0x00 前言
共享内存主要用于进程间通信,常见Shared Memory机制:
- System V shared memory(
shmget/shmat/shmdt):旧 - POSIX shared memory(
shm_open/shm_unlink):新
此外,内存映射mmap机制也可以用于跨进程间通信,参考前文:虚拟内存管理(上),当然了mmap也支持私有映射
- mmap文件共享映射
- mmap匿名共享映射
Shared file mappings:Sharing between unrelated processes, backed by file in filesystem
本文主要关注几个问题:
- mmap的实现机制
- shm的实现机制
- 内核是如何实现共享的?
本文主要基于v4.11.6版本进行分析
tmpfs
tmpfs文件系统,其文件数据都在内存中,掉电会丢失,主要特点:
- 内存文件系统,所有的文件数据都在内存中,掉电丢失
- 数据在内存,数据访问速度很快
- 内存不足,回收到swap中
- 读的时候,不分配物理页面,读取的数据都是
0
[root@X-X-01 corefile]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 16G 4.0K 16G 1% /dev
tmpfs tmpfs 16G 39M 16G 1% /dev/shm
tmpfs tmpfs 16G 266M 16G 2% /run
tmpfs tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/vda1 ext4 99G 18G 77G 19% /
tmpfs tmpfs 3.2G 0 3.2G 0% /run/user/0
/dev/vdb ext4 98G 47G 47G 50% /data
X.X.X.X:/ nfs4 2.5T 1.9T 642G 75% /data/cfs/xxx
tmpfs tmpfs 3.2G 0 3.2G 0% /run/user/30000
共享内存与tmpfs的关系
POSIX共享内存是基于tmpfs来实现的,System V shared memory在内核也是基于tmpfs实现的。tmpfs主要有两个作用:
- 用于SYSTEM V共享内存,还有匿名内存映射;这部分由内核管理,用户不可见(理解为特殊的文件系统)
- 用于POSIX共享内存,由用户负责mount,而且一般mount到
/dev/shm;依赖于CONFIG_TMPFS
内核提供的几种共享内存机制
| 场景 | 说明 | 内核调用链(简) |
|---|---|---|
| 匿名(文件)共享映射 | 父子进程间通信 | mmap_region->shmem_zero_setup |
| ipc共享内存 | 任意进程间共享内存 | newseg->shmem_kernel_file_setup->__shmem_file_setup |
| tmpfs | 实现内存文件系统 | shmem_file_operations.mmap->->shmem_mmap->vma->vm_ops = &shmem_vm_ops |
| memfd | 创建共享匿名文件 | memfd_create->shmem_file_setup |
共享内存页?
前文描述了匿名页和文件页,文件页会关联文件系统中的文件,而匿名页不关联任何文件。而共享内存页同时具备文件页和匿名页的的一些特征(如会关联文件、存在page cache等,同时也具备swap功能)
0x01 mmap的实现原理
mmap系统调用是将一个文件或者其它对象映射到进程的虚拟地址空间,实现磁盘地址和进程虚拟地址空间一段虚拟地址的一一对应关系。通过mmap系统调用可以让进程之间通过映射到同一个普通文件实现共享内存,普通文件被映射到进程虚拟地址空间当中后,进程可以像访问普通内存一样对文件进行一系列操作,而不需要通过 I/O 系统调用来读取或写入
mmap系统调用会将一个文件或其他对象映射到进程的地址空间中,并返回一个指向映射区域的指针,进程可以使用指针来访问映射区域的数据,就像访问内存一样
mmap文件共享(映射)的原理(回顾)
先回顾下,mmap实现文件共享映射的过程
调用 mmap 进行内存文件映射的时候,内核首先会在进程的虚拟内存空间中创建一个新的虚拟内存区域 VMA 用于映射文件,通过 vm_area_struct->vm_file 将映射文件的 struct flle 结构与虚拟内存映射关联起来
struct vm_area_struct {
unsigned long vm_flags; //标记为 MAP_SHARED 共享映射
struct file * vm_file; /* File we map to (can be NULL). */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE */
}
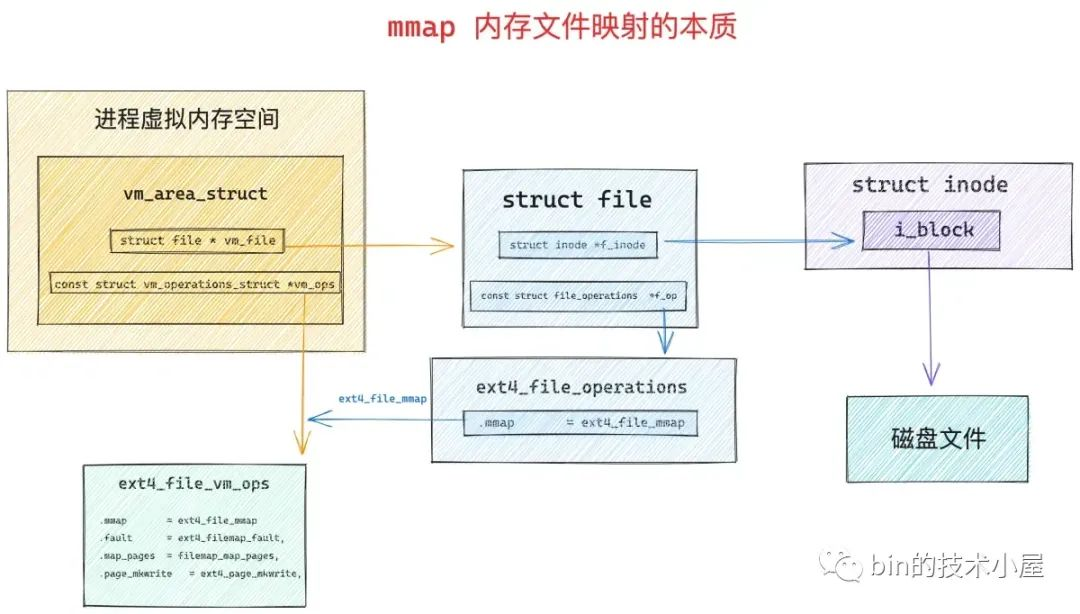
根据 vm_file->f_inode 可以关联到映射文件的 struct inode,近而关联到映射文件在磁盘中的磁盘块 i_block,这个就是 mmap 内存文件映射的本质。站在文件系统的视角,映射文件中的数据是按照磁盘块来存储的,读写文件数据也是按照磁盘块为单位进行的,磁盘块大小为 4K,当进程读取磁盘块的内容到内存之后,站在内存管理系统的视角,磁盘块中的数据被 DMA 拷贝到了物理内存页中,这个物理内存页就是前面提到的文件页,一个文件包含多个磁盘块,当它们被读取到内存之后,一个文件也就对应了多个文件页,这些文件页在内存中统一被一个叫做 page cache 的结构所组织
当多个进程调用 mmap 对磁盘上的同一个文件进行共享文件映射的时候,也都只是在每个进程的虚拟内存空间中,创建出一段用于共享映射的虚拟内存区域 VMA 出来,随后内核会将各个进程中的这段虚拟内存映射区与映射文件关联起来,mmap 共享文件映射的逻辑就结束了,并没有和物理内存建立任何关系
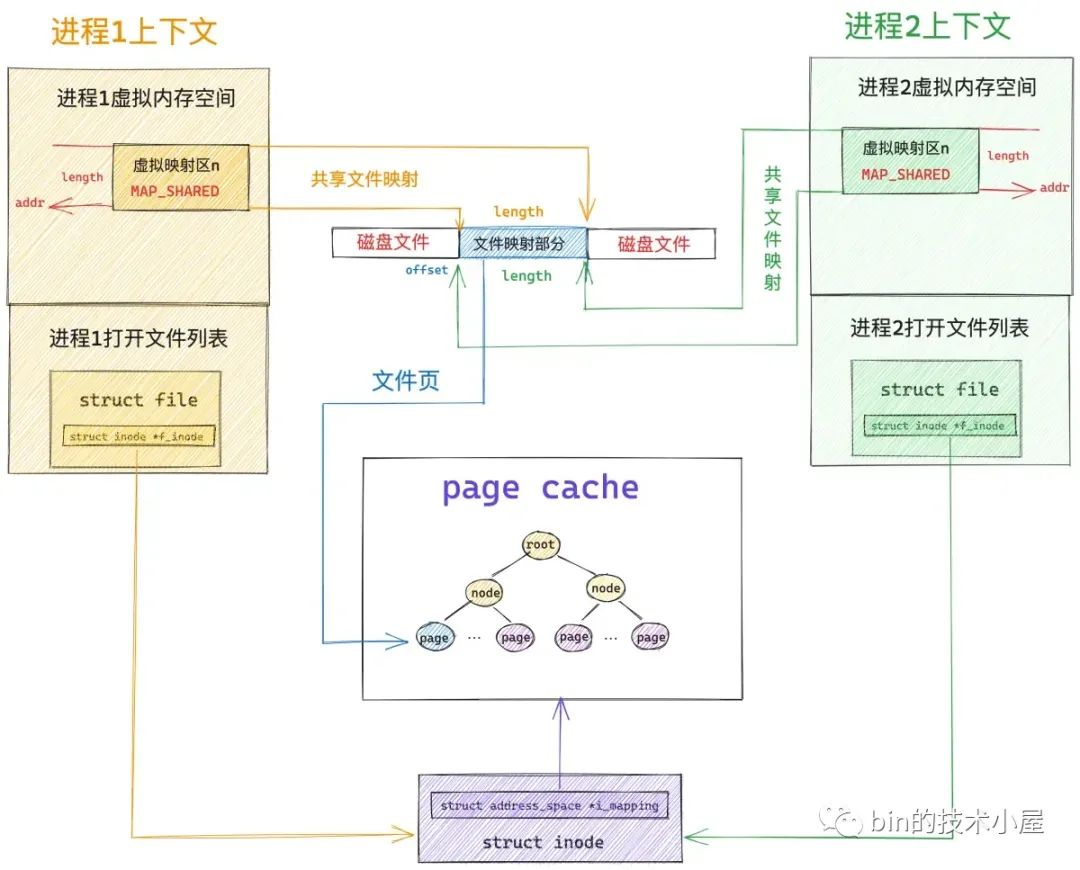
当任意一个进程,比如上图中的进程 1 开始访问这段映射的虚拟内存时,CPU 会把虚拟内存地址送到 MMU 中进行地址翻译,因为 mmap 只是为进程分配了虚拟内存,并没有分配物理内存,所以这段映射的虚拟内存在页表中是没有页表项 PTE 的。随后 MMU 就会触发缺页异常(page fault),进程切换到内核态,在内核缺页中断处理程序中会发现引起缺页的这段 VMA 是共享文件映射的,所以内核会首先通过 vm_area_struct->vm_pgoff 在文件 page cache 中查找是否有缓存相应的文件页(映射的磁盘块对应的文件页)
如果文件页不在 page cache 中,内核则会在物理内存中分配一个内存页,然后将新分配的内存页加入到 page cache 中,并增加页引用计数。随后会通过 address_space_operations 重定义的 readpage(如ext4_readpage)激活块设备驱动从磁盘中读取映射的文件内容,然后将读取到的内容填充新分配的内存页
这里CPU访问虚拟内存,送到MMU翻译,继而发现页表中无PTE导致缺页中断的逻辑,对应于内核函数do_page_fault,见下文分析
struct vm_area_struct {
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE */
}
static inline struct page *find_get_page(struct address_space *mapping,
pgoff_t offset)
{
return pagecache_get_page(mapping, offset, 0, 0);
}
至此文件中映射的内容已经加载进 page cache 了,此时物理内存才正式登场,在缺页中断处理程序的最后一步,内核会为映射的这段虚拟内存在页表中创建 PTE,然后将虚拟内存与 page cache 中的文件页通过 PTE 关联起来,缺页处理就结束了(这里指定的共享文件映射,所以 PTE 中文件页的权限是读写的,后续进程 1 在对这段虚拟内存区域写入的时候不会触发缺页中断,而是直接写入 page cache 中,整个过程没有切态,没有数据拷贝),当内核处理完缺页中断之后,mmap 共享文件映射在内核中的关系图如下:
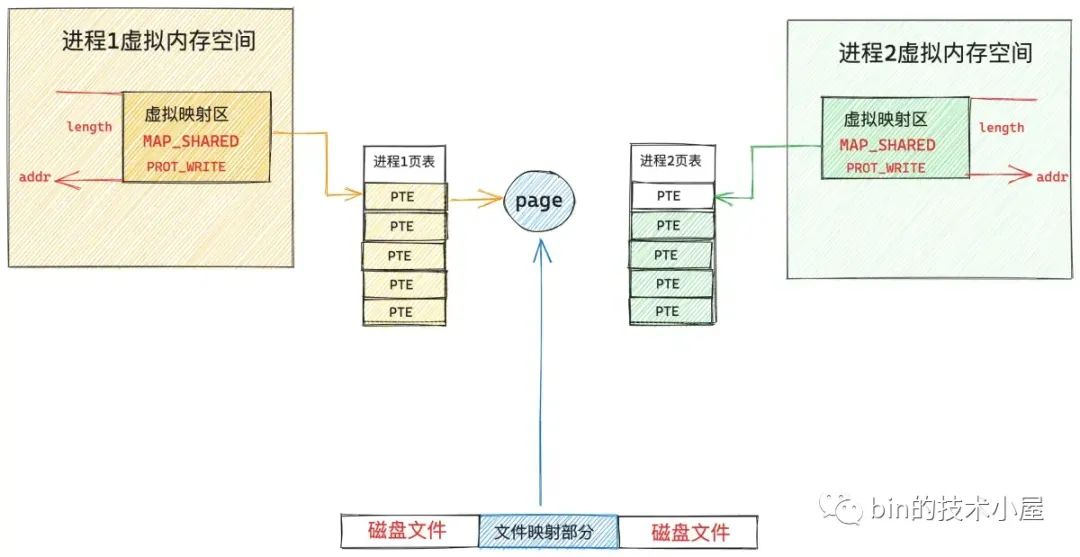
此时在切换到进程 2 的视角中,虽然现在文件中被映射的这部分内容已经加载进物理内存页,并被缓存在文件的 page cache 中了。但是现在进程 2 中这段虚拟映射区在进程 2 页表中对应的 PTE 仍然是空的,当进程 2 访问这段虚拟映射区的时候依然会产生缺页中断。当进程 2 切换到内核态,处理缺页中断的时候,此时进程 2 通过 vm_area_struct->vm_pgoff 在 page cache 查找文件页的时候,文件页已经被进程 1 加载进 page cache 了,进程 2 一下就找到了,不需要再去磁盘中读取映射内容了,内核会直接为进程 2 创建 PTE (由于是共享文件映射,所以这里的 PTE 也是可写的),并插入到进程 2 页表中,随后将进程 2 中的虚拟映射区通过 PTE 与 page cache 中缓存的文件页映射关联起来
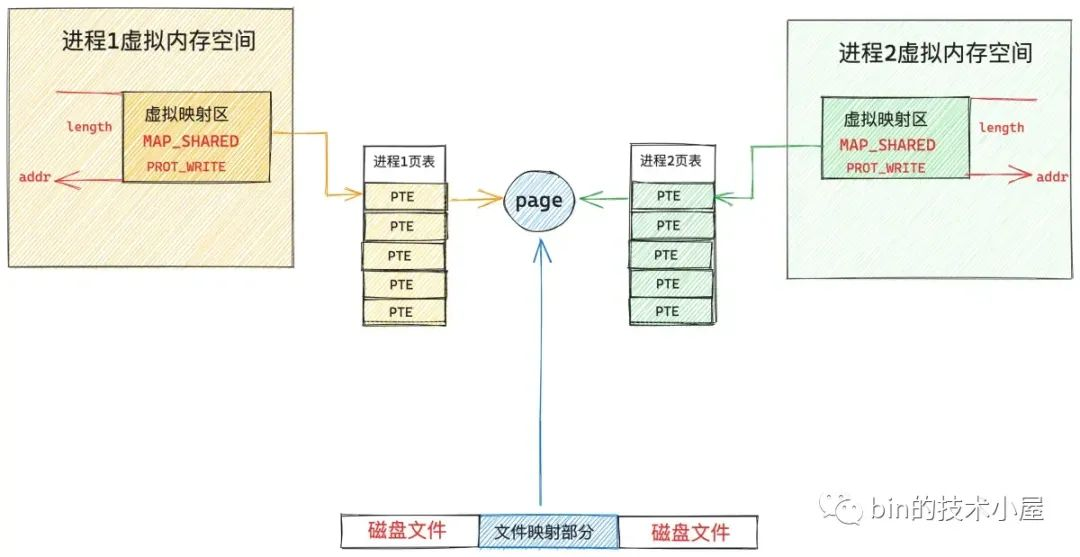
现在进程 1 和进程 2 各自虚拟内存空间中的这段虚拟内存区域 VMA,已经共同映射到了文件的 page cache 中,由于文件的 page cache 在内核中只有一份,它是和进程无关的,page cache 中的内容发生的任何变化,进程 1 和进程 2 都是可以看到的
虚拟内存的分配流程(不同架构)
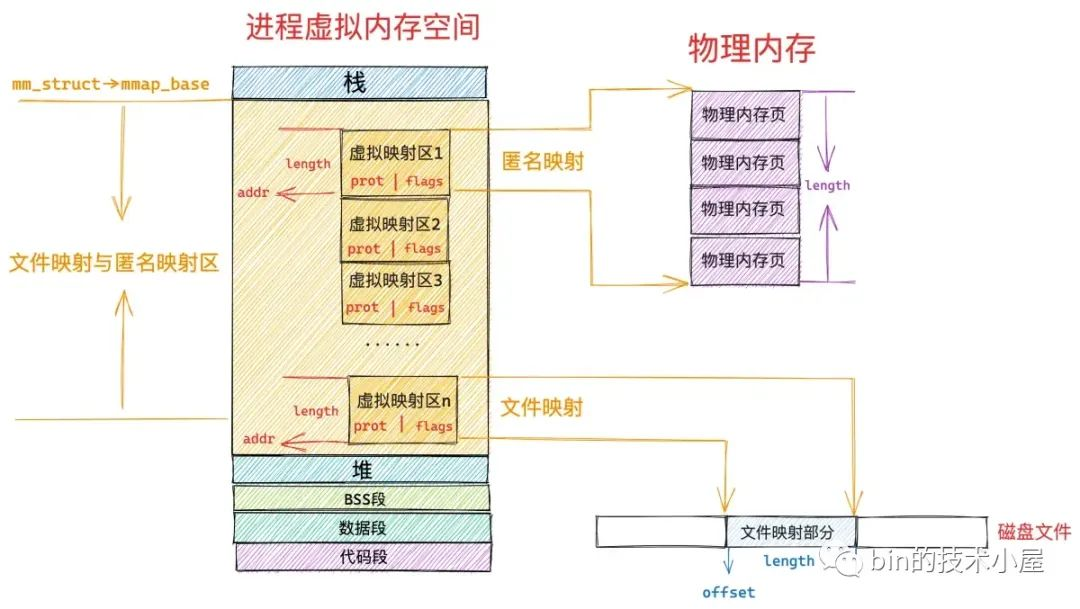
1、文件映射与匿名映射区的布局(/proc/sys/vm/legacy_va_layout)
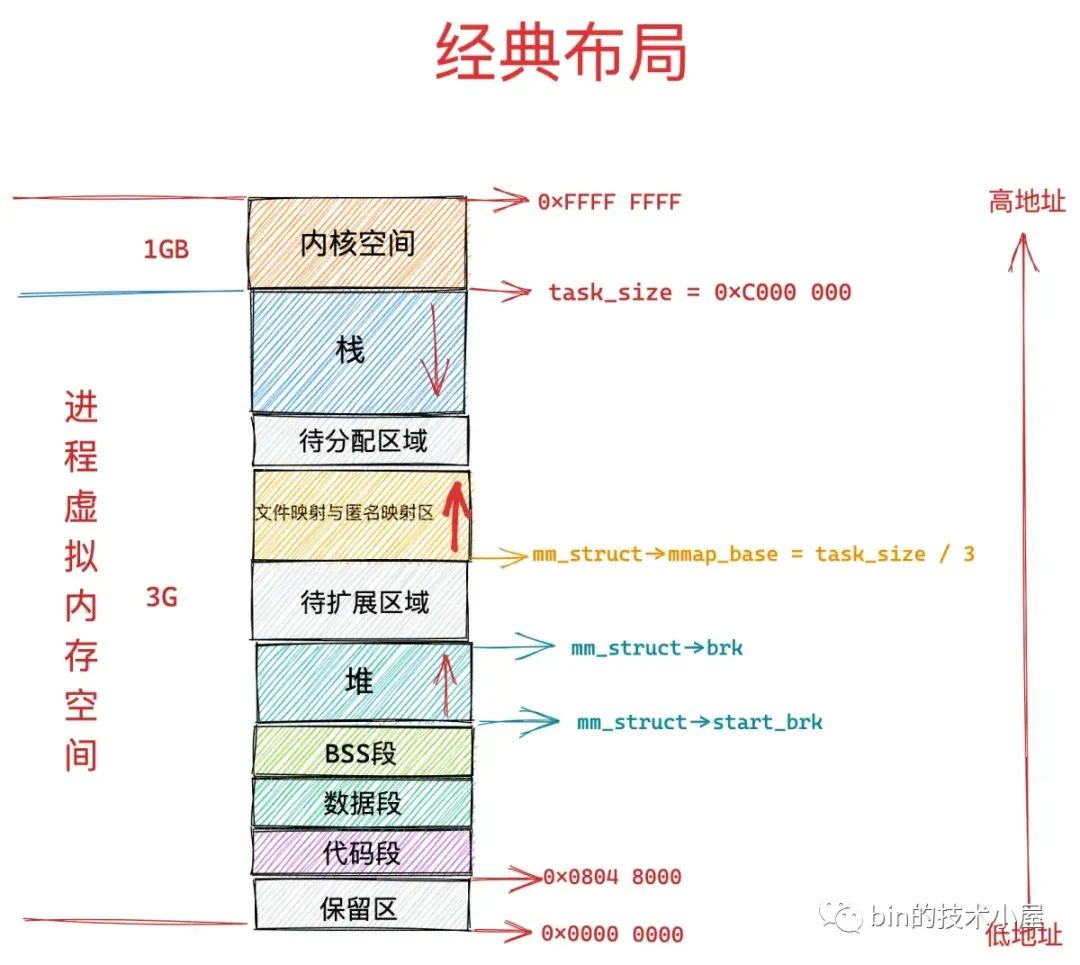
在经典布局(旧)下,文件映射与匿名映射区的地址增长方向是从低地址到高地址,也就是说映射区是从下往上增长,这也就导致了 mmap 在分配虚拟内存的时候需要从下往上搜索空闲 vma。经典布局下,文件映射与匿名映射区的起始地址 mm_struct->mmap_base 被设置在 task_size 的三分之一处,task_size 为进程虚拟内存空间与内核空间的分界线,也就说 task_size 是进程虚拟内存空间的末尾,大小为 3G。这表明了文件映射与匿名映射区起始于进程虚拟内存空间开始的 1G 位置处,而映射区恰好位于整个进程虚拟内存空间的中间,其下方就是堆了,由于代码段,数据段的存在,可供堆进行扩展的空间是小于 1G 的,否则就会与映射区冲突了。这种布局对于虚拟内存空间非常大的体系结构,比如 AMD64 , 是合适的而且会工作的非常好,因为虚拟内存空间足够的大(128T),堆与映射区都有足够的空间来扩展,不会发生冲突。但是对于虚拟内存空间比较小的体系结构,比如 IA-32,只能提供 3G 大小的进程虚拟内存空间,就会出现上述冲突问题
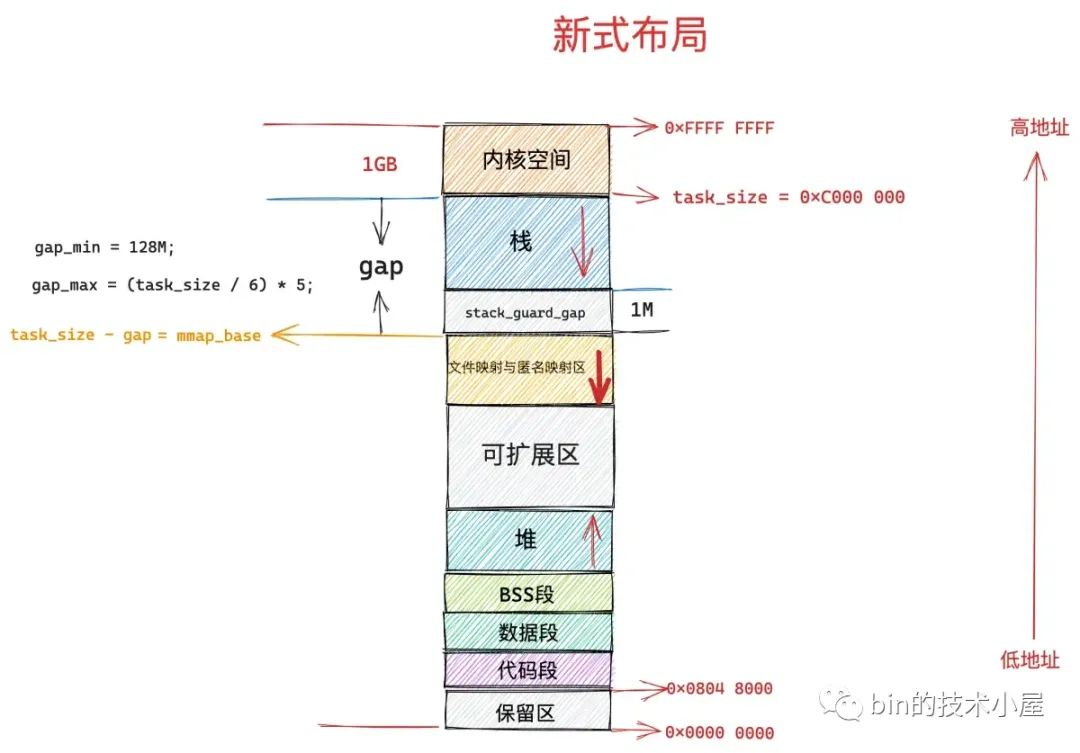
在新式布局下,文件映射与匿名映射区的地址增长方向是从高地址到低地址,也就是说映射区是从上往下增长,这也就导致了 mmap 在分配虚拟内存的时候需要从上往下搜索空闲 vma。在新式布局中,栈的空间大小会被限制,栈最大空间大小保存在 task_struct->signal_struct->rlimp[RLIMIT_STACK] 中。由于栈变为有界的了,所以文件映射与匿名映射区可以在栈的下方立即开始,为确保栈与映射区不会冲突,它们中间还设置了 1M 大小的安全间隙 stack_guard_gap,这样一来堆在进程地址空间中较低的地址处开始向上增长,而映射区位于进程空间较高的地址处向下增长,因此堆区和映射区在新式布局下都可以较好的扩展,直到耗尽剩余的虚拟内存区域
2、内核具体如何对文件映射与匿名映射区进行布局
前文描述过新进程的创建过程:进程虚拟内存空间的创建以及初始化是由 load_elf_binary 函数负责的,当进程通过 fork() 系统调用创建出子进程之后,子进程可以通过前面介绍的 execve 系统调用加载并执行一个指定的二进制执行文件,进程的虚拟内存空间的初始化过程由此开始
TODO
mmap内存映射
核心分为三个步骤:
1、用户进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
- 进程在用户空间调用
mmap,在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址区域 - 为此虚拟内存区域分配一个
vm_area_struct结构,接着对这个结构的各个域进行初始化 - 将新建的虚拟区结构
vm_area_struct插入进程的虚拟地址区域链表或红黑树中
2、调用内核空间的函数 mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
- 为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核已打开文件集中该文件的文件结构体(
struct file),每个文件结构体维护着和这个已打开文件的相关各项信息 - 通过该文件的文件结构体,链接到
file_operations,调用内核函数mmap(int mmap(struct file *filp, struct vm_area_struct *vma),不同于用户空间库函数 - 内核 mmap 函数通过虚拟文件系统 inode 模块定位到文件磁盘物理地址
- 通过
remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中
3、进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
- 进程的读或写操作访问虚拟地址空间这一段映射地址,通过查询页表,发现这一段地址并不在物理页面上。因为目前只建立了地址映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常
- 缺页异常进行一系列判断,确定无非法操作后,内核发起请求调页过程
- 调页过程先在交换缓存空间(swap cache)中寻找需要访问的内存页,如果没有则调用 nopage 函数把所缺的页从磁盘装入到主存中
- 之后进程即可对这片主存进行读或者写的操作,如果写操作改变了其内容,一定时间后系统会自动回写脏页面到对应磁盘地址,也即完成了写入到文件的过程(共享文件映射场景)
注意:修改过的脏页面并不会立即更新回文件中,而是有一段时间的延迟,可以调用msync来强制同步, 将修改过的内容立即保存到文件里
从mmap系统调用开始,核心参数如下:
addr:待映射的虚拟内存区域在进程虚拟内存空间中的起始地址(虚拟内存地址),通常设置成NULL,意思就是完全交由内核来决定虚拟映射区的起始地址(要按照 PAGE_SIZE(4K) 对齐)length:待申请映射的内存区域的大小,如果是匿名映射,则是要映射的匿名物理内存有多大,如果是文件映射,则是要映射的文件区域有多大(要按照 PAGE_SIZE(4K) 对齐)prot:映射区域的保护模式,有PROT_READ、PROT_WRITE、PROT_EXEC等flags:标志位,可以控制映射区域的特性。常见的有MAP_SHARED和MAP_PRIVATE等fd:文件描述符,用于指定映射的文件offset:映射的起始位置,表示被映射对象 (即文件) 从那里开始对映,通常设置为0,该值应该为大小为PAGE_SIZE(4K)的整数倍
其中常用的flags取值:
MAP_SHARED:共享映射(用于多进程之间的通信),对映射区域的写入操作直接反映到文件当中MAP_PRIVATE:私有映射,对映射区域的写入操作只反映到缓冲区当中不会写入到真正的文件MAP_ANONYMOUS:匿名映射将虚拟地址映射到物理内存而不是文件(忽略fd、offset)
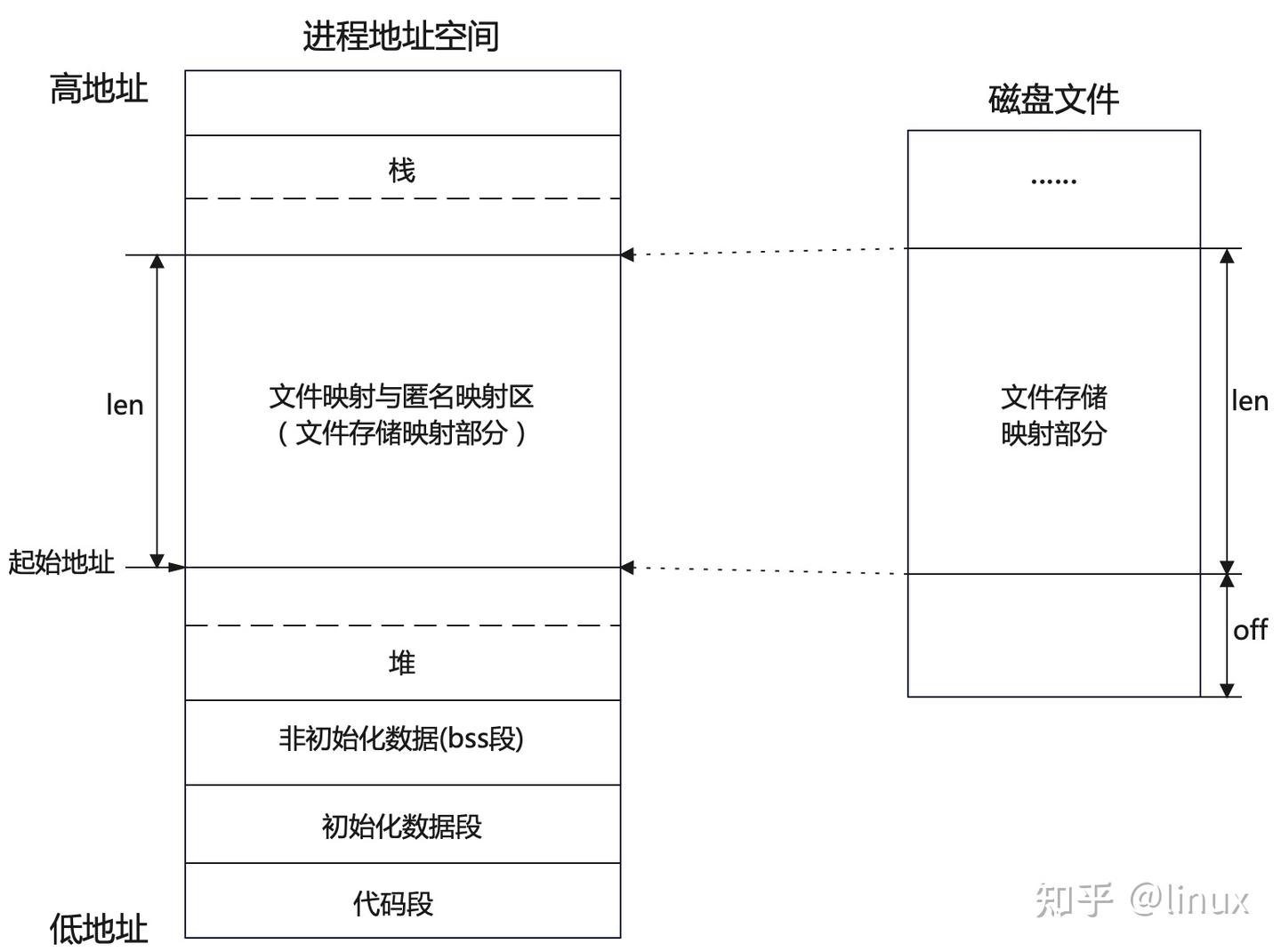 所以可以看到,
所以可以看到,mmap系统调用中最重要的参数就是addr、offset与len(申请长度),内核会根据vma的分配情况,决定本次mmap映射分配的vma的开始地址并返回
虚拟内存地址与vma
mmap系统调用在内核的主要调用链如下:
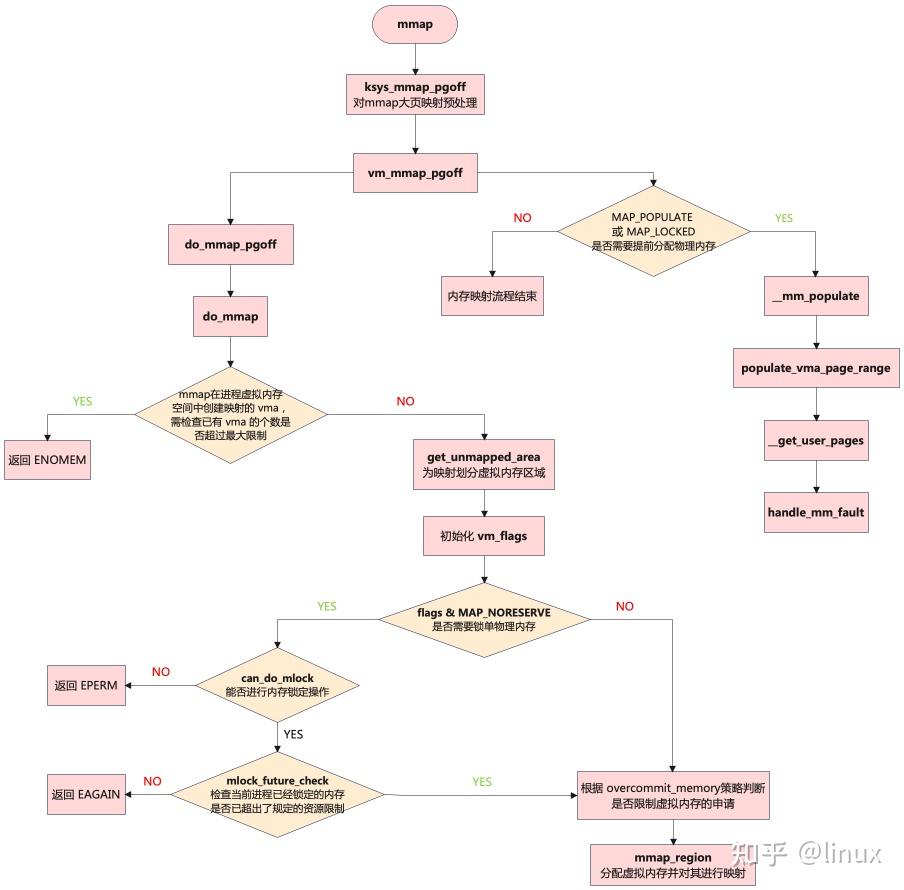
内存映射的整个流程,最核心的过程两步:
get_unmapped_area函数用于在进程地址空间中寻找出一段长度为len,并且还未映射的虚拟内存区域 vma 出来。返回值addr表示这段虚拟内存区域的起始地址mmap_region函数是整个内存映射的核心,它首先会为这段选取出来的映射虚拟内存区域分配 vma 结构,并根据映射信息进行初始化,以及建立 vma 与相关映射文件的关系,最后将这段 vma 插入到进程的虚拟内存空间中
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/kernel/sys_x86_64.c#L87
//mmap 系统调用的本质其实就是在进程虚拟内存空间中划分出一段未映射的虚拟内存区域,随后内核会为这段映射出来的虚拟内存区域创建 vma 结构,并初始化 vma 结构的相关属性
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
long error;
error = -EINVAL;
if (off & ~PAGE_MASK)
goto out;
// 重要:这里,用户态的参数offset会通过`off >> PAGE_SHIFT`转换为页数
// 后面内核都使用页数作为计算参数
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
out:
return error;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/kernel/sys_x86_64.c#L87
// 注意:参数pgoff就是按照PAGE_SHIFT对齐之后的(原始用户传入的)offset
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
unsigned long retval;
if (!(flags & MAP_ANONYMOUS)) { // 预处理文件映射
audit_mmap_fd(fd, flags);
// 通过文件 fd 获取映射文件的 struct file 结构
// 从而获取 inode 信息,关联磁盘文件,后面关闭 fd,仍然可以用 mmap 操作
file = fget(fd);
if (!file)
return -EBADF;
if (is_file_hugepages(file))
len = ALIGN(len, huge_page_size(hstate_file(file)));
retval = -EINVAL;
if (unlikely(flags & MAP_HUGETLB && !is_file_hugepages(file)))
goto out_fput;
} else if (flags & MAP_HUGETLB) {
//MAP_HUGETLB 只能支持 MAP_ANONYMOUS 匿名映射的方式使用 HugePage
struct user_struct *user = NULL;
struct hstate *hs; // 内核中的大页池(预先创建)
// 选取指定大页尺寸的大页池(内核中存在不同尺寸的大页池)
hs = hstate_sizelog((flags >> MAP_HUGE_SHIFT) & SHM_HUGE_MASK);
if (!hs)
return -EINVAL;
// 映射长度 len 必须与大页尺寸对齐
len = ALIGN(len, huge_page_size(hs));
/*
* VM_NORESERVE is used because the reservations will be
* taken when vm_ops->mmap() is called
* A dummy user value is used because we are not locking
* memory so no accounting is necessary
*/
// 在 hugetlbfs 中创建 anon_hugepage 文件,并预留大页内存(禁止其他进程申请)
file = hugetlb_file_setup(HUGETLB_ANON_FILE, len,
VM_NORESERVE,
&user, HUGETLB_ANONHUGE_INODE,
(flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
if (IS_ERR(file))
return PTR_ERR(file);
}
flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE);
//核心:开始内存映射
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
out_fput:
if (file)
fput(file);
return retval;
}
vm_mmap_pgoff函数的核心流程如下:
- 获取进程虚拟内存空间
mm_struct,用于在开始mmap内存映射之前,对进程虚拟内存空间加写锁保护,防止多线程并发修改,映射完成后,再释放写锁 - 调用
do_mmap_pgoff函数开始 mmap 内存映射,在进程虚拟内存空间中分配一段 vma,并建立相关映射关系 - 如果设置了
MAP_POPULATE或MAP_LOCKED属性,则调用mm_populate函数,提前为[ret , ret + populate]这段虚拟内存立即分配物理内存页面,后续访问不会发生缺页中断异常
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/util.c#L296
unsigned long vm_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long pgoff)
{
unsigned long ret;
// 获取进程虚拟内存空间
struct mm_struct *mm = current->mm;
// 是否需要为映射的 vma,提前分配物理内存页,避免后续的缺页
// 取决于 flag 是否设置了 MAP_POPULATE 或者 MAP_LOCKED
// 这里的 populate 表示需要分配物理内存的大小
unsigned long populate;
// 初始化 userfaultfd 链表
LIST_HEAD(uf);
// security钩子
ret = security_mmap_file(file, prot, flag);
if (!ret) {
// 对进程虚拟内存空间加写锁保护,防止多线程并发修改
if (down_write_killable(&mm->mmap_sem))
return -EINTR;
// 开始 mmap 内存映射,在进程虚拟内存空间中分配一段 vma,并建立相关映射关系
// 返回值 ret 为映射虚拟内存区域的起始地址
ret = do_mmap_pgoff(file, addr, len, prot, flag, pgoff,
&populate, &uf);
// 释放写锁
up_write(&mm->mmap_sem);
// 等待 userfaultfd 处理完成
userfaultfd_unmap_complete(mm, &uf);
if (populate){
// 提前分配物理内存页面,后续访问不会缺页,为 [ret , ret + populate] 这段虚拟内存立即分配物理内存
// 分析见下文
mm_populate(ret, populate);
}
}
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/mm.h#L2118
static inline unsigned long
do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot, unsigned long flags,
unsigned long pgoff, unsigned long *populate,
struct list_head *uf)
{
return do_mmap(file, addr, len, prot, flags, 0, pgoff, populate, uf);
}
do_mmap:映射的核心实现
do_mmap核心功能如下:
- 调用
get_unmapped_area函数用于在进程地址空间中寻找出一段长度为len,并且还未映射的虚拟内存区域 vma 出来,返回值addr表示这段虚拟内存区域的起始地址。之后根据不同的文件打开方式设置不同的 vma 标志位flag - 调用
