0x00 前言
本文主要梳理下page cache与管理的若干知识,本文基于v4.11.6的源码
页高速缓存(page cache),它是一种对完整的数据页进行操作的磁盘高速缓存,即把磁盘的数据块缓存在页高速缓存中。page cache是内核为文件创建的内存缓存,用以加速相关的文件操作。当应用程序需要读取文件中的数据时,操作系统先分配一些内存,将数据从存储设备读入到这些内存中,然后再将数据分发给应用程序;当需要往文件中写数据时,操作系统先分配内存接收用户数据,然后再将数据从内存写到磁盘上
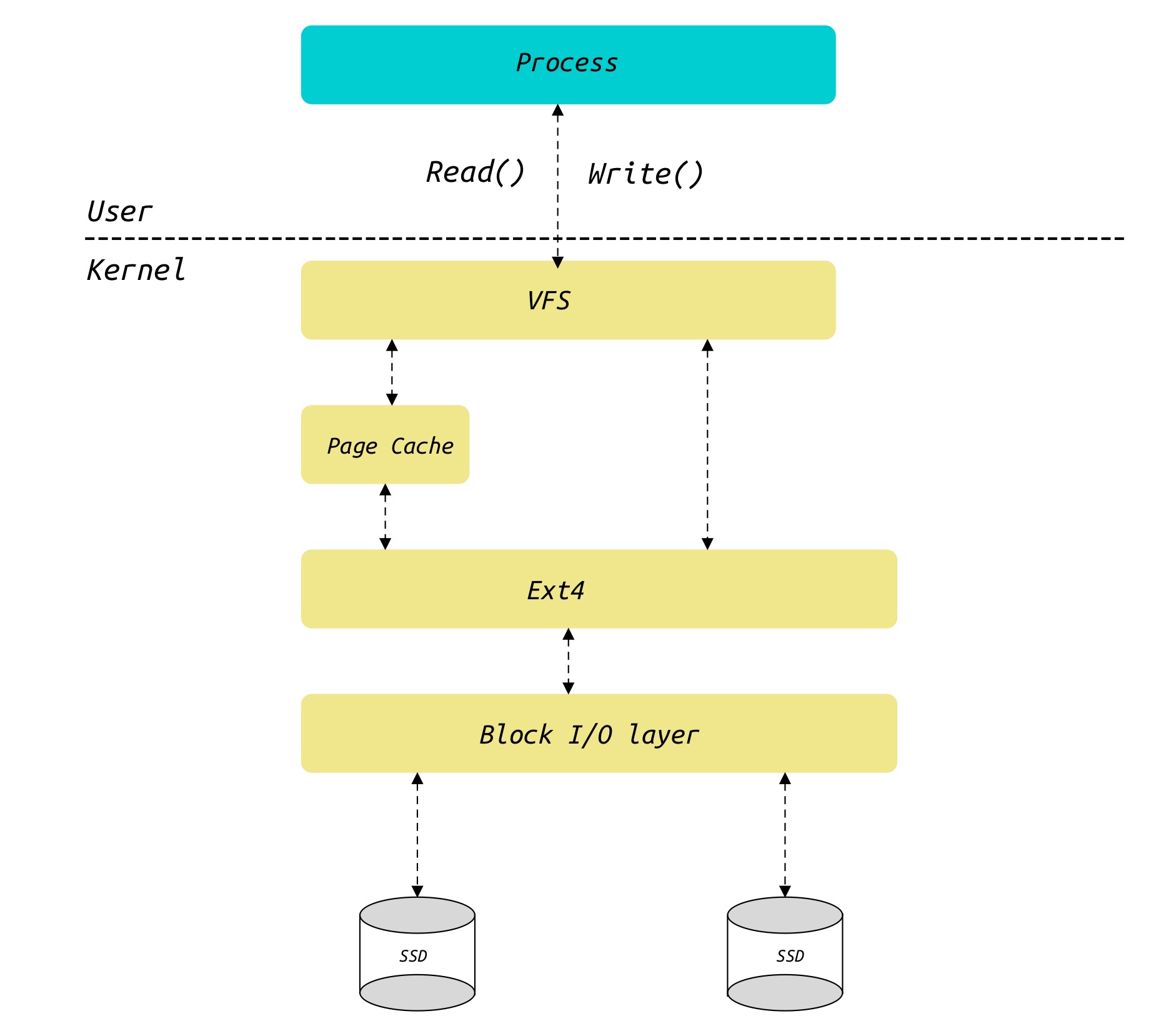
本文涉及到read/write讨论,不考虑O_DIRECT的情况(如MySQL)
0x01 内核如何描述物理内存页
内核物理内存管理(从 CPU 角度看FLATMEM物理内存模型)
以内核默认的平坦内存模型(FLATMEM )为例,来解释下物理内存与虚拟内存(地址)之间的映射关系:
- 内核以页(page)为基本单位对物理内存进行管理,通过将物理内存划分为一页一页的内存块,每页大小为
4K。一页大小的内存块在内核中用struct page来进行管理,struct page中封装了每页内存块的状态信息,比如组织结构、使用信息、统计信息以及与其他结构的关联映射信息等 - 为了快速索引到具体的物理内存页,内核为每个物理页
struct page结构体定义了一个索引编号,即PFN(Page Frame Number),其中PFN与struct page是一一对应的关系 - 内核提供了两个宏来完成 PFN 与 物理页结构体
struct page之间的相互转换,分别是page_to_pfn与pfn_to_page
内核中如何组织管理这些物理内存页 struct page 的方式称之为做物理内存模型,不同的物理内存模型,应对的场景以及 page_to_pfn 与 pfn_to_page 的计算逻辑都是不一样的,介绍下最简单的FLATMEM模型:
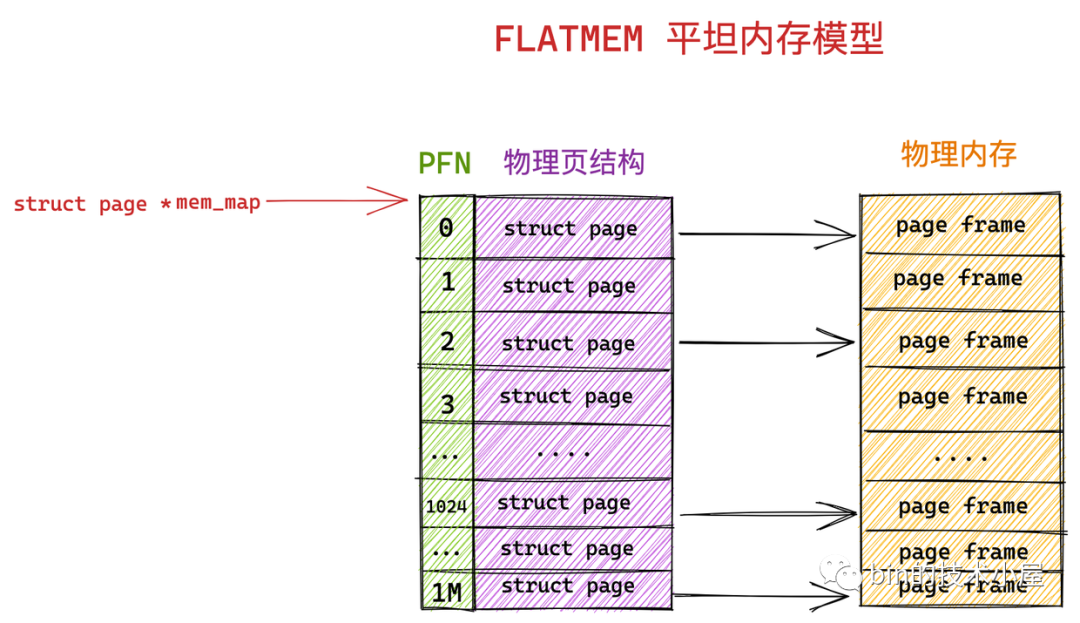
平坦内存模型 FLATMEM的架构如下:先把物理内存想象成一片地址连续的存储空间,在这一大片地址连续的内存空间中,内核将这块内存空间分为一页一页的内存块 struct page,由于这块物理内存是连续的,物理地址也是连续的,划分出来的这一页一页的物理页必然也是连续的,并且每页的大小都是固定的,所以很容易想到用一个数组来组织这些连续的物理内存页 struct page 结构,其在数组中对应的下标即为 PFN
mem_map是数组(虚拟内存地址):是虚拟地址空间中struct page结构体的连续数组(全局的struct page数组指针),此数组在内核的虚拟地址空间中连续存放,数组的每个元素对应一个物理页的元数据(状态信息)。在平坦模型下,系统认为物理内存是连续的,所以内核启动时会申请一个巨大的数组,数组的第 i 个元素就代表第 i 个物理页帧PFN:物理概念,代表物理页的编号ARCH_PFN_OFFSET:物理地址的起始偏移量(x86_64 系统通常为0),但在某些架构上,物理内存可能从一个很高的地址开始(比如0x1000000),这个偏移量就用来修正数组下标- 指针减法:
(page) - mem_map用来计算两个指针之间的元素个数
相关的代码如下,在FLATMEM模型下 ,page_to_pfn 与 pfn_to_page 本质就是基于 mem_map 数组进行偏移操作,其中 mem_map 是全局数组,用来组织所有划分出来的物理内存页。mem_map 全局数组的下标就是相应物理页对应的 PFN
struct page *mem_map; // 全局数组,指向 struct page结构体数组的指针
