0x00 前言
先回顾一下,调用read系统调用之后,内核的调用路径是什么?
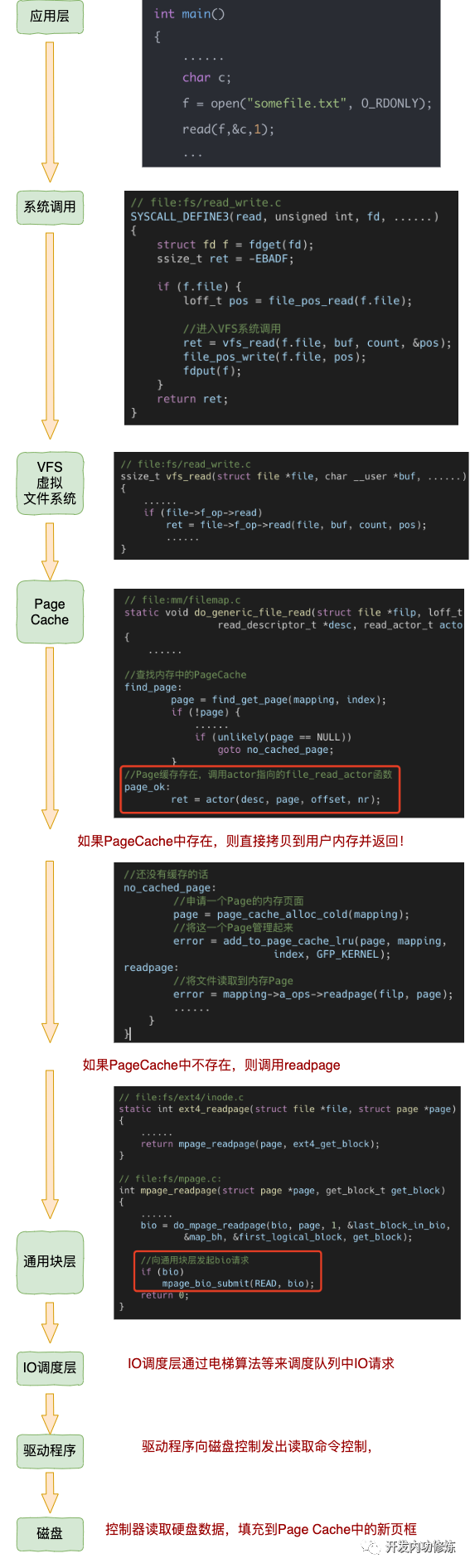
再回顾一下,前文介绍的splice实现零拷贝中的内核读操作,是怎么实现的?
本文主要梳理下基于page cache的内核read实现的若干细节,基于v4.11.6的源码
0x01 generic_file_read_iter的实现细节
通常大部分文件系统的读取read实现,都是将read_iter置为generic_file_read_iter,如本文分析的ext4系统
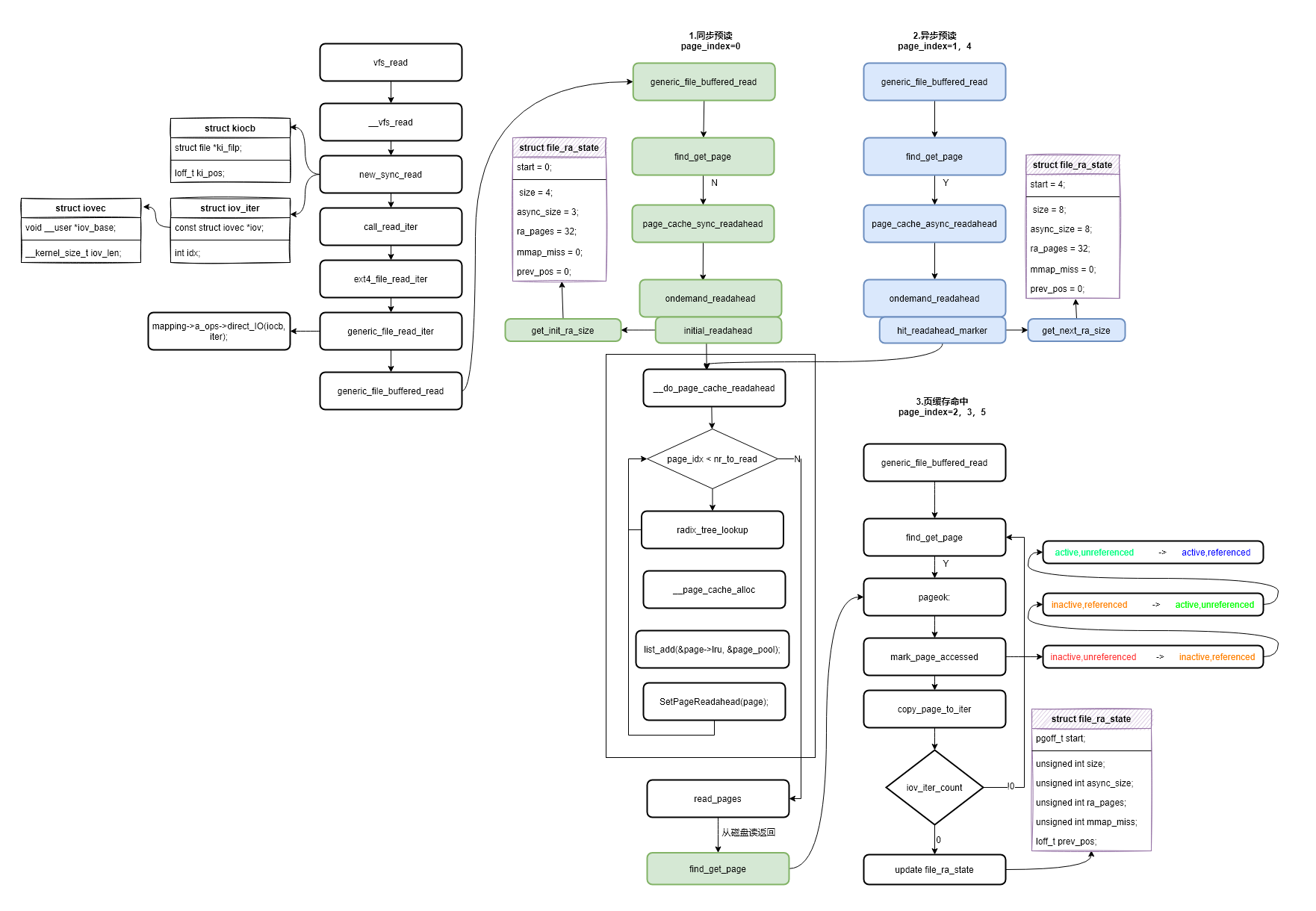
预读函数栈分析的整体流程如上图,用户态程序执行read系统调用后进入到内核虚拟文件系统层vfs_read函数,然后逐层调用,new_sync_read函数中使用struct kiocb结构体封装了struct file结构体,并对当前读取文件的状态进行管理。new_sync_read函数创建struct iov_iter进行内核态与用户态之间数据的拷贝以及记录本次读取长度(len)。而后进入generic_file_read_iter函数进行了direct_IO的判断,即不通过页缓存读取文件数据。如果使用页缓存读取数据就进入了预读的主要处理函数do_generic_file_read/generic_file_buffered_read。generic_file_read_iter的实现如下:
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L2015
/**
* generic_file_read_iter - generic filesystem read routine
* @iocb: kernel I/O control block
* @iter: destination for the data read
*
* This is the "read_iter()" routine for all filesystems
* that can use the page cache directly.
*/
ssize_t
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
struct file *file = iocb->ki_filp;
ssize_t retval = 0;
size_t count = iov_iter_count(iter);
if (!count)
goto out; /* skip atime */
if (iocb->ki_flags & IOCB_DIRECT) {
//非page cache读
......
}
// buffered read
retval = do_generic_file_read(file, &iocb->ki_pos, iter, retval);
out:
return retval;
}
上面函数中iov_iter_count函数,就是用户请求读取的字节数,也就是用户缓冲区的剩余容量,回顾下前文的内容,iov_iter本质是一个迭代器,它的特点是:
- 初始化时,
count被设置为用户调用read(fd, buf, count)时的count参数 - 随着数据拷贝(
pagecopy到iovec),count逐渐减少(变化) - 当
i->count变为0时,表示用户缓冲区已满
static inline size_t iov_iter_count(const struct iov_iter *i)
{
return i->count;
}
继续分析do_generic_file_read的实现,do_generic_file_read 是内核处理缓冲 I/O(Buffered I/O)的核心函数,通过 Page Cache 机制读取文件数据。主要流程如下:
- 计算页索引和偏移:将文件偏移转换为页号
- 循环处理每一页:逐页从 Page Cache 读取
- 页缓存命中/未命中处理
- 数据拷贝到用户空间
- 预读机制:优化顺序读取性能
在调用do_generic_file_read之前,主要注意iov_iter中保存了用户期望copy的长度以及分段iovec(缓冲区)
//filp:要读取的文件对象
//ppos: 指向当前文件偏移量的指针
//iter:用户空间缓冲区的迭代器,支持分散/聚集 I/O
//written:已读取的字节数(用于部分读取的继续)
static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos,
struct iov_iter *iter, ssize_t written)
{
struct address_space *mapping = filp->f_mapping; // 文件的页缓存映射
struct inode *inode = mapping->host; // 文件的 inode(反向)
struct file_ra_state *ra = &filp->f_ra; // 预读状态
pgoff_t index; // 当前页索引
pgoff_t last_index; // 最后页索引
pgoff_t prev_index;
unsigned long offset; // 页内偏移 /* offset into pagecache page */
unsigned int prev_offset;
int error = 0;
if (unlikely(*ppos >= inode->i_sb->s_maxbytes))
return 0;
iov_iter_truncate(iter, inode->i_sb->s_maxbytes);
// 重要:偏移量转换计算
index = *ppos >> PAGE_SHIFT; // 计算当前页索引(注意:是当前文件对象)
prev_index = ra->prev_pos >> PAGE_SHIFT;
prev_offset = ra->prev_pos & (PAGE_SIZE-1);
last_index = (*ppos + iter->count + PAGE_SIZE-1) >> PAGE_SHIFT; // 计算最后一页索引
offset = *ppos & ~PAGE_MASK; //计算页内偏移
// 重要:page操作的核心循环流程
for (;;) { // 无限循环,处理多个页面
struct page *page;
pgoff_t end_index;
loff_t isize;
unsigned long nr, ret;
// 条件调度:允许调度器中断
cond_resched();
find_page:
if (fatal_signal_pending(current)) {
error = -EINTR;
goto out;
}
// find_get_page:从页缓存查找
// step1:查找页缓存
page = find_get_page(mapping, index);
if (!page) {
// 页不在缓存(radix树)中,触发同步预读
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
// 再次尝试查找
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page; // 分配新页
}
// 重要:预读机制(step2)
if (PageReadahead(page)) {
// 异步预读:当读取到标记为预读的页面时触发
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
//step3:页面状态检查
if (!PageUptodate(page)) { // 页面数据不是最新的
/*
* See comment in do_read_cache_page on why
* wait_on_page_locked is used to avoid unnecessarily
* serialisations and why it's safe.
*/
error = wait_on_page_locked_killable(page);
if (unlikely(error))
goto readpage_error;
if (PageUptodate(page)) // 等待后,页面已更新
goto page_ok;
// 检查是否为部分更新页(某些文件系统支持)
if (inode->i_blkbits == PAGE_SHIFT ||
!mapping->a_ops->is_partially_uptodate)
goto page_not_up_to_date;
/* pipes can't handle partially uptodate pages */
// 管道不支持部分更新页
if (unlikely(iter->type & ITER_PIPE))
goto page_not_up_to_date;
// 检查部分更新的具体状态
if (!trylock_page(page))
goto page_not_up_to_date;
/* Did it get truncated before we got the lock? */
if (!page->mapping) // 页面已被截断
goto page_not_up_to_date_locked;
if (!mapping->a_ops->is_partially_uptodate(page,
offset, iter->count))
goto page_not_up_to_date_locked;
unlock_page(page);
}
//step5:重要,page已经准备好,数据拷贝到用户空间
page_ok:
/*
* i_size must be checked after we know the page is Uptodate.
*
* Checking i_size after the check allows us to calculate
* the correct value for "nr", which means the zero-filled
* part of the page is not copied back to userspace (unless
* another truncate extends the file - this is desired though).
*/
//检查文件大小边界
isize = i_size_read(inode);
end_index = (isize - 1) >> PAGE_SHIFT;
if (unlikely(!isize || index > end_index)) {
put_page(page);
goto out; // 已经读到文件末尾
}
/* nr is the maximum number of bytes to copy from this page */
// 计算本页可拷贝的字节数
nr = PAGE_SIZE;
if (index == end_index) { // 最后一页
nr = ((isize - 1) & ~PAGE_MASK) + 1; // 计算文件在最后一页的字节数
if (nr <= offset) { // 偏移已超过文件末尾
put_page(page);
goto out;
}
}
nr = nr - offset; // 减去页内偏移
/* If users can be writing to this page using arbitrary
* virtual addresses, take care about potential aliasing
* before reading the page on the kernel side.
*/
// 处理缓存一致性(写时拷贝等情况)
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
/*
* When a sequential read accesses a page several times,
* only mark it as accessed the first time.
*/
// 标记页面访问(用于页面回收算法)
if (prev_index != index || offset != prev_offset)
mark_page_accessed(page);
prev_index = index;
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
// copy_page_to_iter:拷贝数据到用户空间
//负责从内核页拷贝数据到用户空间缓冲区,处理页边界、部分拷贝等情况,返回实际拷贝的字节数
ret = copy_page_to_iter(page, offset, nr, iter);
//offset:页面内的字节偏移
//index:当前处理的页面索引
//prev_offset:上一次访问的偏移(用于顺序性检测)
//written:总共已读取的字节数
offset += ret;
index += offset >> PAGE_SHIFT;
offset &= ~PAGE_MASK;
prev_offset = offset;
put_page(page);
written += ret;
if (!iov_iter_count(iter))
goto out;
if (ret < nr) {
error = -EFAULT;
goto out;
}
//继续下一页处理
continue;
//step4:从磁盘读取页面的过程
page_not_up_to_date:
/* Get exclusive access to the page ... */
error = lock_page_killable(page);
if (unlikely(error))
goto readpage_error;
page_not_up_to_date_locked:
/* Did it get truncated before we got the lock? */
if (!page->mapping) { // 页面已被截断
unlock_page(page);
put_page(page);
continue; // 重新开始
}
/* Did somebody else fill it already? */
if (PageUptodate(page)) { // 其他进程已更新页面
unlock_page(page);
goto page_ok;
}
readpage:
/*
* A previous I/O error may have been due to temporary
* failures, eg. multipath errors.
* PG_error will be set again if readpage fails.
*/
ClearPageError(page); // 清除之前的错误
/* Start the actual read. The read will unlock the page. */
//重要:调用文件系统的 readpage 方法(实际磁盘读取)
//比如对于ext4系统:调用 ext4_readpage
//此调用会提交 BIO 请求到底层块设备
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/ext4/inode.c#L3224
error = mapping->a_ops->readpage(filp, page);
if (unlikely(error)) {
if (error == AOP_TRUNCATED_PAGE) {
put_page(page);
error = 0;
goto find_page;
}
goto readpage_error;
}
if (!PageUptodate(page)) {
error = lock_page_killable(page);
if (unlikely(error))
goto readpage_error;
if (!PageUptodate(page)) {
if (page->mapping == NULL) {
/*
* invalidate_mapping_pages got it
*/
unlock_page(page);
put_page(page);
goto find_page;
}
unlock_page(page);
shrink_readahead_size_eio(filp, ra);
error = -EIO;
goto readpage_error;
}
unlock_page(page);
}
goto page_ok;
//step7:错误处理
readpage_error:
/* UHHUH! A synchronous read error occurred. Report it */
put_page(page);
goto out;
//step 6:页面分配(缓存未命中)
no_cached_page:
/*
* Ok, it wasn't cached, so we need to create a new
* page..
*/
// 分配cold页面,cold页面更适合一次性的读取操作,同时加入到页面缓存和 LRU 列表
page = page_cache_alloc_cold(mapping);
if (!page) {
error = -ENOMEM;
goto out;
}
error = add_to_page_cache_lru(page, mapping, index,
mapping_gfp_constraint(mapping, GFP_KERNEL));
if (error) {
put_page(page);
if (error == -EEXIST) { // 其他进程已添加
error = 0;
goto find_page;
}
goto out;
}
goto readpage; // 读取新分配的页面
}
//step8:完成
out:
ra->prev_pos = prev_index;
ra->prev_pos <<= PAGE_SHIFT;
ra->prev_pos |= prev_offset;
//*ppos:即file->f_pos更新
*ppos = ((loff_t)index << PAGE_SHIFT) + offset;
file_accessed(filp); // 更新文件访问时间
return written ? written : error;
}
核心流程图如下:
flowchart TB
subgraph init["初始化"]
A[do_generic_file_read 入口] --> B[获取 mapping, inode, ra]
B --> C[*ppos >= s_maxbytes?]
C -->|是| D[return 0]
C -->|否| E[计算 index, prev_index, last_index, offset]
E --> F[进入 for 循环]
end
subgraph loop["主循环"]
F --> G[cond_resched]
G --> H[find_page 标签]
H --> I[fatal_signal_pending?]
I -->|是| J[error=-EINTR, goto out]
I -->|否| K[find_get_page]
K --> L{page 存在?}
L -->|否| M[no_cached_page 分支]
L -->|是| N[PageReadahead?]
N -->|是| O[page_cache_async_readahead]
N -->|否| P[PageUptodate?]
