0x00 前言
前文httprouter分析,分析了基于字符串的radix tree的实现,本文分析下内核的radix tree(ID Radix Tree)
- page cache管理:如4.11.6内核版本中的
radix_tree_root、radix_tree_node,被用于实现内核struct inode维度(文件)的page cache管理,关联结构address_space - 进程pid分配管理:如内核6.18版本的
idr结构、radix_tree_node,不过这里的radix_tree_root与radix_tree_node结构已经被替换为xarray与xa_node实现
旧版本的radix tree实现,在4.20内核之后,被xarray结构所替换
0x01 Radix tree VS 内核IDR
区别1:key的类型
- 字符串Radix Tree,通常key为字符串,支持前缀查找、最长前缀匹配等
- 内核IDR,key为整数(如进程id、文件描述符等),主要用于ID分配和查找
区别2:设计目标
- 字符串Radix Tree:应用于高效的字符串查找、前缀匹配(最长前缀匹配等)
- 内核IDR:实现目的是支持高效的整数ID管理和指针查找,如进程管理(新版本的内核进程管理已经改为IDR)、文件描述符、设备号分配,主要操作如ID分配(寻找空闲ID)、ID查找(通过ID找指针)、ID释放(回收ID)等
区别3:结构
1、字符串Radix Tree结构如下,对于字符串Radix Tree,由于需要按照字符/字节key比较,逐字符匹配,对于共享前缀(前缀压缩),共享前缀存储在节点中,此外,key是变长的
//prefix: 共享字符串前缀,变长
//edges: 子节点边(有序数组),动态数组
//leaf: 叶子数据,稀疏存储,适合长字符串
+-----------+-----------------+-----------+
| 前缀指针 | edge(边)数组 | 叶子数据 |
+-----------+-----------------+-----------+
2、Linux内核IDR结构,关键成员如下:
- 按位分块:整数ID被分成固定大小的位块
- 固定层级:通常3-4层(取决于整数key的位数)
- bitmap优化:使用bitmap快速查找空闲槽位
// 基于位(bit)的Radix Tree
#define IDR_BITS 6
#define IDR_SIZE (1 << IDR_BITS) // 64
struct idr_layer {
DECLARE_BITMAP(bitmap, IDR_SIZE); // 位图标记已用槽位
struct idr_layer __rcu *slots[IDR_SIZE]; // 子节点或数据指针
int count; // 已用槽位计数
};
举例来说,IDR的分层结构与内存布局如下:
层级3(高6位) -> 层级2(中间6位) -> 层级1(低6位) -> 数据指针
63-58 57-52 51-0
+-----------+-----------+-----------+
| 位图 | 指针数组 | 计数 |
+-----------+-----------+-----------+
0x01 radix tree(4.11.6)
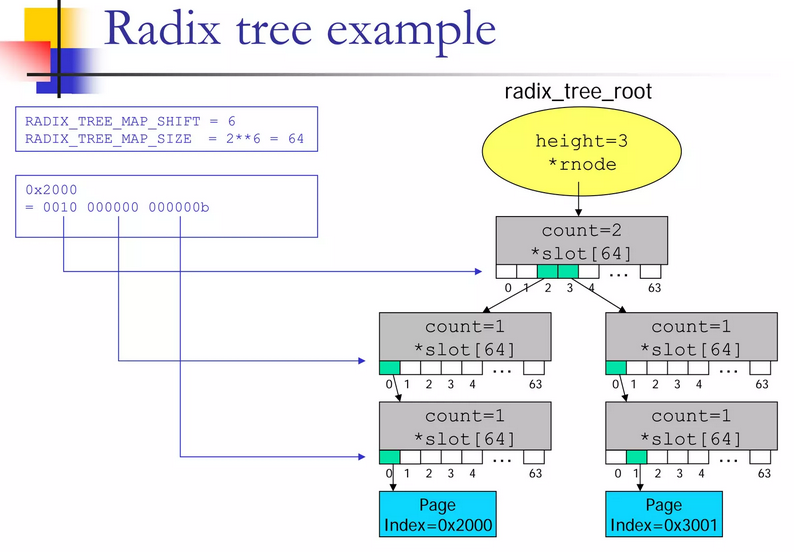
先看下4.11.6版本的IDR实现,假设key值等于0x2000, 其二进制按照6bit一组可以写成0010-000000 -000000,从左到右的index值分别为2/0/0。那么根据key值0x2000找到value的过程如图:
- 在最上层的节点(A)中找到
index为2的slot,其slot[2]指针指向第二层节点中的节点(B) - 在节点(B)中找到
index为0的slot,其slot[0]指针指向第三层节点中的节点(C) - 在节点(C)中找到
index为0的slot,其slot[0]指针指向叶子节点item
数据结构
每一棵radix tree都必须有struct radix_tree_root这样一个管理结点(对象):
gfp_mask:其中第0-24位用做内存分配的标记,在分配struct radix_tree_node结构时,传递给内存分配函数kmem_cache_alloc,第25-27位用作root tagsrnode:rnode用来指向顶层的struct radix_tree_node,也就是radix tree的第一个内部节点;当radix tree 只有一个叶子节点,并且叶子节点的index为0时,也可以可以直接指向一个叶子节点,即(index,ptr)对中的ptr
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/radix-tree.h#L112
struct radix_tree_root {
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode;
};
//https://elixir.bootlin.com/linux/v4.11.6/source/include/linux/radix-tree.h#L93
struct radix_tree_node {
unsigned char shift; /* Bits remaining in each slot */
unsigned char offset; /* Slot offset in parent */
unsigned char count; /* Total entry count */
unsigned char exceptional; /* Exceptional entry count */
struct radix_tree_node *parent; /* Used when ascending tree */
struct radix_tree_root *root; /* The tree we belong to */
union {
struct list_head private_list; /* For tree user */
struct rcu_head rcu_head; /* Used when freeing node */
};
//核心字段:RADIX_TREE_MAP_SIZE = 64
//#define RADIX_TREE_MAX_TAGS 3
void __rcu *slots[RADIX_TREE_MAP_SIZE];
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};
struct radix_tree_node结构代表radix tree的一个内部节点,这个结构内核也改动了多次,核心成员意义如下:
shift:与当前内部节点在radix tree中所处的层级相关,最低一层的节点,shift为0,倒数第二层shift为6。shift从低往高, 逐层递增6offset:表示与当前内部节点相关联的父节点slot数组下标count:表示当前节点包含的child节点的个数,child节点可以是内部节点也可以是叶子节点parent:指向parent 节点tags:这里的tags是二维数组,在64bit系统中,这个数组的定义tag[3][1]相当于一维数组slots:指针数组slot[64], 每个元素指向一个下一级的radix_tree_node结构,或者是叶子节点,注意其定义是带了__rcu标志的
关于void __rcu *slots[RADIX_TREE_MAP_SIZE],这里隐藏了几个细节:
1、__rcu的作用
TODO
2、slots存储的内容是什么?
