在虚拟内存地址),通过页表起始地址 + 页表内偏移 * sizeof(PTE) 就可定位到虚拟内存页对应的 PTE 了,而 PTE 中保存了映射物理内存页的起始地址,再加上虚拟内存地址中保存的物理内存页内偏移,这样就可以定位到虚拟内存地址对应的物理字节了
0x02 内核态的页表
内核线程(始终工作在内核空间中)与普通进程不同,内核线程只能运行在内核态,而在内核态中,所有进程看到的虚拟内存空间全部都是一样的,所以对于内核线程来说并不需要为其单独的定义 mm_struct 结构来描述内核虚拟内存空间,内核线程的 struct task_struct 结构中的 mm 为 NULL,内核线程之间调度是不涉及地址空间切换的,从而避免了无用的 TLB 缓存以及 CPU 高速缓存的刷新
0x03 (单)多级页表
前面已经介绍了页表的若干基础概念,本小节介绍下单级、多级页表的设计,其中典型如32位机器的二级页表,64位机器的四级页表
- 页表的本质其实就是一个物理内存页(即一张页表
4K大小),如在32bit系统中,页表中的一个 PTE 占用4B大小,所以一张页表可以容纳1024个 PTE,即一张页表可以映射1024 * 4K = 4M大小的物理内存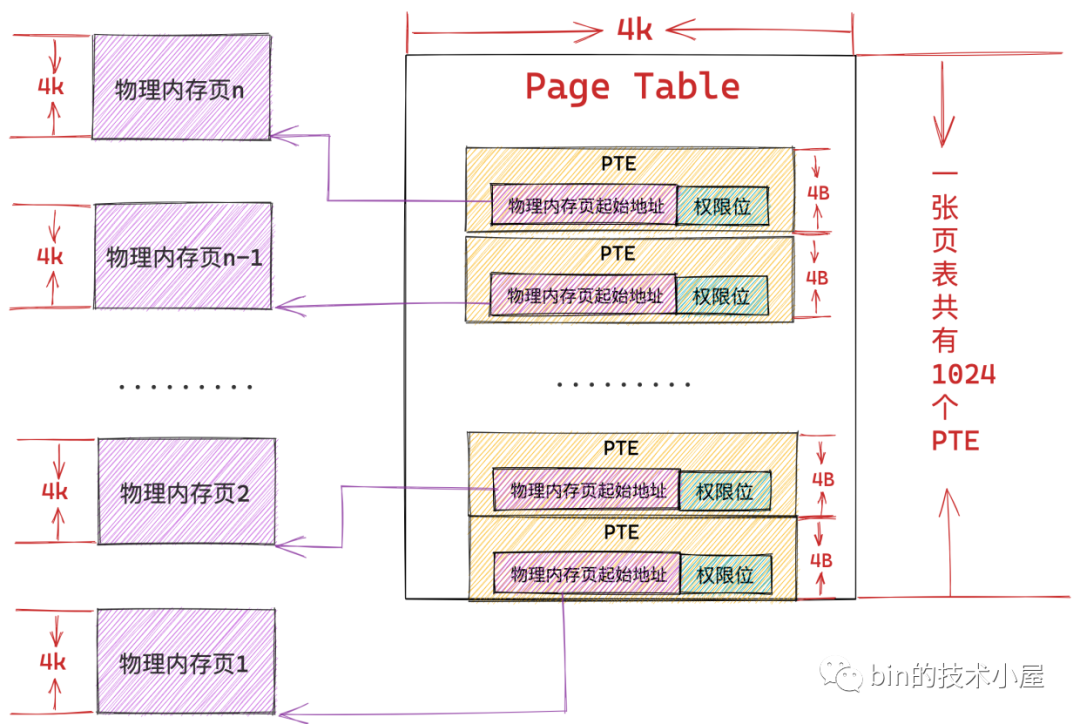
单级页表下的寻址过程
单级页表的局限性
根据上文了解到,在进程中虚拟内存与物理内存的映射是以页为单位的,进程虚拟内存空间中的一个虚拟内存页映射物理内存空间的一个物理内存页,这种映射关系以及访存权限都保存在 PTE 中,所以进程中的一个虚拟内存页对应页表中的一个 PTE,一个 PTE 能够映射 4K 的物理内存,一张页表可以映射 1024 * 4K = 4M 的物理内存。即对单个进程而言,如果需要访问4M大小的内存,那么需要用额外的4K物理内存(一个页表占用)来映射这4M的物理内存(总占用量是4M+4K)
假设系统中有 4G 的物理内存,那么需要 1024 张页表来映射,一张页表占用 4K 物理内存,并且为了映射这 4G 物理内存,额外需要 1024*4K=4M 的物理内存(即1024张页表)来映射。此外,这 4M 物理内存(1024张页表)必须是连续的,由于是单级页表(页表相当于是 PTE 的数组),进程虚拟内存空间中的一个虚拟内存页对应一个 PTE,而 PTE 在页表这个数组中的索引 index 就保存在虚拟内存地址中,内核通过页表的起始地址加上这个索引 index 才能定位到虚拟内存页对应的 PTE,进而通过 PTE 定位到映射的物理内存页
进一步说,因为进程的虚拟内存空间都是独立的,页表也是独立的,一个进程就需要额外的 4M 连续物理内存来支持进程内独立的内存映射关系。那么 100 个进程就需要额外的 400M 连续的物理内存,这是极大的浪费(根据程序局部性原理,某一个特定的时刻,进程只需要很少的物理内存就可以正常运转,那么进程虚拟内存与物理内存之间的映射关系相应也会很少,根本就不需要 4M 的物理内存来保存映射关系)
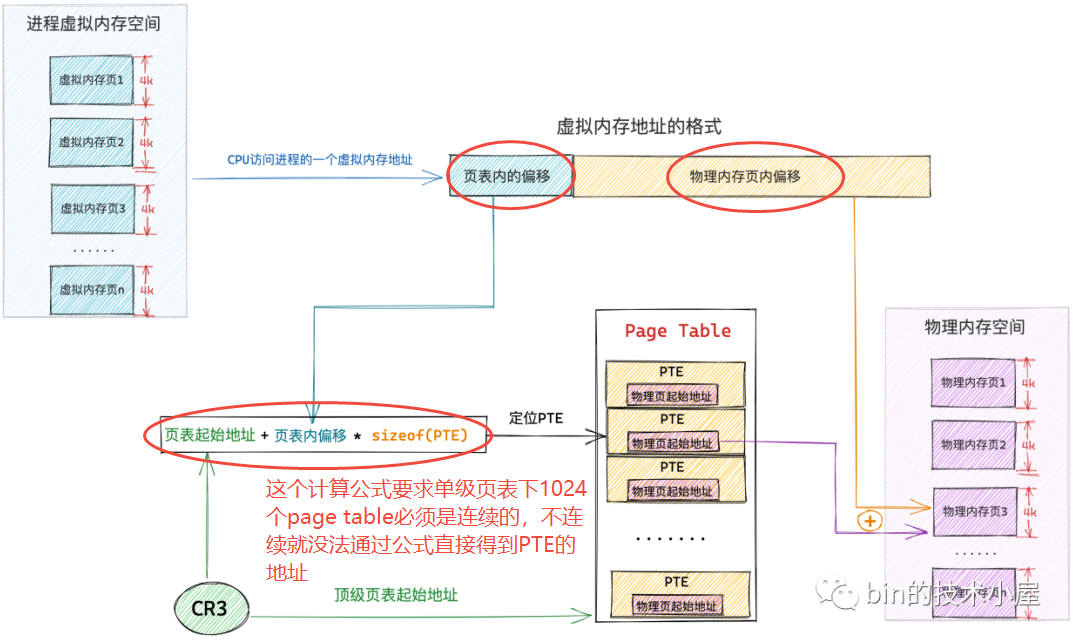
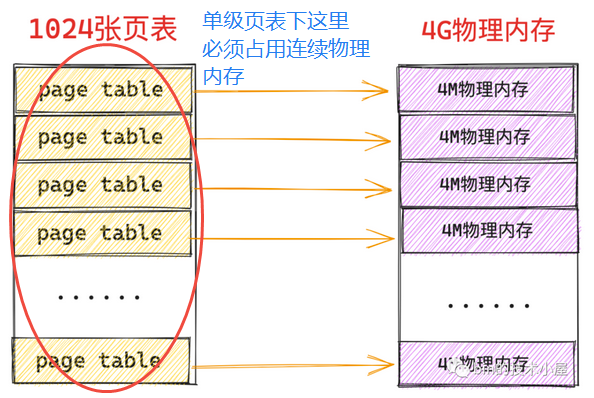
所以,可以采取分级的机制来避免因连续性要求的单级页表本身造成的资源浪费
多级页表
下图说明了多级页表体系下,如何避免一级页表的连续性要求导致的浪费
CPU 提供 MMU(内存管理单元),MMU 使用一个地址转换表,但是它做很多优化和折中处理,这个地址转换表就是多级页表,这里页表特性如下:
- MMU 对虚拟地址空间和物理地址空间进行分页处理
- MMU 采用的多级页表,其中只会对应物理页地址,不会储存虚拟地址,而是将虚拟地址作为页表索引,这进一步缩小了页表的大小
- 虚拟内存页和物理内存页是同等大小的,都为
4KB,各级页表占用的空间也是一个页,即为4KB。MMU 把虚拟地址分为5个位段,各位段的位数根据实际情况有所不同,按照这些位段的数据来索引各级页表中的项,一级一级往下查找,直到页表项,最后用页表项中的地址加页内偏移,就得到了物理地址
页表起始地址(CR3寄存器)
cr3 是 CPU 的一个寄存器,它会指向当前进程的顶级 pgd。如果 CPU 的指令要访问进程的虚拟内存,它就会自动从cr3 里面得到 pgd 在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。需要注意如下:
- cr3 寄存器存放的地址是物理内存地址,cr3 里面存放当前进程的顶级 pgd,这个是硬件的要求,cr3 里面需要存放 pgd 在物理内存的地址,不能是虚拟地址
- 用户进程在运行的过程中,访问虚拟内存中的数据,会被 cr3 里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态,即不需要切换
- cr3 的核心作用是为内存管理单元(MMU)提供查找页表的起点。在分页机制启动的初始阶段,MMU 还没有任何虚拟地址到物理地址的映射信息可用。它需要一个绝对可靠的、不依赖于任何地址转换的物理位置来找到第一级页表