O --> P
P -->|否| Q[wait/lock 与 readpage 分支]
P -->|是| R[page_ok]
R --> S[检查 i_size, 计算 nr]
S --> T[flush_dcache_page 若需要]
T --> U[mark_page_accessed]
U --> V[copy_page_to_iter]
V --> W[更新 offset, index, written]
W --> X{iov_iter_count?}
X -->|空| Y[goto out]
X -->|非空| Z{ret < nr?}
Z -->|是| AA[error=-EFAULT, goto out]
Z -->|否| F
end
subgraph out["退出"]
Y --> AB[ra->prev_pos 更新]
J --> AB
AA --> AB
AB --> AC[*ppos 更新]
AC --> AD[file_accessed]
AD --> AE[return written/error]
end
index与offset的意义
在do_generic_file_read中有两个容易混淆的关键变量,需要明确区分:
index(类型pgoff_t):页索引,表示文件被划分为页面大小的块后,从0开始计数的页面序号,来自*ppos >> PAGE_SHIFT。内核通过find_get_page(mapping, index)在radix树中定位对应的struct pageoffset(类型unsigned long):页内字节偏移,范围0~4095(PAGE_SIZE-1),来自*ppos & ~PAGE_MASK。当定位到page后,offset告诉copy_page_to_iter从页面的哪个字节位置开始拷贝数据
// 用户系统调用:read(fd, buf, count)
// 内核处理时:
loff_t pos = file->f_pos; // 当前文件偏移(字节)
pgoff_t index = pos >> PAGE_SHIFT; // 页索引(第几页)
unsigned long offset = pos & ~PAGE_MASK; // 页内字节偏移(0~4095)
// 类型说明
typedef unsigned long pgoff_t; // 页索引类型
// 示例:文件偏移 pos = 5000 (十进制)
// index = 5000 >> 12 = 1 (第 1 页,从 0 开始计数)
// offset = 5000 & 0xFFF = 904(页内第 904 字节处开始读)
// 在32位系统上:
// pgoff_t 是 32 位
// 最大文件大小 = 2^32 * 4096 = 16TB(实际上受文件系统和其他限制)
此外,再回顾一下,在radix树(IDR树)中,key就是index(页索引),而value就是struct page*即页面指针
struct page* 与 struct page 的关系(FLATMEM)如下:
struct page 是内核为每个物理页帧维护的元数据结构体(约 64 字节),包含 _refcount、flags、mapping、index、lru 等,不包含 4KB 数据本身。所有 struct page 实例连续存放在全局数组 mem_map[] 中
// include/asm-generic/memory_model.h (v4.11.6, FLATMEM)
#define __pfn_to_page(pfn) (mem_map + (pfn))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map))
// 用法示例:
struct page *page = find_get_page(mapping, index);
unsigned long pfn = page_to_pfn(page); // 从 mem_map 偏移算出页帧号
// page 对应的 4KB 数据位于物理地址 pfn << PAGE_SHIFT
// CPU 访问该数据须通过 kmap_atomic(page) / page_address(page) 转为内核虚拟地址
因此 radix 树 value 存的是管理结构体指针(指向 mem_map[pfn]),不能直接解引用 struct page* 当数据缓冲区。读文件数据必须先 kmap_atomic 转为内核 VA,再 copy_page_to_iter
TODO:文本
page_ok标签
page_ok标签处表示当前页面已准备就绪,可以进行用户空间拷贝。这个标签处理单个页面的读取完成,包括:
- 检查文件边界
- 计算可拷贝字节数
- 处理缓存一致性
- 执行实际拷贝
- 更新状态并决定是否继续(检查退出状态)
static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos,
struct iov_iter *iter, ssize_t written){
......
page_ok:
//检查文件大小边界
isize = i_size_read(inode);
end_index = (isize - 1) >> PAGE_SHIFT;
if (unlikely(!isize || index > end_index)) {
put_page(page);
goto out; // 已经读到文件末尾
}
/* nr is the maximum number of bytes to copy from this page */
// 计算本页可拷贝的字节数
nr = PAGE_SIZE;
if (index == end_index) { // 最后一页
nr = ((isize - 1) & ~PAGE_MASK) + 1; // 计算文件在最后一页的字节数
if (nr <= offset) { // 偏移已超过文件末尾
put_page(page);
goto out;
}
}
nr = nr - offset; // 减去页内偏移
// 处理缓存一致性(写时拷贝等情况)
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
/*
* When a sequential read accesses a page several times,
* only mark it as accessed the first time.
*/
// 标记页面访问(用于页面回收算法)
// 这里是执行page的顺序访问检测,只有第一次访问时才标记页面为"已访问",这里影响页面回收算法的决策
if (prev_index != index || offset != prev_offset)
mark_page_accessed(page);
prev_index = index;
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
// copy_page_to_iter:拷贝数据到用户空间
//负责从内核页拷贝数据到用户空间缓冲区,处理页边界、部分拷贝等情况,返回实际拷贝的字节数
ret = copy_page_to_iter(page, offset, nr, iter);
offset += ret; // 更新页内偏移
index += offset >> PAGE_SHIFT; // 如果offset跨页,index增加(下一次需要访问后面的page了)
offset &= ~PAGE_MASK; // 将offset限制在当前页内
prev_offset = offset; // 记录偏移用于下次访问检测
put_page(page); // 在每次循环结束时释放页面引用
/*
引用计数管理机制, 确保页面在使用期间不会被回收
1、find_get_page()增加引用计数
2、使用完毕后必须 put_page()
*/
written += ret; // 累计已读取字节数
if (!iov_iter_count(iter)) // 用户缓冲区用完了,退出
goto out;
if (ret < nr) { // 拷贝失败,退出
error = -EFAULT;
goto out;
}
// 继续下一个循环,处理下一个页面
continue;
......
}
细节一:如何检测copy完成(退出)
从上面代码分析可知在copy_page_to_iter执行完对本page的copy动作完成之后,会依次检查这些(退出)条件是否满足:
- 通常情况下,用户缓冲区的size等于本次要copy的文件page的总字节大小,但实际跨越的page页数,需要由offset来决定,可能跨越多页
- copy大文件的场景,本次copy未到达文件的尾部,用户缓冲区已经耗尽
- copy小文件的场景,本次copy到达了文件尾部(到达了文件最后一页,但未占满最后一页),用户缓冲区还有剩余空间
1、检查用户缓冲区是否已满,代码片段:
if (!iov_iter_count(iter)) // 用户缓冲区已空
goto out; // 退出循环,返回
2、检查copy_page_to_iter(参数nr为希望copy的字节数、返回值为实际copy的字节数)是否拷贝失败,代码片段:
if (ret < nr) { // 实际拷贝字节数小于预期拷贝字节数
error = -EFAULT; // 设置错误
goto out; // 退出循环
}
细节二:对边界条件处理细节,如下描述
1、在copy前发现已经到达了文件的末尾,如下:
isize = i_size_read(inode);
end_index = (isize - 1) >> PAGE_SHIFT;
if (unlikely(!isize || index > end_index)) {
put_page(page);
goto out; // 说明到达了文件末尾
}
2、对最后一页的特殊处理,片段如下:
nr = PAGE_SIZE;
if (index == end_index) { // 当前页面是最后一页
nr = ((isize - 1) & ~PAGE_MASK) + 1;
if (nr <= offset) { // 如果要读取的偏移已超过有效数据,说明已经读取完成了,可以退出
put_page(page);
goto out;
}
}
如何计算本次处理的页面数目
注意到do_generic_file_read中,使用到了for(;;),那么这个循环的退出条件是什么?或者说本次do_generic_file_read处理(读取)了多少页是如何计算出来的?考虑下面几个关键因子:
//参数ppos:对应要读取的文件偏移(指向当前文件偏移量的指针)
//用户请求的数据量
// 原始请求来自用户空间的 read() 调用
// 在 __vfs_read -> generic_file_read_iter -> do_generic_file_read
size_t count = iov_iter_count(iter); // 用户请求的字节数
// 实际读取边界计算
// 计算要读取的页面范围
index = *ppos >> PAGE_SHIFT; // 起始页索引
offset = *ppos & ~PAGE_MASK; // 页内偏移
last_index = (*ppos + iter->count/*待读的总数*/ + PAGE_SIZE-1) >> PAGE_SHIFT; // 最后一页索引
上面的片段中,使用了 iter->count(用户请求的字节数)来计算需要读取的页面范围,但这个计算只是估算,不是限制。此外,对于系统调用read而言,参数ppos来自于struct file结构体中的f_pos字段:
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
// 获取文件偏移
loff_t pos = file_pos_read(f.file);
ret = vfs_read(f.file, buf, count, &pos);
if (ret >= 0)
file_pos_write(f.file, pos);
fdput_pos(f);
}
return ret;
}
//获取file结构的f_pos成员
static inline loff_t file_pos_read(struct file *file)
{
return file->f_pos;
}
所以,这里了解到如下几个关键信息:
- (要读取)文件page的起始页面位置
- 起始页面从哪个offset开始读
- 最后一页的位置
last_index - 估算的读取页数(
[last_index,index])
实际读取中,还需要考虑当前文件的大小(即当前读指针指向的page内容实质已经不满一页),关联如下代码:
......
static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos,
struct iov_iter *iter, ssize_t written)
{
// 在 page_ok 标签处:
// 1. 根据文件大小计算当前页可用的字节数 (nr)
if (index == end_index) {
nr = ((isize - 1) & ~PAGE_MASK) + 1; // 最后一页的有效字节
if (nr <= offset) {
put_page(page);
goto out; // 文件结束
}
}
nr = nr - offset; // 页内从 offset 开始的有效字节
// 2. copy_page_to_iter 会读取 min(nr, iov_iter_count(iter))
// 即会取 nr和 iov_iter_count(iter)的较小值进行拷贝
ret = copy_page_to_iter(page, offset, nr, iter);
......
}
当然针对读大文件的场景,最普遍的情况还是一直copy pages到用户缓冲区已经耗尽
此外,这里内核使用for(;;),主要考虑到一个 read 系统调用可能跨越多个page内存页面(处理跨页读取),其中每个page都需要完成下面的操作:
- 单独查找/分配
- 单独从磁盘读取(如果不在page cache中)
- 单独拷贝到用户空间
static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos,
struct iov_iter *iter, ssize_t written)
{
......
for (;;) {
......
cond_resched(); // 允许调度器中断(防止无限循环)
find_page: //提供直接跳转的标签
......
// 处理某一页(page)
copy_page_to_iter(......)
// 在 page_ok 标签后:
if (!iov_iter_count(iter)) // 用户缓冲区已满
goto out;
if (ret < nr) { // copy_page_to_iter 拷贝不完整
error = -EFAULT;
goto out;
}
continue; // 继续处理下一页
}
......
}
接下来继续跟踪do_generic_file_read的实现拆解分析,首先看下对单个页page的处理逻辑
0x02 do_generic_file_read:计算页索引和偏移
本节主要分析下find_get_page的实现过程,注意到其入参pgoff_t offset,来源于index = *ppos >> PAGE_SHIFT, 即page在文件中的索引index,这让人很容易联想到内核IDR结构的key
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/pagemap.h#L245
static inline struct page *find_get_page(struct address_space *mapping,
pgoff_t offset)
{
//用于从页缓存中获取页面,支持多种获取模式
return pagecache_get_page(mapping, offset, 0, 0);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L1269
//mapping: 页缓存所属的地址空间(文件映射)
//offset: 页面在文件中的页索引
//fgp_flags:获取页面的标志位,控制函数行为
//gfp_mask:内存分配的 GFP 标志
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
page = find_get_entry(mapping, offset);
if (radix_tree_exceptional_entry(page))
page = NULL;
if (!page)
goto no_page;
if (fgp_flags & FGP_LOCK) {
if (fgp_flags & FGP_NOWAIT) {
if (!trylock_page(page)) {
put_page(page);
return NULL;
}
} else {
lock_page(page);
}
/* Has the page been truncated? */
if (unlikely(page->mapping != mapping)) {
unlock_page(page);
put_page(page);
goto repeat;
}
VM_BUG_ON_PAGE(page->index != offset, page);
}
if (page && (fgp_flags & FGP_ACCESSED)){
//标记页面访问
//将页面标记为活跃,避免被快速回收,同时更新页面在 LRU 链表中的位置
mark_page_accessed(page);
}
// 未在radix树中查找到相关的文件页,需要新建
no_page:
if (!page && (fgp_flags & FGP_CREAT)) {
......
// 分配页面
page = __page_cache_alloc(gfp_mask);
if (!page)
return NULL;
if (WARN_ON_ONCE(!(fgp_flags & FGP_LOCK)))
fgp_flags |= FGP_LOCK;
/* Init accessed so avoid atomic mark_page_accessed later */
if (fgp_flags & FGP_ACCESSED)
__SetPageReferenced(page);
// 重要:添加到page cache和全局LRU链表
// 将这个新申请的page根据index插入到普通文件的address_space对应的radix树中
err = add_to_page_cache_lru(page, mapping, offset,
gfp_mask & GFP_RECLAIM_MASK);
if (unlikely(err)) {
put_page(page);
page = NULL;
if (err == -EEXIST) // 竞争条件:其他线程已添加
goto repeat;
}
}
return page;
}
find_get_entry函数用于从页缓存中查找页面,它无锁查找页缓存,并使用 RCU 机制确保并发安全,这里会调用radix_tree_lookup_slot在文件的IDR树中进行查找
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L1169
//mapping:文件的页缓存地址空间
//offset:页面在文件中的索引
struct page *find_get_entry(struct address_space *mapping, pgoff_t offset)
{
void **pagep;
struct page *head, *page;
rcu_read_lock();
repeat:
page = NULL;
/*
radix_tree_lookup_slot:返回指向存储页面指针的槽位的指针,槽位存储的是 void *,可能是 struct page *;如果没有对应的条目,返回 NULL
*/
pagep = radix_tree_lookup_slot(&mapping->page_tree, offset);
if (pagep) {
page = radix_tree_deref_slot(pagep);
if (unlikely(!page))
goto out;
if (radix_tree_exception(page)) {
if (radix_tree_deref_retry(page))
goto repeat;
/*
* A shadow entry of a recently evicted page,
* or a swap entry from shmem/tmpfs. Return
* it without attempting to raise page count.
*/
goto out;
}
head = compound_head(page);
if (!page_cache_get_speculative(head))
goto repeat;
/* The page was split under us? */
if (compound_head(page) != head) {
put_page(head);
goto repeat;
}
/*
* Has the page moved?
* This is part of the lockless pagecache protocol. See
* include/linux/pagemap.h for details.
*/
if (unlikely(page != *pagep)) {
put_page(head);
goto repeat;
}
}
out:
rcu_read_unlock();
return page;
}
add_to_page_cache_lru函数
int add_to_page_cache_lru(struct page *page, struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask)
{
void *shadow = NULL;
int ret;
__SetPageLocked(page);
// __add_to_page_cache_locked:像page cache增加radix节点(page)
ret = __add_to_page_cache_locked(page, mapping, offset,
gfp_mask, &shadow);
if (unlikely(ret))
__ClearPageLocked(page);
else {
if (!(gfp_mask & __GFP_WRITE) &&
shadow && workingset_refault(shadow)) {
SetPageActive(page);
workingset_activation(page);
} else
ClearPageActive(page);
// 向全局的page链表中增加节点
lru_cache_add(page);
}
return ret;
}
所以,这里有个细节是,虽然每个文件(inode)对应的address_space有自己的私有radix树,但所有的页面page都会链接到全局的LRU链表中,使得内核可以进行全局回收
pagecache_get_page 主要调用链分析
本小节,将上面涉及的 find_get_page -> pagecache_get_page -> radix 树查找/插入 -> 预读分配等关键子函数串联起来
(1)radix_tree_lookup_slot:RCU 无锁查找
find_get_entry 在 rcu_read_lock() 临界区内调用 radix_tree_lookup_slot。返回值是指向 slot 的指针 void **pagep,而非直接的 struct page*。slot 里存储的 void * 可能是正常 page 指针,也可能是 exceptional entry(被回收页的 shadow 或 tmpfs 的 swap entry)
// https://elixir.bootlin.com/linux/v4.11.6/source/lib/radix-tree.c#L1061
// 在 radix 树中按 index 查找,返回 &slot(指向存储条目的指针的地址)
void **radix_tree_lookup_slot(struct radix_tree_root *root, unsigned long index);
// find_get_entry 中的使用(mm/filemap.c#L1169)
pagep = radix_tree_lookup_slot(&mapping->page_tree, offset);
if (pagep) {
// 从 slot 中安全取出 page 指针(配合 RCU)
page = radix_tree_deref_slot(pagep);
if (unlikely(!page))
goto out;
// 判断是否为 exceptional entry(shadow entry / swap entry)
if (radix_tree_exception(page)) {
if (radix_tree_deref_retry(page))
goto repeat; // 并发修改,需要重试
goto out; // shadow entry:最近被回收页的占位
}
// 正常 page:投机性增加引用计数
head = compound_head(page);
if (!page_cache_get_speculative(head))
goto repeat; // 引用获取失败(page 正被释放),重试
// 校验 slot 未被并发替换
if (unlikely(page != *pagep)) {
put_page(head);
goto repeat;
}
}
要点如下:
rcu_read_lock()保证查找期间树节点不被释放,但 slot 内容可并发变化page_cache_get_speculative使用原子操作尝试递增引用,避免持有 tree_lockradix_tree_exceptional_entry(page)在pagecache_get_page中把 exceptional 视为”无有效 page”,走no_page分支
(2)__page_cache_alloc:分配物理页帧
当 radix 树中不存在对应 index 的 page(pagecache_get_page 的 FGP_CREAT 分支或预读路径 __do_page_cache_readahead),需要分配一块真实物理内存
// https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/pagemap.h#L204
// include/linux/pagemap.h (v4.11.6)
static inline struct page *__page_cache_alloc(gfp_t gfp)
{
return alloc_pages(gfp, 0); // order=0,从 buddy 分配器分配单个 4KB 物理页
}
// 预读路径中的用法 (mm/readahead.c#L150)
page = __page_cache_alloc(gfp_mask);
if (!page)
break;
page->index = page_offset; // 设置页在文件中的索引
alloc_pages 返回的 struct page 已经关联了 PFN(页帧号),但页内数据此时为未定义内容,需要后续 readpage / BIO 从磁盘 DMA 写入后再 SetPageUptodate
(3)__add_to_page_cache_locked:插入 radix 树
add_to_page_cache_lru 内部调用此__add_to_page_cache_locked函数,将 page 真正挂到文件的 page cache 中(即插入到radix树中)
// https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L608
static int __add_to_page_cache_locked(struct page *page,
struct address_space *mapping, pgoff_t offset,
gfp_t gfp_mask, void **shadowp)
{
int error;
// page 的元数据关联
page->mapping = mapping; // 反向指针:page -> 所属文件的 address_space
page->index = offset; // 页在文件中的索引(和 radix 树 key 一致)
// 在 mapping->page_tree(radix 树)中插入 offset -> page
error = __radix_tree_create(&mapping->page_tree, offset, 0,
&node, &slot);
if (!error) {
mapping->nrpages++; // 该文件的缓存页计数 +1
// 处理 shadow entry(用于 refault distance 统计)
if (shadowp)
*shadowp = __radix_tree_lookup(&mapping->page_tree, offset, ...);
__radix_tree_replace(&mapping->page_tree, node, slot, page, ...);
}
return error;
}
稍微解读下上述代码的逻辑:
TODO
(4)lru_cache_add:加入全局 LRU 链表
// https://elixir.bootlin.com/linux/v4.11.6/source/mm/swap.c#L422
void lru_cache_add(struct page *page)
{
// 不直接操作全局 LRU,而是放入当前 CPU 的 pagevec 缓冲
struct pagevec *pvec = &get_cpu_var(lru_add_pvec);
get_page(page);
if (!pagevec_add(pvec, page))
__pagevec_lru_add(pvec); // pagevec 满了,批量 drain 到 LRU
put_cpu_var(lru_add_pvec);
}
per-CPU pagevec(默认 PAGEVEC_SIZE 个 page 的小数组)起到批量缓冲作用,避免每次插入都竞争全局 zone->lru_lock,__pagevec_lru_add 最终把页加入 inactive 链表
(5)预读路径中的 list_add(&page->lru, &page_pool) + read_pages
在 __do_page_cache_readahead 中,新分配的 page 不会立即调用 add_to_page_cache_lru,而是先挂到本地临时链表 page_pool:
// mm/readahead.c#L150 核心循环(局部)
int __do_page_cache_readahead(struct address_space *mapping, struct file *filp,
pgoff_t offset, unsigned long nr_to_read,
unsigned long lookahead_size){
......
