0x00 前言
httprouter 是非常高效的 http 路由框架,gin 框架的路由也基于此库。使用比较简单:
func main() {
router := httprouter.New()
// 注册路由
router.GET("/", Index)
router.GET("/hello/:name", Hello)
log.Fatal(http.ListenAndServe(":8080", router))
}
理解 httprouter 的核心在于理解 基数树 的实现,路由搜索就是基数树搜索
0x01 基数树 Radix Tree 的实现
httprouter 基于 Radix Tree 实现,Radix Tree 的特点是拥有共同前缀的节点也共享同一个父节点,是一种更节省空间的 Trie 树(前缀树),其中作为唯一子节点的每个节点都与其父节点合并,边既可以表示为元素序列又可以表示为单个元素。 因此每个内部节点的子节点数最多为基数树的基数 r ,其中 r 为正整数,x 为 2 的幂(x>=1),这使得基数树更适用于对于较小的集合(尤其是字符串很长的情况下)和有很长相同前缀的字符串集合。
经典例子:
Priority Path Handle
9 \ *<1>
3 ├s nil
2 |├earch\ *<2>
1 |└upport\ *<3>
2 ├blog\ *<4>
1 | └:post nil
1 | └\ *<5>
2 ├about-us\ *<6>
1 | └team\ *<7>
1 └contact\ *<8>
对应于下面的 GET 请求,*<num> 是方法(handler)对应的指针,从根节点遍历到叶子节点就能得到完整的路由表:
GET("/", func1)
GET("/search/", func2)
GET("/support/", func3)
GET("/blog/", func4)
GET("/blog/:post/", func5)
GET("/about-us/", func6)
GET("/about-us/team/", func7)
GET("/contact/", func8)
通过上面的示例可以看出:
*<数字>代表一个 handler 函数的内存地址(指针)- search 和 support 拥有共同的父节点 s ,并且 s 是没有对应的 handle 的,只有叶子节点(就是最后一个节点,下面没有子节点的节点)才会注册 handler
- 从根开始,一直到叶子节点,才是路由的实际路径
- 路由搜索的顺序是从上向下,从左到右的顺序,为了快速找到尽可能多的路由,包含子节点越多的节点,优先级越高
Radix 树 VS hash 表
在少量长整型数据、普通字符串等 key-value 存储场景,Radix 和 hash 表相比,有如下优势:
- 不需要考虑 Hash 冲突
- 简单,可能会节省空间
- 不需要设计 hash 映射函数
借助于 Radix 树,可以实现对于长整型数据类型的路由,即根据一个长整型(比如一个长 ID)快速查找到其对应的 Value 指针
Radix 树 VS Trie 树
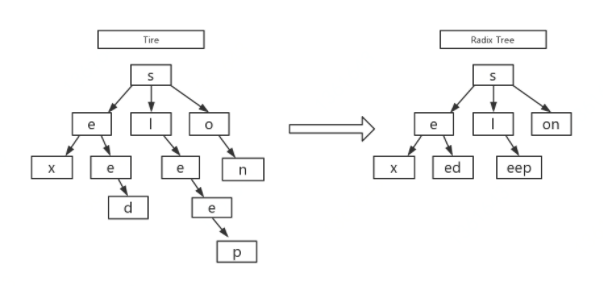
gin的前缀树
engine.GET("/admin/model/get", api.GetTemplate)
engine.GET("/admin/model/query", api.QueryTemplate)
engine.POST("/admin/model/set", api.SetTemplate)
engine.POST("/admin/model/upload", api.UploadTemplate)
engine.POST("/admin/model/uploadv2", api.GetTemplateWithSignature)
engine.POST("/admin/model/update", api.UpdateTemplate)
形成了两棵前缀树,左边是GET方法的树,右边是POST方法树
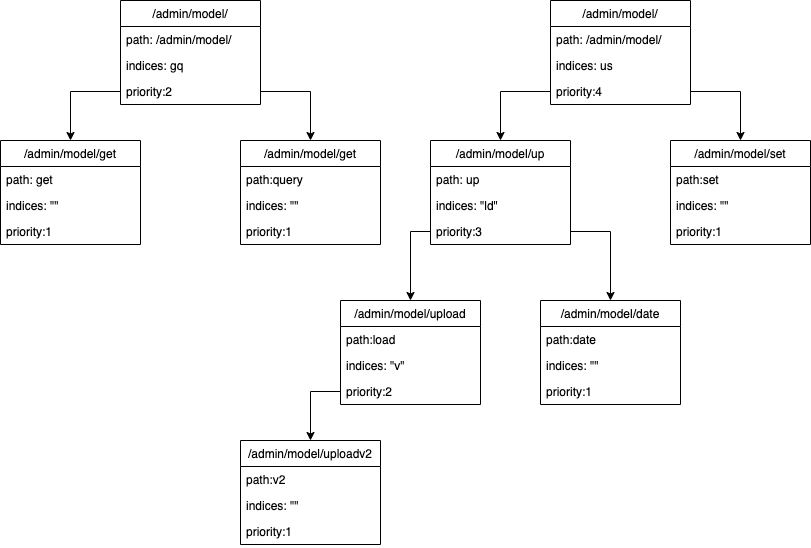
搜索
下图展示了在基数树中进行字符串查找的示例,通过基数树可以提高字符顺序匹配的效率,对于 URL 之类的字符使用基数树来进行归类、匹配非常适合
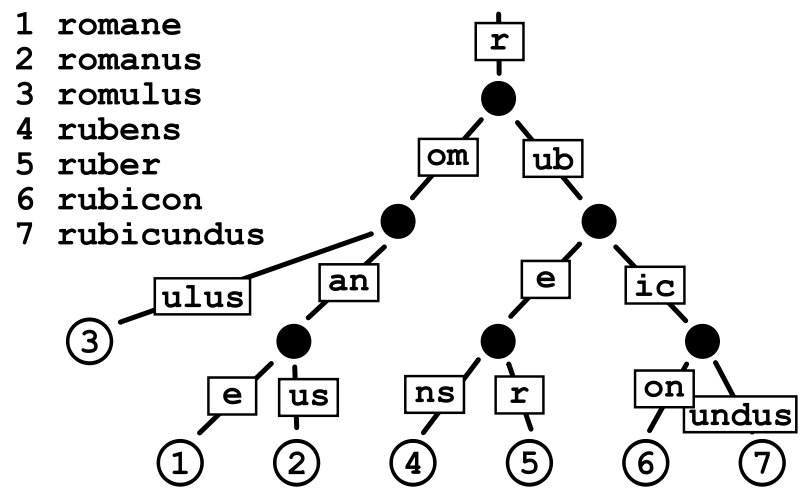
romane
romanus
romulus
rubens
ruber
rubicon
rubicundus
Radix 树的实现
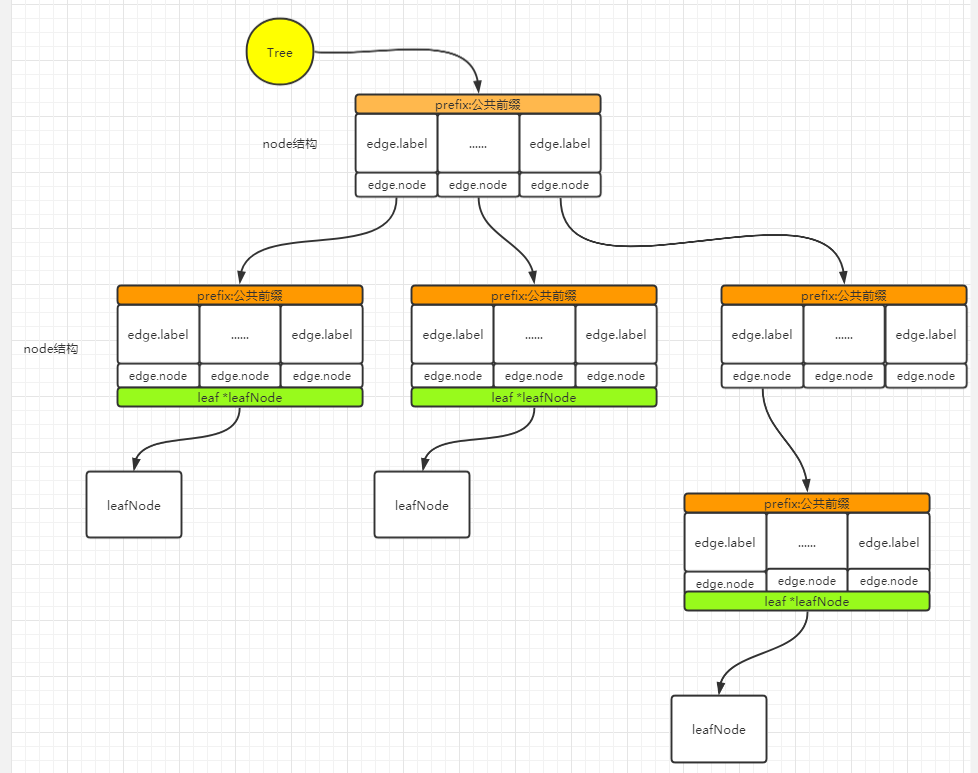
以项目 go-radix 为例,先窥探下 radix 树的结构:
// Tree implements a radix tree. This can be treated as a
// Dictionary abstract data type. The main advantage over
// a standard hash map is prefix-based lookups and
// ordered iteration,
type Tree struct {
root *node // 树的根节点
size int // 树中存储的键值对数量
}
type node struct {
// leaf is used to store possible leaf
leaf *leafNode // 叶子节点指针,如果当前节点是键的终点,则存储实际数据
// prefix is the common prefix we ignore
prefix string // 当前节点共享的前缀字符串
// Edges should be stored in-order for iteration.
// We avoid a fully materialized slice to save memory,
// since in most cases we expect to be sparse
edges edges // 子节点边集合([]edge)
}
type edges []edge
// edge is used to represent an edge node
type edge struct {
label byte // 边的标签(注意:单个字符)
node *node // 指向的子节点
}
// leafNode is used to represent a value
type leafNode struct {
key string // 完整的键
val interface{} // 值指针
}
如上面代码:
Tree:radixTree 开始节点node:radixTree 路径上的节点edge:指向下一层节点的指针edges:把edge封装为 slice,便于操作(特别注意edges始终是有序的,便于二分查找)leafNode:叶子节点
这里比较重要的几个成员如下:
node.prefix:共享前缀压缩,存储多个键的公共前缀,减少内存占用, apple 和 apply 共享 appl 前缀node.edges:子节点连接,通过边的标签(label)快速定位到下一级节点。注意edges是有序存储,可使用排序切片便于二分查找(参考getEdge方法)node.leaf:数据存储,标识当前节点是否是某个键的终点 值kv
注意到,每个node节点对应的edges切片,其中edge结构的label成员仅仅是一个byte,而且label的本质是指向公共前缀prefix之后的下一个字符(第一个字符),而不是最后一个字符
edge && node
- 边(
edge):从父节点指向子节点的连接 - 节点(
node):边的目标,包含实际数据
每个节点都同时具备以下两种功能:
- 存储数据(通过
leaf成员) - 拥有子节点(通过
edges成员)
node实现的方法
//检查当前节点是否是叶子节点
func (n *node) isLeaf() bool {
return n.leaf != nil
}
addEdge:添加边(有序插入),
func (n *node) addEdge(e edge) {
num := len(n.edges)
// 二分查找插入位置:第一个 >= e.label 的索引
idx := sort.Search(num, func(i int) bool {
return n.edges[i].label >= e.label
})
// 扩容并移动元素
//增加一个空位置
n.edges = append(n.edges, edge{})
//将idx及之后的元素后移 copy(dest,src)
copy(n.edges[idx+1:], n.edges[idx:])
//在idx位置插入新edge
n.edges[idx] = e
}
假设当前edges为['a', 'd', 'f'],要插入 'c',那么使用二分查找找到第一个 >= 'c' 的位置是索引1,即'd'的位置,执行后更新为['a', 'c', 'd', 'f']
getEdge:通过二分查找获取edge
func (n *node) getEdge(label byte) *node {
num := len(n.edges)
// 二分查找:第一个 >= label 的索引
// sort.Search返回第一个使条件为true的索引
idx := sort.Search(num, func(i int) bool {
return n.edges[i].label >= label
})
// 检查是否精确匹配
if idx < num && n.edges[idx].label == label/*精确匹配*/ {
return n.edges[idx].node
}
return nil // 未找到
}
updateEdge:更新edge,用于节点分裂时更新父节点指向新的中间节点,需要确保要更新的edge必须存在,否则panic
func (n *node) updateEdge(label byte, node *node) {
num := len(n.edges)
idx := sort.Search(num, func(i int) bool {
return n.edges[i].label >= label
})
if idx < num && n.edges[idx].label == label {
n.edges[idx].node = node // 更新节点指针
return
}
panic("replacing missing edge") // 边必须存在
}
delEdge:用于删除edge
func (n *node) delEdge(label byte) {
num := len(n.edges)
idx := sort.Search(num, func(i int) bool {
return n.edges[i].label >= label
})
if idx < num && n.edges[idx].label == label {
// 将后面的元素前移,覆盖要删除的元素
copy(n.edges[idx:], n.edges[idx+1:])
// 清空最后一个元素(避免内存泄漏)
n.edges[len(n.edges)-1] = edge{}
// 缩容切片
n.edges = n.edges[:len(n.edges)-1]
}
}
如删除['a', 'c', 'd', 'f']中的 'd',首先找到索引2,将索引3的元素'f'复制到索引2,变为['a', 'c', 'f', 'f'],并清空最后一个['a', 'c', 'f', {}],最后缩容['a', 'c', 'f']
用下图可以表示 go-radix 的结构关系:
node的结构如下图:
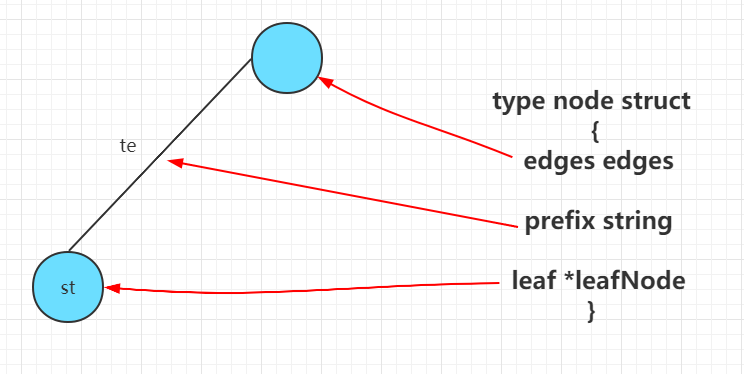
节点间的关系
0x02 go-radix 的主要操作解读
精确查找
1、支持key的前缀匹配,Radix Tree的核心优势是前缀查找,需要支持一个键是另一个键的前缀的场景,如app和apple可以共存,反映在radix中app节点既是有效的key(本身leaf成员不为空),也是apple的父节点
2、查找优化:在向下遍历时,如果遇到包含数据的节点,可以立即返回,不需要到达树的末端
func (t *Tree) Get(s string) (interface{}, bool) {
n := t.root
search := s //查找指针
for {
// Check for key exhaution
// 重要:在任何节点都可能找到数据,不一定是"叶子节点"
if len(search) == 0 { // 检查当前节点是否有数据
// 已经没有带匹配的字符(串)了
if n.isLeaf() {
return n.leaf.val, true
}
break
}
// Look for an edge
n = n.getEdge(search[0])
if n == nil {
break
}
// Consume the search prefix
if strings.HasPrefix(search, n.prefix) {
search = search[len(n.prefix):]
} else {
break
}
}
return nil, false
}
模糊查找(匹配最长前缀)
查找需要按照关键字一层一层匹配即可,如果在某一层的所有 child 节点中都没有匹配到则查找失败,本库做了 优化,返回匹配到最长的 key:
// LongestPrefix is like Get, but instead of an
// exact match, it will return the longest prefix match.
