0x00 简介
Python 中提供了 yield 关键字,用以实现生成器(generator)的功能。如下,计算 fibonacci 数的生成器:
def fib(max):
n,a,b =0,0,1
while n < max:
yield b
a,b =b,a+b
n = n+1
return 'done'
a = fib(10)
print(fib(10))
基于 golang 的 channel 也很容易实现上述代码(注意需要加入一个控制结束的参数 limit):
type fibonacciChan chan int
func (f fibonacciChan) Next() *int {
c, ok := <-f
if !ok {
return nil
}
return &c
}
func fibonacci(limit int) fibonacciChan {
c := make(chan int)
a := 0
b := 1
go func() {
for {
if limit == 0 {
close(c)
return
}
c <- a
a, b = b, a+b
limit--
}
}()
return c
}
调用方式也很简单:
// 输出 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181
f := fibonacci(20)
fmt.Printf("%v", *f.Next())
fmt.Printf("%v", *f.Next())
for r := range f {
fmt.Printf("%v", r)
}
在笔者的项目中,遇到这样的场景,用来生成 RSA-2048bit OpenSSH 秘钥的方法,在 4 核(core),CPU 为 Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz,平均需要 200-300ms 左右,这对于每次 SSH 登录都需要调用的方法来说,耗时还是比较久的(不必要的耗时)。如何来优化这种场景呢?
0x01 解决的方法
对于解决这种需要临时产生并拿来用的数据的应用场景,一个(预先 Prepared)生产者 + 消费者的模型就很适合这种场景的优化。程序启动时,生产者就开始生产 OpenSSH 秘钥,放入缓冲区 Buffer 中,待消费者来取,这样每次的耗时可以大大降低了(当然,这里不排除有消费者速度超过生产者速度的情况,需要增加缓冲区或者增多生产者来优化)。
我们先设计下 generator 需要实现的特性:
- 多 Producer + 多 Consumer
- 线程安全
- 无阻塞,缓冲区无数据可取时,返回错误(降级,让消费者自己去生产)
配合 Golang 的 Channel 机制的线程安全特性,可以很方便的实现上述特性。
0x02 OpenSSH 秘钥生成器
基于 Channel 实现的 generator 的核心代码如下:
type SshKey struct {
Publickey string
Seckey string
}
type SshKeyGenerator struct {
//start, step int
Size int
Queue chan SshKey
Running bool
}
func NewGenerator(size int) *SshKeyGenerator {
gtr := &SshKeyGenerator{
Size: size,
Running: true,
Queue: make(chan SshKey, size),
}
//start producer
go gtr.process()
return gtr
}
func (g *SshKeyGenerator) process() {
defer func() { recover() }()
var i = 0
for {
// 先判断
sk, pk, err := g.NewRsaKeyPair()
if err != nil {
fmt.Println("Generator key pairs error", err.Error())
time.Sleep(1 * time.Second)
continue
}
skeyitem := SshKey{
Publickey: pk,
Seckey: sk,
}
select {
case g.Queue <- skeyitem:
i++
//if full,block
}
}
}
func (g *SshKeyGenerator) Next() *SshKey {
select {
case it := <-g.Queue:
return &it
default:
return nil
}
}
func (g *SshKeyGenerator) Close() {
g.Running = false
close(g.Queue)
}
0x03 其他的应用场景
SnowFlake 算法
snowflake 算法,是 twitter 开源的唯一 ID 生成算法是生成器最佳的应用场景。主要解决了高并发时 ID 生成不重复的问题,它满足了 Twitter 每秒上万条消息的请求,使每条消息有唯一、有一定顺序的 ID ,且支持分布式生成。比如在项目中,我们需要生成这样的一类 id:
- 要求 id 能带有 时间信息:这样即使后端的系统对消息进行分库分表,也能以时间顺序对这些消息进行排序
- id 是分布式唯一的,且可以高效生成
- id 是
int64或者uint64类型 - 基于时间戳构建(同上),可以保证基本有序递增
而 snowflake 正好满足这类场景:
- 毫秒数在高位、自增序列在低位, id 都是趋势递增的
- 不依赖数据库等第三方系统、以服务方式部署
- 可以根据自身业务特性灵活分配 bit 位
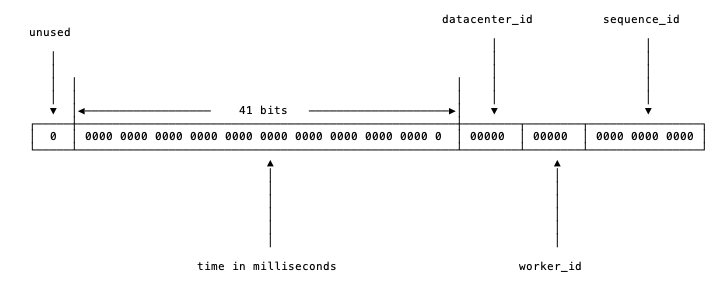
如上图,int64 类型的 id,以 64bit 来存储 id,分为四个部分:
- 开头的第一个 bit(符号位),值固定为
0, 以保证生成的 id 为正数(uint64无此问题) 41位来表示收到请求时的时间戳,单位为毫秒5位来表示数据中心的 id,即Data Center ID5位来表示机器的实例 id,即Worker ID- 最后
12位的循环自增 id(如到达1111,1111,1111后会归0),值上限为2^12 = 4096
各个字段的意义
| 位数 | 取值 | 用途 | 意义 | 代号 |
|---|---|---|---|---|
| 0-11bit | 12bits | 序列号,用来对同一个毫秒之内产生不同的 ID,总量为 2^12 | - | timestamp(时间戳 ,毫秒) |
| 12-21bit | 10bits | 10bit 用来记录机器 ID,总量为 2^10 | 不同的机器上,这里的workerid不可以重复!!! | workerid(工作节点) |
| 22-62bit | 41bits | 用来记录时间戳 | 如果超过了,会出现重复 id | datacenterid(数据中心机房 id) |
| 63bit | 1bit | 符号位,不处理 | - | sequence(序列号) |
- snowflake 机制在同一台机器上,同一毫秒内可以产生
2^12 = 4096条消息,那么一秒共4096000条消息 - 数据中心加上实例 id 共有