LIST_HEAD(page_pool);
for (page_idx = 0; page_idx < nr_to_read; page_idx++) {
pgoff_t page_offset = offset + page_idx;
// 先检查是否已在 page cache 中
page = radix_tree_lookup(&mapping->page_tree, page_offset);
if (page && !radix_tree_exceptional_entry(page))
continue; // 已在 cache,跳过
page = __page_cache_alloc(gfp_mask); // 分配物理页
page->index = page_offset;
list_add(&page->lru, &page_pool); // ★ 临时链到 page_pool
if (page_idx == nr_to_read - lookahead_size)
SetPageReadahead(page); // ★ 标记预读触发页
ret++;
}
if (ret)
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/readahead.c#L199
read_pages(mapping, filp, &page_pool, ret, gfp_mask);
// read_pages 内部对每个 page:
// add_to_page_cache_lru(page, mapping, page->index, gfp) // 插入 radix + LRU
// mapping->a_ops->readpage(filp, page) // 触发磁盘 I/O
......
}
这样设计的原因是,先批量分配再加标记,再一次性提交 I/O(read_pages函数),配合 blk_start_plug/blk_finish_plug 使多个 BIO 请求可以合并,减少磁盘调度开销
read_pages函数用于从ext4文件系统批量读取pages数据,详细的分析见后文
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/readahead.c#L111
static int read_pages(struct address_space *mapping, struct file *filp,
struct list_head *pages, unsigned int nr_pages, gfp_t gfp)
{
struct blk_plug plug;
unsigned page_idx;
int ret;
blk_start_plug(&plug);
if (mapping->a_ops->readpages) {
//调用ext4文件系统的readpages方法,批量
ret = mapping->a_ops->readpages(filp, mapping, pages, nr_pages);
/* Clean up the remaining pages */
put_pages_list(pages);
goto out;
}
for (page_idx = 0; page_idx < nr_pages; page_idx++) {
struct page *page = lru_to_page(pages);
list_del(&page->lru);
if (!add_to_page_cache_lru(page, mapping, page->index, gfp))
mapping->a_ops->readpage(filp, page);
put_page(page);
}
ret = 0;
out:
blk_finish_plug(&plug);
return ret;
}
(6)SetPageReadahead 宏与 PG_readahead
// include/linux/page-flags.h (v4.11.6)
// PG_readahead 与 PG_reclaim 共享同一 bit(enum pageflags 中 PG_reclaim = 18)
// 通过上下文区分:预读分配时设置 = PG_readahead;页回收路径设置 = PG_reclaim
#define SetPageReadahead(page) set_bit(PG_reclaim, &(page)->flags)
#define PageReadahead(page) test_bit(PG_reclaim, &(page)->flags)
#define ClearPageReadahead(page) clear_bit(PG_reclaim, &(page)->flags)
page_cache_async_readahead入口会ClearPageReadahead(page),防止重复触发- 若 page 正在 writeback 且被标记了
PG_reclaim(回收上下文),此时PageWriteback(page)为真,page_cache_async_readahead会直接return,避免与回收语义冲突
page cache 管理链路串联图:
flowchart TB
subgraph lookup["查找路径"]
A1["find_get_page(mapping, index)"] --> A2["pagecache_get_page(mapping, offset, 0, 0)"]
A2 --> A3["find_get_entry"]
A3 --> A4["rcu_read_lock + radix_tree_lookup_slot"]
A4 --> A5["radix_tree_deref_slot"]
A5 --> A6{"exceptional entry?"}
A6 -->|否| A7["page_cache_get_speculative 增加引用"]
A6 -->|是| A8["视为未命中"]
A7 --> A9["返回 struct page*"]
end
subgraph alloc["分配路径 (预读/no_cached_page)"]
A8 --> B1["__page_cache_alloc -> alloc_pages"]
B1 --> B2["page->index = page_offset"]
B2 --> B3{"预读批量?"}
B3 -->|是| B4["list_add to page_pool"]
B3 -->|否| B5["add_to_page_cache_lru"]
B4 --> B6{"page_idx == nr-lookahead?"}
B6 -->|是| B7["SetPageReadahead"]
B6 -->|否| B8["继续循环"]
B4 --> B9["read_pages 批量提交"]
B9 --> B5
end
subgraph insert["radix 插入 + LRU"]
B5 --> C1["__add_to_page_cache_locked"]
C1 --> C2["radix_tree_insert: index -> page"]
C1 --> C3["page->mapping = mapping"]
B5 --> C4["lru_cache_add"]
C4 --> C5["per-CPU pagevec 缓冲"]
C5 --> C6["__pagevec_lru_add -> inactive 链表"]
end
insert --> D1["readpage: 磁盘 I/O 填充数据"]
0x03 循环处理每一页
流程图
flowchart TB
A["find_get_page(mapping, index)"] --> B{page 在 cache 中?}
B -->|否| C["page_cache_sync_readahead 同步预读"]
C --> D["再次 find_get_page"]
D --> E{page 存在?}
E -->|否| F["no_cached_page: 分配新页 + readpage"]
E -->|是| G{PageReadahead?}
B -->|是| G
G -->|是| H["page_cache_async_readahead 异步预读"]
G -->|否| I{PageUptodate?}
H --> I
I -->|是| J["page_ok: 拷贝数据到用户空间"]
I -->|否| K["wait_on_page_locked / lock_page"]
K --> L{等待后 Uptodate?}
L -->|是| J
L -->|否| M["readpage: 文件系统磁盘读取"]
M --> J
F --> M
J --> N["copy_page_to_iter(page, offset, nr, iter)"]
N --> O["更新 offset, index, written"]
O --> P{用户缓冲区已满?}
P -->|是| Q["goto out: 返回"]
P -->|否| R{拷贝完整?}
R -->|否| S["error = -EFAULT, goto out"]
R -->|是| A
循环的过程:几个位置相关变量的变化
由于内核中文件数据被切分为大小相等的页(通常是 4KB),且Page Cache 是以页为管理单位的radix树,在循环中,有下面几个非常重要的遍历变量:
pgoff_t index; // 当前页索引:find_get_page(mapping, index) 的查找键
pgoff_t last_index; // 最后一页索引:循环终止的上界参考
unsigned long offset; // 页内字节偏移(0~4095):copy_page_to_iter 的起始偏移
pgoff_t prev_index; // 上一次读取的页索引:用于 mark_page_accessed 的顺序性检测
unsigned int prev_offset;// 上一次读取的页内偏移:同上,配合 prev_index 使用
index:当前读取位置所属的页面索引(第几页),继承于*ppos >> PAGE_SHIFT,内核必须先算出index,才能通过find_get_page(mapping, index)去内存radix树里找对应的物理页面offset:当前读取位置在页面内的偏移量(0~4095),继承于*ppos & (PAGE_SIZE - 1),当定位到page时(找到页面后),再利用offset告诉copy_page_to_iter从页面的哪个位置开始把数据搬运给用户last_index:本次读取任务结束位置所属的页面索引,继承于(*ppos + count) >> PAGE_SHIFTprev_index:上一次成功读取后的页面索引(用于预读判断)。从f_ra->prev_pos恢复prev_offset:上一次成功读取后的页内偏移量(用于预读判断)。从f_ra->prev_pos恢复last_index - index:剩余需要读取的页面数量(对应于page_cache_sync_readahead函数的入参req_size)。用于指导预读readahead算法的步长
上面的index与offset的初始值又来自于file对象的f_pos成员(代码中的 *ppos)进行单位换算后的结果。前文描述过f_pos 是一个绝对字节偏移量,而内核为了在页面缓存(Page Cache)中定位数据,必须把它拆解成页面编号和页内偏移
读取是一个for (;;),每处理完一个 page,这些变量会按以下逻辑更新:
//1、初始化值(初始状态,循环开始前)
index = *ppos >> PAGE_SHIFT; //index 指向读取起始点所在的页
offset = *ppos & ~PAGE_MASK; //offset 是起始点在该页内的起始位置
last_index = (*ppos + iter->count + PAGE_SIZE-1) >> PAGE_SHIFT; //last_index 确定了循环何时可能结束
//2、循环体内的变化
//在for循环处理每page中,循环中的同步变化,index/offset都会更新
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
unsigned long nr, ret;
......
//last_index - index 的意义,这个差值被传递给预读函数
//它代表了流水线窗口的大小
//如果 last_index - index 很大,说明用户正准备进行一次大规模的顺序读取,内核会据此触发更大规模的预读(Readahead),提前把磁盘后面的数据页加载进内存
page = find_get_page(mapping, index);
if (!page) {
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
page_ok:
......
/* nr is the maximum number of bytes to copy from this page */
//确定拷贝长度 (nr),通常 nr = PAGE_SIZE
nr = PAGE_SIZE;
// 如果当前 index == last_index(读到了最后一页)
// 则 nr 会被修正为文件末尾或请求末尾的边界
if (index == end_index) {
nr = ((isize - 1) & ~PAGE_MASK) + 1;
if (nr <= offset) {
put_page(page);
goto out;
}
}
//减去起始的 offset 后,剩下的 nr 就是本页要拷贝给用户的字节数
nr = nr - offset;
prev_index = index;
//更新位置 (关键步骤): 当 copy_page_to_iter 成功拷贝了 ret 字节后
ret = copy_page_to_iter(page, offset, nr, iter);
//每当成功拷贝完一个页面的一部分数据(ret 字节)后
//保证了每一次for循环开始时,index 都会准确指向当前处理的那个 struct page
offset += ret; // 页内偏移增加
//如果 offset 达到了 PAGE_SIZE,index 会自增
index += offset >> PAGE_SHIFT; // 如果 offset 溢出到 4096,index 自动加 1
// offset 重新回到 0 (如果跨页)
// 如果是页内读取:offset 增加,index 保持不变
// 如果是跨页读取:当 offset 累加超过 4096 时,index 增加 1,offset 变为 0(或新页的起始偏移)
offset &= ~PAGE_MASK; // offset 重新归零或保留余数
//更新上一次记录 (prev_index / prev_offset)
//prev_index、prev_offset这两个变量在循环末尾更新,并最终写回 filp->f_ra->prev_pos
// 这告诉内核下一次读操作是从哪开始的,是顺序读还是随机读
prev_offset = offset;
......
// 累加
written += ret;
f_pos 的维护机制
当调用用户态的 read(fd, buf, count) 时,内核最终会进入 vfs_read 的函数,进而调用 do_generic_file_read
- 读取前:内核从
file->f_pos中取出进程task_struct对于当前打开文件偏移量,并将其地址作为ppos参数传递 - 读取中:
do_generic_file_read使用*ppos来计算具体的index和offset - 读取后:在
out标签处*ppos = ((loff_t)index << PAGE_SHIFT) + offset,会更新f_pos的值,将计算出的新位置写回了ppos。下一次read调用时,起点就是上一次读取结束的位置
0x04 页缓存命中/未命中处理
do_generic_file_read 主循环中,每次以 index 为 key 调用 find_get_page(mapping, index),其返回值决定后续走命中还是未命中分支。核心判定逻辑如下(对应前文 do_generic_file_read 源码):
// mm/filemap.c do_generic_file_read 主循环核心分支
page = find_get_page(mapping, index);
if (!page) {
// ---- 未命中路径 ----
page_cache_sync_readahead(mapping, ra, filp, index, last_index - index);
page = find_get_page(mapping, index); // 预读后再次查找
if (unlikely(page == NULL))
goto no_cached_page; // 仍无:逐页兜底分配
}
// ---- 命中路径 ----
if (PageReadahead(page)) {
page_cache_async_readahead(mapping, ra, filp, page, index, last_index - index);
}
if (!PageUptodate(page)) {
// 页存在但数据未就绪(I/O 进行中或曾出错)
error = wait_on_page_locked_killable(page);
...
goto page_not_up_to_date;
}
goto page_ok; // 数据就绪,拷贝到用户空间
页缓存命中的说明
命中指 find_get_page 在 mapping->page_tree 的 radix 树中找到有效 struct page*(非 exceptional entry),且引用计数已通过 page_cache_get_speculative 递增
命中后有三种子状态:
PageReadahead(page)为真:当前页是预读标记页,触发page_cache_async_readahead在后台启动下一轮预读(进程不阻塞),然后继续检查数据就绪状态PageUptodate(page)为真:跳转page_ok,直接执行copy_page_to_iter拷贝数据到用户空间!PageUptodate(page):说明 I/O 尚未完成(如预读刚提交 BIO 还没回来),进程在wait_on_page_locked_killable/lock_page_killable处阻塞,等待mpage_end_io回调SetPageUptodate+unlock_page唤醒
命中时不涉及新 page 分配与 radix 插入,仅可能触发异步预读(扩大后续窗口) a
未命中的几种情况说明
未命中分两层处理:
第一层:!page条件,radix 树中无此 index
if (!page) {
// 触发同步预读,批量分配 + 磁盘 I/O
page_cache_sync_readahead(mapping, ra, filp, index, last_index - index);
page = find_get_page(mapping, index); // 预读完成后 page 通常已在 radix 树中
if (unlikely(page == NULL))
goto no_cached_page; // 极端情况:预读后仍无(内存紧张等)
}
page_cache_sync_readahead -> __do_page_cache_readahead:批量 __page_cache_alloc、list_add 到 page_pool、read_pages 提交 ext4/BIO。预读返回后再次查找,page 已在 radix 树中,但 PG_uptodate 可能仍为 0(BIO 进行中)
第二层:no_cached_page标签:预读后仍无 page
no_cached_page:
page = page_cache_alloc_cold(mapping); // __page_cache_alloc(mapping_gfp_mask | __GFP_COLD)
if (!page) { error = -ENOMEM; goto out; }
error = add_to_page_cache_lru(page, mapping, index,
mapping_gfp_constraint(mapping, GFP_KERNEL));
if (error) {
put_page(page);
if (error == -EEXIST) { error = 0; goto find_page; } // 竞争:其他线程已添加
goto out;
}
goto readpage; // mapping->a_ops->readpage(filp, page) 单页磁盘读取
这是逐页兜底路径:本地分配单页,add_to_page_cache_lru 插入 radix + LRU,再调用文件系统 readpage 从磁盘填充
0x05 预读机制
page:单个页的状态
在内核 do_generic_file_read 路径中,根据页面在 Page Cache 中的存在(与否)状态、数据的一致性(Uptodate)以及预读标记(Readahead),主要有以下几种类型:
1、缺失页:在上述流程find_get_page中,在 Radix 树中未找到对应 index 的slot,内核判定为缓存未命中(Cache Miss),此时处理过程如下:
- 内核会触发同步预读机制(
page_cache_sync_readahead),内核认为这是首次读取(或随机跳读),尝试批量从磁盘加载数据 - 再次查找:预读后再次查找Radix树,若仍缺失(如内存极度紧张导致刚加入就被回收),则进入
no_cached_page逻辑 - 手动补齐:调用
page_cache_alloc_cold分配物理页,将其加入 Radix 树,并启动文件系统的a_ops->readpage异步 I/O
2、预读触发页(Readahead Page):页面已在缓存中且有效,但被标记了 PG_readahead 位。这里内核判定进程已读到之前预读窗口的阈值点。处理办法如下:
- 触发异步预读:调用
page_cache_async_readahead,内核会立即在后台启动对下一组连续页面的读取请求 - 非阻塞继续:进程不会因为这个标记而停止,它会清除该页面的标记,然后直接进入数据拷贝流程
内核如此实现的目的是维持 I/O 流水线,确保用户读到后面页面时,数据已经提前就绪
3、未就绪页(Not-Uptodate Page):当页面在 Radix 树中存在,但 PG_uptodate 位为 0。该状态表示页面已被创建,但磁盘数据尚未完全搬运到内存(可能由于之前的预读还在进行中,或者读取出错了等原因),处理办法如下:
- 同步等待:调用
lock_page_killable或wait_on_page_locked_killable - 阻塞进程:进程进入睡眠状态,等待磁盘 DMA 完成并触发中断
- 错误恢复:如果锁释放后发现仍非
Uptodate,则说明之前的读取失败,会尝试重新发起readpage
4、理想页(Uptodate Page):页面在缓存中,且 PG_uptodate被置位,且没有 PG_readahead 标记。该页为最理想的状态,处理如下:
- 直接访问:跳过所有预读和等待逻辑,直接跳转到
page_ok标签 - 数据可交付:执行
copy_page_to_iter,将数据由内核copy到用户态
5、截断/无效页(Truncated Page):查找到了页面,但在处理过程中,该页面被另一个进程从文件的 address_space 中移除了(例如文件被截断 truncate),即page->mapping 为空。内核处理办法如下:
- 释放并重试:执行
put_page(page)减少引用 - 跳转
find_page:返回循环起点重新查找。若文件变小了,后续流程会通过i_size_read判定并直接退出
进入预读的条件
从do_generic_file_read的实现可知,进入预读的条件有两种:
static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos,struct iov_iter *iter, ssize_t written){
......
for (;;) { // 无限循环,处理多个页面
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT)
goto would_block;
page_cache_sync_readahead(mapping, //case1
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index); //重新查找
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(mapping, //case2
ra, filp, page,
index, last_index - index);
}
.......
