0x00 前言
本篇文章,总结下在项目中使用 sarama-kafka 库的一些经验。是对前文 关于 Kafka 应用开发知识点的整理(二) 的补充。部分参考阿里云的 kafka最佳实践
0x01 阿里云的最佳实践
Producer 最佳实践
Producer 最佳实践,降低发送消息的错误率:
1、发送消息
发送消息的示例代码如下,时间戳这个可以加,用于在消费端感知消息的时效性(比如重复消费的时候,按照时间过滤掉过期的消息等策略):
Future<RecordMetadata> metadataFuture = producer.send(new ProducerRecord<String, String>(
topic, // 消息主题
null, // 分区编号,建议为 null,由 Producer 分配
System.currentTimeMillis(), // 时间戳(消费时判断时间是否超过预设时间窗口,适时丢弃过期数据)
String.valueOf(value.hashCode()), // 消息键
value // 消息值
));
Consumer 最佳实践
0x02 客户端的选型
前文 关于 Kafka 应用开发知识点的整理(二) 介绍了 Shopify/sarama 的配置及使用情况,在现网中,主要的客户端有下面几个:
Shopify/sarama
- 优点:完全基于 golang 实现,sarama 提供了 mock 包
- 缺点:问题偏多
如果使用sarama,则需要了解其一些比较重要的选项:
| 参数 | 描述 | 备注 |
|---|---|---|
| version | Kafka版本 | 客户端填入的版本号最好与服务端的版本保持一致 |
| groupId | 消费组ID,用于指定消费者组的标识符。通过配置消费组ID,将消费组内的消费者分组,可以实现消费者组内的负载均衡,实现数据的处理和分发 | |
| conf.Consumer.Fetch.Min | 一次请求中拉取信息的最小字节数 | |
| conf.Consumer.Fetch.Default | 一次请求中从集群拉取信息的最大字节数 | |
| conf.Consumer.Retry.Backoff | 读取分区失败后重试之前需要等待的时间,默认为2s |
|
| conf.Consumer.MaxWaitTime | 表示broker在Consumer.Fetch.Min字节可用之前等待的最长时间,默认为250,单位为ms。建议取值范围为[100 ms, 500 ms] |
|
| conf.Consumer.MaxProcessingTime | 消费者期望一条消息处理的最长时间,单位为ms |
|
| conf.Consumer.Offsets.AutoCommit.Enable | 指定是否自动提交更新后的偏移量,true为启用,默认为true |
|
| conf.Consumer.Offsets.AutoCommit.Interval | 提交更新后的偏移量的频率。当conf.Consumer.Offsets.AutoCommit.Enable为false时,该参数无效,默认为1,单位为s |
|
| conf.Consumer.Offsets.Initial | 用于指定消费者在启动时从哪个偏移量开始消费消息。常用值为OffsetNewest和OffsetOldest,默认为OffsetNewest |
OffsetNewest:表示使用最新的偏移量,即从最新消息开始读取。当有已提交的偏移量时,从提交的偏移量开始消费;无提交的偏移量时,消费新产生的数据。OffsetOldest:表示使用最早的偏移量,从最早的消息开始读取。当有已提交的偏移量时,从提交的偏移量开始消费;无提交的偏移量时,从头开始消费 |
| conf.Consumer.Offsets.Retry.Max | 提交请求失败时,最多重试次数,默认为3次 |
sarama的消费组
参考用例:
sarama消费者组的3个重要方法:
// Setup is run at the beginning of a new session, before ConsumeClaim
func (consumer *Consumer) Setup(sarama.ConsumerGroupSession) error {
// Mark the consumer as ready
close(consumer.ready)
return nil
}
// Cleanup is run at the end of a session, once all ConsumeClaim goroutines have exited
func (consumer *Consumer) Cleanup(sarama.ConsumerGroupSession) error {
return nil
}
// ConsumeClaim must start a consumer loop of ConsumerGroupClaim's Messages().
// Once the Messages() channel is closed, the Handler must finish its processing
// loop and exit.
func (consumer *Consumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
// NOTE:
// Do not move the code below to a goroutine.
// The `ConsumeClaim` itself is called within a goroutine, see:
// https://github.com/IBM/sarama/blob/main/consumer_group.go#L27-L29
for {
select {
case message, ok := <-claim.Messages():
if !ok {
log.Printf("message channel was closed")
return nil
}
log.Printf("Message claimed: value = %s, timestamp = %v, topic = %s", string(message.Value), message.Timestamp, message.Topic)
session.MarkMessage(message, "")
// Should return when `session.Context()` is done.
