0x00 前言
前文 Etcd 最佳实(踩)践(坑) 中,了解 CAP 定理中,满足 AP 的典型协议就是 Gossip,本文就介绍下该协议。
Gossip protocol 也叫 Epidemic Protocol (流行病协议),是一种 去中心化、容错并保证最终一致性的协议;其基本思想是通过不断的和集群中的节点 Gossip 交换信息,经过 O(log(N)) 个回合, Gossip 协议即可将信息传递到所有的节点(其中 N 表示节点的个数)。典型的实现有这么几个:
- Redis 集群间通信
- Consul 集群间各节点交换数据
- Prometheus的告警组件alertmanager
- 区块链项目
Gossip 协议的目的是解决状态在集群中的传播和状态一致性的保证两个问题
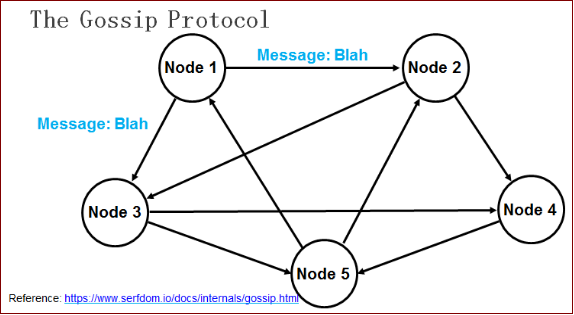
上图中的每个节点均为运行着 Gossip 协议的 Agent(收发 Gossip 协议消息),包括服务器节点与普通节点。最终一致指的是经过一段时间后系统的状态达成一致。
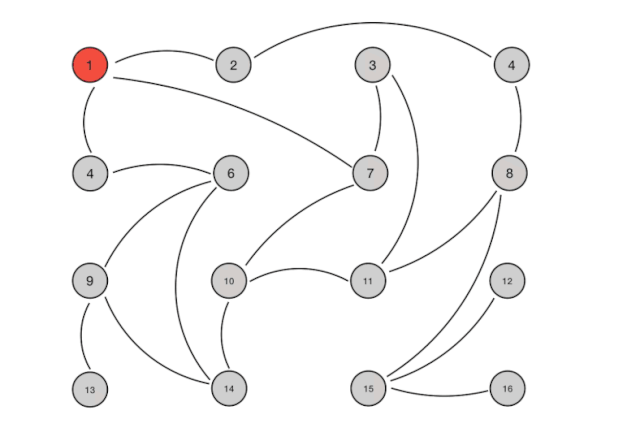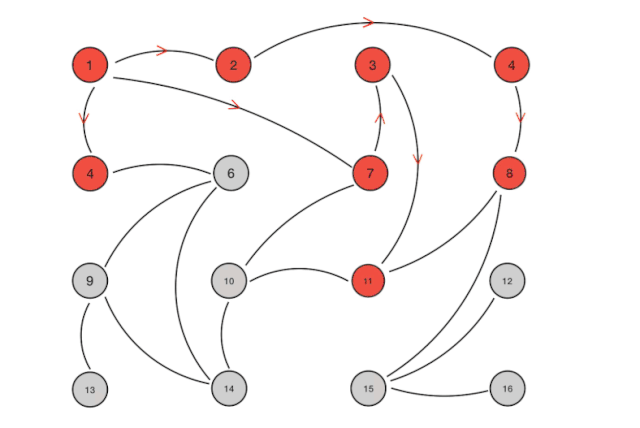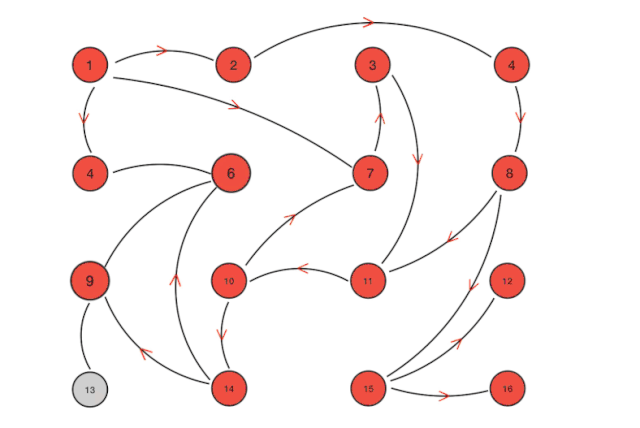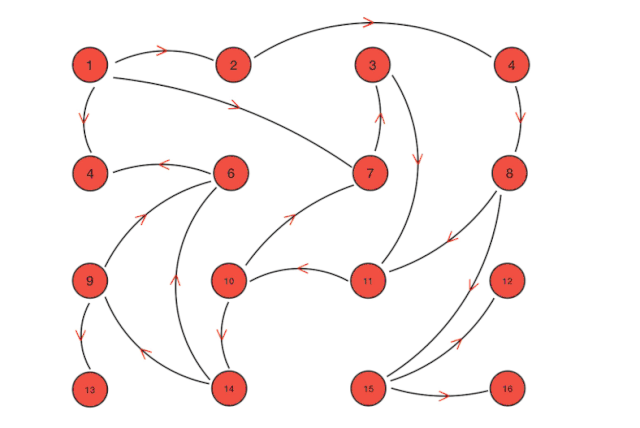
从算法上的解释如下:Gossip 协议本质上是一个并行的图广度优先遍历算法。假设 A 得到某些信息,更新了自身的信息,A 需要将信息告诉 B、C 等,然后 B、C 告诉其他的 D、E、F、G,一直遍历。如果节点 B 收到 A 的消息,发现自己早就知道这个消息就直接忽略,从而可以防止图重复遍历
0x01 Gossip 协议基础
Gossip 协议的特点是:
1、可扩展(Scalable)
gossip 协议是可扩展的,每个节点仅发送固定数量的消息。在数据传送的时候,节点并不会等待消息的 ack,所以消息传送失败也没有关系,因为可以通过其他节点将消息传递给之前传送失败的节点
2、容错(Fault-tolerance)
网络中任何节点的重启或者宕机都不会影响 gossip 协议的运行
3、健壮(Robust)
gossip 协议是去中心化的协议,所以集群中的所有节点都是对等的,没有特殊的节点,所以任何节点出现问题都不会阻止其他节点继续发送消息。任何节点都可以随时 Join/Leave,而不会影响系统的整体服务质量 QOS
4、最终一致性(Convergent consistency)
Gossip 协议实现信息指数级的快速传播,因此在有新信息需要传播时,消息可以快速地发送到全局节点,在有限的时间内能够做到所有节点都拥有最新的数据
Gossip 通信过程
Gossip 协议分为 Push-based 和 Pull-based 两种模式,具体工作流程如下:
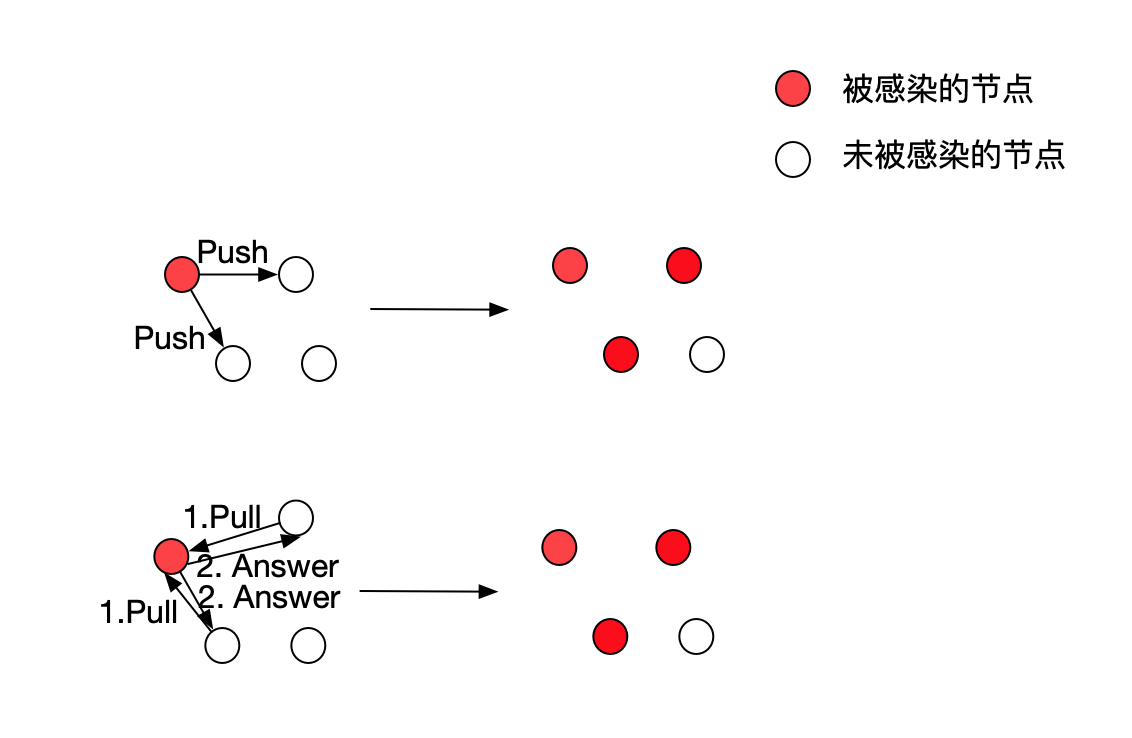
1、Push-based 模式
- 网络中的某个节点随机选择
N个节点作为数据接收对象 - 该节点向其选中的
N个节点传输相应数据 - 接收到数据的节点对数据进行存储
- 接收到数据的节点再从第一步开始周期性执行
如此经过一段时间之后,整个集群都收到了此条 Gossip 消息,从而达到最终一致。另外注意每次消息传递都会选择尚未发送过的节点进行传播(单向的),如 A->B, 则当 B 进行传播的时候,不会再发送给 A
2、Pull-based 模式
- 集群内的所有节点,随机选择其它
k个节点询问有没有新数据 - 接收到请求的节点,返回新数据
通信模式
在 Gossip 协议下,网络中两个节点之间有 3 种通信方式:
- Push: 节点
A将数据(key,value,version)及对应的版本号推送给B节点,B节点更新A中比自己新的数据 - Pull:
A仅将数据 key, version 推送给B,B将本地比A新的数据(Key, value, version)推送给A,A更新本地 - Push/Pull:比
Pull方式多了一步,A再将本地比B新的数据推送给B,B则更新本地
如果把两个节点数据同步一次定义计为一个周期,则在一个周期内,Push 需通信 1 次,Pull 需 2 次,Push/Pull 则需 3 次。虽然消息数增加了,但从效果上来讲,Push/Pull 最好(快),理论上一个周期内可以使两个节点完全一致
Gossip 的缺点
1、消息延迟
由于 Gossip 协议中,节点只会随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网的,因此使用 Gossip 协议会造成不可避免的消息延迟。不适合用在对实时性要求较高的场景下
2、消息存在冗余
Gossip 协议规定,节点会定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,因此就不可避免的存在消息重复发送给同一节点的情况,造成了消息的冗余,同时也增加了收到消息的节点的处理压力
0x02 Consul 中的 gossip 分析
Consul 主要使用 Gossip 协议实现如下功能:
- 集群成员管理
- 消息广播
Consul 的 Agent 之间通过 Gossip 协议进行状态检查,通过节点之间互 ping 而减轻了 Server 的节点的压力。如果有节点宕机,任意与其保持连接的节点发现即可通过 Gossip 广播给整个集群。当该故障机的节点重启后重新加入集群,一段时间后,它的状态也能够通过 Gossip 协议与其他的节点达成一致,这体现出 Gossip 协议具有的天然的分布式容错的特点
两种Gossip池:LAN && WAN 池
1、LAN 池
Consul 中的每个数据中心有一个 LAN 池,它包含了该数据中心的所有成员,包括 clients 和 servers。
2、WAN 池
WAN 池是全局唯一的,所有数据中心的 Server 都应该加入到 WAN 池中,由 WAN 池提供的成员关系信息允许 server 做一些跨数据中心的请求
0x03 gossip库的实现: hashicorp/memberlist
hashicorp/memberlist基于 Gossip 协议,实现了集群内节点发现、节点失效探测、节点故障转移、节点状态同步等(所有动作都在 schedule() 中调用),项目地址。memberlist项目将协议相关的参数都封装成配置项Config,开发者可自行设置调优(gossip协议的收敛速度越快,消耗的带宽越高)。本文代码基于V0.1.5
构建gossip集群的基本步骤
// 1、new配置文件
c := memberlist.DefaultLocalConfig()
// 2、创建gossip网络
m, err := memberlist.Create(c)
// 3、将节点加入到集群
m.Join(parts)
// 4、实现delegate接口
// 5、将需要同步的数据加到广播队列
broadcasts.QueueBroadcast(userdate)
memberlist的协议
1、广播协议
集群的内的广播通过UDP报文向每个节点发送消息(不确保消息一定能发送到),广播先进入广播队列,广播队列里的消息可能被其他更优先的消息覆盖掉。广播队列里的消息发送失败超过一定次数后,会被抛弃
2、数据交互
Push/Pull:每隔一个随机浮动的间隔,会随机选取一个节点建立TCP连接,然后将本地的全部节点 状态、用户数据发送过去,然后对端将其掌握的全部节点状态、用户数据发送回来,然后完成2份数据的合并(设计此主要为了加速集群内信息的收敛速度)
3、通讯协议
