0x00 前言
本文是对前一篇文章 理解 Prometheus 的基本数据类型及应用(基础篇) 的实践以及深入理解,推荐如下几篇文章:
0x01 再看四类指标
指标名称和标签集的每个唯一组合定义了一条时间序列,而每个时间戳和浮点数定义了一个系列中的样本(即一个数据点),Prometheus 其实只有两种数据类型。Gauge 和 Counter,而 Histogram、 Summary 本质上都是 Counter
- counter 的常用场景:网卡上发送和接收的字节数,应用程序中的错误数量
- gauge 的常用场景:CPU 和内存使用的指标,或者队列的大小
四种指标类型的关系如下图所示,Histogram 和 Summary 本质上由多个 Counter(及少量 Gauge)组成:
graph TD
PrometheusMetrics["Prometheus Metrics"] --> Counter["Counter(单调递增)"]
PrometheusMetrics --> Gauge["Gauge(任意增减)"]
PrometheusMetrics --> Histogram["Histogram(分布统计)"]
PrometheusMetrics --> Summary["Summary(客户端分位数)"]
Histogram --> H_count["basename_count - Counter"]
Histogram --> H_sum["basename_sum - Counter"]
Histogram --> H_bucket["basename_bucket - Counter per le"]
Summary --> S_count["basename_count - Counter"]
Summary --> S_sum["basename_sum - Counter"]
Summary --> S_quantile["basename quantile=x - Gauge"]
计数器(Counter)
Counter 类型指标被用于单调增加的测量结果,只增不减。唯一的例外是 Counter 重启,在这种情况下,counter 值会被重置为 0。Counter 的实际值本身并不是十分有用(从另外角度看 counter 的前后两个值是有关系的,后者是由前者累加过来),通常,一个计数器的值经常被用来计算两个时间戳之间的 delta 或者随时间变化的速率;举例如下 counter http_requests_total:
# Counter 的一个典型用例是记录 API 调用次数,这是一个总是会增加的测量值
# 指标名称是 http_requests_total,它有一个名为 api 的 label,值为 add_product,Counter 的值为 4633433。这意味着自从上次服务启动或 Counter 重置以来,add_product 的 API 已经被调用了 4633433 次。按照惯例,Counter 类型的指标通常以_total 为后缀
# HELP http_requests_total Total number of http api requests
# TYPE http_requests_total counter
http_requests_total{api="add_product"} 4633433
单纯的 counter 绝对数字并没有提供多少信息,但配合 PromQL 的 rate 函数可以计算该 API 每秒收到的请求数(增长速率),如下:
# 查询计算了过去 5 分钟内每秒 add_product API 的平均请求数
rate(http_requests_total{api="add_product"}[5m])
又如,为了计算一段时期内 counter 的绝对变化(delta),可以利用 increase 函数,下面的表达式会返回过去 5 分钟内的总请求数的增量,这相当于用每秒的速率乘以间隔时间的秒数:
increase(http_requests_total{api="add_product"}[5m])
rate(http_requests_total{api="add_product"}[5m]) * 5 * 60 #rate 结果 * 时间跨度
仪表(Gauge)
Gauge 指标用于可以任意增加或减少的测量指标(从 gauge 视角来看,前后两个时间点的指标,单从数值看没有关联关系,可理解为离散的点),以主机的内存使用情况为例:
# HELP node_memory_used_bytes Total memory used in the node in bytes
# TYPE node_memory_used_bytes gauge
node_memory_used_bytes{hostname="host1.domain.com"} 943348382
该指标的字面意思是在当前这个时间点测量时,节点 host1.domain.com 使用的内存约为 900 MB。该指标的值是有意义的,不需要任何额外的计算,因为它告诉该节点上消耗了多少内存;与 Counter 指标时不同,rate 和 delta 函数对 Gauge 意义不大。然而,计算特定时间序列的平均数(avg_over_time)、最大值(max_over_time)、最小值(min_over_time)或百分比(quantile_over_time)的函数经常与 Gauge 一起使用。如要计算过去 10 分钟内在 host1.domain.com 上使用的平均内存:
avg_over_time(node_memory_used_bytes{hostname="host1.domain.com"}[10m])
直方图(Histogram)
Histogram 指标对于表示测量的分布很有用,经常被用来测量请求持续时间或响应大小。直方图将整个测量范围划分为一组区间,称为桶,并计算每个桶中有多少测量值。一个直方图指标包括几个部分:
- 一个包含测量次数的 Counter,指标名称使用
_count后缀,参考http_request_duration_seconds_count - 一个包含所有测量值之和的 Counter,指标名称使用
_sum后缀,参考http_request_duration_seconds_sum - 直方图桶(bucket)被暴露为一系列的 Counter,使用指标名称的后缀
_bucket和表示桶的上限的lelabel。Prometheus 中的桶是包含桶的边界的,即一个上限为N的桶(即lelabel)包括所有数值小于或等于N的数据点,参考http_request_duration_seconds_bucket
基于如上细化指标,可以计算出:
1、请求 QPS:rate(<basename>_count),计算每秒的请求次数
2、平均耗时: rate(<basename>_sum[1m]) / rate(<basename>_count[1m])
3、分位数:假设需要计算 90% 的分位数,即 histogram_quantile算法 如下:
按照 le 标签排序,查找第一个满足 >= 90% * <basename>_count 的 le(本例中为 >= 0.9 * 27892 = 25103 即 le 为 1),并记下面的变量值:
bucketStart:buckets[b-1].upperBound对应的le标签的值,即0.5bucketEnd:buckets[b].upperBound对应le标签的值,即1.0buckets[b-1].count与buckets[b].count,分别对应24101与26351count:buckets[b].count - buckets[b-1].count,即26351-24101=2250rank:q * observations - buckets[b-1].count,即25103-24101=1002
最终,公式为:bucketStart + (bucketEnd-bucketStart)*float64(rank/count),即 0.5 + 0.5*(1002/2250) = 0.72 ,在样本量更大的情况下将更加精确(例子在下面)
histogram_quantile 的计算流程如下:
flowchart TD
A["输入: q=0.9, buckets 数据"] --> B["按 le 标签排序 buckets"]
B --> C["计算 observations = 最后一个 bucket 的 count"]
C --> D["计算 rank = q * observations"]
D --> E["二分查找第一个 count >= rank 的 bucket b"]
E --> F["确定 bucketStart = buckets b-1 的 upperBound"]
F --> G["确定 bucketEnd = buckets b 的 upperBound"]
G --> H["count = buckets b count - buckets b-1 count"]
H --> I["rank = rank - buckets b-1 count"]
I --> J["线性插值: bucketStart + bucketEnd-bucketStart * rank/count"]
J --> K["返回分位数估算值"]
histogram_quantile 的参考代码如下:
func bucketQuantile(q float64, buckets buckets) (float64, bool, bool) {
if math.IsNaN(q) {
return math.NaN(), false, false
}
if q < 0 {
return math.Inf(-1), false, false
}
if q > 1 {
return math.Inf(+1), false, false
}
slices.SortFunc(buckets, func(a, b bucket) int {
// We don't expect the bucket boundary to be a NaN.
if a.upperBound < b.upperBound {
return -1
}
if a.upperBound > b.upperBound {
return +1
}
return 0
})
if !math.IsInf(buckets[len(buckets)-1].upperBound, +1) {
return math.NaN(), false, false
}
buckets = coalesceBuckets(buckets)
forcedMonotonic, fixedPrecision := ensureMonotonicAndIgnoreSmallDeltas(buckets, smallDeltaTolerance)
if len(buckets) < 2 {
return math.NaN(), false, false
}
observations := buckets[len(buckets)-1].count
if observations == 0 {
return math.NaN(), false, false
}
rank := q * observations
// 寻找第一个大于 rank 的下标
b := sort.Search(len(buckets)-1, func(i int) bool { return buckets[i].count >= rank })
if b == len(buckets)-1 {
return buckets[len(buckets)-2].upperBound, forcedMonotonic, fixedPrecision
}
if b == 0 && buckets[0].upperBound <= 0 {
return buckets[0].upperBound, forcedMonotonic, fixedPrecision
}
var (
bucketStart float64
bucketEnd = buckets[b].upperBound
count = buckets[b].count
)
if b > 0 {
bucketStart = buckets[b-1].upperBound