#if defined(CONFIG_FLATMEM)
#define __pfn_to_page(pfn) (mem_map + ((pfn)-ARCH_PFN_OFFSET)) //ARCH_PFN_OFFSET 是 PFN 的起始偏移量
#define __page_to_pfn(page) ((unsigned long)((page)-mem_map) + ARCH_PFN_OFFSET)
#endif
/*
__page_to_pfn(page):
((unsigned long)((page) - mem_map) + ARCH_PFN_OFFSET)
(page) - mem_map:计算给定 struct page指针在数组中的索引位置
加上 ARCH_PFN_OFFSET:得到实际的物理页帧号(因为物理内存可能不是从0开始)
__pfn_to_page(pfn):
(mem_map + ((pfn) - ARCH_PFN_OFFSET))
(pfn) - ARCH_PFN_OFFSET:从PFN中减去偏移得到数组索引
mem_map + index:通过数组索引找到对应的 struct page指针
*/
关于__pfn_to_page与__page_to_pfn,需要注意的一点是,这两个操作不直接操作物理内存地址,而是在虚拟地址空间中完成 struct page指针 与 PFN 之间的转换,本质是在虚拟地址空间的 mem_map 数组和物理页帧号 PFN 之间建立转换关系,如下:
虚拟地址空间中的 mem_map 数组:
+-----+-----+-----+-----+-----+
| pg0 | pg1 | pg2 | pg3 | ... | <- struct page 结构体数组
+-----+-----+-----+-----+-----+
^ ^ ^ ^
| | | |
物理页:
+-----+-----+-----+-----+-----+
| PFN0| PFN1| PFN2| PFN3| ... | <- 实际的物理内存页
+-----+-----+-----+-----+-----+
为什么说是虚拟地址空间中的转换呢?mem_map数组本身存在于内核的虚拟地址空间,每个 struct page是虚拟地址空间中的一个对象,PFN 代表的是物理地址的页帧号,上面两个宏实际上是建立了虚拟地址(struct page指针)<-> 物理页编号(PFN)的映射关系
实际使用时的地址转换流程如下:
// 从 struct page 获取物理地址
struct page *page = .......;
unsigned long pfn = page_to_pfn(page); // 1. 得到 PFN
phys_addr_t phys = pfn << PAGE_SHIFT; // 2. PFN 转为物理地址
void *virt = phys_to_virt(phys); // 3. 物理地址转虚拟地址
// 从虚拟内存地址转struct page
pfn = virt_to_pfn(virt); // 虚拟地址转 PFN
page = pfn_to_page(pfn); // PFN 转 struct page
在4.11.6内核,x86_64架构下(三种内存模型)的相关的定义如下:
//https://elixir.bootlin.com/linux/v4.11.6/source/include/asm-generic/memory_model.h#L32
#define page_to_pfn __page_to_pfn
#define pfn_to_page __pfn_to_page
/*
* supports 3 memory models.
