0x00 前言
CronJob 管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行。创建周期性运行的 Job,例如:数据库备份、发送邮件
参考使用文档
举个例子,如下的CRONJOB模版:
apiVersion: batch/v1
kind: CronJob
metadata:
name: my-hello-job
spec:
schedule: "*/1 * * * *" # 每分钟一次
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox # 使用什么镜像
# 在这里定义要执行的代码(命令)
command: ["/bin/sh", "-c"]
args: ["date; echo 'Hello from Kubernetes CronJob'"]
restartPolicy: OnFailure
首先,明确一个概念,在 Kubernetes CronJob 的实现中,真正执行任务的代码并不在 Kubernetes 项目本身的代码库里。比如,对于上面的cronjob配置,真正的任务代码是 image: busybox和 command: ["/bin/sh", "-c", "date; echo 'Hello from Kubernetes CronJob'"]。这段代码被打包在 busybox这个容器镜像里。Kubernetes 是一个编排系统,它的核心职责是管理和管理工作负载,而不是直接执行这些工作负载的业务逻辑。它遵循一种声明式 API和控制器模式:
- (用户)声明期望状态,用户提供一个 YAML 文件,告诉 Kubernetes 想要一个每小時运行一次的任务,这个任务的具体内容是运行
curl http://example.com,控制器确保实际状态匹配期望状态 - CronJob 控制器(核心计划者:实现位于
pkg/controller/cronjob)监听到用户(YAML)的声明,它的工作就是在正确的时间点,创建一个 Job 对象来代表这次任务运行 - Job 控制器接手:Job 控制器发现有一个新的 Job 被创建了,它的工作是创建一个或多个 Pod 来执行这个任务
- kubelet 最终执行:节点上的 kubelet服务监听到有 Pod 被调度到它所在的节点,它的工作是拉取指定的容器镜像并在容器内启动进程
- 任务的执行最终发生在 Pod 里的容器中
从代码层面上来说:
- CronJob 控制器的代码(计划者):只负责计时和创建 Job 对象。它包含一个无限循环,不断地检查是否有 CronJob 到了该触发的时间点。如果到了,它就调用 Kubernetes API 创建了一个 Job 资源。这里不包含任何与具体任务相关的逻辑。
- Job 对象的定义(任务蓝图):定义在CronJob YAML 文件的
spec.jobTemplate.spec.template中,即定义任务代码的地方。它实际上是一个 Pod 模板,其中包含了容器镜像、命令、参数等,真正的任务代码image: busybox和command: ["/bin/sh", "-c", "date; echo 'Hello from Kubernetes CronJob'"]。这段代码被打包在 busybox的容器镜像里 - Job 控制器的代码(任务执行者):位于
pkg/controller/job,这里的代码负责监听 Job 对象的创建。当它发现一个新的 Job 被创建(比如由 CronJob 控制器创建的),它就根据 Job 对象中的 Pod 模板,调用 Kubernetes API 创建一个或多个 Pod。它也不包含任务逻辑 - 最终执行地点(运行时):集群的 Node 节点上,在由 Job 控制器创建的 Pod 中,执行者是节点上的 kubelet服务根据 Pod 的定义,拉取指定的容器镜像(如 busybox),并启动一个容器,在容器内执行命令(如
/bin/sh -c "date; echo ...)。任务代码最终是在这个容器内部运行的。它可以是任何能在容器里运行的东西:一个 Shell 脚本、一个 Python 程序、一个编译好的 Go 二进制文件等
Kubernetes 自身的代码(CronJob/Job 控制器)只是确保这个蓝图(YAML)能在正确的时间被正确地实例化和运行
0x01 review:k8s controller
在分析具体的controller之前,先回顾下kubernetes的controller的工作原理:
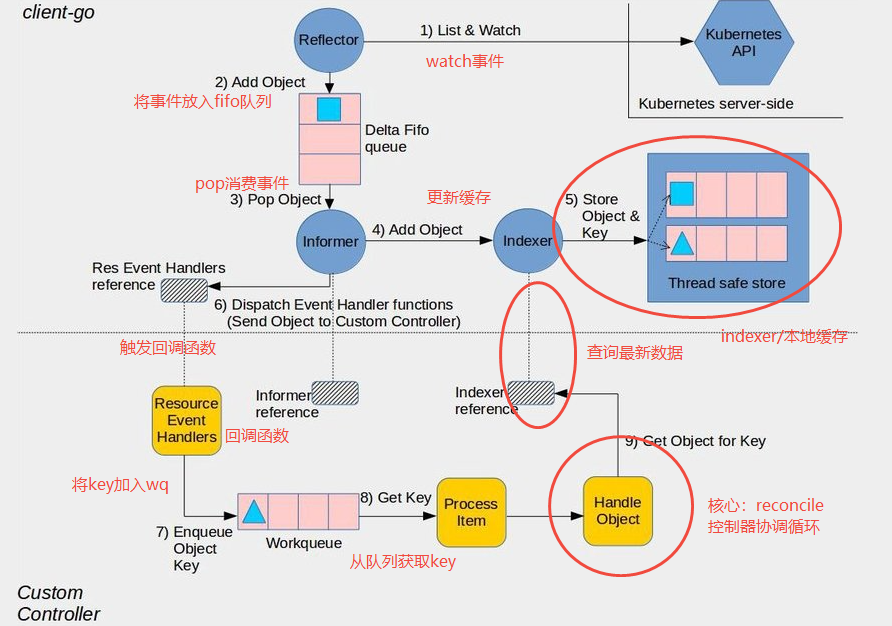
Informer 的核心目标是为客户端(通常是控制器)提供一种高效、可靠的方式来监听(Watch)并缓存特定类型资源(如 Pod/Deployment/ Job 等)的状态变化,并触发相应的业务逻辑。它解决了频繁调用 K8s apiServer 带来的几个问题:
- 性能压力:避免对 apiServer 和 etcd 造成巨大的查询压力
- 可靠性:处理网络中断、控制器重启等场景,保证状态最终一致性
- 解耦:将事件获取与事件处理分离
核心模块
1、Reflector,驱动整个 Informer 的发动机,它通过 List-Watch 机制与 API Server 建立连接
- List机制:在启动时,首先调用 List API 获取该类型资源的全量列表,用于初始化
- Watch机制:在 List 完成后,立即建立一个长连接(HTTP Chunked Response)来监听该资源的所有后续变化(ADD/MODIFIED/DELETED)。如果连接中断,Reflector 会尝试重新建立连接,并从上次中断的资源版本(Resource Version)开始继续监听,避免事件丢失
- 输出:Reflector 将从 API Server 监听到的事件(不是完整的对象,而是事件类型和关联对象)写入下一个模块DeltaFIFO
2、DeltaFIFO是一个生产-消费队列,但存储的是变化(Delta)而不是完整对象
- Delta结构体包含操作类型(Type)和操作对象(Object),如
{Type: Added, Object: Pod{...}} - FIFO特性:保证了事件的处理顺序
- 去重:对于同一个对象,如果多个事件(如多次更新)到达时尚未被处理,DeltaFIFO 会将这些相同对象的 Delta 合并,只保留最新的状态,避免控制器处理不必要的中间状态
- 作为队列而言,Reflector 是生产者,将事件放入 DeltaFIFO;Informer 是消费者,从 DeltaFIFO 中弹出(Pop)事件进行处理
3、Indexer & Local Store,本质是本地缓存,是 Informer 的内存数据库,它包含了两大功能:缓存&&索引
- 存储:Indexer 是 DeltaFIFO 的消费端之一。当 Informer 从 DeltaFIFO 中取出一个事件后,它会根据事件类型(Add/Update/Delete)更新其内部的本地缓存(Store)。此缓存是一个线程安全的键值存储,Key 默认为
<namespace>/<name>的格式,Value 是完整的资源对象 - 索引(Index):除了通过 Key 查找,Indexer 还支持创建自定义索引(基于标签、注解或其他字段),实现快速数据检索