- 使用UDP传输PING消息、间接PING消息、ACK消息、NACK消息、Suspect消息、 Alive消息、Dead消息、用户消息
- 使用TCP传输用户数据、PUSH-PULL消息
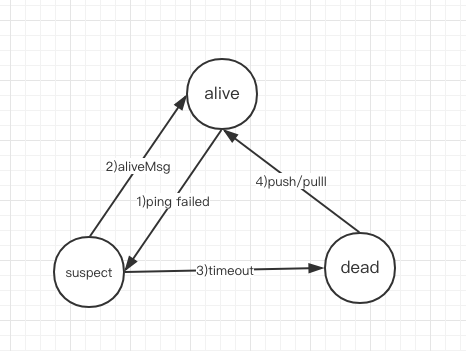
节点状态机
1、alive: 存活节点,当新节点启动时,会向集群内广播Alive消息
2、suspect: 对于 PingMsg 没有应答或应答超时,这个节点的状态是可疑的
- 当探测一些节点失败时,或者suspect某个节点的信息时,会将本地对应的此节点信息标记为suspect,然后启动一个定时器,并发出一个suspect广播,此期间内如果收到其他节点发来的相同的suspect信息时,将本地记录该节点suspect的确认数
+1,当定时器超时后,该节点信息仍然不是alive的,且确认数达到要求,会将该节点标记为dead - 当本节点收到别的节点发来的suspect消息时(和上面对应),本节点是alive的,所以会发送alive广播,从而清除其他节点上的suspect标记
3、dead: 节点已dead
- 当本节点离开集群时或者本地探测的其他节点超时被标记死亡,会向集群发送本节点dead广播。收到dead广播消息的节点会跟本地的记录比较,当本地记录也是dead时会忽略消息,当本地的记录不是dead时,会删除本地的记录再将dead消息再次广播出去,形成再次传播(针对本节点收到其他节点的消息)
- 如果从其他节点收到自身的dead广播消息时,说明本节点相对于其他节点网络分区,此时会发起一个alive广播以修正其他节点上存储的本节点数据(更新)
probe动作(连线):
- 当节点启动后,每隔一定时间间隔,会选取一个节点对其发送PING消息,当PING消息失败后,会随机选取
IndirectChecks个节点发起间接PING的请求和直接更其再发起一个tcp PING消息。收到间接PING请求的节点会根据请求中的地址发起一个PING消息,将PING的结果返回给间接请求的源节点 - 如果探测超时之间内,本节点没有收到任何一个要探测节点的ACK消息,则标记要探测的节点状态为suspect
状态机的转换如下:
Memberlist结点抽象
Memberlist结构定义如下: 比较重要的成员:
nodes:nodeMap:存储系统节点及状态的映射nodeTimers:transport Transport:提供UDP/TCP的本地服务实现,主要用于实现gossip协议交互(通用性)
type Memberlist struct {
sequenceNum uint32 // Local sequence number
incarnation uint32 // Local incarnation number
numNodes uint32 // Number of known nodes (estimate)
pushPullReq uint32 // Number of push/pull requests
config *Config
shutdown int32 // Used as an atomic boolean value
shutdownCh chan struct{}
leave int32 // Used as an atomic boolean value
leaveBroadcast chan struct{}
shutdownLock sync.Mutex // Serializes calls to Shutdown
leaveLock sync.Mutex // Serializes calls to Leave
transport Transport
handoffCh chan struct{}
highPriorityMsgQueue *list.List
lowPriorityMsgQueue *list.List
msgQueueLock sync.Mutex