*/
#if defined(CONFIG_FLATMEM)
// 本文:平坦内存模型
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
ARCH_PFN_OFFSET)
#elif defined(CONFIG_DISCONTIGMEM)
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
})
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
(unsigned long)(__pg - __pgdat->node_mem_map) + \
__pgdat->node_start_pfn; \
})
#elif defined(CONFIG_SPARSEMEM_VMEMMAP)
/* memmap is virtually contiguous. */
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
#elif defined(CONFIG_SPARSEMEM)
/*
* Note: section's mem_map is encoded to reflect its start_pfn.
* section[i].section_mem_map == mem_map's address - start_pfn;
*/
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
#endif /* CONFIG_FLATMEM/DISCONTIGMEM/SPARSEMEM */
在x86_64上,常用CONFIG_SPARSEMEM_VMEMMAP(稀疏内存模型),由于FLATMEM模型要求 mem_map 数组在虚拟地址上必须是连续的,若物理内存中间有巨大的空洞,FLATMEM 依然要为这段空洞分配空的 struct page 结构体,非常浪费空间。而SPARSEMEM_VMEMMAP模型把不连续的物理内存映射到一段连续的 struct page 虚拟地址上。这样既能享受指针减法的高效,又不会浪费内存,简单描述下
SPARSEMEM模型为了支持内存热插拔和巨大的空洞,将内存分成了多个 Section,page_to_pfn 必须先找到这个 page 属于哪个 Section,然后计算该 page 在该 Section 内的偏移,最后加上该 Section 的起始 PFN
原理:page 与 PFN的关系
在前文讨论mmap文件映射缺页中断引发的radix树查找的时候,曾经描述过内核从这个 struct page 中提取出物理页帧号(PFN),然后将其填入进程的 PTE(页表项)中,这样就完成了页表填充,如何理解这个概念呢?这里涉及到软件(内核数据结构)到硬件(MMU/页表)的跨越
由于CPU 并不认识 struct page,所以本质上将这个 PFN 转化成 x86_64 硬件能读懂的 64 位 PTE 值,即将 struct page 转化为硬件能识别的 PTE,主要经历 Page -> PFN -> PTE -> Memory
- 内核世界(软件):使用
struct page,该结构对象存放在内核内存里,记录了页面状态、引用计数等 - 硬件世界(CPU/MMU):只认识物理地址,当访问内存时,MMU 需要的是一个
64位的数字,这个数字代表电信号通往内存条的准确位置 - PFN(Physical Frame Number):物理页帧号(整数),内核提供了
page_to_pfn(page),它根据struct page结构体在内存中的位置,通过数学计算(下标偏移),直接算出它是第几个物理内存页。所以PFN这个数字就是硬件需要的核心信息
1、PTE(页表项)的本质,PTE 是存在于内存中的一段硬件能读懂的数据,格式如下,而页表映射的最终过程(填充PTE的过程),可汇总为如下两步(handle_mm_fault):
- 内核拿到
struct page,通过page_to_pfn算出它是第N个页框 - 内核把
N左移(加上偏移量),填入 PTE 的高位,然后内核再把可读/可写/已存在等权限标志填入 PTE 的低位
63 ~ 12 位 |
11 ~ 9位 |
8 ~ 0 位 |
| PFN (物理页帧号) | os保留 | 权限位 (Dirty, Accessed, Present R/W) |
那么在查找页表的过程中,CPU 重试访问之前缺页的虚拟内存地址,这样查询页表的过程中,PTE已经有值了,那么CPU/MMU 提取出其中的PFN(乘以 4096),即得到真正的物理地址,最后CPU 直接把电信号发往内存条,获得内存中数据
2、handle_mm_fault函数中,最终会调用alloc_set_pte-->set_pte_at填充页表,这里涉及到几个关键的转换实现
page_to_pfn:从struct page到 PFN,所有的struct page都在一个连续的数组mem_map中。用当前的 page 指针减去数组首地址,就得到了它是第几个页(即PFN)pfn_pte:从 PFN 到 PTE 内容转换,将PFN封装为硬件CPU要求的64位格式- 当PTE数值计算好后,内核需要把它真正写入到内存中的页表里,这里会调用
set_pte_at将PTE写入硬件页表
3、set_pte_at:写入页表的实现
#define set_pte_at(mm, addr, ptep, pte) native_set_pte(ptep, pte)
static inline void native_set_pte(pte_t *ptep, pte_t pte)
{
// ptep 是指向页表位置的内核虚拟地址指针,它是通过 handle_mm_fault 逐级找下去得到的,如 PGD -> PUD -> PMD,最终定位到那张包含 512 个项的 PTE 页表页面中的某一个具体位置
// pte 是刚才构造出来的 64 位值
// 细节:在 x86_64 上,直接对对齐的 64 位内存进行赋值是原子的。这保证了PTE变量的原子性
*ptep = pte;
}
当执行完set_pte_at之后,对应的内存条上那 8 字节的PTE格式大致如下:
| bit | 名称 | 含义 |
|---|---|---|
| 0 | P (Present) | 1 表示物理页已存在,MMU 不再报错 |
| 1 | R/W | 0 为只读,1 为读写 |
| 6 | D (Dirty) | 1 表示该页被写过 |
| 12 ~ 51 | Physical Address 这里存储即page_to_pfn 算出的地址高位,即第N个物理页的起始地址 |
|
| 63 | NX | 1 表示禁止执行(No Execute) |
#define page_to_pfn(page) ((unsigned long)((page) - mem_map))