mmap_region函数,首先会为刚才选取出来的映射虚拟内存区域分配 vma 结构,并根据映射信息进行初始化,以及建立 vma 与相关映射文件的关系,最后将这段 vma 插入到进程的虚拟内存空间中(链表或红黑树进行管理)
本小节基于AMD64(X86_64)体系下的经典布局为背景介绍
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L1306
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, vm_flags_t vm_flags,
unsigned long pgoff, unsigned long *populate,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
int pkey = 0;
*populate = 0;
if (!len)
return -EINVAL;
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
// 如果进程带有 READ_IMPLIES_EXEC 标记且文件系统是可执行的,则这段内存空间使用 READ 的属性会附带增加 EXEC 属性
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && path_noexec(&file->f_path)))
prot |= PROT_EXEC;
// 合理:如果不是使用固定地址,则使用的 addr 会进行向下页对齐
if (!(flags & MAP_FIXED))
addr = round_hint_to_min(addr);
/* Careful about overflows.. */
// 申请内存大小页对齐,注意不要溢出
len = PAGE_ALIGN(len);
if (!len)
return -ENOMEM;
/* offset overflow? */
// 判断申请的内存是否溢出
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
/* Too many mappings? */
// 一个进程虚拟内存空间内所能包含的虚拟内存区域 vma 是有数量限制的
// sysctl_max_map_count 规定了进程虚拟内存空间所能包含 vma 的最大个数
// 可以通过 /proc/sys/vm/max_map_count 内核参数调整 sysctl_max_map_count
// mmap 需要在进程虚拟内存空间中创建映射的 vma,这里需要检查已有 vma 的个数是否超过最大限制
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
// 在进程虚拟内存空间中寻找一块未映射的虚拟内存区域,这段虚拟内存区域后续将会用于 mmap 内存映射
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (offset_in_page(addr)) // 如果返回的地址不是按照page对齐的,则直接返回
return addr;
if (prot == PROT_EXEC) {
pkey = execute_only_pkey(mm);
if (pkey < 0)
pkey = 0;
}
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
// 简单的检查,通过 calc_vm_prot_bits 和 calc_vm_flag_bits 将 mmap 参数 prot , flag 中
// 设置的访问权限以及映射方式等枚举值转换为统一的 vm_flags,后续一起映射进 VMA 的相应属性中,相应前缀转换为 VM_
vm_flags |= calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
// 设置了 MAP_LOCKED,表示用户期望 mmap 背后映射的物理内存锁定在内存中,不允许 swap
if (flags & MAP_LOCKED)
if (!can_do_mlock()) // 检查是否可以将本次映射的物理内存锁定
return -EPERM;
// 进一步检查锁定的内存页数是否超过了内核限制
if (mlock_future_check(mm, vm_flags, len))
return -EAGAIN;
if (file) {
// 分支一:文件映射
struct inode *inode = file_inode(file);
switch (flags & MAP_TYPE) {
case MAP_SHARED: // 共享映射
if ((prot&PROT_WRITE) && !(file->f_mode&FMODE_WRITE))
return -EACCES;
/*
* Make sure we don't allow writing to an append-only
* file..
*/
// 确保不向只追加的文件进行写入
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
/*
* Make sure there are no mandatory locks on the file.
*/
// 确保文件上没有强制锁
if (locks_verify_locked(file))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE: // 私有文件映射
if (!(file->f_mode & FMODE_READ)) // 文件如果不可读会报错
return -EACCES;
if (path_noexec(&file->f_path)) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op->mmap)
return -ENODEV;
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
break;
default:
return -EINVAL;
}
} else {
// 分支二:匿名映射
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
/*
* Ignore pgoff.
*/
pgoff = 0; // 忽略 pgoff
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
// 根据匿名 vma 的 addr 设置 pgoff
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
// 通常内核会为 mmap 申请虚拟内存的时候会综合考虑 ram 以及 swap space 的总体大小。当映射的虚拟内存过大
// 而没有足够的 swap space 的时候, mmap 就会失败,设置 MAP_NORESERVE,内核将不会考虑上面的限制因素
// 这样当通过 mmap 申请大量的虚拟内存,并且当前系统没有足够的 swap space 的时候,mmap 系统调用依然能够成功
if (flags & MAP_NORESERVE) {
// 设置 MAP_NORESERVE 的目的是为了应用可以申请过量的虚拟内存,如果内核本身是禁止 overcommit 的
// 那么设置 MAP_NORESERVE 是无意义的,如果内核允许过量申请虚拟内存时(overcommit 为 0 或者 1)
// 无论映射多大的虚拟内存,mmap 将会始终成功,但缺页的时候会容易导致 oom
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE; // 设置 VM_NORESERVE 表示无论申请多大的虚拟内存,内核总会答应
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
// 大页内存是提前预留出来的,并且本身就不会被 swap,所以不需要像普通内存页那样考虑 swap space 的限制因素
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
//重要:内存映射的核心,创建和初始化虚拟内存区域,并加入红黑树管理
addr = mmap_region(file, addr, len, vm_flags, pgoff, uf);
// 假如没有设置 MAP_POPULATE 标志位内核并不在调用 mmap 时就为进程分配物理内存空间,而是直到下次真正访问
// 地址空间时发现数据不存在于物理内存空间时才触发 Page Fault 将缺失的 Page 换入内存空间
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len; // 设置需要分配的物理内存大小
return addr;
}
这里do_mmap 函数还承担了对一些内存映射约束条件的检查,详细可以参考
追踪get_unmapped_area:寻找VMA
这里先看下get_unmapped_area函数的实现,即如何寻找到合适长度的虚拟内存区域,在经典布局下,mm->get_unmapped_area 指向的函数为 arch_get_unmapped_area:
- 如果 mmap 进行的是私有匿名映射,那么内核会通过
mm->get_unmapped_area函数进行虚拟内存的分配 - 如果 mmap 进行的是文件映射,那么内核则采用的是特定于文件系统的
file->f_op->get_unmapped_area函数,若通过 mmap 映射的是 ext4 文件系统下的文件,那么file->f_op->get_unmapped_area指向的是thp_get_unmapped_area函数(专门为 ext4 文件映射申请虚拟内存) - 如果 mmap 进行的是共享匿名映射,由于共享匿名映射的本质其实是基于 tmpfs 的虚拟文件系统中的匿名文件进行的共享文件映射,所以这种情况下
get_unmapped_area函数是需要基于 tmpfs 的虚拟文件系统的,在共享匿名映射的情况下get_unmapped_area指向shmem_get_unmapped_area函数
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L2053
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
// 在进程虚拟空间中寻找还未被映射的 VMA 这段核心逻辑是被内核实现在特定于体系结构的函数中
// 该函数指针用于指向真正的 get_unmapped_area 函数,在经典布局下,真正的实现函数为 arch_get_unmapped_area
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
unsigned long error = arch_mmap_check(addr, len, flags);
if (error)
return error;
/* Careful about overflows.. */
// 映射的虚拟内存区域长度不能超过进程的地址空间
if (len > TASK_SIZE)
return -ENOMEM;
// 如果是匿名映射,则采用 mm_struct 中保存的特定于体系结构的 arch_get_unmapped_area 函数
get_area = current->mm->get_unmapped_area;
if (file) {
// 如果是文件映射,则需要使用 file->f_op 中的 get_unmapped_area 指向的函数来为文件映射申请虚拟内存
// file->f_op 保存的是特定于文件系统中文件的相关操作,如 ext4 文件系统下的 thp_get_unmapped_area 函数
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
} else if (flags & MAP_SHARED) {
/*
* mmap_region() will call shmem_zero_setup() to create a file,
* so use shmem's get_unmapped_area in case it can be huge.
* do_mmap_pgoff() will clear pgoff, so match alignment.
*/
pgoff = 0;
// 共享匿名映射是通过在 tmpfs 中创建的匿名文件实现的,所以这里也有其专有的 get_unmapped_area 函数
// 共享匿名映射的情况下 get_unmapped_area 指向 shmem_get_unmapped_area 函数
get_area = shmem_get_unmapped_area;
}
// 在进程虚拟内存空间中,根据指定的 addr,len 查找合适的 vma
addr = get_area(file, addr, len, pgoff, flags);
if (IS_ERR_VALUE(addr))
return addr;
// vma 区域不能超过进程地址空间
if (addr > TASK_SIZE - len)
return -ENOMEM;
// addr 需要与 page size 对齐
if (offset_in_page(addr))
return -EINVAL;
error = security_mmap_addr(addr);
return error ? error : addr;
}
文件页与内存页映射的函数调用如下:
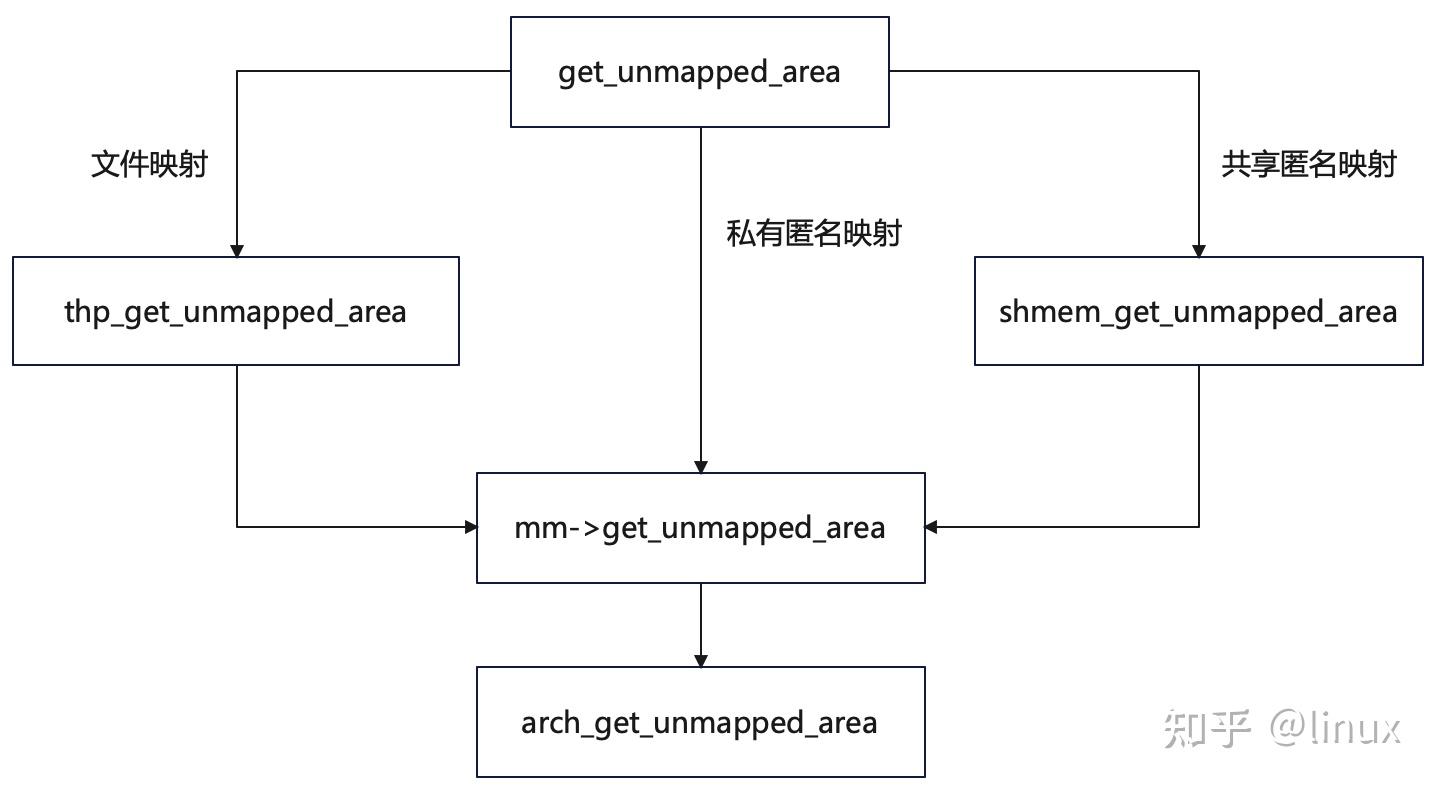
arch_get_unmapped_area 函数的核心作用如下:
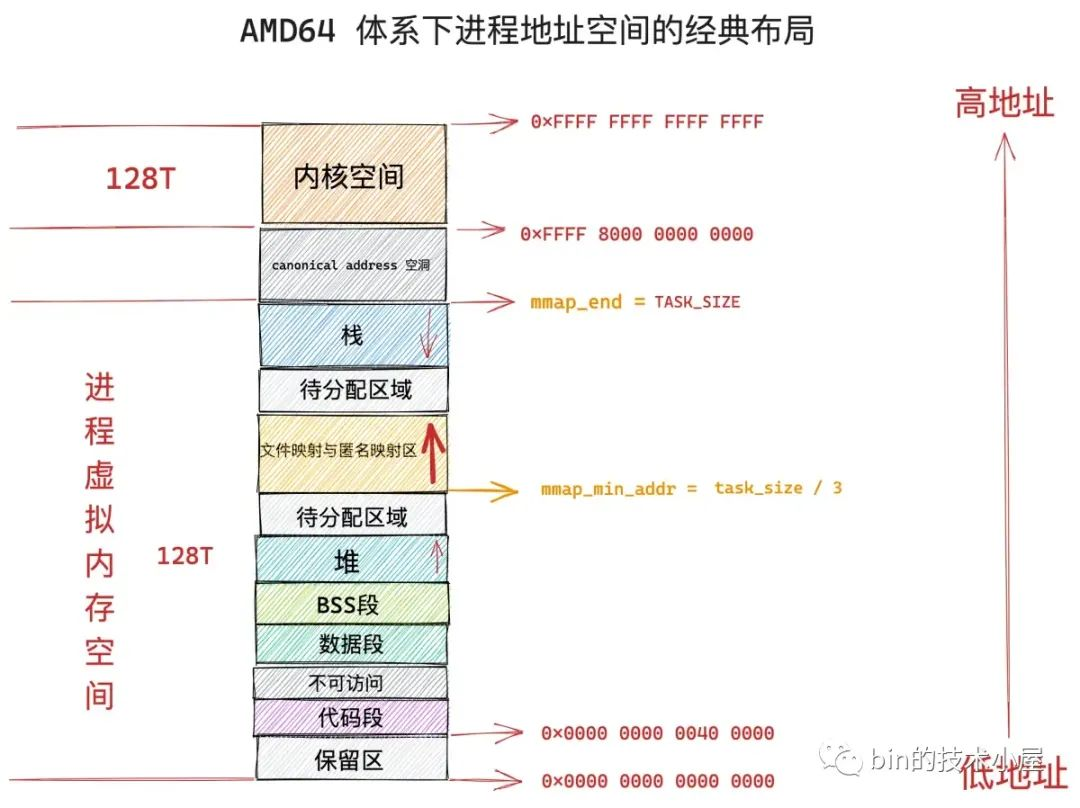
如上图,在经典布局下,mmap 可以映射的虚拟内存范围必须在进程虚拟内存空间 mmap_min_addr 到 mmap_end 这段地址范围内,mmap_min_addr 为 TASK_SIZE 的1/3,mmap_end 为 TASK_SIZE
内核需要检查本次 mmap 映射的虚拟内存长度 len 是否超过了规定的映射范围,如果超过了则返回 ENOMEM 错误,并停止映射流程。如果映射长度 len 在规定的映射地址范围内,内核则会根据指定的映射起始地址 addr,以及映射长度 len,开始在文件映射与匿名映射区,为本次 mmap 映射寻找一段空闲的虚拟内存区域 vma 出来
内核实际找到的可用vma区域,受mmap参数控制,一般有下面几种情况:
- 如果在
flags参数中指定了MAP_FIXED标志,则意味着强制要求内核在指定的起始地址addr处开始映射len长度的虚拟内存区域,无论这段虚拟内存区域[addr , addr + len]是否已经存在映射关系,内核都会强行进行映射,如果这块区域已经存在映射关系,那么后续内核会把旧的映射关系覆盖(解除)掉 - 如果指定了
addr,但是并没有指定MAP_FIXED,则意味着只是建议内核优先考虑从指定的addr地址处开始映射,但是如果[addr , addr+len]这段虚拟内存区域已经存在映射关系,内核则不会按照指定的addr开始映射,而是会自动查找一段空闲的len长度的虚拟内存区域(关联vm_unmapped_area函数) - 如果通过查找发现
[addr , addr+len]这段虚拟内存地址范围并未存在任何映射关系,那么 addr 就会作为 mmap 映射的起始地址。这里面会分为两种情况:- 第一种是指定的
addr比较大,addr位于文件映射与匿名映射区中所有映射区域 vma 的最后面,这样一来[addr , addr + len]这段地址范围当然是空闲可用的 - 第二种情况是指定的
addr恰好位于一个 vma 和另一个 vma 中间的地址间隙中,并且这个地址间隙刚好大于或者等于指定的映射长度len。内核就可以将这个地址间隙映射起来
- 第一种是指定的
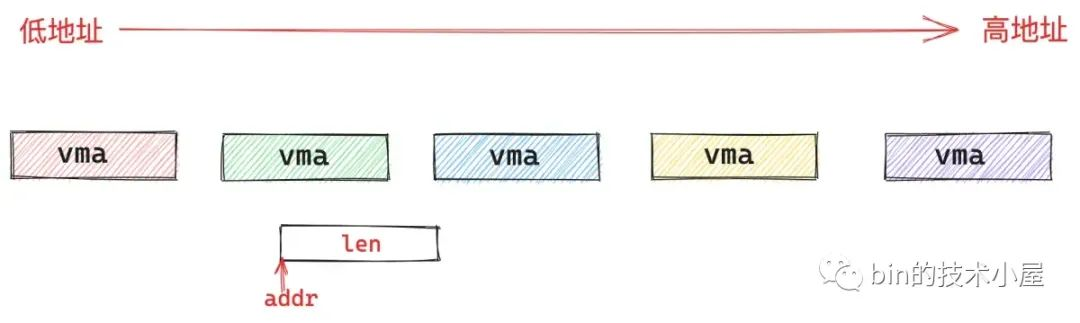
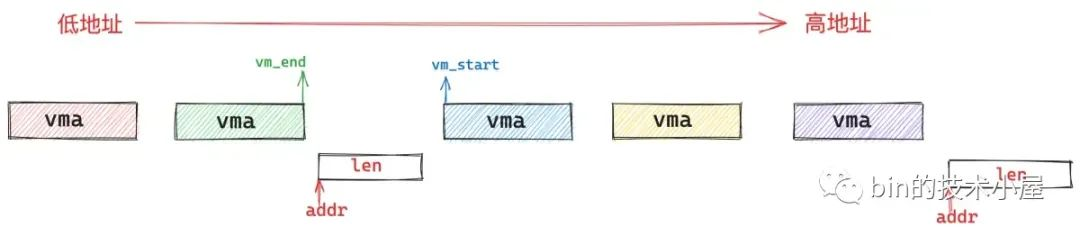
继续分析arch_get_unmapped_area函数的实现:
- 调用
find_vma函数,根据指定的映射起始地址 addr,在进程地址空间中查找出符合addr < vma->vm_end条件的第一个 vma,然后在进程地址空间mm_struct中 mmap 指向的 vma 链表中,找出它的前驱节点pprev - 如果明确指定起始地址
addr,但是指定的虚拟内存范围有一段无效的区域或者已经存在映射关系,内核就不能按照指定的addr开始映射,此时调用vm_unmapped_area函数,内核会自动在文件映射与匿名映射区中按照地址的增长方向寻找一段len大小的虚拟内存范围出来。注意:此时找到的虚拟内存范围的起始地址就不是指定的addr
unmapped_area函数的核心任务就是在管理进程地址空间这些vma的红黑树mm_struct->mm_rb中查找出一个满足条件的地址间隙gap用于内存映射。如果能够找到符合条件的地址间隙 gap 则直接返回,否者就从进程地址空间中最后一个 vma->vm_end 开始映射
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L1966
unsigned long
arch_get_unmapped_area(struct file *filp, unsigned long addr,
unsigned long len, unsigned long pgoff, unsigned long flags)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
struct vm_unmapped_area_info info;
// 进程虚拟内存空间的末尾 TASK_SIZE
// 映射区域长度是否超过进程虚拟内存空间
if (len > TASK_SIZE - mmap_min_addr)
return -ENOMEM;
// 如果指定了 MAP_FIXED 表示必须要从指定的 addr 开始映射 len 长度的区域
// 如果这块区域已经存在映射关系,那么后续内核会把旧的映射关系覆盖掉
if (flags & MAP_FIXED){
//直接返回addr
return addr;
}
// 没有指定 MAP_FIXED,但指定了 addr,内核从指定的 addr 地址开始映射,内核这里会检查指定的这块虚拟内存范围是否有效
if (addr) {
// addr 先保证与 page size 对齐
addr = PAGE_ALIGN(addr);
// 内核这里需要确认一下指定的 [addr, addr+len] 这段虚拟内存区域是否存在已有的映射关系
// 若[addr, addr+len] 地址范围内已经存在映射关系,则不能按照指定的 addr 作为映射起始地址
// 在进程地址空间中查找第一个符合 addr < vma->vm_end 条件的 vma
// 如果不存在这样一个 vma(!vma), 则表示 [addr, addr+len] 这段范围的虚拟内存是可以使用的,内核将会从指定的 addr 开始映射
// 如果存在这样一个 vma ,则表示 [addr, addr+len] 这段范围的虚拟内存区域目前已经存在映射关系了,不能采用 addr 作为映射起始地址
// 这里还有一种情况是 addr 落在 prev 和 vma 之间的一块未映射区域
// 如果这块未映射区域的长度满足 len 大小,那么这段未映射区域可以被本次使用,内核也会从指定的 addr 开始映射
vma = find_vma(mm, addr);
if (TASK_SIZE - len >= addr && addr >= mmap_min_addr &&
(!vma || addr + len <= vma->vm_start))
return addr;
}
// 如果明确指定 addr 但是指定的虚拟内存范围是一段无效的区域或者已经存在映射关系
// 那么内核会自动在地址空间中寻找一段合适的虚拟内存范围出来,这段虚拟内存范围的起始地址就不是指定的 addr
info.flags = 0;
// vma 区域长度
info.length = len;
// 定义从哪里开始查找 vma, mmap_base 表示从文件映射与匿名映射区开始查找
info.low_limit = mm->mmap_base;
// 查找结束位置为进程地址空间的末尾 TASK_SIZE
info.high_limit = TASK_SIZE;
info.align_mask = 0;
//见下
return vm_unmapped_area(&info);
}
在arch_get_unmapped_area函数中,find_vma用于对指定的 addr,在该mm_struct对应的红黑树中查找第一个符合 addr < vma->vm_end 条件的 vma
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L2097
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
{
struct rb_node *rb_node;
struct vm_area_struct *vma;
/* Check the cache first. */
// 进程地址空间中缓存了最近访问过的 vma,首先从进程地址空间中 vma 缓存中开始查找,缓存命中率通常大约为 35%
// 查找条件为:vma->vm_start <= addr && vma->vm_end > addr
vma = vmacache_find(mm, addr);
if (likely(vma))
return vma;
// 进程地址空间中的所有 vma 被组织在一颗红黑树中,为了方便内核在进程地址空间中快速查找特定的 vma
// 这里首先需要获取红黑树的根节点,内核会从根节点开始查找
rb_node = mm->mm_rb.rb_node;
while (rb_node) {
struct vm_area_struct *tmp;
// 获取位于根节点的 vma
tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (tmp->vm_end > addr) {
vma = tmp;
// 判断 addr 是否恰好落在根节点 vma 中: vm_start <= addr < vm_end
if (tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left; // 如果不存在,则继续到左子树中查找
} else{
// 如果根节点的 vm_end <= addr,说明 addr 在根节点 vma 的后边,这种情况则到右子树中继续查找
rb_node = rb_node->rb_right;
}
}
if (vma){
// 更新 vma 缓存
vmacache_update(addr, vma);
}
// 返回查找到的 vma,如果没有查找到,则返回 null,表示进程空间中目前还没有这样一个 vma,后续需要新建
return vma;
}
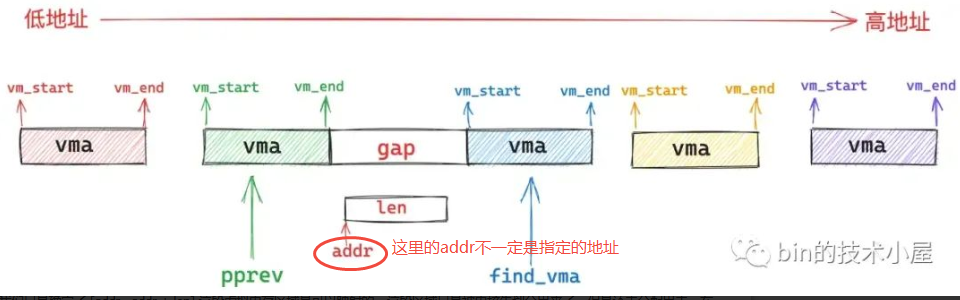
在非MAP_FIXED模式下,如果通过find_vma找到的这个 vma 与 [addr,addr +len] 这段虚拟地址范围有重叠的部分,那么内核就不能按照指定的 addr开始映射,内核需要重新在文件映射与匿名映射区中按照地址的增长方向,找到一段 len 大小的空闲虚拟内存区域
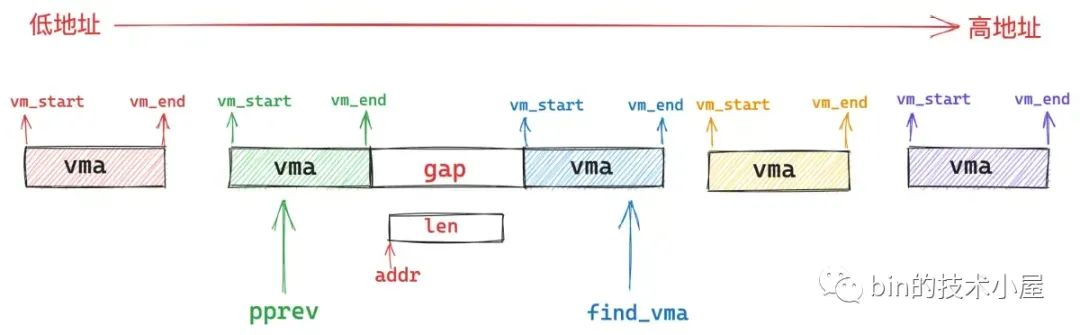
如上图,在这种场景下,有如下限制条件:
- gap 的长度必须大于等于映射参数
length,且gap区间为[gap_start,gap_end],其中gap_start = vma->vm_prev->vm_end、gap_end = vma->vm_start - gap 的起始地址
gap_start不能高于high_limit - length,否则从gap_start地址处开始映射长度length的区域就会超出high_limit的限制;而gap 的结束地址gap_end不能低于low_limit + length,否则映射区域的起始地址就会低于low_limit的限制,这里的low_limit即mm->mmap_base、high_limit即TASK_SIZE
由于在经典布局下,红黑树是按照 vma 的地址增长方向(从低地址到高地址)来组织的,左子树中的所有 vma 地址都低于根节点 vma 的地址,右子树的所有 vma 地址均高于根节点 vma 的地址。假设在左子树中找到了一个地址最低的 vma,并且这个 vma 与其前驱节点vma->vm_prev 之间的地址间隙 gap 满足如下条件:
- gap 的长度大于等于映射长度
length:gap_end - gap_start >= length gap_end >= low_limit + lengthgap_start <= high_limit - length
最差情况下,如果当前prev开始,之后的所有vma之间的gap都不满足映射长度length,那么只能从红黑树最后一个vma之后的区域(如果满足)开始分配vma了。为了加速上面这一遍历搜索,内核提供了rb_subtree_gap的优化机制(每个vma中的成员),当遍历 vma 节点的时候发现vma->rb_subtree_gap < length时,那么整棵红黑树都不需要看了,直接从进程地址空间中最后一个 vma->vm_end 处开始映射
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/mm.h#L2169
static inline unsigned long
vm_unmapped_area(struct vm_unmapped_area_info *info)
{
// 按照进程虚拟内存空间中文件映射与匿名映射区的地址增长方向分为两个函数,用来在进程地址空间中查找未映射的 vma
if (info->flags & VM_UNMAPPED_AREA_TOPDOWN)
// 当文件映射与匿名映射区的地址增长方向是从上到下逆向增长时(新式布局),采用 topdown 查找
return unmapped_area_topdown(info);
else
// 地址增长方向为从下倒上正向增长(经典布局),采用该函数查找,本文主要分析此函数的实现
// 在 AMD64 体系结构下,文件映射与匿名映射区的布局采用的是经典布局,地址的增长方向从低地址到高地址增长
return unmapped_area(info);
}
unsigned long unmapped_area(struct vm_unmapped_area_info *info)
{
/*
* We implement the search by looking for an rbtree node that
* immediately follows a suitable gap. That is,
* - gap_start = vma->vm_prev->vm_end <= info->high_limit - length;
* - gap_end = vma->vm_start >= info->low_limit + length;
* - gap_end - gap_start >= length
*/
struct mm_struct *mm = current->mm;
// 寻找未映射区域的参考 vma (该区域已存在映射关系)
struct vm_area_struct *vma;
// 未映射区域产生在 vma->vm_prev 与 vma 这两个虚拟内存区域中的间隙 gap 中,length 表示本次映射区域的长度
// low_limit ,high_limit 表示在进程地址空间中哪段地址范围内查找,一个地址下限(mm->mmap_base),另一个标识地址上限(TASK_SIZE)
// gap_start, gap_end 表示 vma->vm_prev 与 vma 之间的 gap 范围,unmapped_area 将会在这里产生
unsigned long length, low_limit, high_limit, gap_start, gap_end;
/* Adjust search length to account for worst case alignment overhead */
// 调整搜索长度以考虑最坏情况下的对齐开销
length = info->length + info->align_mask;
if (length < info->length)
return -ENOMEM;
/* Adjust search limits by the desired length */
// 根据需要的长度调整搜索限制
if (info->high_limit < length)
return -ENOMEM;
// gap_start 需要满足的条件:gap_start = vma->vm_prev->vm_end <= info->high_limit - length
// 否则 unmapped_area 将会超出 high_limit 的限制
high_limit = info->high_limit - length;
if (info->low_limit > high_limit)
return -ENOMEM;
// gap_end 需要满足的条件:gap_end = vma->vm_start >= info->low_limit + length
// 否则 unmapped_area 将会超出 low_limit 的限制
low_limit = info->low_limit + length;
/* Check if rbtree root looks promising */
// 首先将 vma 红黑树的根节点作为 gap 的参考 vma,检查根节点是否符合
if (RB_EMPTY_ROOT(&mm->mm_rb))
goto check_highest;
// 获取红黑树根节点的 vma
vma = rb_entry(mm->mm_rb.rb_node, struct vm_area_struct, vm_rb);
// rb_subtree_gap 为当前 vma 及其左右子树中所有 vma 与其对应 vm_prev 之间最大的虚拟内存地址 gap
// 最大的 gap 如果都不能满足映射长度 length 则跳转到 check_highest 处理
if (vma->rb_subtree_gap < length)
goto check_highest; // 从进程地址空间最后一个 vma->vm_end 地址处开始映射
while (true) {
/* Visit left subtree if it looks promising */
// 左子树,获取当前 vma 的 vm_start 起始虚拟内存地址作为 gap_end
gap_end = vma->vm_start;
// gap_end 需要满足:gap_end >= low_limit,否则 unmapped_area 将会超出 low_limit 的限制
// 如果存在左子树,则需要继续到左子树中去查找,因为需要按照地址从低到高的优先级来查看合适的未映射区域
if (gap_end >= low_limit && vma->vm_rb.rb_left) {
struct vm_area_struct *left =
rb_entry(vma->vm_rb.rb_left,
struct vm_area_struct, vm_rb);
// 如果左子树中存在合适的 gap,则继续左子树的查找
// 否则查找结束,gap 为当前 vma 与其 vm_prev 之间的间隙
if (left->rb_subtree_gap >= length) {
vma = left;
continue;
}
}
// 获取当前 vma->vm_prev 的 vm_end 作为 gap_start
gap_start = vma->vm_prev ? vma->vm_prev->vm_end : 0;
check_current:
/* Check if current node has a suitable gap */
// gap_start 需要满足:gap_start <= high_limit,否则 unmapped_area 将会超出 high_limit 的限制
if (gap_start > high_limit)
return -ENOMEM;
if (gap_end >= low_limit && gap_end - gap_start >= length)
goto found; // 找到了合适的 unmapped_area 跳转到 found 处理
/* Visit right subtree if it looks promising */
// 当前 vma 与其左子树中的所有 vma 均不存在一个合理的 gap,那么从 vma 的右子树中继续查找
if (vma->vm_rb.rb_right) {
struct vm_area_struct *right =
rb_entry(vma->vm_rb.rb_right,
struct vm_area_struct, vm_rb);
if (right->rb_subtree_gap >= length) {
vma = right;
continue;
}
}
/* Go back up the rbtree to find next candidate node */
// 如果在当前 vma 以及它的左右子树中均无法找到一个合适的 gap
// 那么这里会从当前 vma 节点向上回溯整颗红黑树,在它的父节点中尝试查找是否有合适的 gap
// 因为这时候有可能会有新的 vma 插入到红黑树中,可能会产生新的 gap
while (true) {
struct rb_node *prev = &vma->vm_rb;
if (!rb_parent(prev))
goto check_highest;
vma = rb_entry(rb_parent(prev),
struct vm_area_struct, vm_rb);
if (prev == vma->vm_rb.rb_left) {
gap_start = vma->vm_prev->vm_end;
gap_end = vma->vm_start;
goto check_current;
}
}
}
check_highest:
/* Check highest gap, which does not precede any rbtree node */
// 流程走到这里表示在当前进程虚拟内存空间的所有 vma 中都无法找到一个合适的 gap 来作为 unmapped_area
// 那么就从进程地址空间中最后一个 vma->vm_end 开始映射
// mm->highest_vm_end 表示当前进程虚拟内存空间中,地址最高的一个 vma 的结束地址位置
gap_start = mm->highest_vm_end;
gap_end = ULONG_MAX; /* Only for VM_BUG_ON below */
if (gap_start > high_limit) // 这里最后需要检查剩余虚拟内存空间是否满足映射长度
return -ENOMEM;
found:
/* We found a suitable gap. Clip it with the original low_limit. */
// 流程走到这里表示已经找到了一个合适的 gap 来作为 unmapped_area,直接返回 gap_start(需要与 4K 对齐)作为映射的起始地址
if (gap_start < info->low_limit)
gap_start = info->low_limit;
/* Adjust gap address to the desired alignment */
// 调整间隙地址到所需的对齐方式
gap_start += (info->align_offset - gap_start) & info->align_mask;
VM_BUG_ON(gap_start + info->length > info->high_limit);
VM_BUG_ON(gap_start + info->length > gap_end);
return gap_start; // 返回找到的地址间隙 gap
}
do_mmap->mmap_region:创建虚拟内存区域(内存映射的本质)
在上一节get_unmapped_area函数结束时,内核已在进程地址空间中找出一段地址范围为[addr,addr + len]的虚拟内存区域供mmap进行映射。接下来追踪下mmap_region及后续函数具体是如何初始化vma并建立映射关系的,mmap_region负责创建虚拟内存区域,其核心流程如下:
- 调用
may_expand_vm函数以检查进程在本次 mmap 映射之后申请的虚拟内存是否超过限制,检查(进程的虚拟内存总数+申请的页数)是否超过地址空间限制,如果是私有的可写映射,并且不是栈,则检查(进程的虚拟内存总数+申请的页数)是否超过最大数据长度 - 调用
find_vma_links函数查找当前进程地址空间中是否存在与指定映射区域[addr, addr+len]重叠的部分,如果有重叠则需调用do_munmap函数将这段重叠的映射部分解除掉,后续会重新映射这部分 - 调用
vma_merge函数,内核先尝试看能不能将待映射的vma和地址空间中已有的vma进行合并,如果可以合并,则不用创建新的vma结构,节省内存的开销。如果不能合并,则从 slab 中取出一个新的 vma 结构,并根据要映射的虚拟内存区域属性初始化 vma 结构中的相关字段 - 调用
vma_link函数把虚拟内存区域 vma 插入到链表和红黑树中。如果 vma 关联文件,那么把虚拟内存区域添加到文件的区间树中,文件的区间树用来跟踪文件被映射到哪些虚拟内存区域 - 调用
vma_set_page_prot函数更新地址空间mm_struct中的相关统计变量,根据虚拟内存标志(vma->vm_flags)计算页保护位(vma->vm_page_prot),如果共享的可写映射想要把页标记为只读,其目的是跟踪写事件,那么从页保护位删除可写位
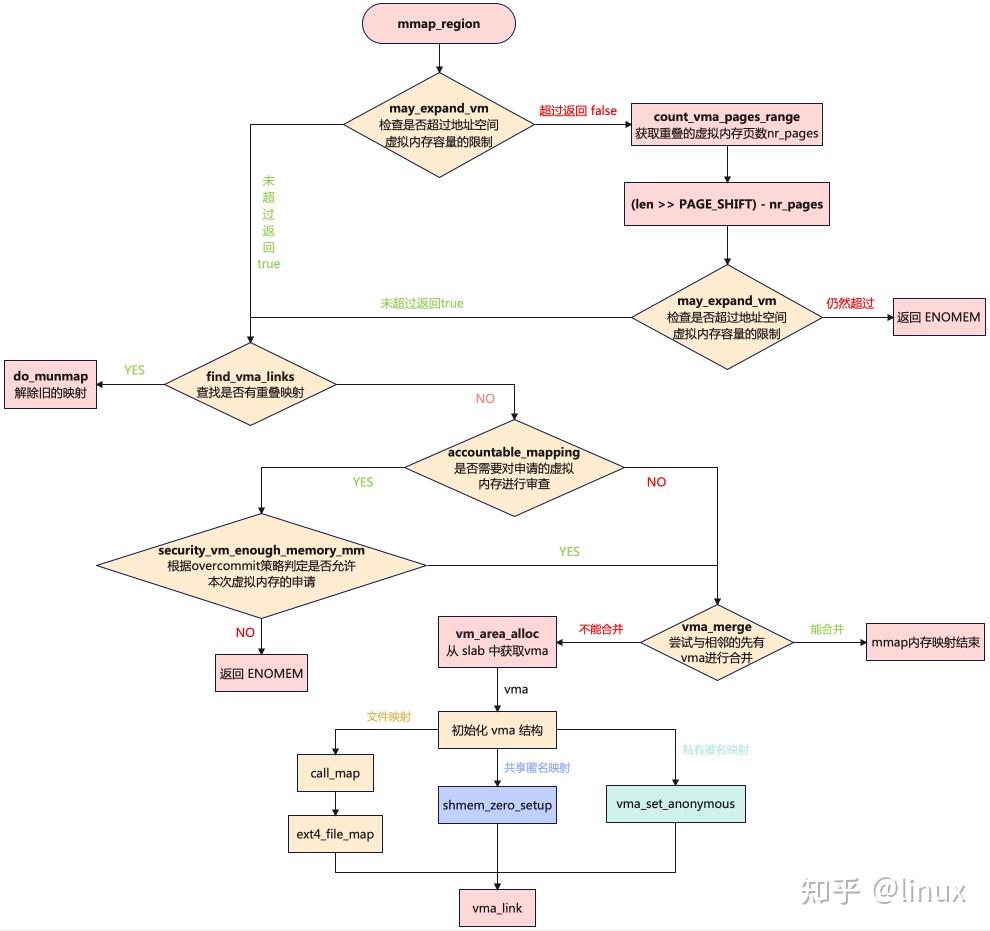
目前只是确定了 [addr , addr + len] 这段虚拟内存区域是可以映射的,这段区域只是被内核先划分出来了,但是还未分配出去,在 mmap_region 函数中需要为这段虚拟内存区域分配 vma 结构,并根据映射方式对 vma 进行初始化,这样这段虚拟内存才算真正的被分配给了进程
此外,内核要需要检查与审计分配资源,并且尽可能的复用vma,即在创建新的 vma 之前,按照最大程度合并的原则,内核会尝试看能不能将当前寻找出来的空闲虚拟内存区域 [addr , addr + len] 与其前一个 vma 以及后一个 vma 进行合并,然后重新调整合并后的 vma 相关属性,如vm_start/vm_end/vm_pgoff等,以及涉及到相关数据结构的改变(见下文描述)
如果不能合并,内核则只能从 slab 缓存中拿出一个 vma 结构来描述这段虚拟内存地址范围 [addr , addr + len],并根据 mmap 映射的这段虚拟内存区域属性初始化 vma 结构中的相关字段
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L1588
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
/* Check against address space limit. */
// 再次检查本次映射是否超过了进程虚拟内存空间中的虚拟内存容量的限制,超过则返回 false
if (!may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)) {
unsigned long nr_pages;
/*
* MAP_FIXED may remove pages of mappings that intersects with
* requested mapping. Account for the pages it would unmap.
*/
// 如果 mmap 指定了 MAP_FIXED,表示内核必须要按照用户指定的映射区来进行映射
// 这种情况下就会导致,指定的映射区 [addr, addr + len] 有一部分可能与现有映射重叠
// 内核将会覆盖掉这段已有的映射,重新按照用户指定的映射关系进行映射
// 所以这里需要计算进程地址空间中与指定映射区[addr, addr + len]重叠的虚拟内存页数 nr_pages
nr_pages = count_vma_pages_range(mm, addr, addr + len);
// 由于这里的 nr_pages 表示重叠的虚拟内存部分,将会被覆盖,所以这部分被覆盖的虚拟内存不需要额外申请
// 这里通过 len >> PAGE_SHIFT 减去这段可以被覆盖的 nr_pages 在重新检查是否超过虚拟内存相关区域的限额
if (!may_expand_vm(mm, vm_flags,
(len >> PAGE_SHIFT) - nr_pages))
return -ENOMEM;
}
/* Clear old maps */
// 如果当前进程虚拟内存地址空间中存在指定映射区域 [addr, addr + len] 重叠的部分
while (find_vma_links(mm, addr, addr + len, &prev, &rb_link,
&rb_parent)) {
// 调用 do_munmap 将这段重叠的映射部分解除掉,后续会重新映射这部分
if (do_munmap(mm, addr, len, uf))
return -ENOMEM;
}
/*
* Private writable mapping: check memory availability
*/
// 判断将来是否会为这段虚拟内存 vma 申请新的物理内存,比如:私有、可写(private writable)的映射方式,内核将来会通过 cow 重新为其分配新的物理内存。
// 私有、只读(private readonly)的映射方式,内核则会共享原来映射的物理内存,而不会申请新的物理内存
// 如果将来需要申请新的物理内存则会根据当前系统的 overcommit 策略以及当前物理内存的使用情况来
// 综合判断是否允许本次虚拟内存的申请。如果虚拟内存不足,则返回 ENOMEM,这样的话可以防止缺页的时候发生 OOM
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
// 根据内核 overcommit 策略以及当前物理内存的使用情况综合判断,是否能够通过本次虚拟内存的申请
// 虚拟内存的申请一旦这里通过之后,后续发生缺页,内核将会有足够的物理内存为其分配,不会发生 OOM
if (security_vm_enough_memory_mm(mm, charged))
return -ENOMEM;
// 凡是设置了 VM_ACCOUNT 的 vma,表示这段虚拟内存均已经过 vm_enough_memory 的检测
// 当虚拟内存发生缺页的时候,内核会有足够的物理内存分配,而不会导致 OOM
// 其虚拟内存的用量都会被统计在 /proc/meminfo 的 Committed_AS 字段中
vm_flags |= VM_ACCOUNT;
}
/*
* Can we just expand an old mapping?
*/
// 为了精细化的控制内存的开销,内核这里首先需要尝试看能不能和地址空间中已有的 vma 进行合并,尝试将当前 vma 合并到已有的 vma 中
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out; // 如果可以合并,则虚拟内存分配过程结束
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
// 如果无法合并,则只能从 slab 中取出一个新的 vma 结构来
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
// 根据要映射的虚拟内存区域属性初始化 vma 结构中的相关字段
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
// 重要:经过PAGE_SHIFT对齐的用户传入的offset参数,最终会存储在vma结构的vm_pgoff成员中
// 注意:这个单位是页数(按PAGE_SHIFT)
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) {
// 如果是文件映射
if (vm_flags & VM_DENYWRITE) {
// 映射的文件不允许写入,调用 deny_write_accsess(file) 排斥常规的文件操作
error = deny_write_access(file);
if (error)
goto free_vma;
}
if (vm_flags & VM_SHARED) {
// 映射的文件允许其他进程可见, 标记文件为可写
error = mapping_map_writable(file->f_mapping);
if (error)
goto allow_write_and_free_vma;
}
/* ->mmap() can change vma->vm_file, but must guarantee that
* vma_link() below can deny write-access if VM_DENYWRITE is set
* and map writably if VM_SHARED is set. This usually means the
* new file must not have been exposed to user-space, yet.
*/
//重要:将文件与虚拟内存映射起来(vma关联struct file对象)
// 递增 file 的引用次数,返回 file 赋给 vma
vma->vm_file = get_file(file);
//重要:
// 将虚拟内存区域 vma 的操作函数 vm_ops 映射成文件的操作函数(和具体文件系统有关)
// ext4 文件系统中的操作函数为 ext4_file_vm_ops,此刻开始,读写内存就和读写文件是一样的了
// call_mmap:调用内核的mmap函数
error = call_mmap(file, vma);
if (error)
goto unmap_and_free_vma;
/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
* Bug: If addr is changed, prev, rb_link, rb_parent should
* be updated for vma_link()
*/
WARN_ON_ONCE(addr != vma->vm_start);
// 文件系统提供的mmap函数可能会修改映射的一些参数。在这里需要在调用 vma_link 前回置
addr = vma->vm_start;
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
// 重要:共享匿名映射
// 共享匿名映射依赖于 tmpfs 文件系统中的匿名文件 /dev/zero,父子进程通过这个匿名文件进行通讯
// 该函数用于在 tmpfs 中创建匿名文件,并映射进当前共享匿名映射区 vma 中
error = shmem_zero_setup(vma);
if (error)
goto free_vma;
}
/*
else { // 私有匿名映射
// 将 vma->vm_ops 设置为 null,只有文件映射才需要 vm_ops 这样才能将内存与文件映射起来
vma_set_anonymous(vma);
}
*/
// 重要:将当前 vma 按照地址的增长方向插入到进程虚拟内存空间的 mm_struct->mmap 链表
// 以及 mm_struct->mm_rb 红黑树中,并建立文件与 vma 的反向映射
vma_link(mm, vma, prev, rb_link, rb_parent);
/* Once vma denies write, undo our temporary denial count */
if (file) {
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
}
file = vma->vm_file;
out:
perf_event_mmap(vma);
// 进程内存状态统计,在开启了 perf 时才会有
vm_stat_account(mm, vm_flags, len >> PAGE_SHIFT);
if (vm_flags & VM_LOCKED) {
if (!((vm_flags & VM_SPECIAL) || is_vm_hugetlb_page(vma) ||
vma == get_gate_vma(current->mm)))
mm->locked_vm += (len >> PAGE_SHIFT);
else
vma->vm_flags &= VM_LOCKED_CLEAR_MASK;
}
if (file)
uprobe_mmap(vma);
/*
* New (or expanded) vma always get soft dirty status.