- 在中间节点(Internal Node)中:
slot存储的是指向下一级radix_tree_node的指针。为了和数据指针区分,内核会将该地址的最低位置为1(关联RADIX_TREE_INTERNAL_NODE标记) - 在叶子节点(Leaf Node)中:
slot存储的就是真正的struct page指针。因为struct page是对齐的,它的最低位一定是0
3、radix tree最多能够容纳的index的最大值,取决于radix tree第一个内部节点的shift值,不同的shift值,能够覆盖的index最大值如下表:
shift |
index的最大值 |
|---|---|
| 0 | 2^6 - 1 |
| 6 | 2^12 - 1 |
| 12 | 2^18 - 1 |
| …… | …… |
| 6*n | 2^(shift+6) - 1 |
4、unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]的作用(见下文)
slots[]:存储真实数据指针/下级节点,用于精确查找特定的indextags[][]:存储状态位图,如在page cache管理中,用于快速扫描所有具有某种状态(如 Dirty)的page
5、为什么void __rcu *slots[RADIX_TREE_MAP_SIZE],要被设计为void *类型的?(见下文)
典型的用法是在struct inode用来管理文件的page cache
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
......
}
正如上面的数据结构,radix tree构建的page index与page ptr(指向struct page的指针)的关联。这里的(key,value)对,就是(index, ptr)对,另外,回答上面第五个问题,作为page cache这棵radix树的value的指针(struct page的地址),到底是存储在哪个字段里面的?
1、page指针(指向struct page的指针)存储在struct radix_tree_node的slots数组中,所以其定义为void *类型。即叶子节点存储page指针,最底层的radix_tree_node节点(叶子节点)的slots数组中存储的是struct page*指针,
每个有效的slot对应一个page指针;而空的slot存储NULL
2、radix树的中间节点存储下级节点指针,非叶子节点的slots数组中存储的是指向下级radix_tree_node的指针,实际类型为struct radix_tree_node *
union成员的作用
union中的两个成员的作用如下:
union {
struct list_head private_list; /* For tree user */
struct rcu_head rcu_head; /* Used when freeing node */
};
//内存重采样:
//当节点进入释放流程时,原来的 private_list.next 和 private_list.prev 所在的位置
//会被重新解释为 rcu_head.next 和 rcu_head.func
struct callback_head {
struct callback_head *next;
void (*func)(struct callback_head *head);
};
typedef struct callback_head rcu_head;
这是个非常经典的内核设计,这两个字段在 radix_tree_node 的生命周期中,绝不会在同一时刻被使用。一个用于节点存活的时候,一个用于节点即将消亡之前
struct list_head private_list:标准的双向链表的节点成员,节点活着时的私有挂钩(内核很常见的定义了),当节点还在基数树中、被正常使用时,如在某些特殊的内存回收算法中,内核可能需要把某些特定的基数树节点串起来,记录在一个待处理列表中。基数树的使用方可以利用这个字段,将多个radix_tree_node串成一个链表,方便批量追踪和管理。此时,该节点在树中是可见的,rcu_head没有任何意义,因为节点还没到被释放的时候struct rcu_head rcu_head:本质是 RCU 异步释放机制的容器,内核用于调用radix_tree_delete等函数导致一个节点被从radix树中移除时的rcu并发读取保护,其原理简单描述是为了保证并发读取者的安全,节点在从树中摘除后不能立即销毁。内核会调用call_rcu(&node->rcu_head, radix_tree_node_rcu_free),该函数的内部逻辑是rcu_head本质上是一个临时的钩子,它包含一个回调函数指针。RCU 子系统会把这个rcu_head挂入 CPU 的私有队列。当所有正在读取的 CPU 都离开了 RCU 临界区(经历了一个宽限期之后),这个回调函数才会被触发,最终执行kmem_cache_free真正释放节点- 使用
union定义是由于上述二者不可能同时生效,即在树中时,节点可能需要被挂在private_list中,此时它绝不会出现在 RCU 的待释放队列中;而在被移除后,节点必须脱离所有的私有链表(否则会导致链表破坏),然后被挂入rcu_head队列等待被销毁,此时它不再属于任何业务链表
tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]的作用
引入一个概念:高效文件系统索引,在 struct radix_tree_node 中,tags 数组是一个分级位图(Hierarchical Bitmap),前文说了RADIX_TREE_MAP_SHIFT被定义成6,即一个内部节点做多有64个child节点, 也即slots指针数组被定义成void *slots[64],这64个槽位使用1个64位整型的bitmap就可以了
RADIX_TREE_MAX_TAGS:通常为3,意味着每个节点同时维护3种不同的状态RADIX_TREE_TAG_LONGS:计算的值,若节点有64个槽位(64bit 系统),那么只需要1个unsigned long(64位)就能为每个槽位提供1个 bit
在page cache中的应用场景是如果 tags[DIRTY] 的第 5 位是 1,则表示 node->slots[5] 指向的子树中至少有一个脏页
/*
* Radix-tree tags, for tagging dirty and writeback pages within the pagecache
* radix trees
*/
/*
tags[0][0]的64bit用来标记page 的dirty状态,bit0-63的值分别对应slot0-63的状态
tags[1][0]的64bit用来标记page 的WRITEBACK状态,bit0-63的值分别对应slot0-63的状态
tags[2][0]的64bit用来标记page 的TOWRITE状态,bit0-63的值分别对应slot0-63的状态
*/
#define PAGECACHE_TAG_DIRTY 0
#define PAGECACHE_TAG_WRITEBACK 1
#define PAGECACHE_TAG_TOWRITE 2
简单介绍下,这个字段在page cache场景的应用,其核心作用是为了实现快速过滤,这里tags 的本质是汇总(Aggregate)子树的状态,如上面的代码,在 Linux 页缓存(Page Cache)中,如果要查找哪些脏页,可以只进入那些 tags 位为 1 的子节点(tags相关位为0的直接跳过)。这样的设计极大的加速了对大文件的脏页的查找效率(避免遍历整个radix树的所有slots节点)
PAGECACHE_TAG_DIRTY:该子树中是否有脏页?PAGECACHE_TAG_WRITEBACK:该子树中是否有正在写回的页?PAGECACHE_TAG_TOWRITE:用于标记当前写回操作需要处理的页
上述特性依赖于tags成员的向上传播的逻辑,当调用 radix_tree_tag_set 设置一个叶子节点的标签时,内核会执行以下动作:
- 设置当前节点对应的位图位
- 向上递归:如果父节点的对应位(位图)还不是
1,就将其设为1 - 一直持续到根节点
这种设计保证了只要根节点的某个 tag 位为 0,其下方的整棵子树绝对不含有该状态的条目。此外,在内核中(调用侧)通过radix_tree_tag_get函数读取tags的函数也被设计为基于rcu机制的无锁,从而提升了读取效率。既然是rcu机制,那么就是容忍读到过时的数据,即在并发修改下,读到一个过时的tags(如page被设置为clean,但是tags标签还未清理)通常也是安全的,内核在真正操作page之前会重新验证
最后,对与root节点struct radix_tree_root的tags,内核使用了gfp_mask成员的25~27bit,用作root tags(对应于radix树只有一个index为0的叶子节点的特殊情况,这个叶子节点不与任何radix_tree_node结构关联),操作root tag的操作函数如下:
static inline void root_tag_set(struct radix_tree_root *root, unsigned int tag)
{
root->gfp_mask |= (__force gfp_t)(1 << (tag + __GFP_BITS_SHIFT));
}