- 类比:想象一下要在一座巨大的图书馆(物理内存)里找一本书(数据),但你只有这本书的虚拟书架号(虚拟地址)。你需要一个目录(页表)来把虚拟书架号转换成实际的物理位置。cr3 存放的就是这个目录本身在图书馆里存放的实际物理位置(物理地址)
CR3 寄存器的工作原理如下:
1、CPU 生成虚拟地址,当 CPU 执行指令需要访问内存(读取指令、读写数据)时,它生成一个虚拟地址。这个地址是程序看到的逻辑地址空间的一部分
2、MMU 介入 - 获取 CR3
- MMU 接收到 CPU 发出的虚拟地址
- MMU 首先读取当前 CPU 的 CR3 寄存器的值。这个值是一个物理地址,指向当前进程使用的顶级页表(在
64位模式下通常是 PML4 表)的基地址
3、多级页表查找过程,MMU 利用虚拟地址的不同部分作为索引,逐级查找页表,这里分不同架构说明。每一级页表条目都包含下一级页表的物理基地址(或最终页面的物理基地址)以及重要的控制位(如存在位、读写权限位、用户/内核位等)
4、64 位模式 (四级页表):
- PML4 (Page Map Level 4):使用虚拟地址的 bits
47:39作为索引,在 CR3 指向的 PML4 表中找到对应的 PML4 条目(PML4E) - PDPT (Page Directory Pointer Table):PML4E 包含下一级页表(PDPT)的物理基地址。使用虚拟地址的 bits
38:30作为索引,在 PDPT 中找到对应的 PDP 条目(PDPE) - PD (Page Directory): PDPE 包含下一级页表(PD)的物理基地址。使用虚拟地址的 bits
29:21作为索引,在 PD 中找到对应的页目录条目(PDE) - PT (Page Table): PDE 包含最后一级页表(PT)的物理基地址。使用虚拟地址的 bits
20:12作为索引,在 PT 中找到对应的页表条目(PTE)
5、32 位模式 (二级页表)
- PD (Page Directory): CR3 直接指向页目录(PD)的物理基地址。使用虚拟地址的 bits
31:22作为索引,在 PD 中找到对应的页目录条目(PDE) - PT (Page Table):PDE 包含页表(PT)的物理基地址。使用虚拟地址的 bits
21:12作为索引,在 PT 中找到对应的页表条目(PTE)
6、获取物理页帧地址,最终找到的页表条目(PTE)包含了目标数据所在的物理内存页(页帧)的基地址(物理页号)。这个基地址通常是物理地址的高位部分(例如,在 4KB 页大小下,PTE 提供 bits 51:12,低 12 位为 0)
7、合成最终物理地址,MMU 将 PTE 提供的物理页帧基地址(高位)与原始虚拟地址中的页内偏移量(低位,例如在 4KB 页大小下是 bits 11:0)组合起来,形成最终的物理内存地址
8、访问物理内存
- MMU 将这个计算出的物理地址发送到内存总线
- 物理内存控制器根据这个物理地址访问实际的 RAM,完成数据的读取或写入操作
9、权限检查与异常处理。在查找页表的每一步,MMU 都会检查相应页表条目中的权限位(如存在位 P、读写位 R/W、用户/内核位 U/S),如果访问违反了权限(如尝试写入只读页、用户程序访问内核页、访问的页不在内存中 P=0),MMU 会触发一个页面错误异常(Page Fault)。CPU 会中断当前程序,跳转到操作系统的页面错误处理程序。操作系统负责处理这个异常(例如,从磁盘调入缺失的页、修复权限、终止非法程序等)
10、TLB 加速:为了加速这个多级查找过程(通常需要 4 次内存访问),CPU 内部有一个叫做 TLB 的高速缓存。TLB 缓存了最近使用过的虚拟地址到物理地址的映射。当 MMU 收到一个虚拟地址时,它首先在 TLB 中查找。如果命中(TLB Hit),就可以直接获得物理地址,无需访问内存中的页表,极大地提高了性能。如果未命中(TLB Miss),MMU 才需要执行上述完整的多级页表查找过程,并将结果缓存到 TLB 中
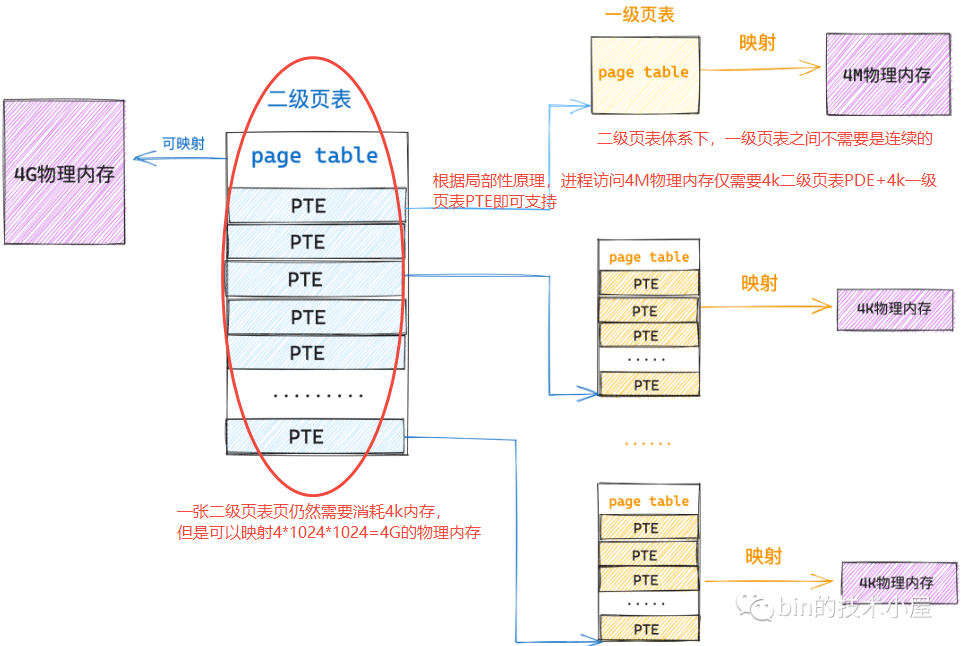
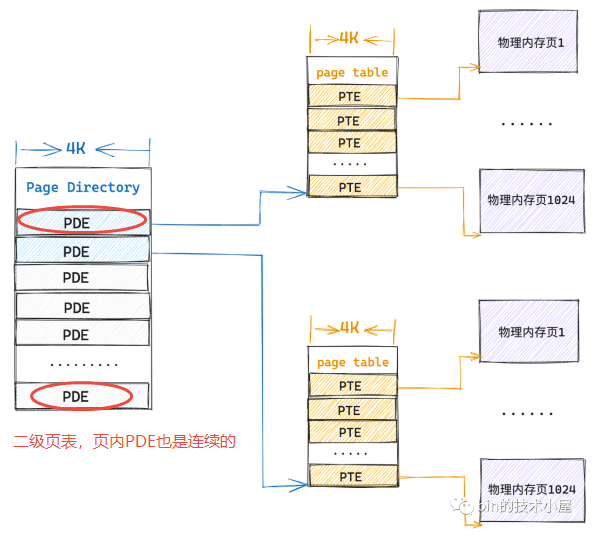
0x04 32位:二级页表
二级页表中的一个 PTE 本质上指向的还是一个物理内存页,即二级页表中也包含了 1024 个 PTE,其中每个PTE指向一个物理内存页(一级页表),如此一张二级页表就可以映射 4G 的物理内存。一般称二级页表中的 PTE为页目录项 (Page Directory Entry即PDE),即一级页表的索引
对比单级页表,二级页表的内存占用:
- 内核只需要一张
4K的页目录表和一张4K的一级页表总共8K的内存就可以支持进程访问一个4K物理页面 - 进程访问
4M的物理内存,依然只需要一张4K的页目录表和一张4K的一级页表即可 - 进程访问