* Otherwise user-space soft-dirty page tracker won't
* be able to distinguish situation when vma area unmapped,
* then new mapped in-place (which must be aimed as
* a completely new data area).
*/
vma->vm_flags |= VM_SOFTDIRTY;
// 更新地址空间 mm_struct 中的相关统计变量
vma_set_page_prot(vma);
return addr;
unmap_and_free_vma:
vma->vm_file = NULL;
fput(file);
// 撤销由设备驱动程序完成的映射
/* Undo any partial mapping done by a device driver. */
unmap_region(mm, vma, prev, vma->vm_start, vma->vm_end);
charged = 0;
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
allow_write_and_free_vma:
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
free_vma:
kmem_cache_free(vm_area_cachep, vma);
unacct_error:
if (charged)
vm_unacct_memory(charged);
return error;
}
接着分析下,mmap_region中主要调用到的几个函数:
may_expand_vm:检查映射的虚拟内存是否超过了内核限制find_vma_linksvma_mergevma_linkcall_mmap
may_expand_vm函数用于检查本次映射是否超过了进程虚拟内存空间中的虚拟内存总量的限制,超过则返回 false,核心逻辑是判断经过本次mmap映射之后,mm->total_vm + npages是否超过了rlimit(RLIMIT_AS)中的限制,mm->data_vm + npages是否超过了rlimit(RLIMIT_DATA)中的限制。如果超过,那么本次mmap内存映射流程在这里就会停止进行
注意:npages是指mmap需要映射的虚拟内存页数
当前进程地址空间中已经映射的虚拟内存页数保存在 mm_struct->total_vm 中,数据区(私有,可写)已经映射的虚拟内存页数保存在 mm_struct->data_vm 中
struct mm_struct {
......
// 进程地址空间中所有已经映射的虚拟内存页总数
unsigned long total_vm; /* Total pages mapped */
// 进程地址空间中所有私有,可写的虚拟内存页总数
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
......
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L3102
bool may_expand_vm(struct mm_struct *mm, vm_flags_t flags, unsigned long npages)
{
// mm->total_vm 表示当前进程地址空间中映射的虚拟内存页总数
// npages 表示此次要映射的虚拟内存页个数
// rlimit(RLIMIT_AS) 表示进程地址空间中允许映射的虚拟内存总量,单位为字节
if (mm->total_vm + npages > rlimit(RLIMIT_AS) >> PAGE_SHIFT)
// 如果映射的虚拟内存页总数超出了内核的限制,那么就返回 false 表示虚拟内存不足
return false;
// 检查本次映射是否属于数据区域的映射,这里的数据区域指的是私有,可写的虚拟内存区域(栈区除外)
// 如果是则需要检查数据区域里的虚拟内存页是否超过了内核的限制
// rlimit(RLIMIT_DATA) 表示进程地址空间中允许映射的私有,可写的虚拟内存总量,单位为字节
// 如果超过则返回 false,表示数据区虚拟内存不足
if (is_data_mapping(flags) &&
mm->data_vm + npages > rlimit(RLIMIT_DATA) >> PAGE_SHIFT) {
/* Workaround for Valgrind */
if (rlimit(RLIMIT_DATA) == 0 &&
mm->data_vm + npages <= rlimit_max(RLIMIT_DATA) >> PAGE_SHIFT)
return true;
if (!ignore_rlimit_data) {
pr_warn_once("%s (%d): VmData %lu exceed data ulimit %lu. Update limits or use boot option ignore_rlimit_data.\n",
current->comm, current->pid,
(mm->data_vm + npages) << PAGE_SHIFT,
rlimit(RLIMIT_DATA));
return false;
}
}
return true;
}
find_vma_links函数的作用是在当前进程地址空间中查找是否存在与指定映射区域[addr, addr+len]重叠的部分,如果查找到现存的vma和该指定映射区域有重叠则返回错误,如果不存在重叠部分,则表示找到 vma 待插入的位置,包括其在链表中的位置 prev 和红黑树中的位置 rb_link 和 rb_parent,分别是待插入节点本身在红黑树中的位置和待插入节点的父节点
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L475
static int find_vma_links(struct mm_struct *mm, unsigned long addr,
unsigned long end, struct vm_area_struct **pprev,
struct rb_node ***rb_link, struct rb_node **rb_parent)
{
struct rb_node **__rb_link, *__rb_parent, *rb_prev;
// 获取红黑树的根节点
__rb_link = &mm->mm_rb.rb_node;
rb_prev = __rb_parent = NULL;
// 遍历整棵红黑树,为[addr,addr+len]这段内存区域查找合适的插入位置
while (*__rb_link) {
struct vm_area_struct *vma_tmp;
__rb_parent = *__rb_link;
vma_tmp = rb_entry(__rb_parent, struct vm_area_struct, vm_rb);
// 插入的 vma 起始地址小于当前红黑树节点 vma 结束地址,则遍历红黑树左子树
if (vma_tmp->vm_end > addr) {
// 如果红黑树中现有 vma 与该映射区域重叠,则返回失败
/* Fail if an existing vma overlaps the area */
if (vma_tmp->vm_start < end)
return -ENOMEM;
__rb_link = &__rb_parent->rb_left; // 向左走,循环遍历查找左子树
} else {
//当 vma_tmp->vm_end <= addr时,说明
// 插入的 vma 起始地址大于当前红黑树节点 vma 结束地址,则遍历红黑树右子树,说明红黑树左子节点到右子节点的VMA区域程递增趋势
// 更新待插入 vma 节点的前一个节点,即其父节点
rb_prev = __rb_parent;
// 向右走循环遍历查找右子树
__rb_link = &__rb_parent->rb_right;
}
}
//走完了
// pprev 待插入 vma 节点的前一个节点的 vma,如果 rb_prev 为空,说明待插入节点是最左子节点,在链表mm->mmap中是头节点
*pprev = NULL;
if (rb_prev)
*pprev = rb_entry(rb_prev, struct vm_area_struct, vm_rb);
*rb_link = __rb_link; // 查找到的待插入 vma 节点位置
*rb_parent = __rb_parent; // 待插入位置节点的父节点
return 0;
}
mmap_region函数在创建新的vma结构之前,内核首先尝试看能不能将当前vma和地址空间中已有的vma进行合并,以避免创建新的vma结构,节省内存的开销。内核本着合并最大化的原则,检查当前映射出来的vma能否与其前后两个vma进行合并,能合并就合并,如果不能合并就从slab中申请新的vma结构。合并条件与限制如下:
- 新映射 vma 的
vm_flags不能设置VM_SPECIAL标志,该标志表示 vma 区域是不可以被合并的,只能重新创建 vma - 新映射 vma 的起始地址
addr必须要与其前一个 vma 的结束地址重合,这样 vma 才能和它的前一个 vma 进行合并,如果不重合,vma 则不能和前一个 vma 进行合并 - 新映射 vma 的结束地址 end 必须要与其后一个 vma 的起始地址重合,这样,vma才能和它的后一个vma进行合并,如果不重合,vma则不能和后一个vma进行合并。注意:如果前后都不能合并,则需新建vma结构
- 新映射 vma 需要与其要合并 vma 区域的
vm_flags相同,否则不能合并 - 如果两个合并区域都是文件映射区,那么它们映射的文件必须是同一个。并且他们的文件映射偏移
vm_pgoff必须是连续的 - 如果两个合并区域都是匿名映射区,那么两个 vma 映射的匿名页
anon_vma必须是相同的 - 合并区域的 numa policy 必须是相同的
- 要合并的
prev和next虚拟内存区域中,不能包含close操作,也就是说vma->vm_ops不能设置有close函数,如果虚拟内存区域操作支持close,则不能合并,否则会导致现有虚拟内存区域prev和next的资源无法释放
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L1084
struct vm_area_struct *vma_merge(struct mm_struct *mm,
struct vm_area_struct *prev, unsigned long addr,
unsigned long end, unsigned long vm_flags,
struct anon_vma *anon_vma, struct file *file,
pgoff_t pgoff, struct mempolicy *policy,
struct vm_userfaultfd_ctx vm_userfaultfd_ctx)
{
// pglen:本次需要创建的 vma 区域大小
pgoff_t pglen = (end - addr) >> PAGE_SHIFT;
// area 表示当前要创建的 vma,next 表示 area 的下一个 vma
// 事实上 area 会在其 prev 前一个 vma 和 next 后一个 vma 之间的间隙 gap 中创建产生
struct vm_area_struct *area, *next;
int err;
/*
* We later require that vma->vm_flags == vm_flags,
* so this tests vma->vm_flags & VM_SPECIAL, too.
*/
// 设置了 VM_SPECIAL 表示 area 区域是不可以被合并的,只能重新创建 vma,并直接退出合并流程
if (vm_flags & VM_SPECIAL)
return NULL;
// 根据 prev vma 是否存在,设置 area 的 next vma
if (prev){
// area 将在 prev vma 和 next vma 的间隙 gap 中产生
next = prev->vm_next;
}
else{
// 如果 prev 不存在,那么 next 就设置为地址空间中的第一个 vma
next = mm->mmap;
}
area = next;
// 新 vma 的 end 与 next->vm_end 相等,表示新 vma 与 next vma 是重合的
// 那么 next 指向下一个 vma,prev 和 next 这里的语义是始终指向 area 区域的前一个和后一个 vma
if (area && area->vm_end == end) /* cases 6, 7, 8 */
next = next->vm_next;
/* verify some invariant that must be enforced by the caller */
VM_WARN_ON(prev && addr <= prev->vm_start);
VM_WARN_ON(area && end > area->vm_end);
VM_WARN_ON(addr >= end);
/*
* Can it merge with the predecessor?
*/
// 判断 area 是否能够和 prev 进行合并
if (prev && prev->vm_end == addr &&
mpol_equal(vma_policy(prev), policy) &&
can_vma_merge_after(prev, vm_flags,
anon_vma, file, pgoff,
vm_userfaultfd_ctx)) {
/*
* OK, it can. Can we now merge in the successor as well?
*/
// 如果 area 可以和 prev 进行合并,那么这里继续判断 area 能够与 next 进行合并
// 内核这里需要保证 vma 合并程度的最大化
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags,
anon_vma, file,
pgoff+pglen,
vm_userfaultfd_ctx) &&
is_mergeable_anon_vma(prev->anon_vma,
next->anon_vma, NULL)) {
/* cases 1, 6 */
// 到此则表示 area 可以和它的 prev,next 区域进行合并
// __vma_adjust 是真正执行 vma 合并操作的函数,会重新调整已有 vma 的相关属性,比如:vm_start,vm_end,vm_pgoff。
// 以及涉及到相关数据结构的改变
err = __vma_adjust(prev, prev->vm_start,
next->vm_end, prev->vm_pgoff, NULL,
prev);
} else{ /* cases 2, 5, 7 */
// 流程到此则表示 area 只能和 prev 进行合并
err = __vma_adjust(prev, prev->vm_start,
end, prev->vm_pgoff, NULL, prev);
}
if (err)
return NULL;
khugepaged_enter_vma_merge(prev, vm_flags);
// 返回最终合并好的 vma
return prev;
}
/*
* Can this new request be merged in front of next?
*/
// 下面这种情况属于,area 的结束地址 end 与 next 的起始地址是重合的
// 但是 area 的起始地址 start 和 prev 的结束地址不是重合的
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags,
anon_vma, file, pgoff+pglen,
vm_userfaultfd_ctx)) {
// area 区域前半部分和 prev 区域的后半部分重合
// 那么就缩小 prev 区域,然后将 area 合并到 next 区域
if (prev && addr < prev->vm_end) /* case 4 */
err = __vma_adjust(prev, prev->vm_start,
addr, prev->vm_pgoff, NULL, next);
else { /* cases 3, 8 */
// area 区域前半部分和 prev 区域是有间隙 gap 的
// 那么这种情况下 prev 不变,area 合并到 next 中
err = __vma_adjust(area, addr, next->vm_end,
next->vm_pgoff - pglen, NULL, next);
/*
* In case 3 area is already equal to next and
* this is a noop, but in case 8 "area" has
* been removed and next was expanded over it.
*/
// 合并后的 area
area = next;
}
if (err)
return NULL;
khugepaged_enter_vma_merge(area, vm_flags);
return area; // 返回合并后的 vma
}
// prev 的结束地址不与 area 的起始地址重合,并且 area 的结束地址不与 next 的起始地址重合
// 这种情况就不能执行合并,需要为 area 重新创建新的 vma 结构
return NULL;
}
在vma_merge中的几处代码细节如下:
prev->vm_end == addr:area的前一个prevvma 的结束地址与area的起始地址addr重合end == next->vm_start:area的后一个nextvma 的起始地址与area的结束地址end重合can_vma_merge_after:判断其参数中指定的 vma 能否与其后一个 vma 进行合并can_vma_merge_before:用于判断参数指定的 vma 能否与其前一个 vma 合并is_mergeable_vma:判断两个 vma 是否能够合并
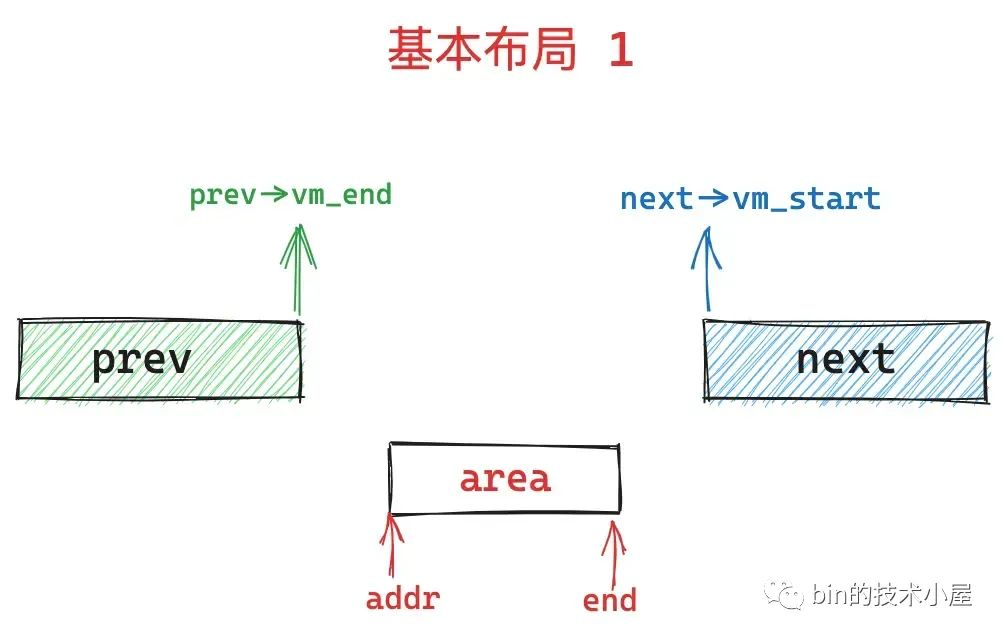
这里对vma_merge执行合并的实现做一个说明,通过 mmap 在进程地址空间中映射出的这个 area 一般是在两个 vma 中产生的,内核源码中使用 prev 指向 area 的前一个 vma,使用 next 指向 area 的后一个 vma,一般有两种基础布局:
1、未指定MAP_FIXED,普通布局
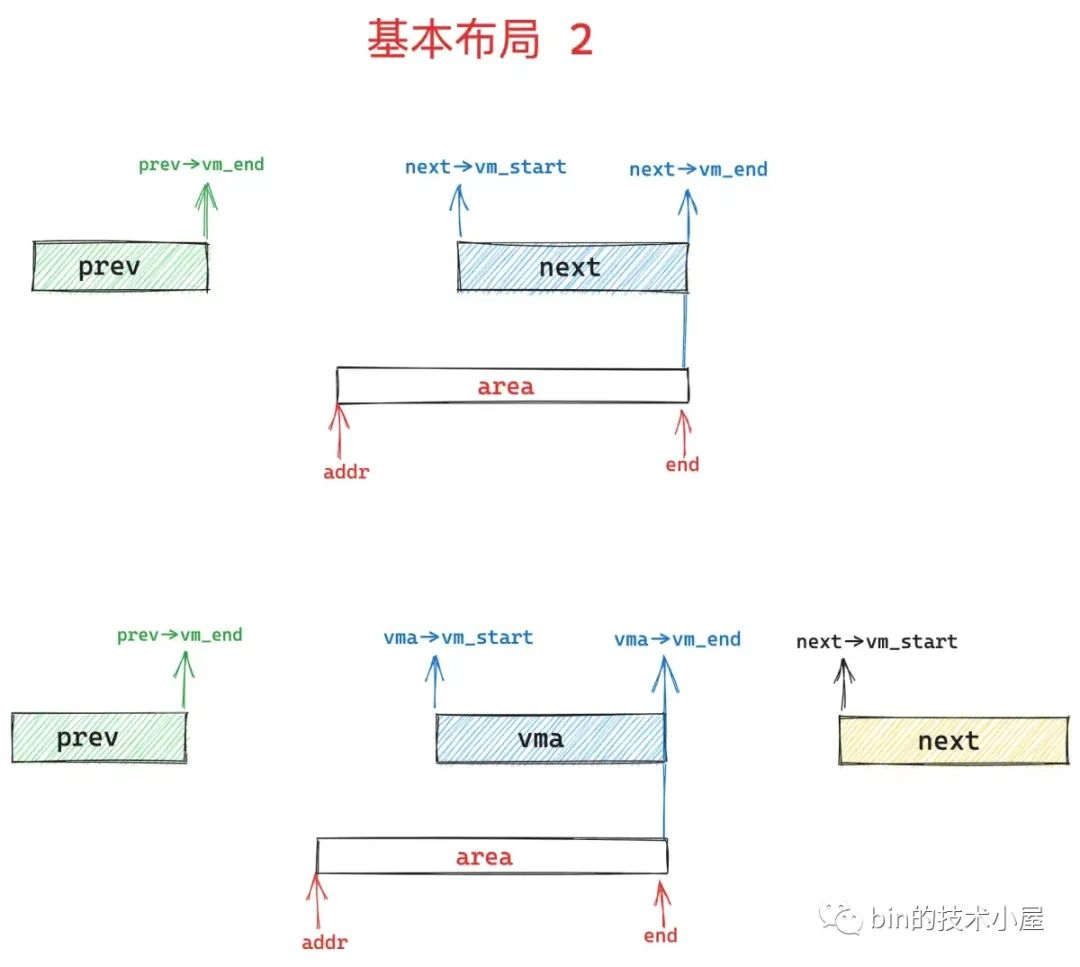
2、指定了MAP_FIXED(强制映射),area 区域有可能会与 prev 区域和 next 区域有部分重合。如果 area 区域的结束地址 end 与 next 区域的结束地址重合,内核会将 next 指针继续向后移动,指向 next->vm_next 区域。保证 area 始终处于 prev 和 next 之间的 gap 中(如下图)
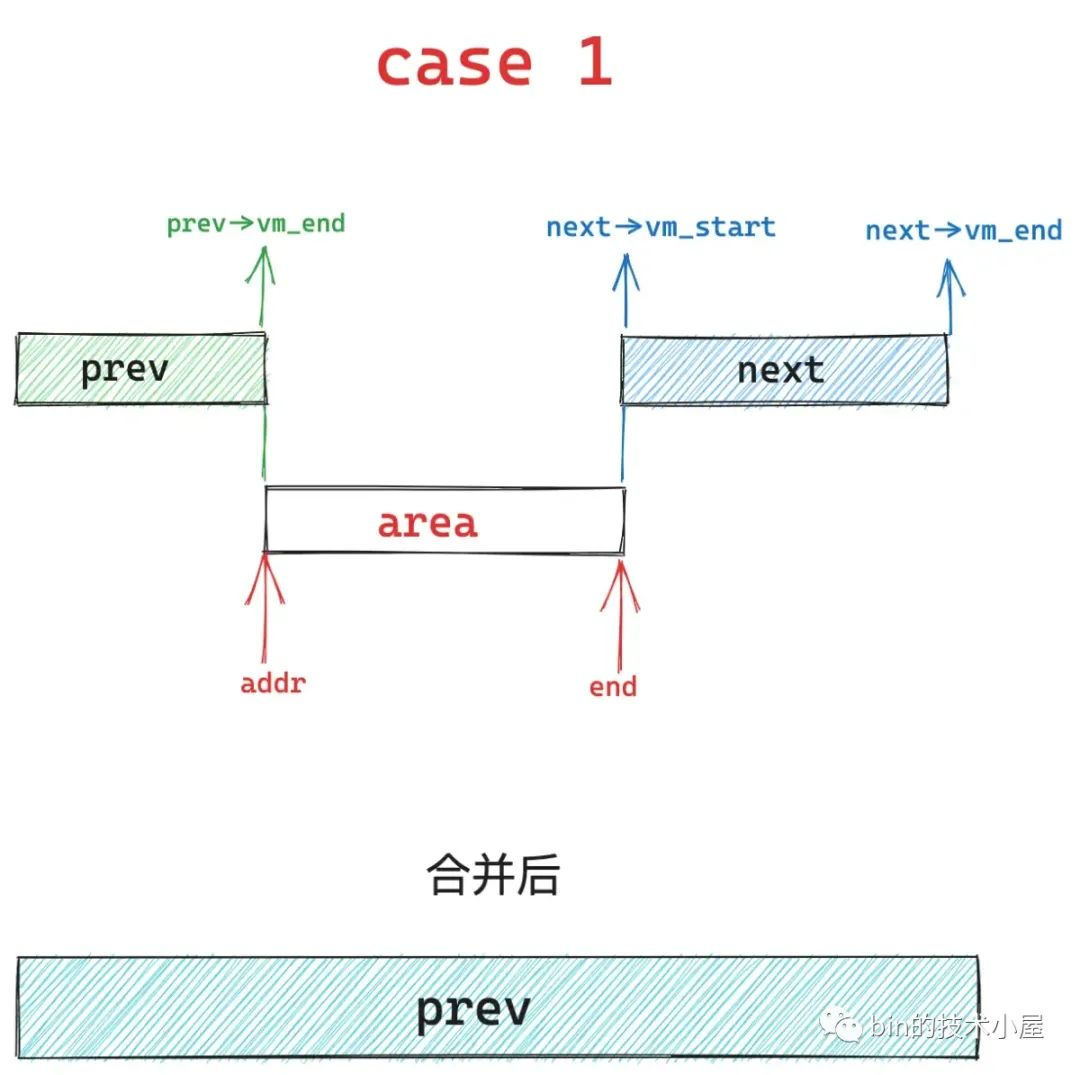
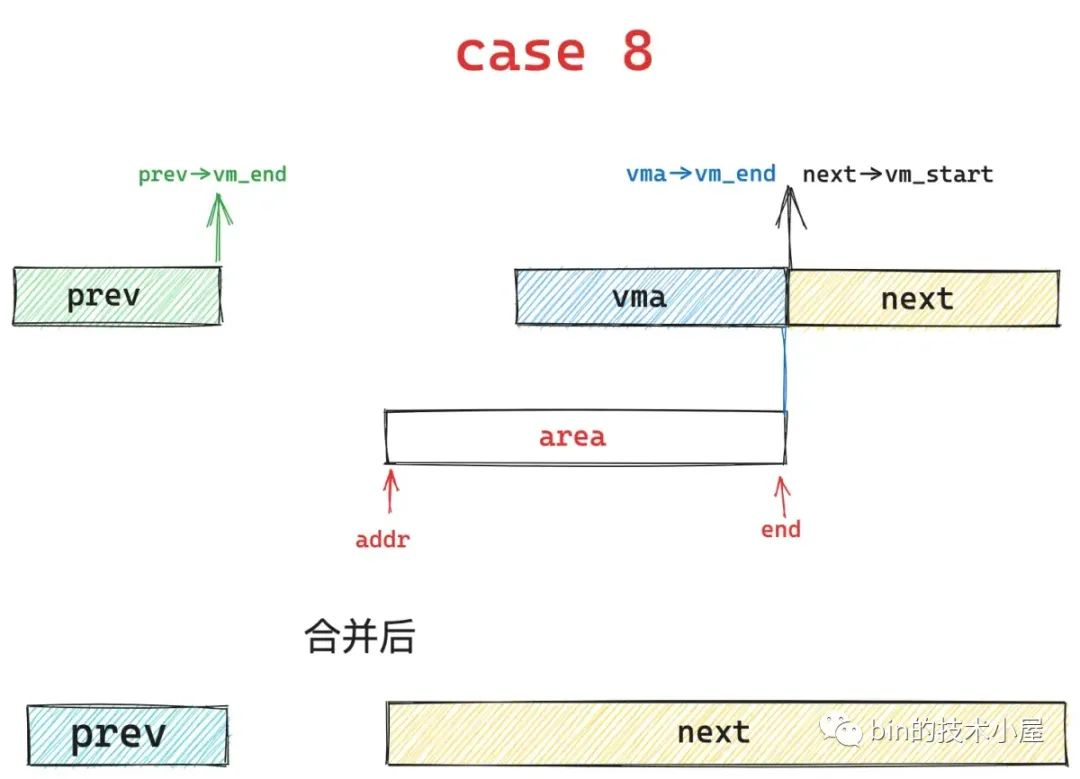
1、case1,在基本布局 1 中,area 的起始地址 addr 与 prev vma 的结束地址重合,同时 area 的结束地址 end 与 next vma 的起始地址重合,内核将会删除 next 区域,扩充 prev 区域,也就是说将这三个区域统一合并到 prev 区域中
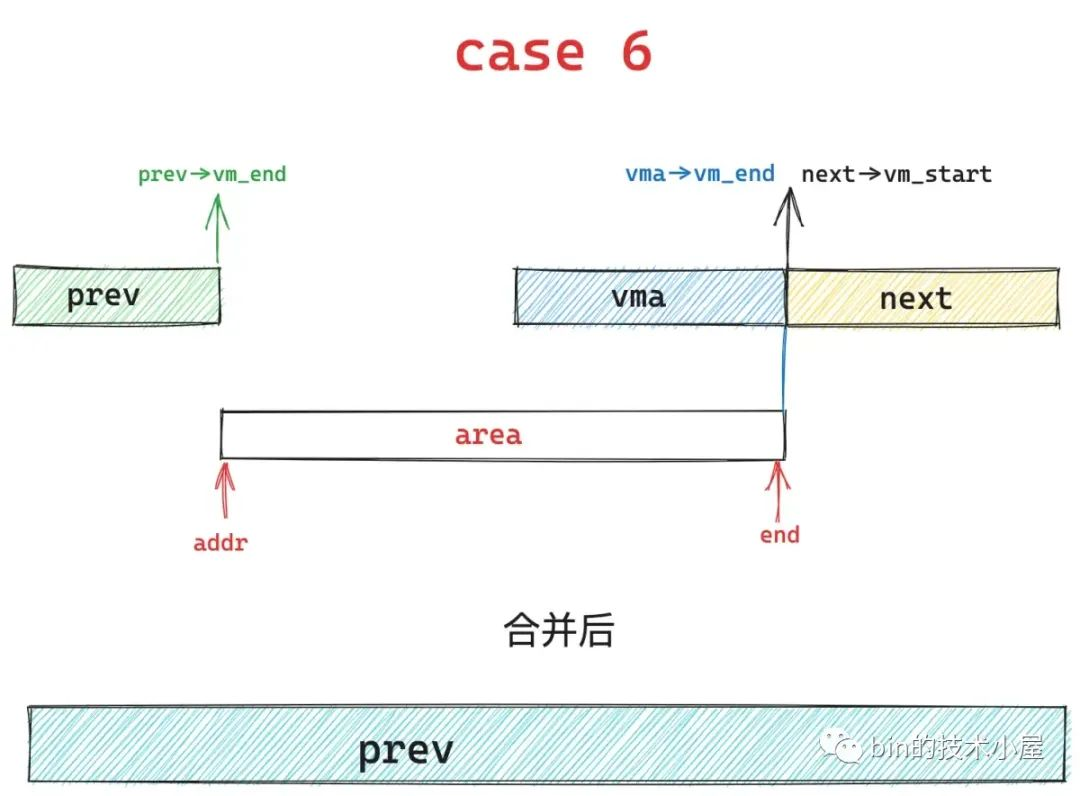
2、case6,在基本布局2的结果,内核会将中间重叠的蓝色区域覆盖掉,然后统一合并到 prev 区域中
case2、case5、case7 属于( area 的起始地址 addr 与 prev vma 的结束地址重合,但是 area 的结束地址 end 不与 next vma 的起始地址重合)
3、case2,area 的结束地址 end 小于 next vma 的起始地址,内核会扩充 prev 区域,将 area 合并进去,next 区域保持不变
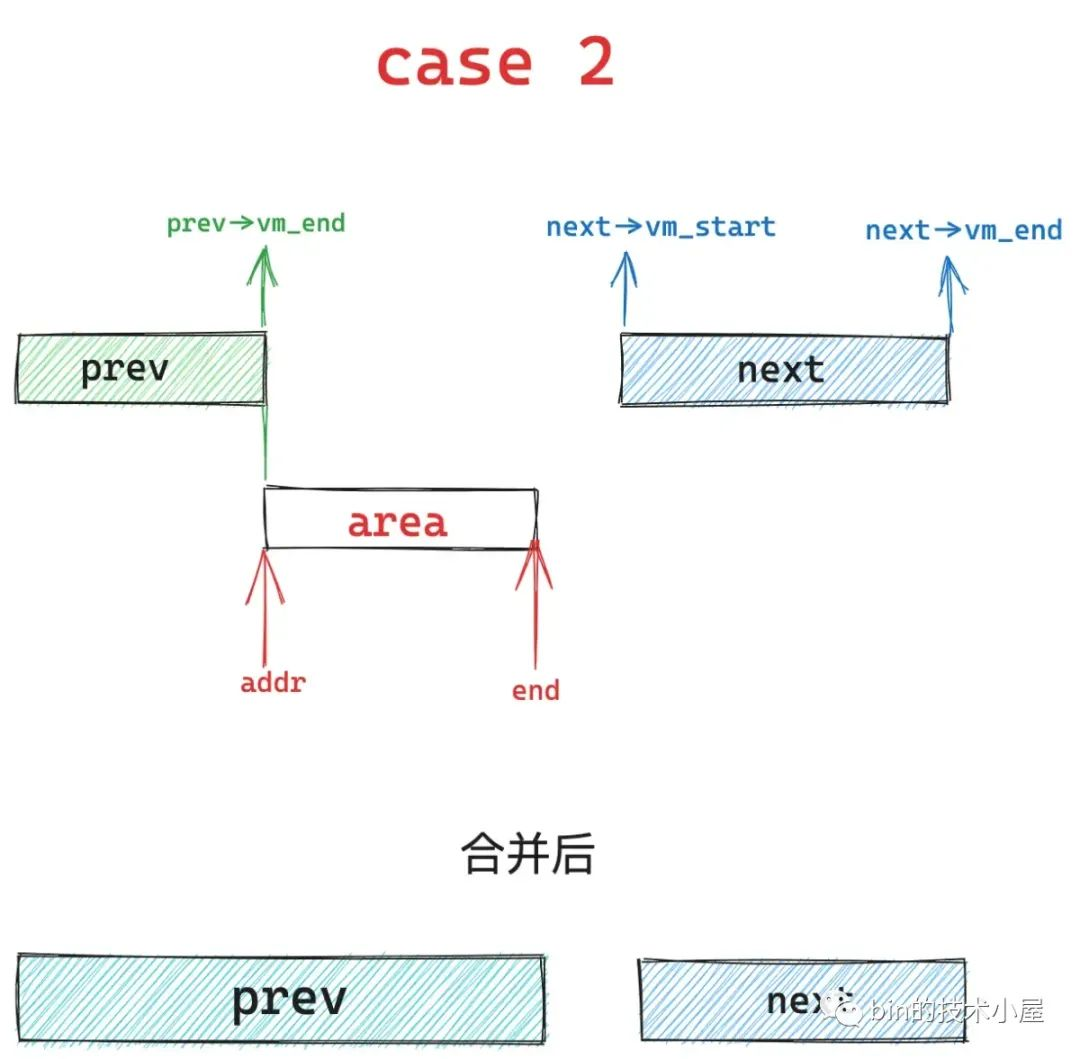
4、case5, area 的结束地址 end 大于 next vma 的起始地址,内核会扩充 prev 区域,将 area 以及与 next 重叠的部分合并到 prev 区域中,剩下的继续留在 next 区域保持不变
5、case7,对应布局2的情况,内核会并扩充 prev 区域。next 区域保持不变

case 3、 case 4 、 case 8属于( area 的结束地址 end 与 next vma 的起始地址重合,但是 area 的起始地址 addr 不与 prev vma 的结束地址重合)
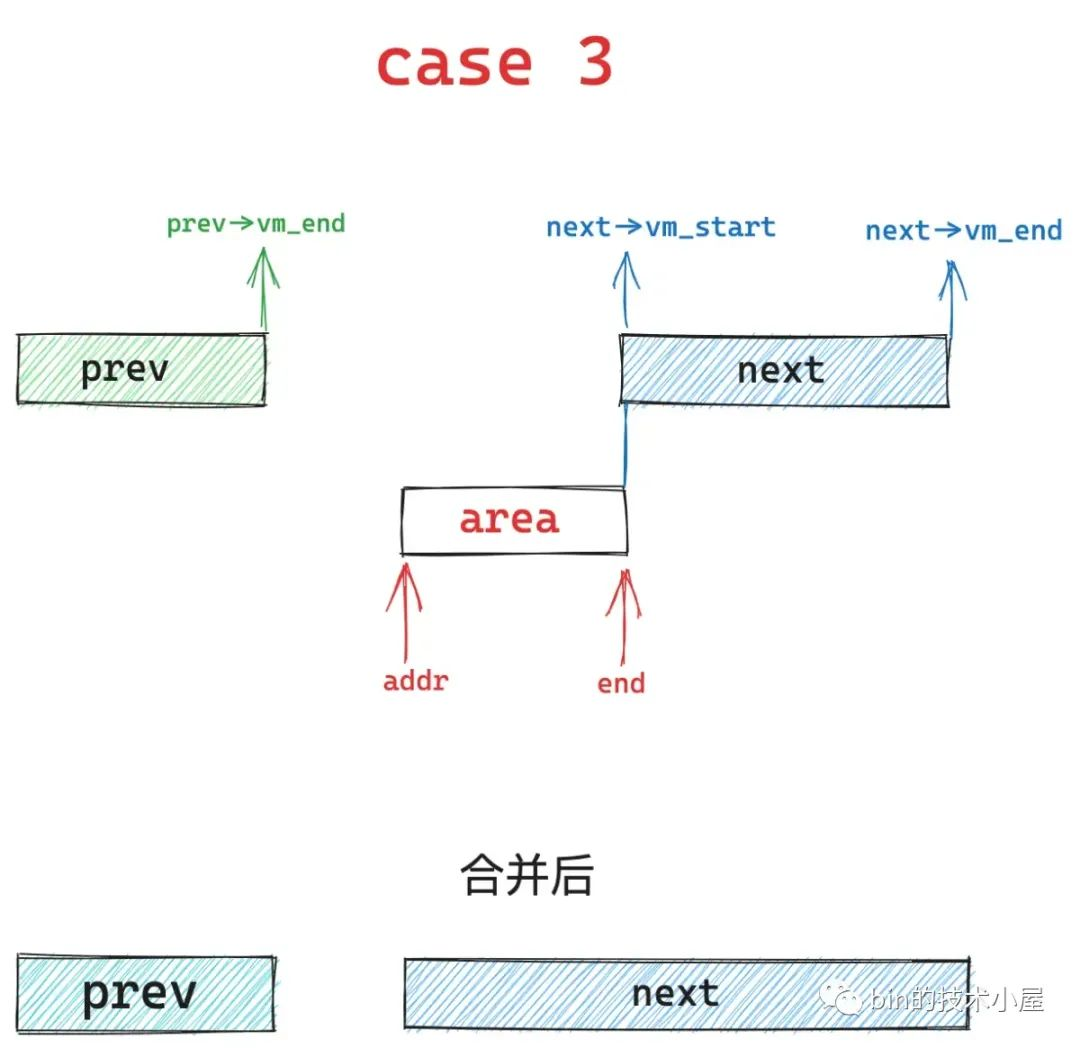
6、case3,当area 的起始地址 addr 大于 prev 区域的结束地址的话,内核会扩充 next 区域,并将 area 合并到 next 中,prev 区域保持不变
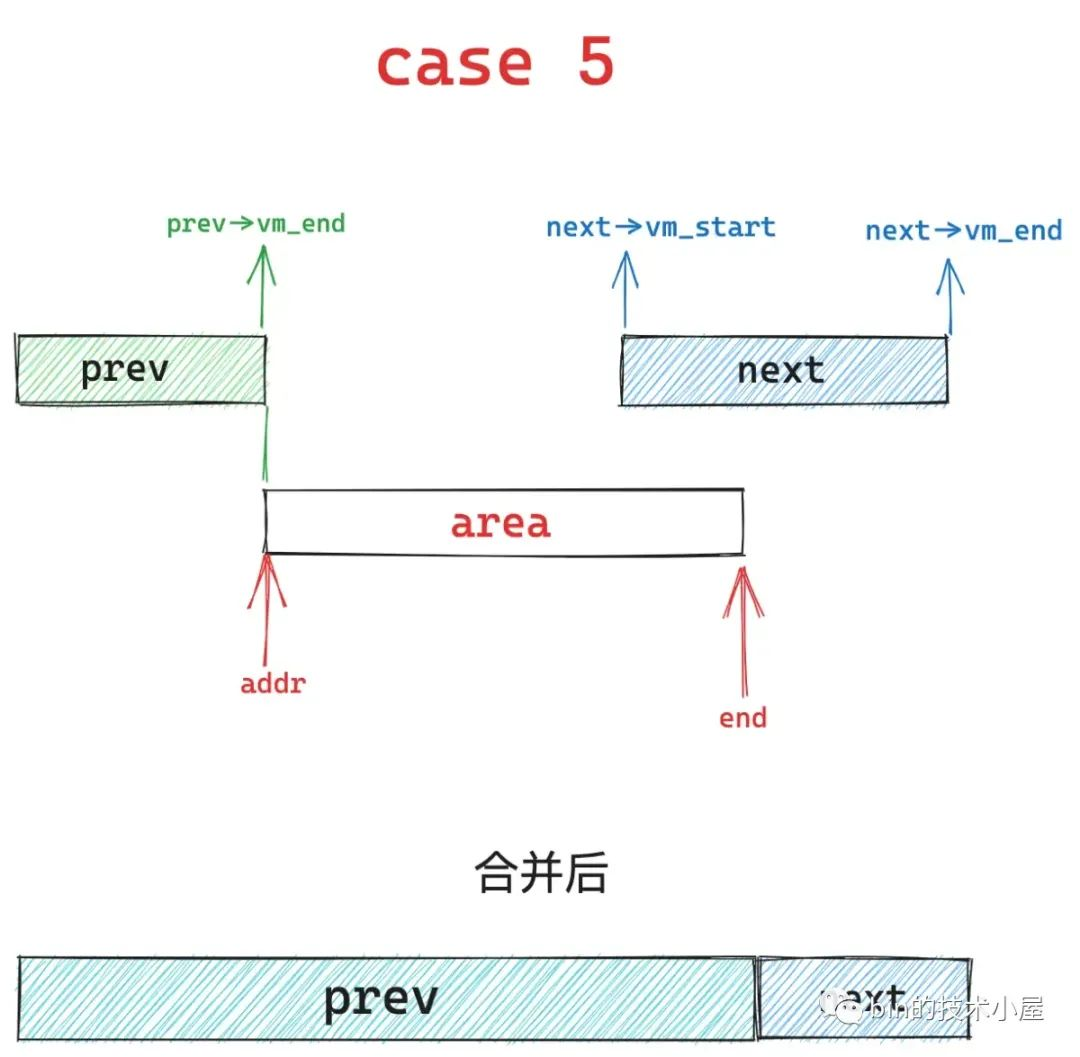
7、case4,area 的起始地址 addr 小于 prev 区域的结束地址,那么内核会缩小 prev 区域,然后扩充 next 区域,将重叠的部分合并到 next 区域中
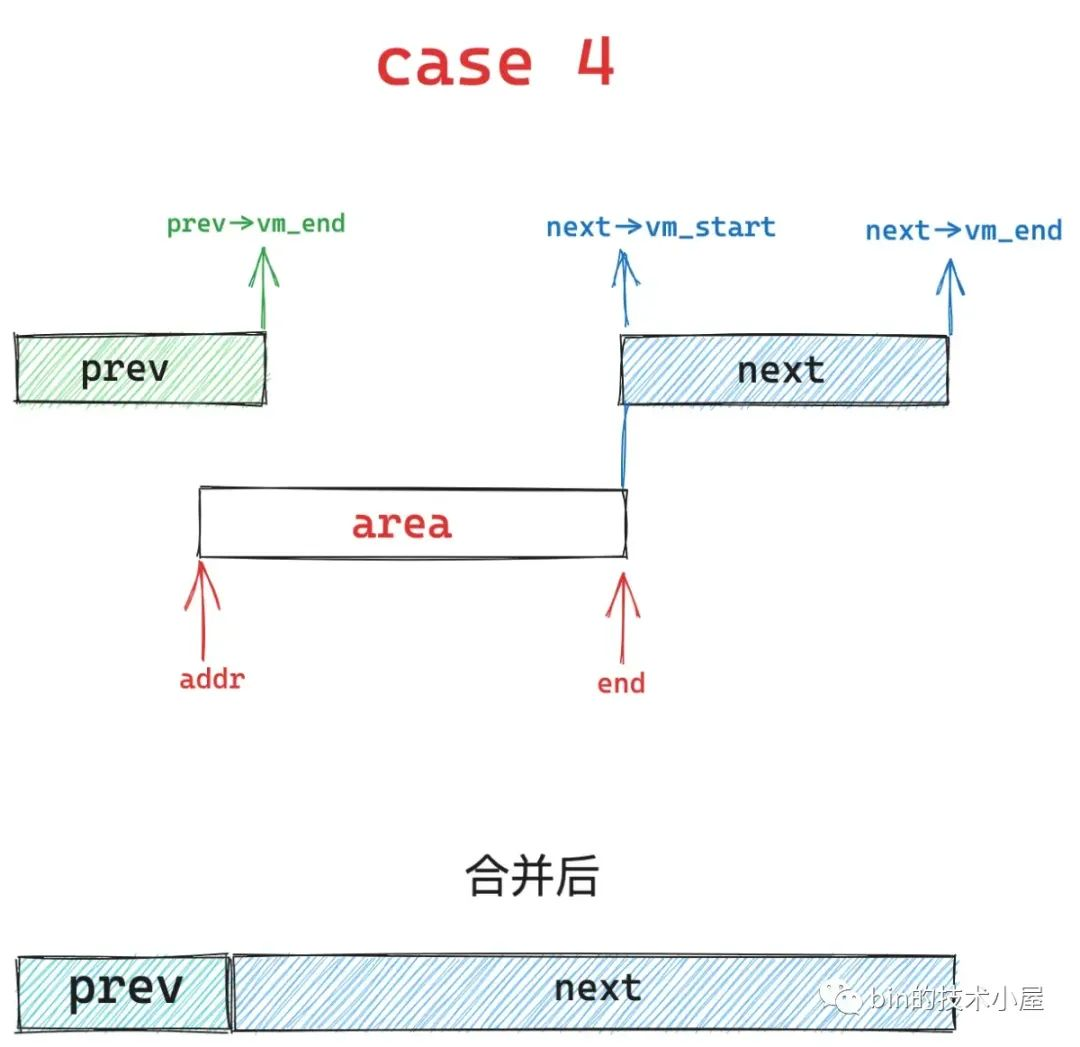
8、case8,也是对应于布局2的情况,内核继续保持 prev 区域不变,然后扩充 next 区域并覆盖下图中蓝色部分,将 area 合并到 next 区域中
最后,vma_link函数会按照虚拟内存地址的增长方向,将本次映射产生的 vma 结构插入到进程地址空间的三类数据结构(mm_struct->mmap 链表结构、mm_struct->mm_rb红黑树结构):
- 调用