}
......
}
- radix tree 中没有找到页缓存,触发同步预读
- 找到页缓存且该页面标记上
PG_Readahead,触发异步预读
在整个预读算法中,file_ra_state记录了当前预读状态
数据结构 file_ra_state(预读窗口)
预读状态结构体file_ra_state(预读窗口)定义如下。内核通过该窗口在当前文件读取流中不断后移,实现对文件页(page)的预读
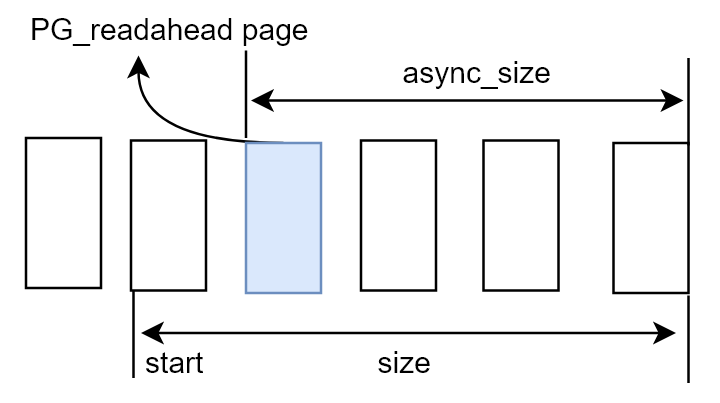
预读(Readahead)算法的核心目标是通过识别用户的读取行为(顺序OR随机),动态调整提前加载到内存中的页面数量,这个提前加载的数量就是预读窗口(Readahead Window)
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/fs.h#L815
struct file_ra_state {
pgoff_t start; // 预读窗口起始页,当前窗口的第一个page索引,初始0
unsigned int size; // 当前预读窗口大小(页面数),当前窗口的页面数量,值为-1表示预读临时关闭,0表示当前窗口为空,初始0
unsigned int async_size; // 异步预读大小,异步预读页面数量,预读窗口还剩余多少未被访问页面时启动下一次预读,初始0
unsigned int ra_pages; // 最大预读页面数,预读窗口最大页面数量。0表示预读暂时关闭,初始32
unsigned int mmap_miss; // mmap 缓存未命中,预读命中率。初始0
loff_t prev_pos; // 上次读取位置, Cache中最近一次读位置。初始-1
};
static inline int ra_has_index(struct file_ra_state *ra, pgoff_t index)
{
return (index >= ra->start &&
index < ra->start + ra->size);
}
static unsigned long get_init_ra_size(unsigned long size, unsigned long max)
{
unsigned long newsize = roundup_pow_of_two(size);
if (newsize <= max / 32)
newsize = newsize * 4;
else if (newsize <= max / 4)
newsize = newsize * 2;
else
newsize = max;
return newsize;
}
static unsigned long get_next_ra_size(struct file_ra_state *ra,
unsigned long max)
{
unsigned long cur = ra->size;
unsigned long newsize;
if (cur < max / 16)
newsize = 4 * cur;
else
newsize = 2 * cur;
return min(newsize, max);
}
file_ra_state结构体维护了readahead 状态信息,相关成员为 start/size/async_size,它们通过O(1)空间来维护 ahead 窗口
start和size二元组构成预读窗口,记录最近一次预读请求的位置start和连续大小sizeasync_size为预读提前量,表示还剩余async_size个未访问页时启动下一次预读
需要注意的是,页索引(page_index)为(size-async_size)的页会被标示为PG_readahead,即表示用户态程序读到该页时需要进行下一次预读,因此async_size的大小决定了当前窗口进行下一次预读并后移的时机,同时PG_readahead只会在某个page(单页)被标记
/*
* The fields in struct file_ra_state represent the most-recently-executed
* readahead attempt:
*
* |<----- async_size ---------|
* |------------------- size -------------------->|
* |==================#===========================|
* ^start ^page marked with PG_readahead
*/
简单描述一次完全顺序执行读请求的预读过程
|、=为单个page#:被标记为PG_readahead的页^:ra->start~:offset当前访问到的值x:文件中待读取的剩余页$:文件页末尾(EOF)
1、初始状态 (Initial)
文件刚打开,预读状态处于冷启动前的初始值。当对一个没有访问过的文件/页进行顺序读时,从 offset = 0,request_size = 1(页为单位)开始,会触发同步预读
|
~
由于没有访问过,file_ra_state中的四元组信息如下:
.start = 0
.size = 0
.async_size = 0
.prev_pos = -1
2、第一次 read (0-4096 字节),内核发现 Page 0 缺失,触发同步预读(ondemand_readahead),预读流程会根据 prev_pos 构造出预读窗口,求出 size 和 async_size,并且在 offset = # 打上 PG_readahead 标记。其中 # 直到右边 | 为 async_size 范围,共预读入 size 大小的页
|===#======|xxxxxxxxxxxxxx$
^
~
3、假设下一次顺序读的起始页(offset)在 ^ 后和 # 前,则不触发预读,由于数据已经被读取到page cache,所以直接返回
|===#======|xxxxxxxxx$
^ ~
4、继续顺序读至 offset = #,则会发出下一次的异步预读
|==========|#======================|xxxxxxxxx$
~ ^
5、预读的过程(位置)会受到文件读取结束位置page的影响,相关代码
readahead 状态
在do_generic_file_read函数中,针对内核设计的文件预读算法,主要是三种状态:
- 首次首部同步预读(第一次读取文件数据)
- 后续异步预读(后续读取,并且命中了预读标识
PG_readahead) - 后续缓存命中读取(缓存命中并且没有进行预读)
以下面的代码为例:
int main()
{
char c[4096];
int in = -1;
in = open("file.txt", O_RDONLY);
int index=0;
//通过用户态调用read系统调用,对文件进行每次4K(4096字节)大小的循环顺序读取
//设置目标读取文件file.txt的大小为128K,预计全部读完需要循环读取32次
while (read(in, &c, 4096/*缓冲区一次4k*/) == 4096)
{
printf("index: %d,len: %ld.\n",index,strlen(c));
memset(c, 0, sizeof(c));
index++;
}
close(in);
return 0;
}
readahead阶段1:首次首部同步预读
第一次调用read->new_sync_read时,参数len=4096,继续执行到do_generic_file_read,该函数首先会获取当然读取文件的struct file,以及本次读取数据在文件内的偏移量loff_t *ppos,从struct file中获取初始预读窗口,初始值只有ra_pages=32(表示窗口最大为32个page),prev_pos=-1表示文件还没有读取过,初始值如下
//struct file_ra_ state *ra = &filp->f_ra;
start=0
size=0
async_size=0
ra_pages=32
mmap_miss=0
prev_pos=-1
接下来do_generic_file_read函数会计算文件内相关页索引以及偏移量,用于计算读取的次数,读取的位置进行读取状态、方式的判断。 页索引(index)初始值为0,表示文件中的第一页数据,核心代码如下:
//页索引
index = *ppos >> PAGE_SHIFT;
//上次页索引
prev_index = ra->prev_pos >> PAGE_SHIFT;
//上次页内偏移量
prev_offset = ra->prev_pos & (PAGE_SIZE-1);
//结束页下标,例如pos读到第1页的数据,则last_index=2
last_index = (*ppos + iter->count + PAGE_SIZE-1) >> PAGE_SHIFT;
//PAGE_MASK是12个0,本次页内偏移量
offset = *ppos & ~PAGE_MASK;
接下来do_generic_file_read函数调用find_get_page,该函数会从该文件inode关联的地址空间(address_space)中尝试读取页索引(index)对应的页(page)。由于是首次读取,该文件的数据页并不会在PageCache中找到,因此会执行同步预读函数page_cache_sync_readahead,实现如下:
首先,判断预读窗口是否处于关闭状态以及检查是否为随机访问模式
// 同步预读一些页面到内存中
// mapping:文件拥有者的addresss_space对象
// ra:包含此页面的文件file_ra_state描述符
// filp:文件对象
// offset:页面在文件内的偏量
// req_size:完成当前读操作需要的页面数
void page_cache_sync_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
pgoff_t offset, unsigned long req_size)
{
/* no read-ahead 预读窗口是否为关闭状态*/
if (!ra->ra_pages)
return;
//当文件模式设置FMODE_RANDOM时,表示文件预期为随机访问
if (filp && (filp->f_mode & FMODE_RANDOM)) {
force_page_cache_readahead(mapping, filp, offset, req_size);
return;
}
/* do read-ahead */
ondemand_readahead(mapping, ra, filp, false, offset, req_size);
}
最后调用ondemand_readahead函数,该函数的主要工作如下:
1、(首次进入)对同步预读窗口进行初始化,通过get_init_ra_size函数计算预读窗口长度(ra->size)
计算窗口长度的函数get_init_ra_size如下:
static unsigned long get_init_ra_size(unsigned long size, unsigned long max){
//size = reqsize = last_index-index;
unsigned long newsize = roundup_pow_of_two(size);//四舍五入到最近的2次幂
if (newsize <= max / 32) //读的小 <1
newsize = newsize * 4; //预读四倍
else if (newsize <= max / 4) //读的中等1-8
newsize = newsize * 2; //预读2倍
else //>8
newsize = max;
return newsize;
}
此时,预读窗口的值更新为如下:
start=0
size=4
async_size=3
ra_pages=32
mmap_miss=0
prev_pos=0
2、(非首次进入)根据预读窗口的当前状态以及offset,调整预读窗口的值
3、当预读窗口取值确定以后,就该调用函数__do_page_cache_readahead进行页的分配与磁盘数据的读取
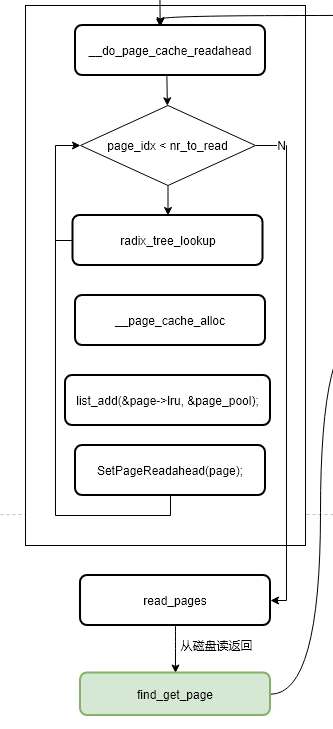
最后,分析下__do_page_cache_readahead的实现
int __do_page_cache_readahead(struct address_space *mapping, struct file *filp,
pgoff_t offset, unsigned long nr_to_read,
unsigned long lookahead_size)
{
......
LIST_HEAD(page_pool);// 将要读取的页存入到这个list当中
......
end_index = ((isize - 1) >> PAGE_SHIFT);
/*
* Preallocate as many pages as we will need.
再次检查页面是否已经被其他进程读进内存,如果没有则申请页面。
nr_to_read是预读窗口的大小,ra->size
*/
for (page_idx = 0; page_idx < nr_to_read; page_idx++) {
pgoff_t page_offset = offset + page_idx;// 计算得到page index
if (page_offset > end_index)// 超过了文件的尺寸就break,停止读取
break;
rcu_read_lock();
//查看是否在page cache,如果已经在了cache中,再判断是否为脏,要不要进行读取
page = radix_tree_lookup(&mapping->page_tree, page_offset);
rcu_read_unlock();
if (page && !radix_tree_exceptional_entry(page))
continue;
// 如果不存在,则创建一个page cache结构
page = __page_cache_alloc(gfp_mask);
if (!page)
break;
// 设定page cache的index
page->index = page_offset;
// 加入到list当中
list_add(&page->lru, &page_pool);
//当分配到第nr_to_read ‐ lookahead_size个页面时,就设置该页面标志PG_readahead,以让下次进行异步预读
if (page_idx == nr_to_read - lookahead_size)
SetPageReadahead(page);
ret++;
}
......
if (ret)
read_pages(mapping, filp, &page_pool, ret, gfp_mask);
......
}
__do_page_cache_readahead的主要流程如下:
1、入参nr_to_read即为本次预读窗口的大小
2、然后循环执行ra->size次,即读取预读窗口中的每个page,调用__page_cache_alloc依次分配page,并保存在链表page_pool中,根据页索引(page_idx = size-async_size)的取值给预读的页设置PageReadahead标识,当用户态程序读到该标识页时进行下一次异步预读
// 这里仅仅只会对唯一的单页进行设置
if (page_idx == nr_to_read - lookahead_size)
SetPageReadahead(page);
3、最后调用read_pages(关联文件系统)进行磁盘读操作,完成后再次执行find_get_page,就能够从缓存中命中页面
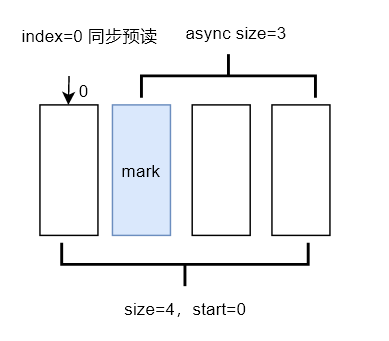
上图展示了首次同步预读后的预读窗口情况,以及当前缓存中数据的状况,用户态当前正在读取的page index 为0,预读窗口size为4,预读4个页面到内存后,给页索引(index=size-async_size)为 1的页设置了预读标识(蓝色),该标识会在下一次用户态程序读到该page时触发异步预读
所以,再次说明了PageReadahead标识只是内核预读算法的一个记号
readahead阶段2:后续异步预读
当第一次用户态read操作读取完成后,用户态程序会进行第二次循环读取read(in, &c, 4096),由于代码设置每次读取一页大小(4k),第二次read系统调用刚好读取page_index = 1的页,do_generic_file_read同样还是率先进行find_get_page,期望能够从page cache中获取到index=1的page
在上面阶段1读取进行同步预读,由于提前预读了下标为0~3的4个页面,本次可以在缓存中命中页面。命中缓存之后,会对当前page进行异步预读标识PageReadahead的判定,即查看当前读取的页面(本次page_index=1)是否被预读窗口标识了预读标识PG_readahead
static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos,struct iov_iter *iter, ssize_t written){
......
if (PageReadahead(page)) {
//检测页标志是否设置了PG_readahead,启动异步预读
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
......