8M的物理内存,需要一张4K页目录表和两张一级页表共12K额外的物理内存 - 极端情况,整个二级页目录表都被映射满了,这时候内核就需要
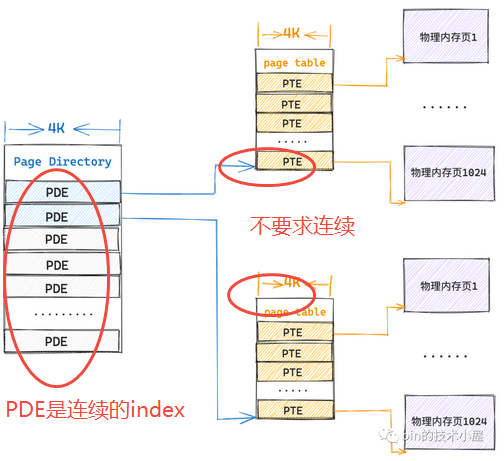
4K(页目录表)+4M(1024张一级页表)的额外内存来保存映射关系 - 在二级页表体系下,上面极端情况中的这
1024张一级页表不要求连续的,只需要保证顶级页表(即PDE页目录表)是连续即可,通过页目录表中的 PDE 可以唯一索引到一张一级页表的起始物理内存地址,而页表内肯定是连续的4K物理内存,所以依然可以通过数组的方式索引到一级页表中的 PTE,进而找到其映射的物理内存页面
32 位页表项 PTE
在进程的虚拟内存空间中,每一个虚拟内存页在页表中都有一个 PTE 与之对应,在 32 位系统中,每个 PTE 占用 4byte,其保存了虚拟内存页背后映射的物理内存页的起始地址,以及进程访问物理内存的一些权限标识位,布局如下:

如上图,由于物理内存划分以页为单位,每页大小为 4K(2^12),所以物理内存页的起始地址都是按照 4K 对齐的,也就导致物理内存页的起始地址的后 12 位全部是 0(图中31~12共20位),只需要在 PTE 中存储物理内存地址的高 20 位就可以了,剩下的低 12 位用来标记一些权限位,重点关注几个权限位:
P(0):表示该 PTE 映射的物理内存页是否在内存中,值为1表示物理内存页在内存中驻留,值为0表示物理内存页不在内存中,可能被 swap 到磁盘上了(当P位为0时,其他权限位将变得没有意义);当通过虚拟内存寻址过程找到其对应 PTE 之后,首先会检查它的P位,如果为0则直接触发缺页中断(page fault),随后进入内核态,由内核的缺页异常处理程序负责将映射的物理页面换入到内存中R/W(1):表示进程对该物理内存页拥有的读/写权限,值为1表示进程对该物理页拥有读写权限,值为0表示进程对该物理页拥有只读权限,进程对只读页面进行写操作将触发 page fault(写保护中断异常),用于写时复制(Copy On Write)的场景U/S(2):为0表示该物理内存页面只有内核才可以访问,为1表示用户空间的进程也可以访问A(5):表示 PTE 指向的这个物理内存页最近是否被访问过,1表示最近被访问过(读或者写访问都会设置为1),0表示没有。该 bit 位被硬件 MMU 设置,由操作系统重置。内核会经常检查该比特位,以确定该物理内存页的活跃程度,不经常使用的内存页,很可能就会被内核 swap out 出去D(6):主要针对文件页使用,当 PTE 指向的物理内存页是一个文件页时,进程对这个文件页写入了新的数据,这时文件页就变成了脏页,对应的 PTE 中D比特位会被设置为1,表示文件页中的内容与其背后对应磁盘中的文件内容不同步了
这里进一步描述下COW的场景,以fork父子进程为例,创建子进程之后,父子进程的虚拟内存空间完全是一模一样的,包括父子进程的页表内容都是一样的,父子进程页表中的 PTE 均指向同一物理内存页面,此时内核会将父子进程页表中的 PTE 均改为只读,并将父子进程共同映射的这个物理页面引用计数加一。当父进程或子进程对该页面发生写操作的时候,假设子进程先对页面发生写操作,随后子进程发现自己页表中的 PTE 只读,于是产生写保护中断,子进程进入内核态,在内核的缺页中断处理程序中发现,访问的这个物理页面引用计数大于 1,说明此时该物理内存页面存在多进程共享的情况,于是发生写时复制(COW),内核为子进程重新分配一个新的物理页面,然后将原来物理页中的内容拷贝到新的页面中,最后子进程页表中的 PTE 指向新的物理页面并将 PTE 的 R/W 位设置为 1,原来物理页面的引用计数减一;后面父进程在对页面进行写操作的时候,同样也会发现父进程的页表中 PTE 是只读的,也会产生写保护中断,但是在内核的缺页中断处理程序中,发现访问的这个物理页面引用计数为 1 了,那么就只需要将父进程页表中的 PTE 的 R/W 位设置为 1即可
//unsigned long 在32位系统中占用4字节(32位)
typedef unsigned long pteval_t;
typedef struct { pteval_t pte; } pte_t;
32 位页目录项 PDE
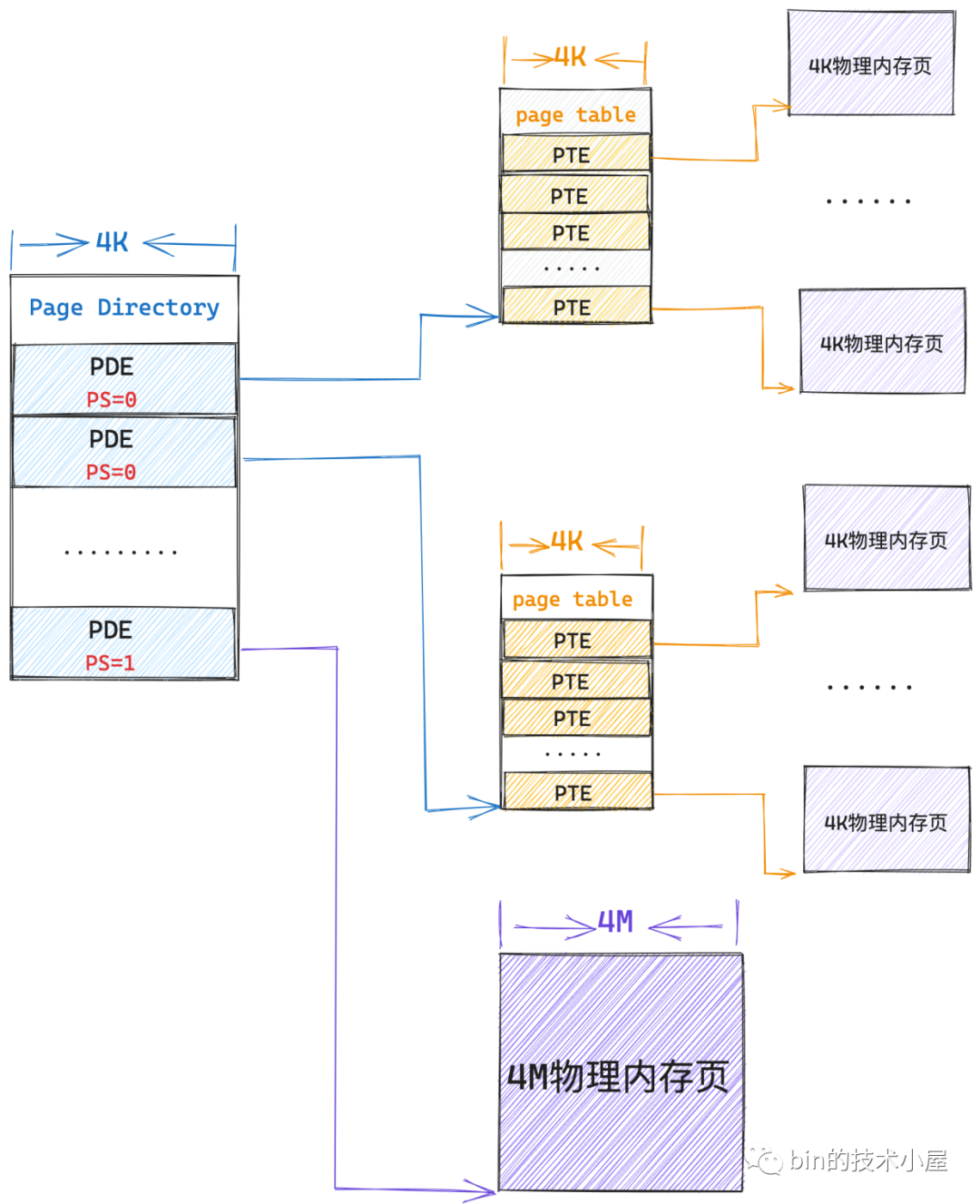
在二级页表中,PDE 用来指向一级页表的起始物理内存地址,而页表的本质是一个物理内存页,因此页表的起始内存地址也是按照 4K 对齐的(仅需要保存下一级页表的高20位地址),后 12 位全部为 0,32位页表PDE的布局如下图

权限位微调如下:
- PDE 中的第
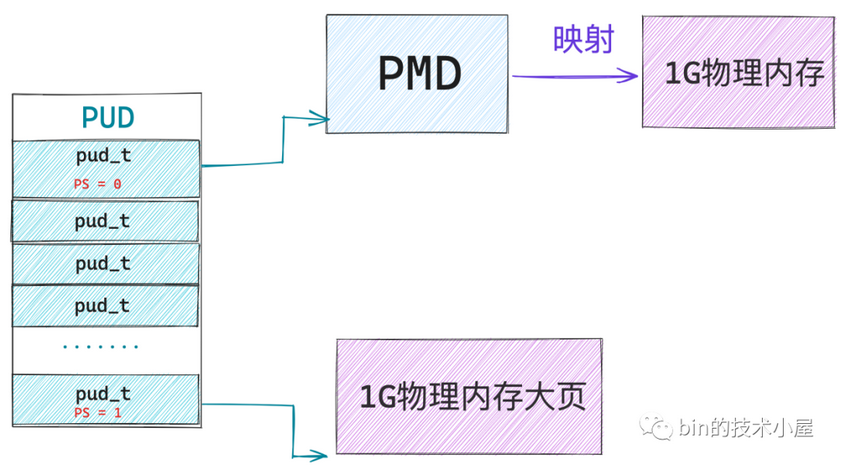
