0x00 前言
这篇文章来源于对一个问题的思考:Linux中两个进程通过有名(mkfifo)或者匿名(pipe)管道进行通信时,在这两个进程的内核VFS视图中,数据是如何流转的?代码基于 v4.11.6 版本
前置基础:
管道
管道应用场景:
- zero copy
- 进程间通信,又分匿名(
pipe)与有名(mkfifo)
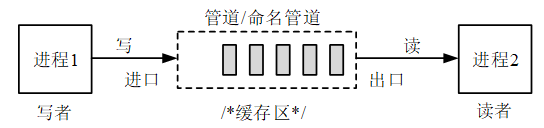
linux的pipe和FIFO都是基于pipe文件系统(pipefs)的,pipe和FIFO都是半双工,即数据流向只能是一个方向。pipe机制(匿名管道)只能在pipe的创建进程及其后代进程(后代进程fork/exec时,通过继承父进程的打开文件描述符表)之间使用,来实现通信;有名pipe FIFO,即可以通过名称查找到pipe,所以无上述匿名管道限制,可以通过名称找到pipe文件,创建相应的pipe,可以实现跨进程间的通信
管道在Linux零拷贝中也有应用,零拷贝是一种优化数据传输的技术,它可以减少数据在内核态和用户态之间的拷贝次数,提高数据传输的效率。在传统的数据传输过程中,数据需要从内核缓冲区拷贝至应用程序的缓冲区,然后再从应用程序缓冲区拷贝到网络设备的缓冲区,最后才能发送出去。而零拷贝技术通过直接在应用程序和网络设备之间传输数据,避免了中间的拷贝过程,从而提高了数据传输的效率
0x01 管道实现分析:数据结构
在内核中,管道本质一个环形缓冲区,通过管道可以将数据从一个文件拷贝另外一个文件
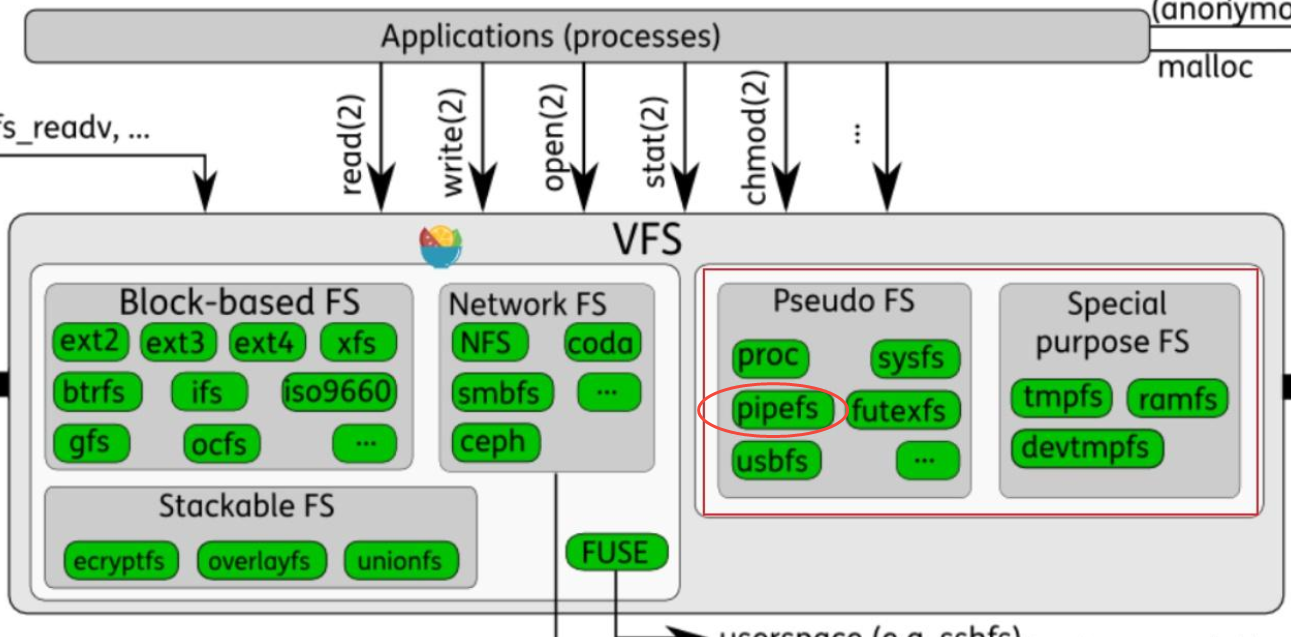
pipefs:文件系统
pipe 是一个伪文件系统(pipefs),内核初始化时会注册到 Linux 系统
内核数据结构
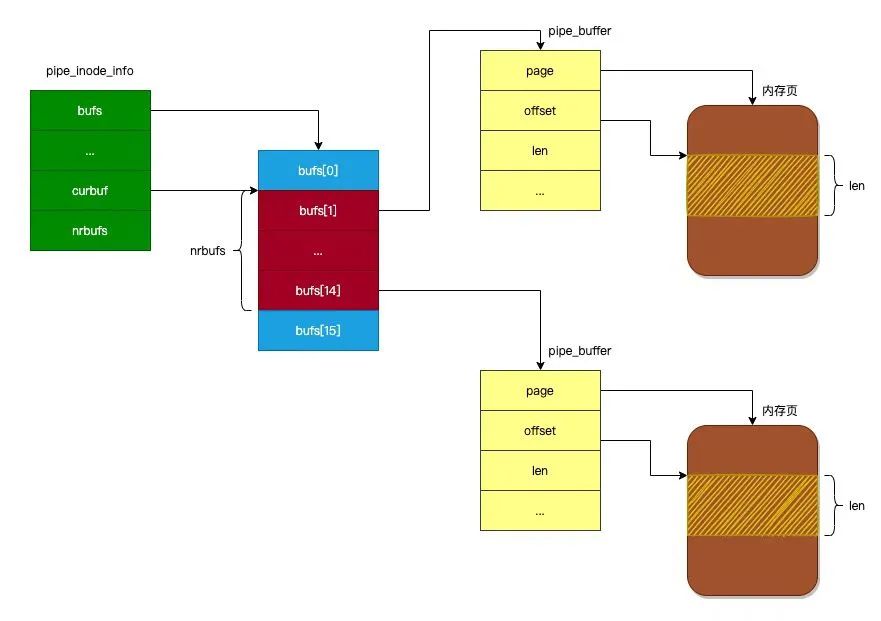
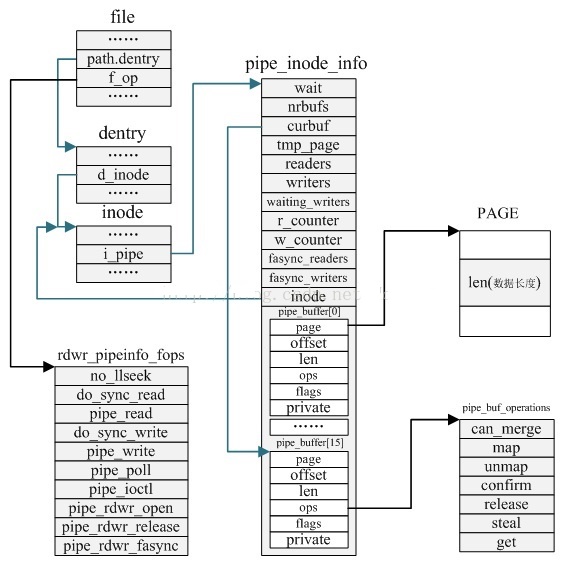
管道本质上是一个内存中的文件,本质上还是基于 Linux 的 VFS,用户进程可以通过 pipe() 系统调用创建一个匿名管道,创建完成之后会有两个 VFS 的 struct file 的 inode 分别指向其写端和读端,并返回对应的两个文件描述符,用户进程通过这两个文件描述符读写管道;管道的容量单位是一个虚拟内存的页,也就是 4KB,总大小一般是 16 个页,基于其环形结构,管道的页可以循环使用,提高内存利用率。Linux 中以 pipe_buffer 结构体封装管道页,file 结构体里的 inode 字段里会保存一个 pipe_inode_info 结构体指代管道,其中会保存很多读写管道时所需的元信息,环形队列的头部指针页,读写时的同步机制如互斥锁、等待队列等
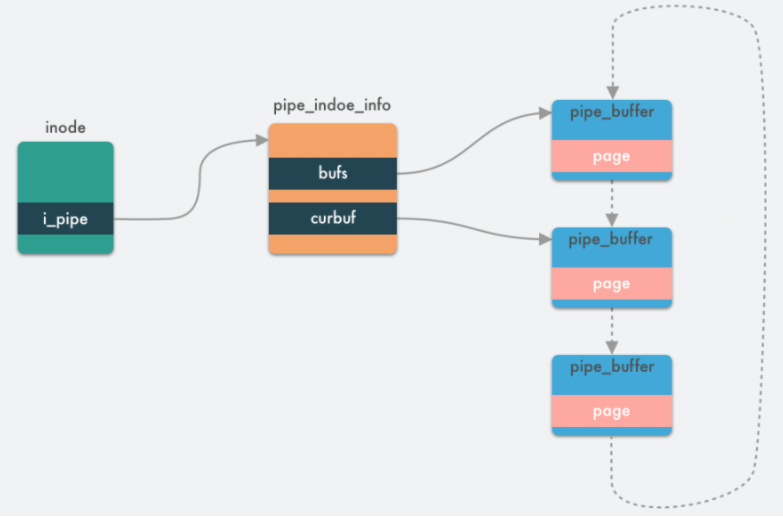
1、pipe_buffer:管道缓存,用于暂存写入管道的数据;写进程通过管道写入端将数据写入管道缓存中,读进程通过管道读出端将数据从管道缓存中读出,成员定义如下:
page:页帧,用于存储pipe数据;pipe缓存与页帧是一对一的关系(注意内核struct page定义了一个物理内存页)offset:页内偏移,用于记录有效数据在页帧的超始地址(只能用偏移,而不能用地址,因为高内存页帧在内核空间中没有虚拟地址与之对应)len:有效数据长度ops:缓存操作集(pipe_buf_operations)flags:缓存标识private:缓存操作私有数据
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/pipe_fs_i.h#L20
struct pipe_buffer {
struct page *page; // 存放数据的页框(物理内存页)
unsigned int offset, len; // 数据的偏移和大小
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
2、pipe_inode_info:定义为管道描述符,用于表示一个管道,存储管道相应的信息
wait:读/写/poll等待队列;由于读/写不可能同时出现在等待的情况,所以可以共用等待队列;poll读与读,poll写与写可以共存出现在等待队列中nrbufs:非空的pipe_buffer数量curbuf:数据的起始pipe_bufferbuffers:整个pipe_inode_info关联pipe_buffer结构的长度tmp_page:页缓存,可以加速页帧的分配过程;当释放页帧时将页帧记入tmp_page,当分配页帧时,先从tmp_page中获取,如果tmp_page为空才从伙伴系统中获取readers:当前管道的读者个数;每次以读方式打开时,readers加1;关闭时readers减1writers:当前管道的写者个数;每次以写方式打开时,writers加1;关闭时writers减1waiting_writers:被阻塞的管道写者个数;写进程被阻塞时,waiting_writers加1;被唤醒时,waiting_writers减1r_counter:管道读者记数器,每次以读方式打开管道时,r_counter加1;关闭时不变w_counter:管道读者计数器;每次以写方式打开时,w_counter加1;关闭时不变fasync_readers:读端异步描述符fasync_writers:写端异步描述符inode:pipe对应的inodebufs:pipe_buffer回环数据(被组织为一个ringbuffer结构)
注意:在高版本中(如v5.10.240)对pipe机制进行了改动,因此引发了有名的Dirty Pipe内核Bug:参考CVE-2022-0847
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t wait;
unsigned int nrbufs, curbuf, buffers;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int waiting_writers;
unsigned int r_counter;
unsigned int w_counter;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
};
此外,注意从pipe_inode_info和pipe_buffer的初始化的过程可以得知,在本文版本 Linux 内核中,使用了 16 个内存页(单页是4k)作为环形缓冲区(见初始化代码),所以环形缓冲区的大小为 64KB(16*4KB)
3、pipe_buf_operations:记录pipe缓存的操作集
can_merge:合并标识;如果pipe_buffer中有空闲空间,有数据写入时,如果can_merge置位,会先写pipe_buffer的空闲空间;否则重新分配一个pipe_buffer来存储写入数据map:由于pipe_buffer的page可能是高内存页帧,由于内核空间页表没有相应的页表项,所以内核不能直接访问page;只有通过map将page映射到内核地址空间后,内核才能访问unmap:map的逆过程;因为内核地址空间有限,所以page访问完后释文地址映射confirm:检验pipe_buffer中的数据release:当pipe_buffer中的数据被读完后,用于释放pipe_bufferget:增加pipe_buffer的引用计数器
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/pipe_fs_i.h#L74
struct pipe_buf_operations {
/*
* This is set to 1, if the generic pipe read/write may coalesce
* data into an existing buffer. If this is set to 0, a new pipe
* page segment is always used for new data.