count -= buckets[b-1].count
rank -= buckets[b-1].count
}
return bucketStart + (bucketEnd-bucketStart)*(rank/count), forcedMonotonic, fixedPrecision
}
测量运行在 host1.domain.com 实例上的 add_product API 的响应时间的 Histogram 指标可以表示为:
# HELP http_request_duration_seconds Api requests response time in seconds
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_sum{api="add_product", instance="host1.domain.com"} 8953.332
http_request_duration_seconds_count{api="add_product", instance="host1.domain.com"} 27892
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0"} 0
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.01"} 0
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.025"} 8
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.05"} 1672
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.1"} 8954
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.25"} 14251
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.5"} 24101
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="1"} 26351
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="2.5"} 27534
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="5"} 27814
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="10"} 27881
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="25"} 27890
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="+Inf"} 27892
本例包括 sum、counter 和 12 个桶,借助于此 sum 和 counter 可以用来计算一个测量值随时间变化的平均值。通过下式可以得到过去 5 分钟的平均请求响应时间(指定了 label):
rate(http_request_duration_seconds_sum{api="add_product", instance="host1.domain.com"}[5m]) / rate(http_request_duration_seconds_count{api="add_product", instance="host1.domain.com"}[5m])
又如,可以被用来计算各时间序列的平均数,计算出所有 API 和实例在过去 5 分钟内的平均请求响应时间(不加 label):
sum(rate(http_request_duration_seconds_sum[5m])) / sum(rate(http_request_duration_seconds_count[5m]))
利用 Histogram,也可以在查询时使用 histogram_quantile 函数计算单个时间序列以及多个时间序列的百分位(Prometheus 使用分位数 0-1 而不是百分位数),例如,要计算在 host1.domain.com 上运行的 add_product API 响应时间的第 99 百分位数以及所有 API 和实例的响应时间的第 99 个百分点(Histograms 进行汇总)
histogram_quantile(0.99, rate(http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com"}[5m]))
histogram_quantile(0.99, sum by (le) (rate(http_request_duration_seconds_bucket[5m]))) #需要注意这里的 sum by (le)
汇总(Summary)
像直方图一样,Summary 指标对于测量请求持续时间和响应体大小很有用。一个 Summary 指标包括这些指标:
- 一个包含总测量次数的 Counter,指标名称使用
_count后缀 - 一个包含所有测量值之和的 Counter。指标名称使用_sum 后缀。可以选择使用带有分位数标签的指标名称,来暴露一些测量值的分位数指标。由于你不希望这些量值是从应用程序运行的整个时间内测得的,Prometheus 客户端库通常会使用流式的分位值,这些分位值是在一个滑动的(通常是可配置的)时间窗口上计算得到的
Summary 通常用来在客户端直接计算出某个值(通常是请求持续时间或响应大小等)的分位数,然后直接上报到 Prometheus,通过 Observe() 函数,Summary 会上报如下三个时序指标:
<basename>{quantile="${val}"}:某个分位数的值<basename>_sum:和 Histogram 的一致,为值的总和<basename>_count:为Observe()函数调用的次数
因此,通过 Summary 可以计算出如下数据:
1、QPS:rate(<basename>_count)
2、平均值: rate(<basename>_sum[1m]) / rate(<basename>_count[1m])
3、分位数:<basename>{quantile="${val}"}
例如,测量在 host1.domain.com 上运行的 add_product API 端点实例的响应时间的 Summary 指标可以表示为:
# HELP http_request_duration_seconds Api requests response time in seconds
# TYPE http_request_duration_seconds summary
http_request_duration_seconds_sum{api="add_product", instance="host1.domain.com"} 8953.332 #所有值的总和
http_request_duration_seconds_count{api="add_product", instance="host1.domain.com"} 27892
http_request_duration_seconds{api="add_product", instance="host1.domain.com", quantile="0"} 0.000131966
http_request_duration_seconds{api="add_product", instance="host1.domain.com", quantile="0.5"} 0.232227334
http_request_duration_seconds{api="add_product", instance="host1.domain.com", quantile="0.90"} 0.821139321
http_request_duration_seconds{api="add_product", instance="host1.domain.com", quantile="0.95"} 1.528948804
http_request_duration_seconds{api="add_product", instance="host1.domain.com", quantile="0.99"} 2.829188272
http_request_duration_seconds{api="add_product", instance="host1.domain.com", quantile="1"} 34.283829292
上例包括总和和计数以及五个分位数。分位数 0 相当于最小值,分位数 1 相当于最大值。分位数 0.5 是中位数,分位数 0.90、0.95 和 0.99 相当于在 host1.domain.com 上运行的 add_product API 后端响应时间的第 90、95 和 99 个百分位。像 Histogram 一样,Summary 指标包括总和和计数,可用于计算随时间的平均值以及不同时间序列的平均值。Summary 提供了比 Histogram 更精确的百分位计算结果,但这些百分位有三个主要缺点:
- 客户端计算百分位是很昂贵的。这是因为客户端库必须保持一个有序的数据点列表,以进行这种计算。在 Prometheus SDK 中的实现限制了内存中保留和排序的数据点的数量,这降低了准确性以换取效率的提高(并非所有的 Prometheus 客户端库都支持汇总指标中的量值)
- 你要查询的量值必须由客户端预先定义。只有那些已经提供了指标的量值才能通过查询返回。没有办法在查询时计算其他百分位。增加一个新的百分位指标需要修改代码,该指标才可以被使用
- 无法把多个 Summary 指标进行聚合计算。在本例中若
add_product的 API 后端运行在10个主机上,在这些服务之前有一个负载均衡器。没有任何聚合函数可以用来计算add_productAPI 接口在所有请求中响应时间的第99百分位数,无论这些请求被发送到哪个后端实例上。只能看到每个主机的第99个百分点。同样也只能知道某个接口,比如add_productAPI 端点的(在某个实例上的)第99百分位数,而无法对不同的接口进行聚合
补充:Histogram 与 Summary 的本质区别
Histogram 并不会保存数据采样点值,每个 bucket 只有一个记录样本数的 counter(float64),即 Histogram 存储的是区间的样本数统计值,因此客户端性能开销相比 Counter 和 Gauge 而言没有明显改变,适合高并发的数据收集。因为 Histogram 在客户端就是简单的分桶和分桶计数,在 Prometheus 服务端基于这么有限的数据做百分位估算,所以的确不是很准确。
Summary 就是解决百分位准确的问题而来的。Summary 直接存储了 quantile 数据,而不是根据统计区间计算出来的。Prometheus 的分位数称为 quantile,其实叫 percentile 更准确——百分位数是指小于某个特定数值的采样点达到一定的百分比
0x02 PromQL 的典型应用:引入
本小节介绍下 PromQL 语言的基础概念,下图表示了 Metric 在 Prometheus 中的样子(假设有如下 5 张网卡的流量 counter 指标 node_network_receive_packets_total):

直接在 Grafana 中使用 node_network_receive_packets_total 来画图会得到 5 条线,不过此图意义不大且无法看到指标变化趋势。因为 Counter 只增加,可以认为是该服务器自存在以来收到的所有的包的数量。Metric 可以通过 label 来进行选择,比如 node_network_receive_packets_total{device="bond0"} 就会只查询到 bond0 的数据(绘制 bond0 这个 device 的曲线), 当然也支持正则表达式,可以通过 node_network_receive_packets_total{device=~"en.*"} 绘制 en0 和 en2 的曲线。其实,metric name 也是一个 label, 所以 node_network_receive_packets_total{device="bond0"} 本质上是 {__name__="node_network_receive_packets_total", device="bond0"} 。但是因为 metric name 基本上是必用的 label,一般用第一种写法