func (t *Tree) LongestPrefix(s string) (string, interface{}, bool) {
var last *leafNode
n := t.root
//search:查找指针
search := s
for {
// Look for a leaf node
if n.isLeaf() {
//叶子节点,注意,这里并没有检查叶子上的剩余子串是否匹配
last = n.leaf
}
// Check for key exhaution
if len(search) == 0 {
break
}
// Look for an edge
n = n.getEdge(search[0])
// 根据当前search的第一个字符,执行label查找
if n == nil {
//没有找到,退出循环
break
}
//根据label找到了对应的下一级节点的node指针(保存在n)
// Consume the search prefix
if strings.HasPrefix(search, n.prefix) {
// 命中了下一级的公共前缀,查找指针直接跨越公共前缀
search = search[len(n.prefix):]
} else {
break
}
}
if last != nil {
// 返回结果(叶子),但不一定是完全匹配的
return last.key, last.val, true
}
return "", nil, false
}
// longestPrefix finds the length of the shared prefix
// of two strings
func longestPrefix(k1, k2 string) int {
max := len(k1)
if l := len(k2); l < max {
max = l
}
var i int
for i = 0; i < max; i++ {
if k1[i] != k2[i] {
break
}
}
return i
}
插入
插入流程如下 代码:
- 开始,从根 root 节点往下找
- 如果在某个 child 节点中找到相同前缀则继续往下找(需匹配完本节点的所有 prefix,看上面的
longestPrefix方法) - 直到查找到某个节点处停止;如果某个 child 节点部分前缀是字符串前缀,则需要将公共前缀作为新节点,原来孩子节点的孩子作为新节点的孩子(分裂的目的是确保了一个节点的孩子数目不会超过总的字符串的个数)
- 新插入的key一定会成为leaf节点
// Insert is used to add a newentry or update
// an existing entry. Returns if updated.
func (t *Tree) Insert(s string, v interface{}) (interface{}, bool) {
var parent *node
n := t.root
//查找指针
search := s
for {
// Handle key exhaution
if len(search) == 0 {
if n.isLeaf() {
// 如果key重复了,返回旧的数据
old := n.leaf.val
n.leaf.val = v
return old, true
}
n.leaf = &leafNode{
key: s,
val: v,
}
t.size++
return nil, false
}
// Look for the edge
//保存parent
parent = n
//向下查找
//注意:如果n不为nil,那么n指向下一层节点,而parent指向当前层级的节点
n = n.getEdge(search[0])
// No edge, create one
// 如果不存在edge,那么需要新建
if n == nil {
e := edge{
label: search[0], //新edge的label为search指针指向的第一个位置的字符!
node: &node{
leaf: &leafNode{ //新的edge默认就是leafNode,合理
key: s,
val: v,
},
prefix: search,
},
}
// n的父节点parent,需要添加一个新的edge
// 新的edge:node为leaf,label为search[0]
// 即将search[0]插入到edges这个有序数组里面
parent.addEdge(e)
t.size++
return nil, false
}
//重要:如果存在edge,那么需要检查插入的字符串是否与当前的node指向的prefix成员完全一致
//如果一致,说明新插入的字符串可以使用这个node,然后继续向下
// 如果不一致,说明需要对当前的节点n进行分裂
// Determine longest prefix of the search key on match
commonPrefix := longestPrefix(search, n.prefix)
if commonPrefix == len(n.prefix) {
//完全一致,说明可以移动查找指针,继续向下
search = search[commonPrefix:]
continue
}
// 重要:不一致,需要分裂当前节点(即创建一个新的node结构,并且把n指向的node做分裂)
// Split the node
t.size++
//分裂步骤1:创建中间节点child
//此时,child节点只包含公共前缀,还没有任何边或叶子数据
child := &node{
prefix: search[:commonPrefix],// 存储公共前缀部分
}
//分裂步骤2:更新父节点指向
//将父节点原来指向n的边,改为指向新的child节点
//边的label保持不变(还是search[0])
parent.updateEdge(search[0], child)
// Restore the existing node
//分裂步骤3:将原节点调整为child的子节点
//关键变化:原节点n的前缀被截断,只保留公共前缀之后的部分
//原节点成为child的子节点
child.addEdge(edge{
label: n.prefix[commonPrefix], // 原节点剩余部分的第一个字符
node: n, // 原节点
})
n.prefix = n.prefix[commonPrefix:] // 缩短原节点前缀
// Create a new leaf node
leaf := &leafNode{
key: s,
val: v,
}
// If the new key is a subset, add to to this node
search = search[commonPrefix:]
if len(search) == 0 {
child.leaf = leaf
return nil, false
}
// Create a new edge for the node
child.addEdge(edge{
label: search[0],
node: &node{
leaf: leaf,
prefix: search,
},
})
return nil, false
}
}
单独描述下插入操作中的分裂边(edge splitting)实现,当新插入的key与现有节点的前缀prefix只有部分匹配时触发分裂
分裂发生的条件(同时满足)
- 找到了匹配的edge(
n = n.getEdge(search[0]返回非nil) - 前缀不完全匹配(公共前缀长度 < 当前节点前缀长度)
分裂的详细步骤:
// 1. 创建新的中间节点(存储公共前缀)
child := &node{
prefix: search[:commonPrefix], // 公共前缀部分
}
parent.updateEdge(search[0], child) // 更新父节点指向child
// 2. 将原节点调整为子节点
child.addEdge(edge{
label: n.prefix[commonPrefix], // 原节点剩余部分的第一个字符
node: n, // 原节点(成为`child`的孩子节点)
})
n.prefix = n.prefix[commonPrefix:] // 缩短原节点前缀
// 3. 处理新插入的键
search = search[commonPrefix:] // 剩余搜索字符串
if len(search) == 0 {
// 新键正好是公共前缀(罕见情况)
child.leaf = &leafNode{key: s, val: v}
} else {
// 创建新分支(注意,这个新的分支即是node又是leaf)
child.addEdge(edge{
label: search[0],
node: &node{
leaf: &leafNode{key: s, val: v},
prefix: search,
},
})
}
分裂的意义是通过分裂提取公共前缀,避免重复存储,结果是原有的二层结构变换为三层结构,即代码中的parent、n的父子结构,分裂后变为parent、child(保存新的公共前缀)、n(缩短原节点前缀,成为child的edge,以及其他可能的兄弟节点),最后再处理新插入的节点。新的待插入的节点与n是平级关系,都是child的孩子节点
最后再看下分裂之后,插入新的节点的部分:
- 当
len(search) == 0时:child节点自身成为叶子节点 - 当
len(search) > 0时:创建新的边edge指向一个新的叶子节点
search = search[commonPrefix:] // 剩余搜索字符串
if len(search) == 0 {
// 新键正好是公共前缀(罕见情况)
// 直接将叶子数据挂在中间节点child上
child.leaf = &leafNode{key: s, val: v}
} else {
// len(search) > 0
// 新key有剩余部分
// 创建新分支
child.addEdge(edge{
label: search[0], // 剩余部分的第一个字符
node: &node{
// 包含实际数据
leaf: &leafNode{key: s, val: v}, //新插入的key成为leaf
prefix: search, //重要:剩余部分作为前缀
},
})
}
首先要明确一点,radix tree中,child节点自身存储了叶子数据(其本身也可能既是node又是leaf)
- case1:新插入的key正好等于公共前缀,直接将叶子数据挂在中间节点
child上,此时child的prefix就是刚好匹配s(待插入的key)的suffix,这种情况下child节点既是中间节点也是叶子节点 - case2:新key有剩余部分,需要创建一个新的叶子节点来存储数据,这个新节点通过edge连接到父节点
child,新节点的prefix是剩余的搜索字符串
//分裂前的结构
parent (父节点)
└── 边[label] -> n (原节点,包含完整前缀和数据)
//分裂后的结构
parent (父节点)
└── 边[label] -> child (新创建的中间节点,存储公共前缀)
├── 边[新label1] -> n (原节点调整,前缀缩短)
└── 边[新label2] -> 新节点 (如果需要,存储新插入的数据)
例如,插入romanus到已有romane的radix树中,分裂前(两层结构)如下:
父节点
└── 边 'r' -> 节点n: prefix="romane", leaf="romane"
插入romanus时,因为前缀非完全匹配,有公共前缀roman(前4个字符), 剩余差异为e与us,所以涉及到分裂过程如下:
1、提取公共前缀
// 分裂前
节点n: prefix = "romane"
// 分裂后
child: prefix = "roman" // 公共部分提取到父节点
节点n: prefix = "e" // 差异部分留在原节点
2、支持多个分支,通过创建中间节点child,可以挂载多个子节点(后续可以挂载其他分支)
原节点n(对应"romane")
新节点(对应"romanus")
3、保持树结构平衡,目的避免创建过深的树结构,通过中间节点合理组织分支,需要处理几种特殊情况:
3.1:新键是公共前缀的完全匹配
search = search[commonPrefix:] // 剩余部分为空
if len(search) == 0 {
child.leaf = &leafNode{key: s, val: v} // child自身存储数据
}
这时结构变为:父节点 -> child (既有前缀roman,又有叶子数据) -> n (原节点)
3.2:需要继续分裂,如果新插入的键与现有结构仍有冲突,可能触发进一步分裂,形成更多层级
最终形成了下面的三层结构:
父节点
└── 边 'r' -> 节点child: prefix="roman" (新中间节点)
├── 边 'e' -> 节点n: prefix="e", leaf="romane" (调整后的原节点)
└── 边 'u' -> 新节点: prefix="us", leaf="romanus" (新插入的节点)
删除字符串
Delete用于删除指定的key,注意删除了叶子节点之后,要检查被删除节点的关联节点已经父节点,如果只剩一条edge,那么需要做节点合并,目的是降低radix tree的高度,压缩中间节点,消除不必要的单链结构
即删除的时候,需要检查两次(上一条edge与下面一条edge),如果存在单edge的情况,那么需要合并
func (t *Tree) Delete(s string) (interface{}, bool) {
var parent *node
var label byte
n := t.root
//搜索指针
search := s
for {
// Check for key exhaution
// 1. 找到要删除的叶子节点
if len(search) == 0 {
if !n.isLeaf() {
//没找到
break
}
// 找到了,执行删除操作
goto DELETE
}
// Look for an edge
// 沿着子树查找
parent = n
label = search[0]
n = n.getEdge(label)
if n == nil {
//没找到
break
}
// Consume the search prefix
if strings.HasPrefix(search, n.prefix) {
search = search[len(n.prefix):]
} else {
break
}
}
return nil, false
DELETE:
//找到了,执行删除操作
// 重要:n指向当前包含被删除leaf的那个node节点
// parent指向n的parent节点
// label保存了最新一次搜索用的字符label
// Delete the leaf
//删除step 1:删除叶子节点
leaf := n.leaf
n.leaf = nil //n.leaf,这个节点会被回收
t.size--
//删除step2:清理空节点
//在删除时,需要检查删除完之后这个n变成了空子树
//如果是空树,那么需要从parent删除这个label
// Check if we should delete this node from the parent
if parent != nil && len(n.edges) == 0 {
//如果满足,则从parent删除该label(该label已经没有节点了)
parent.delEdge(label)
}
// Check if we should merge this node
// 删除step3:合并单子节点
// 即如果n不是root 且 n只有一条边的时候(n.edges长度为1),需要将n与其唯一的child进行合并
if n != t.root && len(n.edges) == 1 {
n.mergeChild()
}
// Check if we should merge the parent's other child
// 删除step4:祖父节点需要合并
//TODO
// 同样还要检查parent这一级,如果parent仅剩一条边,那么也需要把parent和其唯一的child合并
if parent != nil && parent != t.root && len(parent.edges) == 1 && !parent.isLeaf() {
parent.mergeChild()
}
return leaf.val, true
}
// mergeChild:将n指向的node与其唯一的child合并
func (n *node) mergeChild() {