}
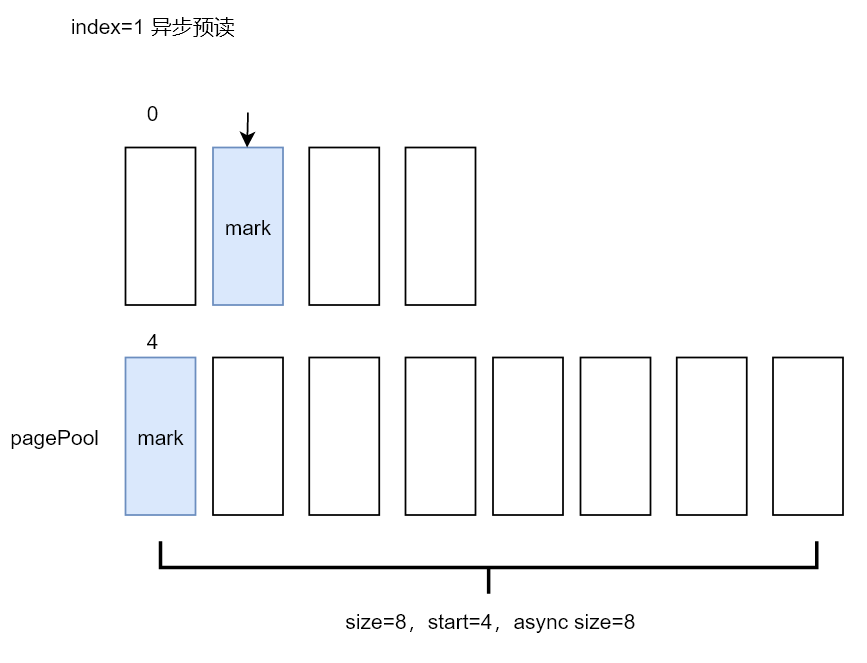
在readahead阶段1同步完成之后,标识了页索引(index)为1的page为PG_readahead,所以本次读取会触发异步预读。触发异步预读之后,page_cache_async_readahead函数的主要工作流程:
- 清除掉当前页面(page)的预读标志
PG_readahead - 同样调用
ondemand_readahead函数(和上面的同步预读相似),不同之处是在ondemand_readahead函数中会重新设置预读窗口长度(ra->size),通常会扩大为原来长度的2/4倍
此时预读窗口的值更新为:
start=4 //表示窗口往后推移了4个页面,将页索引为4的页面作为窗口开始
size=8 //表示窗口的长度扩大为原来的二倍,因为算法觉察到用户态程序是在顺序读取,加大预读的页数
async_size=8 //表示为当前窗口的第一个(index=0)页设置预读标识
ra_pages=32
mmap_miss=0
prev_pos=0
异步预读后的窗口和当前内存缓存页的情况如下图所示,本次预读了index为4~11共8个page,并给index=4的page设置了PG_readahead标识,当前用户态程序读取的page_index=1
readahead阶段3:后续缓存命中读取
至此已经完成两轮read系统调用,由于之前的两次预读,该文件的前12个page已经缓存在内存中(page cache),第三次read会直接命中缓存,并且该页未设置PG_readahead标识,也不会触发异步预读
此时,预读窗口的值更新为如下,本次读取完成后,可以看到预读窗口的大小没有发生变化,只更新了prev_pos,表示上次读文件的起始偏移位置
start=4
size=8
async_size=8
ra_pages=32
mmap_miss=0
prev_pos=8192
当find_get_page函数命中缓存后,会执行pageok标签处的代码片段,然后调用mark_page_accessed函数,为page在其所属的LRU链表中提升等级。其中inactive/unreferenced 为最不活跃页面,active/referenced为最活跃页面
inactive,unreferenced -> inactive,referenced
inactive,referenced -> active,unreferenced
active,unreferenced -> active,referenced
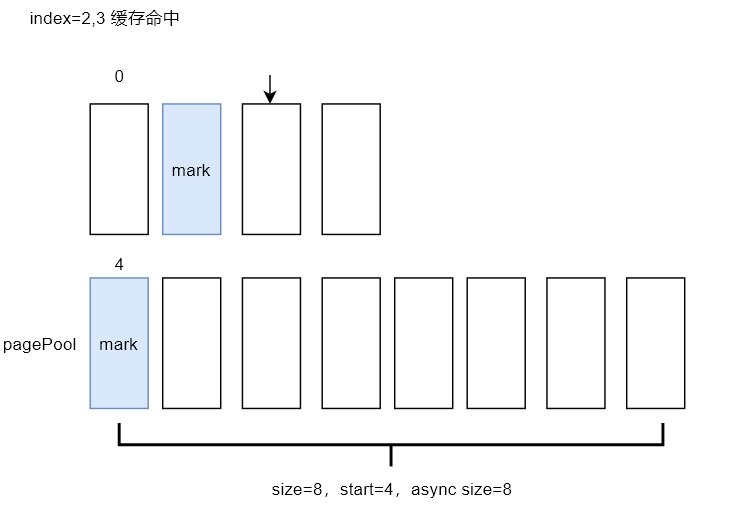
在这个阶段,读取page_index=2,3的页面都会直接命中缓存且不会触发预读机制,当用户态程序快进到读取index=4的page时,内核会再次启动预读
当用户态继续调用read时,读取页索引(page_index)为4的页面,由于page_index=4的页面被标识了PG_readahead,因此会再次启动异步预读,窗口大小变为原来的2倍,即size=16。本次预读了index=12~27,共16个页面,并且index=12的页面会被标识PG_readahead
此时,预读窗口的值更新为如下:
start=12
size=16
async_size=16
ra_pages=32
mmap_miss=0
prev_pos=16384
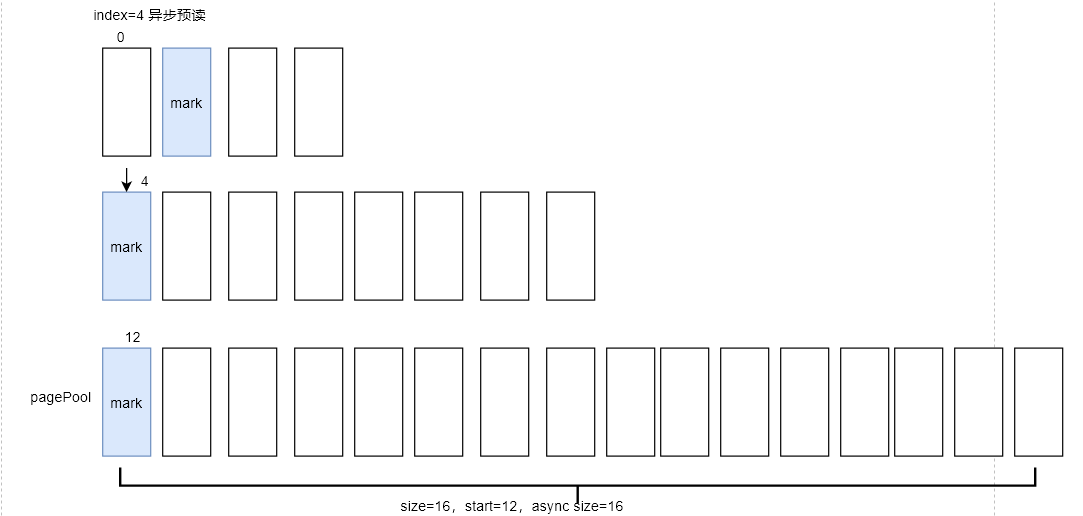
当前用户态程序读取的page_index=4,后面的页面5~11会全部命中缓存,并且不会预读,直接跳到用户态程序读取page_index=12的页面时,内核才会触发异步预读
readahead阶段4:读取page_index=12的页面
本次预读窗口的size会变成32,也就是会预读32个后续page,测试文件的大小为32个页面,上一次已经预读了28个页面index=0~27,本文件还剩余4个页面未被缓存。注意在__do_page_cache_readahead函数中实际分配预读的page时,内核会通过文件的大小,计算文件的最大page_index。同时在分配页面的时候进行判断,若page_index超过了end_index,就会终止页面的分配
int __do_page_cache_readahead(struct address_space *mapping, struct file *filp,
pgoff_t offset, unsigned long nr_to_read,
unsigned long lookahead_size)
{
......
end_index = ((isize - 1) >> PAGE_SHIFT);
......
pgoff_t page_offset = offset + page_idx;// 计算得到page index
......
if (page_offset > end_index)// 超过了文件的尺寸就break,停止读取
break;
......
}
此时,预读窗口的值更新为如下:
start=28
size=32
async_size=32
ra_pages=32
mmap_miss=0
prev_pos=49152
本次异步预读窗口size虽然是32,但是目标文件只有4个剩余page,最终也只会分配4个page进行数据的缓存。最后还会给page_index=28的页面设置PG_readahead标识,当读到该页面时还是会触发异步预读
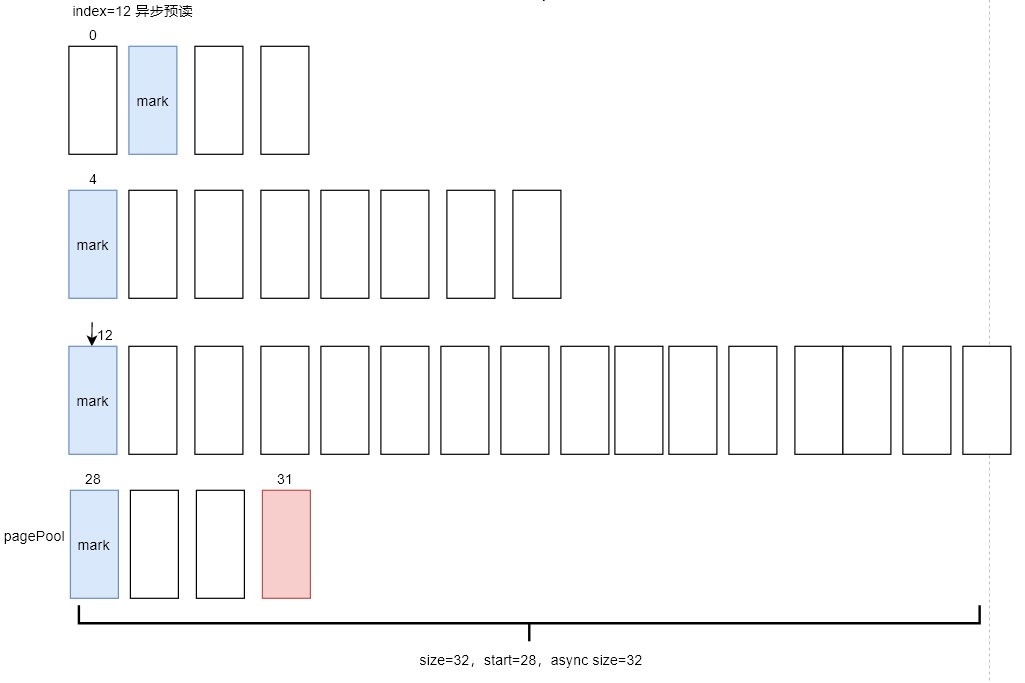
最后,走到读取页索引page_index=28的页面的流程时,此时预读窗口的值更新为如下:
start=28
size=32
async_size=32
ra_pages=32
mmap_miss=0
prev_pos=49152
本次读取窗口size依然会更新,但是窗口size不能大于最大值ra_pages=32,因此本次预读还是32个page(窗口不再更新),同样因为文件已经没有数据,并不会进行实际的page分配和磁盘读取
继续,读取page_index=28的页面后的预读窗口状态:
start=60
size=32
async_size=32
ra_pages=32
mmap_miss=0
prev_pos=114688
读取page_index=31的页面后的预读窗口状态:
start=60
size=32
async_size=32
ra_pages=32
mmap_miss=0
prev_pos=130596
至此整个文件全部读取完成,数据全部缓存在内存中
page_cache_sync_readahead VS page_cache_async_readahead
page_cache_sync_readahead的实现原理
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/readahead.c#L495
void page_cache_sync_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
pgoff_t offset, unsigned long req_size)
{
/* no read-ahead */
if (!ra->ra_pages)
return;
......
/* do read-ahead */
ondemand_readahead(mapping, ra, filp, false/*sync为false*/, offset, req_size);
}
ondemand_readahead函数是预读算法最核心的实现,主要任务是预测用户接下来的读取行为,并提前将数据从磁盘加载到页缓存(Page Cache)中,从而减少 I/O 等待。这个函数本质上是一个状态机,根据当前的读取偏移(offset)、之前的预读状态(ra)以及是否命中了预读标记(hit_readahead_marker)来决定下一步动作。正如前文所说会根据预读状态机及当前读取的参数来决定传入__do_page_cache_readahead 的参数(读多少、在哪设标记),具体流程如下:
1、场景 A,首次顺序读取(初次建仓)或者是重置预读,关联initial_readahead标签
- 文件刚开始读取时(
if (!offset)触发时),第一次读文件,没有任何历史信息,直接从0开始建立预读窗口。当prev_pos == -1且读取连续时,内核会设置一个初始/的ra->size(根据当前读取请求的大小req_size决定)以及ra->async_size做为预读标记的计算因子(满足page_idx == nr_to_read - lookahead_size就会给page_idx位置打上预读标记,其中lookahead_size即为ra->async_size,nr_to_read是__do_page_cache_readahead函数入参),意义为在这一批的第一个页面就打标记,尽快启动下一次预读 - 超大尺寸读取时(
if (req_size > max_pages)触发),用户单次请求的数据量超过了系统默认的最大预读限制。此时不再进行复杂的启发式判断,直接按需读取 - 紧凑的顺序访问(Cache Miss),触发条件为
if (offset - prev_offset <= 1UL),虽然当前预读状态(ra)没匹配上,但当前的offset与上一次读取位置prev_offset是连续的(差0或1个 Page),内核认为这是一个新的顺序流的开始
2、场景B,执行 I/O 提交,关联readit标签
- 预读标记命中(Async Readahead)时:触发条件为
if (hit_readahead_marker),用户读到了之前被标记为PG_readahead的页面。这意味着后台预读跟上了用户的脚步。代码会重新计算start和size,并步进预读窗口 - 完美的顺序流匹配:关联条件为
if (offset == (ra->start + ra->size - ra->async_size) || offset == (ra->start + ra->size)),用户的读取位置正好落在预读窗口的触发点(结束点)。这是预读最理想的情况,直接倍增预读窗口大小,计算逻辑new_size = old_size * 2,对异步策略而言,此时lookahead_size通常等于new_size - 上下文启发式预读成功:关联条件为
if (try_context_readahead(...)),如果不满足简单的顺序逻辑,内核会扫描页缓存,寻找是否存在之前留下的痕迹。如果发现该文件在当前位置附近有连续缓存页,则认为它是顺序流
3、场景C,都不满足(随机读),那么直接返回 I/O,不建立预读窗口
这里有个细节问题:对于同步预读page_cache_sync_readahead和异步预读page_cache_async_readahead,会调用ondemand_readahead,区别在哪里?
对于同步预读而言,在调用上级的触发场景是由当前page缓存缺失(Cache Miss)导致,即当用户尝试读取的 page 不在页缓存中时触发,当前调用进程会阻塞,直到 I/O 请求完成并将数据加载到内存
对异步预读而言,在调用上级的触发是缓存命中(Cache Hit)且命中了带有预读PG_readahead标记的页面,当前调用进程不阻塞,它一边处理已经命中的数据,一边由内核在后台异步启动下一批数据的读取
在 ondemand_readahead 函数内部的逻辑差异,区别主要在入参 hit_readahead_marker,对同步路径hit_readahead_marker = false,函数主要判断这是否是一个新的顺序流:
- 检查连续性:通过
offset - prev_offset判断当前请求是否紧跟上一次请求 - 重置/启动:如果是新流,跳转到
initial_readahead,初始化ra->start为当前offset,并计算一个较小的初始size - 上下文探测: 如果不连续,会通过
try_context_readahead扫描 Page Cache,看看是否有其他进程读过附近的数据,尝试捡起之前的预读流 - 同步预读下,内核会把这一大批 I/O 全部提交。虽然函数叫同步预读,但它发起的请求包含当前急需的页和未来需要的页
而异步路径hit_readahead_marker = true满足时,调用上层函数是踩中标记入口,即内核知道用户已经读到了预读窗口的警戒线,会额外推进预读窗口:
- 确认位置:内核会通过
page_cache_next_hole确认当前缓存的边界 - 推后窗口:它不会从
offset开始,而是将ra->start设置为当前预读窗口之后的第一个 Page - 激进扩张:异步预读通常意味着用户正处于稳定的顺序读取状态,因此它会调用
get_next_ra_size来倍增预读窗口的大小 - 异步预读下,只负责把未来的页面读进来,完全不影响当前正在进行的 Page Cache 拷贝
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/readahead.c#L376
static unsigned long
ondemand_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
bool hit_readahead_marker, pgoff_t offset,
unsigned long req_size)
{
struct backing_dev_info *bdi = inode_to_bdi(mapping->host);
unsigned long max_pages = ra->ra_pages;
pgoff_t prev_offset;
/*
* If the request exceeds the readahead window, allow the read to
* be up to the optimal hardware IO size
*/
if (req_size > max_pages && bdi->io_pages > max_pages)
max_pages = min(req_size, bdi->io_pages);
/*
* start of file
*/
// 初始化时,直接跳转到initial_readahead,进行初始化处理
if (!offset)
goto initial_readahead;
/*
* It's the expected callback offset, assume sequential access.
* Ramp up sizes, and push forward the readahead window.
*/
if ((offset == (ra->start + ra->size - ra->async_size) ||
offset == (ra->start + ra->size))) {
ra->start += ra->size;
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
}
/*
* Hit a marked page without valid readahead state.
* E.g. interleaved reads.
* Query the pagecache for async_size, which normally equals to
* readahead size. Ramp it up and use it as the new readahead size.
*/
//sync模式:false
//async模式:true
if (hit_readahead_marker) {
pgoff_t start;
rcu_read_lock();
start = page_cache_next_hole(mapping, offset + 1, max_pages);
rcu_read_unlock();
if (!start || start - offset > max_pages)
return 0;
ra->start = start;
ra->size = start - offset; /* old async_size */
ra->size += req_size;
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
}
/*
* oversize read
*/
if (req_size > max_pages)
goto initial_readahead; //
/*
* sequential cache miss
* trivial case: (offset - prev_offset) == 1
* unaligned reads: (offset - prev_offset) == 0
*/
prev_offset = (unsigned long long)ra->prev_pos >> PAGE_SHIFT;
if (offset - prev_offset <= 1UL)
goto initial_readahead;
/*
* Query the page cache and look for the traces(cached history pages)
* that a sequential stream would leave behind.
*/
if (try_context_readahead(mapping, ra, offset, req_size, max_pages))
goto readit;
/*
* standalone, small random read
* Read as is, and do not pollute the readahead state.
*/
return __do_page_cache_readahead(mapping, filp, offset, req_size, 0);
initial_readahead:
ra->start = offset;
ra->size = get_init_ra_size(req_size, max_pages);
// 预读算法初始化时:ra->async_size(lookahead_size)的设置规则
// req_size为`last_index - index`,即剩余需要读取的页面数量,用于指导readahead算法的步长
// ra->size为预读算法的窗口长度(由算法更新)
// ra->async_size的初始化值:若窗口长度大于待读取的长度,那么为二者差值,否则等于窗口长度
// 这也容易理解,在预读算法开始时,必须激进一些
// 1. 如果用户请求量较小,那么就将PG_readahead设置的更早一些
// 2. 如果用户请求量较大,超过预读窗口长度,那么就设置预读窗口为下一个PG_readahead
ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size;
readit:
/*
* Will this read hit the readahead marker made by itself?
* If so, trigger the readahead marker hit now, and merge
* the resulted next readahead window into the current one.
*/
if (offset == ra->start && ra->size == ra->async_size) {
ra->async_size = get_next_ra_size(ra, max_pages);
ra->size += ra->async_size;
}
return ra_submit(ra, mapping, filp);
}
最核心的实现__do_page_cache_readahead
static inline unsigned long ra_submit(struct file_ra_state *ra,
struct address_space *mapping, struct file *filp)
{
return __do_page_cache_readahead(mapping, filp,
ra->start, ra->size, ra->async_size/*lookahead_size*/);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/readahead.c#L150
int __do_page_cache_readahead(struct address_space *mapping, struct file *filp,
pgoff_t offset, unsigned long nr_to_read,
unsigned long lookahead_size)
{
/*
1. 关于`lookahead_size`(`ra->async_size`)的意义,定义为**I/O 管道流水线**,从代码可知,此值越大,设置`PG_readahead`的index就越小,就越早出触发预读
2. 如果等 32 页全部读完再启动下一次预读,磁盘会进入空闲状态,等下一次 read 触发 Miss 时才工作,性能会呈锯齿状波动
3. 通过 lookahead_size,在读到第 1 页时,就发出了第 33-64 页的指令
4. 结果:当用户读到第 33 页时,磁盘早就在几毫秒前把数据填好了
*/
struct inode *inode = mapping->host;
struct page *page;
unsigned long end_index; /* The last page we want to read */
LIST_HEAD(page_pool);
int page_idx;
int ret = 0;
loff_t isize = i_size_read(inode);
gfp_t gfp_mask = readahead_gfp_mask(mapping);
if (isize == 0)
goto out;
end_index = ((isize - 1) >> PAGE_SHIFT);
/*
* Preallocate as many pages as we will need.