*/
int can_merge;
/*
* ->confirm() verifies that the data in the pipe buffer is there
* and that the contents are good. If the pages in the pipe belong
* to a file system, we may need to wait for IO completion in this
* hook. Returns 0 for good, or a negative error value in case of
* error.
*/
int (*confirm)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* When the contents of this pipe buffer has been completely
* consumed by a reader, ->release() is called.
*/
void (*release)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* Attempt to take ownership of the pipe buffer and its contents.
* ->steal() returns 0 for success, in which case the contents
* of the pipe (the buf->page) is locked and now completely owned
* by the caller. The page may then be transferred to a different
* mapping, the most often used case is insertion into different
* file address space cache.
*/
int (*steal)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* Get a reference to the pipe buffer.
*/
void (*get)(struct pipe_inode_info *, struct pipe_buffer *);
};
4、anon_pipe_buf_ops && packet_pipe_buf_ops
anon_pipe_buf_ops:匿名管道,默认can_merge开启(支持)packet_pipe_buf_ops:分组化管道,默认can_merge关闭
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/pipe.c#L233
static const struct pipe_buf_operations anon_pipe_buf_ops = {
.can_merge = 1, //匿名管道:默认can_merge为1
.confirm = generic_pipe_buf_confirm,
.release = anon_pipe_buf_release,
.steal = anon_pipe_buf_steal,
.get = generic_pipe_buf_get,
};
static const struct pipe_buf_operations packet_pipe_buf_ops = {
.can_merge = 0,
.confirm = generic_pipe_buf_confirm,
.release = anon_pipe_buf_release,
.steal = anon_pipe_buf_steal,
.get = generic_pipe_buf_get,
};
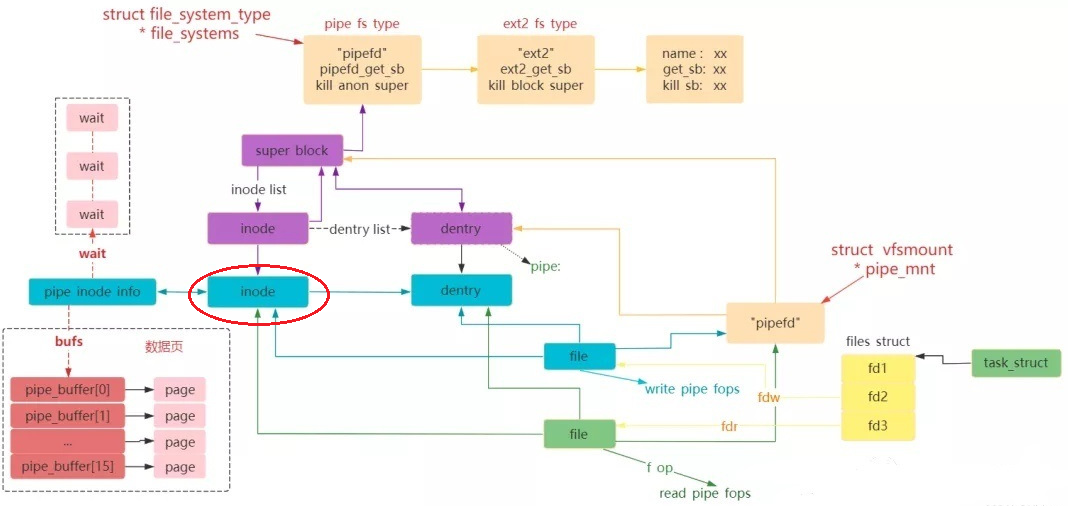
pipefs 在VFS的四大对象及对应的operations
当创建pipe/FIFO时,内核会分配VFS的file/dentry/inode/pipe_inode_info对象,并将file对象的f_op指向fifo_open/pipe_read/pipe_write/pipe_poll等方法,当后续的read/write/poll等系统调用,会通过vfs调用相应的f_op中方法
pipe/FIFO VFS相关结构及操作集如下:
1、文件对象(File):struct file,需要区分读写端fd[0]为读端,fd[1] 为写端,操作集file_operations如下:
注意pipefifo_fops只实现了read_iter/write_iter方法,没有实现write/read方法,这里在读写管道的内核函数调用中会涉及到,参考后文的vfs_write函数
// pipefifo_fops:定义了pipe 文件支持的文件操作有哪些
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read, //pipe读端文件操作/FIFO只读方式文件操作
.write_iter = pipe_write, //pipe写端文件操作/FIFO只写方式文件操作
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
};
在一个进程创建打开了pipe/fifo之后,在进程打开的文件描述符数组中是占据两个fd,其中对于fd[0]读端而言,pipe_write是无用的;反之对写端而言,pipe_read是无用的
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/pipe.c
int do_pipe_flags(int *fd, int flags)
{
struct file *files[2];
int error = __do_pipe_flags(fd, files, flags);
if (!error) {
//通过 fd_install 将文件描述符安装到内核中,以便用户空间可以通过这些文件描述符访问管道
fd_install(fd[0], files[0]);
fd_install(fd[1], files[1]);
}
return error;
}
2、目录项对象(Dentry):通过 mount_pseudo() 创建根目录项,无实际磁盘路径。操作集为simple_dentry_operations
static const struct dentry_operations pipefs_dentry_operations = {
.d_dname = pipefs_dname, //仅需处理内存回收,无磁盘同步逻辑,终删除 dentry(内存临时对象)
};
3、 索引节点对象(Inode),关联扩展结构 struct pipe_inode_info,存储管道核心数据(如环形缓冲区、等待队列),对应于struct inode的struct pipe_inode_info *i_pipe成员
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/fs.h#L554
struct inode {
......
const struct inode_operations *i_op;
struct super_block *i_sb;
struct address_space *i_mapping;
......
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
......
union {
struct pipe_inode_info *i_pipe; // 管道procfs
struct block_device *i_bdev;
struct cdev *i_cdev;
char *i_link;
unsigned i_dir_seq;
};
......
};
4、super_block,超级块对象(Superblock)
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/pipe.c#L1173
static const struct super_operations pipefs_ops = {
.destroy_inode = free_inode_nonrcu,
.statfs = simple_statfs,
};
0x02 管道操作分析
本节仅分析pipe匿名管道的在内核的实现机制
管道创建
系统调用pipe/pipe2,用于创建管道,函数调用链为pipe2->__do_pipe_flags->create_pipe_files
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/pipe.c#L839
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
{
// files 数组,0和1
struct file *files[2];
int fd[2];
int error;
//创建两个 struct file 结构体实例和两个对应的文件描述符
error = __do_pipe_flags(fd, files, flags);
if (!error) {
......
//将两个文件描述符和 struct file 结构体实例关联起来
fd_install(fd[0], files[0]);
fd_install(fd[1], files[1]);
}
return error;
}
//fd:保存创建的两个文件描述符
//files:保存创建的两个 struct file 结构体实例
static int __do_pipe_flags(int *fd, struct file **files, int flags)
{
int error;
int fdw, fdr;
// 检查非法的标志位组合
if (flags & ~(O_CLOEXEC | O_NONBLOCK | O_DIRECT))
return -EINVAL;
// create_pipe_files:根据传入的标志位创建两个 struct file 结构体实例
error = create_pipe_files(files, flags);
if (error)
return error;
// 创建两个文件描述符:用于输入、输出
error = get_unused_fd_flags(flags);
if (error < 0)
goto err_read_pipe;
fdr = error;
error = get_unused_fd_flags(flags);
if (error < 0)
goto err_fdr;
fdw = error;
// 处理审计相关的逻辑
audit_fd_pair(fdr, fdw);
fd[0] = fdr;
fd[1] = fdw;
return 0;
......
}
create_pipe_files是创建pipe的核心实现:
int create_pipe_files(struct file **res, int flags)
{
int err;
// 创建inode节点(创建一个 inode 实例)
struct inode *inode = get_pipe_inode();
struct file *f;
struct path path;
static struct qstr name = { .name = "" };
......
//创建dentry结构
path.dentry = d_alloc_pseudo(pipe_mnt->mnt_sb, &name);
if (!path.dentry)
goto err_inode;
path.mnt = mntget(pipe_mnt);
// 关联dentry与inode的关系
d_instantiate(path.dentry, inode);
// 构建file结构,设置file_operations为管理文件操作符集pipefifo_fops
f = alloc_file(&path, FMODE_WRITE, &pipefifo_fops);
if (IS_ERR(f)) {
err = PTR_ERR(f);
goto err_dentry;
}
f->f_flags = O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT));
// 注意:file结构的private_data指向了inode->i_pipe,即管道的pipe_inode_info节点
f->private_data = inode->i_pipe;
// 创建读端的file结构
res[0] = alloc_file(&path, FMODE_READ, &pipefifo_fops);
if (IS_ERR(res[0])) {
err = PTR_ERR(res[0]);
goto err_file;
}
path_get(&path);
// 0:读端,设置了O_RDONLY标志
res[0]->private_data = inode->i_pipe;
res[0]->f_flags = O_RDONLY | (flags & O_NONBLOCK);
// 1:写端,设置了O_WRONLY标志
res[1] = f;
return 0;
.......
}
create_pipe_files函数中有几个细节:
get_pipe_inode:创建并初始化pipe的inode核心结构struct pipe_inode_info,对应函数alloc_pipe_infod_alloc_pseudo/d_instantiate:构建dentry及inode关联关系alloc_file:两次调用,先初始化写端的file结构、再初始化读端的file结构
static struct inode * get_pipe_inode(void)
{
//创建一个 inode 实例
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
......
inode->i_ino = get_next_ino();
//创建一个 pipe_inode_info 实例
pipe = alloc_pipe_info();
if (!pipe)
goto fail_iput;
// 初始化pipe_inode_info对象
inode->i_pipe = pipe;
pipe->files = 2;
pipe->readers = pipe->writers = 1;
//inode的i_fop与file的fop是一样的
// 初始化inode各个成员的值
inode->i_fop = &pipefifo_fops; //管道的操作函数指针
inode->i_state = I_DIRTY;
inode->i_mode = S_IFIFO | S_IRUSR | S_IWUSR;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
return inode;
......
}
pipe匿名共享的本质
问题:两个进程共享pipe,在内核的本质是什么?回到上面的create_pipe_files函数实现,在关键字节用序号注释标识
1、在get_pipe_inode中初始化了inode节点,并且将inode->i_pipe(union成员)指向了pipe管理结构pipe_inode_info对象
2、在create_pipe_files中,d_instantiate(path.dentry, inode)函数相当于执行了path.dentry->d_inode = inode,将dentry关联到inode结构
3、同时在create_pipe_files函数中,完成了读端写端的struct file的初始化,即files[0] = alloc_file(&path, FMODE_READ, &pipefifo_fops);files[1] = alloc_file(&path, FMODE_WRITE, &pipefifo_fops);,从第二个参数就知道,这两个file限制了各自的功能,也就意味着对应的两个fd也限制了各自的功能
4、在alloc_file函数中,file->f_path = *path,就相当于file[x]->f_path.dentry->d_inode = inode,也即两个file指向了同一个inode,这个就是所谓的两个file关联(记得struct path中存在dentry成员),这就是pipe共享的本质
5、下面这段代码将把pipe放在file中是方便取值,否则给定一个files,若需要获取pipe,就需要从file->f_path.dentry->d_inode->i_pipe来获取,这显然不够优雅
files[0]->private_data = inode->i_pipe;
files[1]->private_data = inode->i_pipe;
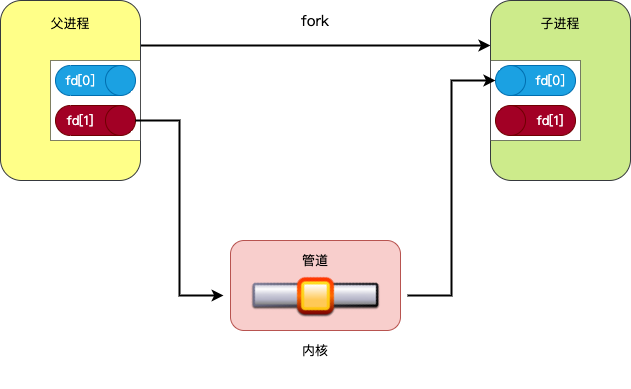
6、至此pipe2系统调用执行完毕,它创建了两个个互相关联的file,然后创建了2个fd,fd与file一一对应,其次file都指向了同一个inode,读写均操作统一inode(即pipe结构pipe_inode_info);此外,由于创建父子进程时,task_struct关联的打开文件描述符表fdtable也要复制一份,即父子进程的文件描述符表均指向上述的pipe结构(当然需要关闭一方的读、另一方的写),这样父子进程便可以借助pipe实现单向通信了
static struct inode * get_pipe_inode(void)
{
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
......
pipe = alloc_pipe_info();
......