static inline void root_tag_clear(struct radix_tree_root *root, unsigned tag)
{
root->gfp_mask &= (__force gfp_t)~(1 << (tag + __GFP_BITS_SHIFT));
}
static inline void root_tag_clear_all(struct radix_tree_root *root)
{
root->gfp_mask &= __GFP_BITS_MASK;
}
static inline int root_tag_get(struct radix_tree_root *root, unsigned int tag)
{
return (__force int)root->gfp_mask & (1 << (tag + __GFP_BITS_SHIFT));
}
内核radix tree的几种形态
基本函数
1、radix_tree_load_root:获取radix树的根节点
2、radix_tree_is_internal_node:判断是否为内部/叶子节点
radix_tree_is_internal_node用来判断节点是否为内部节点(反之叶子节点),返回值为true表示ptr指向的节点是内部节点,false表示ptr为NULL值(叶子节点)
#define RADIX_TREE_ENTRY_MASK 3UL
#define RADIX_TREE_INTERNAL_NODE 1UL
static inline bool radix_tree_is_internal_node(void *ptr)
{
//叶子节点的内存地址至少是按照4字节对齐,即bit0~1需要为0
return ((unsigned long)ptr & RADIX_TREE_ENTRY_MASK) ==
RADIX_TREE_INTERNAL_NODE;
}
//entry_to_node:用来实现将ptr指针的bit0~1位掩掉,也就是将ptr转换为radix_tree_node结构
static inline struct radix_tree_node *entry_to_node(void *ptr)
{
return (void *)((unsigned long)ptr & ~RADIX_TREE_INTERNAL_NODE);
}
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/radix-tree.c#L599
/*
root:标识radix tree的root
nodep:输出参数,用来返回radix tree的第一个节点的地址
maxindex:输出参数,用来返回radix tree的当前能容纳的最大的node值
返回值:
- 如果radix tree目前是空树(形态1)或者只有一个index为0的叶子结点,此时返回0
- 其他形态,返回值等于第一个节点的shift值+6
*/
static unsigned radix_tree_load_root(const struct radix_tree_root *root,
struct radix_tree_node **nodep, unsigned long *maxindex)
{
//先取得`struct radix_tree_root`的`rnode`指针。因为一棵radix tree有且仅有一个`struct radix_tree_root`结构,而`rnode`指向radix tree 的第一个节点,通过它才能遍历整棵radix tree
struct radix_tree_node *node = rcu_dereference_raw(root->rnode);
*nodep = node;
//rnode可以等于NULL, 此时表示一棵空树
//rnode也可以直接指向一个叶子节点; rnode大多数情况是指向一个内部节点
//rnode非NULL时,使用地址最后两个bit来判断
if (likely(radix_tree_is_internal_node(node))) {
node = entry_to_node(node);
*maxindex = node_maxindex(node);
return node->shift + RADIX_TREE_MAP_SHIFT;
}
*maxindex = 0;
return 0;
}
3、节点内存的管理:专用slab的创建
radix_tree_node_cachep是radix树专用的slab,即无论是从percpu的缓冲池分配内存还是直接分配内存,本质上都是从radix_tree_node_cachep这个slab分配内存
void __init radix_tree_init(void)
{
radix_tree_node_cachep = kmem_cache_create("radix_tree_node",
sizeof(struct radix_tree_node), 0,
SLAB_PANIC | SLAB_RECLAIM_ACCOUNT,
radix_tree_node_ctor);
......
}
内核对radix树的内存分配做了优化,支持percpu缓冲池,radix_tree_preloads被定义成percpu的变量,即每个CPU上都有一个struct radix_tree_node的内存池,这个内存池里面的内存对象需要调用__radix_tree_preload函数来填充
/*
* Per-cpu pool of preloaded nodes
*/
struct radix_tree_preload {
unsigned nr;
/* nodes->private_data points to next preallocated node */
struct radix_tree_node *nodes;
};
static DEFINE_PER_CPU(struct radix_tree_preload, radix_tree_preloads) = { 0, };
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/radix-tree.c#L466
static int __radix_tree_preload(gfp_t gfp_mask, unsigned nr)
{
struct radix_tree_preload *rtp;
struct radix_tree_node *node;
int ret = -ENOMEM;
gfp_mask &= ~__GFP_ACCOUNT;
// 因为要访问percpu变量,这里需要禁止抢占,也就是防止,访问percpu变量过程中,执行线程迁移到其他cpu上运行
preempt_disable();
rtp = this_cpu_ptr(&radix_tree_preloads);
while (rtp->nr < nr) {
// 分配内存过程中,可能出现阻塞,所以在调用内存分配函数之前,使能抢占
preempt_enable();
node = kmem_cache_alloc(radix_tree_node_cachep, gfp_mask);
if (node == NULL)
goto out;
//分配内存完成,需要重新禁止抢占,重新获取percpu变量,也需要重新判断percpu内存池的内存对象是否充足
preempt_disable();
rtp = this_cpu_ptr(&radix_tree_preloads);
if (rtp->nr < nr) {
node->parent = rtp->nodes;
rtp->nodes = node;
rtp->nr++;
} else {
kmem_cache_free(radix_tree_node_cachep, node);
}
}
//函数返回时,抢占仍然处于禁止状态
// 后续流程在radix_tree_preload_end函数中调用preempt_enable使能抢占
ret = 0;
out:
return ret;
}
继续看下radix树中节点内存的分配(关联radix_tree_node_alloc函数),在为struct radix_tree_noderadix树的节点分配内存时,radix_tree_node_alloc优先选择从当前cpu上的内存池分配内存,若分配失败会回退到调用kmem_cache_alloc函数从radix_tree_node_cachep slab分配内存
static struct radix_tree_node *
radix_tree_node_alloc(gfp_t gfp_mask, struct radix_tree_node *parent,
struct radix_tree_root *root,
unsigned int shift, unsigned int offset,
unsigned int count, unsigned int exceptional)
{
struct radix_tree_node *ret = NULL;
/*
* Preload code isn't irq safe and it doesn't make sense to use
* preloading during an interrupt anyway as all the allocations have
* to be atomic. So just do normal allocation when in interrupt.