- 作用:控制器所有的查询操作都直接访问本地缓存,减轻了 apiServer 的压力,并加快了控制器的响应速度
4、Informer (Controller)是协调中心,其内嵌了 Reflector 并管理着 DeltaFIFO 的消费过程, 流程控制如下
- 启动 Reflector
- 从 DeltaFIFO 中弹出(pop)事件
- 对于每一个弹出的事件,它首先更新 Indexer 中的本地缓存
- 然后,它将这个事件分发给注册的回调函数(ResourceEventHandler)
5、ResourceEventHandler (回调函数),提供开发者定义的、用于响应特定事件的业务逻辑钩子。这是控制器实现自身业务逻辑的入口。通常需要实现三个方法:
OnAdd(obj interface{}):当有新增对象时调用OnUpdate(oldObj, newObj interface{}):当对象更新时调用OnDelete(obj interface{}):当对象删除时调用
注意:如之前讨论所述,这些回调函数里通常不包含复杂的处理逻辑,识别出关心的对象,然后将其 Key(或一个轻量级结构)扔进 Workqueue
6、Workqueue,主要用于解耦事件接收和事件处理。它是控制器自定义的队列,不同于 DeltaFIFO
- 去重:同一个对象的多个事件可能被合并,避免重复处理
- 重试:如果处理失败,可以将项目重新放回队列(putqueue)等待后续重试
- 延迟:支持延迟入队(AddAfter),用于实现定时任务(如 CronJob 的下次执行时间)
- 消费者:控制器的核心协调循环(Reconcile Loop)会从 Workqueue 中取出项目进行处理
从本质上理解workqueue的生产/消费及reconcile过程,是非常关键的
小结下,informer的协同工作流程实现了水平触发(Level-Triggered)机制,即使事件丢失或控制器重启,控制器最终都会通过对比本地缓存中的状态与期望状态,达到一致的结果,保证了系统的最终一致性(Eventual Consistency)和极高的可靠性
- 启动:Informer 通过 Reflector 的 List-Watch 从 API Server 获取全量数据 + 持续监听变化
- 接收事件:变化事件被 Reflector 放入 DeltaFIFO 队列
- 处理与分发:Informer 消费 DeltaFIFO,先更新本地缓存(Indexer),再调用回调函数(ResourceEventHandler)
- 业务入口:回调函数将需要处理的对象标识放入自定义的工作队列(Workqueue)
- 业务处理:控制器的循环从 Workqueue 中取出项目,通过 Key 从本地缓存(Indexer)中获取最新数据,然后执行真正的业务逻辑(如创建 Pod、更新状态等)
一些细节问题总结
1、关于回调函数,输入/输出?
TODO
0x02 k8s的job controller实现
Job
Job 负责批量处理短暂的一次性任务 (short lived one-off tasks),即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
backoffLimit: 6 # 标记为 failed 前的重试次数,默认为 6
completions: 4 # 要完成job 的 pod 数,若没有设定该值则默认等于 parallelism 的值
parallelism: 2 # 任意时间最多可以启动多少个 pod 同时运行,默认为 1
activeDeadlineSeconds: 120 # job 运行时间
ttlSecondsAfterFinished: 60 # job 在运行完成后 60 秒就会自动删除掉
template:
spec:
containers:
- command:
- sh
- -c
- 'echo ''scale=5000; 4*a(1)'' | bc -l '
image: resouer/ubuntu-bc
name: pi
restartPolicy: Never
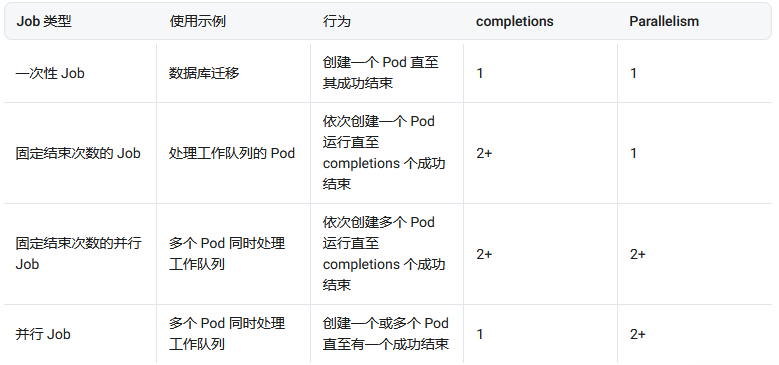
Kubernetes 支持以下几种 Job:
- 非并行 Job:通常创建一个 Pod 直至其成功结束
- 固定结束次数的 Job:设置
.spec.completions,创建多个 Pod,直到.spec.completions个 Pod 成功结束 - 带有工作队列的并行 Job:设置
.spec.Parallelism但不设置.spec.completions,当所有 Pod 结束并且至少一个成功时,Job 就认为是成功
根据 .spec.completions 和 .spec.Parallelism 的设置,可以将 Job 划分为以下几种 pattern:
Job Spec 格式(主要)如下:
spec.template格式同 PodRestartPolicy仅支持Never或OnFailure- 单个 Pod 时,默认 Pod 成功运行后 Job 即结束
.spec.completions标志 Job 结束需要成功运行的 Pod 个数,默认为1.spec.parallelism标志并行运行的 Pod 的个数,默认为1spec.activeDeadlineSeconds标志失败 Pod 的重试最大时间,超过这个时间不会继续重试
Job架构设计
下图说明了Job与pod的关系:
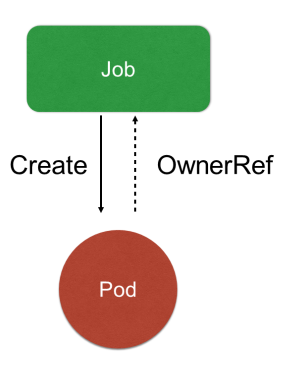
- Job controller负责根据配置创建pod
- job controller跟踪job状态,根据配置及时重试pod或者继续创建
- job controller会自动添加label来跟踪对应的pod,并根据配置并行或者串行创建pod
Job Controller 其实还是主要去创建相对应的 pod,然后 Job Controller 会去跟踪 Job 的状态,及时地根据提交的一些配置重试或者继续创建。由于每个 pod 会有它对应的 label,来跟踪它所属的 Job Controller(ownerReferences),并且还去配置并行的创建,并行或者串行地去创建 pod
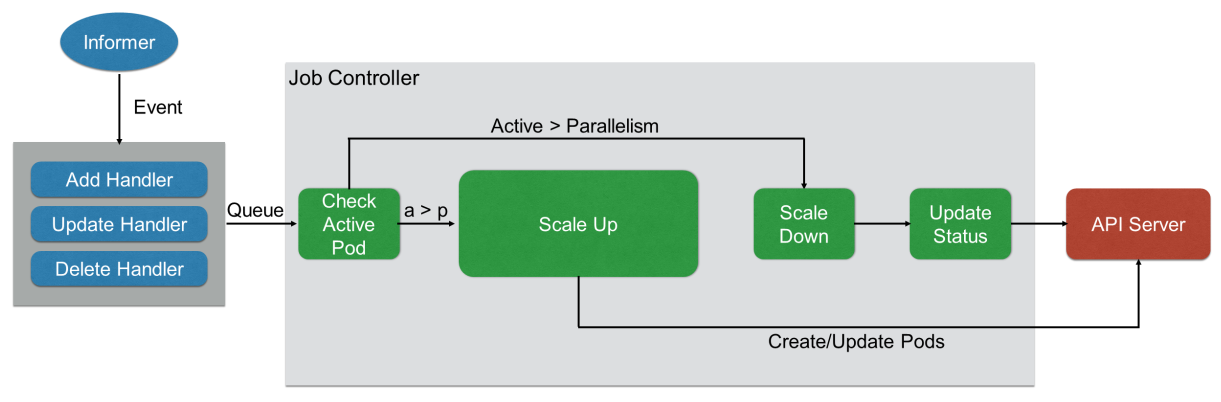
先从上面描述的informer机制来简单的描述下job controller的工作过程:
所有的 job 都是一个 controller,它会 watch k8s集群的 apiServer,当每次提交一个 Job 的 yaml 都会经过 apiServer 写入到 ETCD ,然后 Job Controller 会注册 Handler(ADD/DELETE/UPDATE),即每当有添加/更新/删除等操作的时候,它会通过workQueue这个内存级的消息队列,发到 controller 里面
当从workQueue消费拿到对应的key/value结构之后,通过 Job Controller 检查当前是否有运行的 pod,如果没有的话,通过 Scale up 把这个 pod 创建出来;如果有的话,或者如果大于这个数,对它进行 Scale down,如果这时 pod 发生了变化,需要及时 Update 其状态