// 初始化pipe_inode_info对象
// 将这个inode
inode->i_pipe = pipe;
pipe->files = 2;
pipe->readers = pipe->writers = 1;
//inode的i_fop与file的fop是一样的
//告诉vfs如何读写pipefs(文件系统)等操作
inode->i_fop = &pipefifo_fops;
......
return inode;
......
}
// alloc_file:创建file结构,并关联到path
// fop:传入的值为&pipefifo_fops
struct file *alloc_file(const struct path *path, fmode_t mode, const struct file_operations *fop)
{
struct file *file;
file = get_empty_filp();
if (IS_ERR(file))
return file;
// file关联到dentry
file->f_path = *path;
file->f_inode = path->dentry->d_inode;
file->f_mapping = path->dentry->d_inode->i_mapping;
if ((mode & FMODE_READ) &&
likely(fop->read || fop->read_iter))
mode |= FMODE_CAN_READ;
if ((mode & FMODE_WRITE) &&
likely(fop->write || fop->write_iter))
mode |= FMODE_CAN_WRITE;
file->f_mode = mode;
// 注意:这里会将 file 结构体实例的 f_op 字段设置成 pipefifo_fops 结构体的指针
// 当用户态执行pipefifo_fops支持(如管道关联的fd)的系统调用时,VFS 会调用结构体中相应的函数
file->f_op = fop;
if ((mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_inc(path->dentry->d_inode);
return file;
}
int create_pipe_files(struct file **res, int flag s)
{
int err;
// 1. 创建inode节点并绑定到pipe的管理结构
struct inode *inode = get_pipe_inode();
struct file *f;
struct path path;
static struct qstr name = { .name = "" };
......
path.dentry = d_alloc_pseudo(pipe_mnt->mnt_sb, &name);
if (!path.dentry)
goto err_inode;
path.mnt = mntget(pipe_mnt);
// 2. 关联dentry与inode的关系,将dentry指向inode
d_instantiate(path.dentry, inode);
// 3. 构建(写端)file结构,设置file_operations为管理文件操作符集pipefifo_fops,同时将file->path指向 *path
f = alloc_file(&path, FMODE_WRITE, &pipefifo_fops);
if (IS_ERR(f)) {
err = PTR_ERR(f);
goto err_dentry;
}
f->f_flags = O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT));
// 注意:file结构的private_data指向了inode->i_pipe,即管道的pipe_inode_info节点
f->private_data = inode->i_pipe;
// 4. 创建读端的file结构
res[0] = alloc_file(&path, FMODE_READ, &pipefifo_fops);
if (IS_ERR(res[0])) {
err = PTR_ERR(res[0]);
goto err_file;
}
path_get(&path);
// 5. 快捷访问设置:读/写端file直接访问到pipe结构
// 0:读端,设置了O_RDONLY标志
res[0]->private_data = inode->i_pipe;
res[0]->f_flags = O_RDONLY | (flags & O_NONBLOCK);
// 1:写端,设置了O_WRONLY标志
res[1] = f;
return 0;
.......
}
alloc_pipe_info
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/pipe.c#L620
struct pipe_inode_info *alloc_pipe_info(void)
{
struct pipe_inode_info *pipe;
unsigned long pipe_bufs = PIPE_DEF_BUFFERS; //默认16长度
struct user_struct *user = get_current_user();
unsigned long user_bufs;
//kzalloc 函数与 kmalloc 类似,只不过会初始化分配的内存
pipe = kzalloc(sizeof(struct pipe_inode_info), GFP_KERNEL_ACCOUNT);
if (pipe == NULL)
goto out_free_uid;
......
// 初始化bufs成员
// 调用 kcalloc 函数为 pipe_inode_info 结构体的 bufs 字段分配内存
// kcalloc 与 kzalloc 类似,只不过是分配连续若干个指定大小的内存块
// 默认大小为 PIPE_DEF_BUFFERS (16)个内存页
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),
GFP_KERNEL_ACCOUNT);
if (pipe->bufs) {
init_waitqueue_head(&pipe->wait);
pipe->r_counter = pipe->w_counter = 1;
pipe->buffers = pipe_bufs; //16
pipe->user = user; //当前用户
mutex_init(&pipe->mutex);
return pipe;
}
......
}
pipe读写的实现原理(数据结构)
内核管道实现本质上是基于环形缓冲区(RingBuffer)的设计理念,如 pipe_inode_info 和 pipe_buffer 构成的环形数组)
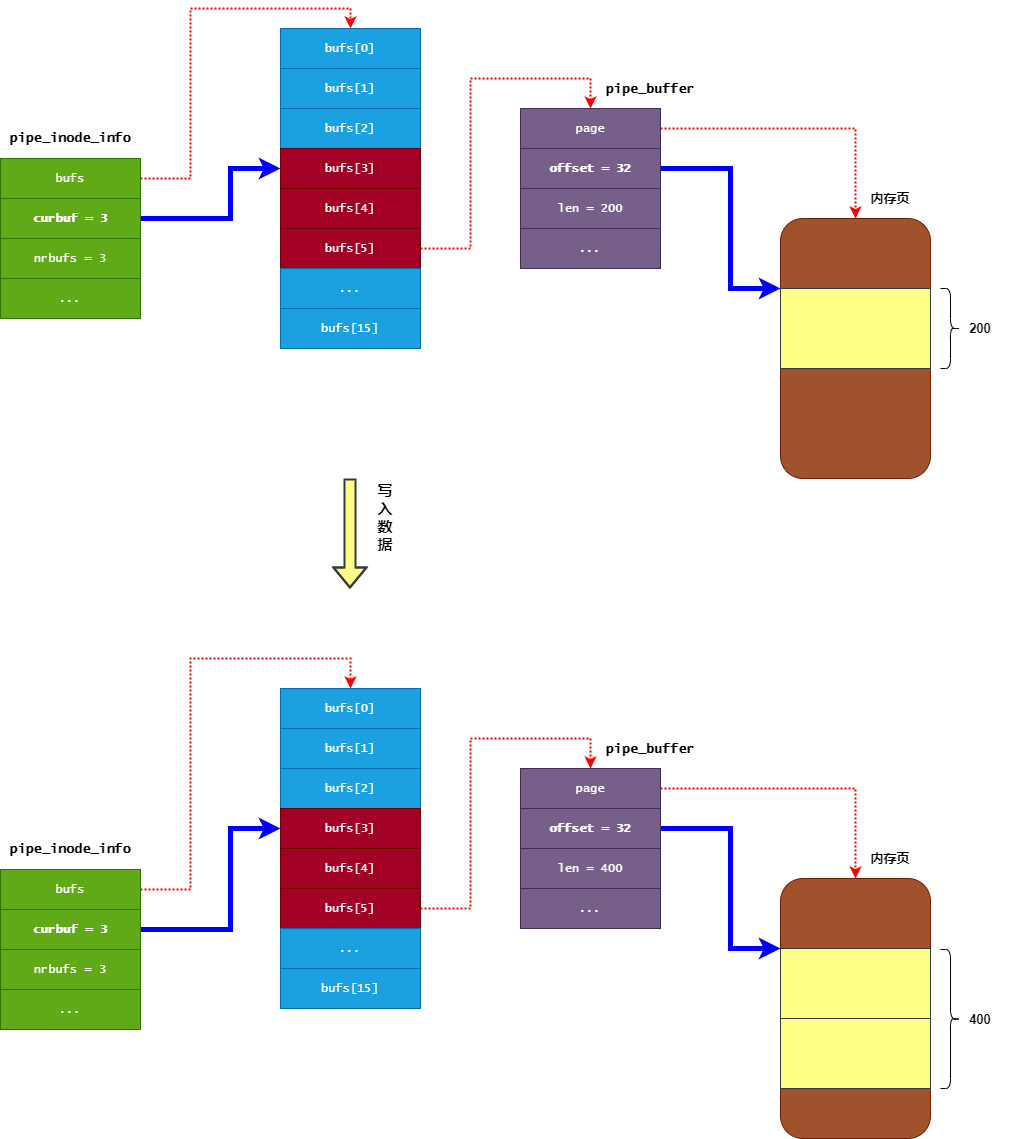
1、环形存储结构,管道数据存储在内核维护的环形数组中,数组元素为 pipe_buffer,每个对应一个物理内存页(默认 16 页),通过 curbuf(当前读位置索引)和 nrbufs(有效缓冲区数量)实现环形遍历
// 计算下一个缓冲区索引
// 此操作通过位运算(&)替代取模,实现高效的环形索引
int newbuf = (pipe->curbuf + bufs) & (pipe->buffers - 1);
2、读写指针分离,其中读指针为pipe->curbuf,标记当前读取的缓冲区起始位置;写指针通过 (curbuf + nrbufs) % buffers 计算得出,指向下一个可写入位置,这与经典环形缓冲区的 head(读)和 tail(写)指针逻辑一致
3、管道的阻塞与唤醒机制,当缓冲区空时,读进程阻塞;缓冲区满时,写进程阻塞。通过等待队列(pipe->wait)和信号(SIGIO)实现读写协同
4、基于环形缓冲区,管道针对进程通信场景也做了若干优化策略
- 按需分配内存页:管道默认不预分配内存,仅在写入数据时
alloc_page()动态申请页 - 小数据合并写入:若最后一个缓冲区(
lastbuf)有剩余空间,新数据可追加到同一页,减少碎片 - 原子性保证:当单次写入
<=PIPE_BUF(通常4KB)时,保证数据完整写入,避免分片
0x03 pipe的读实现
对于普通的ringbuffer,读过程步骤如下:
- 首先通过读指针head来定位到读取数据的起始地址
- 判断环形缓冲区中是否有数据可读
- 读取数据,成功读取后移动读指针head
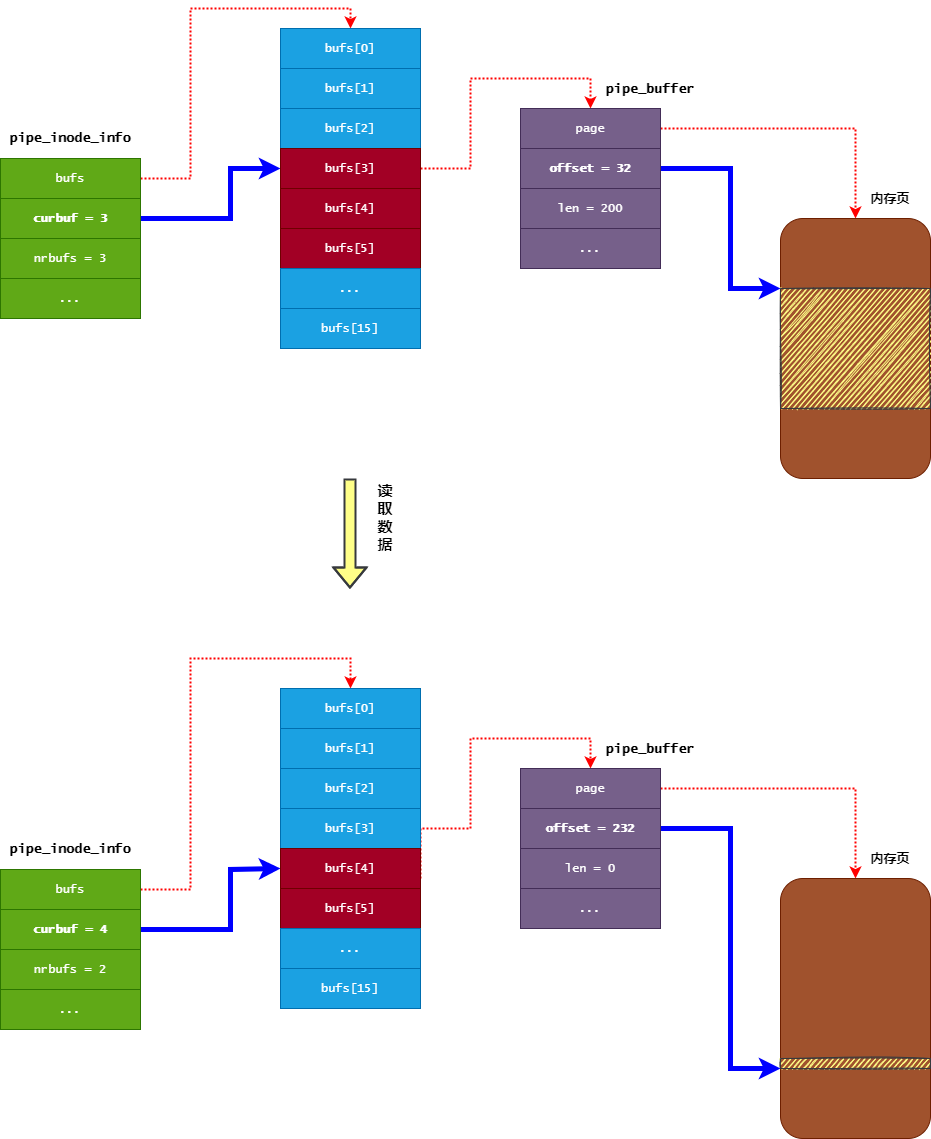
对于内核pipe的ringbuffer,其读指针是由 pipe_inode_info 对象的 curbuf 字段与 pipe_buffer 对象的 offset 字段组合而成,类似于页间序号/页内下标
pipe_inode_info对象的curbuf字段表示读操作要从bufs数组的哪个pipe_buffer中读取数据(初始化为0)pipe_buffer对象的offset字段表示读操作要从内存页的哪个位置开始读取数据- 可能存在读取长度超过一个page size(
4k)的情况,需要注意 - 从缓冲区中读取到
n个字节的数据后,会相应移动读指针n个字节的位置(即增加pipe_buffer对象的offset字段),并且减少n个字节的可读数据长度(即减少pipe_buffer对象的len字段) - 当
pipe_buffer对象的len字段变为0时,表示当前pipe_buffer没有可读数据,那么将会对pipe_inode_info对象的curbuf字段移动一个位置,并且其nrbufs字段进行减一操作
pipe_read的实现如下,对于管道的ringbuffer,读操作步骤如下:
- 通过VFS file/inode 对象来获取到管道的
pipe_inode_info对象 - 通过
pipe_inode_info对象的nrbufs成员,获取管道未读数据占有多少个内存页 - 通过
pipe_inode_info对象的curbuf成员,获取读操作应该从ringbuffer的内存页哪个序号处读取数据 - 通过
pipe_buffer对象的offset成员,获取真正的读指针(位置), 并且从管道中读取数据到用户缓冲区 - 如果当前内存页的数据已经被读取完毕,那么移动
pipe_inode_info对象的curbuf指针,并且减少其nrbufs字段的值 - 如果读取到用户期望的数据长度,退出循环;反之,则移动
curbuf到下一个ringbuffer位置,继续上面的操作
static ssize_t
pipe_read(struct kiocb *iocb, struct iov_iter *to)
{
size_t total_len = iov_iter_count(to);
struct file *filp = iocb->ki_filp;
// 1、从file结构获取管道对象pipe_inode_info
struct pipe_inode_info *pipe = filp->private_data;
int do_wakeup;
ssize_t ret;
/* Null read succeeds. */
if (unlikely(total_len == 0))
return 0;
do_wakeup = 0;
ret = 0;
__pipe_lock(pipe);
// 想想这里为啥是循环
for (;;) {
// 2、获取管道未读数据占有多少个内存页
int bufs = pipe->nrbufs;
if (bufs) {
// 3、获取读操作应该从环形缓冲区的哪个内存页处读取数据(序号)
int curbuf = pipe->curbuf;
// 4、获取页内偏移
struct pipe_buffer *buf = pipe->bufs + curbuf;
size_t chars = buf->len;
size_t written;
int error;
if (chars > total_len)
chars = total_len;
error = pipe_buf_confirm(pipe, buf);
if (error) {
if (!ret)
ret = error;
break;
}
// 5、通过 pipe_buffer 的 offset 字段获取真正的读指针,
// 并且从管道中读取数据到用户缓冲区
written = copy_page_to_iter(buf->page, buf->offset, chars, to);
if (unlikely(written < chars)) {
if (!ret)
ret = -EFAULT;
break;
}
ret += chars;
// 页内:增加 pipe_buffer 对象的 offset 字段的值
buf->offset += chars;
// 页内:减少 pipe_buffer 对象的 len 字段的值
buf->len -= chars;
/* Was it a packet buffer? Clean up and exit */
if (buf->flags & PIPE_BUF_FLAG_PACKET) {
total_len = chars;
buf->len = 0;
}
// 6、如果当前内存页的数据已经被读取完毕
if (!buf->len) {
pipe_buf_release(pipe, buf);
// 移动页间读指针
curbuf = (curbuf + 1) & (pipe->buffers - 1);
// 移动 pipe_inode_info 对象的 curbuf 指针
pipe->curbuf = curbuf;
// 减少 pipe_inode_info 对象的 nrbufs 字段(减1)
pipe->nrbufs = --bufs;
do_wakeup = 1;
}
total_len -= chars;