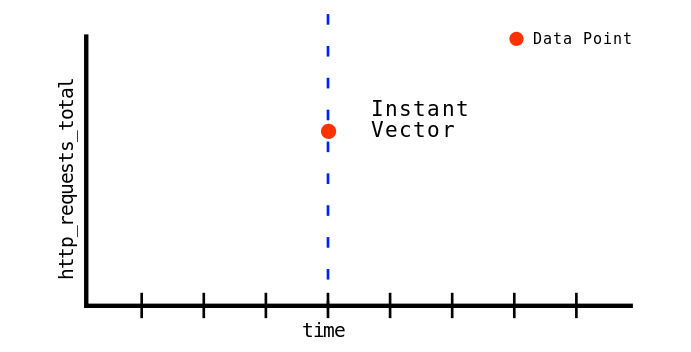
但实际上,如果使用下面的查询语句,将会仅仅得到一个数字,而不是整个 metric 的历史数据(node_network_receive_packets_total{device=~"en.*"} 得到的是下图中黄色的部分(即 Instant Vector),只查询到 metric 的在某个时间点(默认是当前时间)的值

Instant vector selectors
这里描述的 Instant Vector 还是 Range Vector, ** 指的是 PromQL 函数的入参和返回值的类型 **,Instant Vector 就是当前的值,假如查询的时间点是 t,那么查询会返回距离 t 时间点最近的一个值
Range vector selectors
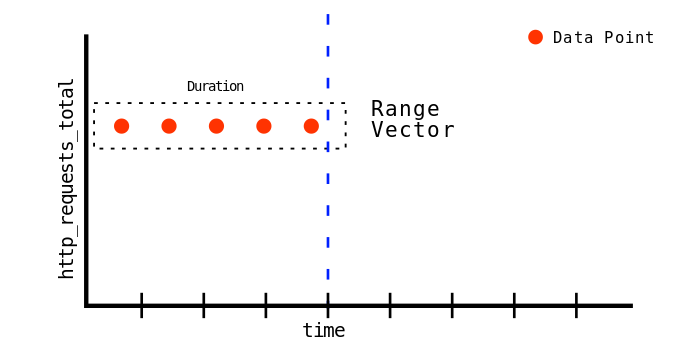
Range Vector 返回的是一个 range 的数据。Range 的表示方法是 [1m],表示 1 分钟的数据,假如对 Prometheus 的采集配置是每 10s 采集一次,那么 1m 内就会有采集 6 次,就会有 6 个数据点,使用 node_network_receive_packets_total{device=~"en.*"}[1m] 查询的话,就可以得到以下的数据:两个 metric 的最后的 6 个数据点,如下图:

Instant vectors VS Range vectors
- Instant vectors 可以用直接被绘制; Range vectors 则不能。这是因为绘制图表需要在
y轴上为x轴上的每个时间戳显示一个数据点。Instant vectors 的每个时间戳只有一个值,而 Range vectors (可能)有很多。为了绘制指标图表,对于在时间序列中显示单个时间戳的多个数据点是没有被定义的 - Instant vectors 可以进行比较和运算; Range vectors 不能
instant vector 的函数
1、sum
http_requests_total 记录了 HTTP 请求的总数,两个标签:status_code(HTTP 响应状态码)和 service(服务名称),样本数据如下:
http_requests_total{status_code="200", service="serviceA"} 1000
http_requests_total{status_code="200", service="serviceB"} 1200
http_requests_total{status_code="404", service="serviceA"} 50
http_requests_total{status_code="404", service="serviceB"} 30
http_requests_total{status_code="500", service="serviceA"} 10
http_requests_total{status_code="500", service="serviceB"} 5
那么,sum by (service) (http_requests_total) 这个公式是计算每个服务 service 的 HTTP 请求总数,不考虑状态码(sum 函数,按照 service 标签进行分组),会返回下面结果:
{service="serviceA"} 1060 #serviceA 有 1060 个 HTTP 请求
{service="serviceB"} 1235 #serviceB 有 1235 个 HTTP 请求
sum by (status_code) (http_requests_total) #按照 status_code 标签对 http_requests_total 指标进行求和
{status_code="200"} 2200
{status_code="404"} 80
{status_code="500"} 15
sum(http_requests_total) #将对所有的 http_requests_total 指标进行求和,计算过程是将所有值相加:1000 + 1200 + 50 + 30 + 10 + 5 = 2295
2295 #结果
2、avg、min、max 等
这几个函数常用于 gauge,不太适合 counter 指标,http_request_duration_seconds 为 Gauge 类型的指标,表示 HTTP 请求的持续时间
http_request_duration_seconds{service="serviceA", request_id="1"} 0.1
http_request_duration_seconds{service="serviceA", request_id="2"} 0.2
http_request_duration_seconds{service="serviceA", request_id="3"} 0.3
http_request_duration_seconds{service="serviceB", request_id="4"} 0.2
http_request_duration_seconds{service="serviceB", request_id="5"} 0.3
http_request_duration_seconds{service="serviceB", request_id="6"} 0.4
min by (service) (http_request_duration_seconds):计算每个服务(按服务分组)的最小 HTTP 请求持续时间
{service="serviceA"} 0.1
{service="serviceB"} 0.2
avg by (service) (http_request_duration_seconds):计算每个服务的平均 HTTP 请求持续时间
serviceA:(0.1 + 0.2 + 0.3) / 3 = 0.2
serviceB:(0.2 + 0.3 + 0.4) / 3 = 0.3
{service="serviceA"} 0.2
{service="serviceB"} 0.3
quantile by (service) (0.5, http_request_duration_seconds): 计算每个服务的中位数(50% 分位数)HTTP 请求持续时间
{service="serviceA"} 0.2
{service="serviceB"} 0.3
count by (service) (http_request_duration_seconds): 计算每个服务的 HTTP 请求持续时间数据点数量
{service="serviceA"} 3
{service="serviceB"} 3
Range Vector 的函数
下面的 PromQL 函数只可用于 range vectors,即入参为 range vectors,返回为 instant vector:
changes(range-vector)
absent_over_time(range-vector)
delta(range-vector)
deriv(range-vector)
holt_winters(range-vector, scalar, scalar)
idelta(range-vector)
irate(range-vector)
predict_linear(range-vector, scalar)
rate(range-vector):计算时间序列在给定时间范围内的平均速率
resets(range-vector)
avg_over_time(range-vector):计算在给定时间范围内的时间序列平均值
min_over_time(range-vector):计算在给定时间范围内的时间序列最小值
max_over_time(range-vector):计算在给定时间范围内的时间序列最大值
sum_over_time(range-vector):计算在给定时间范围内的时间序列总和
count_over_time(range-vector)
quantile_over_time(scalar, range-vector)
stddev_over_time(range-vector)
stdvar_over_time(range-vector)
range vectors 与 counter 的结合相当重要,单调递增 counter 的值永不减少;它要么增加要么保持不变。Prometheus 只允许一种 counter 减少的情况,即在目标重启期间。如果 counter 值低于之前记录的值,则 rate 和 increase 等 range vector 函数将假定目标重新启动并将整个值添加到它所知道的现有值。这也是为什么应该总是先 rate 后 sum,而不是先 sum 后 rate
假设,http_requests_total 5 分钟的时间序列如下:
时间(分钟) service="serviceA" service="serviceB"
----------------------------------------------
0 100 200
1 110 210
2 120 220
3 130 230
4 140 240
1、avg_over_time:avg_over_time(http_requests_total[5m]) 计算过去 5 分钟内 http_requests_total 指标的平均值(聚合所有 label 的指标)
2、rate(http_requests_total{service="serviceA"}[4m]): 计算过去 4 分钟内 serviceA 的 HTTP 请求总数的每秒平均速率(注意 rate 返回的单位始终是 per second),这里描述下具体计算过程
rate 的实际计算逻辑是:取范围窗口内首末两个样本的差值,除以它们之间的时间跨度(秒),并在边界处做外推(extrapolation)校正。简化计算如下:
rate = (last_value - first_value) / time_range_seconds
= (140 - 100) / (4 * 60)
= 40 / 240
≈ 0.1667 (次/秒)
即过去 4 分钟内 serviceA 平均每秒约 0.167 次请求。如果需要每分钟速率,可以将结果乘以 60:0.1667 * 60 ≈ 10(次/分钟)
3、max_over_time(http_requests_total{service="serviceB"}[4m]):计算过去 4 分钟内 serviceB 的 HTTP 请求总数的最大值,即 max(210, 220, 230, 240) = 240
4、avg_over_time(http_requests_total{service="serviceA"}[4m]):计算过去 4 分钟内 serviceA 的 HTTP 请求总数的平均值,将 4 分钟内的数据点相加后除以 4,即 (110 + 120 + 130 + 140) / 4 = 125
5、idelta(http_requests_total{service="serviceB"}[1m]):计算过去 1 分钟内 serviceB 的 HTTP 请求总数最后两个数据点的差值,即 240 - 230 = 10
6、increase(http_requests_total{service="serviceA"}[4m]): 计算过去 4 分钟内 serviceA 的 HTTP 请求总数的增量:140 - 100 = 40(注意:delta() 是为 Gauge 类型设计的函数,对 Counter 应使用 increase();increase 本质等价于 rate() * 时间窗口秒数,会进行外推校正,因此结果可能略大于简单的 end-start 差值)
