0x00 前言
本文以ext4为例,基于v4.11.6的源码来分下page cache机制下write写入过程的内核实现(不涉及块设备层)
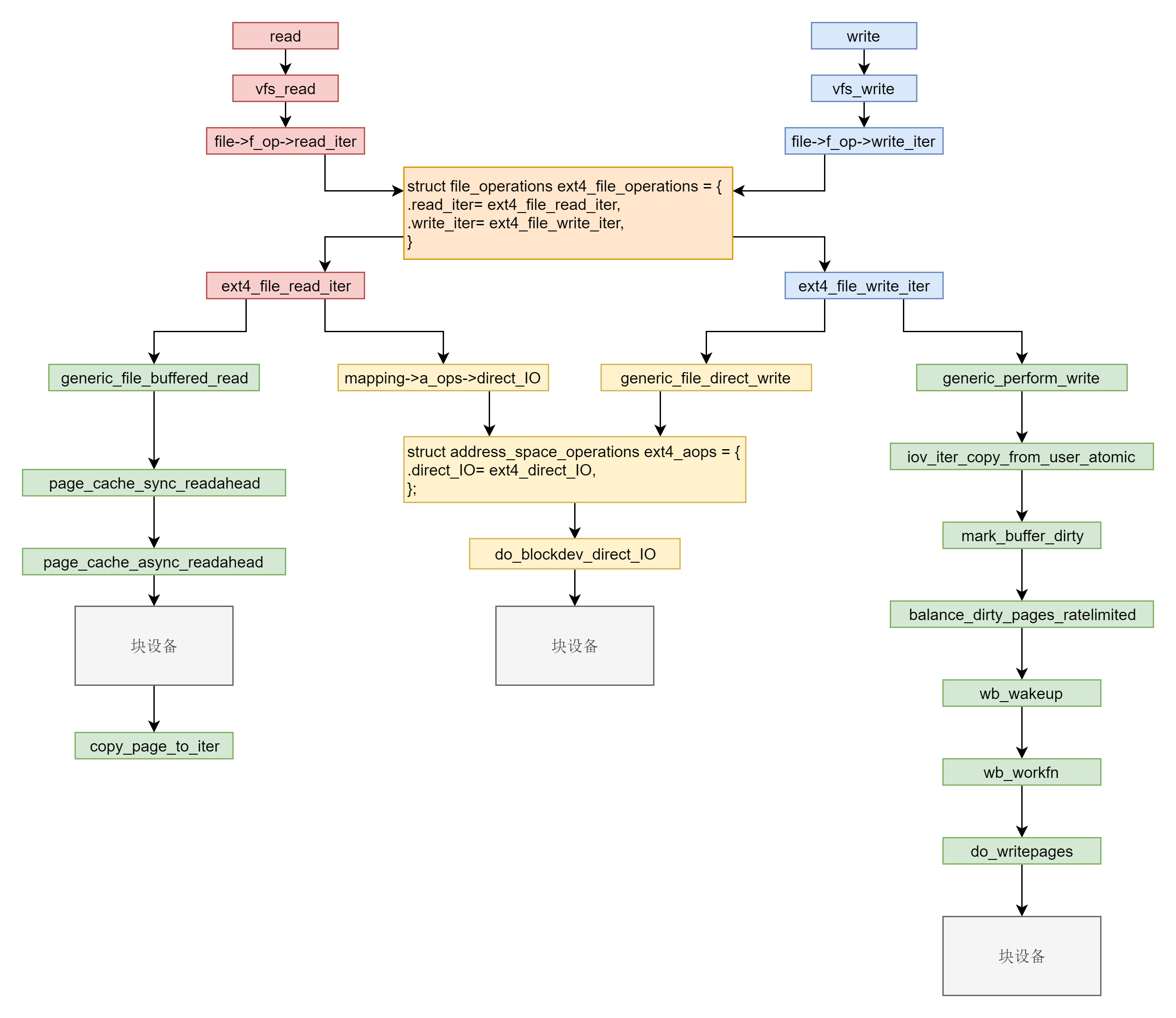
0x01 相关背景知识
ext4文件系统的三种模式
ext4文件系统delay allocation机制
0x02 内核写(write)实现
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
if (ret >= 0){
//成功写入后,更新文件的pos位置
file_pos_write(f.file, pos);
}
fdput_pos(f);
}
return ret;
}
static inline void file_pos_write(struct file *file, loff_t pos)
{
file->f_pos = pos;
}
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
......
ret = rw_verify_area(WRITE, file, pos, count);
if (!ret) {
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
file_start_write(file);
ret = __vfs_write(file, buf, count, pos);
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
inc_syscw(current);
file_end_write(file);
}
return ret;
}
const struct file_operations ext4_file_operations = {
......
.write_iter = ext4_file_write_iter, //只实现了write_iter方法
.mmap = ext4_file_mmap,
.open = ext4_file_open,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
......
};
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/read_write.c#L504
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count,
loff_t *pos)
{
if (file->f_op->write)
......
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos); //go this
else
return -EINVAL;
}
static ssize_t new_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos)
{
// 注意:用户空间的缓冲区地址buf是保存在iov中的
// 该结构体对象记录了用户空间缓冲区地址buf和所要写的字节数len
struct iovec iov = { .iov_base = (void __user *)buf, .iov_len = len };
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = *ppos;
// 将用户态缓冲区地址封装为一个迭代器iter
iov_iter_init(&iter, WRITE, &iov, 1, len);
//调用ext4的write_iter实现:ext4_file_write_iter
ret = call_write_iter(filp, &kiocb, &iter);
BUG_ON(ret == -EIOCBQUEUED);
if (ret > 0)
*ppos = kiocb.ki_pos;
return ret;
}
ext4的ext4_file_write_iter实现
//https://elixir.bootlin.com/linux/v4.11.6/source/fs/ext4/file.c#L203
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct inode *inode = file_inode(iocb->ki_filp);
int o_direct = iocb->ki_flags & IOCB_DIRECT;
int unaligned_aio = 0;
int overwrite = 0;
ssize_t ret;
if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb))))
return -EIO;
inode_lock(inode);
......