同时要去检查它是否是并行的 job,或者是串行的 job,根据设置的配置并行度、串行度,及时地把 pod 的数量给创建出来。最后,它会把 job 的整个的状态更新到 apiserver 里面去,这样就能看到呈现出来的最终效果了
所以,从上面的描述来看,job controller与 job、pod这两个k8s类型是强行关联的
job controller:pod && job
为何在job controller的实现中需要监听 Job 和 Pod 两种资源?这里体现了 Kubernetes 控制器不关心事件,只关心对象的当前状态,并努力使其向期望状态收敛这个过程,即水平触发(Level-Triggered) 和 状态驱动。Controller控制器不会因为一个Pod 已创建的事件就认为万事大吉,而是会持续地、周期性地检查当前活跃的 Pod 数量是否满足 Job 的并行度要求?且成功完成的 Pod 数量是否达到了目标?即使错过某个事件或控制器重启,它也能基于当前状态自我修复,最终达成一致状态
- 监听 Job 对象(控制目标):这是为了要做什么事情,即当用户创建一个 Job 时,或者现有 Job 的规格(如
parallelism)被修改时,Controller 需要通过监听 Job 来感知这些变化。这是驱动整个控制循环的起点 - 监听 Pod 对象(执行单元):这是为了做得怎么样了,任务进行到哪一步,即Job 的期望状态(完成一定数量的 Pod)是通过管理 Pod 来实现的。Controller 必须持续监听这些 Pod 的状态(是 Pending/Running/Succeeded/Failed?),才能准确地更新 Job 的当前状态(
.status),并决定下一步动作(是否需要创建新 Pod 重试,或是否任务已完成)
简单梳理下,Job Controller 与 API Server 的交互场景:
| 操作类型 | 触发条件 | 目的与说明 |
|---|---|---|
| 创建 Pod | 监听到了新的 Job 对象,或其 spec.parallelism允许且需要创建新的 Pod 来完成任务 |
根据 Job 中定义的 Pod 模板,创建实际执行工作的 Pod 实例。这是 Job 的核心动作 |
| 删除 Pod | 管理的 Pod 数量超过了 spec.parallelism的限制,或需要清理已完成的 Pod(特别是旧版控制器策略) |
控制并发度,或在任务完成后进行清理 |
| 更新 Job Status | Pod 状态发生变化(如成功或失败),需要更新 Job 的 .status字段以反映进度(如 succeeded和 failed计数) |
让用户和系统能准确感知 Job 的当前执行状态和进度 |
| Patch Job (Finalizers) | 为确保可靠跟踪,在创建 Pod 时为其添加 finalizer,在 Pod 状态被记录后移除 | 防止 Pod 被意外删除导致任务跟踪丢失,是实现可靠跟踪的核心机 |
| 更新 Job 自身 | 任务完成(达到 spec.completions)或失败(达到 spec.backoffLimit),需要标记 Job 的最终状态 | 将 Job 状态标记为 Complete或 Failed,使其生命周期结束 |
部分基础知识
1、Expectations 机制
Expectations 机制是Job Controller 在内存中维护的一个期望清单,用来记录它刚刚发出的创建或删除 Pod 的指令。其核心作用是确保控制器在真正采取行动前,必须等待并确认上一次的指令已经生效,从而防止重复操作,确保协调过程的最终一致性,Expectations 机制被用来解决分布式下的操作延迟与感知的场景:
最终一致性延迟,即当 Controller 通过 API Server 发出创建 Pod A的请求后,这个变化需要时间才能被集群感知:
- Pod 需要被调度到某个节点上
- Kubelet 需要拉取镜像并启动容器
- Pod 的状态从 Pending变为 Running
- 这个状态变化需要通过 API Server 写回 etcd
事件驱动与重入,Controller 通过 Informer 监听 Pod 的变化。但事件到达的顺序和时机是不确定的,很可能出现如下case:
- Controller 刚创建完
3个 Pod,在它收到任何一个 Pod 的 Created事件之前,下一次同步循环(syncJob) 就因为其他原因(比如定时同步)又被触发了 - 如果没有记录,Controller 会再次检查当前状态,发现并没有pod生成(事件通知滞后了),于是它又会创建
3个新的 Pod。这就导致了重复创建
Expectations 机制就是为了解决上述这种看不到自己的操作结果而导致的重入问题。它的工作原理是一个典型的记账-销账过程,Expectations为每个 Job 对象(通过其 Key 标识)维护一个类似如下结构的计数器
type ControlleeExpectations struct {
add int64 // 期望看到的 Pod 创建成功次数
del int64 // 期望看到的 Pod 删除成功次数
key string // 对应的 Job key
}
Expectations机制的作用如下:
- 防止重复操作:通过记账机制,控制器能清晰地知道已经发出指令了,正在等结果,从而避免在结果返回前再次发出相同指令
- 确保状态收敛的可靠性:它强制控制器必须等待上一次操作的结果被确认后,才能进行下一次可能依赖该结果的协调。这使得复杂的协调逻辑(例如,Job 需要替换失败的 Pod)能够安全地进行
- 应对事件丢失:该机制内建了超时逻辑(默认
5分钟)。如果一条期望迟迟没有被满足(比如一个 Pod 的创建事件永远丢失了),超时后控制器会强制认为该期望已满足,继续后续操作,防止控制器被永远卡住
2、Sync机制
3、Queue
4、orphanQueue VS queue
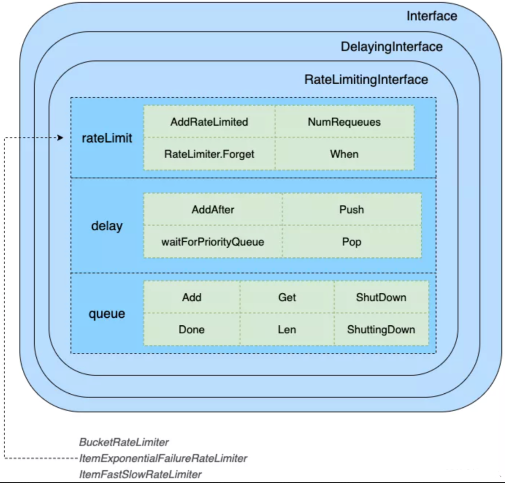
Job controller 实现分析
job_controller实现在此,开发者主要只做了以下几件事:
- 定义了
Controller结构体,并持有了 Workqueue、Informer Lister(用于访问 Indexer)、ClientSet 等依赖 - 实现了
ResourceEventHandler的方法(如addJob、updatePod等),这些是 Workqueue 的生产者 - 实现了
syncHandler(即syncJob函数),这是 Workqueue 的消费者和整个控制器的核心协调reconcile逻辑 - 实现了启动逻辑
Run(),来启动 Informer 和 Worker goroutine
这里需要特别注意,在kubernetes的informer机制中的reflector/deltaFIFO/indexer,这部分从watch到入队列再到消费并更新indexer的工作,这部分工作已经由client-go库中的 SharedInformer 机制自动、透明地完成了,无需开发者实现
Controller定义如下:
type Controller struct {
kubeClient clientset.Interface
podControl controller.PodControlInterface
// To allow injection of the following for testing.