6个比特位脏页标记位无意义了(因为 PDE 指向的是一级页表,页表并不是一个文件页) PS(7): PS 标记为0的时候,PDE 指向一级页表的起始内存地址,起到页目录项的作用;但当 PS 标记为1的时候,PDE 就会被内核拿来当做 PTE 使用,特殊之处在于该 PDE 会指向一个大页内存(4M大页),如下图所示。此时PDE的高20位会用来保存4M大页的起始内存地址(实际上4M内存大页的起始地址都是按照4M对齐的,即4M大页的起始内存地址的后22位全部为0,只需要用高10位表示就可以了,即31~22位)
typedef unsigned long pgdval_t;
二级页表的寻址过程
根据上文介绍的PTE、PDE,二级页表的寻址过程就不难理解了,这里介绍下二级页表的寻址过程
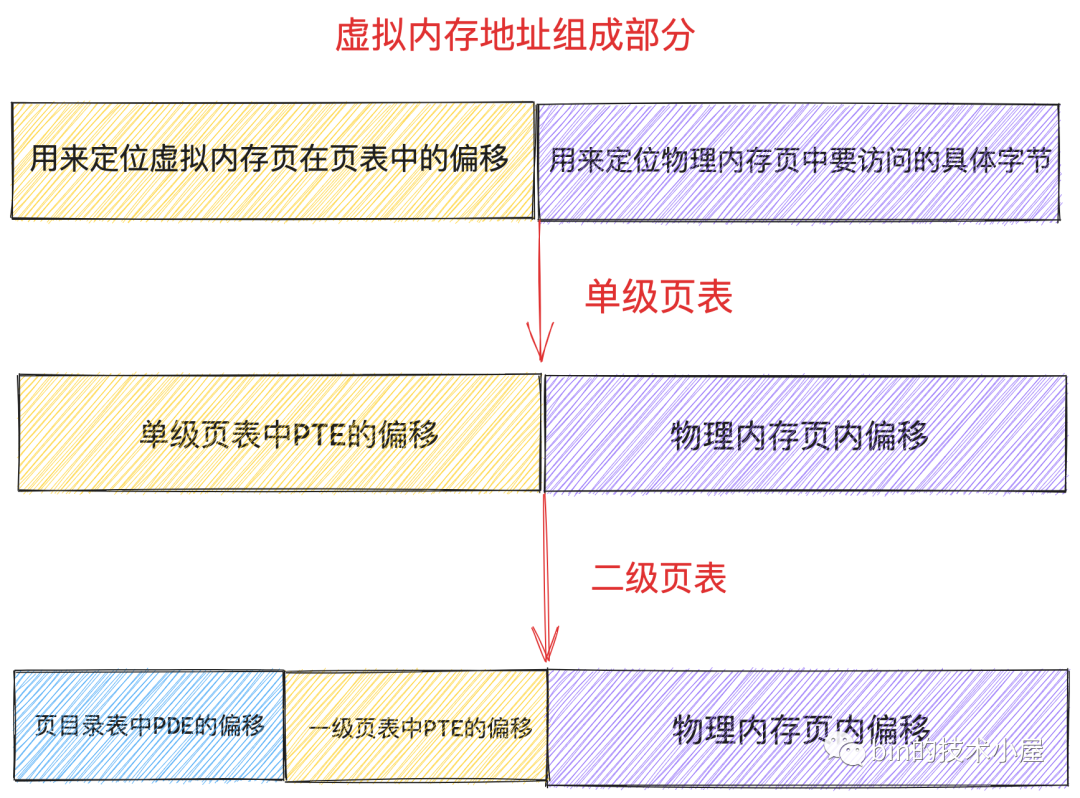
1、二级页表体系下虚拟内存地址的变化
单级页表下虚拟内存地址中只需要保存页表中的 PTE 偏移即可,二级页表下虚拟内存地址需要多保存一份页目录表中 PDE 的偏移,如下图
2、虚拟内存地址的构成
在 32bit 位系统中,虚拟内存地址是32位,页目录表中的 PDE 和页表中的 PTE 也都是32位即4byte(页目录表、页表的本质都是一个4K大小的物理内存页),那么既然一张页目录表大小为4K,那么包含了4KB/4B=1024 个 PDE,要寻址这 1024 个 PDE 需要 10 个 bit,所以虚拟内存地址中的页目录表中 PDE 偏移部分占用 10bit;同理一张页表中有 1024 个 PTE, 要寻址这个 1024 个 PTE 也是需要 10bit,即虚拟内存地址中的一级页表中 PTE 偏移 部分也需要占用 10bit,这样32bit的虚拟内存地址还剩下12bit,刚好可以用于寻址一个4K大小的物理内存页(正好是一个单位)
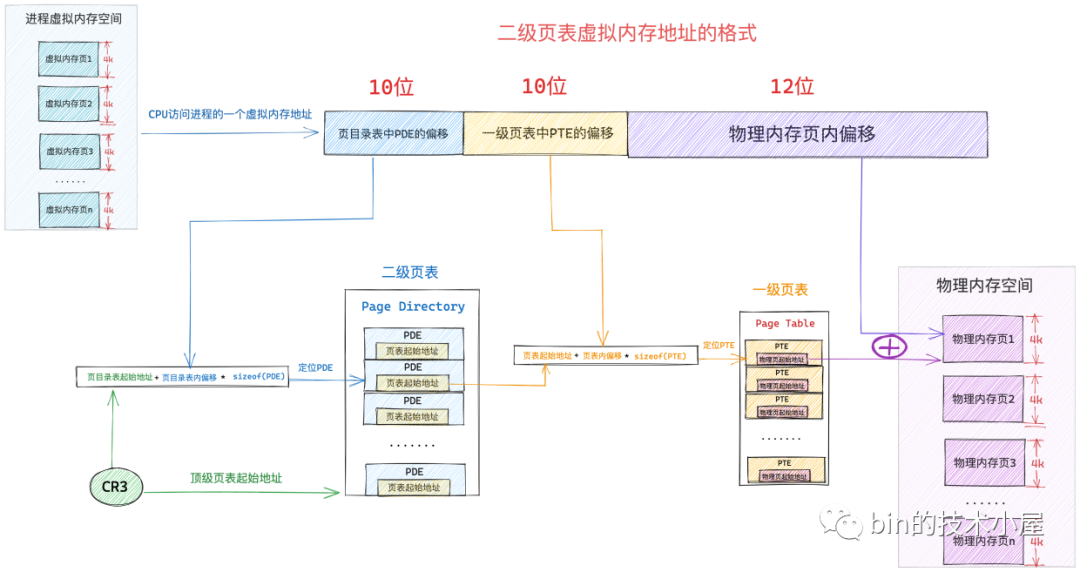
3、二级页表体系下的寻址过程
- 当 CPU 访问进程虚拟内存空间中的一个地址时,会先从 cr3 寄存器中获取页目录表的起始物理内存地址,然后从虚拟内存地址中解析出前
10bit 的内容作为页目录表中 PDE 的偏移,通过页目录表起始地址 + 页目录表内偏移 * sizeof(PDE) 可以定位到该虚拟内存页在页目录表中的 PDE - PDE 中保存了其指向的一级页表的起始物理内存地址,再从虚拟内存地址中解析出下一个
10bit 作为页表中 PTE 的偏移,然后通过页表起始地址 + 页表内偏移 * sizeof(PTE)可以定位到虚拟内存页在一级页表中的 PTE - PTE 中保存了最终映射的物理内存页的起始地址,最后从虚拟内存地址中解析出最后
12个 bit,最终定位到虚拟内存地址对应的物理字节上
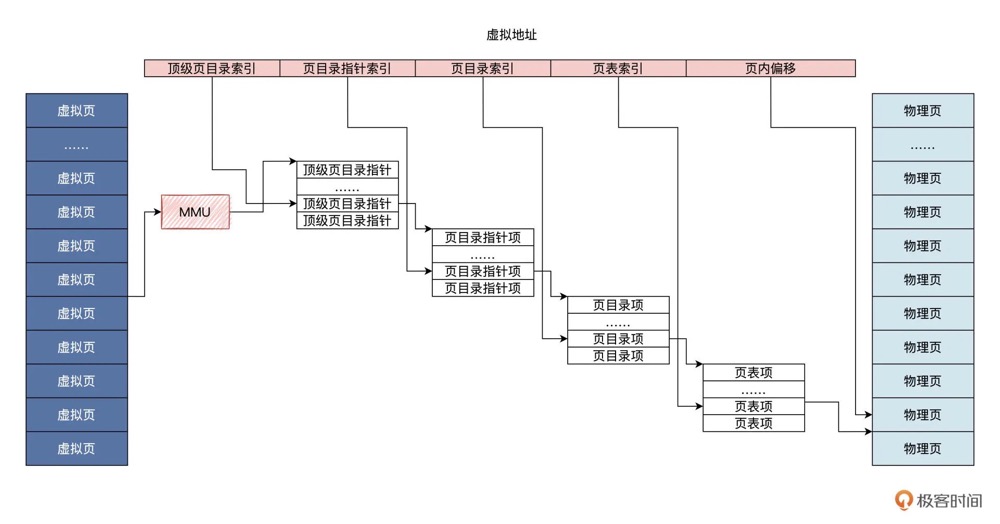
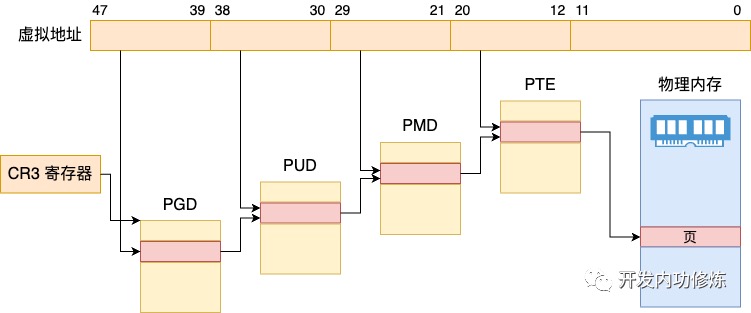
0x05 64位:四级页表
二级页表最多只能映射 4G(2^20 * 4k,即PDE的最大寻址范围*页表大小)的物理内存空间,而 64 位系统中,进程的用户态需要寻址128T 的虚拟内存空间,内核态也有 128T 的虚拟内存空间,二级页表明显是不够的
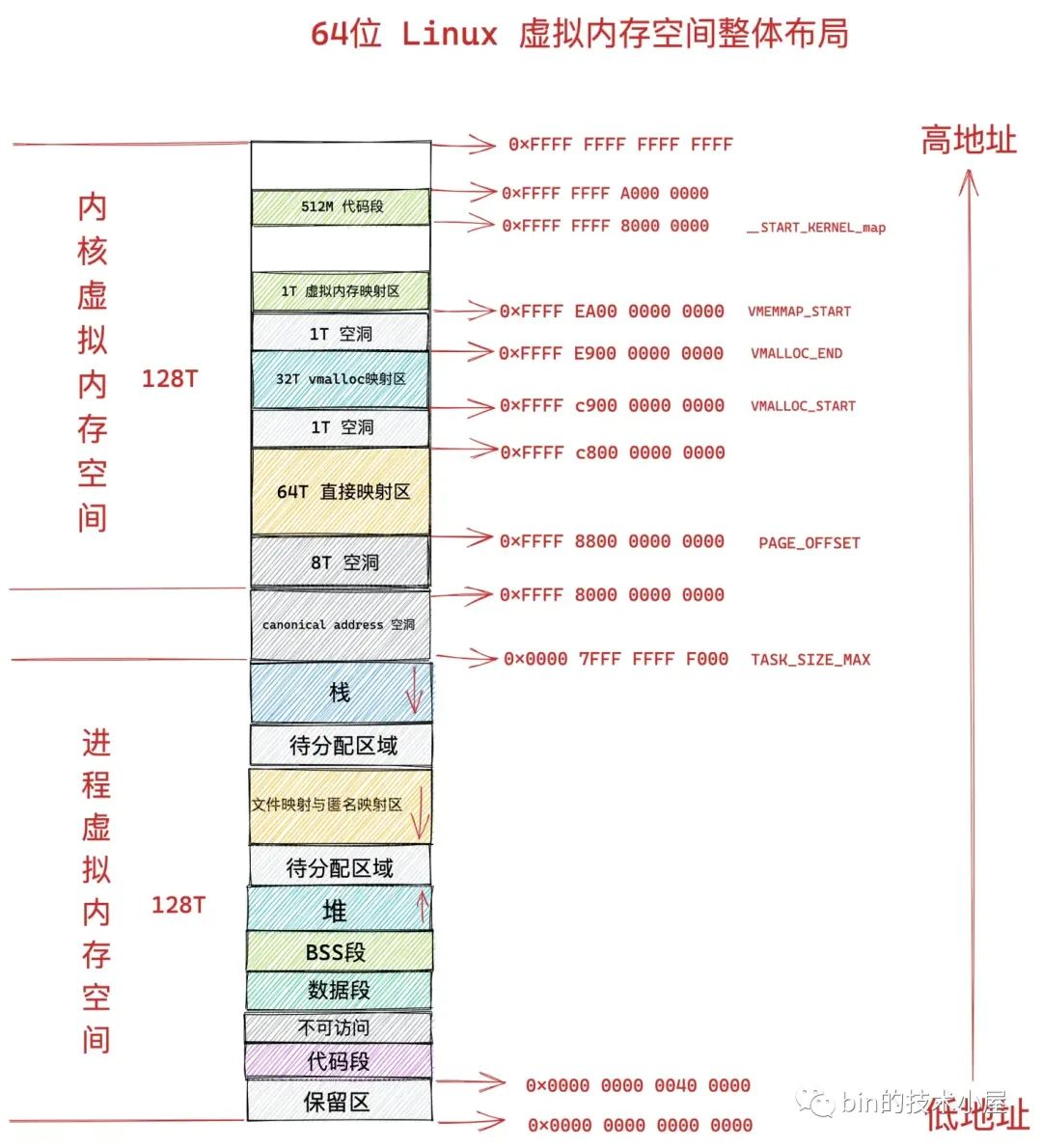
64 位系统中的四级页表对比 32 位系统中的二级页表来说,引入了多两个层级的页目录,分别是四级页表和三级页表,页表整体布局如下图:
64位虚拟内存地址
64 位的虚拟内存地址格式如下:
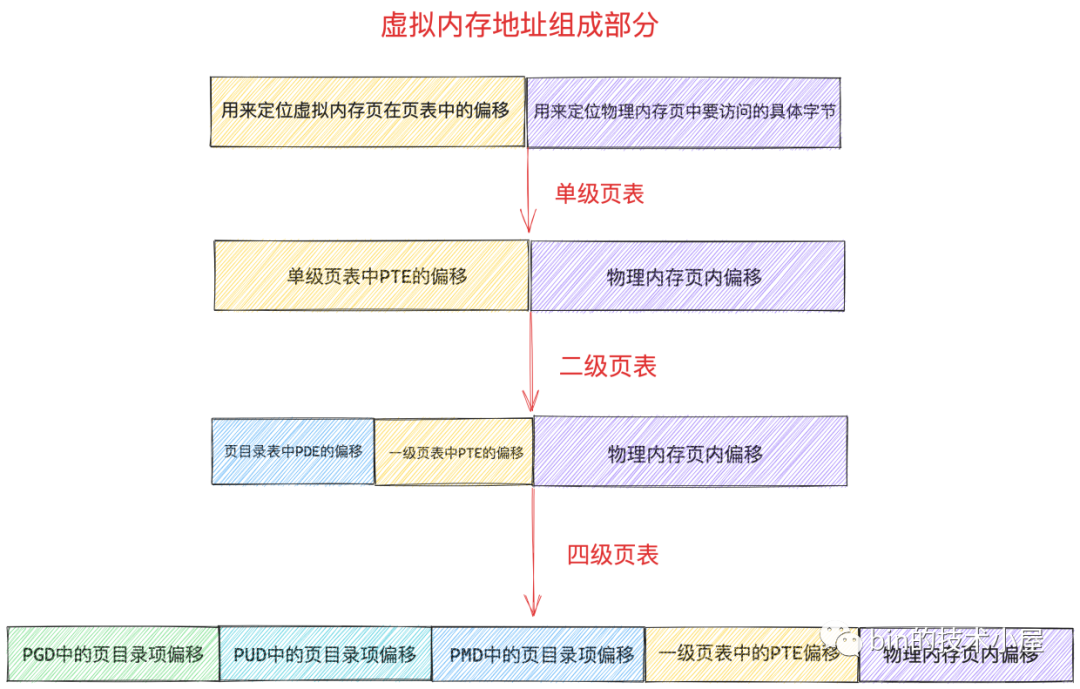
在64位系统重,一张页表 4K 大小,但是页表中的一个 PTE 占用 8 个字节,所以在 64 位系统中一张页表只能包含 512 个 PTE,所以要寻址页表中这 512 个 PTE,只需要用 9 个 bit 即可,因此虚拟内存地址中的一级页表中的 PTE 偏移占用 9 个 bit 位。而一个 PTE 可以映射 4K 大小的物理内存(一个物理内存页),所以在 64 位的四级页表体系下,一张一级页表可以映射的物理内存空间大小为 2M
对PMD(Page Middle Directory)而言,一张中间页目录 PMD 也是 4K,PMD 中的页目录项 pmd_t 也是占用 8byte,所以一张 PMD 可以容纳 512 个 pmd_t,在64 位虚拟内存地址中的 PMD中的页目录偏移也需要占用 9 bit。所以如果用PMD来映射大页内存的话,支持映射的size为2MB*512,共1G物理内存(一个 pmd_t 指向一张一级页表,即一个 pmd_t 可以映射的物理内存为 2M)
同样,对PUD而言,一张上层页目录 PUD 中可以容纳 512 个页目录项 pud_t,在64 位虚拟内存地址中的 PUD中的页目录偏移也需要占用 9 bit,一个 pud_t 指向一张 PMD,因此可以映射 1G 的物理内存,所以一张 PUD 可以映射 512G 的物理内存
最后,对 PGD而言, 可以容纳的页目录 pgd_t 为512个,在64 位虚拟内存地址中的 PGD中的页目录偏移也需要占用 9 bit,一个 pgd_t 可以映射的物理内存为 512G,所以一张 PGD 可以映射的物理内存为 256TB