*/
for (page_idx = 0; page_idx < nr_to_read; page_idx++) {
pgoff_t page_offset = offset + page_idx;
if (page_offset > end_index)
break;
rcu_read_lock();
page = radix_tree_lookup(&mapping->page_tree, page_offset);
rcu_read_unlock();
if (page && !radix_tree_exceptional_entry(page))
continue;
page = __page_cache_alloc(gfp_mask);
if (!page)
break;
page->index = page_offset;
list_add(&page->lru, &page_pool);
if (page_idx == nr_to_read - lookahead_size)
SetPageReadahead(page);
//本次循环中,page cache分配了多少页
//即需要去触发文件系统读多少page
ret++;
}
/*
* Now start the IO. We ignore I/O errors - if the page is not
* uptodate then the caller will launch readpage again, and
* will then handle the error.
*/
if (ret)
read_pages(mapping, filp, &page_pool, ret, gfp_mask);
BUG_ON(!list_empty(&page_pool));
out:
return ret;
}
page_cache_async_readahead的实现原理
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/readahead.c#L530
void page_cache_async_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
struct page *page, pgoff_t offset,
unsigned long req_size)
{
/* no read-ahead */
if (!ra->ra_pages)
return;
/*
* Same bit is used for PG_readahead and PG_reclaim.
*/
if (PageWriteback(page))
return;
ClearPageReadahead(page);
/*
* Defer asynchronous read-ahead on IO congestion.
*/
if (inode_read_congested(mapping->host))
return;
/* do read-ahead */
ondemand_readahead(mapping, ra, filp, true/*async模式为true*/, offset, req_size);
}
0x06 page_ok标签:数据拷贝到用户空间
iov_iter结构的作用:
struct iovec {
void __user *iov_base; // 用户空间缓冲区地址
__kernel_size_t iov_len; // 缓冲区长度
};
struct iov_iter {
const struct iovec *iov; // 当前 iovec
unsigned long nr_segs; // 剩余段数
size_t iov_offset; // 在当前 iovec 中的偏移
size_t count; // 剩余总字节数
......
};
copy_page_to_iter:当page cache中的数据准备好之后,内核调用此函数copy_page_to_iter将数据从内存copy至用户空间的缓冲区。i->type对应四种不同的迭代器类型:
// include/linux/uio.h
#define ITER_IOVEC 0 // 用户空间 iovec,常用于readv/writev, sendmsg/recvmsg
#define ITER_KVEC 1 // 内核空间 kvec,常用于内核内部 I/O
#define ITER_BVEC 2 // 块 I/O 向量,直接 I/O, 块设备操作
#define ITER_PIPE 3 // 管道,关联pipe, splice 系统调用
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/iov_iter.c#L642
//copy_page_to_iter:在read*调用中是内核通过 struct page访问文件内容并拷贝到用户空间的核心实现
/*参数
page:要拷贝的源页面(struct page*)
offset:页面内的字节偏移量
bytes:要拷贝的字节数
i:目标迭代器,表示用户空间缓冲区
*/
size_t copy_page_to_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
if (i->type & (ITER_BVEC|ITER_KVEC)) {
// 处理 bio_vec 或 kvec 类型的迭代器
// 通过kmap_atomic映射页面到内核虚拟地址
void *kaddr = kmap_atomic(page);
// 基于内核的虚拟地址完成copy
size_t wanted = copy_to_iter(kaddr + offset, bytes, i);
// 解除映射
kunmap_atomic(kaddr);
return wanted;
} else if (likely(!(i->type & ITER_PIPE)))
return copy_page_to_iter_iovec(page, offset, bytes, i);
else
return copy_page_to_iter_pipe(page, offset, bytes, i);
}
0x07 copy_page_to_iter 的实现
分支1:copy_page_to_iter对ITER_KVEC类型的处理
关联代码如下:
void *kaddr = kmap_atomic(page);
// 基于内核的虚拟地址完成copy
size_t wanted = copy_to_iter(kaddr + offset, bytes, i);
// 解除映射
kunmap_atomic(kaddr);
在Linux内核中,kmap_atomic函数用于将给定的页面(page)临时映射到内核虚拟地址空间,主要用于高端内存(High Memory)的映射。在x86架构中,对于32位系统,由于虚拟地址空间有限(通常只有4GB),所以需要特殊处理高端内存。而对于64位系统,由于虚拟地址空间巨大(128TB用户空间 + 128TB内核空间),理论上可以不需要高端内存映射,但为了兼容性和优化,内核仍然保留了相关机制
x86_64(64位)的情况: 所有物理内存都位于内核的直接映射区(PAGE_OFFSET ~ PAGE_OFFSET + 物理内存大小),kmap_atomic(page) 实际退化为 page_address(page) -> __va(PFN << PAGE_SHIFT),即线性偏移计算,不涉及页表修改,仅禁用抢占和缺页处理。开销极低
// x86_64 简化路径
static inline void *kmap_atomic(struct page *page)
{
preempt_disable();
pagefault_disable();
return page_address(page); // == __va(page_to_pfn(page) << PAGE_SHIFT)
}
x86_32(32位,HIGHMEM)的情况: 物理内存超过 896MB 的部分(高端内存)无法直接映射到内核虚拟地址空间,kmap_atomic 需要在 fixmap 区域建立临时 PTE 映射(set_pte_at),此处会发生内核页表写入。每个 CPU 有固定数量的映射槽位,使用完毕后通过 kunmap_atomic 释放
size_t copy_to_iter(const void *addr, size_t bytes, struct iov_iter *i)
{
const char *from = addr;
if (unlikely(i->type & ITER_PIPE))
return copy_pipe_to_iter(addr, bytes, i);
iterate_and_advance(i, bytes, v,
__copy_to_user(v.iov_base, (from += v.iov_len) - v.iov_len,
v.iov_len),
memcpy_to_page(v.bv_page, v.bv_offset,
(from += v.bv_len) - v.bv_len, v.bv_len),
memcpy(v.iov_base, (from += v.iov_len) - v.iov_len, v.iov_len)
)
return bytes;
}
这里有一个细节问题,为何copy_to_iter的addr参数需要先把page转为内核虚拟地址呢?思考前文介绍的内核页表转换机制,涉及到内核内存管理和虚拟地址映射,内核需要虚拟地址访问物理内存
copy_to_iter需要内核虚拟地址作为源数据指针,而 struct page本身不提供这个地址,所以必须先用kmap_atomic(page)将物理页面映射到内核虚拟地址空间,然后将映射后的地址传递给 copy_to_iter
先回顾下CPU 工作原理,CPU 只能通过虚拟地址访问内存。当内核需要读写物理内存中的数据时,必须先建立虚拟地址到物理地址的映射
// CPU访问流程
CPU发出指令:mov [0xffff888012345678], eax
|
MMU查找页表:虚拟地址 0xffff888012345678 -> 物理地址 0x12345678
|
内存控制器访问物理内存地址 0x12345678
kmap_atomic 的作用
kmap_atomic是原子操作,作用是建立临时映射,从而使内核能访问物理页面,映射过程如下:
物理页面 (PFN 0x12345)
| 通过 page_to_pfn(page) 获取页帧号
物理地址 = 0x12345000
| 通过 kmap_atomic 建立映射
内核虚拟地址 = 0xffffc90001234500
//for x86_64
void *kmap_atomic(struct page *page)
{
// 如果是低端内存,直接计算地址
if (!PageHighMem(page))
return page_address(page); // 页面地址可以直接计算
// 高端内存:分配固定映射槽位
idx = type + KM_TYPE_NR * smp_processor_id();
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
// 建立页表项:虚拟地址->物理页面
set_pte_at(&init_mm, vaddr, mk_pte(page, kmap_prot));
return (void *)vaddr;
}
低端内存(Low Memory)与高端内存(High Memory)的处理差异:
| 维度 | 低端内存(ZONE_NORMAL) | 高端内存(ZONE_HIGHMEM) |
|---|---|---|
| 适用架构 | x86_32/x86_64 | 仅 x86_32 |
| 物理地址范围 | 0 ~ 896MB |
896MB 以上 |
| 内核虚拟地址 | 直接映射区,__va(phys) |
无永久映射,需 kmap/kmap_atomic |
kmap_atomic 行为 |
page_address(page) 直接返回 |
在 fixmap 区分配槽位,set_pte_at 建立临时映射 |
| 页表操作 | 无 | 有,修改内核页表 PTE |
在 x86_64 上不存在高端内存概念,PageHighMem(page) 始终返回 false,因此 kmap_atomic 永远走低端内存的快速路径
copy_to_iter的实现
继续回到copy_to_iter(kaddr + offset, bytes, i)的调用,这里入参kaddr + offset也说明了从这个虚拟地址开始读取数据,其内部实现操作都需要使用虚拟内存地址
//addr: 内核虚拟地址,指向源数据
//bytes: 要拷贝的字节数
//i: 目标迭代器
size_t copy_to_iter(const void *addr, size_t bytes, struct iov_iter *i)
{
const char *from = addr; //虚拟内存地址
if (unlikely(i->type & ITER_PIPE))
//用于从页缓存拷贝到管道的场景,非零拷贝
return copy_pipe_to_iter(addr, bytes, i);
iterate_and_advance(i, bytes, v,
//下面函数都需要源地址作为参数,而这个源地址必须是可寻址的内核虚拟地址
// 对于 ITER_IOVEC(用户空间缓冲区)
__copy_to_user(v.iov_base, (from += v.iov_len) - v.iov_len,
v.iov_len),
// 对于 ITER_BVEC(块I/O向量)
memcpy_to_page(v.bv_page, v.bv_offset,
(from += v.bv_len) - v.bv_len, v.bv_len),
// 对于 ITER_KVEC(内核空间缓冲区)
memcpy(v.iov_base, (from += v.iov_len) - v.iov_len, v.iov_len)
)
return bytes;
}
上面iterate_and_advance是一个宏定义,简化定义如下:
#define iterate_and_advance(i, n, v, I, B, K) \
while (n) { \
// 获取当前的段 \
v = i->current_segment(); \
\
// 计算这次可拷贝的长度 \
size_t len = min(n, v.len); \
\
if (iov_iter_is_iovec(i)) { \
// 对于iovec:用户空间拷贝 \
__copy_to_user(v.iov_base, from, len); \
} else if (iov_iter_is_bvec(i)) { \
// 对于bvec:页面拷贝 \
memcpy_to_page(v.bv_page, v.bv_offset, \
from, len); \
} else { \
// 对于kvec:内核空间拷贝 \
memcpy(v.iov_base, from, len); \
} \
\
from += len; \
n -= len; \
i->advance(len); \
}
copy_page_to_iter_iovec的实现
copy_page_to_iter_iovec将一个内存页面的数据拷贝到由 iovec 数组描述的用户空间缓冲区
//page:源页面
//offset:页面内的偏移量
//bytes:要拷贝的字节数
//i:迭代器,包含 iovec 数组信息
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/iov_iter.c#L133
static size_t copy_page_to_iter_iovec(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
size_t skip, copy, left, wanted;
const struct iovec *iov;
char __user *buf;
void *kaddr, *from;
if (unlikely(bytes > i->count))
bytes = i->count; // 不能超过迭代器中剩余字节数
if (unlikely(!bytes))
return 0; // 没有要拷贝的字节
wanted = bytes; // 保存原始请求的字节数(用户请求的字节数)
iov = i->iov; // 获取当前 iovec(当前 iovec 结构指针)
skip = i->iov_offset; // 当前 iovec 中的偏移(在当前 iovec 中已处理的字节数)
buf = iov->iov_base + skip; // 目标用户空间地址(目标用户空间缓冲区地址)
copy = min(bytes, iov->iov_len - skip); // 本次可拷贝的字节数(本次调用可拷贝的字节数,取最小)
//针对高端内存优化路径
//fault_in_pages_writeable:由于在快速路径中,__copy_to_user_inatomic不处理缺页
//的情况,所以调用此函数预故障处理,提前触发可能的缺页异常,如果用户空间地址不可写,会返回非0
//fault_in_pages_writeable:提前触发可能的缺页异常,避免在原子上下文中处理
if (IS_ENABLED(CONFIG_HIGHMEM) && !fault_in_pages_writeable(buf, copy)) {
kaddr = kmap_atomic(page); // 原子映射页面(很眼熟)
from = kaddr + offset; // 源地址
/* first chunk, usually the only one */
// 第一个块,通常是唯一的一个块
// __copy_to_user_inatomic:原子的拷贝到用户空间,不会休眠,适合原子上下文;返回未能拷贝的字节数(0表示成功)
left = __copy_to_user_inatomic(buf, from, copy);
copy -= left; // 减去未能拷贝的字节
skip += copy; // 更新当前 iovec 的偏移
from += copy; // 更新源地址偏移
bytes -= copy; // 更新剩余字节数
//case2:处理多个 iovec 的情况
//这里循环处理的原因:用户缓冲区由多个 iovec 组成
//第一个 iovec 填满后,继续填充下一个
//直到所有字节拷贝完成或遇到错误
while (unlikely(!left && bytes)) {
iov++; // 移动到下一个 iovec
buf = iov->iov_base; // 新的目标地址
copy = min(bytes, iov->iov_len); // 计算本次可拷贝的字节数
left = __copy_to_user_inatomic(buf, from, copy);
copy -= left; // 减去失败的字节
skip = copy; // 更新跳过字节数
from += copy; // 更新源地址
bytes -= copy; // 更新剩余字节
}
if (likely(!bytes)) {
// 所有字节已拷贝,跳转到结束处理
kunmap_atomic(kaddr);
goto done;
}
offset = from - kaddr; // 计算新的偏移
buf += copy; // 更新目标地址
kunmap_atomic(kaddr); // 解除原子映射
copy = min(bytes, iov->iov_len - skip); // 重新计算可拷贝字节
}
/* Too bad - revert to non-atomic kmap */
//回退到非原子映射,为什么要回退呢?原因如下:
//1. 原子映射只适合短时间持有
//2. 如果拷贝没有完成,需要回退到普通映射
kaddr = kmap(page); //注意:这里更换为普通映射
from = kaddr + offset;
left = __copy_to_user(buf, from, copy);
copy -= left;
skip += copy;
from += copy;
bytes -= copy;
while (unlikely(!left && bytes)) {
iov++;
buf = iov->iov_base;
copy = min(bytes, iov->iov_len);
left = __copy_to_user(buf, from, copy);
copy -= left;
skip = copy;
from += copy;
bytes -= copy;
}
kunmap(page); // 解除普通映射
//更新迭代器状态
done:
if (skip == iov->iov_len) { // 当前 iovec 已满
iov++; // 移动到下一个
skip = 0; // 重置偏移
}
i->count -= wanted - bytes;
i->nr_segs -= iov - i->iov;
i->iov = iov;
i->iov_offset = skip;
return wanted - bytes;
}
在上面实现中,__copy_to_user_inatomic用于原子拷贝,而__copy_to_user是非原子的,此外前者原子操作,不处理缺页;而后者可能休眠,可处理缺页
0x08 总结:从 page 到用户缓冲区的完整数据链路
小节下,do_generic_file_read 中数据从 page cache 到用户空间的完整过程,分为三个阶段
flowchart TB
subgraph phase1["阶段1: 获取 page 元数据"]
A["do_generic_file_read 循环"] --> B["find_get_page(mapping, index)"]
B --> C["radix tree 查找"]
C --> D["返回 struct page* (内核元数据指针)"]
D --> E["page* 指向 mem_map 数组元素"]
end
subgraph phase2["阶段2: page 转内核虚拟地址"]
E --> F["copy_page_to_iter(page, offset, nr, iter)"]
F --> G{"iter 类型判断"}
G -->|"ITER_IOVEC"| H["copy_page_to_iter_iovec"]
G -->|"ITER_KVEC/BVEC"| I["kmap_atomic(page)"]
G -->|"ITER_PIPE"| J["零拷贝: get_page 引用"]
H --> K["kmap_atomic(page) 快速路径"]
I --> L["page_address: __va(PFN<<PAGE_SHIFT)"]
K --> L
L --> M["得到内核虚拟地址 kaddr"]
end
subgraph phase3["阶段3: 数据写入用户空间"]
M --> N["__copy_to_user_inatomic(buf, kaddr+offset, len)"]
N --> O["x86_64: rep movsb/movsq"]
O --> P{"MMU查询用户页表"}
P -->|"PTE有效"| Q["数据直接写入物理页"]
P -->|"PTE无效"| R["#PF 缺页中断"]
R --> S["do_page_fault -> handle_mm_fault"]
S --> T["分配物理页, 建立用户PTE"]
T --> Q
Q --> U["kunmap_atomic / kunmap"]
U --> V["更新 iov_iter 状态"]
V --> W["put_page 释放引用"]
end
阶段 1:拿到 page 地址(struct page* 的性质)
find_get_page(mapping, index) 从 radix tree 中查找到的 struct page* 指向全局 mem_map 数组中的结构体(FLATMEM 模型),它是 page 的管理元数据(引用计数、flags、mapping 等),而非 page 所承载的 4KB 文件数据本身。核心区别:
struct page*:内核虚拟地址,指向mem_map[PFN](元数据结构体)- page 的物理数据:位于物理内存
PFN << PAGE_SHIFT处,CPU 不能直接用物理地址访问 - 重要:要读取 page 的文件数据内容,必须先将物理页映射为内核可访问的虚拟地址
源码引用(find_get_page -> pagecache_get_page -> find_get_entry -> radix_tree_lookup_slot)已在前文详述
此处重点强调:struct page* 是元数据指针,不是数据地址。与物理页帧数据的对应关系:
// 从 struct page* 获取物理页帧数据的地址(v4.11.6)
unsigned long pfn = page_to_pfn(page); // 页帧号 = page - mem_map
void *kaddr = page_address(page); // x86_64: __va(pfn << PAGE_SHIFT)
// kaddr 是内核虚拟地址,指向 4KB 文件数据
// 直接映射区公式: kaddr = (void *)(PAGE_OFFSET + (pfn << PAGE_SHIFT))
page_to_pfn(page) 本质是 page - mem_map(数组偏移),page_address 在 x86_64 下通过 __va 宏做线性偏移得到内核 VA。这一步不涉及 MMU 页表查询
阶段 2:从 page 获取实际数据(kmap_atomic 地址转换)
源码路径(v4.11.6):
copy_page_to_iter(page, offset, nr, iter)
├── [ITER_BVEC|ITER_KVEC] kmap_atomic(page) -> copy_to_iter(kaddr+offset, ...) -> kunmap_atomic()
├── [ITER_IOVEC] copy_page_to_iter_iovec(page, offset, bytes, i)
│ ├── [快速路径] kmap_atomic(page) -> __copy_to_user_inatomic() -> kunmap_atomic()
│ └── [慢速路径] kmap(page) -> __copy_to_user() -> kunmap()
└── [ITER_PIPE] copy_page_to_iter_pipe(page, ...) -- 零拷贝,仅增加引用
kmap_atomic 在不同架构上的行为差异:
x86_64(64-bit):所有物理内存都在内核的直接映射区(PAGE_OFFSET ~ PAGE_OFFSET + 物理内存大小),kmap_atomic(page) 退化为 page_address(page) -> __va(PFN << PAGE_SHIFT),即线性偏移计算,不涉及页表修改,仅禁用抢占,开销极低
// x86_64 简化路径
static inline void *kmap_atomic(struct page *page)
{
preempt_disable();
pagefault_disable();
return page_address(page); // == __va(page_to_pfn(page) << PAGE_SHIFT)
}
x86_32(32-bit,HIGHMEM):物理内存超过 896MB 的部分无法直接映射,kmap_atomic 需要在 fixmap 区域建立临时 PTE 映射(set_pte_at),此处发生内核页表写入
此阶段的页表操作总结:
- x86_64 上:无页表查询/修改。
kmap_atomic仅做线性地址计算 - x86_32 HIGHMEM 上:内核页表写入。
set_pte_at建立 fixmap -> 物理页的映射
阶段 3:数据写入用户缓冲区(copy_to_user 与缺页中断)
这是页表查询和缺页中断的核心发生位置。当内核拿到物理内存页 page 的内核虚拟地址 kaddr 后,执行 __copy_to_user(buf, kaddr + offset, len) 将数据写入用户空间。过程如下:
3a. MMU 硬件页表查询
CPU 执行 rep movsb/rep movsq(x86_64 汇编 copy_user_generic_string)时:
- 源地址(
kaddr+offset):内核直接映射区虚拟地址,因为内核页表中有永久映射,MMU 查询内核页表 -> 命中 - 目标地址(
buf,即用户传入的iov_base):用户态虚拟地址,MMU 查询当前进程的用户态页表- 若 PTE 存在且可写 -> 直接写入物理页
- 若 PTE 不存在/无写权限 -> 触发缺页异常(#PF)
3b. 缺页中断发生场景
用户调用 read(fd, buf, 4096)
buf = malloc(4096) -- 此时 buf 对应的虚拟页可能还没有分配物理页
-- malloc 使用 brk/mmap 扩展虚拟地址空间
-- 但物理页分配是惰性的(demand paging)
|
v
内核 __copy_to_user(buf, kaddr, 4096)
CPU 写入 buf 地址 -> MMU 查询用户页表 -> PTE 无效
-> #PF 缺页异常 -> do_page_fault()
-> handle_mm_fault() -> 分配物理页,建立 PTE
-> 返回 __copy_to_user 继续执行
3c. 异常表机制(Exception Table)
__copy_to_user 的 x86_64 汇编实现(arch/x86/lib/copy_user_64.S)使用 _ASM_EXTABLE_UA 宏注册异常处理入口。当缺页处理失败(如用户传入非法地址)时:
- 缺页处理程序通过异常表查找 fixup 地址
- 跳转到 fixup 代码,将未拷贝字节数写入
rcx并返回 - 上层
copy_page_to_iter_iovec检测到left > 0,最终do_generic_file_read设置error = -EFAULT
3d. copy_to_user vs __copy_to_user 的区别
copy_to_user(to, from, n)=access_ok(to, n)+__copy_to_user(to, from, n)__copy_to_user跳过access_ok检查,适用于已预先验证地址的场景__copy_to_user_inatomic额外特点:不会主动触发缺页处理(pagefault_disable上下文),用于kmap_atomic快速路径
3e. 用户态 read 返回后
当read() 返回到用户空间后,用户程序访问 buf 中的数据不会再触发缺页,因为 __copy_to_user 在内核态已经完成了物理页分配 + PTE 建立 + 数据写入
mmap 缺页 vs __copy_to_user 缺页的区别?