__vma_link函数将vma插入到链表和红黑树中,其内部调用__vma_link_list函数将vma插入到mm->mmap双向链表中,调用__vma_link_rb函数将vma插入到mm->rb红黑树中 - 调用
__vma_link_file函数将vma添加到文件树中
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L589
static void vma_link(struct mm_struct *mm, struct vm_area_struct *vma,
struct vm_area_struct *prev, struct rb_node **rb_link,
struct rb_node *rb_parent)
{
// 文件 page cache
struct address_space *mapping = NULL;
if (vma->vm_file) {
// 文件映射场景:
// 获取映射文件的 page cache
mapping = vma->vm_file->f_mapping;
i_mmap_lock_write(mapping);
}
// 将 vma 插入到地址空间中的 vma 链表 mm_struct->mmap 以及红黑树 mm_struct->mm_rb 中
__vma_link(mm, vma, prev, rb_link, rb_parent);
// 建立文件与 vma 的反向映射(TODO)
__vma_link_file(vma);
if (mapping)
i_mmap_unlock_write(mapping);
// map_count 表示进程地址空间中 vma 的个数
mm->map_count++;
validate_mm(mm);
}
在vma_link中,还有一个非常重要的操作__vma_link_file,即通过 __vma_link_file 函数建立文件与虚拟内存区域 vma (所有进程)的反向映射关系,这里以文件页的反向映射为例,结构关系如下:
一个文件可以被多个进程一起映射,如此在每个进程的地址空间 mm_struct 结构中都会有一个 vma 结构来与这个文件进行映射,与该文件产生映射关系的所有进程地址空间中的 vma 就挂在 address_space->i_mmap 指向的这棵红黑树中,通过该结构可以找到所有与该文件进行映射的进程。__vma_link_file 函数建立文件页反向映射的核心其实就是将 mmap 映射出的这个 vma 插入到这颗红黑树中:
//i_mmap指向的是一颗红黑树,这颗红黑树正是文件页反向映射的核心数据结构,反向映射关系就保存在这里
struct address_space {
......
struct inode *host; /* owner: inode, block_device */
// page cache
struct radix_tree_root i_pages; /* cached pages */
atomic_t i_mmap_writable;/* count VM_SHARED mappings */
// 文件与 vma 反向映射的核心数据结构,i_mmap 也是一颗红黑树
// 在所有进程的地址空间中,只要与该文件发生映射的 vma 均挂在 i_mmap 中
struct rb_root_cached i_mmap; /* tree of private and shared mappings */
......
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/mmap.c#L561
static void __vma_link_file(struct vm_area_struct *vma)
{
struct file *file;
file = vma->vm_file;
if (file) {
struct address_space *mapping = file->f_mapping;
......
flush_dcache_mmap_lock(mapping);
// address_space->i_mmap 也是一颗红黑树,上面挂着的是与该文件映射的所有 vma(所有进程地址空间)
// 这里将 vma 插入到 i_mmap 中,实现文件与 vma 的反向映射
vma_interval_tree_insert(vma, &mapping->i_mmap);
flush_dcache_mmap_unlock(mapping);
}
}
到这里,mmap内存映射过程的第一阶段就基本完成了,用户进程调用mmap系统调用启动映射过程,在本进程的虚拟地址空间中为映射创建虚拟映射区域vma,并将新建的vma插入进程的虚拟地址区域链表或红黑树中。第二阶段是调用内核空间函数 mmap,实现文件物理地址和进程虚拟地址的一一映射关系
call_mmap->内核mmap的实现
内核mmap函数的原型是int mmap(struct file *filp, struct vm_area_struct *vma),其中参数file指向待映射文件对象的指针,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符 fd,参数vma指向待虚拟内存区域 vma 的指针
该函数通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核已打开文件fd集合中该文件的文件结构体(struct file),每个文件结构体维护着和这个已打开文件相关各项信息。通过该文件的文件结构体,链接到file_operations模块,并调用内核空间函数mmap
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/fs.h#L1736
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
{
//对ext4系统而言,mmap对应于ext4_file_mmap函数
//核心功能是完成将vma的vm_ops成员与ext4文件系统实现的ext4_file_vm_ops绑定
return file->f_op->mmap(file, vma);
}
struct file_operations {
......
int (*mmap) (struct file *, struct vm_area_struct *);
// mmap 函数用于将将设备的内存映射到进程空间中(也就是用户空间),以避免在用户空间和内核空间之间来回复制
......
} __randomize_layout;
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};
ext4_file_vm_ops包含了三个重要实现回调函数:
ext4_filemap_fault:缺页异常处理,当进程访问文件映射区域但对应的页面不在内存中时,内核会调用此函数加载数据filemap_map_pages:批量映射页面,预读和批量映射多个连续页面,减少缺页异常次数,提高性能ext4_page_mkwrite:写时缺页处理,当进程第一次写入一个只读页面时,进行写时复制(Copy-on-Write)处理
四级页表的建立过程
内核在执行文件映射时,此文件所属的文件系统会注册虚拟内存区域的虚拟内存操作集合,其中也包括内核驱动函数mmap,在不同的文件系统中内核驱动函数mmap的实现方式有所不同,但其内部都是通过 remap_pfn_range 函数来建立页表,即实现文件地址和虚拟地址区域的映射关系
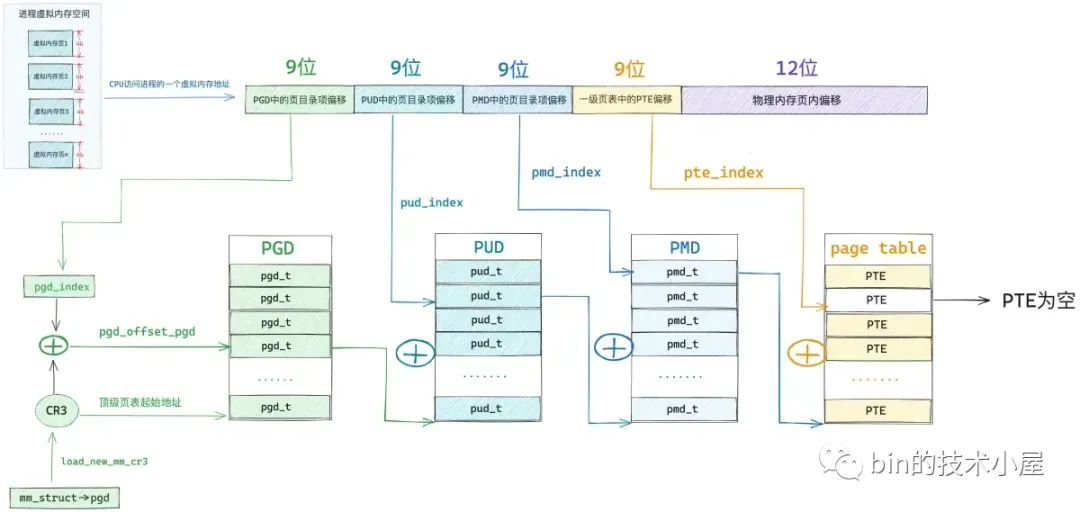
先回想下linux的四级页表模型,以及进程的mm_struct仅保存了CR3寄存器的基地址:
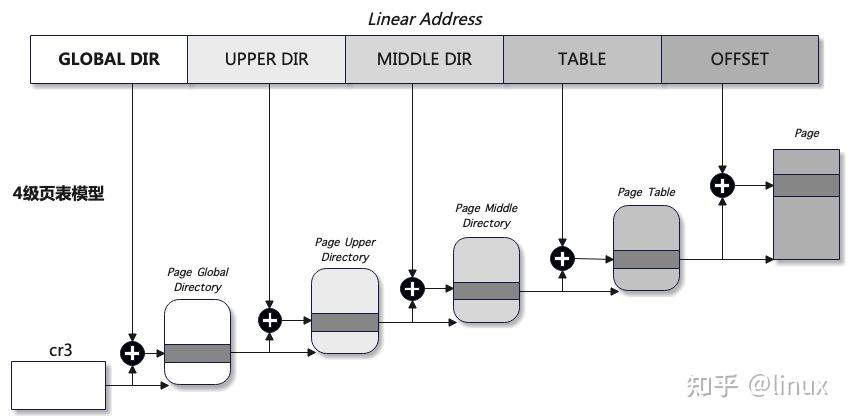
remap_pfn_range函数的核心功能是将物理页帧号pfn对应的物理内存映射到用户空间中要映射的虚拟内存地址的起始地址处。首先调用pgd_offset函数查找addr在页全局目录表中对应的页表项地址pgd,之后刷新TLB缓存,然后从待映射虚拟地址的起始地址addr开始,按照addr和页帧号pfn同步增长的顺序,循环遍历并调用remap_p4d_range函数逐页完成虚拟内存页和物理内存页之间的映射,补齐CR3指向的页表
另外,思考下,下面的函数中为何都要采用do...while循环的方式来处理地址转换呢?因为需要转换的范围是虚拟内存地址addr开始,一直到size长度结束的部分,先看下remap_pfn_range与用户态系统调用mmap的参数差异:
// mmap 系统调用
void *mmap(void *addr, // 期望的起始地址(可以为NULL)
size_t length, // 映射长度
int prot, // 保护标志
int flags, // 映射标志
int fd, // 文件描述符
off_t offset); // 文件偏移
// remap_pfn_range 函数
int remap_pfn_range(struct vm_area_struct *vma, // 内核VMA结构
unsigned long addr, // 实际映射起始地址
unsigned long pfn, // 物理页帧号
unsigned long size, // 映射大小
pgprot_t prot); // 保护标志
mmap的addr:remap_pfn_range的addr(经过内核调整后),都是虚拟内存地址mmap的length:remap_pfn_range的size,前者是用户请求的原始大小,后者是页面对齐后的大小mmap的prot:remap_pfn_range的prot
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L1876
/**
* remap_pfn_range - remap kernel memory to userspace
* @vma: user vma to map to:虚拟内存区域结构体指针,描述了要进行映射的虚拟内存区域。
* @addr: target user address to start at:用户空间中要映射的虚拟地址的起始地址。
* @pfn: physical address of kernel memory:物理页帧号的起始地址,即要映射的物理页面在内存中的索引。
* @size: size of map area:要映射的内存区域大小。
* @prot: page protection flags for this mapping:要应用于映射区域的页面保护标志,通常使用 vm_page_prot 定义。
*/
int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,
unsigned long pfn, unsigned long size, pgprot_t prot)
{
pgd_t *pgd;
unsigned long next;
// 需要映射的虚拟地址尾部:注意要页对齐,因为cpu硬件是以页为单位管理内存的
unsigned long end = addr + PAGE_ALIGN(size);
struct mm_struct *mm = vma->vm_mm;
unsigned long remap_pfn = pfn;
int err;
// 判断该页是否支持写时复制 cow
if (is_cow_mapping(vma->vm_flags)) {
if (addr != vma->vm_start || end != vma->vm_end)
return -EINVAL;
vma->vm_pgoff = pfn;
}
err = track_pfn_remap(vma, &prot, remap_pfn, addr, PAGE_ALIGN(size));
if (err)
return -EINVAL;
// 改变虚拟地址的标志
vma->vm_flags |= VM_IO | VM_PFNMAP | VM_DONTEXPAND | VM_DONTDUMP;
BUG_ON(addr >= end);
pfn -= addr >> PAGE_SHIFT;
// 查找 addr 在页全局目录项中对应的页表项的地址(很熟悉吧)
pgd = pgd_offset(mm, addr);
// 刷新 TLB 缓存,这个缓存和 CPU 的L1、L2、L3的缓存思想一致,既然进行地址转换需要的内存 IO 次数多,且耗时,
// 那么干脆就在 CPU 里把页表尽可能地 cache 起来不就行了么,所以就有了 TLB(Translation Lookaside Buffer)
// 专门用于改进虚拟地址到物理地址转换速度的缓存,其访问速度非常快,和寄存器相当,比 L1 访问还快
flush_cache_range(vma, addr, end);
do {
// 计算下一个将要被映射的虚拟地址,如果 addr 到 end 可以被一个 pgd 映射的话,那么返回 end 的值
next = pgd_addr_end(addr, end);
// 核心:完成虚拟内存和物理内存映射,本质就是填写完 CR3 指向的页表
// 过程就是逐级完成:1级是pgd,上面pgd_offset已经完成;2级是pud,3级是pmd,4级是pte
err = remap_p4d_range(mm, pgd, addr, next,
pfn + (addr >> PAGE_SHIFT), prot);
if (err)
break;
} while (pgd++, addr = next, addr != end);
if (err)
untrack_pfn(vma, remap_pfn, PAGE_ALIGN(size));
return err;
}
继续,remap_p4d_range 函数,其内部也是循环遍历,调用 remap_pud_range 函数完成虚拟内存页和物理内存页之间的映射,逐页补齐页全局目录表
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L1846
static inline int remap_p4d_range(struct mm_struct *mm, pgd_t *pgd,
unsigned long addr, unsigned long end,
unsigned long pfn, pgprot_t prot)
{
// p4d 在五级页表下会使用,在四级页表下 p4d 与 pgd 的值一样
p4d_t *p4d;
unsigned long next;
pfn -= addr >> PAGE_SHIFT;
// 在四级页表下,这里只是将 pgd 赋值给 p4d,后续均以 p4d 作为全局页目录项
p4d = p4d_alloc(mm, pgd, addr);
if (!p4d)
return -ENOMEM;
do {
// 计算下一个将要被映射的虚拟地址,如果 addr 到 end 可以被一个 pud 映射的话,那么返回 end 的值
next = p4d_addr_end(addr, end);
// 完成虚拟内存和物理内存映射,补齐页全局目录表
if (remap_pud_range(mm, p4d, addr, next,
pfn + (addr >> PAGE_SHIFT), prot))
return -ENOMEM;
} while (p4d++, addr = next, addr != end);
return 0;
}
remap_pud_range 函数,其内部也是循环遍历,调用 remap_pmd_range 函数完成虚拟内存页和物理内存页之间的映射,逐页补齐页上级目录表
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L1826
static inline int remap_pud_range(struct mm_struct *mm, p4d_t *p4d,
unsigned long addr, unsigned long end,
unsigned long pfn, pgprot_t prot)
{
pud_t *pud;
unsigned long next;
pfn -= addr >> PAGE_SHIFT;
// 首先 p4d_none 判断全局页目录项 p4d 是否是空的
// 如果 p4d 是空的,则调用 __pud_alloc 分配一个新的页上级目录表 PUD,然后填充 p4d
// 如果 p4d 不是空的,则调用 pud_offset 获取 address 在页上级目录 PUD 中的目录项 pud
pud = pud_alloc(mm, p4d, addr);
if (!pud)
return -ENOMEM;
do {
// 计算下一个将要被映射的虚拟地址,如果 addr 到 end 可以被一个 pud 映射的话,那么返回 end 的值
next = pud_addr_end(addr, end);
// 完成虚拟内存和物理内存映射,补齐页上级目录表
if (remap_pmd_range(mm, pud, addr, next,
pfn + (addr >> PAGE_SHIFT), prot))
return -ENOMEM;
} while (pud++, addr = next, addr != end);
return 0;
}
remap_pmd_range 函数,其内部也是循环遍历,调用 remap_pte_range 函数完成虚拟内存页和物理内存页之间的映射,逐页补齐页中间目录表
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L1805
static inline int remap_pmd_range(struct mm_struct *mm, pud_t *pud,
unsigned long addr, unsigned long end,
unsigned long pfn, pgprot_t prot)
{
pmd_t *pmd;
unsigned long next;
pfn -= addr >> PAGE_SHIFT;
// 首先 pud_none 判断页上级目录项 pud 是不是空的
// 如果 pud 是空的,则调用 __pmd_alloc 分配一个新的页中间目录表 PMD,然后填充 pud
// 如果 pud 不是空的,则调用 pmd_offset 获取 address 在页中间目录 PMD 中的目录项 pmd
pmd = pmd_alloc(mm, pud, addr);
if (!pmd)
return -ENOMEM;
VM_BUG_ON(pmd_trans_huge(*pmd));
do {
// 计算下一个将要被映射的虚拟地址,如果 addr 到 end 可以被一个 pmd 映射的话,那么返回 end 的值
next = pmd_addr_end(addr, end);
// 完成虚拟内存和物理内存映射,补齐页中间目录表
if (remap_pte_range(mm, pmd, addr, next,
pfn + (addr >> PAGE_SHIFT), prot))
return -ENOMEM;
} while (pmd++, addr = next, addr != end);
return 0;
}
remap_pte_range函数首先调用pte_alloc_map_lock函数,判断页中间目录项pmd是不是空的,如果是空的,则调用__pte_alloc分配一个新的页表pt,然后填充pmd;如果不是空的,则调用pte_offset_map_lock获取address在页表PT中的页表项pte。然后在每一次循环中,首先调用pte_mkspecial函数构造页表项的内容,然后调用 set_pte_at 函数将构造的页表项赋值给页表中的 pte,完成虚拟内存页和物理内存页之间的映射,直至循环结束补齐页表
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L1784
static int remap_pte_range(struct mm_struct *mm, pmd_t *pmd,
unsigned long addr, unsigned long end,
unsigned long pfn, pgprot_t prot)
{
pte_t *pte;
spinlock_t *ptl;
// 首先 pte_alloc 判断页中间目录项 pmd 是不是空的
// 如果 pmd 是空的,则调用 __pte_alloc 分配一个新的页表 pt,然后填充 pmd
// 如果 pmd 不是空的,则调用 pte_offset_map_lock 获取 address 在页表 PT 中的页表项 pte
pte = pte_alloc_map_lock(mm, pmd, addr, &ptl);
if (!pte)
return -ENOMEM;
arch_enter_lazy_mmu_mode();
do {
BUG_ON(!pte_none(*pte));
// 这是映射的最后一级:把物理地址的值填写到 pte 表项
// pte_mkspecial 函数构造页表项的内容,set_pte_at 函数将构造的页表项赋值给页表中的 pte
set_pte_at(mm, addr, pte, pte_mkspecial(pfn_pte(pfn, prot)));
// 页帧号加 1,即下一个将要被映射的物理页帧号
pfn++;
} while (pte++, addr += PAGE_SIZE, addr != end); // 计算页表中下一个将要被填充的页表项的地址
arch_leave_lazy_mmu_mode();
pte_unmap_unlock(pte - 1, ptl);
return 0;
}
至此,完成 mmap 内存映射过程的第二阶段,实现文件物理地址和进程虚拟地址的一一映射关系,同时更新的虚拟内存地址–>物理内存地址(pfn)的映射关系也已经保存在TLB缓存中,用于加速地址翻译过程
do_mmap的实现到此完成,调用 mmap 进行内存映射时,内核只是会在进程的虚拟内存空间中为该次映射分配一段虚拟内存,然后建立好这段虚拟内存与相关文件之间的映射关系,至此流程就结束,完成mmap内存映射的实现过程的第一和第二阶段
重要的一点是,此时内核并不会为映射分配物理内存,物理内存的分配工作需要延后到这段虚拟内存被CPU访问的时候,通过缺页中断来进入内核,分配物理内存,即mmap内存映射的实现过程的第三阶段,下文继续介绍
0x0 mmap文件映射实现
以ext4文件系统继续分析,对应的回调函数如下:
const struct file_operations ext4_file_operations = {
......