nodeLock sync.RWMutex
nodes []*nodeState // Known nodes
nodeMap map[string]*nodeState // Maps Addr.String() -> NodeState
nodeTimers map[string]*suspicion // Maps Addr.String() -> suspicion timer
awareness *awareness
tickerLock sync.Mutex
tickers []*time.Ticker
stopTick chan struct{}
probeIndex int
ackLock sync.Mutex
ackHandlers map[uint32]*ackHandler
broadcasts *TransmitLimitedQueue
logger *log.Logger
}
协议的通信通用方法:Transport
memberlist的内部实现包含了全部的通信过程,因此需要一个Transport实现来底层的通信api,memberlist提供的默认实现是NetTransport
Transport
type Transport interface {
// 传入Config中的AdvertiseAddr和AdvertisePort,返回给上层一个用于告知
// 集群内其他成员的本节点ip和端口
FinalAdvertiseAddr(ip string, port int) (net.IP, int, error)
// 向指定addr发送一段数据,返回完成通信的当前时刻,该时刻可以用来判断RTT
WriteTo(b []byte, addr string) (time.Time, error)
// PacketCh 返回一个chan,当每从其他成员收到一个udp报文时,将报文封装成
// *Packet写入该chan,上层逻辑通过该chan读取udp信息
PacketCh() <-chan *Packet
// 创建一个TCP连接给上层使用
DialTimeout(addr string, timeout time.Duration) (net.Conn, error)
// 返回一个chan,每当本地tcp端口收到一个连接,通过该chan交由上层处理
StreamCh() <-chan net.Conn
// 退出时,调用该函数,释放相关通信资源
Shutdown() error
}
默认提供的transport:
type NetTransport struct {
config *NetTransportConfig
packetCh chan *Packet
streamCh chan net.Conn
logger *log.Logger
wg sync.WaitGroup
tcpListeners []*net.TCPListener
udpListeners []*net.UDPConn
shutdown int32
}
初始化Memberlist
在newMemberlist初始化过程中,将建立本地的监听本地的TCP/UDP服务,来处理其他节点传送过来的数据
// newMemberlist creates the network listeners.
// Does not schedule execution of background maintenance.
func newMemberlist(conf *Config) (*Memberlist, error) {
//......
m := &Memberlist{
config: conf,
shutdownCh: make(chan struct{}),
leaveBroadcast: make(chan struct{}, 1),
transport: transport,