e := n.edges[0] //获取唯一的child
child := e.node
n.prefix = n.prefix + child.prefix //合并n与child的前缀字符串(有趣)
n.leaf = child.leaf //(child的leaf变成n的leaf)
n.edges = child.edges //child的edges变成n的edges
}
删除指定前缀
func (t *Tree) DeletePrefix(s string) int {
return t.deletePrefix(nil, t.root, s)
}
// delete does a recursive deletion
func (t *Tree) deletePrefix(parent, n *node, prefix string) int {
// Check for key exhaustion
if len(prefix) == 0 {
// 到达要删除的子树根节点
// Remove the leaf node
subTreeSize := 0
//recursively walk from all edges of the node to be deleted
// 递归遍历要删除的子树,统计键数量(不涉及到修改树的结构)
recursiveWalk(n, func(s string, v interface{}) bool {
// 统计子树中的键数量
subTreeSize++
return false
})
if n.isLeaf() {
//删除case1:叶子命中了规则,清空当前节点的叶子数据
n.leaf = nil
}
// 删除case2:删除整个子树
n.edges = nil // deletes the entire subtree
// Check if we should merge the parent's other child
// 检查父节点是否需要合并
if parent != nil && parent != t.root && len(parent.edges) == 1 && !parent.isLeaf() {
parent.mergeChild()
}
t.size -= subTreeSize
return subTreeSize
}
//len(prefix)!=0时
// Look for an edge
// 查找匹配的边
label := prefix[0]
child := n.getEdge(label)
// 检查前缀匹配关系
if child == nil || (!strings.HasPrefix(child.prefix, prefix) && !strings.HasPrefix(prefix, child.prefix)) {
// 不匹配,退出递归
return 0
}
/*
到达这里说明两种匹配情况:
1. 子节点前缀以搜索前缀开头:strings.HasPrefix(child.prefix, prefix),如子节点前缀"apple",搜索前缀"app",整个子树需要被删除
2. 搜索前缀以子节点前缀开头:strings.HasPrefix(prefix, child.prefix),如搜索前缀"application",子节点前缀"app",需要继续向下搜索
*/
// Consume the search prefix
// 因为有上面的两种情况,所以这里消耗搜索前缀
if len(child.prefix) > len(prefix) {
// 子节点前缀更长,搜索前缀耗尽
prefix = prefix[len(prefix):]
} else {
// 消耗子节点前缀的长度
prefix = prefix[len(child.prefix):]
}
return t.deletePrefix(n, child, prefix)
}
遍历
recursiveWalk提供了前序遍历树的方法,包含处理遍历过程中树结构变化的特殊逻辑。这个实现和普通的遍历有点区别,这个提供了回调函数fn,可以在遍历的时候对radix 树进行修改操作,如:
//case1:在遍历中删除元素
tree.Walk(func(key string, val interface{}) bool {
if val == "key_to_delete" {
tree.Delete(key) // 在遍历回调中删除当前key
}
return false
})
//case2:在遍历中插入新元素
tree.Walk(func(key string, val interface{}) bool {
if strings.HasPrefix(key, "old_") {
newKey := strings.Replace(key, "old_", "new_", 1)
tree.Insert(newKey, val) // 在遍历中插入新key
}
return false
})
而上述操作,会引起树的变化,分为下面几种情况:
1、情况1,edge数变为0,关联如下代码
if len(n.edges) == 0 {
return recursiveWalk(n, fn)
}
可能的情况:
- 遍历子节点时,回调函数修改导致合并
- 当前节点
n的edge数变为0 - 但当前节点可能变成了叶子节点(包含数据)
- 需要重新访问当前节点,检查是否有叶子数据
2、情况2,edge数减少,关联如下代码
i := 0
k := len(n.edges) // 记录初始边数
for i < k {
// 遍历当前edge
// 处理边数量变化
if len(n.edges) >= k {
i++ // 边数没减少,继续下一个
}
k = len(n.edges) // 更新k,但是i指针未更新,重新遍历
}
递归实现如下:
// Walk is used to walk the tree
func (t *Tree) Walk(fn WalkFn) {
recursiveWalk(t.root, fn)
}
// recursiveWalk is used to do a pre-order walk of a node
// recursively. Returns true if the walk should be aborted
func recursiveWalk(n *node, fn WalkFn) bool {
// Visit the leaf values if any
// 1. 先访问当前节点的叶子(前序遍历)
if n.leaf != nil && fn(n.leaf.key, n.leaf.val) {
return true
}
// Recurse on the children
// 2. 递归遍历子节点
i := 0
// 记录当前edge的数量
k := len(n.edges) // keeps track of number of edges in previous iteration
for i < k {
e := n.edges[i]
if recursiveWalk(e.node, fn) {
return true
}
// It is a possibility that the WalkFn modified the node we are
// iterating on. If there are no more edges, mergeChild happened,
// so the last edge became the current node n, on which we'll
// iterate one last time.
// 3. 处理遍历过程中树结构变化的情况
if len(n.edges) == 0 {
return recursiveWalk(n, fn)
}
// If there are now less edges than in the previous iteration,
// then do not increment the loop index, since the current index
// points to a new edge. Otherwise, get to the next index.
// 4. 处理边数量变化的情况
if len(n.edges) >= k {
i++
}
k = len(n.edges)
}
return false
}
小结
1、对radix tree的理解,没有纯粹的叶子节点。在Radix Tree中,每个节点都可以同时包含数据和子节点(与传统的树结构有些区别),节点可以有四种状态:
case1:纯中间节点(只有前缀和子节点)
&node{
prefix: "roman", // 共享前缀
leaf: nil, // 无数据
edges: [{'e', 'u'}] // 有子节点
}
case2:叶子节点(只有数据)
&node{
prefix: "e", // 剩余部分
leaf: &leafNode{key: "romane", val: ...}, // 有数据
edges: [] // 无子节点
}
case3:既是中间节点又是叶子节点
&node{
prefix: "app", // 共享前缀
leaf: &leafNode{key: "app", val: ...}, // 自身有数据
edges: [{'l'}] // 也有子节点
}
case4:空节点(理论上不应该存在)
&node{
prefix: "",
leaf: nil,
edges: []
}
比如,对于如下字符串集合构成的radix树["app", "apple", "application"],构建的Radix Tree如下,其中节点A既是中间节点又是叶子节点,节点B是纯中间节点,节点C、D是传统意义上的叶子节点
节点A: prefix="app", leaf="app"(有数据)
└── 边 'l' -> 节点B: prefix="l"(纯中间节点)
├── 边 'e' -> 节点C: prefix="e", leaf="apple"(叶子节点)
└── 边 'i' -> 节点D: prefix="ication", leaf="application"(叶子节点)
0x03 重点:HTTPROUTER 分析
基于httprouter v1.3.0分析,重点考虑下面两点:
- 路由是是如何注册?如何保存的?– 对应于radix树的构造
- 当请求到来之后,路由是如何匹配,如何查找的?– 对应于radix树的查询
再回归下radix树的要点,对于radix树的每个节点,如果该节点是唯一的子树的话,就和父节点合并。
Param
用于设置路由的方法Handle中的Params作何用处?
func (r *Router) GET(path string, handle Handle) {
r.Handle("GET", path, handle)
}
// DELETE is a shortcut for router.Handle("DELETE", path, handle)
func (r *Router) DELETE(path string, handle Handle) {
r.Handle("DELETE", path, handle)
}
//调用handle
type Handle func(http.ResponseWriter, *http.Request, Params)
看下Handle和http.HandlerFunc 多了Params 参数,该参数就是用来支持路径中的参数绑定,例如:/hello/:name可通过 Params.ByName("name") 来获取路径绑定参数的值;Params 就是一个 Param 的slice,定义如下:
// Parram 是一个 URL 参数,包含了一个 Key 和 一个 Value
// Key 就是注册路由时候的使用的字符串,如: "/hello/:name" ,这个 Key 就是 name
// Value 就是访问路径中获取到的值, 如: localhost:8080/hello/xxxxx ,
// 此时 Value 就是 xxxxx
type Param struct {
Key string
Value string
}
// Params 就是一个 Param 的切片,这样就可以看出来, URL 参数可以设置多个了。
// 它是在 tree 的 GetValue() 方法调用的时候设置的,一会分析树的时候可以看到。
// 这个切片是有顺序的,第一个设置的参数就是切片的第一个值,所以通过索引获取值是安全的
type Params []Param
// ByName 返回传入的 name 的值,如果没有找到就会返回一个空字符串
// 这里就是做了个循环,一担找到就将值返回。
func (ps Params) ByName(name string) string {
for i := range ps {
if ps[i].Key == name {
return ps[i].Value
}
}
return ""
}
Path:特殊匹配模式介绍
httprouter的两种特殊的匹配模式:
1、:name匹配模式:精准匹配的,同时只能匹配一个
Pattern: /user/:name
/user/panday //匹配
/user/you //匹配
/user/panday/profile //不匹配
/user/ //不匹配
因为httprouter这个路由就是单一匹配的,所以使用命名参数的时候,一定要注意,是否有其他注册的路由和命名参数的路由,匹配同一个路径,比如/user/new这个路由和/user/:name就是冲突的,不能同时注册。
2、*name匹配模式,是一种匹配所有的模式,较少用
因为是匹配所有的模式,所以只要*前面的路径匹配,就是匹配的,不管路径多长或有几层,都匹配
Pattern: /user/*name
/user/panday //匹配
/user/you //匹配
/user/panday/profile //匹配
/user/ //匹配
Router
// Router 是一个 http.Handler 可以通过定义的路由将请求分发给不同的函数
type Router struct {
//注册的路由,按照HTTP方法,每个方法对应一棵radix tree
trees map[string]*node
// 这个参数是否自动处理当访问路径最后带的 /,一般为 true 就行。
// 例如: 当访问 /foo/ 时, 此时没有定义 /foo/ 这个路由,但是定义了
// /foo 这个路由,就对自动将 /foo/ 重定向到 /foo (GET 请求
// 是 http 301 重定向,其他方式的请求是 http 307 重定向)。
RedirectTrailingSlash bool
// 是否自动修正路径, 如果路由没有找到时,Router 会自动尝试修复。
// 首先删除多余的路径,像 ../ 或者 // 会被删除。
// 然后将清理过的路径再不区分大小写查找,如果能够找到对应的路由, 将请求重定向到
// 这个路由上 ( GET 是 301, 其他是 307 ) 。
RedirectFixedPath bool
// 用来配合下面的 MethodNotAllowed 参数。
HandleMethodNotAllowed bool
// 如果为 true ,会自动回复 OPTIONS 方式的请求。
// 如果自定义了 OPTIONS 路由,会使用自定义的路由,优先级高于这个自动回复。
HandleOPTIONS bool
// 路由没有匹配上时调用这个 handler 。
// 如果没有定义这个 handler ,就会返回标准库中的 http.NotFound 。
NotFound http.Handler
// 当一个请求是不被允许的,并且上面的 HandleMethodNotAllowed 设置为 ture 的时候,
// 如果这个参数没有设置,将使用状态为 with http.StatusMethodNotAllowed 的 http.Error
// 在 handler 被调用以前,为允许请求的方法设置 "Allow" header 。
MethodNotAllowed http.Handler
// 当出现 panic 的时候,通过这个函数来恢复。会返回一个错误码为 500 的 http error
// (Internal Server Error) ,这个函数是用来保证出现 painc 服务器不会崩溃。
PanicHandler func(http.ResponseWriter, *http.Request, interface{})
}
Router 也实现了 ServeHTTP 方法,因此符合 net/http.Handler 接口,ServeHTTP 方法为处理请求时,查找路由树及 Handler 的逻辑:
// ServeHTTP makes the router implement the http.Handler interface.