.mmap = ext4_file_mmap,
.get_unmapped_area = thp_get_unmapped_area,
......
};
static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma)
{
struct inode *inode = file->f_mapping->host;
if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb))))
return -EIO;
if (ext4_encrypted_inode(inode)) {
int err = fscrypt_get_encryption_info(inode);
if (err)
return 0;
if (!fscrypt_has_encryption_key(inode))
return -ENOKEY;
}
file_accessed(file);
if (IS_DAX(file_inode(file))) {
vma->vm_ops = &ext4_dax_vm_ops;
vma->vm_flags |= VM_MIXEDMAP | VM_HUGEPAGE;
} else {
// 将ext4_file_vm_ops实现绑定到vma->vm_ops
vma->vm_ops = &ext4_file_vm_ops;
}
return 0;
}
0x02 mmap匿名共享映射实现
若使用mmap进行共享匿名映射,父子进程之间需要依赖 tmpfs 文件系统中的匿名文件对共享内存进行访问,当进行共享匿名映射时,内核会在 shmem_zero_setup 函数中,使用 tmpfs 文件系统里为映射创建一个匿名文件(shmem_kernel_file_setup),随后将 tmpfs 文件系统中的这个匿名文件与虚拟映射区 vma 中的 vm_file 关联映射起来,当父进程调用 fork 创建子进程的时候,内核会将父进程的虚拟内存空间全部拷贝给子进程,包括这里创建的共享匿名映射区域 vma,这样一来,父子进程就可以通过共同的 vma->vm_file 来实现共享内存的通信了(mmap 的共享匿名映射其实本质上还是共享文件映射)
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/shmem.c#L4216
int shmem_zero_setup(struct vm_area_struct *vma)
{
struct file *file;
loff_t size = vma->vm_end - vma->vm_start;
// tmpfs 中获取一个匿名文件
file = shmem_kernel_file_setup("dev/zero", size, vma->vm_flags);
if (IS_ERR(file))
return PTR_ERR(file);
if (vma->vm_file)
// 如果 vma 中已存在其他文件,则解除与其他文件的映射关系
fput(vma->vm_file);
// 将 tmpfs 中的匿名文件映射进虚拟内存区域 vma 中
// 后续 fork 子进程的时候,父子进程就可以通过这个匿名文件实现共享匿名映射
vma->vm_file = file;
// 对这块共享匿名映射区相关操作这里直接映射成 shmem_vm_ops
vma->vm_ops = &shmem_vm_ops;
return 0;
}
static const struct vm_operations_struct shmem_vm_ops = {
.fault = shmem_fault,
.map_pages = filemap_map_pages,
#ifdef CONFIG_NUMA
.set_policy = shmem_set_policy,
.get_policy = shmem_get_policy,
#endif
};
0x03 缺页中断的主要处理
上面完成了mmap文件映射到vma创建(文件inode关联vma)的基本过程,对应于应用层系统调用mmap(....)的过程,然后用户拿到了mmap返回的虚拟内存地址进行读写操作时char c = ptr[0]时,若为首次对该虚拟内存地址的访问,那么会触发缺页中断。本小节以ext4文件系统的mmap文件映射过程为例,分析缺页中断的处理过程。缺页中断的核心逻辑中,涉及到的主要内核结构及成员如下:
// vma
struct vm_area_struct {
unsigned long vm_pgoff; // 重要:在映射文件中的偏移(页为单位)
struct file * vm_file; // 映射的文件指针
const struct vm_operations_struct *vm_ops; // 操作集,包含fault函数
......
};
// vm_fault
struct vm_fault {
pgoff_t pgoff; // 缺页地址在文件中的页偏移
unsigned long address; // 缺页的虚拟地址
struct vm_area_struct *vma; // 对应的VMA
......
};
当MMU触发缺页异常时,内核会进入缺页处理流程,缺页异常处理入口函数do_page_fault如下。在do_page_fault中,会通过read_cr2拿到触发缺页中断的虚拟内存地址address,__do_page_fault 是处理缺页异常的核心逻辑。当 CPU 访问某个虚拟内存地址(address)失败时,它会根据该地址所处的上下文(内核态还是用户态、是否在有效 VMA 内等)采取不同的处理策略,核心工作如下:
1、早期校验与上下文判断(前置检查)
2、查找虚拟内存区域(VMA),内核需要确定 address 是否落在一个合法的进程虚拟内存区域内
- 查找 VMA: 搜索进程的
mm_struct,寻找第一个结束地址大于address的 VMA - 栈扩展检查:如果地址不在现有 VMA 内,内核会检查该地址是否紧挨着栈区域。如果是,内核会尝试尝试扩展栈(Expand Stack)
- bad地址处理: 如果找不到匹配的 VMA,说明访问了非法内存,跳转到
bad_area逻辑,通常向进程发送SIGSEGV(段错误)
3、权限校验 (Permission Check),找到 VMA 后,内核会对比 error_code(由硬件压入)和 VMA 的权限:
- 写操作: 如果是写操作导致的缺页,但 VMA 是只读的,触发错误
- 执行操作: 如果是指令获取导致的缺页,但 VMA 不允许执行,触发错误
- 用户权限: 用户态进程尝试访问内核地址,触发错误
4、核心分配逻辑:handle_mm_fault,一旦确认地址合法且权限正确,内核进入最核心的分配阶段,这个过程本质上是自上而下填充页表:
- 页目录填充: 检查并分配 PGD、P4D、PUD、PMD 等各级页目录项
- 触发巨页 (Huge Pages): 如果该区域配置了透明巨页(THP),内核会尝试在此处直接分配
2MB的大页 - 对于常规页page的处理 (
handle_pte_fault):- 匿名映射 (Anonymous): 进程私有内存(如
malloc分配),内核分配一个清零后的物理页框,并在 PTE(页表项)中建立映射 - 文件映射 (File-backed):从磁盘读取文件内容到 Page Cache,然后将
address映射到该物理页 - 写时复制 (COW): 如果是因为写入只读的共享页(如
fork后的子进程),内核会拷贝一份物理页,让进程拥有自己的副本 - 交换出 (Swap-in):如果该页之前被换出到磁盘,内核将其换回内存
- 匿名映射 (Anonymous): 进程私有内存(如
5、错误与收尾
- 成功:更新 MMU 状态,刷新相关的 TLB,函数返回,CPU 重新执行触发异常的那条指令
- 内存不足 (OOM):如果系统无法分配物理内存,可能触发
out_of_memory机制 - 总线错误:如果文件映射对应的磁盘扇区损坏,发送
SIGBUS
在后续的代码中,关注如下一些关键函数代码:
- 查找
find_vma():确认address是否属于进程空间 - 校验&&检查
vma->vm_flags:确认操作权限(读/写/执行)是否合法 - 缺页中断的核心处理&&分配物理内存
handle_mm_fault():填充多级页表,分配物理内存 - 映射物理内存
set_pte_at():将虚拟地址正式指向物理地址
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/mm/fault.c#L1446
dotraplinkage void notrace
do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
unsigned long address = read_cr2(); /* Get the faulting address */
enum ctx_state prev_state;
prev_state = exception_enter();
//重要:address即触发缺页中断的虚拟内存地址
__do_page_fault(regs, error_code, address);
exception_exit(prev_state);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/mm/fault.c#L1215
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
int fault, major = 0;
unsigned int flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE;
tsk = current;
mm = tsk->mm;
......
// 根据虚拟内存地址找到vma
vma = find_vma(mm, address);
if (unlikely(!vma)) {
bad_area(regs, error_code, address);
return;
}
// 合法的vma校验
if (likely(vma->vm_start <= address))
goto good_area;
if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) {
bad_area(regs, error_code, address);
return;
}
......
/*
* Ok, we have a good vm_area for this memory access, so
* we can handle it..
*/
good_area:
if (unlikely(access_error(error_code, vma))) {
bad_area_access_error(regs, error_code, address, vma);
return;
}
// 核心:处理缺页中断的函数
fault = handle_mm_fault(vma, address, flags);
major |= fault & VM_FAULT_MAJOR;
......
check_v8086_mode(regs, address, tsk);
}
而对于文件映射的缺页处理,调用链如下,可以看到handle_mm_fault -> do_fault 是在处理文件映射页面时的一个特定动作
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3870
handle_mm_fault
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3787
-> __handle_mm_fault
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3699
-> handle_pte_fault
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3504
-> do_fault
-> do_shared_fault
-> do_read_fault
上面流程对应的主要内核函数如下:
do_anonymous_page:处理匿名映射的缺页do_fault:处理文件映射的缺页
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/pagemap.h#L423
static inline pgoff_t linear_page_index(struct vm_area_struct *vma,
unsigned long address)
{
pgoff_t pgoff;
......
pgoff = (address - vma->vm_start) >> PAGE_SHIFT;
pgoff += vma->vm_pgoff;
return pgoff;
}
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address), //重要:计算文件页偏移(见下文分析)
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
if (!p4d)
return VM_FAULT_OOM;
vmf.pud = pud_alloc(mm, p4d, address);
if (!vmf.pud)
return VM_FAULT_OOM;
if (pud_none(*vmf.pud) && transparent_hugepage_enabled(vma)) {
ret = create_huge_pud(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
pud_t orig_pud = *vmf.pud;
barrier();
if (pud_trans_huge(orig_pud) || pud_devmap(orig_pud)) {
unsigned int dirty = flags & FAULT_FLAG_WRITE;
/* NUMA case for anonymous PUDs would go here */
if (dirty && !pud_write(orig_pud)) {
ret = wp_huge_pud(&vmf, orig_pud);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pud_set_accessed(&vmf, orig_pud);
return 0;
}
}
}
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
if (!vmf.pmd)
return VM_FAULT_OOM;
if (pmd_none(*vmf.pmd) && transparent_hugepage_enabled(vma)) {
ret = create_huge_pmd(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
pmd_t orig_pmd = *vmf.pmd;
barrier();
if (pmd_trans_huge(orig_pmd) || pmd_devmap(orig_pmd)) {
if (pmd_protnone(orig_pmd) && vma_is_accessible(vma))
return do_huge_pmd_numa_page(&vmf, orig_pmd);
if ((vmf.flags & FAULT_FLAG_WRITE) &&
!pmd_write(orig_pmd)) {
ret = wp_huge_pmd(&vmf, orig_pmd);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pmd_set_accessed(&vmf, orig_pmd);
return 0;
}
}
}
return handle_pte_fault(&vmf);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3699
static int handle_pte_fault(struct vm_fault *vmf)
{
......
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma)){
// 匿名映射的缺页
return do_anonymous_page(vmf);
}
else{
// 文件映射的缺页
return do_fault(vmf);
}
}
......
}
// do_fault:缺页映射的核心实现
static int do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret;
/* The VMA was not fully populated on mmap() or missing VM_DONTEXPAND */
if (!vma->vm_ops->fault)
ret = VM_FAULT_SIGBUS;
else if (!(vmf->flags & FAULT_FLAG_WRITE)) //只读
ret = do_read_fault(vmf);
else if (!(vma->vm_flags & VM_SHARED))
ret = do_cow_fault(vmf);
else
ret = do_shared_fault(vmf); // 共享+读写
/* preallocated pagetable is unused: free it */
if (vmf->prealloc_pte) {
pte_free(vma->vm_mm, vmf->prealloc_pte);
vmf->prealloc_pte = NULL;
}
return ret;
}
在上面的__handle_mm_fault函数中,调用了p4d_alloc/pud_alloc/pmd_alloc/pte...等函数对页表进行修复(注意是修复页表,非翻译),回顾先前的知识,在正常的 CPU 执行过程中,虚拟内存地址转物理地址是由 MMU(内存管理单元)硬件自动完成的,它依赖于进程的四级页表。handle_mm_fault的作用是当四级页表的某个层级(PGD/PUD/PMD/PTE)缺失时,负责把缺少的页表项填进去,并关联一个真正的物理页(最终关联 set_pte_at将物理页地址填入最底层的 PTE,即将物理页的地址写入 PTE),如此重新执行CPU 再次访问 0x12345678 MMU 转换成功,直接访问物理内存
- 页表完整:MMU 直接完成转换,不会进入
handle_mm_fault - 页表为空:MMU 触发异常,内核调用
handle_mm_fault
最后,会根据当然类型是匿名映射或者文件映射来查找(分配)物理内存页:
- 匿名内存:会调用
alloc_pages申请一个全零物理内存页 - 文件映射:关联通过inode查找
address_space逻辑
继续,以do_read_fault->__do_fault调用链路,__do_fault中的vma->vm_ops->fault,这里的fault在ext4文件系统中就对应着ext4_file_vm_ops的fault成员,即ext4_filemap_fault函数
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3397
static int do_read_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret = 0;
......
//__do_fault
ret = __do_fault(vmf);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
ret |= finish_fault(vmf);
unlock_page(vmf->page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
put_page(vmf->page);
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3006
static int __do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret;
//CALL ext4_filemap_fault->filemap_fault
ret = vma->vm_ops->fault(vmf);
......
return ret;
}
// ext4文件系统的mmap文件映射
int ext4_filemap_fault(struct vm_fault *vmf)
{
struct inode *inode = file_inode(vmf->vma->vm_file);
int err;
//调用filemap_fault,先加锁
down_read(&EXT4_I(inode)->i_mmap_sem);
// 最终调用filemap_fault实现
// 包含了查找 address_space 和 新建 Page 的过程
err = filemap_fault(vmf);
up_read(&EXT4_I(inode)->i_mmap_sem);
return err;
}
最终ext4_filemap_fault还是会调用filemap_fault完成缺页中断最后的部分,filemap_fault是通用文件系统缺页处理函数,主要任务是在page cache中查找或加载文件页,以满足文件内存映射的缺页需求
注意在filemap_fault中会调用find_get_page函数对文件页进行查找操作,本质上是调用page cache IDR的查找方法radix_tree_lookup_slot
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L2174
// filemap_fault:核心任务是根据偏移量(pgoff)在 Page Cache 中拿到一个 struct page
int filemap_fault(struct vm_fault *vmf)
{
int error;
struct file *file = vmf->vma->vm_file; // 获取mmap映射的文件
struct address_space *mapping = file->f_mapping; // 文件对应的地址空间(找到radix树即page cache管理入口)
struct file_ra_state *ra = &file->f_ra; // 预读状态
struct inode *inode = mapping->host; // 文件inode
pgoff_t offset = vmf->pgoff;
// 重要:这就是从vm_area_struct获取的偏移(页数)
// 在下面对本文件inode->address_space指向radix树进行查找时,使用的offset查找参数
struct page *page;
loff_t size;
int ret = 0;
// 边界检查,检查请求的页偏移是否超出文件大小
size = round_up(i_size_read(inode), PAGE_SIZE);
if (offset >= size >> PAGE_SHIFT)
return VM_FAULT_SIGBUS;
/*
* Do we have something in the page cache already?
*/
// 1. 首先在page cache中查找(第一次查找),首先尝试在page cache中查找指定偏移的页
/*
参数:vmf->pgoff是单个页面的偏移,只返回这一个页面的指针
函数返回值vmf->page也指向单个页面
*/
page = find_get_page(mapping, offset);
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
/*
* We found the page, so try async readahead before
* waiting for the lock.
*/
// 页面在cache中找到,页面命中处理
// 执行异步预读,预读后续页面
do_async_mmap_readahead(vmf->vma, ra, file, page, offset);
} else if (!page) {
// 2. 页面不在cache中,进行同步预读(页面未命中处理)
/* No page in the page cache at all */
do_sync_mmap_readahead(vmf->vma, ra, file, offset);
//记录主要缺页事件(PGMAJFAULT)
count_vm_event(PGMAJFAULT);
mem_cgroup_count_vm_event(vmf->vma->vm_mm, PGMAJFAULT);
//设置返回码为VM_FAULT_MAJOR(表示需要磁盘I/O)
ret = VM_FAULT_MAJOR;
retry_find:
// 3. 再次查找(重新尝试查找页面)
page = find_get_page(mapping, offset);
if (!page){
// 4. 如果仍然没有,从磁盘读取
goto no_cached_page;
}
}
// 5. 等待页面就绪(尝试锁定页面),防止并发修改
if (!lock_page_or_retry(page, vmf->vma->vm_mm, vmf->flags)) {
put_page(page);
return ret | VM_FAULT_RETRY;
}
// 6. 页面一致性检查
//检查页面是否仍然属于同一个address_space,验证页面索引是否匹配请求的偏移
if (unlikely(page->mapping != mapping)) {
unlock_page(page);
put_page(page);
goto retry_find; //如果不匹配,回退跳转到重新查找
}
VM_BUG_ON_PAGE(page->index != offset, page);
// 7. 检查页面是否最新(是否与磁盘同步),如果不是最新,跳转到重新读取逻辑
if (unlikely(!PageUptodate(page)))
goto page_not_uptodate;
/*
* Found the page and have a reference on it.
* We must recheck i_size under page lock.
*/
// 8. 再次边界检查,在获取页面锁后再次检查文件大小,防止在锁定期间文件被截断
size = round_up(i_size_read(inode), PAGE_SIZE);
if (unlikely(offset >= size >> PAGE_SHIFT)) {
unlock_page(page);
put_page(page);
return VM_FAULT_SIGBUS;
}
// 成功情况下返回,将找到的页面存入vmf->page,另外返回VM_FAULT_LOCKED表示页面已锁定
// 注意:这里仅设置单个页面
vmf->page = page;
return ret | VM_FAULT_LOCKED;
//下面是缺页处理的错误路径:
//1、页面不在缓存中
//2、页面非最新
no_cached_page:
/*
* We're only likely to ever get here if MADV_RANDOM is in
* effect.
*/
// 如果页面不在page cache,调用page_cache_read分配新页并触发读取
// 如果成功,跳回retry_find重新查找
// page_cache_read的主要功能是申请page,并把page加入全局链表
error = page_cache_read(file, offset, vmf->gfp_mask);
/*
* The page we want has now been added to the page cache.
* In the unlikely event that someone removed it in the
* meantime, we'll just come back here and read it again.
*/
if (error >= 0)
goto retry_find;
/*
* An error return from page_cache_read can result if the
* system is low on memory, or a problem occurs while trying
* to schedule I/O.
*/
if (error == -ENOMEM)
return VM_FAULT_OOM;
return VM_FAULT_SIGBUS;
page_not_uptodate:
/*
* Umm, take care of errors if the page isn't up-to-date.
* Try to re-read it _once_. We do this synchronously,
* because there really aren't any performance issues here
* and we need to check for errors.
*/
//如果页面不是最新,需要调用文件系统的readpage方法重新读取
ClearPageError(page);
error = mapping->a_ops->readpage(file, page);
if (!error) {
//等待读取完成
//如果读取成功,重新查找页面(retry_find的部分)
wait_on_page_locked(page);
if (!PageUptodate(page))
error = -EIO;
}
put_page(page);
if (!error || error == AOP_TRUNCATED_PAGE)
goto retry_find;
/* Things didn't work out. Return zero to tell the mm layer so. */
shrink_readahead_size_eio(file, ra);
return VM_FAULT_SIGBUS;
}
整体的缺页流程处理基本结束,这里再说明下两个细节:
1、当页面不在page cache时,page_cache_read的逻辑是什么?page_cache_read的主要功能是于页缓存page cache中分配、插入和读取文件页
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L2074
/*
file: 指向打开的文件结构体指针
offset: 文件中的页偏移(页为单位)
gfp_mask: 内存分配标志
*/
static int page_cache_read(struct file *file, pgoff_t offset, gfp_t gfp_mask)
{
struct address_space *mapping = file->f_mapping;
struct page *page;
int ret;
do {
//使用__page_cache_alloc分配一个页面
page = __page_cache_alloc(gfp_mask|__GFP_COLD);
if (!page)
return -ENOMEM;
//1. 将页面插入页缓存的radix树
//2. 同时将页面添加到LRU链表中
ret = add_to_page_cache_lru(page, mapping, offset, gfp_mask & GFP_KERNEL);
if (ret == 0){
//情况1:插入成功 (ret == 0)时,调用文件系统的readpage方法读取文件数据,这是一个异步操作,启动磁盘I/O
//页面在I/O完成前保持锁定状态
ret = mapping->a_ops->readpage(file, page);
}
else if (ret == -EEXIST) //竞态,其他线程已成功插入同一页面
ret = 0; /* losing race to add is OK */
put_page(page);
} while (ret == AOP_TRUNCATED_PAGE);
return ret;
}
2、filemap_fault中的性能优化,虽然filemap_fault函数主要处理单page缺页,但会通过预读(readahead)机制连续加载多页。从其调用入口page = find_get_page(mapping, offset)来看,这里只查找指定偏移的一页,但通过预读机制实际上在优化连续的内存访问模式。即预读后续页面,减少未来缺页
finish_fault
继续do_read_fault->__do_fault完成之后的流程,即finish_fault的实现。当 filemap_fault 返回了这个 page 给 __do_fault 后,此时页表依然是空的,finish_fault是内核缺页中断(Page Fault)处理中的最好的收尾工作,其核心职责是:决定使用哪个物理页,并将其安装到进程的页表中
1、确定要使用的物理页面,这里会根据是否触发了写时复制(COW)来选择
- COW 场景:如果这是一个私有(Private)且可写(Write)的映射触发了缺页,内核会使用之前在
do_cow_fault中分配并拷贝好数据的vmf->cow_page,参考前文 - 非 COW 场景:如果是只读访问,或者是一个共享映射(Shared Mapping),则直接使用文件系统读取到 Page Cache 中的
vmf->page
2、映射与权限设置(Mapping),主要调用核心函数 alloc_set_pte
- 分配页表项:如果对应的 PTE 表项还没分配,
alloc_set_pte会负责分配 - 设置权限:根据
vma->vm_page_prot结合WRITE标志,计算出该页表项的读写权限(如果是 COW 页面,此时会给它加上可写属性) - 建立映射:调用
set_pte_at将物理页地址填入硬件页表 - 统计与反向映射,若是 COW 页,按匿名页处理(
MM_ANONPAGES);若是原始页,按文件页处理(MM_FILEPAGE)
3、 解锁与清理
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3261
int finish_fault(struct vm_fault *vmf)
{
struct page *page;
int ret;
/* Did we COW the page? */
//验证权限:检查 VMA 权限是否允许读/写
if ((vmf->flags & FAULT_FLAG_WRITE) &&
!(vmf->vma->vm_flags & VM_SHARED))
page = vmf->cow_page; //for cow:使用新分配的匿名页(COW 副本)
else
page = vmf->page; //使用 Page Cache 中的原始文件页
//
ret = alloc_set_pte(vmf, vmf->memcg, page);
if (vmf->pte)
pte_unmap_unlock(vmf->pte, vmf->ptl);
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L3196
int alloc_set_pte(struct vm_fault *vmf, struct mem_cgroup *memcg,
struct page *page)
{
struct vm_area_struct *vma = vmf->vma;
bool write = vmf->flags & FAULT_FLAG_WRITE;
pte_t entry;
int ret;
......
//生成 PTE 内容:使用 mk_pte(page, vma->vm_page_prot) 将物理页地址转换为页表项格式
entry = mk_pte(page, vma->vm_page_prot);
/*
下面这段代码有些意思:
写时复制 (COW) 产生的匿名页 和 共享的文件页/只读页
*/
if (write)
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
/* copy-on-write page */
if (write && !(vma->vm_flags & VM_SHARED)) {
//分支1:私有可写映射 (Private Writable Mapping)
//因为这是 COW 出来的页,它已经脱离了原来的文件映射,变成了匿名页 (Anonymous Page),所以增加进程的匿名页计数
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
//为这个新生成的匿名页建立反向映射
page_add_new_anon_rmap(page, vma, vmf->address, false);
//将该页面的内存消耗计入当前进程所在的 cgroup
mem_cgroup_commit_charge(page, memcg, false, false);
//将该页加入 LRU 链表,以便内核进行内存回收管理
lru_cache_add_active_or_unevictable(page, vma);
} else {
//分支2:共享映射 (Shared Mapping) 或者 只读映射 )(Read-only Mapping)
//增加进程的文件页 (File-backed Page) 计数
inc_mm_counter_fast(vma->vm_mm, mm_counter_file(page));
//建立文件页的反向映射
page_add_file_rmap(page, false);
}
//设置页表:调用 set_pte_at。这一步执行完,虚拟地址到物理地址的映射正式在硬件层面打通
//真正将物理页的地址写入进程页表(PTE)的动作。从此以后,虚拟地址就指向了相应的物理地址
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
/* no need to invalidate: a not-present page won't be cached */
// 重要:设置MMU缓存
update_mmu_cache(vma, vmf->address, vmf->pte);
//set_pte_at && update_mmu_cache结束:CPU 重新执行指令
return 0;
}
vm_mmap_pgoff->mm_populate:立即为映射分配物理内存
上面讨论了通常调用 mmap 进行内存映射的时,内核只是会在进程的虚拟内存空间中为这次映射分配一段虚拟内存,然后建立好这段虚拟内存与相关文件之间的映射关系就结束了,内核并不会为映射分配物理内存。而物理内存的分配工作需要延后到这段虚拟内存被 CPU 访问的时候,通过缺页中断来进入内核,分配物理内存,并在页表中建立好映射关系。但如果在 flags 参数中设置了 MAP_POPULATE、MAP_LOCKED 标志位之后,物理内存的分配动作会提前发生。首先会通过 do_mmap_pgoff 函数在进程虚拟内存空间中分配出一段未映射的虚拟内存区域,返回值 ret 表示映射的这段虚拟内存区域的起始地址,紧接着就会调用 mm_populate,内核会在 mmap 刚刚映射出来的这段虚拟内存区域上,依次扫描这段 vma 中的每一个虚拟页,并对每一个虚拟页触发缺页异常,从而为其立即分配物理内存
那么回到上面mmap调用最初的mmap_pgoff->mm_populate函数的实现:此函数作用是在进程虚拟内存空间中,找出 [ret , ret + populate] 这段虚拟地址范围内的所有 vma,并为每一个 vma 填充物理内存
unsigned long vm_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long pgoff)
{
unsigned long ret;
// 获取进程虚拟内存空间
struct mm_struct *mm = current->mm;
// 是否需要为映射的 VMA,提前分配物理内存页,避免后续的缺页
// 取决于 flag 是否设置了 MAP_POPULATE 或者 MAP_LOCKED,这里的 populate 表示需要分配物理内存的大小
unsigned long populate;
ret = security_mmap_file(file, prot, flag);
if (!ret) {
// 对进程虚拟内存空间加写锁保护,防止多线程并发修改
if (down_write_killable(&mm->mmap_sem))
return -EINTR;
// 开始 mmap 内存映射,在进程虚拟内存空间中分配一段 vma,并建立相关映射关系
// ret 为映射虚拟内存区域的起始地址
ret = do_mmap_pgoff(file, addr, len, prot, flag, pgoff,
&populate, &uf);
// 释放写锁
up_write(&mm->mmap_sem);
if (populate)
// 提前分配物理内存页面,后续访问不会缺页
// 为 [ret , ret + populate] 这段虚拟内存立即分配物理内存
mm_populate(ret, populate);
}
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/gup.c#L1069
int __mm_populate(unsigned long start, unsigned long len, int ignore_errors)
{
struct mm_struct *mm = current->mm;
unsigned long end, nstart, nend;
struct vm_area_struct *vma = NULL;
int locked = 0;
long ret = 0;
VM_BUG_ON(start & ~PAGE_MASK);
VM_BUG_ON(len != PAGE_ALIGN(len));
end = start + len;
// 依次遍历进程地址空间中 [start , end] 这段虚拟内存范围的所有 vma
for (nstart = start; nstart < end; nstart = nend) {
/*
* We want to fault in pages for [nstart; end) address range.