// 7、如果读取到用户期望的数据长度, 退出循环
if (!total_len)
break; /* common path: read succeeded */
}
if (bufs) /* More to do? */
continue;
if (!pipe->writers)
break;
if (!pipe->waiting_writers) {
/* syscall merging: Usually we must not sleep
* if O_NONBLOCK is set, or if we got some data.
* But if a writer sleeps in kernel space, then
* we can wait for that data without violating POSIX.
*/
if (ret)
break;
if (filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
break;
}
}
if (signal_pending(current)) {
if (!ret)
ret = -ERESTARTSYS;
break;
}
if (do_wakeup) {
wake_up_interruptible_sync_poll(&pipe->wait, POLLOUT | POLLWRNORM);
kill_fasync(&pipe->fasync_writers, SIGIO, POLL_OUT);
}
pipe_wait(pipe);
}
__pipe_unlock(pipe);
/* Signal writers asynchronously that there is more room. */
if (do_wakeup) {
wake_up_interruptible_sync_poll(&pipe->wait, POLLOUT | POLLWRNORM);
kill_fasync(&pipe->fasync_writers, SIGIO, POLL_OUT);
}
if (ret > 0)
file_accessed(filp);
return ret;
}
0x04 pipe的写实现
内核pipe的ringbuffer结构没有写指针这个成员,实际上是通过读指针计算出来的:写指针 = 读指针 + 未读数据长度,实际上只需要理解未读取内容的开始位置约等于已写入数据的开始位置这个概念就清楚了
- 首先通过
pipe_inode_info的curbuf字段和nrbufs字段来定位到,应该向哪个pipe_buffer写入数据 - 然后再通过
pipe_buffer对象的offset字段和len字段来定位到,应该写入到内存页的哪个位置(通常情况下offset+len即是写入的开始位置)
pipe_write的实现如下,主要步骤是:
- 如果上次写操作写入的
pipe_buffer还有空闲的空间,那么就将数据写入到此pipe_buffer中,并且增加其len字段的值 - 如果上次写操作写入的
pipe_buffer没有足够的空闲空间,那么就新申请一个内存页,并且把数据保存到新的内存页中,并且增加pipe_inode_info的nrbufs字段的值 - 如果写入的数据已经全部写入成功,那么就退出写操作
当然,这里还涉及到一些细节问题,如:
- 什么情况下
pipe_bufferpage是不能够被can_merge的? 4k情况下,大于或者小于的数据量写入管道,原子性是如何保证的?为什么说数据小于4k才能保证其原子性?pipe_inode_info的tmp_page的作用是什么?
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
ssize_t ret = 0;
int do_wakeup = 0;
// from:用户空间的待写入数据
size_t total_len = iov_iter_count(from);
ssize_t chars;
/* Null write succeeds. */
if (unlikely(total_len == 0))
return 0;
__pipe_lock(pipe);
if (!pipe->readers) {
send_sig(SIGPIPE, current, 0);
ret = -EPIPE;
goto out;
}
/* We try to merge small writes */
// chars:保存用户空间待写入数据的长度
// < 4k:返回实际长度
// >=4k:返回0
chars = total_len & (PAGE_SIZE-1); /* size of the last buffer */
// 1、如果最后写入的 pipe_buffer 还有空闲的空间
if (pipe->nrbufs && chars != 0) {
// 获取写入数据的位置
int lastbuf = (pipe->curbuf + pipe->nrbufs - 1) &
(pipe->buffers - 1);
struct pipe_buffer *buf = pipe->bufs + lastbuf;
int offset = buf->offset + buf->len;
// anon_pipe_buf_ops
// buf->ops->can_merge:管道类型(参考下文)
if (buf->ops->can_merge && offset + chars <= PAGE_SIZE) {
// 注意:在内核4.11.6版本中,必须满足两者才出发合并写入
// 1、管道类型支持数据合并:buf->ops->can_merge为真
// 2、offset+chars<=PAGE_SIZE:当前页剩下的空间(offset)可以容纳待写入的数据长度(chars)
// 否则不满足,就直接分配新内存页进行写入
ret = pipe_buf_confirm(pipe, buf);
if (ret)
goto out;
ret = copy_page_from_iter(buf->page, offset, chars, from);
if (unlikely(ret < chars)) {
ret = -EFAULT;
goto out;
}
do_wakeup = 1;
buf->len += ret;
// 2、如果要写入的数据已经全部写入成功
if (!iov_iter_count(from))
goto out;
}
}
// 3、如果最后写入的 pipe_buffer 空闲空间不足, 那么申请一个新的内存页来存储数据
for (;;) {
int bufs;
if (!pipe->readers) {
send_sig(SIGPIPE, current, 0);
if (!ret)
ret = -EPIPE;
break;
}
bufs = pipe->nrbufs;
if (bufs < pipe->buffers) {
int newbuf = (pipe->curbuf + bufs) & (pipe->buffers-1);
struct pipe_buffer *buf = pipe->bufs + newbuf;
struct page *page = pipe->tmp_page;
int copied;
if (!page) {
// 申请一个新的内存页(物理内存页)
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
if (unlikely(!page)) {
ret = ret ? : -ENOMEM;
break;
}
pipe->tmp_page = page;
}
/* Always wake up, even if the copy fails. Otherwise
* we lock up (O_NONBLOCK-)readers that sleep due to
* syscall merging.
* FIXME! Is this really true?
*/
do_wakeup = 1;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
if (unlikely(copied < PAGE_SIZE && iov_iter_count(from))) {
if (!ret)
ret = -EFAULT;
break;
}
ret += copied;
/* Insert it into the buffer array */
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = copied;
buf->flags = 0;
if (is_packetized(filp)) {
buf->ops = &packet_pipe_buf_ops;
buf->flags = PIPE_BUF_FLAG_PACKET;
}
pipe->nrbufs = ++bufs;
// page已经被使用了,这里tmp_page需要置为NULL
pipe->tmp_page = NULL;
// 如果要写入的数据已经全部写入成功, 退出循环
if (!iov_iter_count(from))
break;
}
if (bufs < pipe->buffers)
continue;
if (filp->f_flags & O_NONBLOCK) {
if (!ret)
ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
if (!ret)
ret = -ERESTARTSYS;
break;
}
if (do_wakeup) {
wake_up_interruptible_sync_poll(&pipe->wait, POLLIN | POLLRDNORM);
kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN);
do_wakeup = 0;
}
pipe->waiting_writers++;
// 注意这里!
pipe_wait(pipe);
pipe->waiting_writers--;
//end of for1
}
out:
__pipe_unlock(pipe);
if (do_wakeup) {
wake_up_interruptible_sync_poll(&pipe->wait, POLLIN | POLLRDNORM);
kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN);
}
if (ret > 0 && sb_start_write_trylock(file_inode(filp)->i_sb)) {
int err = file_update_time(filp);
if (err)
ret = err;
sb_end_write(file_inode(filp)->i_sb);
}
return ret;
}
pipe_write的物理内存分配
在上面的pipe_write实现中,注意这段代码:
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
......
if (!page) {
// 申请一个新的内存页(物理内存页)
// alloc_page返回的是物理内存地址
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
if (unlikely(!page)) {
ret = ret ? : -ENOMEM;
break;
}
pipe->tmp_page = page;
}
......
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
......
}
内核提供了 alloc_page 宏用于这种单内存页分配的场景,当系统中空闲的物理内存无法满足内存分配时,就会导致内存分配失败,会返回 NULL,在物理内存分配成功的情况下, alloc_page 返回的都是指向其申请的物理内存块第一个物理内存页 struct page 指针(特别强调是物理内存页,而不是虚拟内存页),直观理解为返回的是一块物理内存,但是 CPU 可以直接访问的却是虚拟内存,那么地址转换在哪里呢?所以看下copy_page_from_iter的实现就清楚了,在此函数中会通过kmap_atomic进程地址转换
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/iov_iter.c#L657
size_t copy_page_from_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
if (unlikely(i->type & ITER_PIPE)) {
WARN_ON(1);
return 0;
}
if (i->type & (ITER_BVEC|ITER_KVEC)) {
// 通过kmap_atomic将page物理内存地址转为CPU可以访问的虚拟内存地址
void *kaddr = kmap_atomic(page);
size_t wanted = copy_from_iter(kaddr + offset, bytes, i);
kunmap_atomic(kaddr);
return wanted;
} else
return copy_page_from_iter_iovec(page, offset, bytes, i);
}
pipe_read/pipe_write的调用方及入参(1)
以write/read系统调用操作管道为例,调用链为write->vfs_write->__vfs_write,数据流向是用户空间 -> 内核
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/read_write.c#L597
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
struct fd f = fdget_pos(fd);
......