updateStatusHandler func(ctx context.Context, job *batch.Job) (*batch.Job, error)
patchJobHandler func(ctx context.Context, job *batch.Job, patch []byte) error
syncHandler func(ctx context.Context, jobKey string) error
// podStoreSynced returns true if the pod store has been synced at least once.
// Added as a member to the struct to allow injection for testing.
podStoreSynced cache.InformerSynced
// jobStoreSynced returns true if the job store has been synced at least once.
// Added as a member to the struct to allow injection for testing.
jobStoreSynced cache.InformerSynced
// A TTLCache of pod creates/deletes each rc expects to see
expectations controller.ControllerExpectationsInterface
// finalizerExpectations tracks the Pod UIDs for which the controller
// expects to observe the tracking finalizer removed.
finalizerExpectations *uidTrackingExpectations
// A store of jobs
jobLister batchv1listers.JobLister
// A store of pods, populated by the podController
podStore corelisters.PodLister
// Jobs that need to be updated
queue workqueue.RateLimitingInterface
// Orphan deleted pods that still have a Job tracking finalizer to be removed
orphanQueue workqueue.RateLimitingInterface
broadcaster record.EventBroadcaster
recorder record.EventRecorder
clock clock.WithTicker
// Store with information to compute the expotential backoff delay for pod
// recreation in case of pod failures.
podBackoffStore *backoffStore
}
初始化NewController方法,从初始化流程中可以看到 JobController 监听 pod 和 job 两种资源
//NewController->newControllerWithClock
func newControllerWithClock(ctx context.Context, podInformer coreinformers.PodInformer, jobInformer batchinformers.JobInformer, kubeClient clientset.Interface, clock clock.WithTicker) *Controller {
eventBroadcaster := record.NewBroadcaster()
logger := klog.FromContext(ctx)
jm := &Controller{
......
}
jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jm.enqueueSyncJobImmediately(logger, obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
jm.updateJob(logger, oldObj, newObj)
},
DeleteFunc: func(obj interface{}) {
jm.deleteJob(logger, obj)
},
})
jm.jobLister = jobInformer.Lister()
jm.jobStoreSynced = jobInformer.Informer().HasSynced
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jm.addPod(logger, obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
jm.updatePod(logger, oldObj, newObj)
},
DeleteFunc: func(obj interface{}) {
jm.deletePod(logger, obj, true)
},
})
jm.podStore = podInformer.Lister()
jm.podStoreSynced = podInformer.Informer().HasSynced
//调用kubeclient 更新job status
jm.updateStatusHandler = jm.updateJobStatus
//调用kubeclient patch job
jm.patchJobHandler = jm.patchJob
// 核心实现:reconcile
jm.syncHandler = jm.syncJob
metrics.Register()
return jm
}
controller启动Run 方法,其中核心逻辑是调用 jm.worker 执行 syncLoop 操作,worker 方法是 syncJob 方法的别名,最终调用的是 syncJob
// Run the main goroutine responsible for watching and syncing jobs.
func (jm *Controller) Run(ctx context.Context, workers int) {
defer utilruntime.HandleCrash()
logger := klog.FromContext(ctx)
// Start events processing pipeline.
jm.broadcaster.StartStructuredLogging(0)
jm.broadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: jm.kubeClient.CoreV1().Events("")})
defer jm.broadcaster.Shutdown()
defer jm.queue.ShutDown()
defer jm.orphanQueue.ShutDown()
logger.Info("Starting job controller")
defer logger.Info("Shutting down job controller")
if !cache.WaitForNamedCacheSync("job", ctx.Done(), jm.podStoreSynced, jm.jobStoreSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, jm.worker, time.Second)
}
go wait.UntilWithContext(ctx, jm.orphanWorker, time.Second)
<-ctx.Done()
}
workqueue的生产者:ResourceEventHandler
在NewController初始化时,注册的ResourceEventHandler如下:
func newControllerWithClock(ctx context.Context, podInformer coreinformers.PodInformer, jobInformer batchinformers.JobInformer, kubeClient clientset.Interface, clock clock.WithTicker) *Controller {
......
jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jm.enqueueSyncJobImmediately(logger, obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
jm.updateJob(logger, oldObj, newObj)
},
DeleteFunc: func(obj interface{}) {
jm.deleteJob(logger, obj)
},
})
jm.jobLister = jobInformer.Lister()
jm.jobStoreSynced = jobInformer.Informer().HasSynced
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jm.addPod(logger, obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
jm.updatePod(logger, oldObj, newObj)
},
DeleteFunc: func(obj interface{}) {
jm.deletePod(logger, obj, true)
},
})
......
}
TODO
jm.enqueueSyncJobImmediately:
jm.deleteJob:
jm.addPod:
job controller的工作流
workqueue的生产者:ResourceEventHandler
1、AddFunc:enqueueSyncJobImmediately
2、UpdateFunc:updateJob
3、DeleteFunc:deleteJob
4、PodFunc:addPod/updatePod/deletePod
deletePod的主要流程:发现 Pod 被删除 -> 确认其所属的 Job -> 记录已观测到删除事件 -> 触发所属 Job 的同步循环,deletePod这个事件处理函数负责进行逻辑判断和任务分发,它将需要处理的工作推入不同的队列workqueue。然后,这些队列的消费者(Worker)会从队列中取出任务,并调用 KubeClient 等组件去执行最终的、具体的操作
// When a pod is deleted, enqueue the job that manages the pod and update its expectations.
// obj could be an *v1.Pod, or a DeleteFinalStateUnknown marker item.
func (jm *Controller) deletePod(logger klog.Logger, obj interface{}, final bool) {
pod, ok := obj.(*v1.Pod)
if final {
recordFinishedPodWithTrackingFinalizer(pod, nil)
}
// When a delete is dropped, the relist will notice a pod in the store not
// in the list, leading to the insertion of a tombstone object which contains
// the deleted key/value. Note that this value might be stale. If the pod
// changed labels the new job will not be woken up till the periodic resync.
if !ok {
tombstone, ok := obj.(cache.DeletedFinalStateUnknown)
if !ok {
utilruntime.HandleError(fmt.Errorf("couldn't get object from tombstone %+v", obj))
return
}
pod, ok = tombstone.Obj.(*v1.Pod)
if !ok {
utilruntime.HandleError(fmt.Errorf("tombstone contained object that is not a pod %+v", obj))
return
}
}
controllerRef := metav1.GetControllerOf(pod)
hasFinalizer := hasJobTrackingFinalizer(pod)
if controllerRef == nil {
// No controller should care about orphans being deleted.