*/
//优先从percpu的内存池分配内存
if (!gfpflags_allow_blocking(gfp_mask) && !in_interrupt()) {
struct radix_tree_preload *rtp;
/*
* Even if the caller has preloaded, try to allocate from the
* cache first for the new node to get accounted to the memory
* cgroup.
*/
ret = kmem_cache_alloc(radix_tree_node_cachep,
gfp_mask | __GFP_NOWARN);
if (ret)
goto out;
/*
* Provided the caller has preloaded here, we will always
* succeed in getting a node here (and never reach
* kmem_cache_alloc)
*/
rtp = this_cpu_ptr(&radix_tree_preloads);
if (rtp->nr) {
ret = rtp->nodes;
rtp->nodes = ret->parent;
rtp->nr--;
}
/*
* Update the allocation stack trace as this is more useful
* for debugging.
*/
kmemleak_update_trace(ret);
goto out;
}
//percpu的内存池不能满足要求时,才直接从radix_tree_node_cachep这个slab申请内存
ret = kmem_cache_alloc(radix_tree_node_cachep, gfp_mask);
out:
BUG_ON(radix_tree_is_internal_node(ret));
if (ret) {
ret->shift = shift;
ret->offset = offset;
ret->count = count;
ret->exceptional = exceptional;
ret->parent = parent;
ret->root = root;
}
return ret;
}
4、radix_tree_load_root函数:插入/查找之前都需要被调用,用来获取整棵radix树struct radix_tree_root的rnode指针,一棵radix tree有且仅有一个struct radix_tree_root结构,而rnode指向radix tree 的第一个节点,通过它才能遍历整棵radix tree
rnode==NULL:表示一棵空树rnode!=NULL:指向一个内部节点(或叶子节点),前文提到,叶子节点的地址必然按4字节对齐,内部节点的地址内核会对最低位强行置1,因此radix_tree_is_internal_node返回true:内部节点radix_tree_is_internal_node返回false:叶子节点(最低两位bit0~1为0)
#define RADIX_TREE_ENTRY_MASK 3UL
#define RADIX_TREE_INTERNAL_NODE 1UL
static inline bool radix_tree_is_internal_node(void *ptr)
{
return ((unsigned long)ptr & RADIX_TREE_ENTRY_MASK) ==
RADIX_TREE_INTERNAL_NODE;
}
static inline struct radix_tree_node *entry_to_node(void *ptr)
{
return (void *)((unsigned long)ptr & ~RADIX_TREE_INTERNAL_NODE);
}
5、entry_to_node:用来实现将ptr指针的bit0~1清空,也就是将ptr转换为radix_tree_node结构
static inline struct radix_tree_node *entry_to_node(void *ptr)
{
return (void *)((unsigned long)ptr & ~RADIX_TREE_INTERNAL_NODE);
}
IDR查找
__radix_tree_lookup用于查找radix tree中与参数index对应的ptr item,调用函数radix_tree_descend
radix_tree_descend:要查找index对应的ptr item,需要从第一个节点开始逐层下降,最终寻找到radix tree的叶子节点(index对应的那级slots数组存储的是叶子节点),很明显向下的过程中需要经由某一层级的parent节点,该函数计算经由parent节点的哪一个slot才能继续往下进展一层
/*
parent:输入参数,标识radix tree的一个中间节点,要查找index对应的ptr item,需要经由此节点
nodep:输出参数,要查找index对应的ptr item,需要经由parent节点的下一级节点
index:输入参数,待查找节点的index
*/
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/radix-tree.c#L125
static unsigned int radix_tree_descend(const struct radix_tree_node *parent,
struct radix_tree_node **nodep, unsigned long index)
{
//计算index在当前层级的6bit 索引, 也就是在parent节点中的slot编号
unsigned int offset = (index >> parent->shift) & RADIX_TREE_MAP_MASK;
//parent->slots[offset]:指向下一级中间节点或者叶子节点
void __rcu **entry = rcu_dereference_raw(parent->slots[offset]);
......
*nodep = (void *)entry;
return offset;
}
/*
root:输入参数,标识radix tree的root
index:输入参数,待查找节点的index
nodep:输出参数,用来返回index对应的ptr item的parent节点
slotp:输出参数,用来返回index对应的ptr item关联的slot的地址
*/
void *__radix_tree_lookup(const struct radix_tree_root *root,
unsigned long index, struct radix_tree_node **nodep,
void __rcu ***slotp)
{
struct radix_tree_node *node, *parent;
unsigned long maxindex;
void __rcu **slot;
restart:
parent = NULL;
slot = (void __rcu **)&root->rnode;
// 找到radix树的根
radix_tree_load_root(root, &node, &maxindex);
if (index > maxindex)
return NULL;
/*
退出的条件:
1. 到达叶子节点
2. node==NULL
*/
while (radix_tree_is_internal_node(node)) {
unsigned offset;
if (node == RADIX_TREE_RETRY)
goto restart;
parent = entry_to_node(node);
offset = radix_tree_descend(parent, &node, index);
slot = parent->slots + offset;
}
if (nodep)
*nodep = parent;
if (slotp)
*slotp = slot;
return node;
}
TODO:查找的例子
IDR插入
__radix_tree_insert是实现radix树插入的函数,需要注意插入可能会引发树的高度增长(分裂),调用顺序大致如下:
__radix_tree_insert->__radix_tree_create->radix_tree_extend->radix_tree_node_alloc:检查待插入的index,可能会导致radix树增高,若需要增高,则需要创建相关的中间节点,最后在radix树搜索,找到插入index的位置,并为新插入的index创建相关节点__radix_tree_insert->insert_entries:插入index节点
/*
root:输入参数,标识radix tree的root
index:输入参数,待查找节点的index
order:是在CONFIG_RADIX_TREE_MULTIORDER使能时才使用的参数,正常情况下order = 0
item:与index关联的指针,需要插入到radix tree的合适位置
*/
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/radix-tree.c#L985
int __radix_tree_insert(struct radix_tree_root *root, unsigned long index,
unsigned order, void *item)
{
struct radix_tree_node *node;
void __rcu **slot;
int error;
......