内核相关的常量定义如下:
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/include/asm/pgtable_64_types.h#L47
/*
* entries per page directory level
*/
//PTRS_PER_PTE:表示一张页表中可以容纳的 PTE 个数
#define PTRS_PER_PTE 512
/* PAGE_SHIFT determines the page size */
//PAGE_SHIFT:表示一个物理内存页的大小 2^PAGE_SHIFT
#define PAGE_SHIFT 12
/*
* PMD_SHIFT determines the size of the area a middle-level
* page table can map
*/
//PMD_SHIFT :表示一个 pmd_t 可以映射的物理内存范围2^PMD_SHIFT
#define PMD_SHIFT 21
#define PTRS_PER_PMD 512
/*
* 3rd level page
*/
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
/*
* 4th level page in 5-level paging case
*/
#define PGDIR_SHIFT 39
#define PTRS_PER_PGD 512
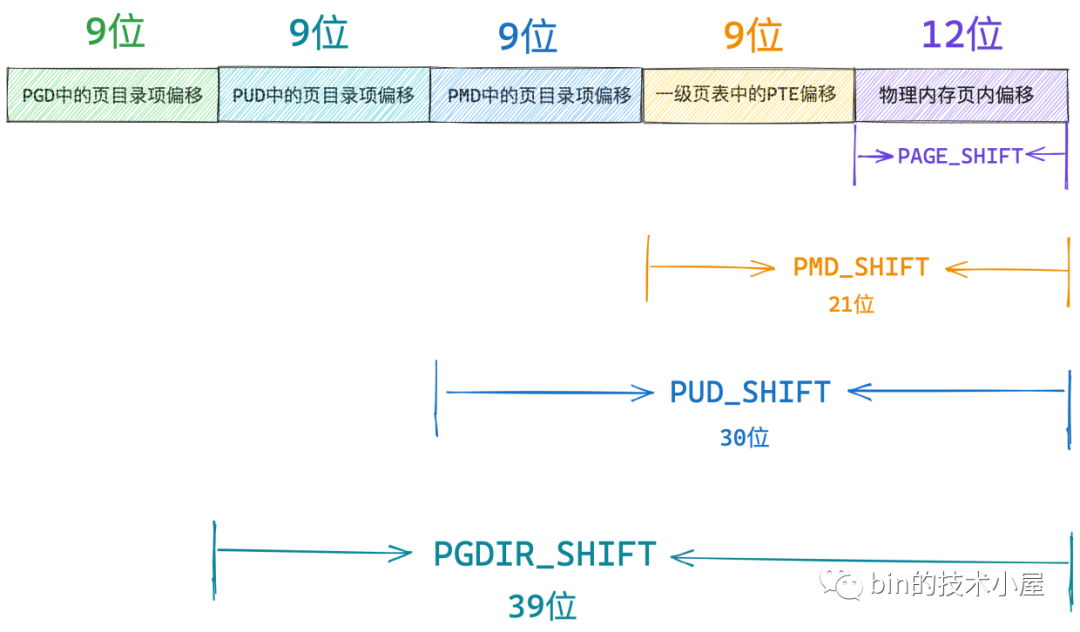
64位虚拟内存地址的操作
上一小节介绍了四级页表中各级页表的容量:
PAGE_SHIFT:表示页表中的一个 PTE 可以映射的物理内存大小(4K)PMD_SHIFT:表示 PMD 中的一个页目录项pmd_t可以映射的物理内存大小(2M)PUD_SHIFT:表示 PUD 中的一个页目录项pud_t可以映射的物理内存大小(1G)PGD_SHIFT:表示 PGD 中的一个页目录项pgd_t可以映射的物理内存大小(512G)
上述定义除了表示对应页目录项映射的物理内存大小之外,内核还提供若干宏/函数获取一个 64 位虚拟内存地址中获取其在对应页目录中的偏移量,参考
// 获取64位虚拟内存地址在 PGD 中的偏移,右移PGDIR_SHIFT
#define pgd_index(address) ( address >> PGDIR_SHIFT)
// 通过 PGD 的起始内存地址加上 pgd_index 就可以得到虚拟内存地址在 PGD 中的页目录项 pgd_t
#define pgd_offset_pgd(pgd, address) (pgd + pgd_index((address)))
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
static inline unsigned long pud_index(unsigned long address)
{
// 将虚拟内存地址右移 PUD_SHIFT 位,并用掩码 PTRS_PER_PUD - 1 掩掉高 9 位 , 只保留低 9 位,就可以得到虚拟内存地址在 PUD 中的偏移
// PTRS_PER_PUD - 1 转换为二进制是 9 个 1,用来截取最低的 9 个比特位
return (address >> PUD_SHIFT) & (PTRS_PER_PUD - 1);
}
/* Find an entry in the third-level page table.. */
//pud_offset:通过 pgd_t 获取 PUD 的起始内存地址 + pud_index 得到虚拟内存地址对应的 pud_t(下一级)
static inline pud_t *pud_offset(pgd_t *pgd, unsigned long address)
{
return (pud_t *)pgd_page_vaddr(*pgd) + pud_index(address);
}
/*--------------------------------------*/
// pmd_offset:获取虚拟内存地址在 PMD 中的页目录项 pmd_t
/* Find an entry in the second-level page table.. */
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long address)
{
return (pmd_t *)pud_page_vaddr(*pud) + pmd_index(address);
}
static inline unsigned long pmd_index(unsigned long address)
{
return (address >> PMD_SHIFT) & (PTRS_PER_PMD - 1);