10位,可以支持单个数据中心部署2^10 = 1024台机器 - timestamp 占用
41位(毫秒单位),可以支持使用69年,2^41/86400/365/1000 = 69,注意,这个年数是个 跨度 的概念。我们的时间毫秒计数不会真的从1970年开始记,如此这样系统跑到2039年就不能用了。所以这里的 timestamp 只是相对于某个时间的增量,一般采用系统部署正式上线的时间即可(注意如下代码实现中的epoch就是 timestamp 的初始值)
这里给出一个普通的定义:
const (
epoch = int64(1577808000000) // 起始时间戳(毫秒)
timestampBits = uint(41) // 时间戳占用位数
datacenteridBits = uint(2) // 数据中心 id 所占位数
workeridBits = uint(7) // 机器 id 所占位数
sequenceBits = uint(12) // 序列所占的位数
timestampMax = int64(-1 ^ (-1 << timestampBits)) // 时间戳最大值
datacenteridMax = int64(-1 ^ (-1 << datacenteridBits)) // 支持的最大数据中心 id 数量
workeridMax = int64(-1 ^ (-1 << workeridBits)) // 支持的最大机器 id 数量
sequenceMask = int64(-1 ^ (-1 << sequenceBits)) // 支持的最大序列 id 数量
workeridShift = sequenceBits // 机器 id 左移位数
datacenteridShift = sequenceBits + workeridBits // 数据中心 id 左移位数
timestampShift = sequenceBits + workeridBits + datacenteridBits // 时间戳左移位数
)
标准 snowflake 库的分析(1)
本小节简单分析下标准 snowflake 的 实现:
+--------------------------------------------------------------------------+
| 1 Bit Unused | 41 Bit Timestamp | 10 Bit NodeID | 12 Bit Sequence ID |
+--------------------------------------------------------------------------+

1、常量设置
Epoch:起始时间,为1288834974657,即用毫秒表示的 epoch 开始时间NodeBits:指的是机器编号的位长,为10StepBits:指的是自增序列的位长,为12nodeMax:1023,也即 workerid 的最大值,不可以超过此值nodeMask:4190208stepMask:4095timeShift:12nodeShift:12var ( // Epoch is set to the twitter snowflake epoch of Nov 04 2010 01:42:54 UTC in milliseconds // You may customize this to set a different epoch for your application. Epoch int64 = 1288834974657 // NodeBits holds the number of bits to use for Node // Remember, you have a total 22 bits to share between Node/Step NodeBits uint8 = 10 // StepBits holds the number of bits to use for Step // Remember, you have a total 22 bits to share between Node/Step StepBits uint8 = 12 // DEPRECATED: the below four variables will be removed in a future release. mu sync.Mutex nodeMax int64 = -1 ^ (-1 << NodeBits) nodeMask = nodeMax << StepBits stepMask int64 = -1 ^ (-1 << StepBits) timeShift = NodeBits + StepBits nodeShift = StepBits )
这里简单列举下 nodeMax、stepMask 的计算方法如下:-1 ^ (-1 << NodeBits)
-1二进制为11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111- 计算
41bits 的 timestamp 最大值,将-1向左位移41位即可获得,11111111 11111111 11111110 00000000 00000000 00000000 00000000 00000000 - 再和
-1进行异或运算即可知道41bits 的 timestamp 的最大值:00000000 00000000 00000001 11111111 11111111 11111111 11111111 11111111
1、结构
Node 结构中的成员初始化,见 NewNode方法:
// A Node struct holds the basic information needed for a snowflake generator
// node
type Node struct {
mu sync.Mutex
epoch time.Time // 设置起始时间 (时间戳 / 毫秒):2020-01-01 00:00:00,有效期 69 年
time int64 // 用于保存上一次的毫秒时间戳
node int64
step int64
nodeMax int64
nodeMask int64
stepMask int64
timeShift uint8
nodeShift uint8
}
2、核心方法
生成 id 的算法比较容易理解,步骤如下(注意加锁):
- 加锁
- 获取当前的毫秒时间戳
- 用当前的毫秒时间戳和上次保存的时间戳进行比较
- 如果和上次保存的时间戳相等,那么对序列号
sequence+1(取 mod) - 如果不相等,那么直接设置 sequence 为
0即可(重置 sequence)
- 如果和上次保存的时间戳相等,那么对序列号
- 然后通过
|运算拼接 snowflake 需要返回的int64id 返回值 - 解锁
注意下面代码中最后 r 生成的位运算,本质就是按照从低位到高位,组成最后的 id 值:
(now)<<n.timeShift:12位的 sequence(n.node << n.nodeShift):10位的 datacenterid(n.step):41位的 timestamp// Generate creates and returns a unique snowflake ID // To help guarantee uniqueness // - Make sure your system is keeping accurate system time // - Make sure you never have multiple nodes running with the same node ID func (n *Node) Generate() ID { n.mu.Lock() now := time.Since(n.epoch).Nanoseconds() / 1000000 // 纳秒转毫秒时间戳 if now == n.time { // 当同一时间戳下多次生成 id 会增加序列号 (+1) n.step = (n.step + 1) & n.stepMask if n.step == 0 { // 如果当前序列超出 12bit 长度,则需要等待下一毫秒 // 下一毫秒将使用 sequence 为 0(因为 now!=n.time 了) for now <= n.time { now = time.Since(n.epoch).Nanoseconds() / 1000000 } } } else { // 不同时间戳(毫秒)下直接使用初始化 sequence 号:0 n.step = 0 } n.time = now r := int64((now)<<n.timeShift | (n.node << n.nodeShift) | (n.step), ) n.mu.Unlock() return r }
一种 snowflake 的变种分析(2)
sonyflake 项目,不过位分配上稍有不同,如下图:

sonyflake的timestamp只用了39bit,通常减小时间的单位为10ms,所以理论上比41位表示的时间还要久(549755813888/86400/365/100 = 174年)。Sequence ID和之前的定义一致,Machine ID即是节点id。
sonyflake比较灵活,提供了用户的外部设置,比较重要的是:CheckMachineID方法,它是由用户提供的检查MachineID是否冲突的函数。
type Settings struct {
StartTime time.Time //可以设置epoch
MachineID func() (uint16, error) //MachineID可以由用户自定义的函数,如果用户不定义的话,会默认将本机IP的低16位作为machine id
CheckMachineID func(uint16) bool //提供了检查节点id是否合法的接口
}
核心生成id的代码基本上逻辑都差不多:
// NewSonyflake returns a new Sonyflake configured with the given Settings.
// NewSonyflake returns nil in the following cases:
// - Settings.StartTime is ahead of the current time.
// - Settings.MachineID returns an error.
// - Settings.CheckMachineID returns false.
func NewSonyflake(st Settings) *Sonyflake {
sf := new(Sonyflake)
sf.mutex = new(sync.Mutex)
sf.sequence = uint16(1<<BitLenSequence - 1)
if st.StartTime.After(time.Now()) {
return nil
}
if st.StartTime.IsZero() {
sf.startTime = toSonyflakeTime(time.Date(2014, 9, 1, 0, 0, 0, 0, time.UTC))
} else {
sf.startTime = toSonyflakeTime(st.StartTime)
}
var err error
if st.MachineID == nil {
sf.machineID, err = lower16BitPrivateIP()
} else {
sf.machineID, err = st.MachineID()
}
if err != nil || (st.CheckMachineID != nil && !st.CheckMachineID(sf.machineID)) {
return nil
}
return sf
}
// NextID generates a next unique ID.
// After the Sonyflake time overflows, NextID returns an error.
func (sf *Sonyflake) NextID() (uint64, error) {
const maskSequence = uint16(1<<BitLenSequence - 1)
sf.mutex.Lock()
defer sf.mutex.Unlock()
current := currentElapsedTime(sf.startTime)
if sf.elapsedTime < current {
sf.elapsedTime = current
sf.sequence = 0
} else { // sf.elapsedTime >= current
sf.sequence = (sf.sequence + 1) & maskSequence
if sf.sequence == 0 {
sf.elapsedTime++
overtime := sf.elapsedTime - current
time.Sleep(sleepTime((overtime)))
}
}
return sf.toID()
}
func (sf *Sonyflake) toID() (uint64, error) {
if sf.elapsedTime >= 1<<BitLenTime {
return 0, errors.New("over the time limit")
}
return uint64(sf.elapsedTime)<<(BitLenSequence+BitLenMachineID) |
uint64(sf.sequence)<<BitLenMachineID |
uint64(sf.machineID), nil
}
问题
1、workid的分配?
2、workid如何合法性校验?
3、ntp导致的时钟回拨问题
0x04 参考
- go-snowflake
- snowflake
- sonyflake
- python 生成器和迭代器有这篇就够了
- Twitter snowflake ID 算法之 golang 实现
- 6.1 分布式 id 生成器
- The idiomatic way to implement generators (yield) in Golang for recursive functions
- 冷饭新炒:理解 Snowflake 算法的实现原理
转载请注明出处,本文采用 CC4.0 协议授权