* Find first corresponding VMA.
*/
if (!locked) {
locked = 1;
down_read(&mm->mmap_sem);
vma = find_vma(mm, nstart);
} else if (nstart >= vma->vm_end)
vma = vma->vm_next;
if (!vma || vma->vm_start >= end)
break;
/*
* Set [nstart; nend) to intersection of desired address
* range with the first VMA. Also, skip undesirable VMA types.
*/
nend = min(end, vma->vm_end);
if (vma->vm_flags & (VM_IO | VM_PFNMAP))
continue;
if (nstart < vma->vm_start)
nstart = vma->vm_start;
/*
* Now fault in a range of pages. populate_vma_page_range()
* double checks the vma flags, so that it won't mlock pages
* if the vma was already munlocked.
*/
//上面是查找指定地址范围内 vma
// 为这段地址范围内的所有 vma 分配物理内存
ret = populate_vma_page_range(vma, nstart, nend, &locked);
if (ret < 0) {
if (ignore_errors) {
ret = 0;
continue; /* continue at next VMA */
}
break;
}
// 继续为下一个 vma (如果有的话)分配物理内存
nend = nstart + ret * PAGE_SIZE;
ret = 0;
}
if (locked)
up_read(&mm->mmap_sem);
return ret; /* 0 or negative error code */
}
populate_vma_page_range 函数则是在 __mm_populate 的处理基础上,为指定地址范围 [start , end] 内的每一个虚拟内存页,通过 __get_user_pages 函数为其分配物理内存,而__get_user_pages 会循环遍历 vma 中的每一个虚拟内存页,首先会通过 follow_page_mask 在进程页表中查找该虚拟内存页背后是否有物理内存页与之映射,如果没有则调用 faultin_page,其底层会调用到 handle_mm_fault 进入缺页处理流程,内核在这里会为其分配物理内存页,并在进程页表中建立好映射关系(前面已经分析)
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/gup.c#L1004
long populate_vma_page_range(struct vm_area_struct *vma,
unsigned long start, unsigned long end, int *nonblocking)
{
struct mm_struct *mm = vma->vm_mm;
// 计算 vma 中包含的虚拟内存页个数,后续会按照 nr_pages 分配物理内存
unsigned long nr_pages = (end - start) / PAGE_SIZE;
int gup_flags;
VM_BUG_ON(start & ~PAGE_MASK);
VM_BUG_ON(end & ~PAGE_MASK);
VM_BUG_ON_VMA(start < vma->vm_start, vma);
VM_BUG_ON_VMA(end > vma->vm_end, vma);
VM_BUG_ON_MM(!rwsem_is_locked(&mm->mmap_sem), mm);
......
// 循环遍历 vma 中的每一个虚拟内存页,依次为其分配物理内存页
return __get_user_pages(current, mm, start, nr_pages, gup_flags,
NULL, NULL, nonblocking);
}
static long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *nonblocking)
{
long i = 0;
unsigned int page_mask;
struct vm_area_struct *vma = NULL;
......
// 循环遍历 vma 中的每一个虚拟内存页
do {
struct page *page;
unsigned int foll_flags = gup_flags;
unsigned int page_increm;
......
retry:
......
cond_resched();
// 在进程页表中检查该虚拟内存页背后是否有物理内存页映射
page = follow_page_mask(vma, start, foll_flags, &page_mask);
if (!page) {
int ret;
// 如果虚拟内存页在页表中并没有物理内存页映射,那么这里调用 faultin_page
// 底层会调用到 handle_mm_fault 进入缺页处理流程,分配物理内存,在页表中建立好映射关系
ret = faultin_page(tsk, vma, start, &foll_flags,
nonblocking);
......
} else if (PTR_ERR(page) == -EEXIST) {
/*
* Proper page table entry exists, but no corresponding
* struct page.
*/
goto next_page;
} else if (IS_ERR(page)) {
return i ? i : PTR_ERR(page);
}
if (pages) {
pages[i] = page;
flush_anon_page(vma, page, start);
flush_dcache_page(page);
page_mask = 0;
}
next_page:
if (vmas) {
vmas[i] = vma;
page_mask = 0;
}
page_increm = 1 + (~(start >> PAGE_SHIFT) & page_mask);
if (page_increm > nr_pages)
page_increm = nr_pages;
i += page_increm;
start += page_increm * PAGE_SIZE;
nr_pages -= page_increm;
} while (nr_pages);
return i;
}
0x0 shmem基础知识
页面类型
对shmem类型的页面而言,其既有匿名页的特点(如page->flags设置PG_swapbacked,具有swap功能),也有文件页的特点(如inode->i_mapping->a_ops = &shmem_aops关联文件inode,有page cache)
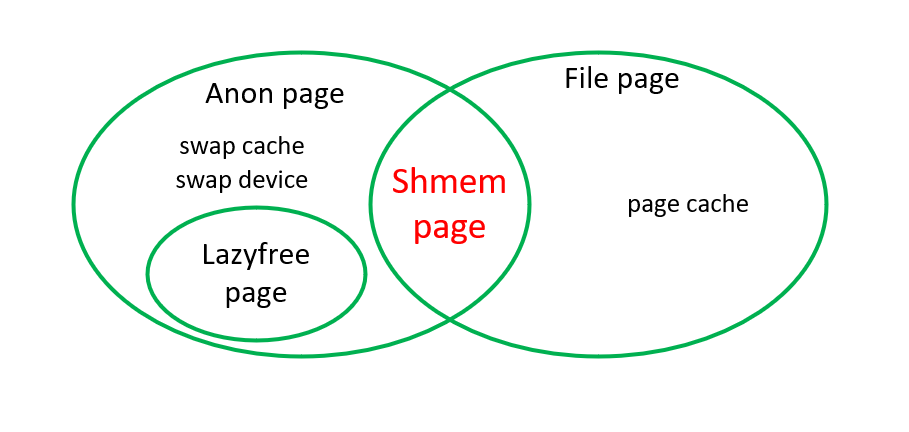
共享内存框架
shmem的整体框架如下:
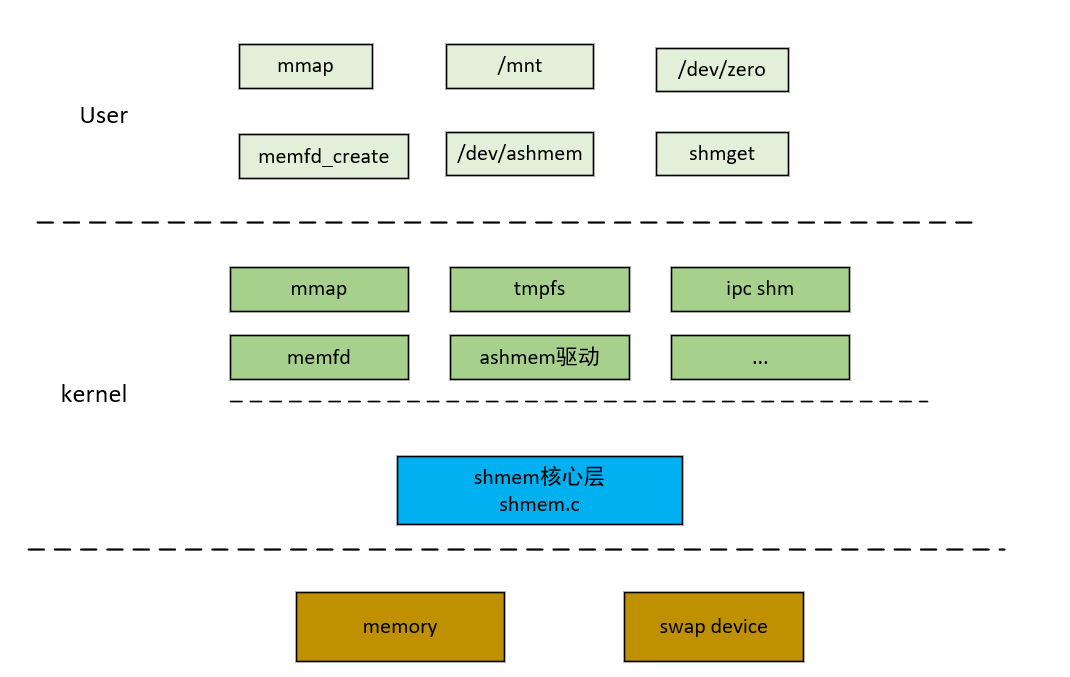
LRU with shmem
内核中,用户态进程使用的物理页面会放入LRU链表中进行老化/回收,其中匿名页面会加入匿名LRU,而文件页会加入文件LRU。虽然shmem页面既有匿名页和文件页的特点,但是由于它有swap特性,它会加入到匿名页LRU
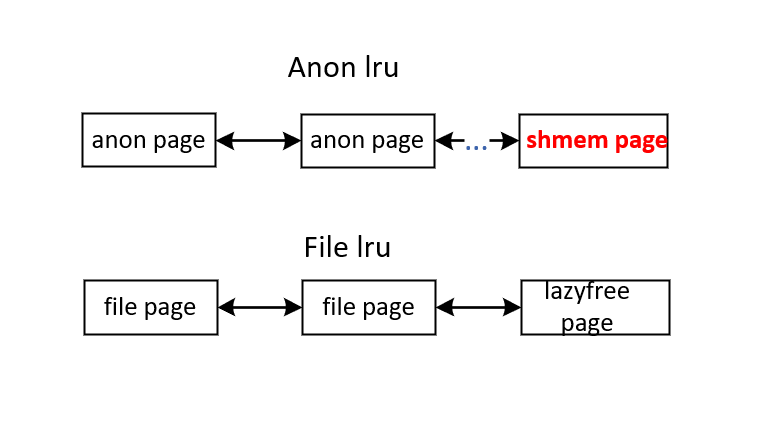
0x0 共享内存原理(shmem)及操作梳理
共享内存原理
基于shmem的内存共享原理如下,可以看到和上文描述的mmap共享机制非常类似:
以memfd为例,实现共享内存的步骤:
- 通过
memfd系统调用等方式创建文件描述符(fd),如本例子send进程会通过memfd系统调用来获得一个unused fd,并将fd关联文件实例(file),这个file就会关联一片共享内存 - 将文件描述符传递给其他进程来实现共享,如可通过unix socket传递文件描述符,实际上传递文件描述符是在接收方申请一个unused fd,然后关联共享内存对应的
struct file对象,如图所示send进程的文件描述符fd=4会关联共享内存对应的file,recv进程的文件描述符fd=5也会关联共享内存对应的file - send/recv进程通过mmap映射共享内存到进程虚拟地址空间
- send进程首次写访问数据,此时会发生缺页异常,page cache查询不到物理页面PAGE1,会申请物理页面(
__page_cache_alloc)并加入文件实例(struct inode)对应的page cache(add_to_page_cache_lru),并通过页表映射PAGE1到send进程的虚拟地址空间,缺页返回后,将数据写入PAGE1(这里都是'a'),注意,这里写入不会切态,因为用户态的函数如memcpy可以直接操作本进程的虚拟内存地址(本质上是直接操作page) - recv进程首次读访问数据时,同样也会发生缺页异常,但是会首先查询page cache,发现PAGE1,然后通过页表映射物理页PAGE1到recv进程的虚拟地址空间,如此缺页返回后,从PAGE1读出数据(都是
'a'),于是实现了内存共享
缺页中断的处理流程
缺页中断的内核调用链基本如下图:
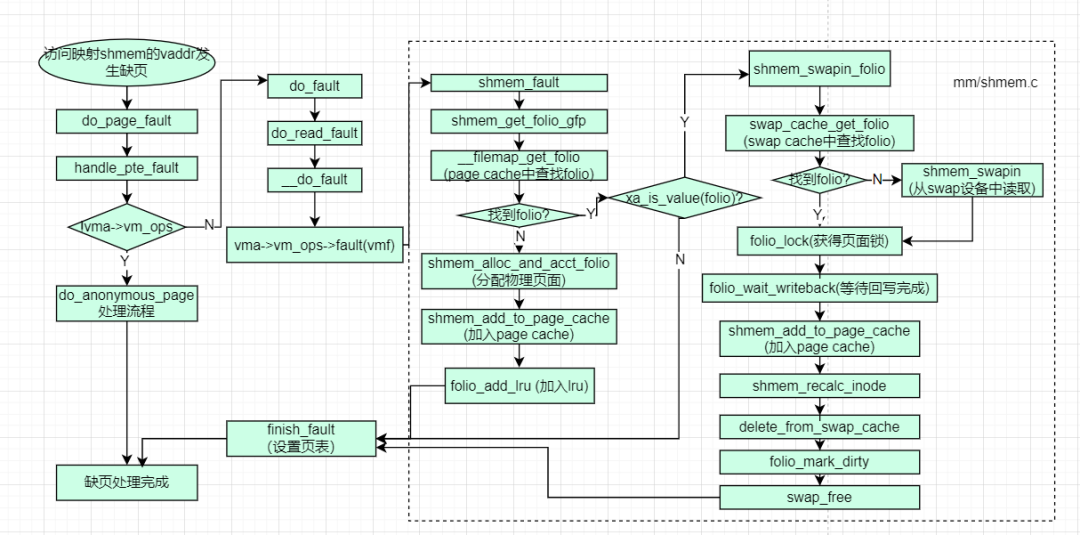
缺页处理步骤框图如下:
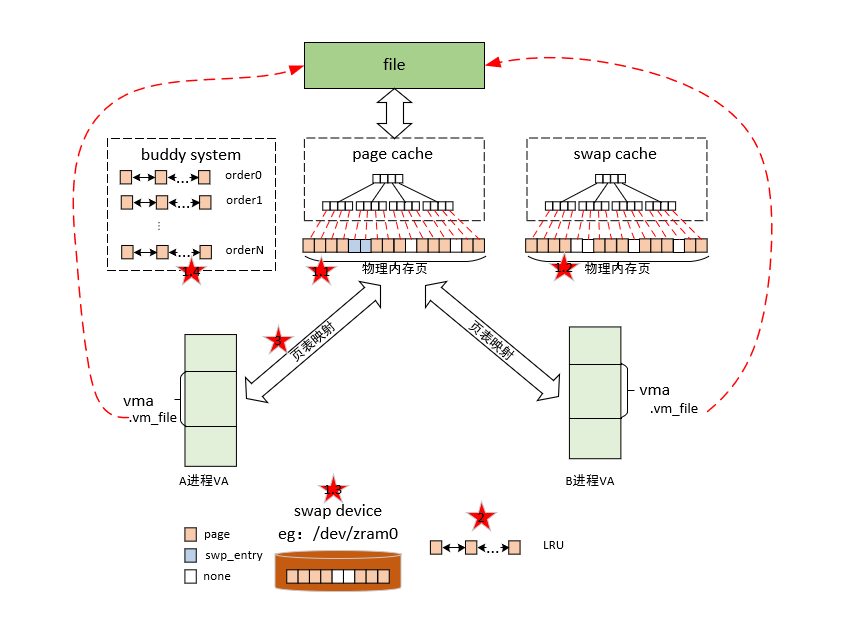
shmem共享内存页面的缺页处理步骤如下,当缺页发生时
- 查找或分配物理页面
- 先从page cache中查找,相关的物理页面可能已经被其他线程加入了page cache,所以首先从page cache查找
- 若找不到从swap cache中查找,页面有可能在回收等场景被加入了swap cache,所以在这里也查找下
- 找不到如果之前有swap out 则swap in,之前如果由于内存回收等场景相关页面被swap out到swap device,那么相关的swap cache对应的位置会被替换为swap entry, 这个时候根据swap entry从swap device中读取物理页面内容
- 否则分配新的folio:上面都尝试了查找但是没有找到,那么有可能是第一次访问这个页面,这个时候需要分配新的物理页面,既是folio
- 新的page加入全局lru,shmem会被加入匿名的lru中,以便内存回收都场景回收到swap device
- 页表映射,将相关的物理页面通过页表映射到进程的虚拟地址空间,这样后面进程就可以正常访问页面数据了
回收shmem页
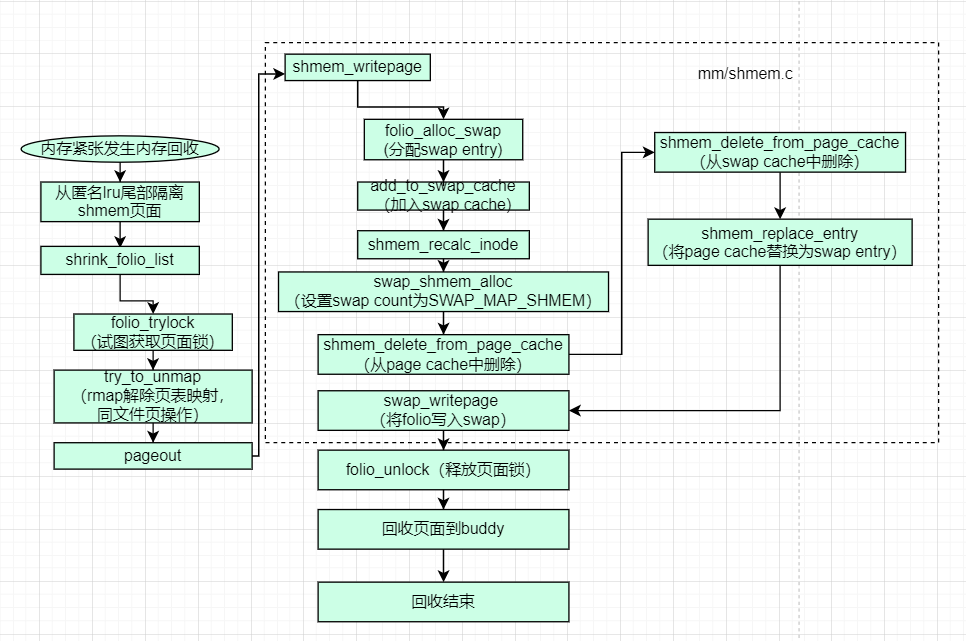
shmem页面回收逻辑如下:
1、从页面从lru中隔离
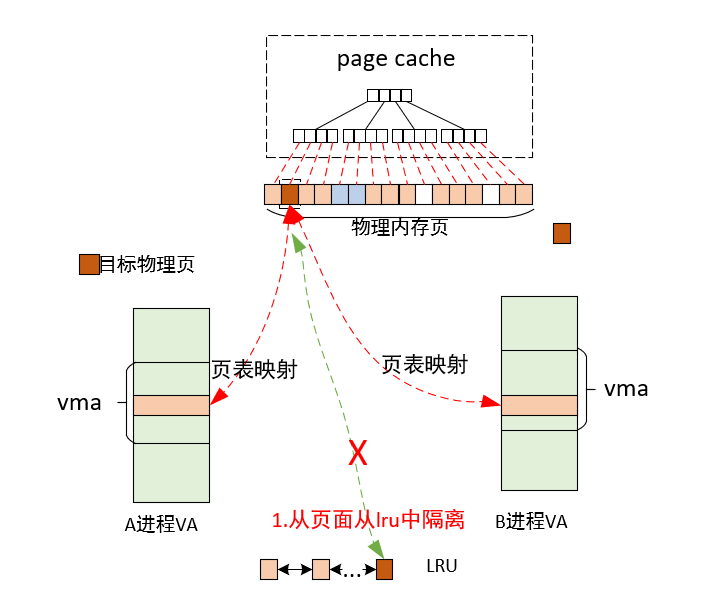
2、申请页面的page lock
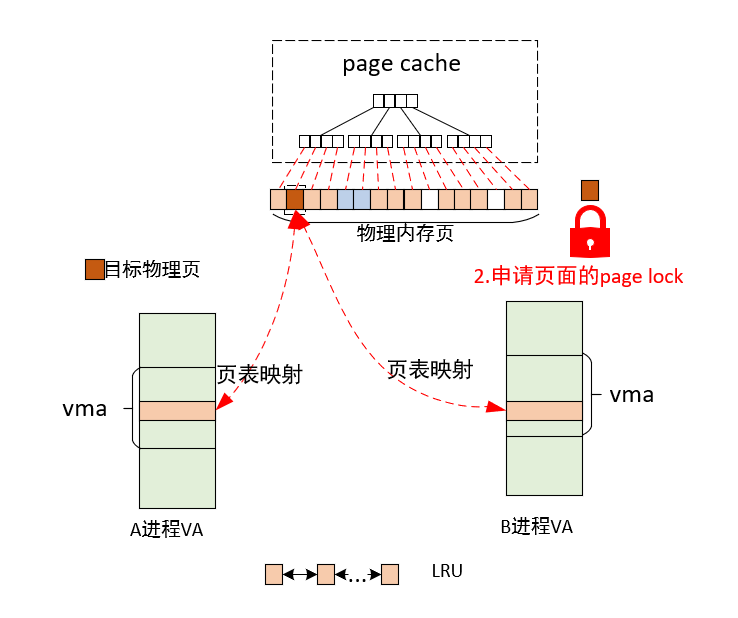
3、rmap反向映射查找解除这个页面的所有页表映射,如send/recv进程
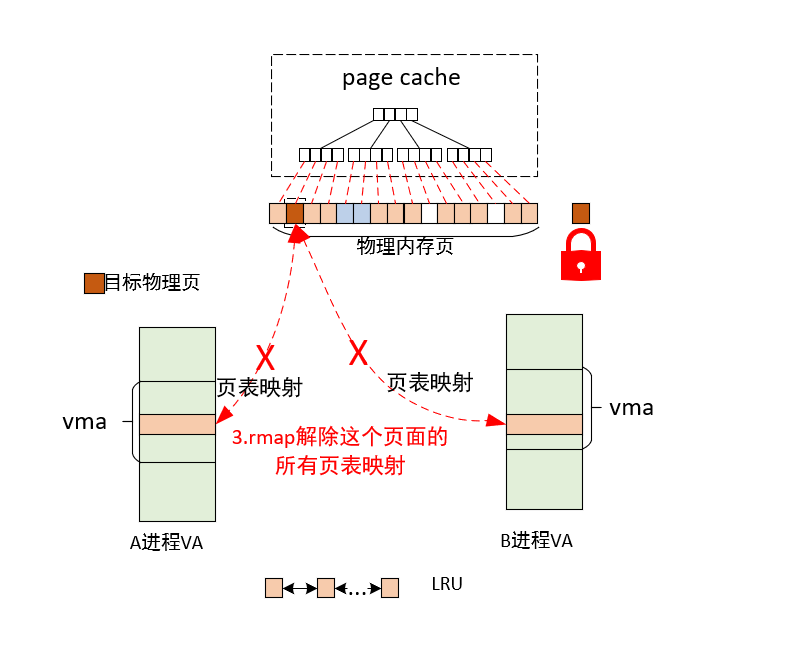
4、分配swap entry,页面加入swap cache
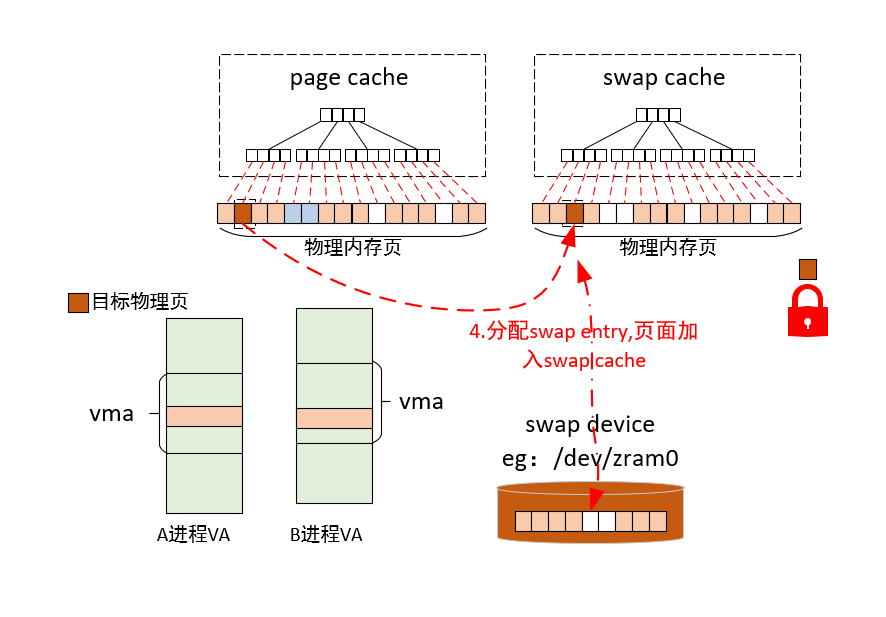
5、替换页面的page cache为swap entry
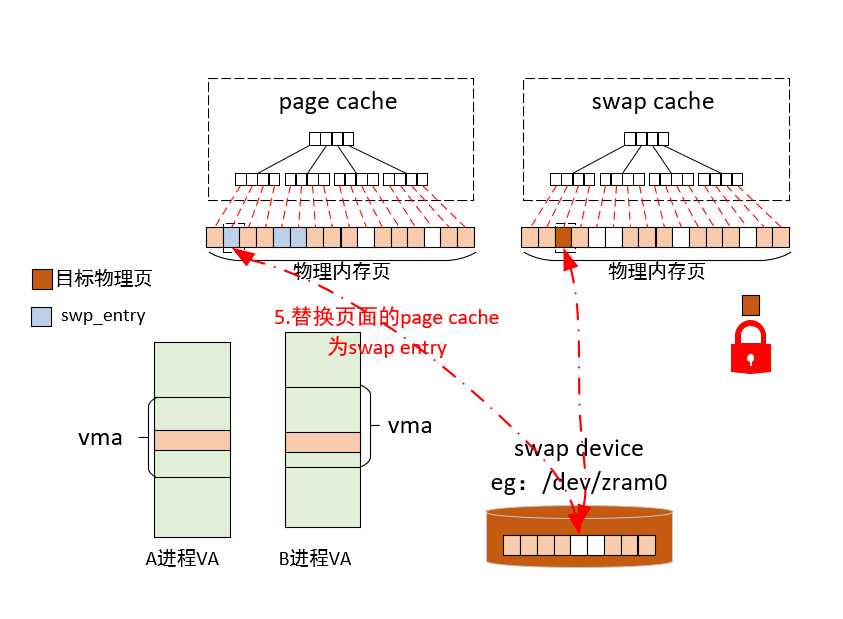
6、页面从swap cache中删除
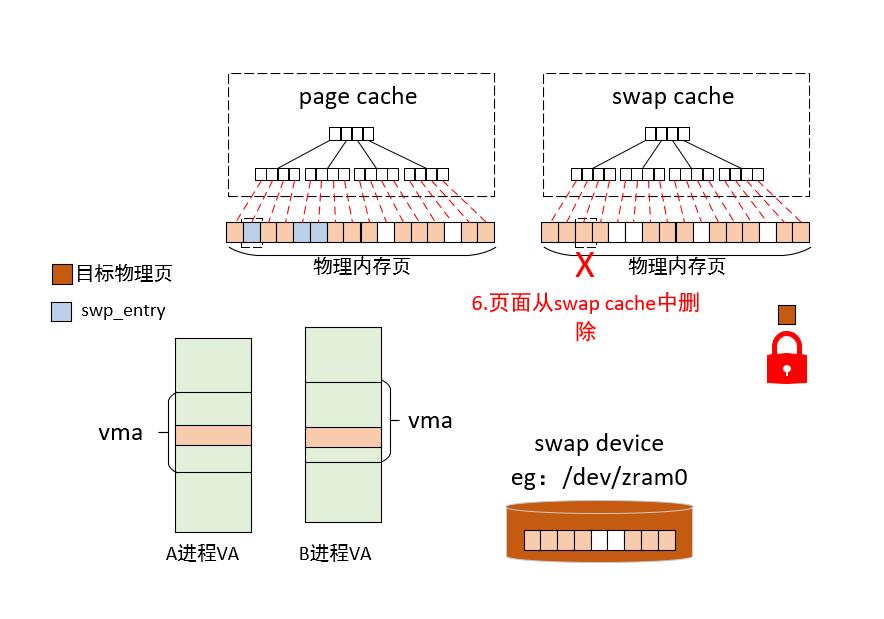
7、页面内容写入swap device
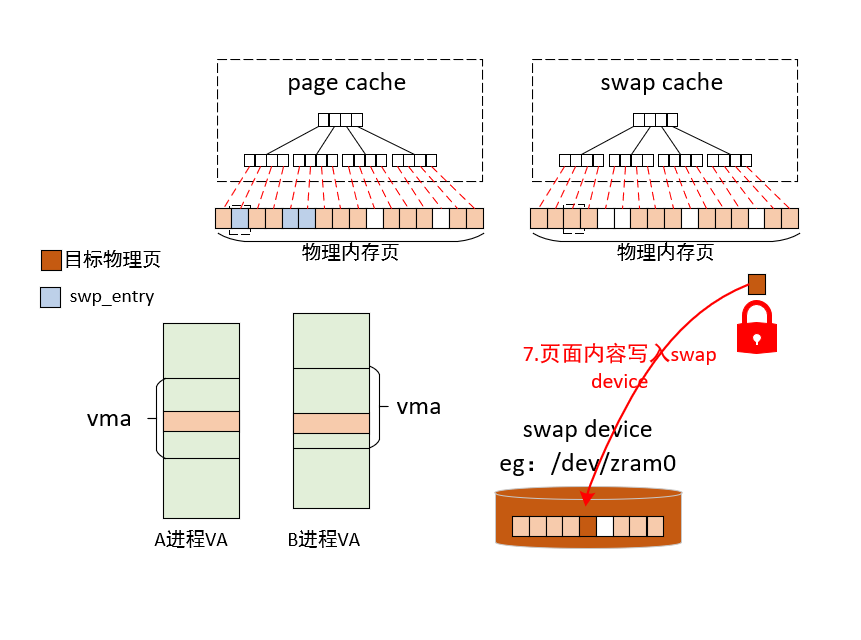
8、释放页面的page lock
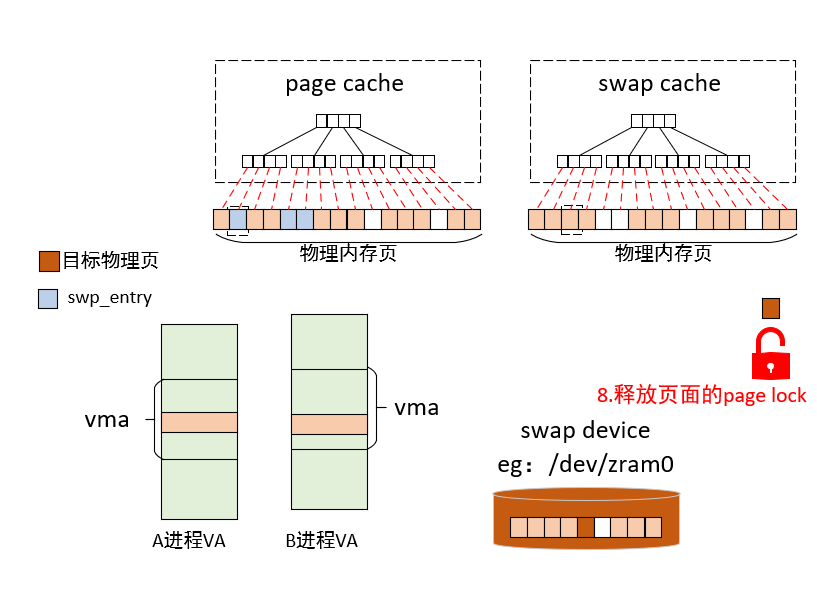
9、页面还给buddy
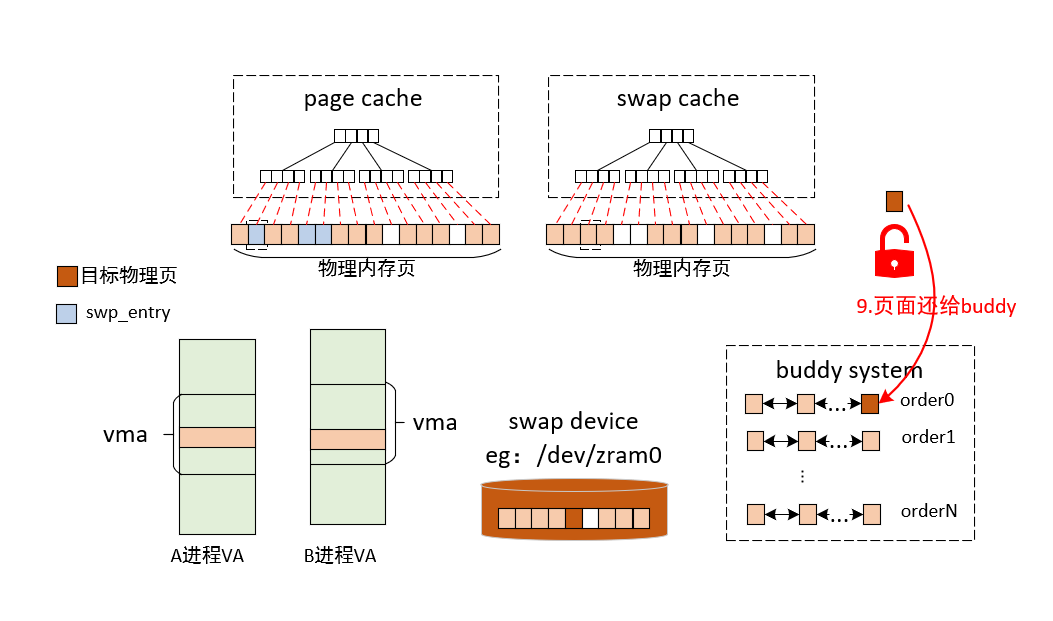
这里需要注意一点的是:shmem页面回收时保存swap entry的方式跟匿名页完全不一样,匿名页在回收时,会将相应的swap entry替换为原来的页表项,而shmem页面会直接清掉原来的页表项,会将swap entry替换为对应的swap cache的位置
0x0 tmpfs的读写实现跟踪
基于tmpfs的读过程
主要涉及的内核调用链如下:
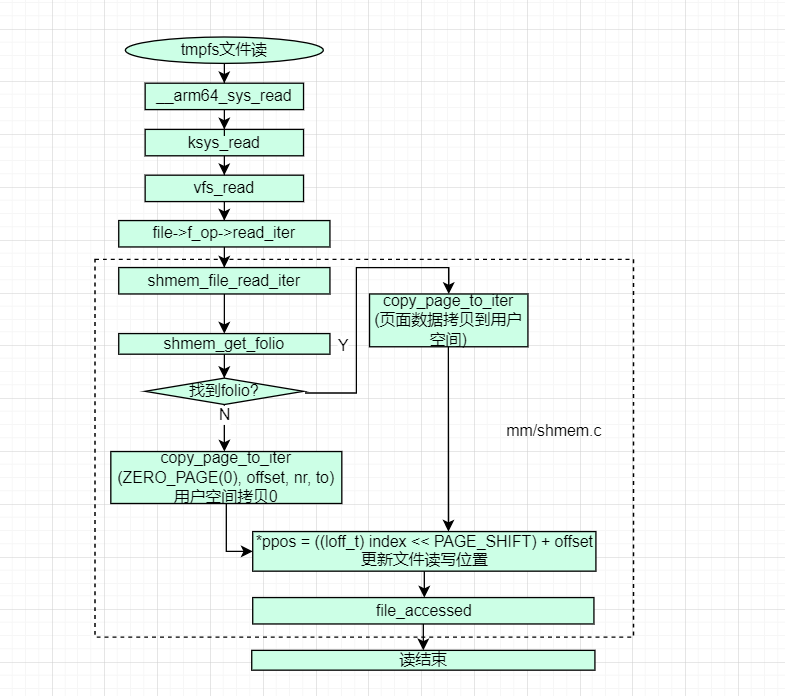
- 按照page cache -> swap cache -> swap device顺序查找文件页面
- 查找并拷贝页面内容到用户空间缓冲区
- 如果找到,则拷贝文件页面数据到用户空间缓冲区
- 如果没有找到,则直接往用户空间缓冲区拷贝
0
- 更新文件读写位置
这里需要注意的是:对于tmpfs文件系统中的文件的读操作来说,按照page cache -> swap cache -> swap device顺序如果查找不到页面,则不会分配新的页面,只会往用户空间缓冲区拷贝0(这有点类似匿名页的第一次读,一般会映射到0页),这种情况也说明了相关文件偏移的页面从来没有被人写访问过
基于tmpfs的写过程
主要涉及的内核调用链如下:
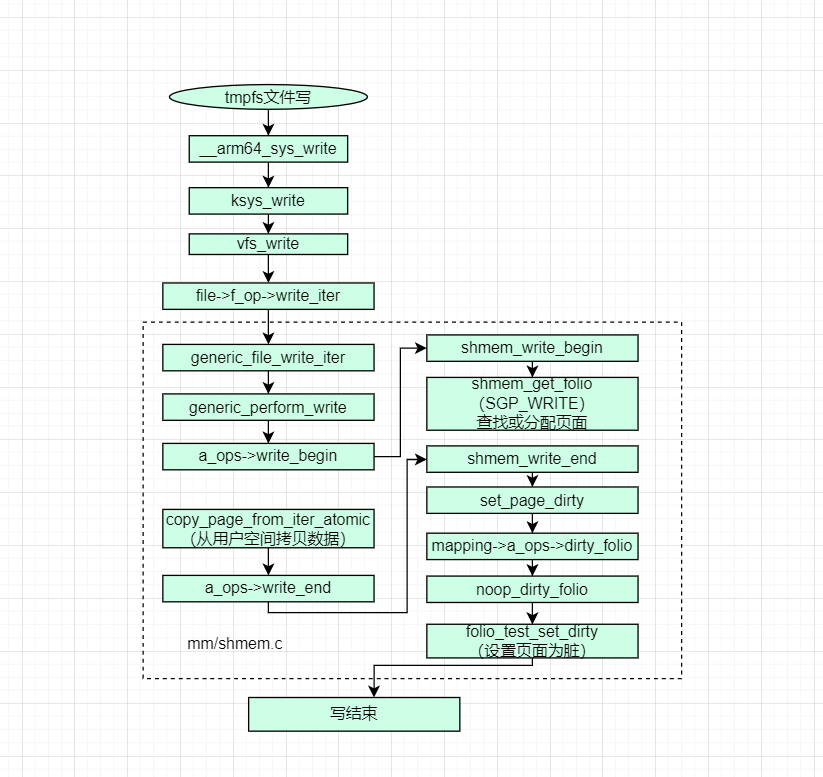
写tmpfs文件的主要步骤如下:
- 查找或分配文件页面,按照page cache -> swap cache -> swap device顺序查找,如果找到,继续下一步;如果没找到,则分配新的页面
- 从用户空间缓冲区拷贝数据到文件页面
- 标记页面为脏
0x0 System V共享内存实现分析
shmget:创建共享内存
shmget() 系统调用
-> newseg()
-> shmem_kernel_file_setup()
-> __shmem_file_setup()
-> shmem_get_inode() // 创建 inode
从调用链的实现跟踪,最终会生成一个inode(因此具有page cache的功能),该inode对应的address_space_operations如下:
static const struct address_space_operations shmem_aops = {
.writepage = shmem_writepage,
.set_page_dirty = __set_page_dirty_no_writeback,
#ifdef CONFIG_TMPFS
.write_begin = shmem_write_begin,
.write_end = shmem_write_end,
#endif
#ifdef CONFIG_MIGRATION
.migratepage = migrate_page,
#endif
.error_remove_page = generic_error_remove_page,
};
shmget:内核实现跟踪
//https://elixir.bootlin.com/linux/v4.11.6/source/ipc/shm.c#L657
SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops shm_ops = {
.getnew = newseg, //newseg
.associate = shm_security,
.more_checks = shm_more_checks,
};
struct ipc_params shm_params;
ns = current->nsproxy->ipc_ns;
shm_params.key = key;
shm_params.flg = shmflg;
shm_params.u.size = size;
return ipcget(ns, &shm_ids(ns), &shm_ops, &shm_params);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/ipc/shm.c#L522
static int newseg(struct ip c_namespace *ns, struct ipc_params *params)
{
key_t key = params->key;
int shmflg = params->flg;
size_t size = params->u.size;
int error;
struct shmid_kernel *shp;
size_t numpages = (size + PAGE_SIZE - 1) >> PAGE_SHIFT;
struct file *file;
char name[13];
int id;
vm_flags_t acctflag = 0;
if (size < SHMMIN || size > ns->shm_ctlmax)
return -EINVAL;
if (numpages << PAGE_SHIFT < size)
return -ENOSPC;
if (ns->shm_tot + numpages < ns->shm_tot ||
ns->shm_tot + numpages > ns->shm_ctlall)
return -ENOSPC;
shp = ipc_rcu_alloc(sizeof(*shp));
if (!shp)
return -ENOMEM;
shp->shm_perm.key = key;
shp->shm_perm.mode = (shmflg & S_IRWXUGO);
shp->mlock_user = NULL;
shp->shm_perm.security = NULL;
error = security_shm_alloc(shp);
if (error) {
ipc_rcu_putref(shp, ipc_rcu_free);
return error;
}
sprintf(name, "SYSV%08x", key);
if (shmflg & SHM_HUGETLB) {
......
} else {
/*
* Do not allow no accounting for OVERCOMMIT_NEVER, even
* if it's asked for.
*/
if ((shmflg & SHM_NORESERVE) &&
sysctl_overcommit_memory != OVERCOMMIT_NEVER)
acctflag = VM_NORESERVE;
file = shmem_kernel_file_setup(name, size, acctflag);
}
error = PTR_ERR(file);
if (IS_ERR(file))
goto no_file;
shp->shm_cprid = task_tgid_vnr(current);
shp->shm_lprid = 0;
shp->shm_atim = shp->shm_dtim = 0;
shp->shm_ctim = get_seconds();
shp->shm_segsz = size;
shp->shm_nattch = 0;
shp->shm_file = file;
shp->shm_creator = current;
id = ipc_addid(&shm_ids(ns), &shp->shm_perm, ns->shm_ctlmni);
if (id < 0) {
error = id;
goto no_id;
}
list_add(&shp->shm_clist, ¤t->sysvshm.shm_clist);
/*
* shmid gets reported as "inode#" in /proc/pid/maps.
* proc-ps tools use this. Changing this will break them.
*/
file_inode(file)->i_ino = shp->shm_perm.id;
ns->shm_tot += numpages;
error = shp->shm_perm.id;
ipc_unlock_object(&shp->shm_perm);
rcu_read_unlock();
return error;
......
}
struct file *shmem_kernel_file_setup(const char *name, loff_t size, unsigned long flags)
{
return __shmem_file_setup(name, size, flags, S_PRIVATE);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/shmem.c#L4133
static struct file *__shmem_file_setup(const char *name, loff_t size,
unsigned long flags, unsigned int i_flags)
{
struct file *res;
struct inode *inode;
struct path path;
struct super_block *sb;
struct qstr this;
if (IS_ERR(shm_mnt))
return ERR_CAST(shm_mnt);
if (size < 0 || size > MAX_LFS_FILESIZE)
return ERR_PTR(-EINVAL);
if (shmem_acct_size(flags, size))
return ERR_PTR(-ENOMEM);
res = ERR_PTR(-ENOMEM);