// If not, will raise `ErrRebalanceInProgress` or `read tcp <ip>:<port>: i/o timeout` when kafka rebalance. see:
// https://github.com/IBM/sarama/issues/1192
case <-session.Context().Done():
return nil
}
}
}
Setup/Cleanup/ConsumeClaim 是 s.handler.ConsumeClaim 的三个接口,需要用户实现;当需要创建一个会话时,先运行 Setup ,然后在 ConsumerClaim 中持续处理消息,最后运行 Cleanup,在两种场景下会触发:
- 新建consumeGroups时(消费者)
- 发生rebalance时(比如某个消费者退出/新建)
在调用了 Setup 之后,后面在独立的协程中调用 ConsumeClaim 接口,持续消费关联分区partition的数据
消费者组测试代码在此,依此启动3个消费者(启动3次二进制程序),同样归属于消费组grp1:
1、启动消费者1:
INFO[0000] setup
INFO[0000] map[t1:[0 1 2] t2:[0 1 2]]
INFO[0000] Sarama consumer up and running!...
2、启动消费者2,同时由于rebalance,消费者1也发生了变化
INFO[0000] setup
INFO[0000] map[t1:[2] t2:[2]]
INFO[0000] Sarama consumer up and running!...
3、消费者1日志,触发了cleanup/setup
INFO[0024] cleanup
INFO[0024] setup
INFO[0024] map[t1:[0 1] t2:[0 1]]
4、再加入消费者3
INFO[0002] setup
INFO[0002] map[t1:[2] t2:[2]]
INFO[0002] Sarama consumer up and running!...
此时消费者1、消费者2都会受到影响:
#消费者1
INFO[0134] cleanup
INFO[0134] setup
INFO[0134] map[t1:[0] t2:[0]]
#消费者2
[0109] cleanup
INFO[0109] setup
INFO[0109] map[t1:[1] t2:[1]]
额外的话题,如何指定消费offset?kafka指定消费offset参数只有OffsetNewest 和 OffsetOldest ,如果想指定 offset 进行消费,可以在Setup中调用ConsumerGroupSession.ResetOffset接口实现(Setup方法是会话最一开始的地方,且这个时候已经能够获取到所有的 topic 和 partition)。当然offset要遵循OffsetNewest、OffsetOldest的规则,同时offset不能过期
func (k *Kafka) Setup(session sarama.ConsumerGroupSession) error {
log.Info("setup")
session.ResetOffset("t2p4", 0, 13, "") //重置消费offset
log.Info(session.Claims())
close(k.ready)
return nil
}
func (k *Kafka) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for message := range claim.Messages() {
log.Infof("[topic:%s] [partiton:%d] [offset:%d] [value:%s] [time:%v]",
message.Topic, message.Partition, message.Offset, string(message.Value), message.Timestamp)
session.MarkMessage(message, "")
}
return nil
}
confluent-kafka-go
此库基于 kafka C/C++ 库 librdkafka 构建,是阿里云官网推荐的 kafka 客户端,参考下面文档:
- Go SDK 收发消息
- 优点:https://github.com/confluentinc/confluent-kafka-go/#confluents-golang-client-for-apache-kafkatm
- 缺点:编译依赖于
CGO,静态编译支持不好,跨平台编译亦如此
segmentio/kafka-go
segmentio/kafka-go 也是一个极佳的备选客户端(许多公司生产环境使用),官方对比其他常见客户端的 优缺点,也是此库的实现动机。此库完全基于 golang 实现
- 优点:提供低级 API 和高级 API(如
reader、writer),以 writer 为例,相对低级 api,它是并发 safe 的,还提供连接保持和重试,无需开发者自己实现,另外writer还支持sync和async写、带context.Context的超时写等 - 缺点:
Writer的sync模式写入比较慢,不推荐使用,推荐使用async模式;此外,segmentio/kafka-go 没有提供 mock 测试包,官方推荐:需要自己建立环境测试,在本地启动一个 kafka 服务,然后运行测试
0x03 再看 Kafka 的高可用:消息备份和同步机制
消息丢失解决
1、生产端丢消息问题解决
只需要 producer 设置 acks 参数,等待 Kafka 所有 follower 都成功后再返回。只需要进行如下设置即可(实际应用需要注意延迟):
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // -1
而关于,ack 参数有如下取值,详细可参考前文 Kafka 生产者的可靠性
const (
// NoResponse doesn't send any response, the TCP ACK is all you get.