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
if (ret >= 0)
file_pos_write(f.file, pos);
fdput_pos(f);
}
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/read_write.c#L542
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
......
ret = rw_verify_area(WRITE, file, pos, count);
if (!ret) {
......
ret = __vfs_write(file, buf, count, pos);
......
}
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/read_write.c#L504
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count,
loff_t *pos)
{
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}
最后调用到__vfs_write,因为对于pipefs文件系统的file定义struct file_operations pipefifo_fops而言,只实现了write_iter/read_iter方法,所以最终调用到new_sync_write函数:
static ssize_t new_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos)
{
//将用户空间传递的缓冲区(`buf`)和长度(`len`)封装到 `struct iovec`
struct iovec iov = { .iov_base = (void __user *)buf, .iov_len = len };
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = *ppos;
iov_iter_init(&iter, WRITE, &iov, 1, len);
//call_write_iter
ret = call_write_iter(filp, &kiocb, &iter);
BUG_ON(ret == -EIOCBQUEUED);
if (ret > 0)
*ppos = kiocb.ki_pos;
return ret;
}
static inline ssize_t call_write_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
// 这里调用pipefifo_fops的write_iter方法:即pipe_write方法
//1.检查管道是否有足够空间容纳数据
//2.将数据复制到管道的环形缓冲区中。
//3.唤醒等待读取该管道的进程(如果有)
//4.返回实际写入的字节数(如果管道已满且非阻塞,可能部分写入或返回 EAGAIN)
return file->f_op->write_iter(kio, iter);
}
简单分析下new_sync_write的实现,new_sync_write函数主要用于处理同步写入操作,是 VFS中实现同步写逻辑的核心函数。强调是同步阻塞操作,即该函数会阻塞直到写入操作完成(或失败),适用于同步 I/O。主要流程如下:
1、封装用户数据到内核结构
- 将用户空间传递的缓冲区(
buf)和长度(len)封装到struct iovec - 通过
iov_iter_init初始化一个迭代器(struct iov_iter),表示需要写入的数据段(支持多段数据,但这里只有一段)
2、初始化同步 I/O 控制块
- 通过
init_sync_kiocb初始化struct kiocb(I/O 控制块),并标记这是一个同步操作(非异步) - 设置写入的起始位置(
kiocb.ki_pos = *ppos),通常对应文件的当前偏移量
3、调用文件操作的具体实现
- 通过
call_write_iter调用文件操作函数指针file->f_op->write_iter,这是 VFS 层到具体文件系统(或设备)的接口 - 对于管道(pipe)类型,
file->f_op->write_iter实际指向pipe_write函数,负责将数据写入管道的缓冲区
4、处理结果并更新位置,检查返回值 ret(实际写入的字节数),若写入成功(ret > 0),更新文件位置指针(*ppos = kiocb.ki_pos)
所以,内核中处处可以看到这种通用性的设计,十分优雅,通过 VFS 抽象接口(write_iter)支持多种文件系统(如 ext4、pipe、socket 等),另外通过迭代器支持,即使用 iov_iter处理分散/聚集 I/O操作(本例中只有一个连续的缓冲区)
pipe_read/pipe_write的调用方及入参(2)
从入口sys_read开始,数据流向是内核 -> 用户空间
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
// 1、从struct file结构获取f_pos成员,作为本次read的起点
loff_t pos = file_pos_read(f.file);
// 2、调用vfs_read-->pipe_read函数,从管道内核缓冲区读取数据(成功时ret为读取长度)
// pos会被同步修改
ret = vfs_read(f.file, buf, count, &pos);
if (ret >= 0){
// 3、更新file_pos_write(f_ops)的值
file_pos_write(f.file, pos);
}
fdput_pos(f);
}
return ret;
}
同样,对管道的读操作,最终也会走到new_sync_read->call_read_iter->pipe_read函数:
static inline ssize_t call_read_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
// 关联pipe_read方法
return file->f_op->read_iter(kio, iter);
}
static ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
//封装用户缓冲区
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
//初始化一个 kiocb(Kernel I/O Control Block) 结构,该结构代表了一个具体的I/O操作
init_sync_kiocb(&kiocb, filp);
//设置本次读取操作的起始偏移量。通常,这个值来自文件结构中的当前位置指针(filp->f_pos),调用者通过 ppos参数传入
// ppos的值来自于进入read函数从struct file中读取的f_pos成员的值
kiocb.ki_pos = *ppos;
//初始化迭代器
/*
参数作用如下:
- READ:指定了迭代器的方向(从内核到用户空间)
- &iov:指向之前创建的 iovec数组
- 1:表示 iovec数组的数量。这里是1,表示这是一个连续的缓冲区(集中读)。如果数量大于1,则支持分散读(scatter-read)
- len:期望读取的总字节数
*/
iov_iter_init(&iter, READ, &iov, 1, len);
/*
call_read_iter实际指向pipe_read,主要完成:
1. 检查管道缓冲区中是否有数据
2. 如果没有数据且管道写端未关闭,则可能进入睡眠等待(阻塞模式)
3. 将数据从管道的环形缓冲区拷贝到 iter所描述的用户空间内存中
4. 唤醒可能正在等待写入该管道的进程
5. 返回实际拷贝的字节数
*/
ret = call_read_iter(filp, &kiocb, &iter);
//安全断言。因为 init_sync_kiocb初始化的是同步I/O,所以绝对不应该返回 -EIOCBQUEUED(这个值表示I/O请求已被异步提交并排队)。如果返回此值,说明内核逻辑有严重错误,触发BUG
BUG_ON(ret == -EIOCBQUEUED);
//处理结果并更新位置(即上面说的f_pos的指针变量)
*ppos = kiocb.ki_pos;
//将实际读取的字节数(或遇到的错误码)返回给上层调用者(如 vfs_read)
return ret;
}
static ssize_t
pipe_read(struct kiocb *iocb, struct iov_iter *to)
{
size_t total_len = iov_iter_count(to);
// struct kiocb的作用是存储struct file指针filp
// 从而定位到管道的管理结构 pipe
// 最终的读还是依靠pipe完成
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
......
}
这里简单分析下new_sync_read函数的实现,new_sync_read是 VFS中同步读操作的核心实现。主要作用是准备一个同步读取操作的上下文,并通过VFS接口调用具体文件系统或设备驱动提供的读取方法,将数据从内核空间(如页缓存、设备、管道等)拷贝到用户空间提供的缓冲区中
1、封装用户缓冲区,主要将用户空间传递的参数(缓冲区地址 buf和期望读取的长度 len)封装成一个 iovec结构,其中struct iovec是描述一个内存区域的通用结构,其成员iov_base指向内存起始地址,iov_len指定长度,这里它封装了用户希望数据被写入的目标地址
2、调用init_sync_kiocb初始化同步I/O控制块 (kiocb)并设置本次读取操作的起始偏移量。init_sync_kiocb会将 kiocb->ki_flags设置为 IOCB_DIRECT(如果是直接IO)或 0,并确保其不是异步的。这标记了这是一个同步操作,函数会等待I/O完成才返回
3、初始化迭代器 (iov_iter),根据之前创建的 iovec,初始化一个迭代器 iov_iter,参数已说明。iov_iter提供了一个统一的接口来处理可能分散的多段数据,极大地增强了函数的通用性
4、调用具体文件系统的读取方法call_read_iter,通过VFS的抽象接口,跳转到具体文件系统、设备或管道(如本例)的读取函数。本函数内部直接调用 filp->f_op->read_iter(&kiocb, &iter),filp->f_op对于pipe而言,其 read_iter方法指向 pipe_read函数
5、结果处理并更新位置,其中在 pipe_read 执行过程中,它会更新 kiocb->ki_pos。这里将这个新位置写回到 ppos所指向的变量(通常是 filp->f_pos)。这样,下一次读取操作就会从正确的位置开始
最后,请注意这里有个小细节,关于更新位置指针的时机,new_sync_write与new_sync_read稍微不同:
- 在
new_sync_write中,只有在ret > 0(成功写入)时才更新*ppos - 而在
new_sync_read中,无论返回值ret是正数(成功读取)还是负数(出错),都会更新*ppos。这是因为即使读取失败(如部分读取后遇到错误),文件位置也可能已经发生了改变,需要反映这个变化,以确保后续操作的正确性
关于写的一些细节
在刚开始分析时,错误的认为管道在写入时必须写满一整页page然后再开始写下一页,实际上并不是,这个行为受到can_merge参数控制。那么什么情况下会出现上述case呢?还是以本文内核版本(anon_pipe_buf_ops 和 packet_pipe_buf_ops)为例,回到内核pipe_write函数的实现:
1、合并写入的条件检查,触发追加写入的条件为:
buf->ops->can_merge == true(匿名管道默认支持)offset + chars <= PAGE_SIZE(当前缓冲区剩余空间足够容纳本次写入)
而不满足条件的行为,若任一条件不满足(如 can_merge=false 或空间不足),跳过追加逻辑,直接进入 for(;;) 循环分配新页写入,不会拆分写入数据
......
if (pipe->nrbufs && chars != 0) {
int lastbuf = (pipe->curbuf + pipe->nrbufs - 1) & (pipe->buffers - 1);
struct pipe_buffer *buf = pipe->bufs + lastbuf;
int offset = buf->offset + buf->len;
// 条件:必须同时满足 (1) 支持合并 且 (2) 剩余空间足够
if (buf->ops->can_merge && offset + chars <= PAGE_SIZE) {
// 执行追加写入操作
......
}else{
//当 offset + chars > PAGE_SIZE(当前缓冲区剩余空间不足)时,
//内核会跳过追加写入逻辑,直接进入分配新页的流程
}
}
......
2、分配新页写入的流程,新页写入特点
- 新分配的页(page)偏移量
buf->offset固定为0,与追加写入(offset = buf->offset + buf->len)完全不同 - 数据从新页的起始位置写入,而非追加到旧页末尾
......
for (;;) {
if (bufs < pipe->buffers) { // 检查环形缓冲区是否有空闲槽位
int newbuf = (pipe->curbuf + bufs) & (pipe->buffers-1);
struct pipe_buffer *buf = pipe->bufs + newbuf;
struct page *page = pipe->tmp_page;
// 分配新页(若 pipe->tmp_page 为空)
if (!page) {
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
pipe->tmp_page = page;
}
// 将数据写入新页(从偏移 0 开始)
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
buf->page = page;
buf->offset = 0; // 新页偏移从 0 开始
buf->len = copied;
pipe->nrbufs++; // 增加有效缓冲区计数
}
}
......