这是一个容易混淆的问题,二者在缺页中断下都可能走到 handle_mm_fault,但入口路径、上下文标志和错误恢复机制有本质差异
(I)两种缺页的触发场景
场景A:mmap 缺页(用户态触发)
用户程序:char *p = mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_ANONYMOUS|MAP_PRIVATE, -1, 0);
*p = 'A'; // 首次写入 → CPU 在用户态执行写操作 → PTE 不存在 → #PF
// error_code: X86_PF_WRITE | X86_PF_USER (bit1=1, bit2=1)
场景B:__copy_to_user 缺页(内核态触发)
用户程序:read(fd, buf, 4096); // buf 由 malloc 分配,物理页可能未映射
内核路径:do_generic_file_read → copy_page_to_iter → __copy_to_user(buf, kaddr, len)
// CPU 在内核态执行 rep movsb 写入 buf → PTE 不存在 → #PF
// error_code: X86_PF_WRITE (bit1=1, bit2=0 因为是内核态)
(II)入口路径对比(v4.11.6 的 __do_page_fault)
v4.11.6 中缺页处理入口是统一的 __do_page_fault(注:较新内核拆分为 do_kern_addr_fault + do_user_addr_fault)。关键判断流程:
// arch/x86/mm/fault.c (v4.11.6 简化)
static noinline void __do_page_fault(struct pt_regs *regs,
unsigned long error_code,
unsigned long address)
{
struct mm_struct *mm = current->mm;
// 1. 如果 address 在内核空间 → vmalloc_fault 或 oops
if (unlikely(fault_in_kernel_space(address)))
goto kernel_space_fault;
// 2. address 在用户空间(不论触发者是用户态还是内核态)
// __copy_to_user: address=buf 在用户空间,但 error_code 无 X86_PF_USER
// mmap 访问: address 在用户空间,error_code 有 X86_PF_USER
// 3. 检查是否禁用了缺页处理(__copy_to_user_inatomic 场景)
if (unlikely(faulthandler_disabled() || !mm)) {
// kmap_atomic 上下文中 pagefault_disable() 已调用
// faulthandler_disabled() 返回 true
// 不会调用 handle_mm_fault,直接走 exception table
goto no_context;
}
// 4. 获取 mmap_sem,查找 VMA
vma = find_vma(mm, address);
if (!vma || vma->vm_start > address)
goto bad_area;
// 5. 权限检查
if (access_error(error_code, vma))
goto bad_area;
// 6. 核心:调用 handle_mm_fault
// mmap 缺页和 __copy_to_user 缺页,走到这里后逻辑完全相同
fault = handle_mm_fault(vma, address, flags);
// 7. 差异点:错误恢复
if (unlikely(fault & VM_FAULT_ERROR)) { ... }
return;
bad_area:
// 用户态触发 → 发送 SIGSEGV
if (error_code & X86_PF_USER) {
force_sig_fault(SIGSEGV, ...);
return;
}
// 内核态触发(__copy_to_user)→ 走 exception table
goto no_context;
no_context:
// 在异常表中查找 fixup 地址
if (fixup_exception(regs, X86_TRAP_PF, error_code, address))
return; // 跳转到 fixup 代码,__copy_to_user 返回未拷贝字节数
// 找不到 fixup → kernel oops
}
关键点:v4.11.6 的 __do_page_fault 根据访问的地址(是否在用户空间)来判断走哪条路径,而不是根据 X86_PF_USER 位。因此对于 __copy_to_user 写用户地址的场景,虽然 CPU 处于内核态,但目标地址在用户空间,依然会进入 find_vma -> handle_mm_fault 流程
(III)handle_mm_fault 内部逻辑:完全相同
当两种缺页都成功走到 handle_mm_fault 时,内部的处理逻辑没有区别:
handle_mm_fault(vma, address, flags)
→ handle_pte_fault(vmf)
→ 如果 PTE 不存在 + VMA 是匿名映射 → do_anonymous_page() // 分配零页
→ 如果 PTE 不存在 + VMA 是文件映射 → do_fault() // filemap_fault
→ 如果 PTE 存在但不可写 + 写访问 → do_wp_page() // COW
→ 如果 PTE 存在但页被 swap out → do_swap_page() // swap in
无论是用户态 *p = 'A' 触发还是内核态 __copy_to_user(buf, ...) 触发,只要 buf 落在一个合法的 VMA 中,handle_mm_fault 都会用相同的逻辑分配物理页、建立 PTE。这是因为 handle_mm_fault 关心的是”VMA 描述的映射属性”,而不是”谁触发了这次访问”
(IV)FAULT_FLAG 差异
构造传入 handle_mm_fault 的 flags 时,有一个标志位不同:
- mmap 缺页:
flags |= FAULT_FLAG_USER(因为error_code & X86_PF_USER) __copy_to_user缺页:flags不含FAULT_FLAG_USER
但 FAULT_FLAG_USER 在 handle_mm_fault 内部仅用于统计和审计(如 perf 的 major-faults/minor-faults 计数归属于哪个上下文),不影响缺页处理的核心逻辑(页面分配、PTE 建立等)。FAULT_FLAG_WRITE 取决于访问类型,两种场景下都会设置此标志
(V)错误恢复的本质差异(最重要的区别)
| 维度 | mmap 缺页(用户态) | __copy_to_user 缺页(内核态) |
|---|---|---|
| error_code | X86_PF_USER 置位 |
X86_PF_USER 未置位 |
handle_mm_fault 成功 |
返回用户态继续执行 | 返回到 rep movsb 继续拷贝 |
| VMA 不存在 / 权限错误 | 发送 SIGSEGV 杀死进程 |
查异常表 fixup -> 返回未拷贝字节数 -> 上层设置 -EFAULT |
handle_mm_fault 返回 OOM |
触发 OOM killer | 同上,走 fixup 返回错误 |
(VI)特殊情况:__copy_to_user_inatomic 完全不触发 handle_mm_fault
在 copy_page_to_iter_iovec 的快速路径中:
kmap_atomic(page) <- pagefault_disable() + preempt_disable()
__copy_to_user_inatomic() <- 如果触发 #PF:
__do_page_fault 检测 faulthandler_disabled() == true
直接跳转 no_context --> fixup_exception
handle_mm_fault 根本不会被调用
kunmap_atomic()
这就是为什么快速路径需要 fault_in_pages_writeable(buf, copy) 预热的原因,提前在非原子上下文中主动触发一次写入用户地址,让正常的缺页处理分配物理页并建立 PTE。这样进入原子上下文后,__copy_to_user_inatomic 大概率不会遇到缺页
缺页对比 mermaid 图:
flowchart TB
subgraph trigger["缺页触发"]
A1["用户态: *p = 'A'<br/>(mmap 匿名页首次写)"]
A2["内核态: __copy_to_user(buf, kaddr, len)<br/>(read 系统调用中)"]
A3["内核态: __copy_to_user_inatomic<br/>(kmap_atomic 原子上下文)"]
end
subgraph pagefault["#PF 缺页异常"]
A1 --> B1["error_code: PF_WRITE | PF_USER"]
A2 --> B2["error_code: PF_WRITE (无 PF_USER)"]
A3 --> B3["error_code: PF_WRITE (无 PF_USER)"]
end
subgraph handler["__do_page_fault"]
B1 --> C["address 在用户空间"]
B2 --> C
B3 --> D{"faulthandler_disabled?"}
D -->|"是 (原子上下文)"| E["跳过 handle_mm_fault"]
D -->|"否"| C
C --> F["find_vma + access_error"]
F --> G["handle_mm_fault(vma, addr, flags)"]
G --> H["handle_pte_fault: 相同逻辑"]
H --> I["分配物理页 + 建立PTE"]
end
subgraph recovery["错误恢复"]
I --> J1["mmap: 返回用户态继续"]
I --> J2["copy_to_user: 返回内核继续 rep movsb"]
E --> K["fixup_exception: 返回未拷贝字节数"]
F -->|"VMA不存在"| L1["mmap: SIGSEGV"]
F -->|"VMA不存在"| L2["copy_to_user: fixup -> -EFAULT"]
end
copy_to_iter 完整调用链深入分析
本小节独立详细分析从 copy_page_to_iter 到底层拷贝函数的完整调用链路:
copy_page_to_iter(page, offset, bytes, i)
|
+-- [ITER_BVEC|ITER_KVEC 路径]
| kmap_atomic(page)
| copy_to_iter(kaddr + offset, bytes, i)
| iterate_and_advance(i, bytes, v, I, B, K)
| |-- [ITER_IOVEC] __copy_to_user(v.iov_base, from, v.iov_len)
| |-- [ITER_BVEC] memcpy_to_page(v.bv_page, v.bv_offset, from, v.bv_len)
| +-- [ITER_KVEC] memcpy(v.iov_base, from, v.iov_len)
| kunmap_atomic(kaddr)
|
+-- [ITER_IOVEC 路径 - read() 最常见场景]
| copy_page_to_iter_iovec(page, offset, bytes, i)
| [快速路径] fault_in_pages_writeable(buf, copy)
| kmap_atomic(page)
| __copy_to_user_inatomic(buf, from, copy)
| kunmap_atomic(kaddr)
| [慢速路径] kmap(page)
| __copy_to_user(buf, from, copy)
| kunmap(page)
|
+-- [ITER_PIPE 路径 - splice 零拷贝]
copy_page_to_iter_pipe(page, offset, bytes, i)
get_page(page) -- 仅增加引用计数,无数据拷贝
(A)iterate_and_advance 宏展开分析
该宏接受回调参数 (i, n, v, I, B, K) 分别对应 IOVEC / BVEC / KVEC 三种迭代器类型。核心逻辑:
- 按段(segment)迭代
iov_iter,每段计算min(n, segment_len - skip)作为本次拷贝长度 - 对 ITER_IOVEC 路径,
v展开为struct iovec,回调I展开为__copy_to_user(v.iov_base, from, v.iov_len) - 对 ITER_BVEC 路径,
v展开为struct bio_vec,回调B展开为memcpy_to_page(...) - 对 ITER_KVEC 路径,回调
K展开为memcpy(v.iov_base, from, v.iov_len) - 每次回调完成后自动推进
i->iov_offset、i->nr_segs、i->count
(B)__copy_to_user 的 x86_64 底层实现
__copy_to_user -> copy_user_generic -> 根据 CPU feature 选择实现:
copy_user_generic_string(REP_GOOD 特性):使用rep movsq+rep movsbcopy_user_enhanced_fast_string(ERMS 特性):使用rep movsbcopy_user_generic_unrolled(旧 CPU fallback):手动展开的拷贝循环
输入约定为rdi=目标(用户地址),rsi=源(内核地址),rcx=字节数。返回值为rcx 中的未拷贝字节数(0 表示成功)。_ASM_EXTABLE_UA 异常表注册,每条可能触发 #PF 的指令都注册了 fixup 入口
(C)__copy_to_user_inatomic vs __copy_to_user 对比
| 特性 | __copy_to_user_inatomic |
__copy_to_user |
|---|---|---|
| 上下文 | 原子(pagefault_disable) |
可休眠 |
| 缺页处理 | 不处理,直接返回未拷贝字节数 | 会触发缺页处理程序 |
| 前置条件 | 需 fault_in_pages_writeable 预热 |
无需预热 |
| 使用场景 | kmap_atomic 快速路径 |
kmap 慢速回退路径 |
(D)memcpy_to_page 实现
用于 BVEC 路径(块设备 I/O),内部也是 kmap_atomic + memcpy + kunmap_atomic的组合逻辑
static inline void memcpy_to_page(struct page *page, size_t offset,
const char *from, size_t len)
{
char *to = kmap_atomic(page);
memcpy(to + offset, from, len);
kunmap_atomic(to);
}
(E)copy_page_to_iter_iovec 快慢路径切换逻辑
copy_page_to_iter_iovec 先尝试 kmap_atomic + __copy_to_user_inatomic 快速路径,失败后回退到 kmap + __copy_to_user 慢速路径,原因如下:
- 快速路径:
kmap_atomic禁用抢占和缺页,__copy_to_user_inatomic不处理缺页。优点是极低开销,缺点是如果用户缓冲区未映射则拷贝失败 fault_in_pages_writeable(buf, copy)预热:在进入原子上下文之前,先尝试触发可能的缺页,确保目标页面已映射- 慢速路径回退:如果原子拷贝仍然失败(竞态条件或页面被回收),使用
kmap(可休眠映射)+__copy_to_user(可处理缺页)完成剩余拷贝
0x09 匿名映射与文件映射的 page cache 差异
前文详细介绍了匿名映射与文件映射的实现,本章节从page cache视角对比下匿名映射与文件映射在 read 系统调用和 page cache 使用上的差异
核心对比
| 维度 | 文件映射(file-backed) | 匿名映射(anonymous) |
|---|---|---|
| 后端 | 磁盘文件 | 无文件后端(swap) |
| page cache | 使用 address_space radix tree | 不使用 page cache |
| read 系统调用 | 通过 VFS -> page cache -> copy_to_user |
不经过 read;直接通过缺页中断分配物理页 |
| 数据来源 | 首次访问从磁盘读入 page cache | 首次访问由内核分配零页 |
| 回收机制 | 脏页 writeback 到文件 | 换出到 swap 分区 |
详细说明
1、read 系统调用仅服务于文件 I/O,匿名映射的内存(如 malloc/mmap(MAP_ANONYMOUS))不走 read 路径
2、文件映射的两种访问方式:
read():VFS -> page cache ->copy_to_user(数据拷贝一次到用户缓冲区)mmap():将 page cache 的物理页直接映射到进程地址空间(零拷贝),通过缺页中断filemap_fault按需加载
3、匿名映射:mmap(MAP_ANONYMOUS|MAP_PRIVATE) 分配的内存,首次访问触发缺页中断,内核分配零页(do_anonymous_page),与 page cache 无关
4、共享文件映射:mmap(MAP_SHARED) 多个进程共享同一 page cache 页,修改后由内核 writeback 到磁盘
flowchart LR
subgraph read_path["read() 系统调用路径"]
R1["用户: read(fd, buf, len)"] --> R2["VFS: vfs_read"]
R2 --> R3["do_generic_file_read"]
R3 --> R4["find_get_page 查 page cache"]
R4 --> R5["copy_page_to_iter: 数据拷贝到 buf"]
end
subgraph mmap_file["mmap() 文件映射路径"]
M1["用户: p = mmap(fd, ...)"] --> M2["建立VMA, 不分配物理页"]
M2 --> M3["用户: *p 首次访问"]
M3 --> M4["#PF → do_fault → filemap_fault"]
M4 --> M5["从 page cache 获取/读入页"]
M5 --> M6["建立 PTE: 用户虚拟地址 → page cache 物理页"]
end
subgraph mmap_anon["mmap() 匿名映射路径"]
A1["用户: p = mmap(MAP_ANONYMOUS)"] --> A2["建立VMA, 不分配物理页"]
A2 --> A3["用户: *p 首次写入"]
A3 --> A4["#PF → do_anonymous_page"]
A4 --> A5["分配零页, 建立 PTE"]
end
需要注意的关键区别:read() 路径数据经过一次拷贝(page cache -> 用户缓冲区),而 mmap() 文件映射是将 page cache 的物理页直接映射到用户地址空间,实现零拷贝访问。匿名映射完全不涉及 page cache 和文件 I/O
0x0A readpage 到 BIO 的完整路径:磁盘数据如何写入物理页
当 page cache 未命中且预读/readpage 需要从磁盘加载数据时,内核通过以下路径提交 I/O 请求(以 ext4 为例):
do_generic_file_read
→ mapping->a_ops->readpage(filp, page) [单页读取]
→ mapping->a_ops->readpages(filp, mapping, pages, nr_pages) [批量预读]
→ ext4_readpage / ext4_readpages
→ mpage_readpage / mpage_readpages
→ do_mpage_readpage
→ submit_bio(READ, bio) [提交 BIO 到块设备层]
→ generic_make_request(bio)
→ 块设备驱动处理 I/O
→ I/O 完成中断
→ end_bio_read_page (如 mpage_end_io)
→ SetPageUptodate(page) [设置页面数据有效]
→ unlock_page(page) [唤醒等待该页面的进程]
blk_start_plug / blk_finish_plug 机制用于将多个 BIO 请求合并后一次性提交给块设备调度器,减少调度开销。read_pages 函数优先使用 readpages(批量接口),如果文件系统未实现则逐页调用 readpage
当 page cache 未命中或预读需要填充 page 时,文件数据从 ext4 所在块设备进入已分配的物理页帧。这条路径与后续 copy_page_to_iter(CPU 拷贝到用户空间)有本质区别,前者由 DMA 硬件直接写物理内存,后者由 CPU 经 MMU 翻译为虚拟地址
调用栈总览
flowchart TB
subgraph vfs_mm["VFS / MM 层"]
A["do_generic_file_read: readpage / read_pages"] --> B["struct page 已分配, PG_locked"]
end
subgraph fs_mpage["ext4 + mpage 层"]
B --> C["ext4_readpage / ext4_readpages"]
C --> D["mpage_readpage / mpage_readpages"]
D --> E["do_mpage_readpage"]
E --> F["构造 struct bio"]
F --> G["bio_add_page: page + offset + len"]
end
subgraph block["块设备层"]
G --> H["submit_bio READ"]
H --> I["generic_make_request"]
I --> J["驱动: dma_map_page 获取 DMA 地址"]
J --> K["DMA 控制器: 磁盘 -> 物理内存"]
end
subgraph done["完成回调"]
K --> L["mpage_end_io (中断/软中断)"]
L --> M["SetPageUptodate"]
M --> N["unlock_page: 唤醒等待进程"]
N --> O["do_generic_file_read 继续: page_ok"]
O --> P["copy_page_to_iter: 拷贝到用户空间"]
end
ext4_readpage -> mpage 层(v4.11.6 源码)
// fs/ext4/inode.c#L3224 — ext4 的 readpage 实现
static int ext4_readpage(struct file *file, struct page *page)
{
int ret = -EAGAIN;
// ... 加密相关检查 ...