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/include/asm/pgtable.h#L699
#define mk_pte(page, pgprot) pfn_pte(page_to_pfn(page), (pgprot))
//https://elixir.bootlin.com/linux/v4.11.6/source/arch/x86/include/asm/pgtable.h#L487
static inline pte_t pfn_pte(unsigned long page_nr, pgprot_t pgprot)
{
// 将 PFN 左移 12 位(因为一个页是 4096 字节,即 2^12)
// 然后加上权限位(pgprot)
// 左移 12 位是因为物理地址 = PFN * 4096
return __pte(((phys_addr_t)page_nr << PAGE_SHIFT) |
massage_pgprot(pgprot));
}
int alloc_set_pte(struct vm_fault *vmf, struct mem_cgroup *memcg,
struct page *page)
{
struct vm_area_struct *vma = vmf->vma;
bool write = vmf->flags & FAULT_FLAG_WRITE;
pte_t entry;
......
//生成 PTE 内容:使用 mk_pte(page, vma->vm_page_prot) 将物理页地址转换为页表项格式
//mk_pte-->pfn_pte:生成64位pte格式
// 核心操作1:生成 PTE 内容:提取 PFN 并加入 VMA 的权限标志
entry = mk_pte(page, vma->vm_page_prot);
/*
下面这段代码有些意思:
写时复制 (COW) 产生的匿名页 和 共享的文件页/只读页
下面这段代码主要是权限位的设置:
1. 此时生成的 PTE 是原始的,在 `handle_mm_fault` 结束前,内核会根据当前的异常类型(读还是写)修改标志位:
- pte_mkdirty(entry):将第 6 位设为 1。告诉 CPU,这个内存页被写过了
- pte_mkwrite(entry):将第 1 位设为 1。如果没设这一位,CPU 写入时会再次触发异常
- _PAGE_PRESENT:将第 0 位设为 1。这是最关键的,只有这一位是 1,MMU 才会认为这个映射是有效的
*/
//核心操作2:如果是写操作,标记为 Dirty 和 Write
if (write)
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
/* copy-on-write page */
if (write && !(vma->vm_flags & VM_SHARED)) {
//分支1:私有可写映射 (Private Writable Mapping)
//因为这是 COW 出来的页,它已经脱离了原来的文件映射,变成了匿名页 (Anonymous Page),所以增加进程的匿名页计数
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
//为这个新生成的匿名页建立反向映射
page_add_new_anon_rmap(page, vma, vmf->address, false);
//将该页面的内存消耗计入当前进程所在的 cgroup
mem_cgroup_commit_charge(page, memcg, false, false);
//将该页加入 LRU 链表,以便内核进行内存回收管理
lru_cache_add_active_or_unevictable(page, vma);
} else {
//分支2:共享映射 (Shared Mapping) 或者 只读映射 )(Read-only Mapping)
//增加进程的文件页 (File-backed Page) 计数
inc_mm_counter_fast(vma->vm_mm, mm_counter_file(page));
//建立文件页的反向映射
page_add_file_rmap(page, false);
}
//核心操作3:将 entry 写入硬件页表
//设置页表:调用 set_pte_at。这一步执行完,虚拟地址到物理地址的映射正式在硬件层面打通
//真正将物理页的地址写入进程页表(PTE)的动作。从此以后,虚拟地址就指向了相应的物理地址
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
/* no need to invalidate: a not-present page won't be cached */
// 核心操作4:设置MMU缓存
update_mmu_cache(vma, vmf->address, vmf->pte);
//set_pte_at && update_mmu_cache结束:CPU 重新执行指令
return 0;
}
小结下,从缺页中断到页表填充过程中,对页表的核心操作链路如下:
- 缺页中断,软件查找:
filemap_fault根据虚拟内存地址(转换为radix树的index)在address_space找到struct page - 地址计算&&格式化:通过
page_to_pfn算出这个页在物理内存区域的第几个位置,通过pfn_pte构造64位的PTE数值 - 物理写入,页表填充完成:
set_pte_at把这个64位整数写进 CPU 维护的那张页表里 - 硬件恢复:缺页异常返回,CPU 再次执行指令。此时 MMU 读到这个新写入的
64位整数,发现P=1,直接提取出物理地址,访问成功
内核对物理内存页的描述
struct page 内核中的物理内存页有两种类型,分别用于不同的场景:
- 匿名页:匿名页背后并没有一个磁盘中的文件作为数据来源,匿名页中的数据都是通过进程运行过程中产生的,匿名页直接和进程虚拟地址空间建立映射供进程使用
- 文件页(内存文件映射):文件页中的数据来自于磁盘中的文件,文件页需要先关联一个磁盘中的文件,然后再和进程虚拟地址空间建立映射供进程使用,使得进程可以通过操作虚拟内存实现对文件的操作
0x02 基础数据结构
address_space
前面在介绍VFS的时候提到了struct inode中的一个重要成员:address_space,address_space对象是文件系统中管理内存页page cache的核心数据结构,即它代表的是一个数据源(通常是文件)在内存中的缓存管理结构
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/fs.h#L554
struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
......