}
/*--------------------------------------*/
//pte_offset_kernel:获取虚拟内存地址在一级页表中的 PTE
static inline pte_t *pte_offset_kernel(pmd_t *pmd, unsigned long address)
{
return (pte_t *)pmd_page_vaddr(*pmd) + pte_index(address);
}
static inline unsigned long pte_index(unsigned long address)
{
return (address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1);
}
64 位页表项 PTE
在 64bit系统中,布局如下图,其中 0~8 之间的bit意义同 32 位一样,在64位系统中一个物理内存页仍然是4K大小
//页表中 PTE 占用64bit
typedef unsigned long pteval_t;
typedef struct { pteval_t pte; } pte_t;

64 位页目录项
64 位四级页表体系下,一共包含了三个层级的页目录:即全局页目录 PGD(Page Global Directory)、上层页目录 PUD(Page Upper Directory)和PMD(Page Middle Directory),其布局如下:
typedef unsigned long pmdval_t;
typedef unsigned long pudval_t;
typedef unsigned long pgdval_t;
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pudval_t pud; } pud_t;
typedef struct { pgdval_t pgd; } pgd_t;

重要bit如下:
PS(7)为0时,该 PDE 指向的是其下一级页目录或者页表的起始内存地址PS(7)为1时,该 PDE 指向的就是一个内存大页,对于 PMD 中的页目录项pmd_t而言,它指向的是一张2M的物理内存大页;对于 PUD 中的页目录项pud_t而言,它指向的是一张1G的物理内存大页。同32位二级页表类似,在64位的pde结构中,大页内存映射的场景下,第12~35位(实际不需要这么多位)会被用来存储大页内存的开始地址
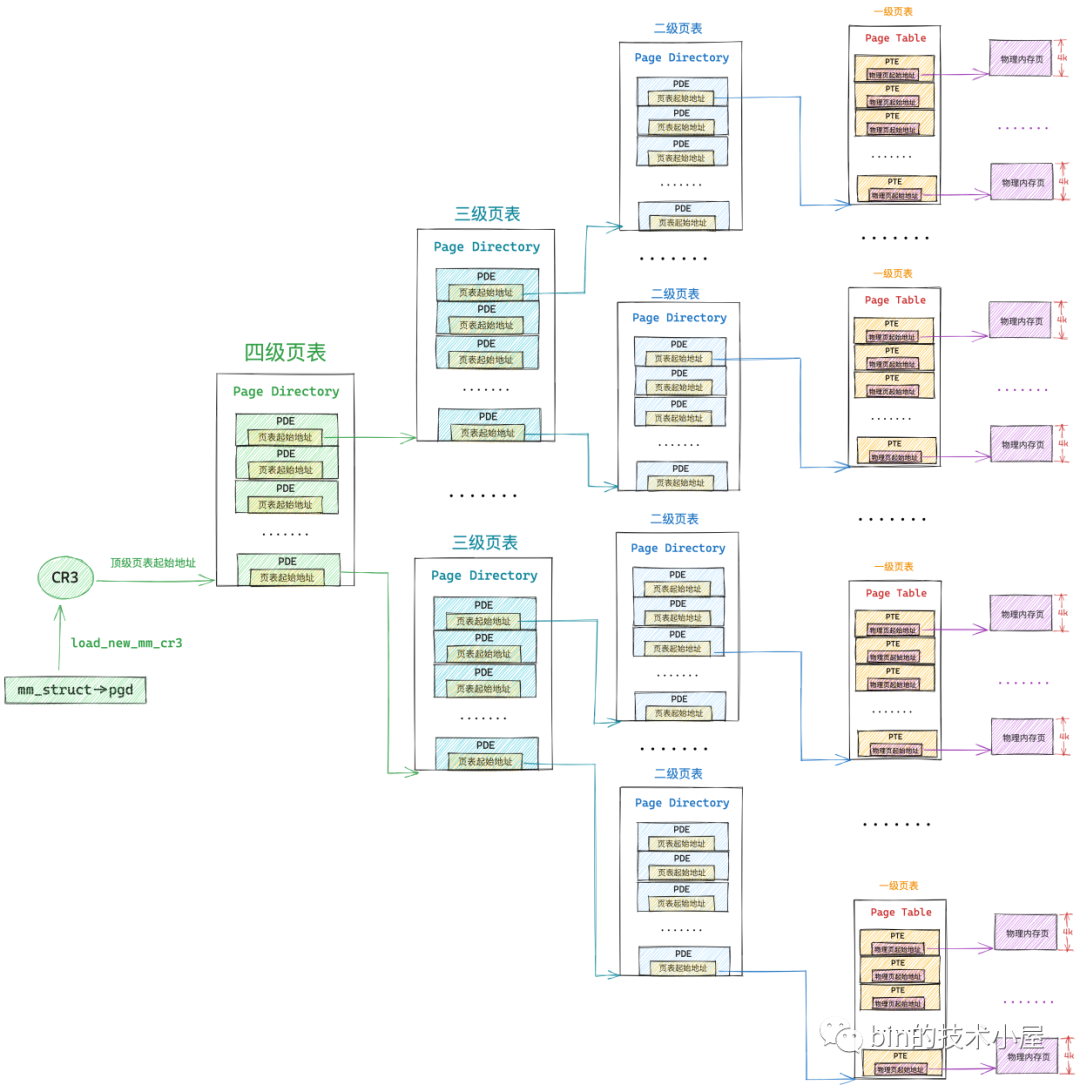
四级页表寻址
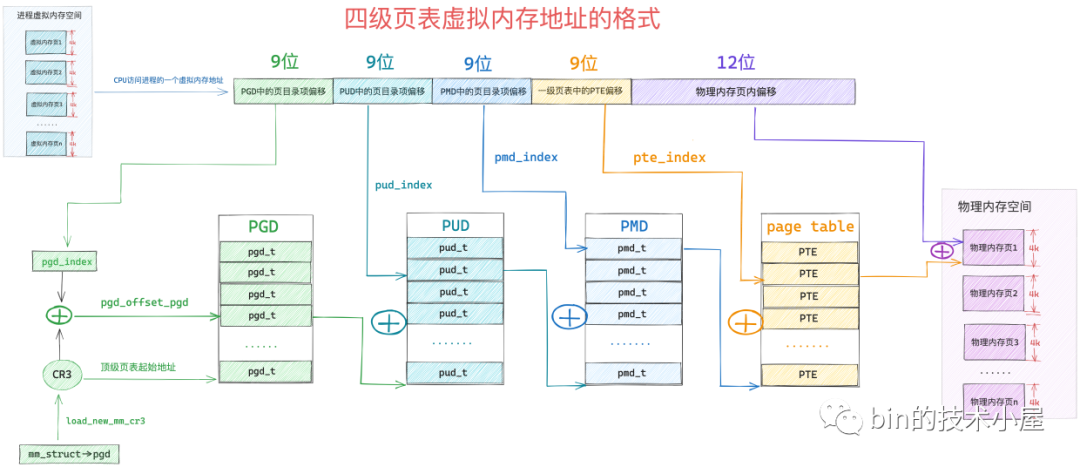
同二级页表寻址过程基本类似,只是说法上稍有区别,四级页表体系下,最顶层的是全局页目录 PGD(Page Global Directory),PGD 中的页目录项叫做 pgd_t,PGD 是四级页表体系下的顶级页表,保存在进程 struct mm_struct 的 pgd 成员中,在进程调度上下文切换的时候,由内核通过 load_new_mm_cr3 方法将 pgd 中保存的顶级页表虚拟内存地址转换物理内存地址,随后加载到 cr3 寄存器中,从而完成进程虚拟内存空间的切换
- PUD(Page Upper Directory):三级页表,上层页目录,PUD 中的页目录项为
pud_t - PMD(Page Middle Directory):二级页表,中间页目录,PMD 中的页目录项为
pmd_t - Page Table:一级页表,最底层的用来直接映射物理内存页面
所以,在四级页表体系下,首先需要定位顶级页表 PGD 中的页目录项 pgd_t,pgd_t 指向的 PUD 的起始内存地址,然后在定位 PUD 中的页目录项 pud_t,后面的寻址过程和二级页表一样。大致的寻址过程如下图
- 首先 MMU 会从 cr3 寄存器中获取顶级页目录
PGD的起始内存地址,然后通过pgd_index从虚拟内存地址中截取 PGD 中的页目录项偏移,这样就定位到了具体的一个pgd_t pgd_t中保存的是 PMD 的起始内存地址,通过pud_index可以从虚拟内存地址中截取 PUD 中的页目录项偏移,从而确定虚拟内存地址在 PUD 中的页目录项pud_t- 根据
pud_t中保存的 PMD 起始内存地址,再加上通过pmd_index获取到的 PMD 中的页目录项偏移,定位到虚拟内存地址在 PMD 中的页目录项pmd_t - 最后,
pmd_t指向具体页表的起始内存地址,通过pte_index获取虚拟内存地址在一级页表中的 PTE 偏移,最终定位到一个具体的 PTE 中,PTE 指向的正是虚拟内存地址映射的物理内存页面,然后通过虚拟内存地址中的低12位(物理内存页内偏移),最终确定到一个具体的物理字节(地址)
最后,思考下为什么CR3寄存器里面保存的必须是物理内存地址?