小结
基于本文 Linux 内核版本中管道缓冲区的典型操作结构体 anon_pipe_buf_ops 和 packet_pipe_buf_ops 的设计,结合管道写入的原子性规则和缓冲区管理机制,小结下
| 分类 | anon_pipe_buf_ops(匿名管道、标准模式) | packet_pipe_buf_ops(数据包模式) |
|---|---|---|
| 写入合并 | 支持合并写入 (can_merge=true),若当前缓冲区有剩余空间时,新数据会追加到现有页面末尾(需满足 offset + 数据长度 <= PAGE_SIZE) |
禁止合并写入 (can_merge=false),每次写入均分配独立新页,即使当前页有剩余空间也不追加 |
| 数据分页 | 可跨页(空间不足时分配新页) | 每PACKET一页,独立存储;有明确的数据包边界的概念,每个写入操作对应一个完整数据包,读端需按包(边界)读取(如 recvmsg) |
原子性(<= PIPE_BUF时) |
1、阻塞模式下,缓冲区不足时阻塞,直到空间足够后原子写入全部数据 2、非阻塞模式下,空间不足时返回 EAGAIN,不写入任何数据 |
与anon_pipe_buf_ops类型一致 |
原子性(> PIPE_BUF时) |
非原子写入,数据可能被拆分到多个页,且可能与其他进程写入交错 | |
| 阻塞与唤醒 | 1、当缓冲区满时,阻塞模式下,写进程休眠,直到读进程消费数据后唤醒 2、缓冲区满时,非阻塞模式下,立即返回 EAGAIN |
非原子写入,但每个数据包独立存储,读端按包消费 |
| 读端关闭处理 | 当读端关闭时,触发 SIGPIPE 信号或 EPIPE 错误 |
与anon_pipe_buf_ops类型一致 |
| 适用场景 | 流式数据(如 shell 管道),优化流式写入性能,支持空间足够时的数据合并,但需注意原子性限制 | 消息传输(如 AF_UNIX 数据包),牺牲合并能力换取消息边界隔离,适用于数据包通信 |
0x05 zero copy with pipe:splice
考虑一个场景,服务端要向客户端连接发送文件,一般过程(如下),在发送文件的过程中,首先需要将文件页缓存(Page Cache)从内核态复制到用户态缓存中,然后再从用户态缓存复制到客户端的 Socket 缓冲区中
- 服务端首先调用
read()读取文件内容 - 服务端通过调用
write()/send()将文件内容发送给客户端连接
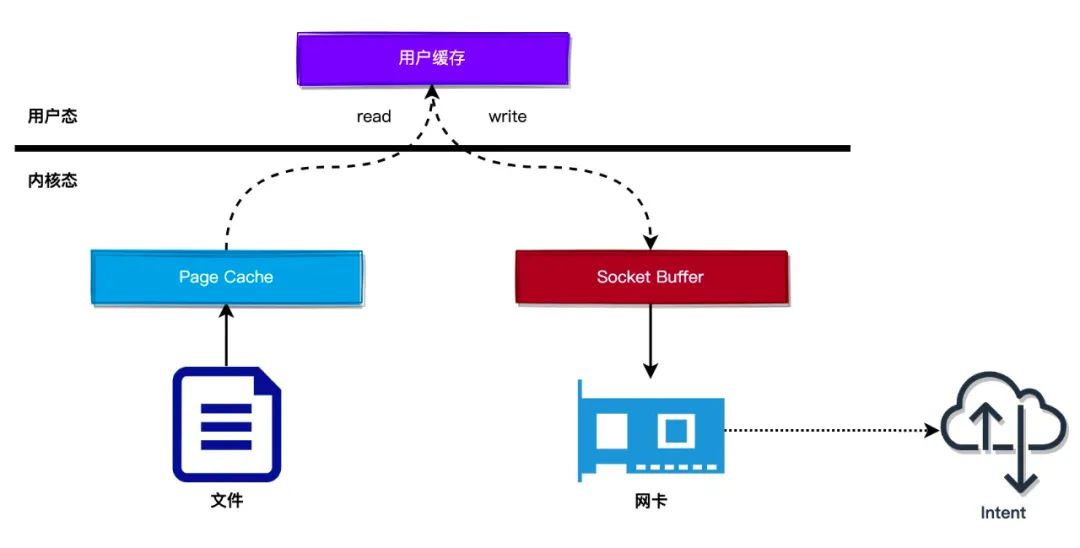
所以,如何优化?在上面的过程中,复制文件数据到用户态缓存这个操作是多余的,可以直接把文件页缓存的数据复制到 socket 缓冲区,这样就可以减少一次拷贝数据的操作,内核提供 splice() 系统调用来完成这个过程,使用 splice() 系统调用可以避免从内核态拷贝数据到用户态,也是零拷贝技术的一种实现
使用 splice 拷贝数据时,需要通过管道作为中转,splice 首先将页缓存(page cache)绑定到管道的写端,然后通过管道的读端读取到页缓存的数据,并且拷贝到 socket 缓冲区中,整个过程如下图:
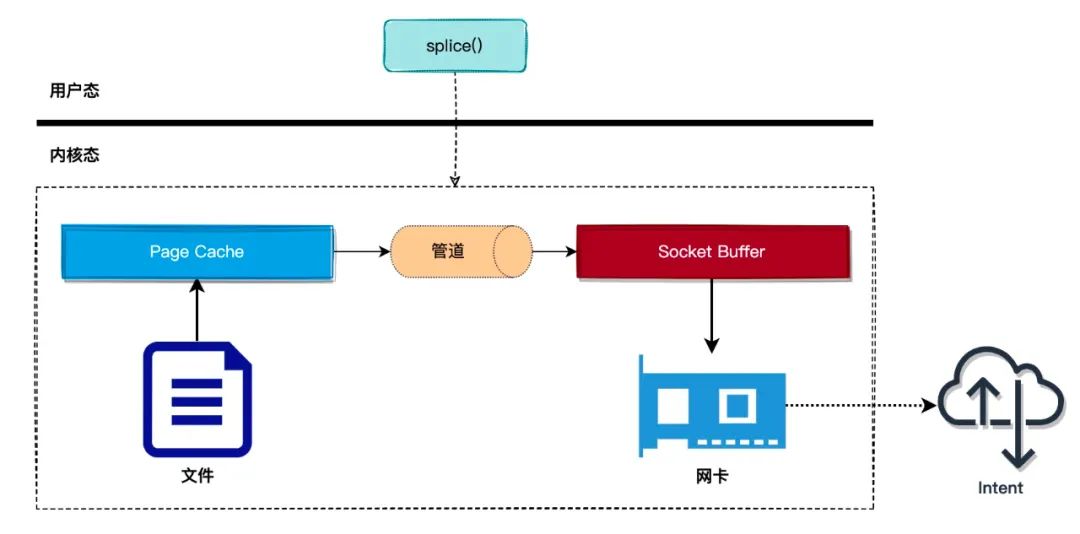
那么,根据上文对pipe内核读写机制的分析,不难猜到,由于管道的本质是内核将其结构中的环形缓冲区绑定到物理内存页上实现读写,而 splice 亦是将管道pipe的环形缓冲区绑定到文件的页缓存page cache,通过将文件页缓存绑定到管道的环形缓冲区后,就可以通过管道的读端读取文件页缓存的数据
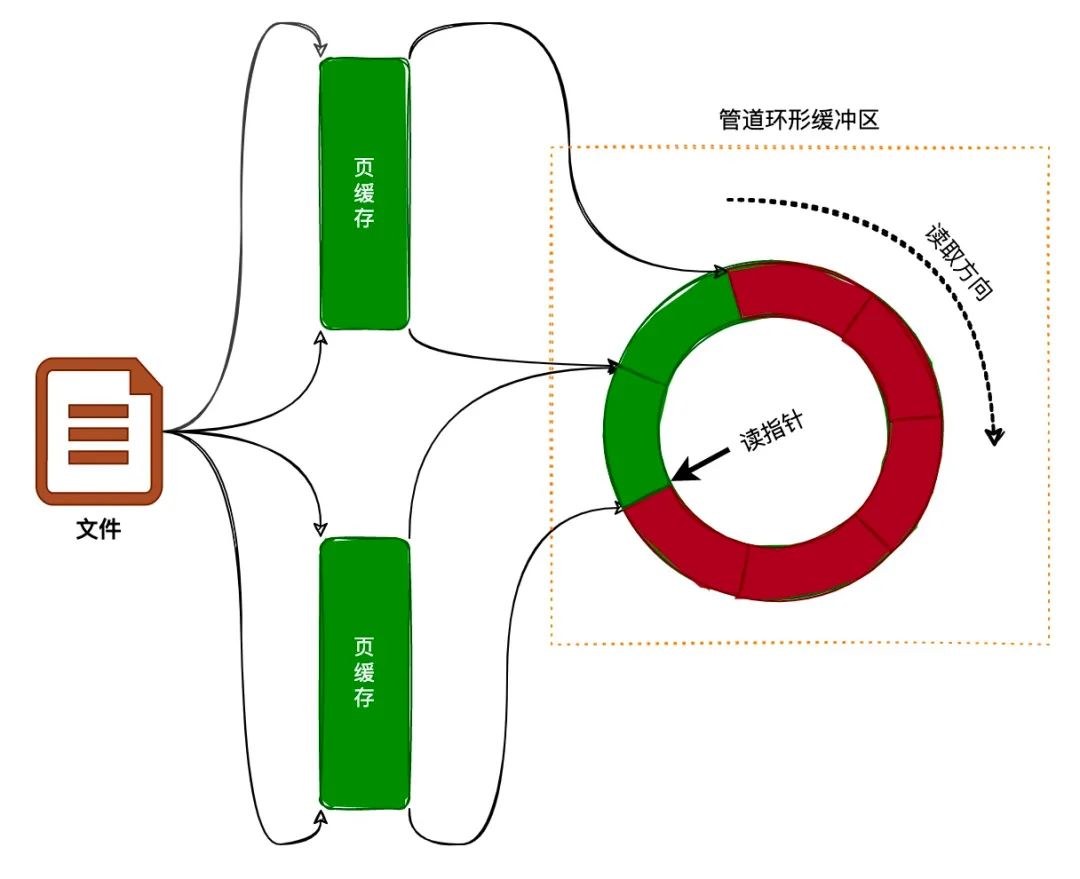
splice 系统调用
splice() 系统调用避免在内核地址空间与用户地址空间的拷贝,从而快速地在两个文件描述符之间传递数据,既然splice 是基于管道缓冲区 (pipe buffer) 机制实现的,所以 splice 的两个入参文件描述符才要求必须有一个是管道设备
//函数原型
ssize_t splice(int fd_in, off64_t *off_in, int fd_out, off64_t *off_out, size_t len, unsigned int flags);
int pfd[2];
pipe(pfd);
//数据流向 file_fd->pfd[1]
ssize_t bytes = splice(file_fd, NULL, pfd[1], NULL, 4096, SPLICE_F_MOVE);
//数据流程 pfd[0]-> socket_fd
bytes = splice(pfd[0], NULL, socket_fd, NULL, bytes, SPLICE_F_MOVE | SPLICE_F_MORE);
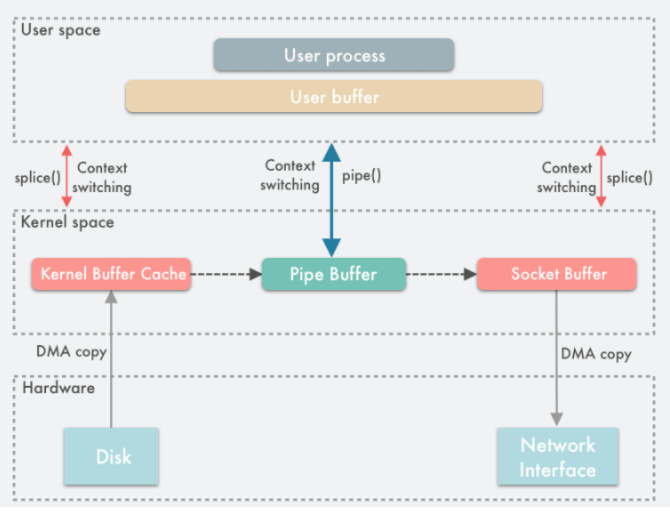
如上,使用 splice() 完成一次磁盘文件到网卡的读写过程如下:
- 用户进程调用
pipe(),从用户态陷入内核态,创建匿名单向管道,pipe()返回,上下文从内核态切换回用户态 - 用户进程调用
splice(),从用户态陷入内核态 - DMA 控制器将数据从硬盘拷贝到内核缓冲区,从管道的写入端”拷贝”进管道,
splice()返回,上下文从内核态回到用户态 - 用户进程再次调用
splice(),从用户态陷入内核态 - 内核把数据从管道的读取端”拷贝”到套接字缓冲区,DMA 控制器将数据从套接字缓冲区拷贝到网卡
splice()返回,上下文从内核态切换回用户态
上面描述的带引号的拷贝,本质上只是splice完成的绑定,并非真正由splice实现了读写过程
又如CVE-2022-0847中的触发场景,其利用情况是从文件向管道传递数据,即fd_in 表示一个普通文件,off_in 表示从指定的文件偏移处开始读取,fd_out 表示一个 pipe 写端
splice()系统调用的核心机制是绑定/重定向,本身并不执行对 Page Cache 的写操作,实现了内核空间内部的数据移动,避免了数据在用户空间和内核空间之间不必要的拷贝,即零拷贝。从上述场景来看,主要用于在两个文件描述符之间移动数据
splice的示例
发送文件给客户端的示例代码如下,使用 splice() 发送文件时,并不需要将文件内容读取到用户态缓存中,需要借助于管道作为中转,从而避免用户态与内核态的数据拷贝
ssize_t splice(int fd_in, loff_t *off_in, int fd_out,
loff_t *off_out, size_t len, unsigned int flags);
int send_file_to_client(int client_fd, char *file)
{
int fd;
struct stat fstat;
int blocks, remain;
int pipefd[2];
fd = open(file, O_RDONLY);
if (fd == -1) {
return -1;
}
stat(file, &fstat);
blocks = fstat.st_size / 4096;
remain = fstat.st_size % 4096;
pipe(pipefd); // 创建管道作为中转
for (i = 0; i < blocks; i++) {
// 1. 将文件内容读取并写入到管道 pipefd[1]
splice(fd, NULL, pipefd[1], NULL, 4096, SPLICE_F_MOVE|SPLICE_F_MORE);
// 2. 将管道的数据(读端)读取(pipefd[0])并发送给客户端连接
splice(pipefd[0], NULL, client_fd, NULL, 4096, SPLICE_F_MOVE|SPLICE_F_MORE);
}
if (remain > 0) {
splice(fd, NULL, pipefd[1], NULL, remain, SPLICE_F_MOVE|SPLICE_F_MORE);
splice(pipefd[0], NULL, client_fd, NULL, remain, SPLICE_F_MOVE|SPLICE_F_MORE);
}
return 0;
}
在上面的例子中,可以发现一个细节,整个实现中并没有write*/read*相关的系统调用出现,为何能完成文件zero copy呢?所以下面拆解一下splice的内核实现
0x06 splice的内核实现
splice() 系统调用的实现,代码如下:
SYSCALL_DEFINE6(splice, int, fd_in, loff_t __user *, off_in,
int, fd_out, loff_t __user *, off_out,
size_t, len, unsigned int, flags)
{
struct fd in, out;
long error;
......