func (r *Router) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 在最开始,就做了 panic 的处理,这样可以保证业务代码出现问题的时候,不会导致服务器崩溃
// 这里就是简单的在浏览器返回一个 500 错误,如果想在 panic 的时候自己处理
// 只需要将 r.PanicHandler = func(http.ResponseWriter, *http.Request, interface{})
// 重写, 添加上自己的处理逻辑即可。
if r.PanicHandler != nil {
defer r.recv(w, req)
}
// 通过 Request 获取当前请求的路径
path := req.URL.Path
// 到基数树中去查找匹配的路由
// 首先看是否有请求的方法(比如 GET)是否存在路由,如果存在就继续寻找
if root := r.trees[req.Method]; root != nil {
// 如果路由匹配上了,从基数树中将路由取出
if handle, ps, tsr := root.getValue(path); handle != nil {
// 获取的是一个函数,签名 func(http.ResponseWriter, *http.Request, Params)
// 这个就是向 httprouter 注册的函数
handle(w, req, ps)
// 处理完成后 return ,此次生命周期就结束了
return
// 当没有找到的时候,并且请求的方法不是 CONNECT 并且 路径不是 / 的时候
} else if req.Method != "CONNECT" && path != "/" {
// 这里就要做重定向处理, 默认是 301
code := 301 // Permanent redirect, request with GET method
// 如果请求的方式不是 GET 就将 http 的响应码设置成 307
if req.Method != "GET" {
// Temporary redirect, request with same method
// As of Go 1.3, Go does not support status code 308.
// 看上面的注释的意思貌似是作者想使用 308(永久重定向),但是 Go 1.3
// 不支持 308 ,所以使用了一个临时重定向。 为什么不能用 301 呢?
// 因为 308 和 307 不允许请求方法从 POST 更改为 GET
code = 307
}
// tsr 返回值是一个 bool 值,用来判断是否需要重定向, getValue 返回来的
// RedirectTrailingSlash 这个就是初始化时候定义的,只有为 true 才会处理
if tsr && r.RedirectTrailingSlash {
// 如果 path 的长度大于 1,只有大于 1 才会出现这种情况,如 p/,path/
// 并且路径的最后是 / 的时候将最后的 / 去除
if len(path) > 1 && path[len(path)-1] == '/' {
req.URL.Path = path[:len(path)-1]
} else {
// 如果不是 / 结尾的,给结尾添加一个 /
// 假设定义了一个路由 '/foo/' ,并且没有定义路由 /foo ,
// 实际访问的是 '/foo', 将 /foo 重定向到 /foo/
req.URL.Path = path + "/"
}
// 将处理过的路由重定向, 这个是一个 http 标准包里面的方法
http.Redirect(w, req, req.URL.String(), code)
return
}
// Try to fix the request path
// 路由没有找到,重定向规则也不符合,这里会尝试修复路径
// 需要在初始化的时候定义 RedirectFixedPath 为 true,允许修复
if r.RedirectFixedPath {
// 这里就是在处理 Router 里面说的,将路径通过 CleanPath 方法去除多余的部分
// 并且 RedirectTrailingSlash 为 ture 的时候,去匹配路由
// 比如: 定义了一个路由 /foo , 但实际访问的是 ////FOO ,就会被重定向到 /foo
fixedPath, found := root.findCaseInsensitivePath(
CleanPath(path),
r.RedirectTrailingSlash,
)
if found {
req.URL.Path = string(fixedPath)
http.Redirect(w, req, req.URL.String(), code)
return
}
}
}
}
// 路由也没有匹配,重定向也没有找到,修复后仍然没有匹配,就到了这里
// 如果没有任何路由匹配,请求方式又是 OPTIONS, 并且允许响应 OPTIONS
// 就会给 Header 设置一个 Allow 头,返回去
if req.Method == "OPTIONS" && r.HandleOPTIONS {
// Handle OPTIONS requests
if allow := r.allowed(path, req.Method); len(allow) > 0 {
w.Header().Set("Allow", allow)
return
}
} else {
// 如果不是 OPTIONS 或者 不允许 OPTIONS 时
// Handle 405
// 如果初始化的时候 HandleMethodNotAllowed 为 ture
if r.HandleMethodNotAllowed {
// 返回 405 响应,通过 allowed() 方法来处理 405 时 allow的值。
// 大概意思是这样的,比如定义了一个 POST 方法的路由 POST("/foo",...)
// 但是调用却是通过 GET 方式,这是就会给调用者返回一个包含 POST 的 405
if allow := r.allowed(path, req.Method); len(allow) > 0 {
w.Header().Set("Allow", allow)
if r.MethodNotAllowed != nil {
// 这里默认就会返回一个字符串 Method Not Allowed
// 可以自定义 r.MethodNotAllowed = 自定义的 http.Handler 实现
// 来按照需求响应, allowd 方法也不太难,就是各种判断和查找,就不分析了。
r.MethodNotAllowed.ServeHTTP(w, req)
} else {
http.Error(w,
http.StatusText(http.StatusMethodNotAllowed),
http.StatusMethodNotAllowed,
)
}
return
}
}
}
// Handle 404
// 如果什么的没有找到,就只会返回一个 404 了
// 如果定义了 NotFound ,就会调用自定义的
if r.NotFound != nil {
// 如果需要自定义,在初始化之后给 NotFound 赋一个值就可以了。
// 可以简单的通过 http.HandlerFunc 包装一个 handler ,例如:
// router.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// w.Write([]byte("什么都没有找到"))
// })
//
r.NotFound.ServeHTTP(w, req)
} else {
// 如果没有定义,就返回一个 http 标准库的 NotFound 函数,返回一个 404 page not found
http.NotFound(w, req)
}
}
node结构:radix树中的节点
node结构代表了Radix树的一个节点,注意到Router结构的定义:
type Router struct {
trees map[string]*node //每个HTTP方法对应一课树
//...
}
node的定义如下:
type node struct {
// 当前节点的 URL 路径
// 如上面图中的例子的首先这里是一个 /
// 然后 children 中会有 path 为 [s, blog ...] 等的节点
// 然后 s 还有 children node [earch,upport] 等,就不再说明了
path string
// 判断当前节点路径是不是含有参数的节点, 上图中的 :post 的上级 blog 就是wildChild节点
wildChild bool
// 节点类型: static, root, param, catchAll
// static: 静态节点, 如上图中的父节点 s (不包含 handler 的)
// root: 如果插入的节点是第一个, 那么是root节点
// catchAll: 有*匹配的节点
// param: 参数节点,比如上图中的 :post 节点
nType nodeType
// path 中的参数最大数量,最大只能保存 255 个(超过这个的情况貌似太难见到了)
// 这里是一个非负的 8 进制数字,最大也只能是 255 了
maxParams uint8
// 和下面的 children 对应,保留的子节点的第一个字符
// 如上图中的 s 节点,这里保存的就是 eu (earch 和 upport)的首字母
indices string
// 当前节点的所有直接子节点
children []*node
// 当前节点对应的 handler
handle Handle
// 优先级,查找的时候会用到,表示当前节点加上所有子节点的数目
priority uint32
}
一共有4种类型的node:
static:静态节点, 如上图中的父节点 s (不包含 handler 的)root:如果插入的节点是第一个, 那么是root节点catchAll:有*匹配的节点param:参数节点,比如上图中的:post节点
一开始树为空,注册路由的过程就是建树的过程;注意children []*node成员,存储满足前缀的子节点指针,可以延申。其中子节点越多,或者说绑定handle方法越多的根节点,priority优先级越高,作者有意识的对每次注册完成进行优先级排序。
This helps in two ways: Nodes which are part of the most routing paths are evaluated first. This helps to make as much routes as possible to be reachable as fast as possible.
It is some sort of cost compensation. The longest reachable path (highest cost) can always be evaluated first. The following scheme visualizes the tree structure. Nodes are evaluated from top to bottom and from left to right.
优先级高的节点有利于handle的快速定位,相信比较好理解,现实中人流量密集处往往就是十字路口,类似交通枢纽。基于前缀树的匹配,让寻址从密集处开始,有助于提高效率。
Tree
0x04 路由注册
路由注册的核心是,最终那些前缀一致的路径会被绑定到Radix树的同一个分支方向上,直接提高了索引的效率,即把各个handler注册到一棵url前缀树上面,根据url前缀相同的匹配度进行分支,以提高路由效率。
路由注册的底层都是调用Handle方法,看下其实现,最后是调用addRoute方法添加路由:
// 通过给定的路径和方法,注册一个新的 handle 请求,对于 GET, POST, PUT, PATCH 和 DELETE
// 请求,相对应的方法,直接调用这个方法也是可以的,只需要多传入第一个参数即可。
// 官方给的建议是: 在批量加载或使用非标准的自定义方法时候使用。
//
// 它有三个参数,第一个是请求方式(GET,POST……), 第二个是路由的路径, 前两个参数都是字符串类型
// 第三个参数就是要注册的函数,比如上面的 Index 函数,可以追踪一下,在这个文件的最上面
// 有 Handle 的定义,它是一个函数类型,只要和这个 Handle 的签名一直的都可以作为参数
func (r *Router) Handle(method, path string, handle Handle) {
// 验证路径是否是 / 开头的,如: /foo 就是可以的, foo 就会 panic,编译的时候机会出错
if path[0] != '/' {
panic("path must begin with '/' in path '" + path + "'")
}
// 因为 map 是一个指针类型,必须初始化才可以使用,这里做一个判断,
// 如果从来没有注册过路由,要先初始化 tress 属性的 map
if r.trees == nil {
r.trees = make(map[string]*node)
}
// 因为路由是一个基数树,全部是从根节点开始,如果第一次调用注册方法的时候跟是不存在的,
// 就注册一个根节点, 这里是每一种请求方法是一个根节点,会存在多个树。
root := r.trees[method]
// 根节点存在就直接调用,不存在就初始化一个
if root == nil {
// 需要注意的是,这里使用的 new 来初始化,所以 root 是一个指针。
root = new(node)
r.trees[method] = root
}
// 向 root 中添加路由,树的具体操作在后面单独去分析。
root.addRoute(path, handle)
}
核心1:addRouter方法
入口是走根节点的root.addRoute()进入的,特别注意,此方法非线程安全,此方法的最终目的是把某个路由(/a/bb/cccc)插入Radix树:
node的addRoute方法分为两步:
- 第一步是根据path和已有的前缀树的匹配,找到剩余的path需要插入的孩子节点的位置
- 第二步是插入到该节点。当一颗树是空树时,增加第一条path的过程便退化为只有第二步
注意到addRoute是node的方法中有个walk标签,猜想是不停的需要调整树到子树中的节点数据以达到最终目标
// addRoute 将传入的 handle 添加到路径中
func (n *node) addRoute(path string, handle Handle) {
fullPath := path
// 请求到这个方法,就给当前节点的权重 + 1
n.priority++
// 计算传入的路径参数的数量,即路径中包含:/*特殊字符的总数
numParams := countParams(path)
// 如果树不是空的(当前节点已经存在注册链路)
// 判断的条件是当前节点的 path 的字符串长度和子节点的数量全部都大于 0
// 就是说如果当前节点是一个空的节点,或者当前的节点是一个叶子节点,就直接
// 进入 else 在当前节点下面添加子节点
if len(n.path) > 0 || len(n.children) > 0 {
// 定义一个 lable ,循环里面可以直接 break 到这里,适合这种嵌套的比较深的
walk:
for {
// 如果传入的节点的最大参数的数量大于当前节点记录的数量,替换
if numParams > n.maxParams {
n.maxParams = numParams
}
// 查找最长的共同的前缀(判断待注册url是否与已有url有重合,提取重合的最长下标)
// 公共前缀不包含 ":" 或 "*"
i := 0
// 将最大值设置成长度较小的路径的长度
max := min(len(path), len(n.path))
// 循环,计算出当前节点和添加的节点共同前缀的长度
for i < max && path[i] == n.path[i] {
i++
}
// 如果相同前缀的长度比当前节点保存的 path 短
// 比如当前节点现在的 path 是 sup ,添加的节点的 path 是 search
// 它们相同的前缀就变成了 s , s 比 sup 要短,符合 if 的条件,要做处理
if i < len(n.path) {
// 将当前节点的属性定义到一个子节点中,没有注释的属性不变,保持原样
child := node{
// path 是当前节点的 path 去除公共前缀长度的部分
path: n.path[i:],
wildChild: n.wildChild,
// 将类型更改为 static ,默认的,没有 handler 的节点
nType: static,
indices: n.indices,
children: n.children,
handle: n.handle,
// 权重 -1
priority: n.priority - 1,
}
// 遍历当前节点的所有子节点(当前节点变成子节点之后的节点),
// 如果最大参数数量大于当前节点的数量,更新
for i := range child.children {
if child.children[i].maxParams > child.maxParams {
child.maxParams = child.children[i].maxParams
}
}
// 在当前节点的子节点定义为当前节点转换后的子节点
n.children = []*node{&child}
// 获取子节点的首字母,因为上面分割的时候是从 i 的位置开始分割
// 所以 n.path[i] 可以去除子节点的首字母,理论上去 child.path[0] 也是可以的
// 这里的 n.path[i] 取出来的是一个 uint8 类型的数字(代表字符),
// 先用 []byte 包装一下数字再转换成字符串格式
n.indices = string([]byte{n.path[i]})
// 更新当前节点的 path 为新的公共前缀
n.path = path[:i]
// 将 handle 设置为 nil
n.handle = nil
// 肯定没有参数了,已经变成了一个没有 handle 的节点了
n.wildChild = false
}
// 将新的节点添加到此节点的子节点, 这里是新添加节点的子节点
if i < len(path) {
// 截取掉公共部分,剩余的是子节点
path = path[i:]
// 如果当前路径有参数
// 如果进入了上面 if i < len(n.path) 这个条件,这里就不会成立了
// 因为上一个 if 中将 n.wildChild 重新定义成了 false
// 什么情况会进入到这里呢 ?