// __radix_tree_create函数调用完成之后
// node指向了待插入指针item的父节点,slot是item插入位置的slot的地址
// 调用rcu_assign_pointer(*slot, item)操作相当于*slot = item
error = __radix_tree_create(root, index, order, &node, &slot);
if (error)
return error;
error = insert_entries(node, slot, item, order, false);
if (error < 0)
return error;
if (node) {
unsigned offset = get_slot_offset(node, slot);
BUG_ON(tag_get(node, 0, offset));
BUG_ON(tag_get(node, 1, offset));
BUG_ON(tag_get(node, 2, offset));
} else {
BUG_ON(root_tags_get(root));
}
return 0;
}
__radix_tree_create函数作用是在查找index的路径上添加中间节点(可能会引起树高度的增长)
/*
root:输入参数,标识radix tree的root
index:输入参数,待查找节点的index
order, 这是在CONFIG_RADIX_TREE_MULTIORDER使能时才使用的参数,正常情况下order = 0
shift:与当前radixtree第一个节点的shift值相关联,这个值决定了树的高度。如果radix tree为空树(形态1)或者radix tree只有一个index为0的叶子节点(形态2),则shift = 0;其他的情况,shift = 第一个内部节点的shift值+ 6
*/
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/radix-tree.c#L794
int __radix_tree_create(struct radix_tree_root *root, unsigned long index,
unsigned order, struct radix_tree_node **nodep,
void __rcu ***slotp)
{
struct radix_tree_node *node = NULL, *child;
void __rcu **slot = (void __rcu **)&root->rnode;
unsigned long maxindex;
unsigned int shift, offset = 0;
unsigned long max = index | ((1UL << order) - 1);
gfp_t gfp = root_gfp_mask(root);
//首先把 slot 指针指向了根节点的 rnode,把整个 root 当作一个虚拟槽位
//radix_tree_load_root 返回当前树的 shift(高度)以及它能覆盖的最大索引 maxindex
shift = radix_tree_load_root(root, &child, &maxindex);
/* Make sure the tree is high enough. */
if (order > 0 && max == ((1UL << order) - 1))
max++;
/* 1. 如果要查找的index值比当前node所能覆盖的最大index值还要大,这时需要实现radix
tree高度的生长(radix_tree_extend函数实现)
2. radix_tree_extend 函数返回时,期望radix tree 已经有足够的高度能够容纳
输入参数index。但是有一种例外,就是当root->rnode为NULL时,树的高度还不能够
容纳输入参数index */
if (max > maxindex) {
//radix_tree_extend:见下分析
int error = radix_tree_extend(root, gfp, max, shift);
if (error < 0)
return error;
// 成功情况下,shift被更新为扩展后的根节点的shift值
shift = error;
// set child(默认为新根)
child = rcu_dereference_raw(root->rnode);
}
// 上面仅仅是扩展了radix树,这里还要对radix树(从新的根到插入的index中的途径)进行一些处理
while (shift > order) {
shift -= RADIX_TREE_MAP_SHIFT;
/* 如果当前节点为NULL,表示到达与index对应的item路径上中间节点缺失,
这时需要把中间节点补上 */
if (child == NULL) {
//如果路径上某个中间节点是空的(NULL),说明这是第一次访问该分支
//这里的child表示slots中的某个槽
child = radix_tree_node_alloc(gfp, node, root, shift,
offset, 0, 0);
if (!child)
return -ENOMEM;
//关键动作:分配一个新节点,并利用 rcu_assign_pointer 挂载到父节点的 slot 中
rcu_assign_pointer(*slot, node_to_entry(child));
if (node)
node->count++;
} else if (!radix_tree_is_internal_node(child)) /* 到达叶子节点,完成退出 */
break;
/* Go a level down */
//下降一级,调用radix_tree_descend找到下一级内部节点
node = entry_to_node(child);
offset = radix_tree_descend(node, &child, index);
slot = &node->slots[offset];
}
// 函数返回时,要填写item所在的父内部节点,以及与item对应slot的地址
if (nodep)
*nodep = node;
if (slotp)
*slotp = slot;
return 0;
}
TODO:__radix_tree_create的细节介绍
radix_tree_extend函数实现radix tree纵向(高度)的生长,高度值变大。每升高一层,radix树的第一个节点的shift值都会递增6,从而使得radix树能容纳的最大index扩大64倍,最终满足index <=( (1 << shift) - 1),radix_tree_extend的最终目的是不停的扩大radix树的高度(并分配相关radix_tree_node)以满足找到可以存储参数index的位置为止
static inline unsigned long shift_maxindex(unsigned int shift){
return (RADIX_TREE_MAP_SIZE << shift) - 1;
}
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/radix-tree.c#L619
/*
root:输入参数,标识radix tree的root
index:输入参数,待查找节点的index。在radix tree中要有足够的高度能够容纳该index
shift:与当前radixtree第一个节点的shift值相关联,这个值决定了树的高度。如果radix tree为空树(形态1)或者radix tree只有一个index为0的叶子节点(形态2),则shift = 0;其他的情况,shift = 第一个内部节点的shift值+ 6
*/
static int radix_tree_extend(struct radix_tree_root *root, gfp_t gfp,
unsigned long index, unsigned int shift){
void *entry;
unsigned int maxshift;
int tag;
/*
1、step1:计算目标高度
下面while循环用来计算,radix tree 需要生长到的高度
只要给定的 index 超过了当前 maxshift 能表示的最大值(例如 64 叉树,高度每增加 1,覆盖范围扩大 64 倍),就不断增加 maxshift
*/
maxshift = shift;
while (index > shift_maxindex(maxshift))
maxshift += RADIX_TREE_MAP_SHIFT;
//2、空树,直接跳出返回计算出的 maxshift,后续调用者(如 create 函数)会发现根是空的,直接从最高层向下分配节点
entry = rcu_dereference_raw(root->rnode);
if (!entry && (!is_idr(root) || root_tag_get(root, IDR_FREE)))
goto out; /* 对于空树,跳过下面的树纵向生长的过程 */
// 以下是树纵向生长的过程,root->rnode已经存在
do {
/* 分配一个node, 该新分配的node将关联到root->rnode,
也就是说这个新分配的node将成为根节点,原先的根节点反而成为新分
配节点的子节点 */
//注意参数parent:传入的是 NULL(因为它将成为新的顶层)
//count 设为 1(参数中的倒数第二个 1),因为这个新节点目前只有一个子节点——即原来的旧根
struct radix_tree_node *node = radix_tree_node_alloc(gfp, NULL,
root, shift, 0, 1, 0);
if (!node)
return -ENOMEM;
//标签(Tags)的向上迁移
/*
这是基数树保持查找效率的关键。如果旧的根节点里有某个标签(比如 DIRTY),那么新的根节点也必须在对应的槽位(这里是 slots[0])打上这个标签
- 如果是 IDR:默认设置 IDR_FREE 标签
- 如果是 Page Cache:遍历所有可能的标签(如 Dirty, Writeback),如果旧根有,新根的 slots[0] 也要有
*/
if (is_idr(root)) {
all_tag_set(node, IDR_FREE);
if (!root_tag_get(root, IDR_FREE)) {
tag_clear(node, IDR_FREE, 0);
root_tag_set(root, IDR_FREE);
}
} else {
/* Propagate the aggregated tag info to the new child */
for (tag = 0; tag < RADIX_TREE_MAX_TAGS; tag++) {
if (root_tag_get(root, tag))
tag_set(node, tag, 0);
}
}
BUG_ON(shift > BITS_PER_LONG);
if (radix_tree_is_internal_node(entry)) {
//entry(旧的root)的父亲节点变为node(新申请的节点)
entry_to_node(entry)->parent = node;
} else if (radix_tree_exceptional_entry(entry)) {
//异常条目:如果旧的根直接就是一个 exceptional entry(比如影子条目),新节点的 exceptional 计数要更新
/* Moving an exceptional root->rnode to a node */
node->exceptional = 1;
}
/*
* entry was already in the radix tree, so we do not need
* rcu_assign_pointer here
*/
node->slots[0] = (void __rcu *)entry; // 旧根变成新根的第一个孩子(原先的根节点关联到新分配节点的slot[0]上 )
entry = node_to_entry(node); // 把新节点包装成 entry
rcu_assign_pointer(root->rnode, entry); // 更新全局根指针
shift += RADIX_TREE_MAP_SHIFT;
} while (shift <= maxshift);
out:
/* 这里最后返回的时候,maxshift还要在加6,因为__radix_tree_create
函数在while循环的判断条件是,当order=0,且shift=0, 循环就结束了 */
return maxshift + RADIX_TREE_MAP_SHIFT;
}
在radix_tree_extend的实现中,有几个很细节的问题
- 为什么新的节点要在
slots[0]这个位置? rcu_assign_pointer的作用是什么?- 为什么不使用
rcu_assign_pointer的方式对node->slots[0] = (void __rcu *)entry进行更新?