// But this pod might have belonged to a Job and the GC removed the reference.
if hasFinalizer {
jm.enqueueOrphanPod(pod)
}
return
}
job := jm.resolveControllerRef(pod.Namespace, controllerRef)
if job == nil || IsJobFinished(job) {
// syncJob will not remove this finalizer.
if hasFinalizer {
jm.enqueueOrphanPod(pod)
}
return
}
jobKey, err := controller.KeyFunc(job)
if err != nil {
return
}
jm.expectations.DeletionObserved(logger, jobKey)
// Consider the finalizer removed if this is the final delete. Otherwise,
// it's an update for the deletion timestamp, then check finalizer.
if final || !hasFinalizer {
jm.finalizerExpectations.finalizerRemovalObserved(logger, jobKey, string(pod.UID))
}
jm.enqueueSyncJobBatched(logger, job)
}
小结下,ResourceEventHandler的实现体现了kubernetes informer的正确的交互模式,即声明式 API,就是告诉系统你期望的状态(如希望这个 Pod 不存在),而不是发出命令式的指令(删除这个 Pod 的缓存记录),因此控制器的工作流程是:
- 观察: 通过 Indexer(缓存)观察系统的当前状态
- 比较: 将当前状态与期望状态(Spec)进行比较
- 驱动: 如果存在差异,则通过 Kubernetes API 发起操作,驱动系统向期望状态收敛
所以在 deleteJob方法实现中的正确逻辑是,它发现了一个需要清理的 Pod(带有 Finalizer 的孤儿 Pod),它没有直接去操作 Indexer,而是调用了 jm.enqueueOrphanPod(pod),该操作最终会导致 Pod 的 Key 被放入Orphan pod的工作队列。队列的消费者(Worker)会调用相应的处理函数,该函数会通过 kubeClient向 apiServer 发起一个 PATCH 或 UPDATE 请求,目的是移除该 Pod 上的 Finalizer
当apiServer 接收到这个请求后,验证请求并更新 etcd 中该 Pod 的资源记录(移除 Finalizer),由于 Pod 的 Finalizer 被移除,且其所有者(Job)已不存在,Pod 会被真正删除。apiServer 会向所有监听 Pod 资源的 Watcher(包括这里的 Job Controller 的 Informer)广播一个 DELETED事件
最后,这里的 Informer 接收到 DELETED事件后,内部逻辑会自动安全地从 Indexer 中移除该 Pod 的条目
workqueue的消费者:syncJob
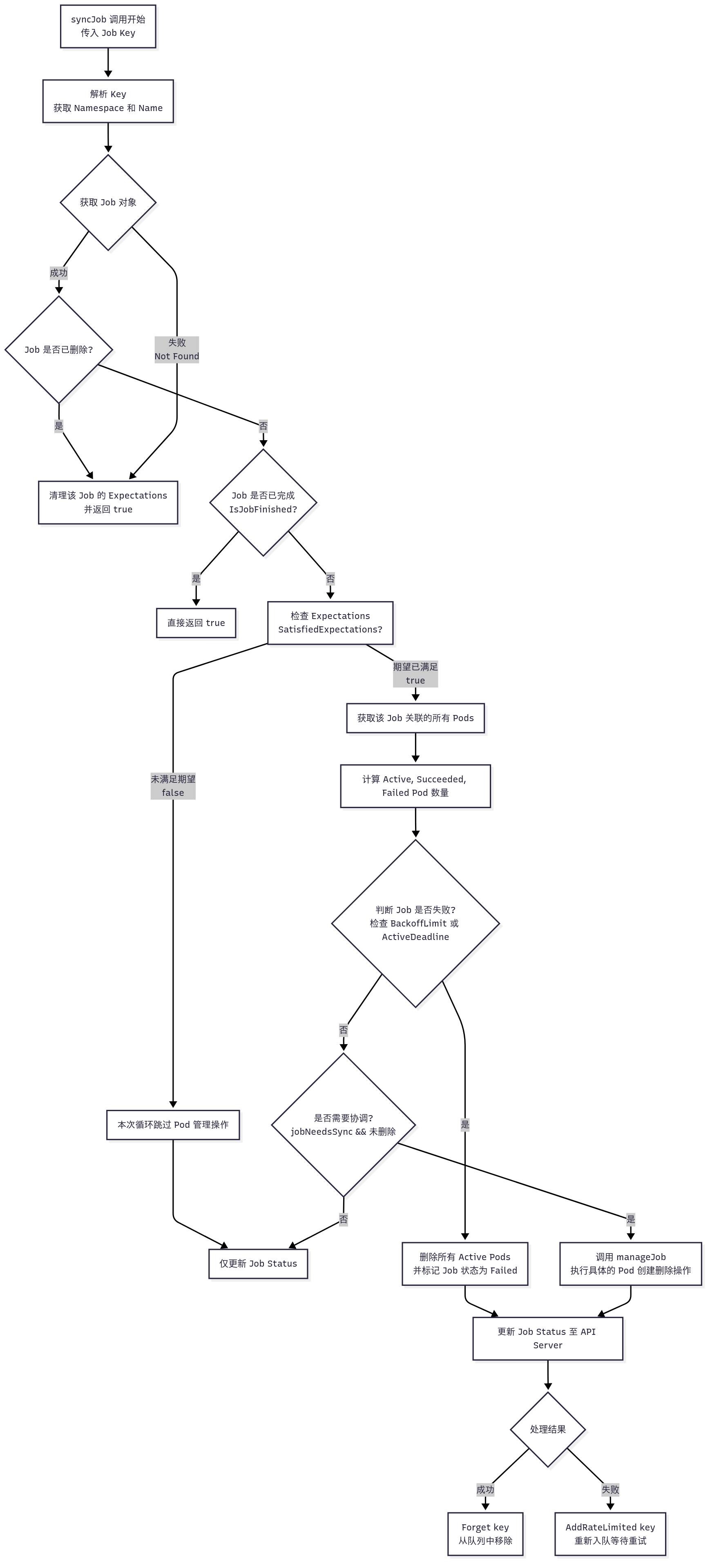
syncJob 是 jobController 的核心方法,主要对workqueue pop出的object进行处理,其主要逻辑为:
1、从 lister(indexer的实例化) 中获取 job 对象
2、通过IsJobFinished方法判断 job 是否已经执行完成,当 job 的 .status.conditions 中有 Complete 或 Failed 的 type 且对应的 status 为 true 时表示该 job 已经执行完成
status:
completionTime: "2019-12-18T14:16:47Z"
conditions:
- lastProbeTime: "2019-12-18T14:16:47Z"
lastTransitionTime: "2019-12-18T14:16:47Z"
status: "True" # status 为 true
type: Complete # Complete
startTime: "2019-12-18T14:15:35Z"
succeeded: 2
3、若Job未执行完成,获取 job 重试的次数
4、调用 jm.expectations.SatisfiedExpectations 判断 job 是否需能进行 sync 操作,其主要判断条件如下:
- 该 key 在 ControllerExpectations 中的 adds 和 dels 都 <= 0,即调用 apiserver 的创建和删除接口没有失败过; 2、该 key 在 ControllerExpectations 中已经超过 5min 没有更新了; 3、该 key 在 ControllerExpectations 中不存在,即该对象是新创建的; 4、调用 GetExpectations 方法失败,内部错误;
5、调用 jm.getPodsForJob 通过 selector 获取 job 关联的 pod,若有孤儿 pod 的 label 与 job 的能匹配则进行关联,若已关联的 pod label 有变化则解除与 job 的关联关系
6、分别计算 active、succeeded、failed 状态的 pod 数
7、判断 job 是否为首次启动,若首次启动其 job.Status.StartTime 为空,此时首先设置 startTime,然后检查是否有 job.Spec.ActiveDeadlineSeconds 是否为空,若不为空则将其再加入到延迟队列中,等待 ActiveDeadlineSeconds 时间后会再次触发 sync 操作
8、判断 job 的重试次数是否超过了 job.Spec.BackoffLimit(默认6次)
- 判断方法一:通过 job 的重试次数以及 job 的状态
- 判断方法二:当 job 的
restartPolicy为OnFailure时 container 的重启次数
上述二者任一个符合都说明 job 处于 failed 状态且原因为 BackoffLimitExceeded
9、判断 job 的运行时间是否达到 job.Spec.ActiveDeadlineSeconds 中设定的值(关联方法为pastActiveDeadline),若已达到则说明 job 此时处于 failed 状态且原因为 DeadlineExceeded
10、根据以上判断如果 job 处于 failed 状态,则调用 jm.deleteJobPods 并发删除所有 active pods
11、若非 failed 状态,根据 jobNeedsSync 判断是否要进行同步,若需要同步则调用 jm.manageJob 进行同步()
12、通过检查 job.Spec.Completions 判断 job 是否已经运行完成,若 job.Spec.Completions 字段没有设置值则只要有一个 pod 运行完成该 job 就为 Completed 状态,若设置了 job.Spec.Completions 会通过判断已经运行完成状态的 pod 即 succeeded pod 数是否大于等于该值
13、通过以上判断若 job 运行完成了,则更新 job.Status.Conditions 和 job.Status.CompletionTime 字段
14、如果 job 的 status 有变化,则通过jm.updateHandler将 job 的 status 更新到 apiserver
至此,job controller的reconcile逻辑基本完成
此外,在上面描述了当 Job 尚未完成(即还处于活跃状态)且需要对其管理的 Pod 进行操作时,在 syncJob 中调用 jm.manageJob 处理非 failed 状态下的 sync 操作
// processNextWorkItem:从workqueue取出并消费object的实现
func (jm *Controller) processNextWorkItem(ctx context.Context) bool {
key, quit := jm.queue.Get()
if quit {
return false
}
defer jm.queue.Done(key)
// syncHandler:即调用syncJob
err := jm.syncHandler(ctx, key.(string))
if err == nil {
// 如果未发生错误,那么
jm.queue.Forget(key)
return true
}
utilruntime.HandleError(fmt.Errorf("syncing job: %w", err))
jm.queue.AddRateLimited(key)
return true
}
// 初始化代码:jm.syncHandler = jm.syncJob
func (jm *JobController) syncJob(key string) (bool, error) {
// 1、计算每次 sync 的运行时间
startTime := time.Now()
defer func() {
klog.V(4).Infof("Finished syncing job %q (%v)", key, time.Since(startTime))
}()
ns, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return false, err
}
if len(ns) == 0 || len(name) == 0 {
return false, fmt.Errorf("invalid job key %q: either namespace or name is missing", key)
}
// 2、从 lister 中获取 job 对象