// 1. 上面的 if 不生效,也就是说不会有新的公共前缀, n.path = i 的时候
// 2. 当前节点的 path 是一个参数节点就是像这种的 :post
// 就是定义路由时候是这种形式的: blog/:post/update
//
if n.wildChild {
// 如果进入到了这里,证明这是一个参数节点,类似 :post 这种
// 不会这个节点进行处理,直接将它的子节点赋值给当前节点
// 比如: :post/ ,只要是参数节点,必有子节点,哪怕是
// blog/:post 这种,也有一个 / 的子节点
n = n.children[0] //
// 又插入了一个节点,权限再次 + 1
n.priority++
// 更新当前节点的最大参数个数
if numParams > n.maxParams {
n.maxParams = numParams
}
// 更改方法中记录的参数个数,个人猜测,后面的逻辑还会用到
numParams--
// 检查通配符是否匹配
// 这里的 path 已经变成了去除了公共前缀的后面部分,比如
// :post/update , 就是 /update
// 这里的 n 也已经是 :post 这种的下一级的节点,比如 / 或者 /u 等等
// 如果添加的节点的 path >= 当前节点的 path &&
// 当前节点的 path 长度和添加节点的前面相同数量的字符是相等的, &&
if len(path) >= len(n.path) && n.path == path[:len(n.path)] &&
// 简单更长的通配符,
// 当前节点的 path >= 添加节点的 path ,其实有第一个条件限制,
// 这里也只有 len(n.path) == len(path) 才会成立,
// 就是当前节点的 path 和 添加节点的 path 相等 ||
// 添加节点的 path 减去当前节点的 path 之后是 /
// 例如: n.path = name, path = name 或
// n.path = name, path = name/ 这两种情况
(len(n.path) >= len(path) || path[len(n.path)] == '/') {
// 跳出当前循环,进入下一次循环
// 再次循环的时候
// 1. if i < len(n.path) 这里就不会再进入了,现在 i == len(n.path)
// 2. if n.wildChild 也不会进入了,当前节点已经在上次循环的时候改为 children[0]
continue walk
} else {
// 当不是 n.path = name, path = name/ 这两种情况的时候,
// 代表通配符冲突了,什么意思呢?
// 简单的说就是通配符部分只允许定义相同的或者 / 结尾的
// 例如:blog/:post/update,再定义一个路由 blog/:postabc/add,
// 这个时候就会冲突了,是不被允许的,blog 后面只可以定义
// :post 或 :post/ 这种,同一个位置不允许使用多种通配符
// 这里的处理是直接 panic 了,如果想要支持,可以尝试重写下面部分代码
// 下面做的事情就是组合 panic 用到的提示信息
var pathSeg string
// 如果当前节点的类型是有*匹配的节点
if n.nType == catchAll {
pathSeg = path
} else {
// 如果不是,将 path 做字符串分割
// 这个是通过 / 分割,最多分成两个部分,然后取第一部分的值
// 例如: path = "name/hello/world"
// 分割两部分就是 name 和 hello/world , pathSeg = name
pathSeg = strings.SplitN(path, "/", 2)[0]
}
// 通过传入的原始路径来处理前缀, 可以到上面看下,方法进入就定义了这个变量
// 在原始路径中提取出 pathSeg 前面的部分在拼接上 n.path
// 例如: n.path = ":post" , fullPath="/blog/:postnew/add"
// 这时的 prefix = "/blog/:post"
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
// 最终的提示信息就会生成类似这种:
// panic: ':postnew' in new path '/blog/:postnew/update/' \
// conflicts with existing wildcard ':post' in existing \
// prefix '/blog/:post'
// 就是说已经定义了 /blog/:post 这种规则的路由,
// 再定义 /blog/:postnew 这种就不被允许了
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
}
// 如果没有进入到上面的参数节点,当前节点不是一个参数节点 :post 这种
c := path[0]
// slash after param
// 如果当前节点是一个参数节点,如 /:post && 是 / 开头的 && 只有一个子节点
if n.nType == param && c == '/' && len(n.children) == 1 {
// /:post 这种节点不做处理,直接拿这个节点的子节点去匹配
n = n.children[0]
// 权重 + 1 , 因为新的节点会变成这个节点的子节点
n.priority++
// 结束当前循环,再次进行匹配
// 比如: /:post/add 当前节点是 /:post 有个子节点 /add
// 新添加的节点是 /:post/update ,再次循环的时候将会用
// /add 和 /update 进行匹配, 就相当于是两次新的匹配,
// 由于 node 本身是一个指针,所以它们一直都会在 /:post 下面搞事情
continue walk
}
// 检查添加的 path 的首字母是否保存在在当前节点的 indices 中
for i := 0; i < len(n.indices); i++ {
// 如果存在
if c == n.indices[i] {
// 这里处理优先级和排序的问题,把这个方法看完再去查看这个方法干了什么
i = n.incrementChildPrio(i)
// 将当前的节点替换成它对应的子节点
n = n.children[i]
// 结束当前循环,继续下一次
// 此时的当前 node n,已经变成了它的子字节,下次循环就从这个子节点开始处理了
// 比如:
// 当前节点是 s , 包含两个节点 earch 和 upport
// 这时 indices 就会有字母 e 和 u 并且是和子节点 earch 和 uppor 相对应
// 新添加的节点如果叫 subject , 与当前节点匹配去除公共前缀 s 后, 就变成了
// ubject ,这时 n = upport 这个节点了,path = ubject
// 下一次循环就拿 upport 这个 n 和 ubject 这个 path 去开始下次的匹配
continue walk
}
}
// 如果上面 for 中也没有匹配上,就将新添加的节点插入
// 如果第一个字符不是通配符 : 并且不是 *
if c != ':' && c != '*' {
// []byte for proper unicode char conversion, see #65
// 将 path 的首字母 c 拼接到 indices 中
n.indices += string([]byte{c})
// 初始化一个新的节点
child := &node{
maxParams: numParams,
}
// 将这个新初始化的节点添加到当前节点的子节点中
n.children = append(n.children, child)
// 这个应该还是在处理优先级,一会再去看这个方法
n.incrementChildPrio(len(n.indices) - 1)
// 将当前节点替换成新生成的节点
n = child
}
// 用当前节点发起插入子节点的动作
// 注意这个 n 已经替换成了上面新初始化的 child 了,只初始化了 maxParams
// 属性,相当于是一个空的节点。insertChild 这个方法一会再去具体查看,
// 现在只要知道它在做具体的插入子节点的动作就行,先把这个方法追踪完。
n.insertChild(numParams, path, fullPath, handle)
return
// 如果公共前缀和当前添加的路径长度相等
} else if i == len(path) { // Make node a (in-path) leaf
// 如果当前节点不是 static 类型的, 就是已经注册了 handle 的节点
// 就证明已经注册过这个路由,直接 panic 了
if n.handle != nil {
panic("a handle is already registered for path '" + fullPath + "'")
}
// 如果是 nil 的,就是没有注册,证明这个节点是之前添加别的节点时候拆分出来的共同前缀
// 例如: 添加过两个截点 /submit 和 /subject ,处理后就会有一个 static 的前缀 sub
// 这是再添加一个 /sub 的路由,就是这里的情况了。
n.handle = handle
}
// 这个新的节点被添加了, 出现了 return , 只有出现这个才会正常退出循环,一次添加完成。
return
}
} else { // Empty tree
// 如果 n 是一个空格的节点,就直接调用插入子节点方法
n.insertChild(numParams, path, fullPath, handle)
// 并且它只有第一次插入的时候才会是空的,所以将 nType 定义成 root
n.nType = root
}
}
简单的注册例子:
func Hello(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
fmt.Fprintf(w, "hello, %s!\n", ps.ByName("name"))
}
router.Handle("GET", "/user/ab/", func(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
//test
})
router.Handle("GET", "/user/abcd/", func(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
//test
})
router.GET("/user/abce/", Hello)
router.Handle(http.MethodGet, "/user/query/:name", func(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
routed = true
want := httprouter.Params{httprouter.Param{"name", "testvalue"}}
if !reflect.DeepEqual(ps, want) {
t.Fatalf("wrong wildcard values: want %v, got %v", want, ps)
}
})
该用例的创建过程如下:
1、首次插入url:/user/ab/,匹配长度大于于当前节点已有的url,则创建子节点,若当前节点是/user/ab/,对应的注册方法是handler1
[root]path=/user/ab/,indices=,wildChild=false,nType=1,priority=1
2、插入一个新url:/user/abcd/,对应的方法是handler2,需要创建/user/ab的子节点/ 和 cd/
[root]path=/user/ab,indices=/c,wildChild=false,nType=1,priority=2
[child]path=/,indices=,wildChild=false,nType=0,priority=1
[child]path=cd/,indices=,wildChild=false,nType=0,priority=1
3、插入一个新url:/user/abce/,对应方法是handler3,树如下
[root]path=/user/ab,indices=c/,wildChild=false,nType=1,priority=3
[child]path=c,indices=de,wildChild=false,nType=0,priority=2
[child]path=d/,indices=,wildChild=false,nType=0,priority=1
-----------------
[child]path=e/,indices=,wildChild=false,nType=0,priority=1
-----------------
-----------------
[child]path=/,indices=,wildChild=false,nType=0,priority=1
4、插入新url:/user/query/:name
[root]path=/user/,indices=aq,wildChild=false,nType=1,priority=4
[child]path=ab,indices=c/,wildChild=false,nType=0,priority=3
[child]path=c,indices=de,wildChild=false,nType=0,priority=2
[child]path=d/,indices=,wildChild=false,nType=0,priority=1
-----------------
[child]path=e/,indices=,wildChild=false,nType=0,priority=1
-----------------
-----------------
[child]path=/,indices=,wildChild=false,nType=0,priority=1
-----------------
-----------------
[child]path=query/,indices=,wildChild=true,nType=0,priority=1
[child]path=:name,indices=,wildChild=false,nType=2,priority=1
子方法1:incrementChildPrio
incrementChildPrio方法主要处理节点之前的关系,添加或者修改已经存在的,拼接出树的结构,真正写入插入节点的数据是在方法子方法1:incrementChildPrio处理完关系后,调用 insertChild 方法完成。
// increments priority of the given child and reorders if necessary
// 通过之前两次的调用,这个 pos 都是 n.indices 中指定字符的索引,也就是位置
func (n *node) incrementChildPrio(pos int) int {
// 因为 children 和 indices 是同时添加的,所以索引是相同的
// 可以通过 pos 代表的位置找到, 将对应的子节点的优先级 + 1
n.children[pos].priority++
prio := n.children[pos].priority
// 调整位置(向前移动)
newPos := pos
// 这里的操作就是将 pos 位置的子节点移动到最前面,增加优先级,比如:
// 原本的节点是 [a, b, c, d], 传入的是 2 ,就变成 [c, a, b, d]
// 这只是个示例,实际情况还要考虑 n.children[newPos-1].priority < prio ,不一定是移动全部
for newPos > 0 && n.children[newPos-1].priority < prio {
// swap node positions
n.children[newPos-1], n.children[newPos] = n.children[newPos], n.children[newPos-1]
newPos--
}
// build new index char string
// 重新组织 n.indices 这个索引字符串,和上面做的是相同的事,只不过是用切割 slice 方式进行的
// 从代码本身来说上面的部分也可以通过切割 slice 完成,不过移动应该是比切割组合 slice 效率高吧
// 感觉是这样,没测试过,有兴趣的可以测试下。
if newPos != pos {
n.indices = n.indices[:newPos] + // unchanged prefix, might be empty
n.indices[pos:pos+1] + // the index char we move
n.indices[newPos:pos] + n.indices[pos+1:] // rest without char at 'pos'
}
// 最后返回的是调整后的位置,保证外面调用这个方法之后通过索引找到的对应的子节点是正确的
return newPos
}
字方法2:insertChild
insertChild最终在叶子节点写入注册的数据(path 和 handler)
// 传入的几个参数:
// numParams 参数个数
// path 插入的子节点的路径
// fullPath 完整路径,就是注册路由时候的路径,没有被处理过的