7、sum by (service) (increase(http_requests_total[1m])):计算每个服务在过去 1 分钟内的 HTTP 请求增量之和
首先需要计算每个服务在过去 1 分钟内的增量:
serviceA:140(第 4 分钟) - 130(第 3 分钟) = 10
serviceB:240(第 4 分钟) - 230(第 3 分钟) = 10
接下来,将按 service 标签对这些增量进行求和。由于只有两个服务,所以求和操作实际上就是将每个服务的增量作为结果。结果是:
{service="serviceA"} 10
{service="serviceB"} 10
8、sum by (service) (rate(http_requests_total[1m])):计算每个服务在过去 1 分钟(60s)内的 HTTP 请求速率之和,按 service 分组
时间(秒) service="serviceA" service="serviceB"
----------------------------------------------
0 100 200
10 102 204
20 104 208
30 106 212
40 108 216
50 110 220
60 112 224
首先需要计算每个服务在过去 1 分钟内的平均速率,如下:
serviceA:rate(http_requests_total{service="serviceA"}[1m]) #在过去 60 秒内,从 100 增加到 112,增量为 12,速率为 12 / 60 = 0.2
serviceB:rate(http_requests_total{service="serviceB"}[1m]) #在过去 60 秒内,从 200 增加到 224,增量为 24,速率为 24 / 60 = 0.4
结果是:
{service="serviceA"} 0.2
{service="serviceB"} 0.4
#在过去 1 分钟内,serviceA 的 HTTP 请求速率为 0.2 次 / 秒,serviceB 的 HTTP 请求速率为 0.4 次 / 秒
注:sum by (label1,label2)这里表示只关心(label1,label2)这两个label,其他的全部聚合(累加)
9、min by (service) (rate(http_request_duration_seconds[1m])):计算每个服务在过去 1 分钟内的最小 HTTP 请求持续时间速率
其他内置函数
可以参考 Prometheus 中文文档,这里列举一些常用的函数
1、histogram_quantile,histogram_quantile(float,instant-vector) 从 bucket 类型的向量中计算 float 分位数的样本的最大值。向量 instant-vector 中的样本是每个 bucket 的采样点数量。每个样本的 labels 中必须要有 le 这个 label 来表示每个 bucket 的上边界,没有 le 标签的样本会被忽略;使用 rate() 函数来指定分位数计算的时间窗口。
例如,一个直方图指标名称为 employee_age_bucket_bucket,要计算过去 10 分钟内 第 90 个百分位数,使用表达式 histogram_quantile(0.9, rate(employee_age_bucket_bucket[10m])),返回表示最近 10 分钟之内 90% 的样本的最大值为 35.714285714285715
{instance="10.0.86.71:8080",job="prometheus"} 35.714285714285715
上面的计算结果是每组标签组合成一个时间序列,在现网中,可能不会对所有这些维度(如 job、instance 和 method)感兴趣,并希望将其中的一些维度进行聚合,则可使用 sum() 函数。例如,以下表达式根据 job 标签来对第 90 个百分位数进行聚合:
# histogram_quantile() 函数必须包含 le 标签
histogram_quantile(0.9, sum(rate(employee_age_bucket_bucket[10m])) by (job, le))
如果要聚合所有的标签,则使用表达式 histogram_quantile(0.9,sum(rate(employee_age_bucket_bucket[10m])) by (le))
histogram_quantile 这个函数是根据假定每个区间内的样本分布是线性分布来计算结果值的(它的结果未必准确),最高的 bucket 必须是 le="+Inf" (否则就返回 NaN)
此外,列举下聚合所有标签的例子:
http_request_duration_seconds_bucket{le="0.1", handler="handlerA", instance="instance1"} 50
http_request_duration_seconds_bucket{le="0.2", handler="handlerA", instance="instance1"} 100
http_request_duration_seconds_bucket{le="0.3", handler="handlerA", instance="instance1"} 150
http_request_duration_seconds_bucket{le="+Inf", handler="handlerA", instance="instance1"} 160
http_request_duration_seconds_bucket{le="0.1", handler="handlerB", instance="instance2"} 20
http_request_duration_seconds_bucket{le="0.2", handler="handlerB", instance="instance2"} 60
http_request_duration_seconds_bucket{le="0.3", handler="handlerB", instance="instance2"} 120
http_request_duration_seconds_bucket{le="+Inf", handler="handlerB", instance="instance2"} 130
那么 histogram_quantile(0.9, sum(rate(http_request_duration_seconds_bucket[10m])) by (le)) 查询,结果将忽略 handler 和 instance 标签,只按 le 标签进行聚合,结果如下:
{le="0.1"} 70
{le="0.2"} 160
{le="0.3"} 270
{le="+Inf"} 290
2、假设 http_request_duration_seconds_bucket 的直方图指标记录了 HTTP 请求的持续时间,指标具有两个标签:le(表示持续时间的上限)和 handler(表示处理 HTTP 请求的程序),计算每个处理程序的 HTTP 请求持续时间的 90% 分位数的过程如下(histogram_quantile(0.9, sum by (le, handler) (rate(http_request_duration_seconds_bucket[5m]))))
http_request_duration_seconds_bucket{le="0.1", handler="handlerA"} 50
http_request_duration_seconds_bucket{le="0.2", handler="handlerA"} 100
http_request_duration_seconds_bucket{le="0.3", handler="handlerA"} 150
http_request_duration_seconds_bucket{le="+Inf", handler="handlerA"} 160
http_request_duration_seconds_bucket{le="0.1", handler="handlerB"} 20
http_request_duration_seconds_bucket{le="0.2", handler="handlerB"} 60
http_request_duration_seconds_bucket{le="0.3", handler="handlerB"} 120
http_request_duration_seconds_bucket{le="+Inf", handler="handlerB"} 130
rate(http_request_duration_seconds_bucket[5m]): 计算过去5分钟内http_request_duration_seconds_bucket指标(histogram)的速率sum by (le, handler) (...):将上一步得到的速率结果按照le和handler标签进行分组,并对每个分组计算总和。这意味着,最后的结果将展示每个持续时间上限(le)和处理程序(handler)在过去5分钟内的 HTTP 请求速率之和histogram_quantile(0.9, ...):根据上一步得到的直方图数据计算90%分位数。具体来说,它会找到一个持续时间值,使得90%的 HTTP 请求持续时间都小于等于这个值
一个插曲:关于 grafana 的绘图原理
Grafana 与 Prometheus 的查询交互流程如下:
sequenceDiagram
participant User as 用户
participant Grafana as Grafana
participant Prom as Prometheus
User->>Grafana: 选择时间范围与 PromQL
Grafana->>Grafana: 根据面板宽度计算 step
Grafana->>Prom: GET /api/v1/query_range?query=rate(xxx[5m])&start=T1&end=T2&step=60
Prom->>Prom: 对每个 step 时间点独立计算 PromQL 得到 Instant Vector
Prom-->>Grafana: 返回时间序列数组 time,value 对
Grafana->>Grafana: 渲染为折线图
Grafana-->>User: 展示图表
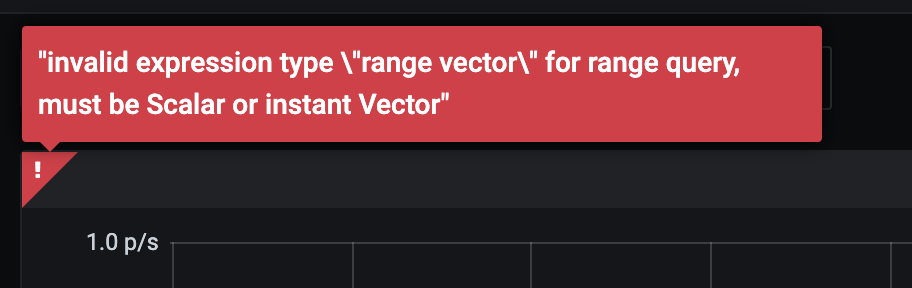
思考一个问题,在 Grafana 中画出来一个 Metric 的图标,需要查询结果是一个 Instant Vector,还是 Range Vector 呢?答案是 Instant Vector,直觉上有些奇怪(绘出的图是一个区间),结论是 Range Vector 基本上只是为了给 PromQL 函数用的,Grafana 绘图只能接受 Instant Vector(Grafana 只接受 Instant Vector, 如果查询的结果是 Range Vector, 会报错)。**Prometheus 的查询 API 是以 HTTP 的形式提供的,Grafana 在渲染一个图标的时候会向 Prometheus 去查询数据 **。查询 API 主要有两类:
-
/query,查询一个时间点的数据,返回一个数据值,通过?time=1627111334参数可以查询指定时间的数据,假如要绘制1个小时内的 Chart 的话,Grafana 首先需要在创建 Chart 的时候传入一个step值(表示多久查一个数据),假设step=1min的话,对每分钟需要查询一次数据。那么 Grafana 会向 Prometheus 发送60次请求,查询60个数据点,即60个 Instant Vector,然后绘制出来一张图表(缺点是请求次数太多) -