NoResponse RequiredAcks = 0
// WaitForLocal waits for only the local commit to succeed before responding.
WaitForLocal RequiredAcks = 1
// WaitForAll waits for all in-sync replicas to commit before responding.
// The minimum number of in-sync replicas is configured on the broker via
// the `min.insync.replicas` configuration key.
WaitForAll RequiredAcks = -1
)
2、消费端丢消息问题
以 sarama 库实现的客户端,kafka 消费数据后入库到 Mysql 的场景为例(采用自动提交模式):通常消费端丢消息都是因为 Offset 自动提交,但是数据并没有插入到 Mysql(比如此时消费者进程 Crash),导致下一次消费者重启后,此条消息会漏掉
a)自动提交模式下的丢消息问题:默认情况下 sarama 是自动提交的方式,间隔为 1 秒钟,此外注意 **sarama 自动提交的原理:先标记再提交 **。代码如下:
// NewConfig returns a new configuration instance with sane defaults.
func NewConfig() *Config {
// …
c.Consumer.Offsets.AutoCommit.Enable = true. // 自动提交
c.Consumer.Offsets.AutoCommit.Interval = 1 * time.Second // 间隔
c.Consumer.Offsets.Initial = OffsetNewest
c.Consumer.Offsets.Retry.Max = 3
// ...
}
这里的自动提交,是基于被标记过的消息 sess.MarkMessage(msg, ""),如果不调用 sess.MarkMessage(msg,""),即使启用了自动提交也没有效果,下次启动消费者依然会从上一次的 Offset 重新消费。示例代码如下
type exampleConsumerGroupHandler struct{}
func (exampleConsumerGroupHandler) Setup(_ ConsumerGroupSession) error { return nil }
func (exampleConsumerGroupHandler) Cleanup(_ ConsumerGroupSession) error { return nil }
func (h exampleConsumerGroupHandler) ConsumeClaim(sess ConsumerGroupSession, claim ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("Message topic:%q partition:%d offset:%d\n", msg.Topic, msg.Partition, msg.Offset)
// 标记消息已处理,sarama 会自动提交
sess.MarkMessage(msg, "")
}
return nil
}
但是,这里还有一个细节:需要保持标记逻辑在插入 mysql 代码之后即可确保不会出现丢消息的问题:
// 正确的调用顺序:
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
// 插入 mysql
insertToMysql(msg)
// 正确:插入 mysql 成功后程序崩溃,下一次顶多重复消费一次,而不是因为 Offset 超前,导致应用层消息丢失了
sess.MarkMessage(msg, "")
}
return nil
}
// 错误的顺序:
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
// 错误 1:不能先标记,再插入 mysql,可能标记的时候刚好自动提交 Offset,但 mysql 插入失败了,导致下一次这个消息不会被消费,造成丢失
// 错误 2:干脆忘记调用 sess.MarkMessage(msg, ""),导致重复消费
sess.MarkMessage(msg, "")
// 插入 mysql
insertToMysql(msg)
}
return nil
}
3、sarama 手动提交模式
另外也可以通过手动提交来处理丢消息的问题(sarama 库不推荐此模式,因为自动提交模式下已经能解决丢消息问题)
consumerConfig := sarama.NewConfig()
consumerConfig.Version = sarama.V2_8_0_0
consumerConfig.Consumer.Return.Errors = false
consumerConfig.Consumer.Offsets.AutoCommit.Enable = false // 禁用自动提交,改为手动