handoffCh: make(chan struct{}, 1),
highPriorityMsgQueue: list.New(),
lowPriorityMsgQueue: list.New(),
nodeMap: make(map[string]*nodeState),
nodeTimers: make(map[string]*suspicion),
awareness: newAwareness(conf.AwarenessMaxMultiplier),
ackHandlers: make(map[uint32]*ackHandler),
broadcasts: &TransmitLimitedQueue{RetransmitMult: conf.RetransmitMult},
logger: logger,
}
m.broadcasts.NumNodes = func() int {
return m.estNumNodes()
}
go m.streamListen() //处理TCP连接及协议包
go m.packetListen() //处理UDP及协议包
go m.packetHandler()
return m, nil
}
####
// Create will create a new Memberlist using the given configuration.
// This will not connect to any other node (see Join) yet, but will start
// all the listeners to allow other nodes to join this memberlist.
// After creating a Memberlist, the configuration given should not be
// modified by the user anymore.
func Create(conf *Config) (*Memberlist, error) {
m, err := newMemberlist(conf)
if err != nil {
return nil, err
}
if err := m.setAlive(); err != nil {
m.Shutdown()
return nil, err
}
m.schedule()
return m, nil
}
各个Gossip节点周期性任务
schedule中通过独立goroutine启动周期性任务:
- 故障检测:
m.probe - 状态合并(Push/Pull 消息):
pushPullTrigger方法 - 向其他节点广播 gossip 消息
// Schedule is used to ensure the Tick is performed periodically. This
// function is safe to call multiple times. If the memberlist is already
// scheduled, then it won't do anything.
func (m *Memberlist) schedule() {
m.tickerLock.Lock()
defer m.tickerLock.Unlock()
// If we already have tickers, then don't do anything, since we're
// scheduled
if len(m.tickers) > 0 {
return
}
// Create the stop tick channel, a blocking channel. We close this
// when we should stop the tickers.