// 注册路由对应的 handle 函数
func (n *node) insertChild(numParams uint8, path, fullPath string, handle Handle) {
var offset int // 已经处理过的路径的所有字节数
// find prefix until first wildcard (beginning with ':'' or '*'')
// 查找前缀,知道第一个通配符( 以 ':' 或 '*' 开头
// 就是要将 path 遍历,提取出参数
// 只要不是通配符开头的就不做处理,证明这个路由是没有参数的路由
for i, max := 0, len(path); numParams > 0; i++ {
c := path[i]
// 如果不是 : 或 * 跳过本次循环,不做任何处理
if c != ':' && c != '*' {
continue
}
// 查询通配符后面的字符,直到查到 '/' 或者结束
end := i + 1
for end < max && path[end] != '/' {
switch path[end] {
// 通配符后面的名称不能包含 : 或 * , 如 ::name 或 :*name 不允许定义
case ':', '*':
panic("only one wildcard per path segment is allowed, has: '" +
path[i:] + "' in path '" + fullPath + "'")
default:
end++
}
}
// 检查通配符所在的位置,是否已经有子节点,如果有,就不能再插入
// 例如: 已经定义了 /hello/name , 就不能再定义 /hello/:param
if len(n.children) > 0 {
panic("wildcard route '" + path[i:end] +
"' conflicts with existing children in path '" + fullPath + "'")
}
// 检查通配符是否有一个名字
// 上面定义 end = i+1 , 后面的 for 又执行了 ++ 操作,所以通配符 : 或 * 后面最少
// 要有一个字符, 如: :a 或 :name , :a 的时候 end 就是 i+2
// 所以如果 end - i < 2 ,就是通配符后面没有对应的名称, 就会 panic
if end-i < 2 {
panic("wildcards must be named with a non-empty name in path '" + fullPath + "'")
}
// 如果 c 是 : 通配符的时候
if c == ':' { // param
// split path at the beginning of the wildcard
// 从 offset 的位置,到查询到通配符的位置分割 path
// 并把分割出来的路径定义到节点的 path 属性
if i > 0 {
n.path = path[offset:i]
// 开始的位置变成了通配符所在的位置
offset = i
}
// 将参数部分定义成一个子节点
child := &node{
nType: param,
maxParams: numParams,
}
// 用新定义的子节点初始化一个 children 属性
n.children = []*node{child}
// 标记上当前这个节点是一个包含参数的节点的节点
n.wildChild = true
// 将新创建的节点定义为当前节点,这个要想一下,到这里这种操作已经有不少了
// 因为一直都是指针操作,修改都是指针的引用,所以定义好的层级关系不会被改变
n = child
// 新的节点权重 +1
n.priority++
// 最大参数个数 - 1
numParams--
// if the path doesn't end with the wildcard, then there
// will be another non-wildcard subpath starting with '/'
// 这个 end 有可能是结束或者下一个 / 的位置
// 如果小于路径的最大长度,代表还包含子路径(也就是说后面还有子节点)
if end < max {
// 将通配符提取出来,赋值给 n.path, 现在 n.path 是 :name 这种格式的字符串
n.path = path[offset:end]
// 将起始位置移动到 end 的位置
offset = end
// 定义一个子节点,无论后面还有没有子节点 :name 这种格式的路由后面至少还有一个 /
// 因为参数类型的节点不会保存 handler
child := &node{
maxParams: numParams,
priority: 1,
}
// 将初始化的子节点赋值给当前节点
n.children = []*node{child}
// 当前节点又变成了新的子节点(到此时的 n 的身份已经转变了几次了,看这段代表的时候
// 脑中要有一颗树,实在想不出来的话可以按照开始的图的结构,将节点的变化记录到一张纸上,
// 然后将每一次的转变标记出来,就完全能明白了)
n = child
// 如果进入倒了这个 if ,执行到这里,就还会进入到下一次循环,将可能生成出来的参数再次去匹配
}
// 如果走到了这里,并且是循环的最后一次,就是已经将当前节点 n 定义成了叶子节点
// 就可以进入到最下面代码部分,进行插入了
// (上面的注释说明的位置是 else 上面,不是为下面的 else 做的注释)
// 进入到 else ,就是包含 * 号的路由了
} else { // catchAll
// 这里的意思是, * 匹配的路径只允许定义在路由的最后一部分
// 比如 : /hello/*world 是允许的, /hello/*world/more 这种就会 painc
// 这种路径就是会将 hello/ 后面的所有内容变成 world 的变量
// 比如地址栏输入: /hello/one/two/more ,获取到的参数 world = one/twq/more
// 不会再将后面的 / 作为路径处理了
if end != max || numParams > 1 {
panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'")
}
// 这种情况是,新定义的 * 通配符路由和其他已经定义的路由冲突了
// 例如已经定义了一个 /hello/bro , 又定义了一个 /hello/*world ,此时就会 panic 了
if len(n.path) > 0 && n.path[len(n.path)-1] == '/' {
panic("catch-all conflicts with existing handle for the path segment root in path '" + fullPath + "'")
}
// currently fixed width 1 for '/'
i--
// 这里是查询通配符前面是否有 / 没有 / 是不行的,panic
if path[i] != '/' {
panic("no / before catch-all in path '" + fullPath + "'")
}
n.path = path[offset:i]
// first node: catchAll node with empty path
// 后面的套路基本和之前看到的类似,就是定义一个子节点,保存通配符前面的路径,
// 有变化的就是将 nType 定义为 catchAll,就是说代表这是一个 * 号匹配的路由
child := &node{
wildChild: true,
nType: catchAll,
maxParams: 1,
}
n.children = []*node{child}
n.indices = string(path[i])
n = child
n.priority++
// second node: node holding the variable
// 将下面的节点再添加到上面,不过 * 号路由不会再有下一级的节点了,因为它会将后面的
// 的所有内容当做变量,即使它是个 / 符号
child = &node{
path: path[i:],
nType: catchAll,
maxParams: 1,
handle: handle,
priority: 1,
}
n.children = []*node{child}
// 这里 return 了,看下上面,因为已经将 handle 保存,查到了叶子节点,所以就直接结束了当前方法
return
}
}
// insert remaining path part and handle to the leaf
// 这里给所有的处理的完成后的节点(不包含 * 通配符方式)的 handle 和 path 赋值
n.path = path[offset:]
n.handle = handle
}
0x05 路由查找
前文ServeHTTP方法中,使用getValue来查找路由对应的handler,如下:
// ServeHTTP makes the router implement the http.Handler interface.
func (r *Router) ServeHTTP(w http.ResponseWriter, req *http.Request) {
if r.PanicHandler != nil {
defer r.recv(w, req)
}
path := req.URL.Path
// 获取本次请求路由(path)的 handle 方法
if root := r.trees[req.Method]; root != nil {
if handle, ps, tsr := root.getValue(path, r.getParams); handle != nil {
//root.getValue 查找路由树的具体方法
if ps != nil {
handle(w, req, *ps)
r.putParams(ps)
} else {
handle(w, req, nil)
}
return
//.....
}
getValue方法
// 通过传入的参数的路径,寻找指定的路由
// 参数: 字符串类型的路径
// 返回值:
// Handle 通过路径找到的 handler , 如果没有找到,会返回一个 nil
// Params 如果路由注册的是参数路由,这里会将参数及值返回,是一个 Param 结构的 slice
// tsr 是一个 boolean 类型的标志,告诉调用者这个路由是否可以被重定向,配合 Router
// 里面的 RedirectTrailingSlash 属性
func (n *node) getValue(path string) (handle Handle, p Params, tsr bool) {
walk: // outer loop for walking the tree
for {
// 如果要找的路径长度大于节点的长度
// 入了根目录 / 一般情况都会满足这个条件,进入到这里走一圈
if len(path) > len(n.path) {
// 如果寻找的路径和节点保存的路径有相同的前缀
if path[:len(n.path)] == n.path {
// 将寻找路径的前缀部分去除
path = path[len(n.path):]
// 如果当前的节点不包含通配符(子节点有 : 或者 * 这种的),就可以直接去子节点继续搜索。
if !n.wildChild {
// 通过查找路径的首字符,快速找到包含这个字符的子节点(性能提升的地方就体现出来了)
c := path[0]
for i := 0; i < len(n.indices); i++ {
// 如果找到了,就继续去 indices 中对应的子节点去找
// 并且进入下一次循环
if c == n.indices[i] {
n = n.children[i]
continue walk
}
}
// 如果进入到了这里,代表没有找到对应的子节点
// 如果寻找路径正好是 / ,因为去除了公共路径
// 假设寻找的是 /hello/ , n.path = hello, 这时 path 就是 /
// 当前的节点如果注册了 handle ,就证明这个是一个路由,tsr 就会变成 true
// 调用者就知道可以将路由重定向到 /hello 了,下次再来就可以找到这个路由了
// 可以去 Router.ServeHTTP 方法看下,是不是会发起一个重定向
tsr = (path == "/" && n.handle != nil)
// 返回,此时会返回 (nil,[],true|false) 这 3 个值
return
}
// 处理是通配符节点(包含参数或*)的情况
// 如果当前节点是通配符节点,子节点肯定只有一个,因为 :name 这种格式的只允许注册一个
// 所以可以把当前节点替换成 :name 或 *name 这种子节点
n = n.children[0]
switch n.nType {
// 当子节点是参数类型的时候,:name 这种格式的
case param:
// find param end (either '/' or path end)
// 查找出寻找路径中到结束或者 / 以前的部分所在的位置
// 比如是 :name 或者 :name/more ,end 就会等于 4
end := 0
for end < len(path) && path[end] != '/' {
end++
}
// save param value
// 保存参数的值, 因为参数是一个 slice ,使用前要初始化一下
if p == nil {
// lazy allocation
p = make(Params, 0, n.maxParams)
// 现在 p 的值是 []Param
}
// 下面两行是将 slice 的长度扩展
// 如果第一次来, p 是一个空格, i = 0
// p = p[:0+1] p 取的是一个位置 0 到 1 的切片,因为切片前开后闭,
// 所以它的长度就变成了 1, 下面就可以向切片添加一个值了
// 第二次来就是在原有的长度再扩展 1 的长度,然后再添加一个值,
// 这样这个参数就会永远是一个有效的最小长度,应该可以提高性能 ?
// 不清楚作者为什么这样做,直接 append 不可以吗? 有兴趣的可以去确定下。
i := len(p)
p = p[:i+1] // expand slice within preallocated capacity
// 这个就是给 Parm 赋值, Key 就是去掉 : 后的值,比如 :name 就是 name
// Value 就是路径到结束位置 end 的值
p[i].Key = n.path[1:]
p[i].Value = path[:end]
// we need to go deeper!
// 上面已经获取了第一个值,但是有可能还会有两个或者更多,所以还要继续处理
// 如果之前找到第一个值的位置比寻找路径的长度小,就是还有 :name 后面还有内容需要去匹配
if end < len(path) {
// 如果还存在子节点, 就将 path 和 node 替换成子节点的,跳出当前循环再找一遍
if len(n.children) > 0 {
path = path[end:]
n = n.children[0]
continue walk
}
// ... but we can't
tsr = (len(path) == end+1)
// 这里返回的是 (nil, [Parm{name, 路径上的值}], true|false)
return
}
// 如果当前节点保存了 handle ,就将 handle 返回给调用者,去发起业务逻辑
if handle = n.handle; handle != nil {
return
} else if len(n.children) == 1 {
// No handle found. Check if a handle for this path + a
// trailing slash exists for TSR recommendation
// 确认它是否有一个 / 的子节点,如果有 tsr = true
n = n.children[0]
tsr = (n.path == "/" && n.handle != nil)
}
// 这里返回的是 [nil, [找到的参数...], true|false]
return
// 如果是 * 这种方式的路由, 就是直接处理参数,并返回,因为它肯定是最后一个节点
// 所以也不会出现子节点,及时路径上后面根再多的 / 也都只是参数的值
case catchAll:
// save param value
if p == nil {
// lazy allocation
p = make(Params, 0, n.maxParams)
}
i := len(p)
p = p[:i+1] // expand slice within preallocated capacity
p[i].Key = n.path[2:]
p[i].Value = path
handle = n.handle
return
default:
// 没想到什么情况会出现无效的类型, 如果出现了就直接 panic
// 现在这个 panic 不会导致服务器崩溃,因为在 ServeHTTP 中做了 Recovery
panic("invalid node type")
}
}
// 如果查询的路径和节点保存的路径相同
} else if path == n.path {
// We should have reached the node containing the handle.