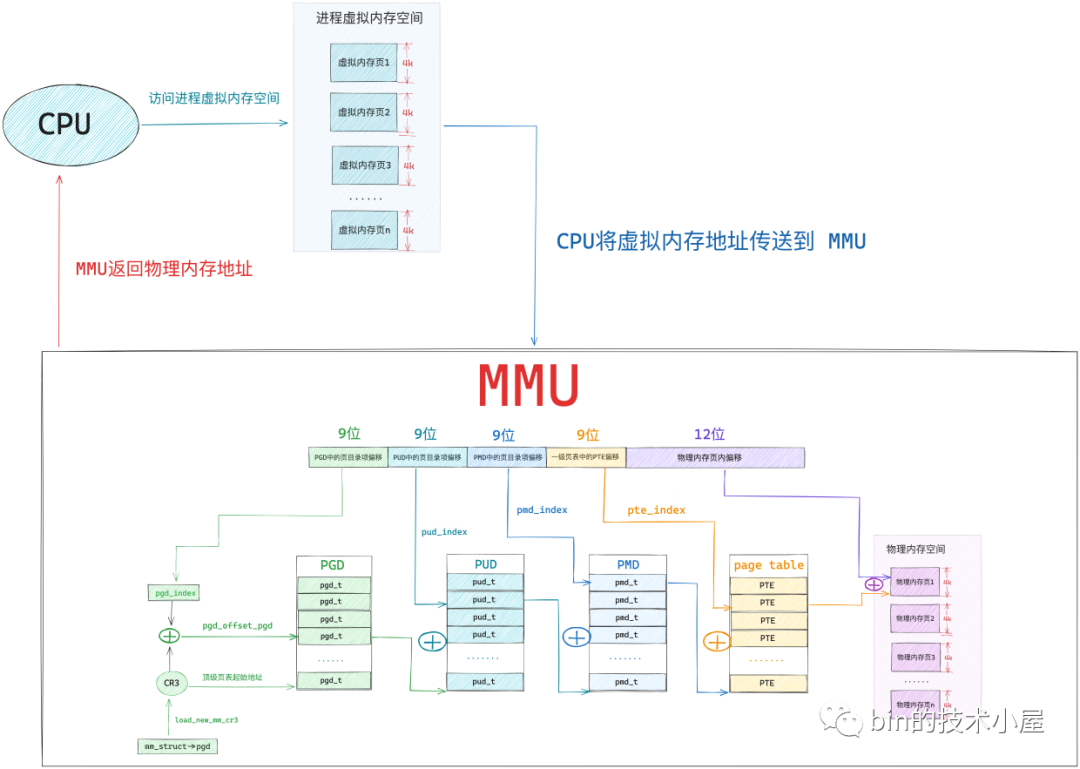
0x06 CPU 的寻址过程
MMU
为了加速虚拟内存地址到物理内存地址的转换过程,CPU 专门引入对页表进行遍历的地址翻译硬件 MMU(Memory Management Unit)加速这过程
TLB
TLB作用是缓存近期虚拟地址与物理地址转换结果,避免每次访问需4次内存查表,若 0x7fffa9b07c14的映射近期被访问过,CPU直接通过TLB获取物理地址(耗时约1~3时钟周期)
物理内存地址
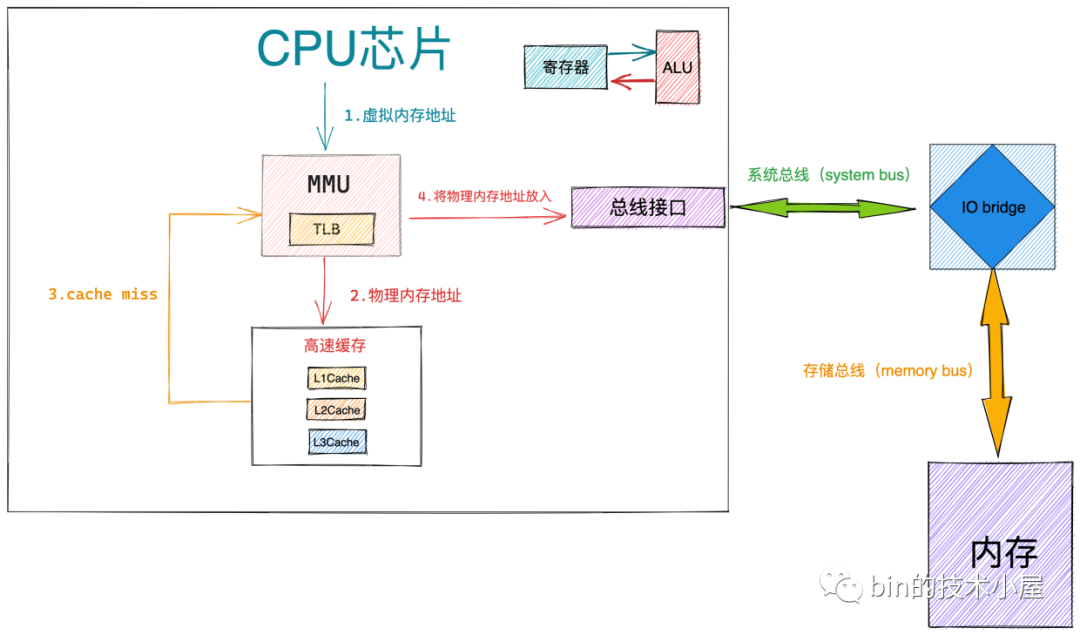
1、当 MMU 获取到最终的物理内存地址,首先会根据物理内存地址到 CPU 高速缓存中去查找数据,如果 cache hit,整个访存操作快速结束
2、如果 cache miss,那么 MMU 会将物理内存地址放到系统总线上传输,随后 IO bridge 会将系统总线上传输的地址信号传递到存储总线上
3、内存中的存储控制器感受到存储总线上的地址信号之后,会将物理内存地址从存储总线上读取出来。并根据物理内存地址定位到具体的存储器模块,随后解析物理内存地址从 DRAM 芯片中取出对应物理内存地址里的数据
4、存储控制器将读取到的数据放到存储总线传输上,随后 IO bridge 将存储总线上的数据信号转换为系统总线上的数据信号,然后继续沿着系统总线传递
5、CPU 芯片感受到系统总线上的数据信号之后,将数据从系统总线上读取出来并拷贝到寄存器中,随后通过 ALU 完成计算
0x07 页表的应用(代码)
页表初始化:进程创建
上面已经介绍了每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都需要有独立的进程页表,这个页表的最顶级的 pgd 存放在 struct task_struct 结构中的 mm_struct 的 pgd 成员中。再回顾前文介绍新进程新创建的时候,会调用 fork,对于内存空间的部分的调用链为 copy_mm->dup_mm,核心步骤如下:
- 创建一个新的
mm_struct,并且通过memcpy初始化为父进程的成员(一样) - 调用
mm_init进行初始化 dup_mmap
// Allocate a new mm structure and copy contents from the mm structure of the passed in task structure.
static struct mm_struct *dup_mm(struct task_struct *tsk){
struct mm_struct *mm, *oldmm = current->mm;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
return mm;
}
//mm_init->mm_alloc_pgd
static inline int mm_alloc_pgd(struct mm_struct *mm){
//分配全局页目录项,赋值给mm_struct 的 pdg 成员变量
mm->pgd = pgd_alloc(mm);
return 0;
}
一个进程的虚拟地址空间包含用户态和内核态两部分。为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表。在内核里面,映射靠内核页表,这里内核页表会拷贝一份到进程的页表。对于内核来讲,init_mm中的pdg成员指向 swapper_pg_dir(指向内核页表最顶级的目录 pgd),内核初始化时就已经完成对init_mm结构的初始化
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
// pgd 页表最顶级目录
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
页表的应用过程
当进程 fork 完成之后,虽然已经初始化了内核页表与顶级的 pgd变量,但对于用户地址空间来讲,还完全没有映射过(用户空间页表一开始是不完整的,只有最顶级目录pgd而已),这就是惰性分配。真正分配的时机是当进程被调度到 CPU 上运行并且对内存地址进行访问的时候
当进程被调度到某个 CPU 上运行的时候,要调用 context_switch 函数进行上下文切换,函数内部对于内存方面的切换会调用 switch_mm_irqs_off,这里面会调用 load_new_mm_cr3函数,如果 CPU 的指令要访问进程的虚拟内存,它就会自动从cr3 里面得到顶级页面 pgd 在物理内存的地址,然后通过虚拟内存地址的拆解,根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据
此外,用户进程在运行的过程中,访问虚拟内存中的数据,会被 cr3 里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态
//https://elixir.bootlin.com/linux/v4.11.6/source/kernel/sched/core.c#L2852
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
arch_start_context_switch(prev);
if (!mm) {
next->active_mm = oldmm;
mmgrab(oldmm);
enter_lazy_tlb(oldmm, next);
} else
switch_mm_irqs_off(oldmm, mm, next); //
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unpin_lock(rq, rf);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/mm/tlb.c#L74
void switch_mm_irqs_off(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
unsigned cpu = smp_processor_id();
if (likely(prev != next)) {
if (IS_ENABLED(CONFIG_VMAP_STACK)) {
/*
* If our current stack is in vmalloc space and isn't
* mapped in the new pgd, we'll double-fault. Forcibly
* map it.
*/
unsigned int stack_pgd_index = pgd_index(current_stack_pointer());
pgd_t *pgd = next->pgd + stack_pgd_index;
if (unlikely(pgd_none(*pgd)))
set_pgd(pgd, init_mm.pgd[stack_pgd_index]);
}
cpumask_set_cpu(cpu, mm_cpumask(next));
//初始化cr3寄存器
//cr3 里面存放当前进程的顶级 pgd
//cr3 里面需要存放 pgd 在物理内存的地址,不能是虚拟地址
load_cr3(next->pgd);
trace_tlb_flush(TLB_FLUSH_ON_TASK_SWITCH, TLB_FLUSH_ALL);
/* Stop flush ipis for the previous mm */
cpumask_clear_cpu(cpu, mm_cpumask(prev));
/* Load per-mm CR4 state */
load_mm_cr4(next);
}
}
CPU对虚拟内存的访问结果
代码运行中,下图说明了虚拟内存地址转换中可能遇到的各种场景,具体步骤如下:
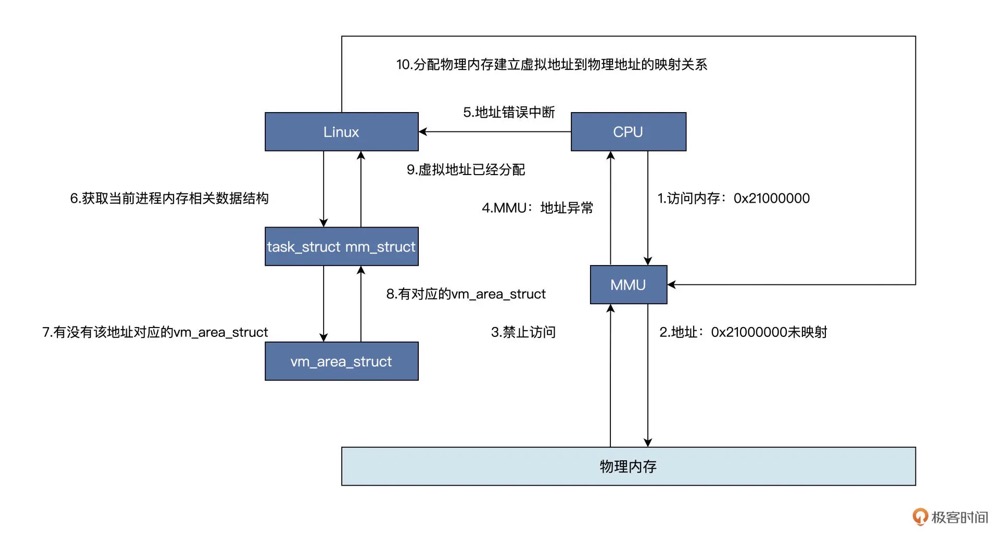
- CPU 使用一个虚拟内存地址访问物理内存,首先会经过 MMU,对于调用
malloc函数的情况是该虚拟地址没有映射到物理内存,所以会通知 CPU 该地址禁止访问(图中1~4步骤为硬件自动完成的) - 然后 CPU 中断到 Linux 内核地址错误处理程序,软件开始工作,内核会对照着当前进程的虚拟地址空间,根据变量地址address去查找对应的
vm_area_struct数据结构,找不到就证明虚拟地址未分配,直接结束,进程会发出段错误;若是找到了,则证明虚拟地址已经分配,接着会分配物理内存,建立虚拟地址到物理地址的映射关系,接着程序就可以继续运行 - 如果对没有进行映射的虚拟内存地址进行读写操作,那么将会发生缺页异常。内核会对缺页异常进行修复,修复过程如下:获取触发缺页异常的虚拟内存地址(读写哪个虚拟内存地址导致的),查看此虚拟内存地址是否被申请(是否在
brk指针内),如果不在brk指针内,将会导致 Segmention Fault 错误(即coredump),进程将会异常退出。如果虚拟内存地址在brk指针内,那么将此虚拟内存地址映射到物理内存地址上,完成缺页异常修复过程,并且返回到触发异常的地方运行 - 缺页异常不止针对用户虚拟内存地址,页表(本质也是物理内存)也同样适用。只有访问虚拟内存的时候,发现没有映射多物理内存,页表也没有创建过,才触发缺页异常。因为Linux 内核使用四级页表来管理虚拟地址空间到物理内存之间的映射的,所以在实际申请物理页面之前,需要先检查一遍需要遍历的各级页表是否存在,不存在的话需要申请物理内存,进入内核调用
do_page_fault(缺页中断处理入口),根据变量地址address去查找对应的vm_area_struct,一直调用到__handle_mm_fault函数,__handle_mm_fault函数会调用pud_alloc和pmd_alloc来创建相应的页目录项,最后调用handle_pte_fault来创建页表项
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/mm/fault.c#L1215
static noinline void __do_page_fault(struct pt_regs *regs, unsigned long error_code,unsigned long address){
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
tsk = current;
mm = tsk->mm;
// 判断缺页是否发生在内核
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
}
......