//获取数据输入侧文件对象(参数)
in = fdget(fd_in);
if (in.file) {
if (in.file->f_mode & FMODE_READ) {
// 获取数据输出侧文件对象(参数)
out = fdget(fd_out);
if (out.file) {
if (out.file->f_mode & FMODE_WRITE)
// do_splice
error = do_splice(in.file, off_in,
out.file, off_out,
len, flags);
fdput(out);
}
}
fdput(in);
}
return error;
}
继续分析一下 do_splice() 函数的实现,分为三种case:
- 若输入端是一个管道,关联
do_splice_from - 若输出端是一个管道,关联
do_splice_to - 若输入/输出端都是管道,关联
splice_pipe_to_pipe
struct pipe_inode_info *get_pipe_info(struct file *file)
{
//是否是一个pipefifo_fops类型
return file->f_op == &pipefifo_fops ? file->private_data : NULL;
}
static long do_splice(struct file *in, loff_t __user *off_in,
struct file *out, loff_t __user *off_out,
size_t len, unsigned int flags)
{
struct pipe_inode_info *ipipe;
struct pipe_inode_info *opipe;
loff_t offset;
long ret;
ipipe = get_pipe_info(in); //第一个参数
opipe = get_pipe_info(out); //第二个参数
......
//省略的代码,如果输入/输出都是一个pipe类型
// CASE1:如果in(ipipe)一个管道
// 对应例子中的第二部分
// 此时in是一个读端
// 2. 将管道的数据(读端)读取(pipefd[0])并发送给客户端连接
// splice(pipefd[0], NULL, client_fd, NULL, 4096, SPLICE_F_MOVE|SPLICE_F_MORE);
if (ipipe) {
if (off_in)
return -ESPIPE;
if (off_out) {
if (!(out->f_mode & FMODE_PWRITE))
return -EINVAL;
if (copy_from_user(&offset, off_out, sizeof(loff_t)))
return -EFAULT;
} else {
offset = out->f_pos;
}
// 读端,必不可能写
if (unlikely(!(out->f_mode & FMODE_WRITE)))
return -EBADF;
if (unlikely(out->f_flags & O_APPEND))
return -EINVAL;
ret = rw_verify_area(WRITE, out, &offset, len);
if (unlikely(ret < 0))
return ret;
file_start_write(out);
// 核心工作:调用 do_splice_from() 函数管道数据拷贝到目标文件句柄
// 参数 ipipe 输入(读)
// 参数 out 输出(写)
ret = do_splice_from(ipipe/*管道读端*/, out/*写入目标file(socket、普通文件)*/, &offset, len, flags);
file_end_write(out);
if (!off_out)
out->f_pos = offset;
else if (copy_to_user(off_out, &offset, sizeof(loff_t)))
ret = -EFAULT;
return ret;
}
//CASE2:如果输出端是一个pipe类型
// 对应示例中的第一部分,从文件读数据->关联到管道的写端
// 1. 将文件内容读取并写入到管道 pipefd[1]
// splice(fd, NULL, pipefd[1], NULL, 4096, SPLICE_F_MOVE|SPLICE_F_MORE);
// 该case中,opipe是一个管道类型
if (opipe) {
if (off_out)
return -ESPIPE;
if (off_in) {
if (!(in->f_mode & FMODE_PREAD)) //写端,必不可以读
return -EINVAL;
if (copy_from_user(&offset, off_in, sizeof(loff_t)))
return -EFAULT;
} else {
offset = in->f_pos;
}
pipe_lock(opipe);
ret = wait_for_space(opipe, flags);
if (!ret){
//调用 do_splice_to() 函数将文件内容与管道绑定
// in不是管道类型
// opipe是管道类型
ret = do_splice_to(in, &offset, opipe, len, flags);
}
pipe_unlock(opipe);
if (ret > 0)
wakeup_pipe_readers(opipe);
if (!off_in)
in->f_pos = offset;
else if (copy_to_user(off_in, &offset, sizeof(loff_t)))
ret = -EFAULT;
return ret;
}
return -EINVAL;
}
这里仅仅讨论下输入、输出仅一方为管道的场景
输出端为管道:do_splice_to(splice_read)
上文描述的示例,关联数据流从文件缓存读并写入(关联)至管道写端pipefd[1],注意这里的写入不是真写入,是将参数in指向的物理内存页(比如在ext4文件系统就是page cache)通过管道的写端与pipe管道的内核的ringbuffer、物理内存页关联(绑定)上,这样对管道的读操作就可以直接操作in指向的物理内存页,避免多余的内存拷贝
static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len/*len是操作长度*/,
unsigned int flags)
{
ssize_t (*splice_read)(struct file *, loff_t *,
struct pipe_inode_info *, size_t, unsigned int);
int ret;
......
if (in->f_op->splice_read)
splice_read = in->f_op->splice_read;
else
splice_read = default_file_splice_read;
return splice_read(in/*假设为ext4*/, ppos, pipe/*pipe for write*/, len, flags);
}
注意对out->f_op->splice_read,不同文件系统有不同的实现,典型的如(还有更多)
默认的default_file_splice_read实现是内核中用于实现通用管道数据读取的函数,当文件系统未提供自定义的 splice_read方法时被调用。其核心逻辑是通过临时内核缓冲区将文件数据拷贝至管道缓冲区,虽然实现了基本功能,但牺牲了零拷贝性能;其他文件系统如ext4则实现了splice方法,其提供的generic_file_splice_read用于实现从文件到管道零拷贝传输的核心函数,其设计目标是复用文件的页缓存(Page Cache),避免数据在用户空间与内核空间之间的冗余拷贝
这里以ext4文件系统为例,分析下其generic_file_splice_read的实现:
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/ext4/file.c#L731
const struct file_operations ext4_file_operations = {
.read_iter = ext4_file_read_iter, //进一步调用
.splice_read = generic_file_splice_read, //ext4文件系统的实现
.splice_write = iter_file_splice_write, //ext4文件系统的实现(写)
.write_iter = ext4_file_write_iter,
};
generic_file_splice_read的核心代码如下:
static inline ssize_t call_read_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
//调用ext4的ext4_file_read_iter方法
return file->f_op->read_iter(kio, iter);
}
ssize_t generic_file_splice_read(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
struct iov_iter to;
struct kiocb kiocb;
int idx, ret;
// iov_iter_pipe:
iov_iter_pipe(&to, ITER_PIPE | READ, pipe, len);
idx = to.idx;
init_sync_kiocb(&kiocb, in);
kiocb.ki_pos = *ppos;
// call_read_iter:
ret = call_read_iter(in, &kiocb, &to);
......
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/ext4/file.c#L58
static ssize_t ext4_file_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
......
return generic_file_read_iter(iocb/*in*/, to/*pipe*/);
}
所以,do_splice_to最核心的实现就是generic_file_read_iter函数,特别注意对于本例中的splice(fd, NULL, pipefd[1], NULL, 4096, SPLICE_F_MOVE|SPLICE_F_MORE)而言,参数struct kiocb *iocb代表源类型(ext4)、读端,而struct iov_iter *iter则代表目标类型(ITER_PIPE)、写端
ssize_t
generic_file_read_iter(struct kiocb *iocb/*源类型*/, struct iov_iter *iter/*目标类型*/)
{
struct file *file = iocb->ki_filp;
ssize_t retval = 0;
size_t count = iov_iter_count(iter);
......
// do_generic_file_read
retval = do_generic_file_read(file, &iocb->ki_pos, iter, retval);
}
do_generic_file_read是最核心的实现,可以解答两个问题(假设一次操作了4k字节,即一页):
- 数据如何从inode关联的物理存储流向inode对应的page(page cache)
- inode对应的page是如何与管道关联起来的(零拷贝)
do_generic_file_read函数在splice调用下的核心流程是:
- 在本文件inode对应 page cache 页缓存里进行搜寻,看看待读取这个文件内容(fd对应的起始指针+offset)是否已经在缓存里,如果是则直接用,否则如果不存在或者只有部分数据在缓存中,则分配一些新的内存页page并进行读入数据操作,同时会增加页框的引用计数,这一步完成之后,内存页就已经包含文件inode对应的读取内容了,同时会预先计算本次需要读(预读)的page数目
- 上一步涉及到的可能有块设备读,page cache预读等知识(后文介绍)
copy_page_to_iter->copy_page_to_iter->copy_page_to_iter_pipe:对于每一页进行处理,最终会调用copy_page_to_iter_pipe实现所谓的zero copy动作(写入数据到管道),但是没有真正拷贝数据,这里只是内存地址指针的移动,即把物理页框、偏移量和数据长度赋值给pipe_buffer完成数据入队操作
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L1760
static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos,
struct iov_iter *iter, ssize_t written)
{
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct file_ra_state *ra = &filp->f_ra;
pgoff_t index;
pgoff_t last_index;
pgoff_t prev_index;
unsigned long offset; /* offset into pagecache page */
unsigned int prev_offset;
int error = 0;
......
//1. 计算要复制的page数目、起始地址及偏移(预估)
index = *ppos >> PAGE_SHIFT;
prev_index = ra->prev_pos >> PAGE_SHIFT;
prev_offset = ra->prev_pos & (PAGE_SIZE-1);
last_index = (*ppos + iter->count + PAGE_SIZE-1) >> PAGE_SHIFT;
offset = *ppos & ~PAGE_MASK;
//2. 循环处理每一个page(按需)
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
unsigned long nr, ret;
......
//3. 根据page的index,在inode对应的radix树(page Cache)
//搜寻对应的page是否存在,如果存在则使用
//不存在,则触发预读,即块设备到page,完成后再搜索page cache
page_ok:
......
//4. 完成radix树的page指针与管道pipe_buffer的page指针的关联(即零拷贝)
ret = copy_page_to_iter(page, offset, nr, iter);
offset += ret;
index += offset >> PAGE_SHIFT;
offset &= ~PAGE_MASK;
prev_offset = offset;
put_page(page);
......
}
// copy_page_to_iter_pipe:零拷贝的绑定实现
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
size_t off;
int idx;
if (unlikely(bytes > i->count))
bytes = i->count;
if (unlikely(!bytes))
return 0;
if (!sanity(i))
return 0;
off = i->iov_offset;
idx = i->idx;
buf = &pipe->bufs[idx];
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
idx = next_idx(idx, pipe);
buf = &pipe->bufs[idx];
}
if (idx == pipe->curbuf && pipe->nrbufs)
return 0;
pipe->nrbufs++;
// 写入数据到管道,没有真正拷贝数据,而是内存地址指针的移动,
// 把物理页框、偏移量和数据长度赋值给 pipe_buffer 完成数据入队操作
// 所以是零拷贝:splice() 所谓的写入数据到管道其实并没有真正地拷贝数据,只进行内存地址指针的拷贝而不真正去拷贝数据
buf->ops = &page_cache_pipe_buf_ops;
get_page(buf->page = page);
buf->offset = offset;
buf->len = bytes;
i->iov_offset = offset + bytes;
i->idx = idx;
out:
i->count -= bytes;
return bytes;
}
小结下do_splice_to的调用链如下:
do_splice_to
|
in->f_op->splice_read(假设in为文件,类型为ext4)
|
generic_file_splice_read(ext4对应的splice_read函数为generic_file_splice_read)
|
call_read_iter
|
file->f_op->read_iter(ext4对应的read_iter函数为ext4_file_read_iter)
|
ext4_file_read_iter
|
generic_file_read_iter
|
do_generic_file_read
|
这里包含了对页缓存的相关操作,包括查找页面缓存、触发预读(miss)、检查页面状态等核心读操作(块设备)
|
copy_page_to_iter
|
copy_page_to_iter_pipe(这就是零拷贝的核心,将上面inode对应的页缓存的page关联到pipe buffer中的page)
splice虽然依赖于管道,但是并不会关联pipe_write()/pipe_read(),pipe_buffer 中保存了数据在内存中的页、偏移量和长度,用于定位数据,注意这里的页不是虚拟内存的页,而用的是物理内存的页框,因为这里是跨进程的管道,因此不能使用虚拟内存来表示,只能使用物理内存的页框定位数据。此外,管道的正常读写操作是通过 pipe_write/pipe_read 来完成的,通过把数据读取/写入环形队列的 pipe_buffer 来完成数据传输;虽然splice() 同样基于 pipe_buffer 实现的,但是它在通过pipe传输数据的时候却是零拷贝,因为它在写入读出时并没有使用 pipe_write/pipe_read 真正地在管道缓冲区写入读出数据,而是通过把数据在内存缓冲区中的物理内存页框指针、偏移量和长度赋值给pipe_buffer 中对应的这些字段来完成数据的”拷贝”,也就是其实只拷贝了数据的内存地址等元信息
还有一点需要注意,管道的默认容量是 16 个内存页(16 * 4KB = 64 KB),一次往管道里写数据的时候最好不要超过 64KB,否则的话 splice() 会阻塞(需要设置管道为O_NONBLOCK模式)
输入端为管道:do_splice_from
当输入端是一个管道(也就是说从管道拷贝数据到输出端句柄),对应示例中的第二部分即参数pipe对应管道的读端,参数out对应客户端socket fd。do_splice_from() 函数的实现如下:
static long do_splice_from(struct pipe_inode_info *pipe, struct file *out,
loff_t *ppos, size_t len, unsigned int flags)
{
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *,
loff_t *, size_t, unsigned int);
if (out->f_op->splice_write){
// 不同文件系统有不同的实现
splice_write = out->f_op->splice_write;
}
else{
splice_write = default_file_splice_write;
}
// 调用splice_write
return splice_write(pipe/*管道读端*/, out/*写入目标*/, ppos, len, flags);
}
注意对out->f_op->splice_write,不同文件系统有不同的实现,典型的如(还有更多)
- ext4文件系统:
iter_file_splice_write - socket/sockfs:
generic_splice_sendpage - 默认的实现:
default_file_splice_write:不具备零拷贝特性
这里以ext4文件系统的iter_file_splice_write的实现为例,写操作相对直观一些(其实和pipe_write过程有点类似),主要步骤如下:
- 获取管道pipe环形缓冲区的读指针
- 调用
pipe_to_file()函数把管道环形缓冲区的数据拷贝到输出端的文件中
ssize_t
iter_file_splice_write(struct pipe_inode_info *pipe, struct file *out,
loff_t *ppos, size_t len, unsigned int flags)
{
struct splice_desc sd = {
.total_len = len,
.flags = flags,
.pos = *ppos,
.u.file = out,
};
// 获取管道读端的信息
int nbufs = pipe->buffers;
struct bio_vec *array = kcalloc(nbufs, sizeof(struct bio_vec),
GFP_KERNEL);
ssize_t ret;
......