// 最终转发到通用 mpage 层
ret = mpage_readpage(page, ext4_get_block);
// ext4_get_block: 将文件逻辑块号转换为磁盘物理扇区号
return ret;
}
// fs/mpage.c#L393 — 单页读取入口
int mpage_readpage(struct page *page, get_block_t get_block)
{
struct bio *bio = NULL;
sector_t last_block_in_bio = 0;
struct buffer_head map_bh;
unsigned long first_logical_block = 0;
map_bh.b_state = 0;
map_bh.b_size = 0;
// do_mpage_readpage 负责:
// 1. 调用 get_block 获取磁盘扇区号
// 2. 构造 bio 并添加 page
// 3. 若 bio 满或无法合并,提交 bio
bio = do_mpage_readpage(bio, page, 1,
&last_block_in_bio, &map_bh,
&first_logical_block, get_block);
if (bio)
mpage_bio_submit(READ, bio); // 提交剩余 bio
return 0;
}
do_mpage_readpage:构造 BIO
// fs/mpage.c (v4.11.6 核心逻辑节选)
static struct bio *do_mpage_readpage(struct bio *bio, struct page *page,
unsigned nr_pages, sector_t *last_block_in_bio,
struct buffer_head *map_bh, unsigned long *first_logical_block,
get_block_t get_block)
{
// 1. 调用 get_block 将文件逻辑块号映射为磁盘扇区号
// map_bh->b_blocknr = 磁盘物理块号
// map_bh->b_size = 连续块的总字节数
// 2. 尝试将 page 合并到现有 bio(连续扇区合并 I/O)
if (bio && (*last_block_in_bio != blocks[0] - 1))
bio = mpage_bio_submit(READ, bio); // 不连续,先提交现有 bio
// 3. 若 bio 为 NULL,分配新 bio
if (bio == NULL) {
bio = mpage_alloc(bdev, blocks[0] << (blkbits - 9),
min_t(int, nr_pages, BIO_MAX_PAGES), GFP_KERNEL);
// bio->bi_bdev = bdev; // 目标块设备
// bio->bi_iter.bi_sector = ...; // 起始扇区号
}
// 4. ★ 关键:将 page 加入 bio 的 scatter-gather 列表
length = first_hole << blkbits;
if (bio_add_page(bio, page, length, 0) < length) {
bio = mpage_bio_submit(READ, bio); // 当前 bio 已满
goto alloc_new;
}
// bio_add_page 内部将 page 登记到 bio->bi_io_vec[]:
// bvec->bv_page = page; // ★ struct page* 指向物理页帧
// bvec->bv_offset = 0; // 页内偏移
// bvec->bv_len = length; // 长度(通常 4096)
// 5. 记录 page 的最后扇区号,供下一个 page 判断连续性
*last_block_in_bio = blocks[blocks_per_page - 1];
return bio;
}
bio_add_page 的核心是把 struct page*、offset、len 组成 struct bio_vec 存入 bio->bi_io_vec[]。I/O 目标是物理页帧,不是虚拟地址
submit_bio 与 DMA 传输
// block/blk-core.c (v4.11.6)
void submit_bio(int rw, struct bio *bio)
{
bio->bi_rw |= rw;
// ... 统计 ...
generic_make_request(bio);
// -> 请求队列 -> I/O 调度器(cfq/deadline/noop) -> 设备驱动
}
块设备驱动接收到请求后的典型步骤:
// 设备驱动内部(以 SCSI/NVMe 为例,简化)
// 1. 从 bio_vec 中取出 page,获取 DMA 地址
dma_addr_t dma_addr = dma_map_page(dev, bvec->bv_page,
bvec->bv_offset, bvec->bv_len,
DMA_FROM_DEVICE);
// dma_map_page 在 x86 上本质是 page_to_phys(page) + offset
// 即物理地址,不经过 MMU/TLB
// 2. 编程磁盘控制器:从磁盘 LBA 读取数据,DMA 写入 dma_addr
// DMA 控制器直接操作物理内存,CPU 不参与数据搬运
// 3. I/O 完成后,中断通知 CPU
dma_unmap_page(dev, dma_addr, bvec->bv_len, DMA_FROM_DEVICE);
// 4. 调用 bio->bi_end_io 完成回调
关键点:磁盘 -> page cache 的数据搬运是 DMA 硬件直写物理内存,CPU 不执行 memcpy / rep movsb,不经过 MMU 页表翻译
mpage_end_io:I/O 完成回调
// fs/mpage.c (v4.11.6)
static void mpage_end_io(struct bio *bio)
{
struct bio_vec *bv;
int i;
// 遍历 bio 中每个 bio_vec 对应的 page
bio_for_each_segment_all(bv, bio, i) {
struct page *page = bv->bv_page;
// 将 page 标记为 uptodate 或 error
page_endio(page, bio_data_dir(bio), bio->bi_error);
}
bio_put(bio);
}
// mm/page_io.c — page_endio 核心逻辑
void page_endio(struct page *page, int rw, int err)
{
if (!rw) { // 读操作
if (!err) {
SetPageUptodate(page); // ★ 标记数据有效
} else {
ClearPageUptodate(page);
SetPageError(page);
}
unlock_page(page); // ★ 唤醒 wait_on_page_locked 的读者
}
}
unlock_page 会唤醒在 do_generic_file_read 中 wait_on_page_locked_killable(page) 处阻塞的进程,使其继续执行到 page_ok 标签
read_pages 与 blk_plug 批量提交
// mm/readahead.c#L111 (v4.11.6)
static int read_pages(struct address_space *mapping, struct file *filp,
struct list_head *pages, unsigned int nr_pages, gfp_t gfp)
{
struct blk_plug plug;
unsigned page_idx;
int ret;
blk_start_plug(&plug); // ★ 开始攒 I/O 请求
if (mapping->a_ops->readpages) {
// ext4 实现了 readpages(批量接口),一次处理多个 page
ret = mapping->a_ops->readpages(filp, mapping, pages, nr_pages);
put_pages_list(pages);
goto out;
}
// 文件系统未实现 readpages,逐页提交
for (page_idx = 0; page_idx < nr_pages; page_idx++) {
struct page *page = lru_to_page(pages);
list_del(&page->lru);
if (!add_to_page_cache_lru(page, mapping, page->index, gfp))
mapping->a_ops->readpage(filp, page);
put_page(page);
}
ret = 0;
out:
blk_finish_plug(&plug); // ★ 一次性提交所有攒的 I/O 到调度器
return ret;
}
blk_start_plug / blk_finish_plug 会把多次 submit_bio 攒到当前线程的 plug list 中,blk_finish_plug 时一次性送入 I/O 调度器排序合并,减少磁盘寻道
磁盘->物理页 vs 物理页->用户缓冲区:两条 “拷贝” 路径对比
一次完整的 read(fd, buf, 4096) 涉及两次数据搬运,机制完全不同:
| 维度 | 路径A:磁盘 -> 物理页(readpage/BIO/DMA) | 路径B:物理页 -> 用户缓冲区(copy_page_to_iter) |
|---|---|---|
| 触发时机 | page cache 未命中 / 预读 | page_ok 且 PageUptodate |
| 数据搬运方式 | DMA 控制器直写物理内存 | CPU 执行 rep movsb / rep movsq |
| 地址类型 | 物理地址(dma_map_page 转换) |
内核 VA(源)+ 用户 VA(目标) |
| MMU / 页表参与 | 不参与,DMA 绕过 MMU | 必须参与,CPU 的每次内存访问都经 MMU 翻译 |
| 缺页中断 | 无 | 用户缓冲区未映射时可触发 #PF -> handle_mm_fault |
| 同步性 | 异步 BIO 提交;进程在 lock_page 处阻塞等 |
同步于 read 系统调用上下文 |
| page 状态变化 | PG_locked -> SetPageUptodate + unlock_page |
无状态变化(仅 get_page/put_page 引用管理) |
| 数据方向 | 块设备 -> page cache 物理页 | page cache -> 进程用户空间 |
flowchart LR
subgraph pathA["路径A: 磁盘 -> 物理页"]
D1["ext4 磁盘块"] -->|"BIO + DMA"| D2["物理页帧 (PFN)"]
D2 --> D3["SetPageUptodate"]
end
subgraph pathB["路径B: 物理页 -> 用户空间"]
P1["kmap_atomic: 内核VA"] -->|"CPU rep movsb"| P2["MMU 查用户页表"]
P2 --> P3["用户 buf 虚拟地址"]
end
D3 -->|"page_ok"| P1
串联一次 read 的完整数据流:
- 路径 A:
__do_page_cache_readahead分配 page ->read_pages-> ext4readpage-> BIO -> DMA 将磁盘数据写入物理页帧 ->mpage_end_io设置PG_uptodate并unlock_page - 路径 B:
copy_page_to_iter->kmap_atomic(page)得到内核 VA ->__copy_to_user(buf, kaddr+offset, len)由 CPU 拷贝到用户malloc缓冲区(若 PTE 不存在则触发缺页建立映射) - 用户态
read返回后读buf:通常不再缺页(路径 B 已建立 PTE 并写入数据)
因此:预读/读盘阶段不涉及用户页表;只有交付给用户缓冲区时才触发 MMU 页表查询和可能的缺页中断
mark_page_accessed 与 LRU 回收
mark_page_accessed 在 page_ok 标签处被调用,用于更新页面在 LRU 链表中的活跃等级。内核使用二次机会法(Two-Chance)进行页面回收:
inactive,unreferenced → inactive,referenced (第一次访问:设置 PG_referenced)
inactive,referenced → active,unreferenced (第二次访问:提升到 active 链表)
active,unreferenced → active,referenced (继续访问:保持活跃)
页面回收器 kswapd 扫描时,优先回收 inactive 链表末尾的页面。只有被多次访问的页面才能晋升到 active 链表,避免一次性大量读取(如 cp 命令)污染 active 链表
file_accessed 的 atime 策略
do_generic_file_read 在 out 标签处调用 file_accessed(filp) 更新文件的访问时间(atime)。默认的 relatime 挂载选项下,内核仅在以下条件之一满足时才会更新 atime:
- atime 早于 mtime 或 ctime
- atime 距今超过 24 小时
这避免了每次 read 都更新 inode 的 atime 导致额外的写 I/O,对读密集型工作负载有显著的性能优化
0x0B 零拷贝splice中的page读
copy_page_to_iter_pipe用于splice函数即零拷贝技术的底层实现,用于从管道读出数据。splice直接将页面从一个文件描述符的页缓存”移动”到另一个文件描述符的缓冲区,不经过用户空间,也不复制页面数据
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/iov_iter.c#L342
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
size_t off;
int idx;
......
off = i->iov_offset;
idx = i->idx;
buf = &pipe->bufs[idx];
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
idx = next_idx(idx, pipe);
buf = &pipe->bufs[idx];
}
if (idx == pipe->curbuf && pipe->nrbufs)
return 0;
pipe->nrbufs++;
buf->ops = &page_cache_pipe_buf_ops;
// 零拷贝技术的核心:不是真正拷贝数据,而是添加页面引用
get_page(buf->page = page);
buf->offset = offset;
buf->len = bytes;
i->iov_offset = offset + bytes;
i->idx = idx;
out:
i->count -= bytes;
//copy done
return bytes;
}
do_generic_file_read 中的页表转换总结
do_generic_file_read 整条执行路径中,不同阶段对 MMU / 页表的依赖程度截然不同:
| 阶段 | 关键函数 | x86_64 页表操作 | 说明 |
|---|---|---|---|
| 查找 page | find_get_page / radix 树遍历 |
无 | 仅操作内核数据结构指针,不读写 page 内数据 |
| 分配 page | __page_cache_alloc |
无 | buddy 分配器返回 struct page*,不建立额外映射 |
| 磁盘填充 | readpage -> BIO -> DMA 写入 |
无 | DMA 使用物理地址,绕过 CPU 的 MMU(见 0x0A) |
| 读取页数据 | kmap_atomic(page) |
无(x86_64) | 直接映射区线性 VA 计算,不修改 PTE |
| 拷贝到用户 | __copy_to_user(buf, kaddr, len) |
查询用户页表 | CPU rep movsb 写用户 VA,MMU 翻译可能触发 #PF |
| 缺页处理 | handle_mm_fault (若 #PF) |
写入用户页表 | 分配物理页 + 建立用户 PTE |
结论:整条 read 路径中,只有最后交付给用户空间时(__copy_to_user)才真正涉及 MMU 页表查询与可能的缺页中断。磁盘到 page cache 的路径完全与用户页表无关
read_pages
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/readahead.c#L111
static int read_pages(struct address_space *mapping, struct file *filp,
struct list_head *pages, unsigned int nr_pages, gfp_t gfp)
{
struct blk_plug plug;
unsigned page_idx;
int ret;
blk_start_plug(&plug);
if (mapping->a_ops->readpages) {
ret = mapping->a_ops->readpages(filp, mapping, pages, nr_pages);
/* Clean up the remaining pages */
put_pages_list(pages);
goto out;
}
for (page_idx = 0; page_idx < nr_pages; page_idx++) {
struct page *page = lru_to_page(pages);
list_del(&page->lru);
if (!add_to_page_cache_lru(page, mapping, page->index, gfp))
mapping->a_ops->readpage(filp, page);
put_page(page);
}
ret = 0;
out:
blk_finish_plug(&plug);
return ret;
}
0x0C 总结
关于预读的一些问题
1、当同步预读触发时,由于内核会提交包含当前page和预读的page的BIO请求,那么当前阻塞的进程应该只等待当前page被cache就会被唤醒吗?
同步预读 page_cache_sync_readahead 提交的是一批 page 的 BIO 请求(通过 read_pages -> a_ops->readpages 或逐页 a_ops->readpage),但调用进程并非等待整批 BIO 完成。具体机制如下:
__do_page_cache_readahead分配并提交多个 page 的读请求后立即返回,此时这些 page 处于 locked 状态(PG_locked置位),PG_uptodate未置位- 回到
do_generic_file_read的主循环,find_get_page找到当前需要的 page 后,检查PageUptodate(page)为 false,进入等待路径 - 调用
wait_on_page_locked_killable(page)或lock_page_killable(page),仅等待当前这一个 page 的 I/O 完成 - 底层 BIO 完成中断回调
end_bio_read_page(如mpage_end_io)会对每个完成的 page 设置PG_uptodate并调用unlock_page(page),从而唤醒等待该 page 的进程
因此,进程只阻塞在当前需要的那一个 page 上。同批次其余预读 page 的 I/O 可能还在进行中,但不会阻塞当前进程。当进程在后续循环中访问这些预读 page 时,如果 I/O 已完成则直接命中(PageUptodate 为 true),否则才会再次阻塞等待
page cache相关
1、page cache:匿名映射与文件映射的区别