sharedJob, err := jm.jobLister.Jobs(ns).Get(name)
if err != nil {
if errors.IsNotFound(err) {
klog.V(4).Infof("Job has been deleted: %v", key)
jm.expectations.DeleteExpectations(key)
return true, nil
}
return false, err
}
job := *sharedJob
// 3、判断 job 是否已经执行完成
//https://github.com/kubernetes/kubernetes/blob/release-1.28/pkg/controller/job/utils.go#L26
if IsJobFinished(&job) {
// 完成即返回
return true, nil
}
// 4、获取 job 重试的次数
previousRetry := jm.queue.NumRequeues(key)
// 5、判断 job 是否能进行 sync 操作
jobNeedsSync := jm.expectations.SatisfiedExpectations(key)
// 6、获取 job 关联的所有 pod
pods, err := jm.getPodsForJob(&job)
if err != nil {
return false, err
}
// 7、分别计算 active、succeeded、failed 状态的 pod 数
activePods := controller.FilterActivePods(pods)
active := int32(len(activePods))
succeeded, failed := getStatus(pods)
conditions := len(job.Status.Conditions)
// 8、判断 job 是否为首次启动
if job.Status.StartTime == nil {
now := metav1.Now()
job.Status.StartTime = &now
// 9、判断是否设定了 ActiveDeadlineSeconds 值
if job.Spec.ActiveDeadlineSeconds != nil {
klog.V(4).Infof("Job %s have ActiveDeadlineSeconds will sync after %d seconds",
key, *job.Spec.ActiveDeadlineSeconds)
jm.queue.AddAfter(key, time.Duration(*job.Spec.ActiveDeadlineSeconds)*time.Second)
}
}
var manageJobErr error
jobFailed := false
var failureReason string
var failureMessage string
// 10、判断 job 的重启次数是否已达到上限,即处于 BackoffLimitExceeded
jobHaveNewFailure := failed > job.Status.Failed
exceedsBackoffLimit := jobHaveNewFailure && (active != *job.Spec.Parallelism) &&
(int32(previousRetry)+1 > *job.Spec.BackoffLimit)
if exceedsBackoffLimit || pastBackoffLimitOnFailure(&job, pods) {
jobFailed = true
failureReason = "BackoffLimitExceeded"
failureMessage = "Job has reached the specified backoff limit"
} else if pastActiveDeadline(&job) {
jobFailed = true
failureReason = "DeadlineExceeded"
failureMessage = "Job was active longer than specified deadline"
}
// 11、如果处于 failed 状态,则调用 jm.deleteJobPods 并发删除所有 active pods
if jobFailed {
errCh := make(chan error, active)
//
jm.deleteJobPods(&job, activePods, errCh)
select {
case manageJobErr = <-errCh:
if manageJobErr != nil {
break
}
default:
}
failed += active
active = 0
job.Status.Conditions = append(job.Status.Conditions, newCondition(batch.JobFailed, failureReason, failureMessage))
jm.recorder.Event(&job, v1.EventTypeWarning, failureReason, failureMessage)
} else {
// 12、若非 failed 状态,根据 jobNeedsSync 判断是否要进行同步
if jobNeedsSync && job.DeletionTimestamp == nil {
active, manageJobErr = jm.manageJob(activePods, succeeded, &job)
}
// 13、检查 job.Spec.Completions 判断 job 是否已经运行完成
completions := succeeded
complete := false
if job.Spec.Completions == nil {
if succeeded > 0 && active == 0 {
complete = true
}
} else {
if completions >= *job.Spec.Completions {
complete = true
if active > 0 {
jm.recorder.Event(&job, v1.EventTypeWarning, "TooManyActivePods", "Too many active pods running after completion count reached")
}
if completions > *job.Spec.Completions {
jm.recorder.Event(&job, v1.EventTypeWarning, "TooManySucceededPods", "Too many succeeded pods running after completion count reached")
}
}
}
// 14、若 job 运行完成了,则更新 job.Status.Conditions 和 job.Status.CompletionTime 字段
if complete {
job.Status.Conditions = append(job.Status.Conditions, newCondition(batch.JobComplete, "", ""))
now := metav1.Now()
job.Status.CompletionTime = &now
}
}
forget := false
if job.Status.Succeeded < succeeded {
forget = true
}
// 15、如果 job 的 status 有变化,将 job 的 status 更新到 apiserver
if job.Status.Active != active || job.Status.Succeeded != succeeded || job.Status.Failed != failed || len(job.Status.Conditions) != conditions {
job.Status.Active = active
job.Status.Succeeded = succeeded
job.Status.Failed = failed
if err := jm.updateHandler(&job); err != nil {
return forget, err
}
if jobHaveNewFailure && !IsJobFinished(&job) {
return forget, fmt.Errorf("failed pod(s) detected for job key %q", key)
}
forget = true
}
return forget, manageJobErr
}
正如上面所描述,jm.manageJob被调用的条件是,Job 未处于完成状态,并且经过计算后发现当前 Pod 的数量与期望状态不一致(需要创建或需要删除)
- Job 未完成:这是最基本的条件。如果 Job 已经成功或失败(通过检查
status.conditions判断),协调循环会跳过 Pod 管理逻辑,直接进入最终的清理和状态更新阶段 - 需要协调 Pod:即使 Job 未完成,也并非总是需要立即操作 Pod。具体包括以下几种情况:
- 需要创建更多 Pod:当前活跃的 Pod 数量少于 Job 的
.spec.parallelism指定的期望数量 - 需要删除多余 Pod:当前活跃的 Pod 数量多于期望数量(通常由于 Job 规格被减小),或者 Job 本身正在被删除(
DeletionTimestamp不为空)
- 需要创建更多 Pod:当前活跃的 Pod 数量少于 Job 的
jm.manageJob主要做的事情就是根据 job 配置的并发数来确认当前处于 active 状态的 pods 数量是否合理,如果不合理的话则进行调整,其主要逻辑如下:
1、首先获取 job 的 active pods 数与可运行的 pod 数即 job.Spec.Parallelism