query_range,接收的参数如?start=<start_timestamp>&end=<end_timestamp>&step=60,在 Prometheus 内部还是对60个点进行了分别计算,然后返回
要注意区分,Range Vector 并不是 grafana 绘制的时间,而是函数计算所需要的时间区间,Grafana 只接受 Instant Vector, 如果查询的结果是 Range Vector, 会报错
常用操作
本小节汇总 PromQL 中常用的运算符和高级语法
1、二元算术运算符
PromQL 支持 +、-、*、/、%(取模)、^(幂运算)六种算术运算符,可用于标量与标量、向量与标量、向量与向量之间的运算:
# 标量与向量:将 bytes 转换为 MB
node_memory_MemTotal_bytes / 1024 / 1024
# 向量与向量:计算内存使用率
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100
# 向量与向量运算时,默认按照所有 label 完全匹配进行一对一(one-to-one)配对
2、比较运算符
支持 ==、!=、>、<、>=、<=,默认行为是过滤不满足条件的时间序列;加上 bool 修饰符则返回 0/1 值而非过滤:
# 过滤:只保留空闲内存低于 1GB 的节点
node_memory_MemAvailable_bytes < 1024*1024*1024
# bool 修饰符:返回 0 或 1,适用于告警表达式
node_memory_MemAvailable_bytes < bool 1024*1024*1024
3、逻辑运算符
and(交集)、or(并集)、unless(差集),仅用于 Instant Vector 之间:
# 交集:同时满足两个条件的时间序列
up{job="api-server"} == 1 and rate(http_requests_total[5m]) > 10
# 差集:所有 up 的实例,排除掉 job=test 的
up == 1 unless up{job="test"}
4、向量匹配(Label Matching)
当两侧向量的 label 集合不完全相同时,需要使用 on() / ignoring() 指定匹配规则,配合 group_left() / group_right() 处理一对多关系:
# on():只按指定 label 匹配
http_requests_total / on(instance) group_left() machine_cpu_cores
# ignoring():忽略某些 label 后匹配
rate(http_requests_total{status="500"}[5m])
/ ignoring(status)
rate(http_requests_total[5m])
# group_left:左侧为"多"的一方(多对一匹配)
# group_right:右侧为"多"的一方(一对多匹配)
5、offset 修饰符
offset 用于将查询的时间偏移到过去某个时间点,常用于同环比计算:
# 查询 1 小时前的 QPS(环比)
rate(http_requests_total[5m] offset 1h)
# 同比:与昨天同一时刻对比
rate(http_requests_total[5m]) - rate(http_requests_total[5m] offset 1d)
# 计算 QPS 的日环比增长率
(rate(http_requests_total[5m]) - rate(http_requests_total[5m] offset 1d))
/
rate(http_requests_total[5m] offset 1d) * 100
6、子查询(Subquery)语法
子查询允许对 Instant Vector 表达式在一个时间范围内进行求值,语法为 expression[range:step]:
# 过去 1 小时内,每 5 分钟计算一次 rate,然后取最大值
max_over_time(rate(http_requests_total[5m])[1h:5m])
# 过去 30 分钟内,每分钟计算一次 P99,然后取平均
avg_over_time(
histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))[30m:1m]
)
# 注意:子查询内层的 expression 必须返回 Instant Vector
# [1h:5m] 表示向前看 1 小时,步长为 5 分钟
# 如果省略 step(写成 [1h:]),则使用全局的 evaluation_interval
核心:rate 计算的本质
rate 函数的计算流程如下图所示,核心是取 Range 窗口内首末样本做差再除以时间跨度(秒),同时处理 Counter reset 场景:
flowchart TD
A["输入: counter_metric 和 range 如 1m"] --> B["获取 range 窗口内的所有样本点"]
B --> C{"检测 Counter Reset?"}
C -->|"某个值 < 前一个值"| D["累加 reset 前的值到后续样本"]
C -->|"无 reset"| E["取首末两个样本"]
D --> E
E --> F["计算增量: last_value - first_value"]
F --> G["计算时间跨度: last_timestamp - first_timestamp"]
G --> H["外推 extrapolation 校正边界"]
H --> I["rate = extrapolated_increase / extrapolated_duration"]
I --> J["返回 Instant Vector: 每秒速率"]
通常 counter 都会与 rate 函数结合计算增量,如下面的计算 node_network_receive_packets_total 在 1m 的时间跨度增量,即查询每秒收到的 packet 数量(同理,increase函数的计算也是类似的):
rate(node_network_receive_packets_total{device=~"en.*"}[1m]) #注意这里的结果是一个instant,只是一个点
上面的公式有两个重要的含义:
rate(node_network_receive_packets_total{device=~"en.*"}[1m])计算的结果只有一个点[1m]里面能用到多少个具体的序列参与计算是由Prometheus的采集周期决定的
先来看一个时间点的计算,假如计算 t 时间点的每秒 packet 数量,rate 函数用这段时间([1m])的总 packet 数量,除以时间跨度 [1m],就得到了一个 “平均值”,以此作为曲线来绘制,通过这种方法就得到了一个点的数据。如下图:
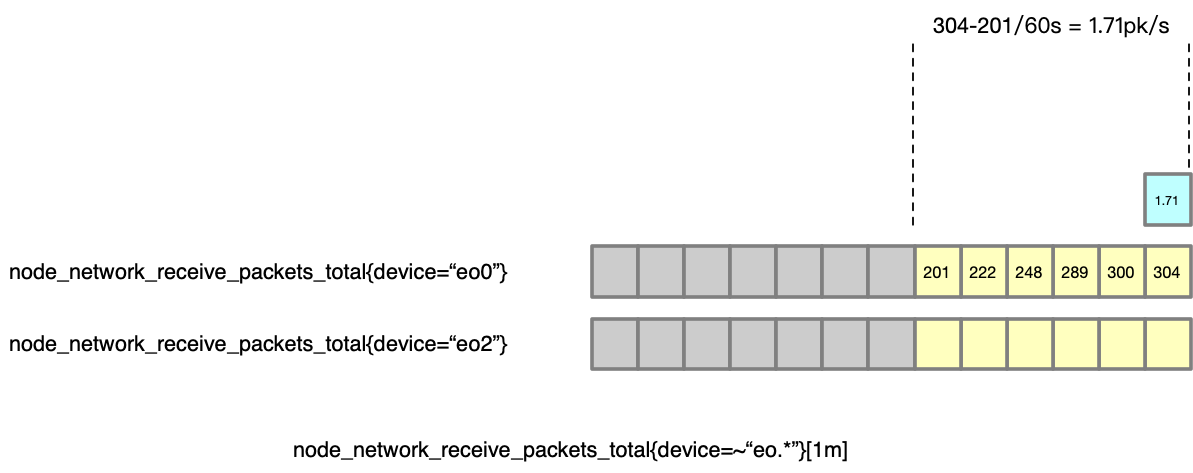
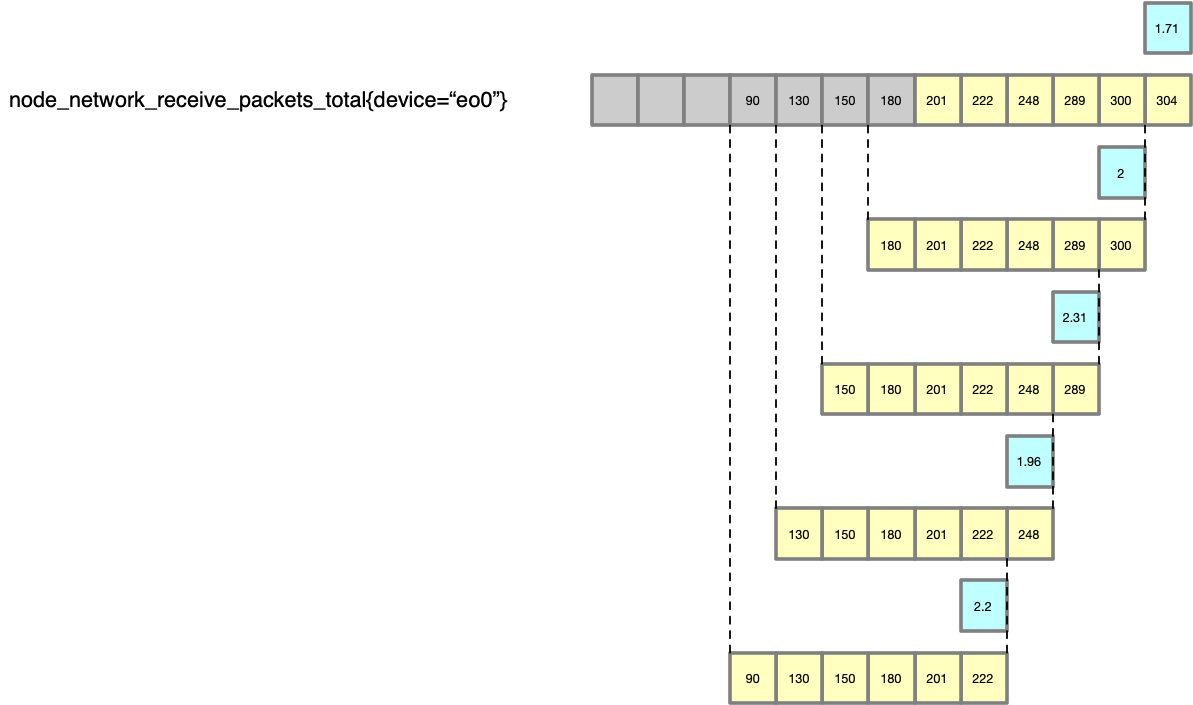
然后,对之前的每一个点,都以此法进行计算,就得到了一个 packet/s 的曲线(最长的那条是原始的数据,黄色的表示 rate 对于每一个点的计算过程,蓝色的框为最终的绘制的点),所以这个 PromQL 查询最终得到的数据点是:<2.2, 1.96, 2.31, 2, 1.71> (即蓝色的点构成的序列),有了这个序列,接下来grafana按照step(步长)、当前时间戳、查询时间范围跨度直接找Prometheus获取对应的rate序列就好了
因为指定的 label 有两个选中的 metric,分别是 en0 和 en2,所以 rate 会分别计算两条曲线,就得到下面的 Chart,有两条线

这样的指标在笔者现网中也是极为常用的。最后在列举下这几个时间(容易混淆)
- grafana 的绘图区间(时间跨度)
- PromQL 的 offset(查询)
- Prometheus 的采集周期:对 Prometheus 的采集配置是每
10s采集一次,那么1m内就会有采集6次,就会有6个数据点,正常情况下通过 range selector[1m]可以采集到6个点,rate等相关的计算函数会基于这些点(序列)进行计算 - 特别注意:
rate(node_network_receive_packets_total{device=~"en.*"}[1m])结果只有一个点,Prometheus的API会根据grafana传入的API参数,通过内部计算返回不同时间戳对应的rate结果即点的序列,继而完成绘图
rate VS irate
上节分析了 rate 的实现,对比 irate 则是计算的最后两个点之间的差值,如下图,注意对比与 rate 方法的不同:
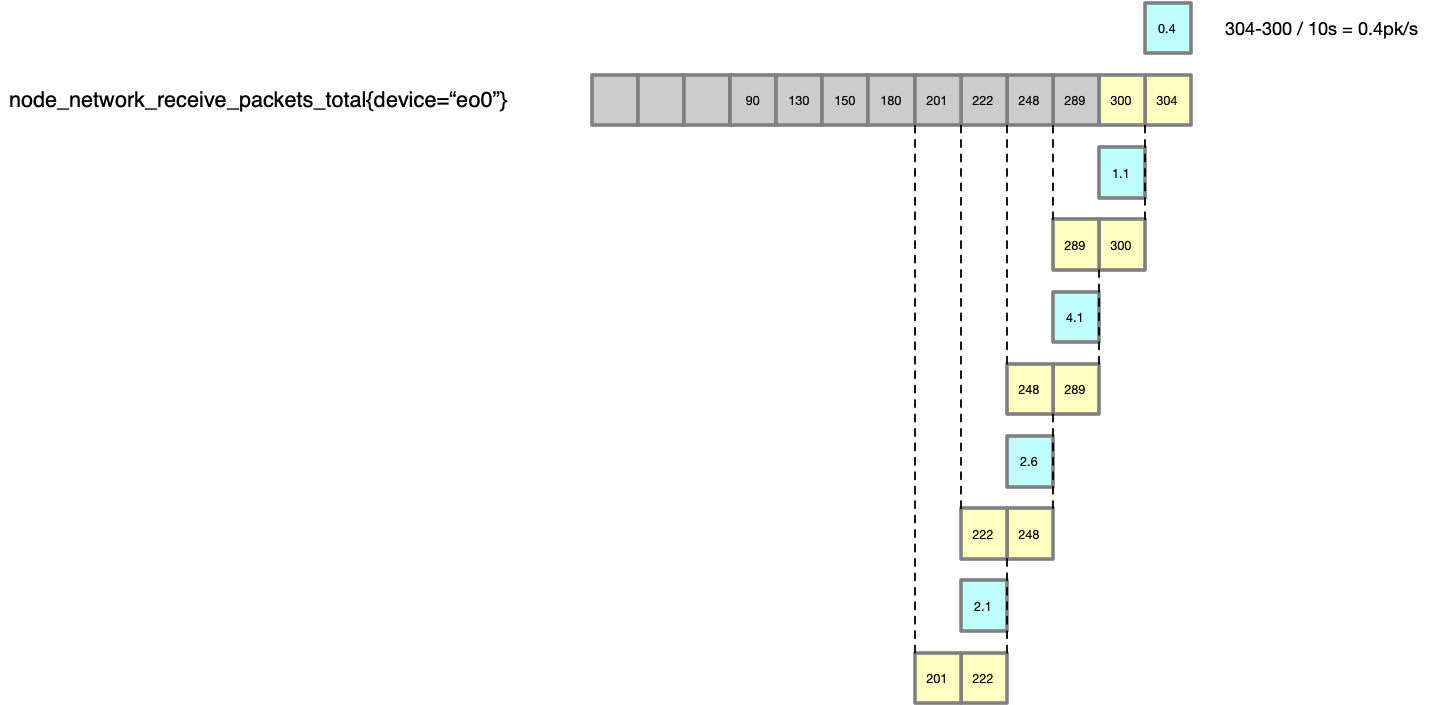
irate 函数因为只用最后两个点的差值来计算,会比 rate 平均值的方法得到的结果,变化更加剧烈,更能反映当时的情况。那既然 irate 函数是用最后两个点计算,这里又为什么需要带上时间跨度 [1m] 参数?这个 [1m] 不是用来计算的,是用来限制找 t-2 个点的时间的,比如,如果中间丢了很多数据,那么显然这个点的计算会很不准确,irate 在计算的时候会最多向前在 [1m] 找点,如果超过 [1m] 没有找到数据点,这个点的计算就放弃了。irate(node_network_receive_packets_total{device=~"en.*"}[1m]) 的指标图更新如下:

对比与 rate,可以看到后者变化更加剧烈,比较适合于 CPU,network 这种资源的变化,使用 irate 更加有意义
increase
increase 本质上等价于 rate() * 时间窗口秒数,它返回的是指定时间窗口内 Counter 的增量。与简单的 end - start 不同,increase 同样会进行外推(extrapolation) 校正以覆盖完整时间窗口,因此结果可能略大于实际的首末差值。例如 increase(http_requests_total[5m]) 返回过去 5 分钟内请求数的增量
小结下,rate/irate/increase 函数接受的都是 Range Vector,返回的是 Instant Vector,另外需要 注意 的是,increase 和 rate 的 range 窗口建议至少为 4 倍采集周期(如 scrape_interval=15s 则 range 至少为 1m),以应对偶尔的采集失败或延迟
使用函数的顺序问题
计算如下公式 P99 的时候,要注意函数顺序(rate、sum 与 histogram_quantile 的次序不能交换):
histogram_quantile(0.99,
sum by (le) # 按照 le 这个 label 进行分组
(rate(http_request_duration_seconds_bucket[10m]))
)
下面的对比图清晰展示了两种函数顺序的差异:
flowchart LR
subgraph correct ["正确: 先 rate 后 sum"]
C1["Counter 时间序列"] --> R1["rate()"]
R1 --> S1["sum()"]
R1 -.- N1["正确处理 Counter Reset"]
end
subgraph wrong ["错误: 先 sum 后 rate"]
C2["Counter 时间序列"] --> S2["sum()"]
S2 --> R2["rate()"]
S2 -.- N2["Reset 变成下降而非归零, rate 误判"]
end
首先,Histogram 本质(http_request_duration_seconds_bucket)也是一个 Counter,所以要使用 rate 先处理,然后根据 le 将 labels 使用 sum 合起来,最后使用 histogram_quantile 来计算。这三个函数的顺序是不能调换的,必须是先 rate 再 sum,最后 histogram_quantile。原因如下:
rate必须在sum之前。前面提到过 Prometheus 支持在 Counter 的数据有下降之后自动处理的,比如服务器重启了,metric 重新从0开始。这个其实不是在存储的时候做的,比如应用暴露的 metric 就是从2033变成0了,那么 Prometheus 就会存储0。 但是在计算rate的时候,就会识别出来这个下降。但是sum不会,所以如果先sum再rate,曲线就会出现非常大的波动(通过rate尽力排除掉疑似0这种对计算结果的干扰)histogram_quantile必须在最后,由于histogram_quantile计算的结果是近似值,去聚合(sum/max/avg这些函数)这个值都是没有意义的,可以参考上述histogram_quantile的分析逻辑
此外,对于 histogram 指标的 PXX 计算,桶的区间越大,越不准确,桶的区间越小,越准确
可以参考下面的文章:
常用 PromQL 汇总
本小节以一个完整的 HTTP Gin API 服务器为例,展示 Counter/Gauge/Histogram(含 Vec)在实际项目中的经典用法,并汇总对应的 PromQL 查询
完整示例:基于 Gin 的 HTTP API 服务器
下面的代码实现了一个典型的 Gin HTTP 服务,定义了 CounterVec(请求总数)、GaugeVec(当前并发请求数)、HistogramVec(请求耗时分布)三种指标,并通过 Prometheus 中间件自动采集:
package main
import (
"fmt"
"math/rand"
"net/http"
"time"
"github.com/gin-gonic/gin"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
// CounterVec:按 method/path/status 维度统计请求总数
httpRequestsTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Namespace: "myapp",
Subsystem: "http",
Name: "requests_total",
Help: "Total number of HTTP requests",
},
[]string{"method", "path", "status"},
)
// HistogramVec:按 method/path 维度统计请求耗时分布
httpRequestDuration = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Namespace: "myapp",
Subsystem: "http",
Name: "request_duration_seconds",
Help: "HTTP request duration in seconds",
Buckets: []float64{0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5, 10},
},
[]string{"method", "path"},
)
// GaugeVec:按 method/path 维度统计当前活跃请求数
httpInflightRequests = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: "myapp",
Subsystem: "http",
Name: "inflight_requests",
Help: "Number of inflight HTTP requests being processed",
},
[]string{"method", "path"},
)
// HistogramVec:按 method/path 维度统计响应体大小分布
httpResponseSizeBytes = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Namespace: "myapp",
Subsystem: "http",
Name: "response_size_bytes",
Help: "HTTP response size in bytes",
Buckets: prometheus.ExponentialBuckets(100, 2, 10),
},
[]string{"method", "path"},
)
)
func init() {
prometheus.MustRegister(httpRequestsTotal)
prometheus.MustRegister(httpRequestDuration)
prometheus.MustRegister(httpInflightRequests)
prometheus.MustRegister(httpResponseSizeBytes)
}
// prometheusMiddleware 封装 Gin 中间件,自动采集请求指标
func prometheusMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
path := c.FullPath()
if path == "" {
path = "unknown"
}
method := c.Request.Method
// Gauge:进入时 +1,退出时 -1
httpInflightRequests.WithLabelValues(method, path).Inc()
defer httpInflightRequests.WithLabelValues(method, path).Dec()
start := time.Now()
c.Next()
duration := time.Since(start).Seconds()
status := fmt.Sprintf("%d", c.Writer.Status())
// Counter:请求计数 +1
httpRequestsTotal.WithLabelValues(method, path, status).Inc()
// Histogram:记录请求耗时
httpRequestDuration.WithLabelValues(method, path).Observe(duration)
// Histogram:记录响应体大小
httpResponseSizeBytes.WithLabelValues(method, path).Observe(float64(c.Writer.Size()))
}
}
func main() {
r := gin.Default()
r.Use(prometheusMiddleware())
// 业务接口
r.GET("/api/users", func(c *gin.Context) {
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
c.JSON(http.StatusOK, gin.H{"users": []string{"alice", "bob"}})
})
r.POST("/api/orders", func(c *gin.Context) {
time.Sleep(time.Duration(rand.Intn(200)) * time.Millisecond)
c.JSON(http.StatusCreated, gin.H{"order_id": "12345"})
})
r.GET("/api/health", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{"status": "ok"})
})
r.GET("/api/slow", func(c *gin.Context) {
time.Sleep(time.Duration(500+rand.Intn(2000)) * time.Millisecond)
c.JSON(http.StatusOK, gin.H{"msg": "done"})
})
// Prometheus 指标暴露端口(建议与业务端口分离)
go func() {
mux := http.NewServeMux()
mux.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":9527", mux)
}()
r.Run(":8080")
}
基于上述代码中定义的指标,以下是在 Grafana/Prometheus 中常用的 PromQL 查询汇总:
1、Counter 经典用法
# 全局 QPS(每秒请求数)
sum(rate(myapp_http_requests_total[5m]))
# 按接口分组的 QPS
sum(rate(myapp_http_requests_total[5m])) by (path)
# 按请求方法分组的 QPS
sum(rate(myapp_http_requests_total[5m])) by (method)
# 错误率(5xx 占总请求的比例)
sum(rate(myapp_http_requests_total{status=~"5.."}[5m]))
/
sum(rate(myapp_http_requests_total[5m]))
# 某接口的错误率
sum(rate(myapp_http_requests_total{path="/api/orders",status=~"5.."}[5m]))
/
sum(rate(myapp_http_requests_total{path="/api/orders"}[5m]))
# 每分钟请求增量
sum(increase(myapp_http_requests_total[1m])) by (path)
# 非 200 请求的 QPS
sum(rate(myapp_http_requests_total{status!="200"}[5m])) by (path, status)
2、Gauge 经典用法
# 当前所有接口的并发请求总数
sum(myapp_http_inflight_requests)
# 按接口分组的并发请求数
sum(myapp_http_inflight_requests) by (path)
# 最近 5 分钟内并发请求的最大值
max_over_time(sum(myapp_http_inflight_requests)[5m:])
# 最近 10 分钟内并发数的平均值(按接口)
avg_over_time(sum by (path) (myapp_http_inflight_requests)[10m:])
3、Histogram(Vec)经典用法
# 全局 P50 延迟
histogram_quantile(0.5,
sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le)
)
# 全局 P90 延迟
histogram_quantile(0.90,
sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le)
)
# 全局 P99 延迟
histogram_quantile(0.99,
sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le)
)
# 按接口分组的 P95 延迟
histogram_quantile(0.95,
sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le, path)
)
# 全局平均延迟
sum(rate(myapp_http_request_duration_seconds_sum[5m]))
/
sum(rate(myapp_http_request_duration_seconds_count[5m]))
# 按接口分组的平均延迟
sum(rate(myapp_http_request_duration_seconds_sum[5m])) by (path)
/
sum(rate(myapp_http_request_duration_seconds_count[5m])) by (path)
# TopN 最慢接口(P99)
topk(5,
histogram_quantile(0.99,
sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le, path)