......
node->slots[0] = (void __rcu *)entry;
entry = node_to_entry(node);
rcu_assign_pointer(root->rnode, entry);
......
接下来回答这几个问题:
1、问题1:TODO
2、问题2:TODO
3、问题3:这里不需要对 node->slots[0] 使用 rcu_assign_pointer,因为此时 node(新申请的)还没挂载到 root->rnode 上,对其他读者不可见,经过前面两步的工作完成后,第三步通过rcu_assign_pointer原子切换,通过一个写屏障,将整个新增加的高度层级瞬间公开给所有的读取者
radix_tree_extend函数的执行说明:
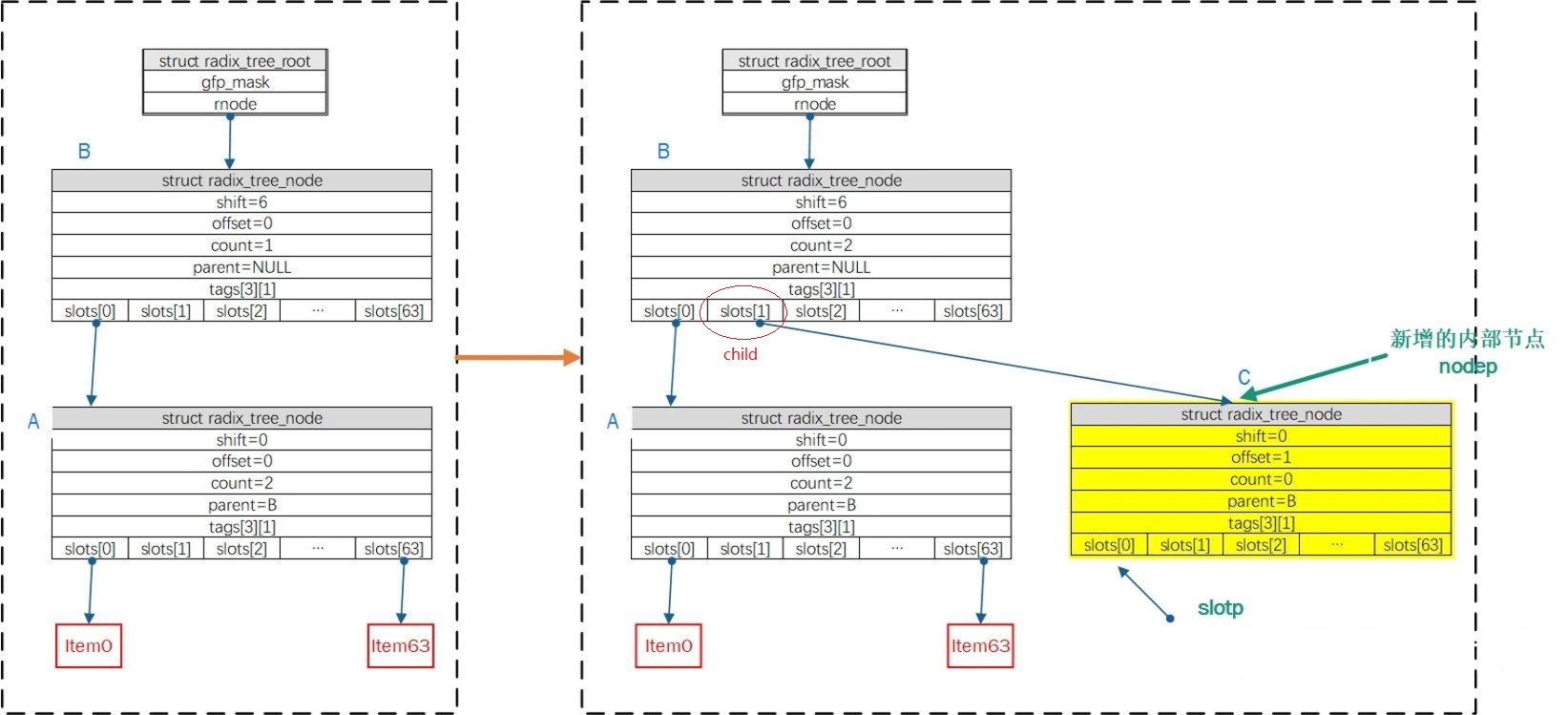
case1:radix_tree_extend函数执行时,已有一个内部节点A(如下图),假设插入index = 64/shift = 6,执行do...while{}逻辑分配内部节点node B,B为新的根节点(node->shift = 6; node->count = 1;node->slot[0]=item0;root->rnode = node),节点A的父节点指向节点B, 返回值为(maxshift + RADIX_TREE_MAP_SHIFT)= 12
IDR插入:示例
__radix_tree_create操作:
继续上面的例子,当执行了radix_tree_extend之后,此时__radix_tree_create函数执行前,radix tree 已经有两层内部节点(参数index = 64/order = 0)
- 调用
radix_tree_load_root && radix_tree_extend后,child指向B节点,maxindex = 64*64-1;shift = 12 - 在
whileloop中,按shift=12递减,此时shift= 6,由于child!=NULL成立,需下降一级,node指向B节点,调用radix_tree_descend后,offset=1;child =NULL;slot = &root->rnode->slots[1];再次触发循环,shift再次递减后(shift= 0),由于child==NULL,分配内部节点C(满足C->shift = 0;C->offset= 1;C->parent = B;B->slot[1] = C),继续下降一级,此时node = C,再次调用radix_tree_descend后,offset=0;child =NULL;slot = &C->->slots[0],完成后如下图 - 在
__radix_tree_create返回后,slotp指针指向了item待插入位置的slot地址,而nodep指针指向待插入指针item的父节点
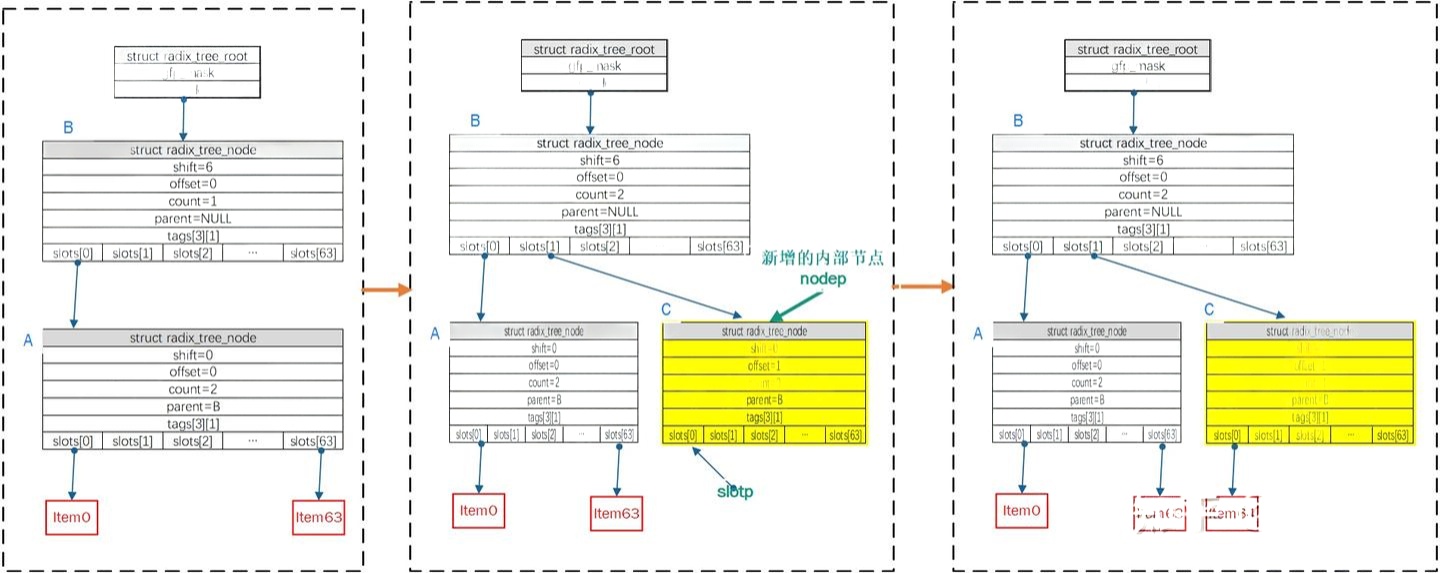
__radix_tree_insert函数中,__radix_tree_create完成之后会调用insert_entries完成插入节点item最后的相关工作,insert_entries函数中,参数node指向了待插入指针item的父节点,参数slot是item插入位置的slot的地址
//https://elixir.bootlin.com/linux/v4.11.6/source/lib/radix-tree.c#L961
static inline int insert_entries(struct radix_tree_node *node,
void __rcu **slot, void *item, unsigned order, bool replace)
{
if (*slot)
return -EEXIST;
// 将item填写到待插入位置
// rcu_assign_pointer(*slot, item)操作相当于*slot = item
rcu_assign_pointer(*slot, item);
if (node) {
// node为item所关联的父节点, item插入后node的子节点个数递增
node->count++;
if (radix_tree_exceptional_entry(item))
node->exceptional++;
}
return 1;
}
继续追踪上面的例子,最左边是radix树的初始形态,即树高2层,最大能容纳的index为64*64-1,调用__radix_tree_create函数返回后,函数参数index=64/order=0,待插入index为64(按6bit划分区间为000001-000000),因此index=64在radix树第一层中的offset是1,第二层中的offset是0
__radix_tree_create函数执行完成,会在第二层新增一个中间节点C,节点C会关联到B节点的offset=1的slot上。此外,C节点的offset为0的slot位置是index=64要插入的位置,最终将index=64 的item插入到C节点的offset为0的slot位置
IDR删除
TODO
0x02 radix tree(6.18)
从 Linux 4.15 开始,内核将 bitmap 换为了radix tree来实现进程id分配(用于管理 32 bit 位的 整数 ID),结构如下:
struct idr {
struct radix_tree_root idr_rt;