// Check if this node has a handle registered.
// 检查下这个节点是否包含 handle ,如果包含就返回
// 会有不包含的情况,比如恰巧这个就是一个相同前缀的节点
if handle = n.handle; handle != nil {
return
}
// 如果查找的路径是 / 又不是根节点,还是个参数节点,就允许重定向
if path == "/" && n.wildChild && n.nType != root {
tsr = true
return
}
// No handle found. Check if a handle for this path + a
// trailing slash exists for trailing slash recommendation
// 如果没有找到,但是有一个 / 的子节点,也允许它重定向
// 就是这个意思,比如定义了一个 /hello/ 路由,但是访问的是 /hello
// 也允许它重定向到 /hello/ 上
for i := 0; i < len(n.indices); i++ {
if n.indices[i] == '/' {
n = n.children[i]
tsr = (len(n.path) == 1 && n.handle != nil) ||
(n.nType == catchAll && n.children[0].handle != nil)
return
}
}
return
}
// Nothing found. We can recommend to redirect to the same URL with an
// extra trailing slash if a leaf exists for that path
// 是否允许重定向的一个验证
tsr = (path == "/") ||
(len(n.path) == len(path)+1 && n.path[len(path)] == '/' &&
path == n.path[:len(n.path)-1] && n.handle != nil)
return
}
}
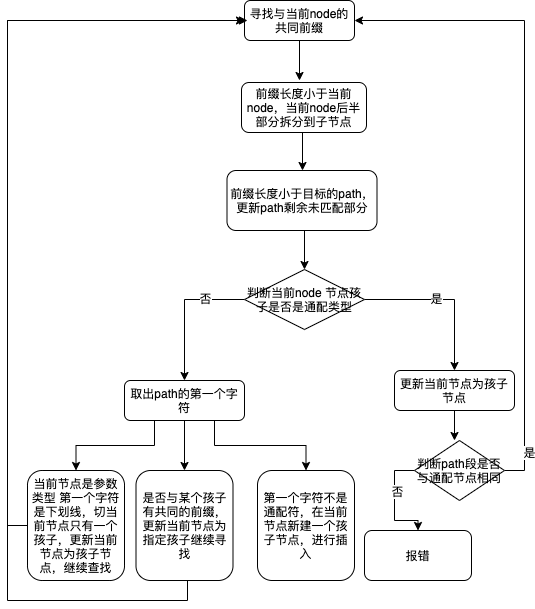
0x06 查找算法
查找算法基本流程如下图:
0x07 基础示例
GET
GET /marketplace_listing/plans/
GET /marketplace_listing/plans/:id/accounts
GET /search
GET /status
GET /support
补充路由:
GET /marketplace_listing/plans/ohyes
1、过程1:插入 GET /marketplace_listing/plans
因为第一个路由没有参数(wildCard),path 都被存储到根节点上了,只有一个节点

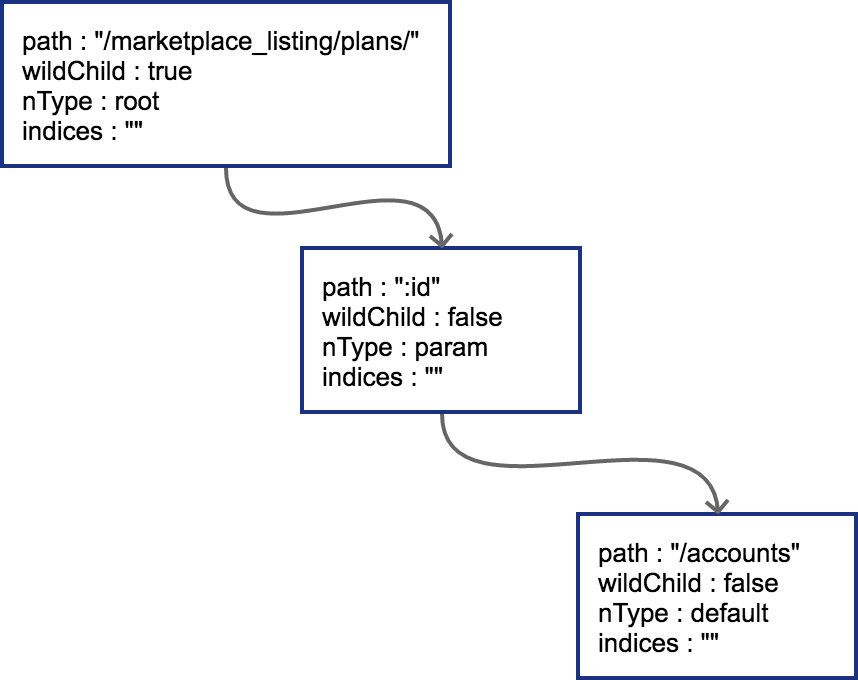
2、过程2(新的路由可以直接作为原路由的子节点进行插入)
插入GET /marketplace_listing/plans/:id/accounts,新路径与之前的路径有共同的前缀,且可以直接在之前叶子节点后进行插入;由于 :id 这个节点只有一个字符串的普通子节点,所以 indices 还依然不需要处理
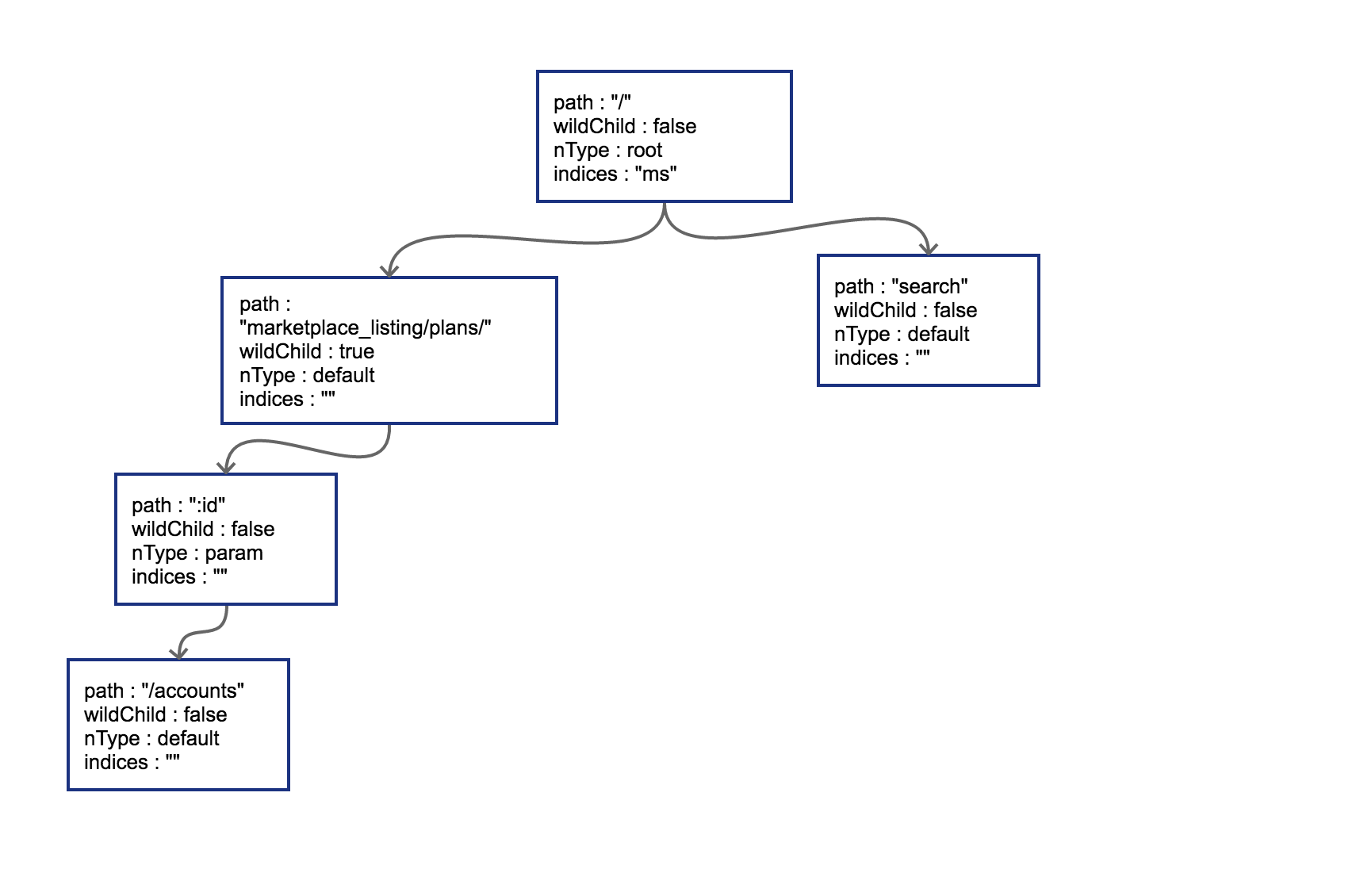
3、过程3(分裂):插入 GET /search,导致树的边分裂
原路径和新的路径在初始的 / 位置会发生分裂,这样需把原有的 root 节点内容下移,再将新路由 search 同样作为子节点挂在 root 节点之下。这时候因为子节点出现多个,需要在 root 节点的 indices 提供子节点索引(即ms 表示子节点的首字母分别为 m-marketplace 和 s-search)
4、过程4(分裂):插入GET /status 和 GET /support,导致在 search 节点上再次发生分裂
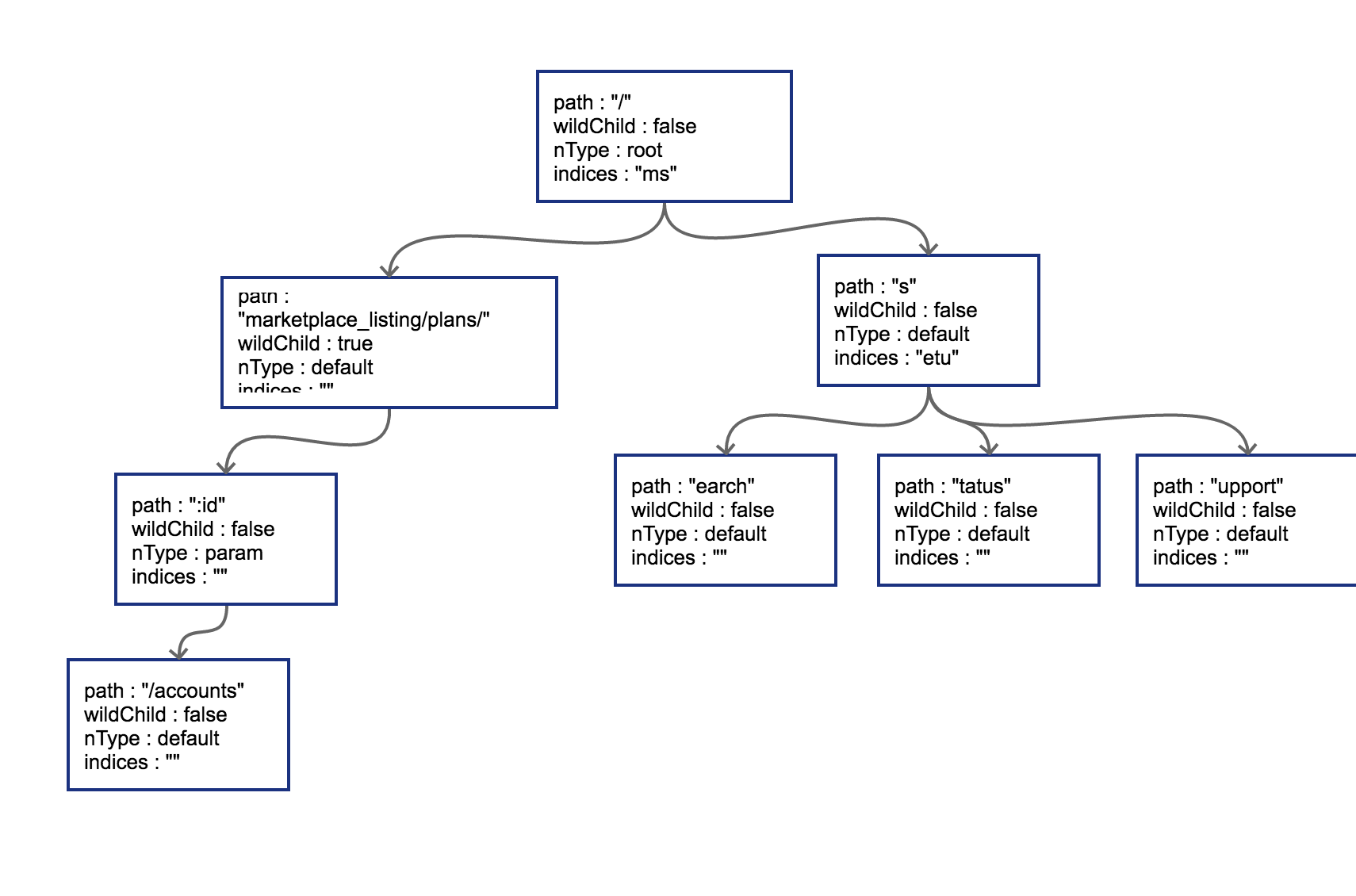
PUT
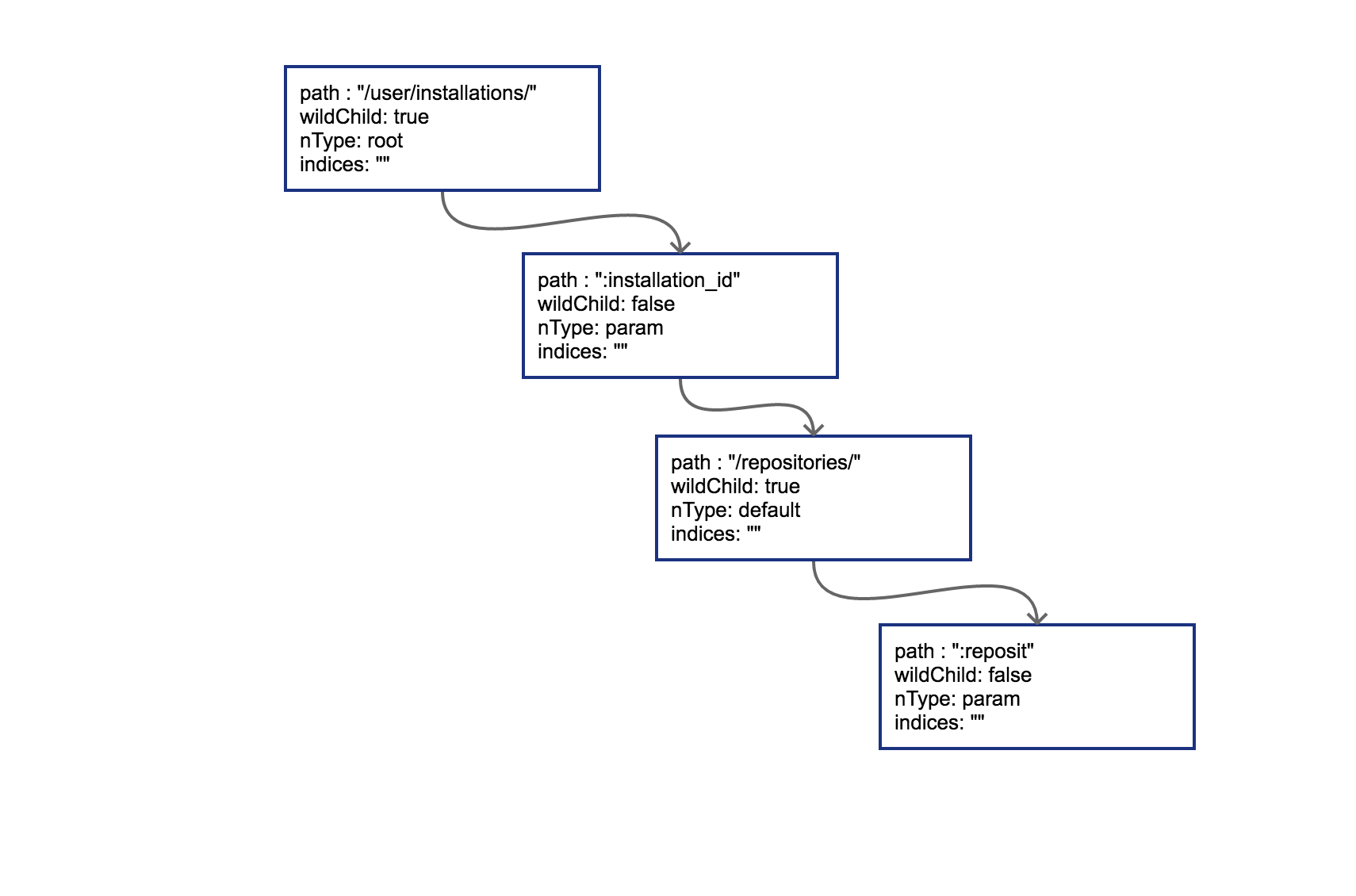
PUT /user/installations/:installation_id/repositories/:repository_id
对应的radix树为:
0x08 特殊示例
本小节摘自gin框架之路由前缀树初始化分析,分析几种比较特殊的情况。前两种情况针对了初始路由信息为空的情况(了解insertChild的过程),第三个case主要用于分析寻找路由的过程。
case1:单条包含两个冒号通配path的一颗前缀树
路由信息: /user/:name/:age,name和age是通配符的名字,radix树构造过程如下:
- 查找到当前path
/user/:name/:age的wildCard为:name,开始的位置是第7个字符 - 判断wildCard是冒号通配符类型且起始位置大于
0,那么path之前的部分/user/设置为当前节点(上面树中的第一层节点)的path,然后更新要处理的path为后半部分,即:name/:age - 设置当前node wildChild为
true - 新建孩子节点,path为wilCard
:name,并且挂接到第一层节点,并将当前节点指向第2层的节点 - 判断path是否处理结束,如果处理结束,则可以退出
- 如果path还没有处理结束,更新path为除去wildCard剩余部分
/:age,并新建孩子节点,挂接到当前的节点(当前还指向第2层)并且设置当前节点为第3层结点 - 更新后的path为
/:age,当前的节点为第3层节点,继续从第一步开始处理。再次循环一遍,两个冒号通配符处理完成
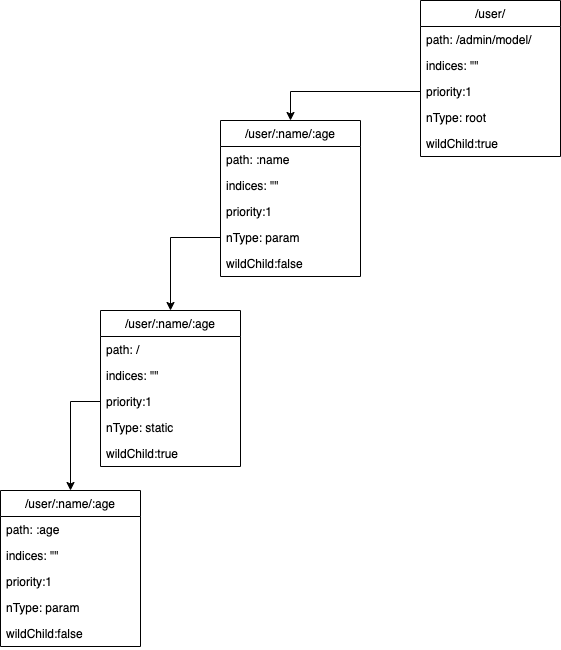
case2:单条包含星号通配path的一颗前缀树
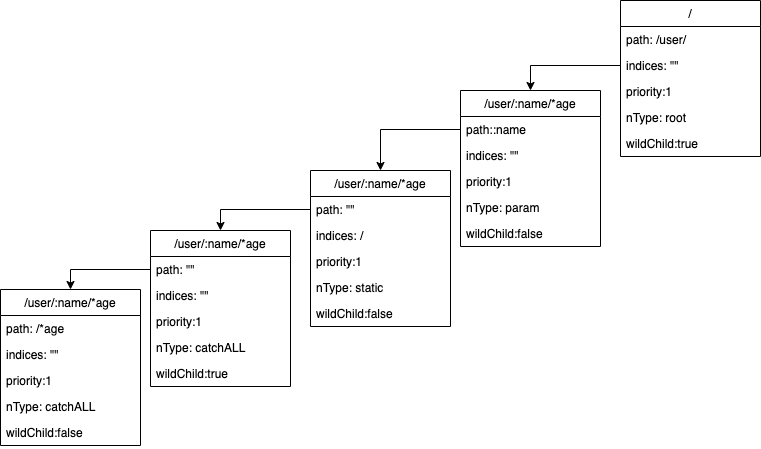
路由信息:/user/:name/*age ,包含一个冒号通配符和一个星号通配符,radix树构造过程如下:
- 查找当前path的wildCard,当前node指向第一层的node,wildCard的查找结果为
:name,位置在第9个 - 按照上面的处理步骤,处理完wildCard,path更新为
/*age,当前node指向第3层,进行下一次循环处理 - 再次查找wildCard结果为
*age位置是第二个符号,进入insertChild插入星号通配符的逻辑 - 查看通配符之前的是否是下划线,不是的话报错,将当前的节点path设置为下划线之前的path,这个时候当前节点path为空
- 生成子节点,即图中的第
4层节点,设置节点类型为catchAll,并挂接到当前节点,设置单前节点的indices为/,当前节点指向第4层节点 - 新建第
5层节点,节点path设置为剩下的path(此处星号通配符之后不再处理),并挂接到当前当前节点
case3:多种path的寻找过程
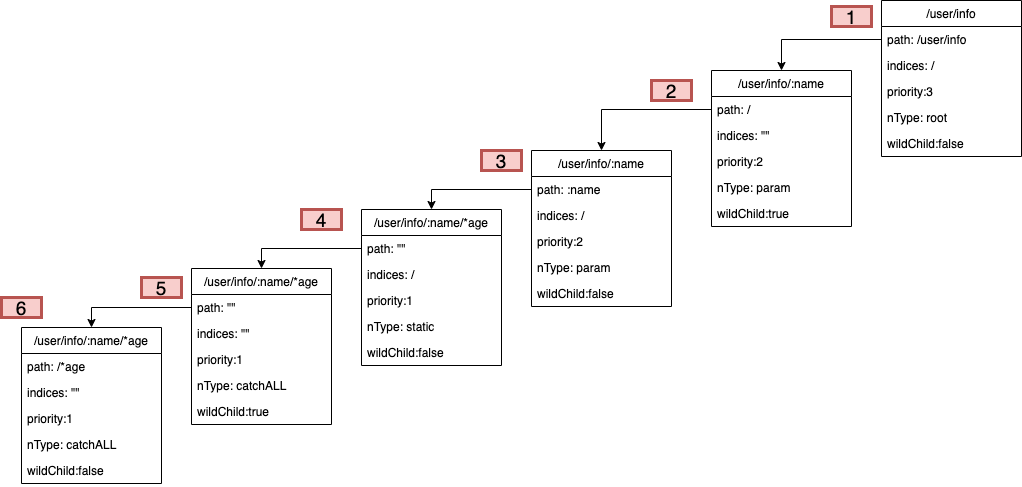
路由信息:第一条/user/info,第二条/user/info/:name,第三条/user/info/:name/*age
- 路由1:root树为空树并且没有通配符,在
insertChild方法中直接设置当前节点(第1层节点),设置path为/user/info - 路由2:先找到与当前节点的最长匹配长度,长度小于单前path长度,重置path为
/:name且当前节点的wilChild为false,取出剩余path第1个字符进行判断,根据第1个字符逻辑 在当前节点新增孩子(图中第2级孩子),并将当前node指向第2层节点,调用insertChild将/:name插入到第2层节点,逻辑同case1,这样形成了第2层和第3层节点 - 路由3:先找到与第
1层节点的共同前缀,path更新为/:name/*age,取出剩余path第一个字符/,/在当前的indices里,对孩子节点做优先级调整,并且将当前节点更新下沉到孩子节点,也就是图中第2层节点,继续下一次循环查找 - path
/:name/*age与第2层节点的共同前缀为/,当前第2层节点wildCard为true,这个时候将当前节点指定到孩子节点,即图中第3层节点,并且判断path在下划线之前的部分,即:name与3层节点的path相同,然后继续循环查找 - path剩余部分为
:name/*age,当前node指向第3层节点,继续查找插入位置;共同前缀为:name,更新path变为/*age,由于在第二部分处理完以后只有第3层节点。这个时候直接新增节点,进入insertChild逻辑。与case2的后半部分按照相同的逻辑,形成第四五六层节点
0x09 其他一些细节
1、编译验证
如下面代码:
var _ http.Handler = New()
上面代码通过 New() 函数初始化一个 Router ,并且指定 Router 实现了 http.Handler 接口 ,如果 New() 没有实现 http.Handler 接口,在编译的时候就会报错了。这里只是为了验证一下, New() 函数的返回值并不需要,所以就把它赋值给 _;常用于编译检查
2、参数查询
封装在http.request中的上下文是个valueCtx,框架提供了一个从上下文获取Params键值对的方法:
func ParamsFromContext(ctx context.Context) Params {
p, _ := ctx.Value(ParamsKey).(Params)
return p
}
3、子节点的冲突问题