const struct inode_operations *i_op;
struct super_block *i_sb;
struct address_space *i_mapping;
......
}
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/fs.h#L379
struct address_space {
/* 拥有此空间的 inode */
struct inode *host; /* owner: inode, block_device */
/* 核心:存储所有 Page Cache 的基数树 */
struct radix_tree_root page_tree; /* radix tree of all pages */
/* 保护基数树的自旋锁 */
spinlock_t tree_lock; /* and lock protecting it */
atomic_t i_mmap_writable;/* count VM_SHARED mappings */
/* 所有的 mmap 映射 VMA 链表 */
struct rb_root i_mmap; /* tree of private and shared mappings */
struct rw_semaphore i_mmap_rwsem; /* protect tree, count, list */
/* 缓存页的总数 */
/* Protected by tree_lock together with the radix tree */
unsigned long nrpages; /* number of total pages */
/* number of shadow or DAX exceptional entries */
unsigned long nrexceptional;
pgoff_t writeback_index;/* writeback starts here */
/* 方法集:readpage, writepage 等 */
const struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits */
spinlock_t private_lock; /* for use by the address_space */
gfp_t gfp_mask; /* implicit gfp mask for allocations */
struct list_head private_list; /* ditto */
void *private_data; /* ditto */
} __attribute__((aligned(sizeof(long))));
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/mm_types.h#L40
struct page {
/* First double word block */
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
union {
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
void *s_mem; /* slab first object */
atomic_t compound_mapcount; /* first tail page */
/* page_deferred_list().next -- second tail page */
};
/* Second double word */
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
};
......
}
每一个文件(一个inode指向的文件)都对应着一个address_space对象,inode中有一个i_mmaping成员,该成员即指向该文件对应的address_space对象,而address_space中的成员page_tree,这个指针指向的就是文件对应的基数树的根,而这棵radix树的叶子节点就是page cache
注意到每个struct page 描述符都包括把page链接到page cache的两个重要字段mapping和index。其中mapping成员指向拥有该页的索引节点的address_space对象,index成员表示在所有者的地址空间中以页大小为单位的偏移量,也就是在所有者的磁盘映射中页中数据的位置
address_space中的host成员指向其所属的struct inode对象,也就是address_space中的host字段与对应inode中的 i_data成员互相指向。对于普通文件而言,inode和address_space的相应指针的指向关系如下:
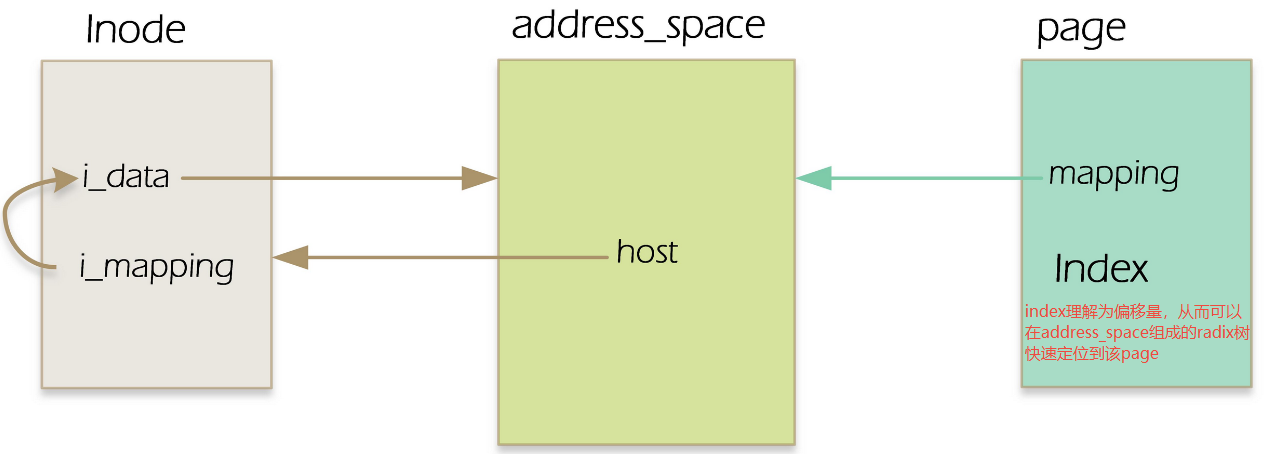
page_tree:它通过文件偏移量(index)作为索引,快速找到对应的物理页pagea_ops:一组函数指针,如缺页中断发现 Page 不存在时,就会调用a_ops->readpage去磁盘读数据,不同的文件系统(ext4/xfs/ nfs等)会实现不同的a_ops
address_space的意义
address_space是inux 统一管理 I/O 的核心,在内核中,不管是 mmap 文件映射场景下的缺页中断,还是普通的 read() 系统调用,最终都会走到 address_space,这意味着无论用哪种方式访问文件,内存里永远只有一份 Page Cache,这就是为什么mmap 后的内存和 read 读到的缓存是实时同步的
mmap文件映射缺页:触发filemap_fault-> 查address_spaceread读系统调用:触发generic_file_read_iter-> 查address_space
内核中的radix tree
因为文件位于慢速的块设备上,如果没有缓存,每一次对文件的读写都要走到块设备,这样的访问速度是无法容忍的。在Linux上操作,如果一次读某个文件慢的话,紧接着读这个文件第二次,速度会有明显的提升。原因是Linux已经将文件的部分内容或全部内容缓存到了page cache,先列举几个问题:
- page cache在内核是通过radix树管理的,为何要使用该数据结构?