unsigned int idr_base;
unsigned int idr_next;
};
#define radix_tree_root xarray
#define radix_tree_node xa_node
//https://elixir.bootlin.com/linux/v6.18/source/include/linux/xarray.h#L300
struct xarray {
spinlock_t xa_lock;
/* private: The rest of the data structure is not to be used directly. */
gfp_t xa_flags;
void __rcu * xa_head;
};
//https://elixir.bootlin.com/linux/v6.18/source/include/linux/xarray.h#L1168
struct xa_node {
unsigned char shift; /* Bits remaining in each slot */
unsigned char offset; /* Slot offset in parent */
unsigned char count; /* Total entry count */
unsigned char nr_values; /* Value entry count */
struct xa_node __rcu *parent; /* NULL at top of tree */
struct xarray *array; /* The array we belong to */
union {
struct list_head private_list; /* For tree user */
struct rcu_head rcu_head; /* Used when freeing node */
};
void __rcu *slots[XA_CHUNK_SIZE]; //核心,指针字段,有点像字符串radix的edges
//默认XA_CHUNK_SIZE为64
union {
//#define XA_MAX_MARKS 3
//#define XA_MARK_LONGS BITS_TO_LONGS(XA_CHUNK_SIZE)
unsigned long tags[XA_MAX_MARKS][XA_MARK_LONGS];
unsigned long marks[XA_MAX_MARKS][XA_MARK_LONGS];
};
};
内核实现的IDR,特点是通常它的每一层只管理一个 6 bits 的分段(关联变量为XA_CHUNK_SHIFT),即其分叉数基本是固定的 64(2^6=64)(根节点除外),层数也是固定的。在基数树节点xa_node结构中,有几个重要成员:
shift:表示了自己在数字中表示第几段数字(内核默认的基数大小为6),这种情况下最低一层的内部节点,shift为0,倒数第二层shift为6,再上一层节点的shift为12,以此类推,shift从低往高, 逐层递增6slots:是一个指针数组,存储的是其指向的子节点的指针。内核默认XA_CHUNK_SIZE是64,也就是是一个*slots[64]。每个元素都指向下一级的树节点,没有下一级子节点的话指针指向NULLtags:用来记录slots数组中每一个下标的存储状态。可以用来表示每一个 slot 是否已经分配出去的状态。它是一个long类型的数组,一个long类型的变量是8个字节,正好有64个bit位
shift的作用是在计算时,计算当前要查询的整数右移的bit数,比如某层的shift为12,那么就右移 12 位取得其结果(作为在该层slots指针数组中的下标)
IDR的简单构造
用 16 bit 的整数(0~65535)来构造idr,已分配ID:100、1000、10000、50000、60000:
#从尾部开始,按照 6 bit 为一组来表示
#每一个 16 bit 位的数字可以表示为一个三段数字
#下面整数:第一段分别是二进制 0000、0000、0010、1100 和 1110,转化成 10 进制后是 0、0、2、12 和 14
100: 0000,000001,100100
1000: 0000,001111,101000
10000: 0010,011100,010000
50000: 1100,001101,010000
60000: 1110,101001,100000
在基数树中,根节点用来存储的每个整数的第一段。如果其中某一个数字已占用,那就把 slot 对应的下标的指针指向其子节点。否则为空。在本例中根节点的 shift 为 12,那就右移 12 位取得其结果
再下面一层节点的 slots 下标是每个值中间 6 个 bit 位的值,其 shift 为 6,最底层树的节点的 slots 是每个值最后 6 个 bit 的值,其 shift 为 0。再将上述每一个整数按照 6 bit 为分段表示,即每个整数,在每层里面slots数组对应的位置。例如 100按每 6 bit 一段拆分表示后为 0,1,36,其第一段是 0 ,那就在基数树的根节点的 slots 的 0 号下标存储其子节点指针;在其第二层节点的 slots 的 1 号下标存储其子节点指针;在第三层节点的 slots 的 36 号下标存储最终的值 100
100: 0,1,36
1000: 0,15,40
10000: 2,28,16
50000: 12,13,16