stopCh := make(chan struct{})
// Create a new probeTicker
if m.config.ProbeInterval > 0 {
t := time.NewTicker(m.config.ProbeInterval)
// 周期性任务1:故障检测
go m.triggerFunc(m.config.ProbeInterval, t.C, stopCh, m.probe)
m.tickers = append(m.tickers, t)
}
// Create a push pull ticker if needed
if m.config.PushPullInterval > 0 {
//周期性任务2:PUSH/PULL
go m.pushPullTrigger(stopCh)
}
// Create a gossip ticker if needed
if m.config.GossipInterval > 0 && m.config.GossipNodes > 0 {
t := time.NewTicker(m.config.GossipInterval)
//周期性任务3:向其他节点广播 gossip 消息
go m.triggerFunc(m.config.GossipInterval, t.C, stopCh, m.gossip)
m.tickers = append(m.tickers, t)
}
// If we made any tickers, then record the stopTick channel for
// later.
if len(m.tickers) > 0 {
m.stopTick = stopCh
}
}
接下来分别分析下这三类任务的实现
3、周期性任务1:故障检测
probe方法如下,周期性的探测集群中状态为 alive 和 suspect 的节点,且每个周期只探测 1 个节点
- 所有的节点是否都已经探测过,如果是,则直接返回
- 重置节点:在节点列表中移除死亡节点,并更新活跃节点,并随机打乱节点列表
- 检查节点是否是否探测:在配置文件中或者状态是
dead和left的节点会跳过 - 开始探测节点
func (m *Memberlist) probe() {
// Track the number of indexes we've considered probing
numCheck := 0
START:
m.nodeLock.RLock()
// Make sure we don't wrap around infinitely
if numCheck >= len(m.nodes) {
m.nodeLock.RUnlock()
return
}
// Handle the wrap around case
if m.probeIndex >= len(m.nodes) {
m.nodeLock.RUnlock()
m.resetNodes()
m.probeIndex = 0
numCheck++
goto START
}
// Determine if we should probe this node
skip := false
var node nodeState
node = *m.nodes[m.probeIndex]
if node.Name == m.config.Name {
skip = true
} else if node.DeadOrLeft() {
skip = true
}
// Potentially skip
m.nodeLock.RUnlock()
m.probeIndex++
if skip {
numCheck++
goto START
}
// Probe the specific node
m.probeNode(&node)
}
探测某个指定节点的方法probeNode如下,其中参数node为要探测的节点,m表示本端节点:
func (m *Memberlist) probeNode(node *nodeState) {
defer metrics.MeasureSince([]string{"memberlist", "probeNode"}, time.Now())
// We use our health awareness to scale the overall probe interval, so we
// slow down if we detect problems. The ticker that calls us can handle
// us running over the base interval, and will skip missed ticks.
probeInterval := m.awareness.ScaleTimeout(m.config.ProbeInterval)
if probeInterval > m.config.ProbeInterval {
metrics.IncrCounter([]string{"memberlist", "degraded", "probe"}, 1)
}
// Prepare a ping message and setup an ack handler.
//获取本节点的IP+PORT,生成PING消息
selfAddr, selfPort := m.getAdvertise()
ping := ping{
SeqNo: m.nextSeqNo(),
Node: node.Name,
SourceAddr: selfAddr,
SourcePort: selfPort,
SourceNode: m.config.Name,
}
ackCh := make(chan ackMessage, m.config.IndirectChecks+1)
nackCh := make(chan struct{}, m.config.IndirectChecks+1)
m.setProbeChannels(ping.SeqNo, ackCh, nackCh, probeInterval)
// Mark the sent time here, which should be after any pre-processing but
// before system calls to do the actual send. This probably over-reports
// a bit, but it's the best we can do. We had originally put this right
// after the I/O, but that would sometimes give negative RTT measurements
// which was not desirable.
sent := time.Now()
// Send a ping to the node. If this node looks like it's suspect or dead,
// also tack on a suspect message so that it has a chance to refute as
// soon as possible.
deadline := sent.Add(probeInterval)
addr := node.Address()
// Arrange for our self-awareness to get updated.
var awarenessDelta int
defer func() {
m.awareness.ApplyDelta(awarenessDelta)
}()
if node.State == StateAlive {
//若探测节点先前的状态为alive
if err := m.encodeAndSendMsg(node.FullAddress(), pingMsg, &ping); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to send ping: %s", err)
if failedRemote(err) {
goto HANDLE_REMOTE_FAILURE
} else {
return
}
}
} else {
//若节点状态为suspect
var msgs [][]byte
if buf, err := encode(pingMsg, &ping); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to encode ping message: %s", err)
return
} else {
msgs = append(msgs, buf.Bytes())
}
s := suspect{Incarnation: node.Incarnation, Node: node.Name, From: m.config.Name}
if buf, err := encode(suspectMsg, &s); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to encode suspect message: %s", err)
return
} else {
msgs = append(msgs, buf.Bytes())
}
compound := makeCompoundMessage(msgs)
if err := m.rawSendMsgPacket(node.FullAddress(), &node.Node, compound.Bytes()); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to send compound ping and suspect message to %s: %s", addr, err)
if failedRemote(err) {
goto HANDLE_REMOTE_FAILURE
} else {
return
}
}
}
// Arrange for our self-awareness to get updated. At this point we've
// sent the ping, so any return statement means the probe succeeded
// which will improve our health until we get to the failure scenarios
// at the end of this function, which will alter this delta variable
// accordingly.