2、判断如果处于 active 状态的 pods 数大于 job 设置的并发数 job.Spec.Parallelism,则并发删除多余的 active pods,需要删除的 active pods 按优先级排序:
- 判断是否绑定了 node:
Unassigned < assigned - 判断 pod phase:
PodPending < PodUnknown < PodRunning - 判断 pod 状态:
Not ready < ready - 若 pod 都为 ready,则按运行时间排序,运行时间最短会被删除:
empty time < less time < more time - 根据 pod 重启次数排序:
higher restart counts < lower restart counts - 按 pod 创建时间进行排序:
Empty creation time pods < newer pods < older pods
3、若处于 active 状态的 pods 数小于 job 设置的并发数,则需要根据 job 的配置计算 pod 的 diff 数并进行创建,计算方法与 completions、parallelism 以及 succeeded 的 pods 数有关,计算出 diff 数后会进行批量创建,创建的 pod 数依次为 1、2、4、8...,呈指数级增长(job 创建 pod 的方式与 rs 创建 pod 是类似的,但是此处并没有限制在一个 syncLoop 中创建 pod 的上限值,创建完 pod 后会将结果记录在 job 的 expectations 中,此处并非所有的 pod 都能创建成功,若超时错误会直接忽略,因其他错误创建失败的 pod 会记录在 expectations 中,expectations 机制的主要目的是减少不必要的 sync 操作)
func (jm *JobController) manageJob(activePods []*v1.Pod, succeeded int32, job *batch.Job) (int32, error) {
// 1、获取 job 的 active pods 数与可运行的 pod 数
var activeLock sync.Mutex
active := int32(len(activePods))
parallelism := *job.Spec.Parallelism
jobKey, err := controller.KeyFunc(job) //从indexer获取完整的数据
if err != nil {
utilruntime.HandleError(fmt.Errorf("Couldn't get key for job %#v: %v", job, err))
return 0, nil
}
var errCh chan error
// 2、如果处于 active 状态的 pods 数大于 job 设置的并发数
if active > parallelism {
diff := active - parallelism
errCh = make(chan error, diff)
jm.expectations.ExpectDeletions(jobKey, int(diff))
klog.V(4).Infof("Too many pods running job %q, need %d, deleting %d", jobKey, parallelism, diff)
// 3、对 activePods 按以上 6 种策略进行排序
sort.Sort(controller.ActivePods(activePods))
// 4、并发删除多余的 active pods
active -= diff
wait := sync.WaitGroup{}
wait.Add(int(diff))
for i := int32(0); i < diff; i++ {
go func(ix int32) {
defer wait.Done()
if err := jm.podControl.DeletePod(job.Namespace, activePods[ix].Name, job); err != nil {
defer utilruntime.HandleError(err)
klog.V(2).Infof("Failed to delete %v, decrementing expectations for job %q/%q", activePods[ix].Name, job.Namespace, job.Name)
jm.expectations.DeletionObserved(jobKey)
activeLock.Lock()
active++
activeLock.Unlock()
errCh <- err
}
}(i)
}
wait.Wait()
// 5、若处于 active 状态的 pods 数小于 job 设置的并发数,则需要创建出新的 pod
} else if active < parallelism {
// 6、首先计算出 diff 数
// 若 job.Spec.Completions == nil && succeeded pods > 0, 则diff = 0;
// 若 job.Spec.Completions == nil && succeeded pods = 0,则diff = Parallelism;
// 若 job.Spec.Completions != nil 则diff等于(job.Spec.Completions - succeeded - active)和 parallelism 中的最小值(非负值);
wantActive := int32(0)
if job.Spec.Completions == nil {
if succeeded > 0 {
wantActive = active
} else {
wantActive = parallelism
}
} else {
wantActive = *job.Spec.Completions - succeeded
if wantActive > parallelism {
wantActive = parallelism
}
}
diff := wantActive - active
if diff < 0 {
utilruntime.HandleError(fmt.Errorf("More active than wanted: job %q, want %d, have %d", jobKey, wantActive, active))
diff = 0
}
if diff == 0 {
return active, nil
}
jm.expectations.ExpectCreations(jobKey, int(diff))
errCh = make(chan error, diff)
klog.V(4).Infof("Too few pods running job %q, need %d, creating %d", jobKey, wantActive, diff)
active += diff
wait := sync.WaitGroup{}
// 7、批量创建 pod,呈指数级增长
for batchSize := int32(integer.IntMin(int(diff), controller.SlowStartInitialBatchSize)); diff > 0; batchSize = integer.Int32Min(2*batchSize, diff) {
errorCount := len(errCh)
wait.Add(int(batchSize))
for i := int32(0); i < batchSize; i++ {
go func() {
defer wait.Done()
err := jm.podControl.CreatePodsWithControllerRef(job.Namespace, &job.Spec.Template, job, metav1.NewControllerRef(job, controllerKind))
// 8、调用 apiserver 创建时忽略 Timeout 错误
if err != nil && errors.IsTimeout(err) {
return
}
if err != nil {
defer utilruntime.HandleError(err)
klog.V(2).Infof("Failed creation, decrementing expectations for job %q/%q", job.Namespace, job.Name)
jm.expectations.CreationObserved(jobKey)
activeLock.Lock()
active--
activeLock.Unlock()
errCh <- err
}
}()
}
wait.Wait()
// 9、若有创建失败的操作记录在 expectations 中
skippedPods := diff - batchSize
if errorCount < len(errCh) && skippedPods > 0 {
klog.V(2).Infof("Slow-start failure. Skipping creation of %d pods, decrementing expectations for job %q/%q", skippedPods, job.Namespace, job.Name)
active -= skippedPods
for i := int32(0); i < skippedPods; i++ {
jm.expectations.CreationObserved(jobKey)
}
break
}
diff -= batchSize
}
}
select {
case err := <-errCh:
if err != nil {
return active, err
}
default:
}
return active, nil
}
几个细节问题
1、indexer的意义
2、在workqueue的生产端(回调函数),如deletePod方法中,为何不直接删除indexer中的数据?