this.name = name;
this.len = strlen(name);
this.hash = 0; /* will go */
sb = shm_mnt->mnt_sb;
path.mnt = mntget(shm_mnt);
path.dentry = d_alloc_pseudo(sb, &this);
if (!path.dentry)
goto put_memory;
d_set_d_op(path.dentry, &anon_ops);
res = ERR_PTR(-ENOSPC);
// shmem_get_inode:核心
inode = shmem_get_inode(sb, NULL, S_IFREG | S_IRWXUGO, 0, flags);
if (!inode)
goto put_memory;
inode->i_flags |= i_flags;
d_instantiate(path.dentry, inode);
inode->i_size = size;
clear_nlink(inode); /* It is unlinked */
res = ERR_PTR(ramfs_nommu_expand_for_mapping(inode, size));
if (IS_ERR(res))
goto put_path;
res = alloc_file(&path, FMODE_WRITE | FMODE_READ,
&shmem_file_operations);
if (IS_ERR(res))
goto put_path;
return res;
put_memory:
shmem_unacct_size(flags, size);
put_path:
path_put(&path);
return res;
}
shmem_get_inode:
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/shmem.c#L2135
static struct inode *shmem_get_inode(struct super_block *sb, const struct inode *dir,
umode_t mode, dev_t dev, unsigned long flags)
{
struct inode *inode;
struct shmem_inode_info *info;
struct shmem_sb_info *sbinfo = SHMEM_SB(sb);
if (shmem_reserve_inode(sb))
return NULL;
inode = new_inode(sb);
if (inode) {
inode->i_ino = get_next_ino();
inode_init_owner(inode, dir, mode);
inode->i_blocks = 0;
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
inode->i_generation = get_seconds();
info = SHMEM_I(inode);
memset(info, 0, (char *)inode - (char *)info);
spin_lock_init(&info->lock);
info->seals = F_SEAL_SEAL;
info->flags = flags & VM_NORESERVE;
INIT_LIST_HEAD(&info->shrinklist);
INIT_LIST_HEAD(&info->swaplist);
simple_xattrs_init(&info->xattrs);
cache_no_acl(inode);
switch (mode & S_IFMT) {
default:
inode->i_op = &shmem_special_inode_operations;
init_special_inode(inode, mode, dev);
break;
case S_IFREG:
inode->i_mapping->a_ops = &shmem_aops; //核心:关联shmem_aops
inode->i_op = &shmem_inode_operations;
inode->i_fop = &shmem_file_operations;
mpol_shared_policy_init(&info->policy,
shmem_get_sbmpol(sbinfo));
break;
case S_IFDIR:
inc_nlink(inode);
/* Some things misbehave if size == 0 on a directory */
inode->i_size = 2 * BOGO_DIRENT_SIZE;
inode->i_op = &shmem_dir_inode_operations;
inode->i_fop = &simple_dir_operations;
break;
case S_IFLNK:
/*
* Must not load anything in the rbtree,
* mpol_free_shared_policy will not be called.
*/
mpol_shared_policy_init(&info->policy, NULL);
break;
}
} else
shmem_free_inode(sb);
return inode;
}
0x0 总结
最后,整理下本文介绍的若干关键知识点
linear_page_index 的细节
在mmap文件映射中,特别要理清虚拟内存地址(用户访问的)、虚拟内存地址(mmap返回的)、offset(mmap参数)、查找radix树的偏移index、vma->vm_start、vma->vm_pgoff之间的关系,思考几个问题:
- 当用户拿着
mmap返回的地址(若干偏移)的新地址,触发内存访问的时候,内核是怎么计算定位到实际的radix树的index的? - page index(页序号) && page offset(页内偏移)
- 当缺页异常发生时,内核需要知道当前访问的这个虚拟内存地址
address,对应文件里的第几个 Page?
步骤1,调用 mmap(addr, length, ......, fd, offset) 时,内核并不会立即把文件内容读入内存,而是创建了一个 vm_area_struct(此时页表项PTE是空的。vma记录如下关键信息:
- 虚拟内存的起始地址
vm_start - 对应的文件偏移量
vm_pgoff
步骤2:在缺页中断处理函数__handle_mm_fault开始对address的转换,即linear_page_index函数,这正是内核将进程的虚拟世界(虚拟地址)映射到文件的物理世界(文件偏移)的关键转折点,linear_page_index作用是将发生缺页的虚拟地址转化为该数据在文件(底层存储)中的逻辑坐标(注意,对于不同的进程,这里的address是随机的)
在建立页表映射时,通常只关心页对齐的地址,linear_page_index 的任务就是确定指定的页被搬到了内存,并把它的地址填进了页表,地址线上的低 12 位物理偏移会自动对齐虚拟地址的低 12 位
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address), //重要:计算文件页偏移(见下文分析)
.gfp_mask = __get_fault_gfp_mask(vma),
};
......
}
static inline pgoff_t linear_page_index(struct vm_area_struct *vma,
unsigned long address)
{
pgoff_t pgoff;
if (unlikely(is_vm_hugetlb_page(vma)))
return linear_hugepage_index(vma, address);
pgoff = (address - vma->vm_start) >> PAGE_SHIFT;
pgoff += vma->vm_pgoff;
return pgoff;
}
从上面代码linear_page_index 的作用就是把这个随机的虚拟地址转换为文件中的第几个页面(变量pgoff)
address:触发缺页的虚拟内存地址vma->vm_start:该虚拟内存区域vma的起始地址vma->vm_pgoff:mmap 系统调用时传入的offset(已转换为页面单位)address - vma->vm_start:计算当前地址距离该映射区域开头的距离(address差异化消除的关键步骤)>>PAGE_SHIFT:转换为页数pgoff+=vma->vm_pgoff:加上mmap时指定的起始偏移,如果映射是从文件开头开始(通常为0)
一旦计算出了 vmf.pgoff(作为 Page Cache 的全局唯一索引),内核就不再关心 address 到底是多少了,在后 filemap_fault 流程中,内核会拿着这个vmf.pgoff去该文件inode的 address_space的radix树中查找(即在 radix树中查找 struct page 的 key),最终不同的进程虽然 address 不同,但经过 linear_page_index 计算后的 pgoff 是完全一致的,这就保证了内核能够引导两个进程指向 Page Cache 中的同一个物理页面,从而实现内存共享
小结下,两个offset,一个是虚拟地址在页面内的偏移(页内偏移 Page Offset),另一个是该页面在整个文件中的偏移(文件页索引)。页内偏移就比较简单了,直接通过 address&(PAGE_SIZE-1)即可得到,即访问的是该 4KB 物理页中的哪一个字节
mmap系统调用的本质
mmap 系统调用分配虚拟内存的本质其实就是在进程的虚拟内存空间中的文件映射与匿名映射区,找出一段未被映射过的空闲虚拟内存区域 vma,这个 vma 就是申请到的虚拟内存
缺页中断 vs address_space(radix树)查不到指定的struct page
在mmap文件映射的场景下,缺页中断(Page Fault)、在page cache(radix树)查找指定的struct page结构(当发现对应的page不存在时,新建page)、页表转换及查找(填充)、page对象关联物理内存页,这几个名词的关系是什么?
缺页中断是一种CPU异常保护机制,而查找 address_space 并新建 Page 是处理缺页中断过程中的一个具体步骤(属于文件映射的场景)
1、缺页中断
什么是缺页中断(Page Fault):是一个宏观的硬件/软件协作机制,通常由 CPU 抛出一个异常信号,当 CPU 试图访问一个虚拟地址,但在硬件页表(Page Table)里找不到对应的物理内存页时,就会触发缺页中断。目前,已涉及到讨论的缺页中断的情况:
- 匿名映射:通过
malloc申请了堆内存,第一次触发写数据时 - 文件映射:访问的代码或数据还在磁盘上,没读进内存
- 写时复制(COW):试图写入一个只读的共享页面
2、当缺页中断发生时,什么场景下会触发查找 address_space呢?答案是基于文件的缺页中断,通过前文知道,内核中每个文件inode在内存(充足)里都有一个 address_space 结构,负责维护该文件已经被读进了内存的部分(Page Cache)。具体流程如下:
- 触发缺页中断:用户进程访问某个文件映射的地址,即CPU寻址
- 内核介入: 发现对应的物理页不存在
- 查找
address_space:内核去该文件inode对应的address_space里的radix树中查找,偏移量offset对应的页面是否在 Page Cache 里,如果在address_space里没找到,内核就会新建一个struct page结构,接着发起磁盘 I/O(预读),把文件内容读进这个新创建的 Page中,最后将这个 Page 挂载到address_space中 - 更新页表: 最后把这个物理页的地址填入进程的页表,让 CPU 能恢复运行
所以,可以把缺页中断看作是目的,而查找 address_space 是为了实现这个目的所采取的步骤(之一)
重要:mmap文件映射的完整过程
第一阶段:mmap 系统调用(占位&&承诺),当调用 mmap 时,内核并没有真正去读文件,也没有分配物理内存。
- 创建 VMA:内核在进程的虚拟地址空间里找一块足够大的区域,新建一个
vm_area_struct(VMA) - 绑定关系:这个 VMA 会记录它是哪个文件(指向
struct file,进而找到 inode)以及偏移量(offset) - 设置钩子:最关键的一步,内核会把这个 VMA 的操作函数(
vma->vm_ops)指向特定文件系统的函数集(比如ext4_file_vm_ops) - 操作结果:此时页表是空的。内核只是承诺了这块虚拟地址属于这个文件
struct file
第二阶段:CPU 触发缺页(兑现承诺),当第一次访问这段虚拟地址(比如 char c = ptr[0])时:
- 硬件尝试翻译:CPU 的 MMU 查找页表(
PGD->PUD->PMD->PTE) - 触发异常:发现 PTE(页表项)为空,硬件自动跳到内核的缺页异常处理程序(Entry Point)
- 进入通用层:内核执行
handle_mm_fault
第三阶段:handle_mm_fault 函数处理缺页中断,目的是为了建立完整页表并关联物理页(负责把各级页表的空洞填满),这一步的核心是根据虚拟内存地址->找到对应的VMA(已建立映射)->找到对应文件的address_space即radix树->将虚拟内存地址转换为radix树的查找偏移->查找radix树并填充对应的物理内存页->返回
- 填表(Walk Tables):如果 PGD/PUD/PMD 缺失,内核会先申请内存把这些页表项填满
- 定位到
do_fault:内核发现这个虚拟地址属于一个文件(struct file)映射的 VMA,于是调用vma->vm_ops->fault - 核心是查找
address_space(在handle_mm_fault里,如果是文件映射,会看到它处理的是struct page物理页描述,而对于address_space来说,它管理的是这个物理页与文件内容的对应关系),即通过 VMA 找到文件的address_space,根据偏移量(offset)在 Page Cache(基数树或者XArray)里,参考,一般有两种结果:- Case A (命中):如果之前有进程读过这个文件,页已经在内存里了,直接获取该页地址
- Case B (未命中):如果不在(radix树查找失败),内核新建一个 Page,发起磁盘 I/O(通过 readpage),把文件内容读进来
- 关联映射,将找回来的(或新读入的)物理页地址填入最底层的 PTE 页表项
- 设置权限(只读/读写),完成
- 这一阶段最关键的函数是上文分析的
ext4_filemap_fault->filemap_fault这个函数,它是 mmap 缺页后处理文件读取的最核心逻辑
对于文件映射来说,这一步完成后,虚拟内存地址指向的物理内存地址中已经存有映射文件的数据了
第四阶段:指令重试
- 返回用户态:
handle_mm_fault执行完后,CPU 重新执行刚才那条报错的指令(char c = ptr[0]) - MMU 成功:这一次,MMU 沿着四级页表能一路走到 PTE,拿到物理地址,读取数据
mmap匿名页映射的完整过程
handle_mm_fault 中有另一条重要支线即匿名页(Anonymous Page)的处理,常见于malloc申请内存等,由于背后无关联磁盘文件,因此处理逻辑与 address_space 完全不同。do_anonymous_page函数是匿名页缺页的处理入口
CPU 硬件(缺页)异常 -> do_page_fault (架构相关入口)
└── handle_mm_fault (通用内存管理层)
└── handle_pte_fault (发现页表项为空)
├── do_anonymous_page (如果是 malloc 的内存 -> 直接要物理页,不找 address_space)
└── do_fault (如果是映射的文件 -> 此时才开始找 address_space)
└── __do_fault
└── vma->vm_ops->fault (具体文件系统的处理函数)
└── find_get_page (去 address_space 里查,找不到就新建 Page 并读磁盘)
do_anonymous_page的实现如下,其机制是典型的懒加载机制
TODO
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/memory.c#L2896
//handle_pte_fault 函数中,当发现该地址不属于文件映射(VMA 没设置 vm_ops)且页表项为空时,会进入 do_anonymous_page
static int do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
pte_t entry;
/* File mapping without ->vm_ops ? */
if (vma->vm_flags & VM_SHARED)
return VM_FAULT_SIGBUS;
/* Check if we need to add a guard page to the stack */
if (check_stack_guard_page(vma, vmf->address) < 0)
return VM_FAULT_SIGSEGV;
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
/* See the comment in pte_alloc_one_map() */
if (unlikely(pmd_trans_unstable(vmf->pmd)))
return 0;
/* Use the zero-page for reads */
if (!(vmf->flags & FAULT_FLAG_WRITE) &&
!mm_forbids_zeropage(vma->vm_mm)) {
entry = pte_mkspecial(pfn_pte(my_zero_pfn(vmf->address),
vma->vm_page_prot));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd,
vmf->address, &vmf->ptl);
if (!pte_none(*vmf->pte))
goto unlock;
/* Deliver the page fault to userland, check inside PT lock */
if (userfaultfd_missing(vma)) {
pte_unmap_unlock(vmf->pte, vmf->ptl);
return handle_userfault(vmf, VM_UFFD_MISSING);
}
goto setpte;
}
/* Allocate our own private page. */
if (unlikely(anon_vma_prepare(vma)))
goto oom;
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
if (!page)
goto oom;
if (mem_cgroup_try_charge(page, vma->vm_mm, GFP_KERNEL, &memcg, false))
goto oom_free_page;
/*
* The memory barrier inside __SetPageUptodate makes sure that
* preceeding stores to the page contents become visible before
* the set_pte_at() write.
*/
__SetPageUptodate(page);
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
if (!pte_none(*vmf->pte))
goto release;
/* Deliver the page fault to userland, check inside PT lock */
if (userfaultfd_missing(vma)) {
pte_unmap_unlock(vmf->pte, vmf->ptl);
mem_cgroup_cancel_charge(page, memcg, false);
put_page(page);
return handle_userfault(vmf, VM_UFFD_MISSING);
}
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, vmf->address, false);
mem_cgroup_commit_charge(page, memcg, false, false);
lru_cache_add_active_or_unevictable(page, vma);
setpte:
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
/* No need to invalidate - it was non-present before */
update_mmu_cache(vma, vmf->address, vmf->pte);
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
release:
mem_cgroup_cancel_charge(page, memcg, false);
put_page(page);
goto unlock;
oom_free_page:
put_page(page);
oom:
return VM_FAULT_OOM;
}
overcommit_memory策略
TODO