awarenessDelta = -1
// Wait for response or round-trip-time.
select {
case v := <-ackCh:
if v.Complete == true {
if m.config.Ping != nil {
rtt := v.Timestamp.Sub(sent)
m.config.Ping.NotifyPingComplete(&node.Node, rtt, v.Payload)
}
return
}
// As an edge case, if we get a timeout, we need to re-enqueue it
// here to break out of the select below.
if v.Complete == false {
ackCh <- v
}
case 0 {
if nackCount := len(nackCh); nackCount < expectedNacks {
awarenessDelta += (expectedNacks - nackCount)
}
} else {
awarenessDelta += 1
}
// No acks received from target, suspect it as failed.
m.logger.Printf("[INFO] memberlist: Suspect %s has failed, no acks received", node.Name)
s := suspect{Incarnation: node.Incarnation, Node: node.Name, From: m.config.Name}
m.suspectNode(&s)
}
4、周期性任务2:Push/Pull
本任务的内容是:周期性的从已知的 alive 的集群节点中选 1 个节点进行 Push/Pull 交换信息,这里交换的信息主要分两类:
- 集群信息
- 用户自定义的状态信息
func (m *Memberlist) pushPull() {
// Get a random live node
m.nodeLock.RLock()
nodes := kRandomNodes(1, m.nodes, func(n *nodeState) bool {
return n.Name == m.config.Name ||
n.State != StateAlive
})
m.nodeLock.RUnlock()
// If no nodes, bail
if len(nodes) == 0 {
return
}
node := nodes[0]
// Attempt a push pull
if err := m.pushPullNode(node.FullAddress(), false); err != nil {
m.logger.Printf("[ERR] memberlist: Push/Pull with %s failed: %s", node.Name, err)
}
}
// pushPullNode does a complete state exchange with a specific node.
func (m *Memberlist) pushPullNode(a Address, join bool) error {
defer metrics.MeasureSince([]string{"memberlist", "pushPullNode"}, time.Now())
// Attempt to send and receive with the node
remote, userState, err := m.sendAndReceiveState(a, join)
if err != nil {
return err
}
if err := m.mergeRemoteState(join, remote, userState); err != nil {
return err
}
return nil
}
5、周期性任务3:广播 gossip 消息
广播所有处于 dead 的节点(只广播一次)
func (m *Memberlist) gossip() {
defer metrics.MeasureSince([]string{"memberlist", "gossip"}, time.Now())
// Get some random live, suspect, or recently dead nodes
m.nodeLock.RLock()
kNodes := kRandomNodes(m.config.GossipNodes, m.nodes, func(n *nodeState) bool {
if n.Name == m.config.Name {
return true
}
switch n.State {
case StateAlive, StateSuspect:
return false
case StateDead:
return time.Since(n.StateChange) > m.config.GossipToTheDeadTime
default:
return true
}
})
m.nodeLock.RUnlock()
// Compute the bytes available
bytesAvail := m.config.UDPBufferSize - compoundHeaderOverhead
if m.config.EncryptionEnabled() {
bytesAvail -= encryptOverhead(m.encryptionVersion())
}
for _, node := range kNodes {
// Get any pending broadcasts
msgs := m.getBroadcasts(compoundOverhead, bytesAvail)
if len(msgs) == 0 {
return
}
addr := node.Address()
if len(msgs) == 1 {
// Send single message as is
if err := m.rawSendMsgPacket(node.FullAddress(), &node.Node, msgs[0]); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to send gossip to %s: %s", addr, err)
}
} else {
// Otherwise create and send a compound message
compound := makeCompoundMessage(msgs)
if err := m.rawSendMsgPacket(node.FullAddress(), &node.Node, compound.Bytes()); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to send gossip to %s: %s", addr, err)
}
}
}
}
一些细节问题
广播风暴 为了避免循环广播造成广播风暴,每个节点用一个uint32 Incarnation来标识每次广播的序号,当收到小于 本地记录的该节点Incarnation的广播消息时,忽略之。Incarnation只有再每一次节点重新alive时,会增长 一次。
0x03 hashicorp/memberlist测试