因为 Indexer 只是一个只读的本地缓存镜像,直接删除它里面的数据没有任何意义,它无法影响 Kubernetes 集群的真实状态。对于job controller的实现来说,Indexer 的角色仅仅是只读缓存(Read-Only Cache),在informer机制中,只有基于watch-list机制的informer模块才能修改indexer,对于controller而言,只读不可修改
小结
最后基于informer的主要机制来梳理下job controller的实现思路:
- Reflector
- Deltafifo
- Indexer
- Informer:上面四个模块都已经封装完成,
NewControllerV2初始化即可 - ResourceEventHandler:pod、job的事件回调方法,应由job controller实现
- Workqueue:入队包括多个case,出队处理
processNextWorkItem - Reconcile:核心的调谐过程,关联方法
syncJob
0x02 k8s的cronjob controller实现
核心controller实现位于cronjob_controllerv2
工作流程
和其他controller实现机制一样,cronjob也遵循kubernetes的controller的一般设计模式
核心代码分析
1、Controller控制器定义,CronJobController结构体定义了控制器对象,Controller 控制器对象是实现 CronJob 功能的核心对象
type ControllerV2 struct {
// 队列中存储发生了变化 (需要同步) 的 CronJob 对象
queue workqueue.RateLimitingInterface
// kubelet 客户端对象:用于执行各项类似 "kubectl ..." 操作
kubeClient clientset.Interface
// Job 列表
jobLister batchv1listers.JobLister
// CronJob 列表
cronJobLister batchv1listers.CronJobLister
}
2、Controller初始化,NewControllerV2 方法用于 CronJob 控制器对象的初始化工作,并返回一个实例化对象
func NewControllerV2(ctx context.Context, ...) (*ControllerV2, error) {
jm := &ControllerV2{
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "cronjob"),
kubeClient: kubeClient,
broadcaster: eventBroadcaster,
recorder: eventBroadcaster.NewRecorder(scheme.Scheme, corev1.EventSource{Component: "cronjob-controller"}),
jobControl: realJobControl{KubeClient: kubeClient},
cronJobControl: &realCJControl{KubeClient: kubeClient},
jobLister: jobInformer.Lister(),
cronJobLister: cronJobsInformer.Lister(),
jobListerSynced: jobInformer.Informer().HasSynced,
cronJobListerSynced: cronJobsInformer.Informer().HasSynced,
now: time.Now,
}
// 增加 Job informer 监听回调方法
jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: jm.addJob, //细节1
UpdateFunc: jm.updateJob,
DeleteFunc: jm.deleteJob,
})
// 增加 CronJob informer 监听回调方法
cronJobsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
// cronJobsInformer的addfunc
jm.enqueueController(obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
jm.updateCronJob(logger, oldObj, newObj)
},
DeleteFunc: func(obj interface{}) {
jm.enqueueController(obj)
},
})
return jm, nil
}
TODO
3、启动控制器Controller,根据控制器的初始化方法 NewControllerV2 的调用链路,可以找到控制器开始启动和执行的地方
// cmd/kube-controller-manager/app/batch.go
func startCronJobController(ctx context.Context, ...) (controller.Interface, bool, error) {
cj2c, err := cronjob.NewControllerV2(ctx, controllerContext.InformerFactory.Batch().V1().Jobs(),
......
)
// 启动单独的 goroutine 来完成控制器的 {初始化 && 运行}
go cj2c.Run(ctx, int(controllerContext.ComponentConfig.CronJobController.ConcurrentCronJobSyncs))
return nil, true, nil
}
ControllerV2.Run 方法执行控制器具体的启动逻辑,注意UntilWithContext方法的参数jm.worker
func (jm *ControllerV2) Run(ctx context.Context, workers int) {
......
// 根据参数配置个数,启动多个 goroutine 处理逻辑
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, jm.worker /*jm.work*/, time.Second)
}
<-ctx.Done()
}
Controller.worker 方法本质上就是一个无限循环轮询器,不断从队列中取出 CronJob 对象,然后进行对应的操作,内部无限循环调用 processNextWorkItem 方法
cronjob最核心的实现都在jm.sync中
func (jm *ControllerV2) worker(ctx context.Context) {
for jm.processNextWorkItem(ctx) {
}
}
func (jm *ControllerV2) processNextWorkItem(ctx context.Context) bool {
// 从队列获取 CronJob 对象
key, quit := jm.queue.Get()
......
// 和其他几个常用的控制器不同
// CronJob 控制器不是通过字段注入的方式设置同步的回调方法
// 而是直接调用 sync 方法进行同步
requeueAfter, err := jm.sync(ctx, key.(string))
switch {
case err != nil:
// 如果同步回调方法执行异常
// 将当前 CronJob 对象重新放入队列
jm.queue.AddRateLimited(key)
case requeueAfter != nil:
// 如果同步回调方法执行成功
// 并且
// CronJob 对象的下次执行时间不为空
// 第一步: 先将当前 CronJob 对象踢出队列
jm.queue.Forget(key)
// 第二步: 将当前 CronJob 对象延迟放入队列
jm.queue.AddAfter(key, *requeueAfter)
}
return true
}
4、CronJob 同步:ControllerV2 的回调处理方法是 sync 方法,该方法是所有 CronJob 对象同步操作的入口方法
func (jm *ControllerV2) sync(ctx context.Context, cronJobKey string) (*time.Duration, error) {
// 通过 key 解析出 CronJob 对象对应的 命名空间和名称
ns, name, err := cache.SplitMetaNamespaceKey(cronJobKey)
// 获取 CronJob 对象
cronJob, err := jm.cronJobLister.CronJobs(ns).Get(name)
......
// 获取 CronJob 对象关联的 Job 对象列表
jobsToBeReconciled, err := jm.getJobsToBeReconciled(cronJob)
// 深度拷贝一个 CronJob 对象 (用户优化操作)
// 拷贝的对象用于计算源对象的所有更新操作
// 并且仅在需要的时候执行一次更新
cronJobCopy := cronJob.DeepCopy()
// 删除完成的 Job
updateStatusAfterCleanup := jm.cleanupFinishedJobs(ctx, cronJobCopy, jobsToBeReconciled)
// 获取 CronJob 对象下次执行的时间和同步 (更新) 状态
requeueAfter, updateStatusAfterSync, syncErr := jm.syncCronJob(ctx, cronJobCopy, jobsToBeReconciled)
// 更新 CronJob 对象状态
if updateStatusAfterCleanup || updateStatusAfterSync {
if _, err := jm.cronJobControl.UpdateStatus(ctx, cronJobCopy); err != nil {
......
return
}
}
// 返回下次 CronJob 的下次执行时间
if requeueAfter != nil {
return requeueAfter, nil
}
return nil, syncErr
}
小结
几个问题
1、为何cronjob controller的实现中,同时注册了job/cronjob两类event的监听事件回调?