consumerConfig.Consumer.Offsets.Initial = sarama.OffsetNewest
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("%s Message topic:%q partition:%d offset:%d value:%s\n", h.name, msg.Topic, msg.Partition, msg.Offset, string(msg.Value))
// 插入 mysql
insertToMysql(msg)
// 手动提交模式下,也需要先进行标记
sess.MarkMessage(msg, "")
consumerCount++
if consumerCount%3 == 0 {
// 手动提交,不能频繁调用,要考虑这里的耗时对性能的影响
t1 := time.Now().Nanosecond()
sess.Commit()
t2 := time.Now().Nanosecond()
fmt.Println("commit cost:", (t2-t1)/(1000*1000), "ms")
}
}
return nil
}
Consumer 的消费位点
Consumer 在重启后会继续消费,这是因为 Kafka 使用 offset(偏移量)来跟踪 Consumer 在分区中的位置。当 Consumer 启动时,它将查询 Kafka 服务器以获取存储在 Zookeeper(或 Kafka Broker)中的上次消费的偏移量,并从该位置继续消费消息。Kafka Consumer 在消费消息时还会定期地将其当前的偏移量提交到 Kafka 服务器。这个提交操作会在消费者处理完一批消息后执行(自动 OR 手动提交)。如果消费者在处理消息期间崩溃或被强制停止,则下一次启动时,Consumer 将从最后提交的偏移量处开始消费。这样 Consumer 可以确保不会错过任何消息,但是也会存在重复消费的问题
此外,如果消费者组的 Consumer 数量发生变化(例如有新 Consumer 加入或旧 Consumer 退出),则每个消费者组的分区重新分配可能会导致 Consumer 从不同的位置开始消费。这时 Consumer 需要重新查询分配的偏移量并从相应的位置开始消费;如下面几张图代表在 Consumer 不同阶段的系统状态:



上图中的几个字段含义:
CURRENT-OFFSET:表示 Consumer 消费了数据之后提交的 offset,即消费者消费了的数据的偏移量。如果为unknown,则表示消费者未提交过 offset,是 Kafka 中消费者在每个分区上当前处理的消息的偏移量。它表示消费者已经成功处理了分区中的哪些消息。CURRENT-OFFSET是消费者组在 Kafka 内部的__consumer_offsetsTopic 中维护的状态信息LOG-END-OFFSET:表示的是该分区的HW,即LEO值,对于 Kafka 中的每个分区,LOG-END-OFFSET是指该分区中最新消息的下一个偏移量。它表示了分区中下一条将被写入的消息的偏移量,LOG-END-OFFSET可以用来衡量分区中消息的总量LAG:表示延迟滞后,也就是生产者已经写到 kafka 集群了,然后有还没有被消费的数量;对于 Kafka 中的每个消费者,LAG是指消费者在每个分区中落后于LOG-END-OFFSET的消息数量。它表示了消费者尚未处理的消息数量,LAG可以用来衡量消费者处理消息的速度和效率。计算公式为:LAG = LOG-END-OFFSET - CURRENT-OFFSET,其中CURRENT-OFFSET是消费者在分区中当前处理的消息偏移量
LOG-END-OFFSET 和 LAG 是 Kafka 监控和调优的重要指标(Consumer 进度)。通过观察这两个指标,可以了解 Consumer 的处理速度,以及是否能够及时处理生产者生成的消息。如果 LAG 持续增加,这可能意味着消费者无法跟上生产者的速度,需要对消费者进行优化或增加消费者实例以提高吞吐量。Consumer 重启时,从何处开始消费和 CURRENT-OFFSET 有关系,结论如下:
1、如果 CURRENT-OFFSET 不是为 unknown(Consumer 以前消费过数据,提交过 offset),重启消费者时 Earliest/Latest/none 都是会从 CURRENT-OFFSET 一直消费到 LOG-END-OFFSET
2、如果 CURRENT-OFFSET 为 unknown,重启 Consumer 后 Earliest/Latest/none 表现均不相同
Earliest模式:会从该分区当前最开始的 offset 消息开始消费(即从头消费),如果最开始的消息 offset 是0,那么消费者的 offset 就会被更新为0Latest:只消费当前 Consumer 启动完成后生产者新生产的数据,旧数据不会再消费,offset 被重置为分区的HWnone:启动消费者时,该 Consumer 所消费的主题的分区没有被消费过,会抛出异常 (一般新建的 Topic 或者用新的消费者组是使用该模式会抛异常)