// 找到待访问地址所在的区域 vm_area_struct
vma = find_vma(mm, address);
if (unlikely(!vma)) {
bad_area(regs, error_code, address);
return;
}
if (likely(vma->vm_start <= address)){
// 找到了vm_area
goto good_area;
}
if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) {
bad_area(regs, error_code, address);
return;
}
......
//call handle_mm_fault--->__handle_mm_fault
fault = handle_mm_fault(vma, address, flags);
......
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3787
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags){
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
// 依次检查/申请每一级页表
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
//call handle_pte_fault
return handle_pte_fault(&vmf);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3699
static int handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {
vmf->pte = NULL;
} else {
/* See comment in pte_alloc_one_map() */
if (pmd_devmap_trans_unstable(vmf->pmd))
return 0;
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
barrier();
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd);
spin_lock(vmf->ptl);
entry = vmf->orig_pte;
if (unlikely(!pte_same(*vmf->pte, entry)))
goto unlock;
if (vmf->flags & FAULT_FLAG_WRITE) {
if (!pte_write(entry))
return do_wp_page(vmf);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else {
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}
在handle_pte_fault 函数中会进行很多种case的内存缺页处理,比如文件映射缺页处理、swap缺页处理、写时复制缺页处理、匿名映射页缺页处理等
最常见的case是对于代码中申请的变量内存,若存在缺页的情况,对应的是匿名映射页缺页处理,会进入do_anonymous_page 函数,该函数先通过 pte_alloc 分配一个页表项,然后通过 alloc_zeroed_user_highpage_movable 分配一个页,在底层会调用伙伴系统(物理内存)的 alloc_page 进行实际的物理页面的分配,接下来要调用 mk_pte将页表项指向新分配的物理页,最后通过set_pte_at 会将页表项放置到页表里面
static int do_anonymous_page(struct vm_fault *vmf){
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
......
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}
最后,再多提一点,关于find_vma的实现,该函数的作用是返回第一个addr 小于vm_end的vma,具体有这么几种情况:
mm_struct里面不存在vma的时候, 返回NULLmm_struct存在的vma的vm_end都小于addr的时候,返回NULLmm_struct存在的vma的vm_end大于addr的vma时候,通过红黑树,找到vm_end最接近addr的vma, 并返回,所以称之为first vma
所以find_vma在没有找到起所属的区间的vma时候,会根据vm_end是否大于addr, 来找到一个最接近的vma, 这样做的目的其实是针对vma出现重叠的情况,便于后面做expand处理等操作
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L2097
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
{
struct rb_node *rb_node;
struct vm_area_struct *vma;
/* Check the cache first. */
//首先检查 VMA 缓存(vmacache),这是一个基于最近访问的缓存机制
// 如果 addr在缓存中找到对应的 VMA,直接返回该 VMA(快速路径)
vma = vmacache_find(mm, addr);
if (likely(vma))
return vma;
rb_node = mm->mm_rb.rb_node;
//若缓存未命中,从红黑树根节点开始遍历
//1. 优先检查左子树(更小地址),但始终记录第一个 vm_end > addr的 VMA
//2. 若找到包含 addr的 VMA(vm_start <= addr < vm_end),立即返回
//3. 若未命中,返回 addr之后最近的 VMA(vm_end > addr)
while (rb_node) {
struct vm_area_struct *tmp;
tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (tmp->vm_end > addr) {
// 若tmp->vm_end > addr时,会把tmp赋值给vma
vma = tmp;
if (tmp->vm_start <= addr){
//至于完全处于vma区间,才会中断查找
break;
}
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
vmacache_update(addr, vma);
return vma;
}
0x08 总结
虚拟内存地址拆解:内核态
分析本文开篇提到的地址(64位),内核空间虚拟地址:ffffffff8101bd40。在64位Linux系统中,虚拟内存地址ffffffff8101bd40的构成反映了操作系统对虚拟地址空间的分层管理和硬件寻址机制
一、地址结构:48位有效地址 + 符号扩展,在x86_64架构中,虚拟地址实际有效位宽为48位(受硬件MMU限制),高16位为符号扩展位(填充第47位的值)
以 ffffffff8101bd40地址为例,说明如下:
- 完整
64位:0xFFFF_FFFF_8101_BD40 - 有效
48位:0xFFFF_8101_BD40(高16位0xFFFF是低48位最高位1的符号扩展) - 规范地址(Canonical Address):高
16位与第47位一致,避免非法访问空洞区
二、地址层级划分:五段式索引(寻址相关),48位有效地址被拆分,用于四级页表索引和页内偏移
| 字段 | 位范围 | 长度 | 作用 | 示例 |
|---|---|---|---|---|
| PGD索引 | 47-39 |
9位 | 定位页全局目录项(Page Global Directory) | 0x1(高位1) |
| PUD索引 | 38-30 |
9位 | 定位页上层目录项(Page Upper Directory) | 0x0 |
| PMD索引 | 29-21 |
9位 | 定位页中间目录项(Page Middle Directory) | 0x01 |
| PTE索引 | 20-12 |
9位 | 定位页表项(Page Table Entry) | 0xBD(189) |
| 页内偏移 | 11-0 |
12位 | 定位物理页内具体位置(4KB页内) | 0x340(832) |
针对本例,页表各层级索引解析如下:
ffffffff8101bd40:有效部分0xFFFF_8101_BD40- PGD索引:
(0xFFFF_8101_BD40 >> 39) & 0x1FF = 0x1 - PUD索引:
(0xFFFF_8101_BD40 >> 30) & 0x1FF = 0x0 - PMD索引:
(0xFFFF_8101_BD40 >> 21) & 0x1FF = 0x1 - PTE索引:
(0xFFFF_8101_BD40 >> 12) & 0x1FF = 0xBD - 页内偏移:
0xFFFF_8101_BD40 & 0xFFF = 0x340
三、内核空间定位,该地址属于内核空间,从64位内核的虚拟内存布局看:
- 地址范围:由于内核空间范围为
0xFFFF_8000_0000_0000~ 0xFFFF_FFFF_FFFF_FFFF(高128TB),而ffffffff8101bd40(0xFFFF_FFFF_8101_BD40)位于此区间 - 高16位特征:全为
1(0xFFFF),符合内核空间规范地址要求 - 用途:指向内核代码、数据结构或设备内存(如内核函数地址、物理内存直接映射区)
四、地址转换流程,从虚拟地址到物理地址需经四级页表转换,由MMU硬件执行
- CR3寄存器定位PGD基址:存储当前进程的页全局目录物理地址
- 逐级索引,依次按照:通过PGD索引找到PUD表基址,通过PUD索引找到PMD表基址,通过PMD索引找到PTE表基址,通过PTE索引获取物理页帧号(PFN)
- 生成物理地址:
物理地址 = (PFN × 4096) + 页内偏移 - 若启用大页(
2MB/1GB),PMD或PUD直接指向物理页 - 缺页处理:若页表项不存在时触发缺页中断,由内核加载物理页并更新页表
虚拟内存地址拆解:用户态
用户空间虚拟地址0x7fffa9b07c14,该地址是Linux系统中的用户空间地址(内核会对用户态/内核态地址空间隔离,内核/用户空间分离,使用高16位标识,防止越权访问)
一、地址类型与范围分析
- 用户空间地址:地址范围
0x0000000000000000~ 0x00007FFFFFFFFFFF(低128TB) - 当前地址:
0x7fffa9b07c14的首16位为0x7fff(小于0x8000),属于用户空间 - 典型用途:指向进程的堆、栈或动态库映射区域(如
malloc分配的内存或共享库代码) - 规范地址验证:高
16位(0x7fff)是第47位(值为1)的符号扩展,符合 Canonical Address 规则,不属于非法空洞区
二、地址层级分解(4KB页),将48位有效地址(0x7fffa9b07c14)拆分为四级页表索引和页内偏移:
| 字段 | 位范围 | 计算方式 | 值(十六进制) |
|---|---|---|---|
| PGD索引 | 47-39 |
(0x7fffa9b07c14 >> 39) & 0x1FF |
0x0FF |
| PUD索引 | 38–30 |
(0x7fffa9b07c14 >> 30) & 0x1FF |
0x1A9 |
| PMD索引 | 29–21 |
(0x7fffa9b07c14 >> 21) & 0x1FF |
0x0B0 |
| PTE索引 | 20–12 |
(0x7fffa9b07c14 >> 12) & 0x1FF |
0x107 |
| 页内偏移 | 11–0 |
0x7fffa9b07c14 & 0xFFF |
0xC14 |
三、地址转换流程,同内核态虚拟地址计算过程
四、典型应用场景
- 堆内存访问:若地址由
malloc分配,可能位于进程堆区(Heap),存储程序变量或动态数据 - 动态库映射:若指向共享库(如
libc.so),可能是库函数的代码或数据段(如全局变量地址) - 栈空间操作:少数情况下可能位于线程栈(Stack),存储局部变量或函数返回地址(需结合上下文确认)
Huge Page
笔者最早接触大页这个概念是在DPDK开发时,Huge Page(大页)是一种通过增大内存页尺寸来优化内存管理的技术,在特定场景下可显著提升系统性能,优点如下:
- 提升TLB(快表)命中率:TLB用于缓存虚拟地址到物理地址的映射,容量有限(通常
64~512条目)。如使用2MB大页后,单条目可覆盖2MB内存(相当于512个4KB页),显著减少TLB Miss。如此当热点数据访问时,TLB命中率提升,减少地址转换延迟,加速内存访问 - 减少页表开销:页表项缩减,对于
2MB的内存大页,管理相同内存时,大页的页表项数量降至1/512或更低,降低页表内存占用及遍历层级 - 缺页异常优化:分配
2MB内存需一次缺页异常,对于普通4K物理内存页需512次,减少内核处理开销 - 避免内存交换Swap:通常大页内存不会被交换到磁盘,保障关键数据(如数据库缓存)常驻物理内存,避免Swap引起的性能抖动
- 降低内存碎片化:大页分配减少小页导致的碎片问题,提升大块连续内存分配成功率