- 从应用层的文件描述符fd,到
struct file,从struct file到struct dentry,再从struct dentry到struct inode,再struct inode到struct address_space, 只要知道文件的偏移量offset(如系统调用read参数),就能从radix_tree中查找对应的页面是否在页高速缓存,这里的整体过程是如何的? - 若A用户的a进程操作文件,将文件带入缓存,那么稍后B用户的b进程操作通一个文件时,同样可以享受文件内容在页高速缓存带来的福利
- page cache预读的原理是什么?
- 要读某文件的第
N个页面,内核是如何判断该页面是否在页高速缓存?如果在,如何找到该页的内容?如果不在,内核是如何处理的?
ext4支持到PB级文件存储,如此页的量级是巨大的。访问大文件时,page cache中存在着有关该文件巨大数量的页,所以内核提供了radix树来加快查找(一个address_space对象对应一个radix树)。struct address_space中成员page_tree指向是基树的根radix_tree_root,基树根中的struct radix_tree_node *rnode指向基树的最高层节点radix_tree_node,radix树节点都是radix_tree_node结构,节点中存放的都是指针,叶子节点的指针指向page描述符,radix树中上层节点指向存放其他节点的指针。一般一个radix_tree_node最多可以有64个指针,字段count表示该radix_tree_node已用节点数
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/radix-tree.h#L93
struct radix_tree_node {
unsigned char shift; /* Bits remaining in each slot */
unsigned char offset; /* Slot offset in parent */
unsigned char count; /* Total entry count */
unsigned char exceptional; /* Exceptional entry count */
struct radix_tree_node *parent; /* Used when ascending tree */
struct radix_tree_root *root; /* The tree we belong to */
union {
struct list_head private_list; /* For tree user */
struct rcu_head rcu_head; /* Used when freeing node */
};
void __rcu *slots[RADIX_TREE_MAP_SIZE];
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};
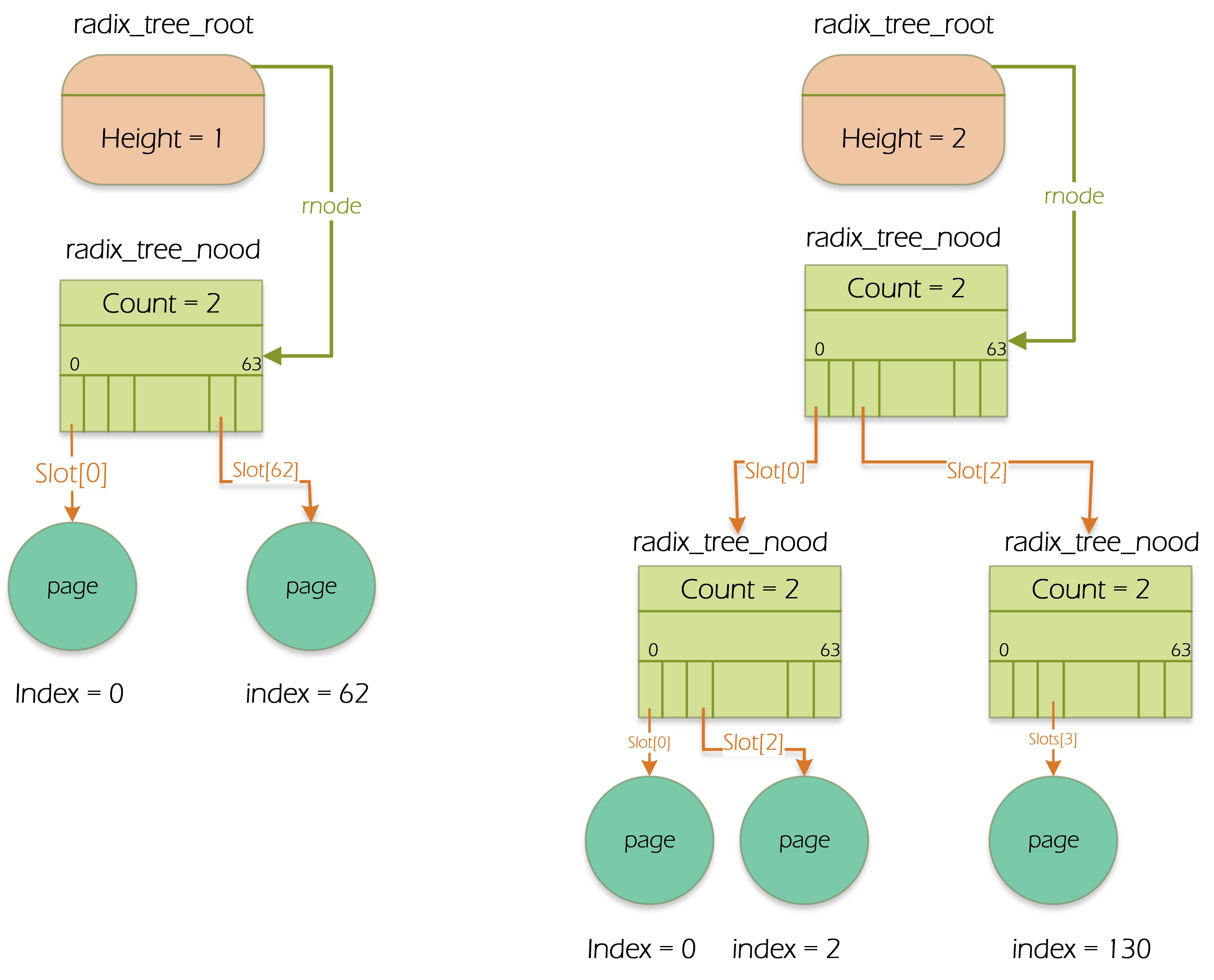
如图,radix树利用文件偏移量作为索引,它是一个多叉树,层级固定,查找速度极快,且非常适合通过 index 范围进行批量操作(如预读)。radix树的叶子节点对应的就是struct page。再回顾下radix树的查询过程,参考前文
- 内核计算文件的
pgoff(比如访问文件的第4096字节,index 就是1) - 从
page_tree的根节点向下跳转,每一层解析 index 的一部分bit - 最底层的叶子节点存放的就是
struct page的指针
address_space与page cache的(状态)管理机制
address_space 对page的管理涉及两个关键状态,脏页(Dirty)和锁定(Locked),简单描述下:
1、页面写入与脏状态:当进程通过 write/mmap 等系统调用修改内存页时
- 内核调用
set_page_dirty() address_space标记该页page为 Dirty- 为了加速扫描radix树中的脏页,radix树的中间节点会设置 Tag,内核回写线程(pdflush/kworker)在扫描脏页时,不需要遍历整棵树,只需要沿着带有
PAGECACHE_TAG_DIRTY标记的路径向下找即可
2、页面回收机制(Eviction)与 LRU:当内存不足时,内核会通过 LRU (Least Recently Used) 算法回收页面(page cache)
address_space中的页面会被挂载到全局的lru_list上- 如果页面是干净的(与磁盘一致),直接释放
- 如果页面是脏的,必须先调用
a_ops->writepage同步到磁盘,才能释放
反向映射