pipe_lock(pipe);
splice_from_pipe_begin(&sd);
while (sd.total_len) {
struct iov_iter from;
size_t left;
int n, idx;
ret = splice_from_pipe_next(pipe, &sd);
if (ret <= 0)
break;
if (unlikely(nbufs < pipe->buffers)) {
kfree(array);
nbufs = pipe->buffers;
array = kcalloc(nbufs, sizeof(struct bio_vec),
GFP_KERNEL);
if (!array) {
ret = -ENOMEM;
break;
}
}
/* build the vector */
left = sd.total_len;
for (n = 0, idx = pipe->curbuf; left && n < pipe->nrbufs; n++, idx++) {
// 1、获取管道环形缓冲区
struct pipe_buffer *buf = pipe->bufs + idx;
size_t this_len = buf->len;
if (this_len > left)
this_len = left;
if (idx == pipe->buffers - 1)
idx = -1;
ret = pipe_buf_confirm(pipe, buf);
if (unlikely(ret)) {
if (ret == -ENODATA)
ret = 0;
goto done;
}
// 先缓存要从(管道)读端读出来的数据
array[n].bv_page = buf->page;
array[n].bv_len = this_len;
array[n].bv_offset = buf->offset;
// left更新为还剩余待取出的数据长度
left -= this_len;
}
// 2、通过iov_iter_bvec+vfs_iter_write,将bio_vec中的数据发送给out(在例子中是客户端的fd)
iov_iter_bvec(&from, ITER_BVEC | WRITE, array, n,
sd.total_len - left);
// ret:成功读出的数据长度
ret = vfs_iter_write(out, &from, &sd.pos);
if (ret <= 0)
break;
sd.num_spliced += ret;
sd.total_len -= ret;
*ppos = sd.pos;
//3、根据ret,更新pipe_buffer中的相关成员
/* dismiss the fully eaten buffers, adjust the partial one */
while (ret) {
struct pipe_buffer *buf = pipe->bufs + pipe->curbuf;
if (ret >= buf->len) {
ret -= buf->len;
buf->len = 0;
pipe_buf_release(pipe, buf);
pipe->curbuf = (pipe->curbuf + 1) & (pipe->buffers - 1);
pipe->nrbufs--;
if (pipe->files)
sd.need_wakeup = true;
} else {
buf->offset += ret;
buf->len -= ret;
ret = 0;
}
}
}
done:
kfree(array);
splice_from_pipe_end(pipe, &sd);
pipe_unlock(pipe);
if (sd.num_spliced)
ret = sd.num_spliced;
return ret;
}
在do_splice_from实现中,最核心的部分是iov_iter_bvec加vfs_iter_write,二者完成了零拷贝的功能
iov_iter_bvec:将管道pipe的读端(对应于参数bvec)封装为struct iov_iter *i对象(前面已经完成了管道pipe_buffer与bvec的转换)vfs_iter_write:将上述iov_iter的数据读出,写入到file中,对应于ext4_file_write_iter函数中的iocb参数
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/iov_iter.c#L880
void iov_iter_bvec(struct iov_iter *i, int direction,
const struct bio_vec *bvec, unsigned long nr_segs,
size_t count)
{
BUG_ON(!(direction & ITER_BVEC));
i->type = direction;
i->bvec = bvec;
i->nr_segs = nr_segs;
i->iov_offset = 0;
i->count = count;
}
ssize_t vfs_iter_write(struct file *file, struct iov_iter *iter, loff_t *ppos)
{
struct kiocb kiocb;
ssize_t ret;
if (!file->f_op->write_iter)
return -EINVAL;
init_sync_kiocb(&kiocb, file);
kiocb.ki_pos = *ppos;
iter->type |= WRITE;
// 对应file->f_op->write_iter(kio, iter);
// ext4文件系统对应的实现是ext4_file_write_iter
ret = call_write_iter(file, &kiocb, iter);
BUG_ON(ret == -EIOCBQUEUED);
if (ret > 0)
*ppos = kiocb.ki_pos;
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/ext4/file.c#L203
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct inode *inode = file_inode(iocb->ki_filp);
int o_direct = iocb->ki_flags & IOCB_DIRECT;
int unaligned_aio = 0;
int overwrite = 0;
ssize_t ret;
if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb))))
return -EIO;
inode_lock(inode);
ret = ext4_write_checks(iocb, from);
if (ret <= 0)
goto out;
......
ret = __generic_file_write_iter(iocb, from);
inode_unlock(inode);
if (ret > 0)
ret = generic_write_sync(iocb, ret);
return ret;
out:
inode_unlock(inode);
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L2874
ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct address_space * mapping = file->f_mapping;
struct inode *inode = mapping->host;
ssize_t written = 0;
ssize_t err;
ssize_t status;
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
} else {
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L2874
//TODO:这里的内容单独分析
written = generic_perform_write(file, from, iocb->ki_pos);
if (likely(written > 0))
iocb->ki_pos += written;
}
out:
current->backing_dev_info = NULL;
return written ? written : err;
}
0x07 总结
can_merge的作用及场景
const struct pipe_buf_operations page_cache_pipe_buf_ops = {
.can_merge = 0,
.confirm = page_cache_pipe_buf_confirm,
.release = page_cache_pipe_buf_release,
.steal = page_cache_pipe_buf_steal,
.get = generic_pipe_buf_get,
};
管道操作的原子性
在APUE中遇到这么一句话:小于 PIPE_BUF 的写操作必须是原子的,要写的数据应被连续地写到管道;大于 PIPE_BUF 的写操作可能是非原子的,内核可能会将数据与其它进程写入的数据交织在一起。POSIX 规定 PIPE_BUF 至少为512字节(Linux 中为4096),语义如下:(n为要写的字节数)
n <= PIPE_BUF且O_NONBLOCK为 disable:写入具有原子性。如果没有足够的空间供n个字节全部立即写入,则阻塞直到有足够空间将n个字节全部写入管道n <= PIPE_BUF且O_NONBLOCK为 enable: 写入具有原子性。如果有足够的空间写入n个字节,则write立即成功返回,并写入所有n个字节;否则一个都不写入,write返回错误,并将errno设置为EAGAINn > PIPE_BUF且O_NONBLOCK为 disable:写入不具有原子性。可能会和其它的写进程交替写,直到将n个字节全部写入才返回,否则阻塞等待写入n > PIPE_BUF且O_NONBLOCK为 enable:写入不具有原子性。如果管道已满,则写入失败,write返回错误,并将errno设置为EAGAIN;否则,可以写入1~n个字节,即部分写入,此时write返回实际写入的字节数,并且写入这些字节时可能与其他进程交错写入
所以,从管道的内核视角容易理解上述原子性及非原子性
1、为什么小于 PIPE_BUF的写操作是原子的?从源码易知,内核通过管道锁__pipe_lock/__pipe_unlock保证单次 write() 操作的原子性(如互斥访问缓冲区),包括合并写入one page以及写入 one page的操作
2、为什么大于PIPE_BUF的写操作是非原子的?由于超过PIPE_BUF,数据必然要写到多个page里面
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
ssize_t ret = 0;
int do_wakeup = 0;
......
__pipe_lock(pipe);
// 检查是否支持(可以)合并写入
......
for (;;) {
int bufs;
bufs = pipe->nrbufs;
if (bufs < pipe->buffers) {
int newbuf = (pipe->curbuf + bufs) & (pipe->buffers-1);
struct pipe_buffer *buf = pipe->bufs + newbuf;
struct page *page = pipe->tmp_page;
int copied;
......
do_wakeup = 1;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
if (unlikely(copied < PAGE_SIZE && iov_iter_count(from))) {
if (!ret)
ret = -EFAULT;
break;
}
ret += copied;
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = copied;
buf->flags = 0;
if (is_packetized(filp)) {
buf->ops = &packet_pipe_buf_ops;
buf->flags = PIPE_BUF_FLAG_PACKET;
}
// 当前页已经被占用,累加一
pipe->nrbufs = ++bufs;
pipe->tmp_page = NULL;
if (!iov_iter_count(from))
break;
}
// 走到这里,说明两件事情:
// 1、说明数据还没写完
// 2、说明还有可用页
// 那么继续写就行了呗
if (bufs < pipe->buffers)
continue;
// 说明bufs== pipe->buffers,即没有可用页了(缓冲区满了,需要按照不同模式的等待处理)
if (filp->f_flags & O_NONBLOCK) {
// 非阻塞模式
if (!ret)
ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
if (!ret)
ret = -ERESTARTSYS;
break;
}
if (do_wakeup) {
// 因为上面的步骤确保了已经向缓冲区成功写入了数据,所以唤醒读进程去读
wake_up_interruptible_sync_poll(&pipe->wait, POLLIN | POLLRDNORM);
kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN);
do_wakeup = 0;
}
pipe->waiting_writers++;
// 内部释放锁并休眠
// 阻塞模式下,写进程把自己睡眠,释放CPU
pipe_wait(pipe);
pipe->waiting_writers--;
}
out:
__pipe_unlock(pipe);
......
}
所以,从这里的实现就可以知道为何跨页的写操作不是原子的:当锁释放期间,若其他进程可获取锁并写入数据,导致本次写入的数据被拆分,并可能与其他进程写入交错(原子性被破坏)
pipe_wait的实现如下,可以看到被阻塞的进程通过schedule让出CPU,这里锁与阻塞唤醒的协同机制为:
1、阻塞时的锁释放,当缓冲区满且为阻塞模式时,pipe_wait() 会执行下面的操作:
- 将当前进程加入等待队列(
prepare_to_wait),休眠直至读进程消费数据后唤醒 - 释放
__pipe_lock(pipe_unlock),允许其他进程操作管道 - 让出CPU(
schedule)
2、唤醒后的锁重获,当本进程被唤醒后(说明缓冲区非满、可写了),在 pipe_wait() 返回前会重新获取 __pipe_lock,继续执行循环写入剩余数据
void pipe_wait(struct pipe_inode_info *pipe)
{
DEFINE_WAIT(wait);
/*
* Pipes are system-local resources, so sleeping on them
* is considered a noninteractive wait:
*/
prepare_to_wait(&pipe->wait, &wait, TASK_INTERRUPTIBLE);
pipe_unlock(pipe);
// 让出CPU
schedule();
// 当缓冲区非满,又可写的时候,会执行到这里
finish_wait(&pipe->wait, &wait);
pipe_lock(pipe);
}
这里额外再提一下,写操作与读操作的锁竞争(协同):
1、读写互斥,由于__pipe_lock 是全局互斥锁,同一时间仅允许一个进程读或写管道:
- 若写进程持有锁,读进程(
pipe_read)会在__pipe_lock处阻塞,直至写操作完成或进入休眠 - 反之亦然,读操作持锁时写进程阻塞
2、性能影响,因锁粒度较大(覆盖整个 write() 调用),频繁小数据写入可能导致读进程饥饿,需依赖唤醒机制平衡:
- 写操作释放缓冲区后,通过
wake_up_interruptible_sync_poll()唤醒读进程 - 读操作消费数据后,唤醒阻塞的写进程
所以,程序中通常使用一对pipe来实现双向通信,避免pipe的这种竞争问题