上述的 3 种值,关联 auto.offset.reset(JAVA),sarama 种仅有两种 选项,OffsetNewest 和 OffsetOldest
sarama.OffsetNewest:从每个分区的最新偏移量(LOG-END-OFFSET)开始消费。这意味着消费者将忽略在启动之前写入的所有消息,只消费启动之后写入的消息sarama.OffsetOldest:从每个分区的最旧偏移量(LOG-BEGIN-OFFSET)开始消费。这将确保消费者处理之前写入的所有消息,包括在消费者启动之前写入的消息
最后,有一个细节需要注意,Kafka 服务端会为每个分区维护消费者组的偏移量,并将其存储在 Kafka 内部的 __consumer_offsets 主题中。这些偏移量会一直保留在 Kafka 中,直到它们被覆盖或者分区数据被删除(过期删除),即 **offset 这个文件(值)默认不是长期有效的 **;Kafka 中的数据保留策略是由以下两个配置参数控制的:
log.retention.hours:用于设置 Kafka 服务器保留日志的时间(以小时为单位),默认值是168h,当日志数据达到这个时间限制时,Kafka 会删除旧的日志段log.retention.bytes:用于设置每个分区可以保留的最大日志大小(以字节为单位),当分区日志大小达到这个限制时,Kafka 会删除旧的日志段
上述参数不仅适用于普通的 Kafka topic,还适用于内部 topic(如 __consumer_offsets)。当消费者组的偏移量数据被删除后,如果该消费者组重新启动,它将根据消费者配置中的 auto.offset.reset(config.Consumer.Offsets.Initial)来确定从哪个偏移量开始消费。注意,该情况通常不会影响正在运行的消费者,因为它们会定期提交偏移量 offset。只有 Consumer 在长时间不活动(超过数据保留期)后重新启动时,这种情况才可能发生。为了避免这种情况,现网中可根据实际需求增加数据保留时间或者确保 Consumer 定期运行
再看:Consumer 的可靠性策略
Consumer 的可靠性策略,即 Consumer 的可靠性策略集中在 consumer 的投递语义上,即
- 何时消费,消费到什么?
- 消费是否会丢?
- 消费是否会重复?
这些语义场景,可以通过 kafka 消费者的参数进行配置
1、AutoCommit(at most once, commit 后挂,实际会丢)
配置如下的 Consumer 收到消息就返回正确给 Broker, 但是如果业务逻辑没有走完中断了,实际上这个消息没有消费成功。这种场景适用于可靠性要求不高的业务。其中 auto.commit.interval.ms 代表了自动提交的间隔。比如设置为 1s 提交 1 次,那么在 1s 内的故障重启,会从当前消费 offset 进行重新消费时,1s 内未提交但是已经消费的 msg, 会被重新消费
enable.auto.commit = true
auto.commit.interval.ms
2、手动 Commit(at least once, commit 前挂,就会重复, 重启还会丢)
配置为手动提交的场景下,业务开发者需要在消费消息到消息业务逻辑处理整个流程完成后进行手动提交。如果在流程未处理结束时发生重启,则之前消费到未提交的消息会重新消费到,即消息显然会投递多次。此应用模式建议业务逻辑明显实现了幂等的场景下使用
enable.auto.commit = false
特别关注下 sarama 库的几个参数的配置:
#intitial = oldest 代表消费者可以访问到的 topic 里的最早的消息,大于 commit 的位置,但是小于 HW。同时也受到 broker 上消息保留时间的影响和位移保留时间的影响。不能保证一定能消费到 topic 起始位置的消息
#如果设置为 newest 则代表访问 commit 位置的下一条消息。如果发生 consumer 重启且 autocommit 没有设置为 false, 则之前的消息会发生丢失,再也消费不到了。在业务环境特别不稳定或非持久化 consumer 实例的场景下,应特别注意
sarama.offset.initial (oldest, newest)
#offsets.retention.minutes 为 1440s
offsets.retention.minutes
3、Exactly once, 较难实现,需要 msg 持久化和 commit 是原子的
消息投递且仅投递一次的语义是很难实现的。首先要消费消息并且提交保证不会重复投递,其次提交前要完成整体的业务逻辑关于消息的处理。在 kafka 本身没有提供此场景语义接口的情况下,这几乎是不可能有效实现的。一般的解决方案,也是进行原子性的消息存储,业务逻辑异步慢慢的从存储中取出消息进行处理
0x04 关于 consumer 的一些再认知
收集下笔者遇到的一些问题
1、如何监控分区消费堆积(消费过慢)?
2、采用 sarama 消费,客户端设置为 sarama.OffsetNewest、自动提交模式,那么如果客户端在重启过程中发生了若干分钟的延迟(期间分区有数据写入且正常),那么在重启之后,消费者从何处开始消费?
3、如何提高 Consumer 消费能力,减少 rebalance 发生?