address_space结构中的i_mmap成员,也是rbtree方式存储,这棵rbtree存储了所有与该address_space相关的映射(包括私有的和共享的),所以i_mmap也是属于特定 inode 的,特点如下:
- 存储所有映射了该文件(inode)的 vma
- 存储类型包括共享映射(
VM_SHARED)以及私有映射(VM_PRIVATE)、匿名映射与文件映射 - 多个进程的 vma 可能在同一棵树上,即不同进程映射到同一个文件(inode)的不同位置,它们对应的所有 VMA 都会被插入到该文件的
i_mmap红黑树中 - 反向映射的场景主要有从物理页找到映射它的所有的 vma、页面回收时快速定位所有映射(参考)以及文件
truncate时解除相关映射等
struct address_space {
......
struct inode *host; /* owner: inode, block_device */
// page cache
struct radix_tree_root i_pages; /* cached pages */
atomic_t i_mmap_writable;/* count VM_SHARED mappings */
// 文件与 vma 反向映射的核心数据结构,i_mmap 也是一颗红黑树
// 在所有进程的地址空间中,只要与该文件发生映射的 vma 均挂在 i_mmap 中
struct rb_root_cached i_mmap; /* tree of private and shared mappings */
......
}
TODO
文件与进程之间的双向映射
- 进程(task_struct)-> 文件(inode):通过进程的
mm_rb定位到vma,从而获取映射的文件 - 文件 -> 进程(task_struct):通过文件的
i_mmap找到所有映射该文件的进程
0x03 struct page的本质
前文已经描述了内核中虚拟内存主要分为两种类型的页,即匿名页与文件页,此外还介绍了虚拟内存地址到物理内存地址的翻译过程、页表体系等
基础结构
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/mm_types.h#L40
struct page {
/* First double word block */
unsigned long flags;
union {
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
void *s_mem; /* slab first object */
atomic_t compound_mapcount; /* first tail page */
/* page_deferred_list().next -- second tail page */
};
/* Second double word */
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
/* page_deferred_list().prev -- second tail page */
};
union {
struct {
union {
atomic_t _mapcount;
unsigned int active; /* SLAB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
int units; /* SLOB */
};
atomic_t _refcount;
};
};
union {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone_lru_lock !
* Can be used as a generic list
* by the page owner.
*/
struct dev_pagemap *pgmap; /* ZONE_DEVICE pages are never on an
* lru or handled by a slab
* allocator, this points to the
* hosting device page map.
*/
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
};
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
/* Tail pages of compound page */
struct {
unsigned long compound_head; /* If bit zero is set */
/* First tail page only */
}
};
......