)
)
# 响应体大小 P90
histogram_quantile(0.90,
sum(rate(myapp_http_response_size_bytes_bucket[5m])) by (le)
)
4、组合查询与告警规则
# 请求延迟突增告警:当前 5 分钟 P99 > 过去 1 小时 P99 的 2 倍
histogram_quantile(0.99, sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le))
>
2 * histogram_quantile(0.99, sum(rate(myapp_http_request_duration_seconds_bucket[1h])) by (le))
# QPS 突增告警:当前 5 分钟 QPS > 过去 1 小时平均 QPS 的 3 倍
sum(rate(myapp_http_requests_total[5m]))
>
3 * sum(rate(myapp_http_requests_total[1h]))
# SLO 检查:P99 延迟 < 500ms
histogram_quantile(0.99, sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le)) < 0.5
# Apdex 分数近似(阈值 T=0.5s):Apdex = (Satisfied + Tolerating/2) / Total
# 其中 Satisfied = le<=T 的请求数,Tolerating = T<le<=4T 的请求数
# 数学等价形式:(bucket{le=T} + bucket{le=4T}) / 2 / total
(
sum(rate(myapp_http_request_duration_seconds_bucket{le="0.5"}[5m]))
+
sum(rate(myapp_http_request_duration_seconds_bucket{le="2"}[5m]))
) / 2
/
sum(rate(myapp_http_request_duration_seconds_count[5m]))
汇总表:
| 场景 | 指标类型 | 核心 PromQL |
|---|---|---|
| QPS(全局/按接口) | CounterVec | sum(rate(myapp_http_requests_total[5m])) by (path) |
| 错误率 | CounterVec | sum(rate(...{status=~"5.."}[5m])) / sum(rate(...[5m])) |
| 每分钟请求增量 | CounterVec | sum(increase(myapp_http_requests_total[1m])) by (path) |
| 当前并发数 | GaugeVec | sum(myapp_http_inflight_requests) by (path) |
| 并发数峰值 | GaugeVec | max_over_time(sum(myapp_http_inflight_requests)[5m:]) |
| P50/P90/P99 延迟 | HistogramVec | histogram_quantile(0.99, sum(rate(..._bucket[5m])) by (le)) |
| 按接口 P95 延迟 | HistogramVec | histogram_quantile(0.95, sum(rate(..._bucket[5m])) by (le, path)) |
| 平均延迟 | HistogramVec | sum(rate(..._sum[5m])) / sum(rate(..._count[5m])) |
| TopN 慢接口 | HistogramVec | topk(5, histogram_quantile(0.99, sum(rate(..._bucket[5m])) by (le, path))) |
| QPS 突增告警 | CounterVec | rate(...[5m]) > 3 * rate(...[1h]) |
| 延迟超标告警 | HistogramVec | histogram_quantile(0.99, ...) > threshold |
注意事项:
- 对 histogram 指标计算分位数时,
sum by (le)是必须的,不能丢掉le标签 - 计算比率(如错误率)时,分子分母都要先
rate再sum,保持一致的时间窗口 histogram_quantile结果是近似值,桶边界的设计直接影响精度,建议根据业务实际延迟分布调整Buckets- 在生产环境中,metrics 暴露端口建议与业务端口分离,避免外部直接访问
0x03 PromQL 的典型应用:实践
sum 用法
sum 是 PromQL 中的一个聚合操作符,用于计算一组时间序列数据的总和。简单地说,sum 的作用是将一组时间序列数据相加,得到一个总和值。这对于计算多个实例(如服务器、容器等)的资源使用情况总和等场景非常有用。当然,sum 计算需要基于同一指标名:
#not ok
http_requests_total{job="api-server", instance="instance-1"}
cpu_usage{job="api-server", instance="instance-1"}
#ok
http_requests_total{job="api-server", instance="instance-1"}
http_requests_total{job="api-server", instance="instance-2"}
假设三台服务器的 CPU 使用率如下,使用 sum(cpu_usage) 可以得到这三台服务器的 CPU 使用率总和,sum 通常与 by 子句配合,以便在对多个标签进行分组求和时更加明确。如果希望按照服务器所在的数据中心对 CPU 使用率求和 sum(cpu_usage) by (datacenter),结果将按照数据中心分组,显示每个数据中心中所有服务器的 CPU 使用率总和。这有点像是一个维度的设计,需要开发者自行规划 label
server1:10%
server2:20%
server3:30%
又如 sum by (job)(rate(http_requests_total{job="node"}[5m])),这个例子的含义是计算过去 5 分钟中,每个 job="node" 的 HTTP 请求的平均速率,并按照 job 的值进行求和,但同时只关心一个特定的 job 值(即 node),这个查询模式在处理多个 job 值的情况下比较有用
0x04 小结
summary vs Histogram
在大多数情况下,histogram 直方图是首选,因为它更灵活,并允许汇总百分位数。在不需要百分位数而只需要平均数的情况下,或者在需要非常精确的百分位数的情况下,使用 summary 是有用的,histogram 与 summary 的对比如下:
Histogram:
- 客户端性能消耗小,服务端查询分位数时消耗大
- 可以在查询期间自由计算各种不同的分位数
- 分位数的精度无法保证,其精确度受桶的配置、数据分布、数据量大小情况影响
- 可聚合,可以计算全局分位数
- 客户端兼容性好
Summary:
- 客户端性能消耗大(因为分位数计算发生在客户端),服务端查询分位数时消耗小
- 只能查询客户端上报的哪些分位数
- 分位数的精度可以得到保证,精度会影响客户端的消耗
- 不可聚合,无法计算全局分位数(因此不支持多实例,平行扩展的 http 服务)
- 客户端兼容性不好
规则:PromQL 要先 rate() 再 sum(),不能 sum() 完再 rate()
这背后与 rate() 的实现方式有关,rate() 在设计上假定对应的指标是一个 Counter,也就是只有 incr(增加)和 reset(归 0) 两种行为。而做了 sum() 或其他聚合之后,得到的就不再是一个 Counter 了。比如 sum() 的计算对象中有一个归 0 了,那整体的和会下降,而不是归零,这会影响 rate() 中判断 reset(归 0) 的逻辑,从而导致错误的结果。此外,建议遵循 Recording Rule 规则:一步到位,直接算出需要的值,避免算出一个中间结果再拿去做聚合
rate(http_requests_total{job="node"}[5m])
sum by (job)(rate(http_requests_total{job="node"}[5m])) # This is okay
rate(sum by (job)(http_requests_total{job="node"})[5m]) # Don't do this
可以参考此文 Rate then sum, never sum then rate
0x05 指标与grafana:典型的面板
以ETCD的指标为例
counter
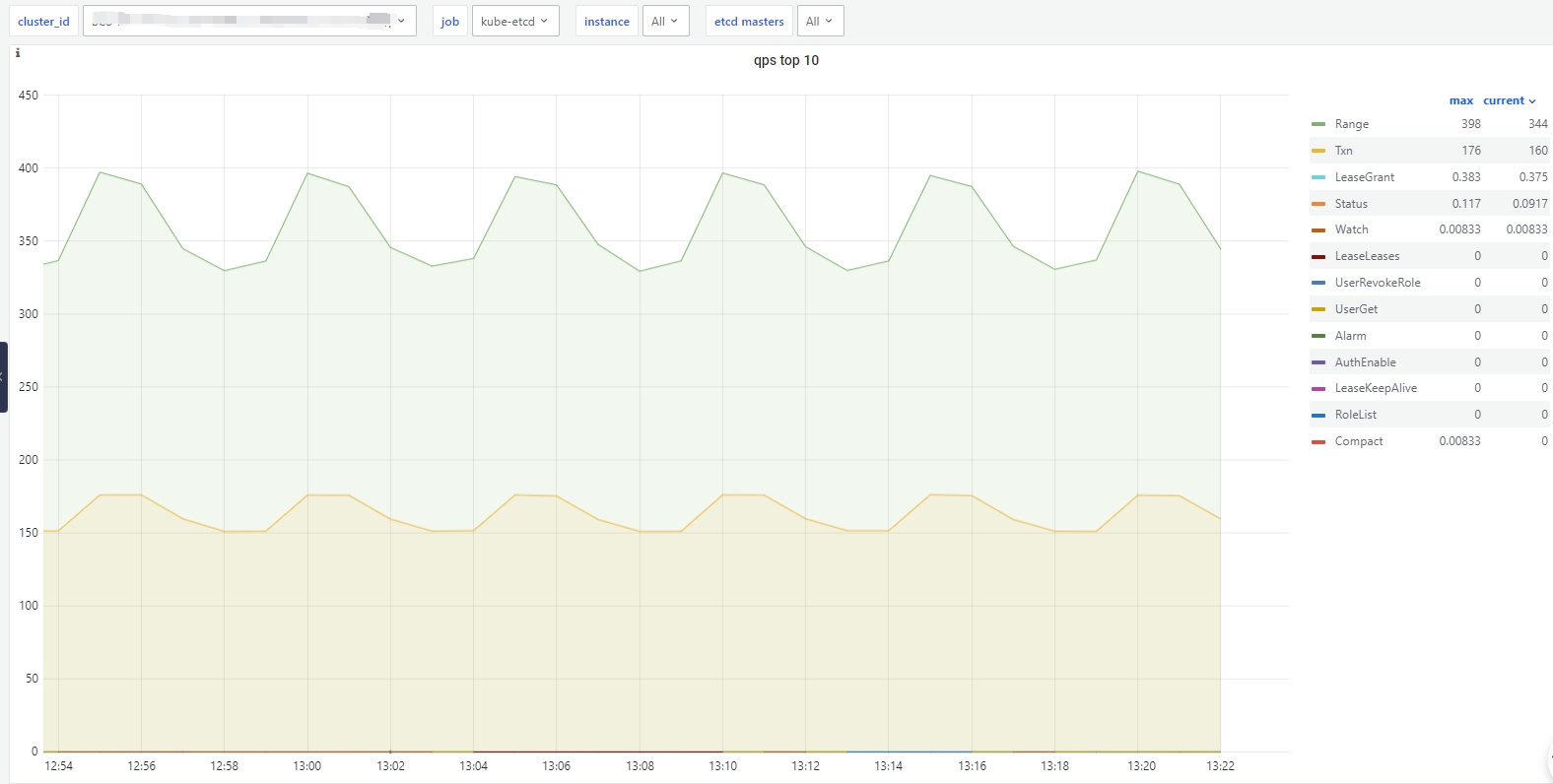
1、qps-top
topk(10, sum by (grpc_method) (rate(xxmonitor:grpc_server_handled_total{bcs_cluster_id="$cluster_id",instance="$instance",job="$job"}[2m])))
2、出流量qps实时
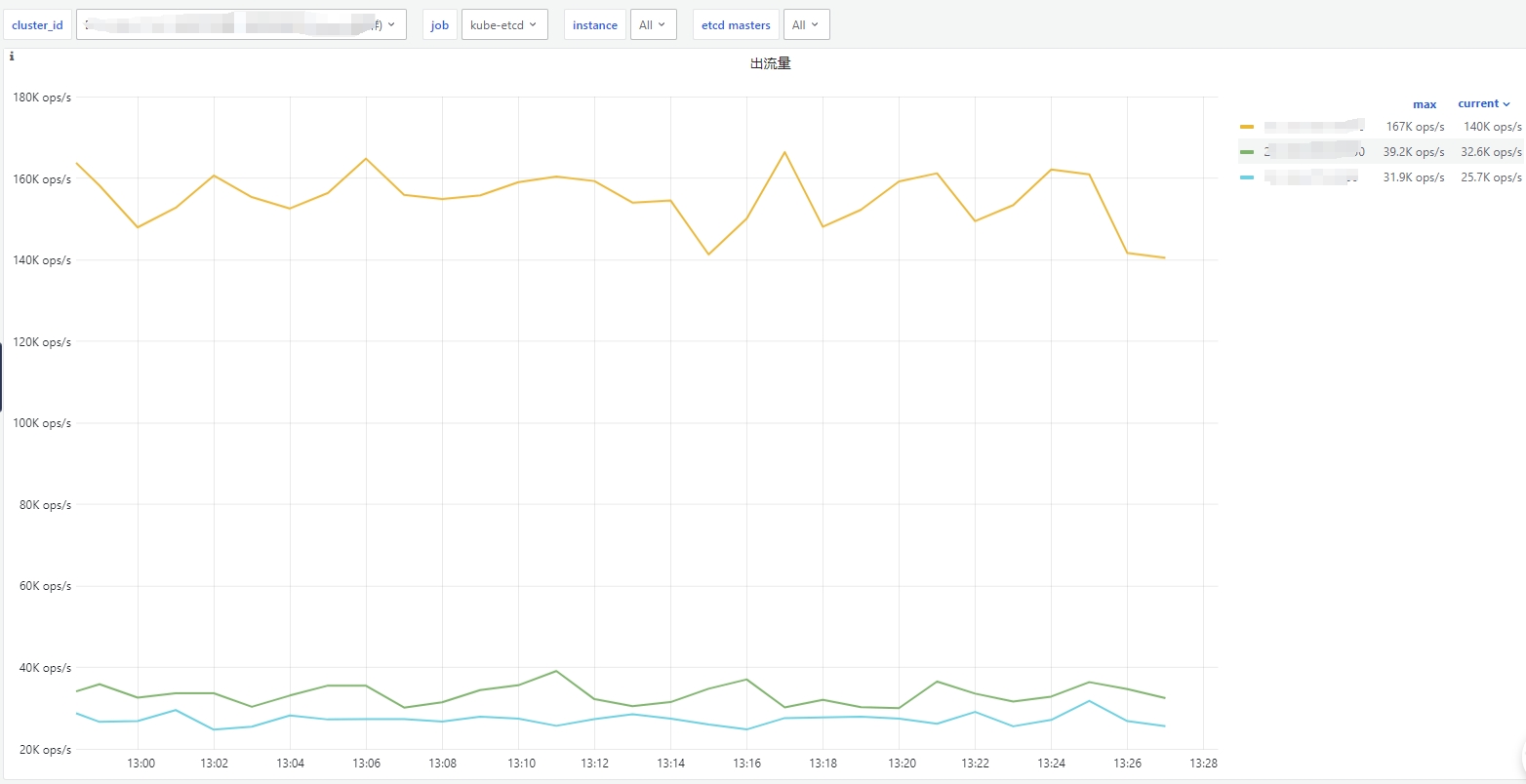
sum by (instance) (rate(xxmonitor:container_network_transmit_packets_total{bcs_cluster_id="$cluster_id",pod=~"etcd"}[2m]))
3、peer节点入流量qps
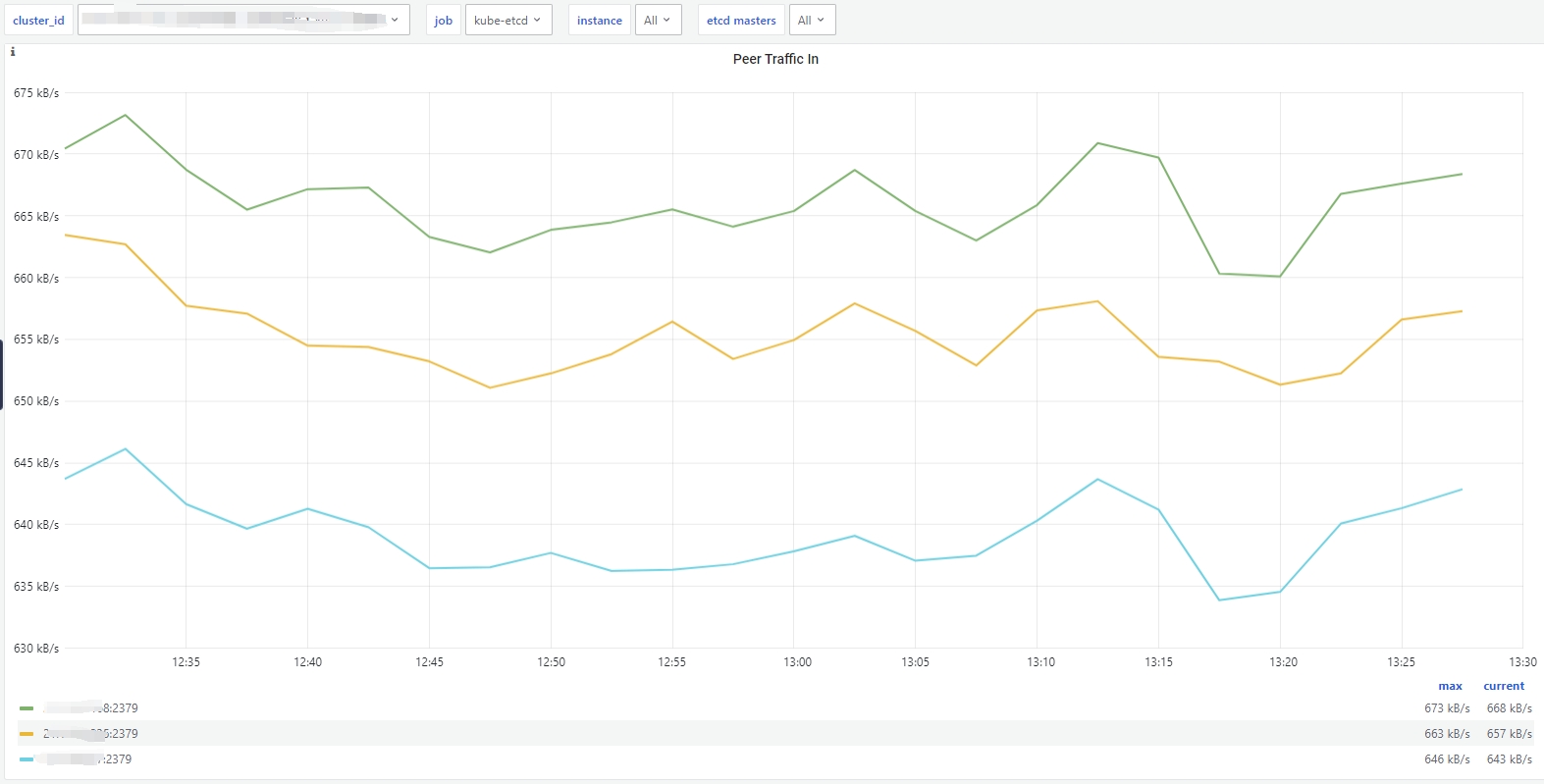
sum by (job, instance) (rate(xxmonitor:etcd_network_peer_sent_bytes_total{bcs_cluster_id="$cluster_id",instance="$instance",job="$job"}[5m]))
gauge
1、master出流量视图
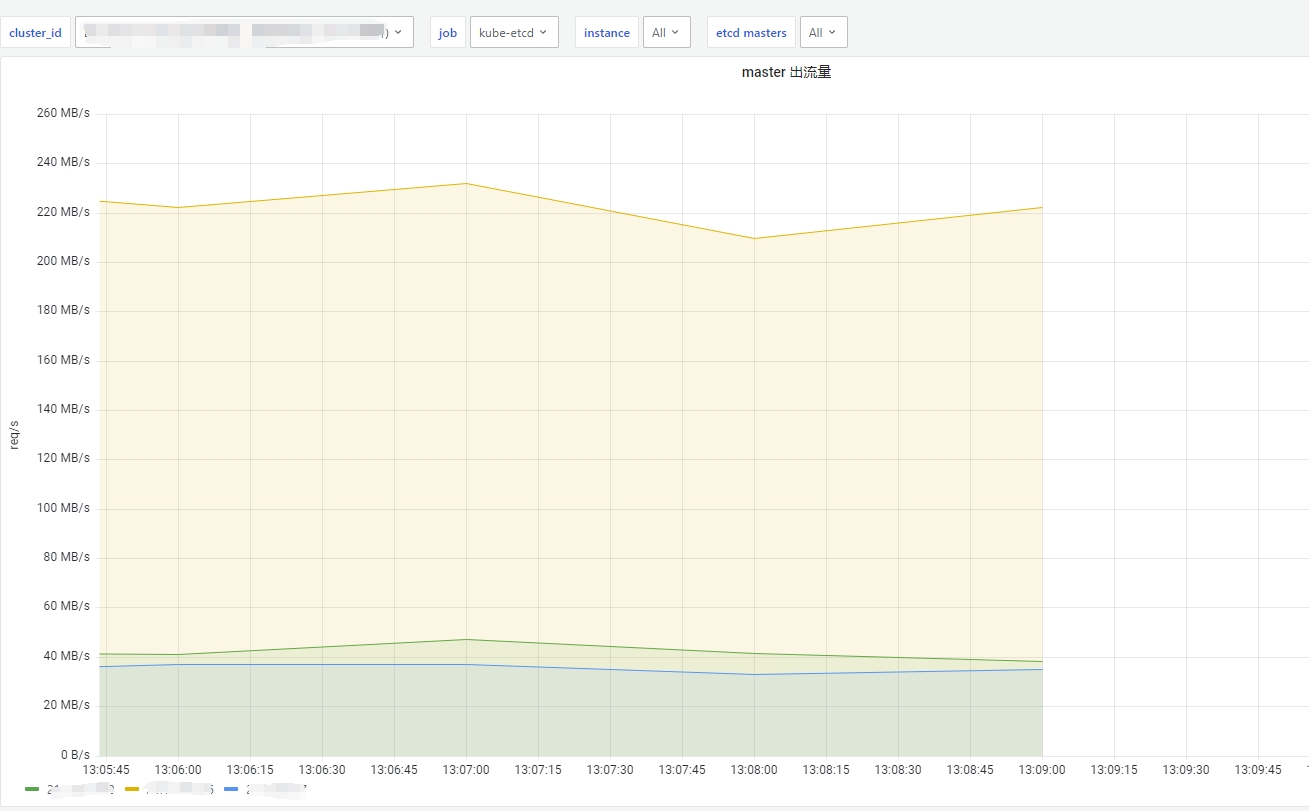
sum by (bk_target_ip) (sum_over_time(xxmonitor:system:net:speed_sent{bk_target_ip="$masters"}[1m]))
histogram
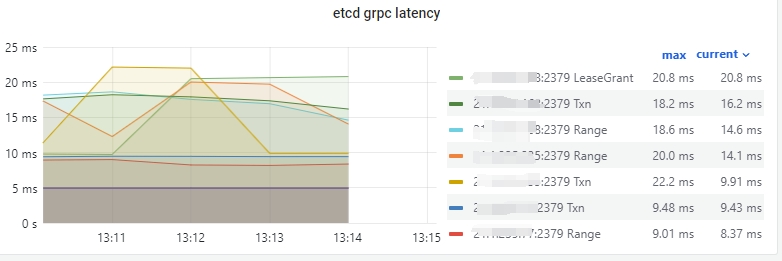
histogram_quantile(0.99, avg by (grpc_method, instance, job, le) (rate(xxmonitor:grpc_server_handling_seconds_bucket{bcs_cluster_id="$cluster_id",grpc_method!~"Watch|Compact",instance="$instance",job="$job"}[2m])))
0x06 Metrics && SLI/SLO
SLI(Service Level Indicator)和SLO(Service Level Objective)是服务质量管理中的两个关键概念:
-
SLI是衡量服务质量的指标,通常用于衡量服务提供商提供的服务在某个方面的表现。SLI可以是吞吐量、延迟、错误率等指标,用于反映服务的性能、可用性、可靠性等,SLI可以帮助服务提供商和客户了解服务的实际状况,并为改进服务提供依据
-
SLO是基于SLI的目标值,它定义了服务提供商希望达到或维持的服务水平。SLO通常以一定的时间范围(例如每月、每季度)为基准,设定SLI的目标值,如
99.9%可用性、平均响应时间小于100ms等,SLO可以作为服务提供商与客户之间的约定,帮助双方明确期望和责任
一个简单的例子:apiserver
1、定义SLI
- 请求延迟:通过Prometheus的
http_request_duration_seconds指标来衡量,该指标可以衡量每个请求的处理时间 - 请求错误率:通过Prometheus的