用memberlist库实现集群节点发现的功能,样例代码参考,下面输出演示了一个3节点的集群,手动停止一个节点后的变化情况(最终变成2个节点)
-------------start--------------
Member: VM_120_245_centos-8002 192.168.10.1
Member: VM_120_245_centos-8003 192.168.10.1
Member: VM_120_245_centos-8001 192.168.10.1
-------------end--------------
2022/10/05 01:01:43 [DEBUG] memberlist: Stream connection from=9.134.120.245:52117
2022/10/05 01:01:44 [DEBUG] memberlist: Initiating push/pull sync with: VM_120_245_centos-8001 192.168.10.1:8001
-------------start--------------
Member: VM_120_245_centos-8001 192.168.10.1
Member: VM_120_245_centos-8003 192.168.10.1
Member: VM_120_245_centos-8002 192.168.10.1
-------------end--------------
-------------start--------------
Member: VM_120_245_centos-8002 192.168.10.1
Member: VM_120_245_centos-8001 192.168.10.1
Member: VM_120_245_centos-8003 192.168.10.1
-------------end--------------
-------------start--------------
Member: VM_120_245_centos-8003 192.168.10.1
Member: VM_120_245_centos-8002 192.168.10.1
Member: VM_120_245_centos-8001 192.168.10.1
-------------end--------------
-------------start--------------
Member: VM_120_245_centos-8002 192.168.10.1
Member: VM_120_245_centos-8003 192.168.10.1
Member: VM_120_245_centos-8001 192.168.10.1
-------------end--------------
-------------start--------------
Member: VM_120_245_centos-8001 192.168.10.1
Member: VM_120_245_centos-8003 192.168.10.1
Member: VM_120_245_centos-8002 192.168.10.1
-------------end--------------
2022/10/05 01:01:58 [DEBUG] memberlist: Stream connection from=9.134.120.245:52122
2022/10/05 01:01:59 [DEBUG] memberlist: Initiating push/pull sync with: VM_120_245_centos-8001 192.168.10.1:8001
-------------start--------------
Member: VM_120_245_centos-8001 192.168.10.1
Member: VM_120_245_centos-8003 192.168.10.1
Member: VM_120_245_centos-8002 192.168.10.1
-------------end--------------
-------------start--------------
Member: VM_120_245_centos-8001 192.168.10.1
Member: VM_120_245_centos-8003 192.168.10.1
Member: VM_120_245_centos-8002 192.168.10.1
-------------end--------------
2022/10/05 01:02:04 [DEBUG] memberlist: Failed UDP ping: VM_120_245_centos-8003 (timeout reached)
2022/10/05 01:02:04 [INFO] memberlist: Suspect VM_120_245_centos-8003 has failed, no acks received
-------------start--------------
Member: VM_120_245_centos-8001 192.168.10.1
Member: VM_120_245_centos-8002 192.168.10.1
Member: VM_120_245_centos-8003 192.168.10.1
-------------end--------------
2022/10/05 01:02:06 [DEBUG] memberlist: Failed UDP ping: VM_120_245_centos-8003 (timeout reached)
2022/10/05 01:02:06 [INFO] memberlist: Suspect VM_120_245_centos-8003 has failed, no acks received
2022/10/05 01:02:07 [INFO] memberlist: Marking VM_120_245_centos-8003 as failed, suspect timeout reached (1 peer confirmations)
2022/10/05 01:02:08 [DEBUG] memberlist: Failed UDP ping: VM_120_245_centos-8003 (timeout reached)
2022/10/05 01:02:08 [INFO] memberlist: Suspect VM_120_245_centos-8003 has failed, no acks received
-------------start--------------
Member: VM_120_245_centos-8001 192.168.10.1
Member: VM_120_245_centos-8002 192.168.10.1
-------------end--------------
-------------start--------------
Member: VM_120_245_centos-8002 192.168.10.1
Member: VM_120_245_centos-8001 192.168.10.1
asim-KV:A distributed in-memory key-value store
asim-kv是另外一个基于memberlist实现的kv项目,可以通过API访问内部存储