避免 rebalance 的方法:一些经验
若无分区 / 消费者组调整等操作,运行中 consumer 出现 rebalance 的原因大概率是 consumer 心跳超时导致:
v0.10.2之前版本的客户端:Consumer 没有独立线程维持心跳,而是把心跳维持与poll接口耦合在一起。其结果就是,如果用户消费出现卡顿,就会导致 Consumer 心跳超时,引发 Rebalancev0.10.2及之后版本的客户端:如果消费时间过慢,超过一定时间(max.poll.interval.ms设置的值,默认5分钟)未进行poll拉取消息,则会导致客户端主动离开队列,而引发 Rebalance
相关的配置参数:session.timeout.ms 表示心跳超时时间(可以由客户端自行设置);max.poll.records 表示每次 poll 返回的最大消息数量;此外,v0.10.2 之前版本的客户端实现心跳是通过 poll 接口来实现的,没有内置的独立线程;v0.10.2 及之后版本的客户端实现中,为了防止客户端长时间不进行消费,Kafka 客户端在 v0.10.2 及之后的版本中引入了 max.poll.interval.ms 配置参数
推荐的解决方案如下:
session.timeout.ms:v0.10.2之前的版本可适当提高该参数值,需要大于消费一批数据的时间,但不要超过30s(建议设置为25s);而v0.10.2及其之后的版本,保持默认值10s即可-
max.poll.records:降低该参数值,建议远远小于 <单个线程每秒消费的条数> * <消费线程的个数> *`max.poll.interval.ms` 的乘积,即尽量不要超过消费者处理的条目数,保证在 `max.poll.interval.ms` 内可以处理完成 -
max.poll.interval.ms:该值要大于max.poll.records/ (<单个线程每秒消费的条数> * < 消费线程的个数 >) 的值 -
尽量提高客户端的消费速度,消费逻辑另起线程进行处理;减少 Group 订阅 Topic 的数量,一个 Group 订阅的 Topic 最好不要超过
5个,建议一个 Group 只订阅一个 Topic v0.10.2可以进行升级到最新版本
重复消费的解决方案
TODO
0x06 一个关于 consumer 的问题排查经过
在工作中遇到过这样的问题,测试环境消费者进程重启后,不消费重启前一段时间(间隔不久)的数据,大致描述如下:
消费者代码采用 sarama.OffsetNewest 消费位点模式,使用消费者组进行消费,消费者进程的启动时间序列大致如下:
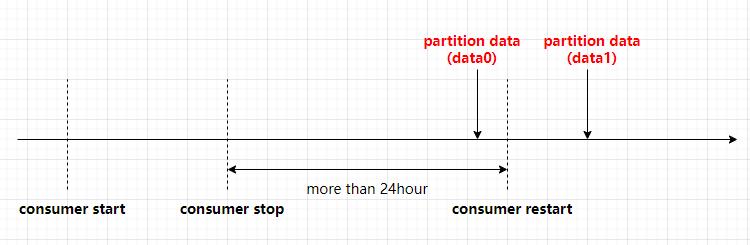
问题是重启后 consumer 不消费 data0 的数据?初步排查已知 kafka 生产者成功写入且消费者模式设置为 sarama.OffsetNewest,从下面几个已知信息入手来排查
-
在 Kafka 中,消费者的偏移量(offset)是由消费者自己维护的,消费者组会跟踪每个分区的偏移量,并将其存储在 Kafka 内部的
__consumer_offsetstopic 中,当然了,这个数据存在有效期(亦或被覆盖或者分区数据被删除) -
Kafka 中的数据保留策略:
log.retention.hours参数用于设置 Kafka 服务器保留日志的时间(小时);log.retention.bytes参数用于设置每个分区可以保留的最大日志大小(字节);offsets.retention.minutes参数用于设置 Kafka 服务器保留已提交消费者偏移量的时间(分钟),该设置主要用于处理长时间不活动的消费者(组)。当这些消费者(组)重新启动时,由于它们的偏移量已经过期并被删除,它们将根据消费者配置中的auto.offset.reset参数(config.Consumer.Offsets.Initial)来确定从哪个偏移量开始消费
再腾讯云 ckafka 的默认消息保留时长为 1 天,所以问题解决:

0x07 参考
- Kafka 最佳实践
- Kafka 设计实现与最佳实践之客户端篇
- Golang 中如何正确的使用 sarama 包操作 Kafka
- Producer implementation
- Go 社区主流 Kakfa 客户端简要对比
- 订阅者最佳实践
- CKafka 数据可靠性说明
- Kafka(Go) 教程 (六)—sarama 客户端 producer 源码分析
- sarama的消费者组分析、使用
转载请注明出处,本文采用 CC4.0 协议授权