http_requests_total和http_requests_failed_total两个指标来计算错误率。http_requests_total表示所有的请求总数,http_requests_failed_total表示失败的请求总数
2、定义SLO
- 平均请求延迟应该小于
100ms:通过PromQL来计算平均请求延迟,然后再与目标值进行比较 - 请求错误率应该小于
1%:可以通过计算http_requests_failed_total与http_requests_total的比值,然后与的目标值进行比较
实现:
var (
httpRequestDuration = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "http_request_duration_seconds",
Help: "HTTP request latency",
Buckets: prometheus.DefBuckets,
},
[]string{"method", "path", "status"},
)
httpRequestsTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Total number of HTTP requests",
},
[]string{"method", "path", "status"},
)
httpRequestsFailedTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_failed_total",
Help: "Total number of failed HTTP requests",
},
[]string{"method", "path"},
)
)
func init() {
prometheus.MustRegister(httpRequestDuration)
prometheus.MustRegister(httpRequestsTotal)
prometheus.MustRegister(httpRequestsFailedTotal)
}
func main() {
router := gin.Default()
router.Use(prometheusMiddleware())
router.GET("/", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{"message": "Hello, World!"})
})
router.GET("/error", func(c *gin.Context) {
c.JSON(http.StatusInternalServerError, gin.H{"message": "An error occurred"})
})
router.GET("/metrics", gin.WrapH(promhttp.Handler()))
router.Run(":8080")
}
func prometheusMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
start := time.Now()
c.Next()
status := c.Writer.Status()
method := c.Request.Method
path := c.FullPath()
httpRequestsTotal.WithLabelValues(method, path, fmt.Sprint(status)).Inc()
httpRequestDuration.WithLabelValues(method, path, fmt.Sprint(status)).Observe(time.Since(start).Seconds())
if status >= http.StatusInternalServerError {
httpRequestsFailedTotal.WithLabelValues(method, path).Inc()
}
}
}
3、计算SLI/SLO
- 平均请求延迟应该小于
100ms:sum(rate(http_request_duration_seconds_sum[5m])) / sum(rate(http_request_duration_seconds_count[5m])) * 1000 - 请求错误率应该小于
1%:sum(rate(http_requests_failed_total[5m])) / sum(rate(http_requests_total[5m])) * 100(注意必须使用rate()计算最近时间窗口的错误率,直接用裸 Counter 做除法得到的是自服务启动以来的总错误率,无法反映当前状态) P99的请求响应时间需要小于500ms:histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le)) * 1000其中sum(rate(http_request_duration_seconds_bucket[5m])) by (le)部分计算了每个延迟桶的速率,然后将其按照延迟上限(le)进行聚合。最后,将结果乘以1000,将其转换为ms
进一步,将指标按照GET/POST进行分组,如下:
sum(rate(http_request_duration_seconds_sum[5m])) by (method) / sum(rate(http_request_duration_seconds_count[5m])) by (method) * 1000
#请求错误率(按GET/POST分组):
sum(rate(http_requests_failed_total[5m])) by (method) / sum(rate(http_requests_total[5m])) by (method) * 100
#P99响应时间(按GET/POST分组):
histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le, method)) * 1000
0x07 Recording Rules(预计算规则)
在生产环境中,复杂的 PromQL 查询(如 histogram P99 计算、多层聚合等)会在每次查询时消耗大量计算资源,尤其在 Dashboard 刷新或告警规则频繁求值时。Recording Rules 允许预先计算这些表达式的结果并将其存储为新的时间序列,从而显著降低查询延迟
Recording Rules 的核心价值
- 降低查询延迟:将复杂的聚合/分位数计算预先完成,Dashboard 查询时直接读取已计算好的指标
- 降低 Prometheus 负载:避免多个 Dashboard 面板或告警规则反复计算同一个复杂表达式
- 简化 PromQL:将长表达式封装为语义清晰的指标名称
命名规范
Prometheus 官方推荐的 Recording Rule 命名格式为 level:metric:operations:
level:聚合级别和标签,如job、instance、pathmetric:原始指标名称operations:应用的操作列表,如rate5m、sum
配置示例
Recording Rules 在 Prometheus 配置文件中通过 rule_files 引入,规则文件使用 YAML 格式:
# prometheus.yml 中引入规则文件
rule_files:
- "rules/recording_rules.yml"
规则文件示例(rules/recording_rules.yml):
groups:
- name: http_recording_rules
interval: 30s
rules:
# 全局 QPS(每 30s 预计算一次)
- record: job:myapp_http_requests:rate5m
expr: sum(rate(myapp_http_requests_total[5m]))
# 按接口分组的 QPS
- record: job_path:myapp_http_requests:rate5m
expr: sum(rate(myapp_http_requests_total[5m])) by (path)
# 全局 P99 延迟
- record: job:myapp_http_request_duration_seconds:p99_5m
expr: histogram_quantile(0.99, sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le))
# 按接口分组的 P95 延迟
- record: job_path:myapp_http_request_duration_seconds:p95_5m
expr: histogram_quantile(0.95, sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le, path))
# 全局平均延迟
- record: job:myapp_http_request_duration_seconds:avg5m
expr: >
sum(rate(myapp_http_request_duration_seconds_sum[5m]))
/
sum(rate(myapp_http_request_duration_seconds_count[5m]))
# 错误率
- record: job:myapp_http_requests:error_rate5m
expr: >
sum(rate(myapp_http_requests_total{status=~"5.."}[5m]))
/
sum(rate(myapp_http_requests_total[5m]))
预计算完成后,在 Grafana 中直接查询这些新指标即可,无需每次重复编写复杂表达式:
# 原始复杂查询
histogram_quantile(0.99, sum(rate(myapp_http_request_duration_seconds_bucket[5m])) by (le))
# 使用 Recording Rule 后的简化查询
job:myapp_http_request_duration_seconds:p99_5m
使用建议
- 对于 Grafana Dashboard 中高频使用的复杂查询(特别是
histogram_quantile相关的),优先创建 Recording Rule interval建议设置为与scrape_interval相同或稍大(如15s或30s)- 告警规则(Alerting Rules)中建议直接引用 Recording Rule 的结果,而非重复编写复杂表达式
- Recording Rule 的计算结果也可以作为其他 Recording Rule 的输入,支持链式预计算
0x08 参考
- 一文带你了解 Prometheus
- 一文搞懂 Prometheus 的直方图
- 如何区分 prometheus 中 Histogram 和 Summary 类型的 metrics?
- Metrics 设计:teleport
- Lock-free Observations for Prometheus Histograms
- golang API
- HISTOGRAMS AND SUMMARIES
- prometheus 的内置函数
- Prometheus 的九个坑
- PromQL 简明教程
- 详解 Prometheus 四种指标类型
- Histogram and Summary
- What is the difference between increase and delta in PromQL?
- P99 是如何计算的
- Understanding Prometheus Range Vectors
- Prometheus 的 Summary 和 Histogram
- PromQL 中 Counter 相关函数 rate(), irate() 与 increase() 的使用与区别
转载请注明出处,本文采用 CC4.0 协议授权