//
ret = __generic_file_write_iter(iocb, from);
inode_unlock(inode);
if (ret > 0){
// https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/fs.h#L2534
// 仅在SYNC模式下有效
ret = generic_write_sync(iocb, ret);
}
return ret;
out:
inode_unlock(inode);
return ret;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L2874
ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct address_space * mapping = file->f_mapping;
struct inode *inode = mapping->host;
ssize_t written = 0;
ssize_t err;
ssize_t status;
/* We can write back this queue in page reclaim */
current->backing_dev_info = inode_to_bdi(inode);
err = file_remove_privs(file);
if (err)
goto out;
err = file_update_time(file);
if (err)
goto out;
if (iocb->ki_flags & IOCB_DIRECT) {
......
} else {
written = generic_perform_write(file, from, iocb->ki_pos);
if (likely(written > 0))
iocb->ki_pos += written;
}
out:
current->backing_dev_info = NULL;
return written ? written : err;
}
EXPORT_SYMBOL(__generic_file_write_iter);
generic_perform_write
//https://elixir.bootlin.com/linux/v4.11.6/source/mm/filemap.c#L2784
ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
struct address_space *mapping = file->f_mapping;
const struct address_space_operations *a_ops = mapping->a_ops;
long status = 0;
ssize_t written = 0;
unsigned int flags = 0;
/*
* Copies from kernel address space cannot fail (NFSD is a big user).
*/
if (!iter_is_iovec(i))
flags |= AOP_FLAG_UNINTERRUPTIBLE;
do {
struct page *page;
unsigned long offset; /* Offset into pagecache page */
unsigned long bytes; /* Bytes to write to page */
size_t copied; /* Bytes copied from user */
void *fsdata;
offset = (pos & (PAGE_SIZE - 1));
bytes = min_t(unsigned long, PAGE_SIZE - offset,
iov_iter_count(i));
again:
/*
* Bring in the user page that we will copy from _first_.
* Otherwise there's a nasty deadlock on copying from the
* same page as we're writing to, without it being marked
* up-to-date.
*
* Not only is this an optimisation, but it is also required
* to check that the address is actually valid, when atomic
* usercopies are used, below.
*/
if (unlikely(iov_iter_fault_in_readable(i, bytes))) {
status = -EFAULT;
break;
}
if (fatal_signal_pending(current)) {
status = -EINTR;
break;
}
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
if (unlikely(status < 0))
break;
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
flush_dcache_page(page);
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
if (unlikely(status < 0))
break;
copied = status;
cond_resched();
iov_iter_advance(i, copied);
if (unlikely(copied == 0)) {
/*
* If we were unable to copy any data at all, we must
* fall back to a single segment length write.
*
* If we didn't fallback here, we could livelock
* because not all segments in the iov can be copied at
* once without a pagefault.
*/
bytes = min_t(unsigned long, PAGE_SIZE - offset,
iov_iter_single_seg_count(i));
goto again;
}
pos += copied;
written += copied;
balance_dirty_pages_ratelimited(mapping);
} while (iov_iter_count(i));
return written ? written : status;
}
ext4文件系统address_space_operations
ext4_da_aops是ext4文件系统默认提供的实现,其他结构还有ext4_journalled_aops、ext4_aops
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
.writepage = ext4_writepage,
.writepages = ext4_writepages,
.write_begin = ext4_write_begin,
.write_end = ext4_write_end,
......
};
static const struct address_space_operations ext4_journalled_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
.writepage = ext4_writepage,
.writepages = ext4_writepages,
.write_begin = ext4_write_begin,
.write_end = ext4_journalled_write_end,
......
};
// https://elixir.bootlin.com/linux/v4.11.6/source/fs/ext4/inode.c#L3779
static const struct address_space_operations ext4_da_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
.writepage = ext4_writepage,
.writepages = ext4_writepages,
.write_begin = ext4_da_write_begin,
.write_end = ext4_da_write_end,
......
};
这三种模式的对比如下:TODO
0x0 generic_perform_write的实现
由于加载ext4分区时,默认方式为delay allocation,对应的write_begin/write_end方法为ext4_da_write_begin/ext4_da_write_end
0x0 SYNC模式下的处理
static inline ssize_t generic_write_sync(struct kiocb *iocb, ssize_t count)
{
if (iocb->ki_flags & IOCB_DSYNC) {
int ret = vfs_fsync_range(iocb->ki_filp,
iocb->ki_pos - count, iocb->ki_pos - 1,
(iocb->ki_flags & IOCB_SYNC) ? 0 : 1);
if (ret)
return ret;
}
return count;
}
int vfs_fsync_range(struct file *file, loff_t start, loff_t end, int datasync)
{
struct inode *inode = file->f_mapping->host;
if (!file->f_op->fsync)
return -EINVAL;
if (!datasync && (inode->i_state & I_DIRTY_TIME)) {
spin_lock(&inode->i_lock);
inode->i_state &= ~I_DIRTY_TIME;
spin_unlock(&inode->i_lock);
mark_inode_dirty_sync(inode);
}
return call_fsync(file, start, end, datasync);
}
static inline int call_fsync(struct file *file, loff_t start, loff_t end,
int datasync)
{
return file->f_op->fsync(file, start, end, datasync);
}
const struct file_operations ext4_file_operations = {
......
.fsync = ext4_sync_file,
......
};
主要还是ext4_sync_file的实现(TODO)