60000: 14,41,32
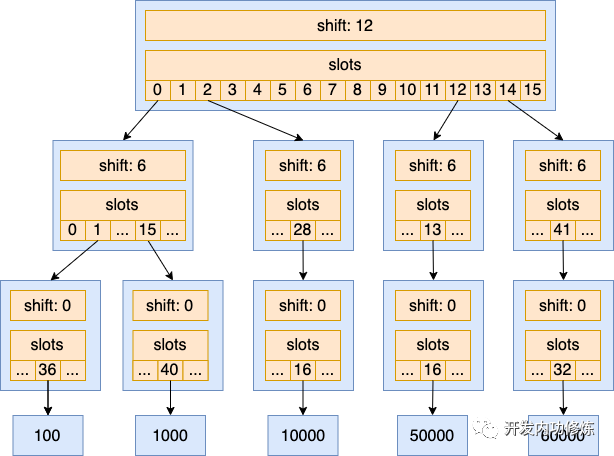
对建立好的基数树进行查找(判断一个整数是否存在),或者是从基数树中分配一个新的整数,只需要分别对这三层的基数树节点进行遍历,分别查看每一层中的 tag 状态位,看 slots 对应的下标是否已经占用即可(不需要bitmap结构那样从头开始遍历)。对于内核而言, 处理32位整数,需要6层节点来存储(对于小型内存系统,可以使用4层基数树,内存更省,但是查找性能会差一些)
性能
对比bitmap的性能比较:参考
0x03 IDR的主要函数
管理32位整数,IDR把每一个ID分级数据进行管理,每一级维护着ID的6位数据,这样就可以把IDR分为6级进行管理(6*6=36,维护的数据大于32位):
31 30 | 29 28 27 26 25 24 | 23 22 21 20 19 18 | 17 16 15 14 13 12 | 11 10 9 8 7 6 | 5 4 3 2 1 0
假设对0B 10 111111 001100 111110 011000 100001,寻址如下:
1. 第一层寻址:ary2=ary1[0b10],得到下一级地址ary2
2. 第二层ary3 = ary2[0b111111]
3. 第三层ary4 = ary3[0b001100]
4. 第四层ary5 = ary4[0b111110]
5. 第五层ary6 = ary5[0b011000]
6. page节点地址(IDR指针) = ary6[0b100001]
0x04 应用场景
进程ID分配
6.18版本通过调用 idr_alloc 函数来申请一个未使用过的PID
//https://elixir.bootlin.com/linux/v6.18/source/kernel/pid.c#L163
struct pid *alloc_pid(struct pid_namespace *ns, pid_t *set_tid,size_t set_tid_size)
{
......
// 进程可能归属多个命名空间,在每一个命令空间中都需要分配进程号
// 实际调用 idr_alloc 来申请整数类型的进程号
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--) {
......
nr = idr_alloc(&tmp->idr, NULL, tid,
tid + 1, GFP_ATOMIC);
......
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
......
}
int idr_alloc(struct idr *idr, void *ptr, int start, int end, gfp_t gfp)
{
u32 id = start;
int ret;
if (WARN_ON_ONCE(start < 0))
return -EINVAL;
ret = idr_alloc_u32(idr, ptr, &id, end > 0 ? end - 1 : INT_MAX, gfp);
if (ret)
return ret;
return id;
}
int idr_alloc_u32(struct idr *idr, void *ptr, u32 *nextid,
unsigned long max, gfp_t gfp)
{
struct radix_tree_iter iter;
void __rcu **slot;
unsigned int base = idr->idr_base;
unsigned int id = *nextid;
......
id = (id < base) ? 0 : id - base;
radix_tree_iter_init(&iter, id);
//核心操作:遍历radix tree的若干节点,并根据每个节点的 tag、slot 等字段找出还未被占用的整数 ID
slot = idr_get_free(&idr->idr_rt, &iter, gfp, max - base);
if (IS_ERR(slot))
return PTR_ERR(slot);
*nextid = iter.index + base;
/* there is a memory barrier inside radix_tree_iter_replace() */
radix_tree_iter_replace(&idr->idr_rt, &iter, slot, ptr);
radix_tree_iter_tag_clear(&idr->idr_rt, &iter, IDR_FREE);
return 0;
}
void __rcu **idr_get_free(struct radix_tree_root *root, ...)
{
......
shift = radix_tree_load_root(root, &child, &maxindex);
while (shift) {
shift -= RADIX_TREE_MAP_SHIFT; //RADIX_TREE_MAP_SHIFT为6
......
// 遍历 tag 状态 bitmap,寻找下一个可用的下标
offset = radix_tree_find_next_bit(node, IDR_FREE,
offset + 1);
start = next_index(start, node, offset);
}
......
}