}
需要注意的一点是:struct page中是不包含存储数据的,其成员仅包含元数据,每个page对应的实际的页面内容放在物理内存中,需要通过虚拟地址访问
文件页与匿名页
| 类别 | 内存来源 | 常用场景 |
|---|---|---|
| 匿名页 | 从伙伴系统分配的新页面 | 进程堆、栈、通过brk/sbrk分配的内存,mmap匿名映射如mmap(MAP_ANONYMOUS)等 |
| 文件页 | Page Cache中的页面 | mmap文件映射,文件读写缓存等 |
如何区分struct page是哪种类型?
struct page {
union {
struct address_space *mapping; // 文件页:指向address_space
//void *s_mem;
void *anon_vma; // 匿名页:反向映射
};
pgoff_t index; // 偏移量
// ...
};
文件页(File-backed Pages)
TODO
匿名页
struct page 存储的位置
struct page结构体本身也需要内存存储,这些内存位于内核的虚拟地址空间,即直接映射区域(线性映射)。mem_map是全局数组,该存储在内核的虚拟地址空间中,位于直接映射区域(Direct Map)
struct page *mem_map; // 全局数组,指向所有struct page
// 系统启动时,内核计算需要多少内存来存储struct page
unsigned long nr_pages = total_physical_pages;
size_t page_struct_size = sizeof(struct page) * nr_pages;
// 为struct page数组分配内存
// 注意:这个内存本身也是物理内存,也需要用struct page描述!
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/page_alloc.c#L6094
TODO
以x86_64为例,虚拟内存地址布局如下,这里直接映射区域是物理地址 + 固定偏移 = 虚拟地址,偏移量是PAGE_OFFSET(x86_64通常是0xffff880000000000),这种1:1映射使得物理地址和虚拟地址可以快速转换
0xffff 8000 0000 0000 ┬───────────────────┐
│ vmalloc区域 │
0xffff 8800 0000 0000 ┼───────────────────┤ <- 这里是struct page数组所在
│ 直接映射区域 │ (PAGE_OFFSET = 0xffff880000000000)
│ 1:1映射物理内存 │
0xffff 8800 0000 0000 ┼──────────────────┤
│ struct page数组 │
│ 物理页描述符 │
0xffff 8800 0010 0000 ┼──────────────────┤
│ 其他内核数据 │
0xffff c900 0000 0000 ┴──────────────────┘
struct page的本质
对于文件inode结构中address_space关联的radix树,其叶子结点存储的value是一个struct page,其本质代表一个物理内存页,即address_space 关联的 Radix 树叶子节点存放的指针,指向的就是该文件偏移量(index)对应的 struct page 结构体实例,注意index的意义是页偏移(PAGE_SHIFT),要点如下:
1、struct page 并不等同于物理内存本身(物理内存是一块 4KB 的电信号存储区域),它是内核用来管理物理页帧(Page Frame)的元数据结构
- 一一对应关系:系统中的每一个物理页帧,在内核初始化时都会创建一个唯一的
struct page实例 - 指向物理地址:通过这个
struct page结构,内核可以非常容易计算出它对应的实际物理起始地址(page_to_phys)
2、 radix树的叶子节点里存储的内容:叶子节点实际上存储的是一个指针,该指针指向内核虚拟地址空间中的 mem_map 数组里的某一个 struct page。为什么存指针而不是直接存储物理地址呢? 因为 struct page 包含了很多极其重要的管理信息,内核在处理缺页中断或文件读写时会使用到,典型的几个成员如下:
flags:标记这个页是否为脏(Dirty)、是否正在被锁定进行磁盘 I/O(Locked)、是否已经是最新的数据(Uptodate)mapping:反向指向它所属的address_spaceindex:记录这个页在文件中的偏移位置_count/_mapcount:引用计数,记录有多少个进程或内核模块正在使用此页
3、缺页中断中的数据流转,结合查找 address_space过程来看,包含了输入/查找/定位/获取/映射的几个过程:
- 输入:缺页中断拿到虚拟地址,计算出文件偏移量
index - 查找:内核拿着
index去address_space中的radix树里查找 - 定位:在 Radix 树的叶子节点找到了一个指针
- 获取:内核拿到这个指针(
struct page *) - 映射:内核从这个
struct page对象中提取出物理页帧号(PFN),然后将其填入进程的 PTE(页表项)中
再思考一下前文描述过的mmap文件映射共享机制,进程 A 与 B 都 mmap 同一个文件(虽然它们的虚拟内存空间与mmap返回的地址都不同),正是由于 Radix 树存的是 struct page 指针,这就实现了 Page Cache 的共享。在进程A 与 B的 handle_mm_fault函数中,最终都会去同一个 address_space 的 Radix 树查找,最终会拿到同一个 struct page 指针,即最终两个进程的虚拟地址最终都指向了同一块物理内存
page cache相关的操作函数
0x0 内核的预读机制
0x0 文件读与page cache
0x0 文件写与page cache
0x0 总结
page cache
- page cache的内存在内核中是匿名的物理页(不与用户进程的逻辑地址进行映射),由
struct page表示,在内核中page cache使用 LRU 管理,当用户进行mmap映射文件时,内核创建对应的vma,在访问到mmap的内存区域时,触发page fault,在page fault回调中page cache内存所属的物理页与用户进程的虚拟地址vma进行映射 - 每个文件的page cache元数据存储于对应的
struct inode->address_space中,因此进程之间可以共享同一个文件的page cache,同一个文件多次open不会影响其page cache - 文件的page cache是延时分配的,当有读写命令时,才会按需创建缓存页
- page cache的脏页是单线程回写的,因此当一个文件大量写入时,写入的性能与单 CPU 的性能有相当的关系
- 对于
struct page结构体,其存储在直接映射区域,虚拟地址=物理地址+固定偏移,而struct page数组占用的(物理)物理页,也用struct page描述。通过简单的加减运算就能